This section describes how implicit conversions work in T-SQL, including the way SQL Server evaluates scalar and filter expressions.
T-SQL expressions have a result datatype, which is determined by the datatype with the highest precedence among the participating operands in the expression. You can find the datatype precedence in Books Online under precedence [SQL Server] / data types / Datatype Precedence (Transact-SQL).
Expression evaluation rules might be a bit confusing in some cases if you’re not aware of this behavior. For example, if you apply an AVG aggregate function to an integer column, the result datatype of the expression will be an integer. So, the average of the integers {2, 3} will be the integer 2 and not 2.5. To force a decimal evaluation, you should either explicitly cast the integer column to a decimal one: AVG(CAST(col1 AS DECIMAL(12, 2))), or implicitly: AVG(1. * col1).
A binary expression involving two operands with different datatypes will first implicitly convert the lower in precedence to the higher before evaluating the result. That’s why in the expression 1. * col1, where col1 is an integer, col1 is implicitly converted to a decimal datatype, and the result datatype of the expression is also decimal. Similarly, the expression 1 + ′1′ evaluates to the integer 2 after implicitly converting the character string ′1′ to an integer, since a character string (VARCHAR) is lower in precedence than an integer (INT).
The same rules apply to CASE expressions. The result datatype of a CASE expression is determined by the highest datatype in precedence among the possible result expressions in the THEN clauses, regardless of which is going to be returned in practice. Take the following CASE expression, for example:
CASE WHEN <logical_expression1> THEN <int_expression> WHEN <logical_expression2> THEN <varchar_expression> WHEN <logical_expression3> THEN <decimal_expression> END
Because the datatype with the highest precedence is DECIMAL, the result datatype of such a CASE expression is predetermined to be DECIMAL. If in practice the second logical expression evaluates to TRUE, SQL Server will attempt to implicitly convert <varchar_expression> to DECIMAL. If the value is not convertible, you will get a conversion error at run time. Try running the following expression and you will get a conversion error:
SELECT
CASE
WHEN 1 > 1 THEN 10
WHEN 1 = 1 THEN 'abc'
WHEN 1 < 1 THEN 10.
END;There are a couple of ways to deal with this problem. One option is to convert all return expressions explicitly to a common type that all can convert to–for example, a VARCHAR. However, such a conversion might cause loss or incorrect functionality–for example, in comparison, sorting, and so on. The other option is to convert all result expressions to SQL_VARIANT, which will be considered a common type, even though all base types will be preserved within it:
SELECT
CASE
WHEN 1 > 1 THEN CAST(10 AS SQL_VARIANT)
WHEN 1 = 1 THEN CAST('abc' AS SQL_VARIANT)
WHEN 1 < 1 THEN CAST(10. AS SQL_VARIANT)
END;To add to the confusion of implicit conversions, SQL_VARIANTs compare differently from regular datatypes. That is, if you compare two expressions with different regular datatypes, the lower in precedence is implicitly converted to the higher. So, the following statement returns ′Bigger′:
-- Comparing regular types IF 12.0 > 10E PRINT 'Bigger' ELSE PRINT 'Smaller';
DECIMAL is considered lower than FLOAT, and is promoted before the comparison. However, with SQL_VARIANTs, if the "datatype family" is higher in the datatype hierarchy, that in itself is sufficient to determine that the value is greater, regardless of whether it really is. So, the following statement returns ′Smaller′ because FLOAT is in the Approximate numeric datatype family, DECIMAL is in the Exact numeric family, and the former is higher in the hierarchy than the latter:
-- Comparing SQL_VARIANTs IF CAST(12.0 AS SQL_VARIANT) > CAST(10E AS SQL_VARIANT) PRINT 'Bigger' ELSE PRINT 'Smaller';
You can find the datatype family hierarchy order in Books Online under sql_variant comparisons.
In the last three versions of SQL Server, handling of implicit conversions in filter expressions changed with each version. Consider the following filter expression pattern: col1 = <scalar_expression>.
When both sides of the expression have the same datatype, the expression is considered a Search Argument (SARG), and the optimizer can consider the potential of using an index on col1, assuming that one exists, based on the selectivity of the query. If you perform manipulation on the base column (f(col1) <operator> <scalar_expression>), it is no longer considered a SARG.
However, there are differences in behavior between the different versions of SQL Server if both sides of the expressions have different datatypes. SQL Server 7.0 always converted the scalar expression’s datatype to the column’s datatype to have a SARG, and allow utilizing an index on col1.
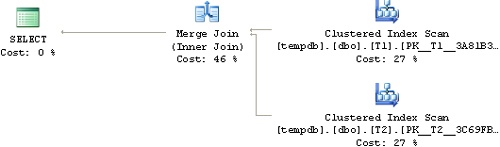
SQL Server 2000 changed the behavior to be more consistent with other implicit conversions. If the scalar expression’s datatype was higher in precedence than the column’s, the column’s datatype was implicitly converted to the scalar expression’s datatype. This could mean that the predicate was not a SARG and that an index could not be utilized, though in some cases the optimizer used Constant Scan and Nested Loops operators to allow using an index. But in a join condition, such as T1.col1 = T2.col2, in which the two sides had different datatypes (even if both were of the same family, such as Exact numerics INT and DECIMAL, and had good indexes), the optimizer could not assume that both indexes apply the same sort of behavior. So, for example, you couldn’t get a Merge Join operator in such a case unless the side with the lower precedence was explicitly sorted with a Sort operator after its datatype was converted.
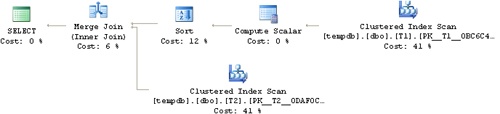
SQL Server 2005 is smarter with filter expressions. It realizes that within the same datatype family, indexes apply the same sorting behavior, so it can rely on indexes. For example, in a filter such as <int_col> = <decimal_expression>, it can utilize an index, and in a join condition such as int_col = decimal_col, it can utilize a Merge Join operator without explicitly sorting the lower side. For example, if you run the following code in both SQL Server 2000 and 2005:
SET NOCOUNT ON; USE tempdb; GO DROP TABLE dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(col1 INT PRIMARY KEY); CREATE TABLE dbo.T2(col1 NUMERIC(12, 2) PRIMARY KEY); INSERT INTO dbo.T1(col1) VALUES(1); INSERT INTO dbo.T1(col1) VALUES(2); INSERT INTO dbo.T1(col1) VALUES(3); INSERT INTO dbo.T2(col1) VALUES(1.); INSERT INTO dbo.T2(col1) VALUES(2.); INSERT INTO dbo.T2(col1) VALUES(3.); SELECT T1.col1, T2.col1 FROM T1 INNER MERGE JOIN T2 ON dbo.T1.col1 = dbo.T2.col1;
You will find that SQL Server 2000 must explicitly sort one of the inputs to get a Merge join, while SQL Server 2005 doesn’t, as you can see in Figure 1-3 and Figure 1-4.
These changes in behavior also apply to constants. Each constant has a datatype, regardless of its context. There are two special cases where the datatype of a constant interpreted by SQL Server might not be what you would expect. These cases are:
<bit_col> = 1 -- or 0 <bigint_col> = <value greater than 2147483647>
Regarding the former, SQL Server treats the value as an INT and not as a BIT. In SQL Server 7.0, the BIT value was converted to an INT because that’s how filters worked. This also meant that if the constant was different than 0, even when not 1, it was always converted to 1.
SQL Server 2000 had more consistent implicit conversions, and because BIT is considered lower than INT, the column was implicitly converted to INT, and the filter was not a SARG. Similarly, a value greater than a 4-byte integer was considered a DECIMAL and not a BIGINT. So, an expression such as the preceding one caused implicit conversion of the BIGINT column and not of the constant. A way around these issues in SQL Server 2000 was to convert the constant explicitly to the column’s datatype, for example, bit_col = CAST(1 AS BIT), bigint_col = CAST(3000000000 AS BIGINT).
In SQL Server 2005, there’s no need for such explicit conversions of the constants because, as I mentioned earlier, it’s smarter in the handling of filter expressions.
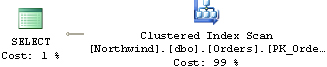
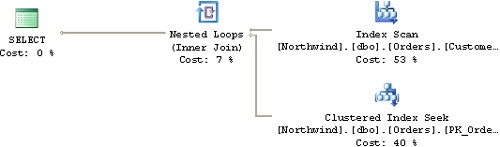
SQL Server 2005 collects string summary statistics to improve cardinality estimations for LIKE predicates with arbitrary wildcards. It collects information about the frequency distribution of substrings for character columns. SQL Server 2000 could produce reasonable selectivity estimates when the LIKE pattern had a constant prefix (col LIKE ′const%′). SQL Server 2005 can now make more accurate selectivity estimations even when the pattern doesn’t have a constant prefix (col LIKE ′%const%′). The optimizer can now make better decisions in terms of when to use an index scan followed by lookups instead of opting for a table scan. As an example, the following query yields a plan with a Table Scan in SQL Server 2000 and an Index Scan followed by Lookups in SQL Server 2005, as shown in Figure 1-5 and Figure 1-6:
USE Northwind; SELECT OrderID, CustomerID, EmployeeID FROM dbo.Orders WHERE CustomerID LIKE N'%Z%';