
3 Data Tables, Reports, and Scripts
Overview
JMP data are organized as rows and columns of a grid referred to as a data table. The columns have names, and the rows are numbered. An open data table is kept in memory and displays a data grid with panels of information about the data table. You can open as many data tables in a JMP session as memory allows.
People often ask about the largest data table that JMP can handle. In general, JMP can handle a data table that is about half the size of the available memory in the machine. For example, if you have 8 GB of available memory, JMP can manage a data table that is (approximately) 4 GB.
Commands in the File, Edit, Tables, Rows, and Cols menus give you a broad range of options for data handling and file management, such as data entry and import, data cleanup, data table manipulation and restructuring, creating numeric summaries, and running JSL (JMP Scripting Language) scripts.
The purpose of this chapter is to tell you about JMP data tables and show hands-on examples to help you get comfortable handling table operations and scripts.
Note: To open the sample data tables used in the examples, use Help > Sample Data Library. You can also select Help > Sample Data and click either Open the Sample Data Directory or See an Alphabetical List of all Sample Data Files.
Chapter Contents
The Ins and Outs of a JMP Data Table
Selecting and Deselecting Rows and Columns
Mousing around a Data Table: Cursor Forms
Create Interactive Web Reports
Give New Shape to a Table: Stack Columns
Create Summary Statistics with the Summary Command
Create Summary Statistics with Tabulate
Opening and Running Stand-alone Scripts
The Ins and Outs of a JMP Data Table
JMP displays data as a data grid, often called a data table. From the data table, you can do table management tasks such as editing cells; creating, rearranging, or deleting rows and columns; subsetting the data; sorting; and combining tables. Figure 3.1 identifies active areas of a JMP data table.
There are a few basic things to keep in mind:
● Column names can use any keyboard character, including spaces. The size and font for names and values is a setting you control through JMP Preferences (File > Preferences, or JMP > Preferences on the Mac).
● If the name of the column is long, you can drag column boundaries to widen the column.
● There is no set limit to the number of rows or columns in a data table.
However, the table must fit in memory.
Figure 3.1 Active Areas of a JMP Spreadsheet
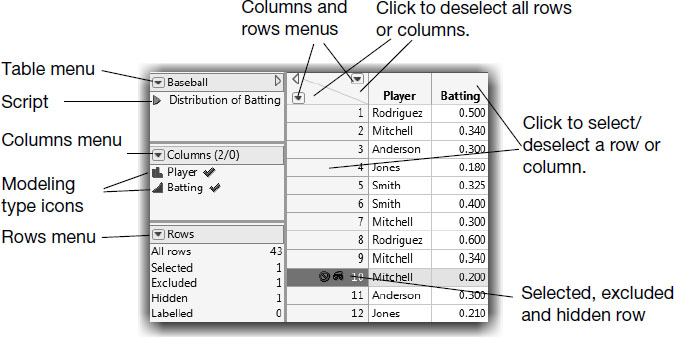
Selecting and Deselecting Rows and Columns
Many actions from the Rows and Cols menus operate only on selected rows and columns. To select rows and columns, highlight them.
● To highlight a row, click the space that contains the row number.
● To highlight a column, click in the column header.
These areas are shown in Figure 3.1.
To extend a selection of rows or columns, drag across the range of rows or columns (in the selection area). You can also hold down Shift and click the first and last row or column of the range. Hold down Ctrl and click (![]() -click on the Macintosh) to make a non-contiguous selection. To select both rows and columns at the same time, drag across table cells in the data grid.
-click on the Macintosh) to make a non-contiguous selection. To select both rows and columns at the same time, drag across table cells in the data grid.
To deselect a row or column, hold down Ctrl and click (![]() -click on the Macintosh) on the row or column. To deselect all rows or columns at once, click the triangular rows or columns area in the upper left corner of the spreadsheet.
-click on the Macintosh) on the row or column. To deselect all rows or columns at once, click the triangular rows or columns area in the upper left corner of the spreadsheet.
Mousing around a Data Table: Cursor Forms
To navigate in the data table, you need to understand how the cursor works in each part of the spreadsheet.
![]() To experiment with the different cursor forms, select Help > Sample Data Library and open Baseball.jmp.
To experiment with the different cursor forms, select Help > Sample Data Library and open Baseball.jmp.
![]() Move the mouse around on the surface areas, and see how the cursor changes form.
Move the mouse around on the surface areas, and see how the cursor changes form.
Arrow cursor (![]() )
)
When a data table is the active window, the cursor is a standard arrow except when it is on a red triangle menu icon, a gray disclosure icon, or a modeling type icon (to the left of a column name in the Columns panel). It is also a standard arrow when it is in the upper left corner of the data grid where it is used to deselect rows and columns.

I-beam cursor (![]() )
)
The cursor is an I-beam when it is over selected text in the data grid, column names or in the Columns panel. It signals that the selected text is editable. Double-click and start typing to replace the existing text.

Selection cursor (![]() )
)
Move the cursor around. The cursor becomes a large thick plus sign when you move it into a column or row selection area. It is used to select items in JMP data tables and reports. Use the selection cursor to select a single row or column. Hold down Shift and click a beginning and ending row (or a beginning and ending column) to select an entire range. Hold down Ctrl and click (![]() -click on the Macintosh) to select multiple rows or columns that are not contiguous.
-click on the Macintosh) to select multiple rows or columns that are not contiguous.

The selection cursor appears in a report window when you select it from the tools menu. It is used to select areas of reports to copy and paste to other locations. See “Copy, Paste, and Drag Data” on page 46 for details about using the selection cursor for cut and paste operations.
Double Arrow cursor (![]() )
)
The cursor changes to a double arrow when placed on a column or row boundary. To change the width of a data table column, click and drag this cursor left or right. To change the height of a data table row, drag this cursor up or down.
List Check cursor (![]() )
)
The cursor changes when it moves over values in columns that have data validation in effect (automatic checking for specific values). It becomes a small, downward-pointing arrow on a column with list checking. When you double-click the cursor, the value highlights and the cursor becomes the standard I–beam; then you enter or edit data as usual. However, you can only enter data values from a list of values that you pre-specify. In addition, you can right-click in columns with list checks to see a menu that lists the possible entries for the column.
Pointer cursor (![]() )
)
The cursor changes to a finger pointer over any red triangle menu icon or gray disclosure icon. That signifies you are over a clickable item. Click a disclosure icon to open or close a window panel or report outline; click red triangle icons to open menus.
![]() After you finish exploring, select File > Close to close the Baseball.jmp data table.
After you finish exploring, select File > Close to close the Baseball.jmp data table.

Creating a New JMP Table
Hopefully, most of the data that you analyze is already in electronic form. However, when you enter data, a JMP data table is like a spreadsheet with familiar data entry features. A short example shows how to start from scratch.
Suppose data values are blood pressure readings collected over six months and recorded in a notebook page as shown in Figure 3.2.
Figure 3.2 Notebook of Raw Study Data Used to Define Rows and Columns

Define Rows and Columns
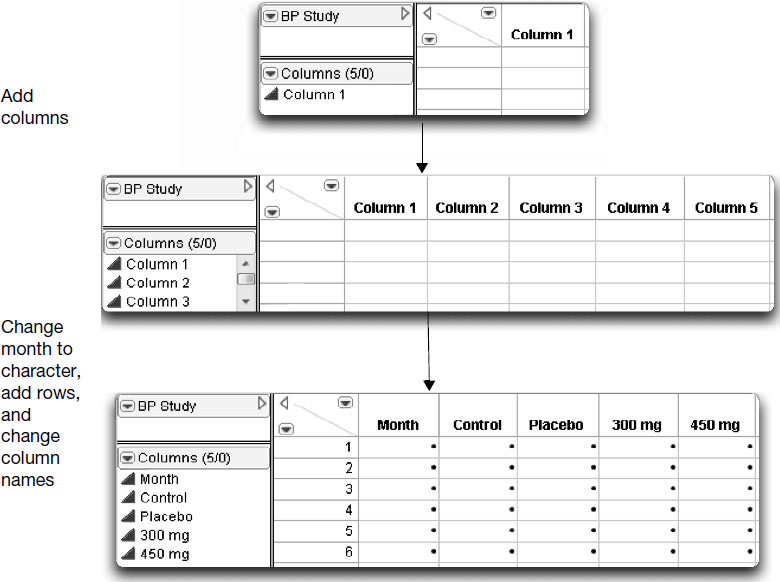
JMP data tables have rows and columns, which represent observations and variables in statistical terms. In JMP, the rows always represent observations, and the columns always represent variables. A cell in the data table grid is defined by the row and column that it is in. The raw data in Figure 3.2 are arranged as five columns (month and four treatment groups) and six rows (months March through August). The first line in the notebook describes each column of values. These descriptions can be used as column names in a JMP data table. To enter this data into JMP, you first need a blank data table.
![]() Select File > New > Data Table (or File > New > New Data Table on the Macintosh) to create a new empty data table, with one column and no rows.
Select File > New > Data Table (or File > New > New Data Table on the Macintosh) to create a new empty data table, with one column and no rows.
Add Columns
You now want to add five columns to the data table to hold the data from the study.
![]() Select Cols > New Columns and type 5 in the Number of columns to add box, and click OK.
Select Cols > New Columns and type 5 in the Number of columns to add box, and click OK.
The default column names are Column 1, Column 2, and so on. You can change them by entering the column names that you want at the top of the columns in the new table.
To edit a column name, first click the column selection area and begin entering the name of the column. Press the Enter or Return key when you are finished, and repeat for the other columns. Or, click Tab to move to the column header for the next column.
![]() Enter the names from the data journal in Figure 3.2 (Month, Control, Placebo, 300 mg, and 450 mg) into the column headers of the new table.
Enter the names from the data journal in Figure 3.2 (Month, Control, Placebo, 300 mg, and 450 mg) into the column headers of the new table.

Set Column Characteristics
Columns can have different characteristics, such as modeling type and data type. By default, the modeling types are continuous, so the columns expect numeric data. However, in this example, the Month column holds a non numeric character variable.
![]() Right-click the column name area for Month and select Column Info to see the Column Info window in Figure 3.3.
Right-click the column name area for Month and select Column Info to see the Column Info window in Figure 3.3.
![]() In the Column Info window, use the Data Type menu to change Month to a character variable (Figure 3.3), and then click OK. Note: If you don’t change the data type, and enter non numeric data into a new column, the data type automatically changes.
In the Column Info window, use the Data Type menu to change Month to a character variable (Figure 3.3), and then click OK. Note: If you don’t change the data type, and enter non numeric data into a new column, the data type automatically changes.
Figure 3.3 Column Info Window

Add Rows
Adding new rows is easy.
![]() Select Rows > Add Rows and ask for six new rows.
Select Rows > Add Rows and ask for six new rows.
Alternatively, if you double-click anywhere in the body of the data table, the data table automatically fills with new rows through the position of the cursor.
The last step is to give the data table a name and save it.
![]() Select File > Save As to name the data table BP Study.jmp. You might also navigate to another folder if you want to save this data table somewhere else.
Select File > Save As to name the data table BP Study.jmp. You might also navigate to another folder if you want to save this data table somewhere else.
The data table is now ready to hold data values. Figure 3.4 summarizes the table evolution so far.
Figure 3.4 JMP Data Table with New Rows, Columns, and Names
Enter Data
Entering data into the data table requires entering values into the appropriate table cells. To enter data into the data table, do the following:
![]() Click on a cell and start entering the appropriate data from the notebook (Figure 3.2).
Click on a cell and start entering the appropriate data from the notebook (Figure 3.2).
The Tab and Return keys are useful keyboard tools for data entry:
● Tab moves the cursor one cell to the right. Pressing Shift and Tab moves the cursor one cell to the left. Moving the cursor with the Tab key automatically sends it to the beginning of the next (or previous) row. Tabbing past the last table cell creates a new row.
● Enter (or Return) either moves the cursor down one cell or one cell to the right, based on the setting in JMP Preferences.
Your results should look like the table in Figure 3.5.
Figure 3.5 Finished Blood Pressure Study Table

The New Column Command
In the first part of this example, you used the New Columns command from the Cols menu to create several new columns in a data table. Often you need to only add a single new column with specific characteristics.
Continuing with the current example, suppose you learn that the blood pressure readings were taken at two labs. During March and April, the readings were taken at a lab called “Accurate Readings Inc.” For the remaining months of the study, the readings were taken at a location called “Most Reliable Measurements Ltd.” You want to include this information in the data table.
![]() Begin by selecting Cols > New Columns, which displays a New Column window like the one shown previously in Figure 3.3.
Begin by selecting Cols > New Columns, which displays a New Column window like the one shown previously in Figure 3.3.
The New Column window lets you set the new column’s characteristics.
![]() Enter a new name, Location, in the Column Name area.
Enter a new name, Location, in the Column Name area.
![]() Because the actual names of the locations are characters, select Character from the Data Type menu.
Because the actual names of the locations are characters, select Character from the Data Type menu.
Notice that the Modeling Type then automatically changes to Nominal.
When you click OK, the new column appears in the table. Enter the data “Accurate Readings Inc.” for March and April and “Most Reliable Measurements Ltd.” for the other months.
Note: You can also add a new column by double-clicking in the column header next to your last column.
Plot the Data
There are many ways to check the data for errors. One way is to plot the data to check for obvious anomalous values. Let’s experiment with the Graph Builder command in the Graph menu.
To plot the months on the horizontal (x) axis and the columns of blood pressure statistics for each treatment group on the vertical (y) axis, follow these steps:
![]() Select Graph > Graph Builder.
Select Graph > Graph Builder.
![]() Drag Month to the X zone.
Drag Month to the X zone.
![]() Select Control, Placebo, 300 mg, and 450 mg and drag them to the Y zone.
Select Control, Placebo, 300 mg, and 450 mg and drag them to the Y zone.
![]() Click the bar chart icon above the graph.
Click the bar chart icon above the graph.
![]() Click Done to see the graph in Figure 3.6.
Click Done to see the graph in Figure 3.6.
Figure 3.6 Initial Bar Chart

Notice that there’s a problem with the values on the x-axis. JMP plots data in alphanumeric order. To change the ordering of labels on a graph, we can assign a column property.
![]() Return to the data table, right-click the Month column name, and select Column Info.
Return to the data table, right-click the Month column name, and select Column Info.
![]() Select the Column Properties menu to view the available properties that can be assigned to the column.
Select the Column Properties menu to view the available properties that can be assigned to the column.
![]() Select Value Ordering and click the Move Up and Move Down buttons to reorder the values.
Select Value Ordering and click the Move Up and Move Down buttons to reorder the values.
![]() Click OK.
Click OK.
![]() Regenerate the graph and confirm that the months are in the correct order.
Regenerate the graph and confirm that the months are in the correct order.
Now, let’s explore the data using a different graph. Because the data are time ordered, we can graph the data using a line chart.
![]() From the bar chart you just created, click the line chart icon above the graph to see the graph shown in Figure 3.7.
From the bar chart you just created, click the line chart icon above the graph to see the graph shown in Figure 3.7.
![]() Double-click the title at the top, type Comparison of Treatment Groups, and then click Done.
Double-click the title at the top, type Comparison of Treatment Groups, and then click Done.
Figure 3.7 Line Chart with New Title

Importing Data
The File > Open command enables you to locate the file that you want to open and then read the file into a JMP data table or as simple text in a JMP script window.
JMP directly reads its own data tables, journals, scripts, projects, reports, add-in files, menu files, application files, and SAS transport files. In addition, JMP can read and write SAS data sets and read SAS program files.
Besides JMP and SAS files, JMP can also read text files with any column delimiter, and can import Microsoft Excel files, R code files, SPSS data files, Minitab files, shape files for maps, and many more. JMP can also connect to a variety of databases and can write SQL queries for importing data. To open database files, you must have an appropriate Open Database Connectivity (ODBC) driver installed on your system.
The example in Figure 3.8 shows a Windows Open Data File window with all supported file types showing.
Figure 3.8 Using the Open Data File Window to Import a File

If the incoming file is not a JMP data table, then JMP determines the file type by the extension appended to its file name and opens it accordingly. This works as long as the file has the structure indicated by its name.
Importing Text Files
In the Open Data File window on Windows, you can first make a selection from the file type menu. In Figure 3.9, the file type selection is Text Files (*.txt,*.csv,*.dat,*.tsv) so that only files with those suffixes show in the list of files above. In this example, Animals.txt is selected to be opened.
The lower area of the window has the following options:
● You can set text import preferences in your JMP Preferences file. The Data, using Text Import preferences option accesses the JMP preference file and uses those settings.
● The Data, using best guess looks at the data and attempts to determine the best way to present them in a JMP table. This is adequate for rectangular text files with no missing fields, a consistent field delimiter, and an end-of-line delimiter
Note: If double quotation marks are encountered when importing text data, JMP changes the delimiter rules to look for a matching end double quotation marks. Other text delimiters, including spaces embedded within the quotation marks, are ignored and treated as part of the text string.
● Data with preview uses the best-guess approach but shows you a sample of the constructed JMP table rows and columns.
● Plain text into Script window writes the text file as it is into a script window without attempting to define fields or columns.
Figure 3.9 Options for Text Files as Files of Type Selection

On the Macintosh, the import options don’t appear until you select a file for the list of readable files. Figure 3.10 shows an example of the Macintosh Open window with a text file selected. The options are in a menu at the bottom of the window. The options are the same as those described for Windows, but appear in a different order and are worded differently.
Figure 3.10 Macintosh Import Window with Text Import Options

Text Import with Preview
The most general and powerful text import option is Data with Preview (Windows) or Data (Using Preview) on the Macintosh. When you select this option, a preview window opens and is automatically filled in with settings from your Preferences file and shows several lines of data as shown in Figure 3.11.
You can identify one or more end-of-field delimiters, end-of-line delimiters, select the option to Strip enclosing quotation marks, and specify on which row to begin reading data.
If your data has fixed-width fields, click the Fixed width fields button. This alters the window so that you can specify the widths of the fields in the input data set.
There is a check box to indicate whether the first line contains column names. You can select this option in the preferences or on the window. Then, the first line becomes column names when the data set is imported, and data are read starting on column 2, or whatever column you specify.
Figure 3.11 Open Text Data With Preview

The example in Figure 3.11 indicates that there are no column names in the first row of data. Clicking Next displays the window in Figure 3.12 to further modify the input options. The default column names at the top of the columns are called C000001, C000002, and so on. Click and type in the name area to change them. If needed, click on the data type icon and select numeric, character, or row state.
Figure 3.12 Name Columns Using Open Text with Preview Windows

Importing Other File Types
Excel Spreadsheets
JMP can directly import Microsoft Excel worksheets and workbooks using the Excel Import Wizard.
When you open an Excel file in JMP, a preview of the file is displayed in the Excel Import Wizard. The wizard enables you to select import options and to open selected worksheets in separate data tables or to combine the worksheets into one data table.
Figure 3.13 Excel Wizard

You can also open selected worksheets directly using the menu list on the Open Data File window.
Note: The JMP Excel Add-In is added to the Excel menu during the installation of JMP on Windows. The Add-In provides a number of options for working with JMP from Excel. For example, from an Excel worksheet, you can transfer selected cells into a new JMP data table and launch a graphing or analysis platform.

Databases
JMP can connect to any database that has a corresponding ODBC driver on your system. Select File > Database > Open Table to import data from relational databases.
In addition, you can build SQL queries to select and import data from an SQL database using Query Builder. This enables you to preview data, build custom data filters, and share queries with others without writing SQL statements. Select File > Database > Query Builder to select a database connection and launch Query Builder. Select Help > JMP Help and refer to the Using JMP book for details about connecting to databases.
Copy, Paste, and Drag Data
You can use the standard copy and paste operations to move data and graphical displays within JMP and from JMP to other applications. The following commands in the Edit menu let you move data around:
Copy
The Copy command in the Edit menu copies the values of selected data cells from the active data table to the clipboard. If no rows are selected, Copy copies all rows. Likewise, you can copy values from specific columns by selecting them. If no columns are selected, all columns are copied. If you select both rows and columns, Copy copies the highlighted cells. Data that you cut or copy to the clipboard can be pasted into JMP tables or into other applications.
If you want to copy part of an analysis window, use the selection tool (![]() ) from the Tools menu. Click on the area that you want to copy to select and highlight it. Hold down the Shift key and click to extend the selection. If nothing is selected, the Copy command copies the entire window to the clipboard.
) from the Tools menu. Click on the area that you want to copy to select and highlight it. Hold down the Shift key and click to extend the selection. If nothing is selected, the Copy command copies the entire window to the clipboard.
Note: If you use Copy With Column Names, the first line of information copied to the clipboard is the JMP column names.
Paste
The Paste command copies data from the clipboard into a JMP data table or report. Paste can also be used with the Copy command to duplicate rows, columns, or any subset of cells defined by selected rows and columns.
To transfer data from another application into a JMP data table, first copy the data to the clipboard from within the other application. Then use the Paste command to copy the values to a JMP data table. Rows and columns are automatically created as needed. If you select Paste With Column Names, the first line of information about the clipboard is used as column names in the new JMP data table.
To duplicate an entire row or column:
1. Select a row or column to be duplicated and select Edit > Copy.
2. Select an existing row or column to receive the values.
3. Select Edit > Paste to transfer the values.
To duplicate a subset of values defined by selecting specific cells, follow the previous steps, but select an identical arrangement of cells to receive the pasted values. If you paste data with fewer rows into a destination with more rows, the source values repeat until all receiving rows are filled.
Drag
You can also move or duplicate rows and columns by dragging. Hold down the mouse in the selection area of one or more selected rows or columns and drag them to a new position in the data table. Hold down Ctrl and drag to duplicate rows and columns instead of moving them.
Moving Data Out of JMP
Two questions that come up as you start using JMP might be “Can I get my data back out of JMP?” and “How do I get results out of JMP?”
The Save As command saves the active data table to a file after prompting you for a name and file type. JMP can save data in any of the following formats:
● JMP Data Tables saves the table in JMP format. This is the default Save As option.
● Excel Workbook saves data tables in Microsoft Excel .xlsx or .xls format. The resulting file is directly readable by most versions of Excel. You can also save data as an Excel workbook by selecting View > Create Excel Workbook.
● Text Export Files converts data from a JMP file to a standard text format, with rows and columns.
The Options button in the Save As window displays choices to describe specific text arrangements:

Export Column Names to Text File has an Export Table Headers check box to request that JMP column names be written as the first record of the text file.
End of Field and End of Line designate the characters to identify the end of each field and end of line in the saved text file. These options are described previously in the section “Importing Data” on page 39.
● SAS Data Set saves the data as a SAS 7 data set (.sas7bdat), readable by SAS 7 or later.
● SAS Transport Files converts a JMP data table to SAS transport file format and saves it in a SAS transport library. The Append To option appends the data table to an existing SAS transport library. If you don’t use Append To, a new SAS transport library is created using the name and location that you provide. If you do not specify a new filename, the SAS transport library replaces the existing JMP data table.
● Select Database > Save Table to save data in database formats that have ODBC drivers installed on your system.
● JSON Data File saves data in a JSON-formatted text file.
On the Macintosh, to save data as a JMP data table, select File > Save As. To save data as text, Excel, SAS or SAS Transport File, or JSON, select File > Export, and then select the appropriate format from the window.
Saving Graphs and Reports
You can use standard copy and paste operations to move graphical displays and statistical reports from JMP to other applications. You can also drag JMP reports and graphs to any other application that supports drag operations, and can save JMP results in a variety of formats.
Copy and Paste
When you copy from a report (results) window, the information is stored on the clipboard. If you want to copy part of a report window, use the selection tool (![]() ) from the Tools menu or toolbar. To copy and paste:
) from the Tools menu or toolbar. To copy and paste:
● Click on the area that you want to copy, hold down the Shift key and click to extend the selected area. Select the Copy command to copy the selected area to the clipboard.
● Select the Paste command to paste the results into a JMP journal or another application.
The format used when pasting depends on the application that you paste into. If the application has a Paste Special command, you can select among paste formats. Rich text, which includes pictures (RTF), unformatted text (TXT), picture (PICT or WMF), bitmap (BMP), and enhanced picture (EMF) are options. On the Macintosh, PDF is available as a Paste Special option.
Drag Report Elements
Any element in a JMP report window that can be selected can be dragged within the same window or into another application. When you drag report elements, they are copied and pasted to the destination area where you drop them.
Save JMP Reports and Graphs

On Windows, you can save selected output in a variety of graphical formats selecting Edit > Save Selection As. Available formats are shown here.
To save the entire report, select File > Save As. More formatting options are available, including saving as a Microsoft PowerPoint presentation, HTML and interactive HTML with data, and Microsoft Word.
On the Macintosh, select File > Export to save in one of the following formats: Text, PNG, TIFF, SVG, EPS, HTML and interactive HTML with data, RTF, and Microsoft PowerPoint.
Create Interactive Web Reports
Sometimes you want to organize your statistical output and graphs, and package these results so that you can easily share your findings with others. The View > Create Web Report command creates HTML output of your reports and graphics. The option also packages selected output as an interactive web report that can be viewed on most devices and browsers. You can specify the ordering of the results, customize styles and descriptive text, and add a company logo. The resulting web report organizes output as thumbnails linked to individual HTML report elements.
Pop-up Menu Commands
Right-click on a report window to see the pop-up menu used in the following examples. The pop-up menu changes depending on where you click (hence its name, pop-up menu). If your cursor is not over a display element with its own pop- up menu, right-clicking shows the menu for the whole platform.
Context Commands for Report Tables
By default, the tables in JMP reports have no formatting to separate rows and columns. Some (or, in many cases, all) available columns for the report are showing. Pop-up menu items for report tables let you modify the appearance and content of the tables.
Right-click in the table area to see a variety of options, including the following:

● Table Style lets you enhance the appearance of a table by drawing borders or other visual styles to the table rows and columns. You can also set these styles in the Styles preferences under Report Tables.
● Columns lets you select which columns you want to show in the analysis table. Analysis tables often have many columns, some of which might be initially hidden. You can turn on many of these options in the Platforms Preferences.
● Sort by Column sorts the rows of a report table. This command displays a list of visible columns in a report, and you select one or more columns to sort by.
● Make into Data Table creates a JMP data table from any analysis table.
● Make into Matrix lets you store a report table as a matrix that is useful when you are using the JMP scripting language (JSL). When the option is selected, the window shown here appears, enabling you to designate the name of the matrix and where it should be stored.
Juggling Data Tables
The data for analysis that reaches you is rarely neat, clean, and ready to go. Unless you can find someone else to do house-keeping on your data, reorganizing the structure of information is often necessary. Each of the following examples uses commands from the Tables, Rows, or Cols menus to reorganize data.
Data Management
Suppose you have the following situation. Person A began a data entry task by entering state names in order of ascending auto theft rates. Then, Person B took over the data entry, but mistakenly entered the auto theft rates in alphabetical order by state (paying no attention to the state names that were already there).

![]() To see the result, select Help > Sample Data Library and open Automess.jmp.
To see the result, select Help > Sample Data Library and open Automess.jmp.
Could this ever really happen? Never underestimate the convolution of data that can appear in an electronic table, and hence a circulated report. Always check your data with common sense.
Here is one way to solve this problem that uses JMP data management tools. First, you need sorted Auto theft values associated with the state names as they are in the table. To do this in JMP (without having to reenter the theft values), do the following:
1. Make a copy of the Automess table.
2. Sort the Auto theft variable in the copy in ascending order.
3. Join the sorted result with the original table, keeping only the State variable from the original table and the Auto theft variable from the sorted table.
Follow theses steps to correct the Automess table.
![]() With Automess.jmp active, select Tables > Subset and click OK.
With Automess.jmp active, select Tables > Subset and click OK.
This automatically creates a duplicate table since no rows or columns were selected in the original table.
The non-descriptive table name is Subset of Automess.jmp, but you don’t need to give this table a descriptive name because it is only temporary.
![]() With this subset table active, right-click the Auto theft column and select Sort > Ascending.
With this subset table active, right-click the Auto theft column and select Sort > Ascending.
Note that tables can also be sorted on multiple columns using Tables > Sort.
Join the incorrectly sorted Automess.jmp table with the correctly sorted Subset of Automess table.
![]() Select Tables > Join.
Select Tables > Join.
![]() When the Join window appears, note which table is listed next to the word Join (either Automess or Subset of Automess). Click the other table’s name in the list of tables.
When the Join window appears, note which table is listed next to the word Join (either Automess or Subset of Automess). Click the other table’s name in the list of tables.
![]() By default, the Matching Specification box is set to By Matching Columns. Use the Matching Specification menu and change the specification to By Row Number.
By default, the Matching Specification box is set to By Matching Columns. Use the Matching Specification menu and change the specification to By Row Number.
![]() Because you don’t want all the columns from both tables in the final result, click the Select columns for joined table check box.
Because you don’t want all the columns from both tables in the final result, click the Select columns for joined table check box.
The variables from both tables appear in list boxes.
![]() Select State from the Automess table and click Select.
Select State from the Automess table and click Select.
![]() Select Auto theft from the Subset of Automess table and click Select.
Select Auto theft from the Subset of Automess table and click Select.
![]() Click OK on the Join launch window.
Click OK on the Join launch window.
Visually verify the new joined data table. The first row is South Dakota with a theft rate of 110 and the last row is the District of Columbia with a rate of 1336. If you want to keep this table, use Save As and specify a name and folder for it.
Give New Shape to a Table: Stack Columns
A typical situation occurs when response data are recorded in two columns and you need them to be stacked into a single column. For example, suppose you collect three months of data and enter it in three columns. If you then want to look at quarterly figures, you need to change the data arrangement so that the three columns stack into a single column. You can do this with the Stack command in the Tables menu.
![]() To see an example of stacking columns, select Help > Sample Data Library and open Cheese Taste.jmp to see the table on the left in Figure 3.14.
To see an example of stacking columns, select Help > Sample Data Library and open Cheese Taste.jmp to see the table on the left in Figure 3.14.
This sample data (McCullagh and Nelder, 1983) has columns for four types of cheese, labeled A, B, C, and D. In a taste test, four judges ranked the cheeses on an ordinal scale from 1 to 9 (1 being awful, and 9 being wonderful). The Response column shows these ratings. The counts for each cheese and for each ranking of taste are the body of the table. Its form looks like a two-way table, but to analyze this data, JMP needs the cheese categories in a single column. To rearrange the data:
![]() Select Tables > Stack.
Select Tables > Stack.
![]() In the Stack window, select the cheeses (A, B, C, and D) from the Select Columns list and click Stack Columns. Leave everything else as is.
In the Stack window, select the cheeses (A, B, C, and D) from the Select Columns list and click Stack Columns. Leave everything else as is.
![]() Click OK to see the table on the lower right in Figure 3.14.
Click OK to see the table on the lower right in Figure 3.14.
Figure 3.14 Stack Columns Example

The Label column shows the cheeses, and the Data column is now the count variable for the response categories (1 through 9). Now use JMP to generate a contingency table.
![]() Select the Data column header area, and select Cols > Preselect Role > Freq to assign the Data column the frequency role for the analysis.
Select the Data column header area, and select Cols > Preselect Role > Freq to assign the Data column the frequency role for the analysis.
This causes the values in the Data column in the Untitled table to be interpreted by analyses as the number of times that row’s response value occurred.
To see how response relates to type of cheese:
![]() Select Analyze > Fit Y by X.
Select Analyze > Fit Y by X.
![]() In the Fit Y by X launch window, assign Response to Y, Response and Label to X, Factor.
In the Fit Y by X launch window, assign Response to Y, Response and Label to X, Factor.
If you preselected its role, Data is already assigned as a Freq variable. If not, assign it on the launch window.
When you click OK, the contingency table platform appears with a mosaic plot, Crosstabs table, Tests table, and menu options. To find more information about the platform components, you can use the Help tool (![]() ) in the Tools menu and click on the platform surface. A simplified version of the Crosstabs table with only counts is shown in Figure 3.15. (Right-click on the contingency table to modify what it displays.) The stacked Cheese data is used again later for further analysis.
) in the Tools menu and click on the platform surface. A simplified version of the Crosstabs table with only counts is shown in Figure 3.15. (Right-click on the contingency table to modify what it displays.) The stacked Cheese data is used again later for further analysis.
Figure 3.15 Contingency Table for the Cheese Data

![]() For practice, see whether you can use the Split command on the stacked data table to reproduce a copy of the Cheese Taste table.
For practice, see whether you can use the Split command on the stacked data table to reproduce a copy of the Cheese Taste table.
Creating Summary Statistics
One of the most powerful and useful commands in the Tables menu is the Summary command.
Summary creates a JMP window that contains a summary table. This table summarizes columns from the active data table, called its source table. It has a single row for each level of a grouping variable that you specify.
A grouping variable divides a data table into groups according to each of its values. For example, a gender variable can be used to group a table into males and females.
When there are several grouping variables (for example, gender and age), the summary table has a row for each combination of levels of all variables. Each row in the summary table identifies its corresponding subset of rows in the source table. The columns of the summary table are summary statistics that you request.
Create Summary Statistics with the Summary Command
The example data used to illustrate the Summary command is the JMP table called Companies.jmp (see Figure 3.16).
![]() Select Help > Sample Data Library and open Companies.jmp.
Select Help > Sample Data Library and open Companies.jmp.
It is a collection of financial information for 32 companies (Fortune 1990). The first column (Type) identifies the type of company with values “Computer” or “Pharmaceutical.” The second column (Size Co) categorizes each company by size with values “small,” “medium,” and “big.” These two columns are typical examples of grouping information.
Figure 3.16 JMP Table to Summarize

![]() Select Tables > Summary.
Select Tables > Summary.
![]() In the Summary window, select the variable Type in the Columns list and click Group to add it to the grouping variables list (shown in Figure 3.17).
In the Summary window, select the variable Type in the Columns list and click Group to add it to the grouping variables list (shown in Figure 3.17).
You can select as many grouping variables as you want. But for now, look at a single variable.
![]() Click OK to see the summary table.
Click OK to see the summary table.
The new summary table appears in an active window as shown at the bottom in Figure 3.17. This table is linked to its source table. When you highlight rows in the summary table, the corresponding rows are also highlighted in its source table.
Figure 3.17 Summary Window and Summary Table

The summary table displays frequency counts (N Rows) for each level of the grouping variables. This example shows 20 computer companies and 12 pharmaceutical companies. You could have requested other statistics on the Summary window. The Statistics menu in the Summary window lists standard univariate descriptive statistics.
To add summary statistics to an existing summary table, follow these steps:
![]() Select Add Statistics Column command from the red triangle menu on the Columns tab at the left of the summary table.
Select Add Statistics Column command from the red triangle menu on the Columns tab at the left of the summary table.

This command displays the Summary window again.
![]() Select any numeric column (for example, Profits $M) from the source table columns list.
Select any numeric column (for example, Profits $M) from the source table columns list.
![]() Select the statistic that you want (for example, Sum) from the Statistics menu on the window.
Select the statistic that you want (for example, Sum) from the Statistics menu on the window.
![]() If desired, repeat to add more statistics to the summary table.
If desired, repeat to add more statistics to the summary table.
![]() Click OK to add the columns of statistics to the summary table.
Click OK to add the columns of statistics to the summary table.
The table in Figure 3.18 shows the sum of Profits ($M) in the summary table grouped by Type.
Figure 3.18 Expanded Summary Table

Another way to add summary statistics to a summary table is with the Subgroup button in the Summary window (Figure 3.17). This method creates a new column in the summary table for each level of the variable that you specify with Subgroup. The subgroup variable is usually nested within all the grouping variables.
Create Summary Statistics with Tabulate
You can use Analyze > Tabulate to create the same table interactively.
With the Companies.jmp table active, follow these steps:
![]() Select Analyze > Tabulate to see the Tabulate window in Figure 3.19. You’ll see the list of variables in the Companies table in the variables list on the left of the window.
Select Analyze > Tabulate to see the Tabulate window in Figure 3.19. You’ll see the list of variables in the Companies table in the variables list on the left of the window.
![]() First, drag the N from the statistics panel to Drop zone for columns. This creates the small table shown here. So far, the table shows the total N of 32 for the whole table.
First, drag the N from the statistics panel to Drop zone for columns. This creates the small table shown here. So far, the table shows the total N of 32 for the whole table.

![]() Next drag the Type variable to the Drop zone for rows (which is now a small box). Now you should see a row for each type of company, with the appropriate N for each type.
Next drag the Type variable to the Drop zone for rows (which is now a small box). Now you should see a row for each type of company, with the appropriate N for each type.

Figure 3.19 Tabulate Window for Dragging and Dropping Variables

![]() Drag Profits ($M) just to the right of N in the tabulate palette.
Drag Profits ($M) just to the right of N in the tabulate palette.
You see a new small gray column outlined in blue, which indicates that you want a new column. When you release the mouse, Tabulate creates the table shown in Figure 3.20.
![]() Select Make Into Data Table from the red triangle menu next to Tabulate to create the summary data table.
Select Make Into Data Table from the red triangle menu next to Tabulate to create the summary data table.
Note: The Sum statistic is the default. If you want a different statistic, right-click on the statistics name in the Tabulate drop zone and select Statistics, then select the one you want. You can also drag a statistic from the list
Figure 3.20 Add Analysis Column and Create Summary Table

Working with Scripts
JMP contains a full-fledged scripting language, used for automating repetitive tasks, scripting instructional simulations, and much more. Several scripts are featured throughout this book to demonstrate statistical concepts.
Scripts are stored in two formats:
● data table scripts
● stand-alone scripts
Creating Scripts
You can write your own scripts, customize existing scripts, or create scripts from any JMP platform.
To create a data table script or stand-alone script from a JMP platform, select Save Script from the red triangle menu on a report. This command provides several options for saving a script, such as To Data Table and To Script Window.
For information about writing JSL code, see the Scripting Index in the Help menu. You can also select Help > JMP Help and refer to the Scripting Guide or JSL Syntax Reference.
Running Data Table Scripts
Data table scripts are listed in the Table panel, as shown here. This example is from the Big Class.jmp sample data table, showing several scripts that have been saved with it.

To work with scripts in a data table, follow these steps:
● Click the green triangle next to the script’s name to run the script.
● Right-click the script name and select Edit to view or edit the script.
Opening and Running Stand-alone Scripts
Stand-alone scripts are stored as simple text files with the JSL (.jsl) extension in the JMP Samples/Scripts folder.
To open and run a stand-alone script:
![]() Select File > Open and navigate to the folder that contains the script that you want.
Select File > Open and navigate to the folder that contains the script that you want.
![]() Double-click the script name to open it.
Double-click the script name to open it.
Some scripts are designed to run when they open. Other scripts open in a script editor window. To execute the script in the script editor window:
![]() Use the shortcut key Ctrl-R (Windows) or
Use the shortcut key Ctrl-R (Windows) or ![]() -R (Macintosh), click the Run Script icon on the toolbar, or right-click in the script and select Run Script.
-R (Macintosh), click the Run Script icon on the toolbar, or right-click in the script and select Run Script.
For example, use the demoMeanTestPValue script available in Help > Sample Data under the Teaching Scripts > Teaching Demonstrations outline.
![]() Run the demoMeanTestPValue script.
Run the demoMeanTestPValue script.
All scripts in the Sample Data window are designed to run automatically.
Figure 3.21 illustrates several key features of a typical instructional script.
Figure 3.21 Test an Estimated Mean with a Hypothesized Mean Window
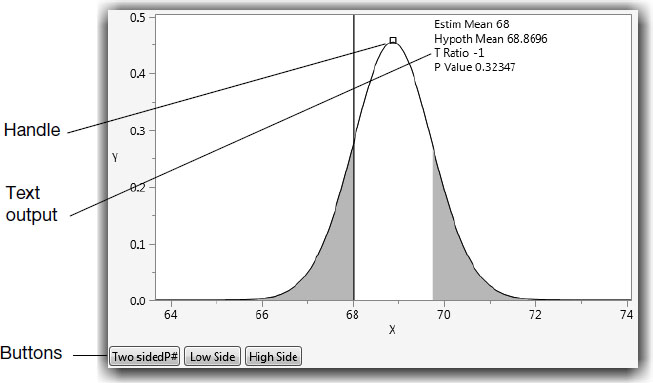
● A handle is a script element that you can drag to update the display as it is dragged. In this case, the handle controls the t-distribution for hypothesized mean and changes as you drag it, adjusting the t-ratio and p-value.
● Text output is sometimes drawn directly on the graphics screen rather than displayed as reports below the window. This script shows the estimated mean, the hypothesized mean, the t-ratio, and the p-value, in the upper right corner of the window.
● Buttons reveal options, set conditions, or trigger actions in the script. In this example, the buttons are for a two-sided p, or the one-sided upper or lower p-value.
To practice with these elements:
![]() Drag the handle to different places in the window and observe how the hypothesized mean and the p-value change.
Drag the handle to different places in the window and observe how the hypothesized mean and the p-value change.
![]() Click the buttons to see how the p-values change.
Click the buttons to see how the p-values change.
To view the JSL code for demoMeanTestPValue, select Help > Sample Data > Open the Sample Scripts Directory, and double-click the script to open it.