
Now that the fundamentals of dynamic SQL, EXEC, and sp_executesql have been covered, this section will demonstrate several ways to apply dynamic SQL.
One of the main uses of dynamic SQL is to construct code dynamically for automated maintenance activities such as performing index defragmentation, backups, and the like. You need to query metadata and environmental information and use it to construct the code.
Caution
Be aware that metadata should be carefully checked for potential SQL Injection attempts (for example, through maliciously named objects).
A classic scenario for automated maintenance code that is constructed dynamically is index defragmentation. You inspect fragmentation information using either DBCC SHOWCONTIG in SQL Server 2000 or sys.dm_db_index_physical_stats in SQL Server 2005. You then rebuild or reorganize indexes with a higher level of fragmentation than a certain threshold that you determine as high enough to justify defragmentation. Example 4-1 has sample code for defragmentation in SQL Server 2005, adapted from Books Online.
Example 4-1. Dealing with fragmentation, adapted from Books Online
-- ensure a USE <databasename> statement has been executed first.
SET NOCOUNT ON;
DECLARE @objectid int;
DECLARE @indexid int;
DECLARE @partitioncount bigint;
DECLARE @schemaname nvarchar(258);
DECLARE @objectname nvarchar(258);
DECLARE @indexname nvarchar(258);
DECLARE @partitionnum bigint;
DECLARE @partitions bigint;
DECLARE @frag float;
DECLARE @command varchar(8000);
-- ensure the temporary table does not exist
IF EXISTS (SELECT name FROM sys.objects WHERE name = 'work_to_do')
DROP TABLE work_to_do;
-- conditionally select from the function, converting object and index IDs
-- to names.
SELECT
object_id AS objectid,
index_id AS indexid,
partition_number AS partitionnum,
avg_fragmentation_in_percent AS frag
INTO work_to_do
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL , NULL, 'LIMITED')
WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0;
-- Declare the cursor for the list of partitions to be processed.
DECLARE partitions CURSOR FOR SELECT * FROM work_to_do;
-- Open the cursor.
OPEN partitions;
-- Loop through the partitions.
FETCH NEXT
FROM partitions
INTO @objectid, @indexid, @partitionnum, @frag;
WHILE @@FETCH_STATUS = 0
BEGIN;
SELECT @objectname = QUOTENAME(o.name),
@schemaname = QUOTENAME(s.name)
FROM sys.objects AS o
JOIN sys.schemas as s ON s.schema_id = o.schema_id
WHERE o.object_id = @objectid;
SELECT @indexname = QUOTENAME(name)
FROM sys.indexes
WHERE object_id = @objectid AND index_id = @indexid;
SELECT @partitioncount = count (*)
FROM sys.partitions
WHERE object_id = @objectid AND index_id = @indexid;
-- 30 is an arbitrary decision point at which to switch
-- between reorganizing and rebuilding
IF @frag < 30.0
BEGIN;
SELECT @command = 'ALTER INDEX ' + @indexname + ' ON '
+ @schemaname + '.' + @objectname + ' REORGANIZE';
IF @partitioncount > 1
SELECT @command = @command + ' PARTITION='
+ CONVERT (CHAR, @partitionnum);
EXEC (@command);
END;
IF @frag >= 30.0
BEGIN;
SELECT @command = 'ALTER INDEX ' + @indexname +' ON ' + @schemaname
+ '.' + @objectname + ' REBUILD';
IF @partitioncount > 1
SELECT @command = @command + ' PARTITION='
+ CONVERT (CHAR, @partitionnum);
EXEC (@command);
END;
PRINT 'Executed ' + @command;
FETCH NEXT FROM partitions INTO @objectid, @indexid, @partitionnum, @frag;
END;
-- Close and deallocate the cursor.
CLOSE partitions;
DEALLOCATE partitions;
-- drop the temporary table
IF EXISTS (SELECT name FROM sys.objects WHERE name = 'work_to_do')
DROP TABLE work_to_do;
GONote
This code uses EXEC and not sp_executesql. Remember that sp_executesql is mainly beneficial for better reuse of execution plans. Because the maintenance activities invoked dynamically here don’t involve querying, plan reuse is not really an issue.
This code defragments indexes in the current database that have a fragmentation level (expressed in code as avg_fragmentation_in_percent) greater than 10 percent. If the fragmentation level is greater than 10 percent and less than 30 percent, this code constructs and invokes an index reorganize operation. If the fragmentation level is greater than or equal to 30 percent, it invokes a full index rebuild operation. These are arbitrary numbers that were chosen for demonstration purposes. You should use your own thresholds based on the performance of the queries and the maintenance window that you have available.
The support that sp_executesql has for output parameters allows you to create very interesting applications. For example, a customer of mine who develops software for salary calculations once asked me to evaluate T-SQL expression strings dynamically. The company had a table that contained several inputs for a calculation in several columns, and they had a T-SQL expression that referred to those inputs in another column. Each row represented the salary computation of a particular employee, and the row could contain a salary computation that was different from other rows based on the employee’s contract.
To provide for this need, you can create a trigger on the table for INSERT and UPDATE statements. The trigger will read the input arguments and the computation from the inserted view for each row, run sp_executesql to return the result of the computation through an output parameter to a local variable defined in the trigger, and use an UPDATE statement to store the result in a result column in the table. Taking this approach would make the table resemble a Microsoft Office Excel spreadsheet.
Here I’ll represent the problem in more generic terms. To demonstrate the technique, first run the code in Example 4-2 to create the Computations table.
Example 4-2. Creating the Computations table
USE tempdb;
GO
IF OBJECT_ID('dbo.Computations') IS NOT NULL
DROP TABLE dbo.Computations;
GO
CREATE TABLE dbo.Computations
(
keycol INT NOT NULL IDENTITY PRIMARY KEY,
arg1 INT NULL,
arg2 INT NULL,
arg3 INT NULL,
computation VARCHAR(4000) NOT NULL,
result INT NULL,
CONSTRAINT CHK_Computations_SQL_Injection
CHECK (REPLACE(computation,'@arg','') NOT LIKE '%[^0-9.+/* -]%')
);The columns arg1, arg2, and arg3 will hold the input arguments for the computation. The computation column will hold T-SQL expressions that refer to the inputs using an @ symbol in front of each argument (for example, @arg1 would stand for the value in arg1). Examples of expressions are as follows: ′@arg1 + @arg2 + @arg3′, ′@arg1 * @arg2 – @arg3′, ′ 2. * @arg2 / @arg1′, or any other valid T-SQL expression that yields a scalar value as a result. A CHECK constraint is defined on the computation column to protect against SQL Injection attempts. The constraint allows only arguments (@arg), digits, dots and basic arithmetic operations; you may want to revise the constraint based on your needs, but bear in mind that the more you "relax" the constraint, the greater is the risk that SQL Injection attempts will succeed. The trigger should evaluate the expression from each modified row and store the result value in the result column.
Run the code in Example 4-3 to create the trg_Computations_iu_calc_result trigger.
Example 4-3. Trigger that calculates the result of the computations
CREATE TRIGGER trg_Computations_iu_calc_result
ON dbo.Computations FOR INSERT, UPDATE
AS
DECLARE @rc AS INT;
SET @rc = @@rowcount;
-- If no rows affected, return
IF @rc = 0 RETURN;
-- If none of the columns: arg1, arg2, arg3, computation
-- were updated, return
IF COLUMNS_UPDATED() & 30 /* 00011110 binary */ = 0 RETURN;
-- Not allowed to update result
IF EXISTS(SELECT * FROM inserted)
AND EXISTS(SELECT * FROM deleted)
AND UPDATE(result)
BEGIN
RAISERROR('Not allowed to update result.', 16, 1);
ROLLBACK;
RETURN;
END
DECLARE
@key AS INT, -- keycol
@in_arg1 AS INT, -- arg1
@in_arg2 AS INT, -- arg2
@in_arg3 AS INT, -- arg3
@out_result AS INT, -- result of computation
@comp AS NVARCHAR(4000), -- computation
@params AS NVARCHAR(100); -- parameter's list for sp_executesql
-- If only one row was inserted, don't use a cursor
IF @rc = 1
BEGIN
-- Grab values from inserted
SELECT @key = keycol, @in_arg1 = arg1, @in_arg2 = arg2,
@in_arg3 = arg3, @comp = N'SET @result = ' + computation
FROM inserted;
-- Generate a string with the in/out parameters
SET @params = N'@result INT output, @arg1 INT, @arg2 INT, @arg3 INT';
-- Calculate computation and store the result in @out_result
EXEC sp_executesql
@comp,
@params,
@result = @out_result output,
@arg1 = @in_arg1,
@arg2 = @in_arg2,
@arg3 = @in_arg3;
-- Update the result column in the row with the current key
UPDATE dbo.Computations
SET result = @out_result
WHERE keycol = @key;
END
-- If only multiple rows were inserted, use a cursor
ELSE
BEGIN
-- Loop through all keys in inserted
DECLARE CInserted CURSOR FAST_FORWARD FOR
SELECT keycol, arg1, arg2, arg3, N'SET @result = ' + computation
FROM inserted;
OPEN CInserted;
-- Get first row from inserted
FETCH NEXT FROM CInserted
INTO @key, @in_arg1, @in_arg2, @in_arg3, @comp ;
WHILE @@fetch_status = 0
BEGIN
-- Generate a string with the in/out parameters
SET @params = N'@result INT output, @arg1 INT, @arg2 INT, @arg3 INT';
-- Calculate computation and store the result in @out_result
EXEC sp_executesql
@comp,
@params,
@result = @out_result output,
@arg1 = @in_arg1,
@arg2 = @in_arg2,
@arg3 = @in_arg3;
-- Update the result column in the row with the current key
UPDATE dbo.Computations
SET result = @out_result
WHERE keycol = @key;
-- Get next row from inserted
FETCH NEXT FROM CInserted
INTO @key, @in_arg1, @in_arg2, @in_arg3, @comp;
END
CLOSE CInserted;
DEALLOCATE CInserted;
END
GOThe trigger first evaluates the number of rows that were affected by the firing statement (INSERT or UPDATE). If zero rows were modified, the trigger simply terminates. It has nothing to do in such a case. The trigger then checks whether one of the four relevant columns (arg1, arg2, arg3, computation) was modified using the COLUMNS_UPDATED() function. I will describe this function in more detail in Chapter 8. This function returns a bitmap with a representative bit for each column. For an UPDATE statement, the bit is turned on if the corresponding column was specified in the SET clause, and it’s turned off if the corresponding column wasn’t specified in the SET clause. For an INSERT statement, all column bits are turned on. If none of the relevant columns were modified, the trigger simply terminates. It has no reason to reevaluate the computation if neither the inputs nor the computation changed. If the statement that fired the trigger was an UPDATE statement, and the column result was modified, the trigger generates an error message and rolls back the update.
The trigger defines local variables to host the input arguments, the computation, and the result value. Each row must be handled separately, so a cursor is needed if there is more than one row.
For each modified row, the trigger reads the inputs and the computation into its local variables. Notice that the trigger adds a prefix to the computation: N′SET @result = ′ + computation. This is a very important trick that allows you to return the result of the computation back to the trigger’s local variable (@out_result) through an output parameter (@result). After reading the inputs and the computation from the current row into the trigger’s local variables, the code invokes sp_executesql to evaluate the expression and store it in @out_result through the output parameter @result:
EXEC sp_executesql @comp, @params, @result = @out_result output, @arg1 = @in_arg1, @arg2 = @in_arg2, @arg3 = @in_arg3;
Now that the result is stored in the @result variable, the trigger updates the corresponding row in the Computations table with the result value.
To test the trigger, issue the following INSERT statements and query the Computations table:
INSERT INTO dbo.Computations(arg1, arg2, arg3, computation) VALUES(1, 2, 3, '@arg1 + @arg2 + @arg3'), INSERT INTO dbo.Computations(arg1, arg2, arg3, computation) VALUES(4, 5, 6, '@arg1 * @arg2 - @arg3'), INSERT INTO dbo.Computations(arg1, arg2, computation) VALUES(7, 8, '2. * @arg2 / @arg1'), SELECT * FROM dbo.Computations;
You get the output shown in Table 4-5.
Table 4-5. Contents of Computations Table After Inserts
keycol | arg1 | arg2 | arg3 | computation | result |
|---|---|---|---|---|---|
1 | 1 | 2 | 3 |
| 6 |
2 | 4 | 5 | 6 |
| 14 |
3 | 7 | 8 | NULL |
| 2 |
Next issue an UPDATE statement that changes the arg1 values in all rows, and then query the table again:
UPDATE dbo.Computations SET arg1 = arg1 * 2; SELECT * FROM dbo.Computations;
You can see the contents of Computations after the update in Table 4-6, and observe that the change is reflected correctly in the result column.
Table 4-6. Contents of Computations Table After Inserts
keycol | arg1 | arg2 | arg3 | computation | result |
|---|---|---|---|---|---|
1 | 2 | 2 | 3 |
| 7 |
2 | 8 | 5 | 6 |
| 34 |
3 | 14 | 8 | NULL |
| 1 |
Bear in mind that dynamic SQL is used to run code that is constructed, among other things, from the computation column values. I added a CHECK constraint to guard against common strings used in SQL Injection; but as I mentioned earlier, it’s almost impossible to guarantee that all cases are covered. There are alternatives to this solution that do not use dynamic SQL. For strings with limited complexity, this can be done in a UDF as shown at http://www.users.drew.edu/skass/sql/infix.sql.txt. A CLR function could also be used to evaluate the expression. If the expression result is given by a UDF, then this example can be much less complex, because the result can be defined as a persisted computed column, and no trigger will be required. It will also not be a security risk from dynamic SQL. Allowing complete flexibility to include SQL expressions in the calculation string is a priority that competes with security, because validation that a string represents only an expression can be done with a T-SQL parser.
Another important use of dynamic SQL is supporting applications that allow users to choose dynamic filters and sorting, which is very typical of many Web applications. For example, paging applications typically need to support dynamic filtering and sorting requests. You can achieve this by using dynamic SQL, but of course you should consider seriously the risk of SQL Injection in your solutions.
Note that static query solutions are available for dynamic filtering and sorting; however, these typically produce very inefficient plans that result in slow-running queries. By using dynamic SQL wisely, you can get efficient plans, and if you define the inputs as parameters, you can even get efficient reuse of execution plans.
In my examples, for simplicity’s sake I’ll demonstrate dynamic filters based on equality operators. Of course, you can apply more complex filtering logic with other operators, and you can also accomplish dynamic sorting in a similar manner by constructing the ORDER BY clause dynamically.
Suppose that you’re given a task to write a stored procedure that returns orders from the Orders table, providing optional filters on various order attributes. You create and populate the Orders table by running the code in Example 4-4.
Example 4-4. Script that creates and populates the Orders table
SET NOCOUNT ON;
USE tempdb;
GO
IF OBJECT_ID('dbo.usp_GetOrders') IS NOT NULL
DROP PROC dbo.usp_GetOrders;
IF OBJECT_ID('dbo.Orders') IS NOT NULL
DROP TABLE dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
OrderID INT NOT NULL,
CustomerID NCHAR(5) NOT NULL,
EmployeeID INT NOT NULL,
OrderDate DATETIME NOT NULL,
filler CHAR(2000) NOT NULL DEFAULT('A')
)
INSERT INTO dbo.Orders(OrderID, CustomerID, EmployeeID, OrderDate)
SELECT OrderID, CustomerID, EmployeeID, OrderDate
FROM Northwind.dbo.Orders;
CREATE CLUSTERED INDEX idx_OrderDate ON dbo.Orders(OrderDate);
CREATE UNIQUE INDEX idx_OrderID ON dbo.Orders(OrderID);
CREATE INDEX idx_CustomerID ON dbo.Orders(CustomerID);
CREATE INDEX idx_EmployeeID ON dbo.Orders(EmployeeID);Write a stored procedure that queries and filters orders based on user inputs. The stored procedure should have a parameter for each of the order attributes: OrderID, CustomerID, EmployeeID, and OrderDate. All parameters should have a default value NULL. If a parameter was assigned with a value, your stored procedure should filter the rows in which the corresponding column is equal to the parameter’s value; otherwise (parameter is NULL), the parameter should simply be ignored. Note that all four columns in the Orders table were defined as NOT NULL, so you can rely on this fact in your solutions. Here’s one common solution that uses static code:
CREATE PROC dbo.usp_GetOrders @OrderID AS INT = NULL, @CustomerID AS NCHAR(5) = NULL, @EmployeeID AS INT = NULL, @OrderDate AS DATETIME = NULL WITH RECOMPILE AS SELECT OrderID, CustomerID, EmployeeID, OrderDate, filler FROM dbo.Orders WHERE (OrderID = @OrderID OR @OrderID IS NULL) AND (CustomerID = @CustomerID OR @CustomerID IS NULL) AND (EmployeeID = @EmployeeID OR @EmployeeID IS NULL) AND (OrderDate = @OrderDate OR @OrderDate IS NULL); GO
I created the stored procedure with the RECOMPILE option to generate a new execution plan whenever the code is run. Without the RECOMPILE option, regardless of the inputs, the stored procedure would reuse the cached execution plan generated for the first invocation, which is not a good idea in this case.
The main trick here is to use the following expression for each input:
(<col> = <@parameter> OR <@parameter> IS NULL)
If a value is specified for <@parameter>, then <@parameter> IS NULL is false, and the expression is equivalent to <col> = <@parameter> alone. If a value is not specified for <@parameter>, it will be NULL, and <@parameter> IS NULL will be true, making the whole expression true.
The problem with this implementation is that it produces inefficient plans. The optimizer doesn’t have the capability to create different branches of a plan, where each branch represents a completely different course of action based on whether a parameter contains a known value or a NULL. Remember that the stored procedure was created with the RECOMPILE option, meaning that for each invocation of the stored procedure the optimizer generated a plan that it perceived as adequate for the given inputs. Still, the plans that the optimizer generated were inefficient. Run the following code, which invokes the stored procedure with different arguments:
EXEC dbo.usp_GetOrders @OrderID = 10248; EXEC dbo.usp_GetOrders @OrderDate = '19970101'; EXEC dbo.usp_GetOrders @CustomerID = N'CENTC'; EXEC dbo.usp_GetOrders @EmployeeID = 5;
Of course, you can specify more than one argument. The optimizer generates the plans shown in Figure 4-1 for the above invocations of the procedure.
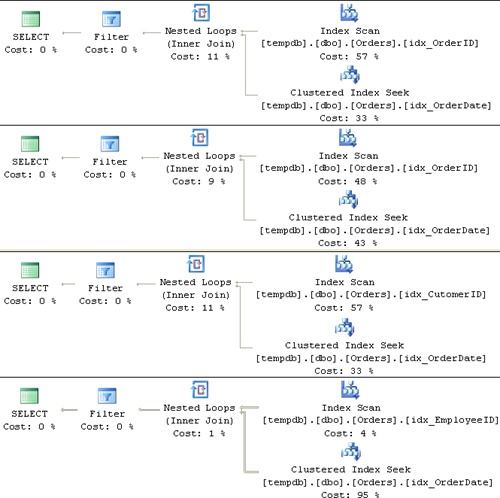
For the first invocation of the stored procedure where the OrderID column is being filtered, you would expect the plan to show an Index Seek operation in the index idx_OrderID, followed by a lookup. For the second invocation of the stored procedure where the OrderDate column is being filtered, you would expect to see an Index Seek operation within the index idx_OrderDate. But that’s not what you get; rather, all plans follow similar logic. First, instead of performing an efficient seek operation within the index created on the column that is being filtered, the plans perform a full scan of the leaf level of an index that contains the filtered value specified. It then performs seek operations to look up the qualifying rows within the clustered index. Finally, the plan filters the rows based on the rest of the filters. If you run this code against a much larger test table, you’ll see a high I/O cost due to the index scans.
Here’s another common implementation of dynamic filters using static code:
ALTER PROC dbo.usp_GetOrders @OrderID AS INT = NULL, @CustomerID AS NCHAR(5) = NULL, @EmployeeID AS INT = NULL, @OrderDate AS DATETIME = NULL WITH RECOMPILE AS SELECT OrderID, CustomerID, EmployeeID, OrderDate, filler FROM dbo.Orders WHERE OrderID = COALESCE(@OrderID, OrderID) AND CustomerID = COALESCE(@CustomerID, CustomerID) AND EmployeeID = COALESCE(@EmployeeID, EmployeeID) AND OrderDate = COALESCE(@OrderDate, OrderDate); GO
The trick here is to use the following expression for each parameter:
<col> = COALESCE(<@parameter>, <col>)
If a value is specified, COALESCE returns that value. If a value isn’t specified, COALESCE returns <col>, in which case the expression <col> = COALESCE(<@parameter>, <col>) will be true (assuming that the column doesn’t allow NULLs). If you rerun the test code, which invokes the stored procedure four times, you will see that all invocations get the same plan, which is shown in Figure 4-2.
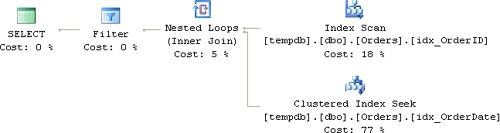
This plan is even worse than the previous one. It follows similar logic as the previous plan, but this time it always: scans the index on OrderID and applies the OrderDate and OrderID filters during that scan, looks up the qualifying rows in the clustered index, and applies the rest of the filters. Again, the index scan operation plus a large number of lookups before further filtering yield a high I/O cost and result in poorly performing code.
By using dynamic SQL, you address two problems. First, you will get efficient plans. Second, the dynamic batch will be able to reuse execution plans when given the same combination of arguments. Example 4-5 shows a stored procedure implementation that uses dynamic SQL.
Example 4-5. Stored procedure usp_GetOrders, dynamic code
ALTER PROC dbo.usp_GetOrders
@OrderID AS INT = NULL,
@CustomerID AS NCHAR(5) = NULL,
@EmployeeID AS INT = NULL,
@OrderDate AS DATETIME = NULL
AS
DECLARE @sql AS NVARCHAR(4000);
SET @sql =
N'SELECT OrderID, CustomerID, EmployeeID, OrderDate, filler'
+ N' FROM dbo.Orders'
+ N' WHERE 1 = 1'
+ CASE WHEN @OrderID IS NOT NULL THEN
N' AND OrderID = @oid' ELSE N'' END
+ CASE WHEN @CustomerID IS NOT NULL THEN
N' AND CustomerID = @cid' ELSE N'' END
+ CASE WHEN @EmployeeID IS NOT NULL THEN
N' AND EmployeeID = @eid' ELSE N'' END
+ CASE WHEN @OrderDate IS NOT NULL THEN
N' AND OrderDate = @dt' ELSE N'' END;
EXEC sp_executesql
@sql,
N'@oid AS INT, @cid AS NCHAR(5), @eid AS INT, @dt AS DATETIME',
@oid = @OrderID,
@cid = @CustomerID,
@eid = @EmployeeID,
@dt = @OrderDate;
GOYou can see that an expression involving a filter on a certain column is concatenated only if a value was specified in the corresponding parameter. The expression 1=1 prevents you from needing to determine dynamically whether to specify a WHERE clause at all when no input is specified. This expression has no effect on performance because the optimizer realizes that it always evaluates to TRUE, and therefore, it’s neutral. Notice that the procedure was not created with the RECOMPILE option. There’s no need for it here because the dynamic batch will naturally reuse a plan when given the same list of arguments. It does this because the query string that will be constructed is the same. You can easily observe the efficient plan reuse here by querying sys.syscacheobjects.
Run the test code, which invokes the stored procedure four times, and observe the desired efficient plans shown in Figure 4-3.
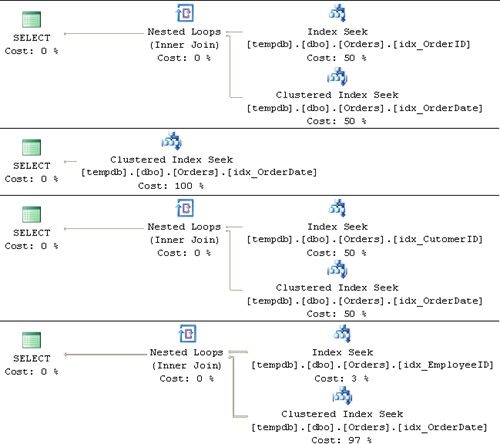
Each plan is different and is optimal for the given inputs. And, as I mentioned earlier, multiple invocations with the same argument list will efficiently reuse previously cached parameterized execution plans.
Tip
Another solution to dynamic filters is to generate multiple stored procedures that invoke static code—one for each possible set of filtered columns. This solution is actually ideal in that it has no security risks, produces efficient plans, and reuses execution plans. In fact, you can use dynamic SQL to generate the different static stored procedures. The number of procedures you need to generate for n parameters is 2n. This solution is realistic when you have a small number of parameters. For example, with four parameters you must create 16 procedures. However, with a large number of parameters, you’ll end up with an unwieldy number of stored procedures.
Pivot queries rotate data from a state of rows to columns, and unpivot queries rotate data from a state of columns to rows. I covered pivoting and unpivoting techniques in Inside T-SQL Querying. In both SQL Server 2000 and 2005, static pivot and unpivot queries could not handle an unknown number of elements that must be rotated. I’ll show you how to deal with an unknown number of elements by using dynamic SQL. In my examples, I’ll use a table called Orders. Run the code in Example 4-6 to create the Orders table and populate it with sample data.
Example 4-6. Creating and populating the Orders table
USE tempdb;
GO
IF OBJECT_ID('dbo.Orders') IS NOT NULL
DROP TABLE dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid int NOT NULL PRIMARY KEY NONCLUSTERED,
orderdate datetime NOT NULL,
empid int NOT NULL,
custid varchar(5) NOT NULL,
qty int NOT NULL
);
CREATE UNIQUE CLUSTERED INDEX idx_orderdate_orderid
ON dbo.Orders(orderdate, orderid);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(30001, '20020802', 3, 'A', 10);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(10001, '20021224', 1, 'A', 12);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(10005, '20021224', 1, 'B', 20);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(40001, '20030109', 4, 'A', 40);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(10006, '20030118', 1, 'C', 14);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(20001, '20030212', 2, 'B', 12);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(40005, '20040212', 4, 'A', 10);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(20002, '20040216', 2, 'C', 20);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(30003, '20040418', 3, 'B', 15);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(30004, '20020418', 3, 'C', 22);
INSERT INTO dbo.Orders(orderid, orderdate, empid, custid, qty)
VALUES(30007, '20020907', 3, 'D', 30);
GOThe following static PIVOT query returns yearly total order quantities per customer, returning a row for each customer and a column for each year, and it generates the output shown in Table 4-7:
SELECT custid,
SUM(CASE WHEN orderyear = 2002 THEN qty END) AS [2002],
SUM(CASE WHEN orderyear = 2003 THEN qty END) AS [2003],
SUM(CASE WHEN orderyear = 2004 THEN qty END) AS [2004]
FROM (SELECT custid, YEAR(orderdate) AS orderyear, qty
FROM dbo.Orders) AS D
GROUP BY custid;The preceding solution is SQL Server 2000 compatible. When using a static query, you have to know in advance which items you want to rotate. Example 4-7 shows the dynamic solution that rotates all years that exist in the Orders table without knowing them in advance.
Example 4-7. Dynamic pivot, pre-2005
DECLARE @T AS TABLE(y INT NOT NULL PRIMARY KEY);
DECLARE
@cols AS NVARCHAR(MAX),
@y AS INT,
@sql AS NVARCHAR(MAX);
-- Populate @T with distinct list of years (result columns)
INSERT INTO @T SELECT DISTINCT YEAR(orderdate) FROM dbo.Orders;
-- Construct the expression list for the SELECT clause
SET @y = (SELECT MIN(y) FROM @T);
SET @cols = N' ';
WHILE @y IS NOT NULL
BEGIN
SET @cols = @cols
+ N',' + NCHAR(13) + NCHAR(10)
+ N' SUM(CASE WHEN orderyear = '
+ CAST(@y AS NVARCHAR(4))
+ N' THEN qty END) AS ' + QUOTENAME(@y);
SET @y = (SELECT MIN(y) FROM @T WHERE y > @y);
END
SET @cols = SUBSTRING(@cols, 2, LEN(@cols));
-- Check @cols for possible SQL Injection attempt
-- Use when example is extended to concatenating strings
-- (not required in this particular example
-- since concatenated elements are integers)
IF UPPER(@cols) LIKE UPPER(N'%0x%')
OR UPPER(@cols) LIKE UPPER(N'%;%')
OR UPPER(@cols) LIKE UPPER(N'%''%')
OR UPPER(@cols) LIKE UPPER(N'%--%')
OR UPPER(@cols) LIKE UPPER(N'%/*%*/%')
OR UPPER(@cols) LIKE UPPER(N'%EXEC%')
OR UPPER(@cols) LIKE UPPER(N'%xp_%')
OR UPPER(@cols) LIKE UPPER(N'%sp_%')
OR UPPER(@cols) LIKE UPPER(N'%SELECT%')
OR UPPER(@cols) LIKE UPPER(N'%INSERT%')
OR UPPER(@cols) LIKE UPPER(N'%UPDATE%')
OR UPPER(@cols) LIKE UPPER(N'%DELETE%')
OR UPPER(@cols) LIKE UPPER(N'%TRUNCATE%')
OR UPPER(@cols) LIKE UPPER(N'%CREATE%')
OR UPPER(@cols) LIKE UPPER(N'%ALTER%')
OR UPPER(@cols) LIKE UPPER(N'%DROP%')
-- look for other possible strings used in SQL Injection here
BEGIN
RAISERROR('Possible SQL Injection attempt.', 16, 1);
RETURN;
END
-- Construct the full T-SQL statement
-- and execute dynamically
SET @sql = N'SELECT custid' + @cols + N'
FROM (SELECT custid, YEAR(orderdate) AS orderyear, qty
FROM dbo.Orders) AS D
GROUP BY custid;';
EXEC sp_executesql @sql;The trick here is to construct the series of CASE expressions in the SELECT list dynamically based on a loop against the table variable (@T) to which you loaded the distinct list of years.
Caution
Note that whenever constructing code from user input—be it direct user input, or data from a table (like in our case)—such code is susceptible to SQL Injection attacks. In our example, we’re constructing code from integer values (years), so the risk is lower; but bear in mind that when you extend this technique to concatenate character strings, the risk is great. I added validation of the string generated in @cols assuming that you might extend the example to character strings. Still, remember that sophisticated hackers will always find ways to circumvent your validations, so never assume that your code is completely safe.
As for SQL Server 2005, following is the static query version of the solution using the native PIVOT operator:
SELECT *
FROM (SELECT custid, YEAR(orderdate) AS orderyear, qty
FROM dbo.Orders) AS D
PIVOT(SUM(qty) FOR orderyear IN([2002],[2003],[2004])) AS P;To support an unknown list of years, you must construct the list of columns served as input to the IN clause dynamically, as shown in Example 4-8.
Example 4-8. Dynamic PIVOT, 2005
DECLARE @T AS TABLE(y INT NOT NULL PRIMARY KEY);
DECLARE
@cols AS NVARCHAR(MAX),
@y AS INT,
@sql AS NVARCHAR(MAX);
-- Construct the column list for the IN clause
-- e.g., [2002],[2003],[2004]
SET @cols = STUFF(
(SELECT N',' + QUOTENAME(y) AS [text()]
FROM (SELECT DISTINCT YEAR(orderdate) AS y FROM dbo.Orders) AS Y
ORDER BY y
FOR XML PATH('')),
1, 1, N''),
-- Check @cols for possible SQL Injection attempt
-- Use when example is extended to concatenating strings
-- (not required in this particular example
-- since concatenated elements are integers)
IF UPPER(@cols) LIKE UPPER(N'%0x%')
OR UPPER(@cols) LIKE UPPER(N'%;%')
OR UPPER(@cols) LIKE UPPER(N'%''%')
OR UPPER(@cols) LIKE UPPER(N'%--%')
OR UPPER(@cols) LIKE UPPER(N'%/*%*/%')
OR UPPER(@cols) LIKE UPPER(N'%EXEC%')
OR UPPER(@cols) LIKE UPPER(N'%xp_%')
OR UPPER(@cols) LIKE UPPER(N'%sp_%')
OR UPPER(@cols) LIKE UPPER(N'%SELECT%')
OR UPPER(@cols) LIKE UPPER(N'%INSERT%')
OR UPPER(@cols) LIKE UPPER(N'%UPDATE%')
OR UPPER(@cols) LIKE UPPER(N'%DELETE%')
OR UPPER(@cols) LIKE UPPER(N'%TRUNCATE%')
OR UPPER(@cols) LIKE UPPER(N'%CREATE%')
OR UPPER(@cols) LIKE UPPER(N'%ALTER%')
OR UPPER(@cols) LIKE UPPER(N'%DROP%')
-- look for other possible strings used in SQL Injection here
BEGIN
RAISERROR('Possible SQL Injection attempt.', 16, 1);
RETURN;
END
-- Construct the full T-SQL statement
-- and execute dynamically
SET @sql = N'SELECT *
FROM (SELECT custid, YEAR(orderdate) AS orderyear, qty
FROM dbo.Orders) AS D
PIVOT(SUM(qty) FOR orderyear IN(' + @cols + N')) AS P;';
EXEC sp_executesql @sql;Notice also that I used an improved technique to concatenate strings using the FOR XML PATH option. I described this efficient technique in Chapter 2.
In a similar manner, you can support dynamic unpivoting. To see how the technique works, first run the code in Example 4-9, which creates and populates the PvtCustOrders table with pivoted total yearly quantities per customer.
Example 4-9. Creating and populating the PvtCustOrders table
USE tempdb;
GO
IF OBJECT_ID('dbo.PvtCustOrders') IS NOT NULL
DROP TABLE dbo.PvtCustOrders;
GO
SELECT *
INTO dbo.PvtCustOrders
FROM (SELECT custid, YEAR(orderdate) AS orderyear, qty
FROM dbo.Orders) AS D
PIVOT(SUM(qty) FOR orderyear IN([2002],[2003],[2004])) AS P;I will show a solution in SQL Server 2005 because the concept is similar in both versions. The only significant difference is that you construct different expressions dynamically since SQL Server 2005 now has a native UNPIVOT operator. Here’s the static query that unpivots the rows in such a way that the result will contain a row for each customer and year, and that generates the output shown in Table 4-8:
SELECT custid, orderyear, qty FROM dbo.PvtCustOrders UNPIVOT(qty FOR orderyear IN([2002],[2003],[2004])) AS U;
Table 4-8. Result of UNPIVOT Query
custid | orderyear | qty |
|---|---|---|
A | 2002 | 22 |
A | 2003 | 40 |
A | 2004 | 10 |
B | 2002 | 20 |
B | 2003 | 12 |
B | 2004 | 15 |
C | 2002 | 22 |
C | 2003 | 14 |
C | 2004 | 20 |
D | 2002 | 30 |
To make the solution dynamic, you use code similar to the pivoting code shown in Example 4-10.
Example 4-10. Dynamic UNPIVOT, SQL Server 2005 version
DECLARE @T AS TABLE(y INT NOT NULL PRIMARY KEY);
DECLARE
@cols AS NVARCHAR(MAX),
@sql AS NVARCHAR(MAX);
-- Construct the column list for the IN clause
-- e.g., [2002],[2003],[2004]
SET @cols = STUFF(
(SELECT N','+ QUOTENAME(y) AS [text()]
FROM (SELECT COLUMN_NAME AS y
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = N'dbo'
AND TABLE_NAME = N'PvtCustOrders'
AND COLUMN_NAME NOT IN(N'custid')) AS Y
ORDER BY y
FOR XML PATH('')),
1, 1, N''),
-- Construct the full T-SQL statement
-- and execute dynamically
SET @sql = N'SELECT custid, orderyear, qty
FROM dbo.PvtCustOrders
UNPIVOT(qty FOR orderyear IN(' + @cols + N')) AS U;';
EXEC sp_executesql @sql;Here, instead of querying the attribute list from the data table, you query the column list from the INFORMATION_SCHEMA.COLUMNS view.