
Chapter 1. Why Machine Learning and Security?
In the beginning, there was spam.
As soon as academics and scientists had hooked enough computers together via the internet to create a communications network that provided value, other people realized that this medium of free transmission and broad distribution was a perfect way to advertise sketchy products, steal account credentials, and spread computer viruses.
In the intervening 40 years, the field of computer and network security has come to encompass an enormous range of threats and domains: intrusion detection, web application security, malware analysis, social network security, advanced persistent threats, and applied cryptography, just to name a few. But even today spam remains a major focus for those in the email or messaging space, and for the general public spam is probably the aspect of computer security that most directly touches their own lives.
Machine learning was not invented by spam fighters, but it was quickly adopted by statistically inclined technologists who saw its potential in dealing with a constantly evolving source of abuse. Email providers and internet service providers (ISPs) have access to a wealth of email content, metadata, and user behavior. Using email data, content-based models can be built to create a generalizable approach to recognize spam. Metadata and entity reputations can be extracted from emails to predict the likelihood that an email is spam without even looking at its content. By instantiating a user behavior feedback loop, the system can build a collective intelligence and improve over time with the help of its users.
Email filters have thus gradually evolved to deal with the growing diversity of circumvention methods that spammers have thrown at them. Even though 85% of all emails sent today are spam (according to one research group), the best modern spam filters block more than 99.9% of all spam, and it is a rarity for users of major email services to see unfiltered and undetected spam in their inboxes. These results demonstrate an enormous advance over the simplistic spam filtering techniques developed in the early days of the internet, which made use of simple word filtering and email metadata reputation to achieve modest results.
The fundamental lesson that both researchers and practitioners have taken away from this battle is the importance of using data to defeat malicious adversaries and improve the quality of our interactions with technology. Indeed, the story of spam fighting serves as a representative example for the use of data and machine learning in any field of computer security. Today, almost all organizations have a critical reliance on technology, and almost every piece of technology has security vulnerabilities. Driven by the same core motivations as the spammers from the 1980s (unregulated, cost-free access to an audience with disposable income and private information to offer), malicious actors can pose security risks to almost all aspects of modern life. Indeed, the fundamental nature of the battle between attacker and defender is the same in all fields of computer security as it is in spam fighting: a motivated adversary is constantly trying to misuse a computer system, and each side races to fix or exploit the flaws in design or technique before the other uncovers it. The problem statement has not changed one bit.
Computer systems and web services have become increasingly centralized, and many applications have evolved to serve millions or even billions of users. Entities that become arbiters of information are bigger targets for exploitation, but are also in the perfect position to make use of the data and their user bases to achieve better security. Coupled with the advent of powerful data crunching hardware and the development of more powerful data analysis and machine learning algorithms, there has never been a better time for exploiting the potential of machine learning in security.
In this book, we demonstrate applications of machine learning and data analysis techniques to various problem domains in security and abuse. We explore methods for evaluating the suitability of different machine learning techniques in different scenarios, and focus on guiding principles that will help you use data to achieve better security. Our goal is not to leave you with the answer to every security problem you might face, but rather to give you a framework for thinking about data and security as well as a toolkit from which you can pick the right method for the problem at hand.
The remainder of this chapter sets up context for the rest of the book: we discuss what threats modern computer and network systems face, what machine learning is, and how machine learning applies to the aforementioned threats. We conclude with a detailed examination of approaches to spam fighting, which provides a concrete example of applying machine learning to security that can be generalized to nearly any domain.
Cyber Threat Landscape
The landscape of adversaries and miscreants in computer security has evolved over time, but the general categories of threats have remained the same. Security research exists to stymie the goals of attackers, and it is always important to have a good understanding of the different types of attacks that exist in the wild. As you can see from the Cyber Threat Taxonomy tree in Figure 1-1,1 the relationships between threat entities and categories can be complex in some cases.
We begin by defining the principal threats that we will explore in the chapters that follow:
- Malware (or virus)
-
Short for “malicious software,” any software designed to cause harm or gain unauthorized access to computer systems.
- Worm
-
Standalone malware that replicates itself in order to spread to other computer systems.
- Trojan
-
Malware disguised as legitimate software to avoid detection.
- Spyware
-
Malware installed on a computer system without permission and/or knowledge by the operator, for the purposes of espionage and information collection. Keyloggers fall into this category.
- Adware
-
Malware that injects unsolicited advertising material (e.g., pop ups, banners, videos) into a user interface, often when a user is browsing the web.
- Ransomware
-
Malware designed to restrict availability of computer systems until a sum of money (ransom) is paid.
- Rootkit
-
A collection of (often) low-level software designed to enable access to or gain control of a computer system. (“Root” denotes the most powerful level of access to a system.)
- Backdoor
-
An intentional hole placed in the system perimeter to allow for future accesses that can bypass perimeter protections.
- Bot
-
A variant of malware that allows attackers to remotely take over and control computer systems, making them zombies.
- Botnet
- Exploit
-
A piece of code or software that exploits specific vulnerabilities in other software applications or frameworks.
- Scanning
-
Attacks that send a variety of requests to computer systems, often in a brute-force manner, with the goal of finding weak points and vulnerabilities as well as information gathering.
- Sniffing
-
Silently observing and recording network and in-server traffic and processes without the knowledge of network operators.
- Keylogger
-
A piece of hardware or software that (often covertly) records the keys pressed on a keyboard or similar computer input device.
- Spam
-
Unsolicited bulk messaging, usually for the purposes of advertising. Typically email, but could be SMS or through a messaging provider (e.g., WhatsApp).
- Login attack
-
Multiple, usually automated, attempts at guessing credentials for authentication systems, either in a brute-force manner or with stolen/purchased credentials.
- Account takeover (ATO)
-
Gaining access to an account that is not your own, usually for the purposes of downstream selling, identity theft, monetary theft, and so on. Typically the goal of a login attack, but also can be small scale and highly targeted (e.g., spyware, social engineering).
- Phishing (aka masquerading)
-
Communications with a human who pretends to be a reputable entity or person in order to induce the revelation of personal information or to obtain private assets.
- Spear phishing
-
Phishing that is targeted at a particular user, making use of information about that user gleaned from outside sources.
- Social engineering
-
Information exfiltration (extraction) from a human being using nontechnical methods such as lying, trickery, bribery, blackmail, and so on.
- Incendiary speech
-
Discriminatory, discrediting, or otherwise harmful speech targeted at an individual or group.
- Denial of service (DoS) and distributed denial of service (DDoS)
-
Attacks on the availability of systems through high-volume bombardment and/or malformed requests, often also breaking down system integrity and reliability.
- Advanced persistent threats (APTs)
-
Highly targeted networks or host attack in which a stealthy intruder remains intentionally undetected for long periods of time in order to steal and exfiltrate data.
- Zero-day vulnerability
-
A weakness or bug in computer software or systems that is unknown to the vendor, allowing for potential exploitation (called a zero-day attack) before the vendor has a chance to patch/fix the problem.
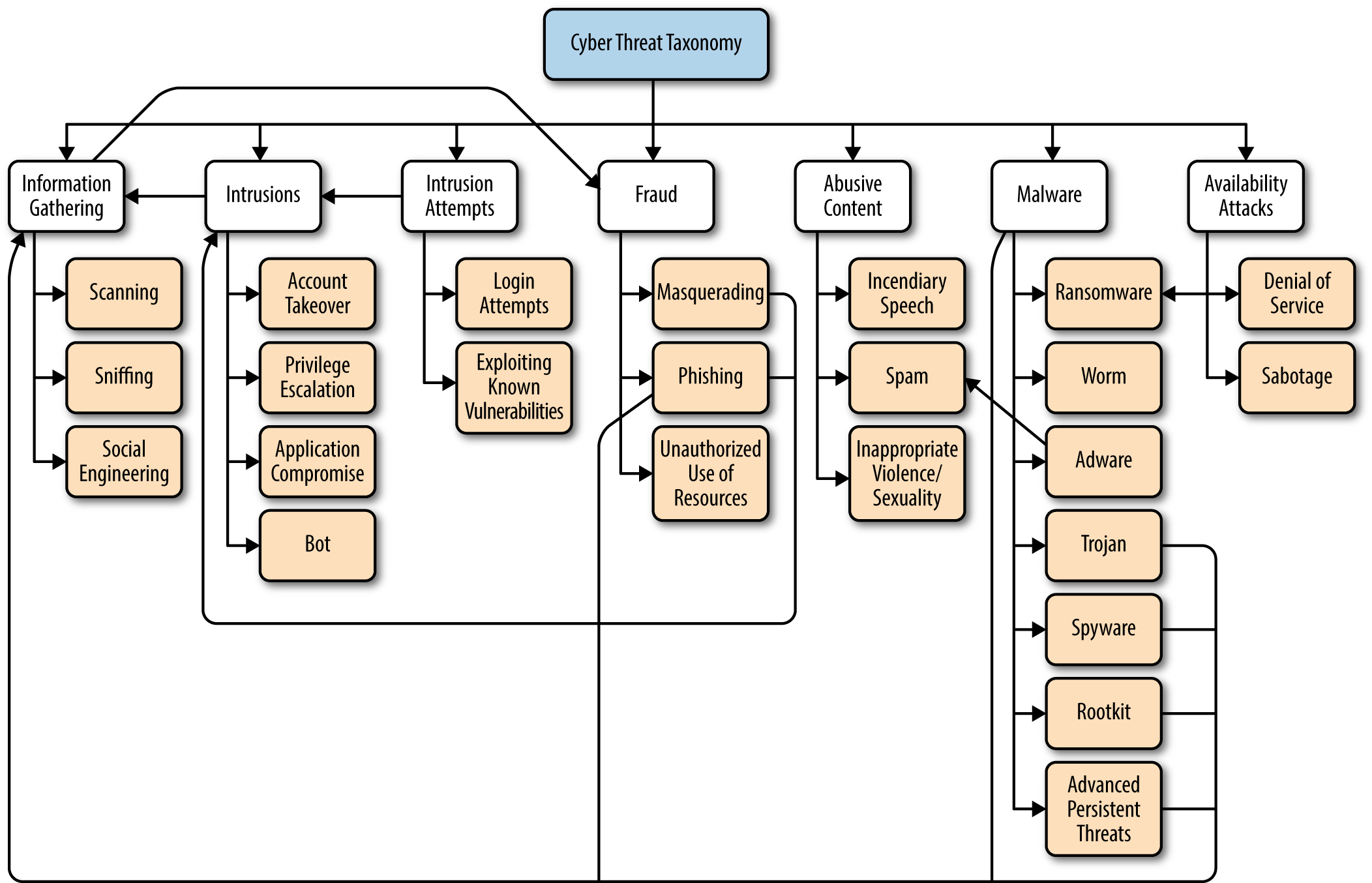
Figure 1-1. Cyber Threat Taxonomy tree
The Cyber Attacker’s Economy
What drives attackers to do what they do? Internet-based criminality has become increasingly commercialized since the early days of the technology’s conception. The transformation of cyber attacks from a reputation economy (“street cred,” glory, mischief) to a cash economy (direct monetary gains, advertising, sale of private information) has been a fascinating process, especially from the point of view of the adversary. The motivation of cyber attackers today is largely monetary. Attacks on financial institutions or conduits (online payment platforms, stored value/gift card accounts, Bitcoin wallets, etc.) can obviously bring attackers direct financial gains. But because of the higher stakes at play, these institutions often have more advanced defense mechanisms in place, making the lives of attackers tougher. Because of the allure of a more direct path to financial yield, the marketplace for vulnerabilities targeting such institutions is also comparatively crowded and noisy. This leads miscreants to target entities with more relaxed security measures in place, abusing systems that are open by design and resorting to more indirect techniques that will eventually still allow them to monetize.
A Marketplace for Hacking Skills
The fact that darknet marketplaces and illegal hacking forums exist is no secret. Before the existence of organized underground communities for illegal exchanges, only the most competent of computer hackers could partake in the launching of cyber attacks and the compromising of accounts and computer systems. However, with the commoditization of hacking and the ubiquitization of computer use, lower-skilled “hackers” can participate in the ecosystem of cyber attacks by purchasing vulnerabilities and user-friendly hacking scripts, software, and tools to engage in their own cyber attacks.
The zero-day vulnerability marketplace has variants that exist both legally and illegally. Trading vulnerabilities and exploits can become a viable source of income for both security researchers and computer hackers.2 Increasingly, the most elite computer hackers are not the ones unleashing zero-days and launching attack campaigns. The risks are just too high, and the process of monetization is just too long and uncertain. Creating software that empowers the common script-kiddy to carry out the actual hacking, selling vulnerabilities on marketplaces, and in some cases even providing boutique hacking consulting services promises a more direct and certain path to financial gain. Just as in the California Gold Rush of the late 1840s, merchants providing amenities to a growing population of wealth-seekers are more frequently the receivers of windfalls than the seekers themselves.
Indirect Monetization
The process of monetization for miscreants involved in different types of computer attacks is highly varied, and worthy of detailed study. We will not dive too deep into this investigation, but we will look at a couple of examples of how indirect monetization can work.
Malware distribution has been commoditized in a way similar to the evolution of cloud computing and Infrastructure-as-a-Service (IaaS) providers. The pay-per-install (PPI) marketplace for malware propagation is a complex and mature ecosystem, providing wide distribution channels available to malware authors and purchasers.3 Botnet rentals operate on the same principle as on-demand cloud infrastructure, with per-hour resource offerings at competitive prices. Deploying malware on remote servers can also be financially rewarding in its own different ways. Targeted attacks on entities are sometimes associated with a bounty, and ransomware distributions can be an efficient way to extort money from a wide audience of victims.
Spyware can assist in the stealing of private information, which can then be sold in bulk on the same online marketplaces where the spyware is sold. Adware and spam can be used as a cheap way to advertise dodgy pharmaceuticals and financial instruments. Online accounts are frequently taken over for the purposes of retrieving some form of stored value, such as gift cards, loyalty points, store credit, or cash rewards. Stolen credit card numbers, Social Security numbers, email accounts, phone numbers, addresses, and other private information can be sold online to criminals intent on identity theft, fake account creation, fraud, and so on. But the path to monetization, in particular when you have a victim’s credit card number, can be a long and complex one. Because of how easily this information is stolen, credit card companies, as well as companies that operate accounts with stored value, often engineer clever ways to stop attackers from monetizing. For instance, accounts suspected of having been compromised can be invalidated, or cashing out gift cards can require additional authentication steps.
The Upshot
The motivations of cyber attackers are complex and the paths to monetization are convoluted. However, the financial gains from internet attacks can be a powerful motivator for technically skilled people, especially those in less-wealthy nations and communities. As long as computer attacks can continue to generate a non-negligible yield for the perpetrators, they will keep coming.
What Is Machine Learning?
Since the dawn of the technological age, researchers have dreamed of teaching computers to reason and make “intelligent” decisions in the way that humans do, by drawing generalizations and distilling concepts from complex information sets without explicit instructions.
Machine learning refers to one aspect of this goal—specifically, to algorithms and processes that “learn” in the sense of being able to generalize past data and experiences in order to predict future outcomes. At its core, machine learning is a set of mathematical techniques, implemented on computer systems, that enables a process of information mining, pattern discovery, and drawing inferences from data.
At the most general level, supervised machine learning methods adopt a Bayesian approach to knowledge discovery, using probabilities of previously observed events to infer the probabilities of new events. Unsupervised methods draw abstractions from unlabeled datasets and apply these to new data. Both families of methods can be applied to problems of classification (assigning observations to categories) or regression (predicting numerical properties of an observation).
Suppose that we want to classify a group of animals into mammals and reptiles. With a supervised method, we will have a set of animals for which we are definitively told their category (e.g., we are told that the dog and elephant are mammals and the alligator and iguana are reptiles). We then try to extract some features from each of these labeled data points and find similarities in their properties, allowing us to differentiate animals of different classes. For instance, we see that the dog and the elephant both give birth to live offspring, unlike the alligator and the iguana. The binary property “gives birth to live offspring” is what we call a feature, a useful abstraction for observed properties that allows us to perform comparisons between different observations. After extracting a set of features that might help differentiate mammals and reptiles in the labeled data, we then can run a learning algorithm on the labeled data and apply what the algorithm learned to new, unseen animals. When the algorithm is presented with a meerkat, it now must classify it as either a mammal or a reptile. Extracting the set of features from this new animal, the algorithm knows that the meerkat does not lay eggs, has no scales, and is warm-blooded. Driven by prior observations, it makes a category prediction that the meerkat is a mammal, and it is exactly right.
In the unsupervised case, the premise is similar, but the algorithm is not presented with the initial set of labeled animals. Instead, the algorithm must group the different sets of data points in a way that will result in a binary classification. Seeing that most animals that don’t have scales do give birth to live offspring and are also warm-blooded, and most animals that have scales lay eggs and are cold-blooded, the algorithm can then derive the two categories from the provided set and make future predictions in the same way as in the supervised case.
Machine learning algorithms are driven by mathematics and statistics, and the algorithms that discover patterns, correlations, and anomalies in the data vary widely in complexity. In the coming chapters, we go deeper into the mechanics of some of the most common machine learning algorithms used in this book. This book will not give you a complete understanding of machine learning, nor will it cover much of the mathematics and theory in the subject. What it will give you is critical intuition in machine learning and practical skills for designing and implementing intelligent, adaptive systems in the context of security.
What Machine Learning Is Not
Artificial intelligence (AI) is a popular but loosely defined term that indicates algorithmic solutions to complex problems typically solved by humans. As illustrated in Figure 1-2, machine learning is a core building block for AI. For example, self-driving cars must classify observed images as people, cars, trees, and so on; they must predict the position and speed of other cars; they must determine how far to rotate the wheels in order to make a turn. These classification and prediction problems are solved using machine learning, and the self-driving system is a form of AI. There are other parts of the self-driving AI decision engine that are hardcoded into rule engines, and that would not be considered machine learning. Machine learning helps us create AI, but is not the only way to achieve it.
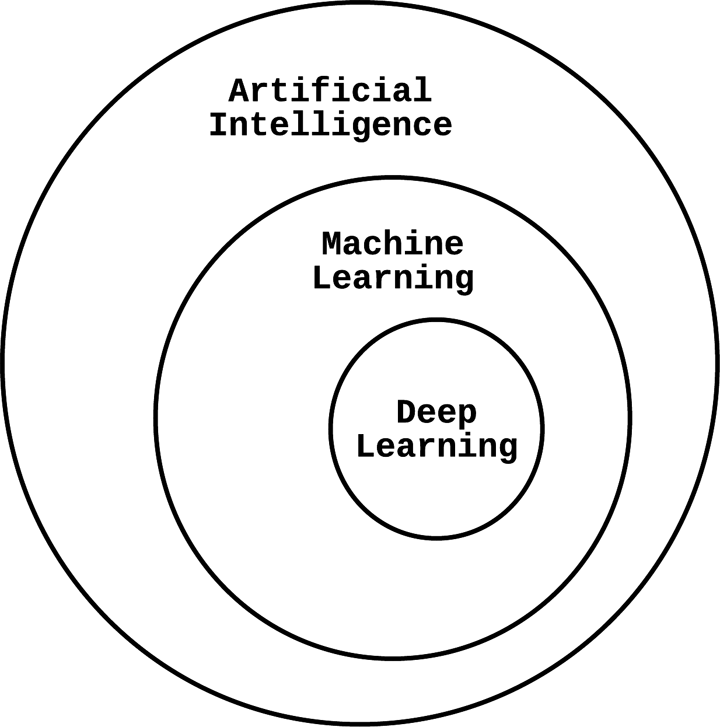
Figure 1-2. Artificial intelligence as it relates to machine learning and deep learning
Deep learning is another popular term that is commonly conflated with machine learning. Deep learning is a strict subset of machine learning referring to a specific class of multilayered models that use layers of simpler statistical components to learn representations of data. “Neural network” is a more general term for this type of layered statistical learning architecture that might or might not be “deep” (i.e., have many layers). For an excellent discussion of this topic, see Deep Learning by Ian Goodfellow, Yoshua Bengio, and Aaron Courville (MIT Press).
Statistical analysis is a core part of machine learning: outputs of machine learning algorithms are often presented in terms of probabilities and confidence intervals. We will touch on some statistical techniques in our discussion of anomaly detection, but we will leave aside questions regarding experimentation and statistical hypothesis testing. For an excellent discussion of this topic, see Probability & Statistics for Engineers & Scientists by Ronald Walpole et al. (Prentice Hall).
Adversaries Using Machine Learning
Note that nothing prevents adversaries from taking advantage of machine learning to avoid detection and evade defenses. As much as the defenders can learn from the attacks and adjust their countermeasures accordingly, attackers can also learn the nature of defenses to their own benefit. Spammers have been known to apply polymorphism (i.e., changing the appearance of content without changing its meaning) to their payloads to circumvent detection, or to probe spam filters by performing A/B tests on email content and learning what causes their click-through rates to rise and fall. Both good guys and bad guys use machine learning in fuzzing campaigns to speed up the process of finding vulnerabilities in software. Adversaries can even use machine learning to learn about your personality and interests through social media in order to craft the perfect phishing message for you.
Finally, the use of dynamic and adaptive methods in the area of security always contains a certain degree of risk. Especially when explainability of machine learning predictions is often lacking, attackers have been known to cause various algorithms to make erroneous predictions or learn the wrong thing.4 In this growing field of study called adversarial machine learning, attackers with varying degrees of access to a machine learning system can execute a range of attacks to achieve their ends. Chapter 8 is dedicated to this topic, and paints a more complete picture of the problems and solutions in this space.
Machine learning algorithms are often not designed with security in mind, and are often vulnerable in the face of attempts made by a motivated adversary. Hence, it is important to maintain an awareness of such threat models when designing and building machine learning systems for security purposes.
Real-World Uses of Machine Learning in Security
In this book, we explore a range of different computer security applications for which machine learning has shown promising results. Applying machine learning and data science to solve problems is not a straightforward task. Although convenient programming libraries remove some complexity from the equation, developers still need to make many decisions along the way.
By going through different examples in each chapter, we will explore the most common issues faced by practitioners when designing machine learning systems, whether in security or otherwise. The applications described in this book are not new, and you also can find the data science techniques we discuss at the core of many computer systems that you might interact with on a daily basis.
We can classify machine learning’s use cases in security into two broad categories: pattern recognition and anomaly detection. The line differentiating pattern recognition and anomaly detection is sometimes blurry, but each task has a clearly distinguished goal. In pattern recognition, we try to discover explicit or latent characteristics hidden in the data. These characteristics, when distilled into feature sets, can be used to teach an algorithm to recognize other forms of the data that exhibit the same set of characteristics. Anomaly detection approaches knowledge discovery from the other side of the same coin. Instead of learning specific patterns that exist within certain subsets of the data, the goal is to establish a notion of normality that describes most (say, more than 95%) of a given dataset. Thereafter, deviations from this normality of any sort will be detected as anomalies.
It is common to erroneously think of anomaly detection as the process of recognizing a set of normal patterns and differentiating it from a set of abnormal patterns. Patterns extracted through pattern recognition must be strictly derived from the observed data used to train the algorithm. On the other hand, in anomaly detection there can be an infinite number of anomalous patterns that fit the bill of an outlier, even those derived from hypothetical data that do not exist in the training or testing datasets.
Spam detection is perhaps the classic example of pattern recognition because spam typically has a largely predictable set of characteristics, and an algorithm can be trained to recognize those characteristics as a pattern by which to classify emails. Yet it is also possible to think of spam detection as an anomaly detection problem. If it is possible to derive a set of features that describes normal traffic well enough to treat significant deviations from this normality as spam, we have succeeded. In actuality, however, spam detection might not be suitable for the anomaly detection paradigm, because it is not difficult to convince yourself that it is in most contexts easier to find similarities between spam messages than within the broad set of normal traffic.
Malware detection and botnet detection are other applications that fall clearly in the category of pattern recognition, where machine learning becomes especially useful when the attackers employ polymorphism to avoid detection. Fuzzing is the process of throwing arbitrary inputs at a piece of software to force the application into an unintended state, most commonly to force a program to crash or be put into a vulnerable mode for further exploitation. Naive fuzzing campaigns often run into the problem of having to iterate over an intractably large application state space. The most widely used fuzzing software has optimizations that make fuzzing much more efficient than blind iteration. Machine learning has also been used in such optimizations, by learning patterns of previously found vulnerabilities in similar programs and guiding the fuzzer to similarly vulnerable code paths or idioms for potentially quicker results.
For user authentication and behavior analysis, the delineation between pattern recognition and anomaly detection becomes less clear. For cases in which the threat model is clearly known, it might be more suitable to approach the problem through the lens of pattern recognition. In other cases, anomaly detection can be the answer. In many cases, a system might make use of both approaches to achieve better coverage. Network outlier detection is a classic example of anomaly detection because most network traffic follows strict protocols and normal behavior matches a set of patterns in form or sequence. Any malicious network activity that does not manage to masquerade well by mimicking normal traffic will be caught by outlier detection algorithms. Other network-related detection problems, such as malicious URL detection, can also be approached from the angle of anomaly detection.
Access control refers to any set of policies governing the ability of system users to access certain pieces of information. Frequently used to protect sensitive information from unnecessary exposure, access control policies are often the first line of defense against breaches and information theft. Machine learning has gradually found its way into access control solutions because of the pains experienced by system users at the mercy of rigid and unforgiving access control policies.5 Through a combination of unsupervised learning and anomaly detection, such systems can infer information access patterns for certain users or roles in an organization and engage in retaliatory action when an unconventional pattern is detected.
Imagine, for example, a hospital’s patient record storage system, where nurses and medical technicians frequently need to access individual patient data but don’t necessarily need to do cross-patient correlations. Doctors, on the other hand, frequently query and aggregate the medical records of multiple patients to look for case similarities and diagnostic histories. We don’t necessarily want to prevent nurses and medical technicians from querying multiple patient records because there might be rare cases that warrant such actions. A strict rule-based access control system would not be able to provide the flexibility and adaptability that machine learning systems can provide.
In the rest of this book, we dive deeper into a selection of these real-world applications. We then will be able to discuss the nuances around applying machine learning for pattern recognition and anomaly detection in security. In the remainder of this chapter, we focus on the example of spam fighting as one that illustrates the core principles used in any application of machine learning to security.
Spam Fighting: An Iterative Approach
As discussed earlier, the example of spam fighting is both one of the oldest problems in computer security and one that has been successfully attacked with machine learning. In this section, we dive deep into this topic and show how to gradually build up a sophisticated spam classification system using machine learning. The approach we take here will generalize to many other types of security problems, including but not limited to those discussed in later chapters of this book.
Consider a scenario in which you are asked to solve the problem of rampant email spam affecting employees in an organization. For whatever reason, you are instructed to develop a custom solution instead of using commercial options. Provided with administrator access to the private email servers, you are able to extract a body of emails for analysis. All the emails are properly tagged by recipients as either “spam” or “ham” (non-spam), so you don’t need to spend too much time cleaning the data.6
Human beings do a good job at recognizing spam, so you begin by implementing a simple solution that approximates a person’s thought process while executing this task. Your theory is that the presence or absence of some prominent keywords in an email is a strong binary indicator of whether the email is spam or ham. For instance, you notice that the word “lottery” appears in the spam data a lot, but seldom appears in regular emails. Perhaps you could come up with a list of similar words and perform the classification by checking whether a piece of email contains any words that belong to this blacklist.
The dataset that we will use to explore this problem is the 2007 TREC Public Spam Corpus. This is a lightly cleaned raw email message corpus containing 75,419 messages collected from an email server over a three-month period in 2007. One-third of the dataset is made up of spam examples, and the rest is ham. This dataset was created by the Text REtrieval Conference (TREC) Spam Track in 2007, as part of an effort to push the boundaries of state-of-the-art spam detection.
For evaluating how well different approaches work, we will go through a simple validation process.7 We split the dataset into nonoverlapping training and test sets, in which the training set consists of 70% of the data (an arbitrarily chosen proportion) and the test set consists of the remaining 30%. This method is standard practice for assessing how well an algorithm or model developed on the basis of the training set will generalize to an independent dataset.
The first step is to use the Natural Language Toolkit (NLTK) to remove morphological affixes from words for more flexible matching (a process called stemming). For instance, this would reduce the words “congratulations” and “congrats” to the same stem word, “congrat.” We also remove stopwords (e.g., “the,” “is,” and “are,”) before the token extraction process, because they typically do not contain much meaning. We define a set of functions8 to help with loading and preprocessing the data and labels, as demonstrated in the following code:9
importstringimportimportnltkpunctuations=list(string.punctuation)stopwords=set(nltk.corpus.stopwords.words('english'))stemmer=nltk.PorterStemmer()# Combine the different parts of the email into a flat list of stringsdefflatten_to_string(parts):ret=[]iftype(parts)==str:ret.append(parts)eliftype(parts)==list:forpartinparts:ret+=flatten_to_string(part)elifparts.get_content_type=='text/plain':ret+=parts.get_payload()returnret# Extract subject and body text from a single email filedefextract_email_text(path):# Load a single email from an input filewithopen(path,errors='ignore')asf:msg=.message_from_file(f)ifnotmsg:return""# Read the email subjectsubject=msg['Subject']ifnotsubject:subject=""# Read the email bodybody=' '.join(mforminflatten_to_string(msg.get_payload())iftype(m)==str)ifnotbody:body=""returnsubject+' '+body# Process a single email file into stemmed tokensdefload(path):email_text=extract_email_text(path)ifnotemail_text:return[]# Tokenize the messagetokens=nltk.word_tokenize(email_text)# Remove punctuation from tokenstokens=[i.strip("".join(punctuations))foriintokensifinotinpunctuations]# Remove stopwords and stem tokensiflen(tokens)>2:return[stemmer.stem(w)forwintokensifwnotinstopwords]return[]
Next, we proceed with loading the emails and labels. This dataset provides each email in its own individual file (inmail.1, inmail.2, inmail.3, …), along with a single label file (full/index) in the following format:
spam ../data/inmail.1 ham ../data/inmail.2 spam ../data/inmail.3 ...
Each line in the label file contains the “spam” or “ham” label for each email sample in the dataset. Let’s read the dataset and build a blacklist of spam words now:10
importosDATA_DIR='datasets/trec07p/data/'LABELS_FILE='datasets/trec07p/full/index'TRAINING_SET_RATIO=0.7labels={}spam_words=set()ham_words=set()# Read the labelswithopen(LABELS_FILE)asf:forlineinf:line=line.strip()label,key=line.split()labels[key.split('/')[-1]]=1iflabel.lower()=='ham'else0# Split corpus into training and test setsfilelist=os.listdir(DATA_DIR)X_train=filelist[:int(len(filelist)*TRAINING_SET_RATIO)]X_test=filelist[int(len(filelist)*TRAINING_SET_RATIO):]forfilenameinX_train:path=os.path.join(DATA_DIR,filename)iffilenameinlabels:label=labels[filename]stems=load(path)ifnotstems:continueiflabel==1:ham_words.update(stems)eliflabel==0:spam_words.update(stems)else:continueblacklist=spam_words-ham_words
Upon inspection of the tokens in blacklist, you might feel that many of the words are nonsensical (e.g., Unicode, URLs, filenames, symbols, foreign words). You can remedy this problem with a more thorough data-cleaning process, but these simple results should perform adequately for the purposes of this experiment:
greenback, gonorrhea, lecher, ...
Evaluating our methodology on the 22,626 emails in the testing set, we realize that this simplistic algorithm does not do as well as we had hoped. We report the results in a confusion matrix, a 2 × 2 matrix that gives the number of examples with given predicted and actual labels for each of the four possible pairs:
| Predicted HAM | Predicted SPAM | |
|---|---|---|
Actual HAM |
6,772 |
714 |
Actual SPAM |
5,835 |
7,543 |
True positive: predicted spam + actual ham |
True negative: predicted ham + actual ham |
False positive: predicted spam + actual ham |
False negative: predicted ham + actual spam |
Converting this to percentages, we get the following:
| Predicted HAM | Predicted SPAM | |
|---|---|---|
Actual HAM |
32.5% |
3.4% |
Actual SPAM |
28.0% |
36.2% |
Classification accuracy: 68.7% |
Ignoring the fact that 5.8% of emails were not classified because of preprocessing errors, we see that the performance of this naive algorithm is actually quite fair. Our spam blacklist technique has a 68.7% classification accuracy (i.e., total proportion of correct labels). However, the blacklist doesn’t include many words that spam emails use, because they are also frequently found in legitimate emails. It also seems like an impossible task to maintain a constantly updated set of words that can cleanly divide spam and ham. Maybe it’s time to go back to the drawing board.
Next, you remember reading that one of the popular ways that email providers fought spam in the early days was to perform fuzzy hashing on spam messages and filter emails that produced a similar hash. This is a type of collaborative filtering that relies on the wisdom of other users on the platform to build up a collective intelligence that will hopefully generalize well and identify new incoming spam. The hypothesis is that spammers use some automation in crafting spam, and hence produce spam messages that are only slight variations of one another. A fuzzy hashing algorithm, or more specifically, a locality-sensitive hash (LSH), can allow you to find approximate matches of emails that have been marked as spam.
Upon doing some research, you come across datasketch, a comprehensive Python package that has efficient implementations of the MinHash + LSH algorithm11 to perform string matching with sublinear query costs (with respect to the cardinality of the spam set). MinHash converts string token sets to short signatures while preserving qualities of the original input that enable similarity matching. LSH can then be applied on MinHash signatures instead of raw tokens, greatly improving performance. MinHash trades the performance gains for some loss in accuracy, so there will be some false positives and false negatives in your result. However, performing naive fuzzy string matching on every email message against the full set of n spam messages in your training set incurs either O(n) query complexity (if you scan your corpus each time) or O(n) memory (if you build a hash table of your corpus), and you decide that you can deal with this trade-off:12,13
fromdatasketchimportMinHash,MinHashLSH# Extract only spam files for inserting into the LSH matcherspam_files=[xforxinX_trainiflabels[x]==0]# Initialize MinHashLSH matcher with a Jaccard# threshold of 0.5 and 128 MinHash permutation functionslsh=MinHashLSH(threshold=0.5,num_perm=128)# Populate the LSH matcher with training spam MinHashesforidx,finenumerate(spam_files):minhash=MinHash(num_perm=128)stems=load(os.path.join(DATA_DIR,f))iflen(stems)<2:continueforsinstems:minhash.update(s.encode('utf-8'))lsh.insert(f,minhash)
Now it’s time to have the LSH matcher predict labels for the test set:
deflsh_predict_label(stems):'''Queries the LSH matcher and returns:0 if predicted spam1 if predicted ham−1 if parsing error'''minhash=MinHash(num_perm=128)iflen(stems)<2:return−1forsinstems:minhash.update(s.encode('utf-8'))matches=lsh.query(minhash)ifmatches:return0else:return1
Inspecting the results, you see the following:
| Predicted HAM | Predicted SPAM | |
|---|---|---|
Actual HAM |
7,350 |
136 |
Actual SPAM |
2,241 |
11,038 |
Converting this to percentages, you get:
| Predicted HAM | Predicted SPAM | |
|---|---|---|
Actual HAM |
35.4% |
0.7% |
Actual SPAM |
10.8% |
53.2% |
Classification accuracy: 88.6% |
That’s approximately 20% better than the previous naive blacklisting approach, and significantly better with respect to false positives (i.e., predicted spam + actual ham). However, these results are still not quite in the same league as modern spam filters. Digging into the data, you realize that it might not be an issue with the algorithm, but with the nature of the data you have—the spam in your dataset just doesn’t seem all that repetitive. Email providers are in a much better position to make use of collaborative spam filtering because of the volume and diversity of messages that they see. Unless a spammer were to target a large number of employees in your organization, there would not be a significant amount of repetition in the spam corpus. You need to go beyond matching stem words and computing Jaccard similarities if you want a breakthrough.
By this point, you are frustrated with experimentation and decide to do more research before proceeding. You see that many others have obtained promising results using a technique called Naive Bayes classification. After getting a decent understanding of how the algorithm works, you begin to create a prototype solution. Scikit-learn provides a surprisingly simple class, sklearn.naive_bayes.MultinomialNB, that you can use to generate quick results for this experiment. You can reuse a lot of the earlier code for parsing the email files and preprocessing the labels. However, you decide to try passing in the entire email subject and plain text body (separated by a new line) without doing any stopword removal or stemming with NLTK. You define a small function to read all the email files into this text form:14,15
defread_email_files():X=[]y=[]foriinxrange(len(labels)):filename='inmail.'+str(i+1)email_str=extract_email_text(os.path.join(DATA_DIR,filename))X.append(email_str)y.append(labels[filename])returnX,y
Then you use the utility function sklearn.model_selection.train_test_split() to randomly split the dataset into training and testing subsets (the argument random_state=123 is passed in for the sake of result reproducibility):
fromsklearn.model_selectionimporttrain_test_splitX,y=read_email_files()X_train,X_test,y_train,y_test,idx_train,idx_test=train_test_split(X,y,range(len(y)),train_size=TRAINING_SET_RATIO,random_state=2)
Now that you have prepared the raw data, you need to do some further processing of the tokens to convert each email to a vector representation that MultinomialNB accepts as input.
One of the simplest ways to convert a body of text into a feature vector is to use the bag-of-words representation, which goes through the entire corpus of documents and generates a vocabulary of tokens used throughout the corpus. Every word in the vocabulary comprises a feature, and each feature value is the count of how many times the word appears in the corpus. For example, consider a hypothetical scenario in which you have only three messages in the entire corpus:
tokenized_messages:{'A':['hello','mr','bear'],'B':['hello','hello','gunter'],'C':['goodbye','mr','gunter']}# Bag-of-words feature vector column labels:# ['hello', 'mr', 'doggy', 'bear', 'gunter', 'goodbye']vectorized_messages:{'A':[1,1,0,1,0,0],'B':[2,0,0,0,1,0],'C':[0,1,0,0,1,1]}
Even though this process discards seemingly important information like the order of words, content structure, and word similarities, it is very simple to implement using the sklearn.feature_extraction.CountVectorizer class:
fromsklearn.feature_extraction.textimportCountVectorizervectorizer=CountVectorizer()X_train_vector=vectorizer.fit_transform(X_train)X_test_vector=vectorizer.transform(X_test)
You can also try using the term frequency/inverse document frequency (TF/IDF) vectorizer instead of raw counts. TF/IDF normalizes raw word counts and is in general a better indicator of a word’s statistical importance in the text. It is provided as sklearn.feature_extraction.text.TfidfVectorizer.
Now you can train and test your multinomial Naive Bayes classifier:
fromsklearn.naive_bayesimportMultinomialNBfromsklearn.metricsimportaccuracy_score# Initialize the classifier and make label predictionsmnb=MultinomialNB()mnb.fit(X_train_vector,y_train)y_pred=mnb.predict(X_test_vector)# Print results('Accuracy {:.3f}'.format(accuracy_score(y_test,y_pred)))>Accuracy:0.956
An accuracy of 95.6%—a whole 7% better than the LSH approach!16 That’s not a bad result for a few lines of code, and it’s in the ballpark of what modern spam filters can do. Some state-of-the-art spam filters are in fact actually driven by some variant of Naive Bayes classification. In machine learning, combining multiple independent classifiers and algorithms into an ensemble (also known as stacked generalization or stacking) is a common way of taking advantage of each method’s strengths. So, you can imagine how a combination of word blacklists, fuzzy hash matching, and a Naive Bayes model can help to improve this result.
Alas, spam detection in the real world is not as simple as we have made it out to be in this example. There are many different types of spam, each with a different attack vector and method of avoiding detection. For instance, some spam messages rely heavily on tempting the reader to click links. The email’s content body thus might not contain as much incriminating text as other kinds of spam. This kind of spam then might try to circumvent link-spam detection classifiers using complex methods like cloaking and redirection chains. Other kinds of spam might just rely on images and not rely on text at all.
For now, you are happy with your progress and decide to deploy this solution. As is always the case when dealing with human adversaries, the spammers will eventually realize that their emails are no longer getting through and might act to avoid detection. This response is nothing out of the ordinary for problems in security. You must constantly improve your detection algorithms and classifiers and stay one step ahead of your adversaries.
In the following chapters, we explore how machine learning methods can help you avoid having to be constantly engaged in this whack-a-mole game with attackers, and how you can create a more adaptive solution to minimize constant manual tweaking.
Limitations of Machine Learning in Security
The notion that machine learning methods will always give good results across different use cases is categorically false. In real-world scenarios there are usually factors to optimize for other than precision, recall, or accuracy.
As an example, explainability of classification results can be more important in some applications than others. It can be considerably more difficult to extract the reasons for a decision made by a machine learning system compared to a simple rule. Some machine learning systems might also be significantly more resource intensive than other alternatives, which can be a dealbreaker for execution in constrained environments such as embedded systems.
There is no silver bullet machine learning algorithm that works well across all problem spaces. Different algorithms vary vastly in their suitability for different applications and different datasets. Although machine learning methods contribute to the notion of artificial intelligence, their capabilities can still only be compared to human intelligence along certain dimensions.
The human decision-making process is informed by a vast body of context drawn from cultural and experiential knowledge. This process is very difficult for machine learning systems to emulate. Take the initial blacklisted-words approach that we used for spam filtering as an example. When a person evaluates the content of an email to determine if it’s ham or spam, the decision-making process is never as simple as looking for the existence of certain words. The context in which a blacklisted word is being used can result in it being a reasonable inclusion in non-spam email. Also, spammers might use synonyms of blacklisted words in future emails to convey the same meaning, but a simplistic blacklist would not adapt appropriately. The system simply doesn’t have the context that a human has—it does not know what relevance a particular word bears to the reader. Continually updating the blacklist with new suspicious words is a laborious process, and in no way guarantees perfect coverage.
Even though your machine-learned model may work perfectly on a training set, you might find that it performs badly on a testing set. A common reason for this problem is that the model has overfit its classification boundaries to the training data, learning characteristics of the dataset that do not generalize well across other unseen datasets. For instance, your spam filter might learn from a training set that all emails containing the words “inheritance” and “Nigeria” can immediately be given a high suspicion score, but it does not know about the legitimate email chain discussion between employees about estate inheritances in Nigerian agricultural insurance schemes.
With all these limitations in mind, we should approach machine learning with equal parts of enthusiasm and caution, remembering that not everything can instantly be made better with AI.
1 Adapted from the European CSIRT Network project’s Security Incidents Taxonomy.
2 Charlie Miller, “The Legitimate Vulnerability Market: Inside the Secretive World of 0-day Exploit Sales,” Proceedings of the 6th Workshop on the Economics of Information Security (2007).
3 Juan Caballero et al., “Measuring Pay-per-Install: The Commoditization of Malware Distribution,” Proceedings of the 20th USENIX Conference on Security (2011).
4 Ling Huang et al., “Adversarial Machine Learning,” Proceedings of the 4th ACM Workshop on Artificial Intelligence and Security (2011): 43–58.
5 Evan Martin and Tao Xie, “Inferring Access-Control Policy Properties via Machine Learning,” Proceedings of the 7th IEEE International Workshop on Policies for Distributed Systems and Networks (2006): 235–238.
6 In real life, you will spend a large proportion of your time cleaning the data in order to make it available to and useful for your algorithms.
7 This validation process, sometimes referred to as conventional validation, is not as rigorous a validation method as cross-validation, which refers to a class of methods that repeatedly generate all (or many) different possible splits of the dataset (into training and testing sets), performing validation of the machine learning prediction algorithm separately on each of these. The result of cross-validation is the average prediction accuracy across these different splits. Cross-validation estimates model accuracy better than conventional validation because it avoids the pitfall of information loss from a single train/test split that might not adequately capture the statistical properties of the data (this is typically not a concern if the training set is sufficiently large). Here we chose to use conventional validation for simplicity.
8 These helper functions are defined in the file chapter1/email_read_util.py in our code repository.
9 To run this code, you need to install the Punkt Tokenizer Models and the stopwords corpus in NLTK using the nltk.download() utility.
10 This example can be found in the Python Jupyter notebook chapter1/spam-fighting-blacklist.ipynb in our code repository.
11 See Chapter 3 in Mining of Massive Datasets, 2nd ed., by Jure Leskovec, Anand Rajaraman, and Jeffrey David Ullman (Cambridge University Press).
12 This example can be found in the Python Jupyter notebook chapter1/spam-fighting-lsh.ipynb in our code repository.
13 Note that we specified the MinHashLSH object’s threshold parameter as 0.5. This particular LSH implementation uses Jaccard similarities between the MinHashes in your collection and the query MinHash, returning the list of objects that satisfy the threshold condition (i.e., Jaccard similarity score > 0.5). The MinHash algorithm generates short and unique signatures for a string by passing random permutations of the string through a hash function. Configuring the num_perm parameter to 128 means that 128 random permutations of the string were computed and passed through the hash function. In general, the more random permutations used in the algorithm, the higher the accuracy of the hash.
14 This example can be found in the Python Jupyter notebook chapter1/spam-fighting-naivebayes.ipynb in our code repository.
15 It is a loose convention in machine learning code to choose lowercase variable names for single columns of values and uppercase variable names for multiple columns of values.
16 In general, using only accuracy to measure model prediction performance is crude and incomprehensive. Model evaluation is an important topic that we discuss further in Chapter 2. Here we opt for simplicity and use accuracy as an approximate measure of performance. The sklearn.metrics.classification_report() method provides the precision, recall, f1-score, and support for each class, which can be used in combination to get a more accurate picture of how the model performs.