
Chapter 23: Using File Input and File Output
In the previous chapter, we introduced many basic file concepts as well as most of the file manipulation functions. We also demonstrated a simple way to open and close files.
In this chapter, we will put that knowledge to better use by developing programs to read and write to/from a sequential file. Our goal in this chapter is to accept input from a console or a file, sort each line in a file, and then write out the result, either to a console or to a file. We will find that there are several subtleties that we will need to address; we will also be using nearly every C skill we have learned so far.
The following topics will be covered in this chapter:
- Creating a template program to process filenames given on the command line
- Creating a program to accept input from either stdin or a file and write output to either stdout or a file
- Creating a function to trim input from fgets()
- Creating a program to accept input from either stdin or a file and write the output in sorted order to stdout or a file
Technical requirements
As detailed in the Technical requirements section of Chapter 1, Running Hello, World!, continue to use the tools you have chosen.
The source code for this chapter can be found at https://github.com/PacktPublishing/Learn-C-Programming-Second-Edition/tree/main/Chapter23.
File processing
Many books have been written about the myriad of data file formats that are out there. These include text-editing file formats, graphics file formats, audio file formats, video formats, and data file formats for various database files and well-known application program files, such as Microsoft Word and Microsoft Excel. Often, custom file formats are closely guarded company secrets or, if not secret, are only documented in the source code that manipulates them.
Along with data file formats, there are nearly as many file processing techniques – far too many to be given even a cursory overview in a beginner's C programming book. File processing techniques are generally divided into sequential-access and random-access files, but this is an oversimplification. Within each of these categories, there can be many variations of how they are internally organized and subsequently processed. Furthermore, in some cases, complex computer programs may open more input and output files as they run. Often, one or more configuration files are first opened, read, and processed to determine how a program behaves. They are then closed, and the program performs processing on other files depending upon the settings in the configuration file(s).
Here, we present some useful ways to open two sequential files using enhanced command-line arguments and then perform relatively simple processing on them.
Our goal in this chapter is to accept input from a console or a file, sort each line in a file, and then write out the result, either to the console or a file. We can just create the file in a text editor and save the file; it will be more interesting to write our own program to do that. We will first start with a program to accept input and write output based on the presence or absence of the arguments given. This program will be built from a program we created in Chapter 22, Working with Files, open_close_argv.c, and a program we created in Chapter 19, Exploring Formatted Input, readString.c.
Processing filenames from the command line
We will begin creating our data file creation program by handling command-line arguments.
In the previous chapter, we created a program that expected two filenames on the command line, which were presented via argv; the input file was the first argument and the output file was the second argument. What if we wanted to permit either argument to be omitted? We could no longer rely on argument positioning; we need a way to further identify which argument is input and which argument is output.
To do that, we will revisit the getopt() built-in command-line facility. This facility is older and simpler than getopt_long(), which we demonstrated in Chapter 20, Getting Input from the Command Line. We will specify two options, -i <input filename> and -o <output filename>, neither of which will be required. getopt() does not have the concept of required or optional arguments, so we'll have to do that processing ourselves if needed. In the program, all arguments will be optional.
Note
getopt() and getopt_long() are declared in the header file, unistd.h, which is not a part of the C standard library. This means that if you are running Unix, macOS, or Linux, this file and function will be available to you. If you are running Windows, unistd.h is a part of the CygWin and MinGW compiler tools. If you are using MFC, this file might be available to you. A Windows version of getopt(), maintained by Microsoft, is available on GitHub at https://github.com/iotivity/iotivity/tree/master/resource/c_common/windows; you will see the getopt.h and getopt.c files.
Let's look at the following program:
- Create a new file called getoptFiles.c. We will use this for both the data creation and the data sorting program; we'll make copies of it and modify the copies when needed later. Add the following header files:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h> // for getopt
#include <sys/errno.h> // for errno
We need stdio.h for the file I/O functions, stdlib.h for the exit() function, string.h for the strerr() function, unistd.h for the getopt() function, and sys/errno.h to convert any errno value into a human-readable string.
- Next, add the following usage() function:
void usage( char* cmd ) {
fprintf( stderr , "usage:
%s [-i inputFName] [-o outputFName] ",cmd );
fprintf( stderr ,
" If -i inputFName is not given,"
" stdin is used. " );
fprintf( stderr ,
" If -o outputFName is not given,"
" stdout is used. " );
exit( EXIT_SUCCESS );
}
This function will be called when either wrong arguments are given to the program or the user provides the -h command-line option. When we call this function, something is not right or the user just wants help. Therefore, we never return from this function; instead, we exit the program.
- Next, add the following lines, which begin the main() function:
int main(int argc, char *argv[]) {
int ch;
FILE* inputFile = NULL;
FILE* outputFile = NULL;
These statements declare variables we'll need in main(). Now, ch will be used by getopt() as it processes command-line switches. File descriptors are then declared for inputFile and outputFile.
- We are now ready to perform command-line processing. Add the following statements:
while( ( ch = getopt( argc , argv , "i:o:h?" ) ) != -1 ) {
switch (ch) {
case 'i':
if( NULL == ( inputFile = fopen( optarg , "r") ) ) {
fprintf( stderr, "input file "%s": %s ",
optarg, strerror(errno));
exit( EXIT_FAILURE );
}
fprintf(stderr,"Using "%s" for input. " ,
optarg );
break;
case 'o':
if( NULL == ( outputFile = fopen( optarg , "a" ) ) ) {
fprintf( stderr, "output file "%s": %s ",
optarg, strerror(errno));
exit( EXIT_FAILURE );
}
fprintf(stderr,"Using "%s" for output. " ,
optarg );
break;
case '?':
case 'h':
default:
usage( argv[0] );
break;
}
}
In the conditional expression of the while()… loop, getopt() is called. The result of getopt() is assigned to ch. If there are no more arguments, getopt() returns -1, and we exit the loop normally. The arguments to getopt() are argc, argv, and a string of valid option letters. The "i:o:h?" string specifies that -i, -o, -h, and -? are valid character options. Note that i and o are followed by :, which indicates that each must be followed by another parameter after that option.
The body of the while()… loop is the switch()… statement where each case processes one of the options retrieved by getopt(). Both the case 'i': and case 'o': statements try to open the given filename parameters; if fopen() fails for either one, it returns NULL and sets errno, in which case, we exit the program after displaying the reason for failure. Otherwise, note that we open outputFile for appending. This is so that we don't delete any data that may already exist in the given outputFilename. If the value of ch is 'h' or '?', which the user entered, or if getopt() found an invalid option, or our switch()... statement encountered something it doesn't handle, usage() is called. At this point, we have processed all of the command-line options. Before we can do actual work, we have to see whether filenames were actually given.
- The following statements finish the work of setting our inputFile and outputFile descriptors:
if( !inputFile ) {
inputFile = stdin;
fprintf( stderr , "Using stdin for input. " );
}
if( !outputFile ) {
outputFile = stdout;
fprintf( stderr , "Using stdout for output. " );
}
Why might inputFile or outputFile be NULL? Well, just because we told getopt() what the valid options are, there is no facility to tell getopt() which ones are required or optional. So, we may have processed the command line with both options, either option, or no options at all. Here is where we handle the case where neither the input option nor the output option was given on the command line. If inputFile is NULL, we set it to the stdin stream. Likewise, if outputFile is NULL, we set it to the stdout stream. At the end of these statements, both file descriptors will either be set to a file or set to one of the console streams, stdin or stdout. We are now ready to do some work.
- The following statements complete main() and our template program:
fprintf( stderr , "Do work here. " );
fprintf( stderr , "Closing files. " );
fclose( inputFile );
fflush( outputFile );
fclose( outputFile );
fprintf( stderr , "Done. " );
return 0;
}
There really is no work to do yet, so we just give a status statement. Then, we close inputFile, flush the outputFile buffer, and finally, close outputFile.
This is a complete program. It doesn't do any useful work; we'll add that in a bit. So, save the file, compile it, and run it. We will exercise our program by giving it the -h option, just an output file, just an input file, and then both. In the last case, we'll also give an input file that does not exist. You should see the following output:

Figure 23.1 – A screenshot of the getOptFiles.c output
First, with only the -? option, we see the usage message. Next, we give an option that is not valid to see how this looks. Then, we give just an output file; this file will be created. After that, we give just an input file that does not exist; you can see the error message fetched from errno.h. When we give an input file that does exist, all is well. Finally, we give both a valid input file and a valid output file.
Note that throughout this program, rather than using printf( … ), we consistently used fprintf( stderr , … ). This is not merely a convention. By doing this, if needed, we can redirect the stderr stream to a file and thereby save anything that would otherwise go to the console.
One thing we have not considered is what happens when the user specifies the same file for input and output. What should happen? This program is not designed to be used in that manner nor does it perform any check to prevent the user from entering the same filename. There is any number of things we could do – prevent the user from either entering the same file or input and output, or allow the two files to be the same, for instance. In the former case, we'd have to perform a name string comparison to see whether they are the same and exit. In the latter case, we'd have to consider completely processing the input file before opening and writing the output file to prevent mayhem from occurring.
This simple program contains many fussy details about handling multiple files. It serves as a generic starting point for any program that must open input and output files.
We will use this program again later as a starting point for our other programs. Since we have proven that this template program works, we can replace the fprintf( stderr , "Do work here. " ); statement with program statements that do really work.
Creating a file of unsorted names
Now that we have getoptFiles.c, we can use it as a starting point for our next sequential file program, createUnsorted.c. This program will be used to create a file of names, one name on a line, that will later become input to the sortNames.c program.
In createUnsorted.c, we will repeatedly read in a single name and write it out. We can test the functionality of this program by using stdin and stdout as well as reading and writing files.
However, before we can go further, we need to consider the issue of dirty input data. We can assume that a name begins with alphanumeric characters and ends with alphanumeric characters; we will assume that anything in between is part of the name, however odd it may appear. What happens if the user enters whitespace either before or after the name? Or if there is whitespace both before and after the name? Recall also that fgets() ends its input scan with <newline> but preserves it. We will see whether we need to consider special processing for <newline> or not.
We will deal with these issues next.
Trimming the input string from fgets()
It would be extremely handy if the C standard library provided routines to trim whitespace both before and after a string. As we have seen, some of the input routines preserve whitespace, including <newline>, and some of the routines do not. Other languages provide functions such as trimLeft(), trimRight(), and trim() that trim both the left and right sides of a string.
Thankfully, writing such a function is not too cumbersome in C. Consider the following function:
int trimStr( char* pStr ) {size_t first , last , lenIn , lenOut ;
first = last = lenIn = lenOut = 0;
lenIn = strlen( pString ); //
char tmpString[ lenIn+1 ]; // Create working copy.
strcpy( tmpStr , pString ); //
char* pTmp = tmpStr; // pTmp may change in Left
// Trim segment
// Left Trim
// Find 1st non-whitespace char; pStr will point to
// that.
while( isspace( pTmp[ first ] ) )
first++;
pTmp += first;
lenOut = strlen( pTmp ); // Get new length after Left Trim.
if( lenOut ) { // Check for empty string. // e.g. " " trimmed to
// nothing.
// Right Trim
// Find 1st non-whitespace char & set NUL character
// there.
last = lenOut-1; // off-by-1 adjustment.
while( isspace( pTmp[ last ] ) )
last--;
pTmp[ last+1 ] = '�'; // Terminate trimmed string.
}
lenOut = strlen( pTmp ); // Length of trimmed string.
if( lenIn != lenOut ) // Did we change anything?
strcpy( pString , pTmp ); // Yes, copy trimmed string
// back.
return lenOut;
}
The trimStr() function takes a pointer to a string and makes a working copy of the string. Because the first character of the string could change, the function uses a pointer to the working copy. This pointer is set to the first character of the working string; it may be the same pointer as that passed in, but we can never be certain of that. In every case, the resulting string will be either, at most, the same number of characters or fewer characters; therefore, we don't have to worry about the new string running beyond the existing string array boundaries.
It first trims whitespace to the left, or beginning, of the working string, and then trims whitespace to the right, or end, of the working string. When trimming from the left, there is the while()… loop to find the first non-whitespace. When that is found, the pointer to the beginning of the string is adjusted.
Before continuing to trim from the right, a check is done to ensure that the string is not empty after trimming; it could have been a string of only whitespace, which would not have been empty.
When trimming from the right, there is another while()… loop that begins at the highest character index and walks back toward the front of the string until it finds a non-whitespace character. When it finds one, it sets the character after it to NULL, terminating the character string.
It should be noted that this function alters the original string when it resets the string terminator. This is a side effect but is the intended effect of the function.
At first glance, this function seems rather convoluted. Does it handle every case we need? Does it handle whitespace? Does it take care of the final <newline>? To prove that this function works as expected, a test program that exercises trimStr() is provided in the source repository, named test_trimStr.c. If we need to change or enhance trimStr(), this test program should also be modified to include any new or altered behaviors. Further exploration of this program is left to the reader as an exercise.
This is a handy function to use whenever you read input from a console or a file. We will use it whenever we get input using fgets().
With this trimStr() function now available, we can proceed to the tasks of the program.
Reading names and writing names
To begin developing the createUnsorted.c program, first copy the getoptFiles.c file into the createUnsorted.c file. We will henceforth modify this file.
Open createUnsorted and add the following enumerated constant definition:
enum { kStringMax = 80 }; Also, add the following function prototypes:
void usage( char* cmd );
int getName( FILE* inFileDesc , char* pStr );
void putName( char* nameStr , FILE* outFileDesc );
int trimStr( char* pString );
In this chapter, for each program, we will follow the following general program organization:
- #include files
- Constant declarations
- struct and enum declarations
- Function prototypes
- main()
- Function definitions (these generally appear after main() in the same order as their prototype declarations)
This is merely a convention. In the next chapter, we will learn about a multi-file program organization that will help to naturally organize program structure.
So, after adding the preceding function prototypes, move the usage() function definition below the main() function in the file. Every other function we add will be below this function in the createUnsorted.c single file.
In the main() function, find the following statement:
fprintf( stderr , "Do work here. " );
Replace it with the following statements:
char nameBuffer[ stringMax ];
while( getName( inputFile , nameBuffer ) ) {putName( nameBuffer , outputFile );
}
The work of this program is essentially contained in the deceptively simple-looking while()… loop. First, an array of 80 characters is declared. This is the buffer into which each new line of input will be read with fgets(), which we'll see in the getName() function. If getName() returns with a non-zero-length string, putName() is called. Actually, the work of this program happens in those two functions. When getName() returns a zero-length string, the while()... loop is done.
The getName() function is a specialized version of fgets(). It uses fgets(), but it adds additional specialized processing that makes it a less general input function. Therefore, getName() cannot be considered a wrapper function for fgets() the way safe_fgets() is a wrapper function for fgets().
When getName() returns 0, an empty string is entered and signals that input has been completed. Otherwise, getName() returns the length of a trimmed string that we need to do something with; in this case, we call the putName() function.
After the usage() function definition, add the getName() function at the end of the program:
int getName( FILE* inFileDesc , char* pStr ) {static int numNames = 0;
int len;
memset( pStr , 0 , stringMax );
if( stdin == inFileDesc )
fprintf( stdout , "Name %d: ", numNames+1 );
fgets( pStr , stringMax , inFileDesc );
len = trimStr( pStr );
if( len ) numNames++;
return len;
}
The function takes a file descriptor as its first function parameter and a pointer to the string buffer to hold the input name as its second function parameter.
We use the numNames static variable when input is coming from a console. It appears in the user prompt as a means to inform the user how many names have been entered. Next, we declare len, which will be used to determine whether we have an empty string after the buffer is trimmed.
First, memset() is called to initialize each character in nameBuffer – here, referenced in the function body as pStr – to '�', or just 0, as is seen here. Then, if we are getting input from stdin, we give the user a prompt for input. A prompt is unnecessary when we are reading from files. fgets() scans in the input stream for up to stringMax-1 characters of input. At this point, there is <newline> in the buffer, which means the length of the string in the buffer will never be less than 1. We can't simply check for <newline> in the last position because stringMax-1 or more characters may have been entered, and we won't have <newline>; however, it will still be in the input buffer. Rather than making assumptions that could later come back to bite us, we call trimStr() on nameBuffer – here, referenced in the function body as pStr. Before exiting the function, we get the new string length. If it is not 0, we increment numNames for the next call to this function, and then len is returned to the caller.
Whenever we get a non-zero-length result from getName(), the work that is currently done is to output that name; this is accomplished with a call to putName(). Add the following function at the end of createUnsorted.c:
void putName( char* pStr , FILE* outFileDesc ) {fputs( pStr , outFileDesc );
fputc( ' ' , outFileDesc );
}
Again, recall that puts() adds <newline> to whatever string it prints. This is not so with fputs(). Just as we had to strip out <newline> with getName(), we have to put it back in the output stream with putName(). This simple function first calls fputs() using the function input parameters and then calls fputc() to write the <newline> single character to the given output stream.
We are not quite done. Now, it is time to add the trimStr() function we encountered in the preceding section to the end of the file. Once you have done that, save the file and compile it. To see this in action, we'll run it with these command-line arguments in the following order:
- createUnsorted
- createUnsorted -o names.data
- createUnsorted -onames.data
- createUnsorted -i names.data
In the first case, stdin and stdout will be used, and nothing will be saved. In the second case, every name that is entered will be appended to names.data. In the third case, more names will be appended to names.data. In the last case, names.data will be read and printed to stdout so that we can see what's in the file. Run the program using three or more names each time. Be sure to add whitespace before and/or after each name before hitting Enter. Your output should look something like the following:

Figure 23.2 – A screenshot of the createUnsorted.c output
As you can see, we entered the names Tom, Dick, and Jane, in the first case. The input strings were sent immediately to the console. In the next case, we entered Tom (leading whitespace), Dick (trailing whitespace), and Jane (whitespace before and afterward). Running the program again with the same options, we entered Adam and Eve. In the last case, the file was input, and it was written to the console, where we can see that the trimming was accomplished and that Adam and Eve were appended after the previous three names in the file.
We now have a moderately robust, yet simple, data entry program that trims input and appends it to an existing data file. There are some subtleties we still haven't considered, such as disk-full errors, end-of-file markers, and wide-character input. These are more advanced topics for a later time; nonetheless, they should not be overlooked.
Now that we have a basic file input program, we can proceed to reading names from the console or a file and sorting them to the console or a file.
Reading unsorted names and sorting them for output
In Chapter 21, Exploring Formatted Input, we read names into an array, sorting them as they were inserted. That works fine when the program can give feedback to the user such as when the array is full, but what if, for file input, we have a very large number of names? For that, we need a different data structure to read in all of the names to sort them.
Recall that in Chapter 18, Using Dynamic Memory Allocation, we created a linked list to contain our deck of cards, which were then randomized and dealt out to four hands. A linked list is one of many useful data structures used to dynamically store and sort large numbers of data elements. We will create another special-purpose linked list for our list of names and add each name to the list in sorted order. This approach will be similar to what we did in Chapter 21, Exploring Formatted Input, but instead of using a fixed-size array, we will use an unbounded singly linked list. Each list item will be a name. And because we will use the list in a very specific manner, we do not have to create all of the functions that a general-purpose linked list would require.
To begin the development of sortNames.c, copy the createUnsorted.c file to sortNames.c. Henceforth, we will be modifying sortNames.c. We will continue using the same general program structure, with main() close to the top of the file and all other functions beneath main().
Before we start making additions to implement our linked list, let's alter the while()… loop in main(), as follows:
char nameBuffer[ kStringMax ];
NameList nameList = {0}; while( getName( inputFile , nameBuffer ) ) {AddName( &nameList , nameBuffer );
}
PrintNames( outputFile , nameList );
DeleteNames( nameList );
We are declaring the NameList structure; this will be the starting point for the list elements that hold information about the list. The only change to the while()… loop is to replace putName() with the AddName() function where most of the work of sorting takes place in dynamic memory. Once all of the names have been processed, we call PrintNames() to write them out in sorted order. Finally, we call DeleteNames() to clean up all the dynamic memory of the list we no longer need after the names have been printed. As before, we explicitly close the files before exiting the program. Note that we have changed only four statements in the part of our program that does the main work of it.
One other thing to do in sortNames.c is to change the following:
if( NULL == ( outputFile = fopen( optarg , "a" ) ) ) {We change it to the following:
if( NULL == ( outputFile = fopen( optarg , "w" ) ) ) {We are changing the open mode from "a" (append) to "w" (write) so that each time we run the program, the output file will be truncated to zero bytes rather than appending sorted results to an existing file.
This program will not compile yet because we've not declared NameList nor the AddName(), PrintNames(), and DeleteNames() functions. We may need a few other functions specifically for list management.
Using a linked list to sort names
The sortNames() program is still relatively simple. However, we are beginning to build segments of code that are very much unlike each other. For instance, the file-handling code, which includes getName(), putName(), and trimStr(), is unrelated to the linked list-handling code, which we will soon develop.
We can, as we have done many times before, dump all of this code in a single file, happily compile it, and run it. Or, we could employ a much more common practice of separating different code segments into separate files so that all of the functions in any given file have a logical relationship. For the sortNames program, the logical relationships are that all of the functions in one file manipulate one kind of structure, the linked list, and all of the functions in another file manipulate file I/O. Among all of the source code files, there must be one and only one main(). All of the files together make up a program. We will explore this in much greater depth in the next chapter, Chapter 24, Working with Multi-File Programs, but we will introduce this concept with the sortNames program here.
To this end, there is only more line to add to sortNames.c. With the other include files at the top of the file, add the following line:
#include "nameList.h"
This statement will direct the compiler to find namelist.h and insert it into the program input stream as if we had typed in the whole file in this location. We will next develop the nameList.h header file. As we shall explore in the next chapter, header files should contain nothing that allocates memory; these are primarily other #include statements, typedef statements, struct declarations, enum declarations, and function prototypes. Save sortNames.c and close it; we are done with it for a while.
In the file directory named sortNames.c, create a file named nameList.h and add the following to it:
#ifndef _NAME_LIST_H_
#define _NAME_LIST_H_
#include <stdio.h>
#include <string.h>
#include <stdbool.h>
#include <stdlib.h>
typedef char ListData;
typedef struct _Node ListNode;
typedef struct _Node {ListNode* pNext;
ListData* pData;
} ListNode;
typedef struct {ListNode* pFirstNode;
int nodeCount;
} NameList;
ListNode* CreateListNode( char* pNameToAdd );
void AddName( NameList* pNames , char* pNameToAdd );
void DeleteNames( NameList* pNames );
bool IsEmpty( NameList* pNames );
void PrintNames( FILE* outputDesc , NameList* pNames );
void OutOfStorage( void );
#endif
Note that the whole header file is wrapped – it begins and ends – with the #ifndef … #endif preprocessor directives. These instructions are a check to see whether the _NAME_LIST_H_ symbol has not yet been encountered by the compiler. If so, define that symbol and include all of the text until #endif. If the symbol has been defined, ignore everything until #endif. This prevents multiple and possibly conflicting declarations in a program requiring many, many headers.
This header file includes other header files that we know will be needed for nameList.c. These headers may be included elsewhere; we include them here to be certain that the header files we need are present – they may not be needed anywhere else.
Next, there is typedef for the custom types, ListData, ListNode, ListNode, and NameList. These are very similar to the linked list program in Chapter 19, Exploring Formatted Output. Lastly, the function prototypes for list manipulation functions are declared. Again, these are very similar to those we saw in Chapter 19, Exploring Formatted Output. Note that some of these functions were not used in sortNames.c. You may also notice that Create<x>List was present in the program in Chapter 19, Exploring Formatted Output, but is absent here. The NameList structure is allocated and initialized in main() of sortNames.c, so we don't really need it.
You may have also noticed that these declarations are very similar to what we have been putting at the beginning of nearly all of our programs. In fact, most of those declarations that we've been putting in our programs typically go in their own header file and are included in the file where main() is found. Again, we will explore this in greater depth in the next chapter.
We are now ready to begin defining the functions we have declared in nameList.h. Create a new file, nameList.c. The very first line in this file should be the following:
#include "nameList.h"
Note that " and " are used instead of < and >. The " and " characters tell the preprocessor to look in local directories for files instead of looking in predefined system locations for standard library header files.
Next, add the following function to nameList.c:
ListNode* CreateListNode( char* pNameToAdd ) {ListNode* pNewNode = (ListNode*)calloc( 1 , sizeof(
ListNode ) );
if( pNewNode == NULL ) OutOfStorage();
pNewNode->pData = (char*)calloc(1,
strlen(pNameToAdd)+1 );
if( pNewNode->pData == NULL ) OutOfStorage();
strcpy( pNewNode->pData , pNameToAdd );
return pNewNode;
}
Recall from Chapter 19, Exploring Formatted Output, that calloc() is used to allocate memory on the heap and return a pointer to it. calloc() is first called to allocate ListNode and is called again to allocate memory for the incoming string. It then copies the incoming string to the ListNode->pData element and returns a pointer to ListNode. We will later have to use free() on each of these chunks of memory allocated with calloc().
Next, add the following function to nameList.c:
void AddName( NameList* pNames , char* pNameToAdd ) {ListNode* pNewName = CreateListNode( pNameToAdd );
if( IsEmpty( pNames ) ) { // Empty list. Insert as 1st // item.
pNames->pFirstNode = pNewName;
(pNames->nodeCount)++;
return;
}
(pNames->nodeCount)++;
ListNode* curr;
ListNode* prev;
curr = prev = pNames->pFirstNode;
while( curr ) {// Perform string comparison here.
if( strcmp( pNewName->pData , curr->pData ) < 0 ) {// Found insertion point before an existing name.
if( curr == pNames->pFirstNode) { // New names comes // before
pNames->pFirstNode = pNewName; // all. Insert at
// front
pNewName->pNext = curr;
} else { // Insert somewhere // in middle
prev->pNext = pNewName;
pNewName->pNext = curr;
}
return;
}
prev = curr; // Adjust pointers for next
// iteration.
curr = prev->pNext;
}
prev->pNext = pNewName; // New name comes after all.
// Insert at end.
}
This is the workhorse function of nameList.c. It takes a NameList pointer and a string to add to the list and first creates a new ListNode class with that string. If NameList is empty, it adjusts the pointers and returns. Otherwise, it enters a while loop to find the correct position among the existing ListNode structures to insert the new name. The while()… loops must handle three possible locations – the beginning of the loop, somewhere in the middle, and, if we get out of the loop, the end of the list.
You may want to review the insertion diagrams and routines from Chapter 19, Exploring Formatted Output. Another very useful exercise is for you to create a drawing of a linked list structure and walk through each path of the function, inserting a node in the beginning, somewhere in the middle, and at the end.
Next, add the following function to nameList.c:
void PrintNames( FILE* outputDesc , NameList* pNames ) {ListNode* curr = pNames->pFirstNode;
while( curr ) {fputs( curr->pData , outputDesc );
fputc( ' ' , outputDesc );
curr = curr->pNext;
}
}
This function starts at the beginning of the NameList structure and walks along with the list, printing out each curr->pData element and <newline>. The curr pointer is adjusted to the next element in the list.
To complement CreateListNode(), add the following function to nameList.c:
void DeleteNames( NameList* pNames ) { while( pNames->pFirstNode ) {ListNode* temp = pNames->pFirstNode;
pNames->pFirstNode = pNames->pFirstNode->pNext;
free( temp->pData );
free( temp );
}
}
In a similar fashion to PrintNames(), DeleteNames() starts at the beginning of the NameList structure and walks along each item of the list. At each ListNode, it removes the node, frees the data element, and then frees the node itself. Note that this is the reverse order of how ListNode was created.
Add the following function to nameList.c:
bool IsEmpty( NameList* pNames ) {return pNames->nodeCount==0;
}
This is a convenience function only used within functions defined in nameList.c. It simply returns the current nodeCount with the NameList structure.
Finally, add the following function to nameList.c:
void OutOfStorage( void ) {fprintf( stderr ,
"### FATAL RUNTIME ERROR ### No Memory Available" );
exit( EXIT_FAILURE );
}
This function is called if the memory is full. Granted, with today's modern memory management systems, this is unlikely. Nonetheless, it is prudent to not overlook this function.
Save nameList.c. We now have sortNames.c, nameList.h, and nameList.c. Note that nameList.h is included in both nameList.c and sortNames.c. We are now ready to compile these three files into a single executable. To compile these programs, enter the following command:
cc sortNames.c nameList.c -o sortNames -Wall -Werror -std=c17
In this command line, we are telling the compiler, cc, to compile two source code programs – sortNames.c and nameList.c. The compiler will assume that to produce the sortNames output executable file, it will need the intermediate compilation results of those two source files; we don't have to name the intermediate files. Also, note that we do not need to specify nameList.h; that directive is given in the #include statement, so we don't need it here.
Every other aspect of this command is the same as we've been using with all other programs.
We are now ready to experiment with sortName.h.
Writing names in sorted order
The only thing left now is to verify our program. We will run the program with these command-line arguments in the following order:
- sortNames
- sortNames -o sorted.data
- sortNames -i names.data
- sortNames -i names.data -o sorted data
In each test case, we will enter the names Tom, Dick, and Jane. The names.data file should be left over from when we ran createUnsorted.c earlier and contain five names. You should see the following output from the first case:
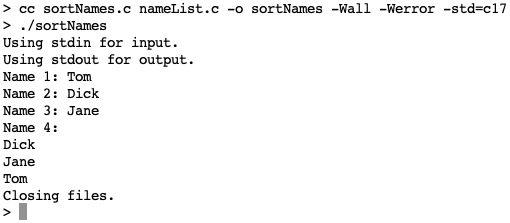
Figure 23.3 – A screenshot of the sortNames.c (first case) output
You should see the following output from the second test case:
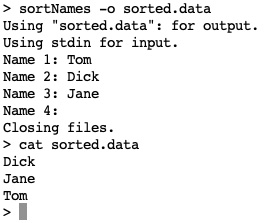
Figure 23.4 – A screenshot of the sortNames.c (second case) output
Here, we use it as input and see that we've sorted those five names, as follows:
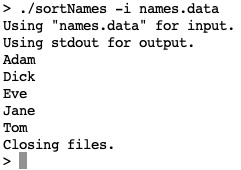
Figure 23.5 – A screenshot of the sortNames.c (third case) output
In the last case, we sort names.data to a file and then print the file with the Unix cat command, as follows:

Figure 23.6 – A screenshot of the sortNames.c (fourth case) output
In the first case, names were entered on a console, sorted, and output to it. In the second case, the same names were entered and written to a file. The file was displayed with the Unix cat command. In the third case, the names.data input file was read, sorted, and printed to a console. In the last case, the same input file was read, sorted, and written to another file; it was displayed with the Unix cat command. In each case, input, sorting, and output behaved as expected.
At this point, I hope it is clear how we've taken all of the concepts from earlier chapters to create a robust, yet simple, name or word sorting program. There are many small nuances of the C standard library routines we have explored, which we have compensated for by writing additional C code.
Another aspect that I hope is profoundly clear is the importance of taking a simple starting point, getting it to a working state, and then verifying the behavior of that code. Remember that each C compiler on each operating system has subtle differences. Therefore, continual testing and verification are programming habits that will serve you well throughout your programming journey.
Summary
In this chapter, we once again demonstrated the importance of developing a complex program step by step from simpler yet operational programs. Here, we took the program from Chapter 22, Working with Files, and built upon it to create a template program, getoptFiles.c. We saw that getoptFiles.c can read from either stdin or a file and can write to either stdout or another file. We then built upon getoptFiles.c, which did little else than open streams, to read lines of text representing names and output those lines as they were read. In the process of doing that, we learned about the subtleties of the fgets() and fputs() functions and how to use them to our advantage by wrapping each in a more capable function of our own.
Lastly, we took the concepts of sorted names from Chapter 22, Working with Files, and applied them to files using dynamic memory structures to accommodate large and unknown numbers of data elements in sortNames.c. There are many concepts that were employed in sortNames.c, both large and small, from all previous chapters.
We also introduced the concept of multi-file C programs, which we will explore further in Chapter 24, Working with Multi-File Programs. Most of the programs you write will consist of three or more source code files, and so it is imperative to understand those mechanisms.
Questions
- Why did we need to run each program several times?
- If an input filename is specified but the file doesn't exist, can we continue executing our program?
- What is the difference between opening an output file for writing and opening an output file for appending?
- Is it always necessary to handle the final <newline> character when using fgets()?