
Clearly, getting all nodes and filtering them is not the best way to find a node. Every worthy database, just like Neo4j, allows you to create indexes in order to find data quickly.
From Version 2.0, in Neo4j, there is a new and recommended type of index, that is, a label index. These are the only indexes supported by Cypher. Therefore, let's create an index for users based on the email property. We only need to execute the following query:
CREATE INDEX ON :User(email)
As this operation of creating an index is asynchronous, we must wait for the indexes to be built and go online. A timeout of one minute for 1000 items should be enough on any modern machine. This is described in the following query:
try (Transaction tx = graphDb.beginTx()) {
Schema schema = graphDb.schema();
schema.awaitIndexesOnline(1, TimeUnit.MINUTES);
}Note
Waiting for an index to go online can be done only with either the Java API or Neo4j Shell at the moment. This means that if you are using the REST API, you have to wait a reasonable interval of time while the server builds the index. Clearly, if you create the index before inserting any data, the index creation will be immediate and data will be indexed automatically.
Once the index is online, we can run the profiler again and dump the plan. This time, we get only one row, as shown in the following output code:
SchemaIndex(identifier="n", _db_hits=0, _rows=1, label="User", query="{emailQuery}", identifiers=["n"], property="email", producer="SchemaIndex")Now, we have only one operation: SchemaIndex. It has no database hits and only one row is processed instead of 1000 database hits. This is a big improvement!
Now, let's see another example that allows us to introduce a new keyword. Suppose that we have a certain number of inactive users in our social network; let's say 10. We express inactive users with the Inactive label. The query to get all the inactive users could be the following:
MATCH (n:User:Inactive) RETURN n
The execution plan of this query is shown in the following code:
Filter(pred="hasLabel(n:Inactive(2))", _rows=10, _db_hits=0) NodeByLabel(identifier="n", _db_hits=0, _rows=1000, label="User", identifiers=["n"], producer="NodeByLabel")
This means that the query is executed in two steps. They are as follows:
- In the first step,
NodeByLabel, all nodes labeledUserare read, which in this case is 1000 rows - The inactive users are then filtered from the set of nodes
Note that if we invert the labels, we would read only 10 rows. The USING SCAN keyword allows you to specify the label to be scanned first. This is described in the following query:
MATCH (n:User:Inactive) USING SCAN u:Inactive RETURN n
The execution plan now becomes the following:
Filter(pred="(hasLabel(n:User(1)) AND hasLabel(n:Inactive(2)))", _rows=10, _db_hits=0) NodeByLabel(identifier="n", _db_hits=0, _rows=10, label="Inactive", identifiers=["n"], producer="NodeByLabel")
As expected, now we are reading only 10 rows instead of 1000 rows.
When you write a query, Cypher will use indexes, if possible, in order to maximize the performance of the query. Therefore, usually you won't need to specify whether or not and to use an index and which one to use. Anyway, you can specify the indexes to be used to make sure that the index is used in the query. Look at the following example query:
MATCH(n:User)
USING INDEX n:User(email)
WHERE n.email = {emailQuery}
RETURN n.userIdThis query makes sure that the index on the email property is used for searching. If the index is not present or cannot be used in the query as is, an error will be returned. Note that the USING INDEX clause must be specified before the WHERE clause that is used to filter users.
To sum up, you can put the USING INDEX instruction in the query when you want a certain index to be used.
Another interesting feature of Neo4j from Version 2.0 is the ability to create a uniqueness constraint on a specific property in a certain label. Consider the following query:
CREATE CONSTRAINT ON (user:User) ASSERT user.userId IS UNIQUE
The preceding code ensures that there won't be two co-existing nodes that have the label User and the same user ID. If you try to create a User node with the same user ID of an existing node in the database, the database will generate an error, as shown in the following screenshot:
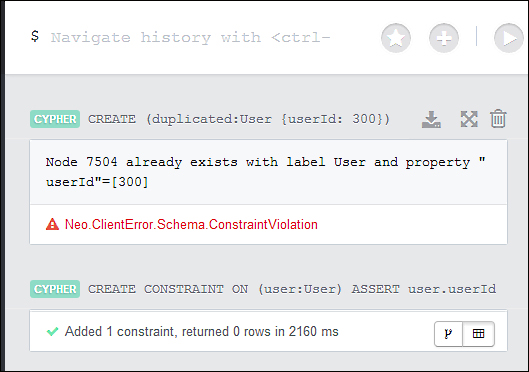
Of course, this feature is useful to guarantee the integrity of your data if your application identifies users by their user ID. You might wonder why we are talking about constraints in this chapter. The reason is because when you create a constraint, Neo4j automatically creates an index on the constrained property. In fact, try to create the index after you create the constraint with the following query:
CREATE INDEX ON :User(userId)
Now, you will get an error that informs you that the index already exists. The following result is shown:
Already constrained CONSTRAINT ON ( user:User ) ASSERT user.userId IS UNIQUE.
Clearly, you can delete the old index and create a new constraint instead.
All in all, if you have a property that must be unique in a labeled set of nodes, create a uniqueness constraint. Besides having your data integrity guaranteed by the database, you will gain a significant performance advantage due to the index that is created along with the constraint.