
Chapter 3: Working with Basic Data Types
Everything in a computer is a sequence of binary digits. C's basic data types enable the compiler to tell the computer how to interpret binary sequences of data. Intrinsic data types are predefined and built into the language.
A binary sequence plus a data type results in a meaningful value. The data type not only leads to a meaningful value, but it also helps you determine what kind of operations on that value make sense. Operations involve manipulating values along with converting or casting a value from one data type into a related data type.
In this chapter, we will cover the following topics:
- Understanding bytes and chunks of data
- Working with whole numbers
- Representing numbers with fractions
- Representing single characters
- Understanding false (or zero) versus true (or anything not exactly zero)
- Understanding how types are implemented on your computer with sizeof()
- Discovering the minimum and maximum values for each type on your computer
Once we have explored C's intrinsic data types in this chapter, we can then use them as building blocks for more complex data representations. This chapter will be the basis for the more complex data representations that we will encounter from Chapter 8, Creating and Using Enumerations, to Chapter 16, Creating and Using More Complex Structures.
Technical requirements
For the remainder of this book, unless otherwise stated, you will continue to use your computer with the following:
- A plain text editor of your choice
- A console, Terminal, or command-line window (depending on your OS)
- The compiler, either GCC or Clang, for your particular OS
For the sake of consistency, it is best if you use the same computer and programming tools. By doing so, you can focus more closely on the details of C on your computer.
The source code for this chapter can be found at https://github.com/PacktPublishing/Learn-C-Programming-Second-Edition/tree/main/Chapter03.
Understanding data types
Everything in a computer is a sequence of binary digits (or bits). A single bit is either off (0) or on (1). Eight bits are strung together to form a byte. A byte is the basic unit of data. Bytes are treated singly, as pairs called 16-bit words, as quadruples to form 32-bit words, or as octets to form 64-bit words. These combinations of sizes of bytes are used in the following ways:
- As instructions for the CPU
- As addresses for the locations of all things in the computer
- As data values
The compiler generates binary instructions from our C statements; therefore, we don't need to deal with these binary instructions since we are writing proper C syntax.
Additionally, we interact with various parts of the computer via the address of that part. Typically, we don't do this directly. For instance, we've discussed how printf() knows how to fetch the data from a function call we make and then move it to the part of the computer that spits it out to the console. We are not, nor should we be, concerned with these addresses, as they could change from computer to computer and from version to version of our operating system.
We will deal with the addresses of some, but not all, things in the computer in Chapter 13, Using Pointers. Again, for the most part, the compiler handles these issues for us.
Both instructions and addresses deal with data. Instructions manipulate data and move it around. Addresses are required for the instructions to be able to fetch the data and then store the data. In between fetching and storing, instructions manipulate it.
Before we get to manipulating data, we need to understand how data is represented and the various considerations for each type of data.
Here is the basic problem. We have a pattern of black and white bits, but what does it mean?

Figure 3.1 – A pattern of black and white bits
To illustrate how a pattern alone might not provide enough information for proper interpretation, let's consider the following sequence. What does 13 mean in this context?

Figure 3.2 – The pattern in the context of numbers
Okay, I know what you are thinking. But wait! Look again. Now, what does 13 mean in this context?

Figure 3.3 – The pattern in the context of letters
Combining both aspects, we can now observe the full spectrum of the problem:
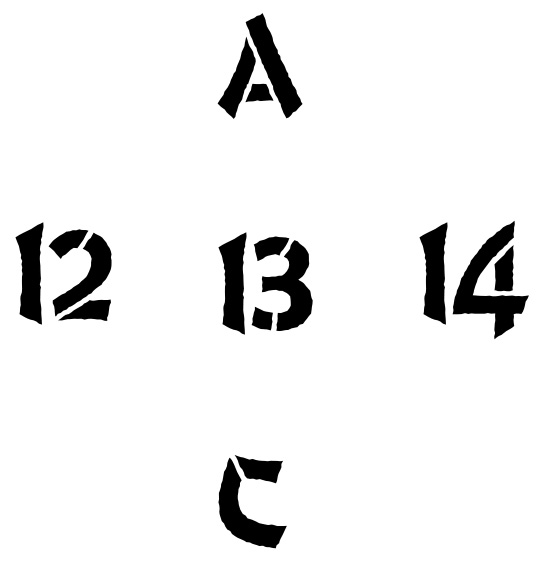
Figure 3.4 – An ambiguous interpretation of the pattern
The central picture is just a two-dimensional pattern of black and white pixels. In one context, the central picture makes sense as the number 13; in another context, the central picture makes more sense as the letter B. We can only resolve the ambiguity of the pixel pattern from its context with other pixel patterns. So, how we interpret the patterns of black and white pixels is entirely dependent upon the context in which we view them.
This is very much like the byte sequences the compiler generates, which the CPU processes. Internally, commands, addresses, and data in the computer are nothing more than sequences of 1s and 0s of various sizes. So, how the computer interprets the patterns of 1s and 0s is entirely dependent upon the context given to them by the computer language and the programmer.
We, as programmers, must provide the guidelines to the compiler, and consequently to the CPU, on how to interpret the sequence. We do this in C by explicitly assigning a data type to the data we want to manipulate. The data type of a value provides the context to correctly interpret a sequence of bits.
C is a strongly typed language. That is, every value must have a type associated with it. It should be noted that some languages infer the type of a piece of data by how it is used. They will also make assumptions about how to convert one data type into another. These are called loosely typed languages. C also does automatic, or implicit, conversions from one type into another, but the rules are fairly specific compared to other programming languages. We can also perform manual, or explicit, conversions with type casting. Type casting is an operation that we might need to do to a value; it will be covered in greater detail in Chapter 5, Exploring Operators and Expressions.
In C, as in most programming languages, there are five basic, and intrinsic, data types. The five basic types are as follows:
- Whole numbers: These numbers can represent a positive-only range of values or a range that includes both positive and negative values.
- Numbers with fractions or decimal numbers: These are all of the numbers between whole numbers, such as ½, ¾, 0.79, and 1.125, as well as other numbers that aren't easily represented using fractions. One such common number is 3.14159, which is a very approximate value for π, or even 3.1415926535897932384626433 – an even more precise but still approximate value for π. Decimal numbers can always include negative values.
- Characters: These are the basis of C strings. Some languages have a separate string type. In C, strings are a special case of arrays of characters – they are not a data type but a special arrangement of contiguous character values. We will begin our encounter with arrays in Chapter 11, Working with Arrays, and then look at strings specifically in Chapter 15, Working with Strings.
- Boolean values: These represent the conditions of YES or NO, or more precisely, TRUE or FALSE. These can be of any size depending on the preference of the compiler and the machine's preferred whole number size.
- Addresses: These are the location of bytes in a computer's memory. C offers the direct addressing of values in memory. Many languages do not allow direct addressing. Pointers will be covered, in full, in Chapter 13, Using Pointers.
Within each of these five types, there are different sizes of types to represent different ranges of values. C has very specific rules about how to convert a given data type into another type. Some are valid, while others make no sense. We will explore all of this in Chapter 4, Using Variables and Assignments.
For now, we need to understand the basic types and the different sizes of values they might represent.
Bytes and chunks of data
The smallest data value in C is a bit. However, bit operations tend to be very expensive and not all that common for most computer problems. In this book, we will not go into bit operations. If you find you need to delve deeper into bit operations in C, please refer to the annotated bibliography in the Appendix for texts that treat this subject more fully.
The basic data value in C is a byte or a sequence of 8 bits. The set of values a byte can represent is 256 or 28 values. These values range from 0 to 255 or 28–1. 0 is a value that must be represented in the set of 256 values; we can't leave that value out. A byte can either represent a positive integer ranging from 0 to 255, or 28–1, or a negative integer ranging from -128 to 127. In either case, there are only 256 unique combinations of 1s and 0s.
While, in our daily routine, most humans don't ordinarily count this high, for a computer, this is a very narrow range of values. A byte is the smallest of the chunks of data since each byte in memory can be addressed directly. Also, a byte is commonly used for alphanumeric characters (similar to those you are now reading) but is not large enough for Unicode characters. American Standard Code for Information Interchange (ASCII) characters, UTF-8, and Unicode characters will be explained in greater detail in Chapter 15, Working with Strings.
Chunks, or bytes, increase in multiples of 2 from 1 byte, 2 bytes, 4 bytes, 8 bytes, and 16 bytes. The following table shows how these could be used:

In the history of computing, there have been various byte ranges for basic computation. The earliest and simplest CPUs used 1-byte integers. These very rapidly developed into 16-bit computers whose address space and largest integer value could be expressed in 2 bytes. As the range of integers increased from 2 to 4, to 8, so too did the range of possible memory addresses and the ranges of floating-point numbers. As the problems that were addressed by computers further expanded, computers themselves expanded. This resulted in more powerful computers with a 4-byte address range and 4-byte integer values. These machines were prevalent from the 1990s to the early part of the 21st century.
Today, most desktop computers are 64-bit computing devices that can address incredibly large numbers of memory and model problems, accounting for all of the atoms in the universe! For problems that require the processing of values that are 128 bytes and higher, very specialized computers have been developed.
You will seldom, if ever, need to consider those astronomically large numbers, but they are necessary to solve mind-bendingly large and complex problems. Nonetheless, what you can do with very small chunks and relatively small ranges of values, you can also do with large ones. It is more important for you to learn how different types are represented and used, regardless of their size.
Notice, in the preceding table, the correlation between the number of bits in a chunk and the exponent in the binary form. Also, notice that the number of bytes is a power of 2: 20, 21, 22, 23, and 24. There are no 3-byte, 5-byte, or 7-byte chunks. They are just not needed.
Additionally, you can observe from the table that the typical use of a chunk is directly related to its size. In C, the machine's preferred whole number size is typically the same as an address. That is, the machine's natural integer size is the count of the largest number of bytes that the machine can address. This is not a hard rule, but it is a common guideline.
Byte allocations and ranges could vary from machine to machine. Embedded computers, tablets, and phones will likely have different sizes for each type than desktop computers or even supercomputers.
Historical Note
Not all computers use this specific combination of bytes. You might encounter some computer systems that employ 24, 36, or even 96 bytes for various representations within their hardware. The C compiler for that computer system will have been adapted for those bit sequences.
Later in this chapter, we'll create the sizes_ranges.c program to confirm and verify the sizes and ranges of integers on your machine. This program will be handy to run whenever you are presented with a new system on which to develop C programs.
Representing whole numbers
The basic whole number type is an integer or just int. Integers can either be positive only, called unsigned, or they can be negative and positive, called signed. As you might expect, the natural use for integers is to count things. You must specify unsigned if you know you will not require negative values.
To be explicit, the default type is signed int, where the signed keyword is optional.
An unsigned integer has 0 as its lowest value; its highest value is when all bits are set to 1. For instance, a single byte value has a possible 256 values, but their range is 0 to 255. This is sometimes called the one-off problem where the starting value for counting is 0 and not 1, as we were taught when we first learned to count. This is a problem because it takes some time for new programmers to adjust their thinking. Until you are comfortable about thinking in this way, the one-off problem will be a common source of confusion and possibly the cause of bugs in your code. We will revisit the need for this kind of thinking when we explore loops (Chapter 7, Exploring Loops and Iterations) and when we work with arrays (Chapter 11, Working with Arrays, and Chapter 12, Working with Multi-Dimensional Arrays) and strings (Chapter 15, Working with Strings).
Representing positive and negative whole numbers
When negative numbers are needed, that is, whole numbers smaller than 0, we specify them with the signed keyword. So, a signed integer will be specified as signed int. The natural use for signed integers is when we want to express a direction relative to zero, either larger or smaller. By default, and without any extra specifiers, integers are signed.
A signed integer uses one of the bits to indicate whether the remaining bits represent a positive or negative number. Typically, this is the most significant bit; the least significant bit is that which represents the value of 1. As with positive whole numbers, a signed integer has the same number of values, but the range is shifted so that half of the values are below 0, or, algebraically speaking, to the left of 0. For instance, a single signed byte has 256 possible values, but their range is from -128 to 127. Remember to count 0 as one of the possible values – hence, the apparent asymmetric range of values (again, there's that pesky one-off problem).
Specifying different sizes of integers
Integers can be specified to have various sizes for their data chunk. The smallest chunk is a single byte. This is called a char type. It is so named for historical reasons. Before Unicode and UTF-8 came along, the full set of English characters, uppercase, lowercase, numbers, punctuation, and certain special characters, could be represented with 256 values. In some languages, a byte is actually called a byte; unfortunately, this is not the case in C.
Here is a list of the basic integer types:
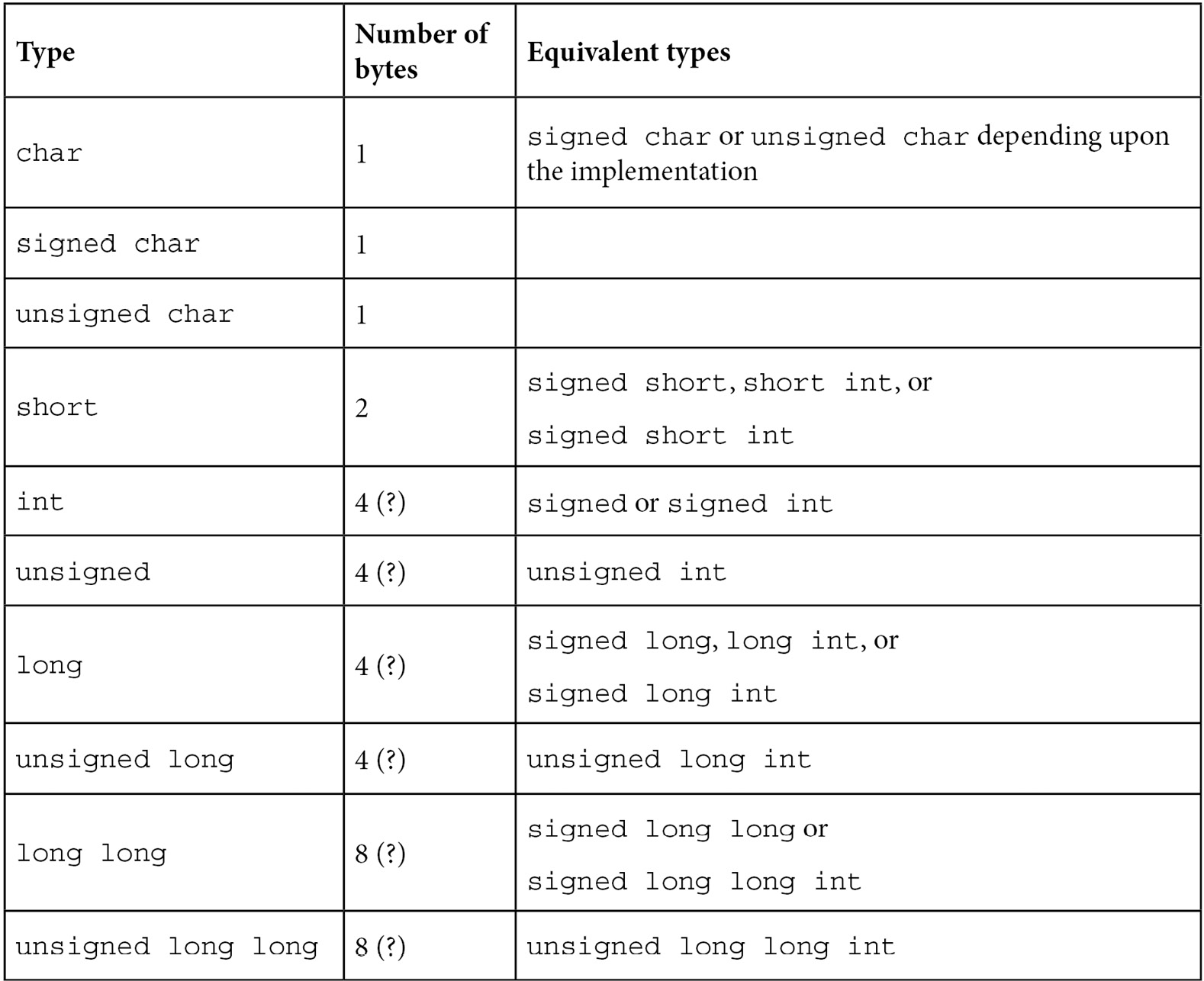
Here are some notes to bear in mind:
- When a signed or unsigned type is specified, the type is guaranteed to be of the specified positive/negative or positive-only ranges. When not specified, the default might be signed.
- The short type is guaranteed to be at least 2 bytes but might be longer depending upon the machine.
- The int, unsigned, long, and unsigned long types are guaranteed to be at least 4 bytes but might be longer depending on the machine.
- The long long and unsigned long long types are guaranteed to be at least 8 bytes but might be longer depending on the machine.
In any implementation, the size of various integer types is left up to the implementor to, essentially, mirror the capabilities of the target CPU. Therefore, the sizes given in the preceding table might not be accurate for every implementation. This makes the portability of C programs unpredictable. To remedy this, C99 added integer types that specify the exact width, the fastest width, and the minimum width of integer values. The basic set of these are of the following forms:
- The int<n>_t or uint<n>_t forms for exact width integer types
- The Int_least<n>_t or uint_least<n>_t forms for the smallest width of an integer (this might be larger)
- The Int_fast<n>_t or uint_fast<n>_t forms for the fastest width for an integer in that implementation
Here, <n> is either 8, 16, 32, or 64.
The values of these types are exactly, or at the very least, that number of bits. There is also intmax_t for the largest possible integer. Such type specifications allow much greater predictability when porting a program from one computer system to a different one with a different possible CPU and operating system. Along with the width of each integer type, there are corresponding minimum and maximum values defined for each type. These types are defined in the somewhat redundant standard library files of stdint.h and inttypes.h.
Do not be too concerned with all of these variations at first. For the most part, you can safely use int until you begin developing programs on a wider variety of hardware where portability is a bigger concern.
While int types represent whole numbers, they are a relatively small set of numbers. The set of numbers between whole numbers – numbers with fractions or decimal numbers – is a much larger set of numbers that requires its own type.
Representing numbers with fractions
Not everything in the world is a whole number. For that, we have numbers with fractions or rational numbers. Rational numbers, represented as p/q where p is the numerator and q is the denominator, are most naturally used to measure things.
A rational number is represented on the computer with the following form:
significand x baseexponent
Here, both the significand and the exponent are signed integers, and the base depends upon the floating-point implementation. The size of each depends on the number of bytes for a given rational number type. There are no unsigned components. This provides a very large range of numbers, from positive to negative, as well as very small fractional values:

Typically, when real numbers are used, either very precise values are desired or the calculations tend to have incredibly large ranges.
Historical Note
Before C23, the floating-point library was implemented with a base 2 significand and the exponent. This is called a binary floating-point system. However, such an implementation might not represent all sets of very small or very large numbers evenly or completely. For this reason, C23 adds the decimal floating-point type where the base for each part is in base 10. This provides a different representation for very small numbers, very large numbers, and numerical distribution. These types are as follows:

For completeness, rational numbers are just one part of the set of real numbers. Real numbers include all rational numbers, irrational numbers, transcendental numbers, such as π, and integers. float, double, and long double represent real numbers with varying ranges and accuracies. The types with larger sizes have greater ranges and precision.
Real numbers exist on a number line. These are contrasted with imaginary numbers, sometimes called complex numbers. They have an imaginary component, which is -11/2, the square root of -1. C99 added the option to manipulate complex numbers by including the Standard Library header, complex.h. These types are as follows:

Because these types are used for very specific kinds of computations, both complex and imaginary types are optional features of the C standard.
Historical Note
In 2008, the C Standards Committee specified a common set of extensions to the C language, known as Embedded C, to address the special needs of embedded systems. Typically, embedded systems are much simpler CPUs, or microprocessors, with very limited memory and I/O designed to perform a single, very limited set of tasks. Embedded C provides consistent program behavior across various embedded environments by specifying fixed-point arithmetic, the management of multiple distinct memory banks, and basic I/O operations. This set of extensions is not addressed in this book.
While we have identified a rather diverse set of representations of numbers with fractions, it is worthwhile noting that float, double, and long double form the most frequently used data types of this group.
Another use for values is to represent alphabetical characters.
Representing single characters
To specify a single character, use char. Typically, the signed char and unsigned char types are not used for single characters but to represent small integer values. C was developed in the time before Unicode and UTF-8. The character set they decided to use was ASCII. All of the necessary characters for printing control, device control, and printable characters and punctuation could be represented in 7 bits.
One reason ASCII was chosen was because of its somewhat logical ordering of uppercase and lowercase letters. An uppercase A and lowercase a are different by only 1 bit. This makes it relatively easy to convert from uppercase into lowercase and vice versa. There is an ASCII table provided for your reference in the Appendix; we also develop a program to print a complete ASCII table in Chapter 15, Working with Strings.
To summarize ASCII's organization, please refer to the following table:

As Unicode, and later UTF-8, were developed and have become standardized, they use 2-byte or 4-byte encodings for the many character sets of the world's languages. 7-bit ASCII codes were incorporated into the lowest 7 bits for backward compatibility with the original ASCII. However, Unicode is not implemented uniformly across all operating systems, whereas UTF-8 is.
Like the set of numbers with fractions, there is a much wider set of character types to reflect the development and use of much larger character sets than just ASCII. As Unicode, and later, UTF-8, were implemented, character types to represent them are available but not presented here. Unicode and UTF-8, both beyond the scope of this book, are briefly explored in the Appendix.
There is another integer value that is very widely used and that has such a specific meaning, it has been given its own type. That is the Boolean type. Another reason it is a unique type is that it can be implemented in many different ways on different systems. We'll discuss this in greater detail next.
Representing Boolean true/false
A Boolean value is one that evaluates to true or false. On some systems, YES and yes are equivalent to true, while NO and no are equivalent to false. For instance, Is today Wednesday? evaluates to true only 1 out of 7 days. On the other 6 days, it evaluates to false.
Before C99, there was no explicit type for a Boolean. A value of any type that is 0 (exactly 0) is considered as also evaluating to a Boolean false. Any value other than exactly 0 (a bit pattern of only 0s) will evaluate to a Boolean value of true. Real numbers rarely, if ever, evaluate exactly to 0, especially after any kind of operation on them. Therefore, these data types would almost always evaluate to true and, hence, would be poor choices as a Boolean substitute.
Since C99, a _Bool type was added, which, when evaluated, will always evaluate to only 0 or 1. When we include the stdbool.h file, we are able to use the bool type as well; this is a bit cleaner than using the cumbersome _Bool type. Also, in stdbool.h, true and false are defined. Any value of the _Bool type will only ever have a value of either 1 (true) or 0 (false) regardless of the value from which it is assigned.
As a general rule, it is always more reliable to test for zero-ness, or false, than to rely on the compiler's implementation for interpreting Boolean true values from other types.
We will delay our discussion of pointer types until Chapter 13, Using Pointers. Now that we know about the other four intrinsic data types, we can explore their sizes and ranges of values.
Understanding the sizes of data types
As discussed earlier, the number of bytes that a type uses is directly related to the range of values it can hold. Up to this point, this has all been necessarily theoretical. Now, let's write a program to demonstrate what we've been exploring.
While we are focusing exclusively on the C standard, we need to be aware that the standard allows for quite a bit of discretion on the part of any compiler implementor. This is necessary because not all CPUs have the same architecture, nor do they all have the same capabilities. Nor should they. Also, compilers are implemented by humans trying to interpret complex standards documents. Humans, despite our best intentions, might not perfectly conform to the standard.
In this light, it is critical to understand the behavior of your compiler on your system. Here and throughout the book, we emphasize the trust but verify principle so that we are not surprised when things do not work as we expect. Many of the programs we present should become a part of your "testing toolbox" when you are given a new system (hardware or compiler) to work with.
C provides a way for programmers to ascertain the sizes of each of the data types on a given system with the sizeof() operator.
The sizeof() operator
The sizeof() operator is a built-in function that takes a C data type as its parameter and returns the number of bytes for that data type. Any programmer needs to know the sizes of the data types on a given system to ensure the data type used will appropriately hold the range of values they expect to encounter. Let's write a program to discover how sizeof() works.
In the first part, we'll set up the necessary include files, declare the function prototypes, and create our main() function. Even though we show this program in two parts, it is really just a single file. The following program, sizes_ranges1.c, shows the first part of our program:
#include <stdio.h>
#include <stdint.h>
#include <stdbool.h>
// function prototypes
void printSizes( void );
int main( void )
{printSizes();
}
Here, the header file, stdio.h, is included, as are two new header files: stdint.h and stdbool.h. Recall that stdio.h declares, among other things, the function prototype for printf(). stdint.h declares the sizes, in bytes, of each of the intrinsic data types. stdbool.h defines the bool data type and the true and false values. These are part of the C Standard Library. We will encounter several other C Standard Library files, but not all of them. All of them are listed, along with a brief description of their purpose, in the Appendix. We will learn a great deal more about header files in Chapter 24, Working with Multi-File Programs.
As you can see, we call a function that has been declared, or prototyped, but has not yet been defined. Let's define it in the next section of the program:
{printf( "Size of C data types " );
printf( "Type Bytes " );
printf( "char %lu " , sizeof( char ) );
printf( "int8_t %lu " , sizeof( int8_t ) );
printf( "uint8_t %lu " , sizeof( uint8_t ) );
printf( "short %lu " , sizeof( short ) );
printf( "int16_t %lu " , sizeof( int16_t ) );
printf( "uint16_t %lu " , sizeof( uint16_t ) );
printf( "int %lu " , sizeof( int ) );
printf( "unsigned %lu " , sizeof( unsigned ) );
printf( "long %lu " , sizeof( long ) );
printf( "unsigned long %lu " , sizeof( unsigned long ) );
printf( "int32_t %lu " , sizeof( int32_t ) );
printf( "uint32_t %lu " , sizeof( uint32_t ) );
printf( "long long %lu " , sizeof( long long ) );
printf( "int64_t %lu " , sizeof( int64_t ) );
printf( "unsigned long long %lu " , sizeof( unsigned long long ));
printf( "uint64_t %lu " , sizeof( uint64_t ) );
printf( " " );
printf( "float %lu " , sizeof( float ) );
printf( "double %lu " , sizeof( double ) );
printf( "long double %lu " , sizeof( long double ) );
printf( " " );
printf( "bool %lu " , sizeof( bool ) );
printf( "_Bool %lu " , sizeof( _Bool ) );
printf( " " );
}
In this program, we need to include the header file, <stdint.h>, which defines the fixed-width integer types. If you omit this include, you'll get a few errors. Try doing that – comment out the include line and see what happens.
To get the new bool definition, we also have to include <stdbool.h>. But what happens if you omit that file?
The return type of sizeof() on my system is size_t; this is analogous to an unsigned long type. (We will learn how this is done in Chapter 10, Creating Custom Data Types with typedef.) To print this value properly, we use the format specifier of %lu to properly print out a value of that type.
On my system, I get the following output:

Figure 3.5 – Output from printSizes()
On my 64-bit operating system, a pointer is 8 bytes (64 bits). So, too, are the long and unsigned long types.
So, how do the values reported by your system differ from these?
For a given computer system, not only do the sizes of data types need to be provided, but also the range of possible values for each data type. These ranges are defined by the compiler maker in other header files.
Ranges of values
Let's extend this program to provide the ranges for each data type. While we could compute these values ourselves, they are defined in two header files: limits.h for integer limits and float.h for real number limits. To implement this, we add another function prototype, add a call to that function from within main(), and then define the function to print out the ranges. In the printRanges() function, we use the fixed-width types to avoid variations from system to system.
Let's add another function. In the following code, the additional include directives and function prototype are highlighted:
#include <stdio.h>
#include <stdint.h>
#include <limits.h>
#include <float.h>
// function prototypes
void printRanges( void );
int main( void ) {printRanges();
}
Now that we have the printRanges() prototype, let's add its definition. The printSizes() function is unchanged:
void printRanges( void ) {printf( "Ranges for integer data types in C " );
printf( "int8_t %20d %20d " , SCHAR_MIN , SCHAR_MAX );
printf( "int16_t %20d %20d " , SHRT_MIN , SHRT_MAX );
printf( "int32_t %20d %20d " , INT_MIN , INT_MAX );
printf( "int64_t %20lld %20lld " , LLONG_MIN , LLONG_MAX );
printf( "uint8_t %20d %20d " , 0 , UCHAR_MAX );
printf( "uint16_t %20d %20d " , 0 , USHRT_MAX );
printf( "uint32_t %20d %20u " , 0 , UINT_MAX );
printf( "uint64_t %20d %20llu " , 0 , ULLONG_MAX );
printf( " " );
printf( "Ranges for real number data types in C " );
printf( "float %14.7g %14.7g " , FLT_MIN , FLT_MAX );
printf( "double %14.7g %14.7g " , DBL_MIN , DBL_MAX );
printf( "long double %14.7Lg %14.7Lg " , LDBL_MIN , LDBL_MAX );
printf( " " );
}
Some of the numbers that appear after % in the format specifier string might appear mysterious. These will be explained in exhaustive detail in Chapter 19, Exploring Formatted Output. The result of the added function should appear as follows, in addition to what we had before:

Figure 3.6 – Output from printRanges()
So, how do the values from your system compare?
Source code formatting guidelines used in this book:
These are guidelines, not hard and fast rules. They are intended to make the code easy to read and understand.
• 2 spaces for each indentation level.
• No space between complex statements—if( for(, while(, do(-- and opening(.
• Single space after opening ( and before closing ) in complex statements.
• Single space before and after each , of function parameters (if line is not too long; these can be removed).
• No space before ; (end of statement).
• Vertical alignment of comments on multiple lines.
• Vertical alignment of variable names in multiple declarations.
• If function parameters exceed a single line, generally, the 2nd line of the function parameter is indented to 1st parameter on preceding line, otherwise, it is indented 2 spaces from function identifier.
• As much as possible, printf() format specifiers are on a single line (see previous guide).
• Long printf() format specifiers can be broken into shorter lines with " ending one line, and " beginning again on the next line (with indentation).
• Opening { are at the end of the line while closing } on a line by themselves.
• Other formatting options are described in the text as they occur.
Be aware that there may be line breaks in the source code text that may cause your code to not compile. Refer to the source code in the repository for proper line breaks, in that case.
Summary
Again, whew!
In this chapter, there were a lot of details about data types, chunk sizes, and value ranges. The key idea from this chapter is to remember that there are only really five data types: integers, real numbers, characters, Booleans, and pointers. Additionally, characters and Booleans can be considered special cases of integers. The fifth type, the pointer, is really just another special case of an integer, but with some specialized operations and implicit behavior.
In the next chapter, we will explore how to use these different types of values when we create and assign values.
Questions
- Identify the four intrinsic types we have encountered (ignore the fifth type, pointers, for now).
- For each of the four intrinsic types, identify each sub-type.
- Why is the size of a data type important?