
SQL Server 2005 introduces a native XML datatype and substantially enhanced XML support. Earlier versions of SQL Server had some support for XML data, but not as a native type and with limited functionality. You can now store XML data, constrain it with XML schemas, index it with specialized XML indexes, and manipulate it using the XQuery language, which follows the W3C standard. XQuery manipulation includes querying (query method), retrieving values (value method), existence checks (exists method), modifying sections within the XML data (modify method) as opposed to overriding the whole thing, shredding XML data into multiple rows in a result set (nodes method), and more. In the following section, I’ll explain why you need the XML data type inside a database, when to use it, and when not to use it. I’ll also provide code samples demonstrating the use of the XML data type. Still, this is a T-SQL programming book, so I won’t go into all the details of XML technologies supported in SQL Server 2005.
More Info
For more information on XML technologies, please refer to Microsoft SQL Server 2005 XML (Sams, 2006) by Michael Rys. Michael is the program manager in charge of XML technologies with the SQL Server development team.
The first question that came to my mind when I heard that SQL Server 2005 will support a native XML data type was: Why do I need such support in a relational database? I’ve been pondering the idea for months and have finally become convinced that such support is important and beneficial. XML is the lingua franca of exchanging data among different applications and different platforms. It is widely used, and almost all modern technologies support it. Databases simply have to deal with XML. Now, XML could be stored as simple text. But plain text representation means having no knowledge of the structure built into an XML document. You could decompose the text, store it in multiple relational tables, and use relational technologies to manipulate the data. But relational structures are quite static and not so easy to change. Think of dynamic or volatile XML structures. Storing XML data in a native XML data type solves these problems, enabling functionality attached to the type that can accommodate support for a wide variety of XML technologies.
With the advent of XML and Object technologies, some people wonder whether the relational model is obsolete. Many developers looking for greater programmatic flexibility feel that their choices are very limited with the relational model. The world is constantly changing, and you need technologies to support these changes. Some people think that storing everything in XML format bridges the gap between object-oriented (OO) applications and relational databases. However, in many cases people are just reinventing the wheel.
I agree that the relational model is limiting, but it is intentionally so! The idea is simple–you need constraints to enforce data integrity. Constraints prevent chaos. When you’re driving, you obey speed limits and traffic lights, allowing drivers to share the same roads and pass through the same crossroads. When you need to store items in real life, you do so in an organized, structured fashion. A pharmacy that keeps its medicines lying around in a muddle probably won’t get many appreciative customers. But the XML data type is structured; in fact, its structure is more relaxed than relational data. So why not use Microsoft Office Word or Excel, which also support structured representation and are even more relaxed than XML, for business applications?
Are schemas really so volatile nowadays? Well, they are volatile for some business cases, but quite stable for the most part. Not being able to find a structure that suits a business problem does not mean that such a structure does not exist. I’ve seen an example in which a sales Orders table included a column with all order details (order lines) for the order as a single XML value. Come on, an order details schema is not volatile; it’s actually so well known that it has a design pattern! I repeat; a relational schema constrains us deliberately. Consider the order details example again; when you are dealing with sales, data integrity is crucial; without it, your company can lose business.
Relational databases support many other constraints besides detailed schema. It’s true that you can program them in a middle tier or in any other layer if you use a so-called XML database, but why reinvent the wheel? Why develop something that’s already developed? In many cases, reinventing the wheel indicates a lack of knowledge. I’ve seen a system that started with an XML database without any constraints except schemas. The idea was to design a flexible system. Well, after a while the customer and the developers realized that they needed more constraints. As time passed, more and more constraints were built into the system. Eventually, the system had no flexibility, which in a sense is a good thing because it did in fact need a fixed schema. But with all the constraints that were built into the system, it was almost impossible for applications to use the data and for administrators to maintain the system, all of which made the system extremely expensive. Remember that data is usually used by more than one application–think of Customer Relationship Management (CRM) systems that need merged data from all possible sources and BI solutions, including reporting, OLAP cubes, and Data Mining models.
A couple of years ago I was in an Italian restaurant with some friends. Itzik wanted a pizza, but the restaurant didn’t have it. The wait staff suggested the closest thing they had–a kind of meat loaf. Itzik asked for one but added, "As long as it looks like a pizza, smells like a pizza, and tastes like a pizza." Why am I recalling this event? Because if a problem needs a detailed schema and constraints, and the data must be available to many applications, I really don’t care what kind of database and model you use–as long as it looks like the relational model, behaves like the relational model, and constrains like the relational model.
I hope that after the introduction, you won’t think that I’m entirely opposed to having XML support inside a relational database. I can actually give many examples where it does make sense.
First of all, I have to admit, a schema sometimes is in fact volatile. Think about situations in which you have to support many different schemas for the same kind of event. There are many such cases within SQL Server itself. DDL triggers are a good example. There are dozens of different DDL events, and each event returns different event information–that is, data with a different schema. If DDL triggers used relational schemas to return event information (as DML triggers do), SQL Server would need to support dozens of different schemas, some of which would be very complicated. A conscious design choice was that DDL triggers will return event information in XML format via the EventInfo function. Event information in XML format is quite easy to manipulate. Furthermore, with this architecture, SQL Server will be able to extend support for new DDL events in future versions more easily.
Another interesting example of internal XML support in SQL Server 2005, and proof that Microsoft is practicing what it preaches, is XML showplans. You can now generate execution plan information in XML format using the SET SHOWPLAN_XML and SET STATISTICS XML statements. Think of the value for applications and tools that need execution plan information–it’s easy to request and parse it now. You can even force the optimizer to use a given execution plan expressed in XML format by using the USE PLAN query hint.
The "XML Best Practices" section in Books Online says that you should use an XML model if your data is sparse (among other circumstances). This is true, though it’s not the only solution. Your data is sparse, having many unknown values, if some columns are not applicable to all rows. Standard solutions for such a problem introduce subtypes or implement an open schema model in a relational environment. Still, a solution based on XML could be the easiest to implement. A solution that introduces subtypes can lead to many new tables. A solution that implements a relational open schema model can lead to complex, dynamic SQL statements.
There are other reasons mentioned in Books Online for using an XML model–for example, a changing structure, which I mentioned earlier. XML inherently supports hierarchical sorted data. This fact makes people wonder whether XML is more appropriate for representing hierarchical data than a relational model. A relational solution that has references among entities is cumbersome. However, a hierarchy can be represented in a relational model as an adjacency list (parent/child attributes) with a self-referencing foreign key constraint. You can then query the data using recursive common table expressions (CTEs). There are also other solutions to representing structures such as graphs, trees, and hierarchies in a relational model.
What if ordering is inherent in your data? I don’t find this a good enough reason to justify using XML. You can have an attribute that defines the order; otherwise, you probably haven’t done your business analysis well.
Finally, another scenario suggested for using XML representation is when you want to modify parts of the data based on its structure. I agree with this reasoning in some cases, and I’ll explain and demonstrate why in the following section.
Objects in .NET applications can be persisted in one of two ways: using binary or XML serialization. Binary serialization is very encapsulated; only applications that know the structure (class) of the object and the way it’s serialized can deserialize it. XML serialization is much more open. All you need to know is the XML schema, and even without it you can browse the data. Now think of objects in a wider sense. Everything you store in a computer is a kind of object. For example, take Microsoft Visio diagrams. They can be stored in internal Visio format or as XML. If they are stored in the internal format, you can open them only with Microsoft Visio. If they are stored in XML format, you can open them even with Notepad. And if you store them using XML format in a database, you can use T-SQL queries to search and manipulate the document data. That is valuable functionality! Imagine you are searching for all Visio documents that include a specific element. If they are stored in internal format, you have to open them one by one and visually check them. If they are stored as XML documents in a file system, you can use full-text indexes and search through them. But if they are stored in a database in an XML column, you can find all documents you need with a single SELECT statement.
As another example for using XML, consider a frequently asked question: "How do you pass an array as a parameter to a stored procedure?" The solution is not that easy. One option is to pass the array of values as a comma-separated string and then use T-SQL code to separate the elements. Another option is to pass the array as an XML parameter, and use the .nodes method to shred the values into a relational presentation.
After this introduction, you should have an idea of when the XML data type is appropriate and when you should stick to the relational model. Having the background covered, I can now discuss the new XQuery language, the XML data type methods, and some other XML enhancements. I’ll also walk you through code samples that you’re likely to find useful.
Note
This section contains queries that require an active connection to the Internet. If you don’t have one, simply read this section without running those queries yourself.
Figure 1-7 has four simple Visio diagrams: an Object-Role Modeling (ORM) diagram for products and their associated properties, an Entity-Relationship (ER) diagram for the product entity, a Unified Modeling Language (UML) class diagram for the product entity, and an ER diagram for customers.
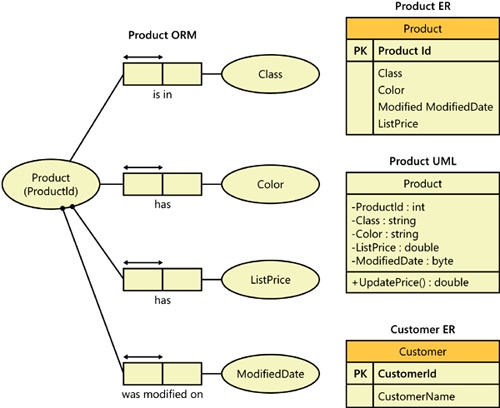
I saved all diagrams in XML format (.vsd Visio files). The XML schema (XSD) for Visio documents is published at http://msdn.microsoft.com/library/default.asp?url=/library/en-us/vissdk11/html/vixmlelemVisioDocument_HV01085731.asp. The filenames of the four diagrams are ProductORM.vdx, ProductER.vdx, ProductUML.vdx, and CustomerER.vdx. These files are available for download at http://www.insidetsql.com as part of the book’s source code download. I’ll demonstrate how to import these files into XML column values in a table and manipulate them. To follow the demonstration, create the folder C:VisioFiles and copy the .vsd files from the book’s CD to that folder.
First prepare a new test database:
USE master; CREATE DATABASE XMLtest; GO USE XMLtest;
Next, use the following code to create a table with an XML column and import the Visio documents into the table:
CREATE TABLE dbo.VisioDocs ( id INT NOT NULL, doc XML NOT NULL ); GO INSERT INTO dbo.VisioDocs (id, doc) SELECT 1, * FROM OPENROWSET(BULK 'C:VisioFilesProductORM.vdx', SINGLE_BLOB) AS x; INSERT INTO dbo.VisioDocs (id, doc) SELECT 2, * FROM OPENROWSET(BULK 'C:VisioFilesProductER.vdx', SINGLE_BLOB) AS x; INSERT INTO dbo.VisioDocs (id, doc) SELECT 3, * FROM OPENROWSET(BULK 'C:VisioFilesProductUML.vdx', SINGLE_BLOB) AS x; INSERT INTO dbo.VisioDocs (id, doc) SELECT 4, * FROM OPENROWSET(BULK 'C:VisioFilesCustomerER.vdx', SINGLE_BLOB) AS x;
You can clearly see the advantage of loading file data using the new BULK rowset provider over the limited support for loading file data in earlier versions of SQL Server. It’s so simple now!
It’s time to check what you loaded:
SELECT id, doc FROM dbo.VisioDocs;
This simple SELECT statement produces the output shown in Table 1-20.
Table 1-20. Visio Documents Stored in an XML Column
id | doc |
|---|---|
1 | <VisioDocument xmlns=″http://schemas.microsoft.co... |
2 | <VisioDocument xmlns=″http://schemas.microsoft.co... |
3 | <VisioDocument xmlns=″http://schemas.microsoft.co... |
4 | <VisioDocument xmlns=″http://schemas.microsoft.co... |
The XML data is shown in the table as a hyperlink. SSMS can, in contrast to SQL Server 2000’s Query Analyzer (QA), properly parse and represent XML data. If you click the hyperlink in the row having id 1, you get the XML data in a new window. Here’s a small snippet of what you get:
<VisioDocument xmlns="http://schemas.microsoft.com/visio/2003/core" key=
"6EBD363F713E11F015D5C3B92BA3B51614E0DDCD04221BE2E5746F025DB606135E3471EE1AFC2FE765E28213490
B60BAC4D061FC55E033D2B6396B8358AECEA0" start="190" metric="0" DocLangID="1033"
buildnum="5130" version="11.0" xml:space="preserve">
<DocumentProperties>
<Creator>Dejan Sarka</Creator>
<Template>C:Program FilesMicrosoft OfficeVisio111033ORMSRC_U.VST</Template>
<Company>Solid Quality Learning</Company>
<BuildNumberCreated>738202634</BuildNumberCreated>
<BuildNumberEdited>738202634</BuildNumberEdited>...You can see that the document has an internal structure, and the structure of course complies with the published XML schema I mentioned earlier. You can now use the XQuery language within a SELECT statement to extract portions of the XML data. For example, the following query returns the company of the creator of each document, generating the output shown in Table 1-21:
SELECT id,
doc.value('declare namespace VI=
"http://schemas.microsoft.com/visio/2003/core";
(/VI:VisioDocument/VI:DocumentProperties/VI:Company)[1]',
'NVARCHAR(50)') AS company
FROM dbo.VisioDocs;Table 1-21. Companies of Creators of Visio Documents
id | company |
|---|---|
1 | Solid Quality Learning |
2 | Solid Quality Learning |
3 | Solid Quality Learning |
4 | Unknown Company |
I used the .value method of the XML data type. This method returns a scalar .value, so it can be specified in the SELECT list. Note that the .value method accepts an XQuery expression as input. It consists of two parts: prolog and body. In the prolog, you declare all namespaces used in the query. In our case, it is the namespace declared by Microsoft for Visio documents, which I copied out of the XML output from the previous example. Namespaces allow you to have elements with the same names describing different entities and attributes, similar to .NET namespaces. Elements inside different namespaces are treated as different elements. If you don’t include the namespace, XQuery would not find any element, and the .value method would return NULL. A namespace is declared with a prefix–that is, an alias you use in the body of the query. In the XQuery expression, you define the path to the element you want to read. Starting from the root element (<VisioDocument>) and going through the second-level element (<DocumentProperties>), you arrive to the element you need (<Company>).
Notice the use of the index [1]. An untyped XML document (without a defined schema) supports multiple elements with the same name in the same level. The .value method must return a scalar value; therefore, you have to specify the exact index of the element in the level you are browsing, even if you know that there is only one. XQuery supports aggregate functions such as Sum, Count, Avg, Min, and Max. You can use those to aggregate multiple values and return the scalar result value. Finally, every column in the returned result set must have a data type, so the XQuery expression converts the returned value to NVARCHAR(50).
Next, suppose you want to find all database model diagrams (ER diagrams). All documents with database models are based on the DBMODL_U.VST template, and the template is included in the <Template> element of the XML schema for Visio documents. You can use the .value method in the WHERE clause like so, returning the output shown in Table 1-22:
SELECT id, 'ER DB Model' AS templatetype FROM dbo.VisioDocs WHERE doc.value( 'declare namespace VI="http://schemas.microsoft.com/visio/2003/core"; (/VI:VisioDocument/VI:DocumentProperties/VI:Template)[1]', 'nvarchar(100)') LIKE N'%DBMODL_U.VST%';
Next, the .query method, as the name implies, is used to query XML data. It returns an instance of an untyped XML value. The method’s input query can be as simple as an XPath expression returning some subelements of an XML value. Or it can be a complex query using a FLOWR statement. FLOWR is an acronym for For, Let, Order by, Where, and Return. The For clause binds one or more iterator variables to input sequences. It’s similar to a standard ForEach loop in OOP languages. Input sequences are either sequences of nodes or sequences of atomic values. The Let clause binds a temporary variable to the result of a query expression. It is similar to the WITH clause in T-SQL used to define a CTE. The Let clause is not implemented in SQL Server 2005. The Where clause applies a filter predicate to the iteration and is similar to a T-SQL query filter. Similarly, the Order by clause is used to order the output similar to a T-SQL query’s ORDER BY clause. The Return clause constructs the result of a FLOWR expression, shaping the XML output.
As an example for using the .query method, the following code invokes a FLOWR expression to iterate through subelements of the <DocumentSettings> element, generating the output shown in Table 1-23:
SELECT doc.query('
declare namespace VI="http://schemas.microsoft.com/visio/2003/core";
for $v in /VI:VisioDocument/VI:DocumentSettings
return $v') AS settings
FROM dbo.VisioDocs;If you click one of the links, you get the settings for the selected document in XML format:
<VI:DocumentSettings xmlns:VI="http://schemas.microsoft.com/visio/2003/ core" TopPage="0" DefaultTextStyle="3" DefaultLineStyle="3" DefaultFillStyle="3" DefaultGuideStyle="4"> <VI:GlueSettings>9</VI:GlueSettings> <VI:SnapSettings>39</VI:SnapSettings> <VI:SnapExtensions>34</VI:SnapExtensions> <VI:DynamicGridEnabled>0</VI:DynamicGridEnabled> <VI:ProtectStyles>0</VI:ProtectStyles> <VI:ProtectShapes>0</VI:ProtectShapes> <VI:ProtectMasters>0</VI:ProtectMasters> <VI:ProtectBkgnds>0</VI:ProtectBkgnds> </VI:DocumentSettings>
As I mentioned earlier, the Return clause can be used to shape the XML value returned. For example, the following query retrieves the <Creator> element, returning it as an attribute called creatorname of an element called <Person>:
SELECT doc.query('
declare namespace VI="http://schemas.microsoft.com/visio/2003/core";
for $v in /VI:VisioDocument/VI:DocumentProperties
return element Person
{
attribute creatorname
{$v/VI:Creator[1]/text()[1]}
}')
FROM dbo.VisioDocs;Here’s the XML value this query returns in the first output row:
<Person creatorname="Dejan Sarka" />
Next, suppose that you want to find all Visio documents with an unknown creator company (<Company> element has "Unknown Company"). You might be thinking of using the .value method in the WHERE clause. However, remember that the XML data type is actually a LOB type. There can be up to 2 GB of data in every single column value. Scanning through the XML data sequentially is not a very efficient way of retrieving a simple scalar value. With relational data, you can create an index on a filtered column, allowing an index seek operation instead of a table scan. Similarly, you can index XML columns with specialized XML indexes. The first index you create on an XML column is the Primary XML index. This index contains a shredded persisted representation of the XML values. For each XML value in the column, the index creates several rows of data. The number of rows in the index is approximately the number of nodes in the XML value. Such an index can already speed up searches for a specific element (using the .exist method, which I’ll describe later). After creating the Primary XML index, you can create up to three secondary XML indexes:
Path, which is especially useful if your queries specify path expressions. It speeds up the .exist method better than the Primary XML index.
Value, which is useful if queries are value based, and the path is not fully specified or it includes a wildcard.
Property, which is very useful for queries that retrieve one or more values from individual XML instances (.value method).
The Primary XML index has to be created first. It can be created only on tables with a clustered primary key. The query you are going to use to find all unknown companies invokes the .value method in the WHERE clause, searching for a single value. The use of the .value method in this case is similar to using the .exist method; therefore, a secondary XML Path index is most appropriate. So you need to create a clustered primary key, then a Primary XML index, and then a secondary one:
ALTER TABLE dbo.VisioDocs ADD CONSTRAINT PK_VisioDocs PRIMARY KEY CLUSTERED (id); CREATE PRIMARY XML INDEX idx_xml_primary ON dbo.VisioDocs(doc); CREATE XML INDEX idx_xml_path ON VisioDocs(doc) USING XML INDEX idx_xml_primary FOR PATH;
Next, invoke the following three statements in a single batch, with Include Actual Execution Plan turned on in SSMS:
SELECT id, doc FROM dbo.VisioDocs WHERE doc.value( 'declare namespace VI="http://schemas.microsoft.com/visio/2003/core"; (/VI:VisioDocument/VI:DocumentProperties/VI:Company)[1]', 'nvarchar(50)') LIKE N'Unknown%'; DROP INDEX idx_xml_primary ON dbo.VisioDocs; SELECT id, doc FROM dbo.VisioDocs WHERE doc.value( 'declare namespace VI="http://schemas.microsoft.com/visio/2003/core"; (/VI:VisioDocument/VI:DocumentProperties/VI:Company)[1]', 'nvarchar(50)') LIKE N'Unknown%';
Both SELECT statements are identical, retrieving documents with unknown companies. The first one uses XML indexes, while the second doesn’t (because it’s invoked after dropping the indexes).
If you look at the cost ratios of the queries in the plan, you will find the first has 3 percent cost out of the whole batch, and the second 97 percent. You realize that the substantial cost difference exists because the first query uses XML indexes while the second doesn’t.
You can use the XML data type to support an open schema environment. Suppose that you need to store contacts in a table. For domestic contacts, you need to store an ID and a foreign spoken language. For foreign contacts, you need to store the mother tongue and a flag that shows whether the contact speaks English or not. You could solve this problem with two subtypes: one for the domestic contacts and one for the foreign ones. You would use a separate table for the subtype-specific attributes; however, I’d like to show how you can implement a solution with a single table using the XML data type. First, create the following Contacts table:
CREATE TABLE dbo.Contacts ( contactid INT NOT NULL PRIMARY KEY, contactname NVARCHAR(50) NOT NULL, domestic BIT NOT NULL, otherattributes XML NOT NULL );
Notice that the table contains a flag that specifies whether the contact is domestic or foreign. Before you start to insert data, you will constrain the input allowed in the otherattributes column. You can constrain the XML data with a schema collection. Values entered into the column will be validated against schemas in the collection and accepted only if they comply with any of the schemas in the collection. Validation against a collection of schemas enables support of different schemas for domestic and foreign contacts. If you wanted to validate XML values only against a single schema, you would define only a single schema in the collection.
You create the schema collection using the new CREATE XML SCHEMA COLLECTION T-SQL statement. You have to supply the XML schema as input–that is, the XSD document. Creating the schema is a task that should not be taken lightly. If you make an error in the schema, some invalid data might be accepted and some valid data might be rejected.
The easiest and safest way that I can suggest to create robust XML schemas is to create relational tables first, and then use the new XMLSCHEMA option of the FOR XML clause. Store the result XML value (the schema) in a variable, and provide the variable as input to the CREATE XML SCHEMA COLLECTION statement. Run the code in Example 1-7 to create the schema collection ContactOtherAttributes with the Domestic and Foreigns schemas.
Example 1-7. Creation script for the ContactOtherAttributes schema collection
CREATE TABLE dbo.Domestic
(
ID NVARCHAR(15),
ForeignLanguage NVARCHAR(50)
);
CREATE TABLE dbo.Foreigns
(
NativeLanguage NVARCHAR(50),
SpeaksEnglish BIT
);
GO
-- Store the Schemas in a Variable and Create the Collection
DECLARE @mySchema NVARCHAR(MAX);
SET @mySchema = N'';
SET @mySchema = @mySchema +
(SELECT *
FROM Domestic
FOR XML AUTO, ELEMENTS, XMLSCHEMA('Domestic'));
SET @mySchema = @mySchema +
(SELECT *
FROM Foreigns
FOR XML AUTO, ELEMENTS, XMLSCHEMA('Foreign'));
-- Create Schema Collection
CREATE XML SCHEMA COLLECTION dbo.ContactOtherAttributes AS @mySchema;
GO
-- Drop Tables
DROP TABLE dbo.Domestic, dbo.Foreigns;You can get information about schema collections by querying the catalog views: sys.xml_schema_collections, sys.xml_schema_namespaces, sys.xml_schema_components and some others:
-- Retrieve information about the schema collection
SELECT *
FROM sys.xml_schema_collections
WHERE name = 'ContactOtherAttributes';
-- Retrieve information about the namespaces in the schema collection
SELECT N.*
FROM sys.xml_schema_namespaces AS N
JOIN sys.xml_schema_collections AS C
ON N.xml_collection_id = C.xml_collection_id
WHERE C.name = 'ContactOtherAttributes';
-- Retrieve information about the components in the schema collection
SELECT CP.*
FROM sys.xml_schema_components AS CP
JOIN sys.xml_schema_collections AS C
ON CP.xml_collection_id = C.xml_collection_id
WHERE C.name = 'ContactOtherAttributes';By executing these queries against the metadata info, you will notice that schema collections are shredded in relational tables. Now you need to alter the XML column from a well-formed state to a schema-validated one:
ALTER TABLE dbo.Contacts ALTER COLUMN otherattributes XML(dbo.ContactOtherAttributes);
Note
When you change an XML column from well-formed to schema-validated, all values in that column are validated, so the alteration can take a while.
Now insert some valid data:
INSERT INTO dbo.Contacts VALUES(1, N'Mike', 1, N' <Domestic xmlns="Domestic"> <ID>012345678901234</ID> <ForeignLanguage>Spanish</ForeignLanguage> </Domestic>'), INSERT INTO dbo.Contacts VALUES(2, N'Herbert', 0, N' <Foreigns xmlns="Foreign"> <NativeLanguage>German</NativeLanguage> <SpeaksEnglish>1</SpeaksEnglish> </Foreigns>'), INSERT INTO dbo.Contacts VALUES(3, N'Richard', 1, N' <Domestic xmlns="Domestic"> <ID>012345678901234</ID> <ForeignLanguage>German</ForeignLanguage> </Domestic>'), INSERT INTO dbo.Contacts VALUES(4, N'Gianluca', 0, N' <Foreigns xmlns="Foreign"> <NativeLanguage>Italian</NativeLanguage> <SpeaksEnglish>1</SpeaksEnglish> </Foreigns>'),
Next try to insert some invalid data:
INSERT INTO dbo.Contacts VALUES(5, N'Tibor', 0, N' <Foreigns xmlns="Foreign"> <Hobbie>Beer</Hobbie> <SpeaksEnglish>1</SpeaksEnglish> </Foreigns>'), GO INSERT INTO dbo.Contacts VALUES(5, N'Kalen', 1, N' <Domestic xmlns="Domestic"> <ID>012345678901234</ID> <ForeignLanguage>Spanish</ForeignLanguage> <ForeignLanguage>German</ForeignLanguage> </Domestic>'), GO
Msg 6965, Level 16, State 1, Line 1 XML Validation: Invalid content. Expected element(s):Foreign:NativeLanguage,Foreign:Speaks English where element 'Foreign:Hobbie' was specified. Location: /*:Foreigns[1]/*:Hobbie[1] Msg 6923, Level 16, State 1, Line 4 XML Validation: Unexpected element(s): Domestic:ForeignLanguage. Location: /*:Domestic[1] /*:ForeignLanguage[2]
The last error was generated because you tried to insert a contact who speaks two foreign languages but the schema supports only one. As you can see, validation against the schema collection is working.
To explain other aspects of the XML data type, I’ll need to insert a contact who speaks two foreign languages. Therefore, you will change the OtherAttributes XML column from schema-validated back to well-formed. Before doing so, try to answer the following question: "Would SQL Server currently prevent me from storing an XML value for a domestic contact (domestic column = 1) who adheres to a foreign contact schema and not a domestic one?" The answer is, actually, no. To further constrain the input, you could add a CHECK constraint verifying the existence of an element corresponding to the input contact type (for example, domestic column = 1, and the XML value contains the <ID> element).
If you need to constrain the XML data beyond schema validation, maybe it is time to rethink your design. Maybe the solution implementing each subtype in a separate table would be more appropriate!
Moving forward, run the following code to remove the schema validation and retry the last insert:
ALTER TABLE dbo.Contacts ALTER COLUMN otherattributes XML; GO INSERT INTO dbo.Contacts VALUES(5, N'Kalen', 1, N' <Domestic xmlns="Domestic"> <ID>012345678901234</ID> <ForeignLanguage>Spanish</ForeignLanguage> <ForeignLanguage>German</ForeignLanguage> </Domestic>'),
Suppose you want to get a single row for every foreign language spoken by domestic contacts. Currently, there are three domestic contacts, together speaking four foreign languages; therefore, you expect four rows in the output. Your first attempt might be to use the .query method, without any formatting of the output. In this case, you will get a linear sequence of the values as shown in Table 1-24:
SELECT contactid, contactname,
otherattributes.query('
declare namespace D="Domestic";
/D:Domestic/D:ForeignLanguage/text()') AS languagespoken
FROM dbo.Contacts
WHERE domestic = CAST(1 AS BIT);Table 1-24. Output of the .query Method
contactid | contactname | languagespoken |
|---|---|---|
1 | Mike | Spanish |
3 | Richard | German |
5 | Kalen | SpanishGerman |
However, you get a single row for Kalen, while she deserves two. Also, the data type returned for the languagespoken column is XML (which is the datatype returned by the .query method), while you want a character type. You might also attempt to use the .value method as follows:
SELECT contactid, contactname,
otherattributes.value('
declare namespace D="Domestic";
/D:Domestic/D:ForeignLanguage/text()',
'NVARCHAR(50)') AS languagespoken
FROM dbo.Contacts
WHERE domestic = CAST(1 AS BIT);This time, you get an error because the .value method requires a singleton sequence–and you know that Kalen speaks two foreign languages. You have to split the query into two parts: one for the first foreign language, and one for the second. Then you need to combine the two result sets into a single one by using the UNION ALL set operation. But you don’t want to return rows with NULLs in the second foreign language, so you have to check whether the second language exists before returning it. You can achieve this by using the .exists method in the WHERE clause of the second SELECT statement. The .exist method simply checks whether the element specified by the path exists, returning 1 if it does and 0 if it doesn’t. Here’s the solution query, returning the output shown in Table 1-25:
SELECT contactid, contactname,
otherattributes.value('
declare namespace D="Domestic";
(/D:Domestic/D:ForeignLanguage/text())[1]',
'NVARCHAR(50)') AS languagespoken
FROM dbo.Contacts
WHERE domestic = CAST(1 AS BIT)
UNION ALL
SELECT contactid, contactname,
otherattributes.value('
declare namespace D="Domestic";
(/D:Domestic/D:ForeignLanguage/text())[2]',
'NVARCHAR(50)')
FROM dbo.Contacts
WHERE domestic = CAST(1 AS BIT)
AND otherattributes.exist('
declare namespace D="Domestic";
(/D:Domestic/D:ForeignLanguage)[2]') = 1;Although the result is correct, you might not be satisfied with the solution. What if you don’t know the maximum number of foreign languages in advance? Considering that the number can be very high, imagine how long the query would become.
It’s time to introduce the .nodes method. This method is useful when you want to shred an XML value into relational data. The result of the .nodes method is a result set that contains logical copies of the original XML instances. In those logical copies, the context node of every row instance is set to one of the nodes identified by the XQuery expression–meaning that you get a row for every single node from the starting point defined by the XQuery expression. The .nodes method returns copies of the XML values, so you have to use additional methods to extract the scalar values out of them. The .nodes method has to be invoked for every row in the table. Do you remember which new T-SQL feature allows you to invoke a right table expression for every row of a left table expression? Of course, it’s the APPLY table operator.
The solution query invokes the .nodes method in the FROM clause for each row in the base table using the CROSS APPLY operator. The .nodes method’s input XQuery expression returns a row for any foreign language spoken. To start simply, the following code will invoke the .query method to return the output of the .nodes method with no manipulation, generating the output shown in Table 1-26:
SELECT contactid, contactname, N.c1.query('.') AS languagespoken
FROM dbo.Contacts
CROSS APPLY
otherattributes.nodes('
declare namespace D="Domestic";
(/D:Domestic/D:ForeignLanguage)') AS N(c1);Table 1-26. Output of the .nodes and .query Methods
contactname | languagespoken | |
|---|---|---|
1 | Mike | <p1:ForeignLanguage xmlns:p1="Domestic">Spanish </p1:ForeignLanguage> |
3 | Richard | <p1:ForeignLanguage xmlns:p1="Domestic">German </p1:ForeignLanguage> |
5 | Kalen | <p1:ForeignLanguage xmlns:p1="Domestic">Spanish </p1:ForeignLanguage> |
5 | Kalen | <p1:ForeignLanguage xmlns:p1="Domestic">German </p1:ForeignLanguage> |
Finally, you can extract the scalar values from the XML result by using the .value method, generating the desired output shown in Table 1-25:
SELECT contactid, contactname,
N.c1.value('(./text())[1]','NVARCHAR(50)') AS languagespoken
FROM dbo.Contacts
CROSS APPLY
otherattributes.nodes('
declare namespace D="Domestic";
(/D:Domestic/D:ForeignLanguage)') AS N(c1);Suppose you want to create a stored procedure that would accept a list of names as a parameter and return all contacts with a name that appears in the input list. Of course, you could use a delimited list and then separate the elements using T-SQL code. However, using an XML input and applying the .nodes method seems simpler to me. Here’s the code implementing the stored procedure:
CREATE PROCEDURE dbo.GetContacts
@inplist XML
AS
SELECT C.*
FROM dbo.Contacts AS C
JOIN (SELECT D1.c1.value('(./text())[1]','NVARCHAR(50)') AS nameneeded
FROM @inplist.nodes('/Names/NameNeeded') AS D1(c1)) AS D2
ON C.contactname = D2.nameneeded;
GOThe procedure uses the .nodes and .value methods to extract the elements from the input list. You create the input list in XML format by using the FOR XML clause extensions. The RAW mode of the FOR XML clause in SQL Server 2005 can now produce named elements (as opposed to just producing a predefined element named "row"). The FOR XML clause can also return element-centric XML instead of attribute-centric XML by using the ELEMENTS keyword, just like the AUTO mode. The FOR XML clause is invalid in views, inline functions, derived tables, and subqueries when they contain a set operation. But you want to get the list of the names by performing a UNION ALL operation between multiple SELECT statements with scalar values. To circumvent the limitation, use a derived table. Here’s sample code to invoke the stored procedure:
DECLARE @inplist AS XML;
SET @inplist=
(SELECT * FROM
(SELECT N'Gianluca' AS NameNeeded
UNION ALL
SELECT N'Mike') AS D
FOR XML RAW('Names'), ELEMENTS);
EXEC dbo.GetContacts @inplist;As mentioned earlier, the XML data type is a LOB. The amount of data stored in a column of this type can be very large. It would not be very practical to replace the complete value when all you need is just to change a small portion of it–for example, a scalar value of some subelement. SQL Server provides you with a .modify method, similar in concept to the .WRITE method for VARCHAR(MAX) and the other MAX types.
Note
You might have noticed that I’m strictly using lowercase for XML data type methods. That’s because they are case sensitive, just like everything in XML.
The W3C standard doesn’t support data modification with XQuery. However, SQL Server 2005 provides its own language extensions to support data modification with XQuery. XQuery supports the following keywords for data modification:
insert
delete
replace value of
As the last XML example, here’s an UPDATE statement that invokes the .modify method and demonstrates all three types of modification:
-- insert a subelement
UPDATE dbo.Contacts
SET otherattributes.modify('
declare namespace D="Domestic";
insert <D:Hobbie>Cigar</D:Hobbie>
into /D:Domestic[1]')
WHERE contactid = 1;
-- Delete 2nd language for Kalen
UPDATE dbo.Contacts
SET otherattributes.modify('
declare namespace D="Domestic";
delete /D:Domestic/D:ForeignLanguage[2]')
WHERE contactid = 5;
-- change the value of an element
UPDATE dbo.Contacts
SET otherattributes.modify('
declare namespace D="Domestic";
replace value of
/D:Domestic[1]/D:ForeignLanguage[1]/text()[1]
with "Russian" ')
WHERE contactid = 3;
-- Show Table Content after Modifications
SELECT * FROM dbo.Contacts;To clean up, drop the XMLtest database:
USE master; DROP DATABASE XMLtest;
This concludes the introduction of XML support in SQL Server 2005. Sure, there’s a lot more that can be said; but I hope this chapter gave you sufficient tools to decide when it is appropriate to use XML and when it isn’t, plus a taste of this distinctive world through the examples I provided.