
6
Cloud Storage
In this chapter, we are going to explore the storage options that are offered by AWS and contrast them with what you may be using on-premise. By the end of this chapter, you will understand the choices available for storing your precious data in the AWS cloud. There are many storage options available at AWS. In fact, most of the storage options could not be replicated on-premise; they’re simply too large and durable.
Picking the right storage solution involves some learning and testing on your part and will most certainly involve an element of change, and of trust. And, as we all know, changing something that isn’t broke is usually hard to do. In the past, you may have always selected network-attached storage (NAS) or spun up a particular version of relational database without thinking about any other storage possibilities because there weren’t any other choices available.
The reality faced today by companies that have not yet moved to the public cloud is that you’re probably close to running out of local network storage. If you’re not yet at a crisis regarding available storage, you’re going to be. Some companies have made the decision that applications that are hosted in the cloud, and the associated storage for the application data, has to be in the cloud due to latency issues. The application is too far away from the local data store. Some companies have decided that certain data records are never going to be moved to the cloud due to compliance issues. Other companies just have a general overall uneasy feeling about losing complete control of where and how their data is stored.
AWS has made great strides in providing storage solutions for companies that want to work in a hybrid mode of operation, where some data will be stored on-premise because of security concerns, rules, and regulations. Amazon has figured out that some customers, such as financial customers, are not allowed to move certain data resources to the cloud. For these types of customers, the hybrid cloud is here to stay. Therefore, create services that allow customers to decide what they want or are allowed to do: store data in the AWS cloud, or access data from their on-premise cloud storage arrays. The reality is, if you connect to AWS with a fast Direct Connect connection of 10 Gbps, the choice of location is yours to make. However, many companies, once they get comfortable with AWS, end up moving their data records to the cloud.
The overall goal of this chapter is to present enough information about the storage option at AWS to allow you to make an informed decision about the available storage options and the data transfer options available at AWS. After all, if you have lots of data and you’re running out of space, you probably want to know how to move that data to the AWS cloud or back on-premise.
The topics for this chapter include these:
File systems—For both Windows (FSx) and Linux (elastic file system [EFS])
EBS—Elastic block storage for Elastic Compute Cloud (EC2) instances
S3—The Simple Storage Service and S3 Glacier: unlimited object storage for static assets and archived storage
RDS—Managed relational database service solutions
Aurora—AWS’s favorite relational database solution for MySQL and PostgreSQL-compatible databases
DynamoDB—A horizontally scalable transactional database service
ElastiCache—In-memory storage solutions
Data transfer options—How to move data to and from the AWS cloud
Note
Certainly, some crown jewels will not be moving to the cloud. Amazon has thought about this reality and is offering a variety of hybrid storage offerings.
At Terra Firma, the cloud will be used for many different types of data records:
Database instances for relational databases such as MySQL for storing the human resources department’s records
Developers who want to explore using DynamoDB for newer applications that don’t need complicated queries
Application caching that was held in RAM for databases and for the caching of user sessions
Archival storage for documentation that needs to be stored somewhere and possibly never read again
Unlimited cloud storage with automated lifecycle rules to ensure cost-effective storage
Shared storage for Linux and Windows applications needing access to the same files
Backups of database and computer instance boot drives and data volumes
Cloud Storage
When you think about what is stored in the cloud, certainly personal records take the prize for the largest amount of storage being used. Corporations and software as a service (SaaS) applications are increasingly using the cloud to store vast quantities of data for everyday tasks like Word and Excel files, machine learning, online gaming results, and anything else you can think of. The reality is that your storage totals in the public cloud will only grow and not shrink. Therefore, the cheap advertised price of storage will get more expensive over time as you hang onto your data records, typically for a long period of time. Out-of-sight data records become expensive to store over time.
Just think of taking a picture with your phone. It’s probably synchronized to store that picture with a public cloud storage service. Billions of pictures are uploaded to the cloud daily. And we’ve all heard about Big Data, which we could summarize as a lot of data that needs to be analyzed for metadata patterns. Some customers have trillions of objects stored in Amazon S3 object storage.
At AWS, there is a wide breadth of storage options—namely, block, object, and file storage—that are similar but not the same as your on-premise storage options shown in Figure 6-1.
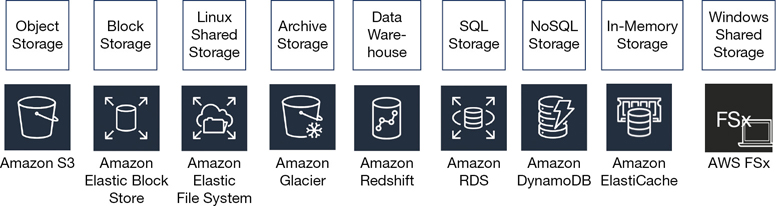
Amazon EFS—Shared scalable file service accessed through a simple interface for multiple EC2 instances at the same time. Data is stored natively as files in a directory tree that is shared over your selected virtual private cloud (VPC) subnets. EFS data records can be accessed by multiple Linux clients at the same time over AWS’s private network using the common protocol NFS 4.x. EFS is as close as we can get to a hosted NAS solution at AWS.
Amazon ElastiCache—In-memory store managed services supporting Memcached and Redis designs.
Object—Object storage at AWS is called Amazon S3. S3 is the Simple Storage Service, and its companion, S3 Glacier, is the archiving component. Each file is defined as an object that is stored in a bucket, and each file is identified by a unique key. The S3 storage array can be thought of as just a great big room—a flat file space where the objects are accessed and managed through simple application programming interface (API) calls, such as GET and PUT requests. The original design for S3 was for accessing content across the Internet. S3 is fast, scalable, durable, and extremely cost-effective cloud storage designed as a static file storage object service. When a file is stored in S3, the entire file is uploaded. When changes to the file are uploaded, the entire file is replaced. S3 is useful for hosting a website’s static content, media files, storage for big data analytics, and archiving records in long-term storage vaults in S3 Glacier. Amazon uses S3 storage to store everything: snapshots, logs, reports, and backups. Everything ends up in S3 storage.
Block storage—Block storage at AWS is called elastic block storage (EBS), or ephemeral storage. Amazon EBS storage arrays are built using solid-state drives (SSDs) or hard disk drive (HDDs) to provide persistent block storage at both slower to faster speeds that are only accessible across the private AWS network. Enabling direct public access to the EBS storage is not possible.
Both Windows and Linux use block disk volumes at AWS presenting block data in the file system format understood by each operating system to applications or directly to the end user. Each EBS volume can be attached to only one EC2 instance at a time.
Many EC2 instance families also include local storage volumes, called ephemeral storage (block storage). Because ephemeral storage, also called instance storage, is actually a local SSD hard drive located on the bare-metal server that hosts the EC2 instance, it’s incredibly fast, but it has no long-term durability. Local instance block storage is designed to be temporary storage only; it can survive an instance reboot but is discarded when an EC2 instance is powered off or fails.
Amazon RDS—Relational database service for a variety of popular database engines including Oracle, SQL Server, MySQL, PostgreSQL, and MariaDB. Behind the scenes, RDS uses EBS volumes when building database instances and stores snapshots in S3 storage.
Amazon FSx for Windows File Server—Fully managed native Microsoft Windows storage with the familiar Windows file shares built with SSD storage on Windows servers. It has full support for the New Technology File System (NTFS) and Server Message Block (SMB) protocols, the Distributed File System (DFS), and integration with existing Active Directory environments.
Amazon FSx for Lustre—Designed for high-speed analysis of high-performance computing (HPC), machine learning, and media processing workflows that store their data in S3. FSx for Lustre provides extreme data processing up to hundreds of Gbps throughput with millions of input/output per second (IOPS) at low latency. FSx for Lustre is integrated with S3 storage, allowing data stored in S3 to be moved to FSx for processing. Then the results are written back to S3.
Which Storage Matches Your Workload?
Before choosing a storage solution at AWS, there’s work to be done on your end. Your application, your operating system, your performance, and your data storage needs dictate what storage solution or solutions to consider using. Review the chart shown in Table 6-1 as a starting point for reviewing how you are currently using on-premise storage compared with what you can do in the AWS cloud.
Table 6-1 Discussion Points for Storage Needs
Storage Considerations |
Details |
|---|---|
Operating system |
Linux and Windows are the supported operating systems at AWS. Windows can support EBS volumes, S3 storage, and Amazon FSx. Linux can use S3, EBS, and EFS. For obtaining the best performance possible from EFS, your Linux distribution and kernel should be current. |
File-sharing protocol |
Amazon EFS uses NFSv4; Windows uses SMB, which is compatible with Amazon FSx. |
Performance |
How fast, predictable, or unpredictable does your storage burst need to be? Each type of application has different requirements. Except for S3, storage solutions at AWS are designed to handle sudden burst requirements. |
Compliance |
You may have external requirements you need to follow (Payment Card Industry (PCI), FedRAMP, or internal rules and regulations. Cloud solutions at AWS have achieved various levels of compliance. The question worth considering is this: Are you in control of your data if all the copies of your data are stored in the cloud? |
Capacity |
What are your daily, monthly, and yearly requirements? What about in two years? Five years? |
Encryption |
What needs to be encrypted for compliance? Data records at rest, or data in transit across the network. |
Clients |
How many clients are going to be accessing the file system at the same time? |
Input/output (I/O) requirements |
What is the percentage of reading and of writing files? Is it balanced or unbalanced? |
Number of files |
How many files will you be storing in the cloud daily, weekly, or long term? |
Current file design |
How many subdirectories deep is your file tree? Is it an efficient design to continue? |
File size per directory |
What is the smallest file size per directory? What’s the largest file size? |
Throughput on-premise |
What is your average throughput on-premise? Are you expecting higher levels of performance in the cloud? Are there specific IOPS requirements? |
Latency |
What can your application live with in terms of overall latency? |
EBS Block Storage
You probably have a storage area network (SAN) providing block-level storage to multiple clients connected to a virtual SAN storage array. You may also still have a separate SAN network running across fiber channel or iSCSI protocols that present the logical unit numbers (LUNs) as hard disks to each client. AWS also has block storage that can be chunked into virtual volumes called EBS volumes. They have a variety of hard drives you can choose from and a variety of speeds, but there is no fiber channel or iSCSI offerings at the customer level.
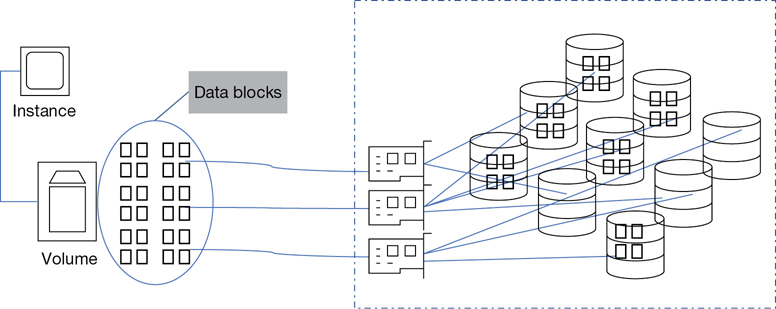
EBS is a block storage service that is accessed only across the private AWS network. Each EBS volume is equivalent to what you think of as a virtual hard disk and can be thought of as an independent storage resource; EBS volumes do not have to be attached to an instance to persist.
When you create an EBS volume, the blocks for the volume are spread across multiple storage arrays, providing a high level of redundancy and durability. Once EBS volumes are created, they are stored within the same availability zone (AZ) where your instances reside, as shown in Figure 6-2, and they provide 99.99 availability. Each single EBS volume can be attached or detached to and from any EC2 instance located in the AZ where it is stored; in addition, multiple EBS volumes can be attached to a single instance at a time.
Note
EBS boot and data volumes should always be separated. Never store data records on the boot drive of an instance.
EBS Volume Types
Several EBS volume types are available depending on your use case. Your decisions for the type of EBS volume chosen will obviously depend on your workload. Different workloads will have different performance needs. For example, different IOPS or throughput needs can be selected for database storage volumes, choosing volumes for boot volumes, or for storage that is not accessed frequently. The general storage requirements for a boot volume will probably not need to be as fast or as large as a data drive for a database instance. In the EBS storage world, there are several choices:
General-Purpose SSD volumes provide a baseline of 3 IOPS per GB with a minimum speed of 100 IOPS that can burst to 3,000 IOPS.
Provisioned IOPS SSD volumes have a maximum IOPS from 100 to 64,000 IOPS.
Throughput Optimized HDD volumes provide good throughput performance for sequential I/O of 40 MBs per TB.
Cold HHD volumes have a baseline of 12 MB/s per TB.
Magnetic HDD volumes average 100 IOPS.
Note
For AWS customers, EBS volumes are used to create boot instances and are typically used as data drives for other customer-built application solutions that involve EC2 instances such as RDS, EMR, ElastiCache, or the data warehousing solution Redshift. Other than these examples, EBS should not always be chosen for storage without considering EFS and FSx or S3. These storage options have no capacity limitations and should be strongly considered for data storage for records that are not being stored in a database. AWS managed service storage solutions use EBS drives in the background (S3 storage arrays, DynamoDB and EFS, and FSx). We just don’t have direct access to the EBS volumes.
General-Purpose SSD (gp2)
The baseline for a general-purpose SSD is designed with a minimum baseline of 100 to 10,000 IOPS with an average of 3 IOPS per GB. Volumes up to 1 TB can burst up to 3,000 IOPS. Volumes larger than 3,000 GB have a baseline of 10,000 IOPS. Bursting is for a use case where applications have periods of idle time followed by periods of high IOPS. The smallest gp2 drive can burst to 3000 IOPS while maintaining a single-digit millisecond latency with throughput up to 160 MB/s.
All EBS storage volumes that support bursting use a burst token bucket design, as shown in Figure 6-3. During quiet idle times, each gp2 volume accumulates burst tokens at a rate of 3 IOPS per GB per second. When the drive needs additional performance using the acquired burst tokens, it can burst up to 3,000 IOPS per second. As your EBS volumes gets larger, your volume is assigned additional burst credits, allowing the drive to burst for a longer time frame. For example, a 300 GB volume can burst up to 40 minutes, 500 GB volumes can burst for almost an hour, and even larger 900 GB volumes can burst for almost 10 hours.

For cold storage and throughput-optimized volumes, burst credits are always accumulating based on the size of the drive. A storage-optimized volume accumulates 40 MB/s per TB; a cold storage volume accumulates 12 MB per TB. Proper testing of your applications is required to know if your data transfer requirements are going to be sequential or random in nature.
For example, if you have a large sequential workload working for three hours on a throughput optimized volume, approximately 5.4 TB of data will be transferred.
If your workload is random in nature, using the same drive in the same working timeframe of three hours, 87 GB of data will be transferred.
Keep in mind that the maximum data transfer speeds are only going to be achieved with modern instances with the latest versions of Windows or Linux.
Note
To do your workload testing on a Linux system, you could use the utility iostat. For Windows systems, use Perfmon. The results will be displayed in sectors. You will then need to know the number of bytes you’re using per sector and multiply the sectors by the number of bytes to come up with the current workload size.
Provisioned IOPS (io1)
EBS volumes, defined as provisioned IOPS, are available from 100 to 64,000 IOPS with throughput up to 320 MB/s. io1 drives are designed for applications and databases that require sustained IOPS. Capacity ranges from 4 GB to 16 TB have a much more consistent single-digit millisecond latency than the general-purpose SSD drives. When you select your IOPS target, AWS hits your target more than 99.9% of the time. For Terra Firma database servers, provisioned IOPS will certainly be a consideration.
Note
You also need to make sure to match your application with its required bandwidth needs regarding storage. If a 2 TB volume is attached to a c4.large instance with a 16 KB workload, the GP2 volume functions close to 6,000 IOPS. Moving to a c4.2xlarge, which has double the dedicated EBS bandwidth, means that your storage bandwidth is increased to 8,000 IOPS.
Ordering storage-optimized EC2 instances provides even higher levels of storage and network throughput than provisioned IOPS EBS drives, as shown in Table 6-2. This additional performance is because storage-optimized instances include local ephemeral storage devices that have much higher random I/O performance and low latency due to the use of directed attached local NVM Express (NVMe) SSD drives utilizing flash storage. In addition, network bandwidth streams are separated from the application bandwidth. For instances hosted by the Nitro hypervisor, the separation of data and network communication channels is enabled by default.
Table 6-2 Increasing Performance with NVMe SSD Drives
Bare-Metal Instance Size |
100% Random Read IOPS |
Write IOPS |
|---|---|---|
i3.large |
100,125 |
35,000 |
i3.xlarge |
206,250 |
70,000 |
i3.2xlarge |
412,500 |
180,000 |
i3.4xlarge |
825,000 |
360,000 |
i3.8xlarge |
1.65 million |
720,000 |
i3.16xlarge |
3.3 million |
1.4 million |
If you need more speed and you want the security of persistent EBS volumes, you can choose to stripe your data volumes together. However, avoid using Redundant Array of Independent Disks (RAID) for redundancy because EBS data volumes are already replicated at the back end. RAID 5 designs using EBS volumes also lose 20% to 30% of usable I/O because of parity checks. However, if your needs are less than what is offered for throughput by storage optimized instances, EBS volume choices should be compared regarding throughput, performance, and cost.
Throughput-optimized volumes—What if overall throughput is more important than high-speed IOPS? Are you looking at small blocks with random I/O, or larger blocks with sequential I/O? For smaller blocks with random I/O requirements, you should first start testing with the general-purpose SSD. However, if you require more than 1,750 MB/s of throughput, you should consider the D2 instance family. Keep in mind that we’re back to looking at ephemeral volume stores instead of persistent EBS storage.
Throughput performance—Consider the throughput-provisioned volumes, which are magnetic drives with a baseline throughput of 40 MB/s up to 500 MB/s. They can also burst at 250 MB/s per TB up to 500 MB/s per volume. The maximum capacity for all block volumes is 16 TB, but the smallest throughput volumes start at 500 GB. These are useful to consider for large block, high-throughput sequential workloads like Hadoop and MapReduce.
Magnetic HDD—If cost is your main concern, the other choice offered is defined as a cold magnetic drive. Applications associated with this type of platter don’t require a high-performance baseline—just storage and cheap cost. Magnetic drives have a much lower baseline of 12 MB/s per TB up to 192 MB/s, with the ability to burst from 80 MB/s up to 250 MB/s per volume. Magnetic drives are ideal for applications that require some throughput but with lower specifications.
Note
EBS volumes have 5 9s reliability for service availability. For durability, the annual failure rate of EBS volumes is between .1% and .2% compared to 3% for commodity hard drives in the industry. If you have 1,000 EBS volumes, you could potentially expect 1 to 2 of those volumes to fail per year.
Elastic EBS Volumes
EBS volumes are an elastic volume service that allows you to increase or change the current volume size and to increase or decrease the provisioned IOPS in real time, as shown in Figure 6-4. There is no maintenance window required when manually scaling volumes. Elastic volumes can also provide cost savings because you do not have to overprovision your storage volumes by planning for future growth; instead, monitor your volumes with CloudWatch metrics, and make changes when necessary.
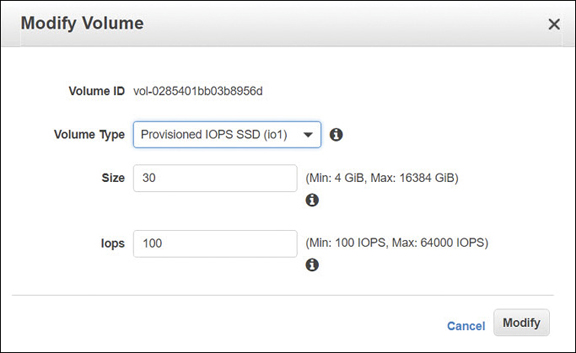
Attaching an EBS Volume
When an EBS volume is attached to an instance, a couple background processes begin running, depending on the hypervisor being used to host the instance:
Instances hosted on the Xen hypervisor—These are associated with a system component called an I/O domain. When an EBS volume is attached, it is attached to the I/O domain. Another system component, called a shared memory segment, is set up at the hypervisor level acting as a queue to handle data access from the instance to the EBS volume.
When your instance wants to perform an I/O call, it first submits a system call to the kernel. Assuming it’s a read request, a block of data is placed in the hypervisor queue. Next, the I/O domain takes the data from the hypervisor queue and sends it to another storage queue, which delivers the data blocks to the EBS volume.
Instances hosted on the Nitro hypervisor—A PCI interface is now used to directly interface with the EBS volume. EBS volumes are attached directly to the Nitro card, which presents a direct storage interface to the EC2 instance. Storage requests are submitted directly to the PCI interface; the Nitro hypervisor has no part to play in communication with EBS storage volumes. This provides a huge performance impact with minimal latency when compared to instances hosted on the Xen hypervisor.
To access the companion videos, register your book at informit.com/register.
Note
The cost for provisioning any of the available EBS volume types is a per-month storage charge based on the number of used GB prorated down to the second. General-purpose solid-state drive (SSD) volumes are charged at $.10 per GB.
Provisioned IOPS volumes are charged at 12.5 cents per GB plus a $0.65 charge per provisioned IOPS.
Throughput volumes range from $0.25 to $0.45 per GB depending on the volume type selected.
Snapshots can be created from any type of EBS volume, and the storage charge for the snapshots is $.05 per GB per month.
EBS Volume Encryption
Both EBS boot and data volumes can be encrypted; the encryption of each volume is performed using separate encryption keys. Note that both encrypted and unencrypted volumes can be attached to the same EC2 instance at the same time. The encryption of EBS volumes is supported by most instances, including the c4, i2, i3, m3, m4, r3, and r4 families. Encryption is no longer a performance issue for EC2 instances hosted on the Nitro hypervisor because the encryption process has been offloaded to custom chipsets on the host, bare-metal server. However, if you choose to use a third-party software encryption process running on an instance rather than the AWS encryption process, the instance’s CPU will have to perform the encryption process at the application level, creating a potential performance issue.
Note
Data encrypted by the EBS encryption process is encrypted before it crosses the network. It also remains encrypted in-flight and at rest and remains encrypted when a snapshot is created of the encrypted volume.
The customer master key used in encryption can be used by all identity and access management (IAM) users of the AWS account once they have been added as key users in the key management service (KMS) console, as shown in Figure 6-5. The customer master key shown in Figure 6-5 protects all the other keys issued for data encryption and decryption of your EBS volumes within your AWS account. All AWS-issued customer master keys are protected by envelope encryption, meaning that AWS is responsible for creating and protecting the “envelope” containing the master keys of all AWS accounts.
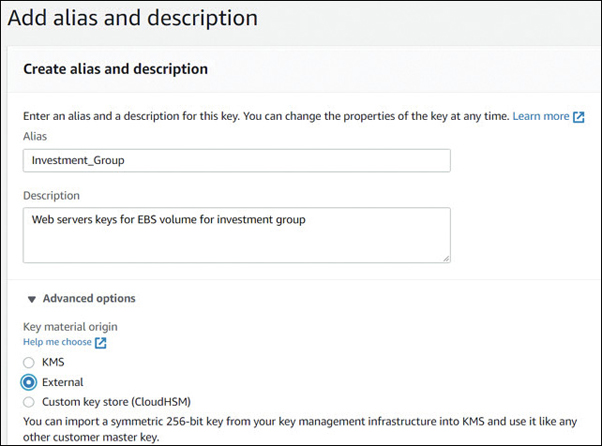
After enabling your customer-managed key using the KMS for your AWS account, for additional security, it’s a good idea to add another key administrator and to enable key rotation of your customer master key. You can also control the additional users in your account who can use each KMS key for encryption and decryption services. Terra Firma decided to use the KMS provided by AWS, create an additional administrator, and enable key rotation of its customer master key.
EBS Snapshots
An EBS snapshot is a point-in-time copy of your EBS volume that is stored in S3 object storage. Because S3 storage is designed for 11 9s durability, your snapshot is safely stored.
The first time a snapshot is taken, every modified block of the EBS volume is part of the master snapshot that is captured and stored in S3. Every additional snapshot from this point forward is defined as an incremental snapshot that records the changes since the last snapshot. Only the blocks that you’ve written and changed are pushed to the snapshot. When you delete a snapshot, only data that is exclusive to that snapshot copy is deleted.
Note
Deploying a daily snapshot schedule greatly reduces the possibility of data loss. AWS has two options for managing snapshots. First, the Data Lifecycle manager allows you to schedule the creation and deletion of EBS snapshots. Second, AWS Backup allows you even more control of your storage by allowing you to centrally manage EBS, RDS, and Storage Gateway snapshots and EFS and DynamoDB backups.
Taking a snapshot from a Linux instance—After starting a snapshot, the snapshot process continues in the background. If there have not been a large number of blocks changed, the process may be quick. If there have been many changes, the process could take several hours to complete. The first thing that you should do before beginning the snapshot process for a boot volume is to quiesce the drive; this means to stop ongoing I/O processes and write all data records currently cached in memory to the volume. You could execute either the sync or the fsfreeze command directly on the EBS volume to quiet the file system. However, the safest method to stop I/O is to simply unmount the drive. After starting the snapshot process, as shown in Figure 6-6, you receive a snapshot ID, which is your confirmation from AWS that the snapshot parameters are confirmed, and the snapshot is being taken in the background.

Taking a snapshot from a Windows instance—For Windows systems, you can use the sync utility to quiesce the file system and then perform the snapshot. Windows also has a built-in operating system service utility called the volume shadow copy service (VSS) that can be used to take application-consistent snapshots. The Simple Service Manager (SSM) now integrates with the Windows VSS, and commands such as ec2-createVSSSnapshot can be executed to create snapshots of Windows applications. The latest Windows Server image (AMI) 2017.11.21 and higher includes the SMM VSS snapshot utilities.
What can we do with snapshots?
Within a region—Snapshots can be used to create an EBS volume within any AZ in the region. Remember: VPCs can span all AZs within the region.
To another region—Using the EBS copy utility, snapshots can be copied to another AWS region, which allows you to prestage, or quickly set up a disaster recovery site in another geographical AWS region.
For automating snapshots—You can use the Amazon EC2 Run command and tags to build your own custom snapshot management system that sets parameters for daily or weekly snapshots and snapshot retention.
Rebuild instances—If the snapshot is a boot drive, you can use it to create a new EC2 instance.
Rebuild a database—If the snapshot is a database instance, you can use it to create a new database instance.
Create volumes—Snapshots can be used to create new EBS volumes.
Tagging EBS Volumes and Snapshots
The one process you should make part of your company’s mandated workflow is the creation of tags when you create AWS resources. Each tag is a key-value pair, and fifty individual tags can typically be created for each AWS resource. Tags can be used for automation, analysis, reporting, compliance checks, and billing to control the creation of a resource. Custom tags can be used for many reasons, including the following examples:
Tags on creation—Tags can be created for EBS volumes at the time of creation.
Cost allocation tags—These allow you to have visibility into your actual snapshot storage costs. In the billing dashboard, selecting Cost Allocation Tags, as shown in Figure 6-7, is where you select and activate tags that can be used for the billing process. Reports and budgets can then be generated, which allows you to view the costs and the usage, broken down by the assigned tags. Alerts can also be created for resources that have been tagged when costs have exceeded 50% of the budget.
Enforced tags—IAM security policies can enforce the use of specific tags on EBS volumes and control who can create tags.
Resource-level permissions—Neither the CreateTags nor the DeleteTags functions can be controlled by IAM resource-level permissions that mandate that EBS volumes be encrypted.
Managed services—AWS Config, AWS Inspector, S3 Inventory, Lambda, AWS Budgets, and Cost Explorer are services that require tags for identification purposes.
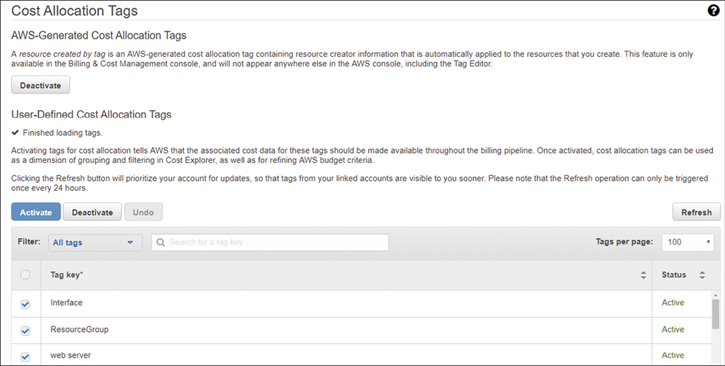
Figure 6-7 Cost allocation tags
EBS Best Practices
There are many best practices for managing your EBS volumes; here are several that apply to every use case:
Create a schedule using AWS Backup to back up your attached EBS volumes with EBS snapshots.
Don’t store data records on your root EBS boot volumes.
Use separate EBS volumes for the operating system, and if necessary, for persistent data records.
Ensure that your EBS data volumes have been set to be deleted after an instance termination; after all, you have a snapshot schedule in place already backing up your data.
Use ephemeral storage volumes for storing temporary files instead of EBS volumes.
S3 Storage
It may still sound enticing that you can sign up to the AWS cloud and provision unlimited storage; however, unlimited storage comes with an unlimited price. The initial price for S3 storage is inexpensive at first, but storage at AWS is assessed a monthly charge, plus potentially a data transfer fee that is applied when you retrieve, replicate, or download files from AWS. It’s a great advantage to have unlimited storage, but we need to make sure we are getting the best bang for our buck. Once you have content stored at S3, storage charges continue forever; fortunately, there are tools available to help minimize storage costs as much as possible when using S3.
S3 storage, launched March 14, 2006, was one of the first AWS services offered. It provided unlimited storage in a container called a bucket that can be made available publicly across the Internet or privately across Amazon’s private network. The default is always private; you must make the decision to make your private S3 bucket public. Whether or not you’ve signed up and are using the S3 storage service directly at AWS, you’re still using S3 storage. Internally, pretty much every data component makes its way to S3 storage, including AMIs, EC2 instance images, database backups, database snapshots, continuous backups from DynamoDB, Redshift, CloudWatch logs, and CloudTrail trails, to provide just a few examples.
Tens of trillions of objects are stored in S3 across many millions of hard drives. There are more than 235 distributed microservices alone that make up the S3 storage service. Objects that are stored in S3 are also subjected to continuous integrity checks through checksums, end-to-end, from the source upload to final bucket destination. Amazon is incredibly serious about ensuring that the S3 storage arrays stay up as much as possible, and if issues occur, solutions execute in the background without anyone noticing.
Note
In a single AWS region, S3 will manage access peaks of up to 60 TB per second per day.
The storage arrays that host S3 storage are the same design as the storage arrays that host EBS, or EFS storage. The difference is how you can access and use the storage; S3 can’t be used as a boot drive or to install software. S3 is primarily designed for unlimited storage capacity with decent read performance and the ability to scale up to handle the many customers who store and retrieve objects from S3 buckets. S3 storage also has a number of durability levels that can be chosen, depending on the type of records being stored. Workloads that you might want to consider using S3 for include these:
Website static records—Stored in S3 Standard and moved to S3-1A or back based on usage using intelligent tiering
Thumbnail images—Could be stored in S3-1A reduced redundancy storage because thumbnails could be re-created
Surveillance video—Could first be stored in S3 Standard using lifecycle policies to automatically move to S3 Glacier for long-term storage or deletion
Historical records—Directly stored in encrypted in S3 Glacier for archival storage
Backups—Stored in S3 delivered by snapshots, AWS Backup, or the Storage Gateway service
Big Data—Stored in S3 and analyzed by Elastic MapReduce (EMR) or FSx Lustre
Note
S3 storage was designed for use by developers first using available software development kits (SDKs) for a variety of popular languages, including Java, .NET, and Ruby Version 3. There are several clients also available for using S3 as the back end for storing anything you can think of; however, direct access to S3 is as easy as accessing a cloud storage such as Dropbox or Microsoft OneDrive. You can directly upload content using the S3 Management Console or by using the command-line interface (CLI). AWS Snowball can also be used to migrate massive amounts of data directly into S3.
Buckets, Objects, and Keys
Following are the key concepts and terms you will come across when working with S3:
Buckets—The containers that store S3 objects.
Unlimited storage—Upload as many objects as you want into an S3 bucket. The only limitation is the size of each object, which is 5 TB each. Use the multipart upload API for objects larger than 5 MB to 5 TB.
Permissions—Define the levels of public or private access to your buckets and objects.
Each AWS account is controlled by a number of soft limits that apply to every AWS service. For S3 buckets, you can create up to 100 buckets per AWS account, and this initial soft limit number of buckets can be increased upon request. An S3 bucket resides in an AWS region that you select. There is no limit to the objects that can be stored in a single bucket, just the size of each object (5 TB). You also can’t create buckets inside of buckets, but you can use delimiters (backslashes) for organization of your objects within each bucket.
Before selecting a particular AWS region for your S3 buckets, you need to consider the factors of compliance, latency, and cost of the S3 service based on its location. As part of the S3 service-level agreement (SLA) with AWS, objects that are stored in a specified AWS region never leave the region unless you decide to transfer them to another region location.
Names for S3 buckets are domain name system (DNS) names that are stored in Route 53, AWS’s global DNS service. Bucket names are defined as global and must be globally unique.
Each object in a bucket contains some mandatory parts, including the data portion and the associated metadata portion, which is the name of the object itself. Each object is identified by a unique key and stored in a bucket with an attached version ID. Optionally, you can add some additional custom metadata to each object when it is being stored. Keep in mind that custom metadata is not encrypted. You can see the mapping for each object showing the bucket + key + version of each object in Figure 6-8.

When you create an S3 bucket, several configuration options are available, as shown in Table 6-3.
Table 6-3 S3 Bucket Configuration Options
S3 Feature |
Details |
|---|---|
Region |
Choose the region for bucket creation |
Policy |
Select S3 bucket security with bucket policy and access control lists (ACLs) |
Website |
Configure an S3 bucket to host a static website |
Logging |
Track access requests to an S3 bucket |
Notifications |
Receive notifications when S3 bucket events happen (GET, PUT, DELETE) |
Versioning |
Store multiple versions of the same object within a single S3 bucket |
Lifecycle |
Create rules for object retention and movement across S3 storage classes |
Cross-region replication |
Automatically replicate objects to other S3 buckets hosted in other S3 regions within your AWS account |
Encryption |
Enable encryption; objects are not encrypted by default |
Tagging |
Add cost allocation tags to help track costs or inventory or to help automate tasks |
Request payment |
Charge the data transfer costs to the end user |
Object lock |
Enable write once read many (WORM) policy on objects or buckets |
Transfer acceleration |
Securely transfer files quickly using CloudFront edge locations for ingress to AWS |
S3 Data Consistency
Objects stored in an S3 bucket are replicated many times to at least three other separate physical storage locations within the region where your bucket is located, providing a high level of durability for each stored object. Replicated data records can’t be instantly consistent in separate physical stored locations; however, Amazon guarantees read-after-write consistency for PUTs for all new objects stored in your S3 bucket. This isn’t difficult to guarantee. Amazon merely reads the location where the object was first stored, thereby guaranteeing a successful first read after write. All objects that are overwritten or deleted follow the rules of eventual consistency; eventually, all copies of each object in all linked storage locations will be the same. With multiple copies of data, replicating updates and deletions takes time to complete.
S3 Storage Classes
S3 storage classes have been designed for different use cases when storing objects in S3 buckets, as shown in Table 6-4.
Table 6-4 S3 Storage Classes
Storage Classes |
Standard |
Intelligent Tiering |
Standard-1A |
One Zone-1A |
Glacier |
Glacier Deep Archive |
|---|---|---|---|---|---|---|
Access Frequency |
NA |
Moves objects to Standard-1A after 30 days |
Infrequent—minimum 30 days |
Re-creatable data |
Archive data |
7 to 10 years |
Access speed (Millisecond) ms |
ms |
ms |
ms |
ms |
Minutes to hours |
Hours |
Number of AZs |
3 |
|
3 |
1 |
3 |
3 |
Cost to retrieve |
$0.0210/GB |
$0.0210/GB to $0.0125 /GB |
$0.0125/GB |
$0.0100/GB |
$0.00040/GB |
$0.00099/GB |
Minimum duration (days) |
None |
30 |
30 |
30 |
90 |
180 |
Availability |
99.99% |
99.9% |
99.9% |
99.5% |
N/A |
N/A |
Minimum object size |
N/A |
N/A |
128 KB |
128 KB |
40 KB |
40 KB |
S3 Standard—This is for data that is regularly accessed by online cloud-hosted applications. It is designed for high performance and durability, offering 11 9s of durability, and 4 9s of availability. Amazon states, “If you store 10,000 objects in S3, on average, you may lose one object every 10 million years.” We’ll have to take Amazon’s word on this.
S3 Intelligent-Tiering—Rules for automatic tiering analyze and move your less accessed objects to lower cost storage classes and back as required. Movement is based on the access of the object and can be defined by the bucket or the object moving from S3 standard to S3 S3-1A, One Zone-1A, or S3 Glacier. Intelligent tiering optimizes your storage costs by monitoring your access patterns at the object level, automating cost savings for your stored objects in S3.
After 30 days of inactivity, your objects are moved from the frequent access tier to the infrequent access tier on an object by object basis. If the infrequent data objects begin to be accessed more frequently, they are moved back to the frequent access tier. The minimum storage duration fee has been removed when using intelligent tiering and replaced with a monitoring fee per object of $2.50 per million objects. Here are several examples where intelligent tiering may save you a great deal of money and management time:
Move all objects older than 90 days to S3-1A.
Move all objects after 180 days to S3 Glacier.
Move all objects over 365 days to S3 Glacier Deep Archive.
S3 Standard-1A—This is designed for less frequently accessed data but offering the same performance of 11 9s durability. The design concept is that you don’t need to access your data frequently. Therefore, in use cases where object access is greater than 30 days, this is a cheaper option than S3 Standard.
S3 One Zone-1A—This is designed for less frequently accessed data that could be re-created if necessary, but with less durability than S3 Standard-1A because it is stored in a single AZ instead of across three AZs. The price point is 20% less than S3-1A.
S3 Glacier—This is long-term archival storage. Even though it’s designed for archival storage, if you need your archived data back quickly, you can get it back within minutes. You do pay additional fees for the expedited access.
S3 Glacier Deep Archive—The concept with this storage option is to remove the need for on-premise tape libraries. It is the cheapest price for storage at AWS, with a price of 4/10 of $.01 per MB. The assumption is that you don’t need this information back, but if you do, retrieval times are within 12 hours.
S3 Management
S3 buckets have a variety of powerful controls to help manage your stored data:
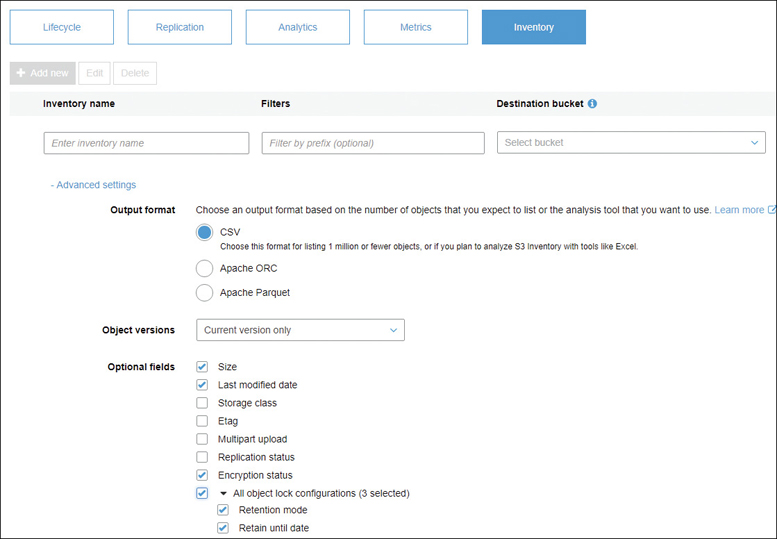
S3 Batch Operations—Although you could sit down and build this yourself using the existing CLI commands, customers have told AWS to “build it.” This service allows you to manage your data, regardless of the size and scale of your S3 storage. The first step is to gather your objects together that you want to analyze; this is most easily done by using the S3 management service S3 Inventory, as shown in Figure 6-9, or you can provide your own comma-delimited text file of S3 resources. Once your S3 inventory has been gathered, you can choose to automate several numbing manual tasks you probably wouldn’t get around to, including copying objects between S3 buckets, replacing existing tags, or changing access controls. You can even run custom Lambda functions to execute your own custom logic.
S3 Object Lock—Retention policies can be enforced by defined “Retain until dates” or “Legal hold dates.” The storage class of the object does not affect S3 object lock settings; however, you must first turn on versioning at the S3 bucket level before you can use the object lock feature.
When objects are written to an S3 bucket, retention management can also control the retention date of the object. Until the defined retention date is reached, the object itself cannot be deleted or modified. Retention management can be deployed at the object level or S3 bucket level. For example, you could add a three-year or a five-year retention policy at the bucket level; from this point forward, all objects placed in the specific S3 bucket inherit the retention policy. This data protection level has added customers who need to adhere to SEC Rule 17-a 4(f), CFTC Regulation 1.3.1, and FINRA Rule 4511. S3 buckets can also be assigned immutable protection at the bucket level, or for specific object in the bucket; that’s (WORM) write once, read many times, as shown in Figure 6-10. There are two modes of protection available for locking S3 objects:
Compliance mode—All deletes are disallowed even for Root AWS accounts.
Governance mode—Allow privileged deletes for WORM-protected buckets or objects.
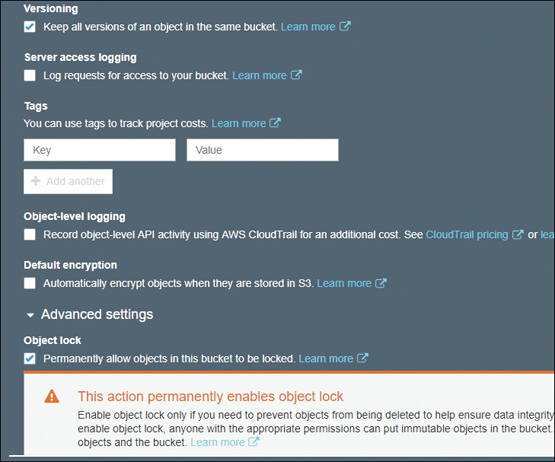
Figure 6-10 Enabling object lock on an S3 bucket
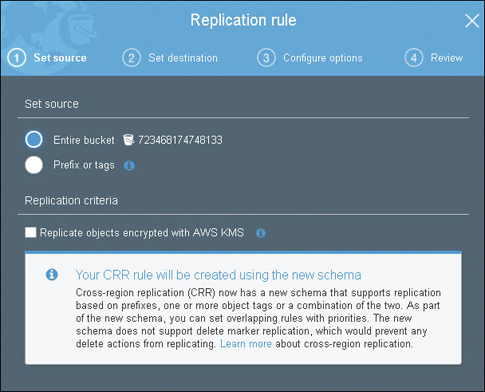
Cross-Region Replication (CRR)—This can be performed from any AWS region to any other region to any S3 storage class and across AWS accounts. The replication process is carried out by enabling CCR at the source bucket for the entire bucket contents or by a prefix or tag, as shown in Figure 6-11. In addition, lifecycle rules can be configured to replicate objects stored in S3 Standard to other S3 storage classes on the destination bucket, or optionally to S3 Glacier. To ensure security, CCR replication is encrypted. The cost for performing CRR is for the copy request, plus an inter-region data transfer charge for the replicated object.
S3 Inventory—If you want to find details about your current object inventory in S3, you can run an inventory process using S3 Inventory. After you select the source bucket for analysis, S3 Inventory creates a flat CSV file based on your query criteria and stores the inventory listing in a specified destination S3 bucket. The inventory listing encompasses current objects and their associated metadata, including the object’s key name, version ID, encryption and replication status, retention date, storage class, object hold status, and object size. The inventory list file can be encrypted using S3-managed or KMS-managed keys.
Note
For S3 buckets, request rate performance rates on the S3 storage array are currently set at 3,500 write transactions per second and 5,500 read transactions per second, per bucket partition. Because of these performance levels, most customers no longer need hashing or randomizing of your key names. Key names are now automatically partitioned, and any buckets that don’t achieve the current read/write transaction specifications have additional partitioning added by AWS. Performance levels are analyzed through machine learning analysis that happens in the background, increasing the performance of each S3 bucket as necessary.
S3 Storage Class Analysis—Through machine learning processes, your S3 storage is categorized into groups of less frequently accessed data by carrying out analysis of retrievals against storage. Analysis can be performed by bucket, protects, or object tags.
Object Tags—Up to 10 tags can be added to each S3 object. The following actions can be performed based on the assigned object tags:
IAM Policy—Which users or groups of users can read an object
Replication—Which objects to be replicated to a bucket in another region
Lifecycle policies—Control lifecycle policies
Versioning
Versioning can be enabled on an S3 bucket, protecting your objects from accidental deletion. Versioning should be enabled before any objects are stored in the S3 bucket, guaranteeing all objects will be protected from deletion. After versioning has been enabled:
Every new PUT of an existing object is created as a new object with a new version ID.
The newest version is defined as the current version, and the previous versions are retained and not overwritten.
Requesting just the S3 key name of an object presents you with the current version of the object.
When a user attempts to delete an object without specifying a version ID, any further access is removed to the object, but the object is retained.
After versioning has been enabled, additional lifecycle management rules for the versioned content, as shown in Figure 6-12, can be created. These define a lifecycle expiration policy that dictates the number of versions that you want to maintain. Lifecycle rules help you manage previous versions of objects by transitioning or expiring specific objects after a certain number of days.
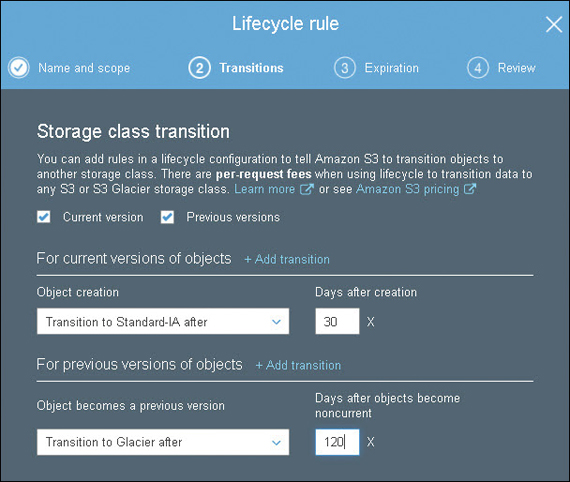
Note
S3 also offers an event notification that alerts you at no additional cost when deletions occur. Versioning with MFA delete can also be enabled on S3 buckets, requiring two forms of authentication to build the leading object.
S3 Bucket Security
By default, only the owner who created the S3 bucket has access to its objects. There are several methods for controlling security for an S3 bucket:
ACL—Controls basic access from other AWS accounts for list and write objects and read and write bucket permissions, public access, and access to S3 logging information. ACLs are available because of backward compatibility and are the weakest type of S3 security.
IAM policy—Granting granular access to other AWS users and groups of IAM users is possible by using IAM trust policies in partnership with resource policies.
Bucket policy—Control direct access on the S3 bucket by creating a bucket policy that is assigned directly to the S3 bucket. A bucket policy can control anonymous access (HTTP/HTTPS), encryption settings, and the source IP address range allowing S3 bucket access.
Note
If you require public access to objects in an S3 bucket, it’s recommended that you create a separate AWS account specifically used for allowing public S3 object access.
S3 block public access—Buckets always start as private, with no default public access. Once S3 block public access is enabled, the attempted changing of security settings to allow public access to objects in the S3 bucket is denied. Block public access settings can be configured on an individual S3 bucket or all S3 buckets in your AWS account by editing the public access settings for your account using the S3 management console. Choices for S3 block public access include the following:
Public—Everyone has access to list objects, write objects, and read and write permissions.
Objects can be public—The bucket is not public; however, public access can be granted to individual objects by users with permissions.
Buckets and objects not public—No public access is allowed to the bucket or the objects within the bucket.
Note
Amazon Macie is another interesting AWS security service that uses artificial intelligence (AI) and machine learning technology to analyze your S3 objects and classify the S3 data based on discovered file formats, such as personally identifiable information (PII) and critical business documents. After analysis, you can create custom policy definitions and receive alerts when S3 documents are moved or specific business documents are shared.
S3 analytics—This allows you to visualize the access patterns on how your stored S3 object data is being used. Analyze your S3 data by bucket, prefix, object tag, or date of last access, as shown in Figure 6-13.
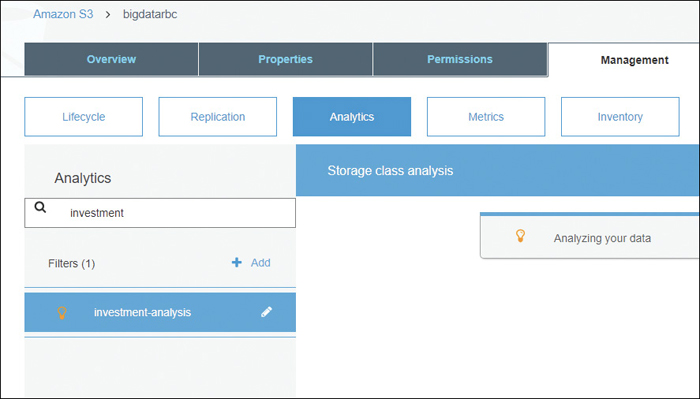
Amazon S3 Glacier Archive Storage
S3 Glacier is an extension of S3 storage that has the lowest cost of any managed storage service at Amazon. The design concept for S3 Glacier is that you don’t want to access the content stored in S3 Glacier very often or ever. In fact, the minimum storage time is 90 days; accessing the content sooner results in a penalty.
Glacier encrypts all stored objects automatically and has the same 11 9s durability as S3 storage. Data is stored in vaults and archives, and these can be set up through the S3 management console. Delivering content into S3 Glacier can be carried out using the following methods:
CLI commands
S3 lifecycle rules
Direct use of the REST API
Use of an SDK
Direct PUT—Store objects directly into S3 Glacier using the S3 API
CRR—Replicate objects to S3 Glacier in another region using CRR and a lifecycle rule
To retrieve objects from S3 Glacier, create a retrieval job using the Management console or by using the S3 API. The retrieval job creates a separate copy of your data and then places it in S3 Standard-1A storage, leaving the actual archived data in its original location in S3 Glacier. You can then access your temporary archived data from S3 using an S3 GET request.
Note
You can retrieve up to 10 GB of Glacier data per month for free.
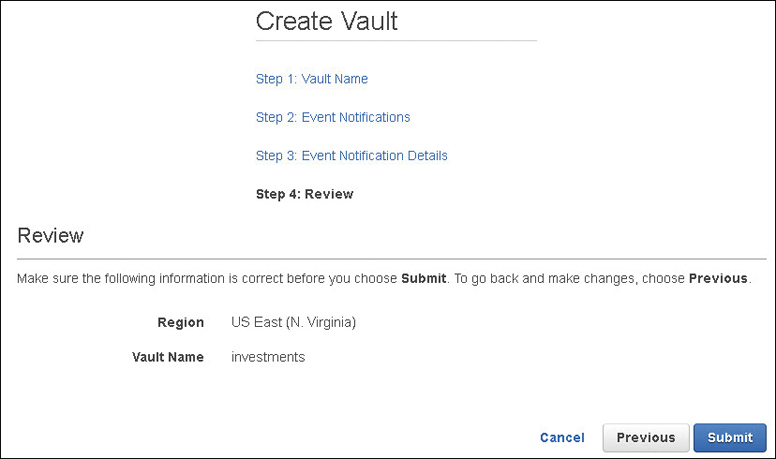
S3 Glacier Vaults and Archives
An S3 Glacier vault is used for storing archives, as shown in Figure 6-14. Each S3 Glacier vault is stored in the AWS region of your choosing, up to 1,000 vaults per AWS region. The term archive, when working with S3 Glacier, is defined as an object (file, document, photo, or video) that is stored. You can store an unlimited number of archives within a single S3 Glacier vault.
Shared File Systems at AWS
We’ve looked at virtual hard drives (EBS) and cloud object storage (S3). There are also several choices at AWS when it comes to storage that can be shared among multiple servers at the same time. Your on-premise storage solutions might include NAS, which is supplied by a dedicated hardware or software appliance serving shared files to multiple clients across the network. Typical file-sharing protocols utilized are the network file system (NFS), SMB, Windows file shares (CIFS), and perhaps even the Apple Filing Protocol (AFP). At AWS, there are shared file system choices for both Windows and Linux clients utilizing most of these popular protocols; here’s an initial summary of the shared storage options at AWS.
EFS—The EFS provides a shared file system using NFS 4.1 designed for both cloud-hosted and on-premise Linux workloads. It is designed to scale on-demand up to petabytes in size and can be shared across many thousands of EC2 instances and accessed from on-premise servers through virtual private network (VPN) and Direct Connect connections.
Amazon FSx for Windows File Server—FSx is a fully managed native Windows file server storage fully compatible with Active Directory Domain Services providing Windows ACLs and a native NTFS Windows Explorer experience. FSx provides GB/s of scaling throughput with sub-millisecond latency and also complies with the Payment Card Industry Data Security Standard (PCI-DSS) and HIPAA compliance standards.
Amazon FSx for Lustre—Lustre provides optimized scale-out storage for short-term processing of compute-intensive workloads, such as high-performance computing (HPC) or video processing. Performance can scale to hundreds of gigabytes per second of throughput, with millions of IOPS performing with sub-millisecond latencies. FSx is integrated with S3 storage, allowing you to initially store massive data sets for analysis in S3, copy data into FSx Lustre for analysis, and then store results back in S3 storage. FSx for Lustre is POSIX compliant and supports PCI-DSS and HIPAA workloads.
AWS Shared Storage Use Cases
Corporations have used various storage solutions for serving a variety of data-sharing needs. AWS storage options can be used for the following:
Home directories: EFS can be used for Linux clients needing shared storage
FSx can be used for Windows clients needing shared storage
S3 buckets can be used for shared data for multiple Web servers; EFS can also be used
Standard line-of-business applications: Either EFS or FSx depending on the type of client and application
Content management systems: EFS or FSx storage arrays can be used
Development environments: EFS and S3 buckets can be used for shared development resources
Backup and disaster recovery: Both S3 and S3 Glacier can be used for backup and longterm storage, including archiving
Elastic File System (EFS)
EFS is a completely managed file system that scales on demand up to petabytes for EC2 Linux instances. EFS removes the need to provision and attach EBS volumes for data storage, and it is a shared storage service allowing you to serve instances hosted on subnets within select VPCs using NFS mount points. The key features of EFS include these:
No networking or file layer to manage—With just a few API calls, your file system is ready right away. You only pay for the storage used and the level of performance. There are no EBS drives to provision, manage, and pay for.
Elastic—The file system automatically grows and shrinks as you add and remove files; you do not have to plan for a final storage size.
Scale—EFS can scale to petabytes of capacity. As EFS grows, performance can scale along with the growth. As the file system grows, the latency remains low, regardless of the number of clients accessing your file system.
Performance—Two performance modes are available: general-purpose and max I/O, which is designed for thousands of instances that need access to the same files at the same time.
EFS Performance Modes
General-Purpose—When you order EFS, the default mode of operation is assigned a throughput performance that supports up to 7,000 operations per second per file system and is recommended as the starting point. Amazon recommends that you monitor your file system using the CloudWatch metric PercentIOLimit; if your file system is operating close to 100%, choose Max I/O instead.
Max I/O Performance—This mode of operation can scale to a much higher level of throughput and operations per second and was designed for situations where thousands of EC2 instances are attached to your file system.
EFS Throughput Modes
The default throughput mode for EFS is called a burst model using performance credits. You can also control the exact throughput of your elastic file system by selecting the provisioned throughput mode and entering any level of throughput up to 1 GB per second.
Using the default burst mode; when your EFS file system reads or writes data to the file system but throughput remains below the assigned baseline rate, it earns burst credits. This may sound like the most boring game ever, but these burst credits are being accumulated for future throughput needs. When your file system requires more throughput, the saved burst credits are cashed in, allowing performance throughput above the current baseline.
Throughput is designed to increase as the number of stored files increases. As files are added to your file system, the amount of throughput allowed is increased based on the allotted file size. For example, a 5 TB EFS file system can burst to 500 MB/sec throughput (5 TB X 100 MB/sec per TB); a 10 TB file system can burst to 1,000 MB/sec of throughput. Using the CloudWatch metric BurstCreditBalance, you can monitor your positive burst credit balance. After testing, you might decide to move up to provisioned throughput with a few mouse clicks, as shown in Figure 6-15.

EFS Security
After creating your file system and mount points in your selected VPC, you can use security groups and optionally network ACLs to further control the EC2 instance and subnet access to the EFS mount points. Access to the files and directories themselves is controlled by your application or operating system user and group permissions. All data stored within the EFS is encrypted at rest, and encryption keys are managed by the AWS KMS.
Note
At a minimum, use a Linux kernel version 4.0 and up when using EFS, or you won’t be happy with the performance levels.
Storage Performance Compared
The available managed storage options at AWS all have different performance characteristics, as shown in Table 6-5.
EBS provides the lowest overall latency when compared to EFS or S3 storage. Remember: EBS volumes are accessible from a single server. There is no ability to further scale the performance of a single block volume when it is under load because the amount of maximum throughput is defined at creation of each volume. EC2 instances use EBS volumes as boot volumes or for database drives with mandated higher IOPS requirements.
EFS is in the middle of latency specs when compared to EBS or S3 object storage. As discussed, EFS has a scalable amount of throughput, resulting in latency levels higher than EBS block storage, but not as high as S3 object storage. EBS also has the advantage of file and record locking, a recognizable tree-storage structure, and the ability to share the contents with multiple clients.
Before the EFS, customers were forced to create their own do-it-yourself file storage systems with multiple EBS volumes for boot and storage needs attached to each instance. EBS is required as a boot device for each instance and for database instances; the rest of your storage does not have to use EBS volumes.
EFS has a lower latency than S3 object storage but a higher latency than an EBS volume. However, there are higher levels of throughput available for scaling the EFS throughput to the many gigabytes per second when using the provisioned throughput mode.
S3 object storage can achieve decent levels of throughput and scalability; however, it has a higher level of latency when compared to EFS or EBS volumes, which makes it inadequate for latency-sensitive applications.
Table 6-5 Comparing S3, EFS, and EBS Storage
Feature
Simple Storage Service (S3)
Elastic Block Storage (EFS)
Elastic File System (EFS)
Costs of storage
Scaled cost based on first 50 TB of storage used and the number of requests made (POST, GET)
Data transfer per GB out of S3
General-purpose SSD $.0.10 per GB per month
Provisioned IOPS SSD $.0.125 per GB per month; $.0.065 per provisioned IOPS per month
Throughput-optimized HD
$.0.045 per GB per month
Cold HD
$.0.025 per GB per month
Standard storage $0.030 GB used per month
Infrequent access storage $0.045 GB used per month
Infrequent Access Requests (per GB transferred) $0.01
Storage size
No limit
Maximum storage size 16 TB
No limit
File size
5 TB
No limit
47.9 TB single file
Data throughput
Supports multipart upload
PUT maximum of 5 GB
SSD, SSD IOPS, and throughput optimized
3 GB/sec per client
Performance
Supports up to 3,500 PUT/LIST/DELETES requests per second per partition
Supports 5,500 GET requests per second per partition
3 IOPS per GB
Provisioned IOPS up to 32,000
Single volumes can be scaled on-demand
Supports up to 7,000 file system operations per second
Data location
Data stays within region or requested AZ
Data stays within the same AZ
Data is stored within the region
Data access options
Public (HTTP, HTTPS) or private network endpoints (Gateway)
Private network from a single instance
Private network from multiple instances
Permissions
ACLs, bucket policies, IAM polices
IAM policies, Operating system security settings (Linux and Windows)
Linux operating system only
File access and updates
Entire file must be replaced
Block-level file changes
POSIX support or file and record locking for access by multiple clients
Encryption
SSE—Amazon S3, AWS-KMS, SSE-C
AWS—KMS—Managed customer master key (CMK) with AES 256-bit encryption
AWS—KMS—Managed CMK with AES 256-bit encryption
Durability
11 9s stored in three separate facilities
99.95 multiple copies within the AZ
Highly available design
Access Control
Pre-signed URLs, OAI
Security group, NACL, IAM
Security group, IAM
Availability
4 9s can survive the loss of two facilities
Cannot survive AZ failure
Stored across multiple AZs
Ideal file type
Static files
Boot drives, database instances SQL, NoSQL
Big data analytics, media workflows (media editing, studio production), or home directories
EFS
File Sync EFS File Sync allows you to sync data from an on-premise NFS to EFS. It is available as an installable agent that runs on EC2 instances, or VMware ESXi environments.
EFS File Sync can be used to copy files from EFSs hosted in different AWS regions. It is much faster than standard Linux copy commands, and the upload is designed for encrypted parallel data transfer to AWS.
Compared to EFS sync, using rsync is a much slower choice because rsync is a single-threaded utility. If you use fpsync, your performance will be much better because you are now working with a multithreaded utility.
You do not have to set up a VPN connection or use a more expensive Direct Connect connection when using EFS file sync.
Amazon FSx for Windows File Server
Although the number of companies running Windows workloads at AWS has dropped compared to Linux workloads, 38% of customers still use Windows Servers. EFS is limited to a Linux client; however, Windows clients now can use FSx for Windows File Server to set up a completely compatible Windows file system, as shown in Figure 6-16. Features include the following:
Windows Shares—FSx is built using Windows file servers and accessed using the SMB protocol 2.0 to 3.11, allowing you to support Windows 7 clients and Windows Server 2008.
File System—Built on SSD drives, FSx file systems can be up to 64 TB with more than 2 Mb per second of throughput. Multi-AZ support for FSx allows you to use Microsoft DFS to replicate between multiple locations supporting up to 300 PB of storage.
Redundancy—Data is stored within an AZ, and incremental snapshots are automatically taken every day. Manual snapshots are supported as well.
Relational Database Service (RDS)
Just like networking services at AWS, the odds are 100% that you’re using databases. Databases at AWS are hosted by several database services, including RDS, which hosts a variety of popular relational database engines, as shown in Table 6-6. Because AWS completely manages RDS, all you need to do is focus on your data and leave the running, monitoring, backing up, and failover of your database instances to Amazon. If this isn’t your style, Amazon has no issue with your building your own EC2 instances and managing every aspect of your database infrastructure.
Table 6-6 RDS Database Engines
Database Engine |
Data Recovery Support |
SSL Support |
Replication |
Encryption |
Real-Time Monitoring |
Compliance Support |
|---|---|---|---|---|---|---|
MariaDB 10.0,1,2,3 |
InnoDB for version 10.2 and XtraDB version 10.0, and 10.1 |
yaSSL, Open SSL, or TLS |
Point-in-time restore and snapshot restore |
AES-256 |
Yes |
HIPAA |
MySQL 5.5–8.0 |
InnoDB |
yaSSL, Open SSL, or TLS |
Point-in-time restore and snapshot restore |
AES-256 |
Yes for 5.5 or later |
HIPAA, PHI, FedRAMP |
SQL Server 2008–2017 |
All versions support data recovery |
SSL |
SQL Server Mirroring, SQL Always On |
AES-256, TDE |
Yes |
N/A |
Oracle 12c, 11g |
All versions support data recovery |
SSL or NNE |
Point-in-time restore and snapshot restore |
AES-256, TDE |
Yes |
N/A |
PostgreSQL |
All versions support data recovery |
SSL |
AWS Synchronous Replication |
AES-256 |
Yes |
HIPAA, PHI, FedRAMP |
Perhaps you don’t want to build and maintain the virtual servers for your databases anymore; if this sounds like you, join the club. There are thousands of AWS customers who have decided that they need databases; they just don’t want to manage the infrastructure anymore. The essential components that make up the relational database service hosted by RDS and managed by AWS include the complete management of the instances hosting your data, automatic backups, synchronous replication from the master to the standby database instance, and automatic failover and recovery as required.
RDS Database Instances
Under the hood of an RDS deployment is a familiar compute component: the EC2 instance. When you order your RDS database instance, the CPU, memory, storage, and its performance (IOPS) are ordered as a bundle. These initial values can be changed later. RDS supports a variety of standard, memory-optimized, and burstable performance EC2 instances that also support Intel hyperthreading, which allows multiple threads to run concurrently on a single Intel Xeon CPU core. Threads are represented as virtual CPUs (vCPUs). RDS pricing can use on-demand EC2 instances. The odds are that you want to use reserved instance (RI) mean pricing, giving you a price break up to 70%. This makes the most sense because your databases are typically always running.
Storage for your database instances is with EBS volumes, which are automatically striped for you, providing additional performance. Volume types can be either general-purpose SSDs, provisioned IOPS SSDs, or magnetic hard drives. (Magnetic drives show up for backward compatibility because some older customers still use them. For production databases, Amazon does not recommend magnetic drives. Furthermore, the drives are limited to 4 TB.) MySQL, MariaDB, Oracle, and PostgreSQL volumes can be from 20 GB to 32 TB. SQL Server is limited to 16 TB storage volumes. General-purpose SSD storage uses burst credits, allowing sustained burst performance; the length of sustained performance depends on the size of the volume. You can have up to 40 RDS database instances for hosting MySQL, MariaDB, or PostgreSQL; these values are defined by AWS account soft limits and can be increased upon request. For more information on burst credits, review the EBS section found earlier in this chapter.
For typical production databases, the recommendation is to use provisioned IOPS, which range from 1,000 to 40,000 IOPS depending on the database engine being used.
Note
For databases running in production, multi-AZ deployments with provisioned IOPS for the master and standby databases and read replicas should be used.
As mentioned, as your needs change, you can independently scale the size of your database compute and change the size and the IOPS of your storage volumes, as shown in Figure 6-17. While changes are being made to compute resources attached to your database instance, your database is unavailable. If your database services are hosted and maintained by the RDS, you don’t have direct access to your database compute instance because Amazon is carrying out the backup, patching, monitoring, and recovery of your database instances for you.
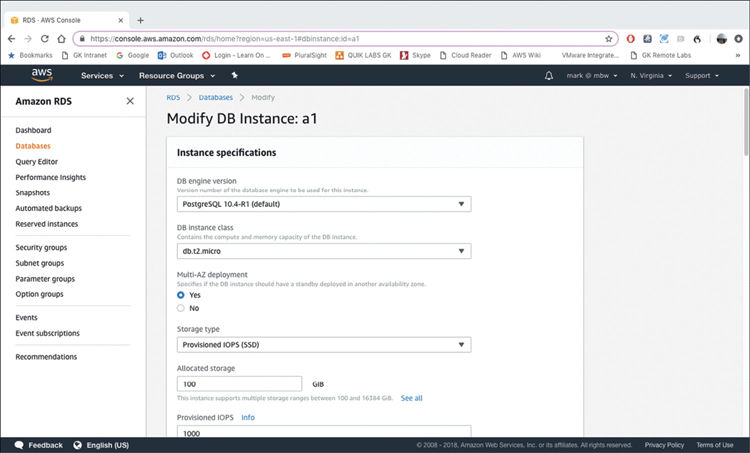
Each database instance runs a specific database engine and version that you choose at installation. RDS supports MySQL, MariaDB, PostgreSQL, Oracle, and Microsoft SQL Server. Just because these database engines are supported by RDS doesn’t mean every version of every listed database engine available is supported by RDS. You must carefully check out the database engines supported and decide if RDS matches your needs; you may have to build your required database design from scratch.
If you decide to build your own database instances, you have to provision the right EC2 instance size, attach appropriate EBS volumes and IOPS, and define and maintain your own database instance snapshot backup schedule. You are also responsible for monitoring the database instances and providing all the maintenance, including failover. It’s no wonder RDS is popular.
High Availability for RDS
Production databases can and should use multi-AZ deployments, which provide failover support with the master database instance located in one AZ and the standby database instance in the other AZ. The technology used for database failover and the master to the standby depends on the database engine type. Most RDS deployments use Amazon’s failover technology. However, SQL Server uses SQL Server mirroring to perform its failovers.
When you order a multi-AZ deployment, it’s Amazon’s job to provision and maintain the master and standby replicas in different AZs, as shown in Figure 6-18. The primary database instance is synchronously replicated to the standby replica, providing data redundancy. Transaction logs are backed up every 5 minutes. Data replication between the database instances creates increased write and commit latencies because of the synchronous data replication between the master and the standby instances. Your database instances and volumes must be sized to be able to perform synchronous replication quickly and reliably without affecting the overall performance required of your database service.

Note
For most RDS designs except for Aurora, the standby replica is treated as a true standby instance and therefore is not used for additional read requests. Additional read replicas can be automatically created using the RDS service. Place the read replicas in the desired regions to handle any additional read requirements.
When issues occur, as they will, the RDS database failover is an automated process that swings into action when problems occur, such as a failure of the primary database instance, or an AZ failure. Failover can also occur if maintenance is being performed. Perhaps the primary and secondary database instance server types are being changed, or software patching is being performed.
When failure happens during the failover process, RDS automatically switches over to the standby replica, as shown in Figure 6-19. The standby replica now becomes the master database instance. Route 53, the AWS DNS service, modifies the RDS endpoint to point to the new master, the standby replica; this process should happen quickly. Re-establishing the availability of the new standby database instance takes a bit more time; the EC2 instance has to be built, and snapshots have to be applied. After the new standby replica is re-created, to ensure all changes have propagated from the master to the standby database, Amazon replays what is called the redo log from the last database checkpoint, making sure all changes have been applied before the new master database is made available.

This recovery process isn’t magic. It’s simply an automated recovery process that you want Amazon to carry out on your behalf. Other real-world issues might be happening on the network with Route 53, the DNS service, or Murphy’s Law.
Note
Database event subscriptions can be created to notify you via text or email that a failover is underway.
Big-Picture RDS Installation Steps
The process for installing a database using RDS is similar for all the supported database engine types except for Aurora. After selecting the database engine, the database instance details are chosen. The initial options that you can define depend on the database engine, as shown in Table 6-7.
Table 6-7 Initial RDS Setup Questions
Database Instance Settings |
Details |
|---|---|
License model |
Bring your own license (BYOL), general-purpose |
Database engine version |
Select desired version to deploy |
Database instance |
Standard, memory-optimized, and burstable performance |
Multi-AZ deployment |
Synchronous AWS replication service; SQL Server uses Native Mirroring or Always On |
Storage type |
SSD, provisioned IOPS, or HDD volumes |
Amount of storage to allocate |
1–16 TB (sizing follows EBS limits) |
Database instance identifier |
Unique identifier if required by database engine |
Master username and password |
For database authentication |
The advanced database instance settings options that can be configured are shown in Table 6-8.
Table 6-8 Advanced RDS Setup Questions
Advanced Database Instance Settings |
Details |
|---|---|
Database port |
Database engine default value |
VPC |
VPC to host database instance |
Database subnet group |
Predefined subnet for database instance |
Public accessibility |
Default is private |
Availability zone |
Specify AZ |
Security group |
Control access to database instance |
Database name |
Unique database name |
Database port |
Default access port of database engine |
Parameter group |
Predefine database engine, database instance, and allocated storage |
Option group |
Additional features per database engine, such as encryption |
Copy tags to snapshot |
Tags to be added to database snapshots |
Encryption |
Encryption type dependent on database engine |
Backup retention |
Number of days automatic backups of database to be retained |
Backup window |
Specific time for database backup |
Enhanced monitoring |
Enables metrics to be gathered in real time |
Log exports |
Publish select logs to CloudWatch |
Auto minor version upgrade |
Allow database engine to receive minor database engine version upgrades automatically |
Maintenance window |
30-minute window to apply database modifications |
Monitoring Database Performance
Once your RDS database has been deployed, you should establish a CloudWatch baseline to calculate the ongoing performance of your database under different times of day to establish an acceptable normal level of operation. Using the RDS console, you can select a variety of metrics that allow you to monitor the number of connections to the database instance, read and write operations, and the amount of storage, memory, and CPU being utilized. A sampling of CloudWatch metrics as shown in Table 6-9 allows you to use metrics to create alarms that can alert you when problems and issues occur.
Table 6-9 CloudWatch RDS Metrics
CW Metric |
Definition |
Reporting |
Values |
|---|---|---|---|
IOPS |
Input and output operations per second |
Average read/write per minute |
Tens of thousands per second |
Read and write latency |
Time it took from request to completion |
One-minute interval |
Per second |
Throughput |
Bytes transferred to or from the database volume |
One-minute interval |
MB/second |
Queue depth |
I/O requests waiting to be carried out |
One-minute interval |
From zero to several hundred |
Best Practices for RDS
There are numerous best practices to carry out when utilizing an RDS deployment:
Monitor your infrastructure with CloudWatch alerts to ensure you are notified when you are about to overload your capacity.
Monitor database performance to define what is acceptable as normal operation. Define baselines for the minimum, maximum, and average values at defined intervals (hourly, half-day, seven days, one week, and two weeks) to create a normal baseline.
Performance metrics to evaluate include CPU utilization, available memory, amount of free storage space, read-write (IOPS, latency, throughput), network receive and transmit throughput, database connections, high CPU or RAM consumption, and disk space consumption.
Provisioned IOPS storage must be matched with the desired EC2 instance for the best performance.
Caching of the DNS name of your database EC2 instance should use a time to live (TTL) of less than 30 seconds to ensure that if failover occurs, the client application connects to the new master server quickly. A longer TTL would cause problems because the failover to the new master would not occur for a longer period.
For the best performance, each database instance should have enough allocated RAM, so the working set of your database resides in memory.
Use IAM users and groups to control access to RDS resources.
Aurora
Another SQL type database service hosted by RDS is Aurora, a fully compatible MySQL and PostgreSQL-managed database as a service (DBaaS). If either MySQL or PostgreSQL is currently being used on-premise and is due to be moved to the AWS cloud, Aurora is well worth evaluating. Comparing the performance of Aurora to MySQL on the same hardware, Aurora has up to five times the performance confirmed by SysBench testing due to use of an SSD virtual SAN showing a cluster storage array replicated six times across three AZs. When deploying Aurora, there are three interesting choices, as shown in Figure 6-20.
Aurora Provisioned—This is the standard deployment where the customer defines the instance class and the advanced details of placement, accessibility, encryption, backup, and failover required.
Provisioned with Aurora parallel query enabled—A single query can be distributed across all the available CPUs in the storage layer, greatly speeding up analytical queries. More than 200 SQL functions, equijoins, and projections can run in parallel format. This feature is only currently available for the MySQL 5.6 compatible version of Aurora that is running on the r3 or r4 family of EC2 instances.
Serviceless—This deployment option is an on-demand deployment of Aurora that works with the MySQL-compatible addition of Aurora. When your application is up and running, a serviceless Aurora database cluster is deployed that scales based on the defined minimum and maximum performance requirements of the application. When your application enters a period of light or minimal activity, the Aurora database is scaled in to the minimum allocated size but remains online and continues to service application requests scaling back out as required.
Rather than defining the database instance class size, for the serviceless option of Aurora, you set the minimum and maximum capacity required. Behind the scenes, the database endpoint points to a fleet of resources that are automatically scaled based on your minimum and maximum requirements. For example, your serviceless database cluster can scale up if the CPU utilization of the application rises above 60% or the connections to the application are more than 80%. The cluster can then scale down if the application CPU load is below 25% utilization and less than 30% of the connections were utilized. Consider a retail environment with multiple branch locations using a centralized point-of-sale. As more customers enter the store and begin purchasing, the system can scale accordingly up and down.

Aurora Storage
When comparing Aurora to SQL databases supported by RDS, there is no need to provision storage in advance for future growth. The internal design of the Aurora storage engine allows for the automatic scaling of its distributed storage architecture from a starting point of 10 GB, up to 64 TB in 10 GB chunks that are stored across multiple SSD drives across multiple AZs, as shown in Figure 6-21. Aurora replicates six copies of its data records across three AZs, providing enhanced durability and 99.99% availability.
The quorum across the three AZs is all six data nodes; the write set is four nodes, and the read set is the two remaining nodes spread across three AZs. Data is stored in a shared cluster storage volume of Aurora data stored on multiple SSD drives. The shared storage volume spans the multiple AZs. The result is that each AZ has a copy of the database cluster data.
Aurora performance enhancements are due to the design of the storage plane, which is an SSD-backed virtualized storage array. Aurora has at a minimum a primary database instance, and it can have up to 15 additional Aurora replicas. Beyond the storage durability, the data transaction logs are being backed up continuously to S3 storage.
Aurora has been designed by locating the underlying SSD storage nodes that make up Aurora’s shared storage volume into what Amazon calls a cell spread across the three AZs helping to limit the size of the blast radius when failures occur.
Aurora’s cluster design has the primary and replica database instances connecting to the same storage plane. The primary database instance carries out the write operations to the cluster volumes in each AZ and offloads the read operations to the replica database instances, as shown in Figure 6-22. This design is different from standard RDS MySQL or PostgreSQL deployments, where standby database instances do not perform read requests.
If the primary database instance becomes unavailable, there is automatic failover to an Aurora Replica. The failover priority for the available Aurora Replicas can also be defined.
When failover occurs, the speed of the failover process is in seconds. Assuming there are additional Aurora replicas in the same or different AZs, which there will be for a production deployment, the canonical name record (CNAME) is changed to point to the Aurora Replica that has been promoted to be the new primary database.
With Aurora, you can lose access to two copies of data without affecting the writing process, and you can lose up to three copies without affecting the ability to read your data. In the background, Aurora is constantly checking and rechecking the data blocks and discs, performing repairs automatically using data from the volumes in the cluster. In addition, Aurora Replicas can be created in different AWS regions. The first Aurora Replica created in a different region acts as the primary Aurora Replica in the new region. You can also add Aurora Replicas in different AWS regions that share the same storage plane.
Note
In the near future, Aurora will be able to operate in a multimaster design where multiple read/write master database instances can be deployed across multiple AZs, improving Aurora’s highavailability design. If one of the master database instances were to fail, other instances in the cluster could take over immediately, maintaining both read and write availability for the cluster.
Communicating with Aurora
Communication with the Aurora cluster is performed with specific endpoints, as shown in Figure 6-23.
The cluster endpoint to the Aurora database cluster is a single URL containing a host address and a port address to simplify connectivity to the primary database instance for all writes, including inserts, updates, deletes, and changes. When failovers occur, the cluster endpoint automatically points to the new primary database instance.
The reader endpoint connects to one of the available Aurora replicas for the database cluster; if there are multiple Aurora replicas, the endpoint uses load balancing to support the read requests. If your Aurora deployment is small, containing a single primary instance, the reader endpoint services read requests from the primary database instance.
The instance endpoint points to the current primary database instance of the database cluster.
Note
Dow Jones used the AWS data migration service to migrate its legacy environment to Aurora. It uses a 1 TB Aurora cluster that can handle 200 transactions per second. Alfresco used Aurora to scale to more than a billion documents with throughput of 3 million transactions per hour.
DynamoDB
Another popular database offered by AWS is DynamoDB. Amazon had internally developed DynamoDB in 2006 and initially started using it to host the familiar shopping cart in the online Amazon store. DynamoDB was publicly launched as a NoSQL database service in 2012 designed for Internet performance at scale for applications hosted at AWS. These days, the Amazon store is completely backed by DynamoDB.
Note
For older applications that are joined at the hip with an SQL database, there may be no reason to change. After all, AWS has use cases for customers using SQL with millions of customers. For newer applications with no legacy concerns or requirements, a nonrelational database such as DynamoDB might be something to consider.
DynamoDB has been designed as a nonrelational database that doesn’t follow the same rules as the standard SQL database (see Table 6-10).
Table 6-10 SQL vs DynamoDB Compared
Features |
SQL Server |
DynamoDB |
|---|---|---|
Database type |
Relational database management system (RDBMS) |
Nonrelational |
Structure |
Tables with rows and columns |
Collection of JavaScript Object Notation (JSON) documents, key-value, graph, or column |
Schema |
Predefined |
Dynamic |
Scale |
Vertical |
Horizontal |
Language |
SQL structured |
JavaScript |
Performance |
Good for online analytical processing (OLAP) |
Built for online transaction processing (OLTP) at scale |
Optimization |
Optimized for storage |
Optimized for read/write |
Query type |
Real-time ad hoc queries |
Simple |
When you initially order DynamoDB, all you can view is the table, sort, and query definitions in addition to optional performance controls. There is no access to the underlying infrastructure. DynamoDB tables can be global in scope, synchronized across multiple AWS regions. There are no limits to the table size you can create, and you also define the read/write performance of each DynamoDB table. The tables contain small pieces of data, but potentially many hundreds of thousands of pieces of data, including website clicks, online gaming, advertising, inventory updates, tweets, voting, and user session state. DynamoDB tables also can horizontally scale; any of the listed examples may require an increase in performance at a moment’s notice.
With an SQL database, there is a defined set of data rules, called the schema, which could be one or more interlinked tables, columns, data types, views, procedures, relationships, and primary keys, to name a few of the components (refer to Table 6-10). With SQL, the database rules have been defined before any data is entered into the rows and columns of the relational databases table following Structured Query Language (SQL).
In comparison, DynamoDB stores its data in tables but doesn’t follow the same rules as a relational database. First, its data is stored in several JSON formats: graph-based, key-value, document, and column. There’s more to DynamoDB than just a simple table, but first let’s think about databases and why we store data there. Databases keep our precious data safe, secure, and reliable. Relational databases have stored and secured our data reliably for years. And some relational databases at AWS can now automatically scale their compute performance and data storage; for example, Aurora Serviceless can now scale on-demand, and all versions of Aurora scale data records automatically. At AWS, some of the operational lines between SQL and DynamoDB are starting to be blurred.
Note
When Amazon looked at how its data operations on its internal Oracle databases were being carried out internally at AWS, it found the following facts. They made Amazon realize that DynamoDB could completely replace its Oracle databases, a task that it completed in 2019.
70% of the queries were single SQL query against the primary key of a single table with a single row of information being delivered.
20% of the queries were queries against multiple rows of a single table.
10% of the queries were complex relational queries.
Database Design 101
DynamoDB has been built for OLTP at scale and stores its data in the format in which the application is going to use it. As a result, there’s no need for complex queries across multiple tables as an SQL database. DynamoDB design uses a single table for the application (see Figure 6-24). An SQL database query can also be plenty fast when it’s performing a search within a specific table.
When you query your data, you want specific results, such as items per order or orders for each customer, regardless of the database type. Taking the SQL example of a product catalog for a company, as shown again by Figure 6-24, on the left side under Products, you could have links to books, albums, and videos. These categories could be broken down into further details such as tracks and actors. There would be relationships defined as one-to-one between product and books, one-to-many between albums and tracks, and many-to-many between videos and actors.
For the SQL database in this example, it would be a complex SQL query to summarize a list of all your products. You would require three distinct queries: one for books, one for products, and one for videos. There would also be several joins and mapping tables that would be used to produce the list.
As a result, the CPU of the database instance could be under a fair amount of load to carry out a complex query task. And because the query request data is stored in multiple tables, it must be assembled before it can be viewed. With DynamoDB, on the right side the same data is stored in a collection of JSON documents.
If you want the total number of products, your DynamoDB query for the database example shown in Figure 6-25 on the right side can be very simple. For example, it might be Select*from Products where type = book. The DynamoDB query process is much simpler. The DynamoDB query gets the data from the single table; it does not have to construct the view of the data from multiple tables.

Note that the structure of the DynamoDB—the schema, if you will—is contained within each document. There is no mandatory schema that defines the fields, of all the records, in a DynamoDB database. DynamoDB makes simple queries, which are less taxing on the application.
DynamoDB Tables
In a DynamoDB table, data is stored as groups of attributes, also known as items. This concept is similar to the rows and columns found in other relational databases.
Each item stored in a DynamoDB database can be stored and retrieved using a primary key that uniquely identifies each item in the table.
When you construct a table in DynamoDB, you must define a primary key. In Figure 6-26, the primary key is defined as the station_id. A hash value is computed for the primary key, and the data in the table is partitioned into multiple partitions, each linked to the primary key hash for the table; in this case, it’s station_id. You can also choose to have a secondary index, such as LastName.

Provisioning Table Capacity
DynamoDB performance is defined in what is called capacity unit sizes:
A single read capacity unit means a strongly consistent read per second, or two eventually consistent reads per second for items up to 4 KB in size.
A single write capacity unit means a strongly consistent write per second for items up to 1 KB in size.
Your design requires some level of read and write capacity units shown in Figure 6-27. The design might require only a defined amount of read and write performance because your tables could initially be small. The default provision capacity is 5 read and 5 write capacity units. However, over time, your design needs may change, and you may have to, or wish to, scale your table performance to a much higher level. With DynamoDB, you can make changes to your read and write capacity units applied to your table by switching from the default provisioned read/write capacity to on-demand and quickly adjusting the amount of scale that your application and therefore your DynamoDB table requires.
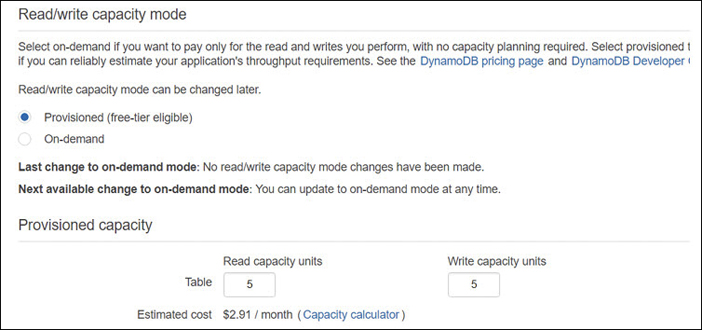
With DynamoDB, both the read capacity units (RCUs) and the write capacity units (WCUs) can be defined for the table; that is, how many reads and writes do you need per second for your table? A single read allows you to read up to 4 KB of data; if your object is under 4 KB, then a single read allows you to gather all the information. A 20 KB object would need 5 RCUs to perform the full read of the object. The same math applies to the writes.
If you provision 300 RCUs for your table, DynamoDB splits up the reads across the three storage partitions. RCUs work on a system using the available tokens for the required read performance. Each token bucket has what is called a fill rate that matches the defined RCUs. For our example, the token bucket is refilled at the RCU rate of 100 tokens per second, ensuring the table has enough tokens for the requested performance. Tokens are emptied from the token bucket at the rate of one token per read request. The number of tokens that are deducted from the bucket depends on the number of read requests and the size of the item read. The larger the item, the more tokens that are required to read the entire item.
When a read request is performed, if there are no tokens left in the token bucket, the read request is throttled. To get around this problem, the token bucket also has a burst token added to your bucket, which is calculated based on the rate of the number of provisioned RCUs multiplied by 300. This equals 5 minutes of additional performance at your defined RCU baseline; for spikes in read and write traffic to your table, you will have up to five minutes of performance credits available to handle the increased load. In addition, anytime your DynamoDB table is not being read or written to, burst tokens are being added to your token bucket up to a maximum of 30,000 tokens.
If you need to exceed read and write capacity throughput units higher than the maximum of 40,000, you can contact Amazon directly to request the desired unit increase.
Adaptive Capacity
To solve the problem of your table being throttled when it runs out of burst credits, DynamoDB has introduced a feature called adaptive capacity that increases the fill rate to the token bucket based on several parameters: the traffic to your table, your provisioned RCU capacity, the throttling rate, and the current multiplier. Adaptive capacity also provides additional burst tokens, so you have a longer period for bursting and don’t run out of tokens as quickly as you would without adaptive capacity being enabled. There are still limits to how many burst credits you will get, which is why DynamoDB introduced a feature called Auto Scaling.
Auto Scaling, as shown in Figure 6-28 allows you to set a lower and upper limit of performance capacity and a desired level of utilization. CloudWatch metrics for monitoring table performance are published to CloudWatch, the monitoring engine at AWS, and alarms are defined to alert Auto Scaling when additional or less performance capacity is required for table reads and writes.
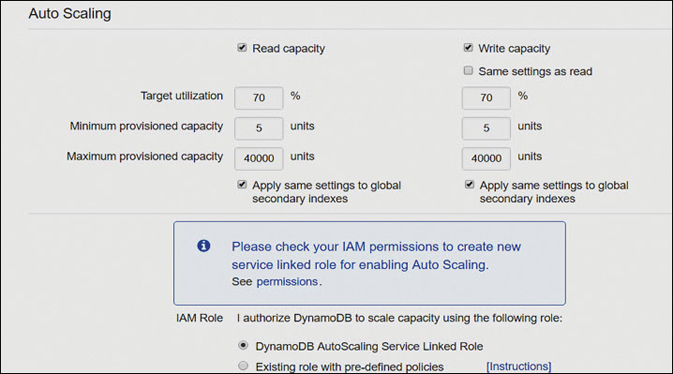
Let’s look at the case for a gaming company that uses DynamoDB as its database for millions of gamers. The information pieces that are being stored—such as game scores—are small, but potentially millions of scores need to be stored at scale. Data is stored in DynamoDB by first issuing a PUT request that is sent to a request router, which checks with the authentication services to see if the requested task is allowed. Assuming everything checks out with security, the request is sent to the DynamoDB storage services, which determine where to first write the items to disk and then replicate to the other storage nodes. DynamoDB employs hundreds of thousands of request routers and storage nodes following a cell-based architecture design to limit when failures occur by storing request routers and storage nodes in multiple partitions and AZs throughout the AWS region, as shown in Figure 6-29.
Data Consistency
Because data is written into the three partition locations across each AZ, data is not initially consistent in all storage partitions; however, after some time, all data locations across all AZs will be consistent. With DynamoDB, you have a choice of how consistent you want your data to be: Eventually Consistent or Strongly Consistent.
If you choose Strongly Consistent, a strongly consistent read produces a result from the storage nodes that performed a successful write of the information being requested.
If you choose Eventual Consistency, the leader node makes a random decision as to which of the storage nodes that are hosting the partition to read from.
The odds are that you will get a consistent read even when eventual consistency has been chosen because two storage partitions out of the three will always have up-to-date data. Typically, the single storage node that is not consistent with the other two nodes is only milliseconds away from being up to date. One of the associated storage nodes will be assigned as the leader node: the initial node that performs the first data write.
Once two of the associated storage nodes have acknowledged a successful write process, the leader storage node communicates with the request router that the write process is successful, which passes that information back to the application and end user.
Each PUT request talks to the leader node first. Then the data is distributed across the AZs, as shown in Figure 6-30. The leader node is always up to date, as is one of the other storage nodes, because there must be an acknowledgment that the PUT is successful into storage locations for a write process to be successful.
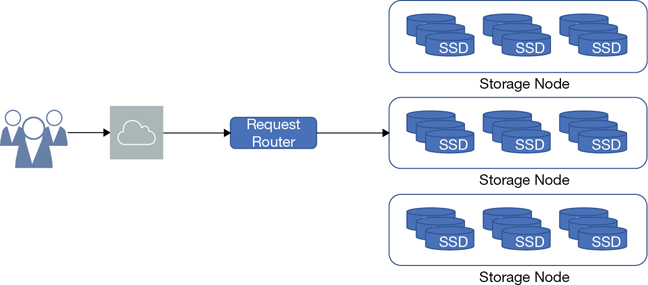
Paxos is the defined technical method to get the multiple storage systems to agree on a particular leader for the peer storage nodes. The leader storage node is always up to date. The leader and the peer storage nodes are also joined with a heartbeat that fires every 1.5 seconds with the associated storage peers. If the peer storage nodes fall out of sync with the leader storage node, an election is performed, and one of the peer storage nodes becomes the new leader node.
The request routers are stateless devices; it does not matter which request router you communicate with that in turn talks to the leader node of the associated storage partition.
As your DynamoDB database scales, the internal design ensures predictable performance through a process called burst capacity. When partitions start to get overloaded, the partition is automatically split and resharded into multiple partitions, which spreads the current read and write capacity units across the available partitions to be able to better serve the required reads and writes of the DynamoDB table.
ACID and DynamoDB
Relational databases promise and deliver great reliability in the exact content of the data being stored. Relational database transactions achieve extremely high levels of storage consistency due to design principles like ACID, which states that your database transactions have a high level of validity due to the properties of atomicity, consistency, isolation, and durability. The ACID standard is followed by relational databases such as Oracle, MySQL, PostgreSQL, and SQL Server; transactions follow the ACID principles as a single process with four conditional variables.
Atomicity—Each database transaction completes successfully, or it’s not accepted.
Consistency—Database transactions are successfully written to disk and validated.
Isolation—Database transactions are isolated and secure during processing.
Durability—Database transactions are committed to persistent storage and logged.
Amazon also supports ACID with DynamoDB across one or more tables hosted within a single AWS region. Two internal DynamoDB operations handle these transactions:
TransactWriteItems—This is a batch write operation with multiple PUT, UPDATE, and DELETE item operations that check for specific conditions that must be satisfied before updates are approved.
TransactGetItems—This is a batch read operation with one or more GET item operations. If the GET item request collides with an active write transaction of the same item type, the read transactions are canceled.
With replicated DynamoDB data, the records must also be exact on the primary and the standby database instances. The process of data replication takes time; it can be fast, but the process of verification does take additional time.
Global Tables
Standard DynamoDB tables are hosted within an AWS region. A global DynamoDB table is multiple DynamoDB tables replicated across multiple AWS regions, as shown in Figure 6-31, synchronized with the same data records. Because the partitions are stored in multiple AWS regions, IAM roles ensure the proper level of security is enforced when writing records to the global DynamoDB table. Data is transferred from one AWS region to the other using a synchronized replication engine in the source and destination AWS region.
The local replication engine compiles all the PUTS, UPDATES, and DELETES to the DynamoDB table and then replicates the local changes across the private AWS network to the associated DynamoDB table in the destination AWS region. Global tables are multimaster by design, so updates performed in one region are repeated and updated in the other AWS region. Both the outbound and the inbound replication engines need to determine what updates are local and need to be shipped to the other region and what updates are replicated. The replicated updates need to be compared using version numbers and millisecond timestamps to ensure data consistency across the DynamoDB global table. Replicated data from global tables works with a last-write conflict resolution; if the timestamps are the same, the local AWS region where the change was initiated wins.
DynamoDB Accelerator (DAX)
DynamoDB response times can be increased to eventually consistent data levels with micro-second latency by adding an in-memory cache to the design. E-commerce online sales, applications with read-intensive needs, and applications performing in-depth analysis over a long-term time frame are some of the use cases that can take advantage of DAX. Your DAX cluster, once provisioned, will be hosted in the VPC of your choice. Applications can use the DAX cluster after the DAX client is installed on the EC2 instances hosting the associated application.
DAX can be designed to be highly available, with multiple nodes hosted across multiple AZs within the AWS region, and can scale out up to 10 replicas. Read operations that DAX will respond to include GetItem, BatchGetItem, Query, and Scan API calls. Write operations are first written to the table and then to the DAX cluster. Write operations include BatchWriteItem, UpdateItem, DeleteItem, and PutItem API calls.
Backup and Restore
There are two options for backup at DynamoDB: point-in-time recovery and on-demand backups.
Point-in-time recovery backup—This allows you to restore your DynamoDB table for up to 35 days. This is a fixed value of retention and cannot be changed. A point-in-time restore point can be chosen up to 5 minutes before the current time. Once point-in-time recovery has been enabled for DynamoDB, continuous backups are performed to S3.
On-demand backup—This allows you to create full backups of DynamoDB tables for long-term storage. The on-demand backup is created asynchronously, applying all changes that happen to a snapshot stored in S3. Each on-demand backup backs up the entire DynamoDB table data each time.
A restored table, regardless of the backup type, includes local and global secondary indexes, encryption settings, and the provisioned read and write capacity of the source table at the time of restore. Only after the table has been restored can you manually re-create any auto scaling policies, assigned IAM policies, tags, and TTL settings that were previously applied.
ElastiCache
To improve performance of existing applications and supported databases, ElastiCache in memory Redis or Memcached caches can be deployed. The two platforms supported by ElastiCache are Redis, up to version 5.0, and Memcached version 1.5 rev. 10. A memory cache is designed for short-term storage of information, unlike DynamoDB or RDS, where the data is persistently stored. ElastiCache is designed to improve application performance by reducing the reads and writes to persistent storage and direct the traffic to an in-memory cache. Common uses include deploying ElastiCache as a read-only database replica or storage queue or as an in-memory read-write NoSQL database.
One of the best examples of using an in-memory cache is for storing session state for a user session; the user session information needs to be stored, but not for the long term, as shown in Figure 6-32. Rather than storing the user session information on the Web instance that the user is connecting to, the user information is instead stored in an in-memory cache; if the Web instance fails, when the user is routed to another Web instance, the user session information is still being held in the separate memory cache and remains available for the duration of the user session. ElastiCache for Redis would be a good choice for storing user state information. Redis use cases include session cache storage, queues, and full webpage cache. Memcached use cases include application caching for database performance, real-time analytics, media streaming, session state, and message queues. ElastiCache features include the following:
Fast performance—Sub-millisecond response time
Management—AWS management of all hardware and software setup and monitoring
Scalable—Read scaling with replicas, write in-memory scaling
Reliable—Multi-AZ and design with automatic failover
Compliant—HIPAA, PCI, and FedRAMP support with encryption at rest and in transit
Figure 6-32 User state information stored in ElastiCache
AWS Data Transfer Options
Regardless of the location of your data, there is an ever-increasing number of tools and services to move your data from on-premise locations—even remote locations off-grid into the AWS cloud. You need to answer several questions before you can choose the proper solution for data transfer into AWS:
What kind of data do you need to transfer from on-premise to AWS?
Data |
AWS Transfer Option |
|---|---|
Virtual server images |
Server migration tools, Export-Import service |
Virtual hard disks |
Server migration tools, Export-Import service |
Database |
Database migration tools |
Bulk storage files |
AWS transfer for SSH File Transfer Protocol (SFTP), AWS Storage Gateway |
Where will the data be used at AWS?
Daily use at AWS |
AWS DataSync, Direct Connect |
Archived use |
Glacier |
Stored forever |
Glacier |
On-premise |
Direct Connect |
How much data needs to be transferred?
Gigabytes |
AWS Transfer for SFTP |
Terabytes |
AWS Snowball, or Snowball Edge |
Exabytes |
AWS Snowmobile |
What are solutions for offline data transfer and hybrid?
Private network connection to AWS |
AWS Direct Connect |
Edge location transfer |
S3 transfer acceleration |
Internet transfer |
AWS DataSync, AWS Transfer for SFTP |
Offline data transfer |
Snowball, Snowball Edge, Snowmobile |
Hybrid storage |
AWS Storage Gateway |
AWS Direct Connect—This allows you to create a private connection from your on-premise data center using a fiber-optic connection to AWS. On the Amazon side, the Direct Connect connection connects to a Direct Connect router. A Direct Connect connection can also be partitioned into up to 50 private virtual interfaces to serve public and private resources at AWS across the Direct Connect connection. In addition, you can use a Direct Connect gateway connection to connect your Direct Connect connection to VPCs within your AWS account that are in the same or a different region, as shown in Figure 6-33.
AWS DataSync—This is a managed data transfer service that helps you automate the movement of large amounts of data from on-premise locations to either S3 buckets or EFS storage. Communication can be over the Internet or across a Direct Connect connection. Both one-time and continuous data transfer are supported using the NFS protocol and parallel processing for fast data transfers. The data sync agent is installed by downloading and deploying the OVA template on a virtual machine that is hosted on your VMware ESXi network. Next, create a data transfer task from your data source (NAS or file system) to the AWS destination—either Amazon EFS or S3 bucket—and then start the transfer. Data integrity verification is continually checked during the transfer process, and data transfers are encrypted using Transport Layer Security (TLS). AWS DataSync also supports both PCI and HIPAA data transfers.
The Snow Family
Meet the Snow family, the new official name of the Snowball and Snowmobile device family: Snowball devices or Snowmobile trucks on demand. Yes, real transport trucks.
AWS Snowball—Petabyte data transfer is possible with multiple Snowball devices; each device can hold up to 80 TB of data. After creating a job request, as shown in Figure 6-34, a Snowball device is shipped to you via UPS. Once you receive your device, hook it up to your local network using its RJ-45 connection. You have to install the client software and enter predefined security information before you can start the data transfer. Once your data transfer has finished, call UPS and ship the Snowball device back to AWS; AWS deposits your data into an S3 bucket. You can also reverse this process and transfer data from AWS back to your on-premise network. All data that is transferred to a Snowball device is encrypted with 256 bit-encryption keys that can be defined using the AWS KMS.
AWS Snowball Edge—Up to 100 TB of capacity and two levels of built-in compute power can be selected with the Snowball Edge device. The two available options are either Storage Optimized or Compute Optimized. The Compute Optimized Snowball device is designed for data processing and storage for remote sites or locations that are not connected to the grid. Perhaps while your data is being transferred to the Snowball device, it could use some additional processing or analysis before being stored. The Snowball Edge device supports the installation of a local EC2 instance, which can carry out the local processing duties; the instance can be built from your instance AMIs.
AWS Snowmobile—Up to hundreds of petabytes of data can be moved with a specialized truck called a Snowmobile. After ordering, AWS employees show up with a 45-foot truck and attach it to your data center. After the truck is filled with data, it is carefully driven back to AWS and uploaded into an S3 bucket of your choice. The truck has a logo “faster than cloud” for easy identification. Okay, that’s not true, but your data does have an escort vehicle for additional safety.
AWS transfer for SFTP—A fully managed transfer service for transferring files into and out of an S3 bucket using the secure SFTP. Simply point your existing SFTP software to the SFTP endpoint at AWS, set up user authentication, select your S3 bucket, and after assigning IAM access roles, you are ready to start transferring data.
AWS Storage Gateway Family
Storage Gateway allows you to integrate your on-premise network to AWS so that your applications and utilities can utilize S3, S3 Glacier, and EFS storage seamlessly. You can use the storage gateway to back up and archive documents, migration services, and tiered storage.
Protocols supported include NFS, SMB, and iSCSI. The actual gateway device can be a hardware device such as a Dell EMC PowerEdge server with a preloaded storage gateway or a virtual machine image that can be downloaded and installed in your VMware or Hyper-V environment. There are three configuration choices available for deploying a storage gateway.
File Gateway—Interfaces directly into S3 storage, which allows you to store and retrieve files using either the NFS or SMB protocol file shares, as shown in Figure 6-35.
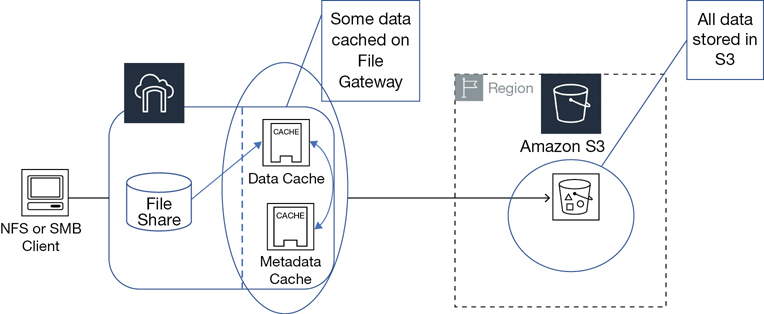
Figure 6-35 Storage Gateway: File Gateway architecture Volume Gateway—Provides S3 cloud storage that can be mounted locally as iSCSI devices for on-premise applications. Data can be stored in S3 buckets with a copy of frequently accessed data cached locally. Alternatively, all data can first be stored locally and then asynchronously backed up to S3.
Tape Gateway—Virtual tape drive that supports a variety of third-party backup applications, such as Veritas or Commvault. It allows you to store and archive data in S3 bucket storage as virtual tapes.
In Conclusion
Whew. There are a few storage options to consider in the AWS cloud! Storage services are different from compute or networking services at AWS because storage is holding the one component we can’t afford to lose: our precious data.
Amazon certainly gives us enough choice when it comes to storage in the cloud, and it seems to realize that you’re probably going to operate in a hybrid mode of operation for the time being.
Of course, I could be completely wrong. You may be planning to move absolutely everything to the cloud. However, you probably want some of your documents under absolute control, which means there may be the possibility of storing certain records on-premise. Only after careful testing of each chosen storage solution will you know whether you have a winner.
Look at the big-picture discussion points below, and start planning your migration to AWS storage. Review some of the charts and figures in this chapter to help you make some initial decisions as to which storage solution is best for your needs.
Top 10 Big-Picture Discussion Points: Storage Options and Considerations
Before deciding on a storage platform, you must decide what you are trying to accomplish.
What is your storage use case that you are trying to solve?
What is your database currently being used for?
Can your existing database be migrated to AWS?
What compliance rules and regulations do you have to follow?
What is the structure of the data that needs to be moved to AWS? Can it live in S3 or S3 Glacier storage?
How often will you need to read or write to your storage?
Do both Linux and Windows workloads need shared data access? Can EFS or FSx offer a solution?
What are your current data processing speeds? Are they adequate? Can AWS match or exceed your current data speeds?
What backup/restore/recovery solution do you need?
Can replicated database storage solve any of your issues?