
WHAT YOU WILL LEARN IN THIS CHAPTER:
How to use arrays
How to declare and initialize arrays of different types
How to declare and use multidimensional arrays
How to use pointers
How to declare and initialize pointers of different types
The relationship between arrays and pointers
How to declare references and some initial ideas on their uses
How to allocate memory for variables dynamically in a native C++ program
How dynamic memory allocation works in a Common Language Runtime (CLR) program
Tracking handles and tracking references and why you need them in a CLR program
How to work with strings and arrays in C++/CLI programs
How to create and use interior pointers
So far, we have covered all the fundamental data types of consequence, and you have a basic knowledge of how to perform calculations and make decisions in a program. This chapter is about broadening the application of the basic programming techniques that you have learned so far, from using single items of data to working with whole collections of data items.
In this chapter, you'll be using objects more extensively. Although you have not yet explored the details of how they are created, don't worry if everything is not completely clear. You'll learn about classes and objects in detail starting in Chapter 7.
You already know how to declare and initialize variables of various types that each holds a single item of information; I'll refer to single items of data as data elements. The most obvious extension to the idea of a variable is to be able to reference several data elements of a particular type with a single variable name. This would enable you to handle applications of a much broader scope.
Let's consider an example of where you might need this. Suppose that you needed to write a payroll program. Using a separately named variable for each individual's pay, their tax liability, and so on, would be an uphill task to say the least. A much more convenient way to handle such a problem would be to reference an employee by some kind of generic name — employeeName to take an imaginative example — and to have other generic names for the kinds of data related to each employee, such as pay, tax, and so on. Of course, you would also need some means of picking out a particular employee from the whole bunch, together with the data from the generic variables associated with them. This kind of requirement arises with any collection of like entities that you want to handle in your program, whether they're baseball players or battleships. Naturally, C++ provides you with a way to deal with this.
The basis for the solution to all of these problems is provided by the array in ISO/IEC C++. An array is simply a number of memory locations called array elements or simply elements, each of which can store an item of data of the same given data type, and which are all referenced through the same variable name. The employee names in a payroll program could be stored in one array, the pay for each employee in another, and the tax due for each employee could be stored in a third array.
Individual items in an array are specified by an index value which is simply an integer representing the sequence number of the elements in the array, the first having the sequence number 0, the second 1, and so on. You can also envisage the index value of an array element as being an offset from the first element in an array. The first element has an offset of 0 and therefore an index of 0, and an index value of 3 will refer to the fourth element of an array. For the payroll, you could arrange the arrays so that if an employee's name was stored in the employeeName array at a given index value, then the arrays pay and tax would store the associated data on pay and tax for the same employee in the array positions referenced by the same index value.
The basic structure of an array is illustrated in Figure 4-1.
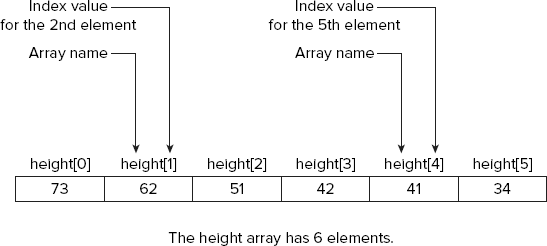
Figure 4-1 shows an array with the name height that has six elements, each storing a different value. These might be the heights of the members of a family, for instance, recorded to the nearest inch. Because there are six elements, the index values run from 0 through 5. To refer to a particular element, you write the array name, followed by the index value of the particular element between square brackets. The third element is referred to as height[2], for example. If you think of the index as being the offset from the first element, it's easy to see that the index value for the fourth element will be 3.
The amount of memory required to store each element is determined by its type, and all the elements of an array are stored in a contiguous block of memory.
You declare an array in essentially the same way as you declared the variables that you have seen up to now, the only difference being that the number of elements in the array is specified between square brackets immediately following the array name. For example, you could declare the integer array height, shown in the previous figure, with the following declaration statement:
long height[6];
Because each long value occupies 4 bytes in memory, the whole array requires 24 bytes. Arrays can be of any size, subject to the constraints imposed by the amount of memory in the computer on which your program is running.
You can declare arrays to be of any type. For example, to declare arrays intended to store the capacity and power output of a series of engines, you could write the following:
double cubic_inches[10]; // Engine size double horsepower[10]; // Engine power output
If auto mechanics is your thing, this would enable you to store the cubic capacity and power output of up to 10 engines, referenced by index values from 0 to 9. As you have seen before with other variables, you can declare multiple arrays of a given type in a single statement, but in practice it is almost always better to declare variables in separate statements.
TRY IT OUT: Using Arrays
As a basis for an exercise in using arrays, imagine that you have kept a record of both the amount of gasoline you have bought for the car and the odometer reading on each occasion. You can write a program to analyze this data to see how the gas consumption looks on each occasion that you bought gas:
// Ex4_01.cpp // Calculating gas mileage #include <iostream> #include <iomanip> using std::cin; using std::cout; using std::endl;
using std::setw;
int main()
{
const int MAX(20); // Maximum number of values
double gas[ MAX ]; // Gas quantity in gallons
long miles[ MAX ]; // Odometer readings
int count(0); // Loop counter
char indicator('y'), // Input indicator
while( ('y' == indicator || 'Y' == indicator) && count < MAX )
{
cout << endl << "Enter gas quantity: ";
cin >> gas[count]; // Read gas quantity
cout << "Enter odometer reading: ";
cin >> miles[count]; // Read odometer value
++count;
cout << "Do you want to enter another(y or n)? ";
cin >> indicator;
}
if(count <= 1) // count = 1 after 1 entry completed
{ // ... we need at least 2
cout << endl << "Sorry - at least two readings are necessary.";
return 0;
}
// Output results from 2nd entry to last entry
for(int i = 1; i < count; i++)
{
cout << endl
<< setw(2) << i << "." // Output sequence number
<< "Gas purchased = " << gas[i] << " gallons" // Output gas
<< " resulted in " // Output miles per gallon
<< (miles[i] - miles[i − 1])/gas[i] << " miles per gallon.";
}
cout << endl;
return 0;
}

The program assumes that you fill the tank each time so the gas bought was the amount consumed by driving the distance recorded. Here's an example of the output produced by this example:
Enter gas quantity: 12.8 Enter odometer reading: 25832 Do you want to enter another(y or n)? y Enter gas quantity: 14.9 Enter odometer reading: 26337 Do you want to enter another(y or n)? y Enter gas quantity: 11.8
Enter odometer reading: 26598 Do you want to enter another(y or n)? n 1.Gas purchased = 14.9 gallons resulted in 33.8926 miles per gallon. 2.Gas purchased = 11.8 gallons resulted in 22.1186 miles per gallon.
Because you need to take the difference between two odometer readings to calculate the miles covered for the gas used, you use only the odometer reading from the first pair of input values — you ignore the gas bought in the first instance as that would have been consumed during miles driven earlier.
During the second period shown in the output, the traffic must have been really bad — or maybe the parking brake was left on.
The dimensions of the two arrays gas and miles used to store the input data are determined by the value of the constant with the name MAX. By changing the value of MAX, you can change the program to accommodate a different maximum number of input values. This technique is commonly used to make a program flexible in the amount of information that it can handle. Of course, all the program code must be written to take account of the array dimensions, or of any other parameters being specified by const variables. This presents little difficulty in practice, however, so there's no reason why you should not adopt this approach. You'll also see later how to allocate memory for storing data as the program executes, so that you don't need to fix the amount of memory allocated for data storage in advance.
Entering the Data
The data values are read in the while loop. Because the loop variable count can run from 0 to MAX - 1, we haven't allowed the user of our program to enter more values than the array can handle. You initialize the variables count and indicator to 0 and 'y' respectively, so that the while loop is entered at least once. There's a prompt for each input value required and the value is read into the appropriate array element. The element used to store a particular value is determined by the variable count, which is 0 for the first input. The array element is specified in the cin statement by using count as an index, and count is then incremented, ready for the next value.
After you enter each value, the program prompts for confirmation that another value is to be entered. The character entered is read into the variable indicator and then tested in the loop condition. The loop will terminate unless 'y' or 'Y' is entered and the variable count is less than the specified maximum value, MAX.
After the input loop ends (by whatever means), the value of count contains one more than the index value of the last element entered in each array. (Remember, you increment it after you enter each new element). This is checked in order to verify that at least two pairs of values were entered. If this wasn't the case, the program ends with a suitable message because two odometer values are necessary to calculate a mileage value.
The output is generated in the for loop. The control variable i runs from 1 to count-1, allowing mileage to be calculated as the difference between the current element, miles[i] and the previous element, miles[i − 1]. Note that an index value can be any expression evaluating to an integer that represents a legal index for the array in question, which is an index value from 0 to one less than the number of elements in the array.
If the value of an index expression lies outside of the range corresponding to legitimate array elements, you will reference a spurious data location that may contain other data, garbage, or even program code. If the reference to such an element appears in an expression, you will use some arbitrary data value in the calculation, which certainly produces a result that you did not intend. If you are storing a result in an array element using an illegal index value, you will overwrite whatever happens to be in that location. When this is part of your program code, the results are catastrophic. If you use illegal index values, there are no warnings produced either by the compiler or at runtime. The only way to guard against this is to code your program to prevent it happening.
The output is generated by a single cout statement for all values entered, except for the first. A line number is also generated for each line of output using the loop control variable i. Miles per gallon is calculated directly in the output statement. You can use array elements in exactly the same way as any other variables in an expression.
To initialize an array in its declaration, you put the initializing values, separated by commas, between braces, and you place the set of initial values following an equals sign after the array name. Here's an example of how you can declare and initialize an array:
int cubic_inches[5] = { 200, 250, 300, 350, 400 };The array has the name cubic_inches and has five elements that each store a value of type int. The values in the initializing list between the braces correspond to successive index values of the array, so in this case cubic_inches[0] has the value 200, cubic_inches[1] the value 250, cubic_inches[2] the value 300, and so on.
You must not specify more initializing values than there are elements in the array, but you can include fewer. If there are fewer, the values are assigned to successive elements, starting with the first element — which is the one corresponding to the index value 0. The array elements for which you didn't provide an initial value are initialized with zero. This isn't the same as supplying no initializing list. Without an initializing list, the array elements contain junk values. Also, if you include an initializing list, there must be at least one initializing value in it; otherwise the compiler generates an error message. I can illustrate this with the following rather limited example.
TRY IT OUT: Initializing an Array
// Ex4_02.cpp // Demonstrating array initialization #include <iostream> #include <iomanip> using std::cout; using std::endl;
using std::setw;
int main()
{
int value[5] = { 1, 2, 3 };
int junk [5];
cout << endl;
for(int i = 0; i < 5; i++)
cout << setw(12) << value[i];
cout << endl;
for(int i = 0; i < 5; i++)
cout << setw(12) << junk[i];
cout << endl;
return 0;
}

In this example, you declare two arrays, the first of which, value, you initialize in part, and the second, junk, you don't initialize at all. The program generates two lines of output, which on my computer look like this:
1 2 3 0 0 −858993460 −858993460 −858993460 −858993460 −858993460
The second line (corresponding to values of junk[0] to junk[4]) may well be different on your computer.
How It Works
The first three values of the array value are the initializing values, and the last two have the default value of 0. In the case of junk, all the values are spurious because you didn't provide any initial values at all. The array elements contain whatever values were left there by the program that last used these memory locations.
A convenient way to initialize a whole array to zero is simply to specify a single initializing value as 0. For example:
long data[100] = {0}; // Initialize all elements to zeroThis statement declares the array data, with all one hundred elements initialized with 0. The first element is initialized by the value you have between the braces, and the remaining elements are initialized to zero because you omitted values for these.
You can also omit the dimension of an array of numeric type, provided you supply initializing values. The number of elements in the array is determined by the number of initializing values you specify. For example, the array declaration
int value[] = { 2, 3, 4 };defines an array with three elements that have the initial values 2, 3, and 4.
An array of type char is called a character array and is generally used to store a character string. A character string is a sequence of characters with a special character appended to indicate the end of the string. The string-terminating character indicates the end of the string; this character is defined by the escape sequence '�', and is sometimes referred to as a null character, since it's a byte with all bits as zero. A string of this form is often referred to as a C-style string because defining a string in this way was introduced in the C language from which C++ was developed by Bjarne Stroustrup (you can find his home page at http://www.research.att.com/~bs/).
This is not the only representation of a string that you can use — you'll meet others later in the book. In particular, C++/CLI programs use a different representation of a string, and the MFC defines a CString class to represent strings.
The representation of a C-style string in memory is shown in Figure 4-2.
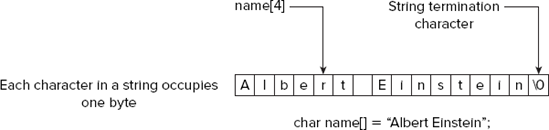
Figure 4-2 illustrates how a string looks in memory and shows a form of declaration for a string that I'll get to in a moment.
Note
Each character in the string occupies one byte, so together with the terminating null character, a string requires a number of bytes that is one greater than the number of characters contained in the string.
You can declare a character array and initialize it with a string literal. For example:
char movie_star[15] = "Marilyn Monroe";
Note that the terminating '�' is supplied automatically by the compiler. If you include one explicitly in the string literal, you end up with two of them. You must, however, allow for the terminating null in the number of elements that you allot to the array.
You can let the compiler work out the length of an initialized array for you, as you saw in Figure 4-1. Here's another example:
char president[] = "Ulysses Grant";
Because the dimension is unspecified, the compiler allocates space for enough elements to hold the initializing string, plus the terminating null character. In this case it allocates 14 elements for the array president. Of course, if you want to use this array later for storing a different string, its length (including the terminating null character) must not exceed 14 bytes. In general, it is your responsibility to ensure that the array is large enough for any string you might subsequently want to store.
You can also create strings that comprise Unicode characters, the characters in the string being of type wchar_t. Here's a statement that creates a Unicode string:
wchar_t president[] = L"Ulysses Grant";
The L prefix indicates that the string literal is a wide character string, so each character in the string, including the terminating null character, will occupy two bytes. Of course, indexing the string references characters, not bytes, so president[2] corresponds to the character L'y'.
The iostream header file contains definitions of a number of functions for reading characters from the keyboard. The one that you'll look at here is the function getline(), which reads a sequence of characters entered through the keyboard and stores it in a character array as a string terminated by '�'. You typically use the getline() function statements like this:
const int MAX(80); // Maximum string length including � char name[MAX]; // Array to store a string cin.getline(name, MAX, ' '), // Read input line as a string
These statements first declare a char array name with MAX elements and then read characters from cin using the function getline(). The source of the data, cin, is written as shown, with a period separating it from the function name. The period indicates that the getline() function you are calling is the one belonging to the cin object. The significance of the arguments to the getline() function is shown in Figure 4-3.
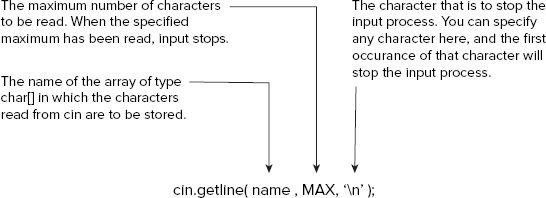
Because the last argument to the getline() function is '
'(newline or end line character) and the second argument is MAX, characters are read from cin until the '
' character is read, or when MAX − 1 characters have been read, whichever occurs first. The maximum number of characters read is MAX − 1 rather than MAX to allow for the '�' character to be appended to the sequence of characters stored in the array. The '
' character is generated when you press the Return key on your keyboard and is therefore usually the most convenient character to end input. You can, however, specify something else by changing the last argument. The '
' isn't stored in the input array name, but as I said, a '�' is added at the end of the input string in the array.
You will learn more about this form of syntax when classes are discussed later on. Meanwhile, just take it for granted as you use it in an example.
TRY IT OUT: Programming with Strings
You now have enough knowledge to write a simple program to read a string and then count how many characters it contains.
// Ex4_03.cpp
// Counting string characters
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
int main()
{
const int MAX(80); // Maximum array dimension
char buffer[MAX]; // Input buffer
int count(0); // Character count
cout << "Enter a string of less than "
<< MAX << " characters:
";
cin.getline(buffer, MAX, '
'), // Read a string until
while(buffer[count] != '�') // Increment count as long as
count++; // the current character is not null
cout << endl
<< "The string "" << buffer
<< "" has " << count << " characters.";
cout << endl;
return 0;
}

Typical output from this program is as follows:
Enter a string of less than 80 characters: Radiation fades your genes The string "Radiation fades your genes" has 26 characters.
How It Works
This program declares a character array buffer and reads a character string into the array from the keyboard after displaying a prompt for the input. Reading from the keyboard ends when the user presses Return, or when MAX-1 characters have been read.
A while loop is used to count the number of characters read. The loop continues as long as the current character referenced with buffer[count] is not '�'. This sort of checking on the current character while stepping through an array is a common technique in native C++. The only action in the loop is to increment count for each non-null character.
There is a library function, strlen(), that will do what this loop does; you'll learn about it later in this chapter.
Finally, in the example, the string and the character count is displayed with a single output statement. Note the use of the escape sequence '"' to output a double quote.
The arrays that you have defined so far with one index are referred to as one-dimensional arrays. An array can also have more than one index value, in which case it is called a multidimensional array. Suppose you have a field in which you are growing bean plants in rows of 10, and the field contains 12 such rows (so there are 120 plants in all). You could declare an array to record the weight of beans produced by each plant using the following statement:
double beans[12][10];
This declares the two-dimensional array beans, the first index being the row number, and the second index the number within the row. To refer to any particular element requires two index values. For example, you could set the value of the element reflecting the fifth plant in the third row with the following statement:
beans[2][4] = 10.7;
Remember that the index values start from zero, so the row index value is 2 and the index for the fifth plant within the row is 4.
Being a successful bean farmer, you might have several identical fields planted with beans in the same pattern. Assuming that you have eight fields, you could use a three-dimensional array to record data about these, declared thus:
double beans[8][12][10];
This records production for all of the plants in each of the fields, the leftmost index referencing a particular field. If you ever get to bean farming on an international scale, you are able to use a four-dimensional array, with the extra dimension designating the country. Assuming that you're as good a salesman as you are a farmer, growing this quantity of beans to keep up with the demand may well start to affect the ozone layer.
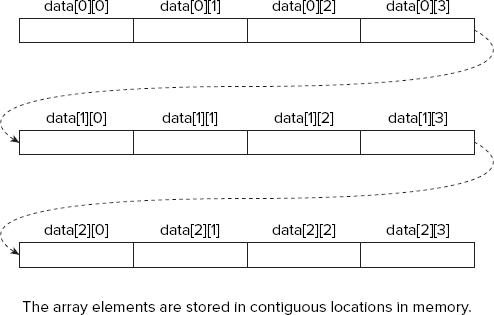
Arrays are stored in memory such that the rightmost index value varies most rapidly. Thus, the array data[3][4] is three one-dimensional arrays of four elements each. The arrangement of this array is illustrated in Figure 4-4.
The elements of the array are stored in a contiguous block of memory, as indicated by the arrows in Figure 4-4. The first index selects a particular row within the array, and the second index selects an element within the row.
Note that a two-dimensional array in native C++ is really a one-dimensional array of one-dimensional arrays. A native C++ array with three dimensions is actually a one-dimensional array of elements where each element is a one-dimensional array of one-dimensional arrays. This is not something you need to worry about most of the time, but as you will see later, C++/CLI arrays are not the same as this. It also implies that for the array in Figure 4-4, the expressions data[0], data[1], and data[2], represent one-dimensional arrays.
To initialize a multidimensional array, you use an extension of the method used for a one-dimensional array. For example, you can initialize a two-dimensional array, data, with the following declaration:
long data[2][4] = {
{ 1, 2, 3, 5 },
{ 7, 11, 13, 17 }
};Thus, the initializing values for each row of the array are contained within their own pair of braces. Because there are four elements in each row, there are four initializing values in each group, and because there are two rows, there are two groups between braces, each group of initializing values being separated from the next by a comma.
You can omit initializing values in any row, in which case the remaining array elements in the row are zero. For example:
long data[2][4] = {
{ 1, 2, 3 },
{ 7, 11 }
};I have spaced out the initializing values to show where values have been omitted. The elements data[0][3], data[1][2], and data[1][3] have no initializing values and are therefore zero.
If you wanted to initialize the whole array with zeros you could simply write:
long data[2][4] = {0};If you are initializing arrays with even more dimensions, remember that you need as many nested braces for groups of initializing values as there are dimensions in the array — unless you're initializing the array with zeros
TRY IT OUT: Storing Multiple Strings
You can use a single two-dimensional array to store several C-style strings. You can see how this works with an example:
// Ex4_04.cpp
// Storing strings in an array
#include <iostream>
using std::cout;
using std::cin;
using std::endl;
int main()
{
char stars[6][80] = { "Robert Redford",
"Hopalong Cassidy",
"Lassie",
"Slim Pickens",
"Boris Karloff",
"Oliver Hardy"
};
int dice(0);
cout << endl
<< "Pick a lucky star!"
<< "Enter a number between 1 and 6: ";
cin >> dice;
if(dice >= 1 && dice <= 6) // Check input validity
cout << endl // Output star name
<< "Your lucky star is " << stars[dice − 1];
else
cout << endl // Invalid input
<< "Sorry, you haven't got a lucky star.";
cout << endl;
return 0;
}

Apart from its incredible inherent entertainment value, the main point of interest in this example is the declaration of the array stars. It is a two-dimensional array of elements of type char that can hold up to six strings, each of which can be up to 80 characters long (including the terminating null character that is automatically added by the compiler). The initializing strings for the array are enclosed between braces and separated by commas.
One disadvantage of using arrays in this way is the memory that is almost invariably left unused. All of the strings are fewer than 80 characters, and the surplus elements in each row of the array are wasted.
You can also let the compiler work out how many strings you have by omitting the first array dimension and declaring it as follows:
char stars[][80] = { "Robert Redford",
"Hopalong Cassidy",
"Lassie",
"Slim Pickens",
"Boris Karloff",
"Oliver Hardy"
};This causes the compiler to define the first dimension to accommodate the number of initializing strings that you have specified. Because you have six, the result is exactly the same, but it avoids the possibility of an error. Here, you can't omit both array dimensions. With an array of two or more dimensions, the rightmost dimension must always be defined.
Note
Note the semicolon at the end of the declaration. It's easy to forget it when there are initializing values for an array.
Where you need to reference a string for output in the following statement, you need only specify the first index value:
cout << endl // Output star name
<< "Your lucky star is " << stars[dice − 1];A single index value selects a particular 80-element sub-array, and the output operation displays the contents up to the terminating null character. The index is specified as dice − 1 as the dice values are from 1 to 6, whereas the index values clearly need to be from 0 to 5.
The variables that you have dealt with so far provide you with the ability to name a memory location in which you can store data of a particular type. The contents of a variable are either entered from an external source, such as the keyboard, or calculated from other values that are entered. There is another kind of variable in C++ that does not store data that you normally enter or calculate, but greatly extends the power and flexibility of your programs. This kind of variable is called a pointer.
Each memory location that you use to store a data value has an address. The address provides the means for your PC hardware to reference a particular data item. A pointer is a variable that stores the address of another variable of a particular type. A pointer has a variable name just like any other variable and also has a type that designates what kind of variables its contents refer to. Note that the type of a pointer variable includes the fact that it's a pointer. A variable that is a pointer, that can hold addresses of locations in memory containing values of type int, is of type 'pointer to int'.
The declaration for a pointer is similar to that of an ordinary variable, except that the pointer name has an asterisk in front of it to indicate that it's a variable that is a pointer. For example, to declare a pointer pnumber of type long, you could use the following statement:
long* pnumber;
This declaration has been written with the asterisk close to the type name. If you want, you can also write it as:
long *pnumber;
The compiler won't mind at all; however, the type of the variable pnumber is 'pointer to long', which is often indicated by placing the asterisk close to the type name. Whichever way you choose to write a pointer type, be consistent.
You can mix declarations of ordinary variables and pointers in the same statement. For example:
long* pnumber, number (99);
This declares the pointer pnumber of type 'pointer to long' as before, and also declares the variable number, of type long. On balance, it's probably better to declare pointers separately from other variables; otherwise, the statement can appear misleading as to the type of the variables declared, particularly if you prefer to place the * adjacent to the type name. The following statements certainly look clearer, and putting declarations on separate lines enables you to add comments for them individually, making for a program that is easier to read.
long number(99); // Declaration and initialization of long variable long* pnumber; // Declaration of variable of type pointer to long
It's a common convention in C++ to use variable names beginning with p to denote pointers. This makes it easier to see which variables in a program are pointers, which in turn can make a program easier to follow.
Let's take an example to see how this works, without worrying about what it's for. I will get to how you use pointers very shortly. Suppose you have the long integer variable number containing the value 99 because you declared it above. You also have the pointer pnumber of type pointer to long, which you could use to store the address of the variable number. But how do you obtain the address of a variable?
What you need is the address-of operator, &. This is a unary operator that obtains the address of a variable. It's also called the reference operator, for reasons I will discuss later in this chapter. To set up the pointer that I have just discussed, you could write this assignment statement:
pnumber = &number; // Store address of number in pnumber
The result of this operation is illustrated in Figure 4-5.
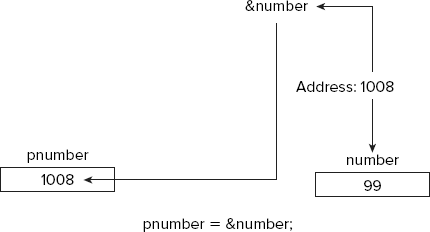
You can use the operator & to obtain the address of any variable, but you need a pointer of the appropriate type to store it. If you want to store the address of a double variable, for example, the pointer must have been declared as type double*, which is type 'pointer to double'.
Taking the address of a variable and storing it in a pointer is all very well, but the really interesting aspect is how you can use it. Fundamental to using a pointer is accessing the data value in the variable to which a pointer points. This is done using the indirection operator *.
You use the indirection operator, *, with a pointer to access the contents of the variable that it points to. The name 'indirection operator' stems from the fact that the data is accessed indirectly. It is also called the dereference operator, and the process of accessing the data in the variable pointed to by a pointer is termed de-referencing the pointer.
One aspect of this operator that can seem confusing is the fact that you now have several different uses for the same symbol, *. It is the multiply operator, it serves as the indirection operator, and it is used in the declaration of a pointer. Each time you use *, the compiler is able to distinguish its meaning by the context. When you multiply two variables, A*B for instance, there's no meaningful interpretation of this expression for anything other than a multiply operation.
A question that usually springs to mind at this point is, "Why use pointers at all?" After all, taking the address of a variable you already know and sticking it in a pointer so that you can dereference it seems like overhead you can do without. There are several reasons why pointers are important.
As you will see shortly, you can use pointer notation to operate on data stored in an array, which often executes faster than if you use array notation. Also, when you get to define your own functions later in the book, you will see that pointers are used extensively for enabling access within a function to large blocks of data, such as arrays, that are defined outside the function. Most importantly, however, you will also see that you can allocate space for variables dynamically — that is, during program execution. This sort of capability allows your program to adjust its use of memory depending on the input to the program. Because you don't know in advance how many variables you are going to create dynamically, a primary way you have for doing this is using pointers — so make sure you get the hang of this bit.
Using pointers that aren't initialized is extremely hazardous. You can easily overwrite random areas of memory through an uninitialized pointer. The resulting damage depends on how unlucky you are, so it's more than just a good idea to initialize your pointers. It's very easy to initialize a pointer to the address of a variable that has already been defined. Here you can see that I have initialized the pointer pnumber with the address of the variable number just by using the operator & with the variable name:
int number(0); // Initialized integer variable int* pnumber(&number); // Initialized pointer
When initializing a pointer with the address of another variable, remember that the variable must already have been declared prior to the pointer declaration.
Of course, you may not want to initialize a pointer with the address of a specific variable when you declare it. In this case, you can initialize it with the pointer equivalent of zero. For this, Visual C++ provides the literal nullptr — a pointer literal that does not point to anything — so you can declare and initialize a pointer using the following statement:
int* pnumber(nullptr); // Pointer not pointing to anything
This ensures that the pointer doesn't contain an address that will be accepted as valid, and provides the pointer with a value that you can check in an if statement, such as:
if(pnumber == nullptr) cout << endl << "pnumber does not point to anything.";
nullptr is a feature introduced by the new standard for C++ that is supported by the Visual C++ 2010 compiler. In the past, 0 or NULL (which is a macro for which the compiler will substitute 0) have been used to initialize a pointer, and of course, these still work. However, it is much better to use nullptr to initialize your pointers.
Note
The reason for introducing nullptr into the C++ language is to remove potential confusion between the literal 0 as an integral value and 0 as a pointer. Having a dual meaning for the literal 0 can cause problems in some circumstances. nullptr is of type std::nullptr_t and cannot be confused with a value of any other type. nullptr can be implicitly converted to any pointer type but cannot be implicitly converted to any integral type except type bool.
Because the literal nullptr can be implicitly converted to type bool, you can check the status of the pointer pnumber like this:
if(!pnumber) cout << endl << "pnumber does not point to anything.";
nullptr converts to the bool value false, and any other pointer value converts to true. Thus, if pnumber contains nullptr, the if expression will be true and will cause the message to be written to the output stream.
TRY IT OUT: Using Pointers
You can try out various aspects of pointer operations with an example:
// Ex4_05.cpp
// Exercising pointers
#include <iostream>
using std::cout;
using std::endl;
using std::hex;
using std::dec;
int main()
{
long* pnumber(nullptr); // Pointer declaration & initialization
long number1(55), number2(99);
pnumber = &number1; // Store address in pointer
*pnumber += 11; // Increment number1 by 11
cout << endl
<< "number1 = " << number1
<< " &number1 = " << hex << pnumber;
pnumber = &number2; // Change pointer to address of number2
number1 = *pnumber*10; // 10 times number2
cout << endl
<< "number1 = " << dec << number1
<< " pnumber = " << hex << pnumber<< " *pnumber = " << dec << *pnumber;
cout << endl;
return 0;
}

You should compile and execute the release version of this example. The debug version will add extra bytes, used for debugging purposes, that will cause the variables to be separated by 12 bytes instead of 4. On my computer, this example generates the following output:
number1 = 66 &number1 = 0012FEC8 number1 = 990 pnumber = 0012FEBC *pnumber = 99
How It Works
There is no input to this example. All operations are carried out with the initializing values for the variables. After storing the address of number1 in the pointer pnumber, the value of number1 is incremented indirectly through the pointer in this statement:
*pnumber += 11; // Increment number1 by 11
The indirection operator determines that you are adding 11 to the contents of the variable pointed to by pnumber, which is number1. If you forgot the * in this statement, you would be attempting to add 11 to the address stored in the pointer.
The values of number1, and the address of number1 that is stored in pnumber, are displayed. You use the hex manipulator to generate the address output in hexadecimal notation.
You can obtain the value of ordinary integer variables as hexadecimal output by using the manipulator hex. You send it to the output stream in the same way that you have applied endl, with the result that all following output is in hexadecimal notation. If you want the following output to be decimal, you need to use the manipulator dec in the next output statement to switch the output back to decimal mode again.
After the first line of output, the contents of pnumber is set to the address of number2. The variable number1 is then changed to the value of 10 times number2:
number1 = *pnumber*10; // 10 times number2
This is calculated by accessing the contents of number2 indirectly through the pointer. The second line of output shows the results of these calculations.
The address values you see in your output may well be different from those shown in the output here since they reflect where the program is loaded in memory, which depends on how your operating system is configured. The 0x prefixing the address values indicates that they are hexadecimal numbers.
Note that the addresses &number1 and pnumber (when it contains &number2) differ by four bytes. This shows that number1 and number2 occupy adjacent memory locations, as each variable of type long occupies four bytes. The output demonstrates that everything is working as you would expect.
A pointer of type char* has the interesting property that it can be initialized with a string literal. For example, you can declare and initialize such a pointer with the statement:
char* proverb ("A miss is as good as a mile.");This looks similar to initializing a char array, but it's slightly different. This creates a string literal (actually an array of type const char) with the character string appearing between the quotes and terminating with '�', and stores the address of the literal in the pointer proverb. The address of the literal will be the address of its first character. This is shown in Figure 4-6.
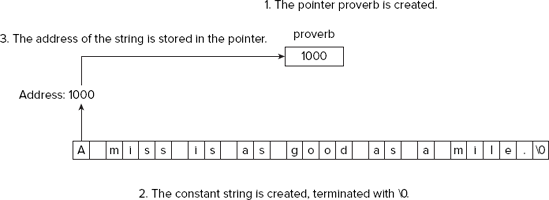
TRY IT OUT: Lucky Stars With Pointers
You could rewrite the lucky stars example using pointers instead of an array to see how that would work:
// Ex4_06.cpp
// Initializing pointers with strings
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
int main()
{char* pstr1("Robert Redford");
char* pstr2("Hopalong Cassidy");
char* pstr3("Lassie");
char* pstr4("Slim Pickens");
char* pstr5 ("Boris Karloff");
char* pstr6("Oliver Hardy");
char* pstr("Your lucky star is ");
int dice(0);
cout << endl
<< "Pick a lucky star!"
<< "Enter a number between 1 and 6: ";
cin >> dice;
cout << endl;
switch(dice)
{
case 1: cout << pstr << pstr1;
break;
case 2: cout << pstr << pstr2;
break;
case 3: cout << pstr << pstr3;
break;
case 4: cout << pstr << pstr4;
break;
case 5: cout << pstr << pstr5;
break;
case 6: cout << pstr << pstr6;
break;
default: cout << "Sorry, you haven't got a lucky star.";
}
cout << endl;
return 0;
}

How It Works
The array in Ex4_04.cpp has been replaced by the six pointers, pstr1 to pstr6, each initialized with a name. You have also declared an additional pointer, pstr, initialized with the phrase that you want to use at the start of a normal output line. Because you have discrete pointers, it is easier to use a switch statement to select the appropriate output message than to use an if, as you did in the original version. Any incorrect values entered are all taken care of by the default option of the switch.
Outputting the string pointed to by a pointer couldn't be easier. As you can see, you simply write the pointer name. It may cross your mind at this point that in Ex4_05.cpp you wrote a pointer name in the output statement, and the address that it contained was displayed. Why is it different here? The answer is in the way the output operation views a pointer of type 'pointer to char.' It treats a pointer of this type in a special way, in that it regards it as a string (which is an array of char), and so outputs the string itself, rather than its address.
Using pointers in the example has eliminated the waste of memory that occurred with the array version of this program, but the program seems a little long-winded now. There must be a better way. Indeed there is — using an array of pointers.
TRY IT OUT: Arrays of Pointers
With an array of pointers of type char, each element can point to an independent string, and the lengths of each of the strings can be different. You can declare an array of pointers in the same way that you declare a normal array. Let's go straight to rewriting the previous example using a pointer array:
// Ex4_07.cpp
// Initializing pointers with strings
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
int main()
{
char* pstr[] = { "Robert Redford", // Initializing a pointer array
"Hopalong Cassidy",
"Lassie",
"Slim Pickens",
"Boris Karloff",
"Oliver Hardy"
};
char* pstart("Your lucky star is ");
int dice(0);
cout << endl
<< "Pick a lucky star!"
<< "Enter a number between 1 and 6: ";
cin >> dice;
cout << endl;
if(dice >= 1 && dice <= 6) // Check input validity
cout << pstart << pstr[dice − 1]; // Output star name
else
cout << "Sorry, you haven't got a lucky star."; // Invalid input
cout << endl;
return 0;
}

How It Works
In this case, you are nearly getting the best of all possible worlds. You have a one-dimensional array of pointers to type char declared, such that the compiler works out what the dimension should be from the number of initializing strings. The memory usage that results from this is illustrated in Figure 4-7.
Compared to using a 'normal' array, the pointer array generally carries less overhead in terms of space. With an array, you would need to make each row the length of the longest string, and six rows of seventeen bytes each is 102 bytes, so by using a pointer array you have saved a whole −1 bytes! What's gone wrong? The simple truth is that for this small number of relatively short strings, the size of the extra array of pointers is significant. You would make savings if you were dealing with more strings that were longer and had more variable lengths.
Space saving isn't the only advantage that you get by using pointers. In a lot of circumstances you save time, too. Think of what happens if you want to move "Oliver Hardy" to the first position and "Robert Redford" to the end. With the pointer array as above, you just need to swap the pointers — the strings themselves stay where they are. If you had stored these simply as strings, as you did in Ex4_04.cpp, a great deal of copying would be necessary — you'd need to copy the whole string "Robert Redford" to a temporary location while you copied "Oliver Hardy" in its place, and then you'd need to copy "Robert Redford" to the end position. This requires significantly more computer time to execute.
Because you are using pstr as the name of the array, the variable holding the start of the output message needs to be different; it is called pstart. You select the string that you want to output by means of a very simple if statement, similar to that of the original version of the example. You either display a star selection or a suitable message if the user enters an invalid value.
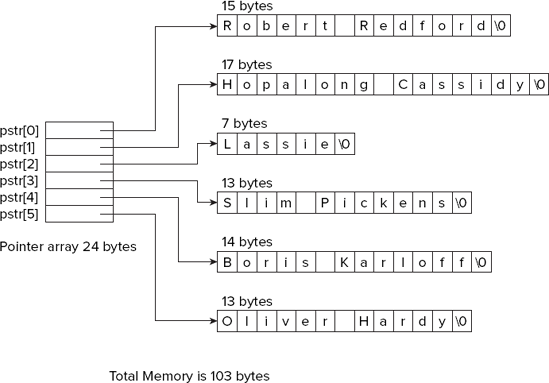
One weakness of the way the program is written is that the code assumes there are six options, even though the compiler is allocating the space for the pointer array from the number of initializing strings that you supply. So if you add a string to the list, you have to alter other parts of the program to take account of this. It would be nice to be able to add strings and have the program automatically adapt to however many strings there are.
A new operator can help us here. The sizeof operator produces an integer value of type size_t that gives the number of bytes occupied by its operand, where size_t is a type defined by the standard library. Many standard library functions return a value of type size_t, and the size_t type is defined within the standard library using a typedef statement to be equivalent to one of the fundamental types, usually unsigned int. The reason for using size_t rather than a fundamental type directly is that it allows flexibility in what the actual type is in different C++ implementations. The C++ standard permits the range of values accommodated by a fundamental type to vary, to make the best of a given hardware architecture, and size_t can be defined to be the equivalent of the most suitable fundamental type in the current machine environment.
Look at this statement that refers to the variable dice from the previous example:
cout << sizeof dice;
The value of the expression sizeof dice is 4 because dice was declared as type int and therefore occupies 4 bytes. Thus this statement outputs the value 4.
The sizeof operator can be applied to an element in an array or to the whole array. When the operator is applied to an array name by itself, it produces the number of bytes occupied by the whole array, whereas when it is applied to a single element with the appropriate index value or values, it results in the number of bytes occupied by that element. Thus, in the last example, you could output the number of elements in the pstr array with the expression:
cout << (sizeof pstr)/(sizeof pstr[0]);
The expression (sizeof pstr)/(sizeof pstr[0]) divides the number of bytes occupied by the whole pointer array, by the number of bytes occupied by the first element of the array. Because each element in the array occupies the same amount of memory, the result is the number of elements in the array.
Note
Remember that pstr is an array of pointers — using the sizeof operator on the array or on individual elements will not tell us anything about the memory occupied by the text strings. pstr[0] is a pointer to a character array and thus occupies just 4 bytes.
You can also apply the sizeof operator to a type name rather than a variable, in which case the result is the number of bytes occupied by a variable of that type. In this case, the type name should be enclosed in parentheses. For example, after executing the statement,
size_t long_size(sizeof(long));
the variable long_size will be initialized with the value 4. The variable long_size is declared to be of type size_t to match the type of the value produced by the sizeof operator. Using a different integer type for long_size may result in a warning message from the compiler.
TRY IT OUT: Using the sizeof Operator
You can amend the last example to use the sizeof operator so that the code automatically adapts to an arbitrary number of string values from which to select:
// Ex4_08.cpp// Flexible array management using sizeof#include <iostream> using std::cin; using std::cout; using std::endl; int main() { char* pstr[] = { "Robert Redford", // Initializing a pointer array "Hopalong Cassidy", "Lassie", "Slim Pickens", "Boris Karloff", "Oliver Hardy" }; char* pstart("Your lucky star is ");int count((sizeof pstr)/(sizeof pstr[0])); // Number of array elementsint dice(0);cout << endl<< " Pick a lucky star!"<< " Enter a number between 1 and " << count << ": ";cin >> dice; cout << endl;if(dice >= 1 && dice <= count) // Check input validitycout << pstart << pstr[dice − 1]; // Output star name else cout << "Sorry, you haven't got a lucky star."; // Invalid input cout << endl; return 0; }
As you can see, the changes required in the example are very simple. You just calculate the number of elements in the pointer array pstr and store the result in count. Then, wherever the total number of elements in the array was referenced as 6, you just use the variable count. You could now just add a few more names to the list of lucky stars, and everything affected in the program is adjusted automatically.
The array pstr in the last example is clearly not intended to be modified in the program, and nor are the strings being pointed to, nor is the variable count. It would be a good idea to ensure that these didn't get modified by mistake in the program. You could very easily protect the variable count from accidental modification by writing this:
const int count = (sizeof pstr)/(sizeof pstr[0]);
However, the array of pointers deserves closer examination. You declared the array like this:
char* pstr[] = { "Robert Redford", // Initializing a pointer array
"Hopalong Cassidy",
"Lassie",
"Slim Pickens",
"Boris Karloff",
"Oliver Hardy"
};Each pointer in the array is initialized with the address of a string literal, "Robert Redford", "Hopalong Cassidy", and so on. The type of a string literal is 'array of const char,' so you are storing the address of a const array in a non-const pointer. The compiler allows us to use a string literal to initialize an element of an array of char* for reasons of backward compatibility with existing code.
If you try to alter the character array with a statement like this:
*pstr[0] = "Stan Laurel";
the program does not compile.
If you were to reset one of the elements of the array to point to a character using a statement like this:
*pstr[0] = 'X';
the program compiles, but crashes when this statement is executed.
You don't really want to have unexpected behavior, like the program crashing at run time, and you can prevent it. A far better way of writing the declaration is as follows:
const char* pstr[] = { "Robert Redford", // Array of pointers
"Hopalong Cassidy", // to constants
"Lassie",
"Slim Pickens",
"Boris Karloff",
"Oliver Hardy"
};In this case, there is no ambiguity about the const-ness of the strings pointed to by the elements of the pointer array. If you now attempt to change these strings, the compiler flags this as an error at compile time.
However, you could still legally write this statement:
pstr[0] = pstr[1];
Those lucky individuals due to be awarded Mr. Redford would get Mr. Cassidy instead because both pointers now point to the same name. Note that this isn't changing the values of the objects pointed to by the pointer array element — it is changing the value of the pointer stored in pstr[0]. You should therefore inhibit this kind of change as well, because some people may reckon that good old Hoppy may not have the same sex appeal as Robert. You can do this with the following statement:
// Array of constant pointers to constants
const char* const pstr[] = { "Robert Redford",
"Hopalong Cassidy",
"Lassie",
"Slim Pickens",
"Boris Karloff",
"Oliver Hardy"
};To summarize, you can distinguish three situations relating to const, pointers, and the objects to which they point:
A pointer to a constant object
A constant pointer to an object
A constant pointer to a constant object
In the first situation, the object pointed to cannot be modified, but you can set the pointer to point to something else:
const char* pstring("Some text");In the second, the address stored in the pointer can't be changed, but the object pointed to can be:
char* const pstring("Some text");Finally, in the third situation, both the pointer and the object pointed to have been defined as constant and, therefore, neither can be changed:
const char* const pstring("Some text");Note
Of course, all this applies to pointers that point to any type. A pointer to type char is used here purely for illustrative purposes. In general, to interpret more complex types correctly, you just read them from right to left. The type const char* is a pointer to characters that are const and the type char* const is a const pointer to characters.
Array names can behave like pointers under some circumstances. In most situations, if you use the name of a one-dimensional array by itself, it is automatically converted to a pointer to the first element of the array. Note that this is not the case when the array name is used as the operand of the sizeof operator.
If you have these declarations,
double* pdata(nullptr); double data[5];
you can write this assignment:
pdata = data; // Initialize pointer with the array address
This is assigning the address of the first element of the array data to the pointer pdata. Using the array name by itself refers to the address of the array. If you use the array name data with an index value, it refers to the contents of the element corresponding to that index value. So, if you want to store the address of that element in the pointer, you have to use the address-of operator:
pdata = &data[1];
Here, the pointer pdata contains the address of the second element of the array.
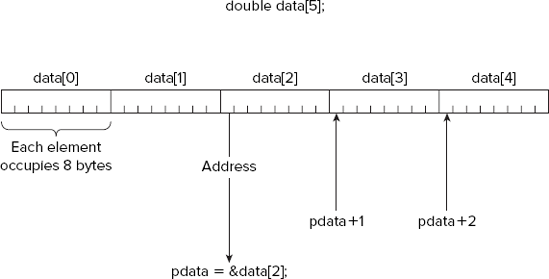
You can perform arithmetic operations with pointers. You are limited to addition and subtraction in terms of arithmetic, but you can also perform comparisons of pointer values to produce a logical result. Arithmetic with a pointer implicitly assumes that the pointer points to an array, and that the arithmetic operation is on the address contained in the pointer. For the pointer pdata, for example, you could assign the address of the third element of the array data to a pointer with this statement:
pdata = &data[2];
In this case, the expression pdata+1 would refer to the address of data[3], the fourth element of the data array, so you could make the pointer point to this element by writing this statement:
pdata += 1; // Increment pdata to the next element
This statement increments the address contained in pdata by the number of bytes occupied by one element of the array data. In general, the expression pdata+n, where n can be any expression resulting in an integer, adds n*sizeof(double) to the address contained in the pointer pdata, because it was declared to be of type pointer to double. This is illustrated in Figure 4-8.
In other words, incrementing or decrementing a pointer works in terms of the type of the object pointed to. Increasing a pointer to long by one changes its contents to the next long address, and so increments the address by four. Similarly, incrementing a pointer to short by one increments the address by two. The more common notation for incrementing a pointer is using the increment operator. For example:
pdata++; // Increment pdata to the next element
This is equivalent to (and more common than) the += form. However, I used the preceding += form to make it clear that although the increment value is actually specified as one, the effect is usually an address increment greater than one, except in the case of a pointer to type char.
Note
The address resulting from an arithmetic operation on a pointer can be a value ranging from the address of the first element of the array to the address that is one beyond the last element. Accessing an address that does not refer to an element within the array results in undefined behavior.
You can, of course, dereference a pointer on which you have performed arithmetic (there wouldn't be much point to it otherwise). For example, assuming that pdata is still pointing to data[2], this statement,
*(pdata + 1) = *(pdata + 2);
data[3] = data[4];
When you want to dereference a pointer after incrementing the address it contains, the parentheses are necessary because the precedence of the indirection operator is higher than that of the arithmetic operators, + and -. If you write the expression *pdata+1, instead of *(pdata+1), this adds one to the value stored at the address contained in pdata, which is equivalent to executing data[2]+1. Because this isn't an lvalue, its use in the previous assignment statement causes the compiler to generate an error message.
You can use an array name as though it were a pointer for addressing elements of an array. If you have the same one-dimensional array as before, declared as
long data[5];
using pointer notation, you can refer to the element data[3], for example, as *(data+3). This kind of notation can be applied generally so that, corresponding to the elements data[0], data[1], data[2], you can write *data, *(data+1), *(data+2), and so on.
TRY IT OUT: Array Names as Pointers
You could practice this aspect of array addressing with a program to calculate prime numbers (a prime number is divisible only by itself and one).
// Ex4_09.cpp
// Calculating primes
#include <iostream>
#include <iomanip>
using std::cout;
using std::endl;
using std::setw;
int main()
{
const int MAX(100); // Number of primes required
long primes[MAX] = { 2,3,5 }; // First three primes defined
long trial(5); // Candidate prime
int count(3); // Count of primes found
bool found(false); // Indicates when a prime is found
do
{
trial += 2; // Next value for checking
found = false; // Set found indicator
for(int i = 0; i < count; i++) // Try division by existing primes
{
found = (trial % *(primes + i)) == 0;// True for exact division
if(found) // If division is exact
break; // it's not a prime
}if (!found) // We got one...
*(primes + count++) = trial; // ...so save it in primes array
}while(count < MAX);
// Output primes 5 to a line
for(int i = 0; i < MAX; i++)
{
if(i % 5 == 0) // New line on 1st, and every 5th line
cout << endl;
cout << setw(10) << *(primes + i);
}
cout << endl;
return 0;
}

If you compile and execute this example, you should get the following output:
2 3 5 7 11
13 17 19 23 29
31 37 41 43 47
53 59 61 67 71
73 79 83 89 97
101 103 107 109 113
127 131 137 139 149
151 157 163 167 173
179 181 191 193 197
199 211 223 227 229
233 239 241 251 257
263 269 271 277 281
283 293 307 311 313
317 331 337 347 349
353 359 367 373 379
383 389 397 401 409
419 421 431 433 439
443 449 457 461 463
467 479 487 491 499
503 509 521 523 541How It Works
You have the usual #include statements for the iostream header file for input and output, and for iomanip, because you will use a stream manipulator to set the field width for output.
You use the constant MAX to define the number of primes that you want the program to produce. The primes array, which stores the results, has the first three primes already defined to start the process off. All the work is done in two loops: the outer do-while loop, which picks the next value to be checked and adds the value to the primes array if it is prime, and the inner for loop that actually checks the value to see whether it's prime or not.
The algorithm in the for loop is very simple and is based on the fact that if a number is not a prime, it must be divisible by one of the primes found so far — all of which are less than the number in question because all numbers are either prime or a product of primes. In fact, only division by primes less than or equal to the square root of the number in question need to be checked, so this example isn't as efficient as it might be.
found = (trial % *(primes + i)) == 0; // True for exact division
This statement sets the variable found to true if there's no remainder from dividing the value in trial by the current prime *(primes+i) (remember that this is equivalent to primes[i]), and to 0 otherwise. The if statement causes the for loop to be terminated if found has the value true because the candidate in trial can't be a prime in that case.
After the for loop ends (for whatever reason), it's necessary to decide whether or not the value in trial was prime. This is indicated by the value in the indicator variable found.
*(primes + count++) = trial; // ...so save it in primes array
If trial does contain a prime, this statement stores the value in primes[count] and then increments count through the postfix increment operator.
After MAX number of primes have been found, they are output with a field width of 10 characters, 5 to a line, as a result of this statement:
if(i % 5 == 0) // New line on 1st, and every 5th line cout << endl;
This starts a new line when i has the values 0, 5, 10, and so on.
TRY IT OUT: Counting Characters Revisited
To see how handling strings works in pointer notation, you could produce a version of the program you looked at earlier for counting the characters in a string:
// Ex4_10.cpp
// Counting string characters using a pointer
#include <iostream>
using std::cin;
using std::cout;
using std::endl;
int main()
{
const int MAX(80); // Maximum array dimension
char buffer[MAX]; // Input buffer
char* pbuffer(buffer); // Pointer to array buffer
cout << endl // Prompt for input
<< "Enter a string of less than "<< MAX << " characters:"
<< endl;
cin.getline(buffer, MAX, '
'), // Read a string until
while(*pbuffer) // Continue until �
pbuffer++;
cout << endl
<< "The string "" << buffer
<< "" has " << pbuffer - buffer << " characters.";
cout << endl;
return 0;
}

Here's an example of typical output from this example:
Enter a string of less than 80 characters: The tigers of wrath are wiser than the horses of instruction. The string "The tigers of wrath are wiser than the horses of instruction." has 61 characters.
How It Works
Here the program operates using the pointer pbuffer rather than the array name buffer. You don't need the count variable because the pointer is incremented in the while loop until '�' is found. When the '�' character is found, pbuffer will contain the address of that position in the string. The count of the number of characters in the string entered is therefore the difference between the address stored in the pointer pbuffer, and the address of the beginning of the array denoted by buffer.
You could also have incremented the pointer in the loop by writing the loop like this:
while(*pbuffer++); // Continue until �
Now the loop contains no statements, only the test condition. This would work adequately, except for the fact that the pointer would be incremented after '�' was encountered, so the address would be one more than the last position in the string. You would therefore need to express the count of the number of characters in the string as pbuffer–buffer-1.
Note that you can't use the array name here in the same way that you have used the pointer. The expression buffer++ is strictly illegal because you can't modify the address value that an array name represents. Even though you can use an array name in an expression as though it is a pointer, it isn't a pointer, because the address value that it represents is fixed.
Using a pointer to store the address of a one-dimensional array is relatively straightforward, but with multidimensional arrays, things can get a little complicated. If you don't intend to use pointers with multidimensional arrays, you can skip this section, as it's a little obscure; however, if you have previous experience with C, this section is worth a glance.
If you have to use a pointer with multidimensional arrays, you need to keep clear in your mind what is happening. By way of illustration, you can use an array beans, declared as follows:
double beans[3][4];
You can declare and assign a value to the pointer pbeans, as follows:
double* pbeans; pbeans = &beans[0][0];
Here you are setting the pointer to the address of the first element of the array, which is of type double. You could also set the pointer to the address of the first row in the array with the statement:
pbeans = beans[0];
This is equivalent to using the name of a one-dimensional array, which is replaced by its address. You used this in the earlier discussion; however, because beans is a two-dimensional array, you cannot set an address in the pointer with the following statement:
pbeans = beans; // Will cause an error!!
The problem is one of type. The type of the pointer you have defined is double*, but the array is of type double[3][4]. A pointer to store the address of this array must be of type double*[4]. C++ associates the dimensions of the array with its type, and the statement above is only legal if the pointer has been declared with the dimension required. This is done with a slightly more complicated notation than you have seen so far:
double (*pbeans)[4];
The parentheses here are essential; otherwise, you would be declaring an array of pointers. Now the previous statement is legal, but this pointer can only be used to store addresses of an array with the dimensions shown.
You can use pointer notation with an array name to reference elements of the array. You can reference each element of the array beans that you declared earlier, which had three rows of four elements, in two ways:
Using the array name with two index values
Using the array name in pointer notation
Therefore, the following two statements are equivalent:
beans[i][j] *(*(beans + i) + j)
Let's look at how these work. The first line uses normal array indexing to refer to the element with offset j in row i of the array.
You can determine the meaning of the second line by working from the inside outwards. beans refers to the address of the first row of the array, so beans+i refers to row i of the array. The expression *(beans+i) is the address of the first element of row i, so *(beans+i)+j is the address of the element in row i with offset j. The whole expression therefore refers to the value of that element.
If you really want to be obscure — and it isn't recommended that you should be — the following two statements, where you have mixed array and pointer notation, are also legal references to the same element of the array:
*(beans[i] + j) (*(beans + i))[j]
There is yet another aspect to the use of pointers that is really the most important of all: the ability to allocate memory for variables dynamically. You'll look into that next.
Working with a fixed set of variables in a program can be very restrictive. You will often want to decide the amount of space to be allocated for storing different types of variables at execution time, depending on the input data for the program. Any program that involves reading and processing a number of data items that is not known in advance can take advantage of the ability to allocate memory to store the data at run time. For example, if you need to implement a program to store information about the students in a class, the number of students is not fixed, and their names will vary in length, so to deal with the data most efficiently, you'll want to allocate space dynamically at execution time.
Obviously, because dynamically allocated variables can't have been defined at compile time, they can't be named in your source program. When they are created, they are identified by their address in memory, which is contained within a pointer. With the power of pointers, and the dynamic memory management tools in Visual C++ 2010, writing your programs to have this kind of flexibility is quick and easy.
In most instances, when your program is executed, there is unused memory in your computer. This unused memory is called the heap in C++, or sometimes the free store. You can allocate space within the free store for a new variable of a given type using a special operator in C++ that returns the address of the space allocated. This operator is new, and it's complemented by the operator delete, which de-allocates memory previously allocated by new.
You can allocate space in the free store for some variables in one part of a program, and then release the allocated space and return it to the free store after you have finished with it. This makes the memory available for reuse by other dynamically allocated variables, later in the same program. This can be a powerful technique; it enables you to use memory very efficiently, and in many cases, it results in programs that can handle much larger problems, involving considerably more data than otherwise might be possible.
Suppose that you need space for a double variable. You can define a pointer to type double and then request that the memory be allocated at execution time. You can do this using the operator new with the following statements:
double* pvalue(nullptr); pvalue = new double; // Request memory for a double variable
This is a good moment to recall that all pointers should be initialized. Using memory dynamically typically involves a number of pointers floating around, so it's important that they should not contain spurious values. You should try to arrange for a pointer not containing a legal address value to be set to nullptr.
The new operator in the second line of code above should return the address of the memory in the free store allocated to a double variable, and this address is stored in the pointer pvalue. You can then use this pointer to reference the variable using the indirection operator, as you have seen. For example:
*pvalue = 9999.0;
Of course, the memory may not have been allocated because the free store had been used up, or because the free store is fragmented by previous usage — meaning that there isn't a sufficient number of contiguous bytes to accommodate the variable for which you want to obtain space. You don't have to worry too much about this, however. The new operator will throw an exception if the memory cannot be allocated for any reason, which terminates your program. Exceptions are a mechanism for signaling errors in C++; you learn about these in Chapter 6.
You can also initialize a variable created by new. Taking the example of the double variable that was allocated by new and the address stored in pvalue, you could have set the value to 999.0, as it was created with this statement:
pvalue = new double(999.0); // Allocate a double and initialize it
Of course, you could create the pointer and initialize it in a single statement, like this:
double* pvalue(new double(999.0));
When you no longer need a variable that has been dynamically allocated, you can free up the memory that it occupies in the free store with the delete operator:
delete pvalue; // Release memory pointed to by pvalue
This ensures that the memory can be used subsequently by another variable. If you don't use delete, and subsequently store a different address value in the pointer pvalue, it will be impossible to free up the memory, or to use the variable that it contains, because access to the address is lost. In this situation, you have what is referred to as a memory leak, especially when it recurs in your program.
Allocating memory for an array dynamically is very straightforward. If you wanted to allocate an array of type char, assuming pstr is a pointer to char, you could write the following statement:
pstr = new char[20]; // Allocate a string of twenty characters
This allocates space for a char array of 20 characters and stores its address in pstr.
To remove the array that you have just created in the free store, you must use the delete operator. The statement would look like this:
delete [] pstr; // Delete array pointed to by pstr
Note the use of square brackets to indicate that what you are deleting is an array. When removing arrays from the free store, you should always include the square brackets, or the results will be unpredictable. Note also that you do not specify any dimensions here, simply [].
Of course, the pstr pointer now contains the address of memory that may already have been allocated for some other purpose, so it certainly should not be used. When you use the delete operator to discard some memory that you previously allocated, you should always reset the pointer, like this:
pstr = nullptr;
This ensures that you do not attempt to access the memory that has been deleted.
TRY IT OUT: Using Free Store
You can see how dynamic memory allocation works in practice by rewriting the program that calculates an arbitrary number of primes, this time using memory in the free store to store the primes.
// Ex4_11.cpp
// Calculating primes using dynamic memory allocation
#include <iostream>
#include <iomanip>
using std::cin;
using std::cout;
using std::endl;
using std::setw;
int main()
{
long* pprime(nullptr); // Pointer to prime arraylong trial(5); // Candidate prime
int count(3); // Count of primes found
int found(0); // Indicates when a prime is found
int max(0); // Number of primes required
cout << endl
<< "Enter the number of primes you would like (at least 4): ";
cin >> max; // Number of primes required
if(max < 4) // Test the user input, if less than 4
max = 4; // ensure it is at least 4
pprime = new long[max];
*pprime = 2; // Insert three
*(pprime + 1) = 3; // seed primes
*(pprime + 2) = 5;
do
{
trial += 2; // Next value for checking
found = 0; // Set found indicator
for(int i = 0; i < count; i++) // Division by existing primes
{
found =(trial % *(pprime + i)) == 0;// True for exact division
if(found) // If division is exact
break; // it's not a prime
}
if (found == 0) // We got one...
*(pprime + count++) = trial; // ...so save it in primes array
} while(count < max);
// Output primes 5 to a line
for(int i = 0; i < max; i++)
{
if(i % 5 == 0) // New line on 1st, and every 5th line
cout << endl;
cout << setw(10) << *(pprime + i);
}
delete [] pprime; // Free up memory
pprime = nullptr; // and reset the pointer
cout << endl;
return 0;
}

Here's an example of the output from this program:
Enter the number of primes you would like (at least 4): 20
2 3 5 7 11
13 17 19 23 29
31 37 41 43 47
53 59 61 67 71How It Works
In fact, the program is similar to the previous version. After receiving the number of primes required in the int variable max, you allocate an array of that size in the free store using the operator new. Note that you have made sure that max can be no less than 4. This is because the program requires space to be allocated in the free store for at least the three seed primes, plus one new one. You specify the size of the array that is required by putting the variable max between the square brackets following the array type specification:
pprime = new long[max];
You store the address of the memory area that is allocated by new in the pointer pprime. The program would terminate at this point if the memory could not be allocated.
After the memory that stores the prime values has been successfully allocated, the first three array elements are set to the values of the first three primes:
*pprime = 2; // Insert three *(pprime + 1) = 3; // seed primes *(pprime + 2) = 5;
You are using the dereference operator to access the first three elements of the array. As you saw earlier, the parentheses in the second and third statements are there because the precedence of the * operators is higher than that of the + operator.
You can't specify initial values for elements of an array that you allocate dynamically. You have to use explicit assignment statements if you want to set initial values for elements of the array.
The calculation of the prime numbers is exactly as before; the only change is that the name of the pointer you have here, pprime, is substituted for the array name, primes, that you used in the previous version. Equally, the output process is the same. Acquiring space dynamically is really not a problem at all. After it has been allocated, it in no way affects how the computation is written.
After you finish with the array, you remove it from the free store using the delete operator, remembering to include the square brackets to indicate that it is an array you are deleting.
delete [] pprime; // Free up memory
Although it's not essential here, you also reset the pointer:
pprime = nullptr; // and reset the pointer
All memory allocated in the free store is released when your program ends, but it is good to get into the habit of resetting pointers to nullptr when they no longer point to valid memory areas.
Allocating memory in the free store for a multidimensional array involves using the new operator in a slightly more complicated form than is used for a one-dimensional array. Assuming that you have already declared the pointer pbeans appropriately, to obtain the space for the array beans[3][4] that you used earlier in this chapter, you could write this:
pbeans = new double [3][4]; // Allocate memory for a 3x4 array
You just specify both array dimensions between square brackets after the type name for the array elements.
Allocating space for a three-dimensional array simply requires that you specify the extra dimension with new, as in this example:
pBigArray = new double [5][10][10]; // Allocate memory for a 5x10x10 array
However many dimensions there are in the array that has been created, to destroy it and release the memory back to the free store, you write the following:
delete [] pBigArray; // Release memory for array pBigArray = nullptr;
You always use just one pair of square brackets following the delete operator, regardless of the dimensionality of the array with which you are working.
You have already seen that you can use a variable as the specification of the dimension of a one-dimensional array to be allocated by new. This extends to two or more dimensions, but with the restriction that only the leftmost dimension may be specified by a variable. All the other dimensions must be constants or constant expressions. So, you could write this:
pBigArray = new double[max][10][10];
where max is a variable; however, specifying a variable for any dimension other than the left-most causes an error message to be generated by the compiler.
A reference appears to be similar to a pointer in many respects, which is why I'm introducing it here, but it really isn't the same thing at all. The real importance of references becomes apparent only when you get to explore their use with functions, particularly in the context of object-oriented programming. Don't be misled by their simplicity and what might seem to be a trivial concept. As you will see later, references provide some extraordinarily powerful facilities, and in some contexts enable you to achieve results that would be impossible without them.
There are two kinds of references: lvalue references and rvalue references. Essentially, a reference is a name that can be used as an alias for something else.
An lvalue reference is an alias for another variable; it is called an lvalue reference because it refers to a persistent storage location that can appear on the left of an assignment operation. Because an lvalue reference is an alias and not a pointer, the variable for which it is an alias has to be specified when the reference is declared; unlike a pointer, a reference cannot be altered to represent another variable.
An rvalue reference can be used as an alias for a variable, just like an lvalue reference, but it differs from an lvalue reference in that it can also reference an rvalue, which is a temporary value that is essentially transient.
Suppose that you have declared a variable as follows:
long number(0L);
You can declare an lvalue reference for this variable using the following declaration statement:
long& rnumber(number); // Declare a reference to variable number
The ampersand following the type name long and preceding the variable name rnumber, indicates that an lvalue reference is being declared, and that the variable name it represents, number, is specified as the initializing value following the equals sign; therefore, the variable rnumber is of type 'reference to long'. You can now use the reference in place of the original variable name. For example, this statement,
rnumber += 10L;
has the effect of incrementing the variable number by 10.
Note that you cannot write:
int& refData = 5; // Will not compile!
The literal 5 is constant and cannot be changed. To protect the integrity of constant values, you must use a const reference:
const int & refData = 5; // OK
Now you can access the literal 5 through the refData reference. Because you declare refData as const, it cannot be used to change the value it references.
Let's contrast the lvalue reference rnumber defined above with the pointer pnumber, declared in this statement:
long* pnumber(&number); // Initialize a pointer with an address
This declares the pointer pnumber, and initializes it with the address of the variable number. This then allows the variable number to be incremented with a statement such as:
*pnumber += 10L; // Increment number through a pointer
There is a significant distinction between using a pointer and using a reference. The pointer needs to be dereferenced, and whatever address it contains is used to access the variable to participate in the expression. With a reference, there is no need for de-referencing. In some ways, a reference is like a pointer that has already been dereferenced, although it can't be changed to reference something else. An lvalue reference is the complete equivalent of the variable for which it is a reference.
You specify an rvalue reference type using two ampersands following the type name. Here's an example:
int x(5); int&& rx = x;
The first statement defines the variable x with the initial value 5, and the second statement defines an rvalue reference, rx, that references x. This shows that you can initialize an rvalue reference with an lvalue so it that can work just like an lvalue reference. You can also write this as:
int&& rExpr = 2*x + 3;
Here, the rvalue reference is initialized to reference the result of evaluating the expression 2*x+3, which is a temporary value — an rvalue. You cannot do this with an lvalue reference. Is this useful? In this case, no; but in a different context, it is very useful.
While the code fragments relating to references illustrate how lvalue and rvalue reference variables can be defined and initialized, this is not how they are typically used. The primary application for both types of references is in defining functions where they can be of immense value; you'll learn more about this later in the book, starting in Chapter 5.
The standard library provides the cstring header that contains functions that operate on null-terminated strings. These are a set of functions that are specified to the C++ standard. There are also alternatives to some of these functions that are not standard, but which provide a more secure implementation of the function than the original versions. In general, I'll mention both where they exist in the cstring header, but I'll use the more secure versions in examples. Let's explore some of the most useful functions provided by the cstring header.
Note
The string standard header for native C++ defines the string and wstring classes that represent character strings. The string class represents strings of characters of type char and the wstring class represents strings of characters of type wchar_t. Both are defined in the string header as template classes that are instances of the basic_string<T> class template. A class template is a parameterized class (with parameter T in this case) that you can use to create new classes to handle different types of data. I won't be discussing templates and the string and wstring classes until Chapter 8, but I thought I'd mention them here because they have some features in common with the functions provided by the String type that you'll be using in C++/CLI programs later in this chapter. If you are really interested to see how they compare, you could always have a quick look at the section in Chapter 8 that has the same title as this section. It should be reasonably easy to follow at this point, even without knowledge of templates and classes.
The strlen() function returns the length of the argument string of type char* as a value of type size_t. The type size_t is an implementation-defined type that corresponds to an unsigned integer type that is used generally to represent the lengths of sequences of various kinds. The wcslen() function does the same thing for strings of type wchar_t*.
Here's how you use the strlen() function:
char * str("A miss is as good as a mile.");
cout << "The string contains " << strlen(str) << " characters." << endl;The output produced when this fragment executes is:
The string contains 28 characters.
As you can see from the output, the length value that is returned does not include the terminating null. It is important to keep this in mind, especially when you are using the length of one string to create another string of the same length.
Both strlen() and wcslen() find the length by looking for the null at the end. If there isn't one, the functions will happily continue beyond the end of the string, checking throughout memory in the hope of finding a null. For this reason, these functions represent a security risk when you are working with data from an untrusted external source. In this situation you can use the strnlen() and wcsnlen() functions, both of which require a second argument that specifies the length of the buffer in which the string specified by the first argument is stored.
The strcat() function concatenates two null-terminated strings. The string specified by the second argument is appended to the string specified by the first argument. Here's an example of how you might use it:
char str1[30]= "Many hands";
char* str2(" make light work.");
strcat(str1, str2);
cout << str1 << endl;Note that the first string is stored in the array str1 of 30 characters, which is far more than the length of the initializing string, "Many hands". The string specified by the first argument must have sufficient space to accommodate the two strings when they are joined. If it doesn't, disaster will surely result because the function will then try to overwrite the area beyond the end of the first string.
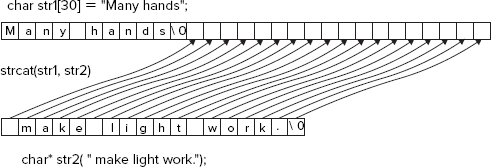
As Figure 4-9 shows, the first character of the string specified by the second argument overwrites the terminating null of the first argument, and all the remaining characters of the second string are copied across, including the terminating null. Thus, the output from the fragment will be:
Many hands make light work.
The strcat() function returns the pointer that is the first argument, so you could combine the last two statements in the fragment above into one:
cout << strcat(str1, str2) << endl;
The wcscat() function concatenates wide-character strings, but otherwise works exactly the same as the strcat() function.
With the strncat() function you can append part of one null-terminated string to another. The first two arguments are the destination and source strings respectively, and the third argument is a count of the number of characters from the source string that are to be appended. With the strings as defined in Figure 4-9, here's an example of using strncat():
cout << strncat(str1, str2, 11) << endl;
After executing this statement, str1 contains the string "Many hands make light". The operation appends 11 characters from str2 to str1, overwriting the terminating '�' in str1, and then appends a final '�' character. The wcsncat() provides the same capability as strncat() but for wide-character strings.
All the functions for concatenating strings that I have introduced up to now rely on finding the terminating nulls in the strings to work properly, so they are also insecure when it comes to dealing with untrusted data. The strcat_s(), wcscat_s(), strncat_s(), and wcsncat_s() functions in <cstring> provide secure alternatives. Just to take one example, here's how you could use strcat_s() to carry out the operation shown in Figure 4-9:
const size_t count = 30;
char str1[count]= "Many hands";
char* str2(" make light work.");
errno_t error = strcat_s(str1, count, str2);
if(error == 0)
cout << " Strings joined successfully." << endl;
else if(error == EINVAL)
cout << "Error! Source or destination string is NULL." << endl;
else if(error == ERANGE)
cout << " Error! Destination string too small." << endl;For convenience, I defined the array size as the constant count. The first argument to strcat_s() is the destination string to which the source string specified by the third argument is to be appended. The second argument is the total number of bytes available at the destination. The function returns an integer value of type errno_t to indicate how things went. The error return value will be zero if the operation is successful, EINVAL if the source or destination is NULLPTR, or ERANGE if the destination length is too small. In the event of an error occurring, the destination will be left unchanged. The error code values EINVAL and ERANGE are defined in the cerrno header, so you need an #include directive for this, as well as for cstring, to compile the fragment above correctly. Of course, you are not obliged to test for the error codes that the function might return, and if you don't, you won't need the #include directive for cerrno.
The standard library function strcpy() copies a string from a source location to a destination. The first argument is a pointer to the destination location, and the second argument is a pointer to the source string; both arguments are of type char*. The function returns a pointer to the destination string. Here's an example of how you use it:
const size_t LENGTH = 22;
const char source[LENGTH] ="The more the merrier!";
char destination[LENGTH];
cout << "The destination string is: " << strcpy(destination, source)
<< endl;The source string and the destination buffer can each accommodate a string containing 21 characters plus the terminating null. You copy the source string to destination in the last statement. The output statement makes use of the fact that the strcpy() function returns a pointer to the destination string, so the output is:
The destination string is: The more the merrier!
You must ensure that the destination string has sufficient space to accommodate the source string. If you don't, something will get overwritten in memory, and disaster is the likely result.
The strcpy_s() function is a more secure version of strcpy(). It requires an extra argument between the destination and source arguments that specifies the size of the destination string buffer. The strcpy_s() function returns an integer value of type errno_t that indicates whether an error occurred. Here's how you might use this function:
const size_t LENGTH(22); const char source[LENGTH] ="The more the merrier!"; char destination[LENGTH]; errno_t error = strcpy_s(destination, LENGTH, source); if(error == EINVAL) cout << "Error. The source or the destination is NULLPTR." << endl; else if(error == ERANGE) cout << "Error. The destination is too small." << endl; else cout << "The destination string is: " << destination << endl;
You need to include the cstring and cerrno headers for this to compile. The strcpy_s() function verifies that the source and destination are not NULLPTR and that the destination buffer has sufficient space to accommodate the source string. When either or both the source and destination are NULLPTR, the function returns the value EINVAL. If the destination buffer is too small, the function returns ERANGE. If the copy is successful, the return value is 0.
You have analogous wide-character versions of these copy functions; these are wcscpy() and wcscpy_s().
The strcmp() function compares two null-terminated strings that you specify by arguments that are pointers of type char*. The function returns a value of type int that is less than zero, zero, or greater than 0, depending on whether the string pointed to by the first argument is less than, equal to, or greater than the string pointed to by the second argument. Here's an example:
char* str1("Jill");
char* str2("Jacko");
int result = strcmp(str1, str2);
if(result < 0)
cout << str1 << " is less than " << str2 << '.' << endl;
else if(0 == result)cout << str1 << " is equal to " << str2 << '.' << endl; else cout << str1 << " is greater than " << str2 << '.' << endl;
This fragment compares the strings str1 and str2, and uses the value returned by strcmp() to execute one of three possible output statements.
Comparing the strings works by comparing the character codes of successive pairs of corresponding characters. The first pair of characters that are different determines whether the first string is less than or greater than the second string. Two strings are equal if they contain the same number of characters, and the corresponding characters are identical. Of course, the output is:
Jill is greater than Jacko.
The wcscmp() function is the wide-character string equivalent of strcmp().
The strspn() function searches a string for the first character that is not contained in a given set and returns the index of the character found. The first argument is a pointer to the string to be searched, and the second argument is a pointer to a string containing the set of characters. You could search for the first character that is not a vowel like this:
char* str = "I agree with everything.";
char* vowels = "aeiouAEIOU ";
size_t index = strspn(str, vowels);
cout << "The first character that is not a vowel is '" << str[index]
<< "' at position " << index << endl;This searches str for the first character that is not contained in vowels. Note that I included a space in the vowels set, so a space will be ignored so far as the search is concerned. The output from this fragment is:
The first character that is not a vowel is 'g' at position 3
Another way of looking at the value the strspn() function returns is that it represents the length of the substring, starting from the first character in the first argument string that consists entirely of characters in the second argument string. In the example it is the first three characters "I a".
The wcsspn() function is the wide-character string equivalent of strspn().
The strstr() function returns a pointer to the position in the first argument of a substring specified by the second argument. Here's a fragment that shows this in action:
char* str = "I agree with everything.";
char* substring = "ever";
char* psubstr = strstr(str, substring);
if(!psubstr)
cout << """ << substring << "" not found in "" << str << """ << endl;
else
cout << "The first occurrence of "" << substring
<< "" in "" << str << "" is at position "
<< psubstr-str << endl;The third statement calls the strstr() function to search str for the first occurrence of the substring. The function returns a pointer to the position of the substring if it is found, or NULL when it is not found. The if statement outputs a message, depending on whether or not substring was found in str. The expression psubstr-str gives the index position of the first character in the substring. The output produced by this fragment is:
The first occurrence of "ever" in "I agree with everything." is at position 13
TRY IT OUT: Searching Null-Terminated Strings
This example searches a given string to determine the number of occurrences of a given substring.
// Ex4_12.cpp
// Searching a string
#include <iostream>
#include <cstring>
using std::cout;
using std::endl;
using std::strlen;
using std::strstr;
int main()
{
char* str("Smith, where Jones had had "had had" had had "had"."
"
"Had had" had had the examiners' approval.");
char* word("had");
cout << "The string to be searched is: "
<< endl << str << endl;
int count(0); // Number of occurrences of word in str
char* pstr(str); // Pointer to search start position
char* found(nullptr); // Pointer to occurrence of word in str
while(true)
{
found = strstr(pstr, word);
if(!found)
break;
++count;
pstr = found+strlen(word); // Set next search start as 1 past the word found
}
cout << """ << word << "" was found "
<< count << " times in the string." << endl;
return 0;
}

The output from this example is:
The string to be searched is: Smith, where Jones had had "had had" had had "had". "Had had" had had the examiners' approval. "had" was found 10 times in the string.
How It Works
All the action takes place in the indefinite while loop:
while(true)
{
found = strstr(pstr, word);
if(!found)
break;
++count;
pstr = found+strlen(word); // Set next search start as 1 past the word found
}The first step is to search the string for word starting at position pstr, which initially is the beginning of the string. You store the address that strstr() returns in found; this will be nullptr if word was not found in pstr, so the if statement ends the loop in that case.
If found is not nullptr, you increment the count of the number of occurrences of word, and update the pstr pointer so that it points to one character past the word instance that was found in pstr. This will be the starting point for the search on the next loop iteration.
From the output, you can see that word was found ten times in str. Of course, "Had" doesn't count because it starts with an uppercase letter.
Dynamic memory allocation works differently with the CLR, and the CLR maintains its own memory heap that is independent of the native C++ heap. The CLR automatically deletes memory that you allocate on the CLR heap when it is no longer required, so you do not need to use the delete operator in a program written for the CLR. The CLR may also compact heap memory to avoid fragmentation from time to time. Thus, at a stroke, the CLR greatly reduces the possibility of memory leaks and memory fragmentation. The management and clean-up of the heap that the CLR provides is described as garbage collection — the garbage being your discarded variables and objects. The heap that is managed by the CLR is called the garbage-collected heap. You use the gcnew operator instead of new to allocate memory in a C++/CLI, program; the 'gc' prefix is a cue to the fact that you are allocating memory on the garbage-collected heap, and not the native C++ heap, where all the housekeeping is down to you.
The CLR garbage collector is able to delete objects and release the memory that they occupy when they are no longer required. An obvious question arises: How does the garbage collector know when an object on the heap is no longer required? The answer is quite simple. The CLR keeps track of every variable that references each object in the heap; when there are no variables containing the address of a given object, the object can no longer be referred to in a program, and therefore can be deleted.
Because the garbage collection process can involve compacting the heap memory area to remove fragmented unused blocks of memory, the addresses of data items that you have stored in the heap can change. Consequently, you cannot use ordinary native C++ pointers with the garbage-collected heap, because if the location of the data that is pointed to changes, the pointer will no longer be valid. You need a way to access objects on the heap that enables the address to be updated when the garbage collector relocates the data item in the heap. This capability is provided in two ways: by a tracking handle (also referred to simply as a handle) that is analogous to a pointer in native C++, and by a tracking reference that provides the equivalent of a native C++ reference in a CLR program.
A tracking handle has similarities to a native C++ pointer, but there are significant differences, too. A tracking handle does store an address, which is automatically updated by the garbage collector if the object it references is moved during compaction of the heap. However, you cannot perform address arithmetic with a tracking handle as you can with a native pointer, and casting a tracking handle is not permitted.
You use tracking handles to reference objects created in the CLR heap. All objects that are reference class types are stored in the heap; therefore, the variables you create to refer to such objects must be tracking handles. For instance, the String class type is a reference class type, so variables that reference String objects must be tracking handles. The memory for value class types is allocated on the stack by default, but you can choose to store values in the heap by using the gcnew operator. This is also a good time to remind you of a point I mentioned in Chapter 2 — that variables allocated on the CLR heap, which includes all CLR reference types, cannot be declared at global scope.
You specify a handle for a type by placing the ^ symbol (commonly referred to as a 'hat') following the type name. For example, here's how you could declare a tracking handle with the name proverb that can store the address of a String object:
String^ proverb;
This defines the variable proverb to be a tracking handle of type String^. When you declare a handle it is automatically initialized with null, so it will not refer to anything. To explicitly set a handle to null you use the keyword nullptr like this:
proverb = nullptr; // Set handle to null
Note that you cannot use 0 to represent null here, as you can with native pointers (even though it is now not recommended). If you initialize a tracking handle with 0, the value 0 is converted to the type of object that the handle references, and the address of this new object is stored in the handle.
Warning
The nullptr keyword in C++/CLI has a different meaning from the nullptr keyword in native C++. This doesn't matter, as long as you are not mixing native C++ code that uses native pointers with C++/CLI code. If you are, you must use __nullptr as the null pointer value for your native C++ pointers and nullptrfor the value of handles in the C++/CLI code. Although you can mix native C++ and C++/CLI code, it is best avoided as far as possible.
Of course, you can initialize a handle explicitly when you declare it. Here's another statement that defines a handle to a String object:
String^ saying(L"I used to think I was indecisive but now I'm not so sure");
This statement creates a String object on the heap that contains the string between the parentheses; the address of the new object is stored in saying. Note that the type of the string literal is const wchar_t*, not type String. The way the String class has been defined makes it possible for such a literal to be used to create an object of type String.
Here's how you could create a handle for a value type:
int^ value(99);
This statement creates the handle value of type int^; the value it points to on the heap is initialized to 99. Remember that you have created a kind of pointer, so value cannot participate in arithmetic operations without dereferencing it. To dereference a tracking handle, you use the * operator in the same way as you do for native pointers. For example, here is a statement that uses the value pointed to by a tracking handle in an arithmetic operation:
int result(2*(*value)+15);
The expression *value between the parentheses accesses the integer stored at the address held in the tracking handle, so the variable result is set to 213.
Note that when you use a handle on the left of an assignment, there's no need to explicitly dereference it to store a result; the compiler takes care of it for you. For example:
int^ result(nullptr); result = 2*(*value)+15;
Here you first create the handle result, initialized to null. Because result appears on the left of an assignment in the next statement, and the right-hand side produces a value, the compiler is able to determine that result must be dereferenced to store the value. Of course, you could write it explicitly like this:
*result = 2*(*value)+15;
Here you explicitly dereference the handle on the left of the assignment.
CLR arrays are different from the native C++ arrays. Memory for a CLR array is allocated on the garbage-collected heap, but there's more to it than that. CLR arrays have built-in functionality that you don't get with native C++ arrays, as you'll see shortly. You specify an array variable type using the keyword array. You must also specify the type for the array elements between angled brackets following the array keyword. The general form for specifying the type of variable to reference a one-dimensional array is array<element_type>^. Because a CLR array is created on the heap, an array variable is always a tracking handle. Here's an example of a declaration for an array variable:
array<int>^ data;
The array variable, data, that you create here can store a reference to any one-dimensional array of elements of type int.
You can create a CLR array using the gcnew operator at the same time that you declare the array variable:
array<int>^ data = gcnew array<int>(100); // Create an array to store 100 integers
This statement creates a one-dimensional array with the name data. Note that an array variable is a tracking handle, so you must not forget the hat following the element type specification between the angled brackets. The number of elements appears between parentheses following the array type specification, so this array contains 100 elements, each of which can store a value of type int. Of course, you can also use functional notation to initialize the variable data:
array<int>^ data(gcnew array<int>(100)); // Create an array to store 100 integers
Just like native C++ arrays, CLR array elements are indexed from zero, so you could set values for the elements in the data array like this:
for(int i = 0 ; i<100 ; i++) data[i] = 2*(i+1);
This loop sets the values of the elements to 2, 4, 6, and so on up to 200. Elements in a CLR array are objects; here you are storing objects of type Int32 in the array. Of course, these behave like ordinary integers in arithmetic expressions, so the fact that they are objects is transparent in such situations.
The number of elements appears in the loop control expression as a literal value. It would be better to use the Length property of the array that records the number of elements, like this:
for(int i = 0 ; i < data->Length ; i++) data[i] = 2*(i+1);
To access the Length property, you use the -> operator, because data is a tracking handle and works like a pointer. The Length property records the number of elements in the array as a 32-bit integer value. If you need it, you can get the array length as a 64-bit value through the LongLength property.
You can also use the for each loop to iterate over all the elements in an array:
array<int>^ values = { 3, 5, 6, 8, 6};
for each(int item in values)
{
item = 2*item + 1;
Console::Write("{0,5}",item);
}The first statement demonstrates that you can initialize an array handle with an array defined by a set of values. The size of the array is determined by the number of initial values between the braces, in this case five, and the values are assigned to the elements in sequence. Thus the handle values will reference an array of 5 integers where the elements have the values 3, 5, 6, 8 and 6. Within the loop, item references each of the elements in the values array in turn. The first statement in the body of the loop stores twice the current element's value plus 1 in item. The second statement in the loop outputs the new value, right-justified in a field width of five characters; the output produced by this code fragment is:
7 11 13 17 13
It is easy to get the wrong idea about what is going on here. The for each loop above does not change the elements in the values array. item is a variable that accesses the value of each array element in turn; it does not reference the array elements themselves.
An array variable can store the address of any array of the same rank (the rank being the number of dimensions, which in the case of the data array is 1) and element type. For example:
data = gcnew array<int>(45);
This statement creates a new one-dimensional array of 45 elements of type int and stores its address in data. The original array referenced by the handle, data, is discarded.
Of course, the elements in an array can be of any type, so you can easily create an array of strings:
array<String^>^ names = { "Jack", "Jane", "Joe", "Jessica", "Jim", "Joanna"};The elements of this array are initialized with the strings that appear between the braces, and the number of strings between the braces determines the number of elements in the array. String objects are created on the CLR heap, so each element in the array is a tracking handle of type String^.
If you declare the array variable without initializing it and then want it to reference an array you create subsequently, you must explicitly create the array in order to use a list of initial values. Here's an example:
array<String^>^ names; // Declare the array variable
names = gcnew array<String^>{ "Jack", "Jane", "Joe", "Jessica", "Jim", "Joanna"};The first statement creates the array variable names, which will be initialized with nullptr by default. The second statement creates an array of elements of type String^ and initializes it with handles to the strings between the braces. Without the explicit gcnew definition the statement will not compile.
You can use the static Clear() function that is defined in the Array class to set any sequence of numeric elements in an array to zero. You call a static function using the class name. You'll learn more about such functions when you explore classes in detail. Here's an example of how you could use the Clear() function to clear an array of elements of type double:
Array::Clear(samples, 0, samples->Length); // Set all elements to zero
The first argument to Clear() is the array that is to be cleared, the second argument is the index for the first element to be cleared, and the third argument is the number of elements to be cleared. Thus, this example sets all the elements of the samples array to 0.0. If you apply the Clear() function to an array of tracking handles such as String^, the elements are set to nullptr and if you apply it to an array of bool elements they are set to false.
It's time to let a CLR array loose in an example.
TRY IT OUT: Using a CLR Array
In this example, you generate an array containing random values and then find the maximum value. Here's the code:
// Ex4_13.cpp : main project file.// Using a CLR array#include "stdafx.h" using namespace System; int main(array<System::String ^> ^args) {array<double>^ samples = gcnew array<double>(50);// Generate random element valuesRandom^ generator = gcnew Random;for(int i = 0 ; i< samples->Length ; i++)samples[i] = 100.0*generator->NextDouble();// Output the samplesConsole::WriteLine(L"The array contains the following values:");for(int i = 0 ; i< samples->Length ; i++){Console::Write(L"{0,10:F2}", samples[i]);if((i+1)%5 == 0)Console::WriteLine();}// Find the maximum valuedouble max(0);for each(double sample in samples)if(max < sample)max = sample;Console::WriteLine(L"The maximum value in the array is {0:F2}", max);return 0; }
Typical output from this example looks like this:
The array contains the following values:
30.38 73.93 29.82 93.00 78.14
89.53 75.87 5.98 45.29 89.835.25 53.86 11.40 3.34 83.39
69.94 82.43 43.05 32.87 59.50
58.89 96.69 34.67 18.81 72.99
89.60 25.53 34.00 97.35 55.26
52.64 90.85 10.35 46.14 82.03
55.46 93.26 92.96 85.11 10.55
50.50 8.10 29.32 82.98 76.48
83.94 56.95 15.04 21.94 24.81
The maximum value in the array is 97.35You first create an array that stores 50 values of type double:
array<double>^ samples = gcnew array<double>(50);
The array variable, samples, must be a tracking handle, because CLR arrays are created on the garbage-collected heap.
You populate the array with pseudo-random values of type double with the following statements:
Random^ generator = gcnew Random; for(int i = 0 ; i< samples->Length ; i++) samples[i] = 100.0*generator->NextDouble();
The first statement creates an object of type Random on the CLR heap. A Random object has functions that will generate pseudo-random values. Here you use the NextDouble() function in the loop, which returns a random value of type double that lies between 0.0 and 1.0. By multiplying this by 100.0 you get a value between 0.0 and 100.0. The for loop stores a random value in each element of the samples array.
A
Randomobject also has aNext()function that returns a random non-negative value of typeint. If you supply an integer argument when you call theNext()function, it will return a random non-negative integer which is less than the argument value. You can also supply two integer arguments that represent the minimum and maximum values for the random integer to be returned.
The next loop outputs the contents of the array, five elements to a line:
Console::WriteLine(L"The array contains the following values:");
for(int i = 0 ; i< samples->Length ; i++)
{
Console::Write(L"{0,10:F2}", samples[i]);
if((i+1)%5 == 0)
Console::WriteLine();
}Within the loop, you write the value of each element with a field width of 10 and 2 decimal places. Specifying the field width ensures the values align in columns. You also write a newline character to the output whenever the expression (i+1)%5 is zero, which is after every fifth element value, so you get five to a line in the output.
Finally, you figure out what the maximum element value is:
double max = 0;
for each(double sample in samples)
if(max < sample)
max = sample;This uses a for each loop just to show that you can. The loop compares max with each element value in turn, and whenever the element is greater than the current value in max, max is set to that value. You end up with the maximum element value in max.
You could use a for loop here if you also wanted to record the index position of the maximum element as well as its value — for example:
double max = 0;
int index = 0;
for (int i = 0 ; i < samples->Length ; i++)
if(max < samples[i])
{
max = samples[i];
index = i;
}The Array class in the System namespace defines a Sort() function that sorts the elements of a one-dimensional array so that they are in ascending order. To sort an array, you just pass the array handle to the Sort() function. Here's an example:
array<int>^ samples = { 27, 3, 54, 11, 18, 2, 16};
Array::Sort(samples); // Sort the array elements
for each(int value in samples) // Output the array elements
Console::Write(L"{0, 8}", value);
Console::WriteLine();The call to the Sort() function rearranges the values of the elements in the samples array into ascending sequence. The result of executing this code fragment is:
2 3 11 16 18 27 54
You can also sort a range of elements in an array by supplying two more arguments to the Sort() function, specifying the index for the first element of those to be sorted, and the number of elements to be sorted. For example:
array<int>^ samples = { 27, 3, 54, 11, 18, 2, 16};
Array::Sort(samples, 2, 3); // Sort elements 2 to 4This statement sorts the three elements in the samples array that begin at index position 2. After executing these statements, the elements in the array will have the values:
27 3 11 18 54 2 16
There are several other versions of the Sort() function that you can find if you consult the documentation, but I'll introduce one other that is particularly useful. This version presumes you have two arrays that are associated such that the elements in the first array represent keys to the corresponding elements in the second array. For example, you might store names of people in one array and the weights of the individuals in a second array. The Sort() function sorts the array of names in ascending sequence and also rearranges the elements of the weights array so that the weights still match the appropriate person. Let's try it in an example.
TRY IT OUT: Sorting Two Associated Arrays
This example creates an array of names, and stores the weights of each person in the corresponding element of a second array. It then sorts both arrays in a single operation.
// Ex4_14.cpp : main project file.// Sorting an array of keys(the names) and an array of objects(the weights)#include "stdafx.h" using namespace System; int main(array<System::String ^> ^args) {array<String^>^ names = { "Jill", "Ted", "Mary", "Eve", "Bill", "Al"};array<int>^ weights = { 103, 168, 128, 115, 180, 176};Array::Sort( names,weights); // Sort the arraysfor each(String^ name in names) // Output the namesConsole::Write(L"{0, 10}", name);Console::WriteLine();for each(int weight in weights) // Output the weightsConsole::Write(L"{0, 10}", weight);Console::WriteLine();return 0; }
The output from this program is:
Al Bill Eve Jill Mary Ted 176 180 115 103 128 168
The values in the weights array correspond to the weight of the person at the same index position in the names array. The Sort() function you call here sorts both arrays using the first array argument — names, in this instance — to determine the order of both arrays. You can see from the output that after sorting, everyone still has his or her correct weight recorded in the corresponding element of the weights array.
The Array class provides functions that search the elements of a one-dimensional array. Versions of the BinarySearch() function use a binary search algorithm to find the index position of a given element in the entire array, or in a given range of elements. The binary search algorithm requires that the elements are ordered, if it is to work, so you need to sort the elements before you search an array.
Here's how you could search an entire array:
array<int>^ values = { 23, 45, 68, 94, 123, 127, 150, 203, 299};
int toBeFound(127);
int position = Array::BinarySearch(values, toBeFound);
if(position<0)
Console::WriteLine(L"{0} was not found.", toBeFound);
else
Console::WriteLine(L"{0} was found at index position {1}.", toBeFound, position);The value to be found is stored in the toBeFound variable. The first argument to the BinarySearch() function is the handle of the array to be searched, and the second argument specifies what you are looking for. The result of the search is returned by the BinarySearch() function as a value of type int. If the second argument to the function is found in the array specified by the first argument, its index position is returned; otherwise a negative integer is returned. Thus, you must test the value returned to determine whether or not the search target was found. Because the values in the values array are already in ascending sequence, there is no need to sort the array before searching it. This code fragment would produce the output:
127 was found at index position 5.
To search a given range of elements in an array you use a version of the BinarySearch() function that accepts four arguments. The first argument is the handle of the array to be searched, the second argument is the index position of the element where the search should start, the third argument is the number of elements to be searched, and the fourth argument is what you are looking for. Here's how you might use that:
array<int>^ values = { 23, 45, 68, 94, 123, 127, 150, 203, 299};
int toBeFound(127);
int position = Array::BinarySearch(values, 3, 6, toBeFound);This searches the values array from the fourth array element through to the last. As with the previous version of BinarySearch(), the function returns the index position found, or a negative integer if the search fails.
Let's try a searching example.
TRY IT OUT: Searching Arrays
This is a variation on the previous example with a search operation added:
// Ex4_15.cpp : main project file.// Searching an array#include "stdafx.h" using namespace System; int main(array<System::String ^> ^args) {array<String^>^ names = { "Jill", "Ted", "Mary", "Eve", "Bill","Al", "Ned", "Zoe", "Dan", "Jean"};array<int>^ weights = { 103, 168, 128, 115, 180,176, 209, 98, 190, 130 };array<String^>^ toBeFound = {"Bill", "Eve", "Al", "Fred"};Array::Sort( names, weights); // Sort the arraysint result(0); // Stores search resultfor each(String^ name in toBeFound) // Search to find weights{result = Array::BinarySearch(names, name); // Search names arrayif(result<0) // Check the resultConsole::WriteLine(L"{0} was not found.", name);elseConsole::WriteLine(L"{0} weighs {1} lbs.", name, weights[result]);}return 0; }
This program produces the output:
Bill weighs 180 lbs. Eve weighs 115 lbs. Al weighs 176 lbs. Fred was not found.
How It Works
You create two associated arrays — an array of names and an array of corresponding weights in pounds. You also create the toBeFound array that contains the names of the people whose weights you'd like to know.
You sort the names and weights arrays, using the names array to determine the order. You then search the names array for each name in the toBeFound array using a for each loop. The loop variable, name, is assigned each of the names in the toBeFound array in turn. Within the loop, you search for the current name with the statement:
result = Array::BinarySearch(names, name); // Search names array
This returns the index of the element from names that contains name, or a negative integer if the name is not found. You then test the result and produce the output in the if statement:
if(result<0) // Check the result
Console::WriteLine(L"{0} was not found.", name);
else
Console::WriteLine(L"{0} weighs {1} lbs.", name, weights[result]);Because the ordering of the weights array was determined by the ordering of the names array, you are able to index the weights array with result, the index position in the names array where name was found. You can see from the output that "Fred" was not found in the names array.
When the binary search operation fails, the value returned is not just any old negative value. It is, in fact, the bitwise complement of the index position of the first element that is greater than the object you are searching for, or the bitwise complement of the Length property of the array if no element is greater than the object sought. Knowing this, you can use the BinarySearch() function to work out where you should insert a new object in an array, and still maintain the order of the elements. Suppose you wanted to insert "Fred" in the names array. You can find the index position where it should be inserted with these statements:
array<String^>^ names = { "Jill", "Ted", "Mary", "Eve", "Bill",
"Al", "Ned", "Zoe", "Dan", "Jean"};
Array::Sort(names); // Sort the array
String^ name = L"Fred";
int position(Array::BinarySearch(names, name));
if(position<0) // If it is negative
position = ∼position; // flip the bits to get the insert indexIf the result of the search is negative, flipping all the bits gives you the index position of where the new name should be inserted. If the result is positive, the new name is identical to the name at this position, and you can use the result as the new position directly.
You can now copy the names array into a new array that has one more element, and use the position value to insert name at the appropriate place:
array<String^>^ newNames = gcnew array<String^>(names->Length+1);
// Copy elements from names to newNames
for(int i = 0 ; i<position ; i++)
newNames[i] = names[i];
newNames[position] = name; // Copy the new element
if(position<names->Length) // If any elements remain in
// names
for(int i = position ; i<names->Length ; i++)
newNames[i+1] = names[i]; // copy them to newNamesThis creates a new array with a length that is one greater than the length of the old array. You then copy all the elements from the old to the new, up to index position position-1. You then copy the new name followed by the remaining elements from the old array. To discard the old array, you would just write:
names = nullptr;
You can create arrays that have two or more dimensions; the maximum number of dimensions an array can have is 32, which should accommodate most situations. You specify the number of dimensions that your array has between the angled brackets immediately following the element type, and separated from it by a comma. The dimension of an array is 1 by default, which is why you did not need to specify it up to now. Here's how you can create a two-dimensional array of integer elements:
array<int, 2>^ values = gcnew array<int, 2>(4, 5);
This statement creates a two-dimensional array with four rows and five columns for a total of 20 elements. To access an element of a multidimensional array, you specify a set of index values, one for each dimension; these are placed, between square brackets, separated by commas, following the array name. Here's how you could set values for the elements of a two-dimensional array of integers:
int nrows(4);
int ncols(5);
array<int, 2>^ values(gcnew array<int, 2>(nrows, ncols));
for(int i = 0 ; i<nrows ; i++)
for(int j = 0 ; j<ncols ; j++)
values[i,j] = (i+1)*(j+1);The nested loop iterates over all the elements of the array. The outer loop iterates over the rows, and the inner loop iterates over every element in the current row. As you can see, each element is set to a value that is given by the expression (i+1)*(j+1), so elements in the first row will be set to 1,2,3,4,5; elements in the second row will be 2,4,6,8,10; and so on, through to the last row, which will be 4,6,12,16,20.
I'm sure you will have noticed that the notation for accessing an element of a two-dimensional array here is different from the notation used for native C++ arrays. This is no accident. A C++/CLI array is not an array of arrays like a native C++ array; it is a true two-dimensional array. You cannot use a single index with a two-dimensional C++/CLI array, because this has no meaning; the array is a two-dimensional array of elements. As I said earlier, the dimensionality of an array is referred to as its rank, so the rank of the values array in the previous fragment is 2. Of course, you can also define C++/CLI arrays of rank 3 or more, up to an array of rank 32. In contrast, native C++ arrays are actually always of rank 1, because native C++ arrays of two or more dimensions are really arrays of arrays. As you'll see later, you can also define arrays of arrays in C++/CLI.
Let's put a multidimensional array to use in an example.
TRY IT OUT: Using a Multidimensional Array
This CLR console example creates a 12×12 multiplication table in a two-dimensional array:
// Ex4_16.cpp : main project file.// Using a two-dimensional array#include "stdafx.h" using namespace System; int main(array<System::String ^> ^args) {const int SIZE(12);array<int, 2>^ products(gcnew array<int, 2>(SIZE,SIZE));for (int i = 0 ; i < SIZE ; i++)for(int j = 0 ; j < SIZE ; j++)products[i,j] = (i+1)*(j+1);Console::WriteLine(L"Here is the {0} times table:", SIZE);// Write horizontal divider linefor(int i = 0 ; i <= SIZE ; i++)Console::Write(L"_____");Console::WriteLine(); // Write newline// Write top line of tableConsole::Write(L" |");for(int i = 1 ; i <= SIZE ; i++)Console::Write(L"{0,3} |", i);Console::WriteLine(); // Write newline// Write horizontal divider line with verticalsfor(int i = 0 ; i <= SIZE ; i++)Console::Write(L"____|");Console::WriteLine(); // Write newline// Write remaining linesfor(int i = 0 ; i<SIZE ; i++){Console::Write(L"{0,3} |", i+1);for(int j = 0 ; j<SIZE ; j++)Console::Write(L"{0,3} |", products[i,j]);Console::WriteLine(); // Write newline}// Write horizontal divider linefor(int i = 0 ; i <= SIZE ; i++)
Console::Write(L"_____");Console::WriteLine(); // Write newlinereturn 0; }
This example should produce the following output:
Here is the 12 times table:
_________________________________________________________________
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
____|____|____|____|____|____|____|____|____|____|____|____|____|
1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
2 | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 22 | 24 |
3 | 3 | 6 | 9 | 12 | 15 | 18 | 21 | 24 | 27 | 30 | 33 | 36 |
4 | 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 | 36 | 40 | 44 | 48 |
5 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | 55 | 60 |
6 | 6 | 12 | 18 | 24 | 30 | 36 | 42 | 48 | 54 | 60 | 66 | 72 |
7 | 7 | 14 | 21 | 28 | 35 | 42 | 49 | 56 | 63 | 70 | 77 | 84 |
8 | 8 | 16 | 24 | 32 | 40 | 48 | 56 | 64 | 72 | 80 | 88 | 96 |
9 | 9 | 18 | 27 | 36 | 45 | 54 | 63 | 72 | 81 | 90 | 99 |108 |
10 | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 |100 |110 |120 |
11 | 11 | 22 | 33 | 44 | 55 | 66 | 77 | 88 | 99 |110 |121 |132 |
12 | 12 | 24 | 36 | 48 | 60 | 72 | 84 | 96 |108 |120 |132 |144 |
_________________________________________________________________How It Works
It looks like a lot of code, but most of it is concerned with making the output pretty. You create the two-dimensional array with the following statements:
const int SIZE(12); array<int, 2>^ products(gcnew array<int, 2>(SIZE,SIZE));
The first line defines a constant integer value that specifies the number of elements in each array dimension. The second line defines an array of rank 2 that has 12 rows of 12 elements. This array stores the products in the 12 × 12 table.
You set the values of the elements in the products array in a nested loop:
for (int i = 0 ; i < SIZE ; i++)
for(int j = 0 ; j < SIZE ; j++)
products[i,j] = (i+1)*(j+1);The outer loop iterates over the rows, and the inner loop iterates over the columns. The value of each element is the product of the row and column index values after they are incremented by 1. The rest of the code in main() is concerned solely with generating output.
After writing the initial table heading, you create a row of bars to mark the top of the table, like this:
for(int i = 0 ; i <= SIZE ; i++) Console::Write(L"_____"); Console::WriteLine(); // Write newline
Each iteration of the loop writes five horizontal bar characters. Note that the upper limit for the loop is inclusive, so you write 13 sets of five bars to allow for the row labels in the table plus the 12 columns.
Next you write the row of column labels for the table with another loop:
// Write top line of table
Console::Write(L" |");
for(int i = 1 ; i <= SIZE ; i++)
Console::Write(L"{0,3} |", i);
Console::WriteLine(); // Write newlineYou have to write the space over the row label position separately because that is a special case with no output value. Each of the column labels is written in the loop. You then write a newline character, ready for the row outputs that follow.
The row outputs are written in a nested loop:
for(int i = 0 ; i<SIZE ; i++)
{
Console::Write(L"{0,3} |", i+1);
for(int j = 0 ; j<SIZE ; j++)
Console::Write(L"{0,3} |", products[i,j]);
Console::WriteLine(); // Write newline
}The outer loop iterates over the rows, and the code inside the outer loop writes a complete row, including the row label on the left. The inner loop writes the values from the products array that correspond to the ith row, with the values separated by vertical bars.
The remaining code writes more horizontal bars to finish off the bottom of the table.
Array elements can be of any type, so you can create arrays where the elements are tracking handles that reference arrays. This gives you the possibility of creating so-called jagged arrays, because each handle referencing an array can have a different number of elements. This is most easily understood by looking at an example. Suppose you want to store the names of children in a class grouped by the grade they scored, where there are five classifications corresponding to grades A, B, C, D, and E. You could first create an array of five elements where each element stores an array of names. Here's the statement that will do that:
array< array< String^ >^ >^ grades(gcnew array< array< String^ >^ >(5));
Don't let all the hats confuse you — it's simpler than it looks. The array variable, grades, is a handle of type array<type>^. Each element in the array is also a handle to an array, so the type of the array elements is of the same form — array<type>^; this has to go between the angled brackets in the original array type specification, which results in array< array<type>^ >^. The elements stored in the array are also handles to String objects, so you must replace type in the last expression with String^; thus you end up with the array type being array< array< String^ >^ >^.
With the array of arrays worked out, you can now create the arrays of names. Here's an example of what that might look like:
grades[0] = gcnew array<String^>{"Louise", "Jack"}; // Grade A
grades[1] = gcnew array<String^>{"Bill", "Mary", "Ben", "Joan"}; // Grade B
grades[2] = gcnew array<String^>{"Jill", "Will", "Phil"}; // Grade C
grades[3] = gcnew array<String^>{"Ned", "Fred", "Ted", "Jed", "Ed"}; // Grade D
grades[4] = gcnew array<String^>{"Dan", "Ann"}; // Grade EThe expression grades[n] accesses the nth element of the grades array, and, of course, this is a handle to an array of String^ handles in each case. Thus, each of the five statements creates an array of String object handles and stores the address in one of the elements of the grades array. As you see, the arrays of strings vary in length, so clearly you can manage a set of arrays with arbitrary lengths in this way.
You could create and initialize the whole array of arrays in a single statement:
array< array< String^ >^ >^ grades = gcnew array< array< String^ >^ >
{
gcnew array<String^>{"Louise", "Jack"}, // Grade A
gcnew array<String^>{"Bill", "Mary", "Ben", "Joan"}, // Grade B
gcnew array<String^>{"Jill", "Will", "Phil"}, // Grade C
gcnew array<String^>{"Ned", "Fred", "Ted", "Jed", "Ed"}, // Grade D
gcnew array<String^>{"Dan", "Ann"} // Grade E
};The initial values for the elements are between the braces.
Let's put this in a working example that demonstrates how you can process arrays of arrays.
TRY IT OUT: Using an Array of Arrays
Create a CLR console program project and modify it as follows:
// Ex4_17.cpp : main project file.// Using an array of arrays#include "stdafx.h" using namespace System; int main(array<System::String ^> ^args) {array< array< String^ >^ >^ grades = gcnew array< array< String^ >^ >{
gcnew array<String^>{"Louise", "Jack"}, // Grade Agcnew array<String^>{"Bill", "Mary", "Ben", "Joan"}, // Grade Bgcnew array<String^>{"Jill", "Will", "Phil"}, // Grade Cgcnew array<String^>{"Ned", "Fred", "Ted", "Jed", "Ed"}, // Grade Dgcnew array<String^>{"Dan", "Ann"} // Grade E};wchar_t gradeLetter('A'),for each(array< String^ >^ grade in grades){Console::WriteLine(L"Students with Grade {0}:", gradeLetter++);for each( String^ student in grade)Console::Write(L"{0,12}",student); // Output the current nameConsole::WriteLine(); // Write a newline}return 0; }
This example produces the following output:
Students with Grade A:
Louise Jack
Students with Grade B:
Bill Mary Ben Joan
Students with Grade C:
Jill Will Phil
Students with Grade D:
Ned Fred Ted Jed Ed
Students with Grade E:
Dan AnnHow It Works
The array definition is exactly as you saw in the previous section. Next, you define the gradeLetter variable as type wchar_t with the initial value 'A'. This is to be used to present the grade classification in the output.
The students and their grades are listed by the nested loops. The outer for each loop iterates over the elements in the grades array:
for each(array< String^ >^ grade in grades)
{
// Process students in the current grade...
}The loop variable grade is of type array< String^ >^ because that's the element type in the grades array. The variable grade references each of the arrays of String^ handles in turn: the first time around the loop references the array of grade A student names, the second time around it references grade B student names, and so on until the last loop iteration when it references the grade E student names.
On each iteration of the outer loop, you execute the following code:
Console::WriteLine(L"Students with Grade {0}:", gradeLetter++);
for each( String^ student in grade)
Console::Write(L"{0,12}",student); // Output the current name
Console::WriteLine(); // Write a newlineThe first statement writes a line that includes the current value of gradeLetter, which starts out as 'A'. The statement also increments gradeLetter to be, 'B', 'C', 'D', and 'E' successively on subsequent iterations of the outer loop.
Next, you have the inner for each loop that iterates over each of the names in the current grade array in turn. The output statement uses the Console::Write() function so all the names appear on the same line. The names are presented right-justified in the output in a field width of 12, so the names in the lines of output are aligned. After the loop, the WriteLine() just writes a newline to the output, so the next grade output starts on a new line.
You could have used a for loop for the inner loop:
for (int i = 0 ; i < grade->Length ; i++)
Console::Write(L"{0,12}",grade[i]); // Output the current nameHere the loop is constrained by the Length property of the current array of names that is referenced by the grade variable.
You could have used a for loop for the outer loop as well, in which case the inner loop needs to be changed further, and the nested loop looks like this:
for (int j = 0 ; j < grades->Length ; j++)
{
Console::WriteLine(L"Students with Grade {0}:", gradeLetter+j);
for (int i = 0 ; i < grades[j]->Length ; i++)
Console::Write(L"{0,12}",grades[j][i]); // Output the current name
Console::WriteLine();
}Now grades[j] references the jth array of names; the expression grades[j][i] references the ith name in the jth array of names.
You have already seen that the String class type that is defined in the System namespace represents a string in C++/CLI — in fact, a string consists of Unicode characters. To be more precise, it represents a string consisting of a sequence of characters of type System::Char. You get a huge amount of powerful functionality with String class objects, making string processing very easy. Let's start at the beginning with string creation.
You can create a String object like this:
System::String^ saying(L"Many hands make light work.");
The variable saying is a tracking handle that references the String object initialized with the string that appears between the parentheses. You must always use a tracking handle to store a reference to a String object. The string literal here is a wide character string because it has the prefix L. If you omit the L prefix, you have a string literal containing 8-bit characters, but the compiler ensures it is converted to a wide-character string.
You can access individual characters in a string by using a subscript, just like an array; the first character in the string has an index value of 0. Here's how you could output the third character in the string saying:
Console::WriteLine(L"The third character in the string is {0}", saying[2]);Note that you can only retrieve a character from a string using an index value; you cannot update the string in this way. String objects are immutable and therefore cannot be modified.
You can obtain the number of characters in a string by accessing its Length property. You could output the length of saying with this statement:
Console::WriteLine(L"The string has {0} characters.", saying->Length);Because saying is a tracking handle — which, as you know, is a kind of pointer — you must use the -> operator to access the Length property (or any other member of the object). You'll learn more about properties when you get to investigate C++/CLI classes in detail.
You can use the + operator to join strings to form a new String object. Here's an example:
String^ name1(L"Beth"); String^ name2(L"Betty"); String^ name3(name1 + L" and " + name2);
After executing these statements, name3 contains the string "Beth and Betty". Note how you can use the + operator to join String objects with string literals. You can also join String objects with numerical values or bool values, and have the values converted automatically to a string before the join operation. The following statements illustrate this:
String^ str(L"Value: "); String^ str1(str + 2.5); // Result is new string L"Value: 2.5" String^ str2(str + 25); // Result is new string L"Value: 25" String^ str3(str + true); // Result is new string L"Value: True"
You can also join a string and a character, but the result depends on the type of character:
char ch('Z'),
wchar_t wch(L'Z'),
String^ str4(str + ch); // Result is new string L"Value: 90"
String^ str5(str + wch); // Result is new string L"Value: Z"The comments show the results of the operations. A character of type char is treated as a numerical value, so you get the character code value joined to the string. The wchar_t character is of the same type as the characters in the String object (type Char), so the character is appended to the string.
Don't forget that String objects are immutable; once created, they cannot be changed. This means that all operations that apparently modify String objects always result in new String objects being created.
The String class also defines a Join() function that you use when you want to join a series of strings stored in an array into a single string with separators between the original strings. Here's how you could join names together in a single string with the names separated by commas:
array<String^>^ names = { L"Jill", L"Ted", L"Mary", L"Eve", L"Bill"};
String^ separator(L", ");
String^ joined = String::Join(separator, names);After executing these statements, joined references the string L"Jill, Ted, Mary, Eve, Bill". The separator string has been inserted between each of the original strings in the names array. Of course, the separator string can be anything you like — it could be L" and ", for example, which results in the string L"Jill and Ted and Mary and Eve and Bill".
Let's try a full example of working with String objects.
TRY IT OUT: Working with Strings
Suppose you have an array of integer values that you want to output aligned in columns. You want the values aligned, but you want the columns to be just sufficiently wide to accommodate the largest value in the array with a space between columns. This program does that.
// Ex4_18.cpp : main project file.// Creating a custom format string#include "stdafx.h"using namespace System;int main(array<System::String ^> ^args){array<int>^ values = { 2, 456, 23, −46, 34211, 456, 5609, 112098,234, −76504, 341, 6788, −909121, 99, 10};String^ formatStr1(L"{0,"); // 1st half of format stringString^ formatStr2(L"}"); // 2nd half of format string
String^ number; // Stores a number as a string// Find the length of the maximum length value stringint maxLength(0); // Holds the maximum length foundfor each(int value in values){number = L"" + value; // Create string from valueif(maxLength<number->Length)maxLength = number->Length;}// Create the format string to be used for outputString^ format(formatStr1 + (maxLength+1) + formatStr2);// Output the valuesint numberPerLine(3);for(int i = 0 ; i< values->Length ; i++){Console::Write(format, values[i]);if((i+1)%numberPerLine == 0)Console::WriteLine();}return 0; }
The output from this program is:
2 456 23
−46 34211 456
5609 112098 234
−76504 341 6788
−909121 99 10How It Works
The objective of this program is to create a format string to align the output of integers from the values array in columns, with a width sufficient to accommodate the maximum length string representation of the integers. You create the format string initially in two parts:
String^ formatStr1(L"{0,"); // 1st half of format string
String^ formatStr2(L"}"); // 2nd half of format stringThese two strings are the beginning and end of the format string you ultimately require. You need to work out the length of the maximum-length number string, and sandwich that value between formatStr1 and formatStr2, to form the complete format string.
You find the length you require with the following code:
int maxLength(0); // Holds the maximum length found for each(int value in values)
{
number = L"" + value; // Create string from value
if(maxLength<number->Length)
maxLength = number->Length;
}Within the loop you convert each number from the array to its String representation by joining it to an empty string. You compare the Length property of each string to maxLength, and if it's greater than the current value of maxLength, it becomes the new maximum length.
The statement that creates a string from value shows how an integer is automatically converted to a string when you combine it with a string using the addition operator. You could also obtain value as a string with the following statement:
number = value.ToString();
This uses the ToString() function that is defined in the System::Int32 value class that converts an integer value to a string.
Creating the format string is simple:
String^ format(formatStr1 + (maxLength+1) + formatStr2);
You need to add 1 to maxLength to allow one additional space in the field when the maximum length string is displayed. Placing the expression maxLength+1 between parentheses ensures that it is evaluated as an arithmetic operation before the string-joining operations are executed.
Finally, you use the format string in the code to output values from the array:
int numberPerLine(3);
for(int i = 0 ; i< values->Length ; i++)
{
Console::Write(format, values[i]);
if((i+1)%numberPerLine == 0)
Console::WriteLine();
}The output statement in the loop uses format as the string for output. With the maxLength plugged into the format string, the output is in columns that are one greater than the maximum length output value. The numberPerLine variable determines how many values appear on a line, so the loop is quite general in that you can vary the number of columns by changing the value of numberPerLine.
The most common requirement for trimming a string is to trim spaces from both the beginning and the end. The Trim() function for a string object does that:
String^ str = {L" Handsome is as handsome does ... "};
String^ newStr(str->Trim());The Trim() function in the second statement removes any spaces from the beginning and end of str and returns the result as a new String object stored in newStr. Of course, if you did not want to retain the original string, you could store the result back in str.
There's another version of the Trim() function that allows you to specify the characters that are to be removed from the start and end of the string. This function is very flexible because you have more than one way of specifying the characters to be removed. You can specify the characters in an array and pass the array handle as the argument to the function:
String^ toBeTrimmed(L"wool wool sheep sheep wool wool wool");
array<wchar_t>^ notWanted = {L'w',L'o',L'l',L' '};
Console::WriteLine(toBeTrimmed->Trim(notWanted));Here you have a string, toBeTrimmed, that consists of sheep covered in wool. The array of characters to be trimmed from the string is defined by the notWanted array; passing that to the Trim() function for the string removes any of the characters in the array from both ends of the string. Remember, String objects are immutable, so the original string is not being changed in any way — a new string is created and returned by the Trim() operation. Executing this code fragment produces the output:
sheep sheep
If you happen to specify the character literals without the L prefix, they will be of type char (which corresponds to the SByte value class type); however, the compiler arranges that they are converted to type wchar_t.
You can also specify the characters that the Trim() function is to remove explicitly as arguments, so you could write the last line of the previous fragment as:
Console::WriteLine(toBeTrimmed->Trim(L'w', L'o', L'l', L' '));
This produces the same output as the previous version of the statement. You can have as many arguments of type wchar_t as you like, but if there are a lot of characters to be specified, an array is the best approach.
If you want to trim only one end of a string, you can use the TrimEnd() or TrimStart() functions. These come in the same variety of versions as the Trim() function. So: without arguments you trim spaces, with an array argument you trim the characters in the array, and with explicit wchar_t arguments those characters are removed.
The inverse of trimming a string is padding it at either end with spaces or other characters. You have PadLeft() and PadRight() functions that pad a string at the left or right end, respectively. The primary use for these functions is in formatting output where you want to place strings either left- or right-justified in a fixed width field. The simpler versions of the PadLeft() and PadRight() functions accept a single argument specifying the length of the string that is to result from the operation. For example:
String^ value(L"3.142"); String^ leftPadded(value->PadLeft(10)); // Result is L" 3.142" String^ rightPadded(value->PadRight(10)); // Result is L"3.142 "
If the length you specify as the argument is less than or equal to the length of the original string, either function returns a new String object that is identical to the original.
To pad a string with a character other than a space, you specify the padding character as the second argument to the PadLeft() or PadRight() functions. Here are a couple of examples of this:
String^ value(L"3.142"); String^ leftPadded(value->PadLeft(10, L'*')); // Result is L"*****3.142" String^ rightPadded(value->PadRight(10, L'#')); // Result is L"3.142#####"
Of course, with all these examples, you could store the result back in the handle referencing the original string, which would discard the original string.
The String class also has the ToUpper() and ToLower() functions to convert an entire string to upper- or lowercase. Here's how that works:
String^ proverb(L"Many hands make light work."); String^ upper(proverb->ToUpper()); // Result L"MANY HANDS MAKE LIGHT WORK."
The ToUpper() function returns a new string that is the original string converted to uppercase.
You use the Insert() function to insert a string at a given position in an existing string. Here's an example of doing that:
String^ proverb(L"Many hands make light work."); String^ newProverb(proverb->Insert(5, L"deck "));
The function inserts the string specified by the second argument, starting at the index position in the old string, which is specified by the first argument. The result of this operation is a new string containing:
Many deck hands make light work.
You can also replace all occurrences of a given character in a string with another character, or all occurrences of a given substring with another substring. Here's a fragment that shows both possibilities:
String^ proverb(L"Many hands make light work."); Console::WriteLine(proverb->Replace(L' ', L'*')); Console::WriteLine(proverb->Replace(L"Many hands", L"Pressing switch"));
Executing this code fragment produces the output:
Many*hands*make*light*work. Pressing switch make light work.
The first argument to the Replace() function specifies the character or substring to be replaced, and the second argument specifies the replacement.
You can compare two String objects using the Compare() function in the String class. The function returns an integer that is less than zero, equal to zero, or greater than zero, depending on whether the first argument is less than, equal to, or greater than the second argument. Here's an example:
String^ him(L"Jacko");
String^ her(L"Jillo");
int result(String::Compare(him, her));
if(result < 0)
Console::WriteLine(L"{0} is less than {1}.", him, her);
else if(result > 0)
Console::WriteLine(L"{0} is greater than {1}.", him, her);
else
Console::WriteLine(L"{0} is equal to {1}.", him, her);You store the integer that the Compare() function returns in result, and use that in the if statement to decide the appropriate output. Executing this fragment produces the output:
Jacko is less than Jillo.
There's another version of Compare() that requires a third argument of type bool. If the third argument is true, then the strings referenced by the first two arguments are compared, ignoring case; if the third argument is false, then the behavior is the same as the previous version of Compare().
Perhaps the simplest search operation is to test whether a string starts or ends with a given substring. The StartsWith() and EndsWith() functions do that. You supply a handle to the substring you are looking for as the argument to either function, and the function returns a bool value that indicates whether or not the substring is present. Here's a fragment showing how you might use the StartsWith() function:
String^ sentence(L"Hide, the cow's outside."); if(sentence->StartsWith(L"Hide")) Console::WriteLine(L"The sentence starts with 'Hide'.");
Executing this fragment results in the output:
The sentence starts with 'Hide'.
Of course, you could also apply the EndsWith() function to the sentence string:
Console::WriteLine(L"The sentence does{0} end with 'outside'.",
sentence->EndsWith(L"outside") ? L"" : L" not");The result of the conditional operator expression is inserted into the output string. This is an empty string if EndsWith() returns true, and L"not" if it returns false. In this instance the function returns false (because of the period at the end of the sentence string).
The IndexOf() function searches a string for the first occurrence of a specified character or substring, and returns the index if it is present, or −1 if it is not found. You specify the character or the substring you are looking for as the argument to the function. For example:
String^ sentence(L"Hide, the cow's outside."); int ePosition(sentence->IndexOf(L'e')); // Returns 3 int thePosition(sentence->IndexOf(L"the")); // Returns 6
The first search is for the letter 'e' and the second is for the word "the". The values returned by the IndexOf() function are indicated in the comments.
More typically, you will want to find all occurrences of a given character or substring. Another version of the IndexOf() function is designed to be used repeatedly, to enable you to do that. In this case, you supply a second argument specifying the index position where the search is to start. Here's an example of how you might use the function in this way:
String^ words(L"wool wool sheep sheep wool wool wool");
String^ word(L"wool");
int index(0);
int count(0);
while((index = words->IndexOf(word,index)) >= 0)
{
index += word->Length;
++count;
}
Console::WriteLine(L"'{0}' was found {1} times in:
{2}", word, count, words);This fragment counts the number of occurrences of "wool" in the words string. The search operation appears in the while loop condition, and the result is stored in index. The loop continues as long as index is non-negative; when IndexOf() returns −1 the loop ends. Within the loop body, the value of index is incremented by the length of word, which moves the index position to the character following the instance of word that was found, ready for the search on the next iteration. The count variable is incremented within the loop, so when the loop ends it has accumulated the total number of occurrences of word in words. Executing the fragment results in the following output:
'wool' was found 5 times in: wool wool sheep sheep wool wool wool
The LastIndexOf() function is similar to the IndexOf() function except that it searches backwards through the string from the end or from a specified index position. Here's how the operation performed by the previous fragment could be performed using the LastIndexOf() function:
int index(words->Length - 1);
int count(0);
while(index >= 0 && (index = words->LastIndexOf(word,index)) >= 0)
{
--index;
++count;
}With the word and words strings the same as before, this fragment produces the same output. Because LastIndexOf() searches backwards, the starting index is the last character in the string, which is words->Length-1. When an occurrence of word is found, you must now decrement index by 1, so that the next backward search starts at the character preceding the current occurrence of word. If word occurs right at the beginning of words — at index position 0 — decrementing index results in −1, which is not a legal argument to the LastIndexOf() function because the search starting position must always be within the string. The additional check for a negative value of index in the loop condition prevents this from happening; if the left operand of the && operator is false, the right operand is not evaluated.
The last search function I want to mention is IndexOfAny(), which searches a string for the first occurrence of any character in the array of type array<wchar_t> that you supply as the argument. Similar to the IndexOf() function, the IndexOfAny() function comes in versions that search from the beginning of a string or from a specified index position. Let's try a full working example of using the IndexOfAny() function.
TRY IT OUT: Searching for Any of a Set of Characters
This example searches a string for punctuation characters:
// Ex4_19.cpp : main project file.// Searching for punctuation#include "stdafx.h" using namespace System; int main(array<System::String ^> ^args) {array<wchar_t>^ punctuation = {L'"', L''', L'.', L',', L':', L';', L'!', L'?'};String^ sentence(L""It's chilly in here", the boy's mother said coldly.");// Create array of space characters same length as sentencearray<wchar_t>^ indicators(gcnew array<wchar_t>(sentence->Length){L' '});int index(0); // Index of character foundint count(0); // Count of punctuation characterswhile((index = sentence->IndexOfAny(punctuation, index)) >= 0){indicators[index] = L'^'; // Set marker++index; // Increment to next character++count; // Increase the count}Console::WriteLine(L"There are {0} punctuation characters in the string:",count);Console::WriteLine(L" {0} {1}", sentence, gcnew String(indicators));return 0; }
This example should produce the following output:
There are 6 punctuation characters in the string: "It's chilly in here", the boy's mother said coldly. ^ ^ ^^ ^ ^
How It Works
You first create an array containing the characters to be found and the string to be searched:
array<wchar_t>^ punctuation = {L'"', L''', L'.', L',', L':', L';', L'!', L'?'};
String^ sentence(L""It's chilly in here", the boy's mother said coldly.");Note that you must specify a single quote character using an escape sequence because a single quote is a delimiter in a character literal. You can use a double quote explicitly in a character literal, as there's no risk of it being interpreted as a delimiter in this context.
Next you define an array of characters with the elements initialized to a space character:
array<wchar_t>^ indicators(gcnew array<wchar_t>(sentence->Length){L' '});This array has as many elements as the sentence string has characters. You'll be using this array in the output to mark where punctuation characters occur in the sentence string. You'll just change the appropriate array element to '^' whenever a punctuation character is found. Note how a single initializer between the braces following the array specification can be used to initialize all the elements in the array.
The search takes place in the while loop:
while((index = sentence->IndexOfAny(punctuation, index)) >= 0)
{
indicators[index] = L'^'; // Set marker
++index; // Increment to next character
++count; // Increase the count
}The loop condition is essentially the same as you have seen in earlier code fragments. Within the loop body, you update the indicators array element at position index to be a '^' character, before incrementing index, ready for the next iteration. When the loop ends, count will contain the number of punctuation characters that were found, and indicators will contain '^' characters at the positions in the sentence where such characters were found.
The output is produced by the following statements:
Console::WriteLine(L"There are {0} punctuation characters in the string:",
count);
Console::WriteLine(L"
{0}
{1}" sentence, gcnew String(indicators));The second statement creates a new String object on the heap from the indicators array by passing the array to the String class constructor. A class constructor is a function that will create a class object when it is called. You'll learn more about constructors when you get into defining your own classes.
A tracking reference provides a similar capability to a native C++ reference in that it represents an alias for something on the CLR heap. You can create tracking references to value types on the stack and to handles in the garbage-collected heap; the tracking references themselves are always created on the stack. A tracking reference is automatically updated if the object referenced is moved by the garbage collector.
You define a tracking reference using the % operator. For example, here's how you could create a tracking reference to a value type:
int value(10); int% trackValue(value);
The second statement defines trackValue to be a tracking reference to the variable value, which has been created on the stack. You can now modify value using trackValue:
trackValue *= 5; Console::WriteLine(value);
Because trackValue is an alias for value, the second statement outputs 50.
Although you cannot perform arithmetic on the address in a tracking handle, C++/CLI does provide a form of pointer with which it is possible to apply arithmetic operations; it's called an interior pointer, and it is defined using the keyword interior_ptr. The address stored in an interior pointer can be updated automatically by the CLR garbage collection when necessary. An interior pointer is always an automatic variable that is local to a function.
Here's how you could define an interior point containing the address of the first element in an array:
array<double>^ data = {1.5, 3.5, 6.7, 4.2, 2.1};
interior_ptr<double> pstart(&data[0]);You specify the type of object pointed to by the interior pointer between angled brackets following the interior_ptr keyword. In the second statement here you initialize the pointer with the address of the first element in the array using the & operator, just as you would with a native C++ pointer. If you do not provide an initial value for an interior pointer, it is initialized with nullptr by default. An array is always allocated on the CLR heap, so here's a situation where the garbage collector may adjust the address contained in an interior pointer.
There are constraints on the type specification for an interior pointer. An interior pointer can contain the address of a value class object on the stack, or the address of a handle to an object on the CLR heap; it cannot contain the address of a whole object on the CLR heap. An interior pointer can also point to a native class object or a native pointer.
You can also use an interior pointer to hold the address of a value class object that is part of an object on the heap, such as an element of a CLR array. This way, you can create an interior pointer that can store the address of a tracking handle to a System::String object, but you cannot create an interior pointer to store the address of the String object itself. For example:
interior_ptr<String^> pstr1; // OK - pointer to a handle interior_ptr<String> pstr2; // Will not compile - pointer to a String object
All the arithmetic operations that you can apply to a native C++ pointer you can also apply to an interior pointer. You can increment and decrement an interior pointer to change the address it contains, to refer to the following or preceding data item. You can also add or subtract integer values and compare interior pointers. Let's put together an example that does some of that.
TRY IT OUT: Creating and Using Interior Pointers
This example exercises interior pointers with numerical values and strings:
// Ex4_20.cpp : main project file.// Creating and using interior pointers#include "stdafx.h" using namespace System; int main(array<System::String ^> ^args) {// Access array elements through a pointerarray<double>^ data = {1.5, 3.5, 6.7, 4.2, 2.1};interior_ptr<double> pstart(&data[0]);interior_ptr<double> pend(&data[data->Length − 1]);double sum(0.0);while(pstart <= pend)sum += *pstart++;Console::WriteLine(L"Total of data array elements = {0} ", sum);// Just to show we can - access strings through an interior pointerarray<String^>^ strings = { L"Land ahoy!",L"Splice the mainbrace!",L"Shiver me timbers!",L"Never throw into the wind!"};for(interior_ptr<String^> pstrings = &strings[0] ;pstrings-&strings[0] < strings->Length ; ++pstrings)Console::WriteLine(*pstrings);return 0;}
The output from this example is:
Total of data array elements = 18 Land ahoy! Splice the mainbrace! Shiver me timbers! Never throw into the wind!
How It Works
After creating the data array of elements of type double, you define two interior pointers:
interior_ptr<double> pstart(&data[0]); interior_ptr<double> pend(&data[data->Length − 1]);
The first statement creates pstart as a pointer to type double and initializes it with the address of the first element in the array, data[0]. The interior pointer, pend, is initialized with the address of the last element in the array, data[data->Length - 1]. Because data->Length is the number of elements in the array, subtracting 1 from this value produces the index for the last element.
The while loop accumulates the sum of the elements in the array:
while(pstart <= pend) sum += *pstart++;
The loop continues as long as the interior pointer, pstart, contains an address that is not greater than the address in pend. You could equally well have expressed the loop condition as !(pstart > pend).
Within the loop, pstart starts out containing the address of the first array element. The value of the first element is obtained by dereferencing the pointer with the expression *pstart; the result of this is added to sum. The address in the pointer is then incremented using the ++ operator. On the last loop iteration, pstart contains the address of the last element, which is the same as the address value that pend contains So, incrementing pstart makes the loop condition false because pstart is then greater than pend. After the loop ends the value of sum is written out, so you can confirm that the while loop is working as it should.
Next you create an array of four strings:
array<String^>^ strings = { L"Land ahoy!",
L"Splice the mainbrace!",
L"Shiver me timbers!",
L"Never throw into the wind!"
};The for loop then outputs each string to the command line:
for(interior_ptr<String^> pstrings = &strings[0] ;
pstrings-&strings[0] < strings->Length ; ++pstrings)
Console::WriteLine(*pstrings);The first expression in the for loop condition declares the interior pointer, pstrings, and initializes it with the address of the first element in the strings array. The second expression determines whether the for loop continues:
pstrings-&strings[0] < strings->Length
As long as pstrings contains the address of a valid array element, the difference between the address in pstrings and the address of the first element in the array is less than the number of elements in the array, given by the expression strings->Length. Thus, when this difference equals the length of the array, the loop ends. You can see from the output that everything works as expected.
The most frequent use of an interior pointer is referencing objects that are part of a CLR heap object, and you'll see more about this later in the book.
You are now familiar with all of the basic types of values in C++, how to create and use arrays of those types, and how to create and use pointers. You have also been introduced to the idea of a reference. However, we have not exhausted all of these topics. I'll come back to the topics of arrays, pointers, and references later in the book.
The pointer mechanism is sometimes a bit confusing because it can operate at different levels within the same program. Sometimes it is operating as an address, and at other times it can be operating with the value stored at an address. It's very important that you feel at ease with the way pointers are used, so if you find that they are in any way unclear, try them out with a few examples of your own until you feel confident about applying them.
WHAT YOU LEARNED IN THIS CHAPTER
TOPIC | CONCEPT |
|---|---|
Native C++ arrays | An array allows you to manage a number of variables of the same type using a single name. Each dimension of an array is defined between square brackets, following the array name in the declaration of the array. |
Array dimensions | Each dimension of an array is indexed starting from zero. Thus, the fifth element of a one-dimensional array has the index value 4. |
Initializing arrays | Arrays can be initialized by placing the initializing values between curly braces in the declaration. |
Pointers | A pointer is a variable that contains the address of another variable. A pointer is declared as a 'pointer to type' and may only be assigned addresses of variables of the given type. |
Pointers to | A pointer can point to a constant object. Such a pointer can be reassigned to another object. A pointer may also be defined as |
References | A reference is an alias for another variable, and can be used in the same places as the variable it references. A reference must be initialized in its declaration. A reference can't be reassigned to another variable. |
The | The operator |
The new operator | The operator |
The | In a CLR program, you allocate memory in the garbage-collected heap using the |
Reference class objects | Reference class objects in general, and |
| You use |
CLR arrays | The CLR has its own array types with more functionality that native array types. CLR arrays are created on the CLR heap. |
Tracking handles | A tracking handle is a form of pointer used to reference variables defined on the CLR heap. A tracking handle is automatically updated if what it refers to is relocated in the heap by the garbage collector. Variables that reference objects and arrays on the heap are always tracking handles. |
Tracking references | A tracking reference is similar to a native reference, except that the address it contains is automatically updated if the object referenced is moved by the garbage collector. |
Interior pointers | An interior pointer is a C++/CLI pointer type to which you can apply the same operation as a native pointer. |
Modifying interior pointers | The address contained in an interior pointer can be modified using arithmetic operations and still maintain an address correctly, even when referring to something stored in the CLR heap. |