
2
Designing with AWS Global Services
In what region of the world are you considering locating your cloud resources? That is one of the main concepts of this chapter—and probably the most important chapter in the overall scheme of moving to AWS. The concepts of regions, availability zones (AZs), edge locations, and costing out your overall design are big-ticket items that you need to understand. At the end of this chapter are the first in a series of top 10 questions to consider relating to global services at AWS.
There is a fair bit of information on costs in this chapter; you want to have an idea as to the price of what you’re attempting on AWS before you get your first monthly bill. Of course, after you get your first monthly bill, the price of using AWS resources will be part of the conversation. And costs at AWS constantly change. At this point in our cloud evolution, prices are continuing to decrease. You also have to come to terms with the service-level agreements (SLAs) available at AWS for the services offered; cloud-based SLAs are certainly not the same as an on-premise SLA.
In this chapter, the concept of a customer’s location will be discussed against the criteria of compliance, latency, services available, and costs. At the end of this chapter, you will have a strong understanding about AWS global, regional, and edge services. The following are the topics for this chapter:
Regions
Availability zones
Edge location services
Location considerations
Compliance factors
SLA considerations
Understanding costs
Questions we will consider and reflect upon for this chapter will be based on our case study Terra Firma and where they think they would like to operate in the cloud and where they are actually going to operate. Terra Firma has location questions to consider. They are based in Canada and the United States currently and hope to expand to Europe in the future. As you probably know, each country in the world has its own rules and regulations regarding the storage of data in the public cloud.
When you review the privacy laws of many countries around the world, the term cloud is not mentioned at all because these agreements are typically old—sometimes many decades old. However, that’s starting to change quickly as the cloud gains popularity. In addition to defined privacy laws, the industry that you work in will have its own set of rules and regulations defined typically as compliance rules that are to be followed. Now let’s add in what I like to call a small helping of customer paranoia, and we end up with a complicated operating landscape to consider. Specifically, Terra Firma is facing these issues:
The CEO doesn’t like moving to the cloud. She also doesn’t like spending money.
Developers are located in Canada and the United States.
There is currently no need for public access to applications, but there could be in the future if a SaaS application is created to allow customers to pay their bills online.
Some of the questions Terra Firma needs to have answered include these:
What region or regions should Terra Firma consider operating in?
How many availability zones should be used?
What edge services are required?
How can we reduce our operating costs?
How can we consolidate our billing for multiple accounts?
What does Amazon have for an SLA?
How much is this going to cost?
Considering Location
Moving your on-premise resources to the AWS cloud involves many decisions at many levels, but location is the most important decision you need to make. At AWS, customers can decide where their resources will be geographically located. If you’re expecting to be able to have precise location information down to a GPS level, that’s not going to happen. However, over time, you will begin to get used to not knowing where your AWS resources are physically located. “Exact location” is an impossible question to completely answer in any detail for applications and services hosted in the AWS cloud. However, your AWS resources will remain hosted in the region that you ultimately select; Amazon guarantees that much.
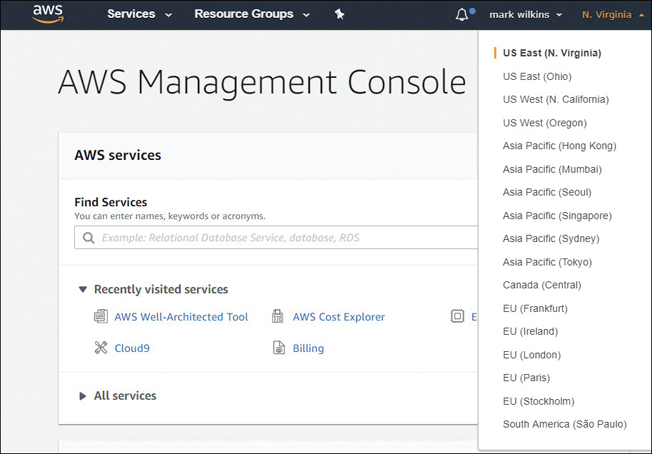
When first beginning to use Amazon cloud services, you probably didn’t think of an exact location other than that you knew you were in the AWS cloud. When you started working with AWS and opened the management console, a default work location, or region, was preselected for you—namely, the US-East region hosted in North Virginia, as shown in Figure 2-1. And you may get lucky; working in Northern Virginia may be the perfect location. Or perhaps compliance rules and regulations or other considerations that we are going to discuss in this chapter will dictate where you can operate in the AWS cloud. Keep in mind that deciding on the best location is complicated, with a few considerations to keep in mind. It’s also a decision that may change over time depending on your project or requirements, which most likely will change from your starting considerations.
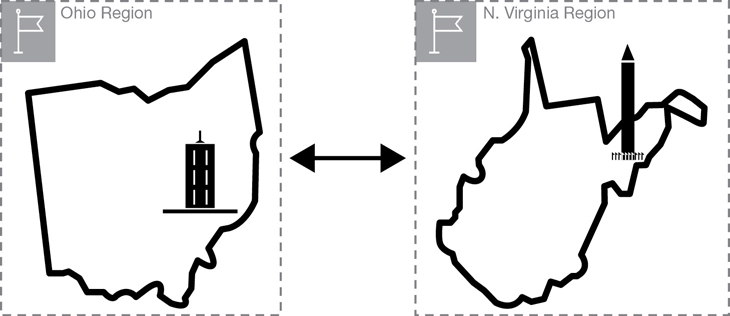
Perhaps your business is spread across the United States, or across the European Union and the United States. If you are operating in a hybrid model (where some of your resources remain on-premise, and other resources have been moved to the cloud), and you have no need for public access across the Internet to your AWS resources, perhaps selecting a region based on where your business is physically located makes the most sense. However, you may have multiple data centers in different geographical locations that match up with different AWS regions, as shown in Figure 2-2. Perhaps you’re creating an application that will be hosted in AWS and require public access, and you’re pretty sure where your customers will be located in the short term. However, you’re not sure where your customers could be coming from in the long term. In that case, there are a few issues to explore regarding your location and where you will be working in AWS.
Once the topic of location begins to be discussed internally, I’ll bet that your company’s owners and executives will start to be very interested in where your compute instances and data records are being stored in the AWS cloud. Typically, location is one of the topics that is forgotten about until a hosted application becomes popular and starts to be utilized; alternatively, audits are performed to reaffirm what resources a key application is using in the local data center. It could be a shock to find out that the most important mission-critical application that your company depends upon is hosted in the AWS cloud. I have been the fly on the wall for a few of these lively discoveries. Stumbling across situations such as this might create some real issues with what your company policy dictates. It is extremely important to understand what compliance rules and regulations your company must follow when working in the public cloud. Let’s start with regions.
AWS Regions
An AWS region, defined in simple terms, is several data centers located in a specific geographical area of the world. Each AWS region is isolated from the others by at least hundreds of kilometers or miles. Therefore, problems within one region will remain localized and will not affect any other region you also may be operating in.
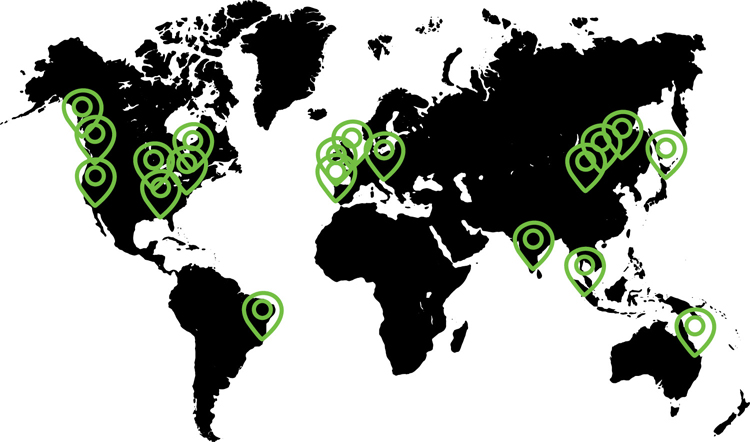
Working in the default AWS region could save you money because Northern Virginia has the best pricing and service availability throughout the AWS cloud. However, this region may not match your compliance rules and regulations unless you are physically located in the Northern Virginia region. Each AWS account can choose to work in any AWS region, except for the GovCloud regions and several regions in China that require separate AWS accounts to be created before access is allowed. We will discuss the GovCloud regions and why you may want to choose them. The current regions available at AWS are shown in Figure 2-3.
Connecting from your physical location to Amazon Web Services is an interesting thought process. Of course, we know our physical location, but we will have only a vague idea as to where AWS resources are really located. This deliberate vagueness ends up being a form of security by design. You don’t know, and neither do the bad guys and gals. Not knowing the real locations of services that we are connecting to was initially uncomfortable and may remain uncomfortable for AWS users, but this uneasy feeling has changed from an initial level of quiet paranoia to an accepted level of trust.
Note
You can’t use the AWS Management console, the AWS software development kits (SDKs), or the command-line interface (CLI) without first choosing a region. The default region is US East (N. Virginia).
You may still be paranoid. Fair enough. However, trusting a hosted cloud service while having no details about its physical location has been going on for a long time. How long have you had a Gmail or Hotmail account? For more than a decade, I’II bet. Have you ever lost anything from hosted email services? I’ll bet you haven’t. If you think about it, most of the world has been beta testing cloud services using Hotmail or Gmail and now Facebook for years. We don’t lose anything. Sometimes we probably wish we could.
Amazon’s physical locations are placed in geographical regions of the world closest to the largest populations. They don’t have regions in areas of the world where there is sparse population. Currently, there are at least 20 AWS regions worldwide. There may be additional regions online by the time you are reading this book because AWS is undergoing continued global expansion of its cloud resources. Depending on what you’re planning to host in the AWS cloud, your physical location comes back into consideration. For example:
If you’re using an application hosted at AWS from a device (phone, computer, tablet, watch, or car), you will need to connect to your hosted application, most likely across the Internet. Connecting to an application at AWS, the end user has no functional need to know anything about the AWS region or regions where your application is hosted. In the background, Amazon’s DNS service (called Route 53) will successfully connect you to your hosted application at AWS. Route 53 can also assist in connecting you to your hosted application when it’s running in multiple regions, connecting you to the closest location.
If you’re planning to move applications from your corporate data centers to the AWS cloud, the location of your place of business might influence the AWS region that you want to utilize if you are planning to operate in a hybrid model (with some resources remaining in the corporate data center and some resources hosted in the cloud).
Selecting a location closest to your corporate data center may not matter at all if all your applications are moving to the AWS cloud.
If you’re creating a public-facing SaaS application, you may think that you need to choose a region closest to where most users are located. The reality is, you’ll solve this issue by using Amazon’s content delivery network (CDN), called CloudFront. You can find more details on CloudFront in Chapter 6, “Cloud Storage.”
Region Isolation
As mentioned, each AWS region is an isolated entity; AWS regions are physically and securely separated from each other, as shown in Figure 2-4. Depending on the scope of your design, the region that you choose to operate in at AWS may always remain separate from the other regions. Or you may decide to use a database service such as DynamoDB, AWS’s managed NOSQL database solution and utilize a feature called global tables, which are hosted and replicated across multiple regions. Perhaps over time, you will decide to operate in multiple regions and use Route 53 for geo-load-balancing your applications hosted in different regions.

Isolated regions allow AWS to guarantee a level of operational compliance and data sovereignty; it recognizes that the industry that you work in may have strict rules and regulations as to how user data is managed and controlled. If your data is stored within an AWS region, your data will never leave its selected region unless you move it or specifically direct AWS to do so. As you will learn about in Chapter 3, “AWS Networking Services,” you can choose to change a region’s default of complete isolation, but this decision is your choice.
Note
Regions are designed to be completely isolated from other AWS regions; if issues made the US East AWS region unavailable; hopefully the US West region would continue to function.
Separation of Essential AWS Services
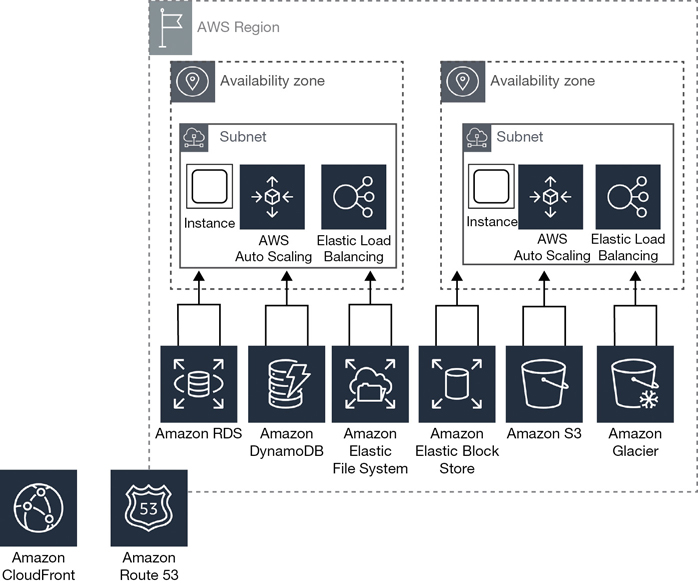
Within each region, AWS has a variety of cloud services designed to support the customers’ needs for storage, load-balancing, DNS services, managed database services, and more. Would it really make sense to have all AWS cloud services offered within a region contained within data center facilities? Amazon doesn’t think so. All AWS cloud services have been designed to be durable and redundant and to retain the ability to fail over when disaster strikes to other backup services contained within the region.
We also don’t know how many separate regional buildings contain these supporting cloud resources and services, but it’s handy to visualize a large cluster of strategically placed buildings as shown in Figure 2-5 wired together with high-speed private networking that supports the nested availability zones contained within each region. A private AWS networking campus spread across each region is designed for fault tolerance and failover.
Availability Zones
An availability zone (AZ) is defined as one or more data centers inside a region. Each region is sliced up into multiple AZs, as shown in Table 2-1. Each AZ is linked to the other AZs in the region through dedicated, redundant, low-latency fiber connections. Internal AWS private network speeds are in the 40 Gbps range. All AZs within a region are linked to each other with redundant private network links that AWS owns.
Table 2-1 Regions and Availability Zones
Region Code |
Region Name |
Availability Zones |
|---|---|---|
us-east-1 |
N. Virginia |
us-east-1a us-east-1b us-east-1c us-east-1d us-east-1e us-east-1f |
us-east-2 |
Ohio |
us-east-2a us-east-2b us-east-2c |
us-west-1 |
N. California |
us-west-1a us-west-1b us-west-1c |
us-west-2 |
Oregon |
us-west-2a us-west-2b us-west-2c |
us-gov-west-1 |
US GovCloud West |
us-gov-west-1a us-gov-west-1b us-gov-west-1c |
ca-central-1 |
Canada |
ca-central-1a ca-central-1b |
eu-west-1 |
Ireland |
eu-west-1a eu-west-1b eu-west-1c |
eu-west-2 |
London |
eu-west-2a eu-west-2b eu-west-2c |
eu-west-3 |
Paris |
eu-west-3a eu-west-3b eu-west-3c |
eu-west-4 |
Stockholm |
eu-west-4a eu-west-4b eu-west-4c |
eu-central-1 |
Frankfurt |
eu-central-1a eu-central-1b eu-central-1c |
ap-northeast-1 |
Tokyo |
ap-northeast-1a ap-northeast-1b ap-northeast-1c ap-northeast-1d |
ap-northeast-2 |
Seoul |
ap-northeast-2a ap-northeast-2c |
ap-northeast-3 |
Osaka |
ap-northeast-3a |
ap-southeast-1 |
Singapore |
ap-southeast-1a ap-southeast-1b ap-southeast-1c |
ap-southeast-2 |
Sydney |
ap-southeast-2a ap-southeast-2b ap-southeast-2c |
ap-south-1 |
Mumbai |
ap-south-1a ap-south-1b |
sa-east-1 |
Sao Paulo |
sa-east-1a sa-east-1b sa-east-1c |
cn-north-1 |
Beijing |
cn-north-1a cn-north-1b |
cn-northwest-1 |
Ningxia |
cn-northwest-1a cn-northwest-1b cn-northwest-1c |
Announced 2020 |
Cape Town |
3 availability zones |
Announced 2020 |
Milan |
3 availability zones |
Announced 2019 |
Bahrain |
3 availability zones |
Announced 2019 |
Hong Kong SAR |
3 availability zones |
US-East |
US GovCloud East |
3 availability zones |
Each AWS region has at least two availability zones, except for Osaka, and many regions have three AZs. A single AWS data center within an AZ is a standard concrete building full of bare-metal servers, air conditioning, and heating, powered by multiple separate power grids located strategically throughout each geographical region. And we don’t really know whether an AZ has multiple data centers or a single one.
A failure of an AZ (typically a single physical data center located within the AZ) will not affect and derail the operation of the AWS services that are specifically designed to live outside the AZs. For example, Amazon’s S3 storage and Elastic Load Balancing (ELB) services are specifically designed to integrate with the data centers within each AZ; but each of these services functions as a standalone entity that will continue to function even if one or all the data centers located within an AZ have failed.
In addition, services defined as global services are designed to sit outside the regions themselves at the perimeter of AWS, defined as the edge location—specifically, DNS services such as Route 53, and CloudFront, AWS’s CDN. You can find more about Route 53 in Chapter 3; for CloudFront, you can find details in Chapter 6.
Even though each AZ is backed by a cluster of multiple data centers, it’s important to also grasp that no two AZs share the same single data center. Each AZ is also isolated from the other AZs within the region.
Availability Zone Distribution
The other interesting design criteria to understand is the balancing and distribution of resources hosted in AZs carried out in the background by AWS. If I log into my AWS account, select the US-East (N. Virginia) region, and create a subnet in availability zone A, the physical location of my subnet is probably not the same as another Amazon customer who has also selected the US-East Northern Virginia region and created a subnet in availability zone A. We each have a subnet in “availability zone A,” but our subnets are probably not in the same availability zone. We are most likely in different physical locations, as shown in Figure 2-6.

Average latency between AZs within a region is around 3 ms. The latency between different instances located in different AZs can be casually tested by running pings between instances located in different AZs. I don’t think you’ll find that latency between AZs within a region is an issue. Certainly, latency testing can be performed from one instance hosted in one AZ to an instance in another AZ if you’re concerned.
Latency from your physical location to AWS can also be tested with the variety of publicly available tools, including Cloud Harmony’s speed test for AWS found here: https://cloudharmony.com/speedtest-for-aws.
Note
Each AZ within each region has a name based on the region it is hosted within and a letter code, such as US-West-1A.
Within a single AZ, the data center private network connections are defined as “intra,” or local to the AZ. The wiring between the AWS regions is defined as “inter,” with international links connecting the regions (see Figure 2-7).
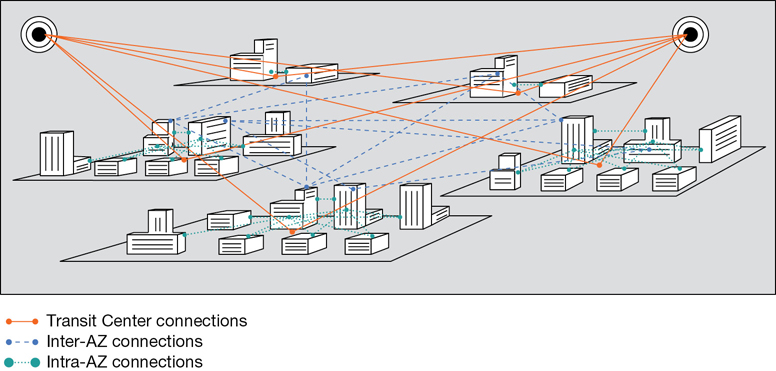
Note
The primary reasons for using AZs in your infrastructure design are for application failover and for database replication.
Multiple Availability Zones
AZs are an important concept to wrap your head around when working with AWS. Key services—specifically the virtual private cloud (VPC), the ELB service, and Elastic Compute Cloud (EC2) Auto Scaling—can function across multiple AZs, providing you, the customer, with the ability to design your applications for scale, resiliency, and high availability. We will revisit availability zones several times throughout this book; specifically, we’ll cover them in Chapter 3 and in Chapter 5, “Planning for Scale and Resiliency.”
You may remember that a few years ago Amazon had issues in Australia. The media announced that “the Amazon cloud was down!” This was true to a point because an AZ in the Asia Pacific region had issues, but not all the AZs within the region had issues. However, if your application or website was hosted in the unavailable AZ, and you had not designed your application or website for automatic failover to another AZ within the region, as shown in Figure 2-8, then there was a 100% possibility that your applications were not available, in this case for several hours.
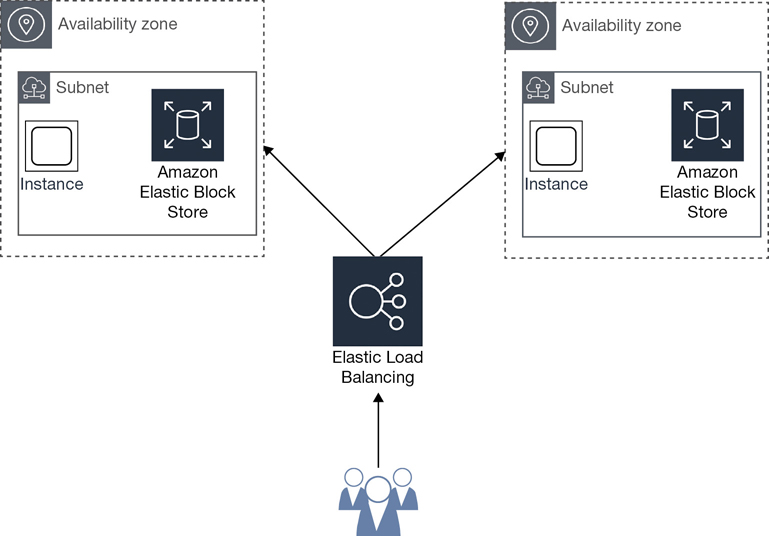
Is this lack of availability of your hosted application Amazon’s fault? Nope. It’s the customer’s fault for not utilizing proper cloud design standards in the hosted applications. In fact, not designing your applications to properly function in multiple AZs negates your service-level agreement (SLA) with AWS. And, if you were down and you had designed your application properly, there was a possibility of getting a credit on your bill for several hours of downtime. But there’s a catch; you usually need to prove that your application was down by providing relevant network traces. I say usually; I’ve seen instances in which a credit was automatically given because the outage was so severe it was obvious that it was the cloud provider’s problem. More details on the AWS SLA are next.
Remember, your availability zone A is probably not in the same physical location as another customer’s availability zone A. Just because it is announced that an AZ is down, there’s no real way of knowing what physical data center is down. An AWS customer’s solution to this problem is having a properly designed application that can fail over between multiple AZs within each region.
Note
An AZ is a single point of failure.
To access the companion videos, register your book at informit.com/register.
What’s the AWS Service-Level Agreement?
Cloud SLAs have been described by many technical people over the years as less than adequate. However, this is typically the conclusion made when comparing a cloud SLA with an on-premise SLA. Imagine that you were the cloud provider with multiple data centers and thousands of customers. How would you design your SLA? Would you not tell your customers, “We do the best job we can, but computers do fail, as we know.” If you think about the difficulty of what to offer a customer when there are hardware and software failures, you would probably come up with the same solution that all cloud providers have arrived at.
You’ve probably heard about SLAs. After all, they are a common part of the computer and service industry. Perhaps you have an SLA for on-premise technical support, or you’ve outsourced your help desk. Each SLA defines the level of support, the hours of support, and the services to be rendered. For example, when hardware breaks down, the response to the breakdown will happen within so many minutes or hours; it will be fixed or replaced within an agreed-upon timeframe. (Perhaps loaner equipment will also be promised.) In every SLA, the guarantee of service availability is the focus of the agreement. Common terms covered in most SLAs also include definitions of quality of service, customer experience, availability, dispute resolution, and, of course, the indemnification clause. Now let’s turn our attention to cloud SLAs.
At Amazon, each service may have a separate SLA, but some services don’t have a specific SLA at all. Certainly, the building blocks of any application—compute, storage, CDN, and DNS services—have defined SLAs. Before we consider an SLA, the first document you need to consider is the AWS Customer Agreement, which lays out the big picture—the terms and conditions that govern your access to the total AWS service. If you’ve already signed up for AWS and checked that check box indicating that you accepted the AWS terms, you have already accepted the customer agreement. Let’s review what you may have already agreed to: the major considerations of the AWS customer agreement.
Changes—The fabled words of from time to time in this section indicate that Amazon is free to make changes, additions, or discontinuation of any AWS service. There could also be changes to each AWS service SLA at any time, and this does happen frequently.
Security and data privacy—Each customer specifies the regions where content is stored. Understand that Amazon will normally move your content (data) within the region; for example, a virtual hard disk is created using the EBS service, and Amazon automatically creates a backup copy in a different location. Or an EBS drive fails and needs to be replaced by the backup image. You create an S3 bucket and upload files; these files are replicated to three separate locations within the region that you specify.
Your responsibilities—Accounts, content, security settings, backup, login credentials, logon keys, and the actions of your end users working with AWS services are the customer’s responsibility.
Termination of your account—If you cancel your account, your content will be held at AWS for at least 30 days.
Indemnification—You, the customer, will hold Amazon harmless from any losses arising from actions performed by your end users, any violations of the service agreement, and any illegal actions. You will also pay Amazon’s legal fees.
Disclaimers—Each AWS service is provided “as is” with no warranty of any kind.
Limitations of Liability—Amazon and its affiliates and licensees are not liable to the customer for anything.
Quality of service—Typically, this term applies to networking performance, or multimedia performance across a network. This term could also mean that the service was slower than expected. Amazon assumes responsibilities for its services; there is a default performance standard for each AWS service that the cloud provider attempts to maintain. Take, for example, the typical complaint of, “This application is so slow it must be the network that’s the issue.” The customer responsibilities must be taken into consideration:
Is the operating system kernel up-to-date, or are you using an older version of the operating system that cannot take advantage of faster network speeds?
Does the chosen instance type have the required network speeds?
Are elastic network interfaces being used on the latest EC2 instances with the most up-to-date Amazon machine images (AMIs)?
Are the SSD-backed volumes of your instances optimized with provisioned IOPS (the number of Input/Output Operations per second)?
Is the instance of Elastic Block Storage (EBS) optimized?
Customer experience—Certainly, the customer experience is based on the “quality” of the service being used. Proper application design using Amazon best practices will result in an excellent customer experience; therefore, the customer experience is the customer’s job.
Availability—This is the number-one consideration when using a cloud service: that the service in question remains available. From time to time, certain services will not be available, and you will have to plan for this occurrence. Each separate SLA will detail Amazon’s desired availability of the service. We must give Amazon kudos: many times, they exceed the published SLA’s specs for months at a time.
Note
Over at www.cloudharmony.com/status-for-aws, we can review the uptime status of AWS services and locations.
Everything Fails
Here is a concept to get your mind around with every cloud service SLA that AWS provides. Each service is going to fail, and you’re not going to have any warning. That’s pretty much the only guarantee we have with hosting applications in the public cloud: the underlying cloud services are going to fail unexpectedly. And don’t get me wrong; AWS services are stable for months; but failures will still happen unexpectedly.
If you think about it, most of the failures we experience in the cloud are compute failures. An instance fails that is powering an application server, a Web server, a database server, or a caching server. What about the data? Your data in the cloud is replicated, at the very least, within the AZ where your instances are running. (If you’re strong, your data records on EBS volumes.) This does not mean you can’t lose data in the cloud; if you never back up your data, you will probably lose it. And because customers are solely in charge of their own data, that is certainly job one: 100% data retention.
Recap—Amazon helps us with data retention by having multiple copies of our EBS volume data hosted within the AZ, or in the case of S3 data, replicating the data contents across three physical locations within the region. These and other common cloud services shown in Table 2-2 illustrate how AWS builds redundancy and failover into every service that it offers, except for the single instance. The only SLAs offered by AWS are for these listed services.
Table 2-2 AWS Service Availability and Projected Downtime
AWS Service |
Availability |
Projected Downtime per Year |
Avoiding Downtime |
|---|---|---|---|
Instances |
99.95% |
One hour, 45 minutes |
A single instance: none Instances that fail over across AZs |
Relational database service (RDS) |
99.95% |
One hour, 45 minutes |
Master/slave database design with synchronous replication across AZs |
EBS volumes |
99.99% |
52 minutes |
Each volume automatically replicated within its AZ |
S3 Storage |
99.9% |
8.76 hours |
Replicated across three physical locations within the region |
Route 53 |
100% |
Hopefully none |
Anycast design—worldwide replication and updating |
Therefore, ordering a single instance to host a website, and not designing your website or with failover to another website instance when issues occur, is simply dumb. Designing your applications stack to fail over between AZs is the bare minimum for being protected by the EC-2 SLA agreement. Customers who don’t follow proper AWS design principals and best practices will have no SLA protection.
Protecting Against Application Failure
It’s time to return to the concept of failure. How do we work around service failure at AWS? We must design for failure. Each customer’s job is to use the available tools and services at AWS to create an application environment with the goal of 100% availability. When failures occur at AWS, automated processes must be designed and in place to ensure proper failover, with minimum to zero data loss. Computer loss, no matter how painful, we can live with. Data loss is obviously unacceptable and does not have to happen. We will be looking at how to design our application stacks hosted at AWS for automatic failover in Chapter 5.
The other reality to accept is knowing that, for example, although the RDS service as shown in Table 2-2 is designed by AWS to fail a mere 52 minutes per year, that does not mean you can schedule this potential downtime. Just because Route 53, AWS’s DNS service, is designed for 100% uptime does not mean that Route 53 will not have issues. The published figures of uptime are not a guarantee; instead, it’s what AWS strives for and most of the time achieves.
When a cloud service fails and you’re down, you’re out of business for that timeframe. Because failures are going to happen, designing your application’s hosted AWS for maximum uptime is the goal. You also must consider all the additional external services that allow us to connect to AWS: your telco, your ISP, and all the other moving bits. Considering all services in the equation, it’s difficult, if not impossible to avoid some downtime. However, we can greatly minimize our downtime and completely minimize our data loss by following the basic cloud design considerations listed in Table 2-3.
Table 2-3 Cloud Design Considerations
AWS Service |
Potential Solution |
|---|---|
Instance |
Load balanced across AZs within a single region |
Database |
Synchronous replication across AZs within a single region |
S3 bucket |
Automatic replication to bucket in different region |
EBS volumes |
Automatic copying of snapshots to different region |
100% Application uptime |
Geo-load-balancing utilizing Route 53 domain name system (DNS) services across regions |
Global Edge Services
Outside of Amazon’s regions is the rest of the world where you and other customers are located. Connecting to Amazon resources from your location requires the ability on Amazon’s end to successfully direct incoming requests from any location to the desired Amazon resource. This area has a worldwide presence and is defined as the edge location with many points of presence wired to AWS services spread across the globe. More than 155 edge locations are available in 2019 pointing to AWS services from most major cities across the globe.
Each edge location is wired into the local and global telecom provider’s mesh of transit networks that are peered and tiered around the world supporting worldwide Internet communications. The cheapest and the slowest way to get to an edge location is across the public Internet You could also use a VPN connection or a private fiber connection, called Direct Connect, from your branch office location, or local data center, to connect to an edge location. There are three data highways connection possibilities found at each edge location:
Internet connections
Direct Connect private connections
AWS private backbone network
Each request to an application hosted at AWS is typically a query for information. Alternatively, my request could be providing an update to existing data records; I have some data I want to move to AWS storage using my application and its associated storage location. It’s important to understand that edge locations are for both the fast uploading and downloading of information to and from AWS.
Services Located at the Edge
There are several essential services at each edge location; some of these services are provided at no additional charge, and depending on your present and future needs, other services can be ordered and utilized at each edge location as required. The services offered at each edge are as follows:
Route 53—Global load balancing DNS services
AWS Shield—Real-time inline distributed denial of service (DDoS) protection services
AWS Web Application Firewall—Layer 7 protection for Hypertext Transfer Protocol (HTTP) and Hypertext Transfer Protocol Secure (HTTPS)
CloudFront—Content delivery network for the fast delivery of both static and dynamic data
AWS Lambda@Edge—Create lambda functions to control CloudFront delivery
Route 53
As a customer accessing an application hosted at AWS from your phone, tablet, or device, an application query will be carried out. Obviously, you will need an Internet connection or a private network connection for your device to begin communicating with AWS services. What service needs to be working to make the initial query? If you’re thinking DNS, you’re right. DNS is still the essential service in today’s cloud. And because we are now operating in the public cloud, the scope of DNS services has changed from local DNS services per corporation to a worldwide global service that knows about where the Amazon regions are located and each requested AWS service resides.
Amazon’s hosted DNS service is called Route 53, named for the standard DNS port number. Route 53 has a public side pointed to the public edge locations that accepts incoming customer requests and then resolves each query to the requested AWS resource located on Route 53’s private side, as shown in Figure 2-9.
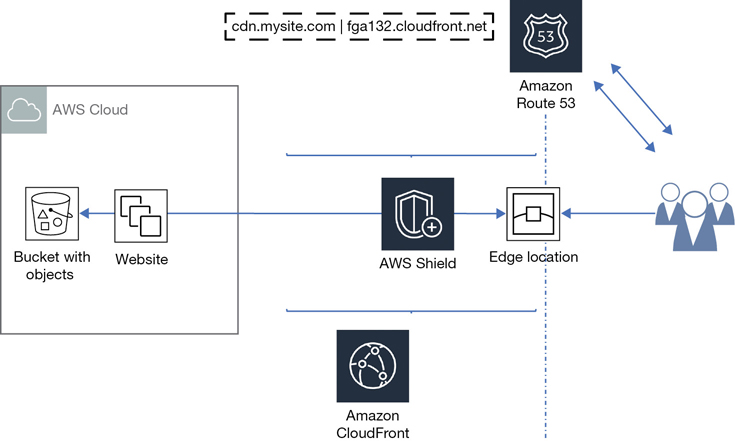
For simplicity sake, let’s pretend that at the edge location is a single DNS server with full knowledge of all AWS resources. Obviously, it’s not a very fault-tolerant design. It would be better to have redundant DNS services wired worldwide that are linked together with full knowledge of all AWS resources. Route 53 is designed using Anycast DNS routing algorithms. In this design, each destination service location is known by all the Anycast DNS servers hosted across the AWS regions. Your physical location will determine the edge location Route 53 directs you to. Once an application request reaches the edge location, the request continues on Amazon’s private high-speed network to the preferred AWS service location.
AWS Shield (Standard)
What if a request that enters an AWS edge location is a malicious request like a DDoS attack, or a bot attack? At each edge location is a service running 24/7 called AWS Shield. Its job is to provide multitenant basic DDoS protection with the design requirement that it analyze and block perceived threats within 1 second for known Layer 3 and 4 attacks.
AWS Shield standard protection is for all AWS customers, but AWS is not really protecting each individual customer. It’s instead protecting its infrastructure located at the edge for all customers. What if you want or need more individualized DDoS protection? If you don’t have the expertise to solve your security issues and would like AWS experts to assist you with real-time custom protection, get out your wallet and connect with the AWS Shield Advanced team.
AWS Shield Advanced
When you can’t solve a sophisticated DDoS attack, perhaps it’s time to sign up for AWS Shield Advanced by selecting Global threat protection from the AWS Shield console. This option allows you to further protect your two- or three-tier applications running on EC2 instances, sitting behind Elastic Load Balancing and CloudFront services. Choosing AWS Shield Advanced, you’ll be working with an expert DDoS response team at AWS with a 15-minute SLA response. After analyzing your situation, solutions to mitigate the more sophisticated DDoS attack are created, applied, and monitored by the team. AWS Shield Advanced customers also get access to a global threat environment dashboard, which reviews the current attack vectors and any DDoS attacks that are currently happening around the world.
An interesting bonus feature is called cost protection, which saves you money if your hosted application that is under attack forces your AWS resources to scale due to the illegitimate demand placed on its services. AWS will refund the additional load balancer, compute, data transfer, and Route 53 query costs borne by you during the DDoS attack. AWS Shield Advanced can run you a few thousand dollars a month, but that may be a drop in the bucket compared to the business losses you may be faced with if your online AWS resources are unavailable due to attacks. You also get the web application firewall (WAF) and the AWS Firewall Manager at no additional cost when you sign up for Shield Advanced.
Web Application Firewall (WAF)
If you want to craft your own protection at the edge, the next service to consider is the WAF for custom filtering of incoming (ingress) public traffic requests at Layer 7 for HTTP and HTTPS requests. The idea behind the WAF is to limit any malicious requests from getting any further into AWS infrastructure to the edge location. Customers can define their own conditions for the WAF to monitor for incoming web requests. WAF rules are created using conditions that are combined into a Web access control list (ACL). Rules either allow, or block, depending on the condition, as shown in Figure 2-10.
The following behaviors are supported by the AWS WAF:
Block requests from specific attackers, or attacks—Block specific IP addresses, countries, and defined conditions.
Serve restricted content to specific users—For example, restrict content to users from a specific IP address range.
Monitor incoming requests properties for analysis—After analysis, conditions and rules can be created for additional protection.
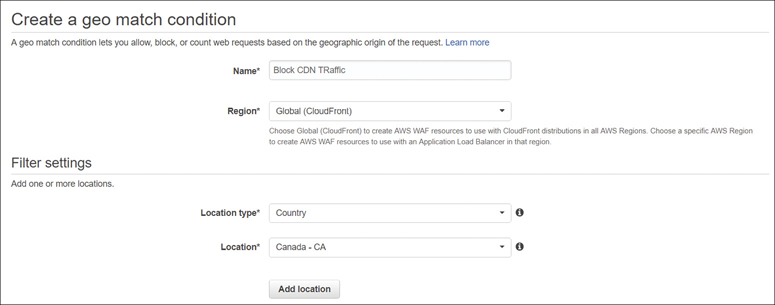
Figure 2-10 Web application firewall rules
WAF rules can be applied to public-facing Application Load Balancers and CloudFront distributions. WAF rules can also be managed across multiple AWS accounts and resources using the AWS Firewall Manager. You can find more details on WAF in Chapter 5.
CloudFront (CF)
CloudFront is AWS’s content delivery network service located at the edge with its own points of presence (POPs). Remember that delivery through each edge location goes both ways; content is delivered outbound to customers, and customers deliver content inbound to AWS through each CloudFront point of presence.
Think of CloudFront as the fast doorway into AWS. CloudFront sits in front of the origin of the request, which could be an EC2 instance, an S3 bucket, or a custom origin location such as resources running in your own data center. CloudFront is essentially a caching service, located at each edge location within each region:
If the requested content is already in the cache, it is delivered quickly.
If the content is not in the cache, CloudFront requests the content from the origin server or location and then delivers your request. It places the request in local cache at the edge, as shown in Figure 2-11.
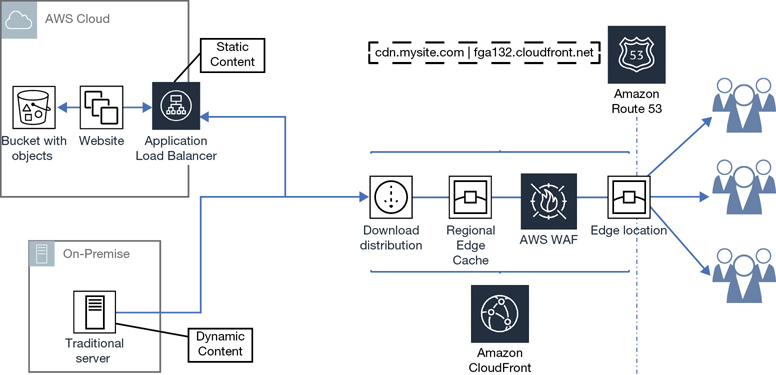
Figure 2-11 CloudFront operation
The delivered data may also be placed in a regional cache, which if available, is a much larger cache location hosted within each AWS region. Think of it as a secondary cache location designed to speed up delivery. If a content request is not in the local edge cache, perhaps it’s in the regional cache.
AWS Lambda@Edge
Lambda is a managed AWS service that allows you to craft custom functions to carry out any task written in a variety of programming languages, including Python, Go, C#, Node.js, or Java. Lambda is available as a hosted service at each edge location, which means that you can craft Lambda functions to control CloudFront content requests from end users, and the responses from the origin service. Lambda sits in the middle of the ingress and egress communication and can completely control traffic flow, as shown in Figure 2-12. For example, Lambda could send specific content to users sending requests from a smart phone versus requests from a traditional computer.

Choosing a Region
Reasons to choose a specific AWS region over another usually depend on four interlinked conditions, namely these:
Compliance rules—Where are you allowed to operate?
Latency issues—How far away are you from the desired cloud service?
Services offered—Is the service that you require offered within the region that you’ve selected?
Pricing realities—Is the pricing reasonable? Pricing is more complicated at AWS than you may first think.
Making a good decision about the best region to operate in takes some quality decision time after evaluating each of these conditions thoroughly. Let’s begin by looking at the most important condition: the compliance rules and regulations that you must follow.
Compliance
The rules and regulations that your company follows in its day-to-day business practices should be analyzed for how they’re potentially going to change once you start hosting applications in the cloud. There is going to be some loss of control; after all, you are working in AWS’s data centers being controlled by their rules.
AWS maintains its data centers, networks, and shared infrastructure adhering to a suite of ISO certifications that mandate a strict level of compliance with security management, information security controls, and best practices while operating in the public cloud. If your company complies by these ISO 27001 standards, perhaps your security standards compared AWS’s standards are closer than you may have thought.
Note
AWS holds certification for compliance with the ISO/IEC 27001:2013, 27017:2015, 27018:2014, and 9001:2015 certifications.
AWS is audited on a rigid schedule by third-party ISO auditors to ensure that they maintain and uphold their overall operations to the ISO 2700:2013 security management standard. Other third-party auditors ensure that AWS lives up to the many other compliance standards and assurance programs that it is also aligned with. Once you sign on as an AWS customer, you have access to the compliance reports aligned with the standards, certifications, or attestations that Amazon has currently achieved and maintains. Some compliance reports are available to all AWS customers upon request; others require that you also sign a nondisclosure agreement (NDA) with AWS. The steps to get started with reviewing the available compliance and attestation reports at AWS follow:
Sign into your AWS account with the root user account credentials.
From the Management console, select Security, Identity and Compliance and select Artifact. The available security and compliance documents are listed.
Choose your compliance program and click Get This Artifact.
Typically, you are asked to agree to the terms of the AWS Artifact NDA.
After acceptance of the security terms, you can download your selected document and review.
Once you gain access to the desired compliance report, you can view the services that were defined as in scope for the review and read the summary information and conclusions.
To begin to understand the compliance rules and regulations that AWS supports, I suggest you follow these steps:
Head over to the compliance website at https://aws.amazon.com/compliance/programs/.
Review the compliance programs that Amazon currently holds.
After selecting a compliance program, review the following details:
What level of certification does AWS hold?
What services are in scope with the selected compliance program?
What does AWS’s Attestation of Compliance cover?
What controls is the customer responsible for?
Do my company’s compliance needs match successfully with AWS?
A detailed review of the scope of the compliance program that you must adhere to is the best first step to follow when analyzing what you can and can’t do in the AWS cloud. If you find that an AWS service you were thinking of using is not yet supported by your compliance program, it’s certainly better to know all these facts before you start.
Would you like to visit an AWS data center and perform your own auditing? Dream on—that’s not going to happen. Random visitors to a data center adhering to a high level of compliance are just not allowed. Even Jeff Bezos would have trouble getting into an AWS data center unless he was cleared to perform data center–specific tasks.
Terra Firma wants to analyze AWS for its level of Payment Card Industry (PCI) compliance. In the future, Terra Firma wants to offer ways for customers to pay their bills online. This requires PCI compliance for the handling of credit card payments regarding storage, processing, and transmitting credit card information. The company wants to use AWS to host the software as a service (SaaS) application and needs to review the responsibilities of the cloud provider and of themselves, the customer. Terra Firma wants to host its compute services for the SaaS application on the standard shared infrastructure at AWS, but it doesn’t know if that’s allowed. Several vice presidents are sure that PCI compliance is not allowed in the cloud, or, if it is allowed in the cloud, bare-metal servers must be used. Here are the steps that Terra Firma followed to get the most up-to-date answer about PCI DSS:
The company downloaded the PCI DSS Attestation of Compliance and Responsibility Summary.
Using the summary report, it could review the services in compliance (in scope with Payment Card Industry Data Security Standard [PCI DSS]) and determine that the standard virtual environment for compute and storage at AWS was PCI compliant for Amazon’s responsibilities.
From the compliance website https://aws.amazon.com/compliance/programs/, Terra Firma could reaffirm that Amazon “does not directly store, transmit, or process any customer cardholder data (CHD).”
Terra Firma now must determine how it can create a cardholder data storage environment that is PCI compliant at the customer level.
From the PCI compliance section of the website, Terra Firma reviewed the requirements for Amazon, the cloud service provider (CSP), and the responsibilities of the client (Terra Firma), as shown in Table 2-4.
Table 2-4 PCI Checklist for Compliance
PCI DSS Requirement
Details
Terra Firma
AWS
AWS Service
Install and maintain firewalls to protect cardholder data
Shared responsibility
Firewalls on instances, firewalls at subnet levels
Firewalls at the cloud perimeter in between AWS clients
Security groups
Network ACLs
Don’t use vendor defaults for passwords and security
Customer’s responsibility
Applications
Network devices
Identity and access management (IAM)
Protect stored cardholder data
Customer’s responsibility
Encrypted data
Secured storage arrays
Third-party
Encrypt transmission of cardholder data across public networks
Customer’s responsibility
Encrypted transmissions
Supplied security controls
VPN connections
Use and update antivirus software
Customer’s responsibility
Third-party software
N/A
AWS marketplace options
Develop and maintain secure systems
Shared responsibility
From the instance
Hypervisor security
Secure API calls, certificates
Develop and maintain secure applications
Customer’s responsibility
On the instance
Hypervisor security
AWS marketplace options
Restrict access to cardholder data
Customer’s responsibility
Access controls
Physical security
IAM
Assign unique IDs to each person with computer access
Customer’s responsibility
Access controls, password policy
Enforcing strong authentication
IAM
Restrict physical access to cardholder data
Amazon’s responsibility
N/A
Physical security
Proprietary
Track and monitor all access to network resources and cardholder data
Shared responsibility
Customer’s virtual environment
Physical infrastructure and hypervisor
CloudTrail, CloudWatch, Guard Dog
Test security systems and processes regularly
Shared responsibility
Customer’s virtual environment
Intrusion detection system/intrusion protection system (IDS/IPS)
AWS Config, Inspector
Define security policies for information security
Shared responsibility
Customer’s security policy
ISO security policies
IAM
Additional PCI DSS requirements for shared hosting providers
Amazon’s responsibility
NA
PCI DSS Audit
NA
AWS and Compliance
AWS supports several compliance programs for a variety of businesses running in regulated industries, including financial, healthcare, and the U.S. government. AWS is an American company, so it stands to reason there are compliance programs supported by AWS that adhere primarily to North American compliance standards. A review of the chart shown in Table 2-5 shows that most of the compliance programs are aligned with U.S. government regulations. Table 2-6 details the global compliance programs AWS is associated with.
Table 2-5 North American Compliance Frameworks
Compliance Frameworks |
Details |
|---|---|
CJIS – Criminal Justice Information Services |
Workloads for state and federal law enforcement agencies at AWS |
FERPA |
Educational agencies and institution’s storage of data records at AWS |
FFIEC |
Rules for federal financial institutions on the use and security of AWS services at AWS |
FISMA |
Security authorizations for government agencies using systems hosted at AWS. Adhering to NIST 800-37 and DIACAP standards in the AWS GovCloud |
GxP |
Rules and guidelines for food and medical products data hosted at AWS |
HIPAA |
Rules for processing, storing, and transmitting protected health information at AWS |
ITAR |
Compliance with International Traffic in Arms Regulations in the AWS GovCloud |
MPPA (Motion Picture Association of America) |
Rules for securely storing, processing, and delivering protected media and content |
NIST |
800–53 Security controls applied to U.S. Federal Information Systems to ensure confidentiality, integrity, and availability (CIA) |
VPAT / Section 508 |
Rules for developing electronic and information technology for people with disabilities |
Table 2-6 Global Compliance Programs
Global Compliance Programs |
Details |
|---|---|
ISO 9001:2015 Compliance |
Requirements for a quality management system, including documentation, management responsibilities, and measurement and analysis |
ISO/IEC 27001:2013 Compliance |
Security management best practices and security controls based on ISO/IEC 27002 |
ISO/IEC 27017:2015 Compliance |
Guidance on the implementation of cloud-specific information security controls |
ISO/IEC 27018:2014 Compliance |
Protection of personal data in the cloud based on ISO/IEC 27002 |
PCI DSS level I (Payment Card Industry Data Security Standard) |
Security standard applied to the storing, processing, or transmitting of CHD or sensitive authentication data |
CSA Security Alliance Controls |
Best practices for security controls requirements in the AWS cloud |
Statement of Controls SOC 1 |
Details of AWS security controls and how they should work |
Statement of Controls SOC 2 |
A service auditors report detailing the testing of AWS’s security controls as they relate to operations and compliance, availability, security, processing, integrity, confidentiality, and privacy |
Statement of Controls SOC 3 |
A white paper providing details on the AWS services that will be audited by SOC 2 |
There are also well-known global compliance programs that AWS supports. The SOC 2 audit is a good place to start in reviewing available security controls at AWS.
Note
All current compliance certifications and attestations that AWS is aligned with are audited and assessed using third-party independent auditors.
HIPAA
If your business needs to comply with the 1996 Health Insurance Portability and Accountability Act (HIPAA), you must provide protections for what is defined as protected health information (PHI). Each healthcare provider, defined as the “covered entity” using AWS services to architect and host its applications, is solely responsible for complying with HIPAA’s rules and regulations. Amazon’s role is defined as a business associate.
Since 2013, Amazon has provided a signed contract called a Business Associate Addendum (BAA). In this contract, Amazon promises to properly safeguard the stored healthcare information and lays out the rules and responsibilities that AWS is undertaking, including a listing of the services and tasks that AWS will carry out on the customer’s behalf. Each customer who enters a BAA with AWS must use only the defined HIPAA-eligible AWS services defined in the BAA.
Over the past few years, many common services available at AWS are now allowed by HIPAA regulations. However, to be sure, check the current compliance documentation at AWS because certifications and regulations are constantly in flux. For example, the AWS Systems Manager Console and Resource Groups are currently not in scope for HIPAA. However, the virtual private cloud (VPC), encrypted EBS volumes, EC2 Instances, and S3 storage are all supported under the HIPAA BAA; each customer decides how encryption is enabled for each service.
Note
A great place to start learning about compliance is reviewing the AWS services in scope by compliance program found here: https://aws.amazon.com/compliance/services-in-scope/
NIST
Your business might also be aligning its compliance rules with NIST, or the National Institute of Standards and Technology. In June 2013, NIST presented its preliminary documentation on defining just what the public cloud industry was doing up to this point. For many companies, including the U.S. government, the NIST definitions have morphed into a set of standards they must achieve and maintain.
There is a wealth of NIST documentation you should review at NIST.gov that deals with cloud security, virtualization, operations, and many other areas of the public cloud. Even if you are not bound by a compliance standard, reviewing and following NIST recommendations can help you in developing a proper level of security in the AWS cloud. Follow this link for a summary of the features, benefits and risks, and recommendations for cloud computing: https://www.nist.gov/publications/cloud-computing-review-features-benefits-and-risks-and-recommendations-secure-efficient.
AWS is compliant with the NIST 800–53 (currently Rev 4) security controls. AWS also has obtained FedRAMP authorization to operate its GovCloud regions. US-GOV-WEST-1 is best at a high-impact level (Level 5) and the US East/West region at a moderate impact level (Level 2). FISMA defines impact levels. For this sentence to make any sense, let’s define all the variables.
NIST 800–53 Rev 4—Provides security guidance for security controls, including access control, auditing and accountability, configuration management, risk assessment, and incident response
FedRAMP—A defined methodology for security assessments, authorization, and continuous monitoring of cloud services and products.
High-impact level—Unclassified National Security Data
Modern impact level—Publicly releasable data
FISMA—The long name is Federal Information Security Management Act. To be compliant with FISMA, all data should be classified based on its sensitivity and automatically encrypted. If you work in the U.S. federal government or any state government, FISMA applies to you. You must follow these requirements:
Maintain an up-to-date inventory of all information systems deployed
Categorize each information system’s level of risk to the appropriate FISMA risk level
Create and maintain a security plan for your organization detailing security policies and controls
Carry out risk assessments against your business processes, security risks at the organizational level, and information systems level
Conduct annual security audits
GovCloud
You may have heard of AWS’s GovCloud. It’s an isolated region that has been designed to match the regulatory compliance requirements of the U.S. government, federal and state agencies, and anybody else who works with the U.S. government, as shown in Figure 2-13. It’s important to note that all AWS regions and services have the same level of security. The differences with GovCloud follow:
Vetted U.S. citizens manage operations of GovCloud.
AWS GovCloud is accessible only to U.S. citizen or green card root account holders.
It is physically and logically isolated from all other AWS regions.
It has provisional authorization for Department of Defense SRG Impact Level 2 (publicly releasable data), Impact Level L4 (unclassified sensitive data), and Impact Level 5 (Unclassified national security data) workloads.
It supports HIPAA, CJIS, and ITAR regulations.
Certain services are not in scope. As of October 2018, several AWS services are under review for inclusion in GovCloud at both the moderate and the high impact levels.

Figure 2-13 Authenticating to GovCloud regions
Latency Concerns
Network latency is typically measured in milliseconds and tells you how much time a packet takes to travel from the source location to its destination. The interface between your end users and a hosted AWS application is typically a browser or app interface that communicates with the hosted application or website hosted in a geographical region. Because AWS is hosted in the cloud, latency is how much time your packets take to travel from AWS to your location. Latency occurs with these scenarios:
Connecting to a hosted application from another geographical location—Connection speeds across the Internet to AWS will be slower the farther away your user location is.
Replicating data records to multiple region locations—If you’re copying files between regions, such as between S3 buckets both located in separate regions, there will be some latency. Comparing that latency figure against replicating records from an S3 bucket hosted in a region in the United States to another region in Europe shows additional latency. There’s some real distance involved between these regions. If you’re not aware, an S3 bucket is a storage service at AWS that allows you to store an unlimited number of records of any type.
Updating read replicas—Read replicas are read-only copies of a read/write database instance. Each read replica can be geographically located in any other AWS region.
Matt Adorjan has carried out an interesting test that has created an ongoing latency test against DynamoDB endpoints in each AWS region on TCP port 443, which you can find additional details about at https://www.cloudping.co/. If you are using the default US East-1 region, that’s Northern Virginia. Your clients were in the United States, and your latency figure will be in the range of 50–60 ms. If your users were in Europe, the latency figure jumps to more than 200 ms. If you users are from China, latency rates could be even higher. These latency figures are computed from TCP pings carried out from a source location to specific AWS endpoints. The latency values that are displayed as shown in Figure 2-14 will depend on where you are, what region your application is in, and the level of security negotiations; that is, are you pinging port 80 or port 443?

Applications hosted in the cloud will be influenced by latency; there is no getting around that fact. Connecting to applications hosted in the cloud and accessed across the Internet is unpredictable because you can’t control the Internet speed. If a hosted application at AWS needs to query a database located in the corporate data center, latency will most certainly rear its head. Slow connection problems can be solved with faster private connection speeds. However, the application that you might need to connect to could be a public-facing application. Because most, if not all, application requests require some form of data transfer in response, using a content distribution network such as AWS CloudFront to cache data records or web pages can really help in speeding up application access.
For another latency example, over at Concurrency Labs (https://www.concurrencylabs.com/blog/choose-your-aws-region-wisely/), you can check out their EC2 intra-region latency ping tests. As they note, there are many factors to consider when trying to accurately calculate latency. Ohio and Northern Virginia offer acceptable latency between two regions in the 26msec range. Data transfer speeds compared between Northern Virginia, Ohio, and Oregon against Tokyo or São Paulo regions show significant latency. Only after testing, you’ll know what you can accept for your applications needs.
Services Offered at Each Region
Not all AWS services are available in all regions, and it can take a long time before a recently introduced service that you are interested in becomes generally available in every region. The newer the service, the longer it might take to get deployed in all regions. And some services can take years to change from preview status to full online status.
For example, the Elastic File System was in preview mode for quite a long time before it was generally available across all AWS regions. Therefore, the services being offered per region might dictate what regions you will choose to operate in. However, core services of compute, networking, and storage are everywhere. It’s the newer AWS services that once introduced take time to become generally available in all regions.
Service availability can also be determined by your compliance rules and regulations. For example, if you are bound by FedRAMP rules and regulations, there are a number of services and management tools that are not approved at this time and perhaps never will be.
Calculating Costs
Costs need to be understood when dealing with a cloud provider. The AWS mantra is to pay for what you use; therefore, you pay for everything that you use. Most costs that will concern customers are not bundled in the price of most services. For example, there’s no charge to spin up a VPC and add subnets. However, we are going to eventually add instances, and there’s certainly costs for hosting, operating, and replicating compute instance traffic across subnets within an availability zone.
Note
There is a price to pay for resiliency and failover; it’s a price worth paying. After all, we want our applications to remain available and our data records to be stored in multiple locations.
Costs at AWS depend on the region that you have selected to operate in; you can pay a little or a lot more for the same service compared to other AWS regions However, you may have no choice if compliance dictates where you can operate at AWS.
Choosing the Central region means you are using AWS resources located in Canada, and depending on the currency exchange rate of your country, pricing in Canada may be less. But are you allowed to operate in Canada? What happens if you compare costs with an EU or São Paulo regions? Expect pricing to be a few hundred percent more!
Note
Over at Concurrency Labs (https://www.concurrencylabs.com/blog/choose-your-aws-regionwisely/) are some excellent examples showing the price differential between N. Virginia and São Paulo.
The human resources system at Terra Firma will require an average of 10 t2 medium EC2 compute instances, sitting behind a load balancer. The load balancer balances the user requests spreading the load across the 10 EC2 instances. Although there are many variables when analyzing pricing, when comparing the Northern Virginia regional costs to the São Paulo region for a load balancer sending traffic to 10 t2 medium EC2 instances within the same AZ, you can expect on average up to an 80% difference, as shown in Figure 2-15.

The biggest and cheapest AWS region is located in the US-East-1 (N. Virginia) region; it also has the largest number of availability zones and AWS services. Other regions with comparable pricing to Northern Virginia include Ohio, located in US-East-2, and Ireland (EU). Your purchase price can also be greatly reduced in many cases by reserving or prepaying your EC2 compute costs. Reserved costs are explored at various times throughout the book, specifically when we are talking about compute costs in Chapter 4, “Compute Services: AWS EC2 Instances.”
Management Service Costs
A management service at AWS can be thought of as a self-contained entity; you sign up for the service, and it performs its various tasks and provides the results. Another concept to consider is how you are charged for using a management service. The cost of a management service at AWS relates to the number of times the service carries out its task (think compute) and the price of storing the results (think storage). How AWS charges for management services used can be broken down by component, as shown in Table 2-7.
Table 2-7 Management Service Charges at AWS
|
AWS Service |
Frequency of Charges |
Components |
Examples |
|---|---|---|---|---|
A |
Management tools |
Number of times management service is executed per month |
Compute, storage, notification, and automation charges |
Config, Inspector, GuardDog |
B |
Compute |
Hourly |
Compute hours plus data transfer charges from instance |
EC2 instance |
C |
Storage |
Monthly per GB stored |
Storage, data transfer, and optionally, encryption, or notification and automation charges |
EBS, S3, Glacier, snapshots, server logs |
D |
Data transfer |
Per GB transferred |
Outbound and inbound packet flow |
Across AZs, Outgoing data |
Management Tools Pricing: AWS Config
As an example of management pricing, let’s look at AWS Config, which gives customers the ability to monitor the configuration of their IaaS resources such as compute, networking, and monitoring against a set of customer-defined rules and capture any changes to the resource’s configuration. For AWS Config to operate, it needs compute cycles to execute its review of resources in your account. It then needs to store the results in S3 storage.
AWS Config is going to charge for the number of configuration items being monitored by Config in your account, per region. It is also going to charge you for the number of custom rules you have defined. If you stick with the default set of managed rules provided by AWS, there are no additional compute charges. An example of an AWS-defined Config rule you could deploy is encrypted-volumes. (All boot volumes attached to EC2 instances must be encrypted.) The management charges for using AWS Config are as follows:
When AWS Config compares this rule against all boot volumes in your account, the rule is defined as an “active rule” because the rule was processed by the Config management service. The first 10 AWS Config rules will be charged a flat rate of $2.00 per AWS Config rule, per region per month.
The next 40 rules will have a slightly lower price per month ($1.50 per processed rule). When you reach 50 rules or more, the price drops further ($1.00 per processed rule).
AWS Config’s data-gathering is carried out using Lambda functions. Lambda is an AWS managed service that runs functions that can be created using several programming languages such as GO, Python, C#, Node.js, and Java. There is no additional cost for executing the standard prebuilt AWS Config rules. However, once you create custom AWS Config rules, additional Lambda charges will be applied for the execution of custom rules. Lambda charges are based on the amount of CPU, RAM, and time taken to complete execution of a function. The more custom rules that you create, the longer it takes for Lambda to finish its tasks, and therefore more you are charged.
AWS Config Results
The results gathered by AWS Config are stored in an S3 bucket. Charges for S3 storage depend on the size of the storage results. For example, S3 storage pricing is $0.023 per GB for the first 50 TB per month. AWS Config is also integrated with CloudWatch and sends detailed information about all configuration changes and notifications to CloudWatch events. An event means something happened that you should know about. Events are charged at $1.00 per 1 million events.
One of the main features of AWS Config is that you can be alerted if your defined rules are found to be out of compliance. For example, a developer creates an unencrypted boot volume; AWS Config can alert you using the Amazon simple notification service. As you may expect, SNS notifications are also charged. The good news is that the first 1 million SNS requests per month are free; after that, they are charged at $0.50 per 1 million SNS requests.
Another concept to consider is that an SNS notification could be directed to call Lambda to perform a custom task. Lambda functions can be crafted to perform any task at AWS you want as Lambda functions can invoke any AWS API call. In this example, if unencrypted boot volumes are found, a custom Lambda function could swing into action, perform a snapshot of the unencrypted boot volume, and then delete the offending EC2 instance and unencrypted volume.
Let’s say you have 500 configuration items in your AWS account that are checked by AWS Config each month with 30 active AWS management rules in the US-East-1 (N. Virginia) region. Your monthly charges would be as follows:
AWS Config costs: 500 * $0.003 = $1.50
AWS Config rules: $2.00 per active rule for the first 10 active config rules = $20
$1.50 for the next 20 active config rules = $15
Total AWS Config monthly charges = $36.50
This is just one example of how complicated costs can be to calculate at AWS; there are many moving parts. Hopefully you can see from this one example that pricing is just not composed of just one charge; it is complicated. There would also be a very minor S3 storage charge for storing the AWS Config results and possibly additional SNS and CloudFront charges for this example. And if your resource configurations were found not to be in compliance with a defined AWS Config rule, notifications and alerts would be generated by AWS Config, resulting in additional costs.
AWS Compute Costs
Compute (think EC2 instance) costs are defined as pay-as-you-go and depend on the size of the instance and the region location of the instance. And then EC2 instance pricing gets complicated once again. Compute pricing can be greatly reduced by prepaying or reserving your EC2 instances. There are also pricing considerations for shared or single tenancy instances. Perhaps you would like to reserve instances based on a re-occurring schedule. There are several other pricing examples for EC2 instances to also consider. Are you using a public or a private IP address? Do you want your instances to be blue or red in color? (Okay, there are no charges for color and no color choices.) Are you communicating with other instances located within the same AZ on the same subnet, or are you communicating across different availability zones? We will deal fully with compute costs and the many choices in Chapter 4.
Note
An MS SQL RDS EC2 instance db.r4.16xlarge pair located on separate subnets across multi-AZs hosted in the Tokyo region, could cost you in the range of $1.9 million for a 3-year reserved price.
Storage Costs
Storage costs at AWS depend on the storage service being used, whether it’s EBS storage volumes, shared file storage using the elastic file system (EFS) or Amazon FSx, S3 object storage, and archival storage using S3 Glacier.
S3 Buckets—An S3 bucket has storage and retrieval and request costs. Optional features such as lifecycle transition costs, storage management, data transfer (outbound directly to the Internet or to CloudFront), transfer acceleration, and cross-region replication to another S3 bucket all have separate and additional costs.
S3 bucket example—100 GB of standard storage in the US-East-1 (N. Virginia) region would cost you roughly $2.21 per month. This includes 5,000 PUT/COPY/POST/LIST requests and 30,000 GET requests, as shown in Figure 2-16.
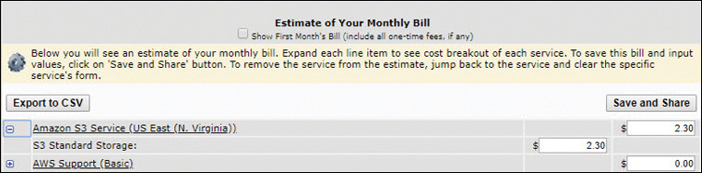
Figure 2-16 S3 storage pricing
S3-Glacier—Glacier storage has storage and retrieval pricing. Retrieval pricing is based on the speed of the data retrieval required. There is also outbound data transfer pricing, which varies based on the destination: outbound directly to the Internet or CloudFront, the CDN network.
S3 Glacier example—Terra Firma has stored 100 TB of archived records in the US East N. Virginia region with data retrieval of 10 GB per month with an average of 20 requests per month. This would cost roughly $411.92. Switching to other regions does not change the price point.
EBS Volumes—Virtual hard drives can be ordered in several flavors: SSD, SSD drives with provisioned IOPS, throughput-optimized drives, or what is defined as Cold HDD (infrequently accessed hard drive storage). You are also charged for snapshot storage in S3 for your EBS volume snapshots.
EBS example—A single general-purpose SSD drive sized at 16384 GB hosted in the US-East-1 (N. Virginia) region would cost you roughly $450 per month. Adding 10 GB of snapshot storage space would bump the monthly charge to $5,052. A provisioned, IOPS SSD drive sized at 8000 GB with 16,000 IOPS hosted in the US-East-1 (N. Virginia) region would cost you roughly $4,997 per month, as shown in Figure 2-17.

Figure 2-17 EBS price calculations
EFS storage—The EFS is for shared file storage. At a minimum, you pay for the total amount of storage used per month. There is also a GB charge for the amount of data that is copied into EFS per month at $0.01 per GB. You can also optionally pay for faster provisioned throughput in MBs per month.
EFS example: Assume the file system hosted in the US-East-1 (N. Virginia) region uses 300 GB of storage for 20 days for a single month. The charges would be as follows:
Total usage (GB-Hours) = 300 GB × 20 days × (24 hours / day) = 144,000 GB-hours.
Converting GB hours to GB-month = $43.20.
Moving your files to EFS Infrequent Access Storage Class further reduces your storage costs by up to 70%.
Data Transfer Costs
The price for running applications in the AWS cloud is usually thought of in terms of compute and storage charges. However, an additional charge is tacked onto the bill for transferring your packets from source to destination. At AWS, these are called data transfer costs, and every customer must spend some time and diligence to understand the actual costs. Your first monthly AWS bill will contain a few data transfer charge surprises. If we looked at every AWS cost, this book would exceed thousands of pages. Data transfer costs are generally higher for data transfer between regions, as compared to inter-region data transfer between AZs.
Note
It’s probably a good idea to subscribe to the Amazon simple notification service (SNS) to get alerts when the prices for services change because prices change all the time. See https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/price-changes.html.
Typically, a link to a cost calculator is present when you order AWS services, but not all costs will be initially visible. Data transfer costs can be expanded into the following breakdowns:
Data transfer costs across AZs within a region, which are higher than costs for data transfer within a single AZ
Data transfer costs between AWS regions
Data transfer costs by service—egress data sent outbound
Between AWS services—egress data sent from an S3 bucket through CloudFront
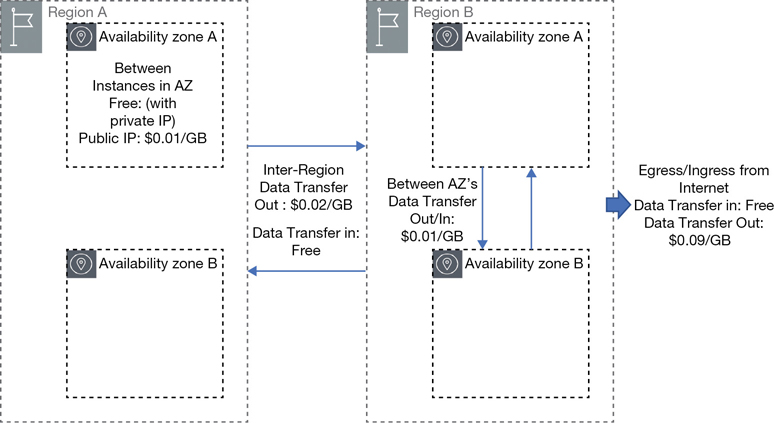
When you transfer data into an AWS region from any service from any other region, it’s free. (As a general rule, incoming data transfers are free for all public cloud providers.) Regional data transfer costs are charged based on data transfer within a region or the transfer of data across regions. Within each region, charges depend on whether you are communicating within an AZ or across AZs, as shown in Figure 2-18.
The design of your hosted applications at AWS will greatly determine your data transfer costs. Here are some design parameters to consider:
AWS services that are hosted in the same region but that are in separate AZs will be charged for outgoing data transfer at $0.01/GB.
When data is transferred between AWS services hosted in different AWS regions, the data transfer charge is $0.02/GB to start.
Data being transferred within the same region and staying within the same AZ is free of charge if you’re using a private IP address.
If you’re using an AWS-assigned public IP address or an assigned elastic IP public address, there will be a charge for the data transfer out from the instance. Charges are per gigabyte transfer, and the minimum charge is $0.01/GB.
The most common replication example is database replication from the master database node to the slave database node. Across AZs, there is a data transfer charge for this replication.
Always use private IP addresses rather than public IP addresses; public IP addresses cost more to send data.
Different AWS regions have different data transfer costs.
Architect your applications and systems for minimal data transfer across AWS regions or AZs.
Architect your AWS environment so that data transfer is restricted within an AZ, or restricted within a single region.
Note
AWS provides a handy API called the AWS pricelist API that enables you to query for the current prices of AWS products and services. For example: https://pricing.us-east-1.amazonaws.com/offers/v1.0/aws/AmazonS3/current/us-east-1/index.csv
Understand Tiered Costs at AWS
Referring to something as free at AWS is complicated. There is a default pricing tier which means you can use a particular AWS service until your data transfer costs exceed the default pre-value, typically 1 GB; then your costs begin to scale based upon a sliding price point. If you then use up to another level, AWS gives you another price break up until another usage or storage point. For example, data transfer out from EC2 instances to the Internet starts at $.09/GB until you reach 10 TB, as shown in Table 2-8. Then additional discounts apply, as shown in Table 2-9. The charge for region-to-region traffic is currently set at $.02/GB, but in the case of US-East-1 and US-East-2, it’s a little lower at $.01/GB.
CloudFront—Outbound CloudFront traffic costs vary based on the geographical location of the cache; pricing starts at $.085/GB in the U.S. regions.
EC-2 Instance Traffic—EC2 traffic between different availability zones hosted within the region costs the same as region-to-region data transfer. ELB-EC2 traffic is free of charge except when the outbound request crosses an availability zone.
ELB—ELB charges are in GB if you are using the Classic Load balancer but switch to LCUs if the Application or Network load balancer is chosen. That’s defined as load balancer capacity units. Then the regional location of your load balancer is considered when calculating the price. The LCU is a complicated calculation that measures the dimensions of your traffic. The dimensions are new connections, active connections, the amount of bandwidth, and the number of rules processed by your load balancer. Whichever dimension is highest is the one you are charged.
Table 2-8 Tiered Storage Cost Example
Data Transfer Out from EC2 Instance to Internet
Up to
Price per month
1 GB
Free
9.999 TB
$0.09 per GB
40 TB
$0.085 per GB
100 TB
$0.07 per GB
Greater than 150 TB
$0.05 per GB
Greater than 500 TB
Call AWS
Optimizing Costs at AWS
Now you know some of the complexity of figuring out costs at AWS. Here’s another concept to consider: running resources at a maximum scale at AWS 24/7 will probably bankrupt your budget. The key word in the last sentence is scale (as in scale out when additional resources are required to support additional user requests and scale in when resources are not required).
The concept of scale is key to understand and implement at AWS if you want any chance at manageable costs when hosting applications in the AWS cloud. AWS has produced some fine documentation called the Well-Architected Framework, which details best practices for optimizing costs at AWS which we briefly discussed in Chapter 1, “Learning AWS.” Let’s further summarize the concepts of optimizing costs at AWS. The concepts briefly discussed in this section will be fully fleshed out in later chapters referenced by chapter location.
Optimize compute—Matching the right instance or service to the right workload (Chapter 4)
Reserved pricing options—Reserved pricing for regions and AZs (Chapter 4)
Elasticity—Scaling resources up and down, in effect increasing and decreasing consumption of cloud services based on your needs (Chapter 5)
Optimized storage—Matching storage with the workload (Chapter 6)
Optimizing Compute Costs
Selecting the best EC2 instance for your needs at the lowest possible cost is the overall goal. Let’s use our use case for a compute example. Terra Firma started its initial testing in the AWS cloud thinking about matching the EC2 instance size at AWS as closely as possible to the virtual machine size they used on-premise. However, the virtual machine that was utilized on-premise was very large and sized with many CPU cores and gigabytes of RAM.
Moving to the AWS cloud, Terra Firma knows that its EC2 instance size at AWS will be smaller as multiple EC2 instances will be deployed, on subnets located across multiple AZs, and located behind an ELB load balancer.
Preliminary testing will evaluate the overall performance of Terra Firma’s application stack under a steady-state load. The number of users accessing the application will remain consistent.
For this initial proof of concept, compute resources will not be scaled up and down; once that application moves from test to production choosing reserved pricing for the compute instances will reduce the price up to 70%.
During initial testing, the entire development environment could be turned off after hours when it’s not being utilized, saving additional compute and data transfer charges.
If the application load changed to an unpredictable schedule, meaning that the number of users accessing the application changed from a small number of users to a large number of users, adding elasticity into the design of this application stack would automatically add or remove compute instances based on the user demand instead of a steady-state schedule.
In summary; if an AWS service or EC2 compute instance is running in your account at AWS, you’re charged for it. Getting used to this fact takes time. After all, you don’t turn off your bare-metal servers every night in your own data centers. Why would you? You’ve already paid for your on-premise resources. However, in the AWS cloud, running all resources 24/7 is not cost-effective. Therefore, each customer needs to decide what remains on 24/7 and what services should be turned off or reduced in operating size when not under high demand, as shown in Table 2-9. This is a major mind shift for customers beginning to work in the AWS cloud.
Table 2-9 What Services Need to Run 24/7 at AWS?
AWS Service |
On-Premise Operation |
At AWS |
|---|---|---|
DNS Servers |
24/7 |
Use Route 53 |
Dev/test environments |
24/7 |
Turn off when not used |
Applications |
24/7 |
Auto Scale based on demand |
Databases |
24/7 |
AWS Auto Scale or Serverless |
Storage arrays |
24/7 |
24/7 (AWS-managed service) |
Websites |
24/7 |
Auto Scale based on demand |
Reserved Pricing
If you use instances or specific compute-related AWS services constantly, reserved pricing is a must. Reserved pricing has many variables, per region, per AZ, standard 1-year or 3-year durations, or reservations that can be converted to another reservation type. Reservations are billing discounts that apply to EC2 instances hosted in a specific AZ, or region. The billing discount could be as high as 75% against the standard on-demand hourly rate.
The other concept of reserved pricing that’s important to understand is that you are guaranteeing the availability of your EC2 instances in your AZ’s when you need them. If you do not reserve EC2 instances in specific AZ’s, there is no guarantee that your EC2 instances will be available when you need them. On-demand instance types are not guaranteed to be always available. If you need EC2 instances for scaling up compute capacity, reserving your instances will guarantee their availability when it’s time to scale. Most reserved pricing is dealing with EC2 instance capacity. Choices for RI pricing at AWS are shown in Table 2-10.
Table 2-10 Reserved Pricing Choices at AWS
Reserved instance pricing options |
Details |
|---|---|
Amazon RDS |
Managed database compute instances |
Amazon EMR |
Hadoop cluster instances |
Amazon ElastiCache |
Memcached or Redis support |
Amazon RedShift |
Data warehouse |
Amazon DynamoDB |
Database throughput |
EC2 instances |
Reserved EC2 instances 1, or 3 years |
Tools for Analyzing Costs at AWS
For preplanning the costs of using hosted cloud services, AWS has several tools available to help analyze compute and storage utilization.
Trusted Advisor
Trusted Advisor is a built-in management service that executes several essential checks against your AWS account resources, as shown in Figure 2-19. It takes just a few minutes to give you a wealth of information. The information presented by Trusted Advisor depends on your level of support. It is the perfect tool to run against any AWS account to gain a quick analysis on the account’s current cost optimization, performance, security, fault tolerance, and service limits. Trusted Advisor can provide you with important cost-optimizing details.

Let’s look at the output from Trusted Advisor in the following context. Terra Firma has a two-tier application running at AWS that is hosted in two separate availability zones utilizing EC2 instances and EBS storage volumes. The relational database service (RDS) is part of the database solution. The application stack is hosted behind a load balancer, and EC2 instances are reserved per AZ’s for a partial upfront one-year standard term. Running Trusted Advisor would help track and alert you to the following potential issues:
Reserved EC2 Instances—The optimized number of partial upfront reserved instances is calculated based on an analysis of your usage history for the past month.
Load balancers—Checks the load-balancing configuration usage.
EBS volume check—Warns you if any EBS volumes in your account are unattached or have a low access rate.
Elastic IP addresses—Warns you if any elastic IP addresses assigned to your account have not been associated. Charges apply if elastic IP addresses in your account are not used.
RDS instances—Checks for idle database instances.
Route 53 records—Checks for the proper creation of latency record sets that should be designed for replication of user requests to the best region.
Reserved reservation expiration check—Checks and alerts you if your reserved reservation is scheduled to expire within the next month. Reserved reservations do not automatically renew.
The trusted advisor can be run from the management console or from the CLI. The basic account and service checks and recommendations are available for any customer at AWS. Customers with business or enterprise support plans have access to all Trusted Advisor checks, including automatic actions that can be carried out with CloudWatch alerts.
Cost Explorer
Cost Explorer provides costing reports for your daily and monthly charges based on the AWS services that you have purchased, as shown in Figure 2-20. The reports offered include:
Monthly costs by service
Daily costs by service
Monthly costs by linked account
Services ordered by AWS Marketplace
Monthly EC2 instances running hours, cost, and usage
Reserved instance reports
Figure 2-20 Cost Explorer details
You can also go back in time and review your past 13 months of operation and forecast your potential bill for the next three months based on your current costs. Forecasts of future AWS charges based on a custom timeframe can be created; costs can also be filtered and grouped based on several parameters, including these:
Availability zone—Where your resources are located.
Instance type—The type of reserve instance used to launch your EC2 and RDS instances.
Purchase option—Choose between on-demand, reserved, spot, or scheduled reserved pricing.
AWS services ordered and used—Choose from a list of AWS services.
Tenancy—Lists dedicated or multitenant reserved instances.
Cost Allocation Tags—Track costs associated with departments by first activating cost allocation assigned tags to selected resources. Both hourly and monthly cost allocation reports can be generated.
Billing and cost management—If you did not create the AWS account that you are using, you may not even know that there is a billing and cost management service at AWS, but it’s there hidden in the management console. Selecting your account name will display the billing and cost management console. If you have several AWS accounts, consolidated billing can be enabled after you link your accounts together using a service called AWS Organizations. Additional features of billing and cost management that can be useful include analyzing current and future costs with the Cost Explorer graphs and receiving email notification when charges reach a defined cost threshold by enabling billing alerts, as shown in Figure 2-21.

Budgets—Once you start using reserved instances, a budget should be created to track what you expect to spend and what you are currently spending. Each budget defines a start and end date and a budgeted amount to track costs against. Each budget report can include the AWS costs as they relate to the AWS services, the associated tags, purchase options, instance types, region and AZ, and other options. Once your budget forecast hits the defined threshold, which can be defined as a percentage or a dollar figure of a budgeted amount, notifications can send alerts to email accounts and an associated SNS topic.
AWS Simple Monthly Calculator
Be prepared to spend some quality time with the Simple Monthly Calculator, as shown in Figure 2-22. Only by using the calculator will you start to see the integrated costs for infrastructure and the inbound and outbound data transfer charges. On the right side are several sample reports to give you an idea about how you could host a marketing website or create a disaster recovery and backup solution. Of course, these costs will not be your actual costs, but they’re certainly enough to get you thinking.
On the left side are the services supported by the Simple Monthly Calculator, which calculates the cost of running a variety of infrastructure as a service (IaaS) components, some developer components, standalone services such as Amazon WorkSpaces and WorkDocs, and the Amazon Elastic Transcoder Service. Regardless of the service selected, you first must choose a region of operation before you can fill out the details. To really take the most advantage of using this calculator, you must know how your applications are going to be designed and operated at AWS.
Terra Firma’s test application is going to use EC2 instances fronted with a public-facing load balancer with EBS storage and a backend SQL database hosted across multiple AZs. Pricing out EC2 instances, after choosing the AWS region for operation, will begin to provide answers to Terra Firma’s many questions.
When you look at the number of choices at AWS available for compute instances, database solutions, and load-balancing pricing, it becomes clear that entering the intimate details of how your application is going to be hosted and running at AWS is necessary to get an accurate price. And if you’re just starting out, you won’t yet know all the answers. But you’ll certainly know what you’re going to be charged component wise, and that is valuable information to have.
Compute: Amazon EC2 Instances
The number of instances: 4
The number of hours used per day: 8
Type: Linux on m4.xlarge (4 vCPUs, 16 GB memory with EBS storage)
Billing option: On-demand
Database: RDS
The number of instances: 2
The number of hours used per day: 8
DB engine version and license choice: SQL Server Enterprise Edition 2016 SP2
Type of database instance: db.m5.xlarge–db.m5.24xlarge
Number of AZs: 2
Data transfer: Intra-Region (within the region) or Inter-Region Data Transfer Out
Elastic Load Balancing
Average number of connections per second: 20
Average connection duration: 45 seconds
Average request per second: 20
Total data processed per hour: 1.1 GB
Total Cost of Ownership (TCO) Calculator
The TCO calculator calculates the cost of your current servers, whether they are physical servers or virtual machines, and their location: on-premise or at a co-location as shown in Figure 2-23. Server types can be defined either as a database or a compute instance. Database choices include running flavors of Oracle, SQL, and MySQL. The non-DB server types can be defined as virtual machines hosted on several hypervisor types: VMware, Hyper-V, or KVM/ZEN. After inputting your server details, you can enter your storage types that you use: storage area network (SAN), network-attached storage (NAS), or object storage. The overall IOPS for each application can also be added for comparison. For networking, you can enter your data center bandwidth, and you can include details on your data center staff’s annual salary and the number of VMs assigned to each admin.

The costs that the TCO calculator provide give you a ballpark of your infrastructure cost but do not consider data transfer costs or any other costs, such as load balancing and failover. However, it’s a start, and if the total cost of the TCO calculator is more than the totals from the AWS Simple Monthly Calculator, your move to the cloud is probably a financially viable option.
In Conclusion
Whew! We’ve made it through the gauntlet of regions, availability zones, edge locations, and the criteria for making the best decisions based on location, location, and more location. There’s a lot of material in this chapter that you probably must review. There are also several big-picture decisions to be made that you want to take your time with rather than having to make on the fly two years from now when you’re under pressure. No one needs or wants that type of pressure. To help alleviate any pressure, political or otherwise, review the top 10 discussion points, bring them into the conference room, and start discussing and arguing, moving toward a consensus. By taking the time to review and discuss this top-10 list, you’re performing the proper steps to create your own SLA: what you’re willing to accept and to risk, and potentially, what stays on-premise.
Top 10 Big-Picture Discussion Points: Compliance, Governance, Latency, and Failover Considerations
What compliance rules and regulations do we have to follow?
What AWS compliance reports should we review?
What regions are we allowed to use?
How many availability zones should we be using?
Does our internal auditor need to ramp up quickly on AWS security?
Who wants to volunteer costing out our current application stack?
What type of reserved instances should we be using?
Is AWS Config a useful tool for monitoring our compliance?
What does the Trusted Advisor help us with?
Should we consider upping our AWS support to the business level for additional Trusted Advisor checks and support discussions with AWS?