
17
Hyperledger
Hyperledger is not a blockchain, but a project that was initiated by the Linux Foundation in December 2015 to advance blockchain technology. This project is a collaborative effort by its members to build an open source distributed ledger framework that can be used to develop and implement cross-industry blockchain applications and systems. The principal focus is to create and run platforms that support global business transactions. The project also focuses on improving the reliability and performance of blockchain systems.
This chapter will, for the most part, discuss Hyperledger projects, and their various features and components. As Hyperledger is so vast it's not possible to cover all projects in detail in this short chapter. As such, we will introduce a variety of the projects available, and then provide detailed discussions on two mainstream projects, Fabric and Sawtooth. Projects under the Hyperledger umbrella undergo multiple stages of development, going from proposal, to incubation, and eventually graduating to an active state. Projects can also be deprecated or put in an end-of-life state where they are no longer actively developed. For a project to be able to move into the incubation stage, it must have a fully working code base along with an active community of developers. The Hyperledger project currently has more than 300 member organizations and is very active with many contributors, and regular meet-ups and talks organized around the globe.
We will first cover some of the various projects under Hyperledger. Then we will move on to examine the design, architecture, and implementation of two mainstream projects, Fabric and Sawtooth, in more detail, covering the following topics on the way:
- Projects under Hyperledger
- Hyperledger reference architecture
- Hyperledger Fabric
- Hyperledger Sawtooth
- Setting up a Sawtooth development environment
Projects under Hyperledger fall into different categories, and we'll start with the introduction of these categories in the next section.
Projects under Hyperledger
There are four categories of projects under Hyperledger. Under each category, there are multiple projects. The categories are:
- Distributed ledgers
- Libraries
- Tools
- Domain-specific
Currently, there are six distributed ledger projects under the Hyperledger umbrella: Fabric, Sawtooth, Iroha, Indy, Besu, and Burrow. Under libraries, there are the Aries, Transact, Quilt, and Ursa projects. The tools category of Hyperledger includes projects such as Avalon, Cello, Caliper, and Explorer. There are also domain-specific projects such as Hyperledger Grid and Hyperledger Labs.
The following diagram visualizes the categorization of Hyperledger projects:

Figure 17.1: Projects under Hyperledger
A brief introduction to all of these projects follows.
Distributed ledgers
Distributed ledgers, as we covered in Chapter 1, Blockchain 101, are a broad category of distributed databases that are decentralized, shared among multiple participants, and updateable only via consensus.
Often, the terms blockchain and distributed ledger are used interchangeably. However, one key difference between distributed ledgers and blockchains is that blockchains are expected to have an architecture in which transactions are handled in batches of blocks, whereas distributed ledgers have no such requirements. All other attributes of distributed ledgers and blockchains are broadly the same. In Hyperledger, distributed ledger is a generic term used to denote both blockchains and distributed ledgers.
Fabric
Hyperledger Fabric is a blockchain project that was proposed by IBM and Digital Asset Holdings (DAH). It is an enterprise-grade permissioned distributed ledger framework, which provides a framework for the development of blockchain solutions and applications. Fabric is based on a modular and pluggable architecture. This means that various components, such as the consensus engine and membership services, can be plugged into the system as required. Currently, its status is active and it is the first project to graduate from incubation to active state.
The source code is available at https://github.com/hyperledger/fabric.
Sawtooth
Hyperledger Sawtooth is a blockchain project proposed by Intel in April 2016. It was donated to the Linux foundation in 2016. Sawtooth introduced some novel innovations focusing on the decoupling of ledgers from transactions, flexible usage across multiple business areas using transaction families, and pluggable consensus. It is an enterprise-grade blockchain with a focus on privacy, security, and scalability.
Ledger decoupling can be explained more precisely by saying that the transactions are decoupled from the consensus layer by making use of a new concept called transaction families. Instead of transactions being individually coupled with the ledger, transaction families are used, which allows more flexibility, rich semantics, and the open design of business logic. Transactions follow the patterns and structures defined in the transaction families.
One of the innovative features that Intel has introduced with Hyperledger Sawtooth is a novel consensus algorithm called Proof of Elapsed Time (PoET). It makes use of the Trusted Execution Environment (TEE) provided by Intel Software Guard Extensions (Intel SGX) to provide a safe and random leader election process. It supports both permissioned and permissionless setups.
This project is available at https://github.com/hyperledger/sawtooth-core.
Iroha
Iroha was contributed by Soramitsu, Hitachi, NTT Data, and Colu in September 2016. Iroha aims to build a library of reusable components that users can choose to run on their own Hyperledger-based distributed ledgers.
Iroha's primary goal is to complement other Hyperledger projects by providing reusable components written in C++ with an emphasis on mobile development. This project has also proposed a novel consensus algorithm called Sumeragi, which is a chain-based Byzantine fault-tolerant consensus algorithm.
Iroha is available at https://github.com/hyperledger/iroha.
Various libraries have been proposed and are being worked on by Iroha, including, but not limited to, a digital signature library (ed25519), a SHA-3 hashing library, a transaction serialization library, a P2P library, an API server library, an iOS library, an Android library, and a JavaScript library.
Indy
This project is under incubation under Hyperledger. Indy is a distributed ledger developed for building decentralized identities. It provides tools, utility libraries, and modules, which can be used to build blockchain-based digital identities. These identities can be used across multiple blockchains, domains, and applications. Indy has its own distributed ledger and uses Redundant Byzantine Fault Tolerance (RBFT) for consensus.
The source code is available at https://github.com/hyperledger/indy-node.
Besu
Besu is a Java-based Ethereum client. It is the first project under Hyperledger that can operate on a public Ethereum network.
The source code of Besu is available at https://github.com/hyperledger/besu.
Burrow
This project is currently in the incubation state. Hyperledger Burrow was contributed by Monax, who develop blockchain development and deployment platforms for business. Hyperledger Burrow introduces a modular blockchain platform and an Ethereum Virtual Machine (EVM)-based smart contract execution environment. Burrow uses Proof of Stake (PoS) and a Byzantine fault-tolerant (BFT) Tendermint consensus mechanism. As a result, Burrow provides high throughput and transaction finality.
The source code is available at https://github.com/hyperledger/burrow.
With this, we have completed an introduction to distributed ledger projects under Hyperledger. Let's now look at the next category, libraries.
Libraries
A number of libraries are currently available under the Hyperledger project. This category includes projects that aim to support the blockchain ecosystem by introducing platforms for interoperability, identity, cryptography, and developer tools. We will now briefly describe each one of these.
Aries
Aries is not a blockchain; in fact, it is an infrastructure for blockchain-rooted, peer-to-peer (P2P) interactions. The aim of this project is to provide code for P2P interactions, secrets management, verifiable information exchange (such as verifiable credentials), interoperability, and secure messaging for decentralized systems. The eventual goal of this project is to provide a dynamic set of capabilities to store and exchange data related to blockchain-based identity.
The code for Aries is available at https://github.com/hyperledger/aries.
Transact
Transact provides a shared library that handles smart contract execution. This library makes the development of distributed ledger software easier by allowing the handling of scheduling, transaction dispatch, and state management via a shared software library. It provides an approach to implement new smart contract development languages named smart contract engines. Smart contract engines implement virtual machines or interpreters for smart contract code. Two main examples of such engines are Seth (for EVM smart contracts) and Sabre (for web assembly Wasm-based smart contracts).
Transact is available at https://crates.io/crates/transact.
Quilt
This utility implements the Interledger protocol, which facilitates interoperability across different distributed and non-distributed ledger networks.
Quilt is available at https://github.com/hyperledger/quilt.
Ursa
Ursa is a shared cryptography library that can be used by any project, Hyperledger or otherwise, to provide cryptography functionality. Ursa provides a C-callable library interface and a Rust crate (library). There are two sub-libraries available in Ursa: LibUrsa and LibZmix. LibUrsa is designed for cryptographic primitives such as digital signatures, standard encryptions schemes, and key exchange schemes. LibZmix provides a generic method to produce zero-knowledge proofs. It supports signature Proofs of Knowledge (PoK), bullet proofs, range proofs, and set memberships.
Ursa is available at https://github.com/hyperledger/ursa.
We've now covered four library projects currently available under Hyperledger. In the next section, we'll explore different tools that can be used in Hyperledger projects.
Tools
There are a number of projects under the tools category in Hyperledger. Tools under Hyperledger focus on providing utilities and software tools that help to enhance the user experience. For example, visualization tools such as blockchain explorers, deployment tools, and benchmarking tools fall into this category. We'll describe some of these briefly.
Avalon
Avalon provides a trusted computer framework that enables privacy and allows off-chain processing of compute-intensive operations in a trusted and secure manner. It provides a guarantee that a computation was performed correctly and privately.
It also allows the improvement of scalability and performance and supports hardware-attested oracles. It is based on the Trusted Compute Specifications published by the Enterprise Ethereum Alliance and is implemented as a separate project.
Avalon is available at https://github.com/hyperledger/avalon.
Cello
The aim behind Cello is to allow the easy deployment of blockchains. This will provide an ability to allow as a service deployments of a blockchain service. Currently, this project is in the incubation stage.
The source code for Cello is available at https://github.com/hyperledger/cello.
Caliper
Caliper is a benchmarking framework for blockchains. It can be used to measure the performance of any blockchain. There are different performance indicators supported in the framework. These include success rate, transaction read rate, throughput, latency, and hardware resource consumption, such as CPU, memory, and I/O. Ethereum, Fabric, Sawtooth, Burrow, and Iroha are currently the supported blockchains in Caliper.
Caliper is available at https://github.com/hyperledger/caliper.
Explorer
This project aims to build a blockchain explorer for Hyperledger Fabric that can be used to view and query the transactions, blocks, and associated data from the blockchain. It also provides network information and the ability to interact with chain code.
The source code for Explorer is available at https://github.com/hyperledger/blockchain-explorer.
With this, we complete the introduction to the Hyperledger project's category of tools. Next, we'll introduce domain-specific projects.
Domain-specific
Under Hyperledger, there are also some domain-specific projects that are created to address specific requirements. Currently, there are two projects under this category, which we will introduce now.
Grid
Grid is a Hyperledger project that provides a standard reference implementation of supply chain-related data types, data models, and relevant business logic encompassing smart contracts. It is currently in the incubation stage.
The code for Grid is available at https://github.com/hyperledger/grid.
Labs
Hyperledger labs provide a quick and easy way to start a project under Hyperledger without going through the official formal process of incubation and activation. This allows the development of research projects, hackathons, and demo projects.
Further details on this project are available at https://github.com/hyperledger-labs.
Each of the aforementioned projects is in various stages of development. This list is expected to grow as more and more members join the Hyperledger project and contribute to the development of blockchain technology. Now, in the next section, we will examine the reference architecture of Hyperledger, which provides general principles and design philosophies that can be followed to build new Hyperledger projects.
Hyperledger aims to build new blockchain platforms that are driven by industry use cases. As there have been many contributions made to the Hyperledger project by the community, the Hyperledger blockchain platform is evolving into a protocol for business transactions. Hyperledger is also evolving into a specification that can be used as a reference to build blockchain platforms as compared to earlier blockchain solutions that address only a specific type of industry or requirement.
In the following section, a reference architecture model is presented that has been published by the Hyperledger project. This architecture can be used by a blockchain developer to build a blockchain that is in line with the specifications of the Hyperledger architecture.
Hyperledger reference architecture
Hyperledger has published a white paper that presents a reference architecture model that can serve as a guideline to build permissioned distributed ledgers. The reference architecture consists of various components that form a business blockchain.
Hyperledger's white paper is available here: https://docs.google.com/document/d/1Z4M_qwILLRehPbVRUsJ3OF8Iir-gqS-ZYe7W-LE9gnE/edit#heading=h.m6iml6hqrnm2
These high-level components are shown in the reference architecture diagram here, which has been drawn from the aforementioned white paper:

Figure 17.2: Reference architecture
In the preceding diagram, starting from the left, we see that we have five top-level components that provide various services. The first is identity, which provides authorization, identification, and authentication services under membership services. Then, we have the policy component, which provides policy services.
After this, we see blockchain and transactions, which consist of the Consensus Manager, Distributed Ledger, the network P2P Protocol, and Ledger Storage services. The consensus manager ensures that the ledger is updateable only through consensus among the participants of the blockchain network.
Finally, we have the smart contracts layer, which provides chaincode services in Hyperledger and makes use of Secure Container technology to host smart contracts. Chaincode can be considered as the Hyperledger equivalent of smart contracts.
Chaincode is a program that implements a specific interface. It is usually written in Java, Node.js, or Go. Even though the terms smart contract and chaincode are used interchangeably in Hyperledger Fabric, there is a subtle difference between chaincode and smart contract. A smart contract can be defined as a piece of code that defines the transaction logic, which controls the transaction life cycle and can result in updating the world state. Chaincode is a relevant but slightly different concept—chaincode is a deployable object that contains smart contracts packaged within it. A single chaincode can contain multiple smart contracts and after deployment, all smart contracts contained within the chaincode are available for use. Generally, however, the terms are used interchangeably.
We will see all these in more detail in the Hyperledger Fabric section shortly.
From a components perspective, Hyperledger contains various elements, as described here:
- Consensus: These services are responsible for facilitating the agreement process between the participants on the blockchain network. Consensus is required to make sure that the order and state of transactions are validated and agreed upon in the blockchain network.
- Smart contracts: These services are responsible for implementing business logic as per the requirements of the users. Transactions are processed based on the logic defined in the smart contracts that reside on the blockchain.
- Communication: This component is responsible for message transmission and exchange between the nodes on the blockchain network.
- Security and crypto: These services are responsible for providing the capability to allow various cryptographic algorithms or modules to provide privacy, confidentiality, and non-repudiation services.
- Data store: This component provides an ability to use different data stores for storing the state of the ledger. This means that data stores are also pluggable, allowing the usage of any database backend, such as
couchdborgoleveldb. - Policy services: This set of services provides the ability to manage the different policies required for the blockchain network. This includes endorsement policy and consensus policy.
- APIs and SDKs: This component allows clients and applications to interact with the blockchain. An SDK is used to provide mechanisms to deploy and execute chaincode, query blocks, and monitor events on the blockchain.
There are certain requirements of a blockchain service. In the next section, as an example, we are going to discuss the design goals of Hyperledger Fabric.
Hyperledger design principles
There are certain requirements of a blockchain service. The reference architecture is driven by the needs and requirements raised by the participants of the Hyperledger project after studying the industry use cases. There are several categories of requirements that have been deduced from the study of industrial use cases and are seen as principles of design philosophy. We'll describe these principles in the following sections.
Modular structure
The main requirement of Hyperledger is a modular structure. It is expected that a cross-industry blockchain will be used in many business scenarios, and as such, functions related to storage, policy, chaincode, access control, consensus, and many other blockchain services should be modular and pluggable. The specification provided in the Hyperledger reference architecture suggests that the modules should be "plug and play" and users should be able to easily remove and add a different module that meets the requirements of the business.
Privacy and confidentiality
This is one of the most critical factors. As traditional blockchains are permissionless, in a permissioned model it is of the utmost importance that transactions on the network are visible to only those who are allowed to view it. The privacy and confidentiality of transactions and contracts are of absolute importance in a business blockchain. As such, Hyperledger's vision is to provide support for a full range of cryptographic protocols and algorithms. We discussed cryptography in Chapter 3, Symmetric Cryptography and Chapter 4, Public Key Cryptography.
It is expected that users will be able to choose appropriate modules according to their business requirements. For example, if a business blockchain needs to be run only between already-trusted parties and performs very basic business operations, then perhaps there is no need to have advanced cryptographic support for confidentiality and privacy. Therefore, users should be able to remove that functionality (module) or replace it with a more appropriate module that suits their needs.
Similarly, if users need to run a cross-industry blockchain, then confidentiality and privacy can be of paramount importance. In this case, users should be able to plug an advanced cryptographic and access control mechanism (module) into the blockchain, which can even allow the usage of hardware of security modules (HSMs).
The blockchain should also be able to handle sophisticated cryptographic algorithms without compromising performance. In addition to the previously mentioned scenarios, due to regulatory requirements in business, there should also be a provision to allow the implementation of privacy and confidentiality policies in conformance with regulatory and compliance requirements.
Identity
In order to provide privacy and confidentiality services, a flexible Public Key Infrastructure (PKI) model that can be used to handle the access control functionality is also required. The strength and type of cryptographic mechanisms are also expected to vary according to the needs and requirements of the users. In certain scenarios, it might be required for a user to hide their identity, and as such, Hyperledger is expected to provide this functionality.
Scalability
This is another major requirement that, once met, will allow reasonable transaction throughput, which will be sufficient for all business requirements and also a large number of users.
Deterministic transactions
This is a core requirement in any blockchain. If transactions do not produce the same result every time they are executed, then regardless of who and where the transaction is executed, achieving consensus is impossible. Therefore, deterministic transactions become a key requirement in any blockchain network. We discussed these concepts in Chapter 10, Smart Contracts.
Auditability
Auditability is another requirement of business hyperledgers. It is expected that an immutable audit trail of all identities, related operations, and any changes is kept.
Interoperability
Currently, there are many blockchain platforms available, but they cannot communicate with each other easily. This can be a limiting factor in the growth of a blockchain-based global business ecosystem. It is envisaged that many blockchain networks will operate in the business world for specific needs, but it is important that they are able to communicate with each other. There should be a common set of standards that all blockchains can follow in order to allow communication between different ledgers. There are different efforts already underway to achieve this, not only under the Hyperledger umbrella, such as Hyperledger Quilt, but also other projects such as Cosmos and Polkadot.
Portability
The portability requirement is concerned with the ability to run across multiple platforms and environments without the need to change anything at the code level. Hyperledger Fabric, for example, is envisaged to be portable, not only at the infrastructure level, but also at the code, library, and API levels, so that it can support uniform development across various implementations of Hyperledger.
Rich data queries
The blockchain network should allow rich queries to be run on the network. This can be used to query the current state of the ledger using traditional query languages, which will allow wider adoption and ease of use.
All of the aforementioned points describe the general guiding principles that allow the development of blockchain solutions that are in line with the Hyperledger design philosophy.
In the next section, we will look at Hyperledger Fabric in detail, which is the first project to graduate to the active status under Hyperledger.
Hyperledger Fabric
Hyperledger Fabric, or Fabric for short, is the contribution made initially by IBM and Digital Assets to the Hyperledger project. This contribution aims to enable a modular, open, and flexible approach toward building blockchain networks.
Various functions in the fabric are pluggable, and it also allows the use of any language to develop smart contracts. This functionality is possible because it is based on container technology (Docker), which can host any language.
Chaincode is sandboxed in a secure container, which includes a secure operating system, the chaincode language, runtime environment, and SDKs for Go, Java, and Node.js. Other languages can be supported too in the future, if required, but this needs some development work. This ability is a compelling feature compared to domain-specific languages in Ethereum, or the limited scripted language in Bitcoin. It is a permissioned network that aims to address issues such as scalability, privacy, and confidentiality. The fundamental idea behind this is modularization, which would allow flexibility in the design and implementation of the business blockchain. This can then result in achieving scalability, privacy, and other desired attributes and fine-tuning them according to requirements.
Transactions in Fabric are private, confidential, and anonymous for general users, but they can still be traced back and linked to the users by authorized auditors. As a permissioned network, all participants are required to be registered with the membership services to access the blockchain network. This ledger also provided auditability functionality to meet the regulatory and compliance needs required by the user.
Membership services
These services are used to provide access control capability for the users of the Fabric network. Membership services perform the following functions:
- User identity verification
- User registration
- Assign appropriate permissions to the users depending on their roles
Membership services make use of a certificate authority (CA) in order to support identity management and authorization operations. This CA can be internal (such as Fabric CA, which is a default interface in Hyperledger Fabric), or an organization can opt to use an external certificate authority. Fabric CA issues enrolment certificates (E-Certs), which are produced by an enrolment certificate authority (E-CA). Once peers are issued with an identity, they are allowed to join the blockchain network. There are also temporary certificates issued called T-Certs, which are used for one-time transactions.
All peers and applications are identified using a certificate authority. An authentication service is provided by the certificate authority. Membership Service Providers (MSPs) can also interface with existing identity services like LDAP.
This section covered the membership services implemented in Hyperledger Fabric. Next, we'll introduce some of Fabric's blockchain services.
Blockchain services
Blockchain services are at the core of Hyperledger Fabric. Components within this category are as follows.
Consensus services
A consensus service is responsible for providing the interface to the consensus mechanism. This serves as a module that is pluggable and receives the transaction from other Hyperledger entities and executes them under criteria according to the type of mechanism chosen.
Consensus in Hyperledger Fabric is implemented as a peer called orderer, which is responsible for ordering the transactions in sequence into a block. An orderer does not hold smart contracts or ledgers. Consensus is pluggable and currently, there are two basic types of ordering services available in Hyperledger Fabric:
- SOLO: This is a basic ordering service intended to be used for development and testing purposes.
- Kafka: This is an implementation of Apache Kafka, which provides an ordering service. It should be noted that currently, Kafka only provides crash fault-tolerance but does not provide Byzantine fault-tolerance. This is acceptable in a permissioned network where the chances of malicious actors are almost none.
In addition, there are also ordering services available in Hyperledger Fabric that are based on more familiar consensus mechanisms such as Raft and PBFT
- Raft: Raft is a crash fault-tolerant and leader-follower-based protocol for achieving distributed consensus.
- PBFT: PBFT is a state machine replication-based BFT protocol that can be used in Hyperledger Fabric to achieve consensus.
We discussed consensus mechanisms in appropriate detail in Chapter 5, Consensus Algorithms. Readers can refer to this chapter to review the Raft and PBFT mechanisms.
In addition to these mechanisms, other mechanisms may become available in the future that can be plugged into Hyperledger Fabric.
Distributed ledger
Blockchain and world state are two main elements of the distributed ledger. Blockchain is simply a cryptographically linked list of blocks (as introduced in Chapter 1, Blockchain 101) and world state is a key-value database. This database is used by smart contracts to store relevant states during execution by the transactions. A blockchain consists of blocks that contain transactions. These transactions contain chaincode, which runs transactions that can result in updating the world state. Each node saves the world state on disk in LevelDB or CouchDB depending on the implementation. As Fabric allows pluggable data stores, you can choose any data store for storage.
A block consists of three main components called block header, block data (transactions), and block metadata.
The following diagram shows a blockchain depiction with the block and transaction structure in Hyperledger Fabric with the relevant fields:

Figure 17.3: Blockchain and transaction structure
Block header consists of three fields, namely Number, Data hash, and Previous hash.
Block data contains an ordered list of transactions. A Transaction is made up of multiple fields such as Transaction ID, Previous transaction ID, Channel ID, Signatures, Read-Write sets, Metadata, and many more.
Block metadata mainly consists of the creator identity, time of creation, and relevant signatures.
The peer-to-peer protocol
The P2P protocol in Hyperledger Fabric is built using Google RPC (gRPC). It uses protocol buffers to define the structure of the messages.
Messages are passed between nodes in order to perform various functions. There are four main types of messages in Hyperledger Fabric: discovery, transaction, synchronization, and consensus. Discovery messages are exchanged between nodes when starting up in order to discover other peers on the network. Transaction messages are used to deploy, invoke, and query transactions, and consensus messages are exchanged during consensus. Synchronization messages are passed between nodes to synchronize and keep the blockchain updated on all nodes.
Ledger storage
In order to save the state of the ledger, by default, LevelDB is used, which is available at each peer. An alternative is to use CouchDB, which provides the ability to run rich queries.
Now that we've established some of the core blockchain services used in Hyperledger Fabric, let's look at some of the chaincode, or smart contract, services available, along with an overview of the APIs and CLIs available in Fabric.
Smart contract services
These services allow the creation of secure containers that are used to execute the chaincode. Components in this category are as follows:
- Secure container: Chaincode is deployed in Docker containers that provide a locked-down sandboxed environment for smart contract execution. Currently, Golang is supported as the main smart contract language, but any other mainstream languages can be added and enabled if required.
- Secure registry: This provides a record of all images containing smart contracts.
- Events: Events on the blockchain can be triggered by endorsers and smart contracts. External applications can listen to these events and react to them if required via event adapters. They are similar to the concept of events introduced in Solidity in Chapter 15, Introducing Web3.
APIs and CLIs
An application programming interface provides an interface into Fabric by exposing various REST APIs. Additionally, command-line interfaces that provide a subset of REST APIs and allow quick testing and limited interaction with the blockchain are also available.
In the preceding sections, we have covered the main elements of Hyperledger Fabric's reference architecture. Next, let's consider a variety of Hyperledger Fabric's components from a network perspective.
Components
There are various components that can be part of the Hyperledger Fabric blockchain. These components include, but are not limited to, the peers, clients, channels, world state database, transactions, membership service providers, smart contracts, and crypto service provider components.
Peers
Peers participate in maintaining the state of the distributed ledger. They also hold a local copy of the distributed ledger. Peers communicate via gossip protocol. There are three types of peers in the Hyperledger Fabric network:
- Endorsing peers or endorsers, which simulate the transaction execution and generate a read-write set. Read is a simulation of a transaction's reading of data from the ledger and write is the set of updates that would be made to the ledger if and when the transaction is executed and committed to the ledger. Endorsers execute and endorse transactions. It should be noted that an endorser is also a committer too. Endorsement policies are implemented with chaincode and specify the rules for transaction endorsement.
- Committing peers or committers, which receive transactions endorsed by endorsers, verify them, and then update the ledger with the read-write set. A committer verifies the read-write set generated by the endorsers along with transaction validation.
- Orderer nodes receive transactions from endorsers along with read-write sets, arrange them in a sequence, and send them to committing peers. Committing peers then perform validation and committing to the ledger.
All peers make use of certificates issued by membership services.
Clients
Clients are software that make use of APIs to interact with Hyperledger Fabric and propose transactions.
Channels
Channels allow the flow of confidential transactions between different parties on the network. They allow the use of the same blockchain network but with separate overlay blockchains. Channels allow only members of the channel to view the transactions related to them; all other members of the network will not be able to view the transactions.
World state database
World state reflects all the committed transactions on the blockchain. This is essentially a key-value store that is updated as a result of transactions and chaincode execution. For this purpose, either LevelDB or CouchDB is used. LevelDB is a key-value store whereas CouchDB stores data as JSON objects, which allows rich queries to run against the database.
Transactions
Transaction messages can be divided into two types: deployment transactions and invocation transactions. The former is used to deploy new chaincode to the ledger, and the latter is used to call functions from the smart contract. Transactions can be either public or confidential. Public transactions are open and available to all participants, while confidential transactions are visible only in a channel open to its participants.
Membership Service Provider
The MSP is a modular component that is used to manage identities on the blockchain network. This provider is used to authenticate clients who want to join the blockchain network. A certificate authority is used in the MSP to provide identity verification and binding services.
Smart contracts
We discussed smart contracts in detail in Chapter 10, Smart Contracts. In Hyperledger Fabric, the same concept of smart contracts is implemented but they are called chaincode instead of smart contracts. They contain conditions and parameters to execute transactions and update the ledger. Chaincode is usually written in Golang or Java.
Crypto service provider
As the name suggests, this is a service that provides cryptographic algorithms and standards for use in the blockchain network. This service provides key management, signature and verification operations, and encryption-decryption mechanisms. This service is used with the membership service to provide support for cryptographic operations for elements of blockchain such as endorsers, clients, and other nodes and peers.
After this introduction to some of the components of Hyperledger Fabric, we will next see what an application looks like when on a Hyperledger network.
Applications on blockchain
A typical application on Fabric is simply composed of a user interface, usually written in JavaScript/HTML, that interacts with the backend chaincode (smart contract) stored on the ledger via an API layer:

Figure 17.4: A typical Fabric application
Hyperledger provides various APIs and command-line interfaces to enable interaction with the ledger. These APIs include interfaces for identity, transactions, chaincode, ledger, network, storage, and events.
In the next section, we'll see how chaincode is implemented.
Chaincode implementation
Chaincode is usually written in Golang or Java. Chaincode can be public (visible to all on the network), confidential, or access-controlled. These code files serve as a smart contract that users can interact with via APIs. Users can call functions in the chaincode that result in a state change, and consequently update the ledger.
There are also functions that are only used to query the ledger and do not result in any state change. Chaincode implementation is performed by first creating the chaincode shim interface in the code. Shims provide APIs for accessing state variables and the transaction context of chaincode. It can either be in Java or Golang code.
The following four functions are required in order to implement the chaincode:
Init(): This function is invoked when the chaincode is deployed onto the ledger. This initializes the chaincode and results in making a state change, which updates the ledger accordingly.Invoke(): This function is used when contracts are executed. It takes a function name as parameters along with an array of arguments. This function results in a state change and writes to the ledger.Query(): This function is used to query the current state of a deployed chaincode. This function does not make any changes to the ledger.Main(): This function is executed when a peer deploys its own copy of the chaincode. The chaincode is registered with the peer using this function.
The following diagram illustrates the general overview of Hyperledger Fabric. Note that peer clusters at the top include all types of nodes: Endorsers, Committers, and Orderers:

Figure 17.5: A high-level overview of a Hyperledger Fabric network
The preceding diagram shows that peers (shown center-top) communicate with each other and each node has a copy of blockchain. In the top-right corner, the membership services are shown, which validate and authenticate peers on the network by using a CA. At the bottom of the diagram, a magnified view of blockchain is shown whereby existing systems can produce events for the blockchain and can also listen for the blockchain events, which can then optionally trigger an action. At the bottom right-hand side, a user's interaction with the application is shown. The application in turn interacts with the smart contract via the Invoke()method, and smart contracts can query or update the state of the blockchain.
In this section, we saw how chaincode is implemented and examined the high-level architecture of Hyperledger Fabric. In the next section, we will discuss the application model.
The application model
Any blockchain application for Hyperledger Fabric follows the MVC-B architecture. This is based on the popular MVC design pattern. Components in this model are View, Control, Model (data model), and Blockchain:
- View logic: This is concerned with the user interface. It can be a desktop, web application, or mobile frontend.
- Control logic: This is the orchestrator between the user interface, data model, and APIs.
- Data model: This model is used to manage the off-chain data.
- Blockchain logic: This is used to manage the blockchain via the controller and the data model via transactions.
The IBM cloud service offers sample applications for blockchain under its blockchain as a service offering. It is available at https://www.ibm.com/blockchain/platform/. This service allows users to create their own blockchain networks in an easy-to-use environment.
After this brief introduction to the application model, let's move onto another important topic, consensus, which is important not only in Hyperledger Fabric, but is also central to blockchain design and architecture.
Consensus in Hyperledger Fabric
The consensus mechanism in Hyperledger Fabric consists of three steps:
- Transaction endorsement: This process endorses the transactions by simulating the transaction execution process.
- Ordering: This is a service provided by the cluster of orderers, which takes endorsed transactions and decides on a sequence in which the transactions will be written to the ledger.
- Validation and commitment: This process is executed by committing peers, which first validate the transactions received from the orderers and then commit that transaction to the ledger.
These steps are shown in the following diagram:

Figure 17.6: The consensus flow
The ordering step is also pluggable. There are a number of ordering services available for the Fabric consensus mechanism. Initially, in some versions of Fabric 1.0, only simple ordering services such as Apache Kafka were available. However, now, other advanced consensus algorithms such as the BFT-SMaRt, Honey Badger, and Simplified BFT implementations are also available.
In the next section, we'll describe how a transaction flows through various stages in Hyperledger Fabric before finally updating the ledger.
The transaction lifecycle in Hyperledger Fabric
There are several steps that are involved in a transaction flow in Hyperledger Fabric. These steps are visualized in the following diagram:

Figure 17.7: The high-level transaction lifecycle
The steps are described in detail as follows:
- Transaction proposal by clients. This is the first step where a transaction is proposed by the clients and sent to endorsing peers on the distributed ledger network. All clients need to be enrolled via membership services before they can propose transactions.
- The transaction is simulated by endorsers, which generates a read-write (RW) set. This is achieved by executing the chaincode, but instead of updating the ledger, only an RW set depicting any reads or updates to the ledger is created.
- The endorsed transaction is sent back to the application.
- The endorsed transactions and RW sets are submitted to the ordering service by the application.
- The ordering service assembles all endorsed transactions and RW sets in order into a block and sorts them by channel ID.
- The ordering service broadcasts the assembled block to all committing peers.
- Committing peers validate the transactions.
- Committing peers update the ledger.
- Finally, notification of success or failure of the transaction by committing peers is sent back to the clients/applications.
The following diagram represents the aforementioned steps and the Fabric architecture from a transaction flow perspective:

Figure 17.8: The transaction flow
As you can see in the preceding diagram, the first step is to propose transactions, which a client does via an SDK. Before this, it is assumed that all clients and peers are registered with the membership service provider.
So far, we have covered the core architecture of Hyperledger Fabric 1.0. This architecture works well but requires some improvements. In order to address these limitations, a new version of Hyperledger Fabric, Fabric 2.0, has been developed. In the next section, we will introduce the core features of Fabric 2.0.
Fabric 2.0
This is a major upgrade to the protocol. The fundamentals remain the same, but some very interesting new features and improvements have been made, which are introduced in the following sections.
Hyperledger Fabric 2.0 was released on January 30, 2010. The latest release is available at https://github.com/hyperledger/fabric/releases/tag/v2.0.1.
New chaincode lifecycle management
In Hyperledger Fabric 2.0, a new decentralized chaincode lifecycle management is implemented, which is the main notable difference between Fabric 1.0 and Fabric 2.0. In the former, an organization administrator can install the chaincode in its own organization and other organizations administrators have to unconditionally agree to instantiate (deploy or upgrade) the chaincode. In other words, there is no agreement process between organizations to agree on the installation of a chaincode. This problem is resolved by introducing checks, which enables peers to only participate in a chaincode if their organizational administrators have agreed to it.
Now let's look at the chaincode lifecycle in Fabric 1.0:
- Each organization administrator installs chaincode on their peers.
- An administrator instantiates the chaincode by deploying or upgrading.
- After results are received, the transaction is submitted to the orderers.
- After ordering, it is submitted to all peers and committed.
Now, we'll look at Fabric 2.0's lifecycle, which highlights the differences between it and Fabric 1.0:
- Install chaincode by putting the package on the filesystem. Each organization administrator installs chaincode on their peers.
- Provide approval by executing the
approveformyorgfunction. This verifies that the organization agrees with the chaincode definition. - Send the ordering service to the orderer.
- Commits to the organization collection. The collection is a private data collection that provides a mechanism to allow private data sharing only between those organizations that are party to the transaction, even if they are within the same channel. In other words, collections allow private data sharing between a subset of organizations on a channel. Even though other organizations are members of the same channel, they cannot see the data shared between a subset of organizations that are sharing data using collection, also called private data collection.
- Other organizations' administrators perform the same steps 1 to 4.
- After these steps are executed, there is a record in each organization indicating the agreement on the chaincode definition.
- Define the chaincode as per the agreement in step 6.
- Submit to ordering.
- Commit to the definition of all peers.
- The organization administrator who committed the chaincode definition now invokes the
initfunction on its own peers and other organizations' peers. - Submit to ordering.
- Commit all the peers.
Note that Fabric 2.0 supports both legacy and new lifecycle patterns, but eventually the legacy lifecycle will become deprecated.
In addition to the chaincode lifecycle management changes in Fabric 2.0, there are also new chaincode application patterns. We will introduce these next.
New chaincode application patterns
There are also new chaincode application patterns introduced in Fabric 2.0 for collaboration and consensus. These are automated checks that can be added by an organization to enable additional validation before a transaction is endorsed. In addition, decentralized agreement is also supported where multiple organizations can propose conditions for an agreement, and when those conditions are met, a collective agreement can be made on a transaction.
Enhanced data privacy
Fabric 2.0 enhances data privacy by introducing collection-level endorsement policies, per-organization collections, and the flexible sharing and verification of private data.
External chaincode launcher
In Hyperledger Fabric 2.0, by default, Docker APIs are used to build and run chaincode. In addition, external builders and launchers can be used if required. In previous versions, there was a requirement to have access to the Docker daemon to build and run chaincode, but in Fabric 2.0 there is no such dependency. There is also no requirement to run chaincode in Docker containers anymore: chaincode can be run in any environment deemed appropriate by the network operator.
Raft consensus
Raft is a Crash Fault-tolerant (CFT) ordering service for achieving consensus. It is based on the etcd library and is based on a leader-follower model. In this model, a leader is elected whose decision is then replicated by its followers.
Better performance
In Fabric 2.0, caching has been introduced at the CouchDB state database level to improve performance by reducing the read latency introduced due to expensive lookup operations in previous versions.
With this section, our introduction to Hyperledger Fabric is complete. Hyperledger Fabric is the flagship project of Hyperledger and is used in a wide variety of applications. A list of cross-industry projects built with Hyperledger Fabric and other Hyperledger projects is being maintained here: https://www.hyperledger.org/learn/blockchain-showcase. Readers can explore this further to understand how Hyperledger Fabric is used in different use cases.
Hyperledger Fabric is continually evolving and more features and changes are expected in future releases. However, no major design changes are expected since the introduction of version 2.0.
In the next section, we'll explore another popular Hyperledger project named Sawtooth.
Hyperledger Sawtooth
Sawtooth is an enterprise-grade distributed ledger that can run in both permissioned and non-permissioned modes. Sawtooth has several new features, which are introduced in the following sections.
Core features
These features include modular design, parallel transaction execution, global state agreement, dynamic consensus, and some other advanced features. We will now explore these features one by one.
Modular design
The modular design of Sawtooth enables separation between the application and the core system. This means that developers can focus on the business objectives instead of worrying about the underlying design of the system. The design of Sawtooth can be viewed as a layered architecture where transaction processors manage the application business logic and, on another layer, validators handle the verification and consensus on transactions. A separate layer called the transaction processing layer is responsible for managing transaction rules, permissions, and consensus-related settings. In summary, Sawtooth separates the core functionality of blockchain from the business logic.
Parallel transaction execution
Usually, blockchains process transactions sequentially. This serial processing is seen as a bottleneck and impacts performance, which makes some blockchains unsuitable for high-throughput use cases. Sawtooth has come up with a remarkable feature in which an advanced parallel scheduler splits the transactions into parallel flows, which results in increased performance due to the parallel execution of transactions.
Global state agreement
Sawtooth ensures that each node has an identical copy of the blockchain database and this database is also cryptographically verifiable. This means that Sawtooth is a cryptographically verifiable distributed ledger with global state agreement.
Dynamic and pluggable consensus algorithms
Sawtooth supports different types of consensus mechanism via a modular mechanism implemented as a separate process. A very interesting feature of Sawtooth is that consensus mechanisms can be changed while a blockchain is running. This means that a different consensus mechanism can be chosen for the same blockchain regardless of what was initially chosen at the network setup. This is a powerful feature that is made possible due to the isolation between the consensus mechanism and transaction semantics.
Multi-language support
Blockchain applications in Sawtooth can be written using various different languages. Sawtooth also includes SDKs for different languages, such as JavaScript, Python, and Go. This feature makes it a flexible choice for many developers.
Enhanced event mechanism
Sawtooth supports the creation and broadcasting of events where applications can subscribe to blockchain-related events or application-specific events. Also, it can relay information about the execution of a transaction to clients without the requirement to store that data in a state.
On-chain governance
Sawtooth allows the on-chain storage, management, and application of configuration settings and permissions, which makes it easier for all clients to refer to a single source of configuration.
Interoperability
Sawtooth supports integration with other blockchain technologies. For example, it introduced a project named seth, which allows EVM-based smart contracts to be deployed on Sawtooth.
Sawtooth has proposed some other novel features, such as the introduction of a new consensus algorithm called PoET, and the idea of transaction families. We'll discuss these concepts in more detail in the upcoming sections.
Consensus in Sawtooth
Sawtooth supports several types of algorithms. A novel mechanism introduced with Sawtooth is called PoET. PoET is a trusted, executed environment-based lottery function that elects a leader randomly based on the time a node has waited for a block proposal.
PoET
PoET is a novel consensus algorithm that allows a node to be selected randomly based on the time that the node has waited before proposing a block. This concept is in contrast to other leader election- and lottery-based proof of work algorithms, such as the PoW used in Bitcoin, where an enormous amount of electricity and computer resources are used in order to be elected as a block proposer. PoET is a type of PoW algorithm but, instead of spending computer resources, it uses a trusted computing model to provide a mechanism to fulfill the PoW requirements. PoET makes use of Intel's SGX architecture (Software Guard Extensions) to provide a TEE to ensure the randomness and cryptographic security of the process.
It should be noted that the current implementation of Hyperledger Sawtooth does not require real hardware SGX-based TEE, as it is simulated for experimental purposes only and, as such, should not be used in production environments. The fundamental idea in PoET is to provide a mechanism of leader election by waiting randomly to be elected as a leader for proposing new transactions.
PoET, however, has a limitation, which has been highlighted by Ittay Eyal. This limitation is called the stale chip problem.
The research paper is available at https://eprint.iacr.org/2017/179.pdf.
This limitation results in hardware wastage, which can result in the waste of resources. The stale chip problem revolves around the idea that it is financially beneficial for malicious actors to collect lots of old SGX chips, which will increase their chances of becoming the miner of the next block. Note that they can collect lots of old SGX chips to build mining rigs, serving only one purpose of mining, instead of buying modern CPUs with SGX, which will not only serve in PoET consensus but will also be useful for other general computation.
Instead, they can choose to just collect as many old SGX-enabled chips as they can and increase their chances of winning the mining lottery. Also, old SGX-enabled CPUs are cheap and can result in the increased use of old, inefficient CPUs. It is similar to Bitcoin miners racing to get as many fast ASICs as possible to increase their chances of becoming the miner. It results in hardware wastage. There is also the possibility of hacking the chip's hardware. If an SGX chip is compromised, the malicious node can win the mining round every time, which results in complete system compromise and undeserved incentivizing of miners. This problem is also called the broken chip problem.
As demonstrated next, there are two types of PoET consensus, one with Intel SGX and another without SGX, along with a development mode mechanism.
PoET CFT
PoET CFT makes use of a simulated SGX environment. It is not dependent on hardware and can run on any processor. It is only CFT and not BFT.
PoET SGX
This is an SGX-dependent consensus mechanism. It provides BFT tolerance and consumes very little CPU processing power.
Devmode
As the name suggests, this is a development mode consensus mechanism that is suitable for testing transaction processors with single validator deployments. This is not intended for production usage. It makes use of a simple, random leader election algorithm for development and testing.
Other consensus mechanisms include PBFT and Raft.
PBFT
PBFT is a leader-based Byzantine fault-tolerant consensus mechanism. This is a commonly used protocol for consortium networks and many newer BFT protocols are based on this protocol. We discussed PBFT in detail in Chapter 5, Consensus Algorithms.
Raft
Raft is a comparatively faster algorithm than PoET. It is a CFT algorithm that works in a leader-follower fashion where a leader is elected for a period (term) of arbitrary time. It has immediate finality due to a lack of forks.
There is another consensus type called quorum voting, which is an adaptation of consensus protocols built by Ripple and Stellar. This consensus algorithm allows instant transaction finality, which is usually desirable in permissioned networks.
In this section, we have looked at the core feature of Sawtooth and explored various consensus mechanisms that Sawtooth supports. In the next section, we'll look at how transactions are generated and processed in Sawtooth.
Just like any other blockchain, in Sawtooth, transactions follow a protocol and a lifecycle. We will explore that in the next section.
Transaction lifecycle
Before describing the transaction flow, let's define what a transaction is. It is a function that, when executed, results in changing the state of the blockchain. Transactions are always made part of a batch, even if there is only one transaction in a batch. Validators receive these batches for processing.
Now that we understand what a transaction is, let's explore how a transaction flows in a Sawtooth network:
- A client submits a transaction to a validator. This is usually achieved by utilizing the REST API available with the validator. By default, port
TCP8008is exposed where REST API is available. - After the transaction is submitted, it is propagated across the validator network.
- One of the validators is elected as a leader, which then creates a candidate block and publishes it on the network.
- This candidate block is propagated across the entire validator network.
- When validators receive this block, it is validated. In addition, transaction processors validate and execute all transactions present in the candidate block.
- Once the block is validated and verified, it is written in its respective local storage and the state is updated accordingly.
This process can be visualized using the following diagram (note that the smaller node displays on the right are identical to the main node display on the center-left):

Figure 17.9: Sawtooth transaction lifecycle
Having understood the transaction flow in Sawtooth, let's explore in more detail what components Sawtooth is made up of and how are they interconnected.
Components
A Sawtooth node is composed of several components. A Sawtooth network is composed of several Sawtooth nodes. A generic Sawtooth node architecture and a network are shown in the following diagram note that the smaller node displays on the right are identical to the main node display on the center-left:

Figure 17.10: Sawtooth node and network
At a fundamental level, a Sawtooth node contains a validator, REST API, consensus engine, and transaction processors.
We will introduce each one of these components and their purpose in the following sections.
Validator
The validator is the component that is responsible for validating batches of transactions. It combines transactions into blocks and maintains consensus on the Sawtooth blockchain network. In addition, validators also perform coordination functions between clients, transaction processors, and other validators on the network. Validators communicate using the gossip protocol.
REST API
REST API is responsible for providing a communication interface between clients and validators. REST APIs are available by default over TCP 8008.
Client
The client is responsible for implementing the client logic. It is responsible for the following functions:
- Transaction creation and payload generation
- The handling of events in the blockchain and application, such as error handling, notifications, and blockchain state updates
- Displaying data to the users
State
The state in a blockchain is represented as a log of all changes made to the blockchain database since the start of the blockchain network or genesis block. All nodes in the Sawtooth network, just like any other blockchain, keep a local copy of the state database. The state is updated as a result of transaction execution and when new blocks are produced, each validator updates its local state database accordingly. The global state, on the other hand, represents the agreement on the state of the blockchain between all nodes on the network.
Transaction processors
Transaction processors are responsible for validating transactions and updating the state. State update and transaction validation is performed based on the rules defined in the associated transaction family. There is always a transaction family associated with a transaction processor. For example, there is a smallbank transaction family for the smallbank_tp transaction processor.
In summary, transaction processors are responsible for:
- Transaction validation
- Block creation
- Business logic or transaction rules
Transaction processors implement the business logic for a transaction family (or Sawtooth application). A transaction processor is responsible for transaction validation and state transition and updates governed by the rules defined in the Sawtooth application.
We will now explore the concept of a transaction family in detail.
Transaction families
A traditional smart contract paradigm provides a solution that is based on a general-purpose instruction set for all domains. For example, in the case of Ethereum, a set of opcodes has been developed for the EVM that can be used to build smart contracts to address any type of requirements for any industry.
While this model has its merits, it is becoming clear that this approach is not very secure as it provides a single interface into the ledger with a powerful and expressive language, which potentially offers a larger attack surface for malicious code. This complexity and generic virtual machine paradigm have resulted in several vulnerabilities that were found and exploited recently by hackers. A recent example is the DAO hack and further Denial of Services (DoS) attacks that exploited limitations in some EVM opcodes. The DAO hack was discussed in Chapter 10, Smart Contracts.
A model shown in the following figure describes the traditional smart contract model, where a Generic virtual machine has been used to provide the interface into the Blockchain for all domains:
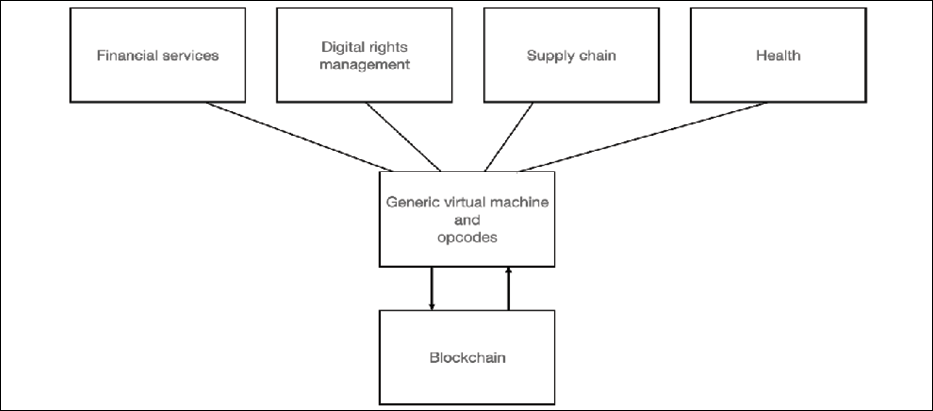
Figure 17.11: The traditional smart contract paradigm
In order to address this issue, Sawtooth has proposed the idea of transaction families. A transaction family is created by decomposing the logic layer into a set of rules and a composition layer for a specific domain. The key idea is that business logic is composed within transaction families, which provides a more secure and powerful way to build smart contracts. Transaction families contain the domain-specific rules and another layer that allows the creation of transactions for that domain. Another way of looking at it is that transaction families are a combination of a data model and a transaction language that implements a logic layer for a specific domain. The data model represents the current state of the blockchain (ledger), whereas the transaction language modifies the state of the ledger. It is expected that users will build their own transaction families according to their business requirements.
Note that a transaction family is also known as a Sawtooth application.
The following diagram represents this model, where each specific domain, such as Financial services, Digital rights management (DRM), Supply chain, and the Health industry, has its own logic layer comprised of operations and services specific to that domain. This makes the logic layer both restrictive and powerful at the same time. Transaction families ensure that operations related to only the required domain are present in the control logic, thus removing the possibility of executing needless, arbitrary, and potentially harmful operations:
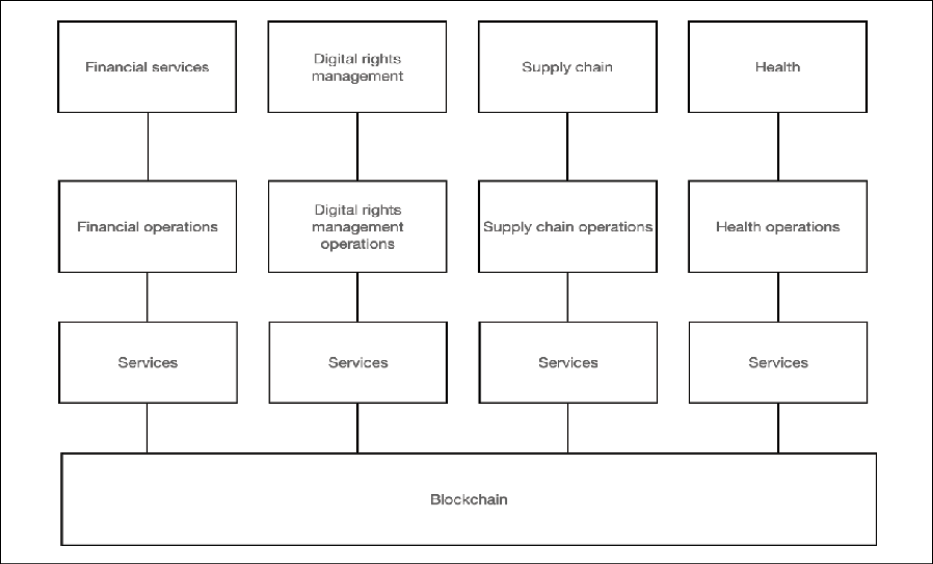
Figure 17.12: The Sawtooth (transaction families) smart contract paradigm
Sawtooth has provided several transaction families as examples. Each transaction family is identified by a name and has an associated transaction processor. The following table will explore these in detail.
|
Transaction family name |
Function |
Language |
TF name |
Transaction processor |
|
BlockInfo |
Provides a mechanism to store information about a configurable number of historic blocks. |
Python |
|
|
|
Identity |
Mechanism for role- and policy-based permissioning. |
Python |
|
|
|
Validator Registry |
Provides a mechanism to add new validators to the network. Used in PoET to keep track of other validators. |
Python |
|
|
|
Settings |
Used for storing on-chain configuration settings. |
Python |
|
|
|
Smallbank |
Provides a workload for comparing performance across different blockchain systems. |
Go |
|
|
|
XO |
An example that allows two users to play a simple game of tic-tac-toe. |
Go, JavaScript/Node.js, and Python |
|
|
A transaction family encompasses application-specific business logic. This business logic defines various transaction types or operations that are permitted on the blockchain. Transaction families keep the transaction rules separate from the Sawtooth core blockchain functionality.
From an implementation point of view, transaction families implement data models and transaction languages for an application. A transaction family includes the following elements:
- A transaction processor, which defines the business logic for the application. A transaction processor performs the following functions:
- Registration with the validator
- Handling of transaction payloads
- State update and retrieval as required
- A data model, which performs the following functions:
- Records data
- Stores data
- Defines valid operations
- Specifies data for the application (payload)
The data model must be the same between a client and a transaction processor. For example, encoding/serialization schemes and so on must be same.
- A client, which is responsible for the following functions:
- Handling the client logic for the application
- Creating and signing for the transactions
- Creating batches of the transactions
- Submitting transaction batches to the validator
Note that clients can use the REST API to submit transaction batches to the validator, or can choose to connect directly to the validator using ZeroMQ. However, usually the REST API is used in practice.
Transaction family is a new concept introduced with Hyperledger Sawtooth. It is a set of operations or types of transactions or a category of transactions that represents specific requirements of a use case. A data model and transaction language for specific applications are both implemented in a transaction family. Next, we will introduce REST APIs, which provide an API interface between a client and a transaction processor.
REST API
This is an optional component that runs as a service on a validator node, which facilitates communication between a client and a transaction processor. A REST API can also run as a separate system. Now that we've covered theoretical aspects and understand the Sawtooth architecture, let's introduce a practical example, which will help to better understand the theory covered so far.
Setting up a Sawtooth development environment
In this section, an introduction is given on how to set up a development environment for Sawtooth. There are a few prerequisites that are required in order to set up the development environment.
The easiest way to get Sawtooth up and running is by using Docker. In the following example, we will set up a 5-node network using Docker.
Prerequisites
For this process, you'll need to first install Docker. In this example we are using:
$ docker -v
Docker version 19.03.8, build afacb8b
Sawtooth supports different consensus algorithms. In this example we will use PoET. However, other options are available too, such as PBFT. The YAML configuration files for both of these options are available at the links in the following sections.
Using PoET
The following link is available to download the YAML file for setting up Sawtooth with the PoET consensus algorithm: https://sawtooth.hyperledger.org/docs/core/nightly/1-2/app_developers_guide/sawtooth-default-poet.yaml
Using PBFT
Here, you can access the YAML file for setting up Sawtooth with PBFT consensus: https://sawtooth.hyperledger.org/docs/core/nightly/1-2/app_developers_guide/sawtooth-default-pbft.yaml
Setting up a Sawtooth network
In this section, we will see how a Sawtooth network can be created. First we start with creating a directory and then we will download specific configuration files, which will help with the configuration of the network.
- Create a directory named
sawtooth:$ mkdir sawtooth - Change the directory to
sawtooth:$ cd sawtooth - Download the PoET YAML file:
$ wget https://sawtooth.hyperledger.org/docs/core/nightly/1-2/app_developers_guide/sawtooth-default-poet.yamlThis command will show an output like the following, indicating that the
sawtooth-default-poet.yamlfile has been downloaded successfully. Note that only the final part of the output is shown for brevity:... 2020-06-29 21:04:22 (51.9 KB/s) - 'sawtooth-default-poet.yaml' saved [16543/16543] - Start the network:
$ docker-compose -f sawtooth-default-poet.yaml upThis will show a long output and will take several minutes to complete. The output will be similar to the following, which shows the progress of the process:
Creating network "sawtooth_default" with the default driver Creating volume "sawtooth_poet-shared" with default driver Pulling intkey-tp-0 (hyperledger/sawtooth-intkey-tp-python:chime)... chime: Pulling from hyperledger/sawtooth-intkey-tp-python - Once the network is started up successfully, we can verify that all the components are up by simply checking it in the Docker dashboard, as shown in the following screenshot:

Figure 17.13: Docker dashboard showing the Sawtooth application
The Docker dashboard shown in Figure 17.13 is available under the main menu in Docker Desktop. This step is optional, and only used to verify that all the required containers are running. As an alternative, an equivalent command line can also be used, for example,
docker ps. - Confirm that the REST API is running by issuing the following command to connect to the REST API container on a node:
$ docker exec -it sawtooth-rest-api-default-0 bashThis will open a prompt like the following:
root@ea64259cf407:/# - Issue the command as shown here:
root@ea64259cf407:/# ps -eaf | grep 8008This will show an output similar to the following, showing that a process is running for the REST API:
root 1 0 0 15:13 ? 00:00:01 /usr/bin/python3 /usr/bin/sawtooth-rest-api --connect tcp://validator-0:4004 --bind rest-api-0:8008Network functionality can be verified by using the following commands:
- Connect to the shell container:
$ docker exec -it sawtooth-shell-default bashThis will open a prompt like the one shown here:
root@3893ec9be013:/# - Check whether the peers are up:
# curl http://sawtooth-rest-api-default-0:8008/peersThis will produce the following output, which displays the list of peers on the network:
{ "data": [ "tcp://validator-1:8800", "tcp://validator-3:8800", "tcp://validator-2:8800", "tcp://validator-4:8800" ], "link": http://sawtooth-rest-api-default-0:8008/peers - Another way to find peers is to use the
sawtoothcommand:# sawtooth peer list --url http://sawtooth-rest-api-default-0:8008This command shows an output similar to the following. It shows the list of peers indicating the protocol used, the name of the validator, and the port:
tcp://validator-1:8800,tcp://validator-2:8800,tcp://validator-3:8800,tcp://validator-4:8800 - The peer list can also be retried using this command:
# sawnet peers list http://sawtooth-rest-api-default-0:8008This command will show the output shown here, which shows that there are other validators available and running:
{ "tcp://validator-0:8800": [ "tcp://validator-1:8800", "tcp://validator-2:8800", "tcp://validator-3:8800", "tcp://validator-4:8800" ] } - Similarly, the block list can also be retrieved:
# sawnet list-blocks http://sawtooth-rest-api-default-0:8008This command will produce the following output, listing the height, ID, and previous hash of the blocks for
node0:-- NODE 0 -- HEIGHT ID PREVIOUS 2 208f39df d22318b9 1 d22318b9 a1116c4f 0 a1116c4f 00000000 - We can also view the Sawtooth settings, as shown in the following command:
$ sawtooth settings list --url http://sawtooth-rest-api-default-0:8008This command shows all the settings of the blockchain:
sawtooth.consensus.algorithm.name: PoET sawtooth.consensus.algorithm.version: 0.1 sawtooth.poet.initial_wait_time: 25 sawtooth.poet.report_public_key_pem: -----BEGIN PUBLIC KEY----- MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEArMvzZi8GT+lI9KeZiInn 4CvFTiuyid+IN4dP1+m... sawtooth.poet.target_wait_time: 5 sawtooth.poet.valid_enclave_basenames: b785c58b77152cbe7fd55ee3851c499000000000000000000000000000000000 sawtooth.poet.valid_enclave_measurements: c99f21955e38dbb03d2ca838d3af6e43ef438926ed02db4cc729380c8c7a174e sawtooth.publisher.max_batches_per_block: 100 sawtooth.settings.vote.authorized_keys: 027ea24d40aa8d01ade0d9c6909e6bb52e5a4f04f9c7f3ea3c67436eadddafa4b9 - The block list can also be retrieved using the command shown here:
# sawtooth block list --url http://sawtooth-rest-api-default-0:8008The output of this command displays the number, block IDs, batches, transactions and the signer:
NUM BLOCK_ID BATS TXNS SIGNER 2 208f39dfb18f264e416cd70ec262c9854ecef9aff6dd0ff473eae7e8eccfa74 a0685c411a5c4d0e410d2e3d40deed54f3fe355e5498c7a0b051ab6277b62faac 1 1 032bccb685d25dc2b0a892d283b72bee15d997e76949d66a... 1 d22318b9f9741386e273f32c0ed76ad3360e4c619cb5a16d74b52ec9e729 b93b561b539c02af46729ee00eda1c89dec8fe65aaa1cfb55beecc5d1acf8960416a 4 4 027ea24d40aa8d01ade0d9c6909e6bb52e5a4f04f9c7f3ea... 0 a1116c4f18b44da5f9ea1c1517fee2029be900b054898c72a2cd99c907493 fed436d7446cbc132715b0649fba247c1ae70423470edc36dee0aef508a9602800b 4 10 027ea24d40aa8d01ade0d9c6909e6bb52e5a4f04f9c7f3ea... - Specific blocks can be queried using the command:
$ sawtooth block show a1116c4f18b44da5f9ea1c1517fee2029be900b054898c72a2cd99c907493 fed436d7446cbc132715b0649fba247c1ae70423470edc36dee0aef508a9602 800b --url http://sawtooth-rest-api-default-0:8008This will show an output similar to the one shown here. The output is truncated for brevity:
batches: - header: signer_public_key: 02071c9bdcd1d42440fdc3655f63561907a396fd0f39d569968114a04dcf801375 transaction_ids: - bba77767e4ceaa405c2d6f33534d4aea840874ed8d577e1f51e1a9bb603451 3250f56c4d67cf860cfd4540028d61374274b26d09bc6583cd120447611134584f header_signature: 5d9a20eff9cca693cb9e146c6285ddf3fd6a8e769e9628c79e5592464924265c550f d33d2581e5aa244a90fa6c7f15e06d1c16fbc2cf2f1b5ae13899d6c3902d trace: false transactions: - header:This output shows the block structure with several fields including the header, transactions, state root hash, and many more.
In this section, we have seen how to set up a Sawtooth network and perform queries to find various pieces of information about the network, such as a list of peers and information about blocks and the blockchain.
An excellent online page where official Sawtooth examples are provided is available at https://sawtooth.hyperledger.org/examples/. Readers are encouraged to visit this page and explore these sample projects.
There are also sample projects available for Sawtooth. One example is Sawtooth_bond, which has been developed as a proof of concept to demonstrate a bond trading platform.
It is available at https://sawtooth.hyperledger.org/examples/bond.html.
With this, a basic introduction to Sawtooth is complete. Sawtooth and Hyperledger in general are very large subjects and cannot be explained entirely in a single chapter. However, this chapter will serve as a solid foundation for further study.
Summary
In this chapter, we have gone through an introduction to the Hyperledger project. Firstly, the core ideas behind the Hyperledger project were discussed, and a brief introduction to all projects under Hyperledger was provided. Two main Hyperledger projects were discussed in detail, namely, Hyperledger Fabric and Sawtooth. All these projects are continuously improving and changes are expected in the next releases. However, the core concepts of all the projects mentioned previously are expected to remain unchanged or change only slightly. Readers are encouraged to visit the relevant links provided in the chapter to see the latest updates.
It is evident that a lot is going on in this space and projects like Hyperledger from the Linux Foundation are playing a pivotal role in the advancement of blockchain technology. Each of the projects discussed in this chapter has novel approaches toward solving the issues faced in various industries, and any current limitations within the blockchain technology are also being addressed, such as scalability and privacy. It is expected that more projects will soon be proposed to the Hyperledger project, and it is envisaged that with this collaborative and open effort, blockchain technology will advance tremendously and collectively benefit the community as a whole.
In the next chapter, we will discuss tokenization which is one of the most prominent applications of blockchain technology and is disrupting many industries, especially the financial industry.