
This chapter is designed to put the book into the context of the Internet as a whole, and the Web in particular. In case you’re not familiar with some of the concepts and technology, or if you classify yourself as a consumer and look at the Web browser and the content behind it as just another application on your computer, the topics will be key in understanding the remainder of the book.
The principal topics covered in this chapter are:
The Internet—. An introduction to the various parts of the Internet.
The World Wide Web—. A look at the components that make up the Web.
Presentation layer—. An introduction to the separation of content and presentation.
Data exchange—. The way in which clients and servers communicate.
Client side scripting—. Dynamic control over the browser.
Server side programming—. Dynamic control over the content.
The first two sections of the chapter look at how the Internet has evolved from its humble beginnings, and introduce the way that people interact with it. The second section, in particular, deals with the relationship between the users and the World Wide Web, from both the consumer and producer aspects.
Then you read about the way that presentation of the content is described, followed by a discussion of some of the mechanisms that allow the exchange of information between the computer displaying the content and the one serving it. This is covered only from a high level—leaving out the actual network implementation—in the interest of staying within the principle of giving just enough information to allow you to make sense of the topic.
Finally, the last two sections dissect the framework of the World Wide Web by splitting it into two component parts—the client (browser) and the server (host). In doing so, these sections set the stage for the discussions of the topics that follow.
You need to be aware that this separation between the client and server exists if you are to make the most of the remainder of the book. It is only when the client and server work independently to achieve a unified goal that the Web truly comes alive.
It all begins with a look at the application of information technology that has made it all possible—the Internet.
The Internet is basically a collection of computers, all connected together in a big network. This topography provides a delivery mechanism in which a piece of information can take multiple routes from one point to another. These multiple routes make the network fairly robust—if one part is missing, information can still travel as long as there are alternative routes.
This information typically takes the form of:
Requests for information or service
Responses containing that information or the result of a service
Informational responses, that is, reasons why the service or information could not be delivered
The information is exchanged in a client/server model; in other words, clients (users) connect to servers on the Internet and use their resources by placing requests with or without data. Typically, many clients can connect to each server at the same time—concurrently—and cause it to carry out operations on their behalf. As long as the server has capacity, that is.
Capacity is measured in two ways—the power of the server and the amount of network resources (bandwidth) available to it. Both of these factors will affect the number of users who can connect at the same time while still being able to deliver the services required of it.
In the beginning, the Internet was powered by less capable servers than are available today, both in terms of network capacity and computing power. Subsequently, most of the content was text only. The servers were not capable of delivering anything more complex, and the interconnected networks were neither fast enough nor reliable enough to allow for the transfer of anything other than plain text.
Email was one of the first Internet applications to be made available to the general public, and was text only. It revolutionized communication possibilities; it had the immediacy of a phone call, but was asynchronous, like a letter. It was also cheap, something that mass mailing companies, and less scrupulous individuals, quickly took advantage of.
Other text interface services included Gopher, which offered hierarchical menus of information. These were accessed through a text-only interface, the precursor to the browser, called a Telnet client. Telnet, in this case, is the protocol used to communicate between the client and the server.
This allowed for some level of interactivity, but response times were slow. This became known as lag among early Internet users. Lag is the time between the request and response. In other words, when using one of the first kinds of chat rooms, lag was the term used for the time delay between the user typing the command and receiving confirmation of the command being executed.
Network performance bottlenecks were also reflected in the time that it took to download files—images, documents and software were all downloaded in this way. The resources were referenced in the text-only interfaces, there were no links per se, and no document-embedded artifacts.
As network performance increased, along with computing power in general, the first wave of innovations brought the concept of hypertext. Hypertext is a way of linking documents together using references that contain the location of other documents and binary resources.
Alongside the possibility of referring to, and downloading, binary resources such as pictures came the idea of embedding the resources in documents. The program that was used to render (display) these pages became known as a browser; among the first wave of such applications was NCSA Mosaic, which later became Netscape Navigator.
The hypertext concept morphed into HTML (HyperText Markup Language, also referred to on occasion as HyperText Meta Language), an open, governed, standard for exchanging information. As a mark-up language, HTML left the actual details of how the page should look to the browser, but provided a structured way to display the documents and link them together.
The actual documents are encoded in plain text. Any graphical elements have to be downloaded inline; they are resources that are referred to in the document, and then displayed rather than just saved.
HTML also put the possibility to publish information to a very wide audience into the hands of the users. This newfound freedom gave rise to a “web” of documents and other resources, all connecting to each other—the World Wide Web.
The World Wide Web (WWW or just Web) is a collection of linked resources. Documents (called pages), images, videos, interactive applets (mini applications), and music (MP3s, for example) are just a few of the resources available to surfers.
However, it doesn’t work by magic, and it is useful to have a handle on the underlying technologies to better understand how Web programming works in practice.
The Web is still a client/server environment, based on requests and responses. These conversations between the browser and the server needed a standard framework for communication, and some protocols were established in order to provide a standard way to exchange information.
The two used most frequently in this book are:
HTTP (HyperText Transfer Protocol)
FTP (File Transfer Protocol)
There is also a standard, MIME (Multipurpose Internet Mail Extensions), for the exchange of emails. The protocols also provide for a set of standard responses that allow the browser to display appropriate information in the event that the requests cannot be fulfilled.
An HTTP server, for example, provides facilities for storing and retrieving documents and other artifacts based on their URL (Universal Resource Locator). It can reply to a request in a number of ways, usually with a numerical code.
The most common of these codes are:
200—. Everything okay, usually followed by the information requested
404—. Resource not found, usually an incorrect URL
500—. Server error, a problem on the server
The Web server itself is just a piece of software that runs on the machine and processes the requests through the network interface. Usually, the Web server software (Apache, Microsoft IIS, and so on) and associated applications are the only things running on the server.
Other applications might include an email server and an FTP server. FTP (File Transfer Protocol) is used for browsing the file system of a remote store and downloading from or uploading items to that store. FTP client applications can be graphical (looking like Windows Explorer) or text based.
Before you learn how information is indexed and located on the Web, note first that there are secure variants on the HTTP and FTP protocols, called HTTPS (HTTP Secure) and SFTP (Secure FTP). These allow the exchange of information through an encrypted channel rather than the plain text usually employed between the client and server applications.
Given the sheer volume of documents and artifacts on the Web, it became imperative that users had a way to find out what was available. This required that there was some kind of service capable of both indexing and retrieving locations for information based on their content. These became known as search engines.
A search engine is a Web based service that allows consumers to locate artifacts on the Internet as a whole. You will be familiar with names such as Google, Yahoo, MSN, Altavista, and so on, which are all examples of search engines.
Historically, searching the Internet started out as a way to search through catalogs of possible information based on the filenames and directory entries in the Gopherspace, which was based around hierarchical menus. In the beginning, searching relied on the descriptions given by the authors.
When full-text search was introduced, the search mechanism become a little more accurate, allowing everything from library catalogs to documentation repositories to be searched by anyone with an Internet connection.
Finally, Web searching became more sophisticated: searching deeply in sites by indexing them in their entirety. This allowed consumers to find information based on the content, rather than just a loose description of what the author intended the page to contain.
Given the volume of information available on the Web, the search engine has become a vital part of the producer-consumer relationship. Search engines are the only way that surfers (the consumers) can often locate information that interests them.
Ideally, you might want these searches to happen in real time, but since this is not really feasible, searches results are based on pre-indexed copies. Each indexing session builds a database that can be searched on demand, with pages returned that fit the query made by the surfer—based on the evaluation of an algorithm usually proprietary to the search engine itself.
In order to keep the database fresh, search engines need to update their databases from time to time. This is either done automatically, by a robot that trawls the Web for changes (the Google approach), or when producers informs the search engine that they have added something to the collection of pages that make up the Web.
This is known as site submission, and has grown from being a formality into something of a commercial opportunity. SEO (Search Engine Optimization) consultants can charge a premium fee to help individuals and companies obtain a good ranking in the results pages.
These rankings are based on the evaluation of the algorithm with respect to the rules that the search engine applies to evaluate the relevancy of the information contained in the database. With such a large number of pages, honing the submission and content submitted has become somewhat scientific.
With the popularity of the Web, getting found has become increasingly difficult; more often than not, pages find themselves pushed down the search engine result pages (SERPs) and therefore not immediately visible to consumers. So, search engines are important.
However, visibility in the search engines is only part of the marketing strategy that gets the page the attention it deserves. Marketing Web pages also includes creating other ways to attract traffic, if that is the aim of the site. Unsurprisingly, it usually is—the Web is, for many people, first and foremost a business opportunity.
The first to really benefit from the opportunity might arguably have been the ISPs, or Internet service providers. Without them, there would be no email, Web hosting, or even Web surfers to try to attract.
The ISP’s role is to give Web surfers the possibility to access the Internet using equipment that is available off the shelf. Running a network capable of tapping into the Internet is an expensive proposition; not many people can afford to run a network connection directly to their home.
Without getting too technical, the backbone of the Internet relies on connecting ISPs and other entry points together using a variety of different networking solutions. ISPs provide an entry point as well as, usually, a routing point for network traffic.
Originally, the role of the ISP was just to provide basic connectivity and email. The ISP would run an email server (receiving and storing email), and possibly offer a gateway into other services. For example, Usenet newsgroups were among the first mass communication and publishing platform (or forum).
ISPs would copy the contents from a central point and provide dial-in users the possibility to download messages and email. The very first connections were over the plain old telephone system, with simple modems providing the possibility for users and servers to exchange data over the phone line.
As the line speeds increased—from slow dial-in, to faster broadband connections—so did the sophistication of the information services provided by the ISP. ISPs began to offer out-of-the-box solutions: customized Web browsers, dialers with pre-programmed numbers, and so on.
Partly this was required because connecting to the Internet used to be a difficult proposition. The first mass-audience versions of operating systems like Microsoft Windows did not offer the possibility to connect to Internet services as part of the retail package.
This gave ISPs an opportunity to give away CDs (or even diskettes in the very beginning) which would automatically configure the PC to connect to their services. These services were expensive in the beginning, but rapidly gave way to local call rate services as the use of the Internet expanded.
Fueled by this popularity, ISPs gave way in importance to other services, such as Web hosting. Consumers began to express a wish to participate in the production of information beyond posting to Usenet newsgroups, and the Web hosting service was born.
Web hosting providers (Web hosts) provide a place for consumers to store pages designed to be consumed by the Web surfing public. ISPs often offer Web hosting services along with their standard connectivity packages.
The kind of package that you will receive will be, as a minimum, an all-in-one HTTP and FTP server with email. In other words, HTTP gives you the possibility to offer Web pages over the Internet, and FTP gives you the possibility to upload pages to the server so that they can be shared with the Web at large.
What the ISP might not offer is the registration of your URL. This is the Web address where your site can be found (for example: http://mysite.com). Early Web hosts (or Web space providers) such as Geocities.com often subdivided their Web space into longer addresses such as:
http://www.geocities.com/CapeCanaveral/Lab/1888
This approach is still often taken by ISPs wanting to offer Web hosting to their clients. In the early days, having a domain name (the bit commonly ending in .com, .net, or .org) was an expensive and technically challenging proposition. However, the price and ease with which the domain can be registered and used has reduced dramatically.
Domain names are centrally managed and distributed under license. Different countries have different policies and registrars, all working to set rules, but all charging different fees for the privilege. All that you need to make sure of is that the registration happens in your name, and that you have the right to update the DNS record at will.
The DNS record points your domain name to your Web hosting provider. The DNS system is a distributed database that is updated automatically by propagation. This means that specific servers (DNS servers) maintaining lists of domain names and IP addresses are propagated across the Internet, thus allowing traffic to be correctly directed.
Without the IP address (a number such as 193.169.137.5), it is impossible to correctly send data to, or receive data from, a server on the Internet. But a dotted number is not very user friendly, so we also need some way to connect a friendly name—the domain name—to the IP address.
That is the role of the DNS (email has a similar mechanism known as MX—mail exchange) and the final IP address that the domain name resolves to is the address of the Web host. One host can have many domain names pointing to it; that is all part of the service.
It is important to realize that, under normal circumstances, one server hosts many different sites. This helps to keep the price reasonable, while providing a good range of services.
Client machines then connect to the host either to download or upload files. Downloading is usually associated with browsing the Websites, and uploading is, as mentioned, the act of placing those files (pages) on the server for others to browse. Static pages make up a large proportion of the content available on the Web, but increasingly producers are taking advantage of other Web hosting services that allow for interactive sites to be built.
Web hosts vary enormously in terms of interactive services provided and the quality of those services. For example, this book is all about Web programming; the aim is for you to learn how to create an interactive (dynamic) Website using a combination of HTML, PHP, and database programming.
Not all of these facilities will be available on all Web hosts. Even where they are, there are different levels of service that are provided. Some might limit the bandwidth (amount of data that can be transferred in a given month), others might allow only a single database of a limited size, and many don’t provide scripting or databases at all.
To get a good mix of services that can be used in a production environment—in other words, expecting to have a certain volume of data transfer and a robust service—it is often necessary to pay a monthly fee. This can range from $3.95 per month right up to $60+ per month, depending on bandwidth and plug-in services offered.
Free Web hosts exist, usually requiring that the user suffer some form of advertising, which is perfectly acceptable for learning purposes. Advertising is as much a part of the Web ethos as search engines are, and worthy of further discussion.
Advertising on the Internet started out as a way for people to try to attract traffic, or at least to alert other users, through banner adverts, to the existence of their site. Over time, it became clear that advertisers would pay money for their banner to be shown more frequently than others, and paid advertising was born.
Displaying adverts on behalf of advertising networks and even direct advertisers used to be a good way to make money from a Website. Over time, however, the impact on surfers has been reduced. Most learn to ignore banner adverts quite quickly, which lessens their impact.
This forced advertisers to move from a pay-per-impression model to a pay-per-click model, which is still in force today. These days, it is therefore more difficult to make money from advertising, but still possible.
The pay-per-impression model meant that advertisers paid the Web content producer to display adverts on their site. This was open to abuse—faked impression rates—as well as being hard to justify. As advertisers saw less and less return from their investment—fewer clicks per thousand impressions—they decided to change the model.
The pay-per-click model pays the content producer only if the advert that has been displayed generates a click from the surfer. In other words, the content producer gets paid only if the visitor clicks the advert, leaves the site, and spends time at the advertiser’s site.
The obvious disadvantage with this is that you have spent so much time trying to make sure that the visitor can find the site that asking them to click on an advert and leave the site seems to run against common sense. The model, however, does work, if only because a proportion of traffic to your site were looking for something else that they might just find among the adverts that you display.
Advertising supports many services on the Internet—from free email to free Web hosting and mailing list services—and it works because there is power in the volumes. The Internet and Web are so popular that even if only a small percentage of visitors to, say, Yahoo click on a banner, it still generates enough income to support the underlying service.
Of course, it would be logical to assume that the big service providers such as Google, Yahoo, MSN, YouTube, MySpace, and so on actually attract bigger advertising dollars than the rest of us. They might even still be being paid on the basis of just displaying the adverts, and not by click.
However, some of the big article repositories, such as About.com and Suite 101.com, earn their income through PPC (pay-per-click) advertising. In the case of Suite101.com, it is shared with the writers in order to compensate them for the right to print their articles.
Social networking sites also use PPC income to support themselves, so clearly it pays off. Of course, it helps to have a site that is centered around the kind of traffic that will generate clicks for advertisers and that attracts high paying advertisers. Generally speaking, the more technical the subject, the less likely a visitor is going to be to click on an advert.
Advertising suppliers include Google (through AdSense), as well as various brokers (such as Commission Junction) that link advertisers and content producers. The latter example caters to both advertising and affiliate schemes. The difference between the two is that advertising only alerts and attracts the visitor to the advertiser’s Website, whereas affiliate schemes actually generate income for the content producer as a percentage of the sales generated.
In other words, Commission Junction might list a collection of advertisers all offering a specific product. Content producers can pick the advertisers that they are attracted to (usually on the basis of a high commission rate) and advertise the actual products on their site.
The visitor will then be enticed (you hope) by the product or offer, and proceed to the advertiser’s site where the sale is affected. The content producer gets nothing for redirecting the visitor, which makes it more risky than the pay-per-click model. However, the rewards are bigger, as is the threat of losing the visitor to the affiliate site altogether.
Again, it is a balancing act between attracting a wide enough spectrum of visitors that you don’t care if some of them click through to other sites, and providing value to those who you want to stay. Part of the reason you want them to stay is that you have something of your own to sell or give away.
Finally, there are actual product suppliers that offer affiliate schemes (such as Amazon.com, eBay.com, and so on) where money can be made by selling their products directly. These outlets are actually making more of an effort to integrate with the content producer’s sites, eschewing the usual approach of capturing the traffic for themselves.
After all, when the box from Amazon arrives, the receiver is going to be well aware where to go next to get a similar product. The advertising is all over the packaging and inserted into the package itself. However, given the opportunity for good Web content producers to profit from selling their goods, one can hardly blame them.
So, advertising generates income that supports services, including free Web hosting and content production. That helps you, the Web programmer and content producer, because it means you can get a lot of services that you will need for free.
For example, many free Web hosts support the provision of their services by advertising revenue, meaning that you get a whole setup, with PHP, MySQL, email, Web space, and a large monthly quota for no cost. Or, Web 2.0 services such as Google Documents provide a state-of-the-art, Microsoft Office-compatible suite of tools to users of the Web for nothing.
You may also want to take advantage of advertising and affiliate selling to supplement income made from the site or your own products. To do this, you will need to customize the offerings as closely as possible to the consumer using client/server programming.
In Web programming, people use the client/server model to deliver content to the visitor in a dynamic fashion. In other words, they move away from serving up static Web pages of the kind that were produced in the past, and provide information that is customized to the needs of the producer-consumer relationship.
There is a split between remote and local processing, where both work together to produce the end result that helps to realize this. For example, the Web browser is a piece of client programming that requests information from the server and displays it to the user. The browser can also process scripts that form part of the response that is delivered to it, making it possible to offer additional features to the end user.
As an example, you can use scripts on the side of the browser to detect the kind of browser being used and reflect that in the services offered (or perhaps the way that they are offered) to the end user. You can also ask for information (in forms) from the end user and use that information in a request to the server to elicit a certain response.
These are all ways in which the client/server relationship can be used to enhance the producer-consumer relationship. These kinds of interactions are at the core of the Web programming paradigm, which is based on a request and response mechanism.
This request and response mechanism is largely synchronous. It happens in a fashion that is prescribed by the protocol being used. You cannot have a response without a request, even if a single request elicits multiple response packages. A server does nothing until the client asks it to.
This can leads to infuriating waits for the whole page to be loaded before the browser can display the content that has been requested by the end user. This is much less of a problem since the advent of fast connections between servers, but at peak times the lag is still very noticeable.
Some tricks such as interlacing can be used for graphics—in these cases, the client/server model relies on the browser supporting this feature. Interlacing works because the image is downloaded in parts; in other words, the file contains a collection of smaller parts of the whole.
The browser can display one part of the image while the next is loading, with the result that the image appears to materialize rather than appear. The first few frames allow a reasonably low quality image to be displayed, which is built upon as the data is downloaded by the browser.
Text and other information such as the layout of the page on the screen cannot be interlaced in this way very easily. For content, this means that the whole page has to be downloaded before the page can be displayed. For the layout, is also important that as much information is conveyed with as little overhead as possible—this is called the presentation layer.
The presentation layer is the term given to the information that allows the browser to display the content. It controls the way that the content is presented, in terms of the font, colors, layout, interactive elements, and so forth. In order to keep some semblance of order, the presentation layer is structured according to specific standards.
Managing the standards is a body known as the World Wide Web Consortium, or W3C. The role of the W3C is to make sure there are standards for the presentation layer, and that these are communicated, formulated, and extended appropriately according to the needs of its members. To quote the mission statement from the W3C site:
“To lead the World Wide Web to its full potential by developing protocols and guidelines that ensure long-term growth for the Web.” W3.org
The standards, called recommendations, make up the open, non-proprietary standards that all Web authors should stick to when creating content. There are more than 400 members of the W3C, covering almost every company with a vested interest in the Web and the technology that drives it.
These companies—from Apple to Yahoo, Google, Microsoft, the BBC, Dow Jones & Company, several educational establishments, telecommunications operators, consulting companies, and many, many more—all work together to make sure that the Web continues to work for everyone. They do this through their work on standards consulting, mainly through the W3C Technical Team, which “contributes to and coordinates the W3C’s activities.”
These standards are important, because you need to be sure that the layout can be communicated effectively to all client systems that might request the content. The standards make sure that everyone—from producer to consumer, developer to Web service provider—are all using the same basis to develop the functionality that is required.
However, despite the standards, each user agent (browser or something else) remains free to render the presentation layer differently. You see, the presentation layer is not there to dictate how the resulting page should look, but rather the hierarchical relationship between the elements on the page.
One example of this is the heading hierarchy—the presentation layer allows the content producer to designate headings of different levels. It is assumed that the levels adhere to strict rules:
They cannot overlap
They have to nest in order
They need to be presented with diminishing visual importance
The exact choice of rendering—bold, italics, large font, small font, the font itself—is left up to the browser or other client software application. There are other non-hierarchical elements which provide possibilities to exert more control over the rendering of the content, but by and large the presentation layer provides a fairly abstract level of control.
The definition of the presentation layer takes the form of an abstract language (meta-language, or mark-up language) that allows one to describe the presentation without the content, as holders for the content without prescribing exact appearance. A top-level heading on one browser might be different from another in appearance while having the same hierarchical weight.
The mark-up language also allows for you to specify exact rendering instructions so that it is possible, with some work, to make the content appear in the same way (within a margin of error) on multiple different browser platforms. The caveat is, of course, that in order to do this, you often need to know the platform (browser) and give slightly different mark-up in order to obtain the same result.
This is the flexibility and power of the mark-up principle on the one hand, and possible disadvantage, as you need to test the implementation on many different platforms to be sure that the appearance is the same. Or, you can just trust that the browser developer has respected the philosophy of the mark-up laid out by the W3C.
This also extends across non-visual and alternative rendering platforms. For example, if the user agent was a Braille device, that would render the same presentation layer and content mix differently than a text-only interface (such as Lynx) or a fully graphical one (such as IE, Firefox, Netscape, and so on).
The mark-up abstracts you away from the implementation details so that you can use the exact same presentation layer definition (within reason), no matter the target rendering platform. There are different flavors of mark-up, but the main language that people use to describe the presentation of content is called HTML.
(As a side note, and for those who are interested, HTML was not the first standard that the W3C tried to establish. In fact, HTML is a kind of subset of something called SGML which tried, in vain, to define any possible mark-up language as a self-contained definition. This concept has since become XML, or eXtensible Markup Language, which is a less complex rendition of SGML.)
HTML (HyperText Mark-Up Language, sometimes also called HyperText Meta Language) is the lingua franca of the World Wide Web. All pages are encoded in some form of HTML, whether it be a version from 1994 or 2007, and Web browsers tend to maintain as much compatibility as possible.
Part of the responsibility is shared with the producers of the Web content. If you use esoteric tags, which are not part of the standard, but which look as if they might follow it and which are only supported by a minority of browsers, you can expect your page to look a bit strange on some platforms. On the other hand, the simpler the use of HTML that is made, the fewer problems the page is likely to have in the longer term.
So, there is a balance that you have to strike between elaborate presentation and maintainability of the code. This job is made easier by the fact that browser application providers tend to be somewhat looser in their adherence to standards than in the past, coupled with techniques such as server side scripting that generate much of the HTML at the same time as the content is presented.
This is the key to HTML—it provides a standard definition for the presentation layer which is robust and well-defined by open standards maintained by the W3C. As a mark-up language, it contains information that is not designed to be interpreted as content (that is, the user never sees the HTML itself) but as presentation information that enriches the actual content.
The page content is enclosed in a mechanism known as tags, which tell the browser how the designer intended the content to be rendered in an abstract fashion. Each tag contains specific information relating to the way that the browser is to begin rendering the content that follows it.
Usually, there is a starting tag and ending tag (although there are exceptions). You might like to think of this as turning formatting on and off, because this makes it easier to conceptualize some of the principles. So, a starting bold text tag tells the browser that, until the ending tag is reached, the content is to be rendered using a bold font.
However, the end result might not always be the same on all platforms, including that of the designer—it is only there to give details of the intention of the designer with respect to the content that is being presented. Bold text on one platform might be of a different size, weight, or font depending on the browser being used.
When the Web was in its infancy, these tags were all put into each document individually, because the pages were static. In other words, once they were created and uploaded to the Web host, they did not change. They might have been linked to (and interlinked) to give the effect of navigating through a dynamic document set, but each page was a single document, edited by hand.
This meant that changing some of the elements required multiple changes on the page; if the designer wanted to insert new levels of heading, that would have knock-on effects through the rest of the page. Some headings would have to be promoted and others demoted.
For example, there might have been ten headings on a page, each denoting a piece of information of diminishing overall hierarchical importance. Heading 1 might have been the page title, heading 2 a section title, heading 3 a sub-section, and so on.
Each heading would have to be detailed separately in terms of size, color, and decoration, and HTML provides a set of relative hierarchical tags (H1, H2, and so on) that you can enclose the heading text in to provide decoration. This takes some of the pain away, but not all.
You still had to change all the H3 tags to H4 if you wanted to insert a new heading item. For menu management especially, this became a painful experience. It meant in some cases that you would have to go through a search and replace exercise whenever you wanted to insert a new menu item.
In addition, once HTML became more precise and offered the possibility to create very detailed tags to specify the exact font, size, and color, as well as discrete position of content on the page, designers became ever more ambitious. In the main, they were still manually editing the pages.
They had tools that made the management of the HTML itself easier, but few tools to maintain congruence between multiple pages if the style of the content had to change. Let us assume, for example, that a company had a Web page where regular content was in green text and menus in black.
Each piece of text has to be marked up as being in either black or green. What happens when the company decides that green is no longer in vogue and wants to change it to red? The Web designer has to go back and change all the mark-up on the static pages so that the content is in red.
A far easier solution is to use a standard tag to describe the content in an abstract fashion (as either Content or Menu text) and then define the fact that Content text is in green and Menu text is in black in a single point. This mechanism is known as defining a style, and the place that it is usually defined is in an external style sheet.
The separation of the positioning and flow information and the actual style details allowed designers to change the individual artifacts with a single change to the style sheet rather than making multiple changes to static pages. The pages could still be static, but it was possible to change the look and feel by simply swapping the style sheets.
This is a trend that has been further enhanced by server side programming, allowing for users (visitors or browsers) to select style sheets dynamically so that their experience is customized accordingly. You shall look at the mechanics of this in later sections; for now, let’s examine how a style sheet works.
A style sheet is a concretization of style information referred to in a page of HTML; each tag can be customized by changing its style. Style sheets give guidelines for the style of all the classes of elements in a page, where the Web designer has determined that they should be different from the default.
Physically, a style sheet can be a separate document, downloaded along with the HTML, or it can be part of the HTML itself. The style information enhances the way that the standard HTML tags are displayed, and is downloaded to the client.
You might give styles for headings, general text, paragraphs, shading, tables, and so on that override the defaults that are chosen by the browser application manufacturer. You will remember that the W3C does not actually mandate any rendering information, but provides a comprehensive framework to support almost any rendering possibility.
In addition to enhancing standard tag styles, you can name element classes. A class, in this case, is a specialization of an element, to which you give a name that is meaningful to you. So, you might create a collection of named classes and have different kinds of tables, paragraphs, headings, and textual elements. For example, you might decide to have a different colored background for certain types of paragraphs, and enclose these with the standard paragraph tag, but with a named class for each kind of paragraph.
These new classes then become specializations of the default. You can change the default independently of the new classes, making it a very powerful mechanism for altering the style of the pages from a central point. This is still static presentation, however.
Dynamic presentation layer generation is also possible, on two fronts. Firstly, you can generate style information and attach it to the page that is being downloaded. This requires server side scripting and is not overly complex.
Secondly, you can write a script that is part of the downloaded page, but that changes the style information dynamically within the page. The difference might not be apparent at first, so an example might help envisage the two mechanisms.
Let’s assume that you want to allow visitors to change the layout of the page so that it matches more exactly their screen size. You do this by attaching a style sheet to the page that contains layout information. This layout information will include discrete positioning for the various elements (menu bars, navigation and advertising sections, and so on) using named tags.
To keep the example simple, assume a vertical MenuSection that is 25% of the screen width, a middle ContentSection that is 50%, and an AdvertisingSection that is 25% of the available screen width. The user has a small screen, and the ContentSection is unreadable, so you want to change the proportions to 15%, 70%, and 25%.
You have two choices—you can generate a collection of styles that meets these proportions using a server side script, or you can create a client side script that does that for you. Either mechanism is acceptable in this case, but each requires a different set of scripts.
In the first case, you dynamically generate the content specifically for each visitor; in the second, you manipulate the styles using a script that is written once for all users. In reality, you will most often use a combination of the two approaches.
This level of dynamic generation is also often a result of data exchange with the server, and again, it can be either the client or server that generates the resulting HTML. So, you might write a script that can dynamically detect the resolution that the user is using and adjust the page accordingly.
This is where the first implementation is weaker. You would need to communicate with the server to tell it what kind of screen the user has, and only then download the correct layout information. In the second case, you could detect and update the layout locally.
You can also change styles dynamically, and asynchronously, as you communicate with the server, usually in reaction to something that the user has done. So, if you have detected that the screen resolution is 640 × 480, and rendered the page accordingly, you could allow the user to change that by selecting a different rendering style.
If there were more items to change than just the layout (the color, for example), you could also handle that by regenerating the page or dynamically altering the styles. The locally scripted solution is the only possible solution in cases where the Web host does not offer support for server side scripting.
So, style sheets allow more control over the rendering, with the possibility to group rendering information into collections, which can then be dynamically altered. Again, this is via an open standard mechanism that is maintained by the W3C.
In the same way that you need a standard way to describe the documents, you also need a standard way to exchange the data that they contain.
I have mentioned that the communication between the client and server is essentially a series of requests and responses. This is the same for all protocols that are used to access the Internet, be it a Web protocol, FTP or email and other messaging systems.
The actual protocol name that is used for data exchange between the client and Web server is called HTTP (HyperText Transfer Protocol), and is the reason that all Web addresses start with the http:// stanza. It is, as mentioned previously, a mechanism for requesting services of a server and displaying the results of those service requests.
Essentially, each request that you have considered until now has been simple enough, and with little actual payload. In other words, you have made a simple request for an artifact, without giving more data than the URL.
The response to this HTTP request then contains a status code, and then the data that represents the page content, and links to various artifacts such as images and style sheets that are external to the page itself. It all happens asynchronously—the Web client first is given the page and is expected to request any of the additional items separately.
The data flow is more or less all downstream towards the client. There is more data received than submitted. The HTTP protocol, however, allows a user agent (browser, client, and so on) to send information to the server as well, in a structured manner.
HTTP provides two mechanisms, called GET and POST. The difference between the two is a regular discussion point for those learning Web programming. Technically, the difference is that a GET request contains data that is part of the URL, whereas a POST request sends the data as part of an independent message.
You might have seen URLs such as:
http://search.live.com/results.aspx?q=Web+programming
In this URL, everything after the ? indicates an HTTP GET request and that the name-value pair represented by q=Web+programming is data destined for the server in order to allow it to perform some kind of service. In the case of this line, it is a search.
Decoding the previous example still further, all data that is destined for the server in this scheme is split into pairs. In this case, q is the command, and Web+programming is the value associated with that command. All data must be in this command=value pairing. The plus sign is used in place of a space, because spaces cannot appear in URLs, and special encoding is needed for this, along with some other characters.
The superficial difference between this and the POST mechanism is that you do not see the data that is being posted to the server as it is part of the payload data that follows the HTTP request.
There is a philosophical difference too. The W3C indicates that the GET request should be used to retrieve information stored on the server, and that the POST request should be used to cause some form of permanent change on the server.
So, if you were in the process of adding a URL for the search engine to index, along with the title, a description, and a category (for example), you would use an HTTP POST request. This makes sense, as there is usually more data connected with giving information to the server than just requesting some data from it.
The resultant data can come back from the server in the form of a dynamically generated Web page, as you have already seen. This is usually generated by the server where the content contains result of the query made via the GET/POST request.
It could be a page of results—like a search engine—or it could be simple confirmation that the data has been received and will be processed. Some interactive sites (such as Web games) take this a step further and provide some visual feedback to the effect that the POST has had an immediate and lasting effect on the state of play.
Aside from the aforementioned Web gaming interfaces, the mechanism on the client side for allowing the user to prepare and submit information is known as a form. It is again something that this defined by the W3C as part of the HTML standard.
The simplest kind of form is a collection of input areas, with a button marked Submit, and is aimed at providing a way for the user to input information to be sent to the server. Common input areas include:
Text boxes (single and multi-line)
Radio buttons and checkboxes
List and drop-down list boxes
In Figure 2.1, many of the available controls are shown. For example, the first is an example of a single line text input area, which is followed by a multi-line version. There is a drop-down list box and a simple checkbox control. Finally, there is a set of option buttons, of which only one in the group can be selected. At the bottom is a Submit button, used to send the result to the server.

Although it is possible to allow the simple interaction with these elements to cause some processing, it is more common to provide a Submit button. The Submit button explicitly sends the form for processing at the server side via a GET or POST request, depending on how the form has been coded by the Web programmer.
There may also be a Reset button, which will reset all the data input areas back to their default values. This is a standard mechanism that is provided by the HTML specification, and the result of the form submission is usually an HTTP response directing the browser to some data.
However, some data may come back in structured fashion that is not designed to be actually displayed to the user but translated by the browser. In the same way that HTML is a holder for content, you can also retrieve data that is used by the client to display content that is also contained in a structure that you define.
Put more simply, there might be a control in the form that is designed to be used to submit information to the server, but which can also be updated by another control that updates its contents dynamically. You need a way to communicate with the server “behind the scenes” and add this new information to the form.
This is known as asynchronous data exchange—you do not have to reload the page in order for it to become apparent, but the data that is retrieved from the server has a direct effect on the contents of the page. This is affected through client side scripting.
An example of this is the Google suggest service (http://suggest.google.com), which provides a text entry area and a dynamically changing list box that contains suggestions retrieved from the Google database. The list box contents are updated with respect to the value being entered by the user in the text entry area.
Here the form is being updated—the drop-down list box is populated with data that is exchanged with the server—asynchronously to the page being loaded. The data being returned is not HTML, because that would cause the page to be reloaded and this is not appropriate in this case.
On top of which, the HTML standard is well defined, and does not allow you to casually start inventing tags that can contain the data that we need. Instead, you need to have the data returned in a way that allows you to extend the basic definition by adding your own definitions.
One such mechanism for data exchange is called XML, which is an open standard for data exchange that allows for the creation of data elements and attributes. Others include JSON, which requires special handling in most browsers and is not usually decodable by the platform itself. The book uses XML, as it is widely supported and understood.
You’ll learn the actual definition of XML and its various rules in the next chapter, when you look at these languages in detail. For now, you just need to know that it is a mechanism by which data can be exchanged with a server.
This data can be used in a variety of different application areas, and is not just used for Web programming. The widest use, until recently, was as a way for bloggers and other information, content, and product providers to inform their fans when new items were available.
For example, RSS (Really Simple Syndication) is based on XML; these are feeds of data that are designed to be read and displayed. If you open an RSS feed in a Web browser, the structured XML is laid bare, as shown in Figure 2.2.
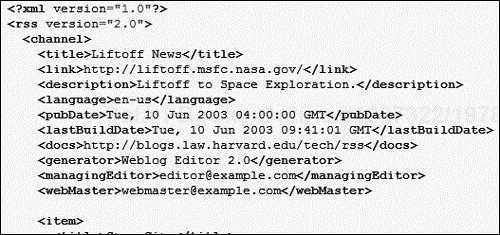
Clearly, this is not designed to be directly viewed by the users, so you need to use other mechanisms to allow it to be rendered correctly. Feed readers exist that will monitor the feed (by loading the XML from time to time) and inform the users of an update.
Where a link to an artifact is provided (such as an MP3 podcast), some feed readers will actually download the content on behalf of the user. This is known as subscribing, and is one of the many non-Web programming applications of XML currently in use.
You’ll look at some more uses later on in Chapter 9, when you read about specific Web 2.0 features of Web programming. The important point to note is that the data is structured and adheres to a specific format. That is, RSS is a specialization of XML (or an application of XML).
A mixture of client and server side technology is needed to allow a user to display feeds in a browser. For example, the server can offer the feeds, but the client needs to be able to display the elements that are contained in each entry to the user in a way that enables them to look at them in a meaningful manner and possibly click on links that are included as part of the feed information.
Part of the browser scripting language has to allow one to manipulate the XML data that is returned—building something that has meaning from the structured data stream. This requires some clever client side programming, because XML manipulation is not an innate part of the HTML specification.
However, it is a part of some standard scripting language implementations that allow the Web programmer to make a request using a special kind of HTTP request—XhttpRequest—and process the data that is returned. Like all areas of Web programming, the client side programming languages (scripting) have to be reasonably standardized to allow producers to be reasonably certain that consumers all experience the same effect regardless of platform.
Just as a reminder—client side scripting is a way to extend the functionality of a Web page beyond static data by requesting that the user agent (the Web browser, for example) do some additional processing on behalf of the Web programmer. This can be for the purpose of making the Web page interactive, dynamic, or just animated in some way.
The content, layout, and other features used in the rendering of the page can all be manipulated using client side scripts. This makes them very useful for displaying items that are platform-, browser-, or user-dependent.
Client side scripting allows you to validate forms, change the document with respect to interaction with the user, and manipulate style information dynamically, as well as generating new content.
Like all programming languages, the client side scripting mechanism usually allows for selective execution (decision making), flow control (loops), and other programming constructs. The script interpreted is either built into the browser (JavaScript, for example) or is interpreted via a plug-in that has to be downloaded from the manufacturer (Flash, for example).
This book’s scope is limited to those solutions that are available to all Web programmers, so I have chosen to use JavaScript as the basis for all discussions of client side scripting. This doesn’t mean that I ignore common plug-ins that can be used with JavaScript to provide extended functionality, just that I assume that browsers have the ability to process JavaScript natively.
If plug-ins are defined that extend the scripting language, you can communicate with them provided that the developer has given you an API that is integrated with the object model of the browser and underlying operating system. In other words, the JavaScript standard gives you an object model that you can use to manipulate the HTML document, and this mechanism is inside the scope of this book.
The discussion of other object models and how to communicate them is outside the scope of this book. Where necessary, I will give code fragments that illustrate how such a plug-in (for example, Microsoft’s Silverlight) can be communicated with, but the exact definition of the object model mechanism itself is an advanced developer topic.
However, it’s worth noting that it is also standardized, but relies on co-ordination between the browser and operating system. Each plug-in is installed as a part of the system software, and HTML allows you to embed an object of the required type in a document.
The browser needs to support the object, through the plug-in, and supply an interface (API—application programming interface) that enables you to use JavaScript to communicate with the plug-in. Some do not have this kind of API, which makes them more or less self-contained.
In order to make the Web programming examples as relevant as possible, the book examples are limited to ones where the plug-in is freely downloadable and provide a standard API or XML interface for communication.
The XHttp mechanism that allows you to do Asynchronous JavaScript and XML (AJAX) is an example of such a case; Microsoft Silverlight is another. In both of these, standard JavaScript and XML programming can be used, and the relevant plug-ins are either freely available or built into the browser.
You will look at both of these in detail later on, but they are both made possible by the use of a standard client side scripting language—ECMAScript, which is a standardization of JavaScript. For the purpose of this book, I treat JavaScript and ECMAScript as equivalent, and avoid areas where they might be differently implemented.
A quick recap—client side scripting lets you manipulate the rendering of the page by adding some logic to be processed by the user agent (browser). The implementation of the scripting language lets you access the content and layout information through the document model. This lets you communicate with objects—be they built-in (like HTML tags) or external (like third-party plug-ins).
This document model also lets you find out information, programmatically, about the client environment (browser, platform, user, and so on) that can help you to generate relevant content on the server side. For example, you might detect that the user is running Windows, and therefore only display advertising that is relevant to Windows users.
Or, you might use a cookie to store information about the user’s last visit to the site and use that to try and help the user navigate through the site when he or she returns. Both of these examples will require a certain amount of server side programming, which allows you to generate content selectively to be sent to the browser.
As you will have realized, server side programming powers the bulk of Websites on the Internet today. From the actual HTTP server (such as Apache or IIS) which handles requests and delivers data, to the various Webmail, interactive applications (such as Facebook, MySpace, YouTube, and so on, without some logic on the server none of these services would be possible.
Before you delve into this subject more deeply, you need to remember that there is a difference between a server side application, such as the Web server, and a server side script. Server side scripts are interpreted by a server side application. I don’t cover applications that can be written to run on the server, but do cover scripted Web applications.
In order to make Websites more interactive, dynamic, and customized, some form of server side programming was required. You have seen how the first pages were static text, and this gave way to style sheets and client side scripting. As the technology expanded, however, Web programmers saw the need to go a step further.
Programmers started to make little programs that were designed to run in the background and generate content. They ran natively as applications capable of interfacing with the Web server and provided functionality from databases to content presentation.
This not a good solution, however, as all operating systems are different, so there was a need to find a standard scripting language which would work everywhere a Web server was present. The reasons for this were many, but the chief features are that:
The scripting language can be mixed with HTML
The scripts run on, and have access to services provided by, the Web server
A scripting language is also interpreted. This means that the manufacturer can distribute an interpreter built for a given platform—a Windows version, a Linux version, a MacOS version, and so on—and all users can exchange scripts without having to build them for each platform.
This is another advantage of using a scripting language rather than building little applications that run on the server—code can be written once and run everywhere. Over time, the community has settled on three possible contenders—ASP (for Microsoft, mainly), Perl, and PHP, which are multiplatform.
Given the target of this book to try to deliver the most relevant information possible, I have chosen to cover PHP as the server side scripting language. This choice is based on the fact that it works on the largest number of platforms (at the time of writing) and is available as freeware.
I might have chosen Perl, but this is a rather daunting language to a newcomer. PHP has the benefit of being slightly easier to understand due to its roots. It is a hypertext processor, and is designed to be embedded in HTML as well as able to stand alone. So the script can be in the Web page or a separate file.
The difference between a client side script, such as a JavaScript which is also embedded in the page, is that the Web server will interpret the PHP that it encounters and send the result of that processing to the client rather than the text of the script itself. So, if you wanted, you could have PHP code to generate JavaScript (or HTML, or style information) which is then delivered to the client.
This might sound complex, but I will only give you as much as you need to get started. You will learn the basics, but will, over time, add to your knowledge as you become more familiar with Web programming. Using PHP, JavaScript, and HTML to make your own projects will be a useful learning exercise in itself—this book gives just enough to get the ball rolling.
So, server side scripts have the advantage of being invisible to the user as the server interprets them at the same time as it serves the Web page. Because they are interpreted on the Web page, they can also be quite lengthy and complex; assume that there is more processing power available to the server than the client.
Being able to build complex applications, coupled with the Open Source philosophy of the PHP community, means that many frameworks have been implemented. Some of these are application frameworks and extensions, and some of them are complete Web content delivery systems, made available to the general public.
The key advantage of using them is that it gives a good starting point for code of your own. Provided that it is Open Source, and provided that the license permits it, you can customize the PHP scripts to your own needs. There are many frameworks that actively encourage this.
In the main, these are CMS (or Content Management Systems), which allow you to create complex document delivery systems. Blogger is an example of a fairly simple CMS implementation. More complex ones allow for categorization of documents, advertising placement, dynamic menus, and other features.
You’ll look at some of the main freely available CMS frameworks in Chapter 8 of the book, as these will be the ones that you come across most frequently. I have chosen ones that allow you to add functionality easily through the use of plug-in modules that you can create, and which can become part of the CMS reasonably seamlessly.
Sometimes, the integration of client and server side scripting leads to very sophisticated user interfaces. Web 2.0 features, for example, rely heavily on the possibility to mix client and server scripting, along with databases and external services such as XML.
Some of the best examples come from the Google Labs—I’ve already mentioned Google Suggest, but they also have Google Sheets (a spreadsheet application) as well as a word processor. All of these rely on server side scripting to provide the back-office functionality—saving, storing, sharing, and so on—and client side scripting to edit the actual information in the document or spreadsheet.
Another good example is the Yahoo Pipes application. This also uses dynamic client side HTML and style sheets mixed with server side programming, which provides data feeds and storage of the user’s account and Pipe information.
The Pipe service allows the user to build up expressions for filtering RSS feeds based on XML and a simple scripting language that is built through the browser. The results are small applications that run as a mixture of client and server side programs, communicating through XML.
These can then be shared with the general public. The end user just sees a resulting XML stream that can be viewed through a feed reader. Yahoo even provides such a reader to display the results; so a general news feed can be filtered and combined with (for example) and Amazon.com product feed to create a valuable revenue generating Website plug-in.
This kind of possibility is part of the definition of Web 2.0, which is the latest trend in Web programming. Key to Web 2.0 is allowing the consumer to become the producer—YouTube, MySpace, Facebook, and Flickr are all examples of Web 2.0 applications.
The ability to create and share information is what powers the Web 2.0 concept, and it is made possible by the integration of client and server technologies over the Internet. This is then combined with other server side applications such as databases to provide the complete package.
So, part of the purpose of server side scripting is to link server applications (databases, for example) with front-end interfaces. The resulting interface may be modified as a result of the data that has been retrieved, or the logic that has been implemented in the script.
The Internet is a collection of interconnected computers, split into client and server roles. The clients access the servers and display the result to the end user (the surfer). The exact nature of the result (appearance and content) is a function of the following:
Client side scripts
Server side scripts
Content stored on the server
All of these are governed by standards. Despite the work of the W3C, the presentation layer definition language is not always as standardized as it might seem. Different browsers might have extensions (such as some Microsoft Internet Explorer text decorations) that are not supported on other platforms, or they might evaluate scripts differently.
In this book, I try to respect standards and give code that will work on all browsers without changes. This is necessarily done by avoiding some of the areas where contentions exist.
However, this might be impossible in some cases, and I give appropriate guidance in these examples to illustrate certain points. Luckily PHP is a stable standard, as is SQL, so this is less of an issue on the server side.
You now understand the underlying philosophy of Web 1.0 (static pages and dynamic content) and Web 2.0 (social networking and user created dynamic content) and are ready to begin learning the underlying technology that drives Web programming.
In Chapters 5 through 9, you will steadily progress through the languages that you need to create the applications that enable you to write Web applications. These will all generate, towards the end user, various flavors of HTML.
So, before you can begin, you need to cover the basics, and you will start with an introduction to HTML, the language of the World Wide Web.