
In this chapter, you will learn one of the implementations of the transformer architecture, developed by Google, called BERT.
Recent work done by researchers at Google AI Language resulted in the publication of a paper known as “BERT (Bidirectional Encoder Representations from Transformers).”
The most important technical advancement that BERT has made is the application of bidirectional training of the popular attention model, transformer, to language modeling. According to the findings of the study on language models, a language model that is trained in both directions at once is able to have a greater awareness of the flow and context of language than models trained in just one direction. The researchers describe a unique training method that they call masked language modeling (MLM) in the publication. This method enables bidirectional training in models, which was previously difficult to do.
BERT also allows us to do transfer learning , which allows the pretrained BERT model to be used in a variety of natural language applications.
Depending on the scale of the model architecture, there are two different pretrained versions of BERT, which are as follows.
BERT-Base has a total of 110 million parameters, 12 attention heads, 768 hidden nodes, and 12 layers.
BERT-Large is characterized by having 24 layers, 1024 hidden nodes, 16 attention heads, and 340 million parameter values.
Workings of BERT
BERT is based on the transformer architecture , which internally makes use of the attention mechanism as discussed in Chapter 2 . BERT’s beauty lies in understanding the context in a sentence and representing a word, keeping the context into account. This means that a word like bank when used in the context of finance has a different representation than when the same word bank is used as in a river bank. BERT only uses the encoder mechanism of the transformer architecture and is mainly used to create better word representations, which can then be used for more downstream applications. The detailed working of transformers was covered in Chapter 2.
The input to the transformer encoder is a sentence of words, and the architecture of BERT is such that it can read in both directions to capture context in words, meaning words that occur both prior to the word in focus and later in the sentence. This overcomes sequential reading, which happens in, say, LSTM-type architectures (although bidirectional LSTMs are possible, they are complex and still have sequential processing) .
In the process of training language models , one of the challenges that must be overcome is identifying a prediction goal. A large number of models provide predictions about the following word in a sequence (e.g., “The sun is sinking in the ___”), which is a directional approach that limits context learning by its very nature. BERT employs two different training tactics in order to overcome this obstacle.
Masked LM (MLM)
Providing BERT with a sentence and then optimizing the weights included inside it in order to produce the same sentence on the other side is what constitutes MLM. Therefore, we give BERT a sentence and ask it to produce the same sentence as the input. Before we really provide BERT that input sentence, we cover up a few tokens.
Before being fed into BERT, word sequences have 15% of their words substituted with [MASK] tokens. This is done before the word sequences are fed into BERT. The model will then make an attempt to make a prediction of the possible value of the masked words. It uses the context provided by surrounding words, both in the left and right directions.
To predict the masked sentence, we will need an additional layer on top of the encoder, which would help in classifying the masked sentence.
The loss function used takes into consideration only the prediction of the masked values. As a direct result of this, the model converges more slowly than directed models do; however, the higher context awareness that it possesses makes up for this shortcoming.

The flowchart represents the structure of masked language from input, masked tokens, BERT, and FFN to the classes column involving 0.05 street, 0.18 market, and others.
Masked language model

A representation of the inference in masked language model work, it depicts the use of the masked language model to predict the masked word, with the model checkpoint.
Masked language model usage for token prediction
This is a screenshot from using the huggingface library, which we will cover in the next chapter.
Next Sentence Prediction
The Next Sentence Prediction (NSP) protocol entails providing BERT with two sentences, designated as sentence A and sentence B. Then, we inquire of BERT, “Hey, does sentence B come after sentence A?” – and depending on the situation, BERT will either say IsNextSentence or NotNextSentence.
- 1.
John went to the restaurant.
- 2.
The kite is flying high in the sky.
- 3.
John ordered a pizza.
Now when we look at these three sentences, we can easily make out that sentence 2 does not follow sentence 1 and, on the contrary, sentence 3 follows sentence 1. This mode of reasoning, which involves dependencies between phrases that span extended time periods, is taught to BERT via NSP .
For training with NSP in mind, the BERT architecture takes positive pairs and negative pairs as inputs.
The positive pair constitutes sentences that are related to each other, whereas the negative pair constitutes sentences not related each other in the sequence. These negative and positive samples constitute 50% each in the dataset.
- 1.
At the beginning of the very first sentence, a [CLS] token is inserted, and at the very end of each sentence, a [SEP] token is placed.
- 2.
Each token now has a sentence embedding that indicates whether it belongs to sentence A or sentence B. Token embeddings and sentence embeddings are conceptually comparable representations of a vocabulary size of 2.
- 3.
Each token receives an additional embedding called a positional embedding so that its position in the sequence may be determined. This is explained in Chapter 2, in the section “Positional Encoding.”
Inference in NSP
- 1.
John went to the restaurant.
- 2.
The kite is flying high in the sky.
- 3.
John ordered a pizza.
Calculate the probability of whether sentence 2 follows sentence 1 and the probability of sentence 3 following sentence 1.
We will again use the huggingface library (which we will cover in the next chapter) to calculate the individual probabilities.
BERT for sentence prediction
This shows that there is a very low probability that sentence 2 follows sentence 1.
This shows that there is a high probability of sentence 3 following sentence 1.
BERT Pretrained Models
BERT is based on the transformer architecture and uses the encoder mechanism primarily. It has many variations including the following.
BERT-Base has a smaller size for its transformer blocks and its hidden layers than OpenAI GPT does, but it has the same overall model size (12 transformer blocks, 12 attention heads, and a size of 768 for the hidden layer).
BERT-Large is an enormous network that accomplishes state-of-the-art results on NLP tasks. It has twice as many attention layers as BERT-Base (24 transformer blocks, 16 attention heads, and a size of 1024 for the hidden layer).
The pretrained BERT models are available at huggingface and can be used directly for the fine-tuning of downstream tasks.
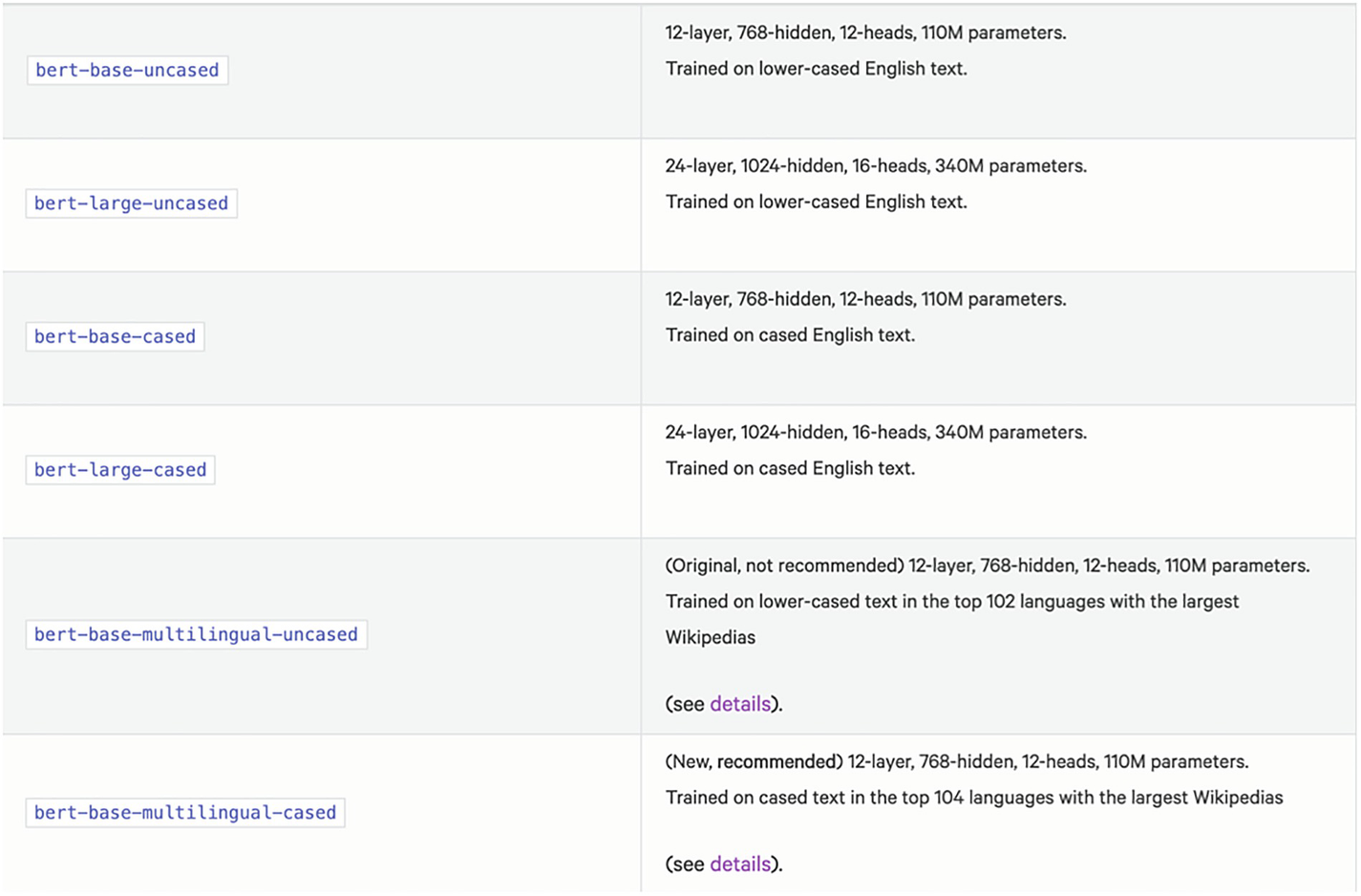
A representation of the bert models involving bert-base-uncased, bert-large-uncased, bert-base-cased, bert-large-cased, bert-base-multilingual-uncased, etc.
Bert models from huggingface
BERT Input Representations
Always consider the first token in a sequence to be a special classification token (also abbreviated CLS). For the purposes of the classification task, the final hidden state that corresponds to this token will be used.
The [SEP] token serves to demarcate the break between the two sentences.
Whenever a sentence pair is being processed, an additional segment embedding is going to be added. This embedding will indicate whether the token belongs to sentence A or sentence B.
The input representation of a given token is constructed by adding positional embedding to the representation of the token.
Use Cases for BERT
BERT can be used for a variety of downstream tasks once we have the proper representations generated by the encoder. These tasks include sentiment analysis, summarization, Q&A, text-to-SQL generation, etc.
Apart from using the pretrained BERT models, we can also fine-tune them with our specific text datasets. This will allow us to take advantage of our own data.
In contrast with other large learning models, such as GPT3, the source code for BERT is freely available to the public and can be viewed on GitHub. This makes it possible for BERT to be utilized in a wider variety of contexts all over the world. This completely changes the dynamic!
It is now possible for developers to quickly get a cutting-edge model like BERT up and running without having to invest a significant amount of time or money in the process.
Also, developers can focus on fine-tuning BERT to tailor the model’s performance to the specific requirements of their individual projects.
If one doesn’t want to spend time fine-tuning BERT, they should be aware that there are thousands of open source and free BERT models that have already been pretrained and are currently available for specific use cases.
- 1.
Analysis of user sentiment on Twitter and other social media
- 2.
Toxic comment detection
- 3.
Speech-to-text
- 4.
Question and answering
And many more.
We take a tweet classification example of BERT in the following using the huggingface library.
Sentiment Analysis on Tweets
Sentiment analysis using BERT

An illustration of the sentiment analysis of the tweets using BERT, which is a large-scale model that is pretrained for English tweets and to instruct tweet training.
Execution of Listing 3-2. This shows downloading of models and tokenizers
This shows how the Bertweet model is able to classify the preceding two tweets.
The POS score shows the positive sentiment, and the NEG score shows the negative sentiment.
Performance of BERT on a Variety of Common Language Tasks
- 1.
SQuAD (Stanford Question Answering Dataset): This is a question and answering dataset from Stanford. Performance of BERT on this dataset was much ahead of existing models and also much better compared with a human.
- 2.
SWAG: Here, SWAG stands for Situations with Adversarial Generations . This is a dataset derived from everyday scenarios and mainly tests common sense and reasoning. Here, also BERT outperformed other models as well as human performance.
- 3.
GLUE: Stands for General Language Understanding Evaluation . This evaluates how a model works in terms of understanding a specific language. There are some specific tasks on which a model is evaluated here. Here, also the performance of BERT was exceptionally good .
Summary
BERT is an extremely complicated and cutting-edge language model that assists individuals in automating their language comprehension. It is supported by training on massive amounts of data and leveraging the transformer architecture to revolutionize the field of natural language processing, which enables it to accomplish state-of-the-art performance.
It appears that untouched NLP milestones have a bright future, thanks to the open source library that BERT provides, as well as the efforts that the incredible AI community is making to continue to improve and share new BERT models.