
Although more and more services are offering their data through APIs, when a service doesn't do this then the only way of getting the data programmatically is to download its web pages and then parse the HTML source code. This technique is called screen scraping.
Though it sounds simple enough in principle, screen scraping should be approached as a last resort. Unlike XML, where the syntax is strictly enforced and data structures are usually reasonably stable and sometimes even documented, the world of web page source code is a messy one. It is a fluid place, where the code can change unexpectedly and in a way that can completely break your script and force you to rework the parsing logic from scratch.
Still, it is sometimes the only way to get essential data, so we're going to take a brief look at developing an approach toward scraping. We will discuss ways to reduce the impact when the HTML code does change.
You should always check a site's terms and conditions before scraping. Some websites explicitly disallow automated parsing and retrieval. Breaching the terms may result in your IP address being barred. However, in most cases, as long as you don't republish the data and don't make excessively frequent requests, you should be okay.
We'll be parsing HTML just as we parsed XML. We again have a choice between pull-style APIs and object-oriented APIs. We are going to use ElementTree for the same reasons as mentioned before.
There are several HTML parsing libraries that are available. They're differentiated by their speed, the interfaces that they offer for navigating within HTML documents, and their ability at handling badly constructed HTML. The Python standard library doesn't include an object-oriented HTML parser. The universally recommended third-party package for this is lxml, which is primarily an XML parser. However, it does include a very good HTML parser. It's quick, it offers several ways of navigating documents, and it is tolerant of broken HTML.
The lxml library can be installed on Debian and Ubuntu through the python-lxml package. If you need an up-to-date version or if you're not able to install the system packages, then lxml can be installed through pip. Note that you'll need a build environment for this. Debian usually comes with an environment that has already been set up but if it's missing, then the following will install one for both Debian and Ubuntu:
$ sudo apt-get install build-essential
Then you should be able to install lxml, like this:
$ sudo STATIC_DEPS=true pip install lxml
If you hit compilation problems on a 64-bit system, then you can also try:
$ CFLAGS="$CFLAGS -fPIC" STATIC_DEPS=true pip install lxml
On Windows, installer packages are available from the lxml website at http://lxml.de/installation.html. Check the page for links to third-party installers in case an installer for your version of Python isn't available.
The next best library, in case lxml doesn't work for you, is BeautifulSoup. BeautifulSoup is pure Python, so it can be installed with pip, and it should run anywhere. Although it has its own API, it's a well-respected and capable library, and it can, in fact, use lxml as a backend library.
Before we start parsing HTML, we need something to parse! Let's grab the version and codename of the latest stable Debian release from the Debian website. Information about the current stable release can be found at https://www.debian.org/releases/stable/.
The information that we want is displayed in the page title and in the first sentence:
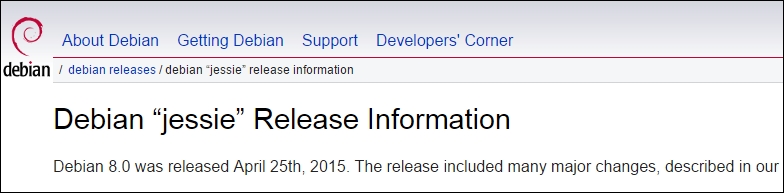
So, we should extract the "jessie" codename and the 8.0 version number.
Let's open a Python shell and get to parsing. First, we'll download the page with Requests.
>>> import requests >>> response = requests.get('https://www.debian.org/releases/stable')
Next, we parse the source into an ElementTree tree. This is the same as it is for parsing XML with the standard library's ElementTree, except here we will use the lxml specialist HTMLParser.
>>> from lxml.etree import HTML >>> root = HTML(response.content)
The HTML() function is a shortcut that reads the HTML that is passed to it, and then it produces an XML tree. Notice that we're passing response.content and not response.text. The lxml library produces better results when it uses the raw response rather than the decoded Unicode text.
The lxml library's ElementTree implementation has been designed to be 100 percent compatible with the standard library's, so we can start exploring the document in the same way as we did with XML:
>>> [e.tag for e in root] ['head', 'body'] >>> root.find('head').find('title').text 'Debian –- Debian u201cjessieu201d Release Information'
In the preceding code, we have printed out the text content of the document's <title> element, which is the text that appears in the tab in the preceding screenshot. We can already see it contains the codename that we want.
Screen scraping is the art of finding a way to unambiguously address the elements in the HTML that contain the information that we want, and extract the information from only those elements.
However, we also want the selection criteria to be as simple as possible. The less we rely on the contents of the document, the lesser the chance of it being broken if the page's HTML changes.
Let's inspect the HTML source of the page, and see what we're dealing with. For this, either use View Source in a web browser, or save the HTML to a file and open it in a text editor. The page's source code is also included in the source code download for this book. Search for the text Debian 8.0, so that we are taken straight to the information we want. For me, it looks like the following block of code:
<body>
...
<div id="content">
<h1>Debian “jessie” Release Information</h1>
<p>Debian 8.0 was
released October 18th, 2014.
The release included many major
changes, described in
...I've skipped the HTML between the <body> and the <div> to show that the <div> is a direct child of the <body> element. From the above, we can see that we want the contents of the <p> tag child of the <div> element.
If we navigated to this element by using the ElementTree functions, which we have used before, then we'd end up with something like the following:
>>> root.find('body').findall('div')[1].find('p').text Debian 8.0 was. ...
But this isn't the best approach, as it depends quite heavily on the HTML structure. A change, such as a <div> tag being inserted before the one that we needed, would break it. Also, in more complex documents, this can lead to horrendous chains of method calls, which are hard to maintain. Our use of the <title> tag in the previous section to get the codename is an example of a good technique, because there is always only one <head> and one <title> tag in a document. A better approach to finding our <div> would be to make use of the id="content" attribute it contains. It's a common web page design pattern to break a page into a few top-level <divs> for the major page sections like the header, the footer and the content, and to give the <divs> id attributes which identify them as such.
Hence, if we could search for <div>s with an id attribute of "content", then we'd have a clean way of selecting the right <div>. There is only one <div> in the document that is a match, and it's unlikely that another<div> like that will be added to the document. This approach doesn't depend on the document structure, and so it won't be affected by any changes that are made to the structure. We'll still need to rely on the fact that the <p> tag in the <div> is the first <p> tag that appears, but given that there is no other way to identify it, this is the best we can do.
So, how do we run such a search for our content <div>?
In order to avoid exhaustive iteration and the checking of every element, we need to use XPath, which is more powerful than what we've used so far. It is a query language that was developed specifically for XML, and it's supported by lxml. Plus, the standard library implementation provides limited support for it.
We're going to take a quick look at XPath, and in the process we will find the answer to the question posed earlier.
To get started, use the Python shell from the last section, and do the following:
>>> root.xpath('body') [<Element body at 0x39e0908>]
This is the simplest form of XPath expression: it searches for children of the current element that have tag names that match the specified tag name. The current element is the one we call xpath() on, in this case root. The root element is the top-level <html> element in the HTML document, and so the returned element is the <body> element.
XPath expressions can contain multiple levels of elements. The searches start from the node the xpath() call is made on and work down the tree as they match successive elements in the expression. We can use this to find just the <div> child elements of <body>:
>>> root.xpath('body/div') [<Element div at 0x39e06c8>, <Element div at 0x39e05c8>, <Element div at 0x39e0608>]
The body/div expression means match <div> children of <body> children of the current element. Elements with the same tag can appear more than once at the same level in an XML document, so an XPath expression can match multiple elements, hence the xpath() function always returns a list.
The preceding queries are relative to the element that we call xpath() on, but we can force a search from the root of the tree by adding a slash to the start of the expression. We can also perform a search over all the descendants of an element, with the help of a double-slash. To do this, try the following:
>>> root.xpath('//h1') [<Element h1 at 0x2ac3b08>]
Here, we've directly found our <h1> element by only specifying a single tag, even though it's several levels below root. This double-slash at the beginning of the expression will always search from the root, but we can prefix this with a dot if we want it to start searching from the context element.
>>> root.find('head').xpath('.//h1') []
This will not find anything because there are no <h1> descendents of <head>.
So, we can be quite specific by supplying paths, but the real power of XPath lies in applying additional conditions to the elements in the path. In particular, our aforementioned problem, which is, testing element attributes.
>>> root.xpath('//div[@id="content"]') [<Element div at 0x39e05c8>]
The square brackets after div, [@id="content"], form a condition that we place on the <div> elements that we're matching. The @ sign before id means that id refers to an attribute, so the condition means: only elements with an id attribute equal to "content". This is how we can find our content <div>.
Before we employ this to extract our information, let's just touch on a couple of useful things that we can do with conditions. We can specify just a tag name, as shown here:
>>> root.xpath('//div[h1]') [<Element div at 0x39e05c8>]
This returns all <div> elements which have an <h1> child element. Also try:
>>> root.xpath('body/div[2]'): [<Element div at 0x39e05c8>]
Putting a number as a condition will return the element at that position in the matched list. In this case this is the second <div> child element of <body>. Note that these indexes start at 1, unlike Python indexing which starts at 0.
There's a lot more that XPath can do, the full specification is a World Wide Web Consortium (W3C) standard. The latest version can be found at http://www.w3.org/TR/xpath-3/.
Now that we've added XPath to our superpowers, let's finish up by writing a script to get our Debian version information. Create a new file, get_debian_version.py, and save the following to it:
import re
import requests
from lxml.etree import HTML
response = requests.get('http://www.debian.org/releases/stable/')
root = HTML(response.content)
title_text = root.find('head').find('title').text
release = re.search('u201c(.*)u201d', title_text).group(1)
p_text = root.xpath('//div[@id="content"]/p[1]')[0].text
version = p_text.split()[1]
print('Codename: {}
Version: {}'.format(release, version))Here, we have downloaded and parsed the web page by pulling out the text that we want with the help of XPath. We have used a regular expression to pull out jessie, and a split to extract the version 8.0. Finally we print it out.
So, run it like it is shown here:
$ python3.4 get_debian_version.py Codename: jessie Version: 8.0
Magnificent. Well, darned nifty, at least. There are some third-party packages available which can speed up scraping and form submission, two popular ones are Mechanize and Scrapy. Check them out at http://wwwsearch.sourceforge.net/mechanize/, and http://scrapy.org.