
CHAPTER 9 Hardware and Software Controls
Overview
In this chapter, we will complete our detailed look at the components of our general information security model, which was introduced in Chapter 4. In Chapter 5, we discussed asset identification and characterization. In Chapter 6, we discussed threats and vulnerabilities. The final component of the general model was controls. We look at some of the most essential and best-known controls in this chapter. At the end of this chapter, you should know about
- Password management
- Firewalls and their capabilities
- Access control lists (ACLs)
- Intrusion detection/prevention systems
- Patching operating systems and applications
- End point protection
- Information security control best practices
The above list is not intended to be comprehensive. This is just a list of the essential controls selected by the authors. A simple example of a control that is not discussed above is antivirus software. Further, once you enter the profession, you will encounter many other information security controls including application-specific controls. The intention of the above list and this chapter is to introduce the best-known controls so that you have an understanding of the basic ideas underlying information security controls. Most of these ideas are generalizable, so they should help you in quickly evaluating the merits of other controls you encounter.
Password management
We have defined passwords as a secret series of characters that only the owner of the identity knows and uses it to authenticate identity. Passwords are designed to be a security mechanism that is simple enough for average users while being secure enough for most applications. Passwords are used to protect data, systems, and networks. A password is typically combined with a username. The username serves as identification. Identification is the presentation of a user identity for the system. Authentication establishes confidence in the validity of a claimed identity.1 Successful use of a username and associated password provides a user access to restricted resources such as email, websites, and sensitive data according to the permissions associated with the identity.
Passwords are known by a few different names depending upon the context. A personal identification number (PIN) is a short (4–6 digits), numerical password. PINs are used when small keypads are necessary (ATM machines), or when regular passwords could potentially create human safety problems (airport fire suppression systems). Since they are short, PINs can be easily guessed and only provide limited security. In general, the use of PINs assumes the existence of other security mechanisms. These include daily withdrawal limits and security cameras in ATMs and physical security at airports.
Another form of passwords is the passphrase. A passphrase is a sequence of words that serves as a password. An example of a passphrase is “Wow!!!thisis#1clasatschooL.” The motivation for using passphrases is that though the human brain can only retain up to about seven chunks of information in short-term memory, each chunk can be fairly large.2 Passphrases can therefore be longer than passwords but easier to remember than an arbitrary sequence of characters. However, it is important to remember that simple passphrases such as “thisisthe#1classatschool” can be predictable and easily guessed by attackers compared to passwords such as “TiT#`CaS.” A long passphrase is not necessarily more secure than passwords or a shorter passphrase.
The security of passwords depends entirely on the inability of intruders to guess passwords. Earlier, we have discussed two sets of password guidelines. The first guideline is related to the complexity of the password itself. The second is related to the diversity of passwords so that passwords stolen from one resource cannot be used at another resource.
The above is the end user's perspective on passwords – a password gets you access to a secure system. However, as a system administrator or security professional, you are responsible to make the system work. In particular, you are responsible for ensuring that the passwords in your custody are safe. This is accomplished through password management. Password management is the process of defining, implementing, and maintaining password policies throughout an enterprise.3 Effective password management reduces the likelihood that systems using passwords will be compromised.
Password management reintroduces the CIA triad because organizations need to protect the confidentiality, integrity, and availability of passwords. Using the terminology introduced in Chapter 5 on asset management, passwords can be seen as restricted and essential information assets. Passwords are restricted because a loss of confidentiality or integrity of passwords can give intruders improper access to information. Passwords are essential because nonavailability of a password can make the underlying protected resource unavailable.
The National Institute for Standards and Technology (NIST), in furtherance of its responsibilities, has published guidelines for the minimum recommendations regarding password management. We use these minimal guidelines as the basis for the information in this section. Organizations with more stringent security requirements may impose additional requirements, including requiring mechanisms other than passwords for authentication.
Password management begins with the recognition of the ways in which passwords can be compromised and takes actions to minimize the likelihood of these compromises. NIST recognizes four threats to passwords – password capturing, password guessing and cracking, password replacing, and using compromised passwords.
Password threats
Password capturing is the ability of an attacker to acquire a password from storage, transmission, or user knowledge and behavior. If passwords are stored improperly in memory by an application, or on the hard drive by the operating system, a user with appropriate credentials on the system may be able to steal the password. Similarly, if passwords are not encrypted during transmission, they can be sniffed by anyone on the network. User knowledge and behavior can be exploited in social engineering attacks.
Password guessing is another threat. In password guessing, an intruder makes repeated attempts to authenticate using possible passwords such as default passwords and dictionary words. Password guessing can be attempted by any attacker with access to the login prompt on the target system. Password cracking is the process of generating a character string that matches any existing password string on the targeted system. Password cracking can only be attempted by an attacker who already has access to encrypted versions of saved passwords. These encrypted versions of passwords are called hashes and will be covered in the chapter on encryption.
Password replacing is the substitution of the user's existing password with a password known to the attacker. This generally happens by exploiting weaknesses in the system's password reset policies using various social engineering techniques.
Compromised passwords are passwords on the system known to unauthorized users. Once such a password is known, it may be exploited to launch other social engineering attacks, changing file permissions on sensitive files, etc. If the compromised password is of a privileged user, say an IT administrator, the attacker may even be able to modify applications and systems for later exploitation. For example, the attacker may be able to create a privileged account for himself (most attackers are indeed men!).
Effective password management attends to these threats. NIST recommendations for minimal measures for password management are creating a password policy, preventing password capture, minimizing password guessing and cracking, implementing password expiration as required.
Password threats demonstrate the recursive nature of information security threats. We have already discussed threats to assets. Ostensibly, in this chapter, we are trying to develop safeguards against the common threats. But we find that these safeguards may themselves be compromised. For example, passwords are a safeguard, but passwords may themselves be compromised. And therefore, specific measures must be taken to keep the safeguards safe.
Password management recommendations
A password policy is a set of rules for using passwords. For users, the password policy specifies what kinds of passwords are allowed. For example, passwords, length, and complexity rules fall in this category. For administrators, the password policy specifies how passwords may be stored, transmitted issued to new users, and reset as necessary. The password policy must take into account any regulations that are specific to the industry in which the organization operates.
Minimizing password guessing and cracking requires attention to how each technology in the organization stores passwords. Access to files and databases used to store passwords should be tightly restricted. Instead of storing the passwords, it is recommended that password hashes are saved (this is discussed in more detail in Chapter 7). All password exchange should be encrypted so that passwords cannot be read during transmission. The identity of all users who attempt to recover forgotten passwords or reset passwords must be strictly verified. Finally all users must be made aware of password stealing attempts through phishing attacks, shoulder surfing, and other methods.
To prevent password guessing and password cracking, passwords must be made sufficiently complex, and accounts must be locked after many successive failed login attempts. This minimizes the opportunities for hackers to guess a password. Placing strict limitations on access to password files and databases reduces the opportunities for password cracking.
Password expiration specifies the duration for which the password may be used before it is required to be changed. Password expiration reduces the likelihood that a compromised password can be used productively. Often, passwords are collected through automated procedures, and it can be a while before an attacker actually tries to use a compromised password. If the password is changed before the attacker attempts to use it, the password compromise may not be very damaging. However, password expiration has its problems, particularly if the organization requires different passwords for different systems. Users forget passwords, requiring costly IT support to recover forgotten passwords. In general, therefore, password expiration should be used judiciously, with longer durations for systems with lower security needs.
Password limitations
While passwords are ubiquitous in information security, they do have many significant limitations. Users often forget passwords, requiring either expensive help desks to respond to user requests or password reset mechanisms. Password reset mechanisms introduce their own vulnerabilities because the challenge questions may not be strong enough. Users often save passwords in locations where other users can see them. Finally, relatively simple social engineering attacks such as phishing can be remarkably successful at stealing passwords.4
For all these reasons, there has been considerable interest in developing alternatives to passwords for authentication. However, coming up with a good alternative is not trivial. Users know how to use passwords and managers are reluctant to ask employees to change work methods unless absolutely necessary. It does not help that there is limited data available on actual losses suffered by organizations due to password theft.
The future of passwords
Various authentication mechanisms have been proposed to replace passwords. One of these is Passfaces, where a user preselects a set of human faces and the user selects a face from this set among those presented during a login attempt. Another is draw-a-secret, where users draw a continuous line across a grid of squares. While passwords are likely to continue to be in use for a while, it would not be surprising if these or other similar mechanisms become more popular in the coming years.
Passwords and the more general concern of managing identities is such an important area of information security in practice that we have an entire chapter on identity and access management later in the book.
Access control5
We have earlier defined access control as the act of limiting access to information system resources only to authorized users, programs, processes, or other systems. We deal with access control systems on a day-to-day basis. For example, locks are a form of access control. In computer security, access control is represented using access control models. Access control models describe the availability of resources in a system. Useful access control models are able to represent the protection needs of information and resources of any type and at varying levels of granularity. At the same time, execution of the models should not place unreasonable computational burden on the operating system. Two common implementations of access control models are access control lists (ACLs) and role-based access control (RBAC).
Access control lists (ACLs)
An access control list (ACL) is a list of permissions attached to specified objects. ACLs use a simple syntax to specify subjects, objects, and allowed operations. For instance, if the ACL for a network connection says (131.247.93.68, ANY, block), the host 131.247.93.68 should be blocked from passing through the network connection to reach any resource on the network. The operating system checks all incoming resource requests for ACL entries that may prohibit access to the resource.
ACLs are commonly used to defend two kinds of resources – files and network connections. File ACLs specify rights for individual users or groups of users to files and executables. The use of the chmod command in Chapter 3 is an example of a File ACL system. Network ACLs specify rules that determine port numbers and network addresses that may be accessed. Network ACLs are a common way to implement firewalls (discussed later in this chapter). Most modern operating systems come with default ACLs that provide reasonable levels of security for the average user. ACLs are some of the simplest controls to implement and many other security controls depend upon ACLs for their effectiveness. For example, ACLs help maintain the integrity and availability of passwords by preventing attackers from overwriting passwords.
ACLs begin with a basic distinction between subjects and objects. Subjects attempt operations on objects. The operations are permitted if allowed by the ACL. ACLs may be represented as an access matrix which specifies the permissions for each subject on each object. An example is shown in Figure 9.1. Each cell in the figure shows the access permissions for the corresponding subject on the corresponding object.
Subject John is the owner of File 1. He also has read and write permissions on the file. Being the owner, John can assign any permissions to any user on the file. In this case, subject Bob has been given the read permission and subject Alice has been given the Execute permission on the file. Thus, each cell is the access control list for each user on the corresponding object.
Limitations
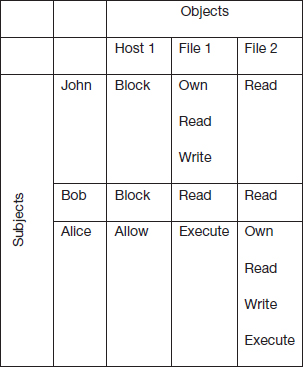
Access control lists are a very simple and effective access control mechanism. They also have some significant limitations. If the permissions for a specific user have to be modified, the permissions for that user must be modified on all the objects to which the user has access. Also, it is not possible to assign permissions based on user responsibilities. If a user changes roles, providing access permissions to the user that are appropriate to their new role requires modifying permissions to the user individually on all applicable objects.
Role-based access control (RBAC)
We have seen that role-based access control assigns permissions to user roles rather than to individual users. Roles are created for job functions and users are assigned roles based on their responsibilities. By defining access permissions for roles, there is a separation between users and access controls. As users evolve within the organization, their roles can be assigned and the access permissions are automatically updated. RBAC therefore reduces the cost and administrative effort required to implement access control in large organizations, compared to ACLs.
Firewalls6
A firewall is a form of protection that allows one network to connect to another network while maintaining some amount of protection. One of the most familiar examples of a firewall is the door to a home or office. The door allows residents to get out of the house, while blocking rain and sleet from entering the home. The door also helps residents maintain some degree of confidentiality.
Network firewalls are hardware or software that prevent the dangers originating on one network from spreading to another network. In practice, network firewalls are used to serve multiple purposes including (1) restricting entry and exit from the network to carefully specified locations, (2) limiting incoming Internet traffic to specific application running on specific devices, and (3) blocking outgoing traffic from hosts suspected to have been compromised. Firewalls are not generally intended to defend against specialized attacks. For example, the doors of a retail store are not designed to detect shoppers with explosives, or shoplifters. Those tasks, where necessary (e.g., at airports), are left to more specialized controls such as human inspectors or antitheft technologies. However, firewalls are a very effective and relatively inexpensive first line of defense against a large number of common nuisances.
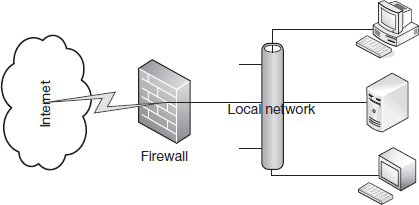
Figure 9.2 shows the common arrangement of a firewall relative to an organization's internal network and external networks such as the Internet. All traffic between the Internet and the organization's network is directed through the firewall where the organization's traffic rules may be implemented.
Firewall decisions
A firewall chooses one of two possible actions on packets that pass through it – allow or deny. Allowed packets continue on to their intended destination, while denied packets are blocked at the firewall. We begin with the basic stance of the firewall – default deny or default allow. A firewall with a default allow stance will allow all packets into the network, except those that are explicitly prohibited. A firewall with a default deny stance blocks all packets, except those explicitly allowed.
Default deny or default allow?
The standard security recommendation is to use the default deny stance. This way, only services known to be safe will be reachable from the Internet. However, users typically prefer the default allow stance, since it allows experimental and other network services to operate.
The default allow stance may be acceptable for novice administrators or students learning how to configure firewalls. For all other uses, the default deny stance should be used.
The basic stance of the firewall is augmented by the administrator who specifies ACL rules to identify allowed packets (assuming a default deny stance). A few representative rules are shown below, using the syntax used by ipfilter, a popular firewall software.
pass in quick from 192.168.1.0/24 to 192.168.10.50 pass out quick from 192.168.10.50 to 192.168.1.0/24 pass in log quick from any to any port = 22 pass out log quick from any port = 22 to any block in all block out all
These rules may be interpreted as follows. The first two rules allow packet to reach and leave from the IP address 192.168.10.50 to any IP address in the 192.168.1.0/24 subnet. 192.168.1.0/24 is a compact way to represent all IP addresses from 192.168.1.0 to 192.168.1.255. This may be useful if, for example, the host 192.168.10.50 is used to provide shared services such as file and printer sharing or a Sharepoint portal to the organization. The second set of rules allows all incoming and outgoing connections to the ssh service (this is a remote login service to UNIX hosts). The SSH rules also specify that all ssh transactions be logged. The organization may like to do this to keep track of all SSH activity. The last two rules specify the default stance of the firewall, which is to deny by default.
Limitations of firewalls
Given their popularity, it is important to know what firewalls cannot do. Some of the important limitations of firewalls include the following:
Insiders and unregulated traffic: Firewalls protect the organization against attacks originating outside the network. If a computer inside the organization is compromised, it can steal data from other computers within the organization without passing through the firewall. Similarly, if a user brings in a flash storage device and copies sensitive data on to that device, there is nothing a firewall can do to prevent such theft because the traffic does not flow through the firewall.
Encrypted traffic: Encrypted data cannot be inspected, and therefore firewalls have limited ability to defend against encrypted data. For example, if a user browses a secure website, the firewall will not be able to examine the encrypted information exchanged between the user and the website.
Configuration: The security and usability afforded by a firewall depends upon its configuration by an administrator. A poorly configured firewall can allow malicious traffic to reach sensitive targets while providing an illusion of security.
Firewall types
There are broadly speaking, two types of firewalls – packet filtering firewalls and deep packet inspection firewalls. Packet filtering firewalls examine the protocol header fields of packets flowing through the firewall to determine whether to allow the packets to enter the network. Packet filtering firewalls may inspect fields such as source and destination IP addresses, destination port addresses, and TCP flags. One use of such a firewall would be to block incoming packets from a host or ISP that has a history of sending large volumes of spam messages. The host or ISP would be identified by the source IP address field.
Deep packet inspection firewalls examine the data carried by a packet, in addition to the protocol headers, to decide how to handle the packet. The data carried by the packet can be compared against a database of known malicious payloads. Such comparison can identify attempts to launch buffer overflow or other attacks that depend on carefully crafted payloads.
Firewall organization
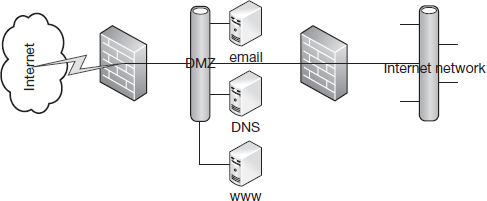
Figure 9.2 is a simplified representation of how firewalls are used. Figure 9.3 is a more representative of the standard firewall configuration. It involves a perimeter firewall, a demilitarized zone, an interior firewall, and a militarized zone.
The perimeter firewall is the firewall that lies between the external network and the organization. It allows hosts outside the organization to access public-facing services offered by the organization such as the web, email, and DNS.
The perimeter network, also called the demilitarized zone, is the network that lies between the external network and the organization's internal network. The perimeter network hosts external services such as http, smtp, and DNS.
The internal network, or the militarized zone, is the location of all the organization's information assets.
The interior firewall limits access to the organization's internal network. Generally, access to the internal network is limited to some specific applications for requests originating from specific hosts on the perimeter network. For example, a university could maintain a portal at the demilitarized zone. Resources such as student records are stored on the internal network. These records can only be accessed using requests that originate from the portal. If the portal is compromised, other information inside the university is not at risk of compromise.
Basic firewall recommendations
If you are tasked with setting up a firewall for a small business or department, here are some settings you can start with. Allow users to access to the following services on the Internet:
Web (port 80, 443) to specified hosts running web servers
Email (ports 25, 465, 585, 993, 995) to specified hosts running email servers
DNS (port 53) to specified hosts running the DNS service
Remote desktop connections (port 3389)
SSH (port 22) to specific UNIX hosts
A general rule of thumb is to allow “secure” services. These are services that encrypt transactions and are in popular use. The popularity of a service is important because it ensures that the relevant software is constantly updated when any security flaws are reported. The most common of these services are SSH (for UNIX connections) and remote desktop (for Windows clients). In a typical commercial organization, these services may typically be allowed to connect to any host within or outside the network.
Another set of services are called “safe” services. These are popular services which can only be used as specified but which do not encrypt their transactions. Examples of such services include email and the web. For these reasons, it is recommended that hosts only be allowed to connect to web servers or email servers on designated hosts, which are maintained by trained and responsible system administrators. This ensures that even if a web server is accidentally enabled by a user on their desktop and not updated any further, the risks posed by such servers is limited.
Two services that were very common in the past but which are discouraged today are Telnet and FTP. These services have been replaced by their secure counterpart (SSH) and the software is generally unmaintained, leaving potential vulnerabilities. These services should generally be blocked, unless there is a special reason to enable them (e.g., to allow legacy applications using these services to work).
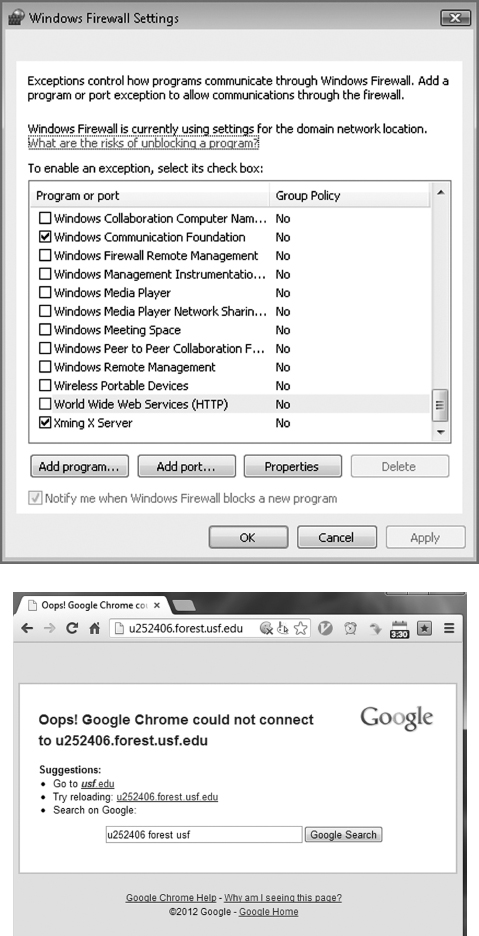
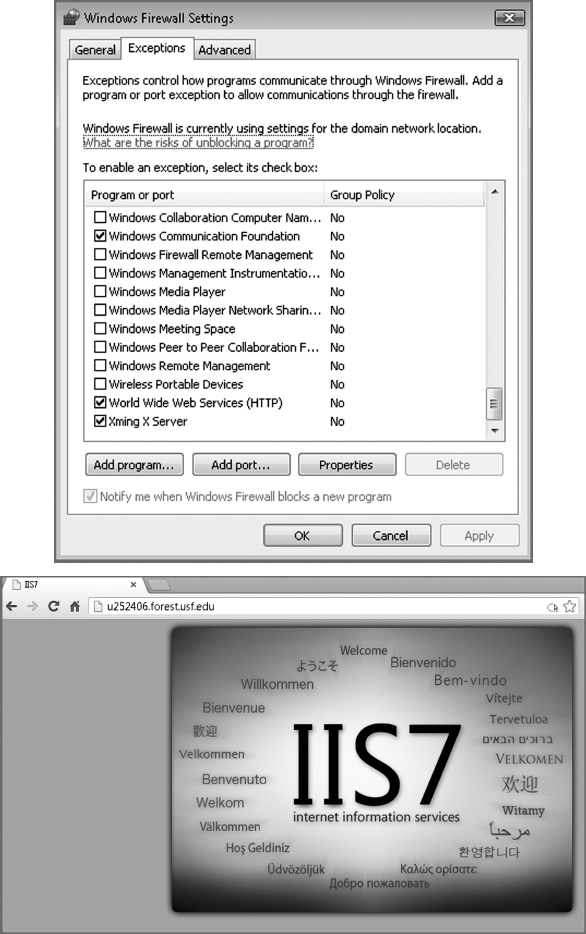
The figures below show the Windows firewall in action. The column on the left shows that when the firewall blocks incoming http requests (default), a website running on the host is not accessible from the outside world. The column on the right shows the same host but this time, with the Windows firewall configured to allow incoming http requests. The site can now be accessed from the outside world (Figures 9.4 and 9.5).
Intrusion detection/prevention systems
IT systems are under constant attack from various sources. For example, Federal agencies have reported that the number of security incidents that placed sensitive information on Federal systems at risk have increased from 5,503 in 2006 to 41,776 in 2010, an increase of over 650% during this period.7 To respond effectively to these incidents, system administrators are interested in technology that can detect intrusion attempts in real time and alert administrators so they can respond promptly. This requirement has led to the development of intrusion detection systems.
Intrusion detection systems (IDS) are hardware devices or software applications that monitor IT systems for malicious activity or violations of usage policies established by the system administrator. Intrusion prevention systems build on IDS and attempt to stop potential intrusions. IDSs and to some extent IPSs have now become an integral part of the IT security infrastructure of most organizations.
Broadly speaking, there are two types of intrusion detection systems – network-based and host-based. Network IDSs (NIDSs) monitor network traffic and application protocol activity to identify suspicious connections. NIDSs are usually included in routers and firewalls.8 Host-based IDSs (HIDSs) are software applications installed on individual hosts that monitor local activity such as file access and system calls for suspicious behavior. To maximize the probability of detecting intrusion attempts, most enterprise environments employ multiple IDSs, each with its own set of rules, to observe system activity from its own perspective.
One interesting function of an IDS is to raise alarms about impending attacks. This is done by watching for reconnaissance activity – host and port scans to identify targets for subsequent attacks. Such scans often precede large-scale attacks. If the system administrator is notified of such scans, they can take necessary actions to be prepared for any of the following attacks.
Detection methods
Contemporary IDSs are based on three detection methods – signatures, anomalies, and protocol states. Most commercial implementations use a combination of all three to maximize effectiveness.
Signature-based IDS
A signature is a sequence of bytes that is known to be a part of malicious software. Signature-based detection methods compare observed events to a database of signatures to identify possible incidents. An example of a signature is an email with a subject line of “ILOVEYOU” and a file attachment called “LOVE-LETTER-FOR-YOU.txt.vbs.” This corresponds to the well-known ILOVEYOU virus released on 5/5/2000 in the Phillipines.
Signature-based detection is very effective against simple well-known threats. It is also computationally very efficient because it uses simple string comparison operations. However, it is not very useful at detecting previously unknown threats, disguised threats, and complex threats. For example, the ILOVEYOU virus would be equally effective if the email subject line read “job offer for you” and the attachment file was called “interview-script.vbs.” However, this simple disguise would make it very difficult for a signature-based IDS to detect the virus.
Another limitation of signature-based IDS technologies is that signature matching is limited to the current unit of activity, e.g., an incoming packet or an individual log entry. Signature-based IDSs do not understand the operations of network protocols. As a result, a signature-based IDS cannot detect port scans since every individual probe packet is a well-formed and legitimate packet. Threat detection of a port scan requires an aggregation of information about the current packet with information about packets received in the past – something signature matching of the current packet alone cannot do. More generally, signature-based IDSs cannot detect attacks composed of multiple events if none of the individual events clearly match the signature of a known attack.
Anomaly-based IDS
Anomaly-based detection is the process of detecting deviations between observed events and defined activity patterns. The administrator defines profiles of normal behavior based on users, hosts, network connections, or applications. For example, a profile for an average desktop PC might define that web browsing comprises an average of 20% of network usage during typical workday hours. The IDPS then compares current activity and flags alarms when web activity comprises significantly more bandwidth than expected. Other attributes for which profiles can be created include the number of emails sent by a user and the level of processor usage for a host in a given period of time.
Anomaly-based detection methods are very effective at detecting previously unknown threats. For example, if a computer is infected with a new type of malware that sends out large volumes of spam email, or uses the computer's processing resources to break passwords, the computer's behavior would be significantly different from the established profiles for the computer. An anomaly-based IDS would be able to detect these deviations and alert the system administrator.
One problem with building profiles for anomaly-based IDS is that it can be very challenging to develop accurate baseline profiles. For example, a computer may perform full backups involving large volumes of network data transfer on the last day of the month. If this is not included as part of the baseline profile, normal maintenance traffic will be considered a significant deviation from the baseline profile and will trigger alarms.
Protocol-state-based IDS*
Protocol-state-based IDS compares observed events against defined protocol activity for each protocol state to identify deviations. While anomaly-based detection uses host or network-specific profiles, stateful protocol analysis specifies how particular protocols should and should not be used. For example, a stateful IDS knows that a user in an unauthenticated state should only attempt a limited number of login attempts or should only attempt a small set of commands in the unauthenticated state. Deviations from expected protocol behavior can be detected and flagged by a protocol-state-based IDS. Other abilities of a stateful protocol IDS is the ability to identify unexpected sequences of commands. For example, issuing the same command repeatedly can indicate a brute-force attack. A protocol-state-based IDS can also keep track of the user id used for each session, which is helpful when investigating an incident.
Protocol analysis can include checks for individual commands, such as monitoring the lengths of arguments. If a command typically has a username argument, an argument with a length of 1,000 characters can be considered suspicious. In addition, if the username contains non-text data, it is even more unusual and merits flagging.
The primary limitation of protocol-state-based IDS is that tracking state for many simultaneous sessions can be extremely resource-intensive, requiring significant investments in computer hardware.
IDS/IPS architecture
Enterprise IDS/IPS deployments follow a typical distributed systems architecture. There are many sensor agents deployed throughout the enterprise, collecting network-based and host-based information. These agents send their data to a central management station, which records all received data in a database and performs various signature-based, anomaly-based, and protocol-state-based analyses on the data. System administrators use desktop or web-based consoles to configure agents, monitor alarms, and take appropriate defensive actions.
Limitations of IDS/IPS
IDS/IPS technologies have two well-known limitations – false positives and evasion.
With the current state of technology, IDSs are not completely accurate. Many alarms raised by IDSs do not represent real threats and many real threats are missed. Flagging safe activity as malicious is called a false positive. Failing to identify malicious activity is called a false negative. Reducing one generally increases the other. For example, a very sensitive IDS will detect more real attacks, but it will also flag many benign transactions as malicious. A less sensitive IDS will not raise too many false alarms, but in the process will also miss many real attacks. Since real attacks are very expensive, organizations generally prefer to maximize the probability of detecting malicious traffic, even if it means having to respond to more false alarms. This comes at the cost of the information security group having to devote more resources to sift through all the false alarms to find the really malicious events.
Evasion is the act of conducting malicious activity so that it looks safe. Attackers use evasion procedures to reduce the probability that attacks are detected by IDPS technologies. For example, port scans can be conducted extremely slowly (over many days) and from many different sources to avoid detection. Malware can be sent as parts of file attachments and appear legitimate.
IDS/IPS therefore cannot be trusted to detect all malicious activity. However, like firewalls, they can be very effective as a part of an organization's overall information security deployment.
The NIST guide is an excellent resource for more information on IDS/IPS technologies.
Patch management for operating systems and applications9
A patch is a software that corrects security and functionality problems in software and firmware. Patches are also called updates. Patches are usually the most effective way to mitigate software vulnerabilities. While organizations can temporarily address known software vulnerabilities through workarounds (placing vulnerable software behind firewalls for example), patches or updates are the most effective way to deal with known software vulnerabilities.
Patch management is the process of identifying, acquiring, installing, and verifying patches. Patches are important to system administrators because of their effectiveness at removing software vulnerabilities. In fact, many information security frameworks impose patch management requirements. For example, the Payment Card Industry (PCI) Data Security Standard (DSS) requires that critical patches must be installed within 1 month of the release of the patch (PCI DSS 2.0 requirement 6.1.b).
Patch management introduces many challenges. The most important of these is that patches can break existing software, particularly software that has been developed in-house using older technologies. The PCI DSS defines appropriate software patches as “those patches that have been evaluated and tested sufficiently to determine that the patches do not conflict with existing security configurations.” Effective enterprise-wide patch management addresses these and related challenges, so that system administrators do not spend time fixing preventable problems.
In recent years, automated patch management software has gained popularity to deal with these issues. In a recent survey of IT professionals, automated patch management software products (such as SUS, HFNetChk, BigFix Enterprise Suite, and PatchLink Update) were used by 64% of the respondents for patch management; 18% used Windows update and 17% applied patches manually.10
NIST identifies the following challenges with enterprise patch management: timing, prioritization, and testing; configuration; alternative hosts; software inventory; resource overload and implementation verification. Each of these is discussed in brief below.
Timing, prioritization, and testing
Ideally, every patch should be installed as soon as it is released by the vendor to protect systems as quickly as possible. However, if patches are installed without exhaustive testing, there is a real risk that operational system might fail, causing immediate disruptions to the normal course of business of the organization. In the short run, many organizations may perceive such disruptions to be more damaging than any potential harm from not installing the patch. Matters are even more complicated in practice because organizations are often short-staffed. To get maximum benefits from the limited staff-time available for patching, it usually becomes necessary to prioritize which patches should be installed first. Therefore, during patch management, timing, prioritization, and testing are often in conflict.
One response to this challenge is patch bundles. Instead of releasing patches as soon as they are ready, product vendors often release aggregates of many patches as patch bundles at quarterly or other periodic schedules. This reduces patch testing effort at organizations and facilitates deployment. Patch bundling can even eliminate the need for prioritization if testing and deployment efforts are sufficiently reduced by bundling. Even if a software vendor uses patch bundles, if it becomes known that an unpatched vulnerability is being actively exploited, the vendor will issue the appropriate patch immediately, instead of waiting for the release time for the bundle.
While prioritizing patches, it is important to consider the importance of the systems which are to be patched in addition to the importance of the vulnerability itself. Web-facing servers may be more important to patch than desktops located behind militarized zones. Dependencies are another consideration. If the installation of one patch requires that some other patches be installed first, the prerequisite patches will also need to be tested and applied, even if the patched vulnerability is not in itself very important.
Configuration
In enterprises environments, patch testing and deployment are complicated by the fact that there are usually multiple mechanisms for applying patches. For example, some software could have been configured to automatically update itself by the end user, in other cases, users may have manually installed some patches or even installed newer versions of software. While the preferred method may be to use centralized patch management tool, in some cases, patching may get initiated by tools such as network vulnerability scanners.
These competing patch installation procedures can cause conflicts. Competing methods may try to overwrite patches, remove previously installed patches, or install patches that the organization has decided not to install for operational stability reasons. Organizations should therefore identify all the ways in which patches could be applied and resolve any conflicts among competing patch application methods.
Users are a related concern in patch management configuration. Users, particularly power users, may override or circumvent patch management processes, e.g., by enabling direct updates, disabling patch management software, installing old and unsupported versions of software, or even uninstalling patches. These user actions undermine the effectiveness of the patch management process. Organizations should therefore take steps to prevent users from adversely affecting the organization's patch management technologies.
Alternative hosts
The typical enterprise environment has a wide array of hardware and software deployed. Patch management is greatly simplified when all hosts are identical, fully managed, and running typical applications and operating systems. Diversity in the computing environment generates considerable challenges during patching. Examples of architecture diversity include hosts managed by end users; tele-work laptops which stay outside the enterprise's environment for extended durations and can collect vulnerabilities; non-standard IT components such as Internet-enabled refrigerators or other appliances; personally owned devices such as smart phones over which the organization has no control; and virtualization, which brings up and tears down computer systems on demand, sometimes with obsolete software.
In this list, appliances are a particularly interesting case because often the manufacturers of these appliances are not very familiar with the importance of patch management and may not support automated procedures for testing and deploying patches. Patch management for these devices can easily become a time-consuming and labor-intensive process.
An effective patch management process should carefully consider all alternative host architectures connected to the organization's IT infrastructure.
Software inventory
For effective testing, enterprise patch management requires that the organization maintain a current and complete inventory of all patchable software installed on each host in the organization. This inventory should also include the correct version and patch status of each piece of software.
Resource overload
After testing is completed, the deployment needs to be managed to prevent resources from becoming overloaded. For example, if many hosts start downloading the same large patch at the same time, it can significantly slow the download speed as the hard drives hunt for the different blocks of software for each individual host. In large organizations, network bandwidth can also become a constraint, particularly if the patches are being transmitted across the continent on WAN networks. Organizations should plan to avoid these resource overload situations. Common strategies include sizing the patch management infrastructure to handle expected request volumes and staggering the delivery of patches so that the enterprise patch management system only delivers patches to a limited number of hosts at any given time.
Implementation verification
Another critical issue with patch management is forcing the required changes on the target host so that the patch takes effect. Depending upon the patch and the target hardware and software, this may require no additional step, may require restarting a patched application or service, rebooting the entire operating system, or making other changes to the state of the host. It can be very difficult to examine a host and determine if a particular patch has taken effect.
One mechanism to deal with this challenge is to use other methods of confirming installation, e.g., using a vulnerability scanner that is independent from the patch management system.11
End-point protection
End-point protection is the security implemented at the end user device. End user devices are desktops, laptops, and mobile devices used directly by consumers of the IT system. End-point security is typically implemented using specialized software applications that provide services such as antivirus protection, antimalware protection, and intrusion detection. End-point protection serves as the defense of last resort, attempting to pick up security problems missed by network controls such as firewalls and intrusion detection systems.
End-point security can offer security that organization-wide systems cannot provide. For example, end-point security systems can confirm that the versions of the operating system, browser, email client, and other software installed on the device are up-to-date and alert the user if necessary to initiate an update. Network-based security controls cannot generally provide such fine-grained security.
End-point protection also provides protection against other compromised devices internal to the network. For example, if a desktop within the network is compromised and begins scanning ports within the network, the end-point security software on targeted hosts can detect the scans and block any further requests from the computer until the matter is resolved.
Well-known firms offering end-point protection software include Symantec and McAfee. Microsoft also includes Windows Defender as part of its operating system.
Operations
End-point security software recognizes malware and viruses using one of two methods – signatures and reputation. Signature-based detection is the traditional method of detecting malicious software. Reputation-based mechanisms are newer and are computationally more efficient at detecting previously unknown threats.
Signature-based end-point protection
We have seen that a signature is a sequence of bytes that is known to be a part of malicious software. Signatures have been the dominant technique used in end-point protection. Traditional virus and malware detection methods have relied on experts performing detailed analysis of each virus and malware executable to identify sequences of bytes that are unique to the virus or malware. In common parlance, these identifying byte sequences are also called virus definitions. Once such a byte sequence is identified, it is added to the end-point software's database of known malicious software.
The end-point protection software examines all incoming, outgoing, and executing files for the presence of any known virus signature. If such a signature is found, the file is immediately quarantined.
Signature-based virus and malware detection have few well-known problems. The most obvious is that it cannot defend against previously unknown threats. When a virus is newly released, its signature will not be present in the end-point databases, and the end-point protection software will consider the software safe.
Secondly, the inability of signature-based detection to block previously unknown viruses encourages growth in the number of viruses. Conceptually, creators of viruses can modify just 1 byte of malware and thwart the ability of signature-based systems to recognize the malware. This encourages developers to create viruses that modify themselves subtly between infections without any intervention from the developer, resulting in an explosion in the sizes of the signature databases. Since every file has to be scanned against all known signatures, eventually, growth in the size of the signature database causes signature-based detection to slow the system significantly. This arms race between viruses and virus signatures comes at the cost of system performance for the end user.
The state of the market in virus signatures12
In 2008, Symantec, a well-known company specializing in end-point protection, discovered over 120 million distinct malware executables. Whereas in 2000, the firm published an average of five new virus signatures each day; in 2008, it published thousands of new virus signatures each day. These new signatures steadily added to the signature detection workload of each computer, taking away computer resources that could be used for more productive tasks.
Reputation-based end-point protection
Reputation-based end-point protection tries to predict the safety of a file based on a reputation score calculated using the file's observable attributes. The influence of each file attribute on the reputation of files is calculated from the observed behaviors of files on user machines. Over time, reputation scores are calculated and periodically updated for every known executable file.13 When an executable file (computer program) is encountered, a reputation-based end-point protection system can determine the file's safety by looking at its reputation score (if known) or by computing the file's likely reputation from the file's observable attributes.
Since reputation-based end-point protection only needs to look at the file's known attributes (such as file size, age, source), this method eliminates the need to scan every byte of every file for the existence of any of millions of known malware signatures. This greatly speeds up the process of virus and malware scanning, enabling computer resources to be devoted to productive tasks, as opposed to signature detection.
Reputation-based methods have built-in resistance to new viruses. Previously unknown files naturally receive a low reputation score, much like how new borrowers like teenagers begin with a low credit score. As a file is used by more users for longer periods of time with no observed malicious effects, the file keeps improving its reputation score. This is similar to how users improve their credit ratings through responsible borrowing. Reputation-based mechanisms thus place a premium on familiarity and can potentially truncate the growth of malware variants.
Relative security versus absolute security
The controls in this chapter are intended to defend against most general threats and attackers. For example, attackers who just want to install bots on computers, any computers. In these situations, security is generally relative. As long as you are more secure than other organizations within the industry, you should be safe because attackers will focus on the easiest targets. This has indeed been the overall approach to information security.
Advanced persistent threats create a new challenge. These are targeted attacks where the attackers are specifically interested in your organization for whatever reason (intellectual property typically). They will try everything in their arsenal until they succeed at obtaining what they want from you. Security in this case is absolute. Your organization needs to be secure enough not to be compromised by the targeted attempts of the determined attacker.
Example case–AirTight networks
After completing his Ph.D. in Computer Science from the University of Maryland at College Park in 1995, Pravin Bhagwat worked as a lead researcher at AT&T Research and IBM Thomas J. Watson Research Center. By 2003, he was a well-recognized pioneer and researcher in wireless networking, eventually co-authoring 5 patents on various aspects of wireless networking.14 In the early attempts made in those days, the industry was trying to create a wireless version of Ethernet. The goal was to enable computers to send data without any need for a wire to carry the data. The commercialization of the technology began around 1997, when IEEE published the 802.11 standard for the emerging wireless Ethernet technology. The standard specified data rates of up to 2Mbps and was designed primarily for use by bar code scanners at retail stores and warehouses. In 1999, the 802.11b standard was published, specifying data rates up to 11Mbps. When computer manufacturers recognized that these data rates were comparable to Ethernet data rates of 10Mbps, they considered the technology as capable of being added as an integral part of computer motherboards.
The integration of wi-fi networks into computers signaled to Pravin that wireless networking would soon become a mainstream technology. He could see that it would soon become commonplace for users to carry computers in briefcases (laptops). Having spent many years in the industry as a technologist, he now began giving serious thought to entrepreneurial opportunities in this sector.
The obvious choice was to get into the business of offering wireless access points. However, by the time Pravin had identified the opportunity, firms such as Aruba, Airespace, Trapeze, Vivato, Airgo and Aerohive had already secured significant levels of funding from marquee investors. Competing in this space would mean competing with well-funded firms with access to the best advisors in the industry. His 3-step framework for entering the technology space was to (1) anticipate a problem, (2) build a superior mousetrap to solve the problem and (3) be ready to serve customers when the anticipated problem manifested itself. Recognizing that others had beat him to this opportunity, he decided to look ahead to figure out what the next opportunity might be in the sector. Not only that, he decided to be prepared with a solution when the opportunity arrived.
Vulnerabilities as a business opportunity
Expertise gained from being involved with technology development from its infancy gave Pravin some unique insights. He realized that the introduction of wireless networking would expose an entire new class of vulnerabilities within organizations. Specifically, until now, businesses never considered their Ethernet (layer 2) cables as a source of threats. Ethernet cables were typically confined within buildings, where traditional physical security procedures would-be attackers from reaching the cables and doing harm. Most security vulnerabilities in this environment therefore occurred at the network layer or above. Since all traffic across organizations passes through a central location, the gateway router, a protecting firewall with well-defined rules was sufficient to handle most attacks in most organizations.
However, this was going to change if wi-fi APs were going to be connected to Ethernet directly. Wireless signals spread in all directions. In a large office complex, signals from one business could be monitored from a neighboring business. It would be possible to unauthorisedly inspect, modify and inject packets and traffic into the network from outside the network through these APs. Or even just by standing in the lobby. This was a completely new vulnerability that would inevitably affect every organization in the world.
Sensing that no one he knew was thinking about the commercial opportunities this vulnerability presented, he decided to work towards developing a solution. He started by putting together what he considered the three essential elements of starting up a company – an idea, a team and the necessary finances to sustain the team until it turns a profit.
But what is a superior mousetrap in information security? An intrusion prevention system? That's a well-known technology. Something that lowers costs? How would you do that? Perhaps by automating something? After much thought he concluded that something that automated key system administration functions could be useful.
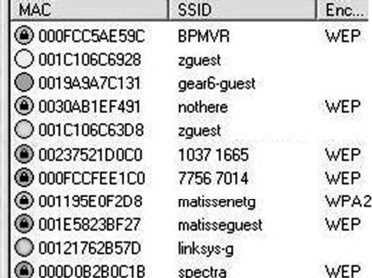

The company therefore focused on automating the detection of rogue access points and wireless network scanning. By the end of 2005, after about two years of intense development, he had a working solution to the problem. Whereas existing solutions listed all available access points on the network (Figure 6), his technology could label each access point in vicinity as internal, external, rogue or misconfigured (Figure 7). His technology allowed a network administrator to clearly identify the access points that needed attention (those in red in Figure 7).
The basic element of Airtight's technology is a hardware box that is added to the network. The box senses the wireless signals in the medium to gather all required information and processes the signals using its proprietary algorithms.
Market catalyst
While the technology was interesting and compelling, he soon ran into another barrier. When he went out to market the technology, potential customers did not recognize the need to take any urgent action. After all, Pravin was trying to get customers to spend money on solving a potential problem that had never existed before and one they had never experienced. It was like he was selling Aspirin to people who hadn't yet experienced a headache. In 2005, wireless security solutions were not a requirement imposed upon companies by either state regulators or industry bodies such as the Payment Card Industry (PCI) consortium. And no one wants to spend money on security unless they absolutely have to. To the extent anyone was interested in wireless security, they were happy with whatever security the access point vendors built into their systems.
The way this was playing out, as of 2007, success was limited to industries where high security was a priority. These included financial institutions, telecom, and government. IT managers in these firms recognized the threat and were willing to invest in technology solutions that added an additional layer of security to their existing wireless networks.
During the years from 2003–2007, the company sustained itself through what Pravin considered the three essentials of sustaining a company after it starts – effort, time and patience, capital. It secured funding from reputed venture capital firms around the world who bought into his vision.
All this changed when Alberto Gonzalez and his activities at T J Maxx became known. Companies became aware of the new threat vector created by wireless networks. In addition, revision 1.1 to the PCI standards introduced a requirement for all companies accepting credit cards to periodically scan their wireless networks for misconfigured access points (there was no such requirement at the time of the TJX incident). Thus Alberto Gonzalez helped educate his customers in a way that he himself could not. Suddenly, companies were experiencing headaches and were looking for the Aspirin that AirTight could provide.
Current status
Airtight products have received numerous industry awards over the years. At the time of writing, the company has 29 patents to its credit, covering different aspects of the technology developed by the firm. In 2012, Gartner MarketScope for wireless LAN intrusion prevention systems ranked Airtight Networks “strong positive,” the only company to achieve that rating in a field that included products from industry leaders such as Cisco, Motorola and Aruba Networks. Airtight has leveraged this product advantage with some success, attracting marquee customers such as Citrix, New York City Transit, and Ryder Systems.
Future directions
After dominating the wi-fi security space for several years, AirTight is now looking to expand its footprint by entering into bigger markets. Remember the wireless access market Pravin gave up in the early days of the company for being late in entering the market? AirTight is now looking at that very market after establishing relationships with some large customers through its wireless security offerings. It is projected that revenues in the wireless access market will rise from approx. $ 4bn. in 2013 to about $20 bn. by 2020. AirTight believes that if they can get security right, which is widely recognized as a considerably more difficult technology to master, they will also be able to do access right.
AirTight is making a push into several industries where there are large-scale distributed wireless deployments such as retail, hospitality, healthcare, and education. Organizations in these industries are large, but have modest security needs. It is entering these industries by introducing features that may be of interest to each of these sectors. For example, customers can enable wi-fi access capabilities using deployed security hardware with simple software upgrades. In the higher education sector, it is developing features that allow professors and students study computer networking by examining live, filtered network traffic within the campus.
At the time of writing in mid-2013, AirTight networks has secured key wi-fi access wins in the retail sector. The firm's technology is being deployed at some well-known national retailers, with thousands of locations each. One of the features deployed at retail locations is big data analytical services to help these firms track visitors across stores and offer customized promotions through cell phones. Another feature allows these establishments to securely offer guest wireless access at each location, with minimal configuration within each store.
Also, to address the tight budgets in higher education, it has developed Cloud managed wireless access point solutions, which eliminate one of the most expensive components in a typical campus-wide WLAN deployment. This model allows institutions to simply deploy wireless access point on the network, where they automatically configure themselves. Network administrators manage the access points using a simple web-browser based interface.
Airtight calls these cloud-managed smart edge-APs in comparison to the traditional controller-managed light-weight APs. These architectural changes leverage the developments in computer hardware over the last decade. As CPUs have become faster, RAM has become cheaper and standards have become prevalent, the trade-offs that necessitated the use of central controllers have changed. Inexpensive access-points (APs) can now pack technology that was prohibitively expensive only a decade ago. The wireless access industry that has already gone through two phases of disruptive change15 in its young life could be in for yet another disruptive change.
REFERENCES
Wireless Field Day 5 presentation by David King, CEO of AirTight Networks, http://www.youtube.com/watch?v=qxNAUeevfvc&list=PLObjX_zORJMAz0EBXmsQqSS5EOWzb96St&index=16 (accessed 8/11/13)
Personal conversation with protagonist by one of the authors
CHAPTER REVIEW QUESTIONS
- What is a password? What is it used for?
- Briefly describe some alternate forms of passwords.
- What is password management? Why is it necessary?
- What are the important threats to passwords?
- What are the important recommendations for password management?
- What are some advantages and limitations of passwords?
- What are firewalls? What are their common uses?
- Write an example firewall rule using the syntax shown in the chapter. Describe what the rule does.
- Write a firewall rule that blocks all incoming web requests (port 80) from the 192.168.0.0/16 network.
- What are some limitations of firewalls?
- What are deep packet inspection firewalls? What additional capabilities do they offer, compared to packet-filtering firewalls?
- What are the differences between the perimeter network and the interior network, from the perspective of information security?
- Draw a diagram of a typical enterprise firewall organization, showing the perimeter firewall, interior firewall, demilitarized zone, and internal network.
- What are the recommendations for a basic firewall configuration?
- What are IDS/IPS?
- What are signature-based IDSs? What are their advantages and limitations?
- What are anomaly-based IDSs? What are their advantages and limitations?
- What are protocol-state-based IDSs? What are their advantages and limitations?
- What is a patch? What is a patch bundle and why is it used?
- What is patch management?
- Briefly describe the important challenges in effective patch management.
- What is end-point protection? Is it necessary in an organization with strong network controls such as firewalls, IDSs, and strong passwords?
- What are some important services offered by end-point protection?
- What are some limitations of signature-based malware detection?
- What is reputation-based malware detection?
EXAMPLE CASE QUESTIONS
- Provide a summary of the security requirements for wireless networks (an Internet search for “PCI wireless requirements” should point you to some useful resources)
- You are the CIO of a medium- to large-sized firm. How important would the size of a vendor firm be in your decision to use its products for your organization's information security? Why would size of the vendor matter to you?
- You are the CIO of a medium- to large-sized firm. How important would the prior existence of a vendor's technology in your firm be in your decision to use its products for your organization's information security? Why would prior experience with the vendor matter to you?
- You are the CEO of a start-up firm offering a compelling product to improve an organization's information security. How may you address the issues raised in the last two questions?
- Visit the website of AirTight networks. What are the primary products and services offered by the company?
HANDS-ON ACTIVITY–HOST-BASED IDS (OSSEC)
In this exercise, you will install and test OSSEC, a Open Source Host-based intrusion detection system, on the Linux virtual machine included with this text. OSSEC performs log analysis, file integrity checking, policy monitoring, rootkit detection, real-time alerting, and active response. For more information, see the OSSEC website http://www.ossec.net
To install OSSEC, open a terminal window and “su” to the root account:
[alice@sunshine ~]$ su - Password: thisisasecret
Copy the OSSEC install files to a temporary directory, uncompress the file and begin the installation process.
[alice@sunshine ~]# cp /opt/book/con- trols/packages/ossec-hids-2.7.tar.gz / tmp/. [alice@sunshine ~]# cd /tmp [alice@sunshine /tmp]# tar zxvf ossec- hids-2.7.tar.gz [alice@sunshine /tmp]# cd ossec-hids-2.7 [alice@sunshine /tmp/ossec-hids-2.7 ]# ./ install.sh
OSSEC HIDS v2.7 Installation Script - http://www.ossec.net You are about to start the installation process of the OSSEC HIDS. You must have a C compiler pre-installed in your system. If you have any questions or comments, please send an e-mail to [email protected] (or [email protected]). - System: Linux sunshine.edu 2.6.32- 279.2.1.el6.i686 - User: root - Host: sunshine.edu -- Press ENTER to continue or Ctrl-C to abort. -- 1- What kind of installation do you want (server, agent, local, hybrid or help)? local - Local installation chosen. 2- Setting up the installation environment. - Choose where to install the OSSEC HIDS [/var/ossec]: /var/ossec - Installation will be made at /var/ ossec. 3- Configuring the OSSEC HIDS. 3.1- Do you want e-mail notification? (y/n) [y]: y - What's your e-mail address? root@ localhost - We found your SMTP server as: 127.0.0.1 - Do you want to use it? (y/n) [y]: y --- Using SMTP server: 127.0.0.1 3.2- Do you want to run the integrity check daemon? (y/n) [y]: y - Running syscheck (integrity check daemon). 3.3- Do you want to run the rootkit detec- tion engine? (y/n) [y]: y - Running rootcheck (rootkit detection). 3.4- Active response allows you to exe- cute a specific command based on the events received. For example, you can block an IP address or dis- able access for a specific user. More information at: http://www.ossec.net/en/manual. html#active-response - Do you want to enable active response? (y/n) [y]: n - Active response disabled. 3.6- Setting the configuration to analyze the following logs: -- /var/log/messages -- /var/log/secure -- /var/log/maillog -- /var/log/httpd/error_log (apache log) -- /var/log/httpd/access_log (apache log) - If you want to monitor any other file, just change the ossec.conf and add a new localfile entry. Any questions about the configuration can be answered by visiting us online at http://www. ossec.net. --- Press ENTER to continue --- - System is Redhat Linux. - Init script modified to start OSSEC HIDS during boot. - Configuration finished properly. - To start OSSEC HIDS: /var/ossec/bin/ossec-control start - To stop OSSEC HIDS: /var/ossec/bin/ossec-control stop - The configuration can be viewed or mod- ified at /var/ossec/etc/ossec.conf Thanks for using the OSSEC HIDS. If you have any question, suggestion or if you find any bug, contact us at [email protected] or using our public maillist at [email protected] ( http://www.ossec.net/main/support/ ). More information can be found at http:// www.ossec.net --- Press ENTER to finish (maybe more information below). ---
You could now start OSSEC with the command given above, but first there is one configuration option that needs to be adjusted. By default, the OSSEC system checks are run every 22 hours. This is fine for general use; however, we'll want to the processes to run more often for these exercises. You'll need to open /var/ossec/etc/ossec.conf in a text editor and change the value in line 76 from 79200 (22 hours in seconds) to 300 and save your changes. Notice that ossec.conf can only be viewed or modified by root. While logged in as root, modify the file using the Gnome Text Editor (Figure 9.8):
[alice@sunshine etc]# gedit /var/ossec/ etc/ossec.conf
To enable line numbers in Gedit, select File → Preferences and enable the “Display line numbers” checkbox.
<!-- Frequency that syscheck is executed - default to every 22 hours → <frequency>300</frequency>
This will cause the system checks to run every 5 minutes instead of every 22 hours. With that change in place, you can now start the OSSEC server. Save your changes and exit the Gnome Text editor to return to the terminal prompt.
[alice@sunshine ossec-hids-2.7]# /var/ ossec/bin/ossec-control start
The programs that make up the OSSEC system are now running, you can view the main OSSEC log at /var/ossec/logs/ossec.log. It provides you with details on the files that OSSEC reads during start-up and the results from the execution of OSSEC programs. If OSSEC detects any events that could be significant from a security standpoint, details are logged to /var/ossec/logs/alerts/alerts.conf. However, OSSEC outputs large amounts of information and viewing it by paging though log files is not very easy. The OSSEC-WebUI package is a web-based interface that provides a much easier way to search and view the recorded alerts (Figure 9.9).
Unlike the main OSSEC package, OSSEC-WebUI does not include an installation script and requires slightly more effort to configure.
[root@sunshine]# cd /home/shared/busi- ness_finance/information_technology/ website/main [root@sunshine main]# cp /opt/book/con- trols/packages/ossec-wui-0.3.tar.gz . [root@sunshine main]# tar zxvf ossec-wui- 0.3.tar.gz [root@sunshine main]# mv ossec-wui-0.3 ossec [root@sunshine main]# groupmems -g ossec -a apache [root@sunshine main]# chmod 777 /tmp [root@sunshine main]# chmod 770 /var/ ossec/tmp [root@sunshine main]# chgrp apache /var/ ossec/tmp [root@sunshine main]# service httpd restart
You should now be able to access the OSSEC-WebUI interface by opening a web browser and visiting http://sunshine.edu/ossec.
To test that OSSEC is working correctly, we will now demonstrate some of the ways the OSSEC is used to monitor for possible security incidents.
File integrity monitoring
The file integrity monitoring system in OSSEC detects changes in system files and alerts you when they happen. This could be caused by an attack, misuse by an internal user, or even a typo by an administrator. To simulate an attack that modifies system files, you will modify a file and view the results in OSSEC-WebUI.

- Modify the contents of /etc/hosts to match this:
127.0.0.1 sunshine.edu localhost hacked. sunshine.edu ::1 sunshine.edu localhost
- Wait 5–10 minutes. The file integrity checks will run every 5 minutes, but they may take a few minutes to complete, so it is best to wait a few more minutes to ensure the full scan has taken place.
- Open the OSSEC-WebUI and select the “Integrity checking” tab.
- Click on the plus sign next to /etc/hosts to expand the details about this file.
- Take a screenshot of this page and submit it to your instructor.
Log monitoring
OSSEC collects, analyzes, and correlates multiple logs throughout your Linux system to let you know what is happening. To demonstrate this, you will do some common system administration tasks that generate audit messages tracked by OSSEC and view the results.
- Install the zsh package using the YUM package manager.
- Create a new user:
Username: ossec-sample
Home Directory: /home/ossec-sample
Password: oSS3c!
- Open a new terminal window and run this command:
[alice@sunshine ~]$ ssh [email protected]
- When prompted for a password, use bisforbanana.
- Open OSSEC-WebUI in a web browser.
- Wait 5–10 minutes for OSSEC to complete all scanning and processing.
- Review the recent alerts captured by OSSEC and locate the ones related to the three events above.
- Copy and paste the data about each event into a Word document.
Deliverable: Submit the document containing the OSSEC results to your instructor.
CRITICAL THINKING EXERCISE–EXTRA-HUMAN SECURITY CONTROLS
Research reported from Australia in November 2012 suggests that security controls are even used in interesting ways outside the human world to deal with the unique problems of surviving in the wild. Horsfield's Bronze-Cuckoos lay their eggs in the nests of Superb Fairy-Wrens, hoping to leave parenting duties to unsuspecting Fairy-Wrens. The eggs of the two species look similar, enabling the ruse.
From the perspective of the Fairy-Wren, the problem is actually much worse. Bronze-Cuckoo eggs hatch 3 days before the Fairy-Wren eggs, 12 days versus 15 days. As soon as they are born, the Bronze-Cuckoo chicks push out the Fairy-Wren eggs from the nest. Without effective detection mechanisms, an aggrieved Fairy-Wren might end up feeding the offending Bronze-Cuckoo chicks, that destroyed her eggs.
While the Wrens are unable to do much to prevent the destruction of their eggs, they have developed a mechanism (control) to avoid feeding the Bronze-Cuckoos. About 10 days after the eggs are laid, the mother begins to sing to her embryos. After birth, the chicks are expected to incorporate the unique notes in the song in their calls for food. If the unique notes are missing, the chicks will be abandoned. The Fairy-Wren embryos get 5 days to learn the notes, the Bronze-Cuckoo embryos only get 2 days, insufficient to learn the notes. The test succeeds about 40% of the time in detecting offenders (Figure 9.10).

REFERENCES
Schneier, B. Cryptogram, November 15, 2012
Yong E., “Fairy Wrens teach secret passwords to their unborn chicks to tell them apart from cuckoo impostors,” Discover Magazine blog, November 8, 2012, http://blogs.discovermagazine.com/notrocketscience/2012/11/08/fairy-wrens-teach-secret-passwords-to-their-unborn-chicks-to-tell-them-apart-from-cuckoo-impostors (accessed 07/18/2013)
Corbyn, Z. “Wrens teach their eggs to sing,” November 8, 2012, http://www.nature.com/news/wrens-teach-their-eggs-to-sing-1.11779 (accessed 07/18/2013)
CRITICAL THINKING EXERCISE QUESTIONS
- Of the controls discussed in this chapter, which control most closely resembles the control used by Fairy-Wren mothers to detect imposters?
- The control used by Fairy-Wren mothers seems rather complex. Some simpler controls suggest themselves. Could you name a few?
DESIGN CASE
You are asked to harden a CentOS machine for a faculty member. He is the recipient of a sizeable grant from the federal government, but it requires that he uses CentOS for some of the data analysis. The results are considered restricted data, so access to the computer has to be restricted. You are not sure exactly how to do it, so it will take some research.
After some research on the web, you found the items listed 1 through 6 below. Write down the exact procedure (the command strings and the file details), you used to implement these changes so that you can replicate them on other machines as needed.
- Change the default port for the sshd daemon from port 22 to port 4444. This minor change will avoid most automated scans to break into the machine using SSH.
- Add the professors' login id (jamesc) to the wheel group.
- Disable SSH logins as root, forcing users to use the sudo command instead. This command allows users listed on the wheel group to elevate their privileges and execute commands as the root user.
- Change password aging parameters for the user jamesc to expire in 60 days.
- Change password history parameters to remember the last three passwords and password length to a minimum of eight characters.
- List the firewall rules and keep a hard copy.
Hint: You may find the following configuration files and commands useful:
- sshd_config
- login.defs
- group
- chage
- system-auth
- iptables
1We have earlier defined authentication as “the process that a user goes through to prove that he or she is the owner of the identity that is being used.”
2Miller, G.A. “The magical number seven, plus or minus two: some limits on our capacity for processing information,” The Psychological Review, 1956, 63: 81–97, http://www.musanim.com/miller1956/ (accessed 11/1/2012).
3NIST Special publication 800-118 (draft), Guide to enterprise password management, http://csrc.nist.gov/publications/drafts/800-118/draft-sp800-118.pdf (accessed 11/1/2012).
4Herley, C. van Oorschot, P.C. and Patrick, A.S. “Passwords: if we're so smart, why are we still using them?” Lecture Notes in Computer Science 5628, 2009, Springer-Verlag.
5Tolone, W. Gail-Joon Ahn and Tanusree Pai, “Access control in collaborative systems,” ACM Computing Surveys, 37(1): 29–41.
6An excellent resource on Internet firewalls is “Building Internet firewalls,” by Elizabeth D. Zwicky, Simon Cooper and D. Brent Chapman, O' Reilly Media, ISBN 978-1-56592-871-8 (896 pages). A lot of information in this section is based on this resource.
7INFORMATION SECURITY: Weaknesses Continue Amid New Federal Efforts to Implement Requirements, United States Government Accountability Office, GAO Report to Congressional Committees, GAO-12-137, October 2011, http://www.gao.gov/assets/590/585570.pdf (accessed 11/23/2012).
8Karen Scarfone and Peter Mell, NIST Guide to Intrusion detection and prevention systems, special publication 800-94, http://csrc.nist.gov/publications/nistpubs/800-94/SP800-94.pdf (accessed 11/23/2012). The National Institute of Standards and Technology (NIST) includes two other categories of IDS – wireless and network behavior analysis (NBA). For the purposes of this chapter, these categories are considered part of NIDS. This guide is the source of much of the information in the section on IDS/IPS.
9Souppaya, M. and Scarfone, K. Guide to enterprise patch management technologies (draft), NIST special publication 800-40 (accessed 11/24/2012).
10Gerace, T. and Cavusoglu, H. “The critical elements of the patch management process,” Communications of the ACM, 52(8), 2009: 117–121.
11For an overview on how Microsoft manages its security patches, see “Software vulnerability management at Microsoft,” at http://go.microsoft.com/?linkid=9760867 (accessed 07/22/2013).
12http://www.symantec.com/connect/blogs/how-reputation-based-security-transforms-war-malware
13It is estimated that there are 10 billion executable files “out there.” Source – personal conversation with industry experts at first NSF meeting of principal investigators on Secure and Trustworthy Cyberspace.
14http://patft.uspto.gov/netahtml/PTO/search-adv.htm
15The phase where access points managed all traffic is considered the first phase and the use of central controllers to manage traffic is considered the second phase