
The last query in the previous section creates a relationship between two nodes. If we run that query twice, we will have two relations between those nodes. In most cases, this redundancy is unnecessary and useless for us. Suppose our social network was online and had a button called "Add Friend". In this scenario, if two users, say A and B, click on this button at the same time to add each other as friends, the relation would be doubled in the database. This is a waste of storage. In this context, we need to check the database and create the relation only if it does not exist. This is why an OPTIONAL MATCH clause is required to prevent double storage. This is illustrated in the following query:
MATCH (a:User {name: "Jack", surname: "Roe"}),
(b:User {name: "Jack", surname: "Smith"})
OPTIONAL MATCH (a) -[r:Knows]- (b)
WITH a,r,b
WHERE r IS NULL
CREATE (a) -[rn:Knows]-> (b)
RETURN a,rn,bThis query, first of all, finds the users Jack Roe and Jack Smith in the database (the MATCH clause), then checks whether they are connected through a relation of the type Knows (the OPTIONAL MATCH clause). If not, (r IS NULL means that the relation cannot be found) the CREATE command that follows will create a relationship between the nodes. The WITH clause is necessary to apply the WHERE clause to the whole query. If the WITH clause is not used, the WHERE clause is applied only to the OPTIONAL MATCH clause.
If you run the preceding query after the query mentioned in the Creating relationships between existing nodes using read-and-write queries section, you'll get no rows. This is because the relationship is already created in the database. Clearly, this query isn't easy to read or write and it's error-prone. For these reasons, Cypher provides us with two keywords to deal with existing data.
The complexity of the preceding query is due to the fact that we have to check the nonexistence of a relationship before creating it. This is because we want that relationship to be unique. Fortunately, Cypher provides us with a command that wraps such a check and ensures that the pattern specified is unique in the database.
For example, we can rewrite the preceding query using the CREATE UNIQUE command, as shown in the following query:
MATCH (a:User {name: "Jack", surname: "Roe"}),
(b:User {name: "Jack", surname: "Smith"})
CREATE UNIQUE (a) -[rn:Knows]-> (b)
RETURN a,rn,bUsing the CREATE UNIQUE command in the preceding query saved us from writing the entire OPTIONAL MATCH and WHERE clauses. My preferred motto is that the more code you write, the more bugs you hide; here, the latter is the preferred choice.
However there are two important differences between the the preceding query and the one in the previous section. They are as follows:
- If the
CREATE UNIQUEcommand finds the relationship multiple times in the database, it will throw an error. For example, if two instances of theKnowsrelationship exist between the usersJack RoeandJack Smith, then the query with theCREATE UNIQUEcommand will fail with an error, while the query with theOPTIONAL MATCHcommand will succeed (it will not create the relationship). Anyway, both theCREATE UNIQUEand theOPTIONAL MATCHcommands won't make any modifications to the database. This difference is not a disadvantage of theCREATE UNIQUEcommand, rather an advantage. An error thrown by the query means that the database is corrupted as it has multiple instances of a relationship (or any pattern) that should be unique. - The query with the
OPTIONAL MATCHcommand returns a row only if it creates a new relationship. However, the query with theCREATE UNIQUEcommand will return a result if it finds a relationship or creates a new one. This can be a useful feature in some contexts; we can know the state of certain paths in the database after theCREATE UNIQUEcommand is executed without performing another read-only query.
Yet, the CREATE UNIQUE command can be even more useful. Suppose we don't know if a user named Jack Smith has been created; if not we have to create and link it to the user Jack Roe. Consider the following read-and-write query:
MATCH (a:User {name: "Jack", surname: "Roe"})
CREATE UNIQUE (a) -[rn:Knows]->
(b:User {name: "Jack", surname: "Smith"})
RETURN a,rn,bFirst of all, it looks for the user Jack Roe in the database, binding it to the variable a. If it cannot be found, the query will finish the execution and return zero rows. Otherwise, it executes the CREATE UNIQUE command, and there are four possible scenarios, which are listed as follows:
- The full path already exists and it is unique; we have the user node
Jack Roewith exactly one relationship with the user nodeJack Smith. In this case, the existing nodes are bound to the variablesa,rn, andb. Then, these variables are returned as result. - Neither the
Jack Smithnode nor the relationship exists in the database. In this case, theCREATE UNIQUEcommand creates the full path. The new relation is bound to the variablern, while the new node is bound to the variableb. - When there are multiple paths, the path
(a)-[:Knows]-(b)exists multiple times. For example, theKnowsrelationship exists multiple times between the nodes. If this happens, a Neo.ClientError.Statement.ConstraintViolation error is thrown because theCREATE UNIQUEcommand can't deal with multiple patterns.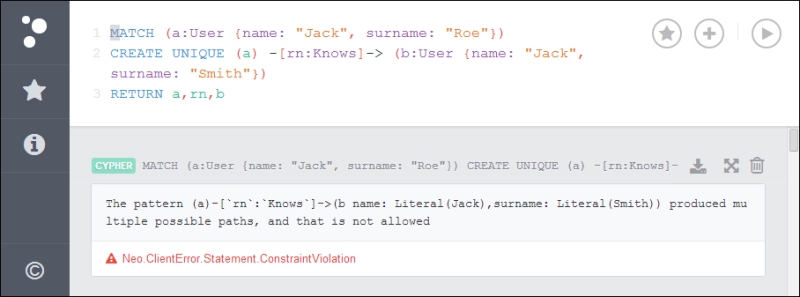
- Both
Jack RoeandJack Smithexist in the database as nodes, but there is noKnowsrelationship between them. As the matching follows the all-or-none rule, the Cypher engine creates a newJack Smithnode and a new relationship bound to the variablern. This is due to the fact that the purpose of theCREATE UNIQUEcommand is to ensure that a whole pattern is unique in the graph and if the node already exists but not the relationship, we do not have the whole pattern in the graph.
The last scenario could be a problem because we would have duplicated a user in the database. We can resolve this issue using the MERGE clause, which is discussed later in the chapter.
To summarize, the following diagram shows how the CREATE UNIQUE clause works:

Just as the MATCH and the CREATE clauses, you can join simple patterns to describe a complex one. Consider the following query:
MATCH (a:User {name: "Jack", surname: "Roe"})
CREATE UNIQUE (a) -[kn:Knows]->
(b:User {name: "Jack", surname: "Smith"}),
(a) -[cw:Colleague]-> (b)This query creates two relationships between two users. Only the relationships not found in the database are created. If you launch this query after the query from the previous section, you'll get a the message Created 1 relationship, returned 0 rows in 307 ms.
In fact, the relationship Knows and the user Jack Smith were already in the database, while the Colleague relationship was missing. If all of them exist, this query makes no modifications to the graph. The second time you launch this query, you'll get the result Returned 0 rows in 229 ms, which means that neither relationships nor nodes were created.
Note that the CREATE UNIQUE command looks for a path that exactly matches the pattern. So, for example, the following query won't match either the existing user node or the existing relationship. Instead, it will create a new relationship and a new node.
MATCH (a:User {name: "Jack", surname: "Roe"})
CREATE UNIQUE (a) -[rn:Knows {friend: true}]->
(b:User {name: "Jack",surname: "Smith", age:34})In fact, we haven't set the age property to the user Jack Smith in our database. However, this could return weird results in some cases (as the preceding example). How to update the user node without creating a new user if a new property is found in the pattern? Again, this issue can be solved using the MERGE clause.
First of all, we need to know how to set the property of an existing node. The SET clause is just the ticket. Let's start with an example. Consider the following query:
MATCH (a:User {name: "Jack", surname: "Roe"})
SET a.age = 34
RETURN aThis query takes the user node Jack Roe and sets the age property for it; then, it returns the updated node. Neo4j Browser shows the result as Set 1 property, returned 1 row in 478 ms.
Note that the SET clause here works on the nodes found using the MATCH clause. This means that we can set a property on a huge list of nodes if we don't write the MATCH clause carefully. The following query sets the city property on all the nodes with the surname property Roe:
MATCH (a:User {surname: "Roe"})
SET a.place = "London"
RETURN aIn our database, this query updates three nodes: Jane, Jack, and Mary Roe. Neo4j Browser shows the result as Set 3 properties, returned 3 rows in 85 ms.
Again, you can change several assignment expressions to make more property changes at the same time. For example, to set the country as well, the query will be as follows:
MATCH (a:User {surname: "Roe"})
SET a.place="London", a.country="UK"
RETURN aThe syntax to set a property to a relationship is the same, as shown in the following query:
MATCH (:User{surname: "Roe"})-[r:Knows]-()
SET r.friend = trueThis query finds all the Knows relationships of users with the surname property Roe and sets the property friend to true for all of them.
The SET clause can also be used to copy all the properties of a node to another. For example, to copy the node x to the node y, use the following query:
SET y = x
Note that all of the destination node's properties will be removed before the node is copied.
Copying a node is useful when a node needs cloning. For example, in our social network, there could be a function to create an alias identity; the user could start cloning his/her own identity and then modify the new one. This command can be coded as shown in the following query:
MATCH (a:User {name: "Jack", surname: "Roe"})
CREATE (b:Alias)-[:AliasOf]->(a)
WITH a,b
SET b = a
RETURN a,bThis query, once it finds the user node to clone, creates a new node with labels Alias and User and have a relationship with the source node of the type AliasOf. Then, it copies all the properties from the source node to it and finally returns the node. The command SET b = a doesn't affect the labels of the node b or its relationships; it just copies the properties.
The SET clause can also be used to add one or more labels to a node, as shown in the following query:
MERGE (b:User {name: "Jack", surname: "Smith"})
SET b:Inactive
The only difference is that we need to use the label separator instead of the property assignment. To chain more labels, just append them with the separator, as shown in the following query:
MERGE (b:User {name: "Jack", surname: "Smith"})
SET b:Inactive:NewUser:MustConfirmEmail
The MERGE clause is a new feature of Cypher, introduced by Neo4j 2.0. The features of the MERGE clause are similar to those of the CREATE UNIQUE command. It checks whether a pattern exists in the graph. If not, it creates the whole pattern; otherwise, it matches it. The main difference is that the pattern doesn't have to be unique. The other differences are as follows:
- The
MERGEclause supports the single node pattern - The
MERGEclause allows users to specify what to do when the pattern is matched and what to do when the pattern is being created
In an earlier section, we saw two issues with the CREATE UNIQUE command. They are as follows:
- How to create a new node if the pattern does not match, but match the existing node if the node exists?
- How to set the variables when merging nodes and relationships?
To answer the first question, let's recall the second query from the Creating unique patterns section:
MATCH (a:User {name: "Jack", surname: "Roe"})
CREATE UNIQUE (a) -[rn:Knows]->
(b:User {name: "Jack", surname: "Smith"})Now, if the intent of this query is to match an existing Jack Smith user node before creating a relationship to it, it will fail. This is because if the relationship does not exist, a new Jack Smith node will be created again. We can take advantage of the single node pattern supported by the MERGE clause and write the following query:
MATCH (a:User {name: "Jack", surname: "Roe"})
MERGE (b:User {name: "Jack", surname: "Smith"})
WITH a,b
MERGE (a) -[rn:Knows]-> (b)
RETURN a,rn,bTo accomplish our goal, we had to split the query in two parts using the WITH clause. The first step is to find the Jack Roe user node in the graph with the MATCH clause. Then, the first MERGE clause ensures that a node with exactly two properties—the name Jack and surname Smith—exists in the database. In the latter part of the query, the focus is on the relationship Knows between the two nodes involved; the second MERGE clause ensures that the relationship exists after the execution. What happens if the Jack Smith user exists twice in the database and the nodes are already related? The MERGE clause wouldn't fail; it would succeed, returning two rows.
Now, about the second problem of how to set properties during merging operations, the MERGE clause supports two interesting features. They are as follows:
ON MATCH SET: This clause is used to set one or more properties or labels on the matched nodesON CREATE SET: This clause is used to set one or more properties or labels on the new nodes
For example, suppose that we want to set the Jack Smith user node's place property to London only if we are creating it, then the following query can be used:
MERGE (b:User {name: "Jack", surname: "Smith"})
ON CREATE SET b.place = "London"If at the same time, we want to set his age property to 34 only if the user already exists, then the following query can be used:
MERGE (b:User {name: "Jack", surname: "Smith"})
ON CREATE SET b.place = "London"
ON MATCH SET b.age = 34Clearly, when we want to set a property in both cases, you can just append a SET clause to a MERGE clause, as shown in the following query:
MERGE (b:User {name: "Jack", surname: "Smith"})
SET b.age = 34In certain applications, such as websites with several client types, parallel applications, and so on, some commands happen to be sent multiple times from external layers to the backend. This is due to a number of reasons, for example, user interfaces are not up to date, users can send a command multiple times, synchronization issues, and so on. In these cases, you could get the command to be executed multiple times; clearly you don't want the second or the nth execution to have an effect on the database. Commands that are executed once but have no effect when executed multiple times again on the same graph later are idempotent. Both MERGE and SET clauses allow you to write idempotent commands that nowadays are very useful in these growing contexts.