
The training of an ensemble of models is understood to be the procedure of training a final set of elementary algorithms, whose results are then combined to form the forecast of an aggregated classifier. The model ensemble's purpose is to improve the accuracy of the prediction of the aggregated classifier, particularly when compared with the accuracy of every single elementary classifier. It is intuitively clear that combining simple classifiers can give a more accurate result than each simple classifier separately. Despite that, simple classifiers can be sufficiently accurate on particular datasets, but at the same time, they can make mistakes on different datasets.
An example of ensembles is Condorcet's jury theorem (1784). A jury must come to a correct or incorrect consensus, and each juror has an independent opinion. If the probability of the correct decision of each juror is more than 0.5, then the probability of a correct decision from the jury as a whole (tending toward 1) increases with the size of the jury. If the probability of making the correct decision is less than 0.5 for each juror, then the probability of making the right decision monotonically decreases (tending toward zero) as the jury size increases.
The theorem is as follows:
- N: The number of jury members
 : The probability of the jury member making the right decision
: The probability of the jury member making the right decision- μ: The probability of the entire jury making the correct decision
- m: The minimum majority of jury members:

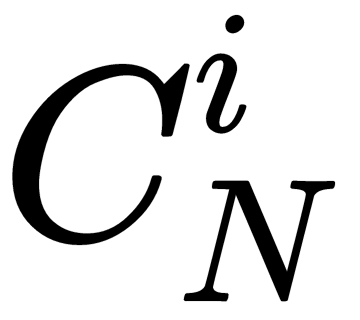 : The number of combinations of N by I:
: The number of combinations of N by I:

If 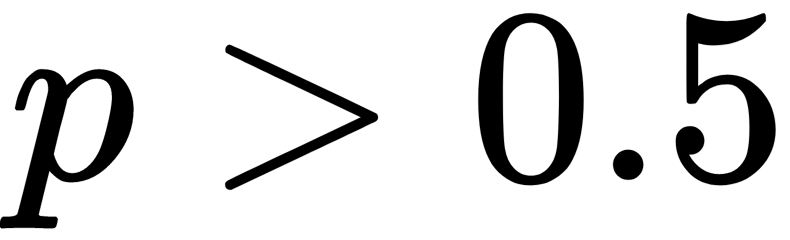 then
then 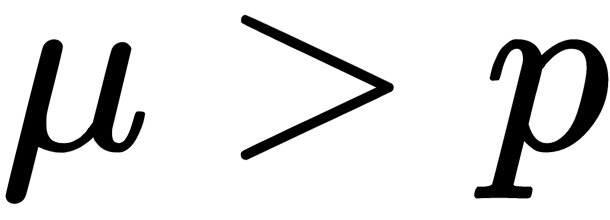
If 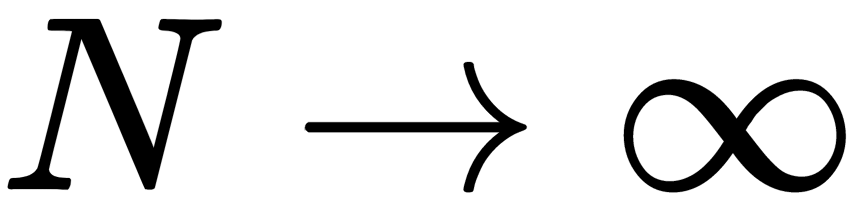 then
then 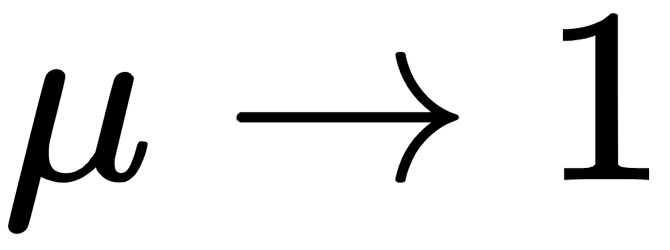
Therefore, based on general reasoning, three reasons why ensembles of classifiers can be successful can be distinguished, as follows:
- Statistical: The classification algorithm can be viewed as a search procedure in the space of the H hypothesis, concerned with the distribution of data in order to find the best hypothesis. By learning from the final dataset, the algorithm can find many different hypotheses that describe the training sample equally well. By building an ensemble of models, we average out the error of each hypothesis and reduce the influence of instabilities and randomness in the formation of a new hypothesis.
- Computational: Most learning algorithms use methods for finding the extremum of a specific objective function. For example, neural networks use gradient descent (GD) methods to minimize prediction errors. Decision trees use greedy algorithms that minimize data entropy. These optimization algorithms can become stuck at a local extremum point, which is a problem because their goal is to find a global optimum. The ensembles of models combining the results of the prediction of simple classifiers, trained on different subsets of the source data, have a higher chance of finding a global optimum since they start a search for the optimum from different points in the initial set of hypotheses.
- Representative: A combined hypothesis may not be in the set of possible hypotheses for simple classifiers. Therefore, by building a combined hypothesis, we expand the set of possible hypotheses.
Condorcet's jury theorem and the reasons provided previously are not entirely suitable for real, practical situations because the algorithms are not independent (they solve one problem, they learn on one target vector, and can only use one model, or a small number of models).
Therefore, the majority of techniques in applied ensemble development are aimed at ensuring that the ensemble is diverse. This allows the errors of individual algorithms in individual objects to be compensated for by the correct operations of other algorithms. Overall, building the ensemble results in an improvement in both the quality and variety of simple algorithms.
The simplest type of ensemble is model averaging, whereby each member of the ensemble makes an equal contribution to the final forecast. The fact that each model has an equal contribution to the final ensemble's forecast is a limitation of this approach. The problem is in unbalanced contributions. Despite that, there is a requirement that all members of the ensemble have prediction skills higher than random chance.
However, it is known that some models work much better or much worse than other models. Some improvements can be made to solve this problem, using a weighted ensemble in which the contribution of each member to the final forecast is weighted by the performance of the model. When the weight of the model is a small positive value and the sum of all weights equals 1, the weights can indicate the percentage of confidence in (or expected performance from) each model.
At this time, the most common approaches to ensemble construction are as follows:
- Bagging: This is an ensemble of models studying in parallel on different random samples from the same training set. The final result is determined by the voting of the algorithms of the ensemble. For example, in classification, the class that is predicted by the most classifiers is chosen.
- Boosting: This is an ensemble of models trained sequentially, with each successive algorithm being trained on samples in which the previous algorithm made a mistake.
- Stacking: This is an approach whereby a training set is divided into N blocks, and a set of simple models is trained on N-1 of them. An N-th model is then trained on the remaining block, but the outputs of the underlying algorithms (forming the so-called meta-attribute) are used as the target variable.
- Random forest: This is a set of decision trees built independently, and whose answers are averaged and decided by a majority vote.
The following sections discuss the previously described approaches in detail.