
Chapter 8
MDWEB: Cataloging and Locating Environmental Resources
8.1. Introduction
Environmental applications are on the rise, especially when it comes to territory development projects subject to stronger and stronger natural and human constraints (risk management, territory management, process observation and resource assessment, cultural heritage management, etc.). All these applications require geo-referenced data. Although these data are locally available and their volume is increasing, due to the explosion in the use of new data sources (GPS readings, airborne and satellite images, etc.) and tools to manage them (GIS, spatial database management system (DBMS) we must however go beyond the data produced to question their ability to be efficiently mobilized to serve the targets that are aimed for, whether we are going for monitoring, diagnosis, or decision helping. To this end, we must implement “decisional” systems allowing us to use the data and processes based on multiple sources and focusing on a single space or a single issue. Designing such systems requires the means to gather necessary resources, make them accessible, and share them (if possible) in a unified manner.
A spatial data infrastructure (SDI) is one of the solutions which is suggested today to ensure the outcome. The architecture of these infrastructures always provides for a discovery service that relies on metadata specific to the shared resources [LIB 03]. It is an essential component that will help both resource dissemination and resource locating. One of the advantages of such a service is undoubtedly its ability to link the need to highlight these data inherent to the producers and the final users who are linked to the location and access to the resource.
This chapter presents MDWEB, an open source tool for cataloging and locating environmental resources (data and documents). This tool is an interesting example of complementarity between various actors, those from research (IRD, LIRMM, CEMAGREF), business (Geomatys), and from the social sphere (data users, managers, etc.).
8.2. Context
8.2.1. Origins
The MDWEB project was initiated in 2003. The design and development of the tool resulted from the functional analysis carried out within the frame of the Observatory Network of Long Term Ecological Monitoring (“Réseau d'Observatoires de Suivi Ecologique à Long Terme”, ROSELT). The goal of this network was to understand and characterize the mechanisms of land degradation, its causes and consequences in circum-Saharan Africa [ROS 04a].
Studying these land degradation mechanisms in the 11 countries in question required mobilizing historical data to ensure the diachronic analysis essential to understanding long-term phenomena. It was thus essential to share the information due to the diagnostics of land degradation on each part of the land to compare the different situations encountered.
These requirements quickly created the need to inventory and describe the pre-existing, collected, and elaborated data. Another requirement was to respect the autonomy of the institutions involved in managing the data throughout the data collection, analysis, and interpretation phases of the monitoring. To this end, sharing the mutualization of these information sources quickly became very useful to build a common knowledge of the studied observatories [DES 03].
This institutional context and the issue of mutualizing data inherent to network-based work then led to the implementation of an information system based on a distributed architecture. This distributed architecture is the forerunner of the current SDIs [ROS 04b].
To provide one of the main components to this information system, we designed a tool ensuring a homogeneous description of the resources to be pooled and located: MDWEB. We structured it around metadata [DES 01]. The tool, in its first version, had four core functions: referencing, researching, locating, and accessing the data.
Functional evolutions followed, taking into account requests based on the projects in which we participated. We will specifically mention ACI PADOUE (inciting concerted action “Sharing data for environmental uses”, PArtage des données pour des Utilisations en Environnement, 2002–2006), the SYSCOLAG program “Integrated Management of COastal and LAGoon SYStems” carried out in the LanguedocRoussillon region [MAZ 06], the PER project (rural excellence center, “pole d'excellence rurale”) [DES 07a] initiated by the DIACT (Interministerial delegation to land use and competitiveness), and the BibioMar project (2009) carried out by the DIREN (Regional Directorate of Environment) of Reunion Island.
Since 2007, MDWEB has undergone a technology transfer from Geomatys1. During this event, new technical orientations were decided [DES 08]. These were directed toward a component-based architecture, strongly service oriented (SOA for service-oriented architecture). These steps were taken with the goal to make MDWEB an essential and autonomous component of current SDIs such as the initiatives of the GMES European program (Global Monitoring for Environment and Security) and the INSPIRE European directive.
8.2.2. Positioning
SDIs are a solution to the rapid evolution of the Internet and standardization initiatives in terms of geographical information use, especially for organizations such as the Open Geospatial Consortium (OGC) and the International Organization for Standardization (ISO). Beyond the institutional, organizational, and legal aspects, from a computer science viewpoint, an infrastructure relies on a distributed architecture based on normalized services. These are the services that provide the primitive functions available to the user such as discover, location, visualization, and data download.
Discovery services are one of the ways to partially make up for distributed and heterogeneous resource interoperability through the descriptive role of metadata. Current search engines (Google, Yahoo, etc.) could potentially ensure such a discovery service, but metadata models on which they rely are unspecific, incomplete, and not explicit to the nature of the resources to be cataloged. That is the cost of their generic aspect. Moreover, they do not bring the flexibility (genericness) required to adapt such a service to a community's specific issue. Finally, indexing and search techniques are “proprietary” and thus depend on the engine.
Many normalization proposals relative to metadata have appeared in the past few years [DCM 05], SensorML [OGC 07a], Darwin Core [TDW 09], ABCD [TDW 06], in various fields such as digital documentation, geographical information, and biological information. When it comes to geographical information, following on the first proposals drawn up by the Federal Geographic Data Committee (FGDC, USA) at the end of the 1990s [FGD 98], the ISO 19115 standard, “Geographical information – metadata” [ISO 03] has been predominantly adopted and is recommended in most SDIs.
A tool combining resource cataloging through metadata models adapted to spatiotemporal resources with a search tool based on this metadata was in our view an essential addition to environmental applications.
In this context, resource cataloging initiatives are already widespread. The explosion of activities on the Internet confirms the interest of scientific communities to disseminate and share their resources and knowledge. There are a few solutions today that match this need to locate and access digital resources. Studying these software solutions [DES 07b] highlights that they are mainly implementing international standards (ISO, OGC) that shape catalog structure and ensure part of their interoperability. It also appears that the support chosen to deploy these tools is generally the Web, if we omit tools included in wider offers (ESRI's ARCCATALOG2) or designed a few years ago (the French Study Center on transportation networks and town planning REPORTS3).
Beside MDWEB, we will mention open source software, called open source, which exists in the geographical information community, GEONETWORK4, developed by the Food and Agriculture Organization (FAO) of the United Nations, and its French version GÉOSOURCE5, which was implemented by the Office for Geological and Mining Research (Bureau de recherches géologiques et minières – BRGM) to answer the needs for French cataloging due to the INSPIRE directives. These two tools are based on mainly equivalent architectures: a DBMS component ensuring the storing of metadata (ORACLE, MS-ACCESS or MYSQL, POSTGRESQL for the open source software) articulated around a Web application server such as TOMCAT/JAVA, APACHE/PHP, and IIS/ASP.
As for user interactivity, most of the tools today offer cartographic modules, which provide support to build geographically based queries and allow, for some, visualization of geo-referenced data. Metadata editing help is a function that is more or less developed depending on the tools.
8.3. Major functionalities and case uses
MDWEB offers two major functionalities. They are articulated around metadata management or “cataloging” and resource search to locate, choose, and access the desired resources, the “locating” function.
We will thus briefly remind the reader what we mean by cataloging (section 8.4) and locating (section 8.5) and add the administration functionality (section 8.6) that appeared necessary. All the roles accessing these functionalities will also be mentioned throughout the uses.
In the context of the data user, the tool must allow the search for a resource from metadata querying. This query is formulated by combining five criteria focusing on the content of the resource (what?), its type (what type of resource ?), its spatial extension (where?), its temporal extension (when?), and the organization management or owning it (who?). The answer obtained will be selected by the user. After this selection, the user will potentially access the resource through a Web protocol (HTTP, FTP, etc.).
In the context of the data producer, the tool must ensure the description of the resources made available through this infrastructure. This description relies on metadata. Within the description function, we will separate the cataloging from the semantic annotation. The first can be considered as the technical description of the resources. The elements linked to cataloging will allow us to characterize the resources. The second notion, semantic annotation, expands the first to focus on the semantic description of the resource. It will rely on existing and expected metadata elements to describe the content of the resource.
8.3.1. Matching roles and functionalities
This tool is meant to be a component in a data infrastructure. We have set the perimeter of the infrastructure to be that of a limited user community (with a common field of interest). In this context, functionalities have been defined for the user of predetermined roles (actors in the UML sense). In the context of a multiuser tool, these different roles allow us to assign and organize the operations required to edit, validate, and publish metadata according to the level of expertise of the actors involved and their role in the organization in which the tool is used. Although the nomenclature is specific to MDWEB, the seven roles offered (see Figure 8.1) rely on functional segmentation inherent to multiuser tools.
The final user: he accesses the search module to locate relevant resources by viewing the afferent metadata, then accesses the resource if it is available online. The locating functionalities are publicly available, so this role is given to anybody in the community looking for resources, from the layman to the cartographer.
The commentator: linked to the production of metadata, he provides commentaries on the existing metadata files that will be useful to monitor editing and to validate metadata. This role is given to someone who has taken part in creating or has expertise over the described data. This can be, for instance, a technician who took part in gathering information.
The author: he inputs or imports metadata to describe and annotate the resource produced. This role is given to the person who is directly involved in creating the set of data, or the person who created it. It can either be the cartography engineer or the study engineer who took part in designing the data set specifications.
The validator: beyond the resource description work, he validates the meta-information of the producer before allowing its dissemination to the community. He makes sure of the quality of the metadata content. This role can be fulfilled by an expert in the field who can be a scientist, or a project manager.
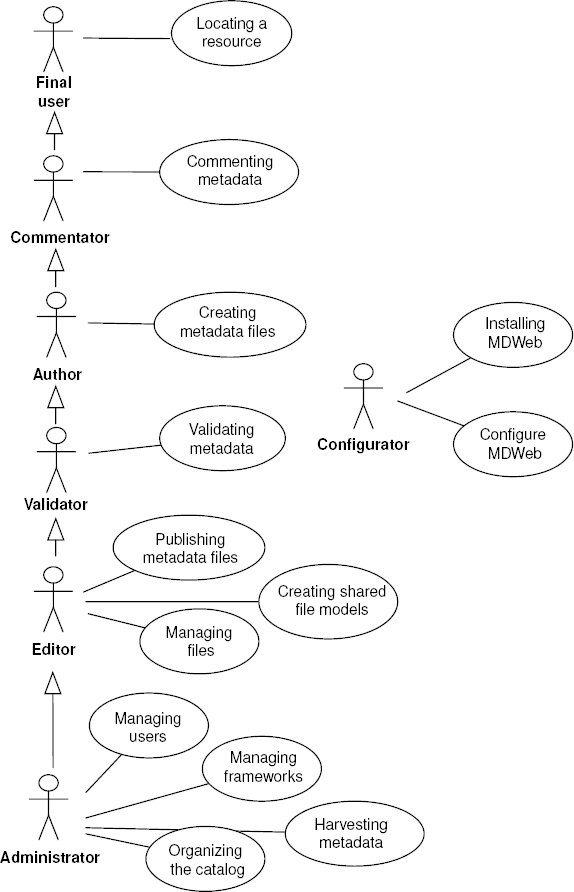
Figure 8.1. Roles and matching functionalities (formalize use case UML)
The editor: he publishes the validated metadata so that it can be queried by the search module. This role can be fulfilled by the field expert or the geomatics expert. A single person often endorses the roles of editor and administrator.
The administrator: he must define the structure of the meta-information (standard, metadata profile) and its organization within the tool (managing the sets of named files), choose the matching frameworks, and define the context of use within the tool (definition of the cartographic context, choice of thesauri). He is in charge of metadata management, and of the roles of the tool users. This role is given to the geomatics data administrator of the organization who has the required geomatics expertise and knowledge of the data processing tool.
The configurator: he installs the tool and configures it to ensure its proper functioning for other users. He does not take part in the editing, metadata administration, and tool administration processes. He is different from the administrator because we think that this role should be given to a system administrator who does not necessarily have knowledge in geomatics.
Each potential actor (besides the final user) is assigned an account and one of the roles defined above by the administrator. Depending on his role, he then has access to the functionalities matching the tasks he has been assigned.
8.4. Cataloging functionality
The cataloging functionality of the tool is based on metadata. Before we describe it in detail, we will present in sections 8.4.1 and 8.4.2 the notions of metadata, of metadata profiles that are widely used and contribute to the structure content of the catalog. Then we will detail the cataloging functionalities in a simplified manner (section 8.4.3) and in a multiuser context in section 8.4.4. Finally, we will provide in Section 8.4.5 the extensions implemented in MDWEB to facilitate metadata management.
8.4.1. Notion of metadata
The notion of metadata is far from being new, but we must admit that today the use and importance of metadata have increased. This highlights the increasing needs for management and location of mass-produced information that is by nature heterogeneous, since it is the results of data production in formats and representations, dispersed with different producers.
In its first meaning, metadata means “data about other data, or data that provides information about other data and allows them to be relevantly used” [BER 93]. When there is no metadata, geo-referenced data in particular can be used only in a restrained manner and we cannot assess the quality of their content.
Thus, metadata must enable management, a relevant and wise use of data. It provides a potential user with the means to know their availability (format and access conditions), their accuracy in meeting specific needs, and the way they can access them (protocol). In our context, metadata elements on which the environmental resource cataloging relies today are imposed by existing standards. In general, metadata and standard structure obey models with more or less complex hierarchies [BAR 05]: “We can describe a metadata standard as an aggregation of sections, each made up of a set of structured metadata elements (...) linked to the description of a specific category of the information...” (see Figure 8.2).

Figure 8.2. Simplified view of the general organization of a standard
Today, the ISO 19115 standard offers a wide and complete model of metadata for geographical information. It has become omnipresent in the environment community This is a federating standard which is based on a synthesis of preexisting standards. Rather exhaustive, it offers a description of geo-referenced resources due to 12 sections (see Figure 8.3). The main sections cover the identification of the main characteristics of the resource (Identification), the information on access constraints (Constraints), information on resource quality, and information on maintenance and resource update. Finally, the ISO 19115 standard offers a section of metadata identification (Metadata) that brings together the elements of metadata file management (creation date, standard, standard version, metadata language, etc.).
A tool coupling the cataloging of resources through specific metadata models (adapted to spatiotemporal resources) with a search tool based on this metadata was, in our view, an essential contribution to environmental applications.
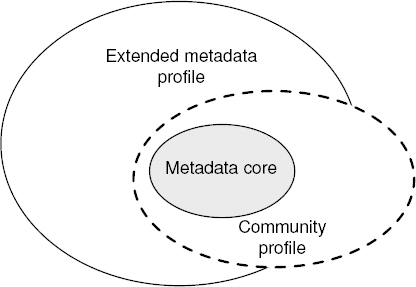
8.4.2. Notion of metadata profile
One of the points of the ISO 19115 standard is its flexibility to different communities, especially due to the implementation of profiles. This notion is offered in ISO standards (ISO 19106 and ISO 19115). A metadata profile can be considered to be a specialization of the standard. A user community can thus select mandatory elements from a metadata profile and add additional non-standard elements (for instance elements linked to the state of the sets of data produced). Figure 8.4 illustrates these two notions.
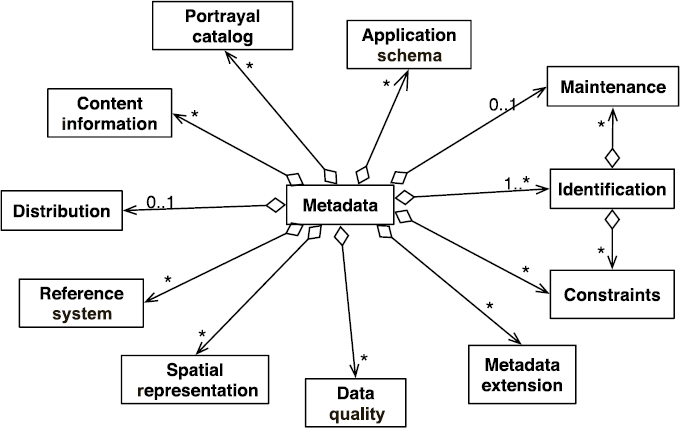
Figure 8.3. Different sections for the standard ISO 19115 (UML formalism)
We have completed this notion by linking a metadata type to a resource type. During the editing phase, we offer the user interfaces that filter and adapt the entry fields according to the type of resource to be described.
For example, when inputting a set of vector data, the profile used to generate the data entry form constrains the metadata element SpatialRepresentationType to the vector value, or offers the input of the class MD_SpatialRepresentation from ISO 19115 by using the MD_VectorSpatialRepresentation specialization that is devoted to the description of vector data, and contains elements describing the topology level (topologyLevel) or even the geometry type geometricObjects. Table 8.1 presents the types of resources and the matching metadata profiles offered by MDWEB by default.
8.4.3. A simplified view of cataloging
The cataloging organization in MDWEB revolves around the notion of metadata sheets. A metadata sheet relies on a profile and matches a set of values that provide information about the metadata elements in these profiles (see Figure 8.5). For instance, MDWEB offers a profile called “Vector layer”, which is provided to describe geographical data in vector mode. This profile is adapted from the standard ISO 19115.
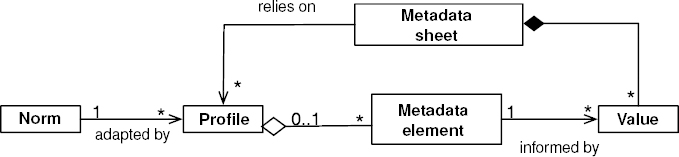
Figure 8.5. The notion of metadata sheet (UML formalism)
Thus, resource cataloging in MDWEB is mainly done by carrying out different applied management operations or operation sequences on a metadata sheet. These operations go from creation to publishing to annotation. The diagram of use case in Figure 8.6 shows the detailed view of the cataloging functionality of a resource in an organization where (to simplify) a single person is in charge of all the operations.
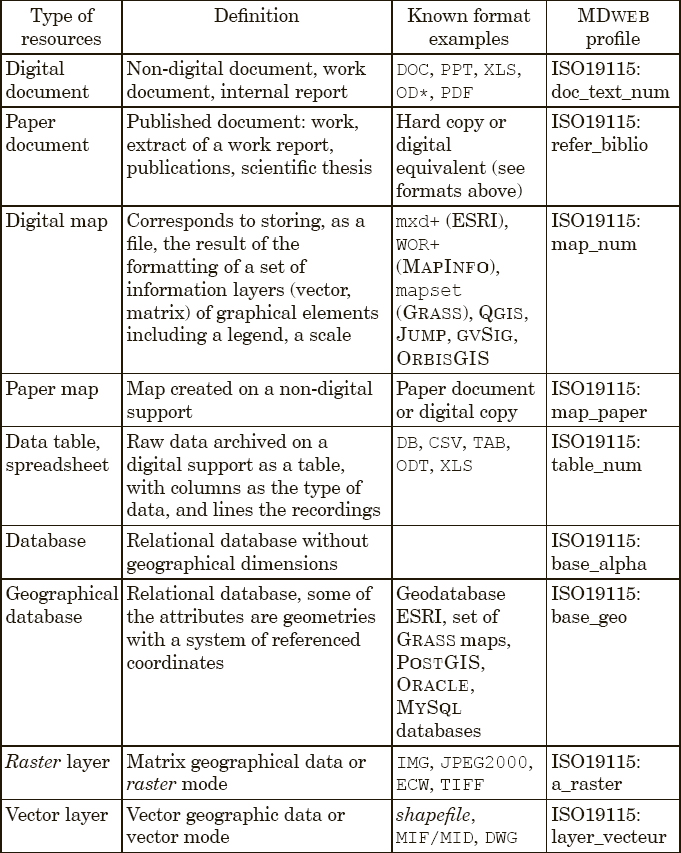
Table 8.1. Resource typology and matching metadata profiles
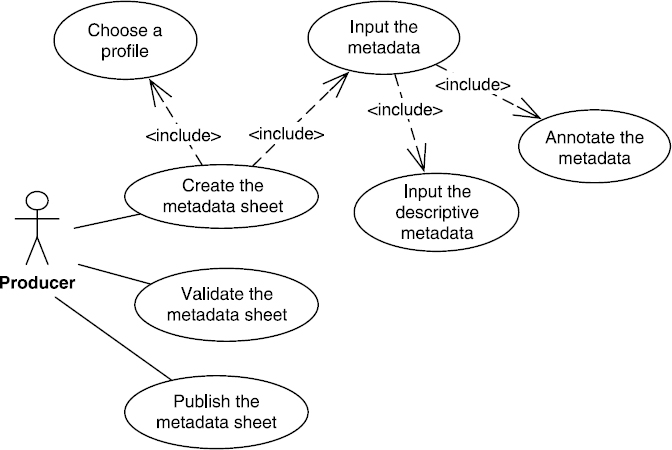
Figure 8.6. Simplified case use for resource cataloging (UML)
The first function is choosing a metadata profile matching the resource to be cataloged. The choice of this profile allows us to load the linked form from which the metadata will be input. During this operation, we have two sub-use cases: inputting descriptive metadata and semantic annotation of the resource through metadata.
The first sub-case covers inputting metadata elements that can be described as “descriptive”. Indeed, these elements bring structure information about properties that are intrinsic to the resource, such as the main characteristics of identification, representation mode, spatial and temporal frameworks, the specification defining the data model, the description of the genealogy; or on information about distribution (access conditions, format, etc.), management and even information allowing us to identify the metadata itself (see Figure 8.6).
The second sub-case covers the input of metadata elements that can be called semantic. Indeed, these metadata elements included in the identification section, such as keywords, and topicCategory, are limited by a list of fixed values (enumeration). When it comes to the input of the element keywords, we have introduced the use of a thesaurus to control the terms on which the indexation and the research will rely. A thesaurus is a set of terms linked together by equivalence relations (synonymy), associative relations, or hierarchical relations [ZAY 10] defined by the standard ISO 2788 [ISO 86].
Various reference thesauri have been added to the MDWEB tool: the multilingual agricultural thesaurus AGROVOC of the FAO and the general multilingual thesaurus GEMET focusing on the environment of the European Environment Information and Observation Network (EIONET). Other than these thesauri, we have introduced the notion of thematic framework. A thematic framework describes, for a given community, the semantics of a field considered through explicit knowledge models. Any model translated the expertise of a community. It is the vector of semantic interoperability between actors to share understanding of the field's concepts. For the MDWEB tool, this framework is stored in a relation diagram allowing us to import models using semantic Web languages (SKOS, Simple Knowledge Organization System; RDF, Resource Description Framework).
A similar approach is implemented for information spatiality. We will call spatial framework a set of relevant geographical objects that are thus referents for the community in question. The community relies on the EX_Geographic-Extent section of the metadata ISO 19115 and provides the user with geographical objects of interest. These geographical objects can be represented in a various ways: geographical names (terms of a thesaurus), encompassing rectangle describing the spatial extent, precise geometry (see Figure 8.7).
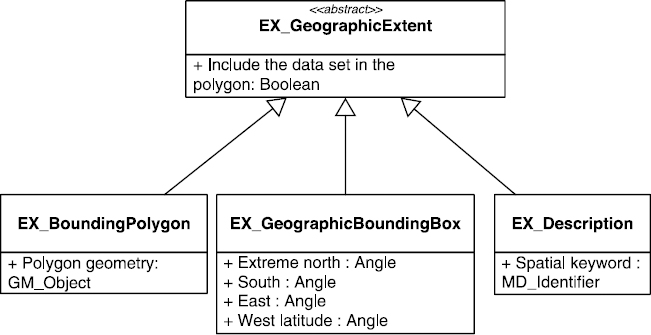
Figure 8.7. Illustrating the three geographical describers of the standard ISO 19115
The two thematic and spatial frameworks are closely linked. The spatial dimension is a mediator between thematic search and spatial search. A spatial term (of the thematic framework) describes the intent (for example, lagoon) of a concept, the latter has an extension in the shape of geographical objects that make up a layer of the spatial framework. Then, the data producer can carry out the validation of the input sheet himself and publish it to allow the search engine to query its content.
8.4.4. Cataloging in a multiuser context
The different functions linked to cataloging can be delegated to various users through roles that will be assigned to them in the tool (see Figure 8.1). This can be useful, and even necessary, within an organization that, due to its configuration (various disseminated teams) and the multidisciplinary aspect of its activities, must ensure the consistency of its metadata and control the publishing phase according to its charter. To this end, the different roles identified match the core competencies of the different levels that will be required for each operation.
In this context, the functions are shared along the role given to the user. Let us rework the use case diagram shown in Figure 8.6 to take this more complex vision of cataloging into account.
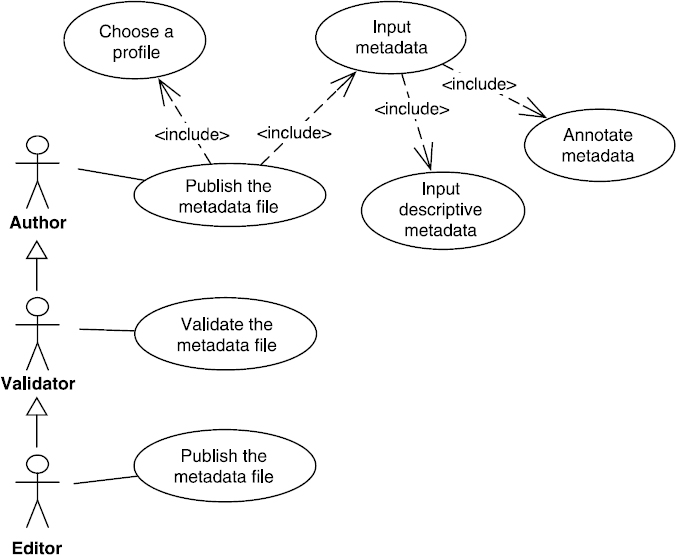
Figure 8.8. Use case for (UML) resource cataloging
Seeing this sharing of functions, managing a metadata sheet requires different actors to be involved. To better describe the various stages through which a metadata sheet will go, let us describe its lifecycle by using the formalism of UML activity diagrams. Figure 8.9 shows a global vision of the different actions and how they are linked, leading to the publication of a metadata sheet.
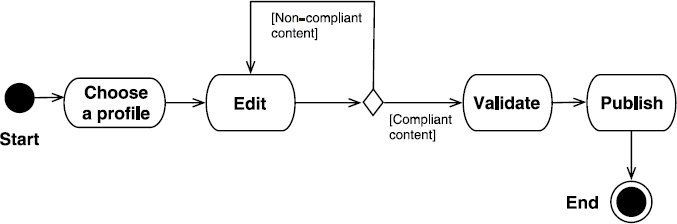
Figure 8.9. Lifecycle of the publication of a metadata sheet (UML activity diagram)
A sequence of four main actions is carried out:
- – the choice of a metadata profile on which to rely when inputting a metadata import;
- – editing that ensures the input/update of the metadata elements within the chosen profile, to describe the resource;
- – the validation of the sheet's content or its compliance to the semantics and format of the metadata elements input; in case it is non-compliant, we will have to modify its content;
- – publication within the tool.
8.4.5. Cataloging extensions
8.4.5.1. Help for metadata input
When editing metadata, the input phase can very quickly become a constraint, and, thus, lead users to lose interest. One of our core concerns was thus, when designing the tool, to help the user as best as we could in carrying out all the tasks they required. Therefore, MDWEB offers a set of facilitation tools.
The first tool helps edit a metadata sheet by prefilling all or more of the elements the sheet contains. To this end, we have implemented mechanisms that rely on the creation of sheet templates or sheet fragments. A sheet template can be defined as a metadata sheet in which certain fields were prefilled in order to be reused to create other sheets. This provides the author with a sheet template that he will be able to reuse to describe resources with identical properties such as distribution formats, contact point coordinates, and geographical extent.
The reuse principle can also be refined by the notion of sheet fragment. It will be used to load values within a specific section of metadata. We can then create fragments allowing us to fix the values of a section of metadata concerning the description of access constraints (MD_Constraints) or even contacts (CI_ResponsibleParty). The fragment is called up and loaded within the form when editing the sheet and will be reattached to the afferent section.
The second tool, within the multicriteria entry and search interfaces, relies on the semantic addition of the two frameworks mentioned in the previous section. The effort to help data entry focused on the elements used to index sheets (keyword section, spatial extent section). For example, inputting keywords is done by providing users with completion component based on the terms in the thesaurus (see Figure 8.10). A second level of use for this framework is possible when inputting data. To expand the field of accessible terms, a navigation interface ensures that we can browse the hierarchical relations and equivalences to the terms of the chosen thesaurus.
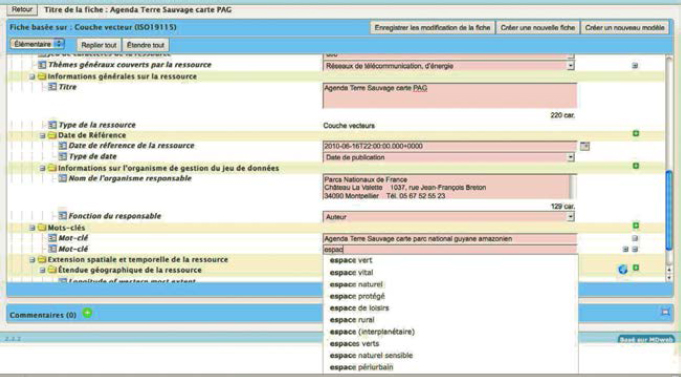
Figure 8.10. Screenshot capture of the autocompletion component used during the editing phase to select the keywords coming from embedded thesauri
The spatial framework exploitation is used to guide the user when filling in the spatial extension section by offering a cartographic interface representing the geographical objects of interest. The user can then either select an existing geometry and its geographical name, or define a specific spatial extent (see Figure 8.11). For a user in search phase, the same components can be used to define location criteria (geometry and geographical name, specific extent) and keywords.
8.4.5.2. Metadata exchange
The current environmental applications are made up of available heterogeneous systems in environments in which each producer provides his own metadata in his own catalog. Providing a global resource vision within a catalog requires gathering metadata produced by all the producers taking part in the data infrastructure.

Figure 8.11. Screenshot of the cartographic component used during the editing phase to help the user enter the spatial extension of the resource
To this end, the cataloging functionalities are completed with metadata import and export function. Indeed, the metadata exchange standard is the ISO specification 19139 [ISO 07] that suggests an XML exchange format for metadata built with the ISO standard 19115. We use this format to transfer metadata. The author user can carry out a transfer during the editing phase. It can happen either by a set of files or file-by-file through a compressed file (archive) or an XML ISO 19139 file. Two scenarios are processed during import. In the case of the transfer of metadata created by MDWEB tools, the file's profile of the transferred metadata is identified and the import is complete. In the opposite case, when transferring from a different tool to MDWEB, the imported file's profile is not necessarily defined, and the user will have to define the matches by selecting an MDWEB metadata profile. Finally, the import process is carried out along two modes: a permissive mode that carries out the import and ignores the non-compliant elements and a strict mode that forces compliance on all the elements contained in the XML file to ensure import.
The automated import of a set of metadata sheets based on a distant catalog is also offered to the administrator. This operation is called harvesting. It is caried out by using the Harvest method of the cataloging Web service of the OGC.
8.5. Locating functionality
The functions that contribute to locating a resource can be presented by the use case diagram of Figure 8.12.
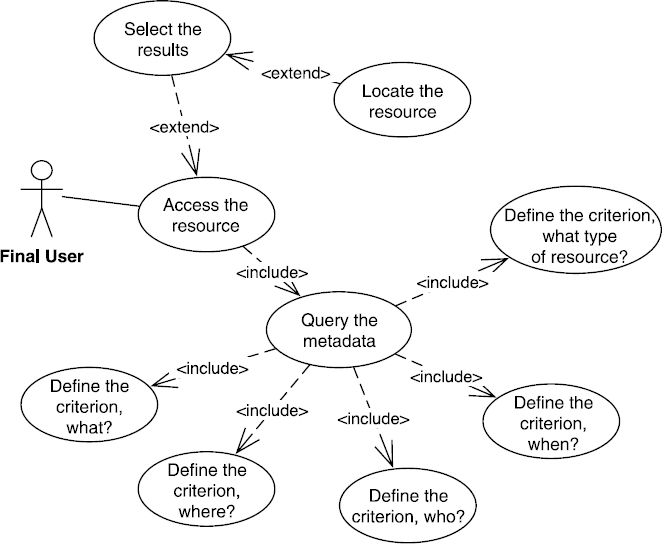
Figure 8.12. Use case to locate (UML) resources
First, the location covers metadata querying. MDWEB focused this query on the need to find a resource. By discovery, we mean the possibility of knowing the existence of a resource and being able to assess its content, and its main characteristics.
To efficiently get usable search results, we need to provide the user with the possibility to create queries of various complexity levels, ranging from a simple query involving the type of resource (what type of resource?), “I wish to locate vector type data” or “I wish to locate data created after September 3, 1990”, to a query covering the nature and characteristics, especially the thematic (what?), spatial (where?), temporal (when?): “I wish to locate data about ZNIEFF protected spaces in the Languedoc-Roussillon region published during the nineties”. we will explain the formulation of these queries by defining one to five criteria then combining them by the logical operator AND if necessary.
Let us precis the nature of each criterion.
- – The “what?” criterion concerns the issue that is dealt with by the resource. Querying this criterion is based on various fields providing information about this content. This is the case of resource title (title), resource abstract (abstract), of the general topic(s) dealt with (topicCategory), and of the keyword field (keyword) for which we have introduced the use of a controlled vocabulary (see section 8.4).
- – The “where?” criterion covers the geographical location of the resource of its spatial extension. This criterion can be answered by the values of the coordinates of a rectangle matching the spatial extent of the resource desired. Its input is facilitated by the availability of a cartographic interface offering geographical objects of interest. The coordinates of the encompassing rectangle will be accessible through interaction (a mouse click) with the selected object. This criterion matches the metadata elements linked to the description of the spatial extension of the resource contained in ISO 19115 class EX_GeographicExtent.
- – The “when?” criterion covers both the period covered by the resource that can be assimilated to its temporal validity and the reference date of the resource. For the latter, it can be the date of creation, revision, or publishing. The criterion matches the metadata elements providing the temporal extension of the resource ISO 19115 EX_TemporalExtent and those matching the resource reference date, date and dateType within the identification section of the resource.
- – The “who?” criterion concerns the organizations linked to the resource through their creation, management, or distribution. This criterion relies on the query of elements in the class ISO 19115 CI_ResponsibleParty and, more specifically, on those defining the name of the organization OrganisationName and its role when it comes to the resource, role.
- – The “what type of resource?” criterion is to link with the resource typology offered in MDWEB (see Table 8.1). It allows us to filter the research by metadata profile.
These five criteria appear to cover most of the questions linked to discovering a resource. We will favor two of these criteria: what and where. They require geographical vocabulary and objects of the two frameworks embedded in the tool (see section 8.4). Thus, they allow us to make the metadata querying easier and more efficient.
The result of a query returns a set of metadata files matching the defined criteria. From this, the user can filter the results to analyze the characteristics of the desired resource in more detail. Other information will allow him to know the conditions and modes of access (Web service, ordering procedure, contacting the manager, etc.).
After this analysis, the user will select the resource(s) to visualize or download it (them), when the service is available online. The access conditions to the resource are described in the afferent metadata elements, classes ISO 19115 MD_TransferOptions and MD_Constraints. In the case of online resources, a Web address (URL or URI) is provided. It can point a static link toward the resource or a dynamic link toward a downloading service, visualization service, etc.
8.5.1. Local and distant metadata querying
By default, querying covers metadata stored in the current MDWEB tool. This is a local query. It can be extended to a querying covering metadata stored in distributed catalogs. This is a distant query.
MDWEB offers a unified query when we carry out a local or distant search. It relies on the implementation of the API offered by the OGC, the Catalog Service for the Web (CSW) [OGC 07b]. It provides methods to query metadata in one or more distant catalogs, and recommends languages to formulate the query and coding formats to retrieve the metadata.
Depending on the tool's installation context, either the addition of distant catalogs is the default, or it is carried out directly by the user. Sending the query will involve distant services whose URL was previously stored.
8.5.2. Monolingual or multilingual querying
Usually, MDWEB carries out a query based on the “what?” criterion by extracting the keyword of one of the thesauri in the language in which the metadata is informed. For example, if a user has a query on the keyword “espace protégé” (protected space), the results provided match the presence of the term “espace protégé” in the following metadata elements: title (title), abstract (abstract), keyword (keyword), and general topics (topicCategory). This is called a monolingual query.
In a transnational sharing infrastructure, this is not enough. Indeed, the query must be extended to formulate queries that will retrieve results no matter which language is used to describe the resources. This is called a multilingual query.
In both cases, the keywords used are extracted from thesauri linked to MDWEB. As we have previously mentioned (see section 8.4.3), the thesauri are structured by the resource description model RDF [W3C 04]. An RDF document is a set triple of subject, predicate, object. The subject represents the resource to be described; the predicate represents a property type applicable to this resource; and the object represents the value of the property that can be either data or another resource. An illustration is provided in Figure 8.13:
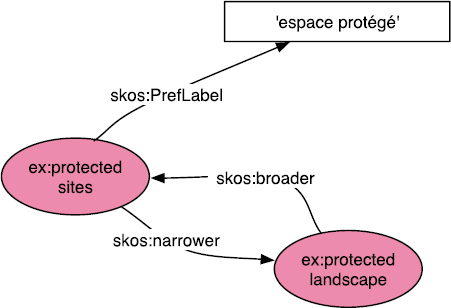
Figure 8.13. Illustration of the RDF triple model with the protected sites concept
The SKOS [SKO 04] vocabulary arises from the RDF model and is used to organize thesauri. In particular, it allows us to define a concept through its unique resource identifier (URI), which identifies it with no ambiguity. To this concept, SKOS allows us to attach a set of properties such as the label, prefLabel, the generalization relations, broader, and specialization relations, narrower, to other concepts. Thus, the concept protected sites is defined by the URI http://www.eionet.europa.eu/gemet/concept/6740 within the GEMET thesaurus whereas its PrefLabel property, whose value is “espaces protégés” in French (which is translated as “protected spaces”), is defined by the URI http://www.w3.org/2 0 04/02/ skos/core#PrefLabel. By using SKOS syntax, this triple can be represented as follows:
<rdf:RDF>
<skos:Concept rdf:about=
"http://www.eionet.europa.eu/
gemet/concept/67 4 0">
<skos:prefLabel xml:lang="fr">espaces
prot'eg'es</skos:prefLabel>
</skos:Concept>
</rdf:RDF>
The PrefLabel property can be declined in other language to allow the concept to be matched to a Spanish term, for example, and the triple shown above thus becomes as follows (“espaces protégés” becoming “lugares protegidos”):
<rdf:RDF>
<skos:Concept rdf:about=
"http://www.eionet.europa.eu/
gemet/concept/67 4 0">
<skos:prefLabel xml:lang="es">Lugares
protegidos</skos:prefLabel>
</skos:Concept>
</rdf:RDF>
This organization allows us to extract various terms from the thesaurus by using the URI of the concept which they match. This mechanism is also indicated when we desire to carry out a multilingual query. Indeed, it will allow us to decline a keyword or expression, input by the user, in various desired languages. This declination relies on keyword translation. The notion of concepts offered by SKOS allows us to match the concept with the term in the desired language through its concept identifier (URI). The previous example is completed by providing the values of the prefLabel property of the protected sites concept in French, Spanish, and English.

When solving the query about the term “espace protégé”, the values in Spanish and English will be used to complete the query that is sent to distant cataloging services. MDWEB allows us to combine different query modes presented in these paragraphs to carry out, for instance, a local and multilingual query or a distant unilingual query.
8.6. Administration functionality
Within an SDI, MDWEB is installed in each organization in charge of data and metadata management. Its installation and configuration, and then the implementation and management of users and different functionalities, requires us to introduce an administration functionality linked to the first two functionalities described in sections 8.4 and 8.5. Figure 8.14 illustrates the main use cases linked to administration. There are two actors involved, the configurator and the administrator.
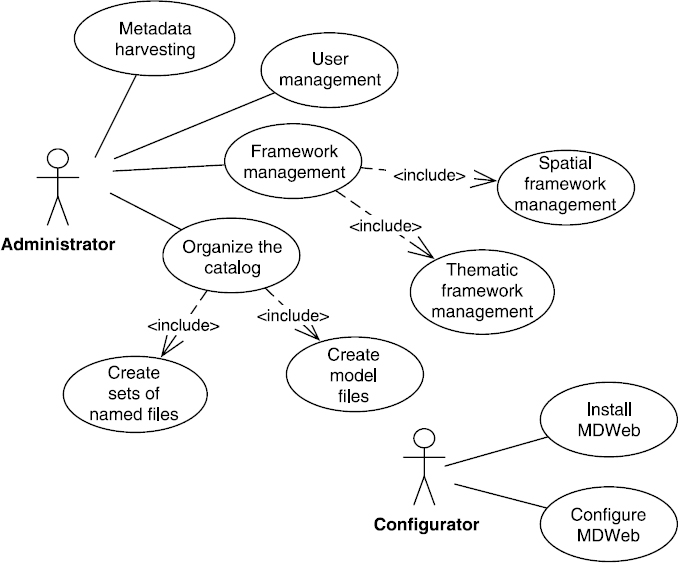
Figure 8.14. Use case for the (UML) tool administration
The configurator is linked to the functionalities that need only system competences. To this end, it is dissociated from the administrator that is considered as a field expert for which MDWEB is implemented. So the configurator deals with use cases that correspond to installing the tool and monitoring specified prerequisites for installation. It notably deals with implementing a JAVA application server and a DBMS.
Then, a configuration phase must be carried out step-by-step to create and people the database linked to MDWEB, parameter the connection to the database, and design the Web services used by MDWEB: the cartographic client of the research application (WMC, Web Map Context), the thesaurus web service ensuring access to keywords for the research and editing applications, and finally the Cataloging service on which local and distant queries rely.
Only then does the administrator get involved to manage the components installed and the users that will be involved in metadata managements. To this effect, he is provided with four features:
- – Framework management, which, in the current version, means choosing metadata profiles that will be available to authors for file editing, choosing the thesauri on which the semantic annotation and metadata queries will rely, and choosing the cartographic context used by the research application. In the latter, editing an XML file to the format given by the WMC specification of the OGC [OGC 05] provides the possibility of describing the geographical layers of the spatial framework and their representation style. This framework must be accessible through an OGC cartographic Web service (WMS, Web Map Service).
- – User management means creating users and providing them with a role.
- – Cataloging covers the creation of prefilled file models (matching the desired resource typology) and the creation of a set of named files. The file models created by the administrator are made available to the community for their future use. The sets of named files (such as “Fauna” and “Flora”) are used to structure the catalog internally. They can be seen as folders/directories in which files about a certain subject or thematic or given organization are stored.
- – Metadata harvesting, mentioned in section 8.4.5, refers to the automatic import of metadata from a distant catalog.
8.7. Architecture
For reasons of adaptability, modularity, and interoperability, MDWEB's architecture is based on components and is an SOA. Indeed, MDWEB must be able to interact (interoperate) with other tools or components relying on metadata within a data infrastructure. In the same way, it must call upon existing services to complete its components. From a logical point of view, according to the n-tier principle, MDWEB is articulated around three levels: the management level consisting of the metadata base and thematic framework, the dialogue level for data-HTTPD server and DBMS, and the application level (JSF, JAVA Server Faces). The tool is developed to be used independently on operating systems such as Windows, MacOS, and Linux. MDWEB is a software suite including client modules and a Web service server. It is all hosted and managed by a JAVA JEE application server: GLASSFISH 3 or APACHE TOMCAT 6. This software architecture ensures MDWEB's great flexibility when deploying, especially to allow it a unique deploying (MDWEB client modules and service server within a same server) up to a deploying based on a distributed architecture made up of multiple application servers and Web service servers.
Figure 8.15 depicts the main elements of this architecture. The client modules are accessible through a Web navigator. There are four and they cover the functionalities described in the previous sections:
- – data research through metadata matching the locating functionalities shown in section 8.5;
- – editing metadata that corresponds to the cataloging and annotating functionalities described in section 8.4;
- – administrating catalogs and users, including the creation of named sets of recordings;
- – designing the tool offering configuration functionalities for the tool and matching frameworks described in section 8.6.
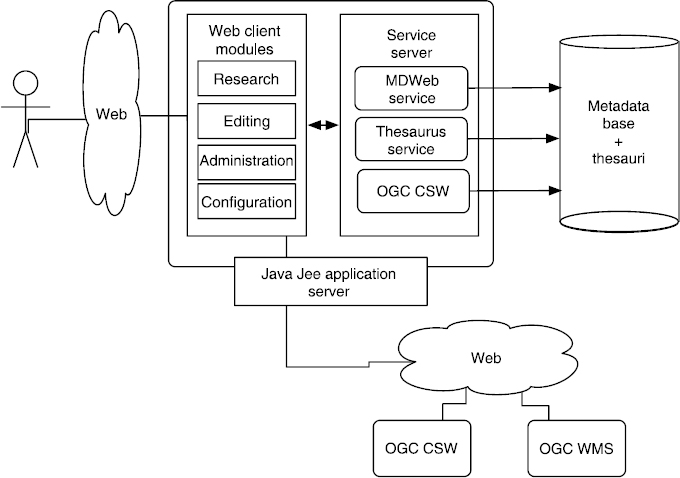
Figure 8.15. MDWEB general architecture diagram
These modules are developed with the JAVA Server Faces framework. This framework was chosen because it is component oriented and thus favors functional stability of developments. This is essential in a long-term project such as MDWEB. The MDWEB service server provides the following elements:
- –A standardized CSW of the OGC providing research interfaces and access to the metadata files stored by MDWEB.
It is completed by the transactional mode (CSW-T) to ensure harvesting operations on the metadaa files coming from distant catalog.
- –A specific MDWEB Web service prodiving interfaces to edit metadata, and administrate and configure the tool.
- – A Web service to access the thesauri, enabling us to use the concepts and relations stored in these thesauri. This service is called upon during research or editing operations. It is based on the GEMET6 Web service API.
- – A relational database ensuring metadata, thesaurus, and used metadata models (standards and profiles) persistence.
The MDWEB server mainly relies on the geographic software component kit CONSTELLATION7 developed by the Geomatys. It provides the SOA and software components that implement the geographic services of the OGC used within different modules of MDWEB. CONSTELLATION notably relies on GEOAPI8, which offers the set of JAVA interfaces compliant with OGC specifications, and on GEOTOOLKIT9, which implements part of these interfaces.
8.8. User community
Since its publication, MDWEB has been used in various fields and by various communities. Most often, it is used:
- – for data inventory or administration reasons in an organization:
- - new technology center and risk management, http://pont-entente. org/,
- - national center for research support10
- – to promote informational legacy:
- – to implement an observatory:
- – to contribute to sharing data within a management project integrated to a territory:
- - SYSCOLAG15 program;
- – as a discovery service within an SDI:
- - Best Practice Network for SDI in Nature Conservation16.
Since 2005, the MDWEB project has had its own Website17 and a set of tools ensuring the monitoring of code releases18, of bug fix requests19, a continuous integration platform20, and user forum21.
The Web site also offers the old and current release of downloads and the matching material to ease installation, and use of the tool. MDWEB is released under two open source licenses. Its PHP version (version 1.X) is disseminated under a CeCILL22 open source license compatible with the GPL license. Version 2 is released under LGPL 3.023. By analyzing downloads on the site, we can venture that MDWEB is widely used in the French and Francophone communities (France, Belgium, Canada, and French-speaking Africa). The tool has been downloaded more than 10,000 times (for all versions).
Engineers and computer science students contributed to version 1.X. There were three study engineers (for 5 years) and 10 computer science masters interns from the University of Montpellier II for these different versions. The Research Institute for Development (IRD) initiated the program within its Desertification unit, and later its Space unit. There was a strong collaboration that sprung up then with the D'OC team of the LIRMM, and it is still ongoing today. Other research organizations in Montpellier, such as the CEMAGREF (UMR TETIS), the CIRAD, and the CEPRALMAR, participated in a more occasional manner.
8.9. Conclusion
We wanted to offer a complete tool based on open source technology that could be modular and adaptable, especially when it comes to making it available and personalizing the frameworks matching the targeted application field. These are some of the points on which MDWEB is different from other open source cataloging solutions from the start. Moreover, it appeared essential to build a tool that was both generic and extensible, according to the standard ISO 19115 and the OGC specifications, using the frameworks matching the targeted field.
The generic approach was validated many times over the period, both by the diverse use made of the tool and by its adaptability to communities' needs. To this end, we have been able to implement other metadata models than ISO 19115 without compromising the architecture and storing diagrams of the metadata. One such example is the Dublin Core or Sensor ML (SML) metadata models which are the suggested models according to the OGC specifications, covering access to observations from Web sensors (SWE, Sensor Web Enablement).
Although metadata is often badly perceived, current projects and initiative of environmental information sharing, especially through the implementation of SDIs, allowed us to promote the use of metadata among the environmental communities. More often than not, these initiatives start out by creating their metadata service before deploying the other services of the infrastructure. That said, there are still limits that can be an impediment to the role given to metadata. Indeed, formulated and implemented metadata within discovery services are often created at the beginning of the project and then suffer from real and permanent updates. This then creates the issue of the freshness of the information provided. From a descriptive point of view, this type of metadata is still limited today to the discovery of resources and does not offer a correct description of the genealogy that would allow us to assess accurately their adequacy versus targeted thematic, temporal, or spatial precision. An effort in this direction should be made to better assess and describe the quality of resources aimed at the targeted uses in diagnostic or natural risk management fields.
8.10. Bibliography
[BAR 05] BARDE J., Mutualisation de données et de connaissances pour la gestion intégrée des zones côtières. Application au programme SYSCOLAG, PhD Thesis, University of Montpellier II, 2005.
[BER 93] BERGERON M., Vocabulaire de la géomatique, Office de la langue frangaise du Québec, Montreal, 1993.
[BER 01] BERNERS-LEE T., HENDLER J., LASSILA O., “The semantic web: a new form of web content that is meaningful to computers will unleash a revolution of new possibilities”, Scientific American, vol. 1, pp. 34–43, 2001.
[DCM 05] Dublin Core metadata initiative, DCMI Abstract Model, 2005.
[DES 01] DESCONNETS J.-C., LIBOUREL T., MAUREL P., MIRALLES A., PASSOUANT M., “Proposition de structuration des métadonnées en géosciences. Spécificité de la communauté scientifique”, Géomatique et espace rural, Journées Cassini 2001, Montpellier, France, 2001.
[DES 03] DESCONNETS J.-C., MOYROUD N., LIBOUREL T., “Méthodologie de mise en place d'observatoires virtuels via les métadonnées”, Inforsid 2003, Actes du XXIème congrès, Nancy, France, 2003.
[DES 07a] DESCONNETS J.-C., LIBOUREL ROUGE T., CLERC S., “Cataloguer pour diffuser les ressources environnementales”, Inforsid 2007, Actes du XXVème congrès, 2007.
[DES 07b] DESCONNETS J.-C., MAUREL P., VALETTE E., LIBOUREL T., TONNEAU J., “Excellence et innovation rurales. Outil Web de gestion des données et référentiel d'analyse de projets PER pour un développement territorial durable”, Congrès joint du 47e ERSA (European Regional Science Association) et du 44e ASRDLF (Association de science régionale de langue francaise), Paris, France, 2007.
[DES 08] DESCONNETS J.-C., HEURTEAUX V., “MDweb 2.0: a java/JEE metadata catalog”, FOSS4G 2008, Free and Open Source Software for Geospatial Conference, Cape Town, South Africa, 2008.
[FGD 98] FEDERAL GEOGRAPHIC DATA COMMITTEE, IContent standard for digital geospatial metadata – FGDC-STD-001-199, 1998.
[ISO 86] INTERNATIONAL STANDARD ORGANIZATION, ISO 2788 – Guidelines for the establishment and development of monolingual thesauri, 1986.
[ISO 03] INTERNATIONAL STANDARD ORGANIZATION, ISO/TC211, ISO 19115 – Geographic Information Metadata, 2003.
[ISO 07] INTERNATIONAL STANDARD ORGANIZATION, ISO/TC211, TS/ISO 19139 – Geographic Information – Metadata – XML schema implementation, 2007.
[LIB 03] LIBOUREL T., DESCONNETS J.-C., MAUREL P., MOYROUD N., PASSOUANT M., “Les métadonnées: pour quoi faire?”, Géo-événement'2003, Paris, France, 2003.
[MAZ 06] MAZOUNI N., LOUBERSAC L., REY-VALETTE H., LIBOUREL T., MAUREL P., DESCONNETS J.-C., “A transdisciplinary and multi-stakeholder approach towards integrated coastal area management. An experiment in Languedoc-Roussillon”, Vie et Milieu (Life & Environment), vol. 4, pp. 265–274, 2006.
[OGC 05] OPEN GEOSPATIAL CONSORTIUM, Web Map Context Documents, 2005.
[OGC 07a] OPEN GEOSPATIAL CONSORTIUM, OpenGIS Catalogue Services Specification 2.0.2 – ISO Metadata Application Profile, 2007.
[OGC 07b] OPEN GEOSPATIAL CONSORTIUM, Sensor Model Language (SensorML) Implementation Specification – OpenGIS Implementation Standard, 2007.
[ROS 04a] ROSELT/OSS, Organisation, fonctionnement et méthodes de ROSELT/OSS, Collection ROSELT/OSS, document scientifique, Observatoire du Sahara et du Sahel, 2004.
[ROS 04b] ROSELT/OSS, Système de circulation de l'information ROSELT: Définitions des métadonnées et élaboration des catalogues de référence, Collection ROSELT/OSS, contribution technique, Observatoire du Sahara et du Sahel, 2004.
[SKO 04] SKOS Simple Knowledge Organization System, 2004.
[TDW 06] TAXONOMIC DATABASE WORKING GROUP, ABCD, Access to Biological Collection Data (ABCD) Primer, 2006.
[TDW 09] TAXONOMIC DATABASE WORKING GROUP, Darwin Core terms, a quick reference guide, 2009.
[W3C 04] WORLD WIDE WEB CONSORTIUM, RDF, Resource Description Framework. W3C Recommendation, 2004.
[ZAY 10] ZAYRIT K., Modèles de données adaptés à la construction partagée d'un thésaurus dédié aux traits fonctionnels, mémoire de stage de Master 2, University of Montpellier II, 2010.
Chapter written by Jean-Christophe DESCONNETS and Thérèse LIBOUREL.
4 http://geonetwork-opensource.org/
6 https://svn.eionet.europa.eu/projects/Zope/wiki/GEMETWebServiceAPI
7 http://www.constellation-sdi.org/
10 http://cnar.mdweb-project.org/
11 http://cataloguecirad.teledetection.fr/
12 http://diact-demo.teledetection.fr
13 http://pnba.mdweb-project.org/
14 http://soga.univ-brest.fr/mdweb/
15 http://syscolag.teledetection.fr/
16 http://www.naturesdi.mdweb-project.org/french-geoportal/search/main.jsf
17 http://www.mdweb-project.org
18 http://hg.mdweb-project.org/mdweb/
19 http://jira.codehaus.org/browse/MDWEB
20 http://hudson.geomatys.com/job/MDweb2/