
STL’s Associative Containers
All of the STL containers you have seen so far have stored individual data elements. In this chapter you will be introduced to associative containers. These containers associate a key with the data values that you are inserting. In the case of the map and unordered_map containers, you are required to supply a value to use as the key, whereas the set and unordered_set containers automatically generate keys from the data you supply. I’ll explain the differences between each of these containers as I work through some examples in this chapter, beginningwith the set container.
You won’t be surprised to find out that a set is a template class and you are required to specialize the set container to store the types you require. Listing 16-1 gives an example of how you can specialize the set template.
Listing 16-1. Specializing set
using namespace std;
using MySet = set<int>;
Once you have specialized a set template you can initialize a container in the same manner as other STL containers. Listing 16-2 shows how you can create and add values to a set.
Listing 16-2. Initializing and Adding to set Containers
MySet mySet = { 2, 1, 0 };
mySet.emplace(4);
mySet.insert(3);
There are two important aspects of Listing 16-2 to which you should pay particular attention. The first is the emplace method used. This method has the same result as the insert method in that the value will be added to the set. However, emplace is actually faster at achieving this than insert in some circumstances. It achieves this speed improvement by avoiding a copy construction when using a set with class types. You should always use emplace rather than insert with all containers when it is available.
The second important aspect is the values we are adding to the set. The first curious feature is that the numbers are not in order. A set will automatically sort the values as they are added, which is one of the reasons you might consider using a set rather than an array, vector, or list. After the final line that inserts the value 3, the set will contain the numbers 0, 1, 2, 3, and 4 in order. The other important feature of the values is that they are all unique. If we had tried to add duplicate values to the set, they would be ignored. This is important to remember and is different to the behavior of array, vector, and list, which would allow you to add duplicate values.
The sample code that accompanies this chapter shows examples of using a set with iterators and the STL find algorithm. This code is identical to the iterator-based and range-based for loops that you have seen with previous containers in Chapters 14 and 15. Hopefully you have begun to get the hang of how to access elements in STL containers.
The next container I will show you is map. A map is conceptually similar to a set, but it requires that you provide a key along with your data.
All of the containers you have seen so far take a single value and store these individual values at discrete locations. The map container is different: It requires that you supply a key along with the value to be stored. You then use this key to retrieve the value from the map. When inserting elements into a map, you are required to supply the values using the pair template. Listing 16-3 shows the template specializations for the map and pair templates.
Listing 16-3. Specializing map and pair
using namespace std;
using MyMap = map<int, string>;
using MyPair = pair<int, string>;
The map and the pair templates are supplied matching parameters to ensure that we are adding the correct types to the map. If we tried to supply the wrong types to a map, the compiler would generate an error.
You can see in Listing 16-4 just how we add elements to our map.
Listing 16-4. Adding Elements to a map
MyMap myMap = { { 2, "Two" }, { 1, "One" }, { 0, "Zero" } };
MyPair node{ 4, "Four" };
myMap.insert(node);
myMap.emplace( 3, "Three" );
The definition of a map can take a list of pairs that should be in the map at the time of its creation. In this example we have added pairs representing the values Zero, One, and Two, along with their respective integer representations as keys.
The insert method requires the use of our pair template to add values to myMap. You can see that we first construct the MyPair object node with the key 4 and value Four. After this, I’ve added an example of the emplace method. You can see how it can be more efficient to use emplace compared with insert in this example. You can leave out the creation of the pair object and a subsequent copy from the pair into the map by using emplace. The map shares a property with set: Both containers sort their values as they are entered. A map container will sort the keys into order as the elements are entered. This is the reason you would use a map rather than a set. If you have a complex class that you would like to store objects of in a map then the sorting and retrieval of these objects would be more efficient if you supplied simple data types such as integers as keys. It would also be possible to store two objects that are identical into a map by giving both objects different keys, as only the keys in a map are required to be unique.
Unsurprisingly, a map cannot be iterated with exactly the same code as some of the other containers, as it stores elements as key–value pairs and our loops must take this into account. Listing 16-5 shows an example of how we can loop over all of the elements stored in a map.
Listing 16-5. Looping over a map
for (const auto& node : myMap)
{
cout << "First: " << node.first << " Second: " << node.second << endl;
}
The for loop itself is the same and C++ has allowed us to abstract out the MyPair type by using the auto keyword in its place. You can access the key and value stored in a pair using the first and second variables. The first variable stores the key and second stores the value.
The find method also supplies an iterator to a map that represents a pair element, as you can see in Listing 16-6.
Listing 16-6. Using map::find
MyMap::iterator found = myMap.find(2);
if (found != myMap.end())
{
cout << "Found First: " << found->first << " Second: " << found->second << endl;
}
To find a value in a map you can use the find method on the map itself, not the stand-alone find algorithm. The find method takes the key you wish to search for as a parameter and if that key does not exist, the end element of the map is returned.
Binary Search Trees
At this point we have covered five different STL containers. In the previous chapter I explained the difference between the way a list and a vector are implemented. set and map are also implemented differently to the linear containers. The map and set containers are implemented as binary search trees.
A node in a binary search tree stores pointers to two nodes, one to the left and one to the right. Figure 16-1 shows a visual representation of a tree.
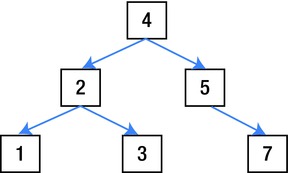
Figure 16-1. A binary search tree
The binary search tree stores the tree in a sorted order to make it a very efficient structure when looking up nodes. The head node of the tree in Figure 16-1 stores the value 4. If we were looking for the node that stores the value 2, we would begin by comparing 2 against the value at the head, which is 4. If our search value is equal to the current node, we have found our value. If it is lower we move to the left node; if it is higher we move to the right node. As 2 is less than 4, in our example we would move to the left node. We would then repeat this process at the new node. We compare first to the value of the node, and 2 equals 2, so we know that we have found the node we were searching for.
The process of repeating the same operation over and over like this is known as recursion. We generally implement recursive algorithms using functions that call themselves. Listing 16-7 shows an implementation of a simple TreeNode class that can be used to recursively search a binary tree structure.
Listing 16-7. A simple TreeNode
class TreeNode
{
private:
int m_value;
TreeNode* m_pLeft = nullptr;
TreeNode* m_pRight = nullptr;
public:
TreeNode(int value)
: m_value{value}
{}
TreeNode* Find(int searchValue)
{
TreeNode* pResult = nullptr;
if (m_value == searchValue)
{
pResult = this;
}
else if (m_pLeft != nullptr && m_value > searchValue)
{
pResult = m_pLeft->Find(searchValue);
}
else if (m_pRight != nullptr && m_value < searchValue)
{
pResult = m_pRight->Find(searchValue);
}
return pResult;
}
};
All of the code you need to search for a value inside a binary search tree is contained within the Find method in Listing 16-7. If you imagine that we have used this class to represent the tree in Figure 16-1, then you would have a pointer to the tree head node stored in our program. You can then call Find on this node and pass it a value to search for.
If we pass in 1, the first if statement in Find would fail. The second if statement would pass so we would return the result of m_pLeft->Find. This call to find would follow the same process: The first if would fail and we would return the result of m_pLeft->Find. This call to find will see the first if statement pass, so we do not call another function; we simply return this. At this point, all of our function calls will unwind. Our last call to Find returns this to the second call to Find, which returns the pointer to the first call to Find, which finally returns it back to the variable being assigned.
Searching for values in a binary tree is, generally, a faster operation than searching through an array, vector, or list. In those collections you would have to potentially compare against every element if the value you were looking for was at the very end of the collection. A binary search tree is much more efficient. In Figure 16-1 we would only ever have to make 3 comparisons to search against 7 different values. If we were to add another level to the tree, we would have 4 comparisons to make against 15 different values, and another layer would be 5 comparisons for 31 values. You can see how quickly these numbers are rising for each level in a binary search tree.
Note Recursion can be a complicated topic for beginning programmers to understand as it ties in with the concept of the program stack. We’ll cover more about this stack in Chapter 22.
The other major algorithm for traversing a collection is called iteration. You have already seen multiple examples of iteration in action and the iterator types you have seen in use take their name from this algorithm. Iterating a binary search tree involves visiting each node in turn, and you can use iterators on a set and a map to visit each element in order.
Binary search trees are one way to store data in associative containers, and another is to use a hash map.
Fast Data Access Using a Hash Map
A binary search tree structure provides fast access to sorted data. The tree is automatically sorted when adding data and you’ve seen how a search of that data can be done very quickly. It is possible to use an even faster structure than a binary search tree when you do not need to iterate over sorted data. A hash map has a constant time insert and retrieval of a value. This means that it will take the same length of time to insert the first element as it will to insert the tenth or the millionth. It also has a constant time retrieval of data. This means that finding data in a container does not increase the time elapsed along with the number of elements the container holds.
Hash maps achieve this by turning the key into a hash value and then using that hash to store the data in an appropriate bucket. The process of writing a hash map is a complicated task, but luckily for us the STL provides us with two ready-made hash map containers, the unordered_set and the unordered_map.
STL unordered_set and unordered_map
The code for unordered_set and unordered_map is going to look very familiar. Listing 16-8 shows how you can specialize these templates.
Listing 16-8. Specializing unordered_set and unordered_map
using namespace std;
using MyUnorderedSet = unordered_set<int>;
using MyUnorderedMap = unordered_map<int, string>;
using MyPair = pair<int, string>;
The unordered_set and unordered_map container templates take the same parameters as the set and map containers. The unordered_set stores a value and calculates the key automatically for the value,whereas the unordered_map requires that you specify the type to use for the key followed by the type for the value.
You can then initialize and add elements to these containers in the same way you did before, as Listing 16-9 shows.
Listing 16-9. Initializing and Adding to unordered_set and unordered_map
MyUnorderedSet myUnorderedSet = { 2, 1, 0 };
myUnorderedSet.emplace(4);
myUnorderedSet.insert(3);
MyUnorderedMap myUnorderedMap = { { 2, "Two" }, { 1, "One" }, { 0, "Zero" } };
myUnorderedMap.emplace(3, "Three");
MyPair node{ 4, "Four" };
myUnorderedMap.insert(node);
The code to find elements in an unordered_set is similar to what you have seen previously, either using the find algorithm or the find method. Listing 16-10 shows both versions.
Listing 16-10. Using find with unordered_set
MyUnorderedSet::iterator found = find(myUnorderedSet.begin(), myUnorderedSet.end(), 2);
if (found != myUnorderedSet.end())
{
cout << "Found : " << *found << endl;
}
found = myUnorderedSet.find(2);
if (found != myUnorderedSet.end())
{
cout << "Found : " << *found << endl;
}
Values in an unordered_map are accessed a little differently. You will have to use either the [] operator or the at method. Both are shown in Listing 16-11.
Listing 16-11. Using [] and at
string& myString = myUnorderedMap[2];
cout << "Found : " << myString << endl;
myString = myUnorderedMap.at(2);
cout << "Found : "<< myString << endl;
These methods differ in a very significant way. The [] operator can be used to insert or retrieve values from an unordered_map. If the key 2 had not existed in myUnorderedMap, a new string would have been added to the map and its reference returned. If the key did already exist, the current string would have been returned. The at method never adds a new element to our unordered_map, instead it throws an exception. Listing 16-12 shows how you can update the at call to handle exceptions.
Listing 16-12. Handling Exceptions
try
{
string& myString = myUnorderedMap.at(5);
cout << "Found : " << myString << endl;
}
catch (const std::out_of_range& outOfRange)
{
cout << "Out of range error: " << outOfRange.what() << endl;
}
Your program would have crashed with an unhandled exception error if you had called this code without the try...catch block. Throwing your own exceptions is as easy as using the throw keyword, as you can see in Listing 16-13.
Listing 16-13. Throwing Exceptions
void ExceptionExample()
{
if (true)
{
throw -1;
}
}
Catching an exception from this method is shown in Listing 16-14.
Listing 16-14. Catching Exceptions
try
{
ExceptionExample();
}
catch (int errorValue)
{
cout << "Error: " << errorValue << endl;
}
Note You’ll see the unordered_map put to practical use in Chapter 21, which covers an EventManager class that stores Event objects keyed by a unique ID value.
Summary
This chapter has introduced you to STL containers based on binary search trees and the hash maps. These containers provide alternatives to the other containers, which are of particular benefit when you are dealing with large sets of data. The set and map containers are useful when you need to have data that is regularly iterated over and you need to be in order, but you also need to find individual elements regularly. The unordered_set and unordered_mapcontainers are useful when you need to know that inserting and retrieving values will always take the same length of time to execute and you do not need the data to be sorted.
The next chapter introduces you to the stack and queue containers. These containers are more specialized versions of existing data structures. Stacks can be used to add and remove elements from the top of the container, whereas queues act in a first in, first out manner.