
9
Manage Documents with Content Management
In Chapter 4, Content Management and Document Processing, you got an overview of the evolution of ECM and what content services are now. You also got introduced to some key capabilities of FileNet Content Manager, the content services platform for CP4BA.
What are the key considerations and design aspects when creating a content services platform? How agile and scalable is the platform? What if regulations are imposed on how I manage the content services platform? How easily can my platform meet those regulations?
Sure, new content can most likely adhere to the regulations by making the needed changes, but what about the existing content? How can I get more business value and insight from the platform? These are common questions enterprise customers ask about their existing platform. We will be able to answer these questions by explaining the design, implementation, and usage of key functionalities provided by the FileNet Content Manager platform.
In this chapter, we’re going to cover the following main topics, with an emphasis on key design considerations and best practices:
- Problem statement
- Designing your content repositories
- Creating a content desktop
- Searching and accessing content from applications
- Advanced topics: extensions and the retention policy
Problem statement
Nowadays, technologies such as Docker and Kubernetes have made it easy to install and deploy a Content Services platform. That means that anyone can create a content services platform. The problem is if I design a platform to meet my specific needs today, will it meet my enterprise needs tomorrow? Is there a way to design a system that is agile enough to meet most enterprise requirements, including federal and industry regulations?
The answer is both yes and no.
FileNet Content Manager has a flexible and robust architecture but a design decision can impact its ability to meet future requirements. Architects face difficulties when it comes to designing an enterprise system. An open design can be flexible but its openness can limit its ability to meet specific regulatory requirements such as the Health Insurance Portability Act (HIPAA), Securities and Exchange Commission rule SEC-17a-4, or even basic data privacy requirements. The reverse is also not the best idea.
A rigid system that is designed to meet very specific requirements or regulations can make it hard or impossible to extend the system to support another business requirement. That is why it is important to define the business and functional requirements for the current state, and also for the future state.
Another important aspect that can easily get lost or missed during the initial design phase is the nonfunctional requirements. The architecture and design of the content service platform can impact nonfunctional requirements, such as patching and upgrades, or even disaster recovery. The scalability and performance of the system as it grows from year one to year three or five is another common concern.
The last aspect to consider is the overall cost of the platform. Again, the design and architecture have an impact on the cost of the platform. One key design consideration that has a direct correlation to cost is whether the platform is single-tenant or multi-tenant. Building a small to medium content service platform can potentially be more costly than building a large multi-tenant platform. This is also true from an operational cost perspective. The more systems to manage, the more resources are needed to manage them.
Designing your content repositories
As mentioned previously, gathering both functional and non-functional requirements is important and needed to design and architect an agile content services platform. Additionally, a view of the future state of the platform is also important.
Next, you will see a list of some common focus areas and questions that will help with the overall design:
- Security:
- Who needs access to the application and its contents?
- Where do these users reside (internal corporate users, external contractors, or partners)?
- Will additional users from another line of businesses or other organizations need access later on?
- Can anyone who is authenticated be allowed to access the system or only a certain set of users or groups?
- Business data:
- What kind of content is being stored?
- How is content added or ingested?
- Does the content need to be retrieved or is the data extracted and residing in the metadata?
- If the content needs to be accessed, how will it be accessed?
- Are there any compliance requirements regarding the content?
- How old will content be when it is archived?
- Applications:
We will delve deeper into these three focus areas and explore in detail the answers to the preceding questions.
Security
If you recall from the earlier chapter on the overview and introduction to content management, one of the main reasons for the ECM system is to help control access to content. It is important to clearly define the security requirements ahead of time and some considerations for future needs or requirements, such as Single Sign-On (SSO). Once you configure security for an ECM system it is very difficult to change after the fact.
Content Platform Engine (CPE), the repository service component of FileNet Content Manager, has an extensive security infrastructure and support for a variety of Lightweight Directory Access Protocol (LDAP) providers, including the System for Cross-Domain Identity Management (SCIM). Configuring FileNet Content Manager security will determine how a user is authenticated, as well as authorization to objects, such as a document, within the system.
One of the very first things a FileNet Content Manager administrator does as part of the security planning is to collaborate with the enterprise security architect. Most enterprises have a set of defined requirements and processes to onboard applications or systems that need to access the corporate security systems such as Microsoft Active Directory LDAP. The onboarding process typically will ask a series of questions, such as which servers will need to connect, how they will connect, and what they will be doing.
Answering these questions will help the FileNet administrator get the right information needed to configure security for the new FileNet domain. The FileNet domain security is what handles both authentication and authorization to the ECM system.
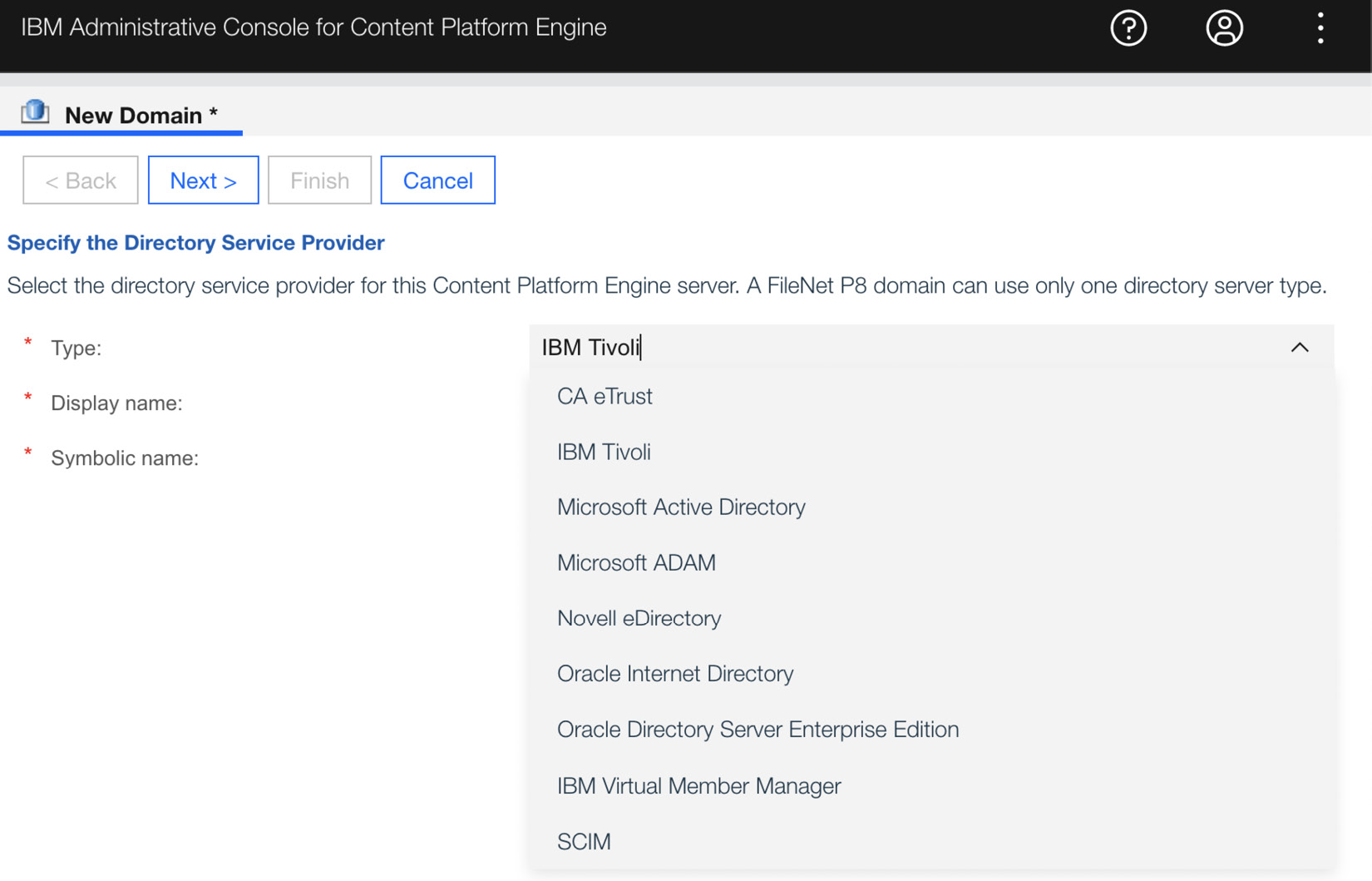
Figure 9.1 – Content Platform Engine Directory Service Provider options
In the onboarding process to enable access to the enterprise security systems, the security liaison will help to provide the information needed to connect to the system. One such piece of information is the LDAP bind user and server names. Given that this is an enterprise security system, ensuring secure access is paramount by using secure communications, such as Secure Sockets Layer (SSL), and enabling firewall rules for only the needed servers:
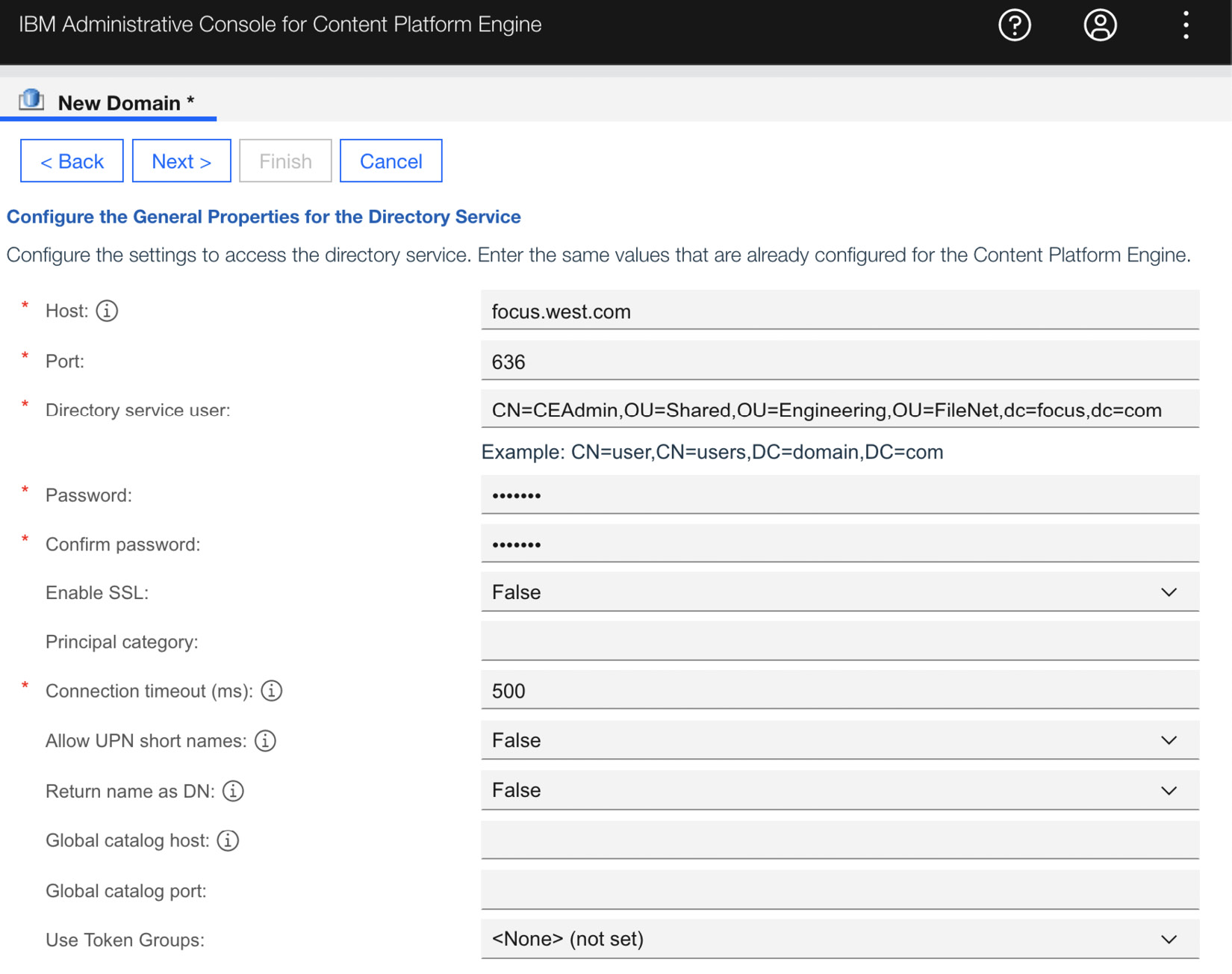
Figure 9.2 – Content Platform Engine Directory Service Provider server configuration
Enterprise LDAP configuration and schema will most likely vary. Not configuring it correctly can cause authentication issues and/or authorization issues. Additionally, this is where it is important to understand where the application users are coming from. Knowing where the current line of business users are and future ones will be will dictate, for example, the base Domain Name (DN) for where the starting point of the LDAP search query is. Restricting the search can cause users and/or groups to be missed.
Widening the search can impact performance since it can search hundreds of thousands of users and groups:
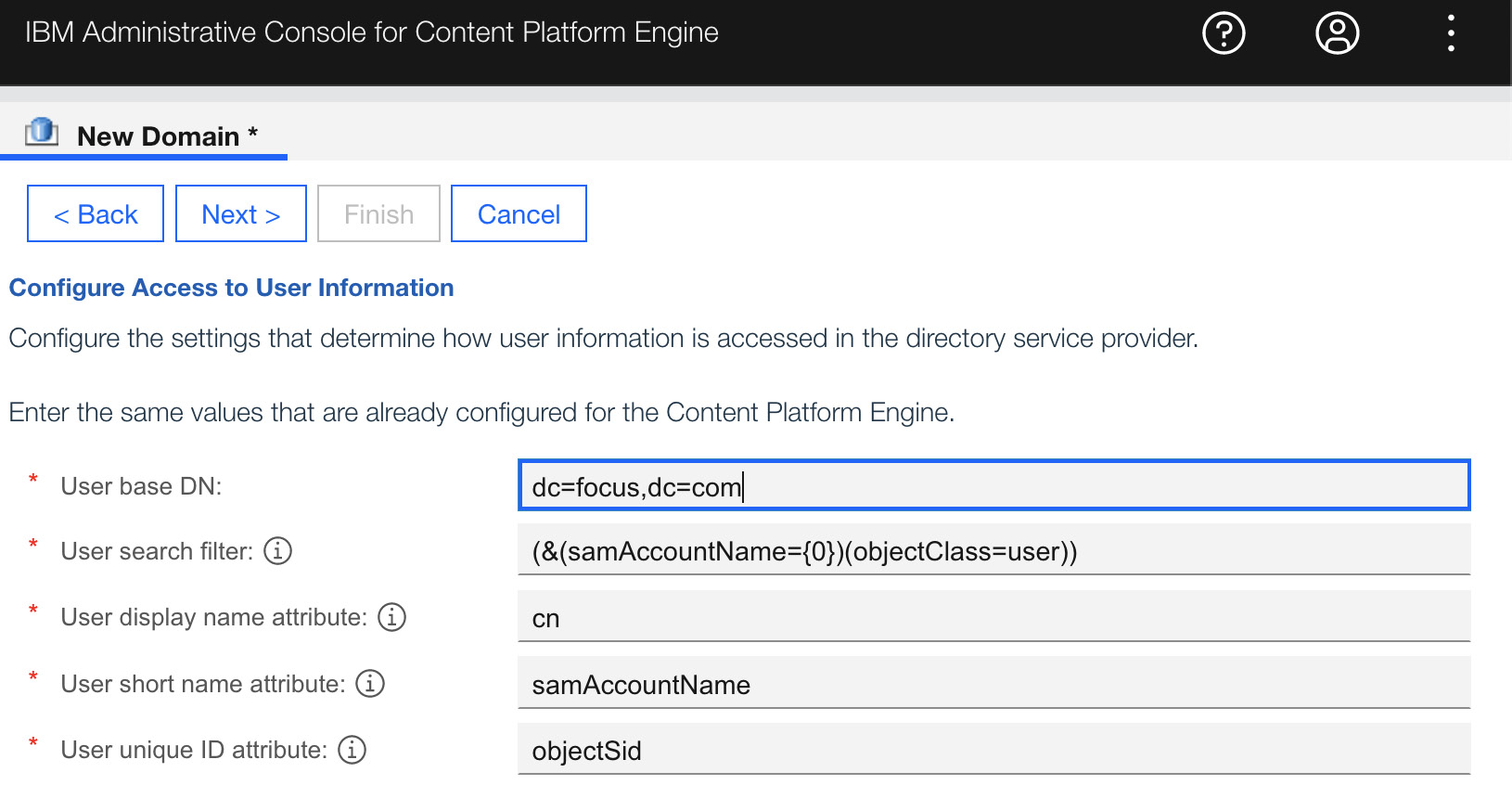
Figure 9.3 – Content Platform Engine Directory Service Provider query configuration
The next level of security is at the repository level, or in the CPE terminology, the object store. Object stores can store a wide range of business-related data such as claims, medical images, or customer-specific data such as an account number. CPE can support many object stores to support different applications or lines of business. Each object store can be configured differently to meet business requirements and security and compliance needs.

Figure 9.4 – Example of object stores for a financial institution
During the creation of the object store, you can define who can administer the object store, such as defining the taxonomy, document classes, and metadata properties:
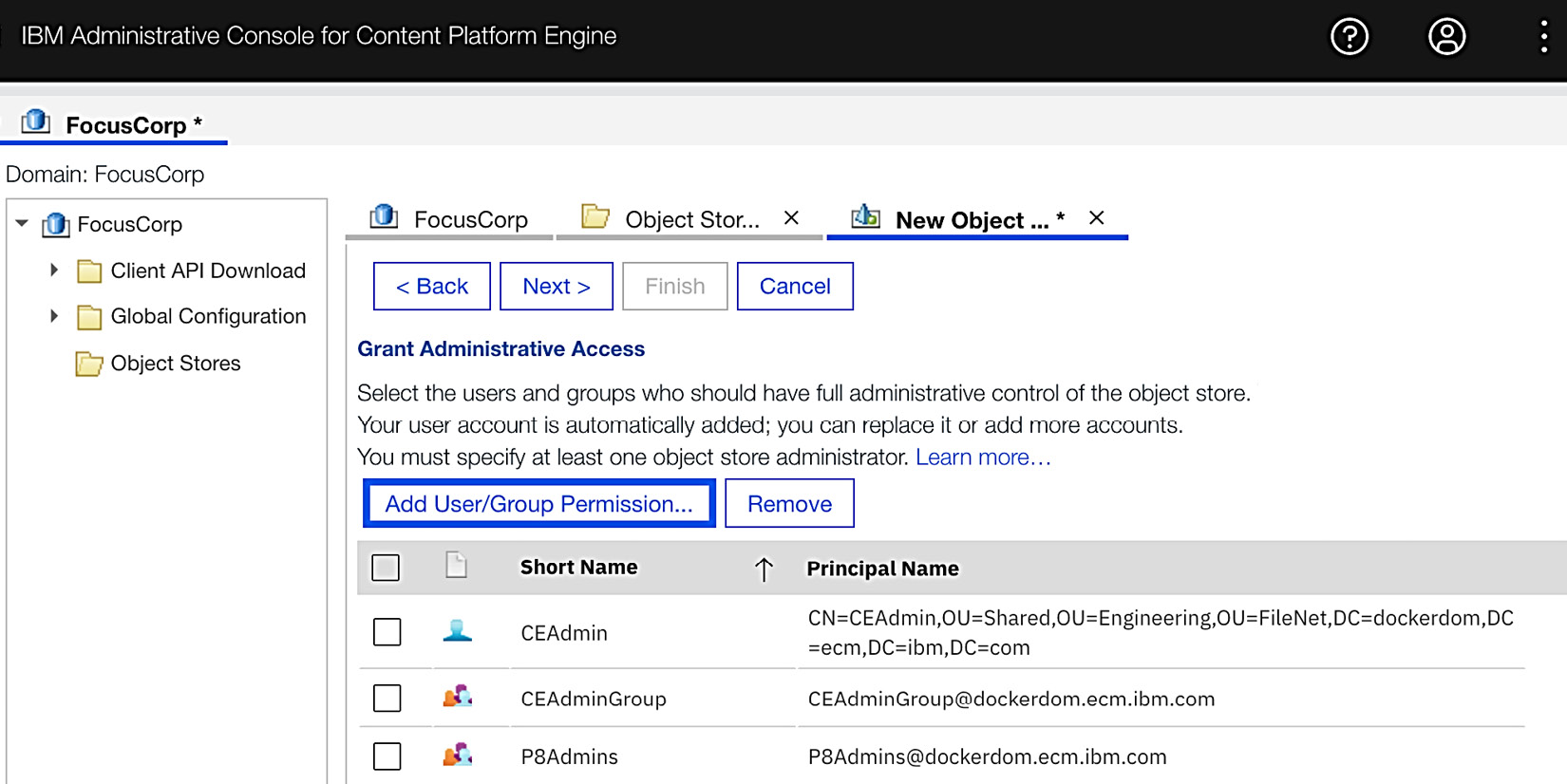
Figure 9.5 – Administrative access configuration for object stores
Additionally, you can define who can access and use the object store. This is important from the perspective of who will be able to access the object store.
In the following example, #AUTHENTICATED-USERS is in an internal CPE group that will allow any users that are authenticated by CPE to access the object store. It is a convenient way to set up the object store, but potentially provides more access than what is required:

Figure 9.6 – Basic access configuration for object stores
So, knowing who needs access to the data in this object store is important. It will help further restrict access to users and groups that do need access, and not provide access to those that don’t. This is important to consider future access needs as well, such as if you plan to add another application or another group to access the data in the object store.
Changing the security configuration of the object store after the fact is not impossible, but can be expensive and time-consuming. The reason for this is that each object within the object store, such as documents, are secured by an Access Control List (ACL) and Access Control Entries (ACEs). Depending on how each object is configured, this could mean updating each object in the object store with the new security configuration. This might be easy to accomplish if you just started and only have a couple of million objects. But what if you are a high-volume enterprise customer and have been active for five years with billions of documents? It is more important to get the right object store security configuration than the domain.
Business data
Before ECM, a lot of enterprises stored content in network file shares. And today, enterprises have cloud drive sprawl where business data is stored in various Google Drive or Microsoft OneDrive drives. Business users have a hard time finding the information needed when they most need it, which impacts productivity. This in turn impacts the business, such as not being able to close a mortgage loan because the underwriter can’t find the supporting documents for the applicant.
Understanding the business data is important to determine how to organize and classify the data so that it is easy to find and manage. What is more important is being able to act on the data and automate the overall business process. Additionally, classifying the data will make it easier to govern the data throughout its lifecycle.
Let us use the mortgage loan application example. The mortgage loan application is either submitted online by a customer or potentially a traditional paper application is filled out at one of the branch offices. The online version of the application generates a digital version of the document. At the branch, the branch employee will scan the application using the MFP to generate the digital version of the application. In either case, regardless of how the mortgage loan application is generated, a digital version of the document is created with the same set of business data.
The digital mortgage application needs to be added to the object store and classified, and the important data needs to be extracted. In CPE, documents can be classified by assigning them to a document class. Creating the custom document class in CPE is easy but what is important is designing the taxonomy and data design so that it is usable by other similar applications.
For example, leveraging object inheritance so that similar objects share common metadata properties ensures the consistency of data mapping:
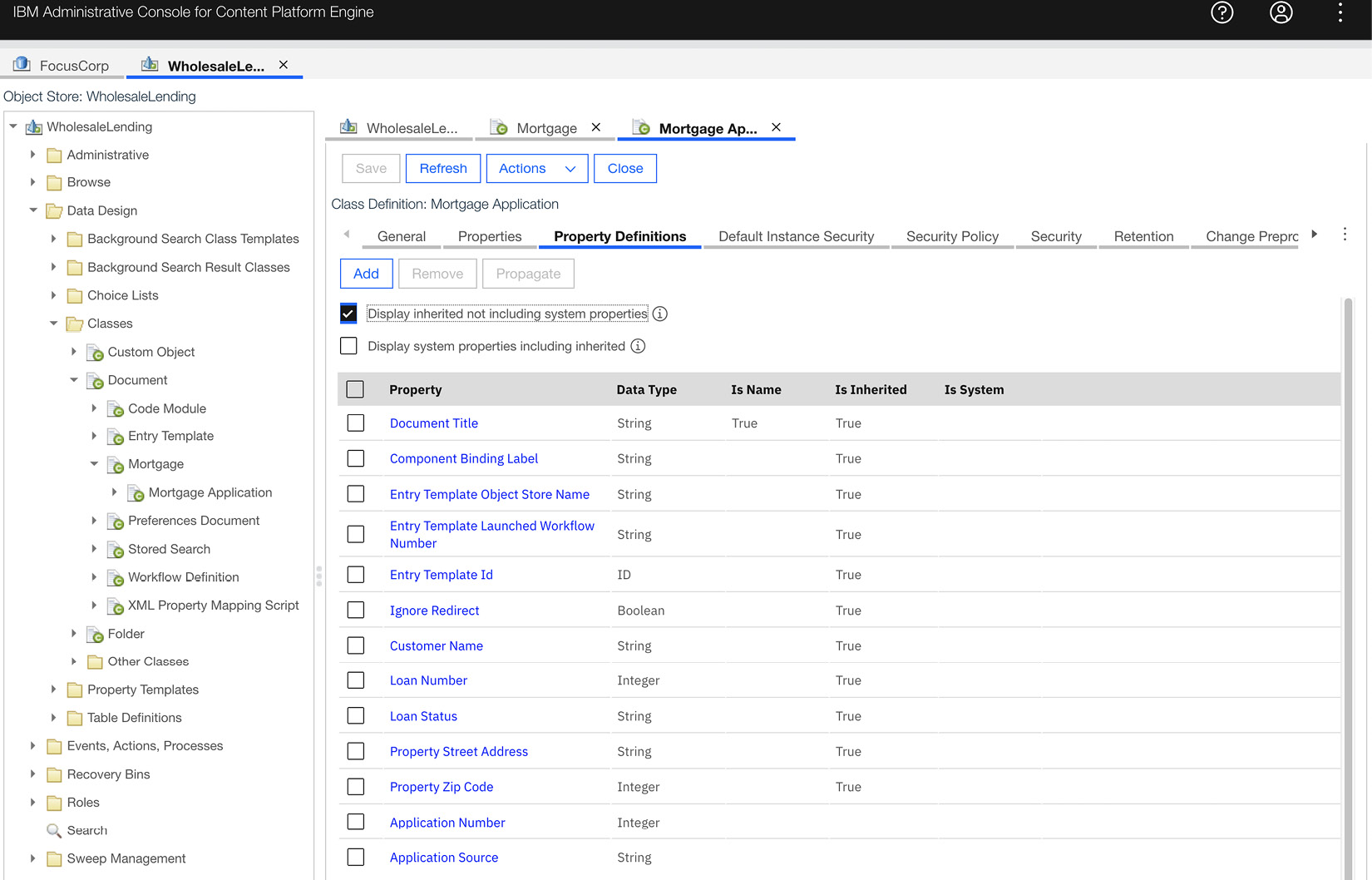
Figure 9.7 – Custom document class with inheritance
In the preceding example, we have created a root customer document class called Mortgage and a subclass of it called Mortgage Application. The parent Mortgage class has a set of properties, such as Customer Name and Loan Status, which is now inherited by the Mortgage Application class. But the Mortgage Application class also has its own unique properties, such as Application Number and Application Source.
These document properties are what will store the extracted data from the mortgage application. It is much easier to search and retrieve property values, such as Loan Number, from the document properties versus having to scan the entire mortgage application. Additionally, CPE can trigger events on document properties to automate the business process such as funding the loan once the underwriter changes the Loan Status property to the funding value.
The example we just went through is a simple one. The applications could require additional data design aspects such as using custom objects to store other business object information such as customer information:
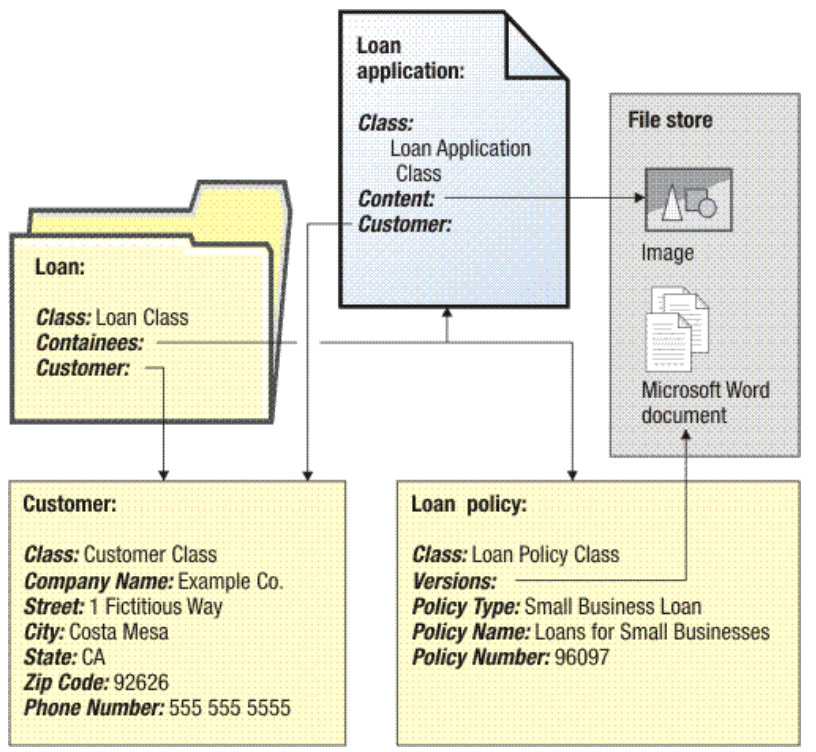
Figure 9.8 – Example of loan data design
It is recommended that you define the complete data design and taxonomy for current applications and future ones. The reason for this is that it is easy to add new classes and properties, but you can’t delete ones that are already in use. Also, it would be wise to document the taxonomy design so that new applications that get onboarded use the same set of taxonomy that is in place. It would be confusing and harder to find data, for example, if you have two different property names for the same data, for instance, customer number.
Now we need to determine how to store the actual application content. CPE has a wide range of storage options depending on the need and requirement for storage. Next is a summary of storage options available in a typical use case.
|
Storage Type |
Use Case |
|
NFS/SMB (for example, IBM Spectrum Scale, NetApp, EMC, or Hitachi Content Platform) |
Scalable high-performance storage for high ingestion and retrieval |
|
Cloud object storage (for example, IBM Cloud Object Storage, Azure Blob Storage, or AWS S3) |
Cost-effective cloud storage option with average performance |
|
Fixed content device/WORM (for example, NetApp SnapLock or EMC ECS) |
Used for retention and compliance requirements |
Table 9.1 – Summary of storage options
In a perfect world, the critical business data in the document is extracted and classified so the need to retrieve the document to view is highly unlikely. In this case, selecting storage that is cheap and still allows retrieval on occasion is the most cost-effective option. Cloud storage such as IBM Cloud Object Storage or AWS S3 is very cost-effective compared to on-premises storage such as NetApp storage appliances.
But we don’t live in a perfect world and in our scenario example, the scanned mortgage applications from the branch only have an 80% accuracy rate. So that means that 20% of the scanned documents will need to be reviewed and the data manually extracted. And business requirements might expect these applications to be remediated quickly so that applications can be processed promptly. In this case, these documents can be stored in fast local storage such as using the NetApp storage appliance. The other applications coming from online can be stored in non-high-performance storage, such as AWS S3. Given that we now have two different storage class requirements, we have a couple of options in terms of configuration. The most straightforward is to create a second subclass of the Mortgage document class for either the online or branch application. The reason for this is that a document class can only have one default storage policy:

Figure 9.9 – Example of default storage policy for a document class
In the preceding example, we decided to assign the fast filesystem storage to the original Mortgage Application document class. Another similar document class will need to be created and the default storage policy set to use AWS S3:
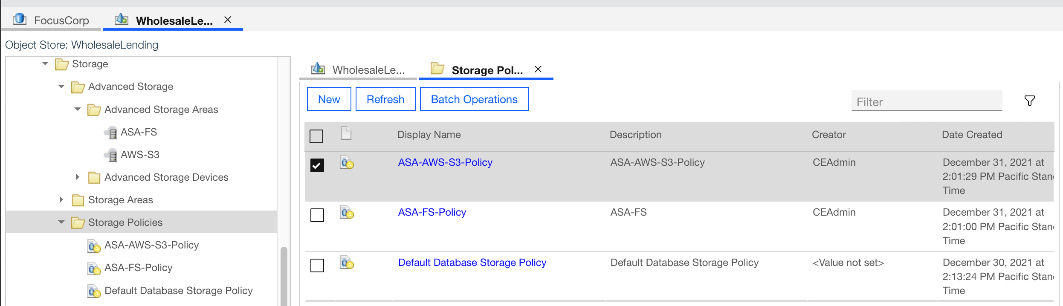
Figure 9.10 – Example of AWS S3 storage policy
Another option is to keep the single Mortgage Application class with a default storage policy for the filesystem and use the content migration sweep policy continuously to move the online application document to AWS S3 storage. This can be done by using a property on the class that is set for where the application originated from. In the case of this example, there is a property called Application Source that has a choice list of Online Application or Branch Application. We will use the filter expression to find documents from the Mortgage Application class with a property of Application Source set as Online Application to move it to the AWS S3 storage policy:
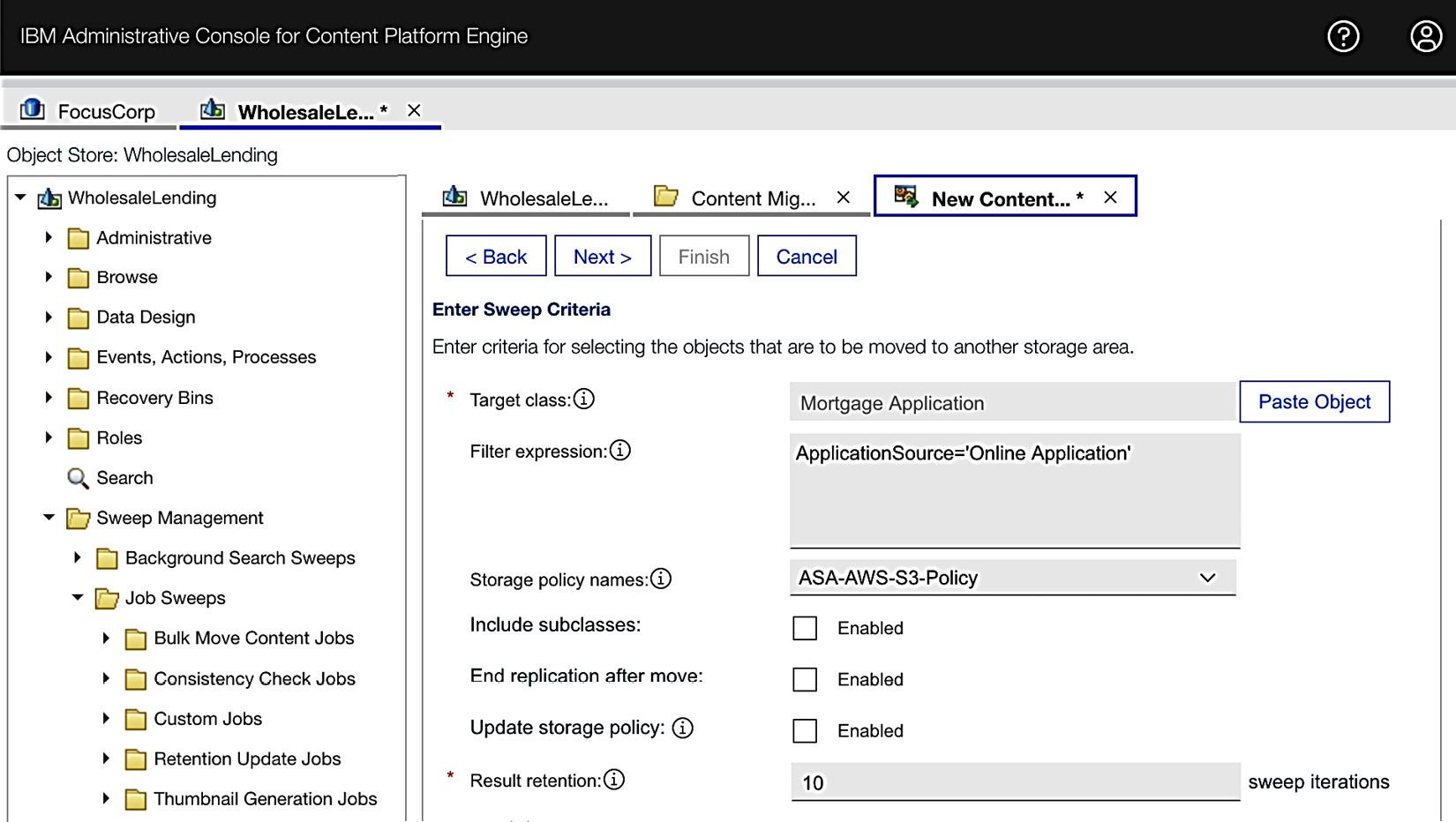
Figure 9.11 – Example of content migration sweep policy configuration
We can also use the same technique to move the old documents in the filesystem storage to AWS S3. That way, we can keep the expense of performant filesystem storage to a minimum. A lot of customers do this today, only keeping the most recent documents that are frequently accessed in fast storage.
Applications
As mentioned earlier, FileNet Content Manager CPE can support multiple applications within a single FileNet domain. There are three possible ways to support various applications within CPE:
- The first is to share the same FileNet domain and the same object store. Applications that need to access the same data should share the same object store so that the data can easily be accessed. Sharing the same data can enable automation based on events and the lifecycle of the data for all applications. Additionally, this will also prevent the need to duplicate the data in another object store.
One of the biggest concerns with sharing an object store is the noisy neighbor effect. It just takes one piece of poorly designed or bad code from an application to impact the performance of the other applications. A good example of this is a bad database query since all applications share the same object store database.
- The second option is to have a different object store with the same domain. This option should be considered and recommended if the application data is different from other applications. Using a different object store will also give more flexibility in configurations, such as object store security, taxonomy, data design, compliance, and storage.
Also, there is an option for applications or lines of business that are not ready to be patched or upgraded by moving the object store so that it’s temporarily disconnected from the FileNet domain. This will entail additional resources to have a separate CPE deployment temporarily until it rejoins the original FileNet domain.
- The last option is to have a separate and dedicated FileNet domain and object store for the application. This option provides the most isolation and segregation to the application but at the cost of resources and maintenance overhead.
The main driver for this option is really application and data isolation and segregation because of strict security and compliance requirements. This approach will also guarantee optimum application performance without worrying about the noisy neighbor issue since the entire resource is dedicated to the application. Most customers who initially decide on this path eventually end up consolidating their FileNet domains to reduce operational costs. The required level of isolation, segregation, security, and compliance can generally be satisfied by sharing a FileNet domain and properly configured object store.
Even the performance concern can be mitigated or solved with proper application testing, performance monitoring, and leveraging Kubernetes container platforms, such as Red Hat OpenShift.
|
Advantages |
Disadvantages | |
|
Shared object store |
|
|
|
Advantages |
Disadvantages | |
|
Separate object store |
|
|
|
Separate FileNet domain |
|
|
Table 9.2 – Summary of options for application
In this section, we learned about the importance of understanding the requirements for security, business data, and applications, and designing and architecting the ECM system upfront with these focus areas in mind, since it will be potentially difficult to change the configuration later.
Creating a content desktop
Now that we have completed the design of the content repository, we need an easy way for the application and LOB users to work with the content. The simplest and easiest way is to use the common runtime UI in CP4BA, which is using Business Automation Navigator (BAN). BAN has a lot of OOTB features and capabilities, as well as many options to customize the UI. A BAN desktop is a good way to isolate an application runtime and configure it specifically to the application requirements, such as only connecting to a specific CPE object store or only loading specific custom code.
In this section, we will look at how to create a desktop and look at some key features and capabilities that should be considered.
Note
The CP4BA content pattern, when deployed, will automatically configure a content desktop when the initialization option is configured in the custom resource.
There are two simple steps in creating a BAN desktop:
- The first thing is to ensure that the FileNet CPE object store repository is configured on the BAN admin desktop. The OOTB configuration for the CPE repository should meet most of the application’s or user’s requirements. But it is recommended to only enable and configure features that are really needed by the application. This will help simplify the user experience and focus on the functionalities that the user should be using. You can later enable features or capabilities that the application or user might be ready to use.
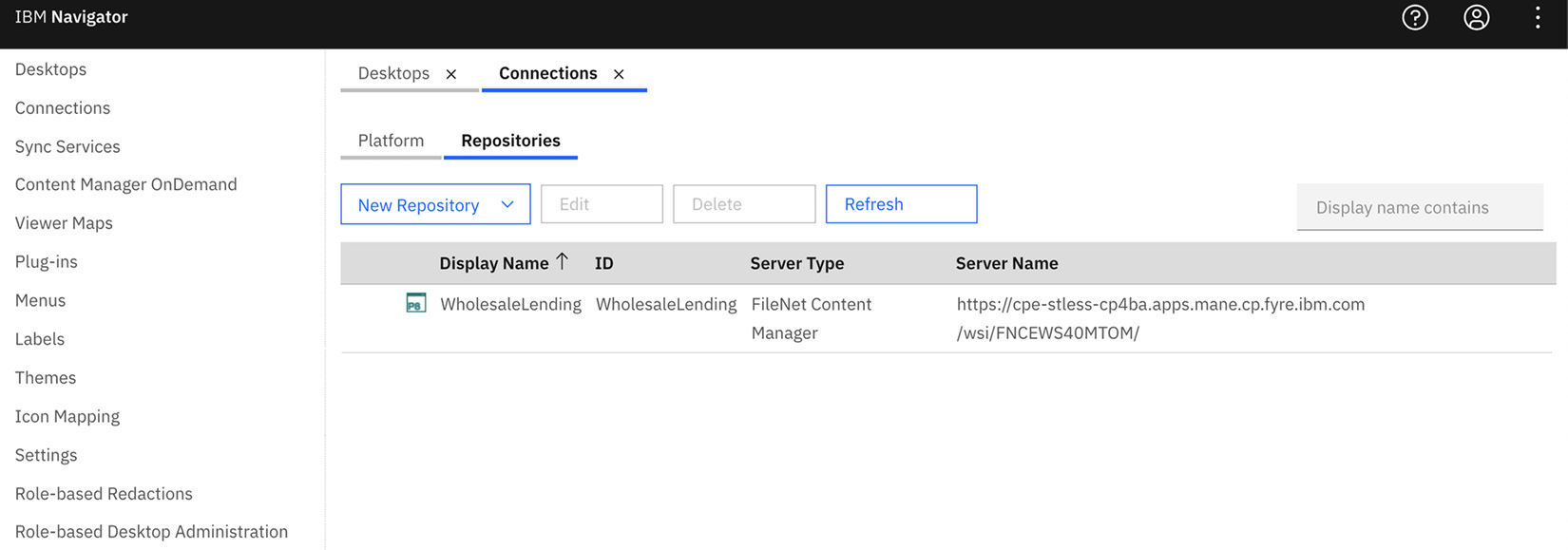
Figure 9.12 – FileNet CPE repository configuration in BAN
- Once you’ve configured the FileNet repository, the next step is to create a BAN desktop. The important configuration step when creating the desktop is selecting the desired authentication connection or repository:

Figure 9.13 – BAN desktop creation
Like the FileNet repository configuration, there are a lot of options and customizations that can be done to the desktop UI.
Some key features for the FileNet repository should be considered depending on the use case of the application and the user’s requirements:
- Entry template
- Role-based redaction
- Teamspace

Figure 9.14 – BAN FileNet repository optional features
Next, let us look at the document entry template.
Document entry template
As an administrator of the application and runtime UI, you want your users to have a simple and consistent way of adding documents to the content repository. Also, you want to limit or prevent the user’s ability to make the wrong choices when adding content. This includes options that the user should not need to configure or even care about such as security. Using a document entry template will ensure that the data being added is usable, consistent, and accurate, and is what the application is expecting.
Using the Entry Template Manager in BAN, the application administrator can create document or folder entry templates that are shared with users. These can be shared with anyone who has access to the BAN desktop or only a set of users or groups:
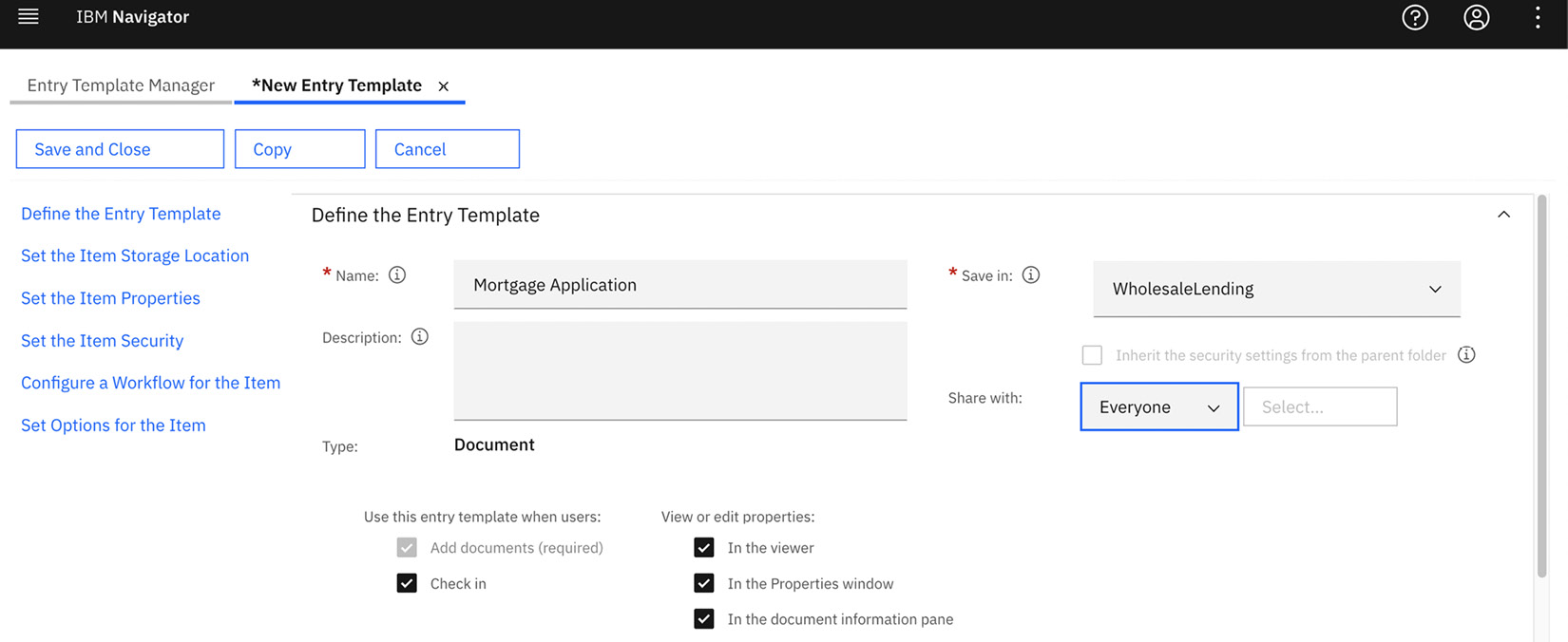
Figure 9.15 – Creating and sharing an entry template with users
Configuring template item properties is key – the properties should be properly filled out, in the expected format, and provide default example values:

Figure 9.16 – Configuring item properties for an entry template
Additionally, configuring the item security ensures that the document security is properly configured automatically and prevents the user from seeing the options. This will prevent the user from misconfiguring document security and potentially breaking the application:
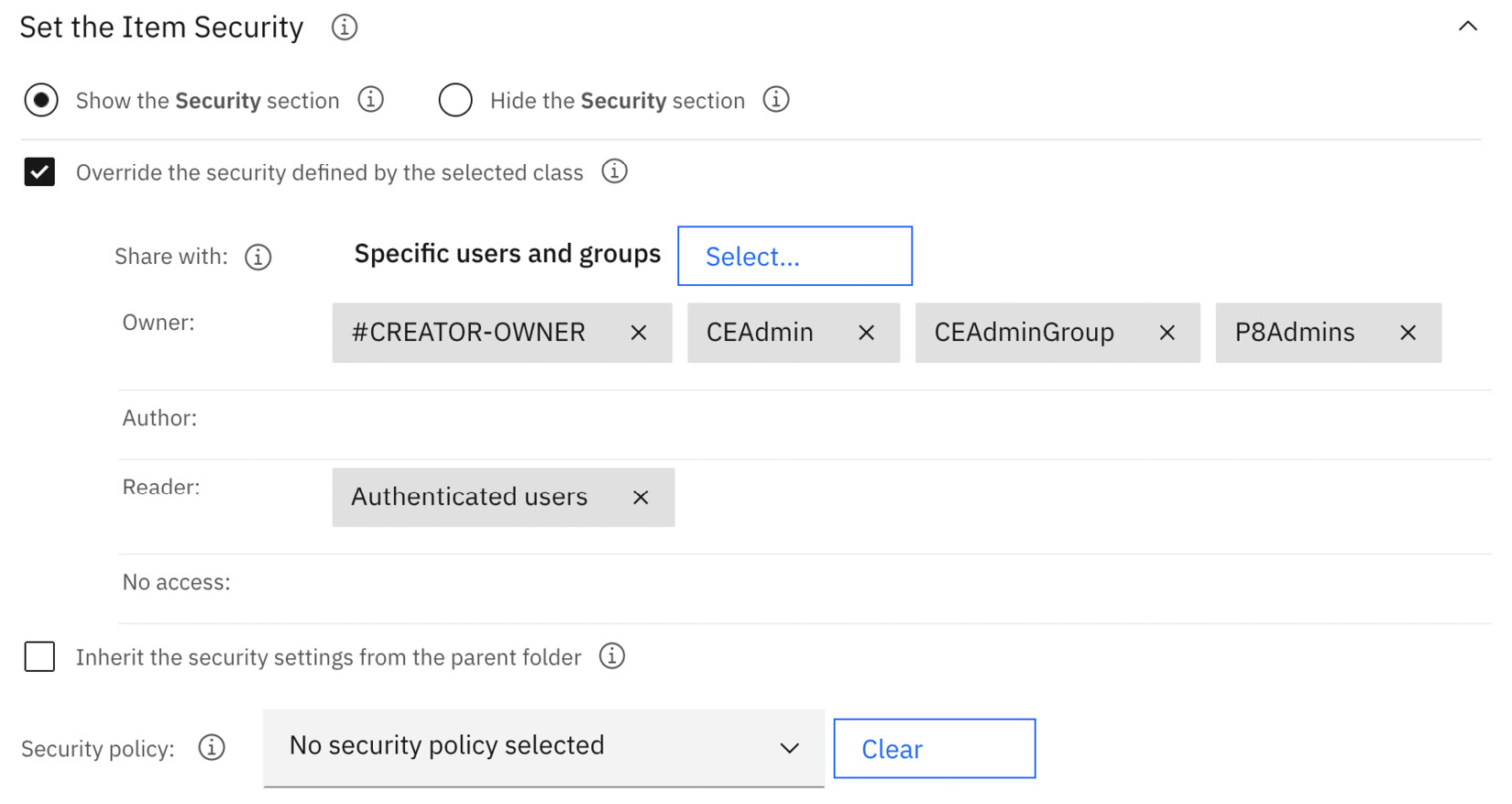
Figure 9.17 – Configuring item security for the entry template
Once the entry template is added, users that the template was shared with can use it to add application documents:

Figure 9.18 – Using the entry template
Next, let us understand role-based redaction.
Role-based redaction
Role-based redaction takes the basic redaction capability in the BAN viewer to include policies and roles that determine who can view the sensitive data in the document. The policy also defines the role of who can redact the document for the sensitive data. Users who don’t have permission to see the sensitive data will not be able to even if they download the document or different versions of the document.
The application administrator can configure role-based redaction on the BAN administration desktop. There are two OOTB redaction reasons: social security number and credit card number. You can create additional ones based on the sensitive data that you want to redact:
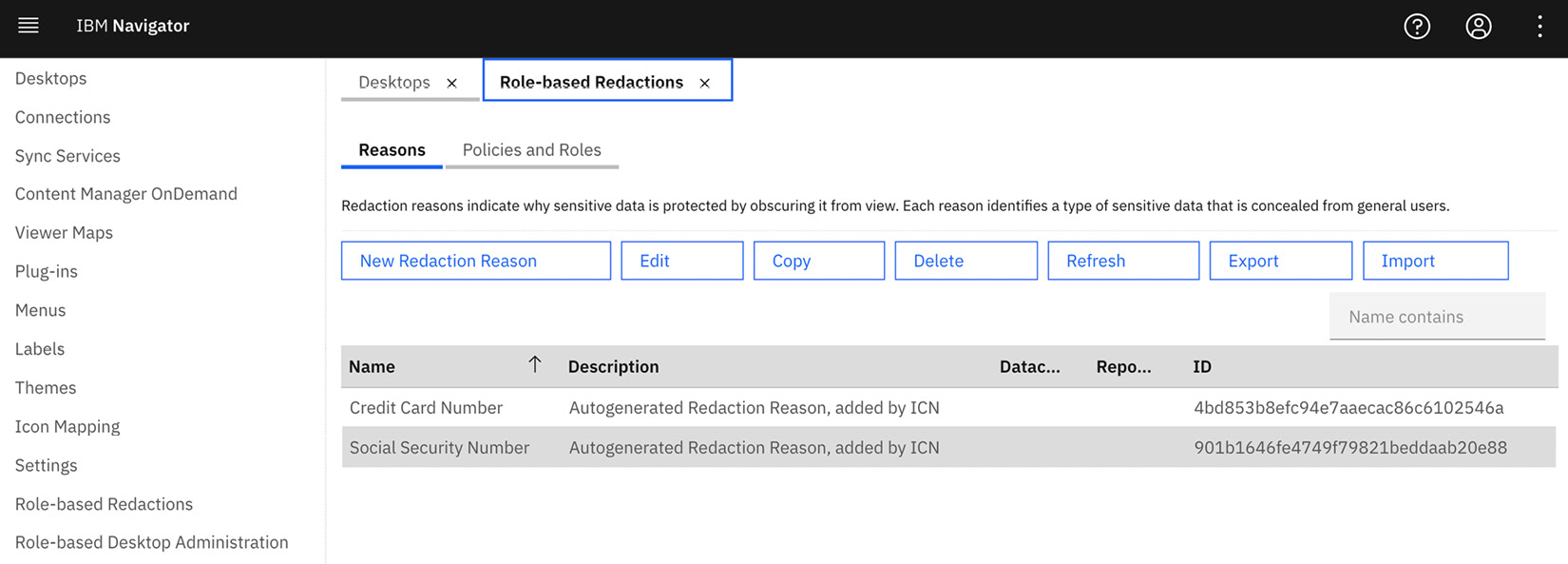
Figure 9.19 – Role-based redaction reasons
Next is creating the redaction policy and roles. The redaction policy includes the redaction reason and two roles, an Editor and a Viewer role. The Editor role is used to redact the document using one of the redaction policies. The document can have multiple redactions and policies. The Viewer role defines who can view the redacted sensitive information. Any users not belonging to one of these roles will not be able to view the redacted sensitive data.
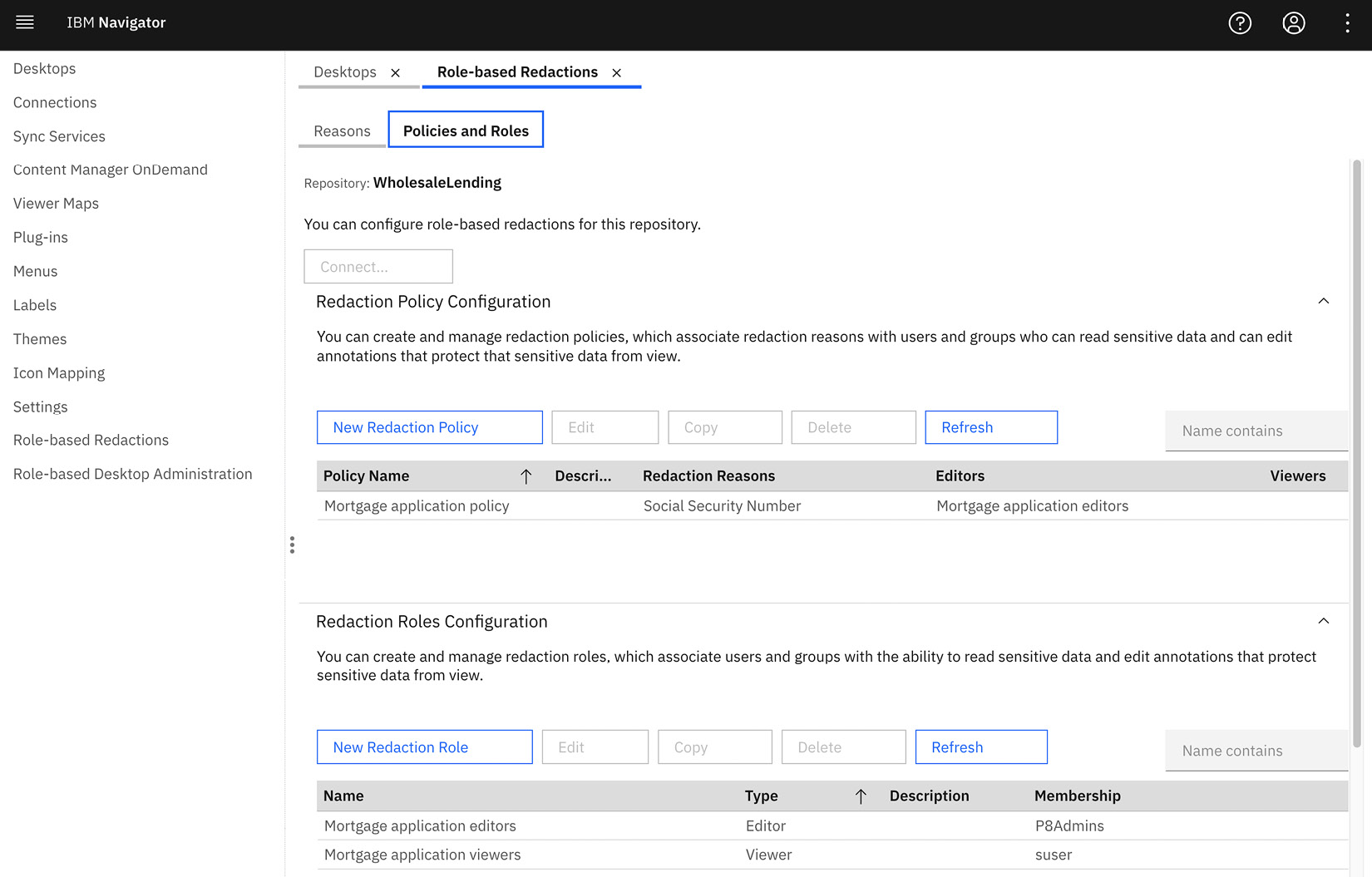
Figure 9.20 – Role-based redaction policies and roles
Once the role-based redaction policy is created, the user with the Editor role can open a document with the viewer to redact the sensitive data within the document, such as social security numbers. Once the document is saved with the redacted annotation, the redaction policy will be enforced if the document is opened again.
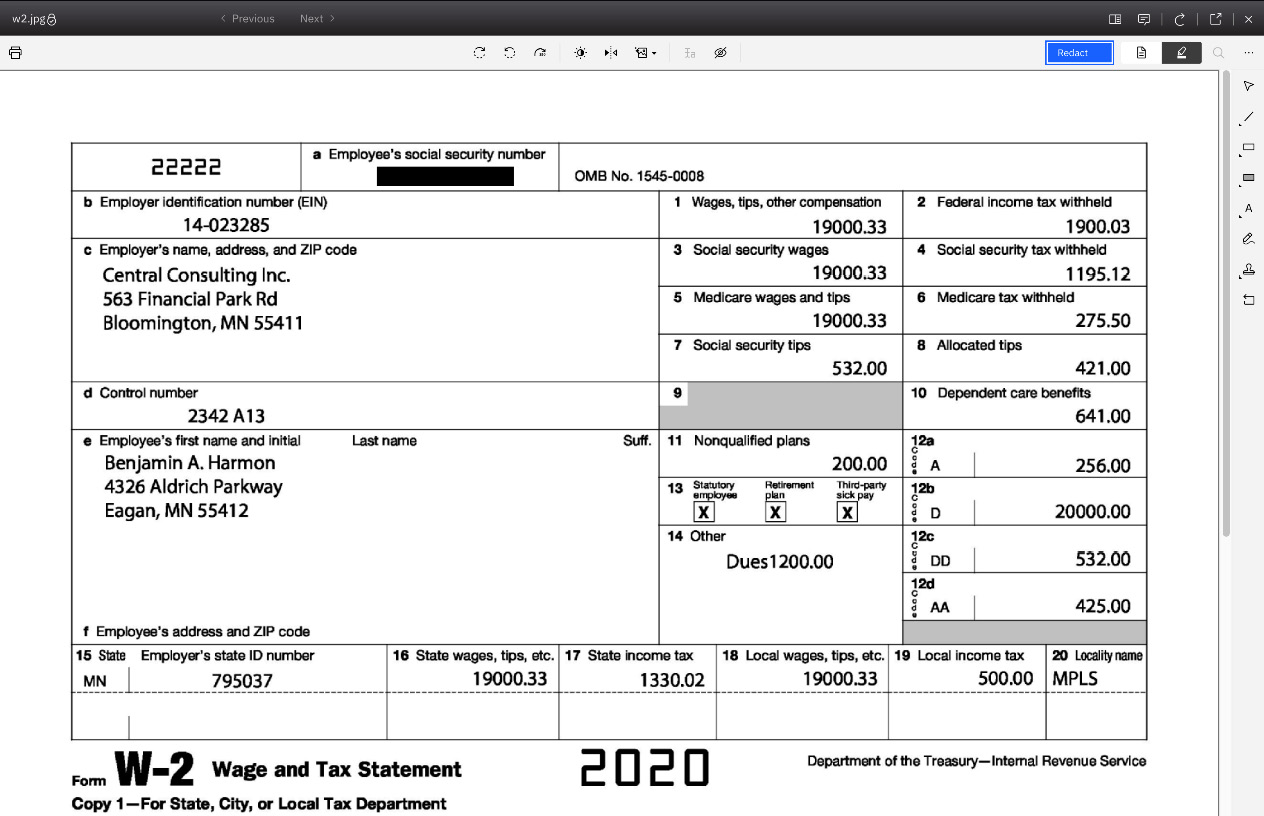
Figure 9.21 – Redacted document based on redaction policies
Teamspaces
Teamspaces is a focus area for teams to collaborate and work on project-specific content. It provides team members with a focused view of documents, folders, and searches that will help the members complete their tasks. Teamspaces are commonly used for recurring projects such as month-end close or quarterly audits.
Note
Task Manager is needed to delete teamspaces. This component can optionally be deployed or deployed as part of another add-on product such as IBM Enterprise Records.
Before users can create a teamspace, a teamspace template needs to be created. The application administrator can set default configurations for the teamspace to ensure consistent configuration and behavior such as base folders and available teamspace roles.

Figure 9.22 – Teamspace template
Once at least one teamspace template is available, users with permission to create a teamspace can create one using the template. The teamspace owner can make some minor changes to the teamspace based on the template definition, such as adding additional subfolders to create new searches. But what is important here is adding team members and assigning the team to a role.
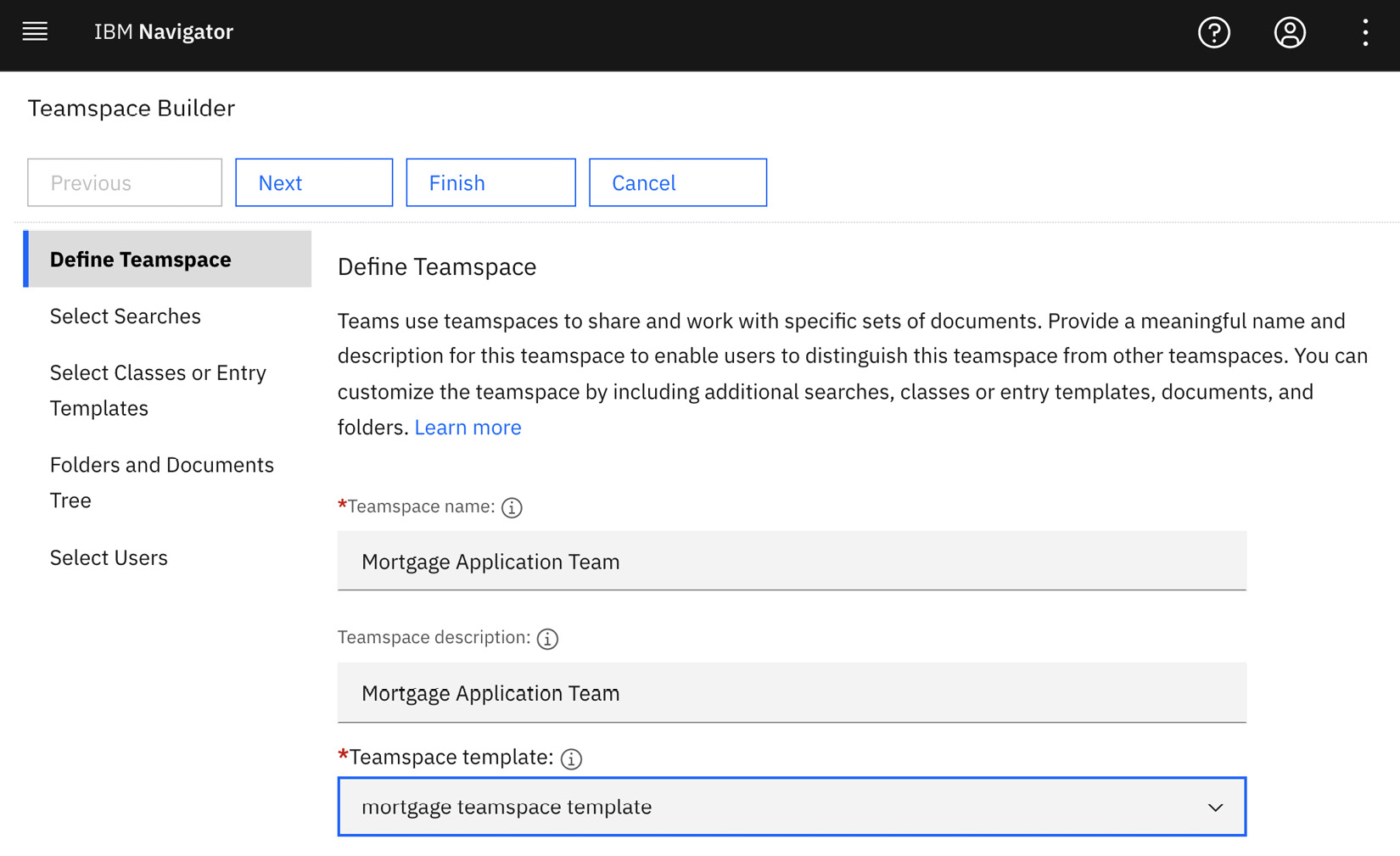
Figure 9.23 – Teamspace creation
Now that the teamspace is created, the team members can work and collaborate on documents and folders specifically for their project. Only members belonging to the teamspace can see and access the teamspace.
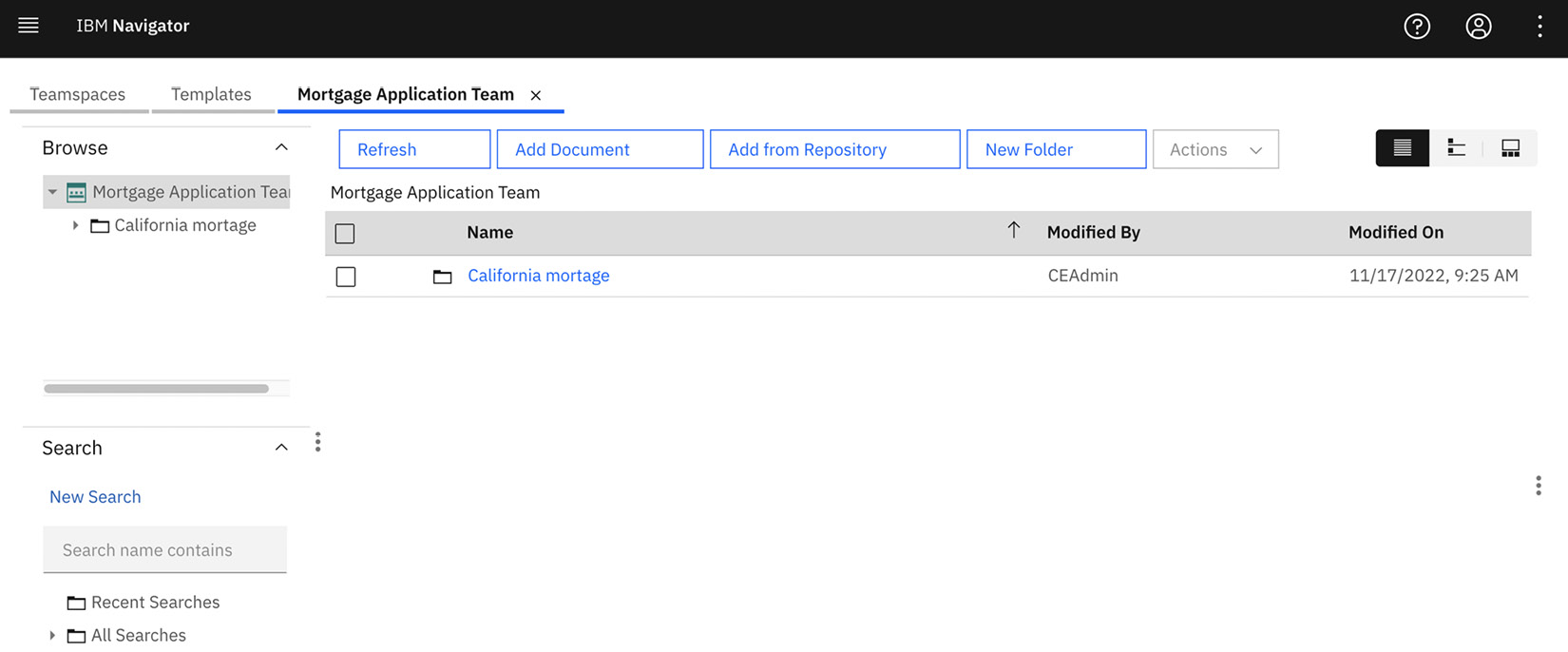
Figure 9.24 – Teamspace
Business Automation Navigator is a rich web UI that provides a lot of capabilities Out-Of-The-Box (OOTB). We learned how we can simplify user experience when working and collaborating on documents by using document entry templates and teamspaces. Additionally, we learned how to embed role-based security features such as redaction into documents.
Searching and accessing content from applications
The most common way to work with content is using the BAN UI. The BAN UI is highly customizable to allow application administrators to create a desktop that focuses on what their end users need to perform their work.
In the previous sections, we have looked at several different ways we can access and work with content using BAN. We explored how to simplify adding document content using an entry template, and we discovered how to collaborate on documents within a teamspace and redact documents using the viewer in BAN.
There is a more simplified way to work with content using BAN and that is using the OOTB browse view. In this view, the user can easily create or browse folders and add or view documents within the configured object store. In this view, the user has a lot more freedom to work with objects within the object store versus a more focused set of actions. Nevertheless, the application administrator can still customize the desktop to limit the view and actions that the user can perform, such as sending emails from documents or even print actions, but still provide some level of freedom.

Figure 9.25 – BAN browse UI
One other common way to access documents is through searching. Using BAN, users can create searches or use saved searches to find documents they are looking to work on. The search capability provides the user with the ability to search for documents based on one or more properties, specific document classes, and within a specific folder.
The user can work with documents, such as view documents, or check out the documents from the search results just like in the browse view:

Figure 9.26 – BAN search UI
Note
It might be necessary to create database indexes to improve search performance and to avoid impacting the overall FileNet environment.
The application administrator can restrict users to only use searches that they create that are optimized for the search operations needed by the users. This will prevent users from performing searches that are not optimized and avoid potential performance impact or outages in the environment:
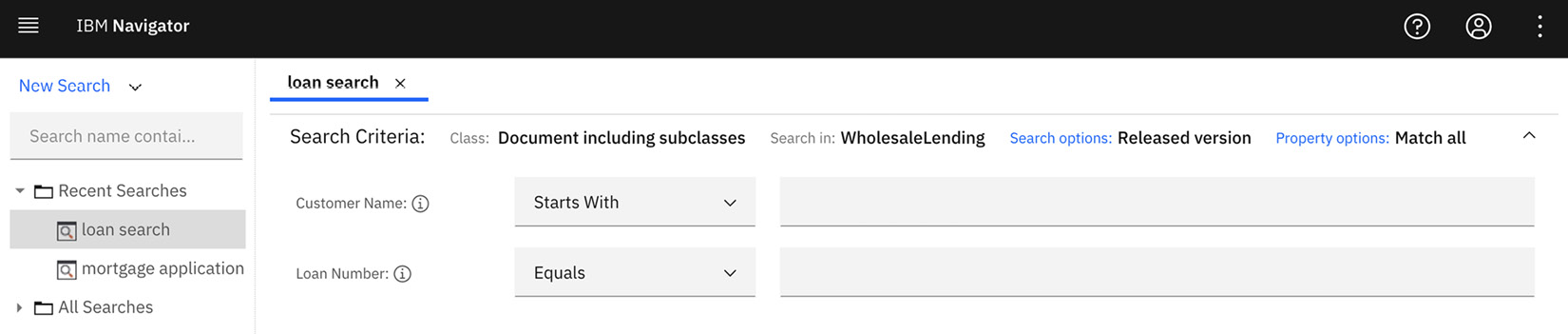
Figure 9.27 – BAN saved search UI
Searching for documents is a widely used feature when working with a large volume of documents. BAN provides administrators with search capabilities that are easy to manage and use for their end users.
Extensions
One of the key capabilities of FileNet is its ability to build and extend the platform to support other applications. The FileNet product portfolio has many integration add-ons, such as IBM Enterprise Records, to enable customers to build their applications and solutions that solve a wide array of use cases. This is also true of CP4BA.
One such CP4BA extension is Business Automation Workflow (BAW), the case management integration. The BAW case management capability allows customers to build a case-centric solution, such as credit card disputes that rely on FileNet active content infrastructure, which enables content-based events for case activities.
BAW case management has a predefined data model that is needed to deploy the capability. The base data model provides the framework for the case management solution to be developed, deployed, and run. The predefined data model extensions are called add-ons in the context of CPE. The add-ons can comprise a wide array of definitions such as classes, custom objects, property definitions, and even code modules. These add-ons are installed or added to an object store to be leveraged by the custom solution. CPE already comes with built-in add-ons to support key OOTB capabilities, such as teamspace and entry templates.
BAW case management integration with FileNet consists of two sets of add-ons, one for the design object store and another for the target object store:
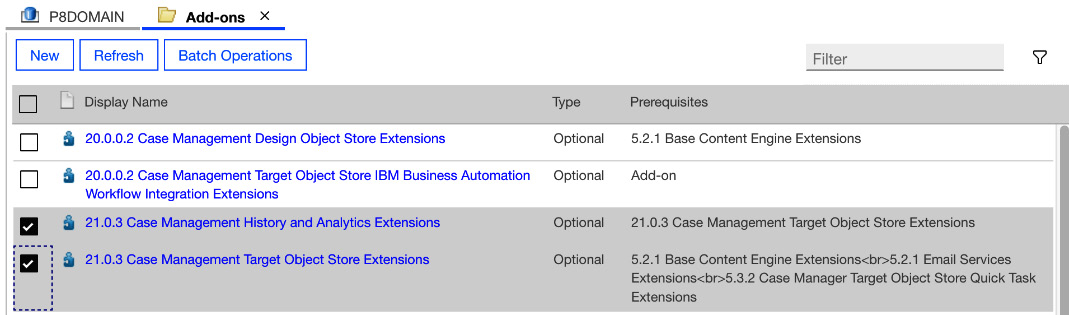
Figure 9.28 – BAW case management add-ons
The BAW case management design object store is used during design time for developers to create the case solution. The case solution can consist of various artifacts that are created and stored in the design object store as the case solution is developed. This not only includes a custom data model, such as document classes, but also other integration extensions and case UI pages. The design object store is also used as a staging object store in higher environments to deploy the solution to the runtime target object store.

Figure 9.29 – BAW design object store
The BAW case management target object store is the runtime object store for the case solution. The case solution is deployed to the target object store and that is where the runtime artifacts are deployed, such as the solution data model, case solution UI pages, runtime security, and case folder structure.
The case folder structure is important since, for every case that gets created, there is an associated case folder. It holds the state of the case in addition to the documents that are added as part of the case process.

Figure 9.30 – BAW target object store case folder
The BAW case client runtime UI is deployed as plugin features within BAN. The plugins are the runtime integration points to BAW and CPE. The plugins are also what customizes the BAN desktop to render the case solution UI pages. Depending on the caseworker user role(s), the case client UI will display the associated UI and the actions the user can perform, such as creating a case or working with active cases.

Figure 9.31 – BAW case client
The BAW case management extension is just one example of CP4BA integration with content services. Other CP4BA capabilities also build on FileNet content services, such as ADP.
Retention policy
Retention management is an important FileNet feature or capability to help enterprises with their compliance needs, such as US Securities and Exchange Commission (SEC) Rule 17a-4. FileNet offers two main ways to implement a retention policy OOTB.
The first option has been around for decades, and that is leveraging a storage vendor feature, called write once, read many, commonly known as WORM storage. Once an electronic file is stored in WORM storage, it is immutable and it can’t be erased until the retention period has expired. This ensures that the records are not altered or deleted. This is the main reason why SEC 17a-4 requires the use of WORM to satisfy its compliance rule.
FileNet CPE has supported WORM storage for over a decade. Many FileNet enterprise customers leverage CPE fixed content device support for WORM storage to meet their compliance needs. WORM storage provides the ability to set a retention policy on the storage volume. The storage volume can be configured for different retention settings to meet different compliance needs depending on the type of documents being stored. Once the retention setting is applied to the volume, any document written to the volume will adhere to the retention policy and will become immutable. Once the retention period expires, only then can the documents be deleted.
Over the years, FileNet has expanded its storage vendor WORM support, such as NetApp SnapLock, Dell EMC Elastic Cloud Storage or Centera, and IBM Spectrum Protect. Each of the storage vendors does have its own set of nuances, such as how it deletes an object or supports specific retention settings, but ultimately it is WORM storage:
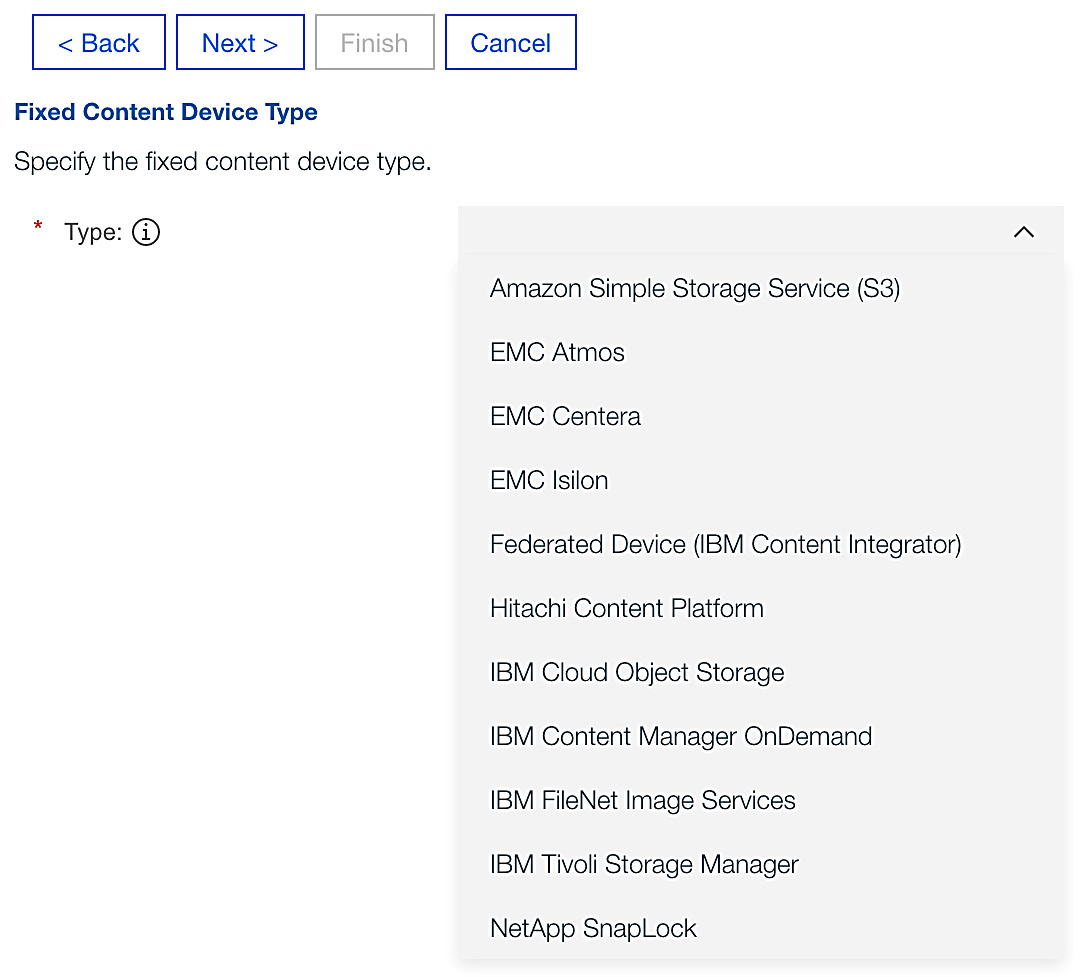
Figure 9.32 – FileNet CPE FCD support
FileNet CPE tightly integrates with these storage vendors to provide native WORM support. This means that CPE can adhere to the retention setting at the storage level. Additionally, CPE can support an aligned mode for retention settings. We will get into more detail about aligned versus unaligned mode later when we talk about the CPE native retention feature.

Figure 9.33 – FileNet CPE NetApp SnapLock FCD creation
Recently, customers have adopted public and private cloud storage. Public cloud vendors, such as IBM and AWS, started to provide storage compliance support through the object locking feature for IBM Cloud Object Storage (ICOS) and AWS S3 storage that is equivalent to WORM. CPE’s Fixed Content Device (FCD) support expanded to include these cloud storage compliance capabilities to meet customers’ migration to the public cloud. Like on-premises storage vendors, the public cloud implementation for WORM-like support varies, including object storage support. FileNet CPE now supports ICOS and AWS S3 as FCD support in aligned mode. Google Cloud Storage can be supported as a FCD solution but in unaligned mode.
The second OOTB option for retention management is using the CPE retention policy. CPE retention can be configured at the class level (document, folder, annotation, or custom object). The retention policy can be configured as None, Indefinite, Period, or Permanent:

Figure 9.34 – FileNet CPE class retention configuration
Similar to storage vendor retention configuration per volume, CPE can vary retention configurations by class to meet compliance needs. Documents added to a class with a retention configuration cannot delete the document until the retention period expires. Additionally, CPE also supports Event-Based Retention (EBR) for events such as employee termination. During the EBR scenario, a custom event handler is created to create or update the retention setting on the object.
CPE retention configuration can work in conjunction with storage vendor FCD configurations. This is what we mean by aligned mode. The CPE retention setting can propagate to the storage retention.

Figure 9.35 – FileNet CPE Aligned versus Non-aligned mode from the IBM FileNet documentation
The advantage of this is that retention is enforced not only at the CPE level but also at the storage level. The majority of FileNet customers implement a retention policy in aligned mode with FCD support for a storage vendor with WORM support.
Summary
In this chapter, we discussed the importance of ECM design, how to best work with documents, and the advanced capabilities of FileNet.
A good and future-proof enterprise management system is not only based on the flexibility of the platform but also the design of the system. We talked about the importance of designing a taxonomy that is consistent and reusable across applications.
We also discussed the security design and application usage to ensure proper isolation and that security compliance needs are met. We looked at how to work with content using OOTB capabilities provided by BAN and through extensions such as BAW. Lastly, we discussed how FileNet can meet compliance needs for storing content using FCD.
In the next chapter, we will learn how to extract and classify documents using Automation Document Processing (ADP).
Further reading
- https://www.ibm.com/docs/en/filenet-p8-platform/5.5.x?topic=features-content-management
- https://www.ibm.com/docs/en/baw/20.x?topic=v2103-case-management
- https://www.ibm.com/docs/en/filenet-p8-platform/5.5.x?topic=objects-retention-content-stored-in-fixed-storage-areas
- https://aws.amazon.com/compliance/secrule17a-4f/
- https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lock-overview.html
- https://www.ibm.com/support/pages/node/6497387
- https://www.ibm.com/support/pages/how-configure-azure-blob-storage-filenet-content-manager