
Chapter 10
Toward Security Metrics Maturity
As you look to improve in any endeavor, it helps to have a view of where you are and a vision for where you need to go. This improvement will need to be continuous and will need to be measured. The requirement of being “continuous and measurable” was stated as one of the main outcomes of this how-to book. Continuous measurements that have a goal in mind are called “metrics.” To that end, this chapter provides an operational security-metrics maturity model. Different from other analytics-related maturity models (yes, there are many), ours starts and ends with predictive analytics.
This chapter will begin to introduce some issues at a management and operations level. Richard Seiersen, the coauthor who is familiar with these issues, will use this chapter and the next to talk to his peers using language and concepts that they should be familiar with. Richard will only selectively introduce more technical issues to illustrate practical actions. To that end, we will cover the following topics:
- The Operational Security Metrics Maturity Model: This is a maturity model that is a matrix of standard questions and data sources.
- Sparse Data Analytics (SDA): This is the earliest metrics stage, which uses quantitative techniques to model risk based on limited data. This can specifically be used to inform new security investments. We provide an extended example of SDA using the R programming language at the very end of this chapter. This is optional material that demonstrates analytics outside of Excel as well as illustrates SDA.
- Functional Security Metrics: These are subject-matter-specific metrics based on early security investments. Most security metrics programs stop at this point of maturation.
- Security Data Marts: This section focuses on measuring across security domains with larger data sets. The following chapter will focus on this topic.
- Prescriptive Security Analytics: This will be a brief discussion on an emerging topic in the security world. It is the amalgam of decision and data science. This is a large, future book-length topic.
Introduction: Operational Security Metrics Maturity Model
Predictive analytics, machine learning, data science—choose your data buzzword—are all popular topics. Maturity models and frameworks for approaching analytics abound. Try Googling images of “Analytics Maturity Models”; there are plenty of examples. Our approach (see Figure 10.1) is different. We don’t require much data or capability to get started. And in fact, the practices you learned in previous chapters shine at this early stage. They help define the types of investments you will need to make to mature your program. So, there is no rush to invest in a “big data” solution and data science. Don’t get us wrong—we are big advocates of using such solutions when warranted. But with all these “shiny” analytics concepts and technology come a lot of distractions—distractions from making decisions that could protect you from the bad guys now. To that end, our perspective is that any analytic maturity model and framework worth its salt takes a decision-first approach—always.

Figure 10.1 Security Analytics Maturity Model
Sparse Data Analytics
N (data) is never enough because if it were “enough” you’d already be on to the next problem for which you need more data. Similarly, you never have quite enough money. But that’s another story.
—Andrew Gelman1
You can use predictive analytics now. Meaning, you can use advanced techniques although your security program may be immature. All of the models presented in Chapters 8 and 9 fit perfectly here. Just because your ability to collect broad swaths of security evidence is low does not mean that you cannot update your beliefs as you get more data. In fact, the only data you may have is subject matter expert beliefs about probable future losses. In short, doing analytics with sparse evidence is a mature function but is not dependent on mature security operations.
From an analytics perspective, Sparse Data Analytics (SDA) is the exclusive approach when data are scarce. You likely have not made an investment in some new security program. In fact, you may be the newly hired CISO tasked with investing in a security program from scratch. Therefore, you would use SDA to define those investments. But, once your new investment (people, process, technology) is deployed, you measure it to determine its effectiveness to continually improve its operation. For a more technical example of SDA please refer to the “SDA Example Model: R Programming” at the end of the chapter.
Functional Security Metrics
After you have made a major investment in a new enterprise-security capability, how do you know it’s actually helping? Functional security metrics (FSMs) seek to optimize the effectiveness of key operational security areas. There will be key performance indicators (KPIs) associated with operational coverage, systems configuration, and risk reduction within key domains. There are several security metrics books on the market that target this level of security measurement. One of the earliest was Andrew Jaquith’s Security Metrics.2 It brought this important topic to the forefront and has a solid focus on what we would call “coverage and configuration” metrics. Unfortunately, most companies still do not fully realize this level of maturity. They indeed may have tens, if not hundreds, of millions of dollars invested in security staff and technology. People, process, and technology for certain silo functions may in fact be optimized, but a view into each security domain with isometric measurement approaches is likely lacking.
Most organizations have some of the following functions, in some form of arrangement:
- malware defense
- vulnerability management
- penetration testing
- application security
- network security
- security architecture
- identity and access management
- security compliance
- data loss prevention
- incident response and forensics
- and many more
Each function may have multiple enterprise and standalone security solutions. In fact, each organization ideally would have sophisticated security metrics associated with each of their functions. These metrics would break out into two macro areas:
- Coverage and Configuration Metrics: These are metrics associated with operational effectiveness in terms of depth and breadth of enterprise engagement. Dimensions in this metric would include time series metrics associated with rate of deployment and effective configuration. Is the solution actually working (turned on) to specification and do you have evidence of that? You can buy a firewall and put it in line, but if its rules are set to “any:any” and you did not know it—you likely have failed. Is logging for key applications defined? Is logging actually occurring? If logging is occurring, are logs being consumed by the appropriate security tools? Are alerts for said security tools tuned and correlated? What are your false positive and negative rates, and do you have metrics around reducing noise and increasing actual signal? Are you also measuring the associated workflow for handling these events?
- Mitigation Metrics: These are metrics associated with the rate at which risk is added and removed from the organization. An example metric might be “Internet facing, remotely exploitable vulnerabilities must be remediated within one business day, with effective inline monitoring or mitigation established within 1 hour.”
Security Data Marts
Note: Chapter 11 is a tutorial on security data mart design. The section below only introduces the concept as part of the maturity model.
“Data mart” is a red flag for some analysts. It brings up images of bloated data warehouses and complex ETL (extraction, transformation, load) programs. But when we say “data mart” we are steering clear of any particular implementation. If you wanted our ideal definition we would say it is “a subject-matter-specific, immutable, elastic, highly parallelized and atomic data store that easily connects with other subject data stores.” Enough buzzwords? Translation: super-fast in all its operations, scales with data growth, and easy to reason over for the end users. We would also add, “in the cloud.” That’s only because we are not enamored with implementation and want to get on with the business of managing security risk. The reality is that most readers of this book will have ready access to traditional relational database management system (RDBMS) technology—even on their laptops.
Security Data Marts (SDM) metrics answer questions related to cross-program effectiveness. Are people, process, and technology working together effectively to reduce risk across multiple security domains? (Note: When we say “security system” we typically mean the combination of people, process, and technology.) More specifically, is your system improving or degrading in its ability to reduce risk over time? An example question could be “Are end users who operate systems with security controls XYZ less likely to be compromised? Or, are there certain vendor controls, or combinations of controls, more effective than others? Is there useless redundancy in these investments?” By way of example related to endpoint security effectiveness, these types of questions could rely on data coming from logs like the following:
- Microsoft’s Enhanced Mitigation Experience Toolkit (EMET)
- Application whitelisting
- Host intrusion prevention systems
- File integrity monitoring
- System configuration (CIS benchmarks, etc.)
- Browser security and privacy settings
- Vulnerability management
- Endpoint reputation
- Antivirus
- Etc. . . .
Other questions could include “How long is exploitable residual risk sitting on endpoints prior to discovery and prioritization for removal? Is our ‘system’ fast enough? How fast should it be and how much would it cost to achieve that rate?”
Data marts are perfect for answering questions about how long hidden malicious activity exists prior to detection. This is something security information and event management (SIEM) solutions cannot do—although they can be a data source for data marts. Eventually, and this could be a long “eventually,” security vendor systems catch up with the reality of the bad guys on your network. It could take moments to months if not years. For example, investments that determine the good or bad reputation of external systems get updated on the fly. Some of those systems may be used by bad actors as “command and control” servers to manage infected systems in your network. Those servers may have existed for months prior to vendor acknowledgment. Antivirus definitions are updated regularly as new malware is discovered. Malware may have been sitting on endpoints for months prior to that update. Vulnerability management systems are updated when new zero-day or other vulnerabilities are discovered. Vulnerabilities can exist for many years before software or security vendors know about them. During that time, malicious actors may have been exploiting those vulnerabilities without your knowledge.
This whole subject of measuring residual risk is a bit of an elephant in the room for the cybersecurity industry. You are always exposed at any given point in time and your vendor solutions are by definition always late. Ask any security professional and they would acknowledge this as an obvious non-epiphany. If it’s so obvious, then why don’t they measure it with the intent of improving on it? It’s readily measurable and should be a priority. Measuring that exposure and investing to buy it down at the best ROI is a key practice in cybersecurity risk management that is facilitated by SDM in conjunction with what you learned in previous chapters. In Chapter 11, we will introduce a KPI called “survival analysis” that addresses the need to measure aging residual risk. But here’s a dirty little secret: If you are not measuring your residual exposure rate, then it’s likely getting worse. We need to be able to ask cross-domain questions like these if we are going to fight the good fight. Realize that the bad guys attack across domains. Our analytics must break out of functional silos to address that reality.
Prescriptive Analytics
As stated earlier, prescriptive analytics is a long book-length topic in and of itself. Our intent here is to initialize the conversation for the security industry. Let’s describe prescriptive analytics by first establishing where it belongs among three categories of analytics:
- Descriptive Analytics: The majority of analytics out there are descriptive. They are just basic aggregates like sums and averages against certain groups of interest like month-over-month burn up and burn down of certain classes of risk. This is a standard descriptive analytic. Standard Online Analytical Processing (OLAP) fares well against descriptive analytics. But as stated, OLAP business intelligence (BI) has not seen enough traction in security. Functional and SDM approaches largely consist of descriptive analytics except when we want to use that data to update our sparse analytic models’ beliefs.
Predictive Analytics: Predictive analytics implies predicting the future. But strictly speaking, that is not what is happening. You are using past data to make a forecast about a potential future outcome. Most security metrics programs don’t reach this level. Some security professionals and vendors may protest and say, “What about machine learning? We do that!” It is here that we need to make a slight detour on the topic of machine learning, a.k.a. data science versus decision science.
Using machine learning techniques stands a bit apart from decision analysis. Indeed, finding patterns via machine learning is an increasingly important practice in fighting the bad guy. As previously stated, vendors are late in detecting new attacks, and machine learning has promise in early detection of new threats. But probabilistic signals applied to real-time data have the potential to become “more noise” to prioritize. “Prioritization” means determining what next when in the heat of battle. That is what the “management” part of SIEM really means—prioritization of what to do next. In that sense, this is where decision analysis could also shine. (Unfortunately, the SIEM market has not adopted decision analysis. Instead, it retains questionable ordinal approaches for prioritizing incident-response activity.)
- Prescriptive Analytics: In short, prescriptive analytics runs multiple models from both data and decision science realms and provides optimized recommendations for decision making. When done in a big data and stream analytics context, these decisions can be done in real time and in some cases take actions on your behalf—approaching “artificial intelligence.”
Simply put, our model states that you start with decision analysis and you stick with it throughout as you increase your ingestion of empirical evidence. At the prescriptive level, data science model output becomes inputs into decision analysis models. These models work together to propose, and in some cases dynamically make, decisions. Decisions can be learned and hence become input back into the model. An example use case for prescriptive analytics would be in what we call “chasing rabbits down holes.” As stated, much operational security technology revolves around detect, block, remove, and repeat. At a high level this is how antivirus software and various inline defenses work. But when there is a breach, or some sort of outbreak, then the troops are rallied. What about that gray area that precedes breach and/or may be an indication of an ongoing breach? Meaning, you don’t have empirical evidence of an ongoing breach, you just have evidence that certain assets were compromised and now they are remediated.
For example, consider malware that was cleaned successfully, but prior to being cleaned, it was being blocked from communicating to a command-and-control server by inline reputation services. You gather additional evidence that compromised systems were attempting to send out messages to now blocked command and control servers. This has been occurring for months. What do you do? You have removed the malware but could there be an ongoing breach that you still don’t see? Or, perhaps there was a breach that is now over that you missed? Meaning, do you start forensics investigations to see if there is one or more broader malicious “campaigns” that are, or were, siphoning off data?
In an ideal world, where resources are unlimited, the answer would be “yes!” But the reality is that your incident response team is typically 100% allocated to following confirmed incidents as opposed to “likely” breaches. It creates a dilemma. These “possible breaches” left without follow-up could mature into full-blown, long-term breaches. In fact, you would likely never get in front of these phenomena unless you figure out a way to prioritize the data you have. We propose that approaches similar to the ones presented in Chapter 9 can be integrated near real time into existing event detection systems. For example, the Lens Model is computationally fast by reducing the need for massive “Node Probability Tables.” It’s also thoroughly Bayesian and can accept both empirical evidence coming directly from deterministic and non-deterministic (data science) based security systems and calibrated beliefs from security experts. Being that it’s Bayesian, it can then be used for learning based on the decision outcomes of the model itself—constantly updating its belief about various scenario types and recommending when certain “gray” events should be further investigated. This type of approach starts looking more and more like artificial intelligence applied to the cybersecurity realm. Again, this is a big, future book-length topic and we only proposed to shine a light on this future direction.
SDA Example Model: R Programming
We want to give you yet another taste for SDA. In this case we will use the R programming language. (You could just as easily do this in Excel, Python, etc.) This will not be an exhaustive “R How-To” section. We will explain code to the extent that it helps explain analytic ideas. An intuitive understanding of the program is our goal. The need for intuition cannot be overemphasized. Intuition will direct your creativity about your own problems. To that end, we believe Excel and scripting are great ways for newcomers to risk analytics to develop intuition for analytics quickly. In fact, if any concepts in previous chapters still seem opaque to you, then take more time with the Excel tools. A picture, and a program, can be worth several thousand words. That same concept applies here: Download R and give it a spin; all of this will make much more sense if you do.
We recommend you use the numerous books and countless online tutorials on R should your interest be piqued. We will be leveraging an R library, “LearnBayes,” that in and of itself is a tutorial. The author of this module, Jim Albert, has a great book3 and several tutorials all available online that you can reference just as we have done here. If you don’t have R, you can go here to download it for your particular platform: https://cran.rstudio.com/index.html. We also recommend the RStudio; it will make your R hacking much easier: https://www.rstudio.com/products/rstudio/download/.
Once you have downloaded R Studio, you will want to fire it up. Type install.packages(“LearnBayes”) at the command line.
For our scenario, here are the facts:
- You are now part of a due diligence team that will evaluate a multibillion-dollar acquisition.
- The company in question has a significant global cloud presence.
- You were told that they have several hundred cloud applications servicing various critical industries with millions of users.
- You have been given less than one week, as your CEO says, to “determine how bad they are, find any ‘gotchas,’ and moreover how much technical debt we are absorbing from a security perspective.”
- Your organization is one of several that are making a play for this company. It’s a bit of a fire sale in that the board of the selling company is looking to unload quickly.
- You will not have all the disclosures you might want. In fact, you will not get to do much of any formal assessment.
Since you want your work to be defensible from a technical assessment perspective, you choose to focus on a subset of the Cloud Security Alliances Controls Matrix. It’s correlated to all the big control frameworks like ISO, NIST, and so forth. You reduce your list to a set of five macro items that represent “must haves.” Lacking any one of these controls could cost several hundreds of thousands of dollars or more per application to remediate.
After a bit of research, you feel 50% confident that the true proportion of controls that are in place is less than 40%. Sound confusing? It’s because we are trying to explain a “proportional picture.” The best way to think about this is in shape terms on a graph. You see a bell shape that has its highest point slightly to the left of center—over the 40% mark on the x-axis. You are also 90% sure that the true value (percentage controls in place) is below the 60% mark on the graph. This moves things a bit further to the left on the graph. If you were 90% sure that the controls state was below 50%, that would make your prior look thinner and taller—denser around the 40% mark.
Let’s assume you conduct your first set of audit/interviews for 10 applications. You find that 3 of the 10 applications have basic controls in place. With this, you input your “prior beliefs” about the company and add the newly acquired data into R:
> library(LearnBayes) > > beta.par <‐ beta.select(list(p=0.5, x=0.40), list(p=0.90, x=.60)) > triplot(beta.par, c(3,7))
As stated, your prior beliefs show that you think the control state for most of the cloud applications in question bunch up around 40%. As you get more data, your ideas start “taking shape.” That is what the posterior reflects. The posterior is what you get after you run your analytics. The posterior, if used as input into another analysis, would then be called your “prior.” The data you start with in your prediction is “prior” to getting your output, which is the “posterior.” Your beliefs are getting less dispersed; that is, denser and hence more certain. Of course this is only after 10 interviews.
Note the “Likelihood” plot. It is a function that describes how likely it is, given your model (hypothesis), that you observed the data. Formally this would be written: P(Data | Hypothesis). In our case, we had 3 passes and 7 fails. If our model is consistent, then the probability that our model reflects our data should be relatively high.
In terms of the preceding code, the beta.select function is used to create (select) two values from our prior probability inputs. The two values go by fancy names: a and b or alpha and beta. They are also called “shape parameters.” They shape the curve, or distribution, seen in Figure 10.2. Think of a distribution as clay and these two parameters as hands that shape the clay. As stated in Chapter 9, the formal name of this particular type of distribution (shape) is called the “beta distribution.” As a and b get larger, our beliefs, as represented by the beta distribution, are getting taller and narrower. It just means there is more certainty (density) regarding your beliefs about some uncertain thing. In our case, that uncertain thing is the state of controls for roughly 200 cloud applications. You can see how the two lists hold the beliefs the CISO had: beta.select(list(p=0.5, x=0.40), list(p=0.90, x=.60)). Those inputs are transformed by the beta.select function into a and b values and stored into the beta.par variable. We can print these values to screen by typing the following:
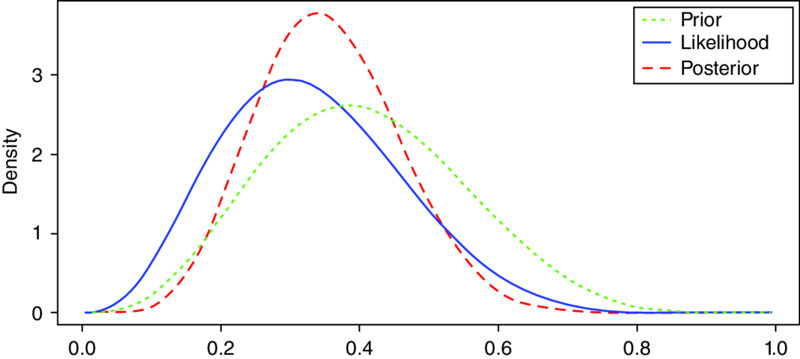
Figure 10.2 Bayes Triplot, beta(4.31, 6.3) prior, s=3, f=7
> beta.par [1] 4.31 6.30
From your vantage point you are only dealing with your beliefs and the new data. The alpha and the beta values work in the background to shape the beta distribution as you get more data. We then use the triplot function to combine our new information (3,7; 3 successes and 7 fails) with our prior beliefs to create a new posterior belief:
> triplot(beta.par, c(3,7))
Let’s assume you conduct 35 total audits with only 5 cloud applications meeting the most fundamental “defense in depth” controls requirements. There are over 200 applications that did not get audited. You now update your model with the new data (see Figure 10.3).
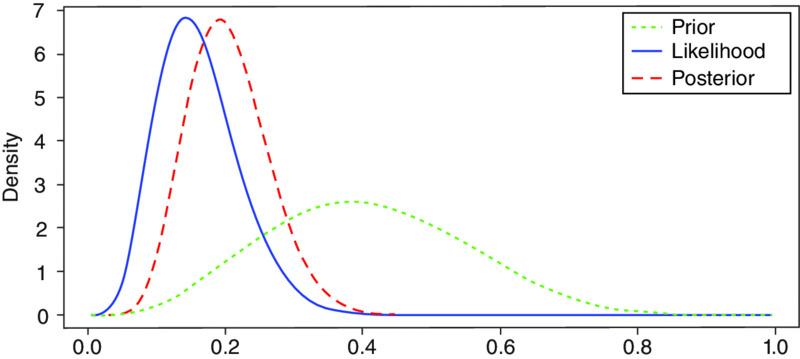
Figure 10.3 Bayes Triplot, beta(4.31, 6.3) prior, s=5, f=30
> triplot(beta.par, c(5,30))
You still have a lot of uncertainty about the real state of the company’s cloud security posture. In fact, it’s looking significantly worse than you had guessed. Therefore, to help your inferences you decide to simulate a large number of outcomes based on your new beliefs (posterior). That’s a fancy way of saying, “I don’t have time to audit everything. What if I use what I know as input into a simulation machine? This machine would simulate 1,000 audits and give me an idea where my future audit results might fall, constrained by what I already know.” Additionally, you frame up your result in terms of your 90% CI, meaning, “I am 90% confident that the true value of company XYZ’s cloud security state is between x% and y%.” Let’s get our 90% CI first:
> beta.post.par <‐ beta.par + c(5, 30) > qbeta(c(0.05, 0.95), beta.post.par[1],beta.post.par[2]) [1] 0.1148617 0.3082632
Pretty straightforward—we get the alpha and beta from our new posterior and feed it into a simple function called qbeta. The first parameter c(0.05,0.95) simply tells us the 90% CI. Now that we have that, let’s simulate a bunch of trials and get the 90% CI from that for thoroughness.
> post.sample <‐ rbeta(1000, beta.post.par[1], beta.post .par[2]) > quantile(post.sample, c(0.05, 0.95)) 5% 95% 0.1178466 0.3027499
It looks like the proportion in question is likely (90% confident) to land between 12% and 30%. We can take this even further and try to predict what the results might be on the next 200 audits. We run that this way:
> num <‐ 200 > sample <‐ 0:num > pred.probs <‐ pbetap(beta.post.par, num, sample) > discint(cbind(sample, pred.probs), 0.90) > [1] 0.9084958 > $set [1] 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [20] 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [39] 55 56
Your model is telling you that you should be 91% confident that the next 200 audits will have between 17 and 56 successful outcomes. You have some financial modeling to do both in terms of remediation cost and the probability of breach. This latter issue is what is most disconcerting. How much risk are you really inheriting? What is the likelihood that a breach may have occurred or may be occurring?
This was a very simple example. It could have easily been done in Excel, Python, or on a smart calculator. But the point is that you can start doing interesting and useful measurements now. As a leader, you will use this type of analytics as your personal form of hand-to-hand combat far more than any other types of metric.