
Chapter 2: Core Operations with spaCy
In this chapter, you will learn the core operations with spaCy, such as creating a language pipeline, tokenizing the text, and breaking the text into its sentences.
First, you'll learn what a language processing pipeline is and the pipeline components. We'll continue with general spaCy conventions – important classes and class organization – to help you to better understand spaCy library organization and develop a solid understanding of the library itself.
You will then learn about the first pipeline component – Tokenizer. You'll also learn about an important linguistic concept – lemmatization – along with its applications in natural language understanding (NLU). Following that, we will cover container classes and spaCy data structures in detail. We will finish the chapter with useful spaCy features that you'll use in everyday NLP development.
We're going to cover the following main topics in this chapter:
- Overview of spaCy conventions
- Introducing tokenization
- Understanding lemmatization
- spaCy container objects
- More spaCy features
Technical requirements
The chapter code can be found at the book's GitHub repository: https://github.com/PacktPublishing/Mastering-spaCy/tree/main/Chapter02
Overview of spaCy conventions
Every NLP application consists of several steps of processing the text. As you can see in the first chapter, we have always created instances called nlp and doc. But what did we do exactly?
When we call nlp on our text, spaCy applies some processing steps. The first step is tokenization to produce a Doc object. The Doc object is then processed further with a tagger, a parser, and an entity recognizer. This way of processing the text is called a language processing pipeline. Each pipeline component returns the processed Doc and then passes it to the next component:

Figure 2.1 – A high-level view of the processing pipeline
A spaCy pipeline object is created when we load a language model. We load an English model and initialize a pipeline in the following code segment:
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("I went there")
What happened exactly in the preceding code is as follows:
- We started by importing spaCy.
- In the second line, spacy.load() returned a Language class instance, nlp. The Language class is the text processing pipeline.
- After that, we applied nlp on the sample sentence I went there and got a Doc class instance, doc.
The Language class applies all of the preceding pipeline steps to your input sentence behind the scenes. After applying nlp to the sentence, the Doc object contains tokens that are tagged, lemmatized, and marked as entities if the token is an entity (we will go into detail about what are those and how it's done later). Each pipeline component has a well-defined task:

Figure 2.2 – Pipeline components and tasks
The spaCy language processing pipeline always depends on the statistical model and its capabilities. This is why we always load a language model with spacy.load() as the first step in our code.
Each component corresponds to a spaCy class. spaCy classes have self-explanatory names such as Language, Doc, and Vocab. We already used Language and Doc classes – let's see all of the processing pipeline classes and their duties:

Figure 2.3 – spaCy processing pipeline classes
Don't be intimated by the number of classes; each class has unique features to help you process your text better.
There are more data structures to represent text data and language data. Container classes such as Doc hold information about sentences, words, and the text. There are also container classes other than Doc:
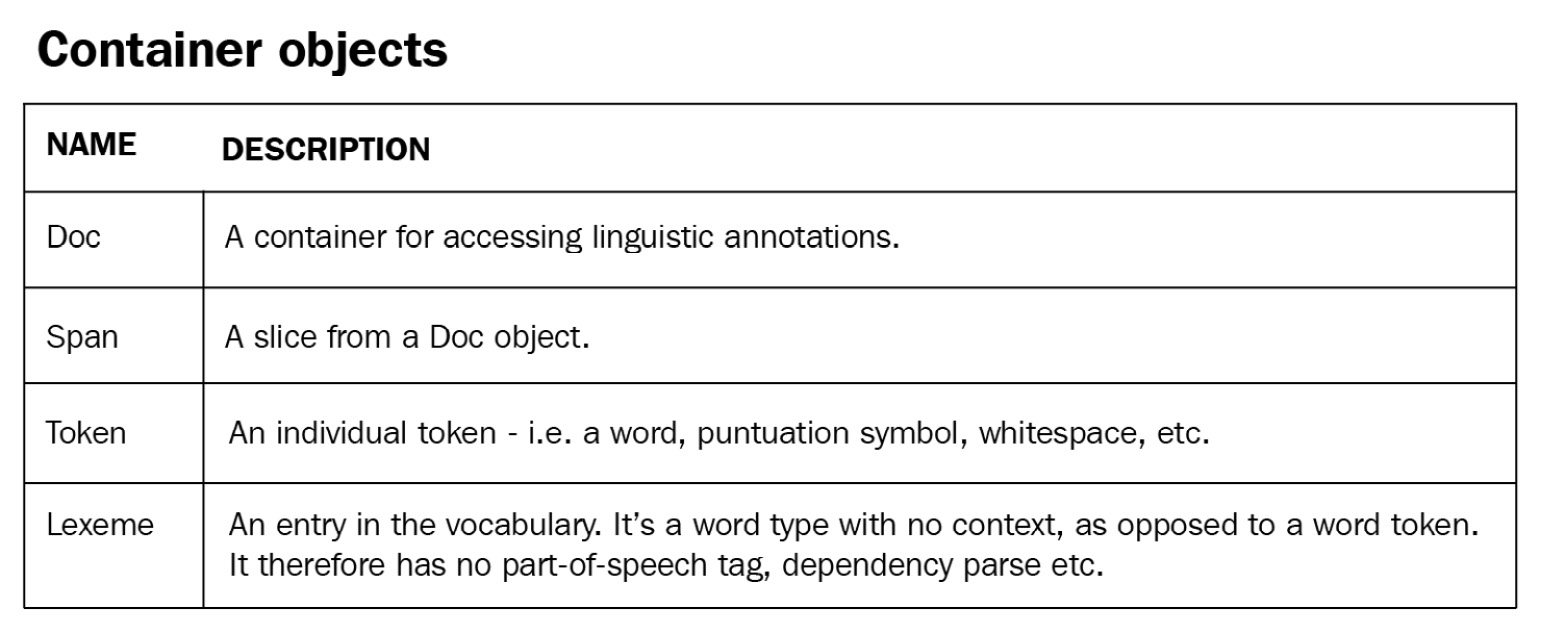
Figure 2.4 – spaCy container classes
Finally, spaCy provides helper classes for vectors, language vocabulary, and annotations. We'll see the Vocab class often in this book. Vocab represents a language's vocabulary. Vocab contains all the words of the language model we loaded:

Figure 2.5 – spaCy helper classes
The spaCy library's backbone data structures are Doc and Vocab. The Doc object abstracts the text by owning the sequence of tokens and all their properties. The Vocab object provides a centralized set of strings and lexical attributes to all the other classes. This way spaCy avoids storing multiple copies of linguistic data:
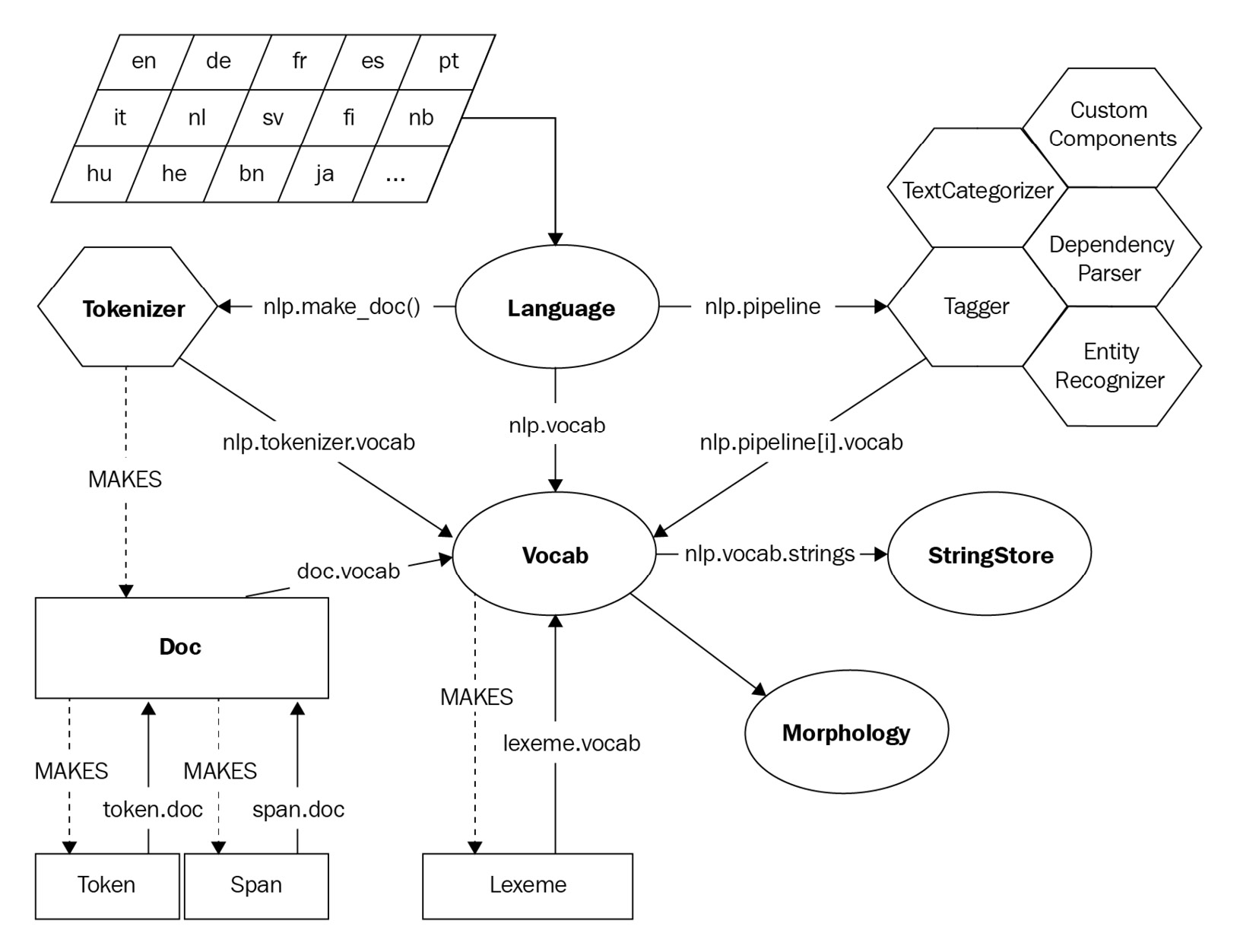
Figure 2.6 – spaCy architecture
You can divide the objects composing the preceding spaCy architecture into two: containers and processing pipeline components. In this chapter, we'll first learn about two basic components, Tokenizer and Lemmatizer, then we'll explore Container objects further.
spaCy does all these operations for us behind the scenes, allowing us to concentrate on our own application's development. With this level of abstraction, using spaCy for NLP application development is no coincidence. Let's start with the Tokenizer class and see what it offers for us; then we will explore all the container classes one by one throughout the chapter.
Introducing tokenization
We saw in Figure 2.1 that the first step in a text processing pipeline is tokenization. Tokenization is always the first operation because all the other operations require the tokens.
Tokenization simply means splitting the sentence into its tokens. A token is a unit of semantics. You can think of a token as the smallest meaningful part of a piece of text. Tokens can be words, numbers, punctuation, currency symbols, and any other meaningful symbols that are the building blocks of a sentence. The following are examples of tokens:
- USA
- N.Y.
- city
- 33
- 3rd
- !
- …
- ?
- 's
Input to the spaCy tokenizer is a Unicode text and the result is a Doc object. The following code shows the tokenization process:
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("I own a ginger cat.")
print ([token.text for token in doc])
['I', 'own', 'a', 'ginger', 'cat', '.']
The following is what we just did:
- We start by importing spaCy.
- Then we loaded the English language model via the en shortcut to create an instance of the nlp Language class.
- Next, we apply the nlp object to the input sentence to create a Doc object, doc. A Doc object is a container for a sequence of Token objects. spaCy generates the Token objects implicitly when we created the Doc object.
- Finally, we print a list of the preceding sentence's tokens.
That's it, we made the tokenization with just three lines of code. You can visualize the tokenization with indexing as follows:

Figure 2.7 – Tokenization of "I own a ginger cat."
As the examples suggest, tokenization can indeed be tricky. There are many aspects we should pay attention to: punctuation, whitespaces, numbers, and so on. Splitting from the whitespaces with text.split(" ") might be tempting and looks like it is working for the example sentence I own a ginger cat.
How about the sentence "It's been a crazy week!!!"? If we make a split(" ") the resulting tokens would be It's, been, a, crazy, week!!!, which is not what you want. First of all, It's is not one token, it's two tokens: it and 's. week!!! is not a valid token as the punctuation is not split correctly. Moreover, !!! should be tokenized per symbol and should generate three !'s. (This may not look like an important detail, but trust me, it is important for sentiment analysis. We'll cover sentiment analysis in Chapter 8, Text Classification with spaCy.) Let's see what spaCy tokenizer has generated:
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("It's been a crazy week!!!")
print ([token.text for token in doc])
['It', "'s", 'been', 'a', 'crazy', 'week', '!', '!', '!']
This time the sentence is split as follows:

Figure 2.8 – Tokenization of apostrophe and punctuations marks
How does spaCy know where to split the sentence? Unlike other parts of the pipeline, the tokenizer doesn't need a statistical model. Tokenization is based on language-specific rules. You can see examples the language specified data here: https://github.com/explosion/spaCy/tree/master/spacy/lang.
Tokenizer exceptions define rules for exceptions, such as it's , don't , won't, abbreviations, and so on. If you look at the rules for English: https://github.com/explosion/spaCy/blob/master/spacy/lang/en/tokenizer_exceptions.py, you will see that rules look like {ORTH: "n't", LEMMA: "not"}, which describes the splitting rule for n't to the tokenizer.
The prefixes, suffixes, and infixes mostly describe how to deal with punctuation – for example, we split at a period if it is at the end of the sentence, otherwise, most probably it's part of an abbreviation such as N.Y. and we shouldn't touch it. Here, ORTH means the text and LEMMA means the base word form without any inflections. The following example shows you the execution of the spaCy tokenization algorithm:

Figure 2.9 – spaCy performing tokenization with exception rules (image taken from spaCy tokenization guidelines (https://spacy.io/usage/linguistic-features#tokenization))
Tokenization rules depend on the grammatical rules of the individual language. Punctuation rules such as splitting periods, commas, or exclamation marks are more or less similar for many languages; however, some rules are specific to the individual language, such as abbreviation words and apostrophe usage. spaCy supports each language having its own specific rules by allowing hand-coded data and rules, as each language has its own subclass.
Tip
spaCy provides non-destructive tokenization, which means that we always will be able to recover the original text from the tokens. Whitespace and punctuation information is preserved during tokenization, so the input text is preserved as it is.
Every Language object contains a Tokenizer object. The Tokenizer class is the class that performs the tokenization. You don't often call this class directly when you create a Doc class instance, while Tokenizer class acts behind the scenes. When we want to customize the tokenization, we need to interact with this class. Let's see how it is done.
Customizing the tokenizer
When we work with a specific domain such as medicine, insurance, or finance, we often come across words, abbreviations, and entities that needs special attention. Most domains that you'll process have characteristic words and phrases that need custom tokenization rules. Here's how to add a special case rule to an existing Tokenizer class instance:
import spacy
from spacy.symbols import ORTH
nlp = spacy.load("en_core_web_md")
doc = nlp("lemme that")
print([w.text for w in doc])
['lemme', 'that']
special_case = [{ORTH: "lem"}, {ORTH: "me"}]
nlp.tokenizer.add_special_case("lemme", special_case)
print([w.text for w in nlp("lemme that")])
['lem', 'me', 'that']
Here is what we did:
- We again started by importing spacy.
- Then, we imported the ORTH symbol, which means orthography; that is, text.
- We continued with creating a Language class object, nlp, and created a Doc object, doc.
- We defined a special case, where the word lemme should tokenize as two tokens, lem and me.
- We added the rule to the nlp object's tokenizer.
- The last line exhibits how the fresh rule works.
When we define custom rules, punctuation splitting rules will still apply. Our special case will be recognized as a result, even if it's surrounded by punctuation. The tokenizer will divide punctuation step by step, and apply the same process to the remaining substring:
print([w.text for w in nlp("lemme!")])
['lem', 'me', '!']
If you define a special case rule with punctuation, the special case rule will take precedence over the punctuation splitting:
nlp.tokenizer.add_special_case("...lemme...?", [{"ORTH": "...lemme...?"}])
print([w.text for w in nlp("...lemme...?")])
'...lemme...?'
Pro tip
Modify the tokenizer by adding new rules only if you really need to. Trust me, you can get quite unexpected results with custom rules. One of the cases where you really need it is when working with Twitter text, which is usually full of hashtags and special symbols. If you have social media text, first feed some sentences into the spaCy NLP pipeline and see how the tokenization works out.
Debugging the tokenizer
The spaCy library has a tool for debugging: nlp.tokenizer.explain(sentence). It returns (tokenizer rule/pattern, token) tuples to help us understand what happened exactly during the tokenization. Let's see an example:
import spacy
nlp = spacy.load("en_core_web_md")
text = "Let's go!"
doc = nlp(text)
tok_exp = nlp.tokenizer.explain(text)
for t in tok_exp:
print(t[1], " ", t[0])
Let SPECIAL-1
's SPECIAL-2
go TOKEN
! SUFFIX
In the preceding code, we imported spacy and created a Language class instance, nlp, as usual. Then we created a Doc class instance with the sentence Let's go!. After that, we asked the Tokenizer class instance, tokenizer, of nlp for an explanation of the tokenization of this sentence. nlp.tokenizer.explain() explained the rules that the tokenizer used one by one.
After splitting a sentence into its tokens, it's time to split a text into its sentences.
Sentence segmentation
We saw that breaking a sentence into its tokens is not a straightforward task at all. How about breaking a text into sentences? It's indeed a bit more complicated to mark where a sentence starts and ends due to the same reasons of punctuation, abbreviations, and so on.
A Doc object's sentences are available via the doc.sents property:
import spacy
nlp = spacy.load("en_core_web_md")
text = "I flied to N.Y yesterday. It was around 5 pm."
doc = nlp(text)
for sent in doc.sents:
print(sent.text)
I flied to N.Y yesterday.
It was around 5 pm.
Determining sentence boundaries is a more complicated task than tokenization. As a result, spaCy uses the dependency parser to perform sentence segmentation. This is a unique feature of spaCy – no other library puts such a sophisticated idea into practice. The results are very accurate in general, unless you process text of a very specific genre, such as from the conversation domain, or social media text.
Now we know how to segment a text into sentences and tokenize the sentences. We're ready to process the tokens one by one. Let's start with lemmatization, a commonly used operation in semantics including sentiment analysis.
Understanding lemmatization
A lemma is the base form of a token. You can think of a lemma as the form in which the token appears in a dictionary. For instance, the lemma of eating is eat; the lemma of eats is eat; ate similarly maps to eat. Lemmatization is the process of reducing the word forms to their lemmas. The following code is a quick example of how to do lemmatization with spaCy:
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("I went there for working and worked for 3 years.")
for token in doc:
print(token.text, token.lemma_)
I -PRON-
went go
there
for for
working work
and and
worked work
for for
3 3
years year
. .
By now, you should be familiar with what the first three lines of the code do. Recall that we import the spacy library, load an English model using spacy.load, create a pipeline, and apply the pipeline to the preceding sentence to get a Doc object. Here we iterated over tokens to get their text and lemmas.
In the first line you see –PRON-, which doesn't look like a real token. This is a pronoun lemma, a special token for lemmas of personal pronouns. This is an exception for semantic purposes: the personal pronouns you, I, me, him, his, and so on look different, but in terms of meaning, they're in the same group. spaCy offers this trick for the pronoun lemmas.
No worries if all of this sounds too abstract – let's see lemmatization in action with a real-world example.
Lemmatization in NLU
Lemmatization is an important step in NLU. We'll go over an example in this subsection. Suppose that you design an NLP pipeline for a ticket booking system. Your application processes a customer's sentence, extracts necessary information from it, and then passes it to the booking API.
The NLP pipeline wants to extract the form of the travel (a flight, bus, or train), the destination city, and the date. The first thing the application needs to verify is the means of travel:
fly – flight – airway – airplane - plane
bus
railway – train
We have this list of keywords and we want to recognize the means of travel by searching the tokens in the keywords list. The most compact way of doing this search is by looking up the token's lemma. Consider the following customer sentences:
List me all flights to Atlanta.
I need a flight to NY.
I flew to Atlanta yesterday evening and forgot my baggage.
Here, we don't need to include all word forms of the verb fly (fly, flying, flies, flew, and flown) in the keywords list and similar for the word flight; we reduced all possible variants to the base forms – fly and flight. Don't think of English only; languages such as Spanish, German, and Finnish have many word forms from a single lemma as well.
Lemmatization also comes in handy when we want to recognize the destination city. There are many nicknames available for global cities and the booking API can process only the official names. The default tokenizer and lemmatizer won't know the difference between the official name and the nickname. In this case, you can add special rules, as we saw in the Introducing tokenization section. The following code plays a small trick:
import spacy
from spacy.symbols import ORTH, LEMMA
nlp = spacy.load('en')
special_case = [{ORTH: 'Angeltown', LEMMA: 'Los Angeles'}]
nlp.tokenizer.add_special_case(u'Angeltown', special_case)
doc = nlp(u'I am flying to Angeltown')
for token in doc:
print(token.text, token.lemma_)
I -PRON-
am be
flying fly
to to
Angeltown Los Angeles
We defined a special case for the word Angeltown by replacing its lemma with the official name Los Angeles. Then we added this special case to the Tokenizer instance. When we print the token lemmas, we see that Angeltown maps to Los Angeles as we wished.
Understanding the difference between lemmatization and stemming
A lemma is the base form of a word and is always a member of the language's vocabulary. The stem does not have to be a valid word at all. For instance, the lemma of improvement is improvement, but the stem is improv. You can think of the stem as the smallest part of the word that carries the meaning. Compare the following examples:
Word Lemma
university university
universe universe
universal universal
universities university
universes universe
improvement improvement
improvements improvements
improves improve
The preceding word-lemma examples show how lemma is calculated by following the grammatical rules of the language. Here, the lemma of a plural form is the singular form, and the lemma of a third-person verb is the base form of the verb. Let's compare them to the following examples of word-stem pairs:
Word Stem
university univers
universe univer
universal univers
universities universi
universes univers
improvement improv
improvements improv
improves improv
The first and the most important point to notice in the preceding examples is that the lemma does not have to be a valid word in the language. The second point is that many words can map to the same stem. Also, words from different grammatical categories can map to the same stem; here for instance, the noun improvement and the verb improves both map to improv.
Though stems are not valid words, they still carry meaning. That's why stemming is commonly used in NLU applications.
Stemming algorithms don't know anything about the grammar of the language. This class of algorithms works rather by trimming some common suffixes and prefixes from the beginning or end of the word.
Stemming algorithms are rough, they cut the word from head and tail. There are several stemming algorithms available for English, including Porter and Lancaster. You can play with different stemming algorithms on NLTK's demo page at https://text-processing.com/demo/stem/.
Lemmatization, on the other hand, takes the morphological analysis of the words into consideration. To do so, it is important to obtain the dictionaries for the algorithm to look through in order to link the form back to its lemma.
spaCy provides lemmatization via dictionary lookup and each language has its own dictionary.
Tip
Both stemming and lemmatization have their own advantages. Stemming gives very good results if you apply only statistical algorithms to the text, without further semantic processing such as pattern lookup, entity extraction, coreference resolution, and so on. Also stemming can trim a big corpus to a more moderate size and give you a compact representation. If you also use linguistic features in your pipeline or make a keyword search, include lemmatization. Lemmatization algorithms are accurate but come with a cost in terms of computation.
spaCy container objects
At the beginning of this chapter, we saw a list of container objects including Doc, Token, Span, and Lexeme. We already used Token and Doc in our code. In this subsection, we'll see the properties of the container objects in detail.
Using container objects, we can access the linguistic properties that spaCy assigns to the text. A container object is a logical representation of the text units such as a document, a token, or a slice of the document.
Container objects in spaCy follow the natural structure of the text: a document is composed of sentences and sentences are composed of tokens.
We most widely use Doc, Token, and Span objects in development, which represent a document, a single token, and a phrase, respectively. A container can contain other containers, for instance a document contains tokens and spans.
Let's explore each class and its useful properties one by one.
Doc
We created Doc objects in our code to represent the text, so you might have already figured out that Doc represents a text.
We already know how to create a Doc object:
doc = nlp("I like cats.")
doc.text returns a Unicode representation of the document text:
doc.text
I like cats.
The building block of a Doc object is Token, hence when you iterate a Doc you get Token objects as items:
for token in doc:
print(token.text)
I
like
cats
.
The same logic applies to indexing:
doc[1]
like
The length of a Doc is the number of tokens it includes:
len(doc)
4
We already saw how to get the text's sentences. doc.sents returns an iterator to the list of sentences. Each sentence is a Span object:
doc = nlp("This is a sentence. This is the second sentence")
doc.sents
<generator object at 0x7f21dc565948>
sentences = list(doc.sents)
sentences
["This is a sentence.", "This is the second sentence."]
doc.ents gives named entities of the text. The result is a list of Span objects. We'll see named entities in detail later – for now, think of them as proper nouns:
doc = nlp("I flied to New York with Ashley.")
doc.ents
(New York, Ashley)
Another syntactic property is doc.noun_chunks. It yields the noun phrases found in the text:
doc = nlp("Sweet brown fox jumped over the fence.")
list(doc.noun_chunks)
[Sweet brown fox, the fence]
doc.lang_ returns the language that doc created:
doc.lang_
'en'
A useful method for serialization is doc.to_json. This is how to convert a Doc object to JSON:
doc = nlp("Hi")
json_doc = doc.to_json()
{
"text": "Hi",
"ents": [],
"sents": [{"start": 0, "end": 3}],
"tokens": [{"id": 0, "start": 0, "end": 3, "pos": "INTJ", "tag": "UH", "dep": "ROOT", "head": 0}]
}
Pro tip
You might have noticed that we call doc.lang_, not doc.lang. doc.lang returns the language ID, whereas doc.lang_ returns the Unicode string of the language, that is, the name of the language. You can see the same convention with Token features in the following, for instance, token.lemma_, token.tag_, and token.pos_.
The Doc object has very useful properties with which you can understand a sentence's syntactic properties and use them in your own applications. Let's move on to the Token object and see what it offers.
Token
A Token object represents a word. Token objects are the building blocks of Doc and Span objects. In this section, we will cover the following properties of the Token class:
- token.text
- token.text_with_ws
- token.i
- token.idx
- token.doc
- token.sent
- token.is_sent_start
- token.ent_type
We usually don't construct a Token object directly, rather we construct a Doc object then access its tokens:
doc = nlp("Hello Madam!")
doc[0]
Hello
token.text is similar to doc.text and provides the underlying Unicode string:
doc[0].text
Hello
token.text_with_ws is a similar property. It provides the text with a trailing whitespace if present in the doc:
doc[0].text_with_ws
'Hello '
doc[2].text_with_ws
'!"
Finding the length of a token is similar to finding the length of a Python string:
len(doc[0])
5
token.i gives the index of the token in doc:
token = doc[2]
token.i
2
token.idx provides the token's character offset (the character position) in doc:
doc[0].idx
0
doc[1].idx
6
We can also access the doc that created the token as follows:
token = doc[0]
token.doc
Hello Madam!
Getting the sentence that the token belongs to is done in a similar way to accessing the doc that created the token:
token = doc[1]
token.sent
Hello Madam!
token.is_sent_start is another useful property; it returns a Boolean indicating whether the token starts a sentence:
doc = nlp("He entered the room. Then he nodded.")
doc[0].is_sent_start
True
doc[5].is_sent_start
True
doc[6].is_sent_start
False
These are the basic properties of the Token object that you'll use every day. There is another set of properties that are more related to syntax and semantics. We already saw how to calculate the token lemma in the previous section:
doc = nlp("I went there.")
doc[1].lemma_
'go'
You already learned that doc.ents gives the named entities of the document. If you want to learn what sort of entity the token is, use token.ent_type_:
doc = nlp("President Trump visited Mexico City.")
doc.ents
(Trump, Mexico City)
doc[1].ent_type_
'PERSON'
doc[3].ent_type_
'GPE' # country, city, state
doc[4].ent_type_
'GPE' # country, city, state
doc[0].ent_type_
'' # not an entity
Two syntactic features related to POS tagging are token.pos_ and token.tag. We'll learn what they are and how to use them in the next chapter.
Another set of syntactic features comes from the dependency parser. These features are dep_, head_, conj_, lefts_, rights_, left_edge_, and right_edge_. We'll cover them in the next chapter as well.
Tip
It is totally normal if you don't remember all the features afterward. If you don't remember the name of a feature, you can always do dir(token) or dir(doc). Calling dir() will print all the features and methods available on the object.
The Token object has a rich set of features, enabling us to process the text from head to toe. Let's move on to the Span object and see what it offers for us.
Span
Span objects represent phrases or segments of the text. Technically, a Span has to be a contiguous sequence of tokens. We usually don't initialize Span objects, rather we slice a Doc object:
doc = nlp("I know that you have been to USA.")
doc[2:4]
"that you"
Trying to slice an invalid index will raise an IndexError. Most indexing and slicing rules of Python strings are applicable to Doc slicing as well:
doc = nlp("President Trump visited Mexico City.")
doc[4:] # end index empty means rest of the string
City.
doc[3:-1] # minus indexes are supported
doc[6:]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "span.pyx", line 166, in spacy.tokens.span.Span.__repr__
File "span.pyx", line 503, in spacy.tokens.span.Span.text.__get__
File "span.pyx", line 190, in spacy.tokens.span.Span.__getitem__
IndexError: [E201] Span index out of range.
doc[1:1] # empty spans are not allowed
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "span.pyx", line 166, in spacy.tokens.span.Span.__repr__
File "span.pyx", line 503, in spacy.tokens.span.Span.text.__get__
File "span.pyx", line 190, in spacy.tokens.span.Span.__getitem__
IndexError: [E201] Span index out of range.
There is one more way to create a Span – we can make a character-level slice of a Doc object with char_span :
doc = nlp("You love Atlanta since you're 20.")
doc.char_span(4, 16)
love Atlanta
The building blocks of a Span object are Token objects. If you iterate over a Span object you get Token objects:
doc = nlp("You went there after you saw me")
span = doc[2:4]
for token in span:
print(token)
there
after
You can think of the Span object as a junior Doc object, indeed it's a view of the Doc object it's created from. Hence most of the features of Doc are applicable to Span as well. For instance, len is identical:
doc = nlp("Hello Madam!")
span = doc[1:2]
len(span)
1
Span object also supports indexing. The result of slicing a Span object is another Span object:
doc = nlp("You went there after you saw me")
span = doc[2:6]
span
there after you saw
subspan = span[1:3]
after you
char_spans also works on Span objects. Remember the Span class is a junior Doc class, so we can create character-indexed spans on Span objects as well:
doc = nlp("You went there after you saw me")
span = doc[2:6]
span.char_span(15,24)
after you
Just like a Token knows the Doc object it's created from; Span also knows the Doc object it's created from:
doc = nlp("You went there after you saw me")
span = doc[2:6]
span.doc
You went there after you saw me
span.sent
You went there after you saw me
We can also locate the Span in the original Doc:
doc = nlp("You went there after you saw me")
span = doc[2:6]
span.start
2
span.end
6
span.start_char
9
span.end_char
28
span.start is the index of the first token of the Span and span.start_char is the start offset of the Span at character level.
If you want a brand-new Doc object, you can call span.as_doc(). It copies the data into a new Doc object:
doc = nlp("You went there after you saw me")
span = doc[2:6]
type(span)
<class 'spacy.tokens.span.Span'>
small_doc = span.as_doc()
type(small_doc)
<class 'spacy.tokens.doc.Doc'>
span.ents, span.sent, span.text, and span.text_wth_ws are similar to their corresponding Doc and Token methods.
Dear readers, we have reached the end of an exhaustive section. We'll now go through a few more features and methods for more detailed text analysis in the next section.
More spaCy features
Most of the NLP development is token and span oriented; that is, it processes tags, dependency relations, tokens themselves, and phrases. Most of the time we eliminate small words and words without much meaning; we process URLs differently, and so on. What we do sometimes depends on the token shape (token is a short word or token looks like an URL string) or more semantical features (such as the token is an article, or the token is a conjunction). In this section, we will see these features of tokens with examples. We'll start with features related to the token shape:
doc = nlp("Hello, hi!")
doc[0].lower_
'hello'
token.lower_ returns the token in lowercase. The return value is a Unicode string and this feature is equivalent to token.text.lower().
is_lower and is_upper are similar to their Python string method counterparts, islower() and isupper(). is_lower returns True if all the characters are lowercase, while is_upper does the same with uppercase:
doc = nlp("HELLO, Hello, hello, hEllO")
doc[0].is_upper
True
doc[0].is_lower
False
doc[1].is_upper
False
doc[1].is_lower
False
is_alpha returns True if all the characters of the token are alphabetic letters. Examples of nonalphabetic characters are numbers, punctuation, and whitespace:
doc = nlp("Cat and Cat123")
doc[0].is_alpha
True
doc[2].is_alpha
False
is_ascii returns True if all the characters of token are ASCII characters.
doc = nlp("Hamburg and Göttingen")
doc[0].is_ascii
True
doc[2].is_ascii
False
is_digit returns True if all the characters of the token are numbers:
doc = nlp("Cat Cat123 123")
doc[0].is_digit
False
doc[1].is_digit
False
doc[2].is_digit
True
is_punct returns True if the token is a punctuation mark:
doc = nlp("You, him and Sally")
doc[1]
,
doc[1].is_punct
True
is_left_punct and is_right_punct return True if the token is a left punctuation mark or right punctuation mark, respectively. A right punctuation mark can be any mark that closes a left punctuation mark, such as right brackets, > or ». Left punctuation marks are similar, with the left brackets < and « as some examples:
doc = nlp("( [ He said yes. ] )")
doc[0]
(
doc[0].is_left_punct
True
doc[1]
[
doc[1].is_left_punct
True
doc[-1]
)
doc[-1].is_right_punct
True
doc[-2]
]
doc[-2].is_right_punct
True
is_space returns True if the token is only whitespace characters:
doc = nlp(" ")
doc[0]
len(doc[0])
1
doc[0].is_space
True
doc = nlp(" ")
doc[0]
len(doc[0])
2
doc[0].is_space
True
is_bracket returns True for bracket characters:
doc = nlp("( You said [1] and {2} is not applicable.)")
doc[0].is_bracket, doc[-1].is_bracket
(True, True)
doc[3].is_bracket, doc[5].is_bracket
(True, True)
doc[7].is_bracket, doc[9].is_bracket
(True, True)
is_quote returns True for quotation marks:
doc = nlp("( You said '1" is not applicable.)")
doc[3]
'
doc[3].is_quote
True
doc[5]
"
doc[5].is_quote
True
is_currency returns True for currency symbols such as $ and € (this method was implemented by myself):
doc = nlp("I paid 12$ for the tshirt.")
doc[3]
$
doc[3].is_currency
True
like_url, like_num, and like_email are methods about the token shape and return True if the token looks like a URL, a number, or an email, respectively. These methods are very handy when we want to process social media text and scraped web pages:
doc = nlp("I emailed you at least 100 times")
doc[-2]
100
doc[-2].like_num
True
doc = nlp("I emailed you at least hundred times")
doc[-2]
hundred
doc[-2].like_num
True doc = nlp("My email is [email protected] and you can visit me under https://duygua.github.io any time you want.")
doc[3]
doc[3].like_email
True
doc[10]
https://duygua.github.io/
doc[10].like_url
True
token.shape_ is an unusual feature – there is nothing similar in other NLP libraries. It returns a string that shows a token's orthographic features. Numbers are replaced with d, uppercase letters are replaced with X, and lowercase letters are replaced with x. You can use the result string as a feature in your machine learning algorithms, and token shapes can be correlated to text sentiment:
doc = nlp("Girl called Kathy has a nickname Cat123.")
for token in doc:
print(token.text, token.shape_)
Girl Xxxx
called xxxx
Kathy Xxxxx
has xxx
a x
nickname xxxx
Cat123 Xxxddd
. .
is_oov and is_stop are semantic features, as opposed to the preceding shape features. is_oov returns True if the token is Out Of Vocabulary (OOV), that is, not in the Doc object's vocabulary. OOV words are unknown words to the language model, and thus also to the processing pipeline components:
doc = nlp("I visited Jenny at Mynks Resort")
for token in doc:
print(token, token.is_oov)
I False
visited False
Jenny False
at False
Mynks True
Resort False
is_stop is a feature that is frequently used by machine learning algorithms. Often, we filter words that do not carry much meaning, such as the, a, an, and, just, with, and so on. Such words are called stop words. Each language has their own stop word list, and you can access English stop words here https://github.com/explosion/spaCy/blob/master/spacy/lang/en/stop_words.py:
doc = nlpI just want to inform you that I was with the principle.")
for token in doc:
print(token, token.is_stop)
I True
just True
want False
to True
inform False
you True
that True
I True
was True
with True
the True
principle False
. False
We have exhausted the list of spaCy's syntactic, semantic, and orthographic features. Unsurprisingly, many methods focused on the Token object as a token is the syntactic unit of a text.
Summary
We have now reached the end of an exhaustive chapter of spaCy core operations and the basic features of spaCy. This chapter gave you a comprehensive picture of spaCy library classes and methods. We made a deep dive into language processing pipelining and learned about pipeline components. We also covered a basic yet important syntactic task: tokenization. We continued with the linguistic concept of lemmatization and you learned a real-world application of a spaCy feature. We explored spaCy container classes in detail and finalized the chapter with precise and useful spaCy features. At this point, you have a good grasp of spaCy language pipelining and you are confident about accomplishing bigger tasks.
In the next chapter, we will dive into spaCy's full linguistic power. You'll discover linguistic features including spaCy's most used features: the POS tagger, dependency parser, named entities, and entity linking.