
APPENDIX A
Information Organization and Classification: Taxonomies and Metadata*
By Barb Blackburn, CRM, with Robert Smallwood; edited by Seth Earley
Information governance (IG) necessarily involves organizing and classifying information. IG is critical to enabling improved search results to base business decisions on, executing records retention schedule (RRS) tasks, and sifting through and finding responsive (relevant) information in the e-discovery process. Well-organized information constructs provide downstream benefits across the organization in not only compliance and legal efforts but also day-to-day decision-making and knowledge worker productivity. It is even more crucial in the era of Big Data.
The creation of electronic documents and records is exploding exponentially and multiplying at an increasing rate. Sifting through all this information results in a lot of wasted, unproductive (and expensive) knowledge worker time. This has real costs to the enterprise. According to the study “The High Cost of Not Finding Information,” “knowledge workers spend at least 15 to 25 percent of the workday searching for information. Only half the searches are successful.”1 Experts point to poor taxonomy design as being at the root of these failed searches and lost productivity.
Taxonomies are at the heart of the solution to harnessing and governing information. Taxonomies are hierarchical classification structures used to standardize the naming and organization of information, and their role and use in managing electronic records cannot be overestimated.
Although the topic of taxonomies can get complex, in electronic records management (ERM) they are a sort of online card catalog that is cross-referenced with hyperlinks that is used to organize and manage records and documents.2
According to Forrester Research, taxonomies “represent agreed-upon terms and relationships between ideas or things and serve as a glossary or knowledge map helping to define how the business thinks about itself and represents itself, its products and services to the outside world.”3
Knowledge workers spend at least 15 to 25 percent of the workday searching for information with only half the searches being successful.
Gartner Group researchers warn that “to get value from the vast quantities of information and knowledge, enterprises must establish discipline and a system of governance over the creation, capture, organization, access, and utilization of information.”4
Over time, organizations have implemented taxonomies to attempt to gain control over their mounting masses of information, creating an orderly structure to harness unstructured information (such as e-documents, e-mail messages, scanned records, and other digital assets), and to improve searchability and access.5
Taxonomies for ERM standardize the vocabulary used to describe records, making it easier and faster for searches and retrievals to be made.
Search engines are able to deliver faster and more accurate results from good taxonomy design by limiting and standardizing terms. A robust and efficient taxonomy design is the underpinning that indexes collections of documents uniformly and helps knowledge workers find the proper files to complete their work. The way a taxonomy is organized and implemented is critical to the long-term success of any enterprise, as it directly impacts the quality and productivity of knowledge workers who need organized, trusted information to make business decisions.
It does not sound so complicated, simply categorizing and cataloging information, yet most enterprises have had disappointing or inconsistent results from the taxonomies they use to organize information. Designing taxonomies is hard work. Developing an efficient and consistent taxonomy is a detailed, tedious, labor-intensive team effort on the front end, and its maintenance must be consistent and regular and follow established IG guidelines in order to maintain its effectiveness.
Once a taxonomy is in place, it requires systematic updates and reviews to ensure that guidelines are being followed and new document and record types are included in the taxonomy structure. Technology tools like text mining, social tagging, and auto-classification can help uncover trends and suggest candidate terms. (More on these technologies later in this chapter.)
When done correctly, the business benefits of good taxonomy design go much further than speeding search and retrieval; an efficient, operational taxonomy also is a part of IG efforts that help the organization to manage and control information so that it may efficiently respond to litigation requests, comply with governmental regulations, and meet customer needs (both external and internal).
Taxonomies are crucial to finding information and optimizing knowledge worker productivity, yet some surveys estimate that nearly half of organizations do not have a standardized taxonomy in place.6
To maximize efficient and effective retrieval of records for legal, business, and regulatory purposes, organizations must develop and implement taxonomies.
Taxonomies speed up the process of retrieving records because end users can select from subject categories or topics.
According to the Montague Institute:
The way your company organizes information (i.e., its taxonomy) is critical to its future. A taxonomy not only frames the way people make decisions, but also helps them find the information to weigh all the alternatives. A good taxonomy helps decision makers see all the perspectives, and “drill down” to get details from each, and explore lateral relationships among them.7 (Emphasis added.)
Without a taxonomy, your company will find it difficult to leverage intellectual capital, engage in electronic commerce, keep up with employee training, and get the most out of strategic partnerships.
With the explosion in growth of electronic documents and records, a standardized classification structure that a taxonomy imposes optimizes records retrievals for daily business operations and also for legal and regulatory demands.8
Since end users can choose from topic areas, subject categories, or groups of documents rather than blindly typing word searches, taxonomies narrow searches and speed search time and retrieval.9
“The link between taxonomies and usability is a strong one. The best taxonomies efficiently guide users to exactly the content they need. Usability is judged in part by how easily content can be found,” according to the Montague Institute.10
Importance of Navigation and Classification
Taxonomies need to be considered from two main perspectives: navigation and classification. Most people consider the former, but not the latter. The navigational construct that is represented by a taxonomy is evident in most file structures and file shares—the nesting of folders within folders—and in many Web applications where users are navigating hierarchical arrangements of pages or links. However, classification is frequently behind the scenes. A document can “live” in a folder that the user can navigate to. But within that folder, the document can be classified in different ways through the application of metadata. Metadata are descriptive fields that delineate a (document or) record's characteristics, such as author, title, department of origin, date created, length, number of pages or file size, and so forth. The metadata is also part of the taxonomy or related to the taxonomy. In this way, usability can be impacted by giving the user multiple ways to retrieve their information.11
Taxonomies need to be considered from two main perspectives: navigation and classification.
Poor search results, inconsistent or conflicting file plans, and the inability to locate information on a timely basis are indications taxonomy work is needed.
When Is a New Taxonomy Needed?
In some cases, organizations have existing taxonomy structures, but they have gone out of date or have not been maintained. They may not have been developed with best practices in mind or with correct representation of user groups, tasks, or applications. There are many reasons why taxonomies no longer provide the full value that they can offer. Certain situations clearly indicate that the organization needs a refactored or new taxonomy.12
If knowledge workers in your organization regularly conduct searches and receive hundreds of pages of results, then you need a new taxonomy. If you have developed a vast knowledge base of documents and records and designated subject matter experts (SMEs), yet employees struggle to find answers, you need a new taxonomy. If there is no standardization of the way content is classified and cataloged, or there is conflict between how different groups or business units classify content, you need a new taxonomy. And if your organization has experienced delays, fines, or undue costs in producing documentation to meet compliance requests or legal demands, your organization needs to work on a new taxonomy.13
Taxonomies Improve Search Results
Taxonomies can improve a search engine's ability to deliver results to user queries in finding documents and records in an enterprise. The way the digital content is indexed (e.g., spidering, crawling, rule sets, algorithms) is a separate issue, and a good taxonomy improves search results regardless of the indexing method.14
Search engines struggle to deliver accurate and refined results since the wording in queries may vary and since words can have multiple meanings. A taxonomy addresses these problems since the terms are set and defined in a controlled vocabulary.
Metadata (data fields that describe content, such as document type, creator, date of creation, etc.) must be leveraged in the taxonomy design effort.
A formal definition of metadata is “standardized administrative or descriptive data about a document [or record] that is common for all documents [or records] in a given repository.” Standardized metadata elements of e-documents should be utilized and supported by including them in controlled vocabularies when possible.15
The goal of a taxonomy development effort is to help users find the information they need, in a logical and familiar way, even if they are not sure what the correct search terminology is. Good taxonomy design makes it easier and more comfortable for users to browse topics and drill down into more narrow searches to find the documents and records they need. Where it really becomes useful and helps contribute to productivity is when complex or compound searches are conducted.
Taxonomies improve search results by increasing accuracy and also improving the user experience.
Metadata, which are the characteristics of a document expressed in data fields, must be leveraged in taxonomy design.
Metadata and Taxonomy
One potential limitation of a purely hierarchical taxonomy is the lack of association between tiers (or nodes). There are often one-to-many or many-to-many associations between records. For example, an employee travels to a certification course. The resultant “expense report” is classified in the Finance/Accounts Payable/Travel Expense node of the taxonomy. The “course completion certificate” that is generated from the same travel (and is included as backup documentation for the expense report) is appropriately classified in the Human Resources/Training and Certification/Continuing Education node. For ERM systems that do not provide the functionality for a multifaceted taxonomy, metadata is used to provide the link between the nodes in the taxonomy (see Figure A.1).
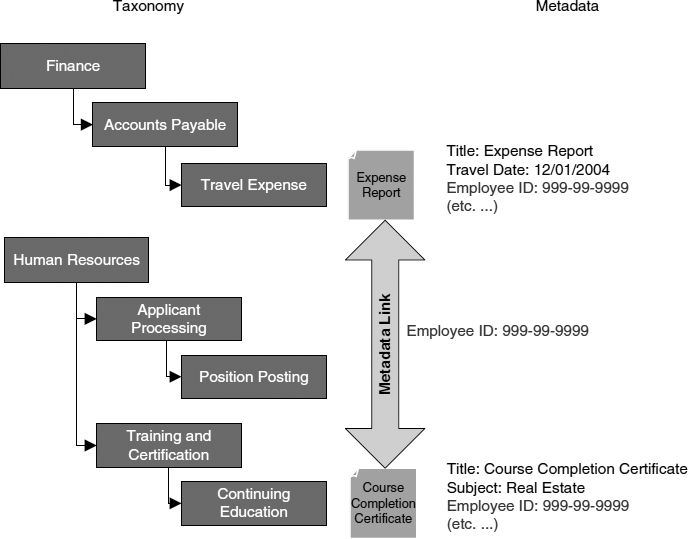
Figure A.1 Metadata Link to Taxonomy Example
Source: Blackburn Consulting
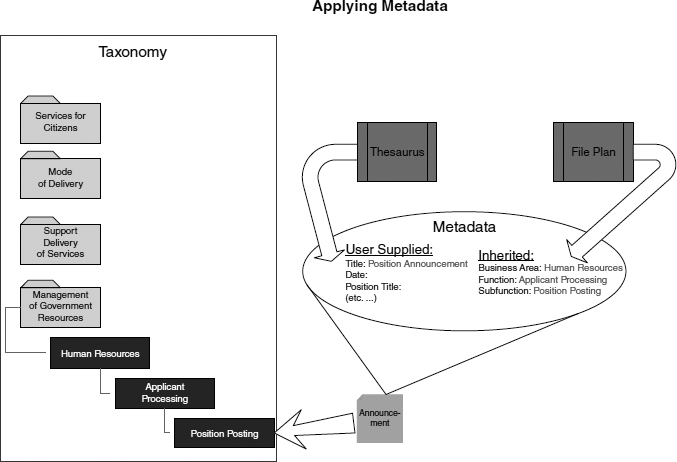
Figure A.2 Application of Metadata to Taxonomy Structure
Source: Blackburn Consulting
Metadata schema must be structured to provide the appropriate associations as well as meet the users' keyword search needs. It is important to limit the number of metadata fields that a user must manually apply to records. Most recordkeeping systems provide the functionality to automatically assign certain metadata to records based on rules that are established in advance and set up by a system administrator (referred in this book as inherited metadata). The record's classification or location in the taxonomy is appropriate for inherited metadata.
Metadata can also be applied by auto-categorization software. This can reduce the burden placed on the user and increase the quality and consistency of metadata. These approaches need to be tested and fine-tuned in order to ensure that they meet the needs of the organization.16
The file plan will provide the necessary data to link the taxonomy to the document via inherited metadata. In most systems, this metadata is applied by the system and is transparent to the users. Additional metadata will need to be applied by the user. To maintain consistency, a thesaurus, which contains all synonyms and definitions, is used to enforce naming conventions (see Figure A.2).
Metadata Governance, Standards, and Strategies
Metadata can be a scary term to a lot of people. It just sounds complicated. And it can get complicated. It is often defined as “data about data,” which is true but somewhat confusing, and this does not provide enough information for most people to understand.
“Meta” derives from a Greek word that means “alongside, with, after, next.” Metadata can be defined as “structured data about other data.”17
In ERM, metadata identifies a record and its contents. ERM metadata describes a record's characteristics so that it may be classified more easily and completely. Metadata fields, or terms, for e-records can be as basic as identifying the name of the document, the creator or originating department, the subject, the date it was created, the document type, the length of the document, its security classification, and its file type.
Creating standardized metadata terms is part of an IG effort that enables faster, more complete, and more accurate searches and retrieval of records. This is important not only in everyday business operations but also, for example, when searching through potentially millions of records during the discovery phase of litigation.
Good metadata management also assists in the maintenance of corporate memory and in improving accountability in business operations.18
Using a standardized format and controlled vocabulary provides a “precise and comprehensible description of content, location, and value.”19 Using a controlled vocabulary means your organization has standardized a set of terms used for metadata elements describing records. This “ensures consistency across a collection” and helps with optimizing search and retrieval functions and records research as well as meeting e-discovery requests, compliance demands, and other legal and regulatory requirements. Your organization may, for instance, decide to use the standardized Library of Congress Subject Headings as standard terms for the “subject” metadata field.20
Metadata also describes a record's relationships with other documents and records and what actions may have been taken on the record over time. This helps to track its history and development.
The role of metadata in managing records is multifaceted; it helps to:
- Identify the records, record creators and users, and the areas within which they are utilized.
- Determine the relationships between records and the knowledge workers who use them, and the relationships between the records and the business processes they are supporting.
- Assist in managing and preserving the content and structure of the record.
- Support IG efforts that outline who has access to records and the context (when and where) in which access to the records is granted.
- Provide an audit trail to document changes to or actions on the record and its metadata.
- Support the finding and understanding of records and their relationships.21
In addition, good metadata management provides additional business benefits including increased management control over records, improved records authenticity and security, and reusability of metadata.22
Metadata terms or fields describe a record's characteristics so that it may be classified, managed, and found more easily.
Metadata terms can be as basic as the name of the document, the creator, the subject, the date it was created, the document type, the length of the document, its security classification, and its file type.
Often, organizations will establish mandatory metadata terms that must accompany a record and some optional ones that may help in identifying and finding it. A record is more complete with more metadata terms included, which also facilitates search and retrieval of records.23 This additional metadata is particularly helpful when knowledge workers are not quite sure which records they are searching for and therefore enter some vague or conceptual search terms. The more detail that is in the metadata fields, the more likely—and faster—that end users can find the records they need to complete their work. Populating metadata fields provides a measurable productivity benefit to the organization, although it is difficult to quantify. Certainly, search times will decrease upon implementation of a standardized metadata program, and improved work output and decisions will also follow.
Standardizing the metadata terms, definitions, and classifications for documents and records is done by developing and enforcing IG policy. This standardization effort gives users confidence that the records they are looking for are, in fact, the complete and current set they need to work with. And it provides the basis for a legally defensible records management (RM) program that will hold up in court.
A metadata governance program must be an ongoing effort that keeps metadata up to date and accurate. Often, once a metadata project is complete, attention to it wanes, maintenance tasks are not executed, and soon the accuracy and completeness of searches for documents and records deteriorates. So metadata maintenance is an ongoing process, and it must be formalized into a program that is periodically checked, tested, and audited.
Types of Metadata
Several types or categories of metadata are described next.
Administrative metadata. Metadata that includes management information about the digital resource, such as ownership and rights management.
Descriptive metadata. Metadata that describes the intellectual content of a resource and is used for the indexing, discovery, and identification of a digital resource.
Preservation metadata. Metadata that specifically captures information that helps facilitate management and access to digital files over time. This inherently includes descriptive, administrative, structural, and technical metadata elements that focus on the provenance, authenticity, preservation activity, technical environment, and rights management of an object.
A metadata governance and management program must be ongoing.
The main types of metadata are: administrative, descriptive, preservation, structural, and technical metadata.
Structural metadata. Metadata that is used to display and navigate digital resources and describes relationships between multiple digital files, such as page order in a digitized book.
Technical metadata. Metadata that describes the features of the digital file, such as resolution, pixel dimension, and hardware. The information is critical for migration and long-term sustainability of the digital resource.24
Core Metadata Issues
Some key considerations and questions that need to be answered for effective implementation of a metadata governance program are listed next.
- Who is the audience? Which users will be using the metadata in their daily operations? What is their skill level? Which metadata terms/fields are most important to them? What has been their approach to working with documents and records in the past, and how can it be streamlined or improved? What terms are important to management? How can the metadata schema be designed to accommodate the primary audience and other secondary audiences? Answers to these questions will come only with close consultation with these key stakeholders.
- Who else can help? That is, which other stakeholders can help build a consensus on the best metadata strategy and approach? What other records creators, users, custodians, auditors, and legal counsel personnel can be added to the team to design a metadata approach that maximizes its value to the organization? Are there subject matter experts (SMEs)? What standards and best practices can be applied across functional boundaries to improve the ability of various groups to collaborate and leverage the metadata?
- How can metadata governance be implemented and maintained? Creating IG guidelines and rules for metadata assignment, input, and upkeep are a critical step—but how will the program continue to be updated to maintain its value to the organization? What business processes and audit checks should be in place? How will the quality of the metadata be monitored and controlled? Who is accountable?
- What will the user training program look like? How will users be trained initially, and how will continued education and reinforcement be communicated? Will there be periodic meetings of the IG or metadata team to discuss issues and concerns? What is the process for adding or amending metadata terms as the business progresses and changes? These questions must be answered, and a documented plan must be in place.
- What will the communications plan be? Management time and resources are also needed to continue the practice of informing and updating users, and encouraging compliance with internal metadata standards and policies. Users need to know on a consistent basis why metadata is important and the value that good metadata management can bring to the organization.
International Metadata Standards and Guidance
Metadata is what gives an e-record its record status; in other words, electronic records metadata is what makes an electronic file a record. There are a number of established international standards for metadata structure, and additional guidance on strategy and implementation has been provided by standards groups, such as the International Organization for Standardization (ISO) and American National Standards Institute/National Information Standards Organization (ANSI/NISO), and other bodies, such as the Dublin Core Metadata Initiative (DCMI).
ISO 15489 Records Management Definitions and Relevance
The international RM standard ISO 15489 states that “a record should correctly reflect what was communicated or decided or what action was taken. It should be able to support the needs of the business to which it relates and be used for accountability purposes.” Its metadata definition is “data describing context, content, and structure of records and their management through time.”25
A key difference between a document and a record is that a record is fixed, whereas a document can continue to be edited. Preventing records from being edited can be accomplished in part by indicating their formal record status in a metadata field, among other controls.
Proving that a record is, in fact, authentic and reliable necessarily includes proving that its metadata has remained intact and unaltered through the entire chain of custody of the record.
ISO Technical Specification 23081–1:2006 Information and Documentation—Records Management Processes—Metadata for Records—Part 1: Principles
[ISO 23081–1] covers the principles that underpin and govern records management metadata. These principles apply through time to:
- Records and their metadata;
- all processes that affect them;
Proving that a record is authentic and reliable includes proving that its metadata has remained intact and unaltered through the record's entire chain of custody.
- any system in which they reside;
- any organization that is responsible for their management.26
This standard provides guidance for metadata management within the “framework” of ISO 15489 and addresses the relevance and roles that metadata plays in RM intensive business processes. There are no mandatory metadata terms set, as these will differ by organization and by location and governing national and state/provincial laws.27 The standard lists 10 purposes or benefits of using metadata in records management, which can help build the argument for convincing users and managers of the importance of good metadata governance and its resultant benefits.
Dublin Core Metadata Initiative
The DCMI produced a basic or core set of metadata terms that have served as the basis for many public and private sector metadata governance initiatives. Initial work in workshops filled with experts from around the world took place in 1995 in Dublin, Ohio (not Ireland). From these working groups arose the idea of a set of “core metadata” or essential metadata elements with generic descriptions. “The fifteen-element ‘Dublin Core’ achieved wide dissemination as part of the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and has been ratified as IETF RFC 5013, ANSI/NISO Standard Z39.85–2007, and ISO Standard 15836:2009.” 28
Dublin Core has as its goals:
Simplicity of creation and maintenance
The Dublin Core element set has been kept as small and simple as possible to allow a nonspecialist to create simple descriptive records for information resources easily and inexpensively, while providing for effective retrieval of those resources in the networked environment.
Commonly understood semantics
Discovery of information across the vast commons of the Internet is hindered by differences in terminology and descriptive practices from one field of knowledge to the next. The Dublin Core can help the “digital tourist”—a nonspecialist searcher—find his or her way by supporting a common set of elements, the semantics of which are universally understood and supported. For example, scientists concerned with locating articles by a particular author, and art scholars interested in works by a particular artist, can agree on the importance of a “creator” element. Such convergence on a common, if slightly more generic, element set increases the visibility and accessibility of all resources, both within a given discipline and beyond.
Goals of the Dublin Core Metadata Initiative are simplicity, commonly understood semantics, international scope, and extensibility.
International scope
The Dublin Core Element Set was originally developed in English, but versions are being created in many other languages, including Finnish, Norwegian, Thai, Japanese, French, Portuguese, German, Greek, Indonesian, and Spanish. The DCMI Localization and Internationalization Special Interest Group is coordinating efforts to link these versions in a distributed registry.
Although the technical challenges of internationalization on the World Wide Web have not been directly addressed by the Dublin Core development community, the involvement of representatives from virtually every continent has ensured that the development of the standard considers the multilingual and multicultural nature of the electronic information universe.
Extensibility
While balancing the needs for simplicity in describing digital resources with the need for precise retrieval, Dublin Core developers have recognized the importance of providing a mechanism for extending the DC [Dublin Core] element set for additional resource discovery needs. It is expected that other communities of metadata experts will create and administer additional metadata sets, specialized to the needs of their communities. Metadata elements from these sets could be used in conjunction with Dublin Core metadata to meet the need for interoperability. The DCMI Usage Board is presently working on a model for accomplishing this in the context of “application profiles.” 29
The fifteen element “Dublin Core” described in this standard is part of a larger set of metadata vocabularies and technical specifications maintained by the Dublin Core Metadata Initiative…. The full set of vocabularies, DCMI Metadata Terms …, also includes sets of resource classes (including the DCMI Type Vocabulary …), vocabulary encoding schemes, and syntax encoding schemes. The terms in DCMI vocabularies are intended to be used in combination with terms from other, compatible vocabularies in the context of application profiles and on the basis of the DCMI Abstract Model. 30
Global Information Locator Service
Global Information Locator Service (GILS) is ISO 23950, the international standard for information searching over networked (client/server) computers, which is a simplified version of structured query language (SQL). ISO 23950 is a federated search protocol that equates to the U.S. standard ANSI/NISO Z39.50. The U.S. Library of Congress is the official maintenance agency for both standards, “which are technically identical (though with minor editorial differences).”31
ISO 23950 grew out of the library science community, although it is widely used, particularly in the public sector.32 The use of GILS has tapered off as other metadata standards at the international, national, industry level, and agency level have been established.33
“It [GILS] specifies procedures and formats for a client to search a database provided by a server, retrieve database records, and perform related information retrieval functions.” It does not specify a format, but information retrieval can be accomplished through full-text search, although it “also supports large, complex information collections.”34 The standard specifies how searches are made and how results are returned.
GILS helps people find information, especially in large, complex environments, such as across multiple government agencies. It is used in more than 40 U.S. states and a number of countries, including Argentina, Australia, Brazil, Canada, France, Germany, Hong Kong, India, Spain, Sweden, Switzerland, United Kingdom, and many others.
Text Mining
On a continuing basis, text mining can be conducted on documents to learn of emerging potential taxonomy terms. Text mining is simply performing detailed full-text searches on the content of document. And with more sophisticated tools like neural computing and artificial intelligence, concepts, not just keywords, can be discovered and leveraged for improving search quality for users.
Another tool is the faceted search (sometimes referred to as faceted navigation or faceted browsing), where, for instance, document collections are classified in multiple ways rather than in a single, rigid taxonomy. Knowledge workers may apply multiple filters to search across documents and records and find better and more complete results. And when they are not quite sure what they are looking for, or if it exists, a good taxonomy can help suggest terms, related terms, and associated content, truly contributing to enterprise knowledge management (KM) efforts, adding to corporate memory and increasing the organizational knowledge base.35 Good KM helps to provide valuable training content for new employees and helps to reduce the impact of turnover and retiring employees.
Search is ultimately about metadata—whether your content has explicit metadata or not. The search engine creates a forward index and determines what words are contained in the documents being searched. It then inverts that index to provide the documents that words are contained in. This is effectively metadata about the content. A taxonomy can be used to enrich that search index in various ways. Index enrichment does require configuration and integration with search engines, but the result is the ability to increase both precision and recall of search results. Search results can also be grouped and clustered using a taxonomy. Doing this allows large numbers of results to be scanned and understood by the user more easily. Many of these functions are determined by the capabilities of search tools and document and RM systems. As search functionality is developed, do not miss this opportunity to leverage the taxonomy.
Text mining is simply performing detailed full-text searches on the content of document.
Records Grouping Rationale
Records are grouped together for five primary reasons:
- They tie together documents with like content, purpose, or theme.
- To improve search and retrieval capabilities.
- To identify content creators, owners, and managers.
- To provide an understandable context.
- For retention and disposition scheduling purposes.36
Taxonomies group records with common attributes. The groupings are constructed not only for RM classification and functions but also to support end users in their search and retrieval activities. Associating documents of a similar theme enables users to find documents when they do not know the exact document name. Choosing the theme or topic enables the users to narrow their search to find the relevant information.
The theme or grouping also places the document name into context. Words have many meanings and adding a theme to them further defines them. For example, the word “article” could pertain to a newspaper article, an item or object, or a section of a legal document. If it were grouped with publications, periodicals, and so on, the meaning would be clear. The challenge here is when to choose to have a separate category for “article” or to group “article” with other similar publications. Some people tend to develop finer levels of granularity in classification structures. These people can be called “splitters.” Those who group things together are “lumpers.” But there can be clear rules for when to lump versus split. Experts recommend splitting into another category when business needs demand that we treat the content differently or users need to segment the content for some purpose. This rule can be applied to many situations when trying to determine whether a new category is needed.37
Management, security, and access requirements are usually based on a user's role in a process. Grouping documents based on processes makes the job of assigning the responsibilities and access easier. For example, documents used in financial processes can be sensitive, and there is a need to restrict access to only those users that have the role in the business with a need to know.
Records retention periods are developed to be applied to a series (or group) of documents. When similar documents are grouped, it is easier to apply retention rules. However, when the grouping for retention is not the same as the grouping for other user views, a cross-mapping (file plan) scheme must be developed and incorporated into the taxonomy effort.
Business Classification Scheme, File Plans, and Taxonomy
In its simplest definition, a business classification scheme (BCS) is a hierarchical conceptual representation of the business activity performed by an organization.38 The highest level of a BCS is called an information series, which signifies “high-level business functions” of a business or governmental agency. The next level is themes, which represent the specific activities that feed into the high-level functions at the information series level. These two top levels are rarely changed in an organization.39
A BCS is often viewed as synonymous with the term “file plan,” which is the shared file structure in an ERM system, but it is not a direct file plan.
Yet a file plan can be developed and mapped back to the BCS and automated through an electronic document and records management system (EDRMS) or ERM system.40
A BCS is required by ISO 15489, the international RM standard. Together with the folders and records it contains, the BCS comprises what in the paper environment was called simply a “file plan.” A BCS is therefore a full representation of the business of an organization.
Classification and Taxonomy
Classification of records extends beyond the categorization of records in the taxonomy. It also must include the application of retention requirements. These are legal and business requirements that specify the length of time a record must be maintained. A records retention schedule is a document that specifies the periods for which an organization's records should be retained to meet its operational needs and to comply with legal and other requirements. The RRS groups documents into records series that relate to specific business activities. This grouping is performed because laws and regulations are mainly based on the business activity that creates the documents. These business activities are not necessarily the same as the activities described in the hierarchy of the taxonomy. Therefore, there must be a method to map the RRS to the Taxonomy. This is accomplished with a File Plan. The File Plan facilitates the application of retention rules during document categorization without requiring a user to know or understand the RRS (see Figure A.3).
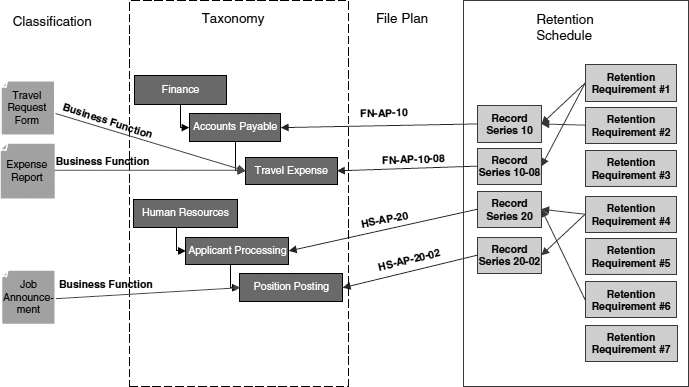
Figure A.3 Mapping the Records Retention Schedule to the Taxonomy
Source: Blackburn Consulting
Prebuilt versus Custom Taxonomies
Taxonomy templates for specific vertical industries (e.g., law, pharmaceuticals, aerospace) are provided by ECM, ERM/EDRMS, KM, enterprise search vendors, and trade associations. These prebuilt taxonomies use consistent terminology, have been tried and tested, and incorporate industry best practices, where possible. They can provide a jump-start and faster implementation at a lower cost than developing a custom taxonomy in-house or with external consulting assistance.
There are advantages and disadvantages to each approach. A prebuilt taxonomy typically will have some parameters that can be configured to better meet the business needs of an organization, yet compromises and trade-offs will have to be made. It also may introduce unfamiliar terminology that knowledge workers will be forced to adapt to, increasing training time and costs, and reducing overall effectiveness. These considerations must be factored into the build-or-buy decision. Using the custom-developed approach, a taxonomy can be tailored to meet the precise business needs of an organization or business unit and can include nuances such as company-specific nomenclature and terminology.41
Frequently, the longer and more costly customized approach must be used, since no prebuilt taxonomies fit well. This is especially the case with niche enterprises or those operating in developing or esoteric markets. For mature industries, more prebuilt taxonomies and template choices exist. Attempting to tailor a prebuilt taxonomy actually can end up taking longer than building one from scratch if it is not a good fit in the first place, so best practices dictate that organizations use prebuilt taxonomies where practical and custom-design taxonomies where needed.
There really is no one size fits all when it comes to taxonomy. And even when two organizations do the exact same thing in the exact same industry, differences in their culture, process, and content will require customization and tuning of the taxonomy. Standards are useful for improving efficiency of a process, and taxonomy projects really are internal standards projects. However, competitive advantage is attained through differentiation. A taxonomy specifically tuned to meet the needs of a particular enterprise is actually a competitive advantage.42
There is one other alternative, which is to “auto-generate” a taxonomy from the metadata in a collection of e-documents and records by using sophisticated statistical techniques, such as term frequency and entity extraction, to attempt to create a taxonomy.43 This method seems to be perhaps the best of both worlds in that it offers instant customization at a low cost, but, although these types of tools can help provide useful insights into the data on the front end of a taxonomy projectand help provide valuable statistical renderings, the only way to focus on user needs is to interview and work with users to gain insights into their business process needs and requirements while considering the business objectives of the taxonomy project. This cannot be done with mathematical computations—the human factor is key.
Best practices dictate that taxonomy development includes designing the taxonomy structure and heuristic principles to align with user needs.
In essence, these auto-generated taxonomy tools can determine which terms and documents are used frequently, but they cannot assess the real value of information being used by knowledge workers and how they use the information. That takes consultation with stakeholders, studied observation, and business analysis.44 Machine-generated taxonomies look like they were generated by machines—which is to say, they are not very usable by humans.45
Thesaurus Use in Taxonomies
In the use of taxonomies, a thesaurus contains the agreed-on synonyms and similar names for terms used in a controlled vocabulary. So, “invoice” may be listed as the equivalent term for “bill” when categorizing records. The thesaurus goes further and lists “information about each term and their relationships to other terms within the same thesaurus.”
A thesaurus is similar to a hierarchical taxonomy but also includes “associative relationships.”46 An associative relationship is a conceptual relationship. It is the “see also” that we may come across in the back of the book index. But the question is, why do we want to see it? Associative relationships can provide a linkage to specific classes of information of interest to users and for particular processes. Use of associative relationships can provide a great deal of functionality in content and document management systems and needs to be considered in RM applications.47
There are international standards for thesauri creation from International ISO, ANSI, and the British Standards Institution (BSI).48
ISO 25964, “Information and Documentation—Thesauri and Interoperability with Other Vocabularies,” “will draw on [the British standard, BS 8723] but reorganize the content to fit into two parts.” Part 1, “Thesauri for Information Retrieval,” of the standard ISO 25964 was published in August 2011. Part 2, “Interoperability with Other Vocabularies,” was approved in 2013.49
Taxonomy Types
Taxonomies used in ERM systems are usually hierarchical where categories (nodes) in the hierarchy progress from general to specific. Each subsequent node is a subset of the higher level node. There are three basic types of hierarchical taxonomies: subject, business-unit, and functional.50
A subject taxonomy uses controlled terms for subjects. The subject headings are arranged in alphabetical order by the broadest subjects, with more precise subjects listed under them. An example is the Library of Congress subject headings used to categorize holdings in a library collection (see Figure A.4). Even the Yellow Pages could be considered a subject taxonomy.
There are three basic types of hierarchical taxonomies: subject, business unit, and functional.

Figure A.4 Library of Congress Subject Headings
It is difficult to establish a universally recognized set of terms in a subject taxonomy. If users are unfamiliar with the topic, they may not know the appropriate term heading with which to begin their search. For example, say people are searching through the Yellow Pages for a place to purchase eyeglasses. They begin their search alphabetically by turning to the E's and scanning for the term “eyeglasses.” Since there are no topics titled “eyeglasses,” they consult the index, find the term “eyeglasses,” and this provides a list of preferred terms or “see alsos” that direct them to “Optical—Retail” for a list of eyeglass businesses. (See Figure A.5.)
In both examples, the subject taxonomy is supported by a thesaurus. Again, a thesaurus is a controlled vocabulary that includes synonyms, related terms, and preferred terms. In the case of the Yellow Pages, the index functions as a basic thesaurus.
In a business unit–based taxonomy, the hierarchy reflects the organizational charts (e.g., department/division/unit). Records are categorized based on the business unit that manages them. Figure A.6 shows the partial detail of one node of a business unit–based taxonomy that was developed for a county government.
One advantage of a business unit–based taxonomy is that it mimics most existing paper-filing system schemas. Therefore, users are not required to learn a “new” system. However, conflicts arise when documents are managed or shared among multiple business units. As an example, for the county government referenced earlier, a property transfer document called the “TD1000” is submitted to the recording office for recording and then forwarded to the assessor for property tax evaluation processing. This poses a dilemma as to where to categorize the TD1000 in the taxonomy.
Another issue arises with organizational changes. When the organizational structure changes, so must the taxonomy based on business units.
In a functional taxonomy, records are categorized based on the functions and activities that produce them (function/activity/transaction). The organization's business processes are used to establish the taxonomy. The highest or broadest level represents the business functions. The next level down the hierarchy constitutes the activities performed for the function. The lowest level in the hierarchy consists of the records that are created as a result of the activity (the transactions).

Figure A.5 Yellow Pages Example
Figure A.7 shows partial detail of one node of a functional taxonomy developed for a state government regulatory agency. The agency organizational structure is based on regulatory programs. Within the program areas are similar (repeated) functions and activities (e.g., permitting, compliance, and enforcement, etc.). When the repeated functions and activities are universalized, the results are a “flatter” taxonomy. This type of taxonomy is better suited to endure organizational shifts and changes. In addition, the process of universalizing the functions and activities inherently results in broader and more generic naming conventions. A functional taxonomy provides flexibility when adding new record types (transactions) because there will be fewer changes to the hierarchy structure.
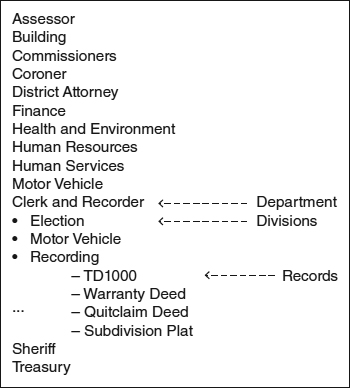
Figure A.6 County Government Business Unit Taxonomy
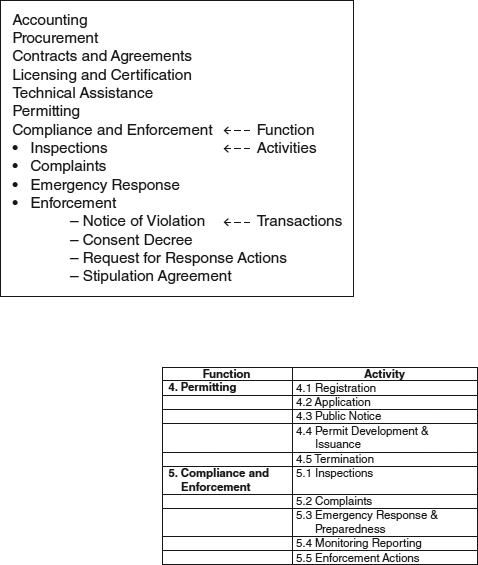
Figure A.7 State Government Regulatory Agency Functional Taxonomy
A functional taxonomy is better suited to endure organizational changes.
One disadvantage of a functional taxonomy is its inability to address case files (or project files). A case file is a collection of records that relate to a particular entity, person, or project. The records in the case file can be generated by multiple activities. For example, at the regulatory agency, enforcement files are maintained that contain records generated by enforcement activities (notice of violation, consent decree, etc.) and other ancillary but related activities, such as contracting, inspections, and permitting.
To address the case file issue at the regulatory agency, metadata cross-referencing was used to provide a virtual case file view of the records collection. (See Figure A.8.)
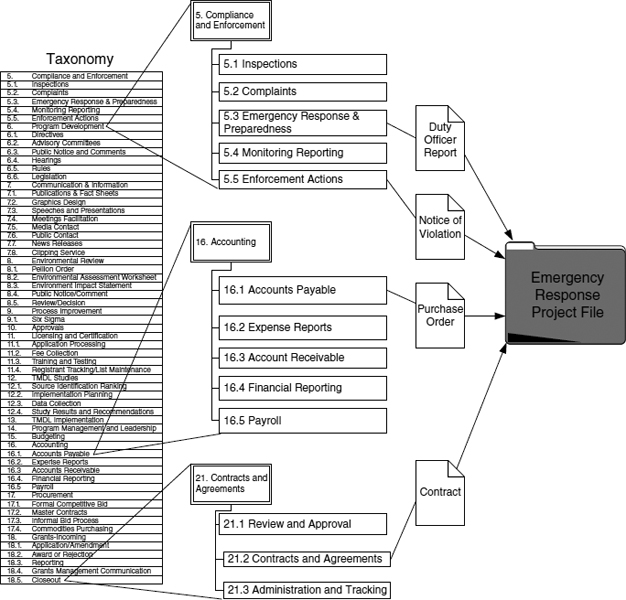
Figure A.8 Metadata Cross-Referencing within a Taxonomy
Source: Blackburn Consulting
One disadvantage of a functional taxonomy is its inability to address case files (or project files).
A hybrid taxonomy is usually the best approach. Certain business units usually do not change over time. For example, accounting and human resources activities are fairly constant. Those portions of the taxonomy could be constructed in a business unit manner even when other areas within the organization use a functional structure. (See Figure A.9.)
Faceted taxonomies allow for multiple organizing principles to be applied to information along various dimensions. Facets can contain subjects, departments, business units, processes, tasks, interests, security levels, and other attributes used to describe information. With faceted taxonomies, there is never really one single taxonomy but rather collections of taxonomies that describe different aspects of information. In the e-commerce world, facets are used to describe brand, size, color, price, and other context-specific attributes. RM systems can also be developed with knowledge and process attributes related to the enterprise.51
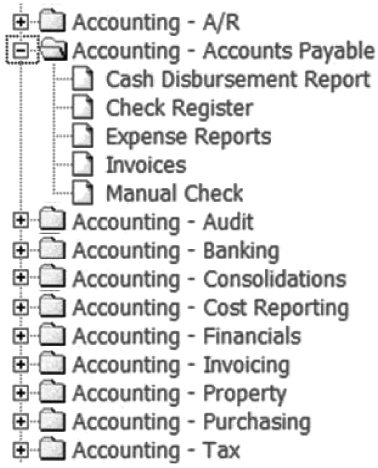
Figure A.9 Basic Accounting Business Unit Taxonomy
Source: Blackburn Consulting
Business Process Analysis
To establish the taxonomy, business processes must be documented and analyzed. There are two basic process analysis methods: top down and bottom up. In the top-down method, a high-level analysis of business functions is performed to establish the higher tiers. Detailed analyses are performed on each business process to fill in the lower tiers. The detailed analyses usually are conducted in a phased approach, and the taxonomy is updated incrementally.
In order to use the bottom-up method, detailed analyses must be performed for all processes in one effort. Using this method ensures that there will be fewer modifications to the taxonomy. However, sometimes conducting a comprehensive analysis is not feasible for organizations with limited resources. A phased or incremental approach is usually more budget friendly and places fewer burdens on the organization's resources.
Many diagramming formats and tools will provide the details needed for the analysis. The most basic diagramming can be accomplished with a standard tool such as Visio® from Microsoft. More advanced modeling tools can be used to produce the diagrams that provide the functionality to statistically analyze process changes through simulation and provide information for architecture planning and other process initiatives within the organization.
Any diagramming format will suffice as long as it depicts the flow of data through the processes showing process steps, inputs, and outputs (documents), decision steps, organizational boundaries, and interaction with information systems. The diagrams should depict document movement within as well as between the subject department and other departments or outside entities.
Figure A.10 uses a swim-lane type diagram. Each horizontal “lane” represents a participant or role. The flow of data and sequence of process steps is shown with lines (the arrows note the direction). Process steps are shown as boxes.

Business processes must be documented and analyzed to develop a taxonomy.
Decision steps are shown as diamonds.

Documents are depicted as a rectangle with a curved bottom line.

The first step is to review any existing business process documentation (e.g., business plans, procedures manuals, employee training manuals, etc.) in order to gain a better understanding of the functions and processes. This is done in advance of interviews in order to provide a base-level understanding to reduce the amount of time required of the interviewees.
Two different types of interviews (high level and detailed business process) are conducted with key personnel from each department. The initial (high-level) interviews are conducted with a representative who will provide an overall high-level view of the department, including its mission, responsibilities, and identification of the functional areas. This person will identify those staff members who will provide details of the specific processes in each of the functional areas identified. For instance, if the department is human resources, functional areas of the department might include: applicant processing, classification, training, and personnel file management. It is expected that this first interview/meeting will last approximately one hour.
The second interviews are detailed interviews that focus on daily processes performed in each functional area. For example, if the function is human resources classification, the process may be the creation/management of position descriptions. It is only necessary to interview one person who represents a particular process—there is no need to interview multiple staff members performing the same function. These second interviews likely will last one to two hours each, depending on the complexity of the process.
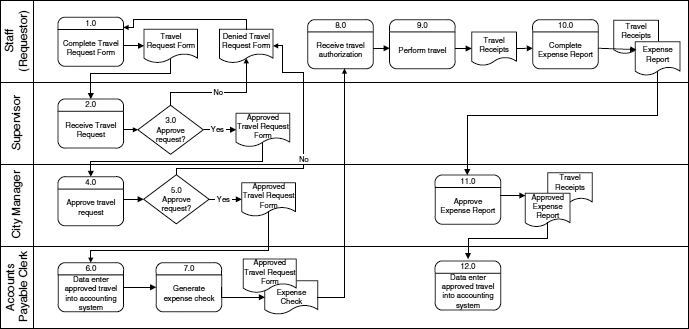
Figure A.10 Business Process Example—Travel Expense Process
Source: Blackburn Consulting
When there are processes that “connect” (e.g., the output from one process is the input to another), it is useful to conduct group interviews with representatives for each process. This often results in a-ha moments when employees from one process finally understand why they are sending certain records to another process. It also brings to light business process improvement opportunities. When employees understand the big-picture process, they can identify unnecessary process steps and redundant or obsolete documents that can be eliminated.
One purpose of process analysis is to develop taxonomy facets that can be used to bring to the surface information for particular steps in the process. In some cases, process steps can directly inform the types of artifacts that are needed at a particular part of the process and therefore be used to develop content types in KM use cases. This is related to RM in that KM applications are simply another lens under which content can be viewed. Process analysis also can help determine the scope of metadata for content. For example, if developing an application to view invoices, if the process includes understanding line item detail, this will dictate a different metadata model than if the process sought only to determine whether invoices over a certain threshold were unpaid. Different processes, different use cases, different metadata.
Taxonomy Testing: A Necessary Step
Once a new taxonomy is developed, it must be tested and piloted to see if it meets user needs and expectations. To attempt the rollout of a new taxonomy without testing it first is imprudent, and will end up costing more time and resources in the long run. So budget the time and money for it.52 Taxonomy testing is where the rubber meets the road; it provides real data to see if the taxonomy design has met user expectations and actually helps them in their work.
User testing provides valuable feedback and allows the taxonomist or taxonomy team to fine-tune the work they have done to more closely align the taxonomy with user needs and business objectives. What may have seemed an obvious term or category may, in fact, be way off. This may result from the sheer focus and myopia of the taxonomy team. So getting user feedback is essential.
Many taxonomy testing tools can assist in the design effort. Once an initial design is drafted, a low-tech approach is to hand-write classification categories and document types on Post-it notes or index cards. Then bring in a sampling of users and ask them to place the notes or cards in the proper category. Track and calculate the results.
Software is available to conduct this card sorting in a more high-tech way, and more sophisticated software can assist in the development and testing effort and to help to update and maintain the taxonomy.
Regardless of the method used, the taxonomy team or even IG team or task force needs to be the designated arbiter when conflicting opinions arise.
There is nothing better than getting quantitative feedback to see if you are hitting the mark with users.
Taxonomy testing is not a one-shot task; with feedback and changes, you progress in iterations closer and closer to meeting user requirements, which may take several rounds of testing and changes.
Taxonomies can be tested in multiple ways. User acceptance throughout the derivation process can be simple conference room pilots or validation, formal usability testing based on use cases, card sorting (open and closed), and tagging processes. Autotagging of content with target taxonomies is also an area that requires testing.53
Taxonomy Maintenance
After a taxonomy has been implemented, it will need to be updated over time to reflect changes in document management processes as well to increase usability. Therefore, users should have the opportunity to suggest changes, addition, and deletions. There should be a formal process in place to manage requests for changes. A person or committee should be assigned the responsibility to determine how and if each requests will be facilitated.
There must be guidelines to follow in making changes to the taxonomy. A U.S. state agency organization uses these guidelines in determining taxonomy changes:
- The new term must have a definition, preferably provided by the proposer of the new term.
- It should be a term someone would recognize even if they have no background within our agency's workings; use of industry standard terminology is preferred.
- Terms should be mutually exclusive from other terms.
- Terms that can be derived using a combination of other terms or facilitated with metadata will not be added.
- The value should not be a “temporary” term—it should have some expectation to have a long life span.
- We should expect that there would be a significant volume of content that could be assigned the value—otherwise, use of a more general document type and clarification through the metadata on items is preferred: if enough items are titled with the new term over time to warrant reconsideration, it will be reconsidered.
There should be a formal process in place to manage requests for taxonomy changes.
A folksonomy uses free-form words to classify documents. A folksonomy approach is useful for updating your taxonomy structure and improves the user search experience.
- For higher-level values in the hierarchy, the relationship between parents and children (functions and activities) is always “is a kind of …” Other relationships are not supported.
- Document type values should not reflect the underlying technology used to capture the content and should not reflect the format of the content directly.
Social Tagging and Folksonomies
Social tagging is a method that allows users to manage content with metadata they apply themselves using keywords or metadata tags. Unlike traditional classification, which uses a controlled vocabulary, social tagging keywords are freely chosen by each individual.
Folksonomy is the term used for this free-form, social approach to metadata assignment.
Folksonomies are not an ordered classification system; rather, they are a list of keywords input by users that are ranked by popularity.54
Taxonomies and folksonomies both have their place. Folksonomies can be used in concert with taxonomies to nominate key terms for use in the taxonomy, which contributes toward the updating and maintenance of the taxonomy while making the user experience better by utilizing users' own preferred terms.
A combined taxonomy and folksonomy approach may provide for an optional free-text metadata field for social tags that might be titled “Subject” or “Comment.” Then users could search that free-form, uncontrolled field to narrow document searches. The folksonomy fields will be of most use to a user or departmental area, but if the terms are used frequently enough, they may need to be added to the formal taxonomy's controlled vocabulary to benefit the entire organization.
In sum, taxonomy development, testing, and maintenance is hard work—but it can yield significant and sustained benefits to the organization over the long haul by providing more complete and accurate information when knowledge workers make searches; better IG and control over the organization's documents, records, and information; and a more agile compliance and litigation readiness posture.
- Knowledge workers spend 15 to 25 percent of an average workday searching for information, often due to poor taxonomy design.
- Taxonomies are hierarchical classification structures used to standardize the naming and organization of information using controlled vocabularies for terms.
- Taxonomies speed up the process of retrieving records because end users can select from subject categories or topics.
- Taxonomies need to be considered from two main perspectives: navigation and classification.
- Poor search results, inconsistent or conflicting file plans, and the inability to locate information on a timely basis are indications that taxonomy work is needed.
- Metadata, which are the characteristics of a document expressed in data fields, must be leveraged in taxonomy design.
- Best practices dictate that taxonomy development includes designing the taxonomy structure and heuristic principles to align with user needs.
- There are three basic types of hierarchical taxonomies: subject, business unit, and functional.
- A hybrid approach to taxonomy design is usually the best.
- An SME can be a valuable resource in taxonomy development. SMEs should not be relied on too heavily, though, or the taxonomy may end up filled with esoteric jargon.
- A document inventory is conducted to gather detailed information regarding the documents managed.
- Business processes must be documented and analyzed to develop a taxonomy.
- User testing is essential, provides valuable feedback, and allows the taxonomist or taxonomy team to fine-tune the work.
- Begin by using low-cost, simple tools for taxonomy development, and migrate to more capable ones as your organization's needs grow and maintenance is required.
- A folksonomy uses free-form words to classify documents. A folksonomy approach is useful for updating your taxonomy structure and improves the user search experience.
Notes
1. ARMA Metro Maryland Newsletter, Cadence Group, “Taxonomies: The Backbone of Enterprise Content Management,” December 2008—January 2009, www.arma-metromd.org/wp-content/uploads/2012/11/2009-01NewImages.pdf.
2. Delphi Group White Paper, “Taxonomy and Content Classification: Market Milestone Report,” 2002, www.delphigroup.com/whitepapers/pdf/WP_2002_TAXONOMY.PDF (accessed April 25, 2012).
4. Cadence Group, “Taxonomies.”
5. Daniela Barbosa, “The Taxonomy Folksonomy Cookbook,” www.slideshare.net/HeuvelMarketing/taxonomy-folksonomy-cookbook (accessed October 12, 2012).
7. Montague Institute Review, “Your Taxonomy Is Your Future” (February 2000), www.montague.com/abstracts/future.html.
8. Free Library, “Creating Order Out of Chaos with Taxonomies,” 2005, www.thefreelibrary.com/Creating+order+out+of+chaos+with+taxonomies%3A+the+increasing+volume+of…-a0132679071 (accessed April 25, 2012).
9. Susan Cisco and Wanda Jackson, “Creating Order Out of Chaos with Taxonomies,” Information Management Journal (May/June 2005), www.arma.org/bookstore/files/Cisco.pdf.
10. Marcia Morante, “Usability Guidelines for Taxonomy Development,” April 2003, www.montague.com/abstracts/usability.html.
11. Seth Earley, e-mail to author, September 10, 2012.
13. Cadence Group, “Taxonomies,” p. 3.
14. DAM News Staff, “8 Things You Need to Know about How Taxonomy Can Improve Search,” May 17, 2010, http://damcoalition.com/index.php/metadata/story/8_things_you_need_to_know_about_how_taxonomy_can_improve_search/.
17. National Archives of Australia, “AGLS Metadata Standard, Part 2—Usage Guide,” Version 2.0, July 2010, www.naa.gov.au/Images/AGLS%20Metadata%20Standard%20Part%202%20%20Usage%20Guide_tcm16-47011.pdf.
18. Kate Cumming, “Metadata Matters,” in Julie McLeod and Catherine Hare, eds., Managing Electronic Records, p. 34 (London: Facet, 2005).
19. Minnesota State Archives, “Electronic Records Management Guidelines: Metadata,” March 12, 2012, www.mnhs.org/preserve/records/electronicrecords/ermetadata.html.
21. Cumming, “Metadata Matters,” p. 35.
23. NISO, “Understanding Metadata,” 2004, www.niso.org/publications/press/UnderstandingMetadata.pdf (accessed October 15, 2012).
24. This and the next section are based on Minnesota State Archives, “Electronic Records Management Guidelines.”
25. National Archives, “Requirements for Electronic Records Management Systems: 2: Metadata Standard,” 2002, www.nationalarchives.gov.uk/documents/metadatafinal.pdf (accessed June 21, 2012).
26. International Organization for Standardization, “ISO 23081-1:2006, Information and Documentation—Records Management Processes—Metadata for Records—Part 1: Principles,” www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=40832 (accessed June 26, 2012).
27. Carl Weise, “ISO 23081-1: 2006, Metadata for Records, Part 1: Principles,” January 27, 2012, www.aiim.org/community/blogs/expert/ISO-23081-1-2006-Metadata-for-records-Part-1-principles.
28. Dublin Core Metadata Initiative, http://dublincore.org/metadata-basics/ (accessed June 26, 2012).
29. Diane Hillman, Dublin Core Metadata Initiative, “User Guide,” November 7, 2005, http://dublincore.org/documents/usageguide/.
30. Dublin Core Metadata Initiative, “Dublin Core Metadata Element Set,” Version 1.1, June 14, 2012, http://dublincore.org/documents/dces/.
31. International Standard Maintenance Agency, Z39.50, Library of Congress www.loc.gov/z3950/agency/ (accessed July 7, 2012).
32. National Information Standards Organization, “ANSI/NISO Z39.50-2003 (R2009) Information Retrieval: Application Service Definition & Protocol Specification,” www.niso.org/apps/group_public/project/details.php?project_id=49 (accessed July 7, 2012).
33. Jenn Riley, “Glossary of Metadata Standards,” 2009–2010, www.dlib.indiana.edu/∼jenlrile/metadatamap/seeingstandards_glossary_pamphlet.pdf (accessed July 9, 2012).
34. Global Information Locator Service, “Initiatives—Includes Spatial Data Initiatives,” www.gils.net/initiatives.html (accessed July 7, 2012).
36. Adventures in Records Management, “The Business Classification Scheme,” October 15, 2006, http://adventuresinrecordsmanagement.blogspot.com/2006/10/business-classification-scheme.html.
38. National Archives of Australia, www.naa.gov.au/Images/classifcation%20tools_tcm16-49550.pdf (accessed December 13, 2013).
39. Adventures in Records Management, “Business Classification Scheme.”
41. Cisco and Jackson, “Creating Order Out of Chaos.”
43. www.earley.com/blog/the-popularity-contest-taxonomy-development-in-the-petabyte-era (accessed April 25, 2012).
46. Hedden, “The Accidental Taxonomist,” 10.
48. Hedden, “The Accidental Taxonomist,” 8.
49. NISO, “Project ISO 25964: Thesauri and Interoperability with Other Vocabularies,” www.niso.org/workrooms/iso25964 (accessed April 25, 2012).
50. This section is adapted with permission from Barb Blackburn, “Taxonomy Design Types,” e-Doc Magazine (May/June 2006): 14, 16, www.imergeconsult.com/img/114BB.pdf (accessed October 12, 2012).
52. Details in this section are from Stephanie Lemieux, “The Pain and Gain of Taxonomy User Testing,” July 8, 2008, www.earley.com/blog/the-pain-and-gain-of-taxonomy-user-testing.
54. Tom Reamy, “Folksonomy Folktales,” KM World 18, no. 9 (October 2009), www.kmworld.com/Articles/Editorial/Feature/Folksonomy-folktales-56210.aspx.
* Portions of this appendix are adapted from Chapter 6 and 16, Robert F. Smallwood, Managing Electronic Records: Methods, Best Practices, and Technologies, © John Wiley & Sons, Inc., 2013. Reproduced with permission of John Wiley & Sons, Inc.