
Chapter 7. Rightsizing Your Microservices: Finding Service Boundaries
One of the most challenging aspects of building a successful microservices system is the identification of proper microservice boundaries. It makes intuitive sense that breaking-up a large codebase into smaller, simpler, more loosely-coupled ones improves maintainability, but how do we decide where and how to split the code into parts, to achieve those desired properties? What rules do we use to know where one service ends, and another one starts?. Answering these fundamental questions is challenging. A lot of teams new to microservices stumble at them. Drawing the microservice boundaries incorrectly can significantly diminish the benefits of using microservices, or in some cases – even derail the entire effort. It is then not surprising that the most frequent, most pressing question microservices practitioners ask is: how to properly “slice” a bigger application into a collection of microservices.
In this chapter, we look deep into the leading methodology for effective analysis, modeling and de-composition of large domains: Domain-Driven Design, explain the efficiency benefits of using Event Storming for domain analysis, and close-out the chapter by introducing the Universal Sizing Formula, a unique guidance for effective sizing of microservices.
Why boundaries matter, when they matter and how to find them
Right in the title of the architectural pattern, we have the word “micro” – the architecture we are designing is that of “micro” services! But how “micro” should our services be? We are obviously not measuring physical length of something to assume that “micro” means one-millionth of a meter, i.e. of the base unit of length in the International System of Units (SI). So what does “micro” mean for our purposes? How are we supposed to “slice” up our larger problem into smaller services to achieve the promised benefits of “micro” services? Maybe we could print our source code on paper, glue everything together and measure the literal length of that? Or jokes aside, should we go by the number of lines in our source code – keeping that small to maintain each of our microservices also small enough? What is “enough”, however? Maybe we just arbitrarily declare that each microservice must have no greater than 500 lines of code? We could also draw boundaries at the familiar, functional edges of our source code and say that each granular capability, represented by a function in source code of our system is a microservice. This way we could build our entire application with, say, serverless functions, declaring each such functions to be a microservice. Clean and easy! Right? Maybe not.
In practice, each of these simplistic approaches has indeed been tried and they all have significant drawbacks. While source lines of code (SLOC) has historically enjoyed some usage as a measure of effort/complexity, it has since been widely acknowledged that “lines of code” is a poor measurement for determining the complexity or the true size of any code, and can be easily manipulated. Therefore, even if our goal were to create “small” services, with the hope of keeping them simple, lines of code would be a poor measurement.
Drawing boundaries at functional edges is even more tempting. And it has become more tempting with the increase in popularity of serverless functions, such as Amazon Web Services’ Lambda functions. Building on top of the productivity and wide adoption of AWS lambdas many teams have rushed into declaring those functions “microservices”. There are a number of significant problems if you go down this road. The most important of which are:
- Drawing boundaries based on technical needs
-
Per Lewis and Fowler microservices should be “organized around business capabilities”, not technical needs. It is one of the key traits of microservice architecture.
- Too much granularity, too soon
-
Explosive level of granularity early in the microservice project lifecycle can introduce crushing levels of complexity that will stop the microservices effort in its tracks, even before it has a chance to take off and succeed.
In Chapter 1 we stated the primary goal of microservice architecture: it is primarily about minimization of coordination costs, in a complex, multi-team environment, to achieve harmony between speed and safety, at scale. Therefore, services should be designed in a way that minimizes coordination needs between the teams working on different microservices. However, if we break code up into functions in a way that does not necessarily lead to coordination minimization, we will have end-up with incorrectly sized microservices. Just assuming that any way of organizing code into serverless functions will reduce coordination is misguided.
Above we stated that an important reason for avoiding size-based or functions-aligned approach when splitting an application into microservices is the danger of premature granularity - having too small, too many services, too early in your microservices journey. If you look into articles published by or about Netflix, SoundCloud, Amazon, and other early adopters of microservices – you will notice that these companies have a lot of microservices! Such companies can easily end up with hundreds or thousands of services representing a complex problem domain. That however does not mean that these companies started with hundreds of very granular microservices on day one. Rather, large number of microservices is what they optimized for after years of development, after having achieved the operational maturity capable of handling the level of complexity associated with the high granularity of microservices.
Be Careful To Not Create Too Many Microservices Too Early
Sizing of services in a microservice architecture is most certainly a journey that should unfold in time. A sure way to sabotage the entire effort is to attempt designing an overly granular system, early in that journey.
Whether you are working on a greenfield project or de-composing an existing monolith, the approach should absolutely be to start very coarse-grained: with a handful of services and increase the granularity over time.
Even if we are starting coarse-grained, taking it slow, we need some reliable methodology to determine how to size microservices. Below we will explore best practices successfully used in the industry.
Domain-Driven Design And Microservice Boundaries
At the onset of figuring-out microservices design best-pratcices, Sam Newman introduced some foundational ground rules, in his book Building Microservices. He suggested that when drawing service boundaries, we should strive for such design that the resulting services are:
- Loosely-coupled
-
services should be fairly unaware and independent of each other, so that a code modification in one of them doesn’t result into ripple effects. This also means we probably want to limit the number of different types of runtime calls from one service to another since, beyond the potential performance problem, chatty communications can also lead to tight coupling of components. Taking our “coordination minimization” approach, the benefit of loose coupling of the services is quite obvious.
- Highly cohesive
-
features present in a service should be highly related, while unrelated features should be encapsulated elsewhere. This way, if you need to change a logical unit of functionality, you should should be able to change it in one place, minimizing time to releasing that change (an important metric). In contrast, If we had to change code in a number of services, we would have to release lots of different services at the same time to deliver that change. That would require significant levels of coordination, especially if those services are “owned” by multiple teams, and would directly compromise our goal of minimizing coordination costs.
- Aligned with business capabilities
-
since most requests for modification or extension of functionality is driven by business needs, if our boundaries are closely aligned with the boundaries of business capabilities, it would naturally follow that the first and second design requirements, above, are more easily satisfied. During the days of Monolith architectures, software engineers often tried to standardize on “canonical data models”. However, the practice demonstrated, over and over again, that detailed data models for modeling reality, do not last for long – they change quite often and standardizing on them leads to frequent rework. Instead, what is more durable is a set of business capabilities that your subsystems provide. An accounting module will always be able to provide the desired set of capabilities to your larger system, regardless of how inner workings may evolve over time.
These design principles have proven to be very useful and received wide adoption among microservices practitioners. However, they are fairly high-level, aspirational principles, and arguably do not provide specific service sizing guidance needed by day-to-day practitioners. In search of such, more practical methodology, many turned to Domain-Driven Design (DDD).
Domain-Driven Design is a software design methodology that significantly pre-dates microservice architecture. It was introduced by Eric Evans, in 2003, in his seminal book of the same name 1. The main premise of the methodology is the assertion that, when analyzing complex systems, we should avoid seeking a single unified domain model representing the entire system, rather:
Multiple models coexist on big projects, and this works fine in many cases. Different models apply in different contexts.
Eric Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software
Once Eric established that a complex system is fundamentally a collection of multiple domain models, he made a critical additional step of introducing the notion of “bounded context”. Specifically, he stated that:
A Bounded Context defines the range of applicability of each model.
Eric Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software
Bounded contexts allow implementation and runtime execution of different parts of the larger system to occur without corrupting the independent domain models present in that system. After defining the notion of “bounded contexts”, very helpfully, Eric went on to also provide a formula for identifying the optimal edges of a bounded context by establishing the concept of Ubiquitous Language.
To understand the meaning of Ubiquitous Language, it is important to observe that a well-defined domain model first and foremost provides a common vocabulary of defined terms and notions, a common language for describing the domain, that subject-matter experts and engineers develop together, in close collaboration balancing the business requirements and implementation considerations. This common language or the shared vocabulary is what we call Ubiquitous Language, in DDD. The importance of this observation lies in acknowledging that same words may carry different meanings in different bounded contexts. A classic example of this is shown on [Link to Come]--the term “account” carries significantly different meaning in Identity & Access Management, Customer Management, and Financial Accounting contexts of an Online Reservation system.
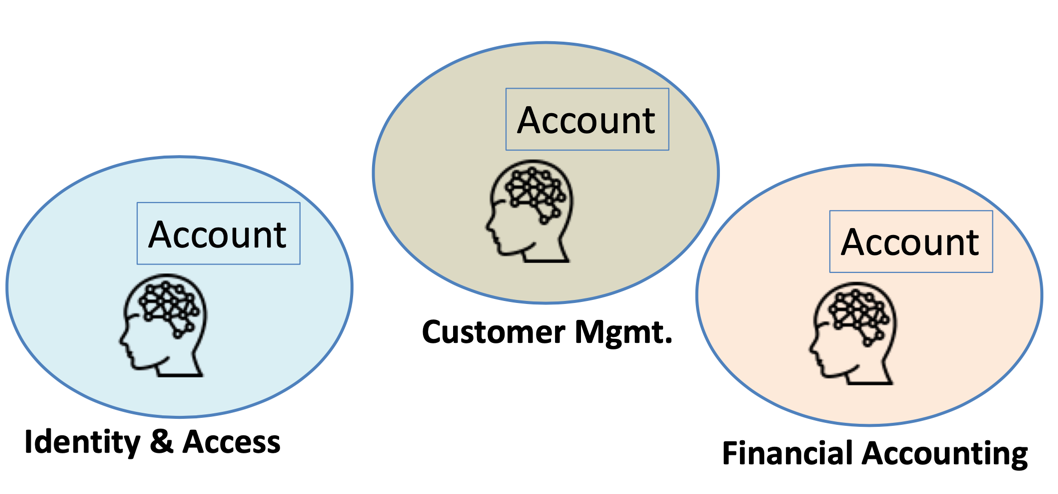
Figure 7-1. “Account” can have different meaning, depending on the domain it appears in.
(Attribution: Icon used in the above diagram were made by https://www.flaticon.com/authors/smashicons from www.flaticon.com)
Indeed, for an identity and access management context, an account is a set of credentials used for authentication and authorization. For customer management bounded context, an account is a set of demographic and contact attributes. While for financial accounting context, it’s probably payment information and a list of past transactions. We can see that the same basic english word is used with significantly different meaning, in different contexts and it is OK because we only need to agree on the ubiquitous meaning of the terms (the ubiquitous language) within the bounded context of a specific domain model. According to DDD, by observing edges across which terms change their meaning, we can identify the boundaries of
In Domain-Driven Design, note that not all terms that come to mind, when discussing a domain model, make into the corresponding ubiquitous language. Concepts, in a bounded context, that are core to the context’s primary purpose are part of the team’s Ubiquitous Language, all others should be left out. To visualize this notion, let’s look at the example from the aforementioned identity and access management context depicted on [Link to Come]:
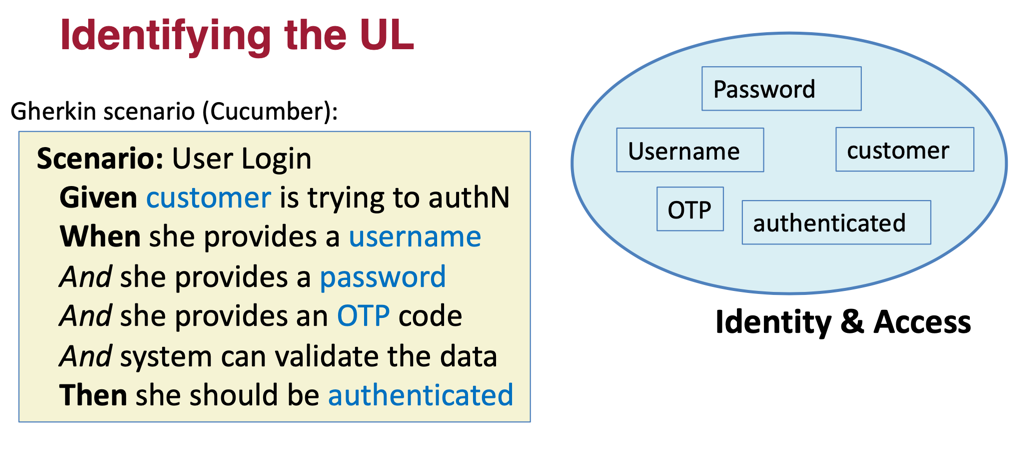
In this example we are using Gherkin syntax (of Cucumber fame) to describe a scenario in the Identity and Access Control bounded context. We can see that key nouns, highlighted on [Link to Come], in the Gherkin-style specification the terms in the related ubiquitous language. Usage of Gherkin is not essential to Domain-Driven Design, but we find it useful, if you are into that kind of thing.
Let’s get more familiar with Domain-Driven Design by exploring some of its key concepts, in the next section.
Basic Notions of Domain-Driven Design
Most of the effort in domain-driven design goes into the development of the ubiquitous language and identifying bounded contexts. However, the design work is not done, once you have the contexts identified. In practice, DDD recognizes three major types of the domains, and related context types: core, supporting, and generic. You can see an example of this on [Link to Come]. It is important to identify the correct type of the domain, in order to make decisions about the level and type of effort that should be applied to its implementation.
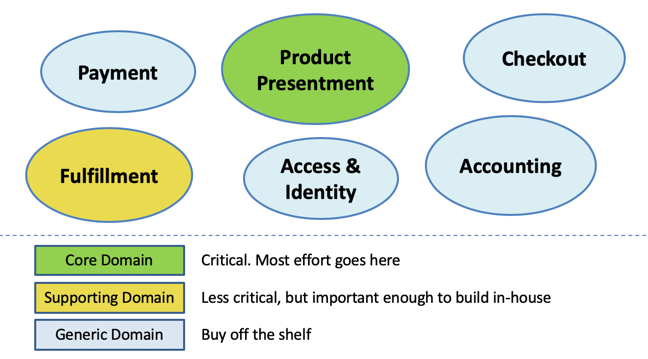
Figure 7-2. Core, Supporting, and Generic domain types.
Core Domain is the distinctive part of a model, central to the user’s goals, that differentiates the application and makes it valuable.
For instance, in [Link to Come], representing possible domains of an online flight reservation system, we could decide that Product Presentment, the user interface that allows customers to find and select desired flights is the core domain. It is essential to customer’s ultimate goal of finding a suitable flight and the overall functionality of the system . Its unique implementation is what differentiates a flight reservation system from, say apparel online store - the online store’s product presentment would likely be significantly different from that of a flight reservation system. Therefore Product Presentment domain is the core domain of the system.
We will further need to identify key “supporting domains” of the system. These are the domains that can materially differentiate us from the competition, in the same space, if we get them right. A well-known example of such key supporting domain comes from the early days of amazon.com The care and level of innovation that Amazon.com poured into the checkout experience on their website, seemingly a commodity functionality, was quite astounding for the outside observers. By inventing the one-click purchasing and fine-tuning smallest details of the experience to maximize conversion and completion rates, Amazon.com put a lot of care in this subdomain, even if it wasn’t a core domain from the first sight.
In our case, we could identify “fulfillment” as a key supporting sub-domain.
And lastly, any large enough system will have generic sub-domains that provide undifferentiated functionality. It is important to identify them, but it may not be economically advisable to pour a lot of in-house effort in implementing them. It may be better to integrate an off-the-shelf solution, instead. It is important to note that even for the same capabilities the categorization as a generic domain will differ from one business application to another. For many, checkout system would have been a generic domain, but for amazon.com it was essential. Similarly, in our case we have marked “Identity and Access Management” as a generic domain. That made sense for a run-of-the-mill online travel reservation system. However, if you are a large financial institution, Identity & Access management is your front door to fend off enormous amount of attacks and fraud, so your perspective on how “generic” of a solution you can afford, will very likely be different.
Armed with the understanding of key types of domains, let’s talk about the key relationship types we observe between domains.
Context Mapping
We’ve already mentioned that in Domain-Driven Design, we do not attempt to describe a complex system with a single domain model. Rather, we design multiple independent models that co-exist in the system. These sub-domains typically communicate with each other using pre-defined interfaces. The representation of various domains in a larger system and the way they collaborate with each other is called a Context Map. Consequently, the act of identifying and describing said collaborations is known as Context Mapping.
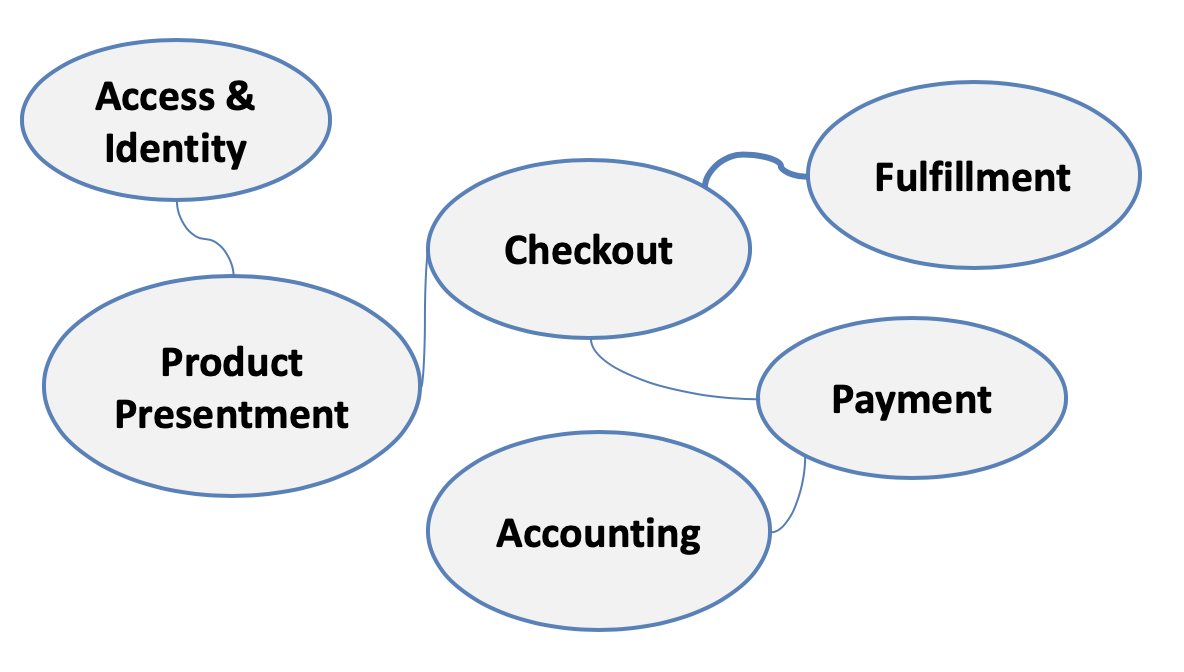
Figure 7-3. Context Mapping
Domain-Driven design identifies several major types of collaboration interactions when mapping bounded contexts.The most basic type is known as "Shared Kernel“. It occurs when two domains are developed largely independently and almost by accident they end-up overlapping on some sub-set of each-other’s domains. Two parties may agree to collaborate on this shared kernel, which may also include shared code and data-model, in addition to the domain description.
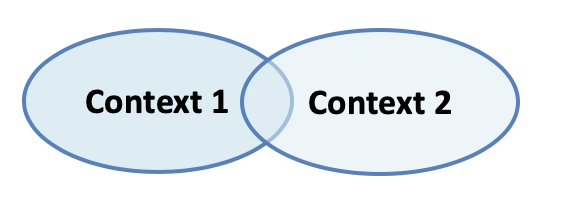
Figure 7-4. Shared Kernel
While tempting on the surface of things (after all, desire for collaboration is one of the most human of instincts), shared kernel is a problematic pattern. Especially so when it’s used for microservice architecture. By definition Shared kernel immediately requires high degree of coordination between two independent teams to even jump-start the relationship, and keeps requiring coordination for any further modifications. Sprinkling your microservice architecture with shared kernels will introduce many points of tight coordination.
As you should remember from our earlier discussions, that level of tight coupling and coordination would destroy the main purpose of a microservice architecture—to minimize coordination costs in order to achieve speed and safety, in harmony, at scale. Shared Kernels are problematic in Domain-Driven Design, in general, but should be avoided even more, when DDD is used in a Microservice Architecture.
Alternatively, two bounded contexts can engage in what DDD calls an Upstream–Downstream kind of relationship. In this type of relationship, Upstream acts as the provider of some capability, and the downstream is the consumer of said capability. Since domain definitions and implementations do not overlap this type of relationship is more loosely coupled than Shared Kernel.
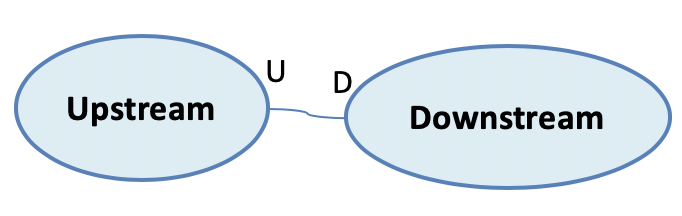
Figure 7-5. Upstream-Downstream Relationship
Depending on the type of coordination and coupling, Upstream-Downstream mapping can be introduced in several forms:
- Customer-Supplier
-
In customer-supplier scenario upstream (Supplier) provides functionality to the downstream (Customer). As long as provided functionality is valuable, everybody is happy, however Upstream carries the overhead of backwards compatibility. When they modify their service they need to make sure that they do not break anything for the customer. More dramatically, downstream (Customer) carries the risk of Upstream intentionally or unintentionally breaking something for it, or ignoring customer’s future needs.
- Conformist
-
An extreme case of the risks for Customer-Supplier relationship is the Conformist relationship. It’s a variation on Upstream-Downstream, when Upstream explicitly does not or cannot care about the needs of its downstream. It’s a “use-it-at-your-own-risk” kind of relationship. Upstream provides some valuable capability that downstream is interested in using, but given that upstream will not cater to its needs, downstream needs to constantly conform to the changes in the upstream.
Conformist relationships often occur in large organizations and systems when a much larger sub-system is used by a smaller one. Imagine developing a new, innovative fintech startup inside a large bank and needing to use, say, enterprise payment system or enterprise credit bureau reporting system. Such large enterprise systems are likely not going to give time of the day to some small, new initiative but you also cannot just re-implement a whole payment system on your own. You will either have to become a Conformist, or another viable solution may be to Separate Ways. The latter doesn’t always mean that you will implement similar functionality yourself. As we already mentioned, something like a payments system is complex enough that no startup should implement it as a side job of another goal, but you might be able go outside the confines of your enterprise and use a commercially-available payments vendor instead, if your company allows it.
In addition to becoming a Conformist or going Separate Ways, downstream has couple more DDD-sanctioned ways of protecting itself from the negligence of its upstream: Anti-Corruption Layer and using upstreams that provide Open Host interfaces.
- Anti-Corruption Layer
-
In this scenario, downstream creates a translation layer called Anti-Corruption Layer between its and the upstream’s Ubiquitous Languages, to guard itself from future breaking changes in the upstreams’s interface. Creation of an ACL is an effective, sometimes necessary, measure of protection, but teams should keep in mind that long-term it can be quite expensive, for the downstream, to maintain it.
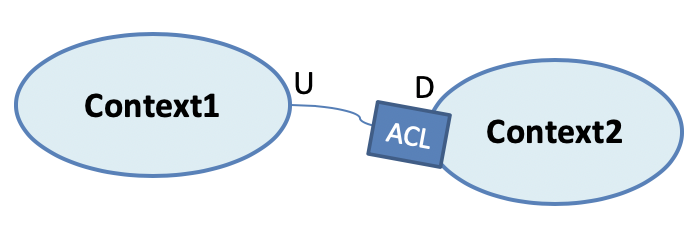
Figure 7-6. Anti-Corruption Layer
- Open Host Service
-
When upstream knows that multiple downstreams may be using its capabilities, instead of trying to coordinate needs of its many current and future consumers, it should instead define and publish a standard interface, which all consumers will need to adopt. Such upstreams are known as Open Host services, in DDD. By providing an open, easy protocol for all authorized parties to integrate with, and maintaining said protocol’s backwards-compatibility or providing clear and safe versioning for it, the Open Host can scale its operations without much drama. Practically all public services (APIs) use this approach. For example, when you are using APIs of a public cloud provider (AWS, Google, Azure etc.), they usually don’t know or cater to you specifically, they have millions of customers, but they are able to provide and evolve a useful service by operating as an Open Host.
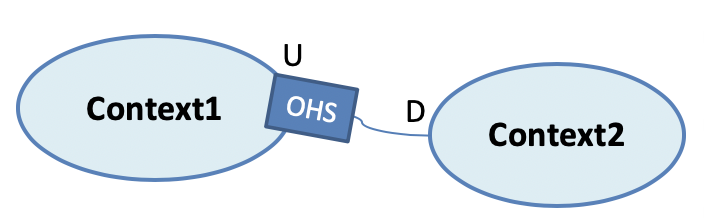
Figure 7-7. Open Host Service
In addition to relation types between domains, context mappings can also differentiate based on the integration interfaces used between bounded contexts.
Synchronous vs. Asynchronous Relationships
Integration interfaces between bounded contexts can be synchronous or asynchronous, as shown on [Link to Come]. None of the integration patterns fundamentally assume one or the other style.
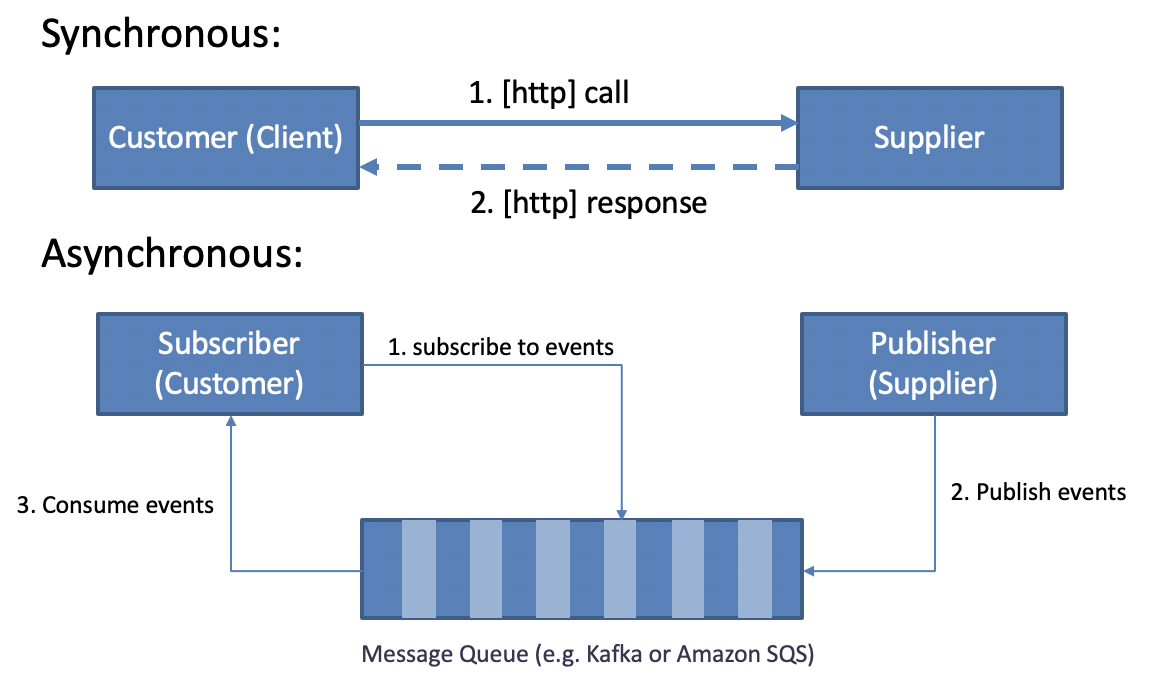
Figure 7-8. Synchronous and Asynchronous Integrations
Common patterns for synchronous integrations between contexts are RESTful APIs deployed over HTTP, gRPC services using binary formats such as protobuf, and more recently: services using GraphQL interfaces.
On the asynchronous side, publish-subscribe type of interactions lead the way. In this interaction pattern, upstream can generate events, and downstream services have workers able and interested in processing those, as depicted in the above diagram.
Publish/Subscribe interactions are more complex to implement and debug, but they can provide superior level of scalability, resilience and flexibility, in that: multiple receivers, even if implemented with heterogenous tech stack, can subscribe to the same events using a uniform approach and implementation.
A good example of such interactions, in the microservices world, can be a loan origination system. When a customer applies for a bank loan, the acquisitions system may publish an event and multiple other domains can consume it, each doing their part of the job, ideally in parallel. Such process could be described as:
-
Message sent (Acquisitions system): loan application submitted
-
Received by fraud-check domain/bounded context
-
Received by credit-check and approval domain/bounded context
-
Received by Anti-Money-Laundering-check domain/bounded context
-
Received by OFAC-check domain/bounded context
These days, a lot of pub/sub interactions between microservices are brokered by various event streaming systems, most popular among which are Kafka, Rabbit MQ, and cloud-provided systems such as AWS SQS or Kinesis.
When implementing your asynchronous interactions, it is easiest to just use the native protocol of the event streaming solution, e.g. have publisher and subscribers talk “directly” to Kafka. However, if you don’t want your entire system to become a “hostage” of today’s choice of the implementation for message-streaming, you may decide to abstract your services away from it. Sure, Kafka is an amazing piece of open-source software, with huge fanbase, but it didn’t even exist several years ago. What happens when next cool system emerges? Will you want to rewrite every single microservice in your architecture just so you can replace Kafka with Even-Cooler-System? Depending on what your answer to this question is, you have a choice. There is a W3C standard called WebSub that allows you model pub/sub interactions, using non-vendor-specific, HTTP-based open protocol:
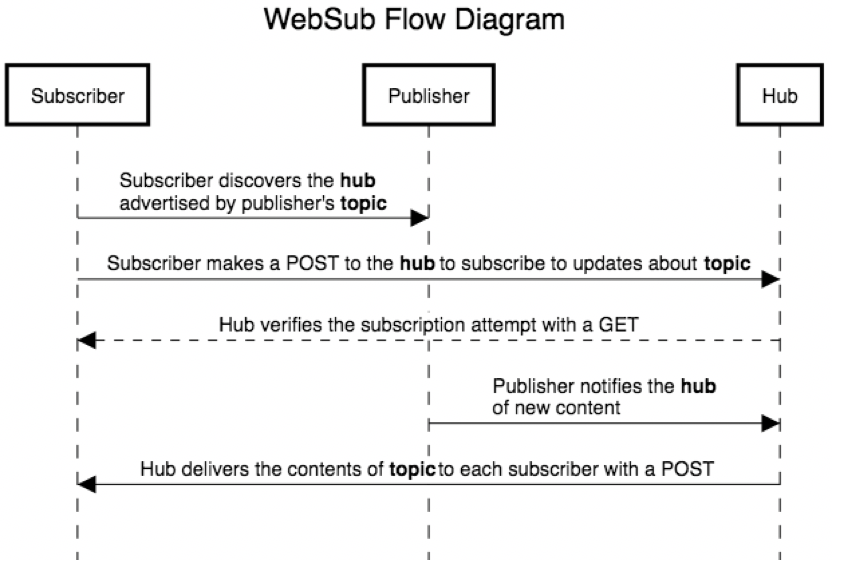
Figure 7-9. WebSub Interaction Flow Diagram
WebSub allows abstracting Pub/Sub model away from specific, non-web protocols used by concrete message broker systems and projecting the interactions onto the standard HTTP layer, with main benefit being ubiquitous familiarity with the protocol, built-in caching and internet-level scalability features.
To wrap up the discussion of Domain-Driven Design’s key concepts, we should explore the concept of an Aggregate. We discuss it in the next section.
A DDD Aggregate
An Aggregate, in DDD, is a collection of related domain objects that can be viewed as a single unit, by external consumers. Those external consumers only reference a single entity in the aggregate, and that entity is known as “aggregate root”, in DDD. Aggregates allow domains to hide internal complexities of a domain, and exposing only information and capabilities (interface) that are “interesting” to an external consumer. For instance, in the upstream/downstream mappings that we discussed earlier, downstream does not have to, and typically will not want to know about every single domain object within the upstream. Instead, it will view the upstream as an aggregate, or a collection of aggregates.
We will see the notion of an aggregate resurfice, later in this chapter when we discuss Event Storming - a powerful methodology that can greatly streamline the process of Domain-Driven Analyze and turn it into a much faster, fun exercise. Without further ado, let’s explore Event Storming in the next section.
Introduction to Event Storming
Domain-Driven Design is a powerful methodology for analyzing both whole-system-level (called “strategic”, in DDD) as well as in-depth (called “tactical”) composition of your large, complex systems. We have also seen that DDD analysis can help us identify fairly autonomous sub-components, loosely coupled across bounded contexts of their respective domains.
It’s very easy to jump to the conclusion that in order to become the masters of properly sizing microservices, we just need to become really good in Domain-Driven Analysis, make our entire company also learn and fall in love with it (because DDD is certainly a team sport) and we’ll be on our way to success!
Unfortunately, that is not quite true. There are couple more things to consider, before we whole-heartedly jump into adopting DDD as the magic wand of microservice sizing. First we have to consider complexity of using full DDD, second, the true applicability of DDD to the problem of microservice sizing. It feels like a great fit, but as we will see later, looks can be deceiving. However, let’s first address the question of complexity.
In the early days of Microservice Architecture, Domain-Driven Design was so universally proclaimed as the one true way to size microservices, that the rise of Microservices gave a huge boost to the practice of Domain-Driven Design, as well—or at least a rise of people’s awareness and increase of referencing it. Suddenly, many speakers were talking about Domain-Driven Design at all kinds of software conferences, a lot of teams started claiming that they were employing it in their daily work. Alas, a close look easily uncovered that the reality was somewhat different and Domain-Driven Design had become one of those “much-talked-less-practiced” things.
Don’t get us wrong, there were people using DDD way before microservices and there are plenty using it now as well, but speaking specifically of using it as a tool for sizing microservices, it was more hype and vaporware than reality.
There are two primary reasons for why more people talked about DDD than practiced it in earnest: it is complex, and it is expensive. Practicing Domain-Driven Design requires quite a lot of knowledge and experience. The original book from Eric Evans alone is a hefty 520 pages long, and you would need to read at least couple more books to really get it, not to mention gain some experience actually implementing it on a number of projects. There simply were not enough people with the skills and experience, and the learning curve was steep.
To exacerbate the problem, as we mentioned, DDD is a team sport and a time-consuming one at that. It’s not enough to have a handful of technologists well-versed in DDD, you also need to sell your business, product, design etc. teams to participate in long and intense domain design sessions, not to mention - explain to them at least the basics of what you are trying to achieve. Now, in the grand scheme of things, is it worth it? Very likely - yes, especially for large, risky, expensive systems it can have many benefits. However, if you are just trying to move fast and size some microservices, and you already cashed-in your political capital at work, selling everybody on the new thing called microservices – good luck also asking a whole bunch of busy people to give you enough time to size your services right! It was just not happening – too expensive, and too time-consuming. If we are honest about it, most people just started using their gut feel or intuition, creating context boundaries that were based on not much more than a lucky guess.
And then suddenly a fellow by the name of Alberto Brandolini, who had invested decades in understanding better ways for teams to collaborate, found a shortcut! He proposed a fun, lightweight, and inexpensive process called Event Storming, which is heavily based and inspired by the concepts of Domain-Driven Design but can help you find bounded contexts in a matter of hours, instead of weeks or months. The introduction of Event Storming was a break-through for inexpensive applicability of DDD specifically for the sake of service sizing. Of course, it is not a full replacement, and it will not give you all of the benefits of formal DDD, otherwise it would be magic, but as far as the discovery of bounded contexts goes, with good approximation - it is indeed magical!
Event Storming
Event Storming is a highly efficient exercise that helps in identifying bounded contexts of a domain in a streamlined, fun, and efficient manner, typically much faster than with more traditional, full Domain-Driven Analysis. It is a pragmatic approach that lowers the cost of DDD analysis enough to make it viable in situations that DDD would not be affordable, otherwise.
Let’s see how this “magic” of Event Storming is actually executed upon.
Event-Storming Process
The beauty of Event-Storming is in its ingenious simplicity. All you need to hold a session of Event Storming is a very long wall (longer the better), a bunch of supplies, mostly stickies and sharpies, 4-5 hours of time from well-represented members of your team, meaning: you want engineers, business stakeholders, product, and design people to all show up.
The process starts by purchasing the supplies. To make things easier Irakli has created an Amazon shopping-list2 he uses for Event Storming sessions. It is comprised of:
-
Large number of stickies of different colors. Most importantly: orange, blue and several other colors, for various object types. You need A LOT of those. Local stores never had enough, which is why I got in the habit of buying online.
-
A roll of 1/2-inch White Artist Tape
-
A long roll of paper (e.g. IKEA Mala Drawing Paper) that we are going to hang on the wall using the artist tape. Go ahead and create multiple “lanes”.
-
At least as many Sharpies as the number of session participants. Everybody needs to have their own!
-
Did we already mention a long, unobstructed wall that we can tape the roll of paper to?

Figure 7-10. Required Supplies For An Event Storming Session
Once we have the supplies, a large room with a wide wall and all required people we (the facilitator) ask everybody to grab a bunch of orange stickies, and a personal Sharpie. Then we give them a simple assignment: to write the key events of the domain, being analyzed, as orange post-it notes (one event per one note), expressed in a verb at past tense, and place notes along a timeline on the roll of paper we had taped to the wall to create a “lane” of time, as shown on [Link to Come].
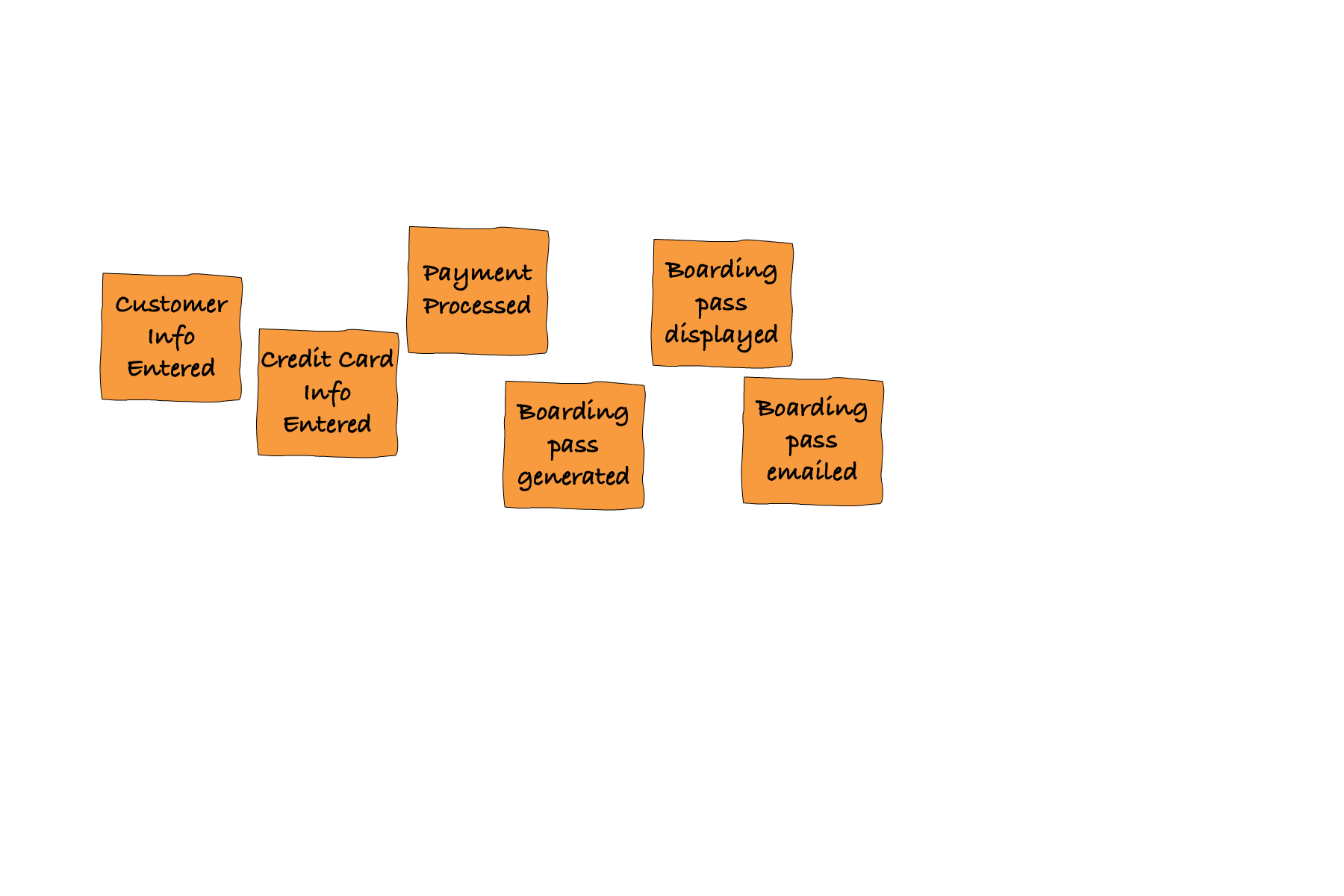
Figure 7-11. An Event Timeline With Post-It Notes
Participants should not obsess about the exact sequence of events and at this stage there should be no coordination of events among participants. The only thing they are asked is to individually think of as many events as possible and put the events they think occur earlier in the time, to the left, while putting the ones that occur later, more to the right. It is not their job to weed-out duplicates. At least - not yet. This phase of the assignment usually takes 30 minutes to an hour, depending on the size of the problem and the number of participants. Usually, you want to see at least 100 event post-its generated before you can call a success.
In the second phase of the exercise, the group looks at the resulting set of notes on the wall, and with the help of the facilitator, starts arranging them into a more coherent timeline, identifying and removing duplicates. Given enough time, it is very helpful for the participants to start creating a “storyline” walking the events in an order that makes something like a “user journey”. In this phase team may have some questions or confusions, we don’t try to solve those, rather capture them as “hotspots” - differently colored post-it notes (typically purple) that have the questions on them. Hotspots will need to be answered offline, in follow-ups. This phase can likewise take 30-60m.
In the third stage, we create what in Event Storming is known as a “reverse narrative”. Basically, walking the timeline backwards - from the end to the start and identifying “commands” - things that caused the events. We use post-its of a different color (typically: blue) for the commands. At this stage your storyboard may look something like [Link to Come].
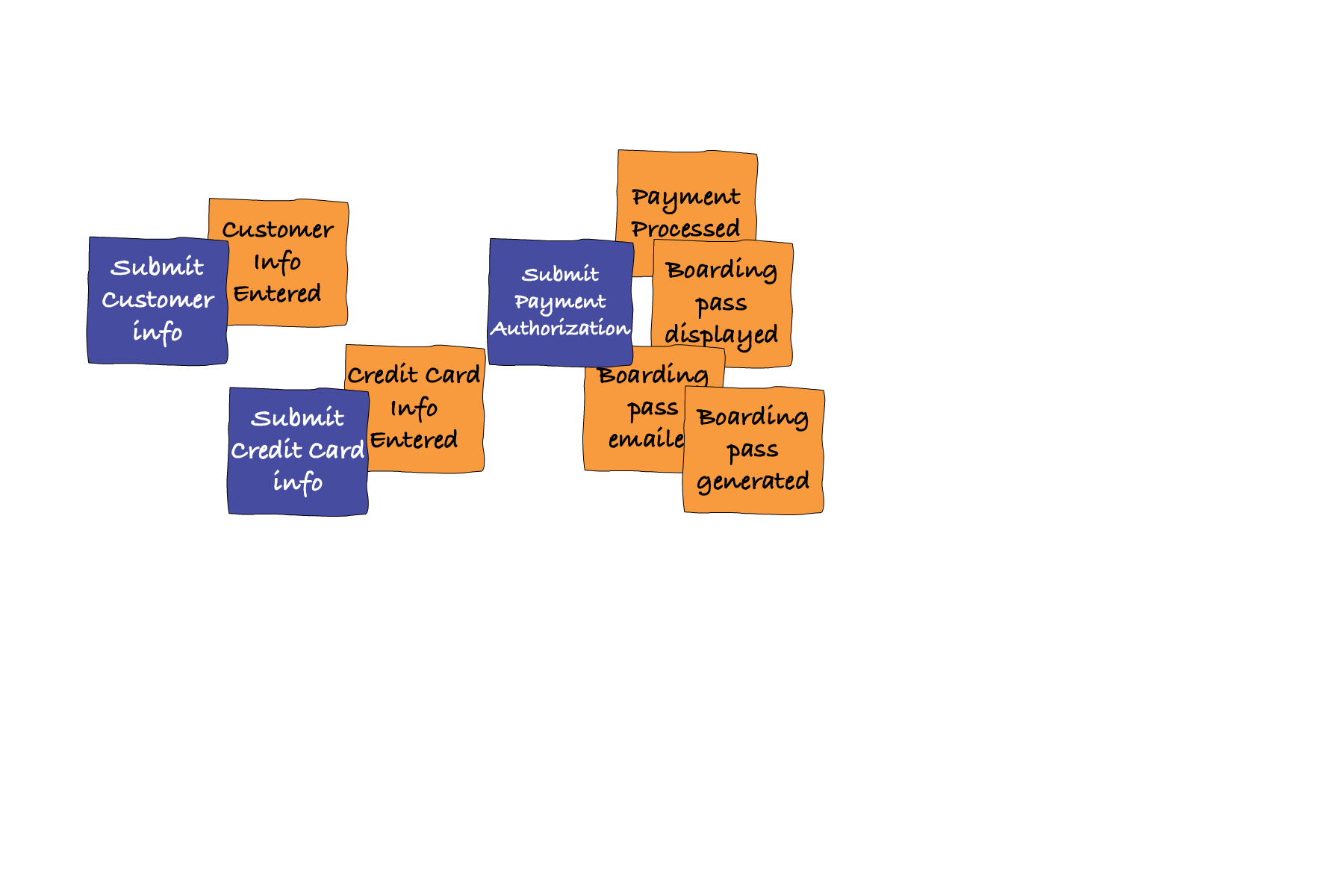
Figure 7-12. Introducing Commands To Event Storming Timeline
Be aware that a lot of commands will have one-to-one relationship with an event. It will feel redundant, like the same thing worded in past vs. present. Indeed, if you look at the diagram above, the first two commands are like that. It often confuses people new to Event Storming. Just ignore it! We don’t pass judgement during event storming, and while some commands may be 1:1 with events, some will not be. For example, “Submit payment authorization” command triggers a whole bunch of events. Just capture what you know/think happens in real life and don’t worry about making things “pretty” or “neat”. The real world you are modeling is also usually messy.
In the next phase, we acknowledge that commands do not produce events directly. Rather, special type of domain entities accept commands and produce events. In Event Storming, these entities are called Aggregates (yes, the name is inspired by the similar notion in Domain-Driven Design). What we do in this stage, is re-arrange our commands and events, breaking the timeline when needed, such that the commands that go to the same aggregate are grouped around that aggregate and events “fired” by that aggregate are also moved to it. You can see an example of this stage of Event Storming on [Link to Come].

Figure 7-13. Aggregates On An Event Storming Timeline
This phase of the exercise can take 15-25 minutes. Once we are done with it, you should discover that our wall now looks less like a timeline of events and more like a cluster of events and commands grouped around “aggregates”.
Guess what? These clusters are the bounded contexts we were looking for.
The only thing left is to classify various contexts by the level of their priority (similar to “root”, “supportive”, and “generic” in DDD). To do it, we create a matrix of bounded context/subdomains and rank them across two properties: difficulty, and competitive edge. In each category we put T-shirt sizes: S, M, or L to rank accordingly. In the end, the decision-making for where to invest effort goes based on the following guideline:
-
Large competitive advantage / Large effort - these are the contexts to design and implement in-house and spend most time on.
-
Small advantage / Large effort - buy!
-
Small advantage / Small effort - great assignments to trainees.
-
Other combinations are a coin-toss and require judgement call.
This last phase, the “competitive analysis” is not part of Brandolini’s original Event Storming process, and was proposed by Greg Young for prioritizing domains in DDD, in general. We find it to be a useful and fun exercise, when taken with the adequate levels of sense of humor.
Entire process is very interactive, requires involvement of all participants and usually ends up being fun. It also requires experienced facilitator to keep things moving smoothly. The good news is: being a good facilitator doesn’t take the same effort as becoming a rocket scientist (or DDD expert). After reading this book and facilitating some mock sessions for practice, you can be a world-class Event Storming facilitator, easily!
As a facilitator, it is a good idea to watch time and have a plan for your session. For a 4-hour session rough allocation of time would look like:
-
Phase 1: (~30mins) Discover Domain Events
-
Phase 2: (~45mins) Enforce the Timeline
-
Phase 3 (~60mins): Reverse Narrative + Command Identification
-
Phase 5 (~30min): Identify Aggregates/Bounded Contexts
-
Phase 6 (~15min): Competitive Analysis
And if you noticed that these times do not add up to 4 hours, keep in mind that you will want to give people some breaks in the middle, as well as leave yourself time to prepare the space and provide guidance in the beginning - prepare the space etc.
The universal sizing formula
Bounded contexts are a fantastic starting point for right-sizing microservices. We have to, however be cautious to not assume that microservice boundaries are synonymous with bounded contexts from DDD or Event Storming. They are not. As a matter of fact, microservice boundaries are not even constant in time, they evolve in time and tend to follow increasing granularity of microservices as the organization and application they are part of mature: 3. On [Link to Come] you can see Adrian Cockroft confirming that they experienced this occurance, at Netflix, as well.
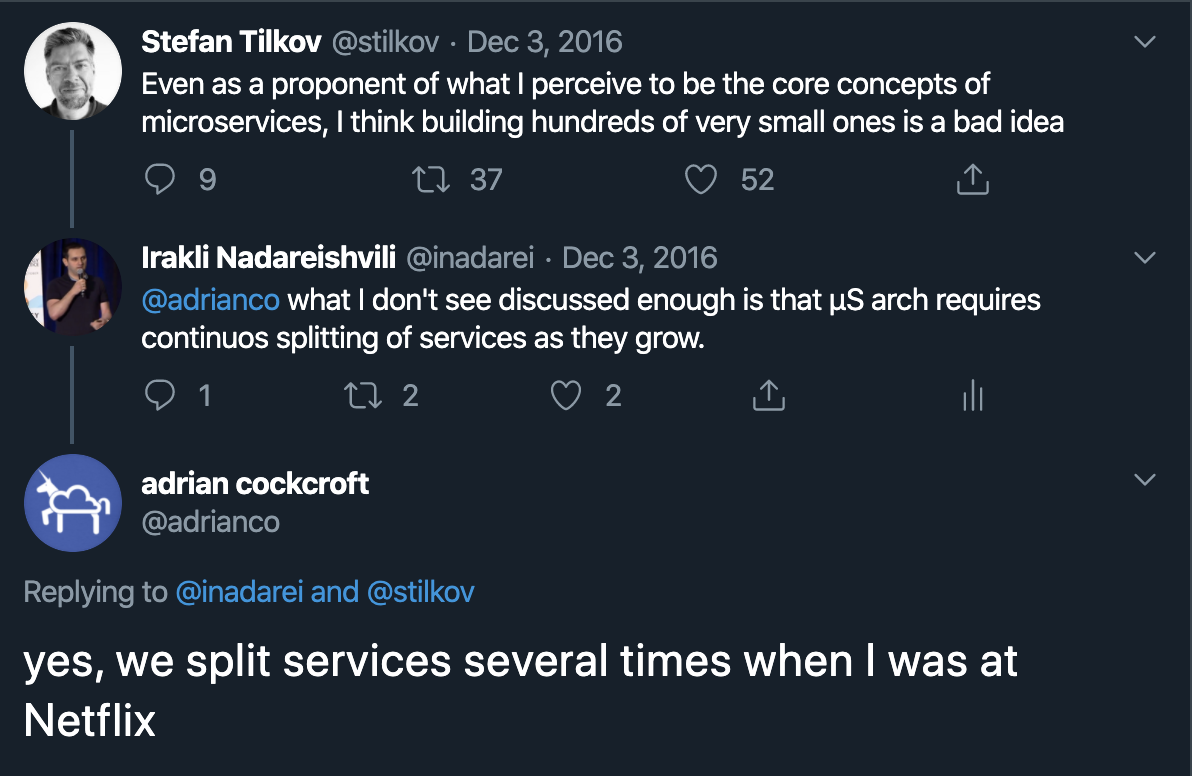
Figure 7-14. Microservices Get Split Over Time
The optimal microservice size evolves over time. In successful scenarios, teams do not start with hundreds of microservices. They start with much smaller number, aligned 1:1 with bounded contexts. At this stage you would observe a fairly coarse-grained design. As time goes by teams split microservices when they run into coordination dependencies that they need to eliminate. Teams are not expected to get service boundaries “right” out of the gate. Instead, boundaries evolve over with a general direction of increased granularity.
We have found that there are three principles thet work well, when thinking about the granularity of microservices, so we called them a Universal Sizing Formula for microservices. It goes like the following:
The Universal Sizing Formula
To achieve reasonable sizing of microservices you should:
-
Start with just a few microservices. Possibly using bounded contexts.
-
Keep splitting, as your application and services grow, being guided by the needs of Coordination Avoidance.
-
Trajectory of being on the right course for decreasing coordination is vastly more important than the current state of how “perfectly” you got service sizing.
Summary
In this chapter we addressed a critical question of how to properly size microservices head-on. We looked at Domain-Driven Design, a popular methodology for modeling decomposition in complex systems, explained the process of conducting a highly-efficient domain analysis with the Event Storming methodology, introduced the Universal Sizing Formula, a unique guidance for effective sizing of microservices.
In the following chapters we will go deeper into the implementation, showing how to manage data in loosely-coupled, componentized, microservices environment and will walk you through a sample implementation for our demo project: online reservation system.
1 http://www.informit.com/store/domain-driven-design-tackling-complexity-in-the-heart-9780321125217 Domain-Driven Design: Tackling Complexity in the Heart of Software by Eric Evans
2 https://www.amazon.com/ideas/amzn1.account.AH66SO5GAUISTPZ6XGQ2RAXIDBWA/K5OLASB3BX40 Amazon shopping list for Event Storming supplies.
3 https://twitter.com/adrianco/status/805276652557111296 Adrian Cockroft on Microservice Sizing