
4
Construction of a Measurement Scale
4.1. Introduction
Previous discussions in this book established that multi-item reflective scales are widely applicable because of the multiplicity of latent (abstract) phenomena requiring multi-indicator measurements. However, it is clear that the process of developing a scale is difficult, time-consuming and costly. In addition, the construction of a reliable and valid scale requires extensive methodological and statistical expertise.
Aware of the importance of this task, several researchers have endeavored to design methodological and technical rules to be followed so as to ensure the development of instruments that measure latent phenomena as effectively as possible. The procedures developed identify a multitude of very useful steps and recommendations. Throughout this chapter, we will provide a better understanding of the steps and procedures that have been most widely used. Examining these steps will lead us to discuss the various improvements recommended to identify the methodological bases required. We will thus seek to consolidate these improvements and avoid mistakes in the process of developing a scale.
4.2. The foundations for producing a multi-item measurement scale
In this section, we will focus on the processes and methodological considerations related to the construction of a multi-item reflective scale. For a long time and in various research disciplines, there has been significant interest in techniques for developing attitude measurement scales (Edwards 1957). However, the first reflections leading to the structuring of an approach began with Peter’s (1979) work on reliability and Churchill’s (1979) work providing a scale development process widely accredited by marketing researchers. Since then, improvements and variants of this process have been proposed. As such, a multitude of contributions have emerged, for example relating to certain stages of construction with Rossiter (2002) or the introduction of new scale validation techniques following the work of Gerbing and Anderson (1988).
In the following sections, we will first present Churchill’s original paradigm, and then examine the different extensions and modifications proposed by other researchers. This approach will later (section 4.3) allow for a synthesis of the steps to be taken, incorporating the main updates to that date. It should be remembered that formative scale production protocols do not follow the same steps and methods (Chapter 3, section 3.2). Thus, we will note whenever necessary the particularities relating to them.
4.2.1. Churchill’s paradigm
Churchill’s (1979) scale development paradigm has clearly dominated construction processes over the past 30 years. Specifically in marketing, it is easy to see that since its publication, most of the scales built have been constructed following the progress of the steps he proposed.
Churchill, with a particular interest in multi-item reflective measurements, structured the process of constructing a scale in a chain of eight steps:
- – the specification of the construct domain: specification is a matter of delimiting the subject or study concept while specifying what is included and what is not. To this end, Churchill suggests using a literature review to clarify the construct, its dimensions and possibly its measurements;
- – the genesis of a sample of items: at this stage, a set of items related to the specified domain is generated. Genesis techniques are those used in exploratory studies. For example, a literature review provides an indication of the definition of the construct and its components. Individual and group interviews with people interested in the field of study, or with some knowledge about it (experts), are used to generate items. In addition, particular attention is paid to the formulation of the items, in particular to avoid certain response biases (social desirability, tendency to agree, etc.);
- – data collection: once the items have been generated, data is collected from a sample of individuals. It is a question of assessing, via a Likert scale format for example, all the items selected during the two previous phases in order to allow, later, the refinement of the measurement;
- – the purification of measurements: the purification is used to reduce the number of initial items to retain only those focused on the domain of the construct. In order to identify the items to be retained, Churchill suggests that two analyses should be performed:
- - a Cronbach alpha reliability test to see the items that are correlated with each other, thus indicating that they belong to the same construct;
- - an exploratory factorial analysis (EFA) to identify the different facets (dimensions) of the construct, if they exist.
Following this, two scenarios are possible:
- - if the results are acceptable (satisfactory alpha coefficient and dimensions in accordance with those conceptualized) additional tests (Cronbach’s alpha, EFA) on the responses of another sample at the same scale should be undertaken;
- - if the results are not acceptable (weak Cronbach’s alpha and factor structure not in line with conceptualization), it is appropriate to return to the first two steps and repeat the process in order to identify the origin of the problem (definition of the construct, sample of items, etc.). An iteration process is thus instigated, until an acceptable solution is reached;
- – data collection: further data collection is required in order to refine the tool to be used;
- – assess reliability: the reliability of new data must be assessed. This reliability is estimated through the internal consistency measurement by Cronbach’s alpha. Good reliability enables the rest of the process to be completed. Otherwise, it is necessary to go back (to step 2) and resume the process;
- – assess validity: the previous steps make it possible to obtain a scale with content (or face) validity that is also reliable. At this stage, the following steps are necessary:
- - first, ensure the validity of the construct: in other words, the convergent validity and the discriminant validity. For this purpose, Churchill recommends the use of the multitrait-multimethod matrix, developed by Campbell and Fiske (1959);
- - second, examine whether the measurement scale as related to other scales of other constructs gives the expected results (nomological or predictive validity).
If the validity is not good, the process must be repeated from the beginning;
- – the development of standards: in order to allow a careful formulation of interpretations, it is necessary to use a set of statistical tests (averages, scores, etc.) to evaluate an individual’s position with regard to a characteristic (or several) and to compare it with other individuals.
4.2.2. Extensions and improvements to the scale development process
Since Churchill’s (1979) article was published, an increase in the number of new measurement scales has been observed in marketing work. Even if this paradigm remains very widely applied, some, whilst citing it as a reference for developing their scales, do not fully follow the process he suggested but sometimes take other arrangements. In addition, discussions about these steps have been published continuously. The ultimate objective is to refine the paradigm and take into account current methodological and statistical advances. Flynn and Pearcy (2001), for example, undertook comparisons between development processes of many scales in order to identify avenues for reflection for better measurement conception. Slavec and Drnovšek (2012) found that some important steps in the development of management science scales have not been exploited. These findings are not new, however. Indeed, Hinkin (1995) observed that some procedures for developing several measurement scales used in management seem inadequate. Diamantopoulos (2005) even criticized the blinded adherence of some researchers to Churchill’s suggested steps. It therefore appears that while the Churchill paradigm offers a useful guide to the construction of new scales, it can, nevertheless, be revised at several levels. Substantial progress in the organization and statistical tools to be used as part of this progression of steps deserves attention.
In this section, we will retrace the main avenues for improving the Churchill paradigm. Clark and Goldsmith (2012, p. 197) pointed out that “no procedure has incorporated all of the key updates to the Churchill paradigm… many marketing scholars refer back to the Churchill paradigm without recognizing the existence of these advances”. The areas for improvement discussed here include:
- – content validation;
- – data collection;
- – the specificities of the population;
- – data analysis.
Further details relating to the design of a scale, purification techniques and validation of a measure will be discussed in other chapters.
4.2.2.1. Content validation
In the progression of steps proposed by Churchill (1979), content validity was addressed. However, it is not uncommon to observe that during the construction of many scales, this validity seems illusory. Bergkvist and Rossiter (2008), considering their work as an extension of Churchill’s scale development procedure, note Churchill’s insistence on giving importance to theoretical considerations as a crucial step in his procedure. Bergkvist and Rossiter (2008) note that, unfortunately, researchers have not paid enough attention to this aspect. This is not a recent observation; Spector (1992, p. 7) has noted that many scale developers do not do enough work at this stage to define the construct. Mowen and Voss (2008, p. 488) noted that “while Churchill’s (1979) approach includes construct definition and domain specification, his discussion of these ideas is limited”; they therefore propose that the definition of a construct should also take into account its antecedents and consequences (determining its nomological network). MacKenzie et al. (2011, p. 295) have pointed out that a poor definition of a construct leads to serious problems including:
- – confusion about what the construct refers to (or does not refer to);
- – deficient indicators because the definition of the focal construct is insufficiently developed or contaminated by the definition of other constructs;
- – invalid conclusions about relationships with others constructs.
In short, without a clear and precise definition of the content of a construct, it is almost impossible to progress in the construction of a scale, whatever the envisaged specification (reflective or formative). One of the undeniable contributions of the C-OAR-SE paradigm proposed by Rossiter (2002) is the particular attention that must be given to the definition of the construct and the validity of its content. In order to obtain a scale that can list all facets of a behavior, it is crucial that the observable indicators selected can be perfectly adjusted to the latent phenomenon in which the researcher is interested. All the steps of purification, validation and empirical testing undertaken for reflective scales are insufficient and unsuccessful if the researcher is not able, from the beginning of the process of genesis of the items, to find the essential and unavoidable qualifiers to cover the phenomenon in question. Straub (1989, p. 150) pointed out that an instrument with content validity “is difficult to create and perhaps even more difficult to verify because the universe of possible contents is virtually infinite”. In a formative model, this step is also fundamental to ensure that all the indicators forming the construct are identified and that no omission of any part of the content to which the phenomenon refers is made.
The first steps of a scale building process are too often rushed. However, it is at this stage that the researcher will find (or not) the key indicators referring to latent content. Sometimes he is confronted by items that seem redundant (same idea formulated in different ways), too long (several words make up the items) or ambiguous (containing difficult or confusing words). A series of questions come to the fore: which items should be retained? Which ones should be deleted? What words and adjectives should be used? At this level, there is also the question of reversed items, the importance of their use and their number. Of course, at this stage, it is not a question of reducing the scale in terms of number of items, but it is necessary to make some judgments about the potential of each item to capture as much reliable and valid information as possible while reducing some possible response biases. In a way, it is a question of undertaking an initial qualitative purification of the list of indicators selected.
With regard to reflective models, the researcher may decide to keep certain items that are considered redundant if they consider them to be potentially interesting. On the other hand, in the case of formative models, the researcher must ensure that all possible indicators are effectively identified and that there is no duplication. To assist in their judgment, the researcher may use experts. Moreover, Rossiter (2002) strongly supports the use of experts not only to generate items, but also to analyze those that have already been identified. Experts can effectively assist the scale developer in assessing each of the items, opposing adjectives, etc., while keeping in mind the definition of the phenomenon to be measured, in order to select those that:
- – best represent the construct;
- – are equivalent for the entire population;
- – limit a priori response bias.
These qualitative explorations with experts should only terminate once an agreement has been reached between the judges. While analyses at later stages of the development process, particularly for reflective models (exploratory factorial analyses, reliability tests, confirmatory analyses, etc.), can provide statistical values to inform these decisions, the use of judges is irreplaceable in order to decipher the meaning of each item and its consistency with the construct under study. This makes it possible to assert the content validity that is often overlooked compared to other types of validity, in particular convergent validity and discriminant validity.
When examining items, one must focus on their ability not only to reproduce the content of a phenomenon, but also to reduce the biases they may generate during administration. Academic experts in scale design can be helpful when discussing and informing choices on topics concerning response formulation, reversed items, response formats, number of echelons, etc., which we will discuss in more detail later (Chapter 5).
Although content validity has often been examined with reference to indicators, it is worth noting that other components of a scale may be important in its assessment. Moreover, some have pointed out the importance of certain scale components, including format (Rossiter 2002) and item formulation (Churchill 1979; MacKenzie et al. 2011) when understanding a construct, but the scale construction processes they have proposed do not highlight this important step when evaluating items and their content.
It is also easy to observe that decisions relating to the design of a scale are often rushed, hence why they ought to be proposed as a separate step in scale development processes in order to highlight their relevance to the production of indicators and the measurement of a construct. While some components of the design of a scale appear to be rather closely associated with data collection systems, the attributes of a scale, or at least some of them, do not serve exclusively to facilitate the collection of quality information from respondents in the population concerned, but guide them in order to gain an understanding of the meaning of the indicators selected in the scale and to choose the best attitudinal response.
4.2.2.2. Data collection
When collecting data, a minimum level of rigor is required. Indeed, focusing on processes of purification or reduction of items through factor analysis is of no use if the data collected does not meet the required methodological standards. Although such recommendations have been made for years, it is easy to see that data collection can have several shortcomings. In the following, we will examine two main points: the number of collections and the sample to be selected.
4.2.2.2.1. The number of collections
Churchill (1979) recommends, in his model, many round-trip processes and increased data collection. He also recommends the use of two collections in the early stages of the process, with the objective of developing and selecting the items to be retained for the remainder of the validation process. However, as Flynn and Pearcy (2001) have already noted, it is not uncommon to observe that some researchers do not fully comply with this recommendation. Some use a single collection for purification. The second is reserved for validation. It is also surprising to see that some use a single collection, which is used for both purification and validation. Although researchers such as Hendrick et al. (2013) have indicated that the same sample should not be used to construct and validate a scale.
Moreover, the strategy, proposed by some, of splitting the sample from the same collection into two subgroups, one for purification and one for validation, is not ideal. Indeed, the analysis of the data from the first sub-sample (purification) quite often results in the deletion of certain items and this strategy of splitting the sample in half from a single unique collection can produce two deficiencies:
- – first, in terms of accuracy of information, responses may depend on the length of a scale, and examine validity from data from the second subsample by using a smaller number of items (the items remaining after purification on the first sub-sample) than the one initially administered, which may then lead to procedural bias, potentially affecting responses;
- – secondly, in terms of sample size, the number of respondents depending on the number of items, this strategy may induce an over-inflated size because it was initially planned for a second and ultimately smaller sub-sample.
At the beginning of the field data collection process, the researcher often has a long list of items that need to undergo purification and reduction in number. It is therefore advisable to take a large sample for this purpose. Once this mission has been carried out and has resulted in an adequate structure, it is useful to validate it: a new collection is required. Admittedly, the difficulties that ensue from surveying certain populations have, in some cases, explained the use of a single sample for both exploration and validation of a structure. It is, however, important to note that this practice does not allow for the easy refinement of a measurement. On the contrary, it would sometimes be easier to use much more than two samples for exploratory purposes.
We recommend the use of multiple collections for purification purposes (exploratory factor analysis and reliability testing) until the properties of the scale are acceptable and stable. Moreover, even during the validation phase of a scale, it is sometimes useful to use several data collections, especially when modifications are made to the scale. As the validation process is a continuous process, certain key steps in the construction of high-performance tools should not be rushed. Baumgartner and Steenkamp (2006) go further in the number of data collections they recommend. They believe that it is even important to use longitudinal surveys to better validate scales. They stress that “the effort expended in data collection must be a fundamental element of research, the main contribution of which is the development of a good instrument for measuring a construct. The additional diagnostic power obtained […] greatly increases the confidence that other researchers can have in new scales and may avoid the need for further modifications” (p. 94).
In other words, the multiplication of samples throughout the process of construction and scale validation is of great interest to achieve a reliable, valid and trustworthy measurement which is to be replicated. These replicates make it possible to ensure, among other aspects, the stability of a scale and therefore its credibility in reuse. Indeed, Baumgartner and Steenkamp (2006) argue that a construct can have two components: a stable one, which they refer to as the trait word, and a temporary one, which they interpret as the state word. Frisou and Yildiz (2011), adhering to this conception, propose in the seventh step of the Churchill process the establishment of certain protocols for verifying the temporal structure (temporal validation) of the construct to be measured, in particular through the test-retest method. It is clear from these debates that the researcher is gradually refining the tool through a succession of data collection, purification and even validation throughout the process of constructing a scale leading to a better measurement of latent phenomena.
4.2.2.2.2. The sample to be selected
Considerations related to data collection are not strictly limited to the number of collections to be used. The sample to be selected is crucial in this process. In particular, two aspects will be raised: the source of the sample and its size:
- – the source of the individuals to be interviewed: it should be noted that, according to several researchers (Hendrick et al. 2013), it is crucial that the sample is drawn from the target population to be considered. Even in the early stages of genesis and purification of the scale, using respondents not concerned with the phenomenon to be operationalized is totally unproductive. On the contrary, it is likely to direct the researcher towards:
- - a misconception of the definition of the phenomenon under study;
- - indicators that may not represent it as effectively.
However, it is not uncommon to observe, during the first stages of the construction process, that populations not concerned by the phenomenon studied, in particular students, are mobilized. It should also be added that the consultation of qualified researchers (experts) in scale design, although important, cannot in any way replace the opinion of the population concerned.
- – the size of the sample to be selected is also a fundamental determinant of obtaining a good quality instrument. In this regard, Flynn and Pearcy (2001), following a comparison of the development processes of 24 published scales, often observed the use of undersized samples. The first or even subsequent data collection does not meet the requirements for the application of exploratory and sometimes even confirmatory factor analyses.
In this regard, the sizes recommended by specialists seem imprecise. Some recommend setting the sample size according to the number of items on the scale, others recommend determining it according to the number of parameters to be estimated. In these different cases, we often observe the number of 5 to 15 individuals to be retained per item or parameter. We note that the choice of the number of individuals to be retained depends on several considerations, in particular the stage of the process in the construction of the scale (exploratory or confirmatory) and therefore on the objective assigned to the data collected on the sample and the statistical analyses to be undertaken.
Some data analysis protocols are indeed more demanding in terms of the size required. For example, Malhotra (2011, p. 543) suggests a size of four to five times the number of items on the scale for an exploratory factor analysis (EFA). While when conducting a confirmatory factor analysis (CFA), Akrout (2010, pp. 138–139) noted the existence of several proposals, pointing out that the sample size may depend on a multitude of factors such as: the number of latent variables, the number of observable indicators, the number of parameters to be estimated, the estimation method, etc. It should be noted, in this last register, that the Partial Least Squares (PLS) estimation method, often used due to its flexibility to a small sample size, requires the rule of 10 observations (individuals) per item as the threshold for its use (Hair et al. 2012, p. 335).
Despite differing opinions on the size to be retained, it is crucial to pay close attention to the sample of respondents from the early stages of the purification process. Indeed, DeVellis (1991, cited in Flynn and Pearcy 2001, p. 412) noted “that small sample sizes may cause instability in covariance estimates”. And, if estimation problems exist, this can lead to problems with the structure of the scale and the items that make it up. It is at the level of these first steps that the researcher decides which items to retain. Erasing items, which potentially bring great significance to the content of a construct, is very risky for the conceptualization of the phenomenon to be measured. In any case, from the beginning of the data collection process in the field and at each of its stages, sufficient size must be ensured according to the objectives and statistical tests envisaged, in order to guarantee a more rapid stability of the results that allow the scale to be developed. The principle of collection-purification iterations only ends once the results, derived from the data of two successive collections, show a good stability.
4.2.2.3. The specificities of the population
We noted in Chapter 2 that some scales should not be used in new situations. We have mentioned, among other things, the problems of equivalence of measures when they are applied to other contexts different to their original context. Although this observation is not meaningless in rendering a measure obsolete, it should be stressed that problems of scale replication may, in some cases, be due to purely methodological causes. Thus, when a scale is constructed on the basis of the perceptions of individuals belonging to particular subgroups and excluding other subgroups composing the same basic population, problems of interpretation and therefore equivalence of the items, the construct and thus the scale as a whole, may exist when it comes to understanding each other’s points of view by this scale.
Caramelli and Van De Vijver (2013) focused on management scales and noted that, for intercultural studies, it is not sufficient to conduct the conception of a scale in only one of the cultural contexts. According to them, it is necessary to question the operationalization of the construct in question across all the cultures included in the study. The merit of this methodology seems to be that it proposes that all stages of the Churchill process should be conducted in each of the cultural groups studied. This logic is very relevant even within the same culture, when the researcher has strong reasons to believe that respondents have differences (in terms of age, religion, language, race, etc.) that may lead them to perceive the phenomenon to be measured differently. In these cases, seeking equivalence of the measurement in all situations (groups) studied is a possible key to approaching the phenomenon safely and then drawing conclusions that can be applied to the entire population studied. In the same vein, MacKenzie et al. (2011) have pointed out that the properties of a measure can vary according to subpopulations.
In order to achieve an equivalent scale (see Chapter 2) for the measurement of a phenomenon and to allow intergroup comparisons, it is essential to ensure, among other things, the following aspects:
- – the construct, the measuring object, has the same meaning across all groups. This aspect is crucial to assess the content validity of the scale. It is therefore important to interact with experts from different groups to better understand the definition of the construct, its content and its boundaries;
- – the indicators (items) finally retained in the scale must have the same meaning in all groups. Beyond the possible translations and the problems that may be associated with them, the items must cover the same facets of the construct according to the different groups;
- – beyond the selected items and their formulation, the format of the scale (Likert, semantics differential, etc.) and the number of response modalities (4, 5, 7 points, etc.) must be perceived in the same way by all the groups constituting the population and therefore equivalently;
- – the same facets of the construct (dimensions) with similar psychometric qualities (reliability, validity) must be observed in the different groups. In this case, the different analyses carried out on the collected data (dimensionality, reliability, validity) must be done on the different groups in order to retain only equivalent, reliable and valid information (same items, same dimensions, acceptable psychometric parameters in all groups, etc.). Indeed, it is not uncommon to observe that some researchers, testing a set of relationships and their meanings on several groups (different cultural groups, groups subjected to different experimental situations, etc.), carry out tests of the scales they use on a single sample, all groups combined without first carrying out preliminary checks on the hypothesis tests, by exploratory factorial analyses and reliability tests on each group. In the absence of such checks, it is difficult, if not impossible, to detect the facets of a specific behavior for each group.
4.2.2.4. Data analyses
Several statistical tests are used during scale development. Each takes place at one or a few steps in the process. Without dwelling on statistical developments, we will focus on some of their contributions to the development of satisfactory scales, and some application errors to avoid. In fact, considerable improvements in the scale development process have been undertaken with increasing interest in the reliability of measurements since Peter’s work (1979) and in their validation since the procedure proposed by Campbell and Fiske (1959). We will then discuss these two aspects: reliability and validity.
4.2.2.4.1. Reliability
It is clear that Churchill insists on reliability testing, especially in the early stages of the process, prior to testing the factor structure of a scale. But does this actually make sense? Churchill recommends examining reliability for each dimension of the scale, purifying items on the basis of Cronbach’s alpha for example, before even ensuring that all items on a scale refer to the same latent conception which seems misled. Of course, this does not exclude, during the preliminary phases of establishing the content validity, carrying out some inter-judge agreement tests. But one should keep in mind that reliability, particularly Cronbach’s reliability, deals with the internal consistency of a set of indicators relating to the same aspect. Relying on this coefficient in the first place to decide which indicators are not satisfactory to delete (after data collection) can wrongly lead to the deletion of items or even important dimensions of the phenomenon studied.
According to several authors (Gerbing and Anderson 1988; Flynn and Pearcy 2001), it is recommended to certify the structure (dimensionality) of a scale before any use of reliability tests. In addition, reliability tests other than Cronbach’s may be relevant in these first steps of purifying a scale, especially when it comes to ensuring the stability of the measurement through test-retest reliability tests. In addition, it should be noted that Cronbach’s alpha is now calculated as an indication and that the factor structure of a scale can only be established following analyses such as the confirmatory factor analysis. Once established, the reliability of the dimensions is examined by other tests, including the Joreskog ρ, which is often considered more reliable than the Cronbach alpha1.
4.2.2.4.2. Validity
Slavec and Drnovšek (2012, p. 39) stress that “reliable and valid measures contribute to the legitimacy and development of a research field”. Baumgartner and Steenkamp (2006, p. 80) suggest that “a proposed scale should be subject to a rigorous constructs validation procedure so that future research can use it with confidence”. With respect to validity, Gerbing and Anderson (1988) attempt to upgrade Churchill’s paradigm while integrating structural equation methods2. They indicate that exploratory factor analysis is satisfactory in the early stages of the scale development process and that factor analysis, in its confirmatory form, appears to be better in the later stages. The structural equation methods are robust for two purposes: the validation of the structure of a scale (convergent and discriminant validity) and the nomological validity of the scale when it is related to other scales related to other constructs.
This is all the more important because, as Gerbing and Anderson (1988) point out, the objective of several studies is not only to develop reliable and valid scales, but also to develop and test theories. Despite the potential of structural equation methods (SEM) in the scale development process, Terblanche and Boshoff (2008, p. 116) note that few developers of new marketing scales are taking advantage of this opportunity. Admittedly since that date (2008) there have been more applications of SEMs, but this suggests that they could be integrated into the scale construction protocol, particularly in conjunction with traditional procedures, including the multitrait-multimethod matrix.
4.3. Updating the process of constructing a measurement scale
In the following, we will set ourselves the objective of structuring the main stages of development of a reflective multi-item scale. It should be noted that there are some specific features of the procedure to be followed for formative models (see Chapter 3, section 3.2) that we will recall. In this proposal, we will try, based on previous work that has developed or discussed the scale development processes available in various disciplines (Churchill 1979; Gerbing and Anderson 1988; Hinkin 1995; 1998; Flynn and Pearcy 2001; Rossiter 2002; Baumgartner and Steenkamp 2006; Rattray and Jones 2007; MacKenzie et al. 2011; Clark and Goldsmith 2012; Slavec and Drnovšek 2012; Caramelli and De Vijver 2013; Hendrick et al. 2013) to bring together knowledge in order to adapt the scale development process.
It should be noted that all the discussions initiated by various authors, even if they sometimes seem different (such as Rossiter’s (2002)), are fundamentally complementary. Our objective is to provide a theoretical framework that can bring together and enrich all the procedures and methodological steps, which are often fragmented and misunderstood. Moreover, several researchers note the need for such an approach. Clark and Goldsmith (2012) suggest that an adaptation of the Churchill paradigm to take into account all advances in tools and methodologies for scale construction and validation is required. Slavec and Drnovšek (2012) have even added that the rigor of a scale’s development methodology can significantly affect the number of citations and its publication in high-level journals. In order to motivate scale developers to pursue a quest for rigor, we emphasize that the efforts that a researcher must make to develop scales are rewarding, not only for the new knowledge gained but also for the development of their career.
In this section, we will first proceed to a summarized presentation of the different steps proposed; the later chapters of this book then offer more detailed discussions of this sequence. In a second step, we will structure the different steps into three main areas of interest that will guide the general approach to be followed when building a measurement scale.
4.3.1. The process of developing a scale: updated sequence
When a researcher initiates a process of constructing a scale in order to operationalize a latent phenomenon, they must know that they are entering a sequential process where each step must be controlled before engaging in the next. At each stage, reflections based on theoretical, empirical and statistical foundations can sometimes lead them to turn back in order to make certain checks or adjustments. Each step may initiate several investigations or even endorse another sequence of steps. For example, quantitative purification of a scale (EFA and reliability) may require several data collections and a back and forth between the literature review and reading of statistical indices. Figure 4.1 illustrates a succession of 13 steps to be taken.

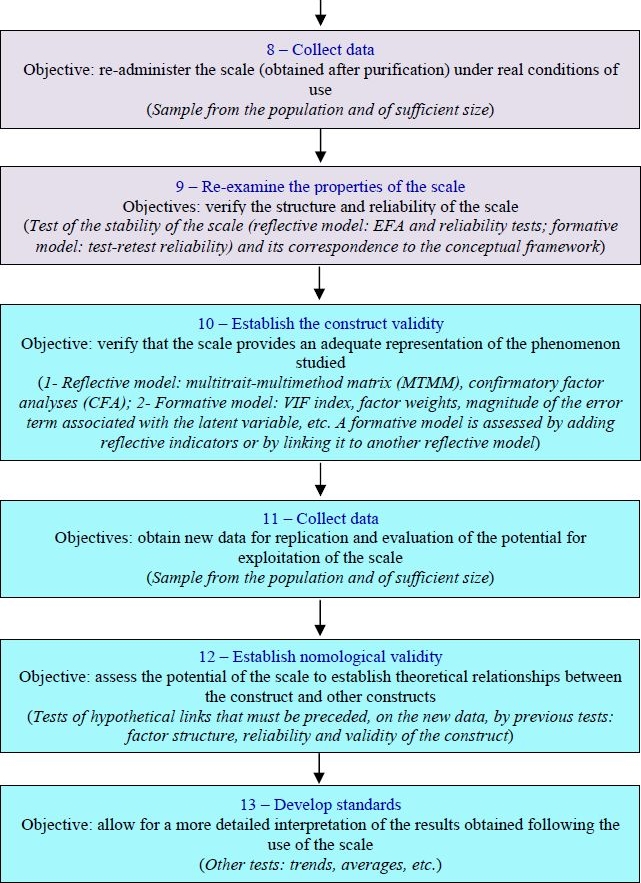
Figure 4.1. Process of constructing a measurement scale
4.3.2. The main axes for developing a scale
This broad spectrum of steps to be taken to develop a measurement scale revolves around three main components in the general scheme depicted in Figure 4.1:
- – define the construct and the attributes of the scale allowing for an understanding of the content of the focal construct (steps: 1, 2, 3, 4, 5);
- – collect data and purify the draft scale (steps: 6, 7, 8, 9);
- – validate the measurement and its ability to identify the phenomena studied (steps: 10, 11, 12, 13).
In the following paragraphs, we will propose a brief discussion of each of these central axes. For each, we will mention the main steps required and the different decisions to be taken. It should be recalled that all these stages are closely linked and that a process of back and forth is often necessary in order to make the adjustments necessary to refine the various choices and to obtain, in the end, an adequate measurement of the phenomenon, which is the object of operationalization.
4.3.2.1. Defining the construct and the attributes validating its content
One of the major concerns of the first five steps is to produce a set of attributes that can capture the true meaning of the content of the phenomenon. This implies: 1) a broad understanding of the latent construct, its extent and its relationships with other phenomena; 2) an active search for indicators that can represent it; 3) reading the nature of the “construct-indicator” links (reflective or formative) to choose the indicators that will represent it; 4) a choice of the different evaluation attributes of the phenomenon (items, response labels, etc.); 5) verification in order to finally evaluate whether all the attributes identified (items, response format, etc.) offer the most appropriate way to apprehend the entire content of the construct and do not induce bias.
This reading of the construct and the different components of the scale, which makes it possible to discover a valid content of the phenomenon and then undertake field tests (axis 2), is based on two important types of investigations: the literature review and qualitative exploratory studies with experts. This first axis thus mobilizes a triangulation between a deductive approach (literature review) and an inductive approach (qualitative exploratory research).
The literature review can concern not only the construct in question (extended to various fields) but also its antecedents, consequences and related concepts in order to have the richest possible vision that delimits it, identifies its dimensions, examines its potential stability over time, allows elements of reflection on the attributes of the scale, etc. These conceptual investigations seek to establish an observation (measurement) close to the latent content and to justify the interest of developing a scale for the phenomenon if none of the existing ones can properly apprehend it.
With regard to empirical explorations, the experts mobilized are essentially individuals who know the subject (construct) or who are interested in the phenomenon to be operationalized. This potentially includes consumers, managers, researchers, etc. Several exploratory techniques (group interviews, individual interviews, etc.) can be used depending on the nature of the phenomenon, the characteristics of the experts, etc. These explorations must involve all categories of the population concerned (cultural groups, age groups, etc.) when the phenomenon is likely to be perceived differently from one group to another. Let us add that the number of these explorations cannot be defined in absolute terms, but the more abstract the construct is, the more fruitful such explorations are in terms of content validity.
It should be recalled that, for formative specifications, the content validity can only be asserted when all formative indicators are identified because no omissions are allowed, unlike reflective specifications where a sample of items may be sufficient for the validity of its content. The latter is the first type of validity to be established, very early in the process of constructing a scale. Indeed, it is not possible to advance in the development of a scale (whatever its specification) if the content validity is not established. Admittedly, it is always possible to decide to turn back and re-examine the correspondence of a set of items to conceptual content in order to ensure the content validity when a doubt arises around the correspondence to the conceptual framework of the structure of a reflective scale (following for example an exploratory factorial analysis).
4.3.2.2. Data collection and scale purifications
This axis mainly concerns four stages (6, 7, 8, 9) whose main concern is to test the draft scale obtained following the previous stages (1, 2, 3, 4, 5), in order to establish a set of purifications on the basis of data from the field (and far from the judgments of experts qualified by some as subjective). This test covers a multitude of aspects:
- – some, applicable to all specifications (reflective and formative), concern the overall assessment of the scale by the population (understanding of the items, ease of administration, understanding of the response format, etc.);
- – others, more technical, are specifically applicable to reflective models (exploratory factorial analyses and classical reliability tests). For formative models, test-retest reliability is possible;
- – and finally, examinations of conceptual attributes (correspondence of the obtained structure to the theoretical definition of the construct and its different facets) are also important to conduct.
Thus, once a set of items has been selected and formatted, a succession of data collections-purifications is required. For these different collections, it is imperative to select individuals from the population concerned because obtaining data from other sources is likely to provoke measurement errors. In addition, as mentioned above, taking into consideration the number of individuals to be retained for these tests is a guarantee of quality. As such, if the objective is to have exclusively a global appreciation of the items formatted (example: in a Likert format), a reduced sample (20 to 30 individuals) may be sufficient. But if the researcher tries to analyze the factor structure and reliability of the scale (in a reflective model), a larger sample is required to allow statistical processing. For the latter, it is commonly accepted to start with exploratory factorial analyses (EFA) and then to carry out reliability tests on each of the dimensions obtained. Reliability can be assessed through several indices, such as Cronbach’s alpha (for reflective models). At this level of reflection, it should be mentioned that decisions are often to be made surrounding the choice of items to be retained (or removed) definitively from the scale (see Chapter 6). In order to make all these judgments operational, a back and forth between reading the statistical results obtained and the conceptual definition of the construct is necessary. Although we have already mentioned the number of possible collections for such an undertaking, it is interesting to recall that this succession of purification collections can only end once a stable factorial structure is obtained that is statistically and conceptually acceptable. Let us not forget that a purification, especially the first one based on the items generated, leads to the elimination of certain indicators, hence the importance of collecting additional data to review the structure of the scale. Although Figure 4.1 highlights two data collection processes for such purifications (steps 6 and 8), it should be noted that this is a minimum amount. Indeed, undertaking further collections, especially for some constructs that appear less stable, is often necessary before progressing to the next steps. This is the case when the first two collections do not result in a close structure, in accordance with the planned conceptualization. This becomes more complicated when the results (EFA, reliability) do not correspond to a potential theoretical structure, hence the urgency to turn back and check the whole process undertaken in the previous steps (1, 2, 3, 4, 5).
4.3.2.3. Validation of the scale and its ability to identify the phenomena studied
If the sequence of steps recommended in the two previous sections is properly carried out, it then gives rise to a series of items potentially distributed over one or more dimensions with good content validity and acceptable reliability for each of them. However, the fact remains that this series is not yet usable. Indeed, the content validity, established on a conceptual basis and based on expert judgments during the initial phases of the process, only makes it possible to reassure oneself that the scale captures the entire domain of the construct studied, but does not make it possible to know if it is able to reproduce the real phenomenon with a population. It is still necessary to test its validity with samples of individuals and to examine its explanatory power on a certain number of phenomena (steps 10, 11, 12, 13).
The validity of the scale used at this stage must be assessed in two steps:
- – first, it is a question of assessing the validity of the construct by testing the convergent validity and the discriminant validity. To do this, particularly for reflective models, alongside the protocol suggested by Campbell and Fiske (1959), it is fruitful to use structural equation methods. For formative models, a few indices can be used to attest to the validity of the construct, in particular the importance of the error term associated with the latent variable;
- – second, it is necessary to test whether the scale obtained is capable of capturing the phenomenon studied in relation to others associated with it in the literature; it is then a question of examining the nomological validity. To this end, the conceptually defined relationships between the phenomenon to be operationalized and the others identified are tested by a variety of methods including structural equations (SEM).
We will discuss the different variants of validity later (Chapter 7). However, it should be noted here that each of these validities (construct validity and nomological validity) should, whenever possible, be based on a new data collection. Replication of collections is indeed likely to promote a more reliable and valid instrument. It is therefore important, in order to refine a scale that can be trusted, to undertake data collection assessing the construct validity (convergent validity and discriminant validity) and another collection to relate this scale to others, in order to ensure its potential to explain the theoretical links that may exist between several constructs (hence the test of nomological validity). It should be noted that, for each new collection, it is imperative, before carrying out the recommended validity test (construct validity or nomological validity), to check again for dimensionality, reliability, etc.
Let us add that the last point to be considered when constructing a scale is the development of a set of standards through the use of a few indices (example: average) to facilitate the interpretation of the scores obtained by the scale. Although this last aspect is very often neglected, we point out its importance for better understanding the distribution of scores among individuals in the studied population and, consequently, in assessing the ability of the scale to provide an interpretation of individuals’ positions on different characteristics, the main objective of the measure.
Table 4.1. Summary of the provisions associated with the scale development process
| Axes/Steps | Main objectives | Main procedures mobilized |
|
a- Defining the construct and the attributes validating its content Steps: 1, 2, 3, 4, 5 |
Understand the phenomenon and delimit its borders. Highlight the conceptual components of the phenomenon. Check the need to develop a scale. Generate a set of items. Establish the type of “construct-indicator” relationship (formative or reflective). Verify, for formative models, that all indicators are identified. Choose, for the reflective models, the items to retain for the next phase. Prepare and facilitate the administration of items: choice of format (Likert, etc.), response modalities (number, labels, etc.), etc. Establish the ability of items and scale format to reproduce the content of the construct and reduce bias in its apprehension: content validity. |
Deductive approach: review of the literature that can cover the phenomenon in several areas, as well as its antecedents and consequences. Inductive approach: exploratory qualitative research with people interested in the phenomenon (experts, managers, researchers, etc.). |
|
b- Data collection and scale purifications Steps: 6, 7, 8, 9 |
Test the understanding of the draft scale (items, format, etc.). Statistically determine the dimensionality of the scale and the items representing them (reflective models). Test the reliability of the scale. Verify that the structure of the scale is stable, theoretically supported and has good psychometric qualities. |
Sample surveys of sufficient size from the population and covering all its specificities (cultural, experimental group, etc.). Statistical purification for reflective models: exploratory factorial analyses and reliability tests. For formative models, test-retest reliability is possible. |
|
c- Validation of the scale and its ability to identify the phenomena studied Steps: 10, 11, 12, 13 |
Re-test reliability. Establish the validity of the construct (convergent validity and discriminant validity). Establish nomological validity. Develop standards. |
Several possible reliability tests for reflective models (ρ from Jöreskog, etc.) in addition to the classic tests. Test-retest reliability for formative models. To test the construct validity:
To test the nomological validity, several methods are possible: structural equations, regression, etc. Additional examinations are relevant: trends, averages, etc. |
4.4. Conclusion
In this chapter, we have outlined the main steps in the process of developing a scale, in particular multi-item reflective scales, while specifying some specificities of formative models. We have tried to draw attention to the mistakes to avoid and the progress to include in the classic steps initiated by Churchill (1979). The divergence of the results of some studies on the same phenomenon may indeed be caused by shortcomings in the process followed during the construction of the measurements. Taking all these considerations into account would encourage a better future use of scales, leading to a better comparison of results, an increase in contributions and, consequently, an increase in behavioral knowledge.
We have thus structured the process of developing scales, in particular reflective scales, in a rhythmic sequence of 13 steps, which we have tried to group into three main areas of reflection. In fact, each of the axes mobilizes a set of tools and involves a multitude of decisions to be taken, which we will discuss more precisely in the following chapters.
It should be noted, however, that the scale development procedure we have proposed does not consist of a fixed sequence of steps, but is dynamic with a back and forth for each modification undertaken (addition and/or deletion of items, modification of the response format, etc.) or when a form of inconsistency is found (factor structure not in conformity with the conceptual framework, poor psychometric qualities, etc.). This concerns the search for continuous adjustment between a latent construct to be operationalized and a tool for its empirical understanding.
4.5. Knowledge tests
- 1) What are the main steps for building a reflective multi-item measurement scale?
- 2) What are the particularities of the process for building a formative scale?
- 3) How important are qualitative interviews in the process of constructing a scale?
- 4) How does one generate an item related to a measurement scale?
- 5) What are the limitations of Churchill’s scale construction paradigm?
- 6) What are the main revisions of the Churchill paradigm?
- 7) What precautions should be taken in a scale construction process in terms of sample size when collecting data in the field?
- 8) How many data collections should be used when building a scale? How does one decide this?
- 9) What are the different objectives associated with data collection during the scale development process?
- 1 For more information on reliability, see Chapter 6, section 6.4.
- 2 Structural equation methods (SEM) use a correlation or covariance matrix to examine the relationships between a set of variables (items) and constructs, allowing the data collected to be compared with the model of the configured relationships (measurement model and structural model).