
In this chapter, we will describe a few advanced topics concerning an Xtext DSL implementation, and some advanced techniques. In the first part of the chapter, we will show how to manually maintain the Ecore model for the AST of an Xtext DSL. This way, you will have full control on the shape of the AST, instead of delegating that to the automatic Xtext Ecore inference mechanisms. Of course, the Xtext grammar and the Ecore model will still have to be consistent, but you will be able tweak the AST structure. You will also be able to add to the AST some derived state, which is computed from the DSL program, but which is not directly present in the program itself. In the first section, we will show how to create an Xtext DSL starting from an existing Ecore model, while in the second section, we will show how to switch to a manually maintained Ecore model, starting from the one generated by Xtext. In the third section, we will use Xcore to maintain the Ecore model for the AST. These first three sections of the chapter assume that you are already familiar with EMF and the Ecore model. In the last section, we will show how to extend an Xbase DSL with new expressions. This will require to customize the Xbase type system and the Xbase compiler in order to handle the new Xbase expressions.
This chapter will cover the following topics:
- How to create an Xtext project from an existing Ecore model
- How to switch to an imported Ecore model
- How to add to the AST some derived state
- How to use Xcore with Xtext
- How to extend Xbase and customize its compiler and type system
In this section, we will implement an Xtext DSL starting from an existing Ecore model, which will represent the structure of AST.
We assume that we already have an EMF Ecore model for representing schools with students and teachers.
This Ecore model has the following structure:
SchoolModel: This is the root element. The featureschoolsis a multi-value containment reference ofSchoolobjects.School: The featurepersonsis a multi-value containment reference ofPersonobjects.Person: This is an abstract class.Studentis aPerson: TheregistrationNumattribute is an integer,teachersis a multi-value non-containment reference ofTeacherobjects, that is, a student can refer to several teachers.Teacheris aPerson.Namedis an abstract class, which is the base class forSchoolandPerson. It contains the string attributename.
Note
During this section, we will modify this Ecore model. If you want to implement the example DSL in this section yourself, while reading, you can download the initial version of the project containing the Ecore model from here: https://github.com/LorenzoBettini/emf-school-model. On the other hand, the sources of the examples of the book contain the Ecore model already modified according to the contents of this chapter.
The class diagram of this model is shown in the next screenshot:

Tip
We implemented this Ecore model using the Ecore diagram editor, which is shown in the preceding screenshot. If you want to try that, you can install the feature "Ecore Diagram Editor (SDK)", if that is not already installed in your Eclipse. Alternatively, you can edit the Ecore model using the standard EMF Ecore tree editor.
We will now create a new Xtext project starting from an existing Ecore model.
Note
Xtext grammar can refer to an existing Ecore model as long as the project containing the Ecore model is an Xtext project. If this is not the case, the Xtext grammar will show lots of errors when referring to the model classes. If the project is not already an Xtext project, you can convert it to an Xtext project by right-clicking on the project and navigating to Configure | Convert to Xtext Project.
In order to create the Xtext project, perform the following steps:
- Navigate to File | New | Project...; in the dialog, navigate to the Xtext category and click on Xtext Project From Existing Ecore Models.
- In the next dialog, press the Add… button to select a GenModel.
- Select the
School.genmodeland press OK, refer to the following screenshot:
- Specify
SchoolModelfor the Entry rule, refer to the following screenshot: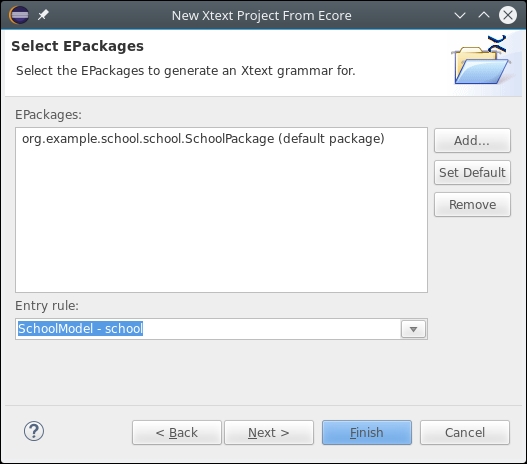
- After you press Next, the dialogs are the same as the ones you have already seen in previous examples. Fill in the details for the following fields and press Finish:
- Project name:
org.example.school - Name:
org.example.school.School - Extensions:
school
- Project name:
The first part of the grammar is slightly different from the grammars we have seen so far, since, instead of the
generate line there is an import line. In fact, this time Xtext will not generate the Ecore model:
grammar org.example.school.School with org.eclipse.xtext.common.Terminals import "http://www.example.org/school"
The School.xtext contains an initial grammar deduced by the Xtext project wizard from the Ecore model. The generated grammar rules are meant only as an initial content. We replace the rules completely with these grammar rules:
SchoolModel returns SchoolModel: schools+=School*; School returns School: 'school' name=STRING '{' persons+=Person* '}'; Person returns Person: Student | Teacher; Student returns Student: 'student' name=STRING 'registrationNum' registrationNum=INT ('{' teachers+=[Teacher|STRING] ( "," teachers+=[Teacher|STRING])* '}')?; Teacher returns Teacher: 'teacher' name=STRING;
The programs of this DSL will have the following shape:
school "A school" { student "A student" registrationNum 100 { "A teacher" } teacher "A teacher" } school "Another school" { teacher "Another teacher" }
Note that in this DSL the names are specified as strings, not as IDs; cross references are declared accordingly, using the [<Type>|<Syntax>] form, that is [Teacher|STRING].
You can now run the MWE2 workflow. Of course, you will get no model/generated folder in the project and no automatically inferred Ecore model.
If we now start writing JUnit tests, for example by modifying the generated stub SchoolParsingTest, and we try to run such tests, we get an exception during the execution of the shape:
java.lang.IllegalStateException: Unresolved proxy http://www.example.org/school#//School. Make sure the EPackage has been registered.
In fact, the generated StandaloneSetup class for DSLs based on an imported Ecore model does not perform any registration of the EMF package. We need to do that ourselves explicitly. In this example, we must modify the SchoolStandaloneSetup as follows:
class SchoolStandaloneSetup extends SchoolStandaloneSetupGenerated { ... override register(Injector injector) { if (!EPackage.Registry.INSTANCE.containsKey(SchoolPackage.eNS_URI)) { EPackage.Registry.INSTANCE.put(SchoolPackage.eNS_URI, SchoolPackage.eINSTANCE); } super.register(injector) } }
If you take a look at the StandaloneSetup generated classes of the other DSLs we implemented so far, you can see that similar instructions are performed.
All the other aspects of an Xtext DSL implementation based on an imported Ecore model work exactly the same as all the other DSLs we implemented so far. For example, we can implement validator checks about possible duplicate elements of the same kind. We can follow the same approach shown in Chapter 9, Type Checking, section Checking for duplicates, based on the fact that the Ecore model has a base class for all elements with a name, Named:
class Schxtends extends AbstractSchoolValidator { protected static val ISSUE_CODE_PREFIX = "org.example.school." public static val DUPLICATE_ELEMENT = ISSUE_CODE_PREFIX + "DuplicateElement" @Check def void checkNoDuplicateSchools(SchoolModel e) { checkNoDuplicateElements(e.schools, "school") } @Check def void checkNoDuplicatePersons(School e) { checkNoDuplicateElements(e.persons.filter(Teacher), "teacher") checkNoDuplicateElements(e.persons.filter(Student), "student") } def private void checkNoDuplicateElements( Iterable<? extends Named> elements, String desc) { val multiMap = HashMultimap.create() for (e : elements) multiMap.put(e.name, e) for (entry : multiMap.asMap.entrySet) { val duplicates = entry.value if (duplicates.size > 1) { for (d : duplicates) error("Duplicate " + desc + " '" + d.name + "'", d, SchoolPackage.eINSTANCE.named_Name, DUPLICATE_ELEMENT) } } } }
As we did for other DSLs, in the School DSL, we do not impose any order in the definition of students and teachers within a school, and they can even be interleaved. All students and teachers are saved into the feature persons in the School class. In fact, in the preceding validator, we filtered the list of persons based on their type, either Student or Teacher, because we allow a teacher and a student to have the same name. We might need to perform such filtering in other parts of the DSL implementation, for example, in the generator. In other DSLs, we implemented utility methods in a model utility class that we used as extension methods. Since now we have complete control on the Ecore model, we can add such utility mechanisms directly in the Ecore model itself.
We first add a new EMF EDataType in the Ecore model, Iterable, whose Instance Type Name is java.lang.Iterable, and we add an ETypeParameter, say T, to the data type.
Then we add two EMF operations to the School class, getStudents() and getTeachers(), that return an Iterable with a EGeneric Type Argument argument Student and Teacher, respectively.
The relevant parts in the Ecore XMI file are as follows:
<eClassifiers xsi:type="ecore:EClass" name="School"
eSuperTypes="#//Named">
<eOperations name="getStudents">
<eGenericType eClassifier="#//Iterable">
<eTypeArguments eClassifier="#//Student"/>
</eGenericType>
</eOperations>
<eOperations name="getTeachers">
<eGenericType eClassifier="#//Iterable">
<eTypeArguments eClassifier="#//Teacher"/>
</eGenericType>
</eOperations>
...
</eClassifiers>
...
<eClassifiers xsi:type="ecore:EDataType" name="Iterable"
instanceClassName="java.lang.Iterable">
<eTypeParameters name="T"/>
</eClassifiers>The resulting Ecore model in the Ecore tree editor will be as in the following screenshot:
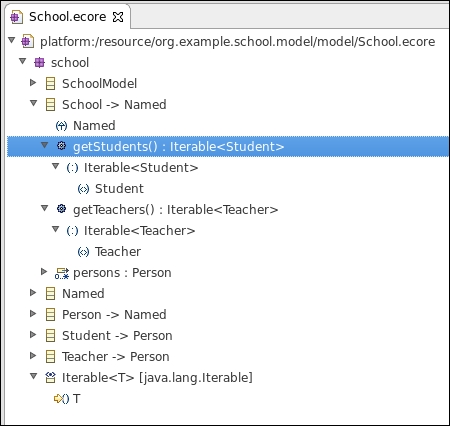
If we now regenerate the Java model code from the modified Ecore model, the SchoolImpl Java class will contain two unimplemented methods for the added operations, of the shape:
/** * @generated */ public Iterable<Student> getStudents() { // TODO: implement this method // Ensure that you remove @generated or mark it @generated NOT throw new UnsupportedOperationException(); } /** * @generated */ public Iterable<Teacher> getTeachers() { // TODO: implement this method // Ensure that you remove @generated or mark it @generated NOT throw new UnsupportedOperationException(); }
We implement these methods using the static utility method com.google.common.collect.Iterables.filter (this is the same method we used in Xtend, since it is available as an extension method), which is part of com.google.guava, so we first need to add this as a dependency in the school.model project:
/** * @generated NOT */ public Iterable<Student> getStudents() { return Iterables.filter(getPersons(), Student.class); } /** * @generated NOT */ public Iterable<Teacher> getTeachers() { return Iterables.filter(getPersons(), Teacher.class); }
Note that we marked these methods as @generated NOT so that a further EMF generation will not overwrite them.
In the validator, we can use these additional methods and avoid the manual filtering:
@Check def void checkNoDuplicatePersons(School e) {
checkNoDuplicateElements(e.teachers, "teacher")
checkNoDuplicateElements(e.students, "student")
}In this section, we describe another mechanism, provided by Xtext, which allows you to add some additional state to the AST model.
For example, let's add another EClass to the School Ecore model, SchoolStatistics, with the integer fields
studentsNumber and teachersNumber and the Iterable<Student> field studentsWithNoTeacher, with the obvious semantics. We then add a field in the School class called statistics, which is a containment reference of type SchoolStatistics. This is a transient feature, so that it will not be saved when the model is serialized. Refer to the following screenshot:

We would like statistics
to be computed once and for all, each time the AST is modified.
Xtext allows you to do that by implementing an org.eclipse.xtext.resource.IDerivedStateComputer. This interface has two methods that you need to implement installDerivedState and discardDerivedState. These are called by Xtext after the AST has been created and when the program is going to be reparsed, respectively. In this example, we will implement the installDerivedState so that for each School object we create and fill a SchoolStatistics instance and set it in the School object. The discardDerivedState method will simply unset the statistics field of each School object:
class SchoolDerivedStateComputer implements IDerivedStateComputer { override discardDerivedState(DerivedStateAwareResource resource) { resource.allContents.filter(School).forEach [ statistics = null ] } override installDerivedState(DerivedStateAwareResource resource, boolean preLinkingPhase) { if (!preLinkingPhase) resource.allContents.filter(School).forEach [ school | school.statistics = SchoolFactory.eINSTANCE.createSchoolStatistics => [ studentsNumber = school.students.size teachersNumber = school.teachers.size studentsWithNoTeacher = school.students.filter[teachers.empty] ] ] } }
The preLinkingPhase parameter tells you whether this method is called before the indexing phase (see Chapter 10, Scoping) or after the indexing phase; it has the same semantics as in the JvmModelInferrer (Chapter 12, Xbase). Since we do not need to index the statistics, we create and set the statistics when the method is called after the indexing phase.
We then need to specify a few custom Guice bindings in SchoolRuntimeModule:
import org.eclipse.xtext.resource.DerivedStateAwareResource import org.eclipse.xtext.resource.DerivedStateAwareResourceDescriptionManager import org.eclipse.xtext.resource.IDerivedStateComputer import org.eclipse.xtext.resource.IResourceDescription import org.example.school.resource.SchoolDerivedStateComputer class SchoolRuntimeModule extends AbstractSchoolRuntimeModule { override bindXtextResource() { DerivedStateAwareResource } def Class<? extends IDerivedStateComputer> bindIDerivedStateComputer() { SchoolDerivedStateComputer } def Class<? extends IResourceDescription.Manager> bindIResourceDescriptionManager() { DerivedStateAwareResourceDescriptionManager } }
Note that, besides
our custom derived state computer, we need to tell Xtext to use a special XtextRe source and a special IResourceDescriptionManager that are aware of derived state.
Tip
When using Xbase, you must not specify the additional bindings for Xtext resource and resource description manager, since Xbase already has its own implementations for these classes and should not be overwritten. Similarly, Xbase has its own default implementation of IDerivedStateComputer. This is the one responsible of calling your JvmModelInferrer implementation: all the mapped Java model elements will be part of the derived state of the resource. If you need to install additional derived state in an Xbase DSL, you can do that directly in the model inferrer.
We can now use this additional statistics field to issue warnings in the validator, in case a school has teachers and a student does not have any teacher:
public static val STUDENT_WITH_NO_TEACHER = ISSUE_CODE_PREFIX + "StudentWithNoTeacher" @Check def void checkStudentsWithNoTeachers(School e) { val statistics = e.statistics if (statistics.teachersNumber > 0) { for (s : statistics.studentsWithNoTeacher) { warning( "Student " + s.name + " has no teacher", s, SchoolPackage.eINSTANCE.named_Name, STUDENT_WITH_NO_TEACHER) } } }
Similarly, we can write a code generator using both the custom operations and the derived statistics. In this example, the generator simply generates a text file with the information about the schools and its contents:
class SchoolGenerator extends AbstractGenerator { override void doGenerate(Resource resource, IFileSystemAccess2 fsa, IGeneratorContext context) { resource.allContents.toIterable.filter(SchoolModel).forEach [ fsa.generateFile ('''«resource.URI.lastSegment».txt''', generateSchools) ] } def generateSchools(SchoolModel schoolModel) { schoolModel.schools.map [ ''' school «name» students number «statistics.studentsNumber» students with no teacher «statistics.studentsWithNoTeacher.size» teachers number «statistics.teachersNumber» teachers «generateTeachers(teachers)» students «FOR it : students» «name» registration number «registrationNum» student's teachers «generateTeachers(teachers)» «ENDFOR» ''' ].join(" ") } def generateTeachers(Iterable<Teacher> teachers) ''' «FOR it : teachers» «name» «ENDFOR» ''' }
Finally, we customize the label provider so that statistics information will appear in the Outline view:
class SchoolLabelProvider extends DefaultEObjectLabelProvider { def text(Named e) { e.eClass.name + " " + e.name } def String text(SchoolStatistics s) { '''teachers «s.teachersNumber», students «s.studentsNumber»››› } }
In the following screenshot, we show the new node with the statistics of a school:
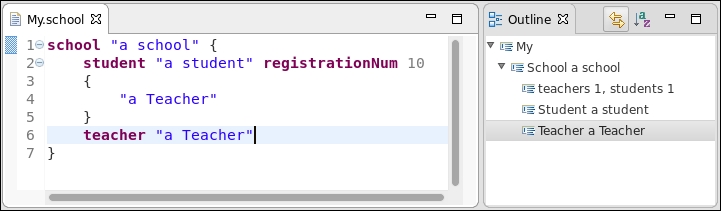
If we modify the the input file, the statistics will be updated consistently, as shown in the following screenshot (note the number of teachers is updated):
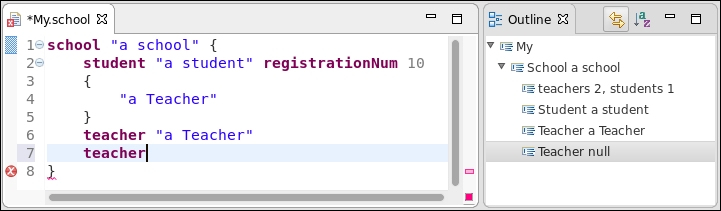
In fact, the nice thing of the derived state computer mechanism is that we do not need to worry about when to update the derived state; Xtext will automatically call our derived state computer at the right moments.
Since now the Ecore model is not automatically inferred and generated by Xtext, you cannot simply add a new rule to the DSL, since the classes for the new rules and the features inside the new rules must already be present in the Ecore model. Thus, when your DSL is based on an imported Ecore model, you first need to add the classes and their features in the Ecore model and then you can add the corresponding rules in the DSL.
Thus, the advantage of manually maintaining the Ecore model is that you have full control on that, and it is easier to have in the AST derived features. The drawback is that you need to keep the Ecore model consistent with your DSL grammar.