
IBM System x Reference Architecture for Hadoop: IBM InfoSphere BigInsights Reference Architecture
Introduction
The IBM® System x® reference architecture is a predefined and optimized hardware infrastructure for IBM InfoSphere® BigInsights™ 2.1, which is a distribution of Apache Hadoop with value-added capabilities that are specific to IBM. The reference architecture provides a predefined hardware configuration for implementing InfoSphere BigInsights 2.1 on System x hardware. The reference architecture can be implemented in two ways to support MapReduce workloads or Apache HBase workloads.
•MapReduce is a core component of Hadoop that provides an offline, batch-oriented framework for high-throughput data access and distributed computation.
•Apache HBase is a schemaless, No-SQL database that is built upon Hadoop to provide high throughput random data reads and writes and data caching.
The predefined configuration provides a baseline configuration for an InfoSphere BigInsights cluster and provides modifications for an InfoSphere BigInsights cluster that is running HBase. The predefined configurations can be modified based on the specific customer requirements, such as lower cost, improved performance, and increase reliability.
Business problem and business value
This section describes the business problem that is associated with big data environments and the value that InfoSphere BigInsights offers.
Business problem
Every day, we create 2.5 quintillion bytes of data. It is so much that 90% of the data in the world today was created in the last two years alone. This data comes from everywhere, such as sensors used to gather climate information, posts to social media sites, digital pictures and videos, purchase transaction records, and cell phone GPS signals. This data is big data.
Big data spans three dimensions:
•Volume. Big data comes in one size; that is large. Enterprises are awash with data, easily amassing terabytes and even petabytes of information.
•Velocity. Often time-sensitive, big data must be used as it is streaming into the enterprise to maximize its value to the business.
•Variety. Big data extends beyond structured data, including unstructured data of all varieties, including text, audio, video, click streams, and log files.
Big data is more than a challenge; it is an opportunity to find insight in new and emerging types of data, to make your business more agile, and to answer questions that, in the past, were beyond reach. Until now, there was no practical way to harvest this opportunity. Today, IBM’s platform for big data uses such technologies as the real-time analytics processing capabilities of stream computing and the massive MapReduce scale-out capabilities of Hadoop to open the door to a world of possibilities.
As part of IBM’s platform for big data, IBM InfoSphere Streams allows you to capture and act on all of your business data, all of the time, just in time.
Business value
IBM InfoSphere BigInsights brings the power of Apache Hadoop to the enterprise. Hadoop is the open source software framework that is used to reliably manage large volumes of structured and unstructured data. InfoSphere BigInsights enhances this technology to withstand the demands of your enterprise, adding administrative, workflow, provisioning, and security features, along with best-in-class analytical capabilities from IBM Research. The result is a more developer and user compatible solution for complex, large-scale analytics.
How can businesses process tremendous amounts of raw data in an efficient and timely manner to gain actionable insights? By using InfoSphere BigInsights, organizations can run large-scale, distributed analytics jobs on clusters of cost-effective server hardware. This infrastructure can be used to tackle large data sets by breaking up the data into chunks and coordinating the processing of the data across a massively parallel environment. When the raw data is stored across the nodes of a distributed cluster, queries and analysis of the data can be handled efficiently, with dynamic interpretation of the data format at read time. The bottom line is that businesses can finally embrace massive amounts of untapped data and mine that data for valuable insights in a more efficient, optimized, and scalable way.
Reference architecture use
When reviewing the potential of using System x with InfoSphere BigInsights, use this reference architecture paper as part of an overall assessment process with a customer.
When working on a big data proposal with a client, you can go through several phases and activities as outlined in the following list and in Table 1:
•Discover the client’s technical requirements and usage (hardware, software, data center, workload, user data, and high availability).
•Analyze the client’s requirements and current environment.
•Exploit with proposals based on IBM hardware and software.
Table 1 Client technical discovery, analysis, and exploitation
|
Discover
|
Analyze
|
Exploit
|
|
New applications
|
•Determine data storage requirements, including user data size and compression ratio.
•Determine high availability requirements.
•Determine customer corporate networking requirements, such as networking infrastructure and IP addressing.
•Determine whether data node OS disks require mirroring.
•Determine disaster recovery requirements, including backup/recovery and multisite disaster recover requirements.
•Determine cooling requirements, such as airflow and BTU requirements.
•Determine workload characteristics, such as MapReduce or HBase.
•Identify cluster management strategy, such as node firmware and OS updates.
•Identify a cluster rollout strategy, such as node hardware and software deployment.
|
•Propose InfoSphere BigInsights cluster as the solution to big data problems.
•Use the IBM System x M4 architecture for easy scalability of storage and memory.
|
|
Existing applications
|
•Determine data storage requirements and existing shortfalls.
•Determine memory requirements and existing shortfalls.
•Determine throughput requirements and existing bottlenecks.
•Identify system utilization inefficiencies.
|
•Propose a nondisruptive and lower risk solution.
•Propose a Proof-of-Concept (PoC) for the next server deployment.
•Propose a InfoSphere BigInsights cluster as a solution to big data problems.
•Use System x M4 architecture for easy scalability of storage and memory.
|
|
Data center health
|
•Determine server sprawl.
•Determine electrical, cooling, space headroom.
•Identify inefficiency concerns.
|
•Propose a scalable InfoSphere BigInsights cluster.
•Propose lowering data center costs with energy efficient System x servers.
|
Requirements
The hardware and software requirements for the System x Reference Architecture for Hadoop: InfoSphere BigInsights are embedded throughout this IBM Redpaper™ within the appropriate sections.
InfoSphere BigInsights predefined configuration
This section describes the predefined configuration for InfoSphere BigInsights reference architecture.
Architectural overview
From an infrastructure design perspective, Hadoop has two key aspects: Hadoop Distributed File System (HDFS) and MapReduce. An IBM InfoSphere BigInsights reference architecture solution has three server roles:
Management nodes Nodes that are implemented on System x3550 M4 servers. These nodes encompass InfoSphere BigInsights daemons that are related to managing the cluster and coordinating the distributed environment.
Data nodes Nodes that are implemented on System x 3650 BD servers. These nodes encompass daemons that are related to storing data and accomplishing work within the distributed environment.
Edge nodes Nodes that act as a boundary between the InfoSphere BigInsights cluster and the outside (client) environment.
The number of each type of node that is required within an InfoSphere BigInsights cluster depends on the client requirements. Such requirements might include the size of a cluster, the size of the user data, the data compression ratio, workload characteristics, and data ingest.
HDFS is the file system in which Hadoop stores data. HDFS provides a distributed file system that spans all the nodes within a Hadoop cluster, linking the files systems on many local nodes to make one big file system with a single namespace.
HDFS has three associated daemons:
NameNode Runs on a management node and is responsible for managing the HDFS namespace and access to the files stored in the cluster.
Secondary NameNode
Typically runs on a management node and is responsible for maintaining periodic check points for recovery of the HDFS namespace if the NameNode daemon fails. The Secondary NameNode is a distinct daemon and is not a redundant instance of the NameNode daemon.
Typically runs on a management node and is responsible for maintaining periodic check points for recovery of the HDFS namespace if the NameNode daemon fails. The Secondary NameNode is a distinct daemon and is not a redundant instance of the NameNode daemon.
DataNode Runs on all data nodes and is responsible for managing the storage that is used by HDFS across the BigInsights Hadoop Cluster.
MapReduce is the distributed computing and high-throughput data access framework through which Hadoop understands jobs and assigns work to servers within the BigInsights Hadoop cluster. MapReduce has two associated daemons:
JobTracker Runs on a management node and is responsible for submitting, tracking, and managing MapReduce jobs.
TaskTracker Runs on all data nodes and is responsible for completing the actual work of a MapReduce job, reading data that is stored within HDFS and running computations against that data.
Additionally, InfoSphere BigInsights has an administrative console that helps administrators to maintain servers, manage services and HDFS components, and manage data nodes within the InfoSphere BigInsights cluster. The InfoSphere BigInsights console runs on a management node.
Component model
Figure 1 illustrates the component model for the InfoSphere BigInsights Reference Architecture.

Figure 1 InfoSphere BigInsights Reference Architecture component model
Regarding networking, the reference architecture specifies two networks for a MapReduce implementation: a data network and an administrative/management network. All networking is based on IBM RackSwitch™ switches. For more information about networking, see “Networking configuration” on page 8.
To facilitate easy sizing, the predefined configuration for the reference architecture comes in three sizes:
Starter rack configuration
Consists of three data nodes, the required number of management nodes, and the required IBM RackSwitch switches.
Consists of three data nodes, the required number of management nodes, and the required IBM RackSwitch switches.
Half rack configuration
Consists of nine data nodes, the required number of management nodes, and the required IBM RackSwitch switches.
Consists of nine data nodes, the required number of management nodes, and the required IBM RackSwitch switches.
Full rack configuration
Consists up to 20 data nodes, the required number of management nodes, and the required IBM RackSwitch switches.
Consists up to 20 data nodes, the required number of management nodes, and the required IBM RackSwitch switches.
The configuration is not limited to these sizes, and any number of data nodes is supported. For more information about the number of data nodes per rack in full-rack and multi-rack configurations, see “Rack considerations” on page 13.
Cluster node and networking configuration and sizing
This section describes the predefined configurations for management nodes, data nodes, and networking for an InfoSphere BigInsights 2.1 solution.
Management node configuration and sizing
Management nodes encompass the following HDFS, MapReduce, and BigInsights management daemons:
•NameNode
•Secondary NameNode
•JobTracker
•BigInsights Console
The management node is based on the IBM System x3550 M4 server. Table 2 lists the predefined configuration of a management node.
Table 2 Management node predefined configuration
|
Component
|
Predefined configuration
|
|
System
|
System x3550 M4
|
|
Processor
|
2 x E5-2650 v2 2.6 GHz 8-core
|
|
Memory - base
|
128 GB = 8 x 16GB 1866 MHz RDIMM
|
|
Disk (OS)
|
4 x 600 GB 2.5-inch SAS
|
|
HDD controller
|
ServeRAID M1115 SAS/SATA Controller
|
|
Hardware storage protection
|
•OS storage on 2 x 600 GB drives that are mirrored by using RAID 1 hardware mirroring.
•Application storage on 2 x 600 GB drives in JBOD or RAID 1 hardware mirroring configuration.
|
|
User space (per server)
|
None
|
|
Administration/management network adapter
|
Integrated 1GBaseT Adapter
|
|
Data network adapter
|
2 x Mellanox ConnectX-3 EN Dual-port SFP+ 10GbE Adapters
|
An InfoSphere BigInsights Hadoop cluster requires 1 - 4 management nodes, depending on the client’s environment. Table 3 specifies the number of required management nodes. In this table, the columns that contain node information represent InfoSphere BigInsights Hadoop services that are housed across cluster management nodes.
Table 3 Required management nodes
|
Environment
|
Required management nodes
|
Node 1
|
Node 2
|
Node 3
|
Node 4
|
|
Development Environment
|
1
|
NameNode1, JobTracker, BigInsights Console
|
N/A
|
N/A
|
N/A
|
|
Production/Test Environment
|
32
|
NameNode
|
JobTracker, Secondary NameNode
|
BigInsights Console
|
N/A
|
|
Production / Test Environment with Highly Available NameNode
|
4b
|
NameNode (Active or Standby)
|
NameNode (Active or Standby)
|
JobTracker
|
BigInsights Console
|
1 In a single management node configuration, place the Secondary NameNode on a data node to enable recoverability of the HDFS namespace if a failure of the management node occurs.
2 For fault recoverability in multirack production/test environments, whenever possible, avoid placing management node 1 and management node 2 in the same rack.
Data node configuration and sizing
Data nodes house the Hadoop HDFS and MapReduce daemons: DataNode, and TaskTracker. The data node is based on the IBM System x3650 BD storage-rich server. Table 4 describes the predefined configuration for a data node.
Table 4 Data node predefined configuration
|
Component
|
Predefined configuration
|
|
System
|
System x3650 BD
|
|
Processor
|
2 x E5-2650 v2 2.6 GHz 8-core
|
|
Memory - base
|
64 GB = 8x 8 GB 1866 MHz RDIMM
|
|
Disk (OS)1
|
3 TB drives: 1 or 2 x 3 TB NL SATA 3.5-inch
4 TB drives: 1 or 2 x 4 TB NL SATA 3.5-inch
|
|
Disk (data)2
|
3 TB drives: 12 x 3 TB NL SATA 3.5-inch (36 TB total)
4 TB drives: 12 x 4 TB NL SATA 3.5-inch (48 TB total)
|
|
HDD controller
|
6 Gb JBOD Controller
|
|
Hardware storage protection
|
None (JBOD). By default, HDFS maintains a total of three copies of data that is stored within the cluster. The copies are distributed across data servers and racks for fault recovery.
|
|
Management network adapter
|
Integrated 1GBaseT Adapter
|
|
Data network adapter
|
Mellanox ConnectX-3 EN Dual-port SFP+ 10GbE Adapter
|
1 OS drives should be the same size as the data drives. If two OS drives are used, drives can be configured in a JBOD or RAID 1 hardware mirroring configuration. Available space on the OS drives can also be used for more HDFS storage, more MapReduce shuffle/sort space, or both.
2 All data drives should be of the same size, 3 TB or 4 TB.
When you estimate disk space within an InfoSphere BigInsights Hadoop cluster, consider the following points:
•For improved fault tolerance and improved performance, HDFS replicates data blocks across multiple cluster data nodes. By default, HDFS maintains three replicas.
•With the MapReduce process, shuffle/sort data is passed from Mappers to Reducers by writing the data to the data node’s local file system. If the MapReduce job requires more than the available shuffle file space, the job will terminate. As a rule of thumb, reserve 25% of total disk space for the local file system as shuffle file space.
•The actual space that is required for shuffle/sort is workload-dependent. In the unusual situation where the 25% rule of thumb is insufficient, available space on the OS drives can be used to provide more shuffle/sort space.
•The compression ratio is an important consideration in estimating disk space. Within Hadoop, both the user data and the shuffle/sort data can be compressed. If the client’s data compression ratio is not available, assume a compression ratio of 2.5.
Assuming that the default three replicas are maintained by HDFS, the total cluster data space and the required number of data nodes can be estimated by using the following equations:
Total Data Disk Space = (User Raw Data, Uncompressed) x (4 / compression ratio)
Total Required Data Nodes = (Total Data Disk Space) / (Data Space per Server)
When you estimate disk space, also consider future growth requirements.
Networking configuration
Regarding networking, the reference architecture specifies two networks:
•Data network
The data network is a private 10GbE cluster data interconnect among data nodes that are used for data access, moving data across nodes within the cluster and ingesting data into HDFS. The InfoSphere BigInsights cluster typically connects to the client’s corporate data network by using one or more edge nodes. These edge nodes can be System x 3550 M4 servers, other System x servers, or other customer specified server. Edge nodes act as interface nodes between the InfoSphere BigInsights cluster and the outside client environment (for example, data ingested from a corporate network into a cluster). Not every rack has an edge node connection to a customer network.
•Administrative/management network
The administrative/management network is a 1GbE network that is used for in-band OS administration and out-of-band hardware management. In-band administrative services, such as Secure Shell (SSH) or Virtual Network Computing (VNC), that run on the host operating system allow administration of cluster nodes. Out-of-band management, by using the Integrated Management Modules (IMM2) within the x3550 M4 and x3650 BD, allows hardware-level management of cluster nodes, such as node deployment or BIOS configuration. Hadoop has no dependency on IMM2. Based on customer requirements, the administration and management links can be segregated onto separate VLANs or subnets. The administrative/management network is typically connected directly into the client’s administrative network.
Figure 2 shows a predefined InfoSphere BigInsights cluster network.

Figure 2 Predefined cluster network
Table 5 shows the IBM rack switches that are used in the reference architecture.
Table 5 IBM rack switches
|
Rack switch
|
Predefined configuration
|
|
1GbE top of rack switch for administration/management network
(two physical links to each node: one link for in-band OS administration and one link for out-of-band IMM2 hardware management).1
|
IBM System Networking RackSwitch G8052
|
|
10GbE top of rack switch for data network (two physical 10GbE links to each node, aggregated).
|
IBM System Networking RackSwitch G8264
|
|
40GbE switch for interconnecting data network across multiple racks (40GbE links interconnecting each G8264 top of rack switches; link aggregation depends on the number of core switches and interconnect topology).2
|
IBM System Networking RackSwitch G8316
|
1 The administrative links and management links can be segregated onto separate VLANS or subnets.
2 To avoid a single point of failure, have redundant core switches.
Figure 3 shows the networking predefined connections within a rack.

Figure 3 Networking predefined configuration
The networking predefined configuration has the following characteristics:
•The administration/management network is typically connected to the client’s administration network. Management and data nodes each have two administration/management network links: one link for in-band OS administration and one link for out-of-band IMM2 hardware management. On the x3550 M4 management nodes, the administration link should connect to port 1 on the integrated 1GBaseT adapter, and the management link should connect to the dedicated IMM2 port. On the System x3650 BD data nodes, the administration link should connect to port 1 on the integrated 1GBaseT adapter, and the management link should connect to the dedicated IMM2 port.
•The data network is a private VLAN or subnet. The two Mellanox 10GbE ports of each data node are link aggregated to G8264 for better performance and improved high availability.
•The cluster administration/management network is connected to the corporate data network. Each node has two links to the G8052 RackSwitch at the top of the rack, one for the administration network and one for the IMM2. Within each rack, the G8052 has two uplinks to the G8264 to allow propagation of the administrative/management VLAN across cluster racks by using the G8316 core switch.
•Not every rack has an edge node connection to the client’s corporate data network. For more information about edge nodes, see “Customizing the predefined configurations” on page 22.
•Given the importance of their role within the cluster, System x3550 management nodes have two Mellanox dual-port 10GbE networking cards for fault tolerance. The first port on each Mellanox card should connect back to the G8264 switch at the top of the rack. The second port on each Mellanox card is available to connect into the client’s data network in cases where the node functions as an edge node for data ingest and access.
Figure 4 shows the rack-level connections in greater detail.
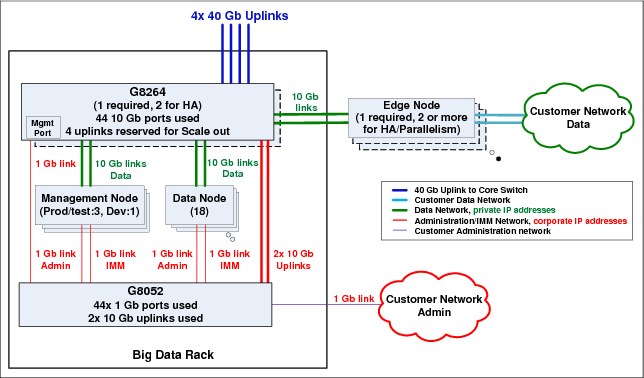
Figure 4 Big data rack connections
The data network is connected across racks by two aggregated 40GbE uplinks from each rack’s G8264 switch to a core G8316 switch.
Figure 5 shows the cross rack networking by using the core switch.

Figure 5 Cross rack networking
Edge node considerations
The edge node acts as a boundary between the InfoSphere BigInsights cluster and the outside (client) environment. The edge node is used for data ingest, which refers to routing data into the cluster through the data network of the reference architecture. Edge nodes can be System x3550 M4 servers, other System x servers, or other client-provided servers.
With the design of the System x3550 management node, the same configuration can be used as an edge node. When you use this configuration as an edge node, the first port on each Mellanox dual-port 10GbE network adapter connects back to the G8264 switch at the top of the node’s home rack. The second port on each Mellanox dual-port 10GbE network adapter connects to the client’s data network. This edge node design serves as a ready-made platform for extract, transform, and load (ETL) tools, such as IBM InfoSphere DataStage®.
Although a BigInsights cluster can have multiple edge nodes, depending on applications and workload, not every cluster rack needs to be connected to an edge node. However, every data node within the BigInsights cluster must be a cluster data network IP address that is routable from within the corporate data network. As gateways into the BigInsights cluster, you must properly size edge nodes to ensure that they do not become a bottleneck for accessing the cluster, for example, during high volume ingest periods.
|
Important: The number of edge nodes and the edge node server physical attributes that are required depend on ingest volume and velocity. Because of physical space constraints within a rack, adding an edge node to a rack can displace a data node.
|
In low volume/velocity ingest situations (< 1 GB/hr), the InfoSphere BigInsights console management node can be used as an edge node. InfoSphere DataStage and InfoSphere Data Click servers can also function as edge nodes. When using InfoSphere DataStage or other ETL software, consult an appropriate ETL specialist for server selection.
In Proof-of-Concept (PoC) situations, the edge node can be used to isolate both cluster networks (data and administrative/management) from the customer corporate network.
Power considerations
Within racks, switches and management nodes have redundant power feeds with each power feed connected from a separate protocol data unit (PDU). Data nodes have a single power feed, and the data node power feeds should be connected so that all power feeds within the rack are balanced across the PDUs.
Figure 6 shows power connections within a full rack with three management nodes.

Figure 6 Power connections
Rack considerations
Within a rack, data nodes occupy 2U of space and management nodes, and rack switches occupy 1U or space.
A one-rack InfoSphere BigInsights implementation comes in three sizes: starter rack, half rack, and full rack. These three sizes allow for easy ordering. However, reference architecture sizing is not rigid and supports any number of data nodes with the appropriate number of management nodes. Table 6 describes the node counts.
Table 6 Rack configuration node counts
|
Rack configuration size
|
Number of data nodes1
|
Number of management nodes2
|
|
Starter rack
|
33
|
1, 3, or 4
|
|
Half rack
|
9
|
1, 3, or 4
|
|
Full rack with management nodes
|
184
|
1, 3, or 4
|
|
Full data node rack, No management nodes
|
20
|
0
|
1 Maximum number of data nodes per full rack based on network switches, management nodes, and data nodes. Adding edge nodes to the rack can displace additional data nodes.
2 The number of management notes depends on development or the production/test environment type. For more information about selecting the correct number of management nodes, see “Management node configuration and sizing” on page 6.
3 The starter rack can be expanded to a full rack by adding more data and management nodes.
4 A full rack with one or two management nodes can accommodate up to 19 data nodes.
An InfoSphere BigInsights implementation can be deployed as a multirack solution. If the system is initially implemented as a multirack solution or if the system grows by adding more racks, to maximize fault tolerance, distribute the cluster management nodes across racks.
In the reference architecture for InfoSphere BigInsights, a fully populated predefined rack with one G8264 switch and one G8052 switch can support up to 20 data nodes. However, the total number of data nodes that a rack can accommodate can vary based on the number of top-of-rack switches and management nodes that are required for the rack within the overall solution design. The number of data nodes can be calculated by the following equation:
Maximum number data nodes = (42U - (# 1U Switches + # 1U Management Nodes)) / 2
|
Edge nodes: This calculation does not consider edge nodes. Based on the client’s choice of edge node, proportions can vary. Every two 1U edge nodes displace one data node, and every one 2U displaces one data node.
|
Figure 7 shows an example of a starter, half-rack, and a full-rack configuration.

Figure 7 Sample configuration
Figure 8 shows an example of scale-out rack configurations.

Figure 8 Sample configuration
InfoSphere BigInsights HBase predefined configuration
This section describes the predefined configuration for InfoSphere BigInsights HBase reference architecture.
Architectural overview
HBase is a schemaless, No-SQL database that is implemented within the Hadoop environment and is included in InfoSphere BigInsights 2.x. HBase has its own set of daemons that run on management nodes and data nodes. The HBase daemons are in addition to the management node and data node daemons of HDFS and MapReduce, as described in “InfoSphere BigInsights predefined configuration” on page 4.
HBase has two more daemons that run on master nodes:
HMaster The HBase master daemon. It is responsible for monitoring the HBase cluster and is the interface for all metadata changes.
ZooKeeper A centralized daemon that enables synchronization and coordination across the HBase cluster.
HBase has one daemon that runs on all data nodes, the HRegionServer daemon. The HRegionServer daemon is responsible for managing and serving HBase regions. Within HBase, a region is the basic unit of distribution of an HBase table, allowing a table to be distributed across multiple servers within a cluster.
Use great care when you consider running MapReduce workloads in a cluster that is running HBase. MapReduce jobs can use significant resources and can have a negative impact on HBase performance and service-level agreements (SLAs). As a rule of thumb, do not run MapReduce jobs on a cluster that is running HBase.
Because HBase is implemented within Hadoop, the reference architecture implementation for HBase has same three server roles as described in “InfoSphere BigInsights predefined configuration” on page 4:
•Management nodes
Based on the System x3550 M4 server, management nodes house the following HDFS, MapReduce, and HBase services:
– NameNode
– Secondary NameNode
– JobTracker
– HMaster
– Zookeeper
•Data nodes
Based on the System x3650 BD server, data nodes house the following HDFS, MapReduce, and HBase services:
– DataNode
– TaskTracker
– HRegionServer
•Edge nodes
Within a BigInsights Cluster running HBase is a specific number of master nodes and a variable number of data nodes, based on customer requirements.
Component model
Figure 9 illustrates the component model for the InfoSphere BigInsights HBase reference architecture.

Figure 9 InfoSphere BigInsights HBase reference architecture component model
Implementing HBase requires a few modifications to the predefined configuration that is described in “InfoSphere BigInsights HBase predefined configuration” on page 16. For considerations specific to HBase for the management nodes and data nodes, see “Cluster node configuration” on page 18.
Networking configuration, edge nodes considerations, and power considerations for the InfoSphere BigInsights HBase predefined configuration are identical to those considerations of the InfoSphere BigInsights predefined configuration. For more information, see “Networking configuration” on page 8 and “Power considerations” on page 13.
Cluster node configuration
This section describes the predefined configurations for management nodes and data nodes for an InfoSphere BigInsights 2.1 HBase solution. The networking configuration is the same as the configuration that is described in “Networking configuration” on page 8.
Management node configuration and sizing
Management nodes house the following HDFS, MapReduce, HBase, and BigInsights management services: NameNode, Secondary NameNode, TaskTracker, HMaster, ZooKeeper, and BigInsights Console. The management node is based on the IBM System x3550 M4 server. Table 7 describes the predefined configuration of a management node.
Table 7 Management node predefined configuration
|
Component
|
Predefined configuration
|
|
System
|
x3550 M4
|
|
Processor
|
2 x E5-2650 v2 2.6 GHz 8 core
|
|
Memory - base
|
128 GB = 8 x 16 GB 1866 MHz RDIMM
|
|
Disk (OS)
|
4 x 600 GB 2.5-inch SAS
|
|
HDD controller
|
ServeRAID M1115 SAS/SATA Controller
|
|
Hardware storage protection
|
•OS storage on 2 x 600 GB drives that are mirrored by using hardware mirroring
•Application storage on 2 x 600 GB drives in JBOD configuration
|
|
User space (per server)
|
None
|
|
Administration/management network adapter
|
Integrated 1GBaseT Adapter
|
|
Data network adapter
|
2 x Mellanox ConnectX-3 EN Dual-port SFP+ 10 GbE Adapter
|
An InfoSphere BigInsights Hadoop cluster that is running HBase requires 1 - 6 management nodes, depending on the cluster size. Table 8 specifies the number of required management nodes. The columns that contain node information represent BigInsights Hadoop daemons that are housed across cluster management nodes.
Table 8 Required management nodes
|
Cluster size
|
Required management nodes
|
Node 1
|
Node 2
|
Node 3
|
Node 4
|
Node 5
|
Node 6
|
|
Starter cluster
|
1
|
NameNode1, JobTracker,
HMaster, BigInsights Console
|
|
|
|
|
|
|
<20 data nodes
|
42
|
NameNode,
Zookeeper
|
JobTracker, HMaster, Zookeeper
|
Secondary NameNode, HMaster, Zookeeper
|
BigInsights Console
|
|
|
|
>= 20 data nodes
|
63
|
NameNode, Zookeeper
|
Secondary NameNode4, Zookeeper
|
JobTracker, Zookeeper
|
HMaster, Zookeeper
|
HMaster, Zookeeper
|
BigInsights Console
|
1 In a single management node configuration, to enable recoverability of the HDFS metadata if a failure of the management node occurs, place the Secondary NameNode on a data node.
2 For HBase fault tolerance and HDFS fault recovery if a management node failure occurs, do not place management nodes 1 and 2 in the same rack as management nodes 3 and 4.
3 For HBase fault tolerance and HDFS fault recovery if a management node failure occurs, do not place management nodes 1 and 2 in the same rack, and do not place management nodes 4 and 5 in the same rack.
4 For HDFS NameNode high availability, the Secondary NameNode can be substituted with a second HDFS NameNode service. Place the active NameNode typically on the node with the fewest total number of management services running.
Data node configuration and sizing
Data nodes house the following Hadoop services: DataNode, TaskTracker, and HRegionServer. The data node is based on the System x3650 BD storage-rich server. This data node differs from the base InfoSphere BigInsights predefined configuration in that HBase data nodes have greater memory capacity. Table 9 describes the predefined configuration for a data node.
Table 9 Data node predefined configuration
|
Component
|
Pre-defined configuration
|
|
System
|
x3650 BD
|
|
Processor
|
2 x E5-2650 v2 2.6 GHz 8 core
|
|
Memory - base
|
128 GB =16 x 8 GB 1866 MHz RDIMM
|
|
Disk (OS)1
|
1 TB drives: 1 or 2 x 1 TB NL SATA 3.5-inch
2 TB drives: 1 or 2 x 2 TB NL SATA 3.5-inch
|
|
1 TB drives: 12 x 1 TB NL SATA 3.5-inch (12 TB total)
2 TB drives: 12 x 2 TB NL SATA 3.5-inch (24 TB total)
|
|
|
HDD controller
|
6 Gb JBOD Controller
|
|
Hardware storage protection
|
None (JBOD). By default, HDFS maintains a total of three copies of data that is stored within the cluster. The copies are distributed across data servers and racks for fault recovery.
|
|
Administration/management network adapter
|
Integrated 1GBaseT Adapter
|
|
Data network adapter
|
Mellanox ConnectX-3 EN Dual-port SFP+ 10GbE
|
1 Ensure that the OS drives are the same size as the data drives. If two OS drives are used, drives can be configured in either a JBOD or RAID1 hardware mirroring configuration. Available space on the OS drives can also be used for extra HDFS storage, extra MapReduce shuffle/sort space, or both.
2 All data drives should be of the same size, either 3 TB or 4 TB.
3 There is a direct relationship between HBase RegionServer JVM heap size and disk capacity whereby the maximum effective disk space usable by an HBase RegionServer is dependant on the JVM heap size. For more information, see: http://hadoop-hbase.blogspot.com/2013/01/hbase-region-server-memory-sizing.html
When you estimate disk space within a BigInsights HBase cluster, keep in mind the following considerations:
•For improved fault tolerance and improved performance, HDFS replicates data blocks across multiple cluster data nodes. By default, HDFS maintains three replicas.
•Reserve approximately 25% of total available disk space for shuffle/sort space.
•Compression ratio is an important consideration in estimating disk space. Within Hadoop, both the user data and the shuffle data can be compressed. If the client’s data compression ratio is not available, assume a compression ratio of 2.5.
•Add an extra 30% - 50% for HBase HFile storage and compaction.
Assuming that the default three replicas are maintained by HDFS and the HFile storage requirements, the upper bound total cluster data space and required number of data nodes can be estimated by using the following equations:
Total Data Disk Space = (User Raw Data, Uncompressed) x (4 / compression ratio) x 150%
Total Required Data Nodes = (Total Data Disk Space) / (Data Disk Space per Server)
When you estimate disk space, also consider future growth requirements.
Rack considerations
Within a rack, each data node occupies 2U, and each management node or switch occupies 1U. The HBase implementation can be deployed in a single-rack or multirack configuration. Table 10 outlines the rack considerations.
|
Important: If the system is initially implemented as a multirack solution or if the system grows by adding more racks, distribute the cluster management nodes across the racks to maximize fault tolerance.
|
Table 10 Rack considerations
|
Cluster size
|
Number of racks
|
Maximum number of data nodes per rack1
|
Number of management nodes per cluster
|
|
Starter rack
|
1
|
32
|
1
|
|
<20 data nodes
|
1 - 2
|
18
|
4
|
|
>= 20 data nodes
|
2+
|
18 - 203
|
6
|
1 The maximum number of data nodes per full rack based on network switches, management nodes, and data nodes. Adding edge nodes to the rack can displace extra data nodes.
2 A starter rack can be expanded to a full rack by adding more data and management nodes.
3 The actual maximum depends on the number of racks that are implemented. To maximize fault tolerance, distribute management nodes across racks. Every two management nodes within a rack displace one data node.
In the reference architecture for the InfoSphere BigInsights solution, a fully populated predefined rack with one G8264 switch and one G8052 switch can support up to 20 data nodes. However, the total number of data nodes that a rack can accommodate can vary based on the number of top of rack switches and management nodes that are required for the rack within the overall solution design. The number of data nodes can be calculated as follows:
Maximum number of data dodes = (42U - (# 1U Switches + # 1U Management Nodes)) / 2
|
Edge nodes: This calculation does not consider edge nodes. Based on the client’s choice of edge node, proportions can vary. Every two 1U edge nodes displace one data node, and every one 2U edge node displaces one data node.
|
Deployment considerations
This section describes the deployment considerations for the InfoSphere BigInsights and the InfoSphere BigInsights HBase reference architectures.
Scalability
The Hadoop architecture is linearly scalable. When the capacity of the existing infrastructure is reached, the cluster can be scaled out by adding more data nodes and, if necessary, management nodes. As the capacity of existing racks is reached, new racks can be added to the cluster. Some workloads might not scale linearly.
When you design a new InfoSphere BigInsights reference architecture implementation, future scale out is a key consideration in the initial design. You must consider the two key aspects of networking and management. Both of these aspects are critical to cluster operation and become more complex as the cluster infrastructure grows.
The networking model that is described in the section “Networking configuration” on page 8 is designed to provide robust network interconnection of racks within the cluster. As more racks are added, the predefined networking topology remains balanced and symmetrical. If there are plans to scale the cluster beyond one rack, initially design the cluster with multiple racks, even if the initial number of nodes might fit within one rack. Starting with multiple racks will enforce proper network topology and prevent future reconfiguration and hardware changes.
Also, as the number of nodes within the cluster increases, many of the tasks of managing the cluster also increase, such as updating node firmware or operating systems. Building a cluster management framework as part of the initial design and proactively considering the challenges of managing a large cluster will pay off significantly in the end.
Extreme Cloud Administration Toolkit (xCAT), which is an open source project that IBM supports, is a scalable distributed computing management and provisioning tool that provides a unified interface for hardware control, discovery, and operating system deployment. Within the InfoSphere BigInsights reference architecture, the System x server IMM2 and the cluster management network provide an out-of-band management framework that management tools, such as xCAT, can use to facilitate or automate the management of cluster nodes.
Proactive planning for future scale out and the development of cluster management framework as a part of initial cluster design provides a foundation for future growth that will minimize hardware reconfigurations and cluster management issues as the cluster grows.
Availability
When you implement an IBM InfoSphere BigInsights cluster on a System x server, consider the availability requirements as part of the final hardware and software configuration. Typically, Hadoop is considered a highly reliable solution. Hadoop and InfoSphere BigInsights best practices provide significant protection against data loss. Generally failures can be managed without causing an outage. Redundancy can be added to make a cluster even more reliable. Consider both hardware and software redundancy.
Customizing the predefined configurations
The predefined configuration provides a baseline configuration for an InfoSphere BigInsights cluster and provides modifications for an InfoSphere BigInsights cluster that is running HBase. The predefined configurations represent a baseline configuration that can be implemented as is or modified based on specific client requirements, such as lower cost, improved performance, and increased reliability.
When you consider modifying the predefined configuration, you must understand key aspects of how the cluster will be used. In terms of data, you must understand the current and future total data to be managed, the size of a typical data set, and whether access to the data will be uniform or skewed. In terms of ingest, you must understand the volume of data to be ingested and ingest patterns, such as regular cycles over specific time periods and bursts in ingest. Consider also the data access and processing characteristics of common jobs and whether query-like frameworks, such as Hive or Pig, are used.
When you design an InfoSphere BigInsights cluster infrastructure, conduct the necessary testing and proof of concepts against representative data and workloads to ensure that the proposed design will achieve the necessary success criteria. The following sections provide information about customizing the predefined configuration. When you consider customization to the predefined configuration, work with a systems architect who is experienced in designing InfoSphere BigInsights cluster infrastructures.
Designing for high availability
Designing for high availability entails assessing potential failure points and planning so that potential failure points do not impact the operation of the cluster. Whenever you address enhanced high availability, you must understand and consider the trade-offs between the cost of outage and the cost of adding redundant hardware components. Within an InfoSphere BigInsights cluster, several single points of failure exist:
•A typical Hadoop HDFS is implemented with a single NameNode service instance. A couple of options exist to address this issue. InfoSphere BigInsights 2.1 supports an active/standby redundant NameNode configuration as an alternative to the standard NameNode/Secondary NameNode configuration. For more information about a redundant NameNode service within an InfoSphere BigInsights cluster, see “Management node configuration and sizing” on page 6.
Also, IBM General Parallel File System (GPFS™)-FPO overcomes the potential for NameNode failures by not depending on stand-alone services to manage the distributed file system metadata. GPFS-FPO also has the added benefits of being POSIX-compliant, having more robust tools for online management of underlying storage, point-in-time snapshot capabilities, and off-site replication. For more information about GPFS-FPO, see “GPFS-FPO considerations” on page 26.
•Even with HDFS maintaining three copies of each data block, a disk drive failure can impact cluster functioning and performance. Nonetheless, the potential for disk failures can be addressed by using RAID 5 or RAID 6 to manage data storage within each data node. The JBOD controller that is specified within the predefined configuration can be substituted with the ServeRAID M5110. Implementing RAID 5 reduces the total available data disk storage by approximately 8.3%, and implementing RAID 6 reduces the total available data disk storage by approximately 16.6%. The use of RAID within Hadoop clusters is atypical and should be considered only for enterprise clients who are sensitive to disk failures because the use of RAID can impact performance.
•The data network in the predefined reference architecture configuration consists of a single network topology. The single G8264 data network switch within each rack represents a single point of failure. Addressing this challenge can be achieved by building a redundant data network that uses an extra IBM RackSwitch G8264 top-of-rack switch per rack and appropriate extra IBM RackSwitch G8316 core switches per cluster.
Designing for high performance
To increase cluster performance, you can increase data node memory or use a high-performance job scheduler and MapReduce framework. Often, improving performance comes at increased cost. Therefore, you must consider the cost/benefit trade-offs of designing for higher performance.
In the InfoSphere BigInsights predefined configuration, data node memory can be increased to 128 GB by using sixteen 8 GB RDIMMs. However, in the HBase predefined configuration, data node memory is already set at the 128GB maximum.
The impact of MapReduce suffle file and other temporary file I/O on data node performance can be workload dependant. In some cases, data node perfomance may be increased by utilizing solid state disk (SSD) for MapReduce shuffle files and other temporary files will also provide higher data node performance. The System x Reference Architecture for Hadoop: InfoSphere BigInsights data nodes utilize the N2215 12Gbps HBA. This HBA provides expanded bandwidth to exploit the performance enhancing characteristics of placing MapReduce suffle files and other temporary files on SSD. When considering the use of SSD, it is important to ensure consistency in SSD to HDD capacity proportions across all BigInsights cluster data nodes.
IBM Platform Symphony® provides a high-performance job scheduler and MapReduce framework that provides substantial performance advantages over standard Hadoop JobTracker and TaskTracker services.
Designing for lower cost
Two key modifications can be made to lower the cost of an InfoSphere BigInsights reference architecture solution. When you consider lower-cost options, ensure that clients understand the potential lower performance implications of a lower-cost design. A lower-cost version of the InfoSphere BigInsights reference architecture can be achieved by using lower-cost data node processors and lower-cost cluster data network infrastructure.
The data node processors can be substituted with the E5-2430 2.2 GHz 6-core processor or the E5-2420 1.9 GHz 6-core processor. These processors require 1333 MHz RDIMMs, which can also lower the per-node cost of the solution.
Using a lower-cost network infrastructure can significantly lower the cost of the solution, but can also have a substantial negative impact on intracluster data throughput and cluster ingest rates. To use a lower-cost network infrastructure, use the following substitutions in the predefined configuration:
•Within each node (data nodes and management nodes), substitute the Mellenox 10GbE dual SFP+ network adapter with the extra ports on the integrated 1GBaseT adapters within the x3550 M4 and x3650 BD.
•Within each rack, substitute the IBM RackSwitch G8264 top-of-rack switch with the IBM RackSwitch G8052.
•Within each cluster, substitute the IBM RackSwitch G8316 core switch with the IBM RackSwitch G8264.
•Although the network wiring schema is the same as the schema that is described in “Networking configuration” on page 8, the media types and link speeds within the data network have changed. The data network within a rack that connects data nodes and management nodes to the lower-cost option G8052 top-of-rack switch is now based on two aggregated 1GBaseT links per node (management node and data node). The physical interconnect between the administration/management networks and the data networks within each rack is now based on two aggregated 1GBaseT links between the administration/management network G8052 switch and the lower-cost data network G8052 switch. Within a cluster, the racks are interconnected by using two aggregated 10GbE links between the substitute G8052 data network switch in each rack and a lower-cost G8264 core switch.
Designing for high ingest rates
Ingesting data into an InfoSphere BigInsights cluster is accomplished by using edge nodes that are connected to the cluster data network switches within each rack (IBM RackSwitch G8264). For more information about cluster networking, see “Networking configuration” on page 8. For more information about edge nodes, see “Edge node considerations” on page 12.
Designing for high ingest rates is not a trivial matter. You must have a full characterization of the ingest patterns and volumes. For example, you must know on which days and at what times the source systems are available or not available for ingest. You must know when a source system is available for ingest and the duration for which the system remains available. You must also know what other factors impact the day, time, and duration ingest constraints.
In addition, when ingests occur, consider the average and maximum size of ingest that must be completed, the factors that impact ingest size, and the format of the source data (structured, semi-structured, unstructured). Also determine whether any data transformation or cleansing requirements must be achieved during the ingest.
If the client is using or planning to use ETL software for ingest, such as IBM InfoSphere DataStage, consult the appropriate ETL specialist, such as an IBM DataStage architect, to help size the appropriate edge node configuration.
The key to successfully addressing a high ingest rate is to ensure that the number and physical attributes of edge nodes are sufficient for the throughput and processors needs for ingest and the ETL needs.
Designing for higher per data node storage capacity or archiving
In situations where higher capacity is required, the main design approach is to increase the amount of data disk space per data node. Using 4 TB drives instead of 3 TB drives increases the total per data node data disk capacity 36 - 48 TB, which is a 33% increase. If 4 TB drives are used as data disk drive, increase the OS drives to 4 TB.
When you increase data disk capacity, you must be cognizant of the balance between performance and throughput. For some workloads, increasing the amount of user data that is stored per node can decrease disk parallelism and negatively impact performance.
The value, enterprise, and performance options
Table 11 highlights potential modifications of the predefined configuration of InfoSphere BigInsights reference architecture for data nodes that provide a value option, an enterprise option, and a performance option. These options represent three potential modification scenarios and are intended as example modifications. Any modification of the predefined configurations should be based in client requirements and are not limited to these examples.
Table 11 System x reference architecture for InfoSphere BigInsights x3650 BD data node options
|
|
Value options
|
Enterprise options
|
Performance options
|
|
Processor
|
2 x E5-2630 v2 2.2 GHz 6-core
|
2 x E5-2650 v2 2.6 GHz 8-core
|
2 x E5-2680 v2 2.8 GHz 10-core
|
|
Memory - base
|
48 GB = 6 x 8 GB
|
64 GB = 8 x 8 GB 1866 MHz
|
128 GB = 16 x 8 GB 1866 MHz1
|
|
Disk (data and OS)
|
MapReduce: 13 or 14 x 3 TB NL SATA 3.5-inch
HBase: 13 or 14 x 1 TB NL SATA 3.5-inch
|
MapReduce: 13 or 14 x 3 TB or 4 TB NL SATA 3.5-inch
HBase: 13 or 14 x 1 TB or 2 TB NL SATA 3.5-inch
|
MapReduce: 13 or 14 x 3 TB or 4 TB NL SATA 3.5-inch
HBase: 13 or 14 x 1 TB or 2 TB NL SATA 3.5-inch
|
|
HDD controller
|
6 Gb JBOD Controller
|
ServeRAID M1115 SAS/SATA Controller
|
6 Gb JBOD Controller
|
|
Hardware storage protection
|
None (JBOD)
|
RAID 5 11+P
RAID 6 10+P+Q (business critical)
|
None (JBOD)
|
|
Data network
|
1GbE switch with 4 x 10GbE uplinks (IBM G8052)
|
Redundant 10GbE switches with 4 x 40GbE Uplinks per switch (IBM G8264)
|
10GbE switch with 4 x 40GbE uplinks (IBM G8264)
|
1 The HBase predefined configuration for data nodes already specifies 96 GB of base memory.
GPFS-FPO considerations
The GPFS is an enterprise-class, distributed, single namespace file system for high-performance computing environments that is scalable, offers high performance, and is reliable. The GPFS-FPO (File Placement Optimizer), previously known as GPFS Share Nothing Cluster, is based on a shared nothing architecture, so that each node on the file system can function independently and be self-sufficient within the cluster. GPFS-FPO can directly substitute for HDFS, removing the need for the HDFS NameNode, Secondary NameNode, and DataNode services.
GPFS-FPO has significant and beneficial architectural differences from HDFS. HDFS is a file system based on Java that runs on top of the operating system file system and is not POSIX-compliant. GPFS-FPO is a POSIX-compliant, kernel-level file system that provides Hadoop a single namespace, distributed file system with some performance, manageability, and reliability advantages over HDFS.
As a kernel-level file system, GPFS is free from the overhead that is incurred by HDFS as a secondary file system, running within a JVM on top of the operating systems file system.
As a POSIX-compliant file system, files that are stored in GPFS-FPO are visible to authorized users and applications by using standard file access/management commands and APIs. An authorized user can list, copy, move, or delete files in GPFS-FPO by using traditional operating system file management commands without logging in to Hadoop.
Additionally, GPFS-FPO has significant advantages over HDFS for backup and replication. Within HDFS, the only method for replication or backup is to manually copy files within the Hadoop command shell. Alternatively, GPFS-FPO provides point-in-time snapshot backup and off-site replication capabilities that significantly enhance cluster backup and replication capabilities.
When substituting GPFS-FPO for HDFS as the cluster file system, the HDFS NameNode and Secondary NameNode daemons are not required on cluster management nodes, and the HDFS DataNode daemon is not required on cluster data nodes. From an infrastructure design perspective, including GPFS-FPO can reduce the number of management nodes that are required.
Because GPFS-FPO distributes namespace metadata across the cluster, no dedicated name service is needed. Management nodes within the InfoSphere BigInsights predefined configuration or BigInsights HBase predefined configuration that are dedicated to running the HDFS NameNode or Secondary NameNode services can be eliminated from the design. The reduced number of required management nodes can provide sufficient space to allow for more data nodes within a rack.
Platform Symphony considerations
InfoSphere BigInsights is built on Apache Hadoop, an open-source software framework that supports data-intensive, distributed applications. By using open-source Hadoop, and extending it with advanced analytic tools and other value-added capabilities, InfoSphere BigInsights helps organizations of all sizes more efficiently manage the vast amounts of data that consumers and businesses create every day.
At its core, Hadoop is a Distributed Computing Environment (DCE) that manages the execution of distributed jobs and tasks on a cluster. As with any DCE, the Hadoop software must provide facilities for resource management, scheduling, remote execution, and exception handling. Although Hadoop provides basic capabilities in these areas, these areas are problems that IBM Platform Computing has been working to perfect for 20 years.
IBM Platform Symphony is a low-latency scheduling solution that supports true multitenancy and sophisticated workload management capabilities. Platform Symphony Advanced Edition includes a Hadoop compatible Java MapReduce API that is optimized for low-latency MapReduce workloads. Higher-level Hadoop applications, such as Pig, Hive, Jaql, and other BigInsights components, run directly on the MapReduce framework of Platform Symphony.
Hadoop components, such as the Hadoop JobTracker and TaskTracker in Symphony, have been reimplemented as Platform Symphony applications. They take advantage of the fast middleware, resource sharing, and fine-grained scheduling capabilities of Platform Symphony.
When Platform Symphony is deployed with InfoSphere BigInsights, Platform Symphony replaces the open-source MapReduce layer in the Hadoop framework. Platform Symphony itself is not a Hadoop distribution. Platform Symphony replaces the MapReduce scheduling layer in the InfoSphere BigInsights software environment to provider better performance and multitenancy in a way that is transparent to InfoSphere BigInsights and InfoSphere BigInsights users.
Clients who are deploying InfoSphere BigInsights or other big data application environments can realize significant advantages by using Platform Symphony as a grid manager:
•Better application performance
•Opportunities to reduce costs through better infrastructure sharing
•The ability to guarantee application availability and quality of service
•Ensured responsiveness for interactive workloads
•Simplified management by using a single management layer for multiple clients and workloads
Platform Symphony will be especially beneficial to InfoSphere BigInsights clients who are running heterogeneous workloads that benefit from low latency scheduling. The resource sharing and cost savings opportunities that are provided by Platform Symphony extend to all types of workloads.
Platform Cluster Manager Standard Edition considerations
IBM Platform Cluster Manager Standard Edition is a cluster management software for deploying, monitoring, and manage scale-out compute clusters. It uses xCAT as the embedded provisioning engine but hides the complexity of the open source tool. It also includes a scalable, flexible, and robust monitoring agent technology that shares the same code base with IBM Platform Resource Scheduler, IBM Platform LSF, and IBM Platform Symphony. The monitoring and management web GUI is powerful and intuitive.
Platform Cluster Manager Standard Edition provides the following capabilities to BigInsights environment:
•Bare metal provisioning: Platform Cluster Manager can quickly deploy operating system, device drivers, and BigInsights software components automatically to a bare metal cluster node
•OS updates: Update and patch operating system on cluster nodes from the management console. If the updates do not change OS kernel, there is no need to reboot the node. This is less disruptive for production environment
•Hardware management and control: Provides power control, firmware updates, server LED control, as well as various consoles to the nodes (BMC, ssh, VNC etc.)
•System monitoring: It monitors both the hardware and system performance for all nodes in BigInsights environment from its monitoring console. Custom monitoring metrics can be easily added by changing the configuration files. Once the custom metrics are added, administrator can define alerts using these metrics as well as alert triggered actions. This automates the system management of the BigInsights cluster.
•GPFS monitoring: Platform Cluster Manager has built-in GPFS monitoring. GPFS is one of the optional distributed file systems supported by BigInsights. GPFS capacity and bandwidth are monitored from the management console to allow system administrators to correlate system and storage performance information for troubleshooting and capacity planning.
IBM Platform Cluster Manager Standard Edition simplifies the deployment and management of the BigInsights infrastructure environment. Furthermore, using Platform Cluster Manager Standard Edition does not require any changes to your BigInsights software configuration.
Hardware Deployment & Management Node (Optional)
Within a BigInsights environment, the deployment and ongoing management of the hardware infrastructure is a non-trivial challenge. Deploying a large number of nodes requires configuring node hardware in a consistent manner, along with the ability to apply node-specific hardware parameters, such as IP addresses and host names. Once deployment is complete, maintaining consistent operating system, driver, and firmware levels or effeiciently making changes to the hardware configuration (for example, changing hardware tuning parameters) requires a robust toolset as clusters grow to hundreds of nodes and larger.
Using a separate hardware deployment and management node within the cluster provides a platform that is independent of the wider cluster where tasks such as initial cluster depoyment, scale-out node deployment, and ongoing hardware management can be performed. Such a node is ideal for housing hardware management tools such as Platform Cluster Manager Standard Edition and xCAT, as well as the cluster hardware deployment/configuration state data that these tools maintain.
shows the recommended configuration for a hardware deployment and management node.
Table 12 Optional Hardware Deployment and Management Node
|
|
Recommended Configuration
|
|
Server
|
System x3250
|
|
Processor
|
E3-1220 3.1GHz 4-core
|
|
Memory - base
|
16GB 1333 MHz
|
|
Disk
|
2 x 1 TB NL SATA
|
|
HDD controller
|
ServeRAID C100 for System x
|
|
Storage protection
|
Hardware mirroring (RAID1)
|
|
Network (Admin & IMM Networks)
|
Integrated 1Gb Ethernet ports1
|
1 The x3250 comes standard with two of its four integrated 1Gb Ethernet ports activated. These ports should be used to connect the hardware deployment and management node(s) to both the cluster in-band administration and out-of-band Integrated Management Module (IMM) networks. Access to the IMM network is necessary for low-level hardware management tasks, such as applying firmware updates or modifying BIOS parameters.
In environments where fault tolerance and high availablility is required for the hardware deployment and management tools, the use of two hardware deployment and management nodes is recommended.
General Purpose Big Data Nodes
This document has focused on using the herein-described predefined x3550 management node and x3650 BD data node as core components of an InfoSphere BigInsights solution. However, these predefined nodes can often be used to support other big data workloads that are often associated with an InforSphere BigInsights solution.
The predefined data node, based on the System x3650 BD server, offers a storage rich, efficient memory, and outstanding uptime providing an ideal, purpose-built platform for big data workloads. The x3650 BD is a purpose-built platform for big data workloads requiring high throughput and high capacity, such as databases like DB/2, ETL tools like InfoSphere DataStage, or search and discovery tools like InfoSphere Data Explorer.
The predefined management node, based on the System x 3550 server, offers a high memory, high throughput for management serices, such as GPFS-FPO metadata servers and Platform Symphony management servers; or data-in-motion analytics tools, such as InfoSphere Streams.
The x3650 BD and the x3550 may provide perfect platforms for many of the tools and services that are often apart of a complete solution.
Predefined configuration bill of materials
This section describes the predefined configuration bill of materials for IBM InfoSphere BigInsights.
InfoSphere BigInsights predefined configuration bill of materials
This section provides ordering information for the InfoSphere BigInsights predefined configuration bill of materials. This bill of materials is provided as a sample of a full rack configuration. It is intended as an example only. Actual configurations will vary based on geographic region, cluster size, and specific client requirements.
Data node
Table 13 lists the parts information for the data node.
Table 13 Data node bill of materials
|
Part number
|
Description
|
Quantity
|
|
5466
|
IBM System x3650 M4 BD
|
18
|
|
A4T7
|
PCIe Riser Card 2 (1 x8 LP for Slotless RAID)
|
18
|
|
A4T6
|
PCIe Riser Card for slot 1 (1 x8 FH/HL + 1 x8 LP Slots)
|
18
|
|
A3PM
|
Mellanox ConnectX-3 EN Dual-port SFP+ 10GbE Adapter
|
18
|
|
5977
|
Select Storage devices; RAID configured by IBM is not required
|
18
|
|
A22S
|
IBM 3TB 7.2K 6 Gbps NL SATA 3.5-inch G2HS HDD
|
252
|
|
A4RV
|
IBM System x 750W High Efficiency Platinum AC Power Supply
|
18
|
|
A4WC
|
System Documentation and Software, US English
|
18
|
|
A4S4
|
Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W
|
18
|
|
A4AS
|
Additional Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W
|
18
|
|
A3QG
|
8 GB (1x8 GB, 1Rx4, 1.5V) PC3-14900 CL13 ECC DDR3 1866 MHz LP RDIMM
|
108
|
|
A3YY
|
N2215 SAS/SATA HBA for IBM System x
|
18
|
|
A4RQ
|
System x3650 M4 BD Planar
|
18
|
|
A4RG
|
System x3650 M4 BD Chassis ASM without Planar
|
18
|
|
6311
|
2.8m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
18
|
|
A4RR
|
3.5-inch Hot Swap BP Bracket Assembly, 12x 3.5
|
18
|
|
A4RS
|
3.5-inch Hot Swap Cage Assembly, Rear, 2 x 3.5
|
18
|
|
2306
|
Rack Installation >1U Component
|
18
|
|
A4RH
|
BIOS GBM
|
18
|
|
A4RJ
|
L1 COPT, 1U RIASER CAGE - SLOT 2
|
18
|
|
A4RK
|
L1 COPT, 1U BUTTERFLY RIASER CAGE - SLOT 1
|
18
|
|
A4RN
|
x3650 M4 BD Agency Label
|
18
|
|
A4RP
|
Label GBM
|
18
|
|
A50F
|
2x2 HDD BRACKET
|
18
|
|
A207
|
Rail Kit for x3650 M4 BD, x3630 M4, and x3530 M4
|
18
|
|
A2M3
|
Shipping Bracket for x3650 M4 BD and 3630 M4
|
18
|
Management node
Table 14 lists the parts information for the management node.
Table 14 Management node
|
Part number
|
Description
|
Quantity
|
|
7914FT1
|
System x3550 M4
|
3
|
|
A1H3 ***
|
System x3550 M4 2.5-inch Base Without Power Supply
|
3
|
|
5977
|
Select Storage devices; RAID configured by IBM is not required
|
3
|
|
A1MZ
|
ServeRAID M1115 SAS/SATA Controller for System x
|
3
|
|
A2XD
|
IBM 600 GB 10K 6 Gbps SAS 2.5-inch SFF G2HS HDD
|
12
|
|
A228
|
IBM System x Gen-III Slides Kit
|
3
|
|
A229
|
IBM System x Gen-III CMA
|
3
|
|
A1HG
|
System x3550 M4 4x 2.5-inch HDD Assembly Kit
|
3
|
|
A1ML
|
IBM Integrated Management Module Advanced Upgrade
|
3
|
|
A1H5
|
System x 750W High Efficiency Platinum AC Power Supply
|
3
|
|
A1HL
|
System x3550 M4 PCIe Gen-III Riser Card 2 (1 x16 FH/HL Slot)
|
3
|
|
A2ZQ
|
Mellanox ConnectX-3 EN Dual-port SFP+ 10GbE Adapter
|
6
|
|
A1HJ
|
System x3550 M4 PCIe Riser Card 1 (1 x16 LP Slot)
|
3
|
|
A1HP ***
|
System Documentation and Software, US English
|
3
|
|
A3QL
|
16 GB (1 x16 GB, 2Rx4, 1.5V) PC3-14900 CL13 ECC DDR3 1866 MHz LP RDIMM
|
24
|
|
A1H5
|
System x 750W High Efficiency Platinum AC Power Supply
|
3
|
|
6263
|
4.3m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
6
|
|
A2U6
|
IBM System x Advanced Lightpath Kit
|
3
|
|
A3WR
|
Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W
|
3
|
|
A3X9
|
Additional Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W with Fan
|
3
|
|
2305
|
Rack Installation of 1U Component
|
3
|
|
A3XM
|
System x3550 M4 Planar
|
3
|
|
A1HB
|
System x3550 M4 System Level Code
|
3
|
|
A1HD
|
System x3550 M4 Agency Label GBM
|
3
|
Administration/management network switch
Table 15 lists the parts information for the administration/management network switch.
Table 15 Administration/management network switch
|
Part number
|
Description
|
Quantity
|
|
7309HC1
|
IBM System Networking RackSwitch G8052 (Rear to Front)
|
1
|
|
6311
|
2.8m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
2
|
|
A1DK
|
IBM 19-inch Flexible 4 Post Rail Kit
|
1
|
|
2305
|
Rack Installation of 1U Component
|
1
|
Data network switch
Table 16 lists the parts information for the data network switch.
Table 16 Data network switch
|
Part number
|
Description
|
Quantity
|
|
7309HC3
|
IBM System Networking RackSwitch G8264 (Rear to Front)
|
1
|
|
6311
|
2.8m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
2
|
|
A1DK
|
IBM 19-inch Flexible 4 Post Rail Kit
|
1
|
|
2305
|
Rack Installation of 1U Component
|
1
|
Rack
Table 17 lists the parts information for the rack.
Table 17 Rack
|
Part number
|
Description
|
Quantity
|
|
1410RC4
|
e1350 42U rack cabinet
|
1
|
|
6012
|
DPI Single-phase 30A/208V C13 Enterprise PDU (US)
|
4
|
|
2202
|
Cluster 1350 Ship Group
|
1
|
|
2304
|
Rack Assembly - 42U Rack
|
1
|
|
2310
|
Cluster Hardware & Fabric Verification - 1st Rack
|
1
|
|
4271
|
1U black plastic filler panel
|
1
|
Cables
Table 18 lists the parts information for the cables.
Table 18 Cables
|
Part number
|
Description
|
Quantity
|
|
3735
|
0.5m Molex Direct Attach Copper SFP+ Cable
|
2
|
|
3736
|
1m Molex Direct Attach Copper SFP+ Cable
|
4
|
|
3737
|
3m Molex Direct Attach Copper SFP+ Cable
|
36
|
|
2323
|
IntraRack CAT5E Cable Service
|
42
|
InfoSphere BigInsights HBase predefined configuration bill of materials
This section provides ordering information for the InfoSphere BigInsights HBase predefined configuration bill of materials. This bill of materials is provided as a sample of a full rack configuration. It is intended as an example only. Actual configurations will vary based on geographic region, cluster size, and specific client requirements.
Data node
Table 19 lists the parts information for the data node.
Table 19 Data node
|
Part number
|
Description
|
Quantity
|
|
5466
|
IBM System x3650 M4 BD
|
18
|
|
A4T7
|
PCIe Riser Card 2 (1 x8 LP for Slotless RAID)
|
18
|
|
A4T6
|
PCIe Riser Card for slot 1 (1 x8 FH/HL + 1 x8 LP Slots)
|
18
|
|
A3PM
|
Mellanox ConnectX-3 EN Dual-port SFP+ 10GbE Adapter
|
18
|
|
5977
|
Select Storage devices; RAID configured by IBM is not required
|
18
|
|
A22T
|
IBM 2TB 7.2K 6 Gbps NL SATA 3.5-inch G2HS HDD
|
252
|
|
A4RV
|
IBM System x 750W High Efficiency Platinum AC Power Supply
|
18
|
|
A4WC
|
System Documentation and Software, US English
|
18
|
|
A4S4
|
Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W
|
18
|
|
A4AS
|
Additional Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W
|
18
|
|
A3QG
|
8 GB (1x8 GB, 1Rx4, 1.5V) PC3-14900 CL13 ECC DDR3 1866 MHz LP RDIMM
|
108
|
|
A3YY
|
N2215 SAS/SATA HBA for IBM System x
|
18
|
|
A4RQ
|
System x3650 M4 BD Planar
|
18
|
|
A4RG
|
System x3650 M4 BD Chassis ASM without Planar
|
18
|
|
6311
|
2.8m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
18
|
|
A4RR
|
3.5-inch Hot Swap BP Bracket Assembly, 12x 3.5
|
18
|
|
A4RS
|
3.5-inch Hot Swap Cage Assembly, Rear, 2 x 3.5
|
18
|
|
2306
|
Rack Installation >1U Component
|
18
|
|
A4RH
|
BIOS GBM
|
18
|
|
A4RJ
|
L1 COPT, 1U RIASER CAGE - SLOT 2
|
18
|
|
A4RK
|
L1 COPT, 1U BUTTERFLY RIASER CAGE - SLOT 1
|
18
|
|
A4RN
|
x3650 M4 BD Agency Label
|
18
|
|
A4RP
|
Label GBM
|
18
|
|
A50F
|
2x2 HDD BRACKET
|
18
|
|
A207
|
Rail Kit for x3650 M4 BD, x3630 M4, and x3530 M4
|
18
|
|
A2M3
|
Shipping Bracket for x3650 M4 BD and 3630 M4
|
18
|
Management node
Table 20 lists the parts information for the management node.
Table 20 Management node
|
Part number
|
Description
|
Quantity
|
|
7914FT1
|
System x3550 M4
|
4
|
|
A1H3 ***
|
System x3550 M4 2.5-inch Base Without Power Supply
|
4
|
|
5977
|
Select Storage devices; RAID configured by IBM is not required
|
4
|
|
A1MZ
|
ServeRAID M1115 SAS/SATA Controller for System x
|
4
|
|
A2XD
|
IBM 600 GB 10K 6 Gbps SAS 2.5-inch SFF G2HS HDD
|
16
|
|
A228
|
IBM System x Gen-III Slides Kit
|
4
|
|
A229
|
IBM System x Gen-III CMA
|
4
|
|
A1HG
|
System x3550 M4 4x 2.5-inch HDD Assembly Kit
|
4
|
|
A1ML
|
IBM Integrated Management Module Advanced Upgrade
|
4
|
|
A1H5
|
System x 750W High Efficiency Platinum AC Power Supply
|
4
|
|
A1HL
|
System x3550 M4 PCIe Gen-III Riser Card 2 (1 x16 FH/HL Slot)
|
4
|
|
A2ZQ
|
Mellanox ConnectX-3 EN Dual-port SFP+ 10GbE Adapter
|
8
|
|
A1HJ
|
System x3550 M4 PCIe Riser Card 1 (1 x16 LP Slot)
|
4
|
|
A1HP ***
|
System Documentation and Software, US English
|
4
|
|
A3QL
|
16 GB (1 x16 GB, 2Rx4, 1.5V) PC3-14900 CL13 ECC DDR3 1866 MHz LP RDIMM
|
32
|
|
A1H5
|
System x 750W High Efficiency Platinum AC Power Supply
|
4
|
|
6263
|
4.3m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
8
|
|
A2U6
|
IBM System x Advanced Lightpath Kit
|
4
|
|
A3WR
|
Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W
|
4
|
|
A3X9
|
Additional Intel Xeon Processor E5-2650 v2 8C 2.6 GHz 20 MB Cache 1866 MHz 95W with Fan
|
4
|
|
2305
|
Rack Installation of 1U Component
|
4
|
|
A3XM
|
System x3550 M4 Planar
|
4
|
|
A1HB
|
System x3550 M4 System Level Code
|
4
|
|
A1HD
|
System x3550 M4 Agency Label GBM
|
4
|
Administration/management network switch
Table 21 lists the parts information for the administration/management network switch.
Table 21 Administration/management network switch
|
Part number
|
Description
|
Quantity
|
|
7309HC1
|
IBM System Networking RackSwitch G8052 (Rear to Front)
|
1
|
|
6311
|
2.8m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
2
|
|
A1DK
|
IBM 19-inch Flexible 4 Post Rail Kit
|
1
|
|
2305
|
Rack Installation of 1U Component
|
1
|
Data network switch
Table 22 lists the parts information for the data network switch.
Table 22 Data network switch
|
Part number
|
Description
|
Quantity
|
|
7309HC3
|
IBM System Networking RackSwitch G8264 (Rear to Front)
|
1
|
|
6311
|
2.8m, 10A/100-250V, C13 to IEC 320-C14 Rack Power Cable
|
2
|
|
A1DK
|
IBM 19-inch Flexible 4 Post Rail Kit
|
1
|
|
2305
|
Rack Installation of 1U Component
|
1
|
Rack
Table 23 lists the parts information for the rack.
Table 23 Rack
|
Part number
|
Description
|
Quantity
|
|
1410RC4
|
e1350 42U rack cabinet
|
1
|
|
6012
|
DPI Single-phase 30A/208V C13 Enterprise PDU (US)
|
4
|
|
2202
|
Cluster 1350 Ship Group
|
1
|
|
2304
|
Rack Assembly - 42U Rack
|
1
|
|
2310
|
Cluster Hardware and Fabric Verification - 1st Rack
|
1
|
Cables
Table 24 lists the parts information for the cables.
Table 24 Cables
|
Part number
|
Description
|
Quantity
|
|
3735
|
0.5m Molex Direct Attach Copper SFP+ Cable
|
4
|
|
3736
|
1m Molex Direct Attach Copper SFP+ Cable
|
4
|
|
3737
|
3m Molex Direct Attach Copper SFP+ Cable
|
36
|
|
2323
|
IntraRack CAT5E Cable Service
|
44
|
References
For more information, see the following references:
•IBM General Parallel File System (GPFS)
– IBM Internet
– IBM Information Center
•IBM InfoSphere BigInsights
– IBM Internet
– IBM Information Center
•IBM Integrated Management Module (IMM2) and Open Source xCAT
– IBM IMM2 User's Guide
– IMM and IMM2 Support on IBM System x and BladeCenter Servers, TIPS0849
– SourceForge xCAT Wiki
– xCAT 2 Guide for the CSM System Administrator, REDP-4437
– IBM Support for xCAT
•IBM Platform Computing
– IBM Internet
– IBM Platform Computing Integration Solutions, SG24-8081
– Implementing IBM InfoSphere BigInsights on System x, SG24-8077
– Integration of IBM Platform Symphony and IBM InfoSphere BigInsights, REDP-5006
– SWIM Benchmark
•IBM RackSwitch G8052 (1GbE Switch)
– IBM Internet
– IBM System Networking RackSwitch G8052, TIPS0813
•IBM RackSwitch G8264 (10GbE Switch)
– IBM Internet
– IBM System Networking RackSwitch G8264, TIPS0815
•IBM RackSwitch G8316 (40GbE Switch)
– IBM Internet
– IBM System Networking RackSwitch G8316, TIPS0842
•IBM System x3550 M4 (Management Node)
– IBM Internet
– IBM System x3550 M4, TIPS0851
•IBM System x3650 M4 BD(Data Node)
– IBM Internet
– IBM System x3630 M4 BD, TIPS1102
•IBM System x Reference Architecture for Hadoop: InfoSphere BigInsights:
– IBM Internet
– Implementing IBM InfoSphere BigInsights on System x, SG24-8077
•Open Source Software
– Hadoop
– Avro
– Flume
– Hbase
– Hive
– Lucene
– Oozie
– Pig
– Zookeeper
The team who wrote this paper
This paper was produced by a team of specialists from around the world working at the International Technical Support Organization (ITSO), Raleigh Center.
Steven Hurley covers Technical Sales Readiness for STG analytics offerings. With a total of six years at IBM, Steve has been in the area of Hadoop analytics for one year. Having over 15 years of experience within IT, Steve has held various technical and leadership roles in
his career.
his career.
James C. Wang is an IBM Senior certified consulting IT specialist who is working as a lead solution architect of the Worldwide Big Data Systems Center. He has 29 years of experience at IBM in Server Systems availability and performance. He has worked in various leadership roles in Smart Analytics technical sales support, Worldwide Design Center for IT Optimization and Business Flexibility, Very Large Database Competency Center and IBM pSeries® Benchmark Center. James is responsible for leading the BDSC team, providing System x reference architectures for Big Data offerings, developing technical sales education and sales support material, and providing technical sales support.
Stephen Smith is a Senior Technical Writer at the IBM ITSO, Raleigh Center. His background in IT technical writing extends over 25 years, during which has he authored over 150 publications that cover a wide assortment of technologies, most notably IBM products and services.
Thanks to the following people for their contributions to this project:
David Watts
IBM ITSO, Raleigh Center
IBM ITSO, Raleigh Center
Bruce Brown
Big Data Sales Acceleration Architect
Big Data Sales Acceleration Architect
Benjamin Chang
Consulting IT Specialist, System x, Global Techline
Consulting IT Specialist, System x, Global Techline
Belinda Harrison
Program Manager, STG Big Data Systems Center
Program Manager, STG Big Data Systems Center
Shirley Hoffman
Technical Specialist, STG Big Data Systems Center
Technical Specialist, STG Big Data Systems Center
Yonggang Hu
Chief Architect, Application Middleware, IBM Platform Computing
Chief Architect, Application Middleware, IBM Platform Computing
Zane Hu
Architect, IBM Platform Symphony
Architect, IBM Platform Symphony
Jim Huang
Software Engineer, InfoSphere BigInsights
Software Engineer, InfoSphere BigInsights
Bob Louden
IT Specialist, System Networking, Global Techline
IT Specialist, System Networking, Global Techline
Ray Perry
STG Lab Services
STG Lab Services
Gord Sissions
Product Marketing Manager, IBM Platform Computing
Product Marketing Manager, IBM Platform Computing
Scott Strattner
Network Architect, STG Poughkeepsie Benchmark Center
Network Architect, STG Poughkeepsie Benchmark Center
Stewart Tate
STSM, Information Management Performance Benchmarks and Solutions Development
STSM, Information Management Performance Benchmarks and Solutions Development
Dave Willoughby
STSM, System x Optimized Solutions Hardware Architect
STSM, System x Optimized Solutions Hardware Architect
Joanna Wong
Executive IT Specialist
Executive IT Specialist
Now you can become a published author, too!
Here's an opportunity to spotlight your skills, grow your career, and become a published author—all at the same time! Join an ITSO residency project and help write a book in your area of expertise, while honing your experience using leading-edge technologies. Your efforts will help to increase product acceptance and customer satisfaction, as you expand your network of technical contacts and relationships. Residencies run from two to six weeks in length, and you can participate either in person or as a remote resident working from your home base.
Find out more about the residency program, browse the residency index, and apply online at:
Stay connected to IBM Redbooks
•Find us on Facebook:
•Follow us on Twitter:
•Look for us on LinkedIn:
•Explore new IBM Redbooks® publications, residencies, and workshops with the IBM Redbooks weekly newsletter:
•Stay current on recent Redbooks publications with RSS Feeds:
Steven Hurley
James C. Wang
Stephen Smith
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.