
Why Big Data and What Is It? Basic to Advanced Big Data Journey for the Medical Industry
Neha Sharma⁎; Malini M. Patil†; Madhavi Shamkuwar‡ ⁎ Society for Data Science, Pune, India
† JSS Academy of Technical Education, Bengaluru, India
‡ ZES’s, Zeal Institute of Business Administration Computer Application and Research, Pune, India
Abstract
The idea of big data is mainly reflected in its dimensions, which are popularly known as the Big Vs, which stands for Volume, Variety, Velocity, and Veracity. However, the concept goes beyond the Big Vs and testing of hypotheses, to focus on data analysis, hypothesis generation, and ascertaining the progressive strength of association. Preliminary study reveals that big data analytics adopts many data mining methods, such as descriptive, diagnostic, predictive, and prescriptive analytics. This evolving technology has tremendous application in healthcare, such as surveillance of safety or disease, predictive modeling, public health, pharma data analytics, clinical data analytics, healthcare analytics, and research. Moreover, the journey of big data in the medical domain is proving to be one of the important research thrusts of recent times. Study reveals that medical data is very specific and heterogeneous due to varied data sources such as scanned images, CT scan reports, doctor prescriptions, electronic health records (EHRs), etc. Medical data analytics faces some bottlenecks due to missing data, high dimensions, bias, and limitations of the study of patients through observation. Therefore, special big data techniques are required to handle them. Besides, many ethical, legal, social, clinical, and utility challenges are also a part of the data-handling process, which makes the role of big data in the medical field very challenging. Nevertheless, big data analytics is a fuel to the healthcare system that will provide a healthier life to patients; the issues and bottlenecks when removed from the system will be a boon for the entire human race. The chapter focuses on understanding the big data characteristics in medical big data, medical big data analytics, and its various applications in the interest of society.
Keywords
Big data; Medical big data; Healthcare data; Medical big data analytics; Healthcare data analytics; Data analytics; Pharmacology data analytics
8.1 Introduction
Big data analytics is the most significant technology of the fourth industrial revolution, which is mainly about digital transformations. In a very short span of time, the technology has covered various sectors, namely, e-commerce, mobile applications, sensor networks, geospatial communication systems, healthcare, etc. For every such domain, the data arrival rate is in exabytes and even greater. The healthcare system, besides being unique and massive due to the speed of data arrival, is also highly challenging to handle due to its heterogeneous nature. Patient data is present in multiple forms from the inception of the disease, with medical history, treatment period, posttreatment process, postoperative data, and the diagnostics data available as CT scans, ultrasound reports, X-rays, MRI, and ECG. The size and type of this complex data surpass the capacity of common software tools to store, manage, and analyze. Healthcare data analytics contains the solution to the problems discussed here, with a handshake of technology and healthcare resulting in computational and statistical methods. The technology-healthcare duo has given both vision and tools for medical data analytics. It is a breakthrough work for today and into the future.
The healthcare sector is highly influenced by the fast-changing world, with population growth and lifestyles of people resulting in chronic diseases. Big data has penetrated the sector due to its multifaceted methodologies and one-stroke solution for the healthcare sector. It is expected that every person should and must have a healthcare system that is easily accessible, quantitative, and cost efficient. An optimized patient-centric system used for effective detection of diseases, their treatment and follow up is what researchers, scientists, and many healthcare organizations are looking for.
Apart from healthcare organizations, pharmaceutical industries are also greatly influenced by the growth and impact of big data. The pharma industry is not only the drug discovery or drug manufacturing industry, but it is a confluence of the chemical industry, academicians, mathematicians, doctors, technocrats, and business organizations looking to provide a better healthcare system to humankind. It is a new avenue in research in which pharmaceutical data plays a vital role in data analysis. The pharma industry is considered to be a subset of medical data, as it manages data regarding medicines. For better analytics, both pharma data and medical data are to be handled separately. Healthcare or medical data analytics is a very challenging subject because of its interdisciplinary nature, but it has the potential to provide a new avenue for medication.
Medical big data processing can also be managed using cognitive approaches, and natural language processing may be used to handle the same. If a patient record consists of noise or has any missing data (symptoms), during preprocessing that can be filled in by counseling the patient and rechecking the data. A cognitive approach is more suitable in the case of patients suffering from emotional disorders such as depression problems, as representation of data under these cases is quite complex and totally different.
This chapter presents the journey of medical big data in a systematic way. The next section reviews the work done by researchers on various aspects of medical big data; Section 8.3 presents big data, medical big data, and value derivation from it. Section 8.4 presents medical big data analytics, and Section 8.5 discusses various applications of medical big data. Finally, Section 8.6 discusses the challenges and Section 8.7 summarizes the chapter with conclusions, followed by references.
8.2 Related Work
This section presents a survey of research work that has already been carried out or is being carried out to exploit the big data generated in the medical industry. Colossal amounts of data of diverse types are generated every single moment from varied medical data sources, such as clinical notes, test readings, pathology data, pharmacology data, scientific web pages, data related to gene structure and protein structure, webpages and social media of the medical world, drug reviews, etc. This data satisfies all the dimensions of big data and qualifies as medical or healthcare big data and is available for analytics. An article in the Stanford Medicine Health Trends Report by L.B. Minor highlights the power of healthcare big data and ways to harness it [1], whereas Fodeh et al. present the scope of mining big data in biomedicine and the healthcare sector [2]. However, one of the critical aspects of medical big data analytics is collection and preprocessing of large volumes of data available from different sources in various forms. There are a few researchers like Chard et al. who have been rigorously working to develop a tool to gather the multielement datasets from multiple sources and share the integrated dataset with big data analysts and scientists to analyze the large and complex dataset [3]. A few researchers have created pipelines for specialized data, such as Jenkins et al. who proposed a specialized framework for data and methodology sharing in the domain of the diffusion tensor image process [4] and Sarraf and Ostadhashem who have developed a platform to convert functional magnetic resonance imaging (fMRI) data to resilient distributed datasets [5].
Medical data analytics is not only about collecting various types of data but also about maintaining its quality so as to have meaningful explorations after analysis. Becker et al. have presented various issues related to data quality [6]. According to them origin of data could be one of the reasons for data quality, but the other bigger reason is handing its complexities while maintaining the integrity. Wang discusses the challenges in the health and biomedical informatics pipeline in terms of data quality, feature extraction, data modeling, actionable decision making, and feedback [7]. Systematic research using medical big data was also presented in his paper with a main focus on patients and outcome-based precision healthcare.
The application of big data analytics to this huge set of structured and unstructured data helps to fully understand the hidden meaning and correlation in the data as well as obtain insight. Kaushal discussed various possible applications of big data analytics in the medical industry, whereas Luo et al. presented an elaborate literature survey on big data applications in the specialized field of public health informatics, clinical informatics, bioinformatics, and imaging informatics [8, 9]. Viceconti et al. claim that a robust and effective medical solution can be developed by combining big data analytics and virtual physiological human (VPH) technologies [10]. Tafti et al. presented bigNN, an open-source toolkit based on big data neural networks, which was designed and developed to classify the large volume of biomedical texts efficiently and perform text analytics [11]. Jordanski et al. have used a machine-learning approach to perform big data analytics and present a model to predict wall shear distribution for carotid bifurcation and abdominal aortic aneurysm [12].
Lee et al. have proposed a hybrid framework using rule-based learning and machine-learning techniques to design a natural language processing system for automatic deidentification of psychiatric notes [13]. There are many researchers who are developing a prediction system using big data for mental illness [14–18], symptom severity [19], heart failure [20], diabetes [21], epilepsy [22] and many more. Also, electronic health records are being used to develop prediction systems for different requirements [23, 24].
Though there are numerous big data applications of medical data, Miller highlights that there is a dearth of appropriate infrastructure for biomedical data to perform big data analytics and build an intelligent healthcare system [25]. Teknolojileri et al. and Lee et al. present the importance of big data analytics in biomedical informatics along with its expectation, promise, and challenges [26]. Wang et al. propose a new citizen science paradigm on a Massive Online Open Course (MOOC) platform to train volunteers to understand the concepts and details regarding hypertension and to support big data research by creating the right kind of data [27, 28].
8.3 Big Data and Medical Big Data
It is a digital world now and that fact contributes to the generation of a vast amount of data. The medical industry is no different. This section presents basic information regarding big data and attempts to understand the relevance of big data for the medical industry.
8.3.1 Big Data Dimensions
Big data is that data engendered by various instruments and websites, like sensors for various applications, blogs, social media sites like Facebook, Twitter, or LinkedIn, electronic health records, GPS signals, and many more. It is called big data because it requires a novel architecture, different techniques, complex algorithms, and powerful analytics to manage the data of higher scale and to extract knowledge from diverse and complex data [29]. As the magnitude of data upsurges above a precarious point, qualitative issues become more important than quantitative issues in capturing, storing, processing, analyzing, and visualizing the data. Usually, volume, variety, velocity, and veracity characterize big data, but the definition goes beyond these four Vs [29]. It has potential to accrue value over time, to give unbiased representation of the real world, to link with other related datasets, to be valuable and used again, and to revolutionize a systems-level multidimensional understanding alongside of the popular four Vs of big data [30, 31]. So big data is not only about four Vs but has several other dimensions, like variability, visualization, value, virality, viscosity, and volatility. In 2001 research company Gartner used only three Vs to define big data. But as time went on, through research and work experiences while handling different applications, many Vs were introduced, as shown in Fig. 8.1 and as defined in this section.
- 1. Variety: Big data is a collection of a variety of data like digital photos, sensor data for different applications, electrocardiogram (ECG), electronic health record (EHR), social websites data, audio, etc.
- 2. Velocity: Velocity is the measure of the speed of data coming from sources like networks, mobile phones, machines, and sensors. The flow of data is continuous but includes structured and unstructured data formats.
- 3. Veracity: This refers to the need for understanding data and the quality of data generated. Veracity refers to disturbances in the data like noise, biases, etc. It is the biggest challenge in the big data field, as data is always in a doubtful stage. The data is not useful if it’s not accurate.
- 4. Variability: It refers to the constant change in data meaning. Variety and variability differ slightly, where providing different flavors of juices is variety and getting the same flavor of juice with a different taste is variability.
- 5. Visualization: Collected data has to be presented in human understandable form to make it more significant to everyone. But due to the numerous characteristics like volume, velocity, etc. of big data, this becomes a difficult task. With the help of visualization, it is possible to provide a clean and complete picture of the data.
- 6. Value: Until and unless the gathered data obtains some value, it is useless. Getting the value from the big data is the key point of research.
- 7. Volume: Volume refers to the vast amount of data, which is measured nowadays in zettabytes and yottabytes. The data is generated at very high speeds and in big quantities due to advancements in technology. Volume itself is a reason to decide whether it is big data or not.
- 8. Virality: It refers to the speed with which the data spreads across the network. In data analytics, along with data, time also plays an important role. The time of spreading the news also has a critical role in analysis.
- 9. Viscosity: Viscosity refers to oppositions to the flow of data. It may be an external entity like a network or may be an internal entity like the variety of data.
- 10. Volatility: Volatility indicates the lifetime of the stored data. The decision to keep or discard the data after fetching the information is the volatility of data.

8.3.2 Big Data for Medical Industry
The unpredictability of the medical industry is due to the range of diseases, their comorbid conditions, variety of treatments, different outcomes, and the fine details of study plans, analytical techniques, and methodologies for collection, preprocessing, exploring, and understanding of healthcare data [32]. The diverse sources of big data for the medical industry are case records, clinical data, electronic records, outpatient reports, medical images, web data, biometric data, biomarker data, and many more [33, 34]. Integration of these information sources creates a huge dataset with high dimension, enhanced complexity, incongruences, and missing values. Tanaka et al. [35] have outlined the characteristics of medical big data and contrasted it with conventional clinical epidemiological information. Investigation of medical big data is a hard and equally sensitive task [31]. As per the literature, there is no specific method, protocol, or benchmark to measure the performance of medical big data analytics [32]. Collection of medical big data, however, adopts protocols and is relatively structured [36], but it is expensive due to the involvement of costly instruments and people (practitioners, patients, technicians, etc.). It is also prone to uncertainties such as measurement faults, missing values, or coding errors. This clearly indicates that there is a need of a domain expert to perform big data analytics for the medical industry and also to construe the results [37]. Another typical feature of medical big data is the constant change in patient characteristics and treatment decisions with respect to time [38].
The main focus of any big data project is to decipher the information hidden in the data heap on the maximum possible dimensions in a cost-effective manner [39]. As per Iwashyna and Liu [40], data, queries, analytical method, and objective are the four driving factors of any big data project [40]. A medical big data analytics project may consider data from various sources such as website, social media, online healthcare, information systems, etc. to perform analysis, respond to the queries, and meet the set objectives. Hence, big data technology is rapidly becoming an integral part of the medical industry, boosting the continuous learning about the healthcare system and encouraging research and operations, as shown in Fig. 8.2 [40].
8.3.2.1 Types of Medical Big Data
Medical data and clinical epidemiology can be considered medical big data. Let us assume that a medical big dataset has n = number of samples and p = number of parameters. Depending on the value of n and p, the medical big data is divided into three types: large n and small p; small n and large p; and large n and large p [30]. Administrative data is an example of data with large n and small p, which often suffers from incompleteness, noisiness, and inconsistency. Such datasets can be analyzed with classical statistical methods. Understanding the context and reason behind data collection is as important as data cleaning, and it might generate spurious associations. Therefore, it is essential to have expertise to be able to discriminate between domains of scientific and statistical significance. Microarray datasets are examples of data with small n and large p and classical statistical methods may not be efficient due to the curse of dimensionality and multiple testing issues. The final type of medical big data has large n and large p and can be dealt with by scientific or statistical methods depending on certain circumstances. There are many common features and differences among medical big data analysis and clinical epidemiology, which is presented in Table 8.1.
Table 8.1
| Application | Hypothesis-generating |
| Questions of interest | Update the dataset and algorithm for analysis to overcome the constraint of locally or temporally stable association. |
| Domain knowledge | Highly significant for understanding the results |
| Sources of data | The detest may comprise multiple relevant sources |
| Data collection | Automated data collection without the direct supervision of any person |
| Analysis of data coverage | Significant portion of entire population |
| Data size | Massive |
| Nature of data | Data may be structured as well as unstructured |
| Quality of data | Not so good |
| Research questions for data analysis | Are not similar to that of research question for data collection |
| Underlying assumption of the model | Generally not present |
| Tools for analytics | Often are automated data mining tools |
| Analytical outputs | Usually are in the form of models, predictions, patterns |
| Privacy and ethics | It is a matter of concern |
8.3.2.2 Issues With Medical Big Data
Apart from the regular issues faced in big data analytics, medical data analytics has joined with healthcare system specific issues. Detailed descriptions of those issues are presented in this section.
8.3.2.2.1 Incompleteness and Missing values
Big data analysis for the medical industry handles data collected from many sources for different purposes but suffers from incompleteness in datasets and missing values of the variables. The simplest way to handle missing values or incomplete data is to remove the case from the dataset or add the data value, provided the missing value is independent of observed and unobserved data values. Besides, many data mining algorithms are able to handle missing values during preprocessing, but in the case of medical big data, this is a highly critical and challenging task [41]. Missing data might show different associations with existing observed and unobserved data values, which can be of three different types:
- (1) Missing completely at random (MCAR)—Missing data has no association with observed and unobserved data. In this case adding the missing data would not affect the analysis process.
- (2) Missing at random (MAR)—Missing data has no association with unobserved data but is associated with observed data. In this case, missing data can be added for observed data.
- (3) Not missing at random (NMAR)—Missing data has association with unobserved data.
WinBUGS, R, SAS, Stata, etc. are some automated tools to handle incompleteness or missing values for all the three types [42]. All the tools would give the same result if the missing value is less than 10%. If the missing value is between 10% and 60%, then the tools might give various suggestions. However, if the missing value is more than 60%, then most of the tools fail to give reasonable results [42].
8.3.2.2.2 Heterogeneity
The data sources are from a variety of diagnoses conducted on patients, namely patient personal information, prescriptions, electronic medical records, X-ray images, scanned images of all types, diagnosis records, doctors’ handwritten prescriptions. Data preprocessing or data preparation of heterogeneous data is very complex work. Heterogeneous or highly unstructured data is also collected from various wearable devices, health monitoring devices, dietician notes, and insurance reports. Digitization of unstructured data is to be carried out precisely so that data should not be inconsistent. This may form the basis for the prediction of clinical emergencies based on previous experience and current conditions.
8.3.2.2.3 Dimensionality, Scalability, and Complexity
Medical data has high dimensionality with too many observed attributes compared to traditional databases. Gene sequence or microarray data are examples of high-dimensional medical datasets. High dimensionality and the large scale of the dataset makes it so complex that existing data management methods, sampling approaches, machine-learning techniques, and other analytics methods are inadequate. In 1950, for the first time the term “curse of dimensionality” was coined by Richard Bellman to explain the situation [30]. Model overfitting, sparsity of the data, computational cost, model complexity, and multicollinearity are critical issues with high dimensionality [30]. Feature selection or a dimension reduction method is used to handle high dimensionality [43, 44]. However, one needs to be careful of losing important information and understanding the thin difference between false positive and novel insight [45].
8.3.2.2.4 Timeliness
Speed or velocity of big data is another major concern when voluminous data is to be processed. The larger the size of the data, the longer the time required to process it. Speed is directly proportional to the data-gathering process and data-analysis process. In the case of emergencies, the medical big data needs to be processed very urgently for some immediate diagnosis purpose. This is a major task in medical big data analysis. Sometimes, partial results may help the doctors to predict the future consequences of treatment. To achieve this, indexes are created in advance to process huge data for quick results, as it is not practical to examine the complete dataset to find appropriate elements. Indexing is the implementation criteria of medical big data.
8.3.2.2.5 Privacy, Security, and Ethics
Data privacy and security are the major concerns while handling medical big data. Most of the organizations have adopted laws for handling EHR records. Inappropriate handling of personal data is highly not advised. With respect to a big data point of view, such data access points are very risky as they use a distributed computing approach. They face sociotechnical problems. In the case of the location-based service architecture used in handling medical big data, various data sources are combined and the locations are shown by the service provider, which raises the privacy concerns of a patient record. Data sharing can bring an advantage at societal levels and therefore should be further promoted. The organization can provide appropriate technical and organizational measures to control the privacy attacks.
Possible testing of the usage of big data techniques and methods will not have any issues with regard to benchmark datasets. Another notion is followed in big data design techniques. It is commonly referred to as “privacy by design.” To develop privacy aware designs and computing environments in medical big data, analysts can follow this essential principle and practice the same.
To support the data uses in understanding this difficult landscape, ethical guidelines have been generated and professional codes of conduct are being discussed under different implementation environments. Ethical thinking is advised to be followed in the engineering and innovation community.
8.3.3 Medical Big Data: Value Derivation
The three key drivers of big data in the healthcare system are to improve healthcare quality with better patient treatment, to increase medical data availability, and to increase analytic capabilities for identifying medical trends and patterns. The new era of technology in terms of big data has resulted in better patient outcomes and reduction in resource data wastage [33].
Big data finds associations among different variables, to find a signal that triggers the trend-pattern identification [46]. Big data analytics focuses on identifying correlation or patterns of complex structured and unstructured data [33].
The possible benefits of medical big data in healthcare are: (1) to prescribe personalized medicine; (2) to use specialized tools to perform analytics on patient’s record, images, and other data; (3) to plan diagnostics, decide treatments, and share educational messages; (4) to perform big data analyses for the entire population of the healthcare industry to reveal hidden patterns that would be unable to be found if the data is in smaller batches; and (5) medical fraud detection and prevention [47].
Big data uses devices with high resolution for generating medical images, for example, next-generation sequencing or microarray, which monitors the characteristics of the molecule during treatment and is highly useful for prediction and patient treatment decisions, and continuously monitors the patient’s health [38].
Rumsfeld et al. [33] in their research have identified various areas in which medical big data analytics can substantially improve the state of healthcare. A few applications are: (1) disease and treatment heterogeneity; (2) predictive model for risk and resource use; (3) medical device and drug safety surveillance; (4) population management; (5) performance measurement and quality of care; (6) public health; (7) precision medicine and clinical decision support; and (8) research applications. Basically, predictive analytics using medical big data learns from change of data behavior from previous experience and predicts the behavior of disease, treatment, etc. in future, in order to make better patient care decisions. The data thus predicted give a crystal-clear view of future insights in terms of data associations, across time, demographics, a wide geographic area, or experiential learning from a significant fraction of a whole population [48, 49]. The significance of medical big data will be revealed if it generates future insights on which actions can be planned.
8.4 Medical Big Data Analytics
8.4.1 Need and Importance
Big data analytics in the healthcare sector has a greater future as it has positive impact on the lives of individuals in curing disease, preventing disease epidemics, lowering the treatment costs, and giving better treatment quality as depicted in Fig. 8.3. The data-driven behavior of big data analytics has highly influenced the treatment methods and models. The cognitive approach toward patient’s behavior will be understood if a patient sends an “illness signal” at their origin time and the treatment will be done faster and in a simpler way. Initially it was costly and time consuming to gather voluminous data for medical use. With the advent of technologies, data collection, storage, and trend analysis have become crucial for better patient care. Big data analytics have highly empowered stakeholders with the tools for treatment planning, inventory tracking, and patient intensive care. The tools of big data analysis comprise algorithms of data mining with advanced search techniques that determine correlations and patterns in huge databases that already existed [50]. An application that applies data analytics to clinical problems is called clinical data analytics [51]. Regardless of its applications, the data analytics algorithms are categorized as supervised, semisupervised, and unsupervised learning. Supervised learning uses a “training set” that has classified data to predict a known output, draw inferences, and further test data. Semisupervised learning provides a balanced performance and better precision among small labeled datasets and larger unlabeled data collection [32, 52]. Unsupervised learning, on the other hand, helps the analyzer to discover the obvious data patterns or groups within unlabeled data.

8.4.2 Data Mining in Medical Big Data
The most common methods in medical big data are modeling, prediction, inference, clustering, classification, and regression [30, 37]. Classification is a predictive modeling, a type of supervised learning in which the predicting variable or output vector is categorical in nature. Based on vector measurements taken on objects, they are assigned to the predefined set of classes, i.e., predicting variables. A few popular techniques are logistic regression, decision trees, naïve Bayesian methods, Bayesian networks, neural networks, and support vector machine. Clustering techniques include principal components– based clustering, k-means clustering, and self-organizing maps.
A decision support system is designed that assigns a particular diagnosis out of a pool of possible diagnoses or predicts trends for many biomarkers. A statistical analysis tool is mainly used for depicting the relationship between a dependent variable and one or more independent variables, especially when an output variable is continuous. The most commonly used technique of regression is linear regression and it is applicable to longitudinal analysis of patients’ data or decision support systems [30, 52].
Iavindrasana et al. [51] have concisely presented a data mining process in nine steps, as shown in Fig.8.4.
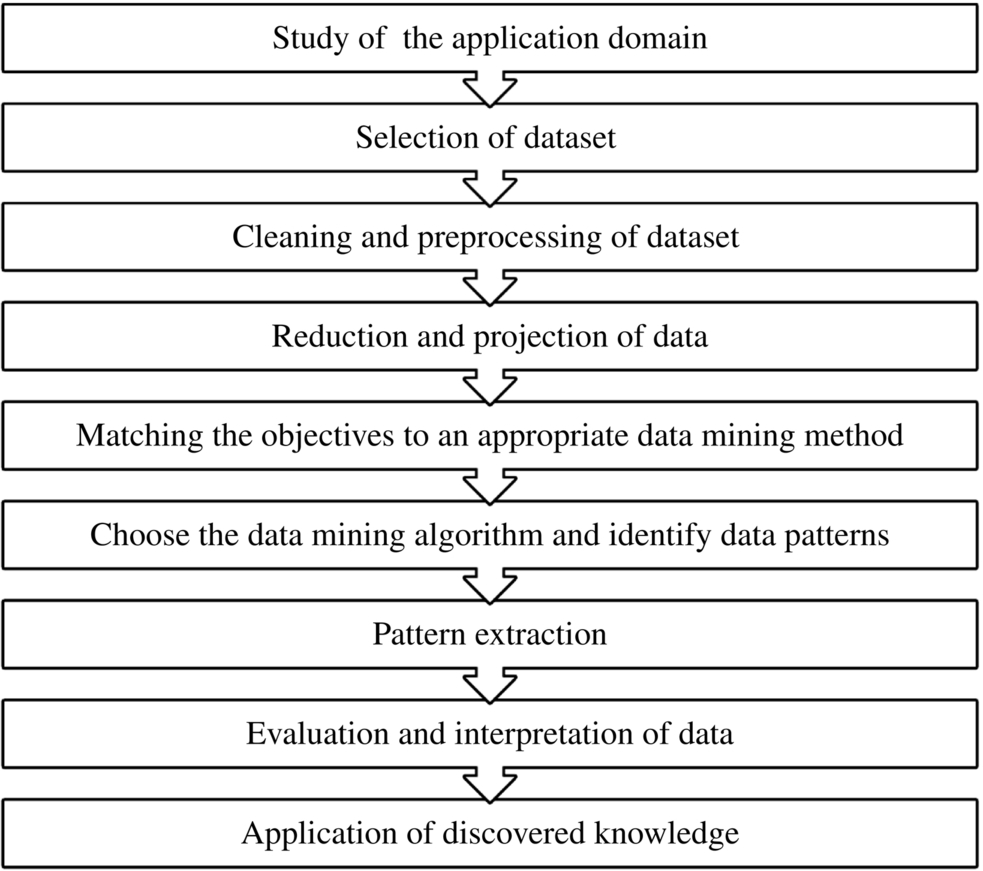
Data cleaning and preprocessing suffers from various issues; in the case of numerical data, the issues involved are pertaining to data type, viz., binary, nominal, ordinal, or numerical; variable domination; data redundancies; missing value; and outlier issues. Data reduction and projection steps cover the process to overcome the curse of dimensionality and reduce the number of variables to improve the efficiency of computation. The pattern extraction involves dividing the dataset into training and testing sets and testing the model build on the training set. The methodologies used to split the dataset are cross validation, leave-one-out, stratified cross validation, and bootstrapping methods. For evaluation of the model, the performance metrics used are sensitivity, accuracy, specificity, receiver operating characteristic (ROC) curve, recall, precision, f-measure, number of positive predictions, and number of false positives [51]. The pattern extraction step involves evaluation of various algorithms and choosing the best algorithm on the basis of performance, termed a bake-off. In healthcare, apart from performance, transparency or understandability is another major issue considered.
The entire process of medical big data analytics is depicted in Fig. 8.5.

8.5 Applications of Medical Big Data
Big data is helping to solve predictions regarding patients that eventually benefit staffing; a solution to this problem has been implemented in Paris. An article in Forbes discusses the strategy implemented by four hospitals running under the umbrella of Assistance Publique-Hôpitaux de Paris to integrate data from various sources so that hourly and daily predictions regarding number of patients visiting the hospitals are made. Data scientists have applied time series analysis techniques on the key datasets of 10 years of hospital admissions records. The hidden patterns thus discovered helped to predict the number of patient admission rates and thus the staff availability is improved. Machine-learning algorithms serve as an important tool to select the most accurate algorithm to analyze and predict the future patient admissions trends. Forbes in its concluding remarks said that a web browser–based interface designed to serve the purpose will predict the future trends for the next 15 days. As the number of patients increased in the predicted time, more staff can be made available so that the waiting time of patients is reduced and better patient care is guaranteed.
- (2) Electronic Health Records
EHRs are the most common form of using big data analytics in healthcare; they digitally store the patient’s reports such as demographics, medical history, allergies, laboratory test results, etc. A secured information system is implemented to make these records available to both the public and private sector. With such a system in place, there is no paperwork and no data duplication, as each record contains an updatable file where the doctors can make changes over time.
EHRs generate warnings and reminders for tracking patient prescriptions given by doctors and alerts for conduct of particular laboratory tests needed. EHR implementation is a worthy goal to be achieved, but many countries are still struggling to implement it. As per HITECH results, the United States is leading with 94%, but many European nations are lagging behind. The research further shows that the European nations will implement EHR by the year 2020, as drafted by the European Commission.
In the United States, Kaiser Permanente has provided a model that can be effectively followed by the EU. They have designed and implemented a system called HealthConnect, which is much easier to use and shares data regarding all the available facilities. An estimated $1 million is saved by reducing the office visits and pathology tests for cardiovascular disease, as per report by McKinsey on integrated systems on big data healthcare.
- (3) Real-Time Alerting
Real-time alerting is one of the crucial functionalities provided by healthcare analytics with the use of big data. In hospitals, a real-time system called Clinical Decision Support (CDS) software aids the doctors and health practitioners with advice and prescriptions given to the patient on the spot. On the other hand, this real-time system is costly so doctors prefer the patients to stay away from hospitals. Recently “personal analytics devices” has been a trending business intelligence buzzword, referring to devices with which the patient’s health data is continuously monitored by wearable devices and shared via the cloud.
This information further will be used for the sound health state of the general public, where doctors are implementing strategies as per the socioeconomic status of the patients. The sophisticated tools used by institutions and care managers will monitor the voluminous data stream and respond to the results frequently.
For instance, if there is a sudden increase in a patient’s blood pressure, an alarm will be sent to the personal doctor, who will then visit the patient and take corrective actions to lower the blood pressure. The Asthmapolis system, a GPS enabled inhaler, is used to identify asthma trends on larger populations as well as at the individual level. The data thus derived will be aggregated from the CDC so that better treatment plans for asthma can be planned.
- (4) Enhancing Patient Engagement
People have become more health conscious and as a result they have been more inclined toward the use of smart devices to record blood pressure and pulse rate, track sleeping habits, and monitor their daily routine on a permanent basis. Potential health risks can be identified using this vital information in conjunction with other trackable data.
In future, heart disease may be predicted by the occurrence of an elevated heart rate and chronic insomnia. With the use of smart devices, the patient will be involved in health monitoring activities and health insurance companies can motivate their clients to live a healthy life by giving money back to all those who use smart devices to track their health. Specific health trends will be identified by a system, under a development process in which physicians can depend on the data available in the cloud. Patients will become more independent and the number of hospital visits will be reduced for patients suffering from asthma, hypertension, or other chronic issues.
- (5) Prevent Opioid Abuse in the United States
Opioids are a group of drugs primarily used for pain relief but also containing illegal drugs such as heroin. Currently the United States is facing the adverse effects of an opioid crisis. Deaths due to opioids are more prevalent than other causes of death. Most accidental deaths in the United States occur due to overdose of opioids, as compared to other accidental deaths. An article in Forbes written by Bernard Marr, an analytics expert, said that in Canada, consumption of opioids is termed a “national health crisis.” As an indicator of the sensitivity of this problem, in the United States President Obama had earmarked $1.1 billion for finding solutions to this healthcare problem.
Extensive use of analytics applied to medical big data can provide solutions to many problems in healthcare. To tackle this problem, data scientists from Blue Cross Blue Shield are using Fuzzy Logix. Analysts from Fuzzy Logix working on insurance and pharmacy data identified 742 risk factors associated with opioid consumption. The system they developed is accurate enough to predict individuals with risks of using opioids.
This project provides hope for all those whose lives have been damaged by the use of this drug, but as a result the system is becoming more costly. It is difficult to reach out to opioid “high risk” people and preventing them from using drugs is a delicate task.
- (6) Informed Strategic Planning Using Health Data
Strategic planning in healthcare is a must, and big data analytics caters exactly to healthcare needs. Care managers can analyze the factors that prohibit patients from receiving a treatment. For the same, an extensive analysis needs to be conducted that obtains check-up results of patients with different demographics.
Another application was designed by the University of Florida using Google Maps to depict various real-time issues viz. population and spread of chronic disease in the form of heat maps. The availability of medical services in the intense areas is then compared with the real-time data and decisions are made regarding healthcare delivery strategies augmented by more healthcare units in the heated areas.
- (7) Big Data Might Just Cure Cancer
The Cancer Moonshot program is a system developed for curing cancer using bigdata. This program was initiated by President Barrack Obama in the second term of his administration. The goal of this program was to cure Cancer in just half the time required to cure it in normal way.
Researchers from the medical field are using massive data to achieve better success in their treatments and identify useful trends. The outcome of this initiative will be better treatment plans and greater recovery rates. Related to this, samples of tumors stored in biobanks are interlinked with patient treatment records. This data can be referenced in order to see the mutations and interaction among cancer proteins and map related treatment plans and trends for better patient outcomes. Furthermore, the treatment trend analysis may give surprising results; for example, the presence of desipramine, an antidepressant, can cure certain types of lung cancer.
This type of research demands interlinking of various institutions, hospitals, and nonprofit organizations so that the patients’ treatment records are made available. Access to patient biopsy reports and performing the required analysis will be allowed by other institutions. Also, cancer tissue samples of clinical trial patients will be genetically sequenced and added to the global cancer database.
Big data analytics in finding a cancer cure faces certain hurdles that could overweigh its benefits. First, due to incompatible data systems the datasets are unable to interface with other. Second, the laws of any country assure privacy of its citizens, but such a system can release patient information with or without the patient’s consent.
- (8) Predictive Analytics in Healthcare
The potential of predictive analytics has already been unleashed for business applications and it will be explored more in the near future. A research project in the United States by Optum Labs has collected datasets from 30 million patients so that the quality of delivery care can be increased.
These business intelligence tactics help doctors and health practitioners to make decisions based on the available datasets and provide better patient treatment. When the patient has a complex medical history and suffers from multiple health disorders, strategies of business intelligence are helpful. New tools will predict who is at risk of diabetes, blood pressure, or heart disease, for example, and thereby patients can be advised to have regular physicals or make use of weight management programs or dietary plans, etc.
- (9) Fraud Reduction and Security Enhancement
The healthcare sector is 200% more susceptible to data breaches as compared to other sectors, as selling personal health data can be lucrative. A data breach generally leads to dramatic consequences. Thus, it has become a norm for many organizations to make certain provisions to protect against security threats by applying algorithms that would detect network traffic, changes in the patterns, and any unacceptable or suspicious behavior. Due to security concerns the patient datasets become more vulnerable and thus organizations face security issues. The solution to security issues is to implement technologies such as firewalls, encryption technology, antivirus software, etc. that will resolve them. The use of technology will further help to prevent fraud and deal with inaccurate claims in a systematic way, yielding better results. Furthermore, analytics helps patients to receive more benefits from insurance claims and the caregivers are paid faster and with better returns on investment. The Centers for Medicare and Medicaid Services’s new advanced analytics system saved over $210.7 million due to fraud in its second year of use, almost double the amount of its first year.
- (10) Telemedicine
For over 40 years, telemedicine has been present in the market; however, its presence has bloomed with the influx of new technology like smartphones, wearables, online video conferencing, and wireless devices. The delivery of remote clinical services, i.e., telemedicine, is done through technology. This remote clinical service includes preliminary consultations, early diagnosis, monitoring of remote patients, and healthcare education for medical professionals. Another remote clinical service is telesurgery, which is performed using highly skilled robots with precision at high speed and using real-time data from a remotely located patient.
Telemedicine further provides personalized patient treatment plans, preventing hospitalizations or readmissions. Healthcare data analytics helps clinicians to predict the critical medical events in the patient’s life and prevent the patient’s health from deteriorating.
The costs of hospital admission are reduced and the quality of service is increased with the help of telemedicine, as a patient need not visit the hospital as often. The waiting time for patients is reduced, as their state can be monitored and consultation can be anywhere and anytime.
- (11) Medical Imaging and Big Data
In the United States, every year about $12 billion in medical imaging procedures are performed. Radiologists examine each medical image individually, analyze and store it for several years to be accessed by the hospitals. This procedure is quite expensive both in terms of money and time.
Carestream is a medical imaging provider with products developed using big data analytics. Carestream algorithms are designed in such a way to read the image in a unique manner. These algorithms analyze hundreds of thousands of images and then identify specific patterns found in the medical image pixels and further convert them into a number. This number serves a specific purpose for the diagnosis, eventually helping the doctors in their treatment. The Carestream algorithms are so powerful that the radiologists will look at the number and not the medical image to make their decisions. This saves them from having to remember so many complex medical images along with all the other information that they have to keep in memory. Thus, Carestream algorithms are having a huge impact on the education, experience, skillset, and role of radiologists.
- (12) Preventing Unnecessary ER Visits
The purpose of using big data analytics in healthcare is to predict future disease-treatment trends and patterns but also to automate the entire process and save time, money, and energy. In Oakland, California a woman visited local hospitals 900 times, i.e., on more than a daily basis for 3 years looking for a cure for mental illness and substance abuse. The situation with her was worsened by the fact that her medical records were not shared between local emergency rooms, which of course increased the costs to taxpayers and hospitals. Her treatment costs thus increased and the basic responsibility of taking care of a patient was not fulfilled.
Alameda County Hospitals implemented and evaluated PreManage ED, a data sharing platform, to help solve this issue by sharing medical records between emergency departments. The PreManage ED system allows hospital staff to view patient's test reports from other hospitals, preventing unnecessary assignments of tests and medicines as well as maintaining coherency in the treatment given to the patient by different hospitals.
8.5.1 Pharmacology Big Data Analytics: A Case
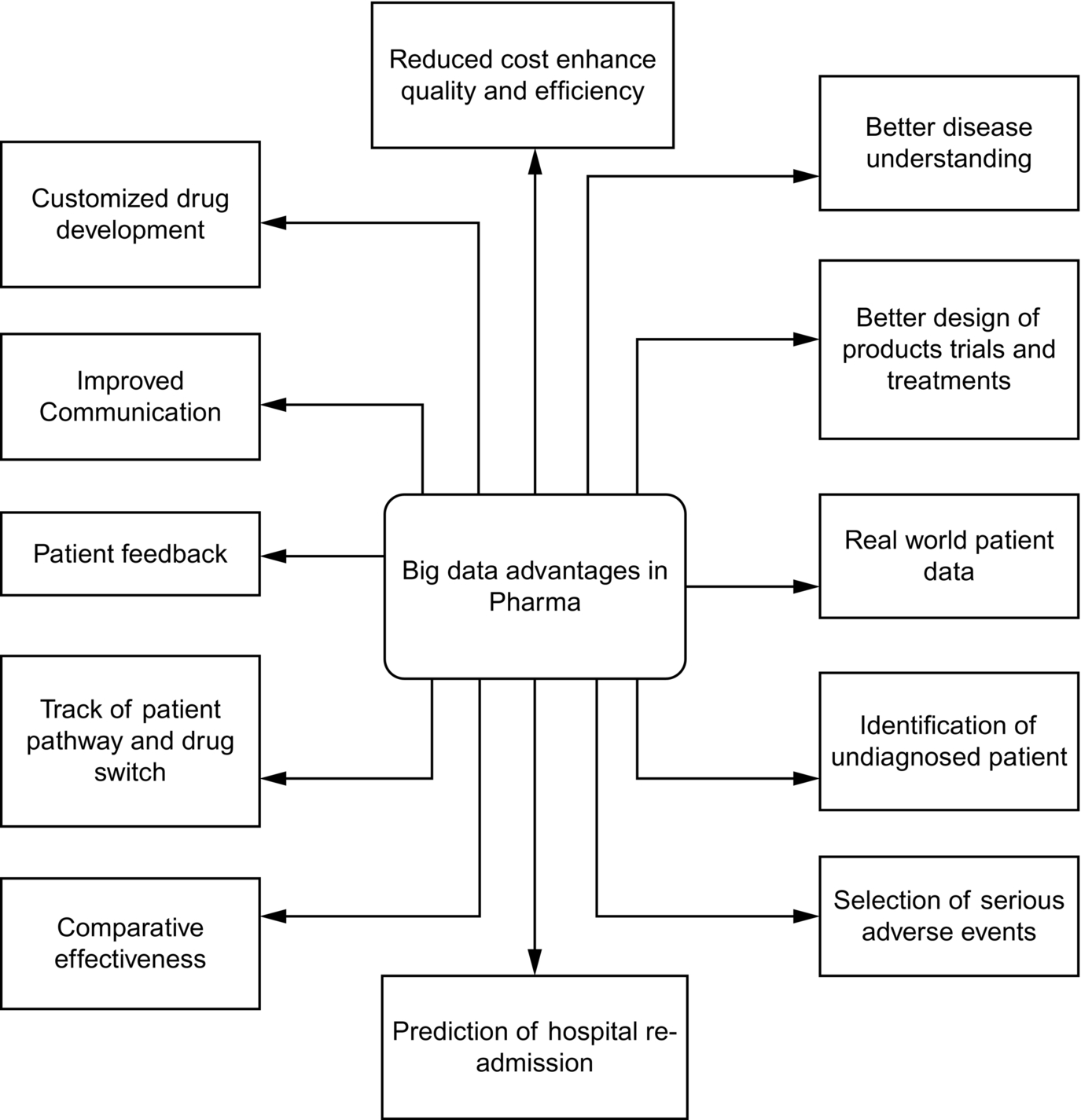
Data without analysis are worthless. As more data evolve, more questions will arise and will lead us to think in innovative way. The research and development wing of pharmacology can make enormous use of big data. If a pharmacology company has the right team and the right tools for data mining and machine learning, it will be able to discover a new drug in a shorter time. Better analysis and earlier predictions provide more profit and a brighter future to the pharmaceutical industry, since with analysis of the patient history, a company can increase its efficiency both in its drug discovery methods and its marketing. Pharmacology data analytics (PDA) is the process of examining datasets and drawing conclusions with the assistance of specialized systems and software [8]. A consumer wishes to get the right medicine at the right time to improve their condition in the right way, for the right patient [9]. In earlier days it was easier to analyze the data because the amount was smaller and the data were more structured. However, due to the advances in current technology much more real-world data (noisy data) is being generated. This scenario represents a major challenge for data scientists to clean the data and bring the information into a structured format. Collection of unstructured data is simple, compared to collection of structured data. The problem with unstructured data is the processing and analysis of the data. When a patient visits a doctor, the prescription written by the doctor is referred to as unstructured data, whereas that same data, when it becomes computerized using patient monitoring system software, becomes structured. Another good example is filling in a given preprinted form produces structured data, whereas that information when written in a paragraph format becomes unstructured data. Using big data analytics, it’s possible to predict disease, prevent disease, and analyze trends in pharmacological data, etc. as shown in Fig. 8.6.
8.6 Challenges for Medical Big Data
Big data analytics obviously has great potential but the “state of science” and the fact that the field is still unproven must be kept in mind. [33]. The challenges imposed by the use of big data analytics in the medical field are critical and are hard to outline. First, as big data analytics is a recent technology, its practical benefits are less evident. Second, big data analytics suffers from inherent methodological issues: data quality, data inconsistency, data incompleteness, privacy, timeliness, heterogeneity, restrictions of observational studies, instability, analytical issues, validation, and legal issues. The data quality needs to be improved, especially regarding electronic health records, being sensitive in nature. For example, in the field of nephrology, codes for chronic kidney disease are not assigned in administrative databases despite the fact that this is a prominent research area, and most cases of acute kidney injury that don’t require dialysis have no codes assigned in claim databases. Thus dramatic changes are required in practices like these, and the technical issues must be solved for better results. Finally, clinical integration and utility of big data analytics are some of the most neglected areas. The substantial benefits of big data analytics in the healthcare sector will be reaped if there is high clinical integration, which is not the case at present [33]. The real worth of big data analytics lies in providing effective, quick-response, and improved patient care along with optimum utilization of resources with less waste. When this sensitive sector is satisfied with big data performance, it will be one of the best gifts that technology can give to mankind.
8.7 Conclusion
Medical data is scattered across many heterogeneous data sources governed by different departments, hospitals, states, and countries, leading to bottlenecks in “big data in the medical field.” A new infrastructure will be formed as a result of integrating various data sources provided by collaborative efforts of data providers. The need of the hour is to design business intelligence strategies and further extend them to revamp the existing system into a new online reporting software system. The healthcare sector needs to widen its strategic horizons, which are currently based on standard regression methods, to the latest tools such as predictive analytics, machine learning, and graph analytics. On the other hand, the healthcare sector has made great advances, especially in the United States, with respect to EHRs.
The industry has adapted and adopted some of the newer healthcare analytics applications. With all of us being potential patients, we can only hope that the needed changes will be made and we will witness the equivalent of the Industrial Revolution in the healthcare sector in the near future.