
7
Validity of a Measurement Scale
7.1. Introduction
The reliability test is used to reveal if the items are consistent, but does not reveal if they are valid. Admittedly, reliability is an essential condition for assessing the qualities of a measure, especially its validity, but it is insufficient to ensure it. “Validity refers to the degree to which instruments truly measure the constructs which they are intended to measure” (Peter 1979, p. 6), which is a central concern when choosing or developing a scale. This means checking the level of appreciation of the value of the construct given by the measurement aside from random and systematic errors. In the absence of such an examination, it is almost impossible to predict whether the absence or even the presence of a theoretical link between two constructs, through a set of measures, is a result that can be trusted to capture reality. Thus it is all the more regrettable to invest time, effort and costs without achieving credible results. Perfect validity, resulting from a total absence of measurement error, is often far from possible, but an assessment of the potential of a scale to represent reality can be estimated.
In this chapter, we will discuss the notion of validity associated with measurement scales in several ways. More specifically, we will first present (section 7.2) three types of validity: content validity, construct validity and nomological validity. In the second instance (section 7.3), we will retrace, particularly for a reflective multi-item scale, the different possibilities for checking the construct validity often considered as the most difficult to carry out. Far from a statistical demonstration of the protocol for evaluating the construct validity, we will attempt to present the main bases of its verification. Thirdly (section 7.4), we will close the chapter with some thoughts and advice on scale validation designs.
7.2. The main forms of the validity of a measurement scale
Three main forms of validity must be established when developing (or even adopting or adapting) a scale, but at different stages of the process: content validity, construct validity and nomological validity. It is relevant to note that these three types are interrelated, overlapping and sometimes even the definitions of each of them do not clearly display their boundaries with the other types of validity. For example, for Rossiter (2002), the validity of the construct can be summarized by or limited to the content validity.
7.2.1. Content validity
Often confused with face validity, content validity, sometimes called consensus validity, seeks to determine whether the scale reproduces the content of the phenomenon. In other words, it is a question of assessing whether the items generated reproduce the content of the phenomenon studied in its different facets. This underlines the importance of the phase of defining the phenomenon and generating indicators that can explain it. Chandler and Lyon (2001, p. 106) propose to assess face validity by “comparing the defined construct to the applied measures for that construct”, which is the first step in verifying content validity. According to the same authors “content validity is an iterative process, with evidence for content validity compiling with each successive study in a research stream” (pp. 106–107). Hardesty and Bearden (2004) argue that face validity is the ability to ensure that each item measures what it is supposed to measure, while content validity assumes that the sample of selected items represents the entire domain of the construct. Rossiter (2002), although he distinguishes between face validity and content validity, assumes that the latter, which he equates with an appeal to reason, is the most decisive aspect, or even the only element to be considered for a construct.
Representing the content of a phenomenon through a set of items first involves a literature review to better conceptually define the phenomenon, its dimensions, its manifestations, etc. and then the opinions of a number of experts (researchers, managers, consumers, etc.). These experts have to do two principal activities: first propose items to explicate the phenomenon, second evaluate the clarity, quality and importance of the indicators in order to make a first selection and identify those that seem most representative of the mental processes that refer to the construct studied. The use of experts very early in the scale development process in this quest for content validation also helps, in addition to the conceptual framework, to inform decisions about the nature of the specification of construct-indicator relationships (formative or reflective).
As noted in Chapter 3, such a review avoids errors in the development and evaluation procedures of the scale. The choice of experts is therefore crucial: they must be well informed about the construct, its dimensions or any other aspect that may help in its understanding. An expert is any person who is concerned, involved or has knowledge of the phenomenon to be measured. From one construct to another, the potentially solicited experts can be very different.
The subjective judgments provided by the researcher about the construct are thus largely based on conceptual definitions and exploratory qualitative investigations with experts. Content validity is the first to be assessed before embarking on data collection from the population concerned. This is the minimum level of validity required to consider field tests. Without questioning the other types of validity of a scale, it is recurrent issue to insist on the relevance of content validity and to recall that some researchers, notably Rossiter (2002; 2008), attest to its privileged status in the conception of a measurement (see chapters 3 and 4). Hair et al. (2011, p. 146) have even proposed that for the evaluation of formative indicators, the literature review and expert judgment are the most important aspects.
Ensuring the content validity therefore means that the selected items are significantly representative of the domain of the construct to be measured, and that it is then possible to undertake empirical tests. MacKenzie et al. (2011, p. 304) suggest two decisions when assessing content validity:
- – verify that each item taken individually is representative of an aspect of the content domain of the construct;
- – check if all the items taken collectively are representative of the entire content domain of the construct.
Although some researchers have attempted to structure (Schriesheim et al. 1993; MacKenzie et al. 2011; Malhotra et al. 2012), use (Uhrich and Benkenstein 2010) or support (Tojib and Sugianto 2006) a quantitative procedure that provides statistical indicators to demonstrate the degree of agreement between different judges in assessing content, the assessment of this validity remains more qualitative. On this subject, Hinkin (1995) specifies that content validity is made through the construction of items that capture the domain or construct being studied, adding that according to Stone (1978, cited by Hinkin 1995, p. 969) there are no quantitative indices to establish it but judgments must be made by evaluating the correspondence of the measure to the theoretical construct.
In order to clarify these apparently divergent points of view, we will note that quantitative indices are welcome. They reassure the scale developer about the a priori adequacy of its content to a construct. These indices function as indicators of the reliability of qualitative data derived from judges’ assessments. As an indication, Perreault and Leigh (1989) presented some indices to attest to inter-judge reliability, including Cohen’s Kappa coefficient, which is often used for this purpose. As in any qualitative protocol, it is obviously fruitful to ensure the coherence of the approach and the results that emerge. Nevertheless, estimates of the degree of agreement between the experts cannot be used as sufficient evidence of the quality of the measuring instrument, but can be used as an indication to continue the scale development process.
It should be recalled that, although content validity is necessary to conduct the rest of the scale construction process, it is not sufficient to attest to the correspondence of scale to the measurement of the phenomenon (Malhotra et al. 2012). Indeed, other levels of validity, which we will discuss below, must be established to authorize the use of the measuring instrument. It must also be stressed that content validity is not only an assessment of quality when developing a scale, but is also almost decisive when adapting or even adopting a scale. Each time a scale is borrowed, modified or constructed, it is imperative to focus on the items one by one to verify their correspondence with certain aspects of the phenomenon to be evaluated (face validity) and to verify if all the selected items are capable of reproducing the content of the phenomenon to be operationalized (content validity), in the context of the proposed study.
Let us add that the inspection of the format of the items (type of scale, number of response points, response labels, etc.) is also important in order to reach content validation. Indeed, it is not only the content of an item that contributes to the meaning created in the mind of a respondent regarding a phenomenon. All the design attributes of a scale are to be considered because they form a cluster of signals on which respondents base their understanding of content and therefore of the construct to be examined. From one format to another, the content of the items may differ significantly according to other perceptions (see Chapter 5). Even if this seems to make the process of operationalizing a construct more cumbersome, such an undertaking makes it possible to have more confidence in the choice of indicators and a faster and more precise adjustment of the scale for the indicated phenomenon.
Hinkin (1998) has attested in this regard that investing time and effort to assess the adequacy of content at the very beginning of the research process reduces subsequent problems concerning the inadequacy of the psychometric properties of the measure. Moreover, as MacKenzie et al. (2011) have pointed out, all the care taken in defining the focal construct must also be considered for its different dimensions when it is multidimensional (definition, distinction from other constructs, nature of the relationships with the focal construct, etc.). There is no doubt about the relevance of this phase of content validation for each latent construct and its indicators.
Figure 7.1 proposes, for a construct with two dimensions A and B, an illustration to support the understanding of the concepts of face validity and content validity of a sample of items.
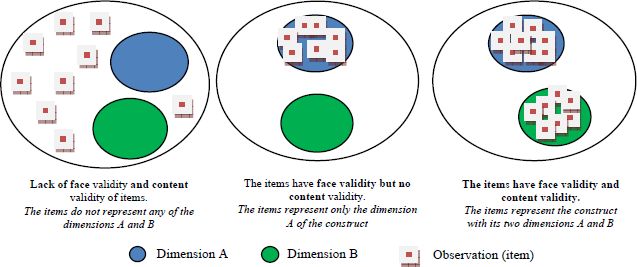
Figure 7.1. Distinction between face validity and content validity
7.2.2. Construct validity
This aspect of validity, also called trait validity, “refers to how well the items in the questionnaire represent the underlying conceptual structure” (Rattray and Jones 2007, p. 238). According to Peter (1981, p. 134), “the term construct validity generally is used to refer to the vertical correspondence between a construct which is at an unobservable, conceptual level and a purported measure of it which is at an operational level”. Bagozzi and Yi (2012, p. 18) define the construct validity as: “the extent to which the indicators of a construct measure what they are purported to measure”. The construct validity thus seeks to establish whether the scale provides an adequate representation of the phenomenon studied. To do this, two components of the construct validity are to be estimated, namely, convergent validity and discriminant validity, defined as follows:
- – convergent validity consists of seeing whether the items establishing a priori the same phenomenon are strongly correlated;
- – discriminant validity consists of seeing whether the items establishing a priori different phenomena (or distinct dimensions of the same phenomenon) are not correlated or at most weakly correlated.
This construct validity has mobilized the most investigations by developers and users of measurement scales, particularly reflective ones. Moreover, it seems to be the most difficult to demonstrate. The presentation of the main protocols of its assessment will be discussed in section 7.3.
7.2.3. Nomological validity
This validity, sometimes called predictive validity, focuses on studying the potential of a measurement scale of a phenomenon to establish links with other measurement scales of other constructs that are theoretically supposed to be linked. Bergkvist (2015, p. 247) notes that some definitions of predictive validity are not universally accepted. In fact, according to several researchers (Venkatraman and Grant 1986; Gurviez and Korchia 2002; Brahma 2009), it is generally accepted that:
- – predictive validity seeks to link the construct, through its measurement, to a single antecedent or consequence;
- – nomological validity attempts to ensure that the construct can be associated with several constructs in a network of more complex relationships.
According to Bagozzi (1981b, p. 327), the difference between predictive validity and nomological validity is a matter of degree, not nature. Figure 7.2 illustrates the distinction between these two often confused types of validity.
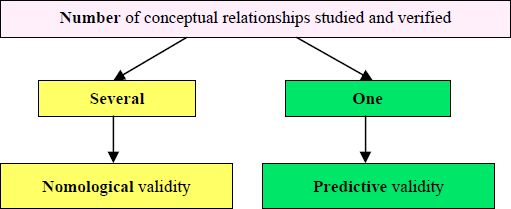
Figure 7.2. Distinction between nomological validity and predictive validity
That being said, can a measurement scale that proves to have good content validity and reliability, while demonstrating good construct validity, be considered scientifically interesting to use if it does not enable identification of the planned conceptual links? We do not believe so; the nomological validity must be demonstrated to prove the adequacy of the measure to identify the phenomenon under study and its interdependence with other phenomena. This validity may not have received the attention it deserves in the development processes of many scales, as researchers often overlook this step. However, it must not be forgotten that the objective of the measure is not only to enable an adequate reading of a construct, but also and above all, to allow a confrontation of this construct with others that can lead to a better interpretation of the underlying phenomena.
To establish this validity, it is a question of choosing, according to the available theoretical foundations, a hypothetical framework supporting relationships between the phenomenon under study and other phenomena. Let us add that when the scale is first-order reflective multidimensional, which is often the case with many marketing constructs, it is necessary to identify the specific hypotheses for each of the dimensions. It should be noted, however, that the objective of nomological validity is not to seek to test hypotheses relating to problem-defining hypothetico-deductive research, but rather to focus on a few relationships identified and approved in literature in order to test the nomological validity of a new scale under construction.
On the technical side, the data obtained from the administration of different scales relating to the different phenomena studied with a sample of respondents would make it possible, through the appropriate statistical analyses (e.g. regression, structural equation methods), to test whether such relationships can exist. When relationships are established, the nomological validity of the scale under construction is a priori shown. However, it should be noted that the absence of links does not make it possible to definitively decide whether nomological validity is sufficient or not. Indeed, the absence of relationships can reflect one of the following two alternatives:
- – absence of nomological validity;
- – absence of the presumed conceptual links.
What then can be done to reassure oneself as to this nomological validity when the tested links are not verified? It is possible, for example, to re-compare the newly designed scale with other scales testing other links between the construct under study and other phenomena. Moreover, as we pointed out in Chapter 2, replicating the measurement of a phenomenon by confronting it with other construct measures makes it possible to support the nomological validity of a scale, even when it is already established. However, Peter (1981) points out that even when links are confirmed between two concepts (C1 and C2) by two measures (M1 and M2), the results do not definitively confirm nomological validity. He also argues that other aspects may explain such a relationship, including the possibility that the two instruments (M1 and M2) actually measure a single construct (C1, C2 or even C3).
This suggests that nomological validity is only obtained when several theoretically proven links between the studied construct and other constructs are empirically confirmed through the confrontation of the scale to be validated with others already validated. If the confirmation of nomological validity fails, the test must be repeated with other variables to verify other conceptual links or, if necessary, challenge the scale, while reverting to previous steps in developing the scale. Figure 7.3 shows this search for nomological validity.

Figure 7.3. Finding the nomological validity of a measurement scale. For a color version of this figure, see www.iste.co.uk/frikha/marketing.zip
Note that nomological validity is essential for all types of specifications (reflective and formative) and cannot be assessed if the previous validation steps (example: content validity) are not passed. Indeed, nomological validation of a measurement is a step that is at the end of the scale development process. Of course, this does not mean that once the scale is validated, its future adaptations (or adoptions) will be exempt from investigation (for reflective scales: content validity, dimensionality, reliability and construct validity). In fact, once developed and validated, an instrument has the potential to be reused, but all the verifications we have previously presented must be implemented again to verify the equivalence and adequacy of the measure of the studied construct and the context of its use.
| Types of validity | Definitions | Steps in the development process | Main reviews |
| The validity of a scale | The ability of a scale to really measure the construct that it seeks to understand. | The concern for validity is omnipresent in the process of choosing and constructing a scale. | Content validity. Construct validity. Nomological validity. |
| Content validity | A question of establishing, after having verified that each item corresponds to certain aspects of the phenomenon (face validity), that all the items generated and formatted (scale format, response labels, etc.) reproduce the content of the construct in its different facets. | This concern is crucial at the beginning of the scale development process. | Literature review. Expert opinion. |
| Construct validity | The aim is to demonstrate that the scale provides an adequate representation of the phenomenon studied. It is in a way the correspondence between a conceptual construct and an operational measurement scale. | This concern for validity is at an intermediate stage in the process of developing a reflective scale. Once content validity is established a stable, reliable and conceptually and empirically acceptable factor structure (EFA) is obtained. Similarly for formative models, this concern for validity is important once the content validity is established. | Convergent validity, which consists in seeing if the items measuring a priori the same phenomenon are strongly correlated. Discriminant validity: consists in seeing if the items measuring a priori different phenomena (or distinct dimensions of the same phenomenon) are not correlated or at most weakly correlated. |
| Nomological validity | The aim is to establish that the construct studied can be associated (through the designed scale) with other constructs in a network of theoretically defined complex relationships. | This concern for validity lies at the end of the process of constructing a scale, once the content validity and the construct validity are verified. | Literature review defining a hypothetical framework to be tested. Empirical testing of hypotheses. |
7.3. Protocols for checking the construct validity
Of the three types of the validity of a measurement scale previously described, the construct validity has garnered great interest in construction processes and choice of scales (in particular multi-item reflectives), leading to protocol developments for its verification. Two main approaches are possible to test it: the multitrait-multimethod matrix (MTMM) and confirmatory factor analysis (CFA). These two approaches are based on two different measurement logics: for the MTMM, a logic of multiple measurement methods, while for the CFA, a single measurement method logic (no duplication required). In addition, it should be noted that these two protocols propose an assessment of reliability, which is, it should be recalled, a necessary condition for progress in the search for the construct validity.
7.3.1. The multitrait-multimethod matrix (MTMM)
This matrix is developed by Campbell and Fiske (1959) to assess the construct validity (convergent validity and discriminant validity). This approach has been the subject of some discussion on its potential to estimate validity (Bagozzi and Yi 1991; 1993; Cote 1995). Although not very popular with very modest applications (compared to the CFA), mainly because of the difficulty of using multiple measurement methods with the same items (traits), the MTMM approach seems relevant for studying the validity of several constructs and measurement methods (Heeler and Ray 1972; Lammers 1985; Tein et al. 1994; NeiBecker 1997) and its use has been highly recommended. For example, in the field of research on family purchasing decision making, such an approach has often been proved to attest to the validity of the constructs studied and to make comparisons between different traits (items) and measurement methods; in short, to construct and compare measurement scales (Szybillo et al. 1979; Seymour and Lessne 1984; Hopper et al. 1989; Frikha 2009).
MTMM is a matrix of correlations between different items (traits) measured by different methods, which of course presumes that the data has metric properties. In the case where three traits are measured by three methods, the matrix takes the following form (Figure 7.4).

Figure 7.4. Multitrait-multimethod matrix. For a color version of this figure, see www.iste.co.uk/frikha/marketing.zip
Malhotra et al. (2012) have suggested that the MTMM approach can be used to establish the convergent and discriminant validity of single-item measurements. However, the use of such an approach seems to be encouraged when several methods of measuring different traits (items) are considered. While the difficulty of finding different measurement methods for the same traits has sometimes been pointed out (Peter 1981; Brée 1991), this approach offers great richness where applied in that it provides a wealth of information (see section 7.4). The three main benefits are as follows:
- – first, it allows us to verify if a construct (trait) can be measured by different methods. This possibility is of paramount importance because it can inform us, for example, about the possibility of having several formats of a scale (measurement method) that can be associated with the selected items;
- – second, it allows us to study whether the traits (items) can be differentiated from each other;
- – third, it offers the possibility of distinguishing variations between different traits (items) caused by their individual characteristics from those due to measurement methods.
Moreover, Heeler and Ray (1972) have long pointed out that the possibilities for validating studies seem to expand with the MTMM approach.
It should be noted that it is also possible to introduce in this matrix the monotrait-monomethod reliability diagonal which represents the correlations of the measurements of the same trait using the same method, for example by making measurements spaced by a time interval, which recalls the principle of test-retest reliability. However, this reliability diagonal is not often indicated. Particularly adapted to multi-item reflective scales, for each of the two facets of the construct validity, the MTMM matrix operates as follows.
7.3.1.1. Convergent validity
Convergent validity considers that the same trait (item) measured by two or more different methods gives the same results. This reflects the degree of agreement between different methods in their evaluations of a trait, estimated by the strength of the correlation between measures of the same trait (item). Measurements of the same phenomenon must then be correlated. In this MTMM matrix, it is the correlations represented on the monotrait-multimethod diagonal that make it possible to assess the convergent validity. In order to demonstrate good convergent validity, these different coefficients must be significantly different from zero and sufficiently high. In the previous figure “rA2A1”, for example, the correlation coefficient of item (trait) “A” measured by method “1” and the same item “A” measured by method “2” is shown. The measurement method “1” can be in Likert format and the method “2” in icon format.
7.3.1.2. Discriminant validity
Discriminant validity suggests that one trait must be distinguishable from another. This implies that the same instrument gives different results when used to measure different phenomena (items). According to this logic, measurements of the same trait must be more correlated than measurements of different traits. According to the MTMM matrix, to test the discriminant validity, three conditions must be verified:
- – the correlation between two different measures of the same trait must be higher than the correlations of different traits measured by different methods. To do this, each correlation coefficient of convergent validity (monotrait-heteromethod) must be higher than the correlation coefficients located on the same line and in the same column, in the heterotrait-heteromethod triangles. To assess this aspect, it is necessary to count the proportion of times the diagonal values are higher than the corresponding values in the heterotrait-heteromethod triangles;
- – the correlation between two different measures of the same trait must be higher than the correlations of different traits measured by the same method. Each correlation coefficient of convergent validity (monotrait-heteromethod) must be higher than the correlation coefficients in the heterotrait-monomethod triangles determined by one of the two traits (items) composing the diagonal coefficient. To evaluate this condition, it is necessary to count the proportion of times the diagonal values are greater than the corresponding values in the heterotrait-monomethod triangles;
- – the same trend in correlation coefficients should be observed in all heterotrait triangles. That said, the way in which the different items are correlated must be similar in all monomethod and heteromethod triangles. To assess this third condition, it is possible to carry out a visual consultation of the correlation coefficients when the matrix is simple (a small number of coefficients) or to calculate the Kendall concordance coefficient W1.
Below is an example illustrating the application of a multitrait-multimethod matrix from Frikha (2009).
7.3.2. Confirmatory factor analysis
Structural equation modeling (SEM) methods examine the relationships that may exist between variables (items) and constructs to evaluate both measurement models (scales) and underlying structural models (Gerbing and Anderson 1988). These methods can thus be used at two stages of the measurement scale validation process:
- – when establishing the construct validity (convergent validity and discriminant validity) while testing the links between the observable variables (items) and the construct(s) reflecting them (measurement model);
- – when establishing nomological validity by confronting the scale with others according to a theoretical framework assuming a set of links between the different crossed constructs (structural model).
Apart from its potential to evaluate all the properties of a scale (reliability, convergent validity, discriminant validity and nomological validity), the success of structural equation modelling methods, also known as structural equations with latent variables and measurement errors, has been greatly facilitated and encouraged by the development of ad hoc software, the consideration of measurement errors and, in addition, the possibility of using a single measurement method to collect data used to establish the validity of the construct, unlike the MTMM approach. Listing the scales that have been subjected to this construct’s validation protocol has now become impossible given its use. Indeed, the application of SEM for scale development covers many areas and is widespread (Guiry et al. 2006; Frikha and Khrouf 2013; Hollebeek et al. 2014). Figure 7.6 illustrates the measurement models of three constructs (X, Y and Z) related in a structural model.

Figure 7.6. Measurement model and structural model. For a color version of this figure, see www.iste.co.uk/frikha/marketing.zip
In this section, we will focus only on the evaluation of a reflective measurement model to attest to the quality of the fit of the measurement model and to evaluate, in addition to reliability, the construct validity (convergent validity and discriminant validity). The evaluation of a measurement model by structural equation methods thus seeks to confirm (or not) the structure of the scale (to empirical data) where a set of items is identified as reflecting a latent construct (reflective model). Although nomological validity is also important to verify and structural equation modeling methods are very efficient tools for this undertaking, it should be noted that depending on the constructs to be crossed, several statistical methods can be used to verify the established relationships. Without dwelling on the technical considerations that are often quite elaborate but very explicit in several writings (Jöreskog and Sörbom 1982; Bagozzi and Yi 1988; Akrout 2010), we will present in the following the main foundations and the general approach to be followed during a confirmatory factor analysis.
The structural equation modeling methods, while using a correlation or covariance matrix, compare the collected data with the model of the configured relationships. Several methods are possible, some based on covariance estimation (CB-SEM) and others based on variance estimation (PLS-SEM). Before implementing a confirmatory factor analysis, it is necessary to ensure that a set of conditions for applying the proposed estimation method are met, in particular in terms of sample size, the nature of the variables, etc. For example, for the Maximum Likelihood (ML) estimation method, often used for its robustness in estimating a measurement model, it is imperative, among other things, to verify the normality of the data and to have a sufficient number of observations. For this last point, the debates are very rich: a number 10 times greater than the number of observable variables (items) seems to be a minimum requirement. Admittedly, other estimation protocols are possible when restrictions exist in terms of sample size, data normality or, in the context of a purely formative measurement model, such as the partial least squares method (PLS) (Roy 2008; Henseler et al. 2009; Wetzels et al. 2009; Hair et al. 2011; Wong 2013; Hair et al. 2014).
More generally, several estimation methods are possible, each with its own constraints and advantages. Once all the conditions required for the application of the chosen estimation technique have been met, the researcher can progress in the analysis of the measurement model. He or she specifies all the links between the items associated with the latent variables they are supposed to capture and analyzes the quality of the scale. In this perspective of evaluating the validity of a reflective measurement model, a series of steps are generally to be followed. These are mainly the verification of the quality of the model fit, the assessment of reliability, convergent validity and discriminant validity.
7.3.2.1. The adjustment of a model
It is possible to assess the quality of the adjustment of a measurement model to empirical data collected using several indices. For the most commonly used maximum likelihood (ML) estimation method, the indices are generally grouped into three main categories: absolute indices, incremental indices and parsimony indices (see examples: Jöreskog and Sörbom 1982; Bagozzi and Yi 1988; Akrout 2010; Malhotra 2011; Bagozzi and Yi 2012). Among these indices, we note the following ones:
- – absolute indices: these indices make it possible to see if the model fits the empirical data collected. One of the most frequently recommended indices is the Chi-square test. This test is considered not significant for a value of p ≥ 0.05. Other absolute indices are also frequently used, such as the GFI (Goodness of Fit Index) and the AGFI (Adjusted Goodness of Fit Index) for which values above 0.9 are often considered acceptable. For other indices such as RMSEA (Root Mean Square Error of Approximation), RMSR (Root Mean Square Residual) and SRMSR (Standardized Root Mean Square Residual), low values close to zero are requested, although the suggested thresholds for these indices are different, a value below 0.05 is often considered acceptable;
- – incremental indices: these indices attempt to compare the specified measurement model with another model, which is generally the null model where all variables (items) are assumed to be independent. Among the most commonly used indices are: NFI (Normed Fit Index), CFI (Comparative Fit Index), TLI (Tucker Lewis Index) and IFI (Incremental Fit Index). For these indices, the closer the value is to 1, the better. The usual acceptable values are generally greater than 0.9;
- – parsimony indices: in addition to the incremental indices, parsimony indices compare the adjustment of models of varying complexity according to the number of parameters to be estimated. Among them are: PGFI (Parsimony Goodness-of-Fit Index) and PNFI (Parsimony Normed Fit Index). Among the compared models, the one with the highest values for these two indices (PGFI and PNFI) has a better fit. For other indices such as the AIC (Akaike Information Criterion), the lower the value of this index for a model, the better the fit of the model in question.
7.3.2.2. Reliability
The reliability tests previously presented (chapter 6) are of greater use during the exploratory phases and, more particularly, following the exploratory factor analysis. Other tests are more suitable for confirmatory factor analysis. Indeed, during the validation phases of a measurement, it is essential to have less risk when assessing the reliability of all selected items. As we have already noted, in parallel with the examination of the construct validity from this confirmatory factor analysis perspective, it is possible to re-examine the reliability of a construct. However Bagozzi and Yi (2012, p. 16) believe that the use of structural equation modeling methods “makes such a practice unnecessary or redundant, because the information provided in factor loadings and error variances incorporates reliability so to speak”.
However, it is possible to present reliability more explicitly. To take this initiative, it is common to calculate the Jöreskog rho coefficient (ρ) (1971), which is less sensitive than Cronbach’s alpha to the components of a scale. The generally acceptable thresholds for Jöreskog rho are the same as those used to assess Cronbach’s alpha: a value greater than 0.8 recommended for a confirmatory step in the scale development process. In addition to this test, other reliability indices exist such as Fornell and Larker’s rho (1981). For this index, a value greater than 0.60 is often considered acceptable.
7.3.2.3. Convergent validity
In order to assess convergent validity, several methods are possible. Without mentioning all these methods, we present those that are most used:
- – Anderson and Gerbing (1988, p. 416) propose to examine the loadings associated with items that are supposed to represent the same construct that allow, when they are high, the attestation of the convergence of the items to the construct in question. Hair et al. (2011) suggest that loadings should have a minimum value of 0.7. But we note that some scale developers accredit a threshold of 0.5. Hair et al. (2009, p. 679) believe that a value of 0.5 is possible, but that it is preferable to have a value of 0.7 or more;
- – another index, proposed by Fornell and Larker (1981), also makes it possible to evaluate the convergent validity, namely the average variance extracted (AVE), explaining the variance explained by the model. For this index (AVE), values above 0.5 are generally considered acceptable.
7.3.2.4. Discriminant validity
Discriminant validity is a question of establishing that one construct can be distinguished from the others. To test discriminant validity, a variety of methods are available. In this regard, Voorhees et al. (2016, p. 119), based on a content analysis of a wide range of articles, found that some tests are more common, but noted that each test has its advantages and limitations. Among the most widely used tests:
- – the method proposed by Fornell and Larker (1981) suggests comparing the estimated AVE for each construct with the shared variance (the square correlation) between the construct and the other constructs in the model. When the value of the AVE, for a construct, is greater than the shared variance (squared correlations) between it and all the other constructs, then the discriminant validity is established;
- – another possibility for assessing discriminant validity, which according to Voorhees et al. (2016, p. 122) has been wrongly attributed to different authors such as Anderson and Gerbing (1988), who attributed it to Jöreskog (1971, see Anderson and Gerbing 1988, p. 416), consists in comparing two models: one without constraint (the correlation of factors is free) and one under constraint (the correlation between two factors is fixed at 1), the comparison of the Chi-square difference of the models, when significant, provides evidence of the discriminant validity. More specifically, a lower Chi-square value for the unconstrained model indicates that the traits are not correlated, thus attesting to the discriminant validity.
7.4. Practical guides for assessing the validity of a measurement scale
Of the different protocols for assessing the validity of a measurement scale, we will attempt, in this section, to raise some questions and propose some warnings. The objective is to allow for a better visualization of the quality of a scale and a better use of the recommended tests. It should be noted that, in general, a single index may not be sufficient to demonstrate the reliability and validity of a scale. Multiplying indices and approaches provides more robust evidence on the quality of a scale. Moreover, although the general approach to be followed to support the different technical steps of validating a scale has been the subject of much writing, we believe that multiplying practical guides can help scale developers in the different choices to be made. Below, we will make some recommendations.
7.4.1. Focus on confirmatory factor analysis (CFA)
Confirmatory factor analysis, which is widely used for validation purposes, has some limitations and precautions are required, in particular two: reading the resulting indices and selecting the proposed modifications.
7.4.1.1. Precautions when reading the indices
When using confirmatory factor analysis to test the adequacy of the measurement model, it is desirable to use several adjustment indices. It should be recalled that the above-mentioned indices are not the only available parameters, some of them are specific to the recommended estimation method. That said, when the above-mentioned indices are used, particularly with the use of the maximum likelihood (ML) estimation method, it is generally recommended to use at least two indices of each type (absolute, incremental, parsimonious). However, it is necessary, on the one hand, to avoid choosing indices according to their values and, on the other hand, to keep in mind that for many indices, the acceptability thresholds are different and are often the result of expert judgment. In addition, the values of some indices may vary according to a set of parameters including the sample size, the number of items and the parameters to be estimated. Apart from these considerations, no method of assessing the reliability and construct validity (convergent and discriminant validity) proposed in the confirmatory factor analysis seems infallible. For example, Bagozzi (1981a) commented on Fornell and Larker’s (1981) proposals, presented above, while noting some limitations. The interpretation of the indices must, therefore, be done with great caution.
7.4.1.2. Precautions when choosing modifications proposed by structural equation modeling methods (SEM)
Sometimes a measurement model is not valid following a confirmatory factor analysis. In this case, although the structural equation modeling methods offer tools to examine the possibilities of modifications to be made at the scale level, it is not insignificant to point out that the use of the modification protocols suggested by these methods (SEM) must be done with great moderation. Care must be taken in the search for a model that fits better to the data. This by no means concerns technical or, more specifically, statistical research on a model that makes it possible to obtain better indices, but, as Anderson and Gerbing (1988, p. 416) have already pointed out, we must seek a theoretical support that provides the foundations for a structure to be tested. The authors point out that “re-specification decisions should not be based on statistical considerations alone but rather taken in conjunction with theory and content considerations… both greatly reduce the number of alternate models to investigate”.
Browne (2001, p. 113), on the other hand, drew attention to the fact that some use confirmatory factor analysis (CFA) for exploration purposes, which is not its objective, but that of the more appropriate exploratory factor analysis (EFA). Hair et al. (2009, p. 664) note that when a researcher conducts a confirmatory factor analysis, they assume from the outset that each item is linked to a single well-defined construct, the CFA only allowing a predetermined theoretical structure to be confirmed or rejected. All technically feasible modifications are of no interest if no theoretical framework can support the conception of indicator relationships with the latent construct(s) being measured, hence the omnipresent concern for content validity. Even the few possible purifications of items that can be considered in addition to those already undertaken at the initial stages of the scale development process (dimensionality, reliability), particularly when the SMCs (squared multiple correlation) associated with some items are very small, must be subjected to such reflections. A model can only be considered good or bad in terms of a theoretical framework and empirical and statistical support. Moreover, with each modification undertaken, it is desirable to re-test the envisaged model with new empirical data, hence the importance of this iteration process of collecting-validations and of going back and forth between the steps of the scale development process.
7.4.2. Focus on the multitrait-multimethod matrix (MTMM)
Although often neglected in favor of confirmatory factor analysis (CFA), the multitrait-multimethod approach (MTMM) to assess the construct validity accommodates to several situations (multiple products, multiple contexts, multiple respondents, multiple scale formats, etc.) with a large potential for exploitation, even if it is subject to some limitations. We will discuss below some of its potential applications and some of its limitations.
7.4.2.1. Potential applications of MTMM
Particularly suitable for reflective measurement scales, the MTMM matrix has a number of advantages that should be highlighted:
- – the use of MTMM can be important in intercultural studies. Indeed, each sample from a culture can be considered as a method of measuring the same items. Of course, different evaluations between cultures of the same aspect (item) are possible, but for measurements of the same trait, higher correlations must logically be observed than between those of measurements of items supposed to be different. This method ensures that the same element is measured (across different groups) and that the necessary comparisons between cultures are then made;
- – the usefulness of the MTMM can be decisive for testing different formats (Likert, semantic differential, etc.) of a scale. Admittedly, the use of such an approach entails the use of different measurement methods, but even if it is sometimes difficult to make a clear distinction between different response formats, it is at least possible to observe the format potentially most interesting to retain, allowing for a greater convergence of perceptions materialized by the highest correlations when measuring the same trait (item) compared to the other traits supposed to be distinct. In addition, this approach makes it possible to assess whether different formats can give the same level of evaluation of the same item without altering its meaning, which could reassure us about the possibilities of future adaptation of the scale to different study contexts;
- – for some areas of interest, the MTMM approach can be very useful in assessing the validity of the construct while allowing a more precise examination of differences where they exist between the evaluation of different traits. As such, the field of research on decision-making dynamics within the family unit has benefited greatly from this matrix to better understand the perceptions of family group members. Indeed, this approach makes it possible to target the different traits (example: the roles played in a purchasing decision) or factors (example: types of products) for which the perceptions of the different members selected to measure everyone’s involvement (example: parents or children) converge and/or diverge, which allows for a better understanding of power dynamics within the family. The possibility of examining convergences and divergences for different items according to different groups of individuals can be extended to the understanding of many phenomena where groups of individuals, with different specificities, are retained as methods of measuring the same indicators;
- – the MTMM approach can also be very useful for detecting:
- - redundant items (for which correlations are high);
- - measurement methods that do not allow convergence in the evaluation of the same item (low correlation between different measures of the same item);
- - measurement methods causing a problem of distinction between divergent items (high correlation between measurements of different items).
This approach therefore offers a valuable diagnostic tool to identify problems in the construct validity (items and/or methods) when they exist.
7.4.2.2. The limits of the MTMM
The multitrait-multimethod method (MTMM) is based on correlation coefficients. However, no level of the coefficient is explicitly given to indicate good convergent validity, which may be a potential source of subjectivity in the analysis of the results. In order to circumvent this limit, the researcher, while relying on their judgment, may rely on the advice of experts in the field of research to accredit an acceptable threshold for the correlation coefficient. With regard to discriminant validity and more particularly for the first two conditions, it is logical that when the coefficients of convergent validity are all higher than the discriminant coefficients, discriminant validity is established. But this is not always the case. What proportion, in terms of the number of converging coefficients that are lower than the corresponding discriminating coefficients, should be used to accept the first two conditions of discriminant validity? In this case, the researcher must argue their choices and adjust them in relation to the findings observed in the context of their research discipline.
7.4.3. Synergy in perspective
The growing interest in protocol development to ensure the construct validity should not lead scale developers to turn a blind eye to the need to establish other forms of validity associated with a scale. Indeed, there is no reason to believe that the construct validity is sufficient to establish the validity of a measurement scale.
Validity should be seen as a sequential process in which all steps are involved at some moment in the scale development process. The most important thing is to take full care of each of the components of validity to ensure a faster, less costly process and, above all, to ensure that the results are as close as possible to the true value of the phenomenon being studied. We will relay below some of the synergy effects that can result from the different variants of the validity of a scale and/or their validation protocols:
- – it is clear that reading the indices for assessing convergent and discriminant validity, according to the two validation protocols of a construct (CFA and MTMM), are largely based on the researcher’s judgments, the thresholds defined by experts and research in a specific field. Indeed, as we have already pointed out, the levels of the various indices considered acceptable to attest to the construct validity are more often based on use than on a real fixed scientific assessment. It is also very useful to note that each approach has its advantages and disadvantages. This shows the value of triangulation, not only of the indices, but also of the approaches in particular of the validation that the researcher could consider. No one construct validity method (MTMM and CFA) can be considered superior to the other. Each can be used for a relevant evaluation of certain aspects of a measure. These approaches seem rather complementary. For example, Kim and Lee (1997) used the logic supported by the two approaches to construct validation (MTMM and CFA) to allow for a more detailed examination of the measurements. Bagozzi (2011, pp. 288–289) explicitly supported the benefits that can be derived from exploiting different approaches to establishing the construct validity and even the potential gains that can be made by combining different protocols in the same study;
- – whatever the method used to test the construct validity (MTMM or CFA), the examination of discriminant validity is of no interest when convergent validity is not established. Moreover, this logic can be applied to the whole process. Thus, for a reflective model, unless content validity is established, it is not appropriate to test the dimensionality of a scale (EFA). Similarly, it is only when reliability is confirmed for each of the established dimensions that it is possible to focus on testing the construct validity and finally, of the nomological validity. Of course, this in no way excludes the interest of undertaking, at times, a back and forth between steps in order to adjust the scale. For example, when the dimensions identified through an exploratory factor analysis do not match the researcher’s expectations, it is necessary to turn back, return to the conceptual framework and potentially solicit some experts to better explain the factors obtained and attest to the validity of their content. Once the explanations have been found, come back to the field to collect new data, test dimensionality, reliability, convergent validity, etc.;
- – it is very useful to document the entire procedure used for testing and validating the measurement model. Indeed, in addition to all the details relating to the definition of the construct, the production of items, etc. highlighting all of the considerations and indicators used to evaluate the scale effectively ensures its relevance in identifying the expected realities. Admittedly, the objective of this undertaking is not to overload the discussion with overly technical comments that are useless for understanding the general approach adopted, but to provide a framework for analyzing the scale in order to facilitate the study of its equivalence with other contexts and thus facilitate its future adoption;
- – evaluating the content validity of a set of items is of great interest not only for establishing a first diagnosis concerning the correspondence of indicators to the definition of the construct and its different facets, but also to undertake an arbitration for a first purification of the items. Indeed, given the considerations in terms of the sample size required for adequate field tests and its dependence on the number of items, this qualitative purification has the advantage of making the number of essential observations less constraining. Admittedly, this judgment must not reduce the number of indicators to be kept, but must be able to justify the interest of the items to be used for the next steps and to verify for the formative models that all the items are identified without omission. Content validity is by no means an unnecessary step, it ensures that the development of the scale progresses more seamlessly and facilitates the other steps of the process.
7.5. Conclusion
For a better assessment of its potential to adequately represent the construct and allow for its future application, any draft scale deserves careful consideration. Indeed, a detailed evaluation of the quality of the tool provides evidence of the robustness of the conclusions that can be drawn from its use. We have, therefore, emphasized the fertile notion of validity. From validation approaches, we have identified a set of practical recommendations.
At the end of this chapter, it is clear that the measuring instrument can only be refined gradually. The protocols and statistical tests for validating a scale are not exempt from a funnel approach that promotes step-by-step tool adjustment. The process of building and validating a measurement scale seems long, tedious, thorny, etc., to such an extent that it never seems to end. In order to provide respondents with adequate support (scale) to make their evaluations as accurate as possible around a phenomenon that is difficult to observe, the validation of a measurement scale seems to take advantage of the benefits of multiple indices and evaluation methods. Reducing errors that can damage the quality of an instrument does indeed require the deployment of a very detailed examination that can be fostered by the synergy of the efforts made by many research studies in this field.
7.6. Knowledge test
- 1) How does one distinguish between content validity and face validity?
- 2) How important is the content validity in a scale building process? How does one establish it?
- 3) How does one measure the construct validity of a reflective multi-item measurement scale? Which protocol should be chosen?
- 4) What are the necessary conditions to set up a multitrait-multimethod analysis (MTMM)?
- 5) What are the requirements for implementing a confirmatory factor analysis (CFA)?
- 6) What differences can be highlighted between a multitrait-multimethod analysis (MTMM) and a confirmatory factor analysis (CFA)?
- 7) How does one distinguish between predictive validity and nomological validity? In your opinion, what is the most interesting to check in a measurement scale construction process? Why?
- 8) How does one establish the nomological validity of a measurement scale?
- 9) To what extent can the triangulation of several approaches and statistical indicators be beneficial for the validation of a measurement scale? Give examples.
- 1 The Kendall concordance coefficient W is a non-parametric test, making it possible here to compare the correlations between the items in the different triangles of the matrix to see if the correlations of the items are similar in all the heterotrait triangles.