
Classes of Attack
Introduction
The severity of a particular attack type and its impact to your systems depends on two things: how the attack is carried out, and what damage is done to the compromised system. An attacker being able to run code on his machine is probably the most serious kind of attack for a home user. For an e-commerce company, a denial of service (DoS) attack or information leakage may be of more immediate concern. Every vulnerability that can lead to compromise can be traced to a particular category, or class, of attack. The properties of each class give you a rough feel for how serious an attack in that class is, as well as how hard it is to defend against.
In this chapter, we explain each of the attack classes in detail, including the kinds of damage they can cause the victim, as well as what the attacker may gain by using them.
Identifying and Understanding the Classes of Attack
As we mentioned, attacks can be placed into one of a few categories. Our assertion regarding the severity of attack is something we should look into for a better understanding. Attacks can lead to anything from leaving your systems without the ability to function, to giving a remote attacker complete control of your systems to do whatever he pleases. We discuss severity of attacks later in this chapter, placing them on a line of severity. Let’s first look at the different types of attacks and discuss them.
In this section, we examine seven categorized attack types. These seven attack types are the general criteria used to classify security issues:
Denial of Service
What is a denial of service (DoS) attack? A DoS attack takes place when availability to a resource or service is intentionally blocked or degraded by an attacker. Although the attack may not compromise the confidentiality or integrity of the resource, the attack impedes the availability of the resource to its regular authorized users. These types of attacks can occur through one of two vectors: either on the local system, or remotely from across a network. The attack may concentrate on degrading processes, degrading storage capability, destroying files to render the resource unusable, or shutting down parts of the system or processes. Let’s take a closer look at each of these items.
Local Vector Denial of Service
Local denial of service attacks are common, and in many cases, preventable. Although any type of denial of service can be frustrating and costly, local denials of service attacks are typically the least painful to handle. Given the right security support structure, these types of attacks are easily traced, and the attacker is easily identified.
Three common types of local denial of service attacks are process degradation, disk space exhaustion, and index node (inode) exhaustion.
Process Degradation
One local denial of service is the degrading of processes. This occurs when the attacker reduces performance by overloading the target system, by either spawning multiple processes to eat up all available resources of the host system, by spawning enough processes to fill to capacity the system process table, or by spawning enough processes to overload the central processing unit (CPU).
An example of this type of attack is exhibited through a recent vulnerability discovered in the Linux kernel. By creating a system of deep symbolic links, a user can prevent the scheduling of other processes when an attempt to dereference the symbolic link is made. Upon creating the symbolic links, then attempting to perform a head or cat of one of the deeply linked files, the process scheduler is blocked, therefore preventing any other processes on the system from receiving CPU time. The following is source code of mklink.sh; this shell script will create the necessary links on an affected system (this problem was not fully fixed until Linux kernel version 2.4.12):
echo A numerical argument is required.
mklink 0 /../../../../../../. /etc/services
Another type of local denial of service attack is the fork bomb. This problem is not Linux-specific, and it affects a number of other operating systems on various platforms. The fork bomb is easy to implement using the shell or C. The code for shell is as follows:
In both of these scenarios, an attacker can degrade process performance with varying effects—these effects may be as minimal as making a system perform slowly, or they may be as extreme as monopolizing system resources and causing a system to crash.
Disk Space Exhaustion
Another type of local attack is one that fills disk space to capacity. Disk space is a finite resource. Previously, disk space was an extremely expensive resource, although the current industry has brought the price of disk storage down significantly. Although you can solve many of the storage complications with solutions such as disk arrays and software that monitors storage abuse, disk space will continue to be a bottleneck to all systems. Software-based solutions such as per-user storage quotas are designed to alleviate this problem.
This type of attack prevents the creation of new files and the growth of existing files. An added problem is that some UNIX systems will crash when the root partition reaches storage capacity. Although this isn’t a design flaw on the part of UNIX itself, a properly administered system should include a separate partition for the log facilities, such as /var, and a separate partition for users, such as the /home directory on Linux systems, or /export/home on Sun systems.
Attackers can use this type of denial of service to crash systems, such as when a disk layout hasn’t been designed with user and log partitions on a separate slice. They can also use it to obscure activities of a user by generating a large amount of events that are logged to via syslog, filling the partition on which logs are stored and making it impossible for syslog to log any further activity.
Such an attack is trivial to launch. A local user can simply perform the following command:
cat /dev/zero > -/maliciousfile
This command will concatenate data from the /dev/zero device file (which simply generates zeros) into malicious file, continuing until either the user stops the process, or the capacity of the partition is filled.
A disk space exhaustion attack could also be leveraged through such attacks as mail bombing. Although this is an old concept, it is not commonly seen. The reasons are perhaps that mail is easily traced via SMTP headers, and although open relays can be used, finding the purveyor of a mail bomb is not rocket science. For this reason, most mail bombers find themselves either without Internet access, jailed, or both.
Inode Exhaustion
The last type of local denial of service attack we discuss is inode exhaustion, similar to the disk capacity attack. Inode exhaustion attacks are focused specifically on the design of the file system. The term inode is an acronym for the words index node. Index nodes are an essential part of the UNIX file system.
An inode contains information essential to the management of the file system. This information includes, at a minimum, the owner of a file, the group membership of a file, the type of file, the permissions, size, and block addresses containing the data of the file. When a file system is formatted, a finite number of inodes are created to handle the indexing of files with that slice.
An inode exhaustion attack focuses on using up all the available inodes for the partition. Exhaustion of these resources creates a similar situation to that of the disk space attack, leaving the system unable to create new files. This type of attack is usually leveraged to cripple a system and prevent the logging of system events, especially those activities of the attacker.
Network Vector Denial of Service
Denial of service attacks launched via a network vector can essentially be broken down into one of two categories: an attack that affects a specific client or service, or an attack that targets an entire system. The severity and danger of these attacks vary significantly. These types of attacks are designed to produce inconvenience, and are often launched as a retaliatory attack.
Network vector attacks, as mentioned, can affect specific services or an entire system; depending on whom is targeted and why, these types of attacks include client, service, and system-directed denials of service. The following sections look at each of these types of denial of service in a little more detail.
Client-Side Network DoS
Client-side denials of service are typically targeted at a specific product. Their purpose is to render the user of the client incapable of performing any activity with the client. One such attack is through the use of what’s called JavaScript bombs.
By default, most Web browsers enable JavaScript. This is apparent anytime one visits a Web site, and a pop-up or pop-under ad is displayed. However, JavaScript can also be used in a number of malicious ways, one of which is to launch a denial of service attack against a client. Using the same technique that advertisers use to create a new window with an advertisement, an attacker can create a malicious Web page consisting of a never-ending loop of window creation. The end result is that so many windows are “popped up,” the system becomes resource-bound.
This is an example of a client-side attack, denying service to the user by exercising a resource starvation attack as we previously discussed, but using the network as a vector. This is only one of many client-side attacks, with others affecting products such as the AOL Instant Messenger, the ICQ Instant Message Client, and similar software.
Service-Based Network DoS
Another type of denial of service attack launched via networks is service-based attacks. A service based attack is intended to target a specific service, rendering it unavailable to legitimate users. These attacks are typically launched at a service such as a Hypertext Transfer Protocol Daemon (HTTPD), Mail Transport Agent (MTA), or other such service that users typically require.
An example of this problem is a vulnerability that was discovered in the Web configuration infrastructure of the Cisco Broadband Operating System (CBOS). When the Code Red worm began taking advantage of Microsoft’s Internet Information Server (IIS) 5.0 Web servers the world over, the worm was discovered to be indiscriminate in the type of Web server it attacked. It would scan networks searching for Web servers, and attempt to exploit any Web server it encountered.
A side effect of this worm was that although some hosts were not vulnerable to the malicious payload it carried, some hosts were vulnerable in a different way. CBOS was one of these scenarios. Upon receiving multiple Transmission Control Protocol (TCP) connections via port 80 from Code Red infected hosts, CBOS would crash.
Though this vulnerability was discovered as a casualty of another, the problem could be exploited by a user with one of any readily available network auditing tools. After attack, the router would be incapable of configuration, requiring a power-cycling of the router to make the configuration facility available. This is a classic example of an attack directed specifically at one service.
System-Directed Network DoS
A denial of service directed towards a system via the network vector is typically used to produce the same results as a local denial of service: degrading performance or making the system completely unavailable. A few approaches are typically seen in this type of attack, and they basically define the methods used in entirety. One is using an exploit to attack one system from another, leaving the target system inoperable. This type of attack was displayed by the land.c, Ping of Death, and teardrop exploits of a couple years ago, and the various TCP/IP fragmented packet vulnerabilities in products such as D-Link routers and the Microsoft ISA Server.
Also along this line is the concept of SYN flooding. This attack can be launched in a variety of ways, from either one system on a network faster than the target system to multiple systems on large pipes. This type of attack is used mainly to degrade system performance. The SYN flood is accomplished by sending TCP connection requests faster than a system can process them. The target system sets aside resources to track each connection, so a great number of incoming SYNs can cause the target host to run out of resources for new legitimate connections. The source IP address is, as usual, spoofed so that when the target system attempts to respond with the second portion of the three-way handshake, a SYN-ACK (synchronization-acknowledgment), it receives no response. Some operating systems will retransmit the SYN-ACK a number of times before releasing the resources back to the system. The exploit code for the SYN flooder syn4k.c was written by Zakath. This SYN flooder allows you to select an address the packets will be spoofed from, as well as the ports to flood on the victim’s system.
One can detect a SYN flood coming from the preceding code by using a variety of tools, such as the netstat command shown in Figure 8.1, or through infrastructure such as network intrusion detection systems (IDSs).
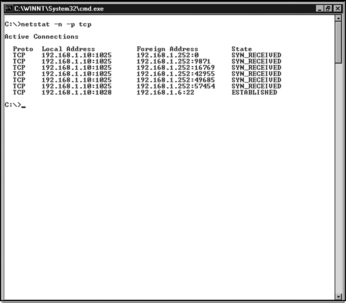
On several operating system platforms, using the –n parameter displays addresses and port numbers in numerical format, and the –p switch allows you to select only the protocol you are interested in viewing. This prevents all User Datagram Protocol (UDP) connections from being shown so that you can view only the connections you are interested in for this particular attack. Check the documentation for the version of netstat that is available on your operating system to ensure that you use the correct switches.
Additionally, some operating systems support features such as TCP SYN cookies. Using SYN cookies is a method of connection establishment that uses cryptography for security. When a system receives a SYN, it returns a SYN+ACK, as though the SYN queue is actually larger. When it receives an ACK back from the initiating system, it uses the recent value of the 32-bit time counter modulus 32, and passes it through the secret server-side function. If the value fits, the extracted maximum segment size (MSS) is used, and the SYN queue entry rebuilt.
Let’s also look at the topic of smurfing or packeting attacks, which are typically purveyed by script kiddies. The smurf attack performs a network vector denial of service against the target host. This attack relies on an intermediary, the router, to help, as shown in Figure 8.2. The attacker, spoofing the source IP address of the target host, generates a large amount of Internet Control Message Protocol (ICMP) echo traffic directed toward IP broadcast addresses. The router, also known as a smurf amplifier, converts the IP broadcast to a Layer 2 broadcast and sends it on its way. Each host that receives the broadcast responds back to the spoofed source IP with an echo reply. Depending on the number of hosts on the network, both the router and target host can be inundated with traffic. This can result in the decrease of network performance for the host being attacked, and depending on the number of amplifier networks used, the target network becoming saturated to capacity.

The last system-directed denial of service attack using the network vector is distributed denial of service (DDoS). This concept is similar to that of the previously mentioned smurf attack. The means of the attack, and method of which it is leveraged, however, is significantly different from that of smurf.
This type of attack depends on the use of a client, masters, and daemons (also called zombies). Attackers use the client to initiate the attack by using masters, which are compromised hosts that have a special program on them allowing the control of multiple daemons. Daemons are compromised hosts that also have a special program running on them, and are the ones that generate the flow of packets to the target system. The current crop of DDoS tools includes trinoo, Tribe Flood Network, Tribe Flood Network 2000, stacheldraht, shaft, and mstream. In order for the DDoS to work, the special program must be placed on dozens or hundreds of “agent” systems. Normally an automated procedure looks for hosts that can be compromised (buffer overflows in the remote procedure call [RPC] services statd, cmsd, and ttdbserverd, for example), and then places the special program on the compromised host. Once the DDoS attack is initiated, each of the agents sends the heavy stream of traffic to the target, inundating it with a flood of traffic. To learn more about detection of DDoS daemon machines, as well as each of the DDoS tools, visit David Dittrich’s Web site at http://staff.washington.edu/dittrich/misc/ddos.
Information Leakage
Information leakage can be likened to leaky pipes. Whenever something comes out, it is almost always undesirable and results in some sort of damage. Information leakage is typically an abused resource that precludes attack. In the same way that military generals rely on information from reconnaissance troops that have penetrated enemy lines to observe the type of weapons, manpower, supplies, and other resources possessed by the enemy, attackers enter the network to perform the same tasks, gathering information about programs, operating systems, and network design on the target network.
Service Information Leakage
Information leakage occurs in many forms. Banners are one example. Banners are the text presented to a user when they attempt to log into a system via any one of the many services. Banners can be found on such services as File Transfer Protocol (FTP), secure shell (SSH), telnet, Simple Mail Transfer Protocol (SMTP), and Post Office Protocol 3 (POP3). Many software packages for these services happily yield version information to outside users in their default configuration, as shown in Figure 8.3.

Another similar problem is error messages. Services such as Web servers yield more than ample information about themselves when an exception condition is created. An exception condition is defined by a circumstance out of the ordinary, such as a request for a page that does not exist, or a command that is not recognized. In these situations, it is best to make use of the customizable error configurations supplied, or create a workaround configuration. Observe Figure 8.4 for a leaky error message from Apache.

Protocol Information Leakage
In addition to the previously mentioned cases of information leakage, there is also what is termed protocol analysis. Protocol analysis exists in numerous forms. One type of analysis is using the constraints of a protocol’s design against a system to yield information about a system. Observe this FTP system type query:
elliptic@ellipse:∼$ “telnet parabola.cipherpunks.com 21
Connected to parabola.cipherpunks.com.
220 parabola FTP server (Version: 9.2.1-4) ready.
215 UNIX Type: L8 Version: SUNOS
This problem also manifests itself in such services as HTTP. Observe the leakage of information through the HTTP HEAD command:
elliptic@ellipse:∼$ “telnet www.cipherpunks.com 80
Connected to www.cipherpunks.com.
Date: Wed, 05 Dec 2001 11:25:13 GMT
Last-Modified: Wed, 28 Nov 2001 22:03:44 GMT
Connection closed by foreign host.
Attackers also perform protocol analysis through a number of other methods. One such method is the analysis of responses to IP, an attack based on the previously mentioned concept, but working on a lower level. Automated tools, such as the Network Mapper, or Nmap, provide an easy-to-use utility designed to gather information about a target system, including publicly reachable ports on the system, and the operating system of the target. Observe the output from an Nmap scan:
elliptic@ellipse:∼$ nmap -sS -O parabola.cipherpunks.com
Starting nmap V. 2.54BETA22 (www.insecure.org/nmap/)Interesting ports on parabola.cipherpunks.com (192.168.1.2):(The 1533 ports scanned but not shown below are in state: closed)
| Port | State | Service |
| 21/tcp | open | ftp |
| 22/tcp | open | ssh |
| 25/tcp | open | smtp |
| 53/tcp | open | domain |
| 80/tcp | open | http |
Remote operating system guess: Solaris 2.6 − 2.7
Uptime 5.873 days (since Thu Nov 29 08:03:04 2001)
Nmap run completed -- 1 IP address (1 host up) scanned in 67 seconds
First, let’s explain the flags used to scan parabola. The sS flag uses a SYN scan, exercising half-open connections to determine which ports are open on the host. The O flag tells Nmap to identify the operating system, if possible, based on known responses stored in a database. As you can see, Nmap was able to identify all open ports on the system, and accurately guess the operating system of parabola (which is actually a Solaris 7 system running on a Sparc).
All of these types of problems present information leakage, which could lead to an attacker gaining more than ample information about your network to launch a strategic attack.
Leaky by Design
This overall problem is not specific to system identification. Some programs happily and willingly yield sensitive information about network design. Protocols such as Simple Network Management Protocol (SNMP) use clear text communication to interact with other systems. To make matters worse, many SNMP implementations yield information about network design with minimal or easily guessed authentication requirements, ala community strings.
Sadly, SNMP is still commonly used. Systems such as Cisco routers are capable of SNMP. Some operating systems, such as Solaris, install and start SNMP facilities by default. Aside from the other various vulnerabilities found in these programs, their default use is plain bad practice.
Leaky Web Servers
We previously mentioned some Web servers telling intrusive users about themselves in some scenarios. This is further complicated when things such as PHP, Common Gateway Interface (CGI), and powerful search engines are used. Like any other tool, these tools can be used in a constructive and creative way, or they can be used to harm.
Things such as PHP, CGI, and search engines can be used to create interactive Web experiences, facilitate commerce, and create customizable environments for users. These infrastructures can also be used for malicious deeds if poorly designed. A quick view of the Attack Registry and Intelligence Service (ARIS) shows the number three type of attack as the “Generic Directory Traversal Attack” (preceded only by the ISAPI and cmd.exe attacks, which, as of the time of current writing, are big with Nimda variants). This is, of course, the dot-dot (¨) attack, or the relative path attack (…) exercised by including dots within the URL to see if one can escape a directory and attain a listing, or execute programs on the Web server.
Scripts that permit the traversal of directories not only allow one to escape the current directory and view a listing of files on the system, but they allow an attacker to read any file readable by the HTTP server processes ownership and group membership. This could allow a user to gain access to the passwd file in /etc or other nonprivileged files on UNIX systems, or on other implementations, such as Microsoft Windows OSs, which could lead to the reading of (and, potentially, writing to) privileged files. Any of the data from this type of attack could be used to launch a more organized, strategic attack. Web scripts and applications should be the topic of diligent review prior to deployment. More information about ARIS is available at http://aris.securityfocus.com.
A Hypothetical Scenario
Other programs, such as Sendmail, will in many default implementations yield information about users on the system. To make matters worse, these programs use the user database as a directory for e-mail addresses. Although some folks may scoff at the idea of this being information leakage, take the following example into account.
A small town has two Internet service providers (ISPs). ISP A is a newer ISP, and has experienced a significant growth in customer base. ISP B is the older ISP in town, with the larger percentage of customers. ISP B is fighting an all-out war with ISP A, obviously because ISP A is cutting into their market, and starting to gain ground on ISP B. ISP A, however, has smarter administrators that have taken advantage of various facilities to keep users from gaining access to sensitive information, using tricks such as hosting mail on a separate server, using different logins on the shell server to prevent users from gaining access to the database of mail addresses. ISP B, however, did not take such precautions. One day, the staff of ISP A get a bright idea, and obtains an account with ISP B. This account gives them a shell on ISP B’s mail server, from which the passwd file is promptly snatched, and all of its users mailed about a great new deal at ISP A offering them no setup fee to change providers, and a significant discount under ISP B’s current charges.
As you can see, the leakage of this type of information can not only impact the security of systems, it can possibly bankrupt a business. Suppose that a company gained access to the information systems of their competitor. What is to stop them from stealing, lying, cheating, and doing everything they can to undermine their competition? The days of Internet innocence are over.
Why Be Concerned with Information Leakage?
Some groups are not concerned with information leakage. Their reasons for this are varied, including reasons such as the leakage of information can never be stopped, or that not yielding certain types of information from servers will break compliance with clients. This also includes the fingerprinting of systems, performed by matching a set of known responses by a system type to a table identifying the operating system of the host.
Any intelligently designed operating system will at least give the option of either preventing fingerprinting, or creating a fingerprint difficult to identify without significant overhaul. Some go so far as to even allow the option of sending bogus fingerprints to overly intrusive hosts. The reasons for this are clear. Referring back to our previous scenario about military reconnaissance, any group that knows they are going to be attacked are going to make their best effort to conceal as much information about themselves as possible, in order to gain the advantage of secrecy and surprise. This could mean moving, camouflaging, or hiding troops, hiding physical resources, encrypting communications, and so forth. This limiting of information leakage leaves the enemy to draw their own conclusions with little information, thus increasing the margin of error.
Just like an army risking attack by a formidable enemy, you must do their best to conceal your network resources from information leakage and intelligence gathering. Any valid information the attacker gains about one’s position and perimeter gives the attacker intelligence from which they may draw conclusions and fabricate a strategy. Sealing the leakage of information forces the attacker to take more intrusive steps to gain information, increasing the probability of detection.
Regular File Access
Regular file access can give an attacker several different means from which to launch an attack. Regular file access may allow an attacker to gain access to sensitive information, such as the usernames or passwords of users on a system, as we discussed briefly in the “Information Leakage” section. Regular file access could also lead to an attacker gaining access to other files in other ways, such as changing the permissions or ownership of a file, or through a symbolic link attack.
Permissions
One of the easiest ways to ensure the security of a file is to ensure proper permissions on the file. This is often one of the more overlooked aspects of system security. Some single-user systems, such as the Microsoft Windows 3.1/95/98/ME products, do not have a permission infrastructure. Multiuser hosts have at least one, and usually several means of access control.
For example, UNIX systems and some Windows systems both have users and groups. UNIX systems, and Windows systems to some extent, allow the setting of attributes on files to dictate what user, and what group have access to perform certain functions with a file. A user, or the owner of the file, may be authorized complete control over the file, having read, write, and execute permission over the file, while a user in the group assigned to the file may have permission to read, and execute the file. Additionally, users outside of the owner and group members may have a different set of permissions, or even no permissions at all.
Many UNIX systems, in addition to the standard permission set of owner, group, and world, include a more granular method of allowing access to a file. These infrastructures vary in design, offering something as simple as the capability to specify which users have access to a file, to something as complex as assigning a member a role to allow a user access to a variety of utilities. The Solaris operating system has two such examples: Role-Based Access Control (RBAC), and Access Control Lists (ACLs).
ACL allows a user to specify which particular system users are permitted access to a file. The access list is tied to the owner and the group membership. It additionally uses the same method of permissions as the standard UNIX permission infrastructure.
RBAC is a complex tool, providing varying layers of permission. It is customizable, capable of giving a user a broad, general role to perform functions such as adding users, changing some system configuration variables, and the like. It can also be limited to giving a user one specific function.
Symbolic Link Attacks
Symbolic link attacks are a problem that can typically be used by an attacker to perform a number of different functions. They can be used to change the permissions on a file. They can also be used to corrupt a file by appending data to it or by overwriting a file completely, destroying the contents.
Symbolic link attacks are often launched from the temporary directory of a system. The problem is usually due to a programming error. When a vulnerable program is run, it creates a file with one of a couple attributes that make it vulnerable to being attacked.
One attribute making the file vulnerable is permissions. If the file has been created with insecure permissions, it can allow an attacker to alter it. This will permit the attacker to change the contents of the temporary file. Depending on the design of the program, if the attacker is able to alter the temporary file, any input placed in the temporary file could be passed to the user’s session.
Another attribute making the file vulnerable is the creation of insecure temporary files. In a situation where a program does not check for an existing file before creating it, and a user can guess the name of a temporary file before it is created, this vulnerability may be exploited. The vulnerability is exploited by creating a symbolic link to the target file, using a guessed file name that will be used in the future. The following example source code shows a program that creates a predictable temporary file:
/* lameprogram.c - Hal Flynn <[email protected]> */
/* does not perform sufficient checks for a */
/* file before opening it and storing data */
char a[] = “This is my own special junk data storage. ”;
char junkpath[] = “/tmp/junktmp”;
This program creates the file /tmp/junktmp without first checking for the existence of the file.
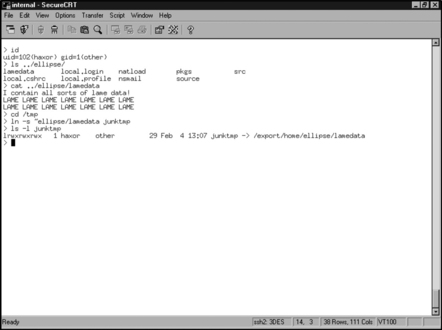
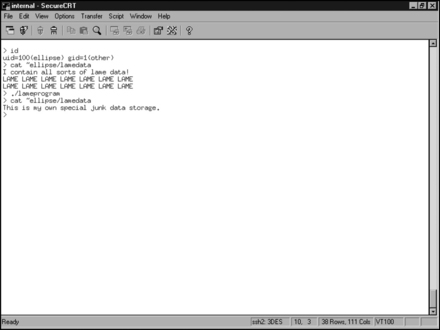
When the user executes the program that creates the insecure temporary file, if the file to be created already exists in the form of a symbolic link, the file at the end of the link will be either overwritten or appended. This occurs if the user executing the vulnerable program has write-access to the file at the end of the symbolic link. Both of these types of attacks can lead to an elevation of privileges. Figures 8.5 and 8.6 show an exploitation of this program by user haxor to overwrite a file owned by the user ellipse.
Misinformation
The concept of misinformation can present itself in many ways. Let’s go back to the military scenario. Suppose that guards are posted at various observation points in the field, and one of them observes the enemy’s reconnaissance team. The guard alerts superiors, who send out their own reconnaissance team to find out exactly who is spying on them.
Now, you can guess that the enemy general has already thought about this scenario. Equally likely, he has also considered his options. He could hide all of his troops and make it appear as if nobody is there. “But what if somebody saw my forces entering the area” would be his next thought. And if the other side were to send a “recon” team to scope out his position and strength, discovering his army greater than theirs, they would likely either fortify their position, or move to a different position where they would be more difficult to attack, or where they could not be found.
Therefore, he wants to make his forces seem like less of a threat than they really are. He hides his heavy weapons, and the greater part of his infantry, while allowing visibility of only a small portion of his force. This is the same idea behind misinformation.
Standard Intrusion Procedure
The same concept of misinformation applies to systems. When an attacker has compromised a system, much effort is made to hide her presence and leave as much misinformation as possible. Attackers do this in any number of ways.
One vulnerability in Sun Solaris can be taken advantage of by an attacker to send various types of misinformation. The problem is due to the handling of ACLs on pseudo-terminals allocated by the system. Upon accessing a terminal, the attacker could set an access control entry, then exit the terminal. When another user accessed the system using the same terminal, the previous owner of the terminal would retain write access to the terminal, allowing the previous owner to write custom-crafted information to the new owner’s terminal. The following sections look at some of the methods used.
Log Editing
One method used by an attacker to send misinformation is log editing. When an attacker compromises a system, the desire is to stay unnoticed and untraceable as long as possible. Even better is if the attacker can generate enough noise to make the intrusion unnoticeable or to implicate somebody else in the attack.
Let’s go back to the previous discussion about denial of service. We talked about generating events to create log entries. An attacker could make an attempt to fill the log files, but a well-designed system will have plenty of space and a log rotation facility to prevent this. Instead, the attacker could resort to generating a large amount of events in an attempt to cloak their activity. Under the right circumstances, an attacker could create a high volume of various log events, causing one or more events that look similar to the entry made when an exploit is initiated.
If the attacker gains administrative access on the system, any hopes of log integrity are lost. With administrative access, the attacker can edit the logs to remove any event that may indicate intrusion, or even change the logs to implicate another user in the attack. In the event of this happening, only outside systems that may be collecting system log data from the compromised machine or network intrusion detection systems may offer data with any integrity.
Some tools include options to generate random data and traffic. This random data and traffic is called noise, and is usually used as either a diversionary tactic or an obfuscation technique. Noise can be used to fool an administrator into watching a different system or believing that a user other than the attacker, or several attackers, are launching attacks against the system.
The goal of the attacker editing the logs is to produce one of a few effects. One effect would be the state of system well-being, as though nothing has happened. Another effect would be general and total confusion, such as conflicting log entries or logs fabricated to look as though a system process has gone wild—as said earlier, noise. Some tools, such as Nmap, include decoy features. The decoy feature can create this effect by making a scan look as though it is coming from several different hosts.
Rootkits
Another means of misinformation is the rootkit. A rootkit is a ready-made program designed to hide an attacker’s activities inside a system. Several different types of rootkits exist, all with their own features and flaws. Rootkits are an attacker’s first choice for keeping access to a system on a long-term basis.
A rootkit works by replacing key programs on the system, such as ls, df, du, ps, sshd, and netstat on UNIX systems, or drivers, and Registry entries on Windows systems. The rootkit replaces these programs, and possibly others with the programs it contains, which are customized to not give administrative staff reliable details. Rootkits are used specifically to cloak the activity of the attacker and hide his presence inside the system.
These packages are specifically designed to create misinformation. They create an appearance of all being well on the system. In the meantime, the attacker controls the system and launches attacks against new hosts, or he conducts other nefarious activities.
Kernel Modules
Kernel modules are pieces of code that may be loaded and unloaded by a running kernel. A kernel module is designed to provide additional functionality to a kernel when needed, allowing the kernel to unload the module when it is no longer needed to lighten the memory load. Kernel modules can be loaded to provide functionality such as support of a non-native file system or device control. Kernel modules may also have facinorous purposes.
Malicious kernel modules are similar in purpose to rootkits. They are designed to create misinformation, leading administrators of a system to believe that all is well on the host. The module provides a means to cloak the attacker, allowing the attacker to carry out any desired deeds on the host.
The kernel module functions in a different way from the standard rootkit. The programs of the rootkit act as a filter to prevent any data that may be incriminating from reaching administrators. The kernel module works on a much lower level, intercepting information queries at the system call level, and filtering out any data that may alert administrative staff to the presence of unauthorized guests. This allows an attacker to compromise and backdoor a system without the danger of modifying system utilities, which could lead to detection.
Kernel modules are becoming the standard in concealing intrusion. Upon intrusion, the attacker must simply load the module, and ensure that the module is loaded in the future by the system to maintain a degree of stealth that is difficult to discover. From that point on, the module may never be discovered unless the drive is taken offline and mounted under a different instance of the operating system.
Special File/Database Access
Two other methods used to gain access to a system are through special files and database access. These types of files, although different in structure and function, exist on all systems of all platforms. From an NT system to a Sun Enterprise 15000 to a Unisys Mainframe, these files are common amongst all platforms.
Attacks against Special Files
The problem of attacks against special files becomes apparent when a user uses the RunAs service of Windows 2000. When a user executes a program with the RunAs function, Windows 2000 creates a named pipe on the system, storing the credentials in clear text. If the RunAs service is stopped, an attacker may create a named pipe of the same name. When the RunAs service is used again, the credentials supplied to the process will be communicated to the attacker. This allows an attacker to steal authentication credentials, and could allow the user to log in as the RunAs user.
Attackers can take advantage of similar problems in UNIX systems. One such problem is the Solaris pseudo-terminal problems we mentioned previously. Red Hat Linux distribution 7.1 has a vulnerability in the upgrade portion of the package. A user upgrading a system and creating a swap file exposes herself to having swap memory snooped through. This is due to the creation of the swap file with world-readable permissions. An attacker on a system could arbitrarily create a heavy load on system memory, causing the system to use the swap file. In doing so, the attacker could make a number of copies of swap memory at different states, which could later be picked through for passwords or other sensitive information.
Attacks against Databases
At one point in my career, I had considered becoming an Oracle database administrator. I continued on with the systems and security segment of my career. As I got more exposure to database administration, I discovered the only thing I could think of that was as stressful as having the entire financial well-being of a company resting on me would be going to war. And given my pick of the two, I think I would take the latter.
Databases present a world of opportunity to attackers. Fulfilling our human needs to organize, categorize, and label things, we have built central locations of information. These central locations are filled with all sorts of goodies, such as financial data, credit card information, payroll data, client lists, and so forth. The thought of insecure database software is enough to keep a CEO awake at night, let alone send a database administrator into a nervous breakdown. In these days of post-dot-com crash, e-commerce is still alive and well. And where there is commerce, there are databases.
Risky Business
Databases are forced to fight a two-front war. They are software, and are therefore subject to the problems that all software must face, such as buffer overflows, race conditions, denials of service, and the like. Additionally, databases are usually a backend for something else, such as a Web interface, graphical user interface tool, or otherwise. Databases are only as secure as the software they run and the interfaces they communicate with.
Web interfaces tend to be a habitual problem for databases. The reasons for this are that Web interfaces fail to filter special characters or that they are designed poorly and allow unauthorized access, to name only two. This assertion is backed by the fact that holes are regularly found in drop-in e-commerce packages on a regular basis.
Handling user-supplied input is risky business. A user can, and usually will, supply anything to a Web front end. Sometimes this is ignorance on the part of the user, while other times this is the user attempting to be malicious. Scripts must be designed to filter out special characters such as the single quote (‘), slash (/), backslash (), and double quote (“) characters, or this will quickly be taken advantage of. A front-end permitting the passing of special characters to a database will permit the execution of arbitrary commands, usually with the permission of the database daemons.
Poorly designed front-ends are a different story. A poorly designed front-end will permit a user to interact and manipulate the database in a number of ways. This can allow an attacker to view arbitrary tables, perform SQL commands, or even arbitrarily drop tables. These risks are nothing new, but the problems continue to occur.
Database Software
Database software is an entirely different collection of problems. A database is only as secure as the software it uses—oftentimes, that isn’t particularly reassuring.
For example, Oracle has database software available for several different platforms. A vulnerability in the 8.1.5 through 8.1.7 versions of Oracle was discovered by Nishad Herath and Brock Tellier of Network Associates COVERT Labs. The problem they found was specifically in the TNS Listener program used with Oracle.
For the unacquainted, TNS Listener manages and facilitates connections to the database. It does so by listening on an arbitrary data port, 1521/TCP in newer versions, and waiting for incoming connections. Once a connection is received, it allows a person with the proper credentials to log into a database.
The vulnerability, exploited by sending a maliciously crafted Net8 packet to the TNS Listener process, allows an attacker to execute arbitrary code and gain local access on the system. For UNIX systems, this bug was severe, because it allowed an attacker to gain local access with the permissions of the Oracle user. For Windows systems, this bug was extremely severe, because it allowed an attacker to gain local access with LocalSystem privileges, equivalent to administrative access. We discuss code execution in the next section.
Database Permissions
Finally, we discuss database permissions. The majority of these databases can use their own permission schemes separate from the operating system. For example, version 6.5 and earlier versions of Microsoft’s SQL Server can be configured to use standard security, which means they use their internal login validation process and not the account validation provided with the operating system. SQL Server ships with a default system administrator account named SA that has a default null password. This account has administrator privileges over all databases on the entire server. Database administrators must ensure that they apply a password to the SA account as soon as they install the software to their server.
Databases on UNIX can also use their own permission schemes. For example, MySQL maintains its own list of users separate from the list of users maintained by UNIX. MySQL has an account named root (which is not to be confused with the operating system’s root account) that, by default, does not have a password. If you do not enter a password for MySQL’s root account, then anyone can connect with full privileges by entering the following command:
If an individual wanted to change items in the grant tables and root was not passworded, she could simply connect as root using the following command:
Even if you assign a password to the MySQL root account, users can connect as another user by simply substituting the other person’s database account name in place of their own after the –u if you have not assigned a password to that particular MySQL user account. For this reason, assigning passwords to all MySQL users should be a standard practice in order to prevent unnecessary risk.
Remote Arbitrary Code Execution
Remote code execution is one of the most commonly used methods of exploiting systems. Several noteworthy attacks on high profile Web sites have been due to the ability to execute arbitrary code remotely. Remote arbitrary code is serious in nature because it often does not require authentication and therefore may be exploited by anybody.
Returning to the military scenario, suppose the enemy General’s reconnaissance troops are able to slip past the other side’s guards. They can then sit and map the others’ position, and return to the General with camp coordinates, as well as the coordinates of things within the opposing side’s camp.
The General can then pass this information to his Fire Support Officer (FSO), and the FSO can launch several artillery strikes to “soften them up.” But suppose for a moment that the opposing side knows about the technology behind the artillery pieces the General’s army is using. And suppose that they have the capability to remotely take control of the coordinates input into the General’s artillery pieces—they would be able to turn the pieces on the General’s own army.
This type of control is exactly the type of control an attacker can gain by executing arbitrary code remotely. If the attacker can execute arbitrary code through a service on the system, the attacker can use the service against the system, with power similar to that of using an army’s own artillery against them. Several methods allow the execution of arbitrary code. Two of the most common methods used are buffer overflows and format string attacks.
The Attack
Remote code execution is always performed by an automated tool. Attempting to manually remotely execute code would be at the very best near impossible. These attacks are typically written into an automated script.
Remote arbitrary code execution is most often aimed at giving a remote user administrative access on a vulnerable system. The attack is usually prefaced by an information gathering attack, in which the attacker uses some means such as an automated scanning tool to identify the vulnerable version of software. Once identified, the attacker executes the script against the program with hopes of gaining local administrative access on the host.
Once the attacker has gained local administrative access on the system, the attacker initiates the process discussed in the “Misinformation” section. The attacker will do his best to hide his presence inside the system. Following that, he may use the compromised host to launch remote arbitrary code execution attacks against other hosts.
Although remote execution of arbitrary code can allow an attacker to execute commands on a system, it is subject to some limitations.
Code Execution Limitations
Remote arbitrary code execution is bound by limitations such as ownership and group membership. These limitations are the same as imposed on all processes and all users.
On UNIX systems, processes run on ports below 1024 are theoretically root-owned processes. However, some software packages, such as the Apache Web Server, are designed to change ownership and group membership, although it must be started by the superuser. An attacker exploiting an Apache HTTP process would gain only the privileges of the HTTP server process. This would allow the attacker to gain local access, although as an unprivileged user. Further elevation of privileges would require exploiting another vulnerability on the local system. This limitation makes exploiting nonprivileged processes tricky, as it can lead to being caught when system access is gained.
The changing of a process from execution as one user of higher privilege to a user of lower privilege is called dropping privileges. Apache can also be placed in a false root directory that isolates the process, known as change root, or chroot.
A default installation of Apache will drop privileges after being started. A separate infrastructure has been designed for chroot, including a program that can wrap most services and lock them into what is called a chroot jail. The jail is designed to restrict a user to a certain directory. The chroot program will allow access only to programs and libraries from within that directory. This limitation can also present a trap to an attacker not bright enough to escape the jail.
If the attacker finds himself with access to the system and bound by these limitations, the attacker will likely attempt to gain elevated privileges on the system.
Elevation of Privileges
Of all attacks launched, elevation of privileges is certainly the most common. An elevation of privileges occurs when a user gains access to resources that were not authorized previously. These resources may be anything from remote access to a system to administrative access on a host. Privilege elevation comes in various forms.
Remote Privilege Elevation
Remote privilege elevation can be classified to fall under one of two categories. The first category is remote unprivileged access, allowing a remote user unauthorized access to a system as a regular user. The second type of remote privilege elevation is instantaneous administrative access.
A number of different vectors can allow a user to gain remote access to a system. These include topics we have previously discussed, such as the filtering of special characters by Web interfaces, code execution through methods such as buffer overflows or format string bugs, or through data obtained from information leakage. All of these problems pose serious threats, with the end result being potential disaster.
Remote Unprivileged User Access
Remote privilege elevation to an unprivileged user is normally gained through attacking a system and exploiting an unprivileged process. This is defined as an elevation of privileges mainly because the attacker previously did not have access to the local system, but does now. Some folks may scoff at this idea, as I once did. David Ahmad, the moderator of Bugtraq, changed my mind.
One night over coffee, he and I got on the topic of gaining access to a system. With my history of implementing secure systems, I was entirely convinced that I could produce systems that were near unbreakable, even if an attacker were to gain local access. I thought that measures such as non-executable stacks, restricted shells, chrooted environments, and minimal setuid programs could keep an attacker from gaining administrative access for almost an eternity. Later on that evening, Dave was kind enough to show me that I was terribly, terribly wrong.
Attackers can gain local, unprivileged access to a system through a number of ways. One way is to exploit an unprivileged service, such as the HTTP daemon, a chrooted process, or another service that runs as a standard user. Aside from remotely executing code to spawn a shell through one of these services, attackers can potentially gain access through other vectors. Passwords gained through ASP source could lead to an attacker gaining unprivileged access under some circumstances. A notorious problem is, as we discussed previously, the lack of special-character filtering by Web interfaces. If an attacker can pass special characters through a Web interface, the attacker may be able to bind a shell to a port on the system. Doing so will not gain the attacker administrative privileges, but it will gain the attacker access to the system with the privileges of the HTTP process. Once inside, to quote David Ahmad, “it’s only a matter of time.”
Remote Privileged User Access
Remote privileged user access is the more serious of the two problems. If a remote user can obtain access to a system as a privileged user, the integrity of the system is destined to collapse. Remote privileged user access can be defined as an attacker gaining access to a system with the privileges of a system account. These accounts include uucp, root, bin, and sys on UNIX systems, and Administrator or LocalSystem on Windows 2000 systems.
The methods of gaining remote privileged user access are essentially the same as those used to gain unprivileged user attacks. A few key differences separate the two, however. One difference is in the service exploited. To gain remote access as a privileged user, an attacker must exploit a service that runs as a privileged user.
The majority of UNIX services still run as privileged users. Some of these, such as telnet and SSH, have recently been the topic of serious vulnerabilities. The SSH bug is particularly serious. The bug, originally discovered by Michal Zalewski, was originally announced in February of 2001. Forgoing the deeply technical details of the attack, the vulnerability allowed a remote user to initiate a malicious cryptographic session with the daemon. Once the session was initiated, the attacker could exploit a flaw in the protocol to execute arbitrary code, which would run with administrative privileges, and bind a shell to a port with the effective userid of 0.
Likewise, the recent vulnerability in Windows 2000 IIS made possible a number of attacks on Windows NT systems. IIS 5.0 executes with privileges equal to that of the Administrator. The problem was a buffer overflow in the ISAPI indexing infrastructure of IIS 5.0. This problem made possible numerous intrusions, and the Code Red worm and variants.
Remote privileged user access is also the goal of many Trojans and backdoor programs. Programs such as SubSeven, Back Orifice, and the many variants produced can be used to allow an attacker remote administrative privileges on an infected system. The programs usually involve social engineering, broadly defined as using misinformation or persuasion to encourage a user to execute the program. Though the execution of these programs do not give an attacker elevated privileges, the use of social engineering by an attacker to encourage a privileged user to execute the program can allow privileged access. Upon execution, the attacker needs simply to use the method of communication with the malicious program to watch the infected system, perform operations from the system, and even control the users ability to operate on the system.
Other attacks may gain a user access other than administrative, but privileged nonetheless. An attacker gaining this type of access is afforded luxuries over the standard user, because this allows the attacker access to some system binaries, as well as some sensitive system facilities. A user exploiting a service to gain access as a system account other than administrator or root will likely later gain administrative privileges.
These same concepts may also be applied to gaining local privilege elevation. Through social engineering or execution of malicious code, a user with local unprivileged access to a system may be able to gain elevated privileges on the local host.
Identifying Methods of Testing for Vulnerabilities
Testing a system for vulnerabilities is the best way to ensure that the system is, or is not, vulnerable to a particular problem. Vulnerability testing is a necessary and mandatory task for anybody involved with the administration or security of information systems. You can only understand system security by attempting to break into your own systems.
Up to this point, we have discussed the different types of vulnerabilities that may be used to exploit a system. In this section, we discuss the methods of finding and proving that vulnerabilities exist. We also discuss some of the methods used in gathering information prior to launching an attack on a system, such as the use of Nmap.
Proof of Concept
One standard method used among the security community is what is termed proof of concept. Proof of concept can be roughly defined as an openly discussed and reliable method of testing a system for a vulnerability. It is usually supplied by either a vendor, or a security researcher in a full disclosure forum.
Proof of concept is used to demonstrate that a vulnerability exists. It is not a exploit per se, but more of a demonstration of the problem through either some small segment of code that does not exploit the system for the attacker’s gain, or a technical description that shows a user how to reproduce the problem. This proof of concept can be used by a member of the community to identify the source of the problem, recommend a workaround, and in some cases recommend a fix prior to the release of a vendor-released patch. It can also be used to identify vulnerable systems.
Proof of concept is used as a tool to notify the security community of the problem, while giving a limited amount of details. The goal of this approach is simply to produce a time buffer between the time when the vulnerability is announced, to the time when malicious users begin producing code to take advantage of this vulnerability and go into a frenzy of attacks. The time buffer is created for the benefit of the vendor to give them time to produce a patch for the problem and release it.
Automated Security Tools
Automated security tools are software packages designed by vendors to allow automated security testing. These tools are typically designed to use a nice user interface and generate reports. The report generation feature allows the user of the tool to print out a detailed list of problems with a system and track progress on securing the system.
Automated security tools are yet another double-edged sword. They allow legitimate users of the tools to perform audits to secure their networks and track progress of securing systems. They also allow malicious users with the same tool to identify vulnerabilities in hosts and potentially exploit them for personal gain.
Automated security tools are beneficial to all. They provide users who may be lacking in some areas of technical knowledge the capability to identify and secure vulnerable hosts. The more useful tools offer regular updates, with plug-ins designed to test for new or recent vulnerabilities.
A few different vendors provide these tools. Commercially available are the CyberCop Security Scanner by Network Associates, NetRecon by Symantec, and the Internet Scanner by Internet Security Systems. Freely available is Nessus, from the Nessus Project.
Versioning
Versioning is the failsafe method of testing a system for vulnerabilities. It is the least entertaining to perform in comparison to the previously mentioned methods. It does, however, produce reliable results.
Versioning consists of identifying the versions, or revisions, of software a system is using. This can be complex, because many software packages include a version, such as Windows 2000 Professional, or Solaris 8, and many packages included with a versioned piece of software also include a version, such as wget version 1.7. This can prove to be added complexity, and often a nightmare in products such as a Linux distribution, which is a cobbled-together collection of software packages, all with their own versions.
Versioning is performed by monitoring a vendor list. The concept is actually quite simple—it entails checking software packages against versions announced to have security vulnerabilities. This can be done through a variety of methods. One method is to actually perform the version command on a software package, such as the uname command, shown in Figure 8.7.

Another method is using a package tool or patch management tool supplied by a vendor to check your system for the latest revision (see Figure 8.8).

Versioning can be simplified in a number of ways. One is to produce a database containing the versions of software used on any one host. Additionally, creating a patch database detailing which fixes have been applied to a system can ease frustration, misallocation of resources, and potential vulnerability.
Standard Research Techniques
It has been said that 97 percent of all attackers are script kiddies. The group to worry about is the other three percent. This group is exactly who you want to emulate in your thinking. Lance Spitzner, one of the most well rounded security engineers (and best all-around guys) in the security community wrote some documents sometime ago that summed it up perfectly. Borrowing a maxim written by Sun Tzu in The Art of War, Spitzner’s papers were titled “Know Your Enemy.” They are available through the Honeynet Project at http://project.honeynet.org.
We should first define an intelligent attack. An attack is an act of aggression. Intelligence insinuates that cognitive skills are involved. Launching an intelligent attack means first gathering intelligence. This can be done through information leakage or through a variety of other resource available on the Internet. Let’s look at some methods used via a Whois database, the Domain Name System (DNS), Nmap, and Web indexing.
Whois
The Whois database is a freely available compilation of information designed to maintain contact information for network resources. Several Whois databases are available, including the dot-com Whois database, the dot-biz Whois database, and the American Registry of Internet Numbers database, containing name service-based Whois information, and network-based Whois information.
Name Service-Based Whois
Name service-based Whois data provides a number of details about a domain. These details include the registrant of the domain, the street address the domain is registered to, and a contact number for the registrant. This data is supplied to facilitate the communication between domain owners in the event of a problem. This is the ideal method of handling problems that arise, although these days the trend seems to be whining to the upstream provider about a problem first (which is extremely bad netiquette). Observe the following information:
elliptic@ellipse:∼$ who is cipherpunks.com
Domain names in the .com, .net, and .org domains can now be registered with many different competing registrars. Go to http://www.internic.net for detailed information.
Referral URL: http://www.enom.com
>>> Last update of whois database: Mon, 10 Dec 2001 05:15:40 EST <<<
The Registry database contains ONLY .COM, .NET, .ORG, .EDU domains and Registrars.
Found InterNIC referral to whois.enom.com.
Access to eNom’s Whois information is for informational
purposes only. eNom makes this information available “as is,”
and does not guarantee its accuracy. The compilation, repackaging,
dissemination or other use of eNom’s Whois information in its
entirety, or a substantial portion thereof, is expressly prohibited
without the prior written consent of eNom, Inc. By accessing and
using our Whois information, you agree to these “terms.
Elliptic Cipher ([email protected])
Elliptic Cipher ([email protected])
Elliptic Cipher ([email protected])
Elliptic Cipher ([email protected])
DOMAIN CREATED : 2000-11-12 23:57:56
DOMAIN EXPIRES : 2002-11-12 23:57:56
In this example, you can see the contact information for the owner of the Cipherpunks.com domain. Included are the name, contact number, fax number, and street address of the registering party.
The Whois database for name service also contains other information, some of which could allow exploitation. One piece of information contained in name service records is the domain name servers. This data can present a user with a method to attack and potentially control a domain.
Another piece of information that is regularly abused in domain name records is the e-mail address. In a situation where multiple people are administering a domain, an attacker could use this information to launch a social engineering attack. More often then not though, this information is targeted by spammers. Companies such as Network Solutions even sell this information to “directed marketing” firms (also know as spam companies) to clutter your mail box with all kinds of rubbish, according to Newsbytes article “ICANN To Gauge Privacy Concerns Over ‘Whois’ Database” available at www.newsbytes.com/news/01/166711.html.
Network Service-Based Whois
Network service-based Whois data provides details of network management data. This data can aid network and security personnel with the information necessary to reach a party responsible for a host should a problem ever arise. It provides data such as the contact provider of the network numbers, and in some situations the company leasing the space. Observe the following Whois information:
elliptic@ellipse:∼$ whois -h whois.arin.net 66.38.151.10
GT Group Telecom Services Corp. (NETBLK-GROUPTELECOM-BLK-3) GROUPTELECOM-BLK-3
Security Focus (NETBLK-GT-66-38-151-0) GT-66-38-151-0
To single out one record, look it up with “!xxx”, where xxx is the handle, shown in parenthesis following the name, which comes first.
The ARIN Registration Services Host contains ONLY Internet Network Information: Networks, ASN’s, and related POC’s. Please use the whois server at rs.internic.net for DOMAIN related Information and whois.nic.mil for NIPRNET Information.
As you can see from this information, the address space from 66.38.151.0 through 66.38.151.63 is used by SecurityFocus. Additionally, this address space is owned by GT Group Telecom.
This information can help the attacker determine the boundaries for a potential attack. If the attacker wanted to compromise a host on a network belonging to SecurityFocus, the attacker would need only target the hosts on the network segment supplied by ARIN. The attacker could then use a host on the network to target other hosts on the same network, or even different networks.
Domain Name System
Domain Name System (DNS) is another service an attacker may abuse to gain intelligence before making an attack on a network. DNS is used by every host on the Internet, and provides a choke point through its design. We do not focus on the problems with the protocol, but more on abusing the service itself.
A host of vulnerabilities have been discovered in the most widely deployed name service resolving package on the Internet. The Berkeley Internet Name Domain, or BIND, has in the past had a string of vulnerabilities that could allow an attacker to gain remote administrative access. Also notable is the vulnerability in older versions that allowed attackers to poison the DNS cache, fooling clients into visiting a different site when typing a domain name. Let’s look at the methods of identifying vulnerable implementations of DNS.
Digging
Dig is freely available—it’s distributed with BIND packages. It is a flexible command-line tool that can be used to gather information from DNS servers. Dig can be used both in command-line and interactive modes. The dig utility is supplied with many free operating systems and can be downloaded as part of the BIND package from the Internet Software Consortium.
Dig can be used to resolve the names of hosts into IP addresses, and reverse-resolve IP addresses into names. This can be useful, because many exploits do not include the ability to resolve names, and need numeric addresses to function.
Dig can also be used to gather version information from name servers. In doing so, an attacker may be able to gather information on a host and potentially launch an attack. By identifying the version of a name server, we may be able to find a name server that can be attacked and exploited to our gain (recall our discussion about versioning).
Consider the following example use of dig:
elliptic@ellipse:∼$ dig @pi.cipherpunks.com TXT CHAOS version.bind
; >>< DiG 8.2 >><< @pi.cipherpunks.com TXT CHAOS version.bind
;; res options: init recurs defnam dnsrch
;; -<<HEADER>>- opcode: QUERY, status: NOERROR, id: 6
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; version.bind, type = TXT, class = CHAOS;; ANSWER SECTION:VERSION.BIND. 0S CHAOS TXT “8.2.1”
;; FROM: ellipse to SERVER: pi.cipherpunks.com 192.168.1.252
;; WHEN: Mon Dec 10 07:53:27 2001
From this query, we were able to identify the version of BIND running on pi, in the cipherpunks.com domain. As you can see, pi is running a version of BIND that is vulnerable to a number of attacks, one of which is NXT buffer overflow discovered in 1999, and allows an attacker to gain remote access to the vulnerable system with the privileges of BIND (typically run as root).
Loosely implemented name services may also yield more information than expected. Utilities such as dig can perform other DNS services, such as a zone transfer. A zone transfer is the function used by DNS to distribute its name service records to other hosts. By manually pulling a zone transfer, an attacker can gain valuable information about systems and addresses managed by a name server.
nslookup
nslookup, short for Name Service Lookup, is another utility that can be handy. It can yield a variety of information, both good and bad. It is also freely available from the Internet Software Consortium.
nslookup works much the same way as dig, and like dig provides both a command line and interactive interface to work from. Upon use, nslookup will seek out information on hosts through DNS and return the information. nslookup can yield information about a domain that may be sensitive as well, albeit public.
For example, nslookup can be used to find information about a domain such as the Mail Exchanger, or MX record. This can lead to a number of attacks against a mail server, including attempting to spam the mail server into a denial of service, attacking the software to attempt to gain access to the server, or using the mail server to spam other hosts if it permits relaying. Observe the following example:
Default Server: cobalt.speakeasy.org
Server: cobalt.speakeasy.org Address: 216.231.41.22
cipherpunks.com preference = 10, mail exchanger = parabola.
cipherpunks.com nameserver = DNS1.ENOM.COM
cipherpunks.com nameserver = DNS2.ENOM.COM
cipherpunks.com nameserver = DNS3.ENOM.COM
cipherpunks.com nameserver = DNS4.ENOM.COM
cipherpunks.com nameserver = DNS5.ENOM.COM
DNS1.ENOM.COM internet address = 66.150.5.62
DNS2.ENOM.COM internet address = 63.251.83.36
DNS3.ENOM.COM internet address = 66.150.5.63
DNS4.ENOM.COM internet address = 208.254.129.2
DNS5.ENOM.COM internet address = 210.146.53.77
Here, you can see the mail exchanger for the cipherpunks.com domain. The host, parabola.cipherpunks.com, can then be tinkered with to gain more information. For example, if the system is using a version of Sendmail that allows you to expand user accounts, you could find out the e-mail addresses of the system administrators. It can also yield what type of mail transport agent software is being used on the system, as in the following example:
elliptic@ellipse:∼$ “telnet modulus.cipherpunks.com 25
Trying 192.168.1.253… Connected to 192.168.1.253.
220 modulus.cipherpunks.com ESMTP Server (Microsoft Exchange Internet Mail Service 5.5.2448.0) ready
As you can see, the mail server happily tells us what kind of software it is (Microsoft Exchange). From that, you can draw conclusions about what type of operating system runs on the host modulus.
Nmap
An attack to gain access to a host must be launched against a service running on the system. The service must be vulnerable to a problem that will allow the attacker to gain access. It is possible to guess what services the system uses from some methods of intelligence gathering. It is also possible to manually probe ports on a system with utilities such as netcat to see if connectivity can be made to the service.
The process of gathering information on the available services on a system is simplified by tools such as the Network Mapper, or Nmap. Nmap, as we previously mentioned, uses numerous advanced features when launched against a system to identify characteristics of a host. These features include things such as variable TCP flag scanning and IP response analysis to guess the operating system and identify listening services on a host.
Nmap can be used to identify services on a system that are open to public use. It can also identify services that are listening on a system but are filtered through an infrastructure such as TCP Wrappers, or firewalling. Observe the following output:
elliptic@ellipse:∼$ nmap -sS -O derivative.cipherpunks.com
Starting nmap V. 2.54BETA22 (www.insecure.org/nmap/)Interesting ports on derivative.cipherpunks.com (192.168.1.237):
(The 1533 ports scanned but not shown below are in state: closed)
Remote operating system guess: Solaris 2.6 − 2.7
Uptime 11.096 days (since Thu Nov 29 08:03:12 2001)
Nmap run completed –– 1 IP address (1 host up) scanned in 60 seconds
Let’s examine this scan a piece at a time. First, we have the execution of Nmap with the sS and O flags. These flags tell Nmap to conduct a SYN scan on the host, and identify the operating system from the IP responses received. Next, we see three columns of data. In the first column from the left to right, we see the port and protocol that the service is listening on. In the second column, we see the state of the state of the port, either being filtered (as is the telnet service, which is TCP Wrapped), or open to public connectivity, like the rest.
Web Indexing
The next form of intelligence gathering we will mention is Web indexing, or what is commonly called spidering. Since the early 90s, companies such as Yahoo!, WebCrawler, and others have used automated programs to crawl sites, and index the data to make it searchable by visitors to their sites. This was the beginning of the Web Portal business.
Indexing sites for a database is usually performed by an automated program. These programs exist in many forms, by many different names. Some different variants of these programs are robots, spiders, and crawlers, all of which perform the same function but have distinct and different names for no clear reason. These programs follow links on a given Web site and record data on each page visited. The data is indexed and referenced in a relational database and tied to the search engine. When a user visits the portal, searching for key variables will return a link to the indexed page.
However, what happens when sensitive information contained on a Web site is not stored with proper access control? Because data from the site is archived, this could allow an attacker to gain access to sensitive information on a site and gather intelligence by merely using a search engine. As mentioned before, this is not a new problem. From the present date all the way back to the presence of the first search engines, this problem has existed. Unfortunately, it will continue to exist.
The problem is not confined to portals. Tools such as wget can be used to recursively extract all pages from a site. The process is as simple as executing the program with the sufficient parameters. Observe the following example:
elliptic@ellipse:∼$ wget -m -x http://www.mrhal.com--11:27:35-- http://www.mrhal.com:80/
=> Error! Hyperlink reference not valid. Connecting to www.mrhal.com:80… connected! HTTP request sent, awaiting response… 200 OK Length: 1,246 [“text/html]
11:27:35 (243.36 KB/s) – Error! Hyperlink reference not valid. saved [1246/1246]
Loading robots.txt; please ignore errors. ––11:27:35–– http://www.mrhal.com:80/robots.txt
=> Error! Hyperlink reference not valid. Connecting to www.mrhal.com:80… connected! HTTP request sent, awaiting response… 404 Not Found 11:27:35 ERROR 404: Not Found.
––11:27:35–– http://www.mrhal.com:80/pics/hal.jpg
{kind=link}
=> Error! Hyperlink reference not valid. Connecting to www.mrhal.com:80… connected! HTTP request sent, awaiting response… 200 OK Length: 16,014 [image/jpeg]
11:27:35 (1.91 MB/s) - Error! Hyperlink reference not valid. saved [16014/16014] […]
FINISHED ––11:27:42––Downloaded: 1,025,502 bytes in 44 files
We have denoted the trimming of output from the wget command with the [. . .] symbol, because there were 44 files downloaded from the Web site www.mrhal.com (reported at the end of the session). Wget was executed with the m and x flags. The m flag, or mirror flag, sets options at the execution of wget to download all of the files contained within the Web site www.mrhal.com by following the links. The x flag is used to preserve the directory structure of the site when it is downloaded.
This type of tool can allow an attacker to index or mirror a site. Afterwards, the attacker can make use of standard system utilities to sort through the data rapidly. Programs such as grep will allow the attacker to look for strings that may be of interest, such as “password,”“root,”“passwd,” or other such strings.
Summary
There are seven categories of attack, including denial of service (DoS), information leakage, regular file access, misinformation, special file/database access, remote arbitrary code execution, and elevation of privileges.
A denial of service attack occurs when a resource is intentionally blocked or degraded by an attacker. Local denial of service attacks are targeted towards process degradation, disk space consumption, or inode consumption. Network denial of service attacks may be launched as either a server-side or client-side attack (one means of launching a denial of service attack against Web browsers are JavaScript bombs). Service-based network denial of service attacks use multiple connections to prevent the use of a service. System-directed network denial of service attacks are similar to a local DoS and to using SYN flooding to fill the connection queue, or using a smurf attack to deny service by filling network resources to capacity with traffic. Distributed denial of service (DDoS) attacks are also system-directed network attacks; distributed flood programs such as tfn and shaft can be used deny service to networks.
Information leakage is an abuse of resources that usually precludes attack. We examined information leakage through secure shell (SSH) banners and found that we can fingerprint services such as a Hypertext Transfer Protocol (HTTP) or File Transfer Protocol (FTP) server using protocol specifications. The Simple Network Management Protocol (SNMP) is an insecurely designed protocol that allows easy access to information; Web servers can also yield information, through dot-dot-slash directory traversal attacks. We mentioned an incident where one Internet service provider (ISP) stole the passwd file of another to steal customers, and we dispelled any myths about information leakage by identifying a system as properly designed when it can cloak, and even disguise, its fingerprint.
Regular file access is a means by which an attacker can gain access to sensitive information such as usernames or passwords, as well as the ability to change permissions or ownership on files—permissions are a commonly overlooked security precaution. We differentiated between single-user systems without file access control and multiuser systems with one or multiple layers of access control; Solaris Access Control Lists (ACL) and Role-Based Access Control (RBAC) are examples of additional layers of permissions. We discussed using symbolic link attacks to overwrite files owned by other users.
Misinformation is defined as providing false data that may result in inadequate concern. Standard procedures of sending misinformation include log file editing, rootkits, and kernel modules. Log file editing is a rudimentary means of covering intrusion; the use of rootkits is a more advanced means by replacing system programs; and kernel modules are an advanced, low-level means of compromising system integrity at the kernel level.
Special file/database access is another means to gain access to system resources. We discussed using special files to gain sensitive information such as passwords. Databases are repositories of sensitive information, and may be taken advantage of through intermediary software, such as Web interfaces, or through software problems such as buffer overflows. Diligence is required in managing database permissions.
Remote arbitrary code execution is a serious problem that can allow an attacker to gain control of a system, and may be taken advantage of without the need for authentication. Remote code execution is performed by automated tools. Note that it is subject to the limits of the program it is exploiting.
Elevation of privileges is when a user gains access to resources not previously authorized. We explored an attacker gaining privileges remotely as an unprivileged user, such as through an HTTP daemon running on a UNIX system, and as a privileged user through a service such as an SSH daemon. We also discussed the use of Trojan programs, and social engineering by an attacker to gain privileged access to a host, and noted that a user on a local system may be able to use these same methods to gain elevated privileges.
Vulnerability testing is a necessary and mandatory task for anybody involved with the administration or security of information systems. One method of testing is called proof of concept, which is used to prove the existence of a vulnerability. Other methods include using automated security tools to test for the vulnerability and using versioning to discover vulnerable versions of software.
An intelligent attack uses research methods prior to an attack. Whois databases can be used to gain more information about systems, domains, and networks. Domain Name System (DNS) tools such as dig can be used to gather information about hosts and the software they use, as well as nslookup to identify mail servers in a domain. We briefly examined scanning a host with Nmap to gather information about services available on the host and the operating system of the host. Finally, we discussed the use of spidering a site to gather information, such as site layout, and potentially sensitive information stored on the Web.
Solutions Fast Track
Identifying and Understanding the Classes of Attack
![]() There are seven classes of attacks: denial of service (DoS), information leakage, regular file access, misinformation, special file/database access, remote arbitrary code execution, and elevation of privileges.
There are seven classes of attacks: denial of service (DoS), information leakage, regular file access, misinformation, special file/database access, remote arbitrary code execution, and elevation of privileges.
![]() Denial of service attacks can be leveraged against a host locally or remotely.
Denial of service attacks can be leveraged against a host locally or remotely.
![]() The gathering of intelligence through information leakage almost always precedes attack.
The gathering of intelligence through information leakage almost always precedes attack.
![]() Insecure directory and file permissions can allow local users to gain access to information that may be sensitive to other users or the system.
Insecure directory and file permissions can allow local users to gain access to information that may be sensitive to other users or the system.
![]() Information on a compromised system can never be trusted and can only again be trusted when the operating system has been restored from a known secure medium (such as the vendor distribution medium).
Information on a compromised system can never be trusted and can only again be trusted when the operating system has been restored from a known secure medium (such as the vendor distribution medium).
![]() Databases may be attacked either through either interfaces such as the Web or through problems in the actual database software, such as buffer overflows.
Databases may be attacked either through either interfaces such as the Web or through problems in the actual database software, such as buffer overflows.
![]() Many remote arbitrary code execution vulnerabilities may be mitigated through privilege dropping, change rooting, and non-executable stack protection.
Many remote arbitrary code execution vulnerabilities may be mitigated through privilege dropping, change rooting, and non-executable stack protection.
![]() Privilege elevation can be exploited to gain remote unprivileged user access, remote privileged user access, or local privileged user access.
Privilege elevation can be exploited to gain remote unprivileged user access, remote privileged user access, or local privileged user access.
Identifying Methods of Testing for Vulnerabilities
![]() Vulnerability testing is a necessary part of understanding the security of a system.
Vulnerability testing is a necessary part of understanding the security of a system.
![]() Using automated security tools is common. Most security groups of any corporation perform regularly scheduled vulnerability audits using automated security tools.
Using automated security tools is common. Most security groups of any corporation perform regularly scheduled vulnerability audits using automated security tools.
![]() Versioning enables a busy security department to assess the impact of a reported vulnerability against currently deployed systems to determine how to manage risk.
Versioning enables a busy security department to assess the impact of a reported vulnerability against currently deployed systems to determine how to manage risk.
![]() Information from Whois databases can be used to devise an attack against systems or to get contact information for administrative staff when an attack has occurred.
Information from Whois databases can be used to devise an attack against systems or to get contact information for administrative staff when an attack has occurred.
![]() Domain Name System (DNS) information can yield information about network design.
Domain Name System (DNS) information can yield information about network design.
![]() Web spidering can be used to gather information about directory structure or sensitive files.
Web spidering can be used to gather information about directory structure or sensitive files.
Frequently Asked Questions
The following Frequently Asked Questions, answered by the authors of this book, are designed to both measure your understanding of the concepts presented in this chapter and to assist you with real-life implementation of these concepts. To have your questions about this chapter answered by the author, browse to www.syngress.com/solutions and click on the “Ask the Author” form. You will also gain access to thousands of other FAQs at ITFAQnet.com
Q: Can an attack be a member of more than one attack class?
A: Yes. Some attacks may fall into a number of attack classes, such as a denial of service that stems from a service crashing from invalid input.
Q: Where can I read more about preventing DDoS attacks?
A: Dave Dittrich has numerous papers available on this topic available on his Web site http://staff.washington.edu/dittrich/ In particular, Dave’s site links to papers that do a terrific job of capturing the impacts of DDoS attacks to business and e-commerce.
Q: How can I prevent information leakage?
A: A number of papers are available on this topic. Some types of leakage may be prevented by the alteration of things such as banners or default error messages. Other types of leakage, such as protocol-based leakage, will be stopped only by rewrite of the programs and the changing of standards.
Q: Is preventing information leakage “security through obscurity?”
A: Absolutely not. There is no logical reason for communicating credentials of a software package to users that should not be concerned with it. Stopping the flow of information makes it that much more resource-intensive for an attacker and increases the chances of the attacks being discovered.
Q: Where can I find out more about exploits?
A: Through full disclosure mailing lists such as Bugtraq (www.securityfocus.com) or through exploit archives such as PacketStorm (www.packetstormsecurity.org) or Church of the Swimming Elephant (www.cotse.com).
Q: How can I protect my Whois information?
A: Currently, there is little that you can do. You can always lie when you register your domain, but you might have problems later when you need to renew. Also, should you ever get into a domain dispute, having false registration information won’t be likely to help your case.