
Chapter 10. Connecting to the Data
Introduction
You often hear Struts referred to as a
model-view-controller (MVC) framework for web
applications. Struts can help you build web
applications that separate the data (model) from the presentation
(view); however, Struts doesn’t provide a framework
for the model. Rather, it supports custom Actions
which broker the interaction between the view
and model.
This chapter contains several recipes that offer different approaches to interacting with your application’s model. You will find solutions related to accessing relational data by using JDBC and the popular Hibernate object/relational mapping framework. This chapter shows you ways to create pluggable interfaces for your business services. Finally, this chapter demonstrates some techniques for working with XML-based data stored in flat files.
10.1. Accessing JDBC Data Sources from an Action
Problem
You want to access a data source directly from a Struts
Action.
Solution
Don’t do it! Only access the data source from within your application’s model.
Discussion
Though Struts is referred to as an MVC framework for web
applications, Struts doesn’t attempt to provide the
model of that paradigm. Struts provides only the bridge between the
view and the model, Struts Actions. An
Action shouldn’t access the
database; an Action shouldn’t
need to know how the data is stored and accessed. Instead, an
Action acts as a thin façade to your
business services, marshalling data from the view to the model and
back. The following FAQ from the Struts web site puts it quite
succinctly:
Ideally, all the database access code should be encapsulated behind the business API classes, so Struts doesn’t know what persistence layer you are using (or even if there is a persistence layer). It passes a key or search String and gets back a bean or collection of beans. This lets you use the same business API classes in other environments, and lets you run unit tests against your business API outside of Struts or a HTTP environment.
While Struts does support the data-source element
for configuring JDBC data sources, the Struts release notes state
that this element may not be supported in the future. According to
the Struts documentation, you should use the
data-source element when you need to pass a
javax.sql.DataSource to a legacy API. This results
in a dependency between the Action and the
persistence layer as illustrated in Figure 10-1.
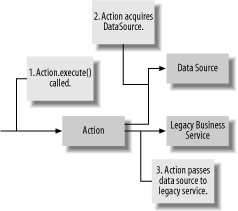
A better approach in this situation is to create a façade
around the legacy API. The façade provides a
data-independent implementation of the legacy API. Internally, the
façade is responsible for acquiring the required data
source and delegating calls to the legacy service, passing the data
source as needed. Your Actions can interact with
the façade without needing to be bound to the persistence
details. This (better) model is shown in Figure 10-2.
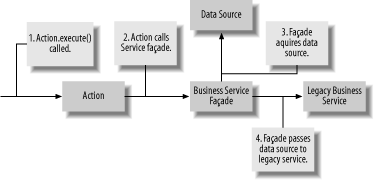
The
façade-based architecture
results in a more flexible system that can adapt from low-level
changes to legacy systems without requiring you to rewrite your
Actions.
See Also
The Struts FAQ on database-related issues can be found at http://struts.apache.org/faqs/database.html. For more information on accessing databases, see Java Database Best Practices by George Reese (O’Reilly).
10.2. Displaying Relational Data
Problem
You want to display data from a relational database, but you don’t know the structure of the data.
Solution
Use the RowSetDynaClass class
(org.apache.commons.beanutils.RowSetDynaClass)
provided by the Jakarta Commons BeanUtils project.
Tip
The JAR files for BeanUtils are included with the Struts distribution so no additional download is needed.
Start by creating a data access object, like the one shown in Example 10-1, which performs the database query and returns
a BeanUtils RowSetDynaClass created from a JDBC
result set.
package com.oreilly.strutsckbk.ch05;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
import org.apache.commons.beanutils.RowSetDynaClass;
public class UserDao {
public RowSetDynaClass getUsersRowSet( ) throws Exception {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
RowSetDynaClass rowSet = null;
try {
conn = getConnection( );
stmt = conn.createStatement( );
rs = stmt.executeQuery("select * from users");
rowSet = new RowSetDynaClass(rs);
}
finally {
if (conn != null) conn.close( );
}
return rowSet;
}
private Connection getConnection( ) throws Exception {
Class.forName("com.mysql.jdbc.Driver");
return DriverManager.getConnection("jdbc:mysql://localhost/test");
}
}Create an Action that retrieves the
RowSetDynaClass from the data access object and
stores it in the servlet request. The Action shown
in Example 10-2 retrieves a row set from the data
access object of Example 10-1.
package com.oreilly.strutsckbk.ch05;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.beanutils.RowSetDynaClass;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
public class ViewUsersAction extends Action {
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response)
throws Exception {
UserDao dao = new UserDao( );
RowSetDynaClass rowSet = dao.getUsersRowSet( );
request.setAttribute("rowSet", rowSet);
return mapping.findForward("success");
}
}Then create a JSP page, such as the one shown in Example 10-3, that iterates through the
RowSetDynaClass stored in the request, first
retrieving the column names, and then the data itself.
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<%@ page import="org.apache.commons.beanutils.*" %>
<%@ taglib uri="http://jakarta.apache.org/struts/tags-bean" prefix="bean" %>
<%@ taglib uri="http://jakarta.apache.org/struts/tags-logic" prefix="logic" %>
<html>
<head>
<title>Struts Cookbook - Chapter 5 : Viewing Row Sets</title>
</head>
<body>
<h2>Viewing Row Sets</h2>
<bean:define id="cols" name="rowSet" property="dynaProperties"/>
<table border="2">
<tr>
<logic:iterate id="col" name="cols">
<th><bean:write name="col" property="name"/></th>
</logic:iterate>
</tr>
<logic:iterate id="row" name="rowSet" property="rows">
<tr>
<logic:iterate id="col" name="cols">
<td>
<bean:write name="row" property="<%=((DynaProperty)col).
getName( )%>"/>
</td>
</logic:iterate>
</tr>
</logic:iterate>
</table>
</body>
</html>Of course, you tie the Action to the JSP using an
action element in the
struts-config.xml:
<action path="/ViewUsers"
type="com.oreilly.strutsckbk.ch05.ViewUsersAction">
<forward name="success" path="/view_users.jsp"/>
</action>Discussion
A sizeable percentage of web applications use a relational database for storing data. In an architecture that emphasizes separation of concerns, controller actions interact with the model through business objects, data transfer objects, and service-oriented interfaces. But sometimes it makes more sense to provide direct views of data in the database.
The
RowSetDynaClass
provides an effective mechanism for accessing and retrieving data
from JDBC result sets. This class, provided in the Jakarta Commons
BeanUtils package, maps a JDBC result set—rows and columns
retrieved from a relational database—to a JavaBean which can be
accessed on a JSP page.
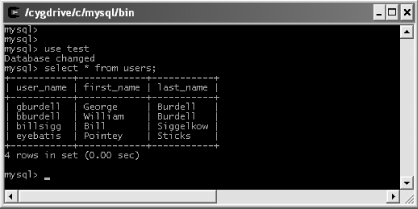
Figure 10-3 shows the results of executing the “select * from users” query from Example 10-1 against a MySQL test database.
You construct a RowSetDynaClass by passing the
JDBC ResultSet to the
RowSetDynaClass’s constructor.
Because the data is copied, you can safely close the
ResultSet and JDBC Connection
without losing data. The RowSetDynaClass includes
the data and contains the name and type of each column. In Example 10-3, the dynaProperties array
property is used to render the table column headers. Then, the
rowSet property is used to access a
List of DynaBeans. Each
DynaBean represents a row. Each field of the row
is retrieved by name from each DynaBean.
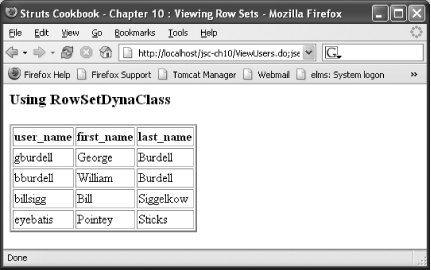
Figure 10-4 shows the generated page for the /ViewUsers action.
See Also
The API documentation for the BeanUtils packages is the best source
of additional information for the RowSetDynaClass.
The BeanUtils API can be found at http://jakarta.apache.org/commons/beanutils/.
You can consult the chapter on BeanUtils in the Jakarta Commons Cookbook by Tim O’Brien (O’Reilly).
If you’re familiar with JSTL, you can use the SQL
tags instead of the RowSetDynaClass to display
relational data However, you need to be judicious in using these tags
since you will be coupling your application’s view
to the model. You can find a tutorial on the JSTL SQL tag library at
http://java.sun.com/webservices/docs/1.0/tutorial/doc/JSTL8.html#63722.
10.3. Mapping SQL Data to Java Objects
Problem
You want to map SQL statements to Java objects without having to employ a full-blown object-relational mapping framework.
Solution
Use iBATIS SQL maps.
Discussion
There is a middle-ground in Java database access, a shadowy land that lies between straight JDBC and full-blown ORM, a place known as the iBATIS zone. iBATIS (pronounced “eye-bay-tis”), created by Clinton Begin, provides an elegant framework for mapping SQL statements and results to Java objects. It offers the simplicity and control of straight JDBC, yet it supports data mapping, caching, and transactions, features usually available from complex object-relational mapping tools. This recipe introduces you to the core feature of iBATIS: SQL maps. It doesn’t delve into the full-functionality of iBATIS; you can find additional reference documentation and tutorials online at http://www.ibatis.com.
SQL maps allow you to specify how Java objects map to the inputs and outputs of an SQL statement. The inputs traditionally take the form of parameters bound to an SQL where clause. SQL maps let you map object properties to statement parameters. For output, SQL maps let you specify a Java object that maps to the result set returned by an SQL statement.
You can use iBATIS to access and display the data used in Recipe 10-2. Start by downloading iBATIS from http://www.ibatis.com. For this example, iBATIS Version 2.0.7 was used. Extract the distribution into a directory such as /ibatis-2.0.7. Copy the ibatis-sqlmap-2.jar and ibatis-common-2.jar files to your WEB-INF/lib folder.
Next, you create the configuration files that specify how you connect to your database. iBATIS, by default, searches for its configuration files in the application’s class path. This example stores these files in the application’s top-level src directory; when the application is compiled, the configuration files are copied to the WEB-INF/classes directory.
iBATIS reads database connection settings from a properties file. Example 10-4 shows the sqlMapConfig.properties used to connect to a MySQL database.
iBATIS reads and uses these properties in its XML configuration file. Example 10-5 shows the sqlMapConfig.xml used in this recipe.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE sqlMapConfig
PUBLIC "-//iBATIS.com/DTD SQL Map Config 2.0//EN"
"http://www.ibatis.com/dtd/sql-map-config-2.dtd">
<sqlMapConfig>
<properties resource="sqlMapConfig.properties"/>
<transactionManager type="JDBC">
<dataSource type="SIMPLE">
<property name="JDBC.Driver" value="${driver}"/>
<property name="JDBC.ConnectionURL" value="${url}"/>
<property name="JDBC.Username" value="${username}"/>
<property name="JDBC.Password" value="${password}"/>
</dataSource>
</transactionManager>
<sqlMap resource="UserSqlMap.xml"/>
</sqlMapConfig>The properties element makes the configuration
properties of Example 10-4 available as variables
(${
propertyName
})
that can be used throughout the rest of the XML configuration file.
The sqlMap element references an SQL Map
configuration file for use by this application. Typically,
you’ll have one SQL map file for each table.
For this example, you want to map the results of selecting all rows from the users table into a collection of objects. Figure 10-5 shows the structure of the users table.
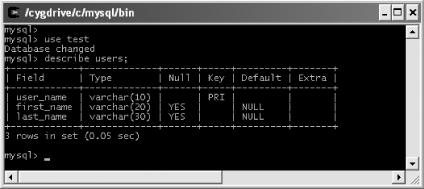
Example 10-6 shows the UserSqlMap.xml file that enables this mapping.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE sqlMap
PUBLIC "-//iBATIS.com/DTD SQL Map 2.0//EN"
"http://www.ibatis.com/dtd/sql-map-2.dtd">
<sqlMap namespace="UserSqlMap">
<select id="getAllUsers" resultClass="com.oreilly.strutsckbk.ch10.User">
SELECT user_name as username,
first_name as firstName,
last_name as lastName
FROM users
</select>
</sqlMap>The select element defines how a select SQL select
statement, contained in the element’s body, maps to
a Java class. When the query is executed, iBATIS will return a
collection of Java objects of the type specified by the
resultClass attribute. Example 10-7 shows the User object. By using the
"column as
name" syntax in the query, you
automatically map a column to JavaBean property.
package com.oreilly.strutsckbk.ch10;
public class User {
public String getUsername( ) {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword( ) {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getFirstName( ) {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName( ) {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
private String username;
private String password;
private String firstName;
private String lastName;
}Now you need to create the data access object that retrieves the collection of users. Example 10-8 shows the action used in this recipe that uses the SQL Maps API to execute the query and map the results.
package com.oreilly.strutsckbk.ch10;
import java.io.Reader;
import java.sql.SQLException;
import java.util.List;
import com.ibatis.common.resources.Resources;
import com.ibatis.sqlmap.client.SqlMapClient;
import com.ibatis.sqlmap.client.SqlMapClientBuilder;
public class MyUserDao {
private static final SqlMapClient sqlMapClient;
static {
try {
Reader reader = Resources.getResourceAsReader("sqlMapConfig.xml");
sqlMapClient = SqlMapClientBuilder.buildSqlMapClient(reader);
} catch (Exception e) {
e.printStackTrace( );
throw new RuntimeException("Unable to create iBATIS sql map
client.", e);
}
}
public List getAllUsers( ) throws SQLException {
return sqlMapClient.queryForList("getAllUsers", null);
}
}This data access object provides a getAllUsers( )
method to retrieve the results returned by the
“getAllUsers” SQL map statement
shown in Example 10-6. The
SqlMapClient serves as a façade over
the iBATIS API. This object is thread-safe; you can define and
initialize it in a static block and use it throughout your action.
Example 10-9 shows the data access object which utilizes the iBATIS API.
package com.oreilly.strutsckbk.ch10;
import java.util.List;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
public class ViewMyUsersAction extends Action {
public ActionForward execute(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response) throws
Exception {
MyUserDao dao = new MyUserDao( );
List users = dao.getAllUsers( );
request.setAttribute("users", users);
return mapping.findForward("success");
}
}The actual JSP page to render the users object is shown in Example 10-10. Unlike the solution for Recipe 10.2, the object used on the page is a well-known
custom business object. You access its properties using
run-of-the-mill Struts bean:write or JSTL
c:out tags.
<%@ page contentType="text/html;charset=UTF-8" language="java" %> <%@ taglib uri="http://struts.apache.org/tags-bean" prefix="bean" %> <%@ taglib uri="http://struts.apache.org/tags-logic" prefix="logic" %> <html> <head> <title>Struts Cookbook - Chapter 10 : Using iBATIS</title> </head> <body> <h3>Using iBATIS</h3> <table border="2"> <tr> <th>Username</th> <th>First Name</th> <th>Last Name</th> </tr> <logic:iterate id="user" name="users"> <tr> <td> <bean:write name="user" property="username"/> </td> <td> <bean:write name="user" property="firstName"/> </td> <td> <bean:write name="user" property="lastName"/> </td> </tr> </logic:iterate> </table> </body> </html>
This results in a display like that shown in Figure 10-6.
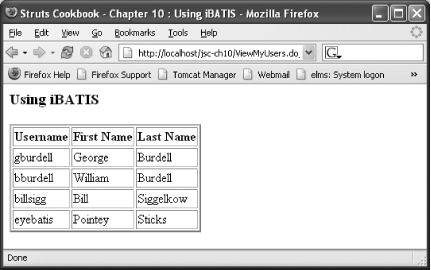
This recipe hints at the capabilities of iBATIS SQL maps. If your application needs some means of mapping objects to data and back, you should consider iBATIS. It may be exactly what you were looking for.
See Also
Documentation, examples, and tutorials for iBATIS can be found at http://www.ibatis.com. You will also find the iBATIS data access object (DAO) framework. This framework is highly extensible yet provides a simple means of getting started with iBATIS. This DAO layer can even be used against non-iBATIS mapped data.
10.4. Integrating Struts with Hibernate
Problem
You want to use Hibernate for object/relational mapping in your Struts application.
Solution
Use a servlet filter such as the Persistence class
shown in Example 10-11.
package com.jadecove.util;
import java.io.*;
import javax.servlet.*;
import net.sf.hibernate.*;
import net.sf.hibernate.cfg.Configuration;
/**
* Filter which manages a ThreadLocal hibernate session. Obtain the session
* by calling Persistance.getSession( ).
*/
public class Persistence implements Filter {
/**
* Holds the current hibernate session, if one has been created.
*/
protected static ThreadLocal hibernateHolder = new ThreadLocal( );
protected static SessionFactory factory;
public void init(FilterConfig filterConfig) throws ServletException {
// Initialize hibernate
try {
doInit( );
}
catch (HibernateException ex) {
throw new ServletException(ex);
}
}
/**
* This method should only be called when this class is used directly -
* that is, when using this class outside of the servlet container.
* @throws HibernateException
*/
public static void doInit( ) throws HibernateException {
factory = new Configuration( ).configure( ).buildSessionFactory( );
}
public void doFilter(ServletRequest request,
ServletResponse response,
FilterChain chain)
throws IOException, ServletException {
if (hibernateHolder.get( ) != null)
throw new IllegalStateException(
"A session is already associated with this thread! "
+ "Someone must have called getSession( ) outside of
the context "
+ "of a servlet request.");
try {
chain.doFilter(request, response);
}
finally {
Session sess = (Session)hibernateHolder.get( );
if (sess != null) {
hibernateHolder.set(null);
try {
sess.close( );
}
catch (HibernateException ex) {
throw new ServletException(ex);
}
}
}
}
/**
* ONLY ever call this method from within the context of a servlet request
* (specifically, one that has been associated with this filter). If you
* want a Hibernate session at some other time, call getSessionFactory( )
* and open/close the session yourself.
*
* @return an appropriate Session object
*/
public static Session getSession( ) throws HibernateException {
Session sess = (Session)hibernateHolder.get( );
if (sess == null) {
sess = factory.openSession( );
hibernateHolder.set(sess);
}
return sess;
}
/**
* @return the hibernate session factory
*/
public static SessionFactory getSessionFactory( ) {
return factory;
}
/**
* This is a simple method to reduce the amount of code that needs
* to be written every time hibernate is used.
*/
public static void rollback(net.sf.hibernate.Transaction tx) {
if (tx != null) {
try {
tx.rollback( );
}
catch (HibernateException ex) {
// Probably don't need to do anything - this is likely being
// called because of another exception, and we don't want to
// mask it with yet another exception.
}
}
}
public void destroy( ) {
// Nothing necessary
}
}Declare the filter in your web.xml file with a filter mapping configured for all URLs that need access to persistent data. Here the filter mapping is set to all URLs:
<filter>
<filter-name>PersistenceFilter</filter-name>
<filter-class>com.jadecove.util.Persistence</filter-class>
</filter>
<filter-mapping>
<filter-name>PersistenceFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>You get a session from the filter by calling the static
getSession( ) method. Here’s an
example method that you can use in your own DAOs:
protected Session getSession( ) throws PersistenceException {
Session session = null;
try {
session = Persistence.getSession( );
} catch (HibernateException e) {
log.error("Exception accessing persistence session");
throw new PersistenceException(
"Exception accessing persistence session", e);
}
return session;
}Discussion
If you haven’t heard of Hibernate, then you’ve obviously been sleeping in a cave. Hibernate is one of the most popular object/relational mapping frameworks in use today. It can be used to provide transparent persistence for Java objects, populating and storing object properties using data stored in a relational database.
The
Persistence filter
shown in Example 10-11 provides a Hibernate session
for every servlet request that goes through the filter. It uses a
ThreadLocal variable to hold the Hibernate session
(see Sidebar 10-1). Each HTTP request is a
separate thread; therefore, each request has its own Hibernate
session. The Hibernate session is automatically closed when the
request is complete—that is, immediately before the HTTP
response is sent. The finally block in the
doFilter( ) method closes the Hibernate session
and sets the value for the session in the
ThreadLocal variable to null.
A class that needs to load or store persistent data gets a Hibernate
session by calling the static Persistence.getSession(
) method.
Hibernate can defer the loading of specific object properties from the database. The database won’t be accessed until that property’s accessor method is explicitly called. This feature is known as lazy-loading. Since Hibernate persists a graph of objects, lazy-loading can allow you to retrieve a complex object without necessarily paying the performance price of retrieving all the data from the database. The one caveat to this feature is that a lazy-loaded property can only be retrieved if that object is associated with an open Hibernate session.
Without using the Persistence filter, a Hibernate
session would have to remain open if you needed to lazy-load a
property on a JSP page. However, it is dangerous to leave a Hibernate
session—essentially a database connection—open between
user requests. If you close the Hibernate session before forwarding
to a JSP page, attempting to access a lazy-loaded property will fail
because an open Hibernate session isn’t available.
The Persistence filter solves this problem.
Because the Hibernate session is opened by a filter; the session
remains open until the request is complete. JSP pages and other web
resources can successfully read persistent object properties, even if
they are lazy-loaded.
For unit testing, the Persistence filter can be
used outside of the application server. In this case, you use the
Persistence class to initialize Hibernate and
retrieve a Hibernate session factory. Example 10-12
shows an abstract JUnit test base class that uses the
Persistence class.
package com.jadecove.facet;
import junit.framework.TestCase;
import net.sf.hibernate.Session;
import com.jadecove.util.Persistence;
public abstract class PersistenceTestCase extends TestCase {
public PersistenceTestCase(String name) {
super(name);
}
protected void setUp( ) throws Exception {
super.setUp( );
Persistence.doInit( );
openSession( );
doSetUp( );
}
/**
* Override this method to provide test-specific set-up
*/
protected void doSetUp( ) throws Exception {
}
/**
* Override this method to provide test-specific tear-down
*/
protected void doTearDown( ) throws Exception {
}
protected void tearDown( ) throws Exception {
super.tearDown( );
session.close( );
doTearDown( );
}
protected void openSession( ) throws Exception {
session = Persistence.getSessionFactory( ).openSession( );
}
protected void closeSession( ) throws Exception {
session.close( );
}
protected Session session;
}See Also
The Persistence filter of the Solution is based on a recommended practice presented on the Hibernate web site. The relevant page can be found at http://www.hibernate.org/43.html.
If you were to search the Internet for “Struts
Hibernate” you’d probably come upon
the HibernatePlugin for Struts. This class can be
used as a Hibernate session factory; however, it
doesn’t have the advantages afforded by the
Persistence filter. This class can also be found
on the Hibernate web site at http://www.hibernate.org/105.html.
10.5. Decoupling Your Application from External Services
Problem
You want to decouple your Struts application from a specific implementation of an external business service.
Solution
Create an interface that provides an API for the business service. Then
use a ServiceFactory class like the one shown in
Example 10-13 to provide access to the service.
package com.oreilly.strutsckbk.ch10;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class ServiceFactory {
private static Log log = LogFactory.getLog(ServiceFactory.class);
public SecurityService createSecurityService( ) {
SecurityService service = null;
try {
service = (SecurityService)
Class.forName(securityServiceImpl).newInstance( );
} catch (Exception e) {
log.error(
"Unable to create SecurityService for impl:"+
securityServiceImpl);
}
return service;
}
protected void setSecurityServiceImpl(String securityServiceImpl) {
this.securityServiceImpl = securityServiceImpl;
}
private String securityServiceImpl;
}You can use a Struts PlugIn, like the one shown in
Example 10-14, to bind a service implementation to the
interface, and store a reference to the service in the servlet
context.
package com.oreilly.strutsckbk.ch10;
import javax.servlet.ServletException;
import org.apache.struts.action.ActionServlet;
import org.apache.struts.action.PlugIn;
import org.apache.struts.config.ModuleConfig;
public class ServiceFactoryPlugin implements PlugIn {
public void init(ActionServlet servlet, ModuleConfig config) throws
ServletException {
ServiceFactory factory = new ServiceFactory( );
factory.setSecurityServiceImpl(securityService);
servlet.getServletContext( ).setAttribute("APP_SERVICE_FACTORY",
factory);
}
public void destroy( ) {
}
public void setSecurityService(String securityService) {
this.securityService = securityService;
}
private String securityService;
}Discussion
In corporate environments, it’s more likely that a web application will be used as a private intranet application than as a public site on the World Wide Web. These internal applications commonly interface to existing corporate software-based services. These services could be Java-based applications, Enterprise JavaBeans, or web services to name a few. Your web application will have little control of the interface to the legacy system; likewise, you’re likely to receive little notice when the interface changes. You can mitigate these risks by decoupling your application from the underlying service using the approach shown in the Solution. Using the Solution, you can easily replace the interface to the implementation with a simplified implementation for testing and development.
Suppose your corporation provides a security service that authenticates existing users and allows the addition of new users. The current service is based on a legacy in-house developed application, but future plans are to move to a system based on Lightweight Directory Access Protocol (LDAP). Your Struts application that will interface to this system needs to be able to support the current and future implementations of the security service.
You can apply techniques in the Solution to this problem. The first thing you will want to do is define an interface for this service like the one shown in Example 10-15.
For development and testing purposes, you can create an
implementation of the SecurityService, like that
shown in Example 10-16, that uses an in-memory
Map of user data.
package com.oreilly.strutsckbk.ch10;
import java.util.HashMap;
import java.util.Map;
public class MemorySecurityService implements SecurityService {
public void authenticate(String username,
String password)
throws UnknownUserException, PasswordMatchException {
if (users.get(username) == null) {
throw new UnknownUserException( );
} else if (!users.get(username).equals(password)) {
throw new PasswordMatchException( );
}
return;
}
public void add(User user) throws DuplicateUsernameException {
if (users.containsKey(user.getUsername( )))
throw new DuplicateUsernameException( );
users.put(user.getUsername( ),user.getPassword( ));
}
private static Map users;
static {
users = new HashMap( );
users.put("gpburdell","gotech");
users.put("fflintstone","yabbadabbado");
users.put("mpython","nopuftas");
}
}Now you can use a ServiceFactory (Example 10-13) that knows how to create a new
SecurityService given the name of a class that
implements the SecurityService interface.
A Struts Plug-In (Example 10-14) can be used to
create, configure, and store an instance of the
ServiceFactory in the servlet context. The plug-in
is configured in the struts-config.xml to create
instances of the SecurityService interface using
the specified implementation:
<plug-in className="com.oreilly.strutsckbk.ch10.ServiceFactoryPlugin">
<set-property property="securityService"
value="com.oreilly.strutsckbk.ch10.MemorySecurityService"/>
</plug-in>It’s a good idea to create a
BaseAction (Example 10-17) that
accesses the servlet context to retrieve the service factory and
returns an implementation of the service interface.
package com.oreilly.strutsckbk.ch10;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpServletRequest;
import org.apache.struts.action.Action;
public class BaseAction extends Action {
public SecurityService getSecurityService(HttpServletRequest request) {
ServletContext ctx = request.getSession(true).getServletContext( );
ServiceFactory factory = (ServiceFactory)
ctx.getAttribute("APP_SERVICE_FACTORY");
return factory.createSecurityService( );
}
}As you add more types of services, you can add corresponding methods
to the ServiceFactory and
ServiceFactoryPlugin. Alternatively, the
ServiceFactory and
ServiceFactoryPlugin could be made to return any
type of service by some agreed on name. Regardless of your preferred
approach, this
Service Locator
pattern yields code that is more flexible and easier to test than
more tightly coupled systems.
See Also
Struts plug-ins are discussed in Recipe 2.1. The Spring Framework takes pluggability like this to the nth degree. Recipe 10.6 shows you how to integrate an existing Struts application with the Spring Framework.
The Service Locator pattern is considered a Core J2EE Pattern. A page that documents this and other related patterns can be found at http://www.corej2eepatterns.com/Patterns2ndEd/ServiceLocator.htm.
Martin Fowler compares the Service Locator pattern to the Inversion of Control/Dependency Injection pattern in his must-read article at http://www.martinfowler.com/articles/injection.html.
10.6. Integrating Spring with Struts
Problem
You’ve heard about the Spring framework and want to use it with your Struts application.
Solution
There is no better way of learning than by doing. This recipe shows you how to apply Spring to the struts-example web application.
Discussion
There are many ways to use Spring. The Solution shown here uses Spring for two main purposes:
To configure portions of the model
To inject model dependencies into Struts Actions
Here’s what you need to do:
Download the Spring framework from http://www.springframework.org. At the time of this writing, Version 1.1 had just been released.
Download the Struts 1.2.4 source distribution.
Copy the Struts libraries, struts-example classes, struts-example web resources, and struts-example configuration files into a web application directory structure.
Copy the spring.jar file from the downloaded Spring framework into the web-application’s WEB-INF/lib folder.
Now that you’ve got these mundane preliminaries out
of the way, you can get to the gist of Spring. The first thing you
are going to do is change the MemoryDatabase used
by the struts-example to be managed and loaded
by Spring instead of by a Struts plug-in.
In the struts-example, the
MemoryDatabasePlugIn loads and opens the
MemoryUserDatabase. To use Spring instead of this
plug-in, you need to make a minor change to the
MemoryUserDatabase source. Change the
open( ) method to read the input file from the
classpath instead of the filesystem. This makes the solution easier
to deploy. Here’s the revised open() method with the two modified lines shown in bold.
public void open( ) throws Exception {
InputStream fis = null;
BufferedInputStream bis = null;
try {
// Acquire an input stream to our database file
if (log.isDebugEnabled( )) {
log.debug("Loading database from '" + pathname + "'");
}
fis = this.getClass( ).getResourceAsStream(pathname);
bis = new BufferedInputStream(fis);
// Construct a digester to use for parsing
Digester digester = new Digester( );
digester.push(this);
digester.setValidating(false);
digester.addFactoryCreate
("database/user",
new MemoryUserCreationFactory(this));
digester.addFactoryCreate
("database/user/subscription",
new MemorySubscriptionCreationFactory( ));
// Parse the input stream to initialize our database
digester.parse(bis);
bis.close( );
bis = null;
fis = null;
} catch (Exception e) {
log.error("Loading database from '" + pathname + "':", e);
throw e;
} finally {
if (bis != null) {
try {
bis.close( );
} catch (Throwable t) {
;
}
bis = null;
fis = null;
}
}
}This change enables the MemoryUserDatabase to
require the MemoryDatabasePlugin no longer. With
this revised version of the MemoryUserDatabase,
all you have to do is relocate the database.xml
file from the WEB-INF directory to the web
application’s classes folder.
Move database.xml to the subdirectory of
WEB-INF/classes that contains the
MemoryUserDatabase.class file
(WEB-INF/classes/org/apache/struts/webapp/example/memory).
Change the MemoryUserDatabase to be managed by
Spring instead of the plug-in. Remove the
MemoryDatabasePlugIn configuration from the
struts-config.xml; it’s no
longer needed. Create the
applicationContext-struts.xml file in the
WEB-INF folder as shown in Example 10-18.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="userDatabase"
class="org.apache.struts.webapp.example.memory.
MemoryUserDatabase"
init-method="open"
destroy-method="close">
<property name="pathname">
<value>database.xml</value>
</property>
</bean>
</beans>This spring-beans configuration file is the
heart of Spring. The first bean element, shown in
Example 10-18, configures the
MemoryUserDatabase. The nested
property element specifies a dependency that will
be injected after the MemoryUserDatabase class is
constructed. In this case, the pathname property
is set to the path of the XML file containing the list of users for
the struts-example application. After Spring
instantiates the class (using its default constructor), property
values are set based on the nested property
elements. The init-method and
destroy-method attributes allow you to control the
lifecycle of the class. The init-method attribute
specifies the name of a method that will be called once property
values have been set. The method, named by the
destroy-method attribute, will be called when the
object is evicted from Spring’s application context.
For Spring to work, it has to load the XML files that it will use to
create the managed bean objects. In addition, each created object
must be stored in Spring’s application context. For
Struts applications, Spring comes with a Struts plug-in that performs
these tasks. Here’s the plug-in
element used for this Solution:
<plug-in className="org.springframework.web.struts.ContextLoaderPlugIn">
<set-property property="contextConfigLocation"
value="/WEB-INF/applicationContext-struts.xml"/>
</plug-in>Like other plug-ins, the ContextLoaderPlugin can
be passed through a comma-separated list of configuration files. For
the Solution, only a single configuration file is used, the XML file
shown in Example 10-18.
Recall that the MemoryDatabasePlugin instantiated
and opened the MemoryUserDatabase, storing the
created instance in the servlet context under a well-known key value.
Since you are no longer using the plug-in, you can change how the
Actions acquire a reference to the
MemoryUserDatabase.
The “Spring-way” of doing this is
to let Spring control the creation of the Actions.
In a non-Spring Struts application, Actions are
created by the RequestProcessor. When the
RequestProcessor receives a request for a given
path, it determines your corresponding action configuration,
instantiates the specified Action class, and calls
Action.execute( ). So, how do you let Spring
control the creation of the Actions instead of the
RequestProcessor?
The answer is the DelegatingActionProxy. This
class, originally created as part of the original Struts Spring
Plug-in effort led by Don Brown, is a general-purpose
Action that proxies requests to custom
Actions. The proxy action determines your custom
Action associated with a request by matching the
action path with a bean name in
Spring’s configuration file. At runtime, Spring
instantiates your custom Action and injects any
required dependencies.
The Actions provided in the
struts-example extend from a
BaseAction that provides a helper method for
acquiring the UserDatabase:
protected UserDatabase getUserDatabase(HttpServletRequest request) {
return (UserDatabase) servlet.getServletContext( ).getAttribute(
Constants.DATABASE_KEY);
}This method retrieves the UserDatabase from the
servlet context, placed there by the
MemoryDatabasePlugin. This is the kind of
dependency that Spring was made to handle. Since the
UserDatabase is a Spring-managed object, you can
replace this method, which requires the servlet request, with a
common property getter method. The getter method returns the
UserDatabase from an instance variable of the the
BaseAction. You will create a setter method that
sets the value of that instance variable.
Tip
Hold the phone! Did I say create an instance variable in a Struts
Action? Doesn’t this violate
thread safety
(see Recipe 6.4)? If you
use the DelegatingActionProxy shown here, you
don’t need to worry about thread safety for the
Actions. Spring will create a new
Action instance for every
request; alleviating thread-safety concerns.
Spring calls the setter method when an Action
instance is created. Subclasses of the BaseAction
call the getter method to retrieve the
UserDatabase. Each Action that
needs the UserDatabase is configured with this
dependency via a Spring configuration file. The complete
applicationContext-struts.xml file with the new
entries for each Action is shown in Example 10-19.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN"
"http://www.springframework.org/dtd/spring-beans.dtd">
<beans>
<bean id="userDatabase"
class="org.apache.struts.webapp.example.memory.MemoryUserDatabase"
init-method="open"
destroy-method="close">
<property name="pathname">
<value>database.xml</value>
</property>
</bean>
<bean name="/Welcome"
class="org.apache.struts.webapp.example.WelcomeAction">
<property name="userDatabase">
<ref bean="userDatabase"/>
</property>
</bean>
<bean name="/SaveSubscription"
class="org.apache.struts.webapp.example.SaveSubscriptionAction">
<property name="userDatabase">
<ref bean="userDatabase"/>
</property>
</bean>
<bean name="/SaveRegistration"
class="org.apache.struts.webapp.example.SaveRegistrationAction">
<property name="userDatabase">
<ref bean="userDatabase"/>
</property>
</bean>
<bean name="/SubmitLogon"
class="org.apache.struts.webapp.example.LogonAction">
<property name="userDatabase">
<ref bean="userDatabase"/>
</property>
</bean>
</beans>The last step is to change the
action elements in
the struts-config.xml file to use the
DelegatingActionProxy instead of the
Actions directly. For example,
here’s the new action mapping for the
/SubmitLogon path. The only thing that changed was
the type attribute, which refers to the
Spring-provided DelegatingActionProxy:
<action path="/SubmitLogon"
type="org.springframework.web.struts.DelegatingActionProxy"
name="LogonForm"
scope="request"
input="logon">
<exception key="expired.password"
type="org.apache.struts.webapp.example.ExpiredPasswordException"
path="/ExpiredPassword.do"/>
</action>Once you understand how Spring works, it makes programming easier. In
fact, it’s probably harder to convert existing code
to use
Spring than writing new code. When you
write new Actions and business services, you
won’t need to worry about breaking out dependencies
like you had to do with the UserDatabase in this
recipe. Most of your objects will be plain-old-Java-objects (POJOs)
that won’t have any hardcoded dependencies on other
objects. You wire your objects together in your
spring-beans.xml file, and
you’re ready.
See Also
The original web site for the Struts Spring plug-in can be found at http://struts.sourceforge.net/struts-spring/. For the latest on the Spring framework, including its built-in support for Struts, go to http://www.springframework.org.
10.7. Loading XML Data into Your Application
Problem
You want an easy way to load XML data into application-scoped objects when your application starts up.
Solution
Use the
DigestingPlugIn
provided in Struts 1.2.
First, decide on the class that will represent the data. If the data
will be used in drop-down lists, a convenient option is to use use
the Struts-provided LabelValueBean
(org.apache.struts.util.LabelValueBean). Next,
create the XML-formatted datafile. The
struts-example includes a file called
server-types.xml
that represents types of electronic mail server types:
<lv-beans>
<lv-bean label="IMAP Protocol" value="imap" />
<lv-bean label="POP3 Protocol" value="pop3" />
</lv-beans>Create the rules file that controls how the Digester will parse the
data into objects. The lvb-digester-rules.xml
file shown in Example 10-20, from the
struts-example, specifies the parsing rules to
create an ArrayList of
LabelValueBeans from the
server-types.xml file.
<digester-rules>
<object-create-rule pattern="lv-beans"
classname="java.util.ArrayList"/>
<pattern value="lv-beans/lv-bean">
<object-create-rule classname="org.apache.struts.util.
LabelValueBean" />
<set-properties-rule />
<set-next-rule methodname="add" />
</pattern>
</digester-rules>Finally, add a plug-in declaration to your
struts-config.xml for each file to be parsed and
loaded:
<plug-in className="org.apache.struts.plugins.DigestingPlugIn">
<set-property property="key"
value="serverTypes"/>
<set-property property="configPath"
value="/WEB-INF/server-types.xml"/>
<set-property property="digesterPath"
value="/WEB-INF/lvb-digester-rules.xml"/>
</plug-in>You can now access the data from an Action or JSP
page. The DigestingPlugIn stores the data as a
servlet context attribute where the attribute name is the value of
the key property.
Discussion
The DigestingPlugIn, a new feature of Struts 1.2,
provides an easy way to load static, XML-formatted lookup data into
the servlet context. The struts-example
application, included with the Struts 1.2 source distribution, uses
this plug-in. The examples shown in the Solution are taken from the
struts-example. If the data you are loading will
be used in drop-down lists, you can store the data as a
List of LabelValueBeans. In
fact, you can use the lvb-digester-rules.xml
shown in Example 10-20 to load any set of XML data
that conforms to the following format:
<lv-beans>
<lv-bean label="
Foo
"
value="
foo
" />
<lv-bean label="
Bar
"
value="
bar
" />
<lv-bean label="
Baz
"
value="
baz
" />
</lv-beans>But you are by no means limited to this format. Using custom Digester rules, you can translate any XML file into an object representation. For example, suppose that you wanted to keep a list of Canadian provinces, including province capitals and date established as an application-scoped object. The object that you want to hold data about each province in is shown in Example 10-21.
package com.oreilly.strutsckbk.ch10;
public class Province {
public String getCapital( ) {
return capital;
}
public void setCapital(String capital) {
this.capital = capital;
}
public int getEstablished( ) {
return established;
}
public void setEstablished(int established) {
this.established = established;
}
public String getName( ) {
return name;
}
public void setName(String name) {
this.name = name;
}
private String name;
private String capital;
private int established;
}The XML file, WEB-INF/canadian-provinces.xml, containing the data to load is shown in Example 10-22.
<provinces>
<province name="Alberta" capital="Edmonton"
founded="1905"/>
<province name="British Columbia" capital="Victoria"
founded="1871"/>
<province name="Manitoba" capital="Winnipeg"
founded="1870"/>
<province name="New Brunswick" capital="Fredericton"
founded="1867"/>
<province name="Newfoundland and Labrador" capital="St. John's"
founded="1949"/>
<province name="Nova Scotia" capital="Halifax"
founded="1867"/>
<province name="Ontario" capital="Toronto"
founded="1867"/>
<province name="Prince Edward Island" capital="Charlottetown"
founded="1873"/>
<province name="Quebec" capital="Quebec City"
founded="1867"/>
<province name="Saskatchewan" capital="Regina"
founded="1905"/>
</provinces>You create the Digester rules file that will parse the XML data into objects. The WEB-INF/province-digester-rules.xml file is shown in Example 10-23.
<digester-rules>
<object-create-rule pattern="provinces"
classname="java.util.ArrayList"/>
<pattern value="provinces/province">
<object-create-rule
classname="com.oreilly.strutsckbk.ch10.Province" />
<set-properties-rule>
<alias attr-name="founded" prop-name="established"/>
</set-properties-rule>
<set-next-rule methodname="add" />
</pattern>
</digester-rules>First, the object-create-rule element tells the
Digester the type of object to create when it encounters a certain
pattern. In this case, when the Digester encounters the
provinces element, it creates an
ArrayList. The next pattern specifies nested
province elements. For each of these, the Digester
creates an instance of the Province class.
The Digester uses the values of XML attributes to set object property
values. The set-properties-rule element defines
how XML attributes map to object properties. Unless specified, the
Digester maps attributes to properties based on name. If you have an
XML attribute with a different name than its corresponding object
property, the alias element explicitly defines the
mapping. In Example 10-23, all of the attribute names
of the province element match the property names
of the Province class (except for the
founded attribute, which maps to the
established property).
You configure the DigestingPlugIn by setting
properties that define the servlet context key for the created
object, the location of the XML datafile, and the location of the
Digester rules file. Table 10-1 shows the
properties you can set on the DigestingPlugIn.
|
|
The name of the servlet context attribute that the created object will be stored under. |
|
|
Indicates how the
The value defaults to |
|
|
Path to the datafile to be loaded. This value is resolved based on
the setting for the |
|
|
Indicates how the
The value defaults to |
|
|
Path to the XML datafile containing the Digester rules. This value is
resolved based on the setting for the
|
The loaded data can be accessed from the application-scope. For
example, the html:optionsCollection tag can be
used to set the label and value for a drop-down as shown in this
snippet from the subscription.jsp file of the
struts-example:
<html:select property="type">
<html:options collection="serverTypes" property="value"
labelProperty="label"/>
</html:select>See Also
Recipe 10.8 demonstrates how to use the Digester to refresh application-scoped data on demand.
The JavaDocs for the
DigestingPlugIn
can be found at http://struts.apache.org/api/org/apache/struts/plugins/DigestingPlugIn.html.
The homepage for the Digester can be found at http://jakarta.apache.org/commons/digester/.
O’Reilly’s ONJava.com has a good article called “Learning and Using Jakarta Digester” by Phillip K. Janert, Ph.D. at http://www.onjava.com/pub/a/onjava/2002/10/23/digester.html.
10.8. Refreshing Application Data
Problem
You want the ability to refresh application-scoped objects cached in the servlet context.
Solution
Provide an interface, such as the one shown in Example 10-24, which indicates if an object can be refreshed.
package com.oreilly.strutsckbk.ch10;
/**
* An object that can be refreshed from its original source.
*/
public interface Refreshable {
public void refresh( ) throws CacheException;
}Create an Action, such as the one shown in Example 10-25, which refreshes objects in the servlet
context. Alternatively, you could create a base Action that provides
a protected method for refreshing a named object. This may be
necessary to avoid chaining to the
ContextRefreshAction whenever you need to refresh
data.
package com.oreilly.strutsckbk.ch10;
import java.util.Enumeration;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
public class ContextRefreshAction extends Action {
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
throws Exception {
String name = request.getParameter("name");
ServletContext ctx = servlet.getServletContext( );
if (name != null && !"".equals(name)) {
refreshObject(name, ctx);
}
else {
Enumeration names = ctx.getAttributeNames( );
while (names.hasMoreElements( )) {
name = (String) names.nextElement( );
refreshObject(name, ctx);
}
}
return mapping.findForward("success");
}
private void refreshObject(String name, ServletContext ctx)
throws CacheException {
Object obj = ctx.getAttribute(name);
if (obj != null && obj instanceof Refreshable) {
((Refreshable) obj).refresh( );
}
}
}Warning
Action chaining should be avoided in a Struts application. For an explanation, see Sidebar 6-1 in Chapter 6.
You can define an action in your
struts-config.xml file for the
ContextRefreshAction:
<action path="/ContextRefresh"
type="com.oreilly.strutsckbk.ch10.ContextRefreshAction">
<forward name="success" path="/index.jsp"/>
</action>Discussion
The Solution shows a flexible approach for refreshing
application-scoped data. The Refreshable interface
indicates if an object can be refreshed and provides a method that
implementers use to reload cached data.
You need to use the Solution if the data in question isn’t cached by some other mechanism. Data backed by a database or persistence layer is probably cached. For these data, it’s better to access the data and not worry about caching.
For data not backed by persistence layer—for example, a flat
file of Java properties or XML-formatted
information—it’s common to store those data in
the servlet context. The data can be retrieved via the Servlet API or
JSP tags. Data can be loaded into the servlet context using a
ServletContextListener (Recipe 7.1) or a Struts PlugIn (Recipe 2-1). If the data seldom changes and you
don’t mind periodic application restarts, then
bouncing the application will reload the data from its original
source.
On the other hand, if the data may change more frequently and
you don’t want to restart the application, then you
can use a mechanism such as the one shown in the Solution. To
illustrate how this interface would be used, you can apply the
Solution to the data loaded by the DigestingPlugIn
shown in Recipe 10.7.
The basic approach is to provide a class that knows how to refresh
itself using the Digester. First, create the
RefreshableList abstract base class shown in Example 10-26.
package com.oreilly.strutsckbk.ch10;
import java.util.*;
public abstract class RefreshableList implements Refreshable, List {
public void add(int arg0, Object arg1) {
backingList.add(arg0, arg1);
}
public boolean add(Object arg0) {
return backingList.add(arg0);
}
public boolean addAll(Collection arg0) {
return backingList.addAll(arg0);
}
public boolean addAll(int arg0, Collection arg1) {
return backingList.addAll(arg0, arg1);
}
public void clear( ) {
backingList.clear( );
}
public boolean contains(Object arg0) {
return backingList.contains(arg0);
}
public boolean containsAll(Collection arg0) {
return backingList.containsAll(arg0);
}
public Object get(int arg0) {
return backingList.get(arg0);
}
public int indexOf(Object arg0) {
return backingList.indexOf(arg0);
}
public boolean isEmpty( ) {
return backingList.isEmpty( );
}
public Iterator iterator( ) {
return backingList.iterator( );
}
public int lastIndexOf(Object arg0) {
return backingList.lastIndexOf(arg0);
}
public ListIterator listIterator( ) {
return backingList.listIterator( );
}
public ListIterator listIterator(int arg0) {
return backingList.listIterator(arg0);
}
public Object remove(int arg0) {
return backingList.remove(arg0);
}
public boolean remove(Object arg0) {
return backingList.remove(arg0);
}
public boolean removeAll(Collection arg0) {
return backingList.removeAll(arg0);
}
public boolean retainAll(Collection arg0) {
return backingList.retainAll(arg0);
}
public Object set(int arg0, Object arg1) {
return backingList.set(arg0, arg1);
}
public int size( ) {
return backingList.size( );
}
public List subList(int arg0, int arg1) {
return backingList.subList(arg0, arg1);
}
public Object[] toArray( ) {
return backingList.toArray( );
}
public Object[] toArray(Object[] arg0) {
return backingList.toArray(arg0);
}
protected List backingList;
}This class decorates the List interface with the
Refreshable interface. The only abstract method is
refresh( ). You can extend this class to provide
different ways of refreshing list contents. An implementation that
uses the Digester is shown in Example 10-27.
package com.oreilly.strutsckbk.ch10;
import java.net.URL;
import java.util.List;
import org.apache.commons.digester.Digester;
import org.apache.commons.digester.xmlrules.DigesterLoader;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class DigestedList extends RefreshableList {
private static Log log = LogFactory.getLog(DigestedList.class);
public DigestedList(List list, URL sourceUrl, URL rulesUrl) {
this.sourceUrl = sourceUrl;
this.rulesUrl = rulesUrl;
this.backingList = list;
}
public synchronized void refresh( ) throws CacheException {
Digester digester = DigesterLoader.createDigester(rulesUrl);
try {
List list = (List) digester.parse(sourceUrl.openStream( ));
if (list != null)
backingList = list;
else {
log.error("Returned list was null due to unknown error");
throw new CacheException("Backing list was null.");
}
} catch (Exception e) {
log.error("Unable to redigest list.", e);
throw new CacheException("Unable to redigest list.");
}
}
private URL sourceUrl;
private URL rulesUrl;
}This class maintains instance variables for the original URL of the
data source file and the URL of the Digester rules used to parse the
source file. In the refresh( ) method, an instance
of a Digester is created. The data in the source
file is parsed, and the results are cast into a
java.util.List. If the returned data is
null or any other exception occurs, a
CacheException is thrown.
Now that you have the classes that implement the
Refreshable interface, you need to create a
mechanism for loading the data on the application startup. The
DigestingListPlugIn in Example 10-28 extends the DigestingPlugIn
for the purpose of creating refreshable lists and storing them in the
servlet context. It overrides storeGeneratedObject()to provide this functionality.
package com.oreilly.strutsckbk.ch10;
import java.io.IOException;
import java.net.URL;
import java.util.List;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.struts.plugins.DigestingPlugIn;
public class DigestingListPlugin extends DigestingPlugIn {
private static Log log = LogFactory.getLog(DigestingPlugIn.class);
public DigestingListPlugin( ) {
}
protected void storeGeneratedObject(Object obj) {
if (!(obj instanceof List))
throw new IllegalArgumentException(
"Digested object must be a list but is:"+obj);
List list = (List) obj;
URL sourceUrl = null;
URL rulesUrl = null;
try {
sourceUrl = getConfigURL(configPath, configSource);
rulesUrl = getConfigURL(digesterPath, digesterSource);
DigestedList digestedList = new DigestedList(list,
sourceUrl,
rulesUrl );
servlet.getServletContext( ).setAttribute(key, digestedList);
} catch (IOException e) {
log.error("Unable to create URL.", e);
}
}
}You configure a DigestingListPlugIn plug-in in the
struts-config.xml file like the
DigestingPlugIn:
<plug-in className="com.oreilly.strutsckbk.ch10.DigestingListPlugIn">
<set-property property="key"
value="serverTypes"/>
<set-property property="configSource"
value="servlet"/>
<set-property property="configPath"
value="/WEB-INF/server-types.xml"/>
<set-property property="digesterPath"
value="/WEB-INF/lvb-digester-rules.xml"/>
</plug-in>To see the refreshable lists in action, you need to modify the data
source. You can modify the file using a text editor, the hard part is
finding the file. The DigestingListPlugIn, like
the DigestingPlugIn (Recipe 10.7), uses the configSource
property to treat the data source file (identified by the
configPath property) as relative to the classpath
(classpath), the filesystem
(file), or the web application context
(servlet). The default value is
servlet. If you were to deploy the Solution to
Tomcat 5, you would find the file located at
$CATALINA_HOME/webapps/jsc-ch10/WEB-INF/server-types.xml.
Once you modify the file, you can use your browser to post a request
to a URL that triggers the ContextRefreshAction:
http://localhost/jsc-ch10/ContextRefresh.do
If you wanted only to refresh a specific object, you can specify it by name:
http://localhost/jsc-ch10/ContextRefresh.do?name=serverTypes
Now that you’ve got a generic mechanism for refreshing data, you can extend this mechanism for reloading property files, comma-separated value files, and other types.
See Also
The subject of caching data comes up often on the struts-user mailing list. If you search the archives for caching, you will find a number of threads related to this topic.
The DigestingPlugIn is specifically discussed
in
Recipe 10.7.