
Earlier I mentioned that when you create a stored procedure, SQL Server parses your code and then attempts to resolve it. If resolution was deferred, it will take place at first invocation. Upon first invocation of the stored procedure, if the resolution phase finished successfully, SQL Server analyzes and optimizes the queries within the stored procedure and generates an execution plan. An execution plan holds the instructions to process the query. These instructions include which order to access the tables in; which indexes, access methods, and join algorithms to use; whether to spool interim sets; and so on. SQL Server typically generates multiple permutations of execution plans and will choose the one with the lowest cost out of the ones that it generated.
Note that SQL Server won’t necessarily create all possible permutations of execution plans; if it did, the optimization phase might take too long. SQL Server will limit the optimizer by calculating a threshold for optimization, which is based on the sizes of the tables involved as well as other factors.
Stored procedures can reuse a previously cached execution plan, thereby saving the resources involved in generating a new execution plan. This section will discuss the reuse of execution plans, cases when a plan cannot be reused, and a specific issue relating to plan reuse called the "parameter sniffing problem."
The process of optimization requires mainly CPU resources. SQL Server will, by default, reuse a previously cached plan from an earlier invocation of a stored procedure, without investigating whether it actually is or isn’t a good idea to do so.
To demonstrate plan reuse, first run the following code, which creates the usp_GetOrders stored procedure:
USE Northwind;
GO
IF OBJECT_ID('dbo.usp_GetOrders') IS NOT NULL
DROP PROC dbo.usp_GetOrders;
GO
CREATE PROC dbo.usp_GetOrders
@odate AS DATETIME
AS
SELECT OrderID, CustomerID, EmployeeID, OrderDate
FROM dbo.Orders
WHERE OrderDate >= @odate;
GOThe stored procedure accepts an order date as input (@odate) and returns orders placed on or after the input order date.
Turn on the STATISTICS IO option to get back I/O information for your session’s activity:
SET STATISTICS IO ON;
Run the stored procedure for the first time, providing an input with high selectivity (that is, an input for which a small percentage of rows will be returned); it will generate the output shown in Table 7-5:
EXEC dbo.usp_GetOrders '19980506';
Table 7-5. Output of EXEC dbo.usp_GetOrders ′19980506′
OrderID | CustomerID | EmployeeID | OrderDate |
|---|---|---|---|
11074 | SIMOB | 7 | 1998-05-06 00:00:00.000 |
11075 | RICSU | 8 | 1998-05-06 00:00:00.000 |
11076 | BONAP | 4 | 1998-05-06 00:00:00.000 |
11077 | RATTC | 1 | 1998-05-06 00:00:00.000 |
Examine the execution plan produced for the query, shown in Figure 7-1.
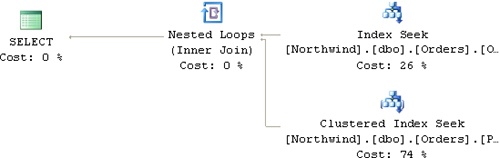
Because this is the first time the stored procedure is invoked, SQL Server generated an execution plan for it based on the selective input value and cached that plan.
The optimizer uses cardinality and density information to estimate the cost of the access methods that it considers applying, and the selectivity of filters is an important factor. For example, a query with a highly selective filter can benefit from a nonclustered, noncovering index, while a low selectivity filter (that is, one that returns a high percentage of rows) would not justify using such an index.
For highly selective input such as that provided to our stored procedure, the optimizer chose a plan that uses a nonclustered noncovering index on the OrderDate column. The plan first performed a seek within that index (Index Seek operator), reaching the first index entry that matches the filter at the leaf level of the index. This seek operation caused two page reads, one at each of the two levels in the index. In a larger table, such an index might contain three or four levels.
Following the seek operation, the plan performed a partial ordered forward scan within the leaf level of the index (which is not seen in the plan but is part of the Index Seek operator). The partial scan fetched all index entries that match the query’s filter (that is, all OrderDate values greater than or equal to the input @odate). Because the input was very selective, only four matching OrderDate values were found. In this particular case, the partial scan did not need to access additional pages at the leaf level beyond the leaf page that the seek operation reached, so it did not incur additional I/O.
The plan used a Nested Loops operator, which invoked a series of Clustered Index Seek operations to look up the data row for each of the four index entries that the partial scan found. Because the clustered index on this small table has two levels, the lookups cost eight page reads: 2 × 4 = 8. In total, there were 10 page reads: 2 (seek) + 2 × 4 (lookups) = 10. This is the value reported by STATISTICS IO as logical reads.
That’s the optimal plan for this selective query with the existing indexes.
Remember that I mentioned earlier that stored procedures will, by default, reuse a previously cached plan? Now that you have a plan stored in cache, additional invocations of the stored procedure will reuse it. That’s fine if you keep invoking the stored procedure with a highly selective input. You will enjoy the fact that the plan is reused, and SQL Server will not waste resources on generating new plans. That’s especially important with systems that invoke stored procedures very frequently.
However, imagine that the stored procedure’s inputs vary considerably in selectivity–some invocations have high selectivity while others have very low selectivity. For example, the following code invokes the stored procedure with an input that has low selectivity:
EXEC dbo.usp_GetOrders '19960101';
Because there is a plan in cache, it will be reused, which is unfortunate in this case. I provided the minimum OrderDate that exists in the table as input. This means that all rows in the table (830) qualify. The plan will require a clustered index lookup for each qualifying row. This invocation generated 1,664 logical reads, even though the whole Orders table resides on 22 data pages. Keep in mind that the Orders table is very small and that in production environments such a table would typically have millions of rows. The cost of reusing such a plan would then be much more dramatic, given a similar scenario. Take a table with 1,000,000 orders, for example, residing on about 25,000 pages. Suppose that the clustered index contains three levels. Just the cost of the lookups would then be 3,000,000 reads: 1,000,000 × 3 = 3,000,000.
Obviously, in a case such as this, in which a lot of data access is involved and there are large variations in selectivity, it’s a very bad idea to reuse a previously cached execution plan.
Similarly, if you invoked the stored procedure for the first time with a low selectivity input, you would get a plan that is optimal for that input–one that issues a table scan (unordered clustered index scan)–and that plan would be cached. Then, in later invocations, the plan would be reused even when the input has high selectivity.
At this point, you can turn off the STATISTICS IO option:
SET STATISTICS IO OFF;
You can observe the fact that an execution plan was reused by querying the sys.syscacheobjects system view (or master.dbo.syscacheobjects in SQL Server 2000), which contains information about execution plans:
SELECT cacheobjtype, objtype, usecounts, sql FROM sys.syscacheobjects WHERE sql NOT LIKE '%cache%' AND sql LIKE '%usp_GetOrders%';
This query generates the output shown in Table 7-6.
Table 7-6. Execution Plan for usp_GetOrders in sys.syscacheobjects
cacheobjtype | objtype | usecounts | sql |
|---|---|---|---|
Compiled Plan | Proc | 2 |
|
Notice that one plan was found for the usp_GetOrders procedure in cache, and that it was used twice (usecounts = 2).
One way to solve the problem is to create two stored procedures–one for requests with high selectivity, and a second for low selectivity. You create another stored procedure with flow logic, examining the input and determining which procedure to invoke based on the input’s selectivity that your calculations estimate. The idea is nice in theory, but it’s very difficult to implement in practice. It can be very complex to calculate the boundary point dynamically without consuming additional resources. Furthermore, this stored procedure accepts only one input, so imagine how complex things would become with multiple inputs.
Another way to solve the problem is to create (or alter) the stored procedure with the RECOMPILE option, as in:
ALTER PROC dbo.usp_GetOrders @odate AS DATETIME WITH RECOMPILE AS SELECT OrderID, CustomerID, EmployeeID, OrderDate FROM dbo.Orders WHERE OrderDate >= @odate; GO
The RECOMPILE option tells SQL Server to create a new execution plan every time it is invoked. It is especially useful when the time it takes to generate a plan is a small portion of the run time of the stored procedure, and the implications of running the procedure with an inadequate plan would increase the run time substantially.
First run the altered procedure specifying an input with high selectivity:
EXEC dbo.usp_GetOrders '19980506';
You will get the plan shown in Figure 7-1, which is optimal in this case and generates an I/O cost of 10 logical reads.
Next run it specifying an input with low selectivity:
EXEC dbo.usp_GetOrders '19960101';
You will get the plan in Figure 7-2, showing a table scan (unordered clustered index scan), which is optimal for this input. The I/O cost in this case is 22 logical reads.

Note that when creating a stored procedure with the RECOMPILE option, SQL Server doesn’t even bother to keep the execution plan for it in cache. If you now query sys.syscacheobjects, you will get no plan back for the usp_GetOrders procedure:
SELECT * FROM sys.syscacheobjects WHERE sql NOT LIKE '%cache%' AND sql LIKE '%usp_GetOrders%';
In SQL Server 2000, the unit of compilation was the whole stored procedure. So even if you wanted just one particular query to be recompiled, you couldn’t request it. If you created the stored procedure with the RECOMPILE option, the whole procedure went through recompilation every time you invoked it.
SQL Server 2005 supports statement-level recompile. Instead of having all queries in the stored procedure recompiled, SQL Server can now recompile individual statements. You’re provided with a new RECOMPILE query hint that allows you to explicitly request a recompilation of a particular query. This way, other queries can benefit from reusing previously cached execution plans if there’s no reason to recompile them every time the stored procedure is invoked.
Run the following code to alter the procedure, specifying the RECOMPILE query hint:
ALTER PROC dbo.usp_GetOrders @odate AS DATETIME AS SELECT OrderID, CustomerID, EmployeeID, OrderDate FROM dbo.Orders WHERE OrderDate >= @odate OPTION(RECOMPILE); GO
In our case, there’s only one query in the stored procedure, so it doesn’t really matter whether you specify the RECOMPILE option at the procedure or the query level. But try to think of the advantages of this hint when you have multiple queries in one stored procedure.
To see that you get good plans, first run the procedure specifying an input with high selectivity:
EXEC dbo.usp_GetOrders '19980506';
You will get the plan in Figure 7-1, and an I/O cost of 10 logical reads.
Next run it specifying an input with low selectivity:
EXEC dbo.usp_GetOrders '19960101';
You will get the plan in Figure 7-2 and an I/O cost of 22 logical reads.
Don’t get confused by the fact that syscacheobjects shows a plan with the value 2 as the usecounts:
SELECT cacheobjtype, objtype, usecounts, sql FROM sys.syscacheobjects WHERE sql NOT LIKE '%cache%' AND sql LIKE '%usp_GetOrders%';
The output is the same as in Table 7-6. Remember that if there were other queries in the stored procedure, they could potentially reuse the execution plan.
As I mentioned earlier, a stored procedure will reuse a previously cached execution plan by default. There are exceptions that would trigger a recompilation. Remember that in SQL Server 2000, a recompilation occurs at the whole procedure level, whereas in SQL Server 2005, it occurs at the statement level.
Such exceptions might be caused by issues related to plan correctness or plan optimality. Plan correctness issues include schema changes in underlying objects (for example, adding/dropping a column, adding/dropping an index, and so on) or changes to SET options that can affect query results (for example, ANSI_NULLS, CONCAT_NULL_YIELDS_NULL, and so on). Plan optimality issues that cause recompilation include making data changes in referenced objects to the extent that a new plan might be more optimal–for example, as a result of a statistics update.
Both types of causes for recompilations have many particular cases. At the end of this section, I will provide you with a resource that describes them in great detail.
Naturally, if a plan is removed from cache after a while for lack of reuse, SQL Server will generate a new one when the procedure is invoked again.
To see an example of a cause of a recompilation, first run the following code, which creates the stored procedure usp_CustCities:
IF OBJECT_ID('dbo.usp_CustCities') IS NOT NULL
DROP PROC dbo.usp_CustCities;
GO
CREATE PROC dbo.usp_CustCities
AS
SELECT CustomerID, Country, Region, City,
Country + '.' + Region + '.' + City AS CRC
FROM dbo.Customers
ORDER BY Country, Region, City;
GOThe stored procedure queries the Customers table, concatenating the three parts of the customer’s geographical location: Country, Region, and City. By default, the SET option CONCAT_NULL_YIELDS_NULL is turned ON, meaning that when you concatenate a NULL with any string, you get a NULL as a result.
Run the stored procedure for the first time, and you will get the output shown in abbreviated form in Table 7-7:
EXEC dbo.usp_CustCities;
Table 7-7. Output of usp_CustCities when CONCAT_NULL_YIELDS_NULL Is ON (Abbreviated)
CustomerID | Country | Region | City | CRC |
|---|---|---|---|---|
CACTU | Argentina | NULL | Buenos Aires | NULL |
OCEAN | Argentina | NULL | Buenos Aires | NULL |
RANCH | Argentina | NULL | Buenos Aires | NULL |
ERNSH | Austria | NULL | Graz | NULL |
PICCO | Austria | NULL | Salzburg | NULL |
MAISD | Belgium | NULL | Bruxelles | NULL |
SUPRD | Belgium | NULL | Charleroi | NULL |
QUEDE | Brazil | RJ | Rio de Janeiro | Brazil.RJ.Rio de Janeiro |
RICAR | Brazil | RJ | Rio de Janeiro | Brazil.RJ.Rio de Janeiro |
HANAR | Brazil | RJ | Rio de Janeiro | Brazil.RJ.Rio de Janeiro |
GOURL | Brazil | SP | Campinas | Brazil.SP.Campinas |
WELLI | Brazil | SP | Resende | Brazil.SP.Resende |
TRADH | Brazil | SP | Sao Paulo | Brazil.SP.Sao Paulo |
FAMIA | Brazil | SP | Sao Paulo | Brazil.SP.Sao Paulo |
COMMI | Brazil | SP | Sao Paulo | Brazil.SP.Sao Paulo |
... | ... | ... | ... | ... |
As you can see, whenever Region was NULL, the concatenated string became NULL. SQL Server cached the execution plan of the stored procedure for later reuse. Along with the plan, SQL Server also stored the state of all SET options that can affect query results. You can observe those in a bitmap called setopts in sys.syscacheobjects.
Set the CONCAT_NULL_YIELDS_NULL option to OFF, telling SQL Server to treat a NULL in concatenation as an empty string:
SET CONCAT_NULL_YIELDS_NULL OFF;
And rerun the stored procedure, which will produce the output shown in abbreviated form in Table 7-8:
EXEC dbo.usp_CustCities;
Table 7-8. Output of usp_CustCities when CONCAT_NULL_YIELDS_NULL Is OFF (Abbreviated)
CustomerID | Country | Region | City | CRC |
|---|---|---|---|---|
CACTU | Argentina | NULL | Buenos Aires | Argentina..Buenos Aires |
OCEAN | Argentina | NULL | Buenos Aires | Argentina..Buenos Aires |
RANCH | Argentina | NULL | Buenos Aires | Argentina..Buenos Aires |
ERNSH | Austria | NULL | Graz | Austria..Graz |
PICCO | Austria | NULL | Salzburg | Austria..Salzburg |
MAISD | Belgium | NULL | Bruxelles | Belgium..Bruxelles |
SUPRD | Belgium | NULL | Charleroi | Belgium..Charleroi |
QUEDE | Brazil | RJ | Rio de Janeiro | Brazil.RJ.Rio de Janeiro |
RICAR | Brazil | RJ | Rio de Janeiro | Brazil.RJ.Rio de Janeiro |
HANAR | Brazil | RJ | Rio de Janeiro | Brazil.RJ.Rio de Janeiro |
GOURL | Brazil | SP | Campinas | Brazil.SP.Campinas |
WELLI | Brazil | SP | Resende | Brazil.SP.Resende |
TRADH | Brazil | SP | Sao Paulo | Brazil.SP.Sao Paulo |
FAMIA | Brazil | SP | Sao Paulo | Brazil.SP.Sao Paulo |
COMMI | Brazil | SP | Sao Paulo | Brazil.SP.Sao Paulo |
... | ... | ... | ... | ... |
You can see that when Region was NULL, it was treated as an empty string, and as a result, you didn’t get a NULL in the CRC column. Changing the session option in this case changed the meaning of a query. When you ran this stored procedure, SQL Server first checked whether there was a cached plan that also has the same state of SET options. SQL Server didn’t find one, so it had to generate a new plan. Note that regardless of whether the change in the SET option does or doesn’t affect the query’s meaning, SQL Server looks for a match in the set options state in order to reuse a plan.
Query sys.syscacheobjects, and you will find two plans for usp_CustCities, with two different setopts bitmaps, as shown in Table 7-9:
SELECT cacheobjtype, objtype, usecounts, setopts, sql FROM sys.syscacheobjects WHERE sql NOT LIKE '%cache%' AND sql LIKE '%usp_CustCities%';
Table 7-9. Execution Plans for usp_CustCities in sys.syscacheobjects
cacheobjtype | objtype | usecounts | setopts | sql |
|---|---|---|---|---|
Compiled Plan | Proc | 1 | 4347 | CREATE PROC dbo.usp_CustCities ... |
Compiled Plan | Proc | 1 | 4339 | CREATE PROC dbo.usp_CustCities ... |
Why should you care? Client interfaces and tools typically change the state of some SET options whenever you make a new connection to the database. Different client interfaces change different sets of options, yielding different execution environments. If you’re using multiple database interfaces and tools to connect to the database and they have different execution environments, they won’t be able to reuse each other’s plans. You can easily identify the SET options that each client tool changes by running a trace while the applications connect to the database. If you see discrepancies in the execution environment, you can code explicit SET commands in all applications, which will be submitted whenever a new connection is made. This way, all applications will have sessions with the same execution environment and be able to reuse one another’s plans.
When you’re done experimenting, turn the CONCAT_NULL_YIELDS_NULL option back ON:
SET CONCAT_NULL_YIELDS_NULL ON;
This is just one case in which an execution plan is not reused. There are many others. At the end of the following section, I’ll provide a resource where you can find more.
As I mentioned earlier, SQL Server will generate a plan for a stored procedure based on the inputs provided to it upon first invocation, for better or worse. "First invocation" also refers to the first invocation after a plan was removed from cache for lack of reuse or for any other reason. The optimizer "knows" what the values of the input parameters are, and it generates an adequate plan for those inputs. However, things are different when you refer to local variables in your queries. And for the sake of our discussion, it doesn’t matter if these are local variables of a plain batch or of a stored procedure. The optimizer cannot "sniff" the content of the variables; therefore, when it optimizes the query, it must make a guess. Obviously, this can lead to poor plans if you’re not aware of the problem and don’t take corrective measures.
To demonstrate the problem, first insert a new order to the Orders table, specifying the GETDATE function for the OrderDate column:
INSERT INTO dbo.Orders(OrderDate, CustomerID, EmployeeID) VALUES(GETDATE(), N'ALFKI', 1);
Alter the usp_GetOrders stored procedure so that it will declare a local variable and use it in the query’s filter:
ALTER PROC dbo.usp_GetOrders @d AS INT = 0 AS DECLARE @odate AS DATETIME; SET @odate = DATEADD(day, -@d, CONVERT(VARCHAR(8), GETDATE(), 112)); SELECT OrderID, CustomerID, EmployeeID, OrderDate FROM dbo.Orders WHERE OrderDate >= @odate; GO
The procedure defines the integer input parameter @d with a default value 0. It declares a datetime local variable called @odate, which is set to today’s date minus @d days. The stored procedure then issues a query returning all orders with an OrderDate greater than or equal to @odate. Invoke the stored procedure using the default value of @d, which will generate the output shown in Table 7-10:
EXEC dbo.usp_GetOrders;
Table 7-10. Output of usp_GetOrders
OrderID | CustomerID | EmployeeID | OrderDate |
|---|---|---|---|
11079 | ALFKI | 1 | 2006-02-12 01:23:53.210 |
Note
The output that you get will have a value in OrderDate that reflects the GETDATE value of when you inserted the new order.
The optimizer didn’t know what the value of @odate was when it optimized the query. So it used a conservative hard-coded value that is 30 percent of the number of rows in the table. For such a low-selectivity estimation, the optimizer naturally chose a table scan, even though the query in practice is highly selective and would be much better off using the index on OrderDate.
You can observe the optimizer’s estimation and chosen plan by requesting an estimated execution plan (not actual). The estimated execution plan you get for this invocation of the stored procedure is shown in Figure 7-3.
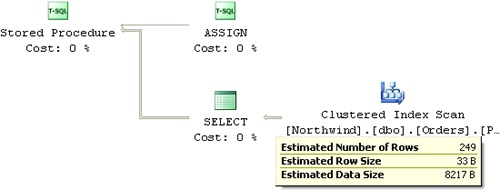
You can see that the optimizer chose a table scan (unordered clustered index scan), due to its selectivity estimation of 30 percent (249 rows / 830 total number of rows).
There are several ways to tackle the problem. One is to use, whenever possible, inline expressions in the query that refer to the input parameter instead of a variable. In our case, it is possible:
ALTER PROC dbo.usp_GetOrders @d AS INT = 0 AS SELECT OrderID, CustomerID, EmployeeID, OrderDate FROM dbo.Orders WHERE OrderDate >= DATEADD(day, -@d, CONVERT(VARCHAR(8), GETDATE(), 112)); GO
Run usp_GetOrders again, and notice the use of the index on OrderDate in the execution plan:
EXEC dbo.usp_GetOrders;
The plan that you will get is similar to the one shown earlier in Figure 7-1. The I/O cost here is just four logical reads.
Another way to deal with the problem is to use a stub procedure. That is, create two procedures. The first procedure accepts the original parameter, assigns the result of the calculation to a local variable, and invokes a second procedure providing it with the variable as input. The second procedure accepts an input order date passed to it and invokes the query that refers directly to the input parameter. When a plan is generated for the procedure that actually invokes the query (the second procedure), the value of the parameter will, in fact, be known at optimization time.
Run the code in Example 7-3 to implement this solution.
Example 7-3. Using a stub procedure
IF OBJECT_ID('dbo.usp_GetOrdersQuery') IS NOT NULL
DROP PROC dbo.usp_GetOrdersQuery;
GO
CREATE PROC dbo.usp_GetOrdersQuery
@odate AS DATETIME
AS
SELECT OrderID, CustomerID, EmployeeID, OrderDate
FROM dbo.Orders
WHERE OrderDate >= @odate;
GO
ALTER PROC dbo.usp_GetOrders
@d AS INT = 0
AS
DECLARE @odate AS DATETIME;
SET @odate = DATEADD(day, -@d, CONVERT(VARCHAR(8), GETDATE(), 112));
EXEC dbo.usp_GetOrdersQuery @odate;
GOInvoke the usp_GetOrders procedure:
EXEC dbo.usp_GetOrders;
You will get an optimal plan for the input similar to the one shown earlier in Figure 7-1, yielding an I/O cost of only four logical reads.
Don’t forget the issues I described in the previous section regarding the reuse of execution plans. The fact that you got an efficient execution plan for this input doesn’t necessarily mean that you would want to reuse it in following invocations. It all depends on whether the inputs are typical or atypical. Make sure you follow the recommendations I gave earlier in case the inputs are atypical.
Finally, there’s a new tool provided to you in SQL Server 2005 to tackle the problem–the OPTIMIZE FOR query hint. This hint allows you to provide SQL Server with a literal that reflects the selectivity of the variable, in case the input is typical. For example, if you know that the variable will typically end up with a highly selective value, as you did in our example, you can provide the literal ′99991231′, which reflects that:
ALTER PROC dbo.usp_GetOrders @d AS INT = 0 AS DECLARE @odate AS DATETIME; SET @odate = DATEADD(day, -@d, CONVERT(VARCHAR(8), GETDATE(), 112)); SELECT OrderID, CustomerID, EmployeeID, OrderDate FROM dbo.Orders WHERE OrderDate >= @odate OPTION(OPTIMIZE FOR(@odate = '99991231')); GO
Run the stored procedure:
EXEC dbo.usp_GetOrders;
You will get an optimal plan for a highly selective OrderDate similar to the one shown earlier in Figure 7-1, yielding an I/O cost of four logical reads.
Note that you might face similar problems when changing the values of input parameters before using them in queries. For example, say you define an input parameter called @odate and assign it with a default value of NULL. Before using the parameter in the query’s filter, you apply the following code:
SET @odate = COALESCE(@odate, '19000101'),
The query then filters orders where OrderDate >= @odate. When the query is optimized, the optimizer is not aware of the fact that @odate has undergone a change, and it optimizes the query with the original input (NULL) in mind. You will face a similar problem to the one I described with variables, and you should tackle it using similar logic.
More Info
For more information on the subject, please refer to the white paper "Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005," by Arun Marathe, which can be accessed at http://www.microsoft.com/technet/prodtechnol/sql/2005/recomp.mspx.
When you’re done, run the following code for cleanup:
DELETE FROM dbo.Orders WHERE OrderID > 11077;
GO
IF OBJECT_ID('dbo.usp_GetOrders') IS NOT NULL
DROP PROC dbo.usp_GetOrders;
GO
IF OBJECT_ID('dbo.usp_CustCities') IS NOT NULL
DROP PROC dbo.usp_CustCities;
GO
IF OBJECT_ID('dbo.usp_GetOrdersQuery') IS NOT NULL
DROP PROC dbo.usp_GetOrdersQuery;
GO