
Bagging (from the bootstrap aggregation) is one of the earliest and most straightforward types of ensembles. Bagging is based on the statistical bootstrap method, which aims to obtain the most accurate sample estimates and to extend the results to the entire population. The bootstrap method is as follows.
Suppose there is an X dataset of size M. Evenly take from the dataset N objects and return each object. Before selecting the next one, we can generate N sub-datasets. This procedure means that N times, we select an arbitrary sample object (we assume that each object is picked up with the same probability 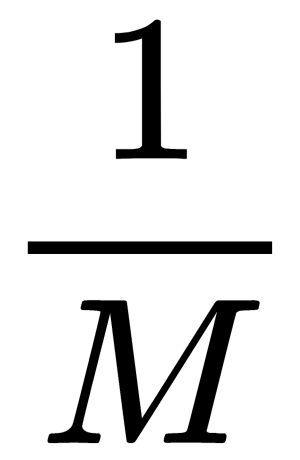 ), and each time, we choose from all the original M objects.
), and each time, we choose from all the original M objects.
We can imagine this as a bag from which balls are taken. The ball selected at a given step is returned to the bag following its selection, and the next choice is again made with equal probability from the same number of balls. Note that due to the ball being returned each time, there are repetitions.
Each new selection is denoted as X1. Repeating the procedure k times, we generate k sub-datasets. Now, we have a reasonably large number of samples, and we can evaluate various statistics of the original distribution.
The main descriptive statistics are the sample mean, median, and standard deviation. Summary statistics—for example, the sample mean, median, and correlation—can vary from sample to sample. The bootstrap idea is to use sampling results as a fictitious population to determine the sample distribution of statistics. The bootstrap method analyzes a large number of phantom samples, called bootstrap samples. For each sample, an estimate of the target statistics is calculated, then the estimates are averaged. The bootstrap method can be viewed as a modification of the Monte Carlo method.
Suppose there is the X training dataset. With the help of bootstrap, we can generate  sub-datasets. Now, on each sub-dataset, we can train our
sub-datasets. Now, on each sub-dataset, we can train our 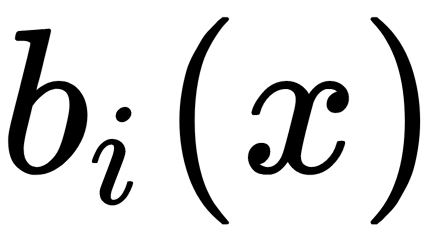 classifier. The final classifier averages these classifier responses (in the case of classification, this corresponds to a vote), as follows:
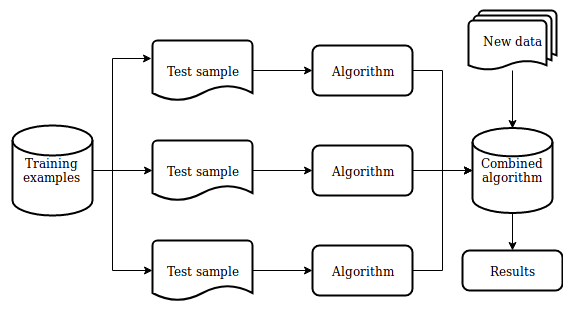
classifier. The final classifier averages these classifier responses (in the case of classification, this corresponds to a vote), as follows: 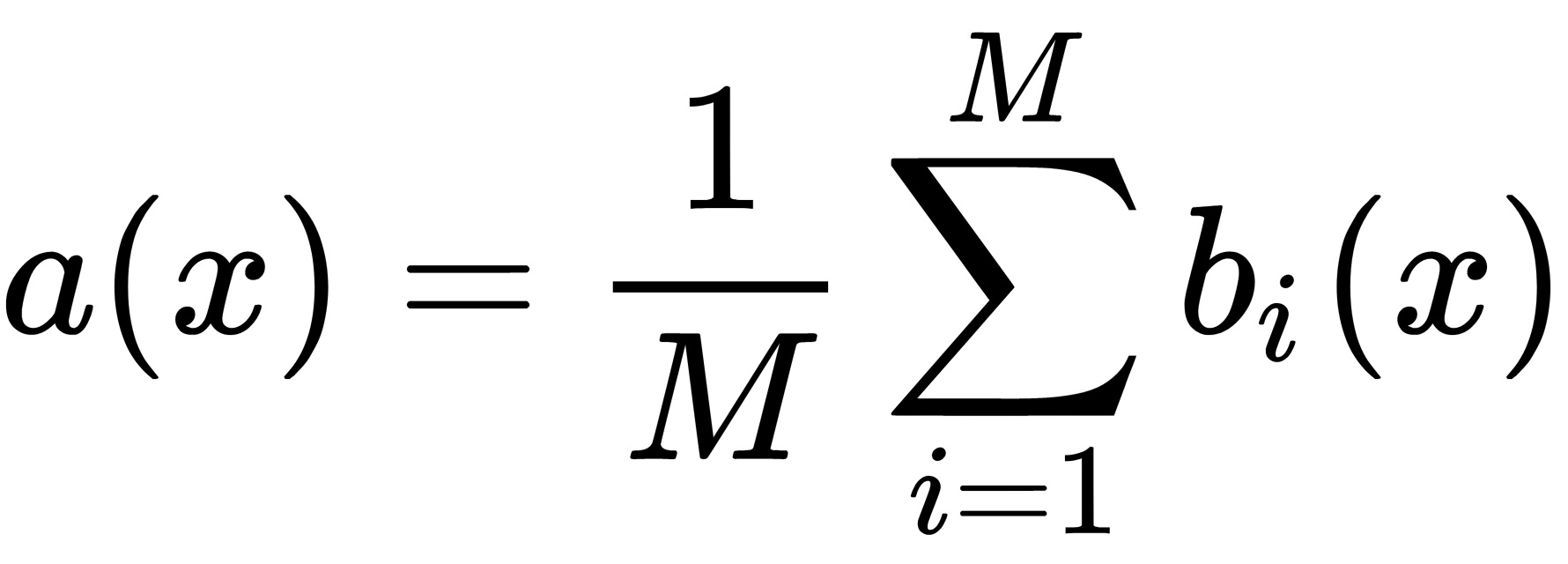 . The following diagram shows this scheme:
. The following diagram shows this scheme:
Consider the regression problem by using simple algorithms  . Suppose that there is a true answer function for all y(x) objects, and there is also a distribution on
. Suppose that there is a true answer function for all y(x) objects, and there is also a distribution on 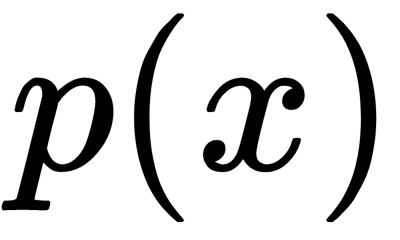 objects. In this case, we can write the error of each regression function as follows:
objects. In this case, we can write the error of each regression function as follows:
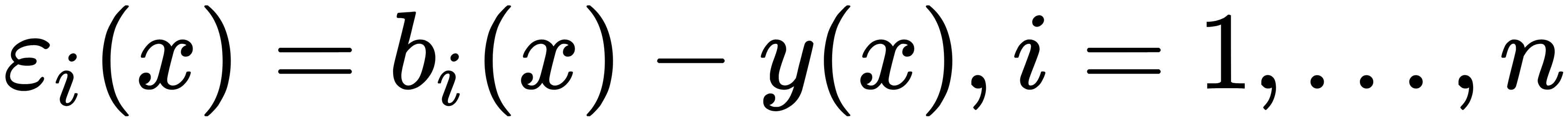
We can also write the expectation of the Mean Squared Error (MSE) as follows:
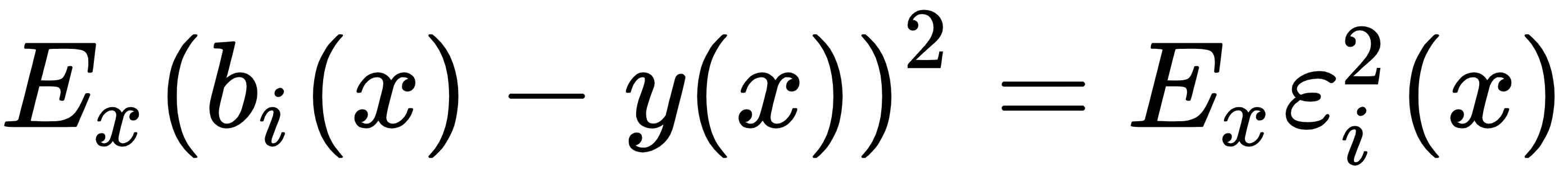
The average error of the constructed regression functions is as follows:
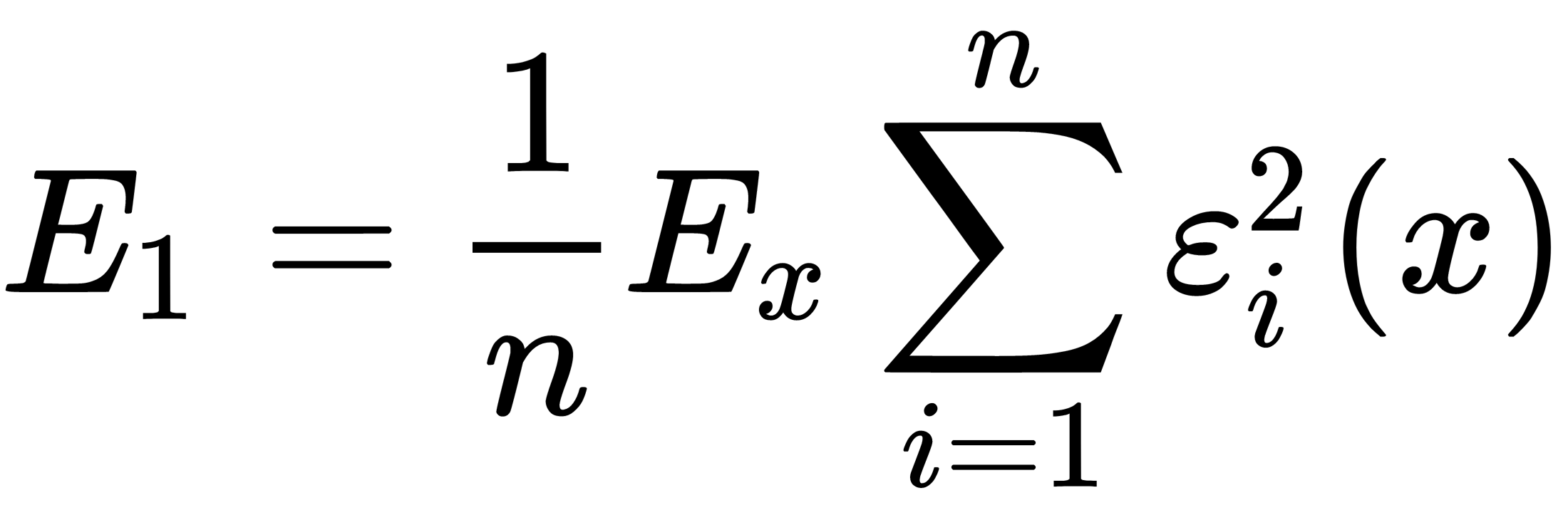
Now, suppose the errors are unbiased and uncorrelated, as shown here:
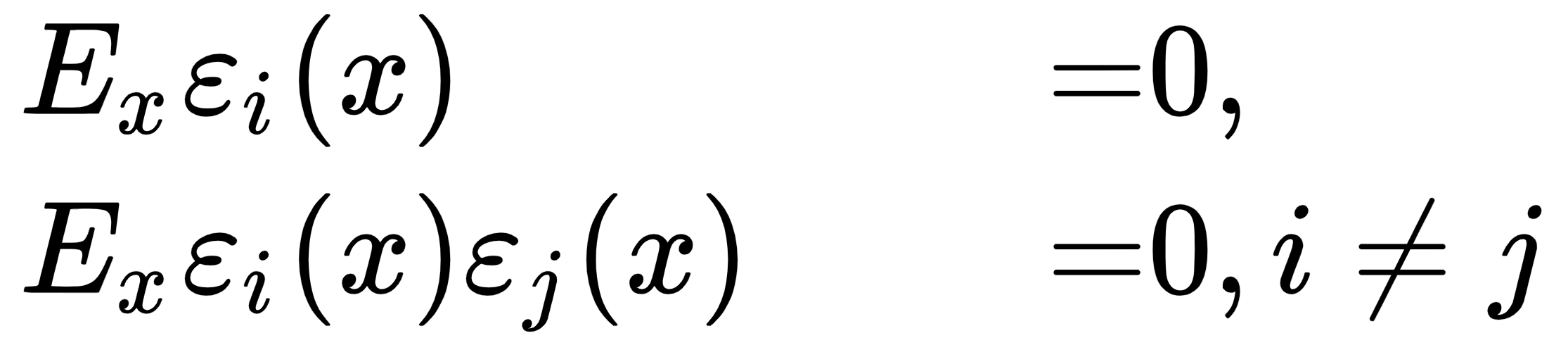
Now, we can write a new regression function that averages the responses of the functions we have constructed, as follows:
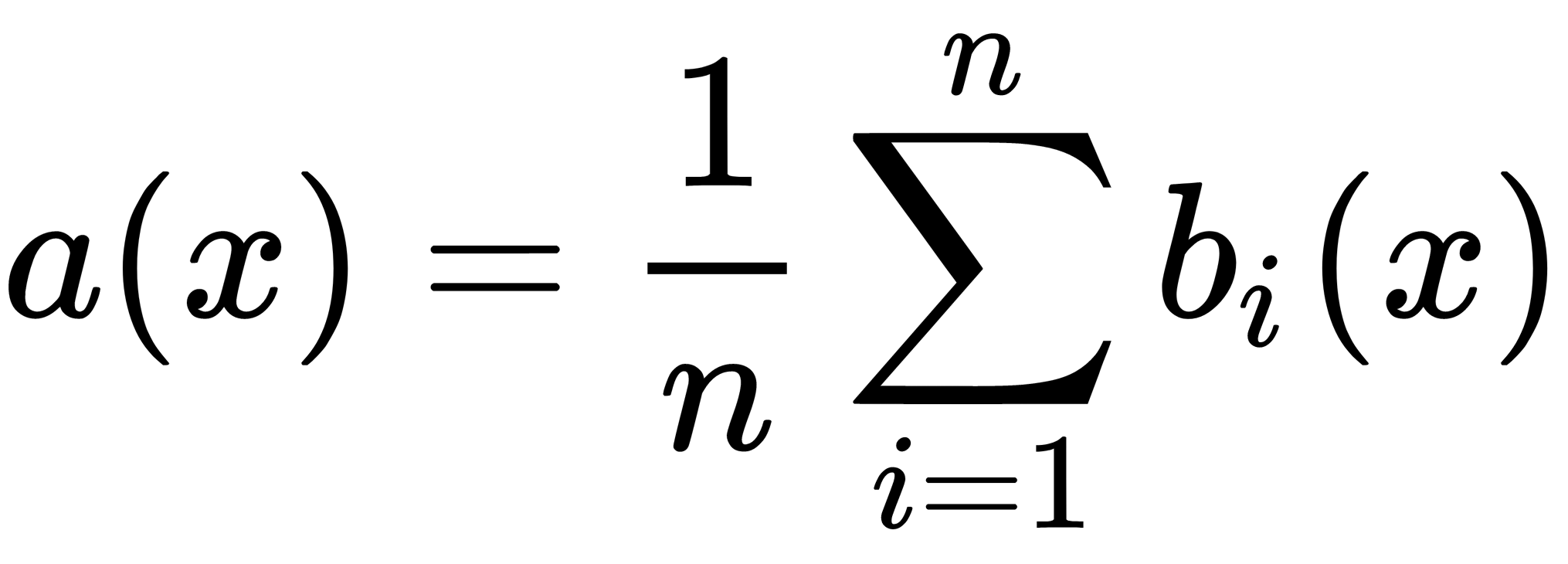
Let's find its root MSE (RMSE) to see an effect of averaging, as follows:
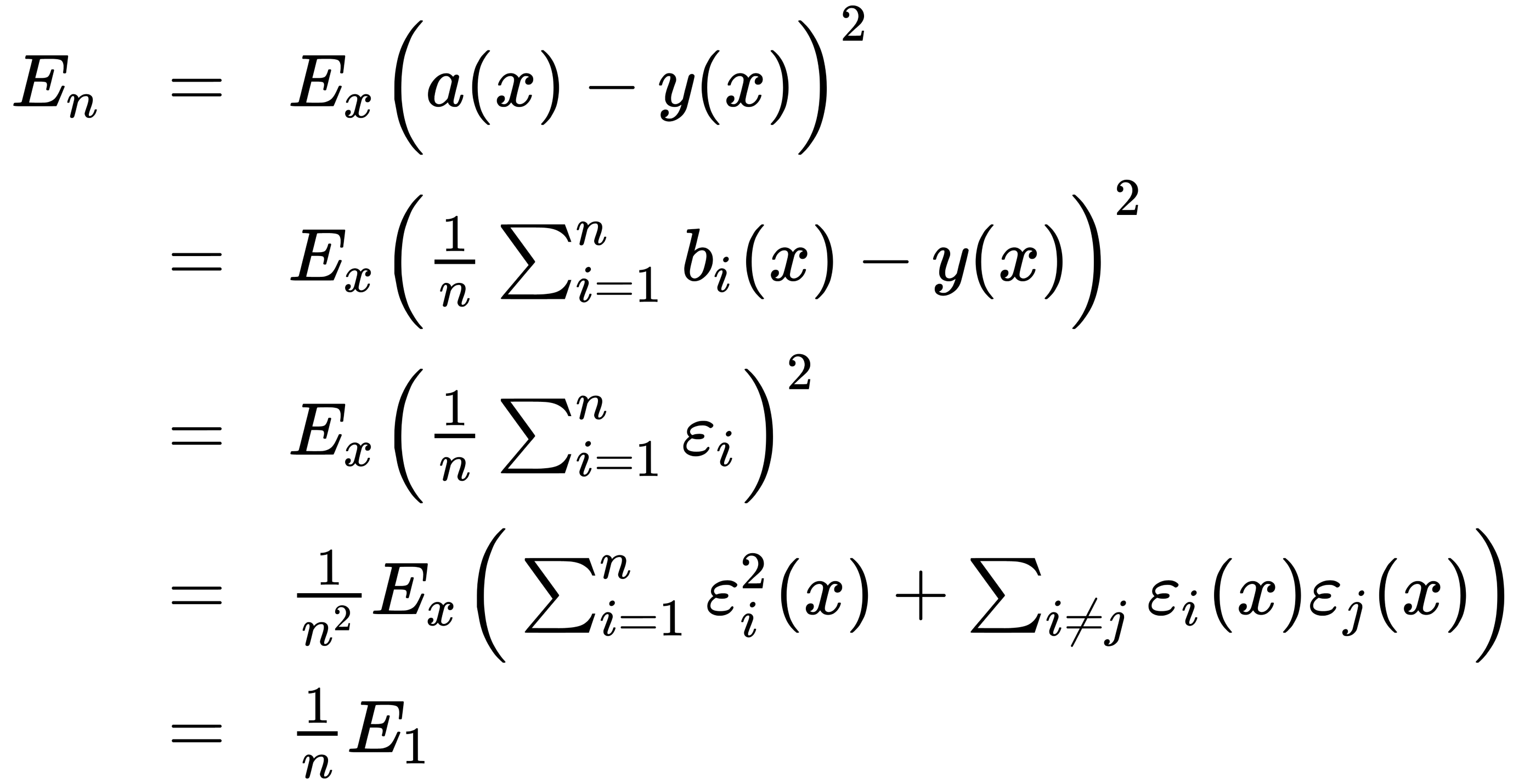
Thus, averaging the answers allowed us to reduce the average square of the error by n times.
Bagging also allows us to reduce the variance of the trained algorithm and prevent overfitting. The effectiveness of bagging is based on the underlying algorithms, which are trained on various sub-datasets that are quite different, and their errors are mutually compensated during voting. Also, outlying objects may not fall into some of the training sub-datasets, which also increases the effectiveness of the bagging approach.
Bagging is useful with small datasets when the exclusion of even a small number of training objects leads to the construction of substantially different simple algorithms. In the case of large datasets, sub-datasets are usually generated that are significantly smaller than the original one.
Notice that the assumption about uncorrelated errors is rarely satisfied. If this assumption is incorrect, then the error reduction is not as significant as we might have assumed.
In practice, bagging provides a good improvement to the accuracy of results when compared to simple individual algorithms, particularly if a simple algorithm is sufficiently accurate but unstable. Improving the accuracy of the forecast occurs by reducing the spread of the error-prone forecasts of individual algorithms. The advantage of the bagging algorithm is its ease of implementation, as well as the possibility of paralleling the calculations for training each elementary algorithm on different computational nodes.