
Python has APIs that allow us to write both multithreading and multiprocessing applications. The principle behind multithreading and multiprocessing is simply to take copies of our code and run them in additional threads or processes. The operating system automatically schedules the threads and processes across available CPU cores to provide fair processing time allocation to all the threads and processes. This effectively allows a program to simultaneously run multiple operations. In addition, when a thread or process blocks, for example, when waiting for IO, the thread or process can be de-prioritized by the OS, and the CPU cores can be allocated to other threads or processes that have actual computation to do.
Here is an overview of how threads and processes relate to each other:
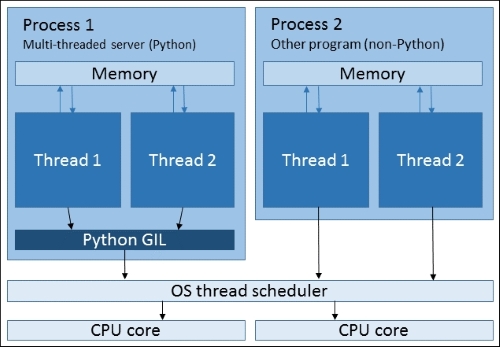
Threads exist within processes. A process can contain multiple threads but it always contains at least one thread, sometimes called the main thread. Threads within the same process share memory, so data transfer between threads is just a case of referencing the shared objects. Processes do not share memory, so other interfaces, such as files, sockets, or specially allocated areas of shared memory, must be used for transferring data between processes.
When threads have operations to execute, they ask the operating system thread scheduler to allocate them some time on a CPU, and the scheduler allocates the waiting threads to CPU cores based on various parameters, which vary from OS to OS. Threads in the same process may run on separate CPU cores at the same time.
Although two processes have been displayed in the preceding diagram, multiprocessing is not going on here, since the processes belong to different applications. The second process is displayed to illustrate a key difference between Python threading and threading in most other programs. This difference is the presence of the GIL.
The CPython interpreter (the standard version of Python available for download from www.python.org) contains something called the Global Interpreter Lock (GIL). The GIL exists to ensure that only a single thread in a Python process can run at a time, even if multiple CPU cores are present. The reason for having the GIL is that it makes the underlying C code of the Python interpreter much easier to write and maintain. The drawback of this is that Python programs using multithreading cannot take advantage of multiple cores for parallel computation.
This is a cause of much contention; however, for us this is not so much of a problem. Even with the GIL present, threads that are blocking on I/O are still de-prioritized by the OS and put into the background, so threads that do have computational work to do can run instead. The following figure is a simplified illustration of this:
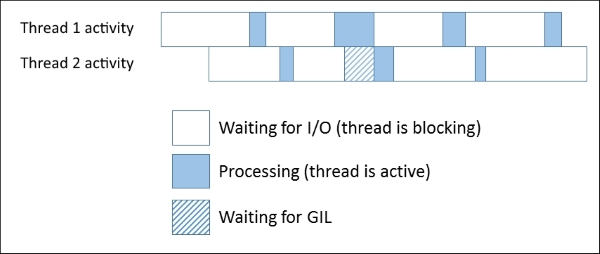
The Waiting for GIL state is where a thread has sent or received some data and so is ready to come out of the blocking state, but another thread has the GIL, so the ready thread is forced to wait. In many network applications, including our echo and chat servers, the time spent waiting on I/O is much higher than the time spent processing data. As long as we don't have a very large number of connections (a situation we'll discuss later on when we come to event driven architectures), thread contention caused by the GIL is relatively low, and hence threading is still a suitable architecture for these network server applications.
With this in mind, we're going to use multithreading rather than multiprocessing in our echo server. The shared data model will simplify the code that we'll need for allowing our chat clients to exchange messages with each other, and because we're I/O bound, we don't need processes for parallel computation. Another reason for not using processes in this case is that processes are more "heavyweight" in terms of the OS resources, so creating a new process takes longer than creating a new thread. Processes also use more memory.
One thing to note is that if you need to perform an intensive computation in your network server application (maybe you need to compress a large file before sending it over the network), then you should investigate methods for running this in a separate process. Because of quirks in the implementation of the GIL, having even a single computationally intensive thread in a mainly I/O bound process when multiple CPU cores are available can severely impact the performance of all the I/O bound threads. For more details, go through the David Beazley presentations linked to in the following information box:
Note
Processes and threads are different beasts, and if you're not clear on the distinctions, it's worthwhile to read up. A good starting point is the Wikipedia article on threads, which can be found at http://en.wikipedia.org/wiki/Thread_(computing).
A good overview of the topic is given in Chapter 4 of Benjamin Erb's thesis, which is available at http://berb.github.io/diploma-thesis/community/.
Additional information on the GIL, including the reasoning behind keeping it in Python can be found in the official Python documentation at https://wiki.python.org/moin/GlobalInterpreterLock.
You can also read more on this topic in Nick Coghlan's Python 3 Q&A, which can be found at http://python-notes.curiousefficiency.org/en/latest/python3/questions_and_answers.html#but-but-surely-fixing-the-gil-is-more-important-than-fixing-unicode.
Finally, David Beazley has done some fascinating research on the performance of the GIL on multi-core systems. Two presentations of importance are available online. They give a good technical background, which is relevant to this chapter. These can be found at http://pyvideo.org/video/353/pycon-2010--understanding-the-python-gil---82 and at https://www.youtube.com/watch?v=5jbG7UKT1l4.