
Deadlocks occur when two or more processes block each other such that they enter a blocking chain that cannot be resolved without the system’s intervention. With no intervention, processes involved in a deadlock would have to wait indefinitely for one another to relinquish their locks.
SQL Server automatically detects deadlock situations and resolves them by terminating the transaction that did less work. The transaction that was chosen as the deadlock victim will receive error 1205. You can trap such an error with exception-handling code and determine a course of action. Exception handling with deadlock examples is described in the next chapter.
SQL Server gives you a tool to control precedence between sessions in terms of which will be chosen as the deadlock victim. You can set the DEADLOCK_PRIORITY session option to one of the following values: LOW, NORMAL (default), or HIGH. Precedence in terms of choosing the deadlock victim will be based on deadlock priorities, and then by the amount of work.
Some deadlock scenarios are desirable–or more accurately, by design. For example, by using the repeatable read isolation level you prevent lost updates by creating a deadlock instead. Of course, there are other techniques to avoid lost updates–for example, having readers specify the UPDLOCK hint when reading data. But generally speaking, you might expect some deadlocks to occur to have the benefit of providing some consistency. However, I have to say that in my experience, most deadlocks I’ve seen are undesired ones caused by lack of sufficient indexes, unnecessarily long-running transactions, and so on. By understanding the concurrency architecture of the product you might be able to reduce undesired deadlocks, but it’s very hard to avoid them altogether. So you still need to maintain exception-handling code that deals with those–for example, by retrying the transaction.
In the following sections, I’ll provide deadlock examples and suggest ways to troubleshoot and avoid them.
Let’s start with a simple and classic deadlock example. I apologize if you’ve seen such examples a thousand times already. I promise to be more exciting in the following examples. Here I just want to make sure that the basics are covered, so bear with me.
Open two new connections, and call them connections 1 and 2. Issue the following code from connection 1:
SET NOCOUNT ON; USE testdb; GO BEGIN TRAN UPDATE dbo.T1 SET col1 = col1 + 1 WHERE keycol = 2;
The code opened a new transaction and modified a row in T1. To achieve the modification, the transaction obtained an exclusive lock on the row. Because the transaction remains open, it keeps the exclusive lock on the row.
Issue the following code from connection 2, which updates a row in T2 within a transaction and keeps the transaction open, preserving the exclusive lock on the row:
SET NOCOUNT ON; USE testdb; GO BEGIN TRAN UPDATE dbo.T2 SET col1 = col1 + 1 WHERE keycol = 2;
Issue the following code from connection 1, which attempts to read data from T2:
SELECT col1 FROM dbo.T2 WHERE keycol = 2; COMMIT TRAN
The SELECT query is blocked because it attempts to acquire a shared lock on the row in T2 that is locked exclusively by the other transaction. This is a normal blocking situation–it’s not a deadlock yet. Connection 2 might terminate the transaction at some point, releasing the lock on the resource that connection 1 needs.
Next issue the following code from connection 2, attempting to query the data from T1:
SELECT col1 FROM dbo.T1 WHERE keycol = 2; COMMIT TRAN
At this point, the two processes enter a deadlock, because each is waiting for the other to release its locks. SQL Server intervenes, terminating the transaction in connection 2 and producing the following error:
Msg 1205, Level 13, State 51, Line 1 Transaction (Process ID 54) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Don’t you find it a bit ironic that SQL Server uses the terminology "has been chosen" to notify a process of the failure? Sort of reminds me of some spam messages notifying me that I’ve been chosen and won some prize. But I shouldn’t digress.
Connection 1 has now obtained the lock it waited for. It reads the data and commits.
This particular deadlock can be avoided if you swap the order in which you access the tables in one of the transactions, assuming that this swap does not break the application’s logic. If both transactions access the tables in the same order, such a deadlock will not happen. You can make it a practice when developing transactions to access tables in a particular order (say, by table name order), as long as this makes sense to the application and doesn’t break its logic. This way you can reduce the frequency of deadlocks.
Another example for a deadlock demonstrates the most common cause for deadlocks that I’ve stumbled into in production systems–lack of sufficient indexes. Processes might end up being in conflict with each other even when they need mutually exclusive resources. This can happen when you’re lacking indexes on filtered columns. SQL Server has to scan all rows if there’s no index on the filtered columns. Thus a conflict can occur when one process holds a lock on a row, while another scans all rows to check whether they qualify to the filter instead of seeking the desired row directly through an index.
As an example, currently there are no indexes on T1.col1 and T1.col2. Run the following code in connection 1, which opens a transaction, modifies a row in T1 where col1 = 101, and keeps the transaction open, thus preserving an exclusive lock on the row:
BEGIN TRAN UPDATE dbo.T1 SET col2 = col2 + 'A' WHERE col1 = 101;
Similarly, run the following code in connection 2, which opens a transaction, modifies a row in T2 where col1 = 203, and keeps the transaction open, thus preserving an exclusive lock on the row:
BEGIN TRAN UPDATE dbo.T2 SET col2 = col2 + 'B' WHERE col1 = 203;
Now, in connection 1, try to query a row from T2 that is not locked by connection 2:
SELECT col2 FROM dbo.T2 WHERE col1 = 201; COMMIT TRAN
Because there’s no index on col1, SQL Server must scan all rows and acquire shared locks to see whether they qualify to the query’s filter. However, your transaction cannot obtain a shared lock on the row that is exclusively locked by connection 2; thus, it is blocked.
A similar blocking scenario will take place if, from connection 2, you now try to query a row that is not locked from T1:
SELECT col2 FROM dbo.T1 WHERE col1 = 103; COMMIT TRAN
Of course, a deadlock occurs, and one of the processes is "chosen" as the deadlock victim (connection 2 in this case), and you receive the following error:
Msg 1205, Level 13, State 51, Line 1 Transaction (Process ID 54) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
SQL Server gives you several tools to troubleshoot deadlocks. You can start SQL Server’s service with the trace flags 1204 and 1222, causing deadlocks to report information in SQL Server’s error log (for details, please refer to http://msdn2.microsoft.com/en-us/library/ms178104(SQL.90).aspx). Another powerful tool for troubleshooting deadlocks is running traces while the deadlock occurs. If you can reproduce the deadlock by invoking some specific activity from the application, you can run the trace in a controlled manner. Start the trace right before you invoke the specific activity, and stop it right after the deadlock occurs. If you cannot reproduce the deadlock manually or predict when it will take place, you will have to keep the trace running in the background, which of course has a cost.
The trace should include the following events:
SQL:StmtStarting. This event will be recorded for each start event of a statement in a batch. If your statements are issued from stored procedures or triggers, use the SP:StmtStarting event. Make sure you trace a Starting event and not a Completed event because the statement that will be terminated will not complete. On the other hand, a Starting event will be traced even for statements that are terminated.
Lock:Timeout. This event will be produced when a session requests a lock and cannot obtain it. It will help you see which statements were blocked.
Lock:Deadlock Chain. This event will be produced for each process involved in the deadlock chain. It allows you to identify the process IDs of the processes involved in the deadlock and focus on their activities in the trace.
Lock:Deadlock. This event simply indicates when the deadlock took place.
Deadlock Graph. This is a new event in SQL Server 2005, and it generates an XML value with the deadlock information. If you choose this event, you can specify in the trace’s Event Extraction Settings tab that you want to save deadlock XML events separately–you can direct these deadlock graphs to a single file or to distinct files.
As an example, when I traced the deadlock I described in this section I got the trace data shown in Figure 9-1.
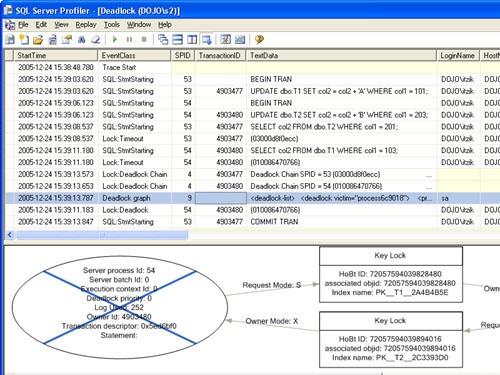
By looking at the TextData attribute of the Lock:Deadlock Chain event, you can easily identify the IDs of the processes and transactions involved in the deadlock and focus on them. Also, the Deadlock Graph event gives you a graphical view of the deadlock. You can follow the series of SQL:StmtStarting events for statements belonging to the processes involved in the deadlock. The Lock:Timeout events allow you to identify which statements were blocked. Analyzing this trace should lead you to the conclusion that, logically, the processes should not be in conflict and that your tables might be missing indexes on the filtered columns. If you examine the indexes on the tables, you can confirm your suspicions. To prevent such deadlocks in the future, create the following indexes:
CREATE INDEX idx_col1 ON dbo.T1(col1); CREATE INDEX idx_col1 ON dbo.T2(col1);
Now retry the series of activities.
Note
With such tiny tables as in our example, SQL Server will typically choose to scan the whole table even when indexes do exist on the filtered columns. Of course, in larger production tables SQL Server will typically use indexes for queries that are selective enough.
When you retry the activities, because our tables are so tiny, specify an index hint to make sure that SQL Server will use the index.
Start by issuing the following code from connection 1 to open a transaction and update a row in T1:
BEGIN TRAN UPDATE dbo.T1 SET col2 = col2 + 'A' WHERE col1 = 101;
Issue the following code from connection 2 to open a transaction, and update a row in T2:
BEGIN TRAN UPDATE dbo.T2 SET col2 = col2 + 'B' WHERE col1 = 203;
Go back to connection 1, and query a row that is not locked by connection 2 from T2 (and, in our case, remember to specify an index hint):
SELECT col2 FROM dbo.T2 WITH (index = idx_col1) WHERE col1 = 201; COMMIT TRAN
The row was obtained through the index created on T2.col1, and there was no conflict. The query ran successfully, and the transaction committed.
Connection 2 can now query the row from T1:
SELECT col2 FROM dbo.T1 WITH (index = idx_col1) WHERE col1 = 103; COMMIT TRAN
The query ran successfully, and the transaction committed.
By creating indexes on the filtered columns, you were able to avoid a deadlock. Of course, a deadlock can still happen if processes will block each other in cases where both attempt to access the same resources. In such cases, if possible, you might want to consider applying the approach I suggested in the previous section–namely, revising the order in which you access the tables in one of the transactions.
Make sure that you don’t drop the index on T1, as it is used in the following section’s example.
Many programmers think that deadlocks can take place only when multiple tables are involved. Keep in mind that a table can have multiple indexes, meaning that multiple resources can still be involved even when multiple processes interact with a single table.
Before I demonstrate such a scenario, let’s first run the following UPDATE statement to make sure that T1.col2 is set to 102 where keycol = 2:
UPDATE dbo.T1 SET col1 = 102, col2 = 'B' WHERE keycol = 2;
To generate a deadlock, first run the following code in connection 1:
SET NOCOUNT ON; USE testdb; GO WHILE 1 = 1 UPDATE dbo.T1 SET col1 = 203 - col1 WHERE keycol = 2;
An endless loop invokes, in each iteration, an UPDATE statement against T1, alternating the value of col1 between 102 and 101 in the row where keycol = 2.
Next issue the following code from connection 2:
SET NOCOUNT ON;
USE testdb;
GO
DECLARE @i AS VARCHAR(10);
WHILE 1 = 1
SET @i = (SELECT col2 FROM dbo.T1 WITH (index = idx_col1)
WHERE col1 = 102);Again, I used an index hint here just because the T1 table is so tiny and SQL Server might decide not to use the index in such a case. This code also invokes an endless loop, where in each iteration, it issues a SELECT statement against T1 that returns the value of col2 where col1 = 102.
After a few seconds, a deadlock should occur, and the transaction in connection 2 will be terminated. And this is to show that a deadlock can in fact take place even though the processes involved interact with a single table. See if you can figure out the cause of the deadlock.
The chain of events that lead to the deadlock is illustrated in Figure 9-2.
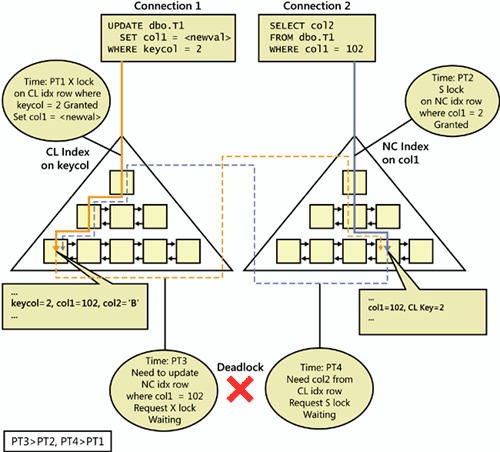
Currently, the table T1 has a clustered index defined on keycol and a nonclustered one defined on col1. With both endless loops running concurrently, there are bound to be occasions where both UPDATE and SELECT statements start running more or less at the same point in time (PT1 = PT2). The UPDATE transaction obtains an exclusive lock in the clustered index on the row where keycol = 2. It modifies the value of col1 from 102 to 103. Then at point in time PT3 (where PT3 > PT2), it attempts to obtain an exclusive lock on the row in the nonclustered index where col1 = 102 in order to modify the column value there as well.
Before the UPDATE transaction manages to obtain the lock on the row in the nonclustered index (attempt at point in time PT3), the SELECT transaction obtained a shared lock on that row (at point in time PT2). The SELECT transaction then (at point in time PT4, where PT4 > PT1) attempts to obtain a shared lock on the clustered index row that is currently locked by the UPDATE transaction. The SELECT transaction needs the row from the clustered index in order to return the col2 value from that row. And you’ve got yourself a deadlock!
Now that you’ve figured out this deadlock, try to think of ways to avoid it. For example, obviously if you drop the nonclustered index from T1, such a deadlock will not occur, but such a solution can hardly be considered reasonable. You’ll end up with slow queries and other types of deadlocks, such as the ones I described in the previous section. A more viable solution would be to create a covering index for the SELECT query that includes col2. Such an index will satisfy the SELECT query without the need to look up the full data row from the clustered index, thus avoiding the deadlock.
When you’re done, run the following code for cleanup:
USE testdb;
GO
IF OBJECT_ID('dbo.T1') IS NOT NULL
DROP TABLE dbo.T1;
IF OBJECT_ID('dbo.T2') IS NOT NULL
DROP TABLE dbo.T2;