
Chapter 11
Challenges and Proposals for Software Development Pooling in Geomatics
This chapter aims to draw up a list of the various issues specific to resource pooling in geomatics and to suggest a few ideas to solve them. We use the term “pooling” to refer to any grouping of resources that allows us to lower development costs and improve scientific progress. During the design and development activities that we have presented, there are various types of resources which can be pooled: the abstract models and the corresponding expertise, and the implementation models and the corresponding components. This chapter is divided into two parts: the first dealing with the requirements and challenges and the second with the suggestions of solution.
11.1. Requirements and challenges
In this section we will describe the main requirements of pooling and analyze the obstacles to it, first in terms of function and component implementation, then in terms of abstract models.
11.1.1. Pooling function implementations
A first requirement is to pool function implementations. This requirement creates the classical challenges of interoperability. Some have already been solved because of the progress in modular architecture and norms facilitating interoperability in the field of geographical information, which we will summarize in section 11.1.1.1. Challenges remain and will be detailed in sections 11.1.1.2 and 11.1.1.3.
11.1.1.1. Reusing functions implemented in geomatics
Manipulating geographical data requires many functions, as we mentioned in Chapter 1 (e.g. loading data, modeling, integrating different data among themselves, visualizing). During the design phase of a new geomatics software project, some of the functions are not targeted by innovation. We should then look at the pros and cons of an ad hoc implementation or reuse.
Reusing implemented functions is generally encouraged by the current breakthroughs in reusable software design. Indeed, the reuse of an implemented function requires us to have an access interface to this function. In this case we can talk of an interface in a very broad sense of communication ability with a piece of software: when it comes to what we can ask and what kind of answer we get, a key element is the interface contract specifying the possible interaction with the piece of software. And in the past years, we have seen a proliferation in the development of software providing interface contracts to interact with them on a programming level: software that can be configured with a simple file, libraries offering programming interfaces, libraries offering extension points, and open source libraries. Moreover, normalized exchange formats of UML model representation, such as XMI (XML Metadata Interchange), also help integrate existing model components within new models.
More specifically, in geomatics, reusing implemented functions is also encouraged by the breakthroughs in interoperability between software manipulating geographical data, as we have seen in the introduction to this book (section 1.2.2). To be more precise, interoperability refers to the use of conventions to help communication. These conventions concern the content exchanged, the requested functions, and the interaction mode to obtain the function. In the case of the exchanged contents, there are de facto standards which have been around for a long time to exchange geographical data between components. The most famous one is ESRI's shapefile format. In the past few years, the work of the ISO/OGC have led to defining more evolved norms to structure geographical data. There are metamodels to model data (such as Feature [OGC 09]) and a XML implementation (GML or GeoRSS). As for functions and interaction modes, the work of the ISO/OGC has also focused on providing precise functions (data query, catalog query, and data drawing) and more precisely providing it through a Web service type interface. The most famous interface specifications are the Web Map Service (WMS), Web Feature Service (WFS), Web Coverage Service (WCS) and Catalog Services for the Web (CSW) norms. Not only does the norm help reuse existing components but it also discourages ad hoc implementation. Finally, geomatics norms are often complex and the cost of the implementation incites people to reuse pre-existing interoperable components rather than reimplement these norms.
Some pieces of software already correspond in part to this need for the most elementary functions in a GIS project. Most of the developments which require storing in a database management system (DBMS) rely on POSTGRESQL or ORACLE. The JAVA pieces of software manipulating geographical data often reuse the JAVA Topology Suite to represent geometries and carry out a few elementary operations on these geometries (intersections, convex hull, etc.). In the Web domain, due to the dissemination of ISO/OGC norms previously mentioned, some implementations have been proposed, such as the MAPSERVER, GEOSERVER, GEONETWORK, or even MDWEB pieces of software, which are widely used. Among the projects presented in this book, ORBISGIS uses MDWEB components for the cataloging part, to benefit from these functionalities while sparing the cost of implementing relatively complex norms (CSW norms). Moreover, the initiatives to facilitate free access to a base map and data location on this base map have been successful. For example, we can mention Google API or Geoportail's API. In the field of non-Web application development, some GIS, such as UDIG, QGIS, or OpenJUMP, offer extension points to reuse their graphical interface.
The display and interaction functions via a graphical interface (select, edit, etc.) are also often reused since their development requires specific knowledge (2D JAVA libraries, for instance), which is often different from the analysis expertise that certain teams have, and their development is relatively costly. In this case, there is a triple advantage. The reuser has access both to the drawing functions as well as to the function provided as plugins with this tool. He/she can also choose to distribute his/her function to other users of the tool by providing them with his/her plugin. So OpenJUMP users can easily connect to the WEBGEN services because of a dedicated plugin and the WEBGEN community can connect to other works published in OpenJUMP.
11.1.1.2. The challenge of defining interoperable interfaces
The breakthroughs in interoperability should not obfuscate the issues which remain when it comes to exchanging content and functions.
In the case of content, as we have explained it in the introduction of this book (section 1.1.1), a specificity of geographical data is the lack of consensual model to structure it. The work of organizations like ISO and OGC is a considerable improvement for interoperability but still has its limits.
On the one hand, the current norms do not cover enough modeling elements. Many mathematical elements involved in models (point, line, and polygons) are covered by abstract norms. Yet there are many complex structures used in geomatics, such as trees, graphs, networks, and partitions. Moreover, there is a lack of consensus about other non-mathematical elements, such as models of lakes, roads, or buildings, and, to exchange these elements, the norms must allow us to share not only the data but also the model definitions. And the current norms for geographical metadata do not currently allow us to formally transcribe a model's entire semantics.
Additionally, the interoperability of the content exchanged in random access memory is not guaranteed by the norms which limit themselves to XML implementation (serialization). Thus the different JAVA implementations of Feature (such as the implementation in GEOTOOLS, the implementation in DEEGREE, and the implementation in GEOXYGENE) are not interoperable. However, this is an area that requires a very large amount of work: a great number of adaptors must be encoded because many classes are embedded one in the other to describe complex geometry. This is the point of works being carried out to define a GEOAPI, a set of JAVA interface functions implementing ISO/OGC models to describe geometries and objects.
In our view, the most controversial issue is the description of functionalities proposed to promote their reuse [LEM 06]. We will mention here two types of function description necessary to pooling.
The first type is the detailed description of input and output of the function, including pre-conditions and post-conditions, the conditions and effects on the manipulated representation. When pooling means that an application automatically parses the description of a function to call it up or to combine it with another function, this application needs this first type of description. It implies on the one hand a clear identification of input and output, and on the other hand, the use of logical formalism to write them formally A substantial obstacle here is how we can find and share what we can call “the function's validity context”. This refers to the requirements concerning the input data for the tool to actually provide the described functionality. These conditions are not always limited to being compliant to the specified input format. The difficulty is double in this case: knowing the conditions and expressing them without ambiguity. The process is generally developed and tested in a limited context (on specific data). There is no unitary testing in geographical information [BUC 07, BUC 08]. Moreover, non-ambiguous communication of these conditions to an application requires models with formal semantics able to express these wordings (KIF1, SWRL2, etc.).
The second type of function description is the designation of its global effect. This type is often necessary when the pooling involves experts in a field since they must be able to identify a function with an understandable term (drawing, simplification, and calibration) and not with the formal description of its input and output. There is no consensus on typology in this field. [BER 87] and [TOM 91] proposed a data operation classification adapted to raster or unique data. Their underpinned goal is to arrive at a general methodology for thematic data analysis. [MIT 99] also proposed a task and subtask model to formalize the process of thematic map writing. [LIN 10] proposed an environment to help scientists design and validate processing chains based on the expert knowledge of manipulated data and process categories. [GIO 94] and [ALB 96] proposed a GIS operation classification aiming to facilitate the design of processes above various GIS tools: a process is described through abstract operations and can be carried out in different GIS tools offering different implementations of the operations described. There is also a very high-level ISO taxonomy (ISO 19119) that has, for example, a geoprocessing services category subdivided into four categories according to the nature of the information processed: spatial, thematic, temporal, and metadata. The OGC consortium that wishes to define interface specifications for geographical data processing services called to the definitions of specialized profiles for Web processing services [OGC 07a, OGC 07b]
11.1.1.3. The challenge of modular development
Another obstacle to function implementation pooling is that the techniques of modular programming are not yet widely used. Few researchers design functions as modules reusable by others, meaning that few of them grasp the fact that their functions could be useful to others and make the effort of implementing functions as reusable components. Yet, when a function is not designed in a modular fashion, trying to extract it retroactively from its original application by copying the method query sequence which matches it requires us to know the variable used by these methods to document them accurately. This experiment was carried out in the COGIT laboratory3 to design a service that automatically improves color contrast from a method embedded in an existing applications. The authors analyzed the difficulties they came across to extract a method from its original context so as to provide it as a service [BUC 08]. We can explain the lack of modular development by the fact that these approaches are still new and sometimes complicated to establish. Moreover, this investment has little scientific value in the short term.
In addition, an increasing issue that goes against reusing code in a JAVA development context is the evolution of widespread libraries, such as the XERCES library for XML data management in JAVA or the GEOTOOLS library, of which different versions are not always compatible. When such libraries are frequently used, it can create conflicts when reusing a component in a development. The two components cannot be executed in the same process since they use incompatible versions of the same libraries. This issue is solved with interprocess communication and more generally with the Web-based programming which allows us to avoid platform incompatibilities.
Finally, when it comes to the source code, the issue of the exercise is to first understand a code, a program structure, and the detail of the methods. The current literature is still insufficient. A JAVA program literature is typically organized according to the packages and classes. However, this organization is not always the organization of the functions. What is more, using code commentaries can create a language problem. This caused a delay in the adoption of the open source GVSIG piece of software by non-Spanish speakers. A last challenge in code pooling is to help find more input from developers taking up an open source code. Globally, we should accept lifecycles that alternate divergence and integration phases. During the divergence phases, subprojects appear and must be self-sufficient enough to explore an aspect of software development without being constrained by other aspects. During the integration phases, the divergence must be reduced to the minimum, when possible, to allow for efficient integration of various building blocks. The concordance of both phases is delicate but divergence is necessary for code progression. In a more general way, this is the issue of collaborative publishing of models, based for instance on collaborative development tools such as SVN [MIC 11].
11.1.2. Pooling models and expertise
11.1.2.1. The need for it
Another type of resource that can be shared covers the models and algorithms used. For example, the 3D building generalization algorithm proposed by Martin Kada [KAD 02] was taken up and improved in GEOXYGENE by using the description he made of it in a scientific article. GENEXP-LANDSITES codes tessellation algorithms described in literature and normally developed for other uses [ADA 07]. AROM-ST is derived from the AROM language, itself developed on the basis of many different French works on knowledge representation [DUC 98]. GEOLIS, specific to geolocated data, is built from a generic data storing and querying system [FER 04]. To share these resources, it is important to define a set of framework articles which described the models and which can be quoted. Moreover, the access to a demonstrator or prototype is an advantage that helps pooling. There are many structures which help this kind of pooling since it is at the heart of research's progress: conferences, workshops, journals, and reference sites (CITEULIKE, ARXIV, HAL, and ORI-OAI). Let us mention that in the specific field of geographical information, this is the most important type of pooling. Indeed, this field is multidisciplinary and its breakthroughs are often due to teams whose members have different fields of competences learning to share and integrate their models and methods.
Another type of resource is the expertise used during the development: user implication method, library ownerships, and design patterns. Pooling these resources means publishing and reading scientific articles, possibly in the fields which are not connected to geomatics (such as ergonomics, work psychology, sociology, or cognitive anthropology), exchanges during conference and workshops or on forums. It can also rely on the transfer of people, such as a postdoctoral candidate or a contributor. The establishment of collaborative projects, under the impulse of funding from the European Commission or the French National Research Agency, among others, is an efficient way to pool methods and development in promoting team collaboration.
11.1.2.2. A challenge: the diversity and gaps in the existing expertise
The final obstacle to resource pooling in geomatics seems to be the difficulty we have in knowing what is existing – what has been done, what can be reused, and how. This difficulty is the consequence, on the one hand, of the abundant and heterogeneous aspect of the existing (a lot of things but they are hard to grasp and compare), and, on the other hand, of the diversity of necessary expertises. As we underlined it in the introduction of this book, geomatics is a scientific field at the crossroads of other fields (such as cartography, databases, mathematics, and geography). Many competences make up geomatics. It appears that geomatics has built itself in the past few years on various fields whose vocabularies were always separate. Its vocabulary is thus particularly ambiguous since it refers to various original disciplines without explicitly mentioning them. When we talk of a building model, for example, is it a conceptual diagram or a set of data representing a building or even a simulation method reconstructing a building from photographs? This ambiguity is hard to avoid even for similar disciplines and this book has encountered a great amount of it. Moreover, geomatics is a rapidly changing field along with information and communication technologies, and it must integrate emerging themes such as information infrastructures, localized services, or even geographical information retrieval. Its vocabulary is permanently being rebuilt to adapt to technological evolutions and research breakthroughs. Finally, this field still has not been identified by scientists who do not belong to it but might encounter issues linked to this field. All of this makes pooling difficult.
Finally, in the case when we pool software resources without pooling expertise, we might end up with processing or geographical data misuses. This use does indeed often require a certain level of expertise both in the application of the tool and the analysis of the results. The data or function provider might fear that bad decisions might be made due to the resources he/she provided because he/she will not have been able to accompany the process built on his/her resources.
11.2. Solutions
The previous section showed the main challenges for pooling resources useful to geomatics software development. This section will confront us with interoperability, tool and algorithms cataloging, and model indexation issues in scientific communities and to the issues of communication from one community to the other.
This section presents existing solutions or solutions currently being developed to remove some of these impediments.
11.2.1. Reference frameworks and metadata
A key concept for pooling is the concept of a reference framework. From what we have said previously, we can deduce that three types of reference frameworks are needed:
- – design frameworks allow us to build the most interoperable components possible;
- – description and cataloging frameworks;
- – competence frameworks for the visibility of scientific communities facilitating knowledge pooling.
The first solutions go the way of providing frameworks for resource design, typically specification implemented with characteristic interfaces in a given domain which the designers are intended to follow so that their code will be interoperable. GEOAPI and the WEBGEN community work on the precise definition of structures that can be shared, want to facilitate the sharing between libraries and the design of interoperable services. We will classify the MOBIDIC platform among these solutions, a platform found in the context of mobile service development [LOP 09]. The authors allow the developers of localized Web services or other software components to integrate into their services context elements (not only the user's location but also the size of the roaming device's scree and memory). The values of these context elements are acquired due to the Mobidic middleware present on the client side.
There is other work currently focused on building semantic frameworks to describe components to ease their cataloging and use: thesauri, taxonomies, or ontologies. These frameworks are useful inasmuch as they are used to build resources (for an attribute value domain, for example), and especially when building metadata. The projects which aim to facilitate the construction and publication of metadata are a key element in pooling.
In general, Web services are very fond of frameworks to describe their interface and do their cataloging. Indeed, there are already existing frameworks for their description, such as the standard Web Service Description Language (WSDL) and frameworks for their cataloging (such as ebXML and ebRIM). In geomatics, Lutz and Klien [LUT 06] used an ontology to reuse specific Web services which are geographical object providing services (in the WFS standard). Thus their ontology is centered on the description of geographical objects. In the same way, WEBGEN is centered on the design of reusable generalization Web services and also deals with service description. Burghardt et al. [BUR 05] propose precise typologies for generalization processing services. Their work underlines the need to use various classifications to describe a functionality and list processing services. Thus one of the proposed classifications organizes processes according to their signatures, i.e. according to the input and output data types; another classification organizes the processes according to the functional components of a generalization process (data preparation, generalization operations, and process control). [LEM 06] proposes various ontologies to catalog and facilitate the design of processing services: an ontology of real-world objects, an ontology of database objects, an ontology of atomic operations, and an ontology of complex operations. His proposal insists on allowing us to check the consistency of a processing chain at the input and output data level. [TOU 10] proposes an ontology to describe application conditions and generalization process effects to organize different generalization processes in a heterogeneous space. The MOBIDIC platform previously mentioned also proposes a service description language that promotes the discovery and assembly of mobile services developed with this platform [LOP 09]. This model, called WSRM, enriches the Web service description standards with the service application domain (such as online learning) and the service use context (which can be a client- and user-side prerequisite in terms of user location and client physical characteristics).
That said, reusable resources are not all Web services. For example, in [BUC 08], the authors focus on the issue of reusing processes embedded in applications which have not been designed as Web services. The authors take up a principle of the Service Oriented Architecture approach: a relevant concept on which software reusability can be grounded is the concept of the services provided by the software. From there, they suggest a specific metadata model, called model and function metadata (MFM), to describe services provided by software resources and how to access these services. Their proposal does not impose a framework for the metadata literature (e.g. the function taxonomy) but offers the designers the possibility of building and exchanging the frameworks which they will use in their descriptions. In the field of process descriptions, a pioneering work was written by [BEC 02] who proposed a model for urban model interconnections. In this case, the expression urban model refers to a process allowing us to calculate, with known quantities, quantities that we are looking to simulate or approach. [BEC 02]'s proposal is to match each module with an adaptor complying to a common description model. His proposal also helps carry out a complex process that uses various urban models in a synchronized manner, which can be transposed to engineering in the context of Web services. Since then, design methods consisting of specifying components through interface contracts before implementing them have also helped reuse their component functions and their composition.
The work on the semantic Web or on the manipulation of spatiotemporal data also goes in the direction of helping to share documents or data available on the Web by matching them with structured metadata complying to non-ambiguous models. They focus on data and do not deal at all with service integration.
Finally, when it comes to improving the visibility of domains of expertise, and in the long term, scientific communities, let us mention the work in progress of American researchers in geomatics: a group of American researchers, each a key researcher in their own field, has established a corpus of knowledge in geographical computer science which have around a hundred sections, called the GIS&T Body of Knowledge (GIS&T BoK) [DIB 07]. Actors of the GIS&T BoK are spreading out their work to the international community and are contacting the main associations in the field of geographical computer sciences to validate this framework and eventually adapt it to specific context. Other initiatives are multiplying to provide greater visibility to geomatics training, whether this is for future students or for employers. A survey was carried out in France, supported by the MAGIS research group and the AFIGEO association, to study geomatics in French. In Europe, the authors of [RIP 11] have also studied and compared various ways to teach geomatics.
11.2.2. Test cases to improve description of implemented functions and progress within a community
A promising proposal for resource pooling in a research community, which was debated within the Pooling project of the MAGIS research group and within the WEBGEN community, is the definition of a more or less large set of test cases. For example, the 3D computer graphics researchers working on illuminance models use a common 3D set often called “Cornell box” to compare their illuminance models (see Figure 11.1). This set is made up of a box in which there are relatively simple objects. The data for this test case are available to everyone [COR 98].

Sharing these common test cases holds various advantages for a research community:
- – It facilitates the comparison of various approaches (such as, for instance, the different types of illuminances models: the display of their effect on the Cornell box allows us to get a sufficient idea of their differences).
- – It facilitates the data access for the approach test. This is especially true in fields where the question of data acquisition is an issue.
- – It promotes communication within the research community and outside it, allowing researchers to communicate about their work on use cases that might be more significant for the audience (or at least cover a larger spectrum). In particular, this makes it much easier to teach the goals and techniques of a specific field of research to junior researchers or students.
- – It promotes collaboration between researchers and users: the users can suggest test cases in which they take interest.
- – It enables the identification of a large number of issues which the research community more or less deliberately allows to slide.
- – It promotes the specification of some functions. These functions sometime require concrete examples to be clearly communicated (such as functional tests). This is in particular the case for cartographic functions.
Various initiatives have been carried out on the sharing of test cases. For example, in information searching, test campaigns were organized for search engines focusing on identical issues. The reason for organizing these campaigns was the cost linked to the construction of test sets (sets of queries and relevance assessments) in this field. The test campaigns allowed us to compare, in the most unbiased way possible, these engines and helped the research progress in this field [GEY 06, PAL 10].
The research community in automatic generalization also developed a project called European Spatial Data Research Network (EuroSDR) focusing on the assessment of automatic generalization software [BUR 08, STÖ 08, STÖ 09]. The software was assessed on identical generalization test cases proposed by different European cartography agencies; some of them are mentioned in Figure 11.2. The first test case was provided by the Catalonia Cartography Institute, the second by the United Kingdom's Ordnance Survey, the third by the Netherlands' Cartographic Institute, and the fourth by the French National Geography Institute.
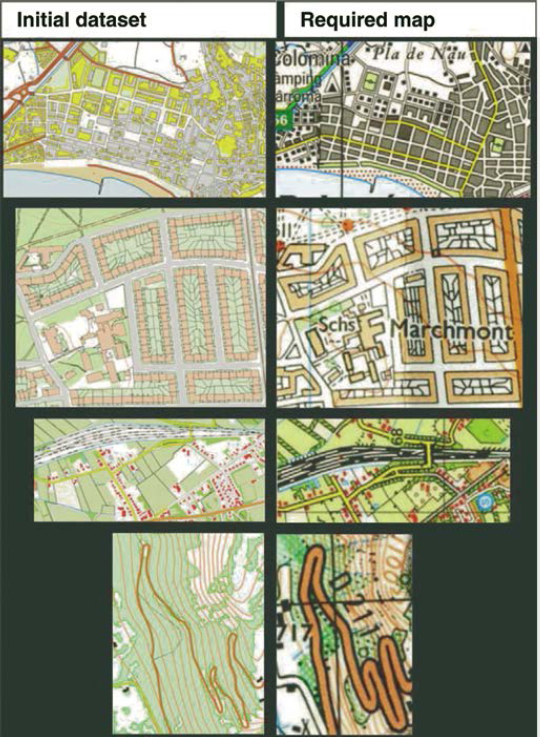
Figure 11.2. Generalization test cases examples
To design a satisfying set of test cases, we must respect as best as possible two opposite constraints. On the one hand, we must have a sufficiently low number of examples, to ensure that each of them is known and used by a maximum of persons. On the other hand, we must have a sufficiently large number of examples, to ensure that all the types of issues are covered. For example, if more generalization test cases could be proposed, they would have to cover as best as possible the criteria space allowing us to qualify a generalization issue type. These criteria can be:
- – the types of data considered (buildings, buildings and roads, weather data, etc.);
- – the magnitude of the detail level change;
- – the type of geographical landscape in question (urban, rural, coastal, mountainous area, etc.);
- – the domain (hiking map, road map, planning map, etc.);
- – the size of the data (2D, 3D, spatiotemporal data, etc.).
This list is obviously not exhaustive and the criteria mentioned are not independent, one from another. If all the tests cover enough of the possible issues, a user with a given issue will be able to find a test case that will be similar to them, and thus have an idea of the research results that might interest them.
11.3. Conclusion
The need for pooling is strong in geomatics. It goes beyond the field of software developments studied in this book. The main pivots are the sharing of frameworks: frameworks to design resources (essentially API), frameworks for description (ontologies), and frameworks for the positioning of a scientific field. It is also essential to keep a critical eye on the norms, since they have a key role in pooling and their establishment and dissemination cannot be solely based on the needs of different lobbies. Moreover, frameworks are not enough. Two types of tools must be linked to the frameworks to facilitate pooling: tools helping to build and validate metadata and tools helping to use metadata to search for resources and use them. The first type should still be the focus of proposals and we believe that the designing of test cases and test games is very promising in this respect. The second type of tool is the catalog, represented in this book by the MDWEB project (Chapter 6).
Beyond function, model, or component pooling, expertise pooling is a source of innovation. To this end, the pooling must integrate different points of view: that of the researchers, the thematicians (geographers, archaeologies, geomorphologists, etc.), or the computer scientists (database or image processing specialists, as well as knowledge engineering specialists); that of the users (land planners, land managers [LAR 05], even drivers or hikers [DOM 10]); and that of geomaticians, the latter having a specific role as broker between different disciplines. Thus the GENGHIS project presented in the book (Chapter 5) brought together computer scientists, geomaticians, and mountain risk specialists to develop a tool based on a spatial and temporal knowledge representation system, the AROM-ST system. In the same way, the GEOLIS project (Chapter 6) gathered computer scientists and geographers to offer a geographical data querying system based on a logical information system.
There are other techniques to explore jointly and they can promote innovation in geomatics: let us mention, without claiming to be exhaustive, qualitative reasoning models over time and space developed in artificial intelligence [LEB 07, LIG 10], analogy reasoning models (such as case-based reasoning), current models of knowledge representation (conceptual graphs, description logics), and ontology development techniques, or even the different approaches developed within the framework of information systems. Innovation is also promoted when we are better at taking into account the geomatics users and uses, as [NOU 09] suggested recently. This is the way geomatics stand to gain from a better integration of social and cognitive science research work.
11.4. Bibliography
[ADA 07] ADAMCZYK K., ANGEVIN F., COLBACH N., LAVIGNE C., LE BER F., MARI J.-F., “GenEXP, un logiciel simulateur de paysages agricoles pour l'étude de la diffusion de transgènes”, Revue Internationale de Géomatique, vol. 17, nos. 3–4, pp. 469–487, 2007.
[ALB 96] ALBRECHT J., “Universal GIS operations for environmental modeling”, Proceedings of the 3rd International Conference on Integrating GIS and Environmental Modeling, Santa Barbara, USA, 1996.
[BEC 02] BECAM A., YEHUDI: Un environnement pour l'interopérabilité de modèles urbains distribués et homogènes, PhD in Computer Science and Information Society, INSA Lyon, 2002.
[BER 87] BERRY J., “Fundamental operations in computer-assisted map analysis”, IJGIS, vol. 1, no. 2, pp. 119–136, 1987.
[BIS 97] BISHR Y., Semantic aspects of interoperable GIS, PhD Thesis, ITC, The Netherlands, 1997.
[BUC 07] BUCHER B., BALLEY S., “A generic preprocessing service for more usable data processing services”, Proceedings of the 10th AGILE Conference, Aalborg, Denmark, 2007.
[BUC 08] BUCHER B., JOLIVET L., “Acquiring service oriented descriptions of GI processing software from experts”, Proceedings of the 11th AGILE Conference, Girona, Spain, 2008.
[BUR 05] BURGHARDT D., NEUN M., WEIBEL R., “Generalization services on the web – a classification and an initial prototype implementation”, CaGIS, 2005.
[BUR 08] BURGHARDT D., SCHMID S., DUCHÊNE C., STÖTER J., BAELLA B., REGNAULD N., TOUYA G., “Methodologies for the evaluation of generalised data derived with commercial available generalisation systems”, 11th ICA Workshop on Generalisation and Multiple Representation, Montpellier, France, 2008.
[COR 98] Cornell University Program of Computer Graphics, The Cornell Box (online), 1998, available at http://www.graphics.cornell.edu/online/box/.
[DIB 07] DIBIASE D., DEMERS M., JOHNSON A., KEMP K., LUCK A., PLEWE B., WENTZ E., “Introducing the first edition of the GIS&T Body of Knowledge”, Cartography and Geographic Information Science, vol. 34, no. 2, pp. 113–120, 2007.
[DOM 10] DOMINGUÈS C., BALDIT-SCHNELLER P., “Les randonneurs définissent leurs cartes. Exploitation d'une enquête semi-directive à questions ouvertes avec des outils statistiques et linguistiques”, SAGEO'10, Spatial Analysis and Geomatics, Toulouse, France, 2010.
[DUC 98] DUCOURNAU R., EUZENAT J., MASINI G., NAPOLI A., (eds), Langages et modèles à objets – Etat des recherches et perspectives, Collection Didactique D-019, INRIA, Le Chesnay, France, 1998.
[FER 04] FERRÉ S., RIDOUX O., “Introduction to logical information systems”, Information Processing & Management, vol. 40, no. 3, pp. 383–419, 2004.
[GEY 06] GEY F., LARSON R., SANDERSON M., JOHO H., CLOUGH P., PETRAS V., “GeoCLEF: the CLEF 2005 cross-language geographic information retrieval track”, CLEF 2005 Proceedings, LNCS 4022, pp. 908–919, 2006.
[GIO 94] GIORDANO A., VEREGIN H., BORAK E., LANTER D., “A conceptual model of GIS-based spatial analysis”, Cartographica, vol. 31, no. 4, pp. 44–51, 1994.
[KAD 02] KADA M., “Automatic generalization of 3D building models”, GIS – Geo-Information-Systems, Journal for Spatial Information and Decison Making, vol. 9, pp. 30–36, 2002.
[LAR 05] LARDON S., PIVETEAU V., “Méthodologie de diagnostic pour le projet de territoire: une approche par les modèles spatiaux”, Géocarrefour, vol. 80, no. 2, 2005.
[LEB 07] LE BER F., LIGOZAT G., PAPINI O. (eds), Raisonnements sur l'espace et le temps: des modèles aux applications, Traité IGAT – Géomatique, Hermes-Lavoisier, Paris, 2007.
[LEM 06] LEMMENS R., Semantic interoperability in distributed geo-service, PhD thesis, ITC, Enschede, The Netherlands, 2006.
[LIG 10] LIGOZAT G., Raisonnement qualitatif sur le temps et l'espace, Collection Ingénierie des langues, Hermes-Lavoisier, Paris, 2010.
[LIN 10] LIN Y., PIERKOT C., MOUGENOT I., DESCONNETS J.-C., LIBOUREL T., “A framework to assist environmental information processing”, ICEIS, pp. 76–89, 2010.
[LOP 09] LOPEZ-VELASCO C., GENSEL J., VILLANOVA-OLIVER M., MARTIN H., “Vers une plate-forme de génération de SIG mobiles adaptés au contexte d'utilisation”, Revue Internationale de Géomatique, vol. SIG mobiles, 2009.
[LUT 06] LUTZ M., KLIEN E., “Ontology-based retrieval of geographic information”, International Journal of Geographical Information Science, vol. 20, no. 3, pp. 233–260, 2006.
[MIC 11] MICHAUX J., BLANC X., SUTRA P., SHAPIRO M., “A semantically rich approach for collaborative model edition”, Proceedings of the 26th Symposium on Applied Computing, SAC2011, Taichung, Taiwan, 2011.
[MIT 99] MITCHELL A., The ESRI Guide to GIS Analysis, Volume 1: Geographic Patterns &Relationships, ESRI Press, Redlands, CA, 1999.
[NOU 09] NOUCHER M., La donnée géographique aux frontières des organisations: approche socio-cognitive et systémique de son appropriation, PhD Thesis, EPFL, 2009.
[OGC 07a] OPEN GEOSPATIAL CONSORTIUM, OGC Web Services Initiative – Phase 5 (OWS-5) – Annex B OWS-5 Architecture, 2007.
[OGC 07b] OPEN GEOSPATIAL CONSORTIUM, OpenGIS Web Processing Service – OpenGIS standard, 2007.
[OGC 09] OPEN GEOSPATIAL CONSORTIUM, The OpenGIS Abstract Specification – Topic 5: Features, version 5, 2009.
[PAL 10] PALACIO D., CABANAC G., SALLABERRY C., HUBERT G., “Measuring geographic ir systems effectiveness in digital libraries: evaluation framework and case study”, ECDL'10, 14th European Conference on Research and Advanced Technology for Digital Libraries, Glasgow, UK, pp. 340–351, 2010.
[PIE 08] PIERREL J.-M., “De la nécessité et de l'intérêt d'une mutualisation informatique des connaissances sur le lexique de notre langue”, Contribution à la table ronde “Lexique” 1er Congrès Mondial de la Linguistique Frangaise, 9–12 July, Paris, France, pp. 15–30, 2008, available at: http://www.linguistiquefrancaise.org/http://dx.doi.org/10.1051/cmlfO8330.
[RIP 11] RIP F., GRINIAS E., KOTZINOS D., “Analysis of quantitative profiles of GI education: towards an analytical basis for EduMapping”, Proceedings of the 14th International Conference on Geographic Information Science (AGILE'11), Utrecht, The Netherlands, 2011.
[STÖ 08] STÖTER J., DUCHÊNE C., TOUYA G., BAELLA B., PLA M., ROSENSTAND P., REGNAULD N., UITERMARK H., BURGHARDT D., SCHMID S., ANDERS K.H., DÁVILA F., “Astudy on the state-of-the-art in automated map generalisation”, 11th ICA Workshop on Generalisation and Multiple Representation, Montpellier, France, 2008.
[STÖ 09] STÖTER J., BURGHARDT D., DUCHÊNE C., BAELLA B., BAKKER N., BLOK C., PLA M., REGNAULD N., TOUYA G., SCHMID S., “Methodology for evaluating automated map generalization in commercial software”, Computers, Environment and Urban Systems, vol. 33, no. 5, pp. 311–324, 2009.
[TOM 91] TOMLIN C.D., “Cartographic modelling”, in MAGUIRE D.J., GOODCHILD M.F., RHIND D. (eds), Geographical Information Systems: Principles and Application, vol. 1, Longman, Harlow, pp. 361–374, 1991.
[TOU 10] TOUYA G., “Relevant space partioning for collaborative generalisation”, 12th ICA Workshop on Generalisation and Multiple Representation, Zürich, Switzerland, 12–13 September 2010.
Chapter written by Bénédicte BUCHER, Julien GAFFURI, Florence LE BER and Thérèse LIBOUREL.
1 http://www.ksl.stanford.edu/knowledge-sharing/kif/