
Chapter 8. Dealing with the Data
When it comes to practical Microservices development, one of the early challenges that almost everyone hits is dealing with the data. If it wasn’t for data, it would be easy enough to take a complicated mess of an implementation and turn it into “bite-size”, manageable microservices that perform functions on the network. But, when we have to start thinking about the persistent data that microservices need to read from and write to, the picture gets a lot more complicated.
Looking at various aspects of modeling data, specifically in the context of microservices, we quickly notice that the design considerations for logical and physical models when implementing microservices are not the same as designing data tables for the conventional, N-tier, monolithic applications. In this chapter we will see why the differences arise, which patterns do the microservices practitioners commonly use and what are the various techniques employed to tackle the additional complexities we face, when implementing microservices systems.
In this chapter, we’ll cover why microservices need to “own their own data” and what it means for your architecture. We will discuss when and how to use the three most discussed patterns for Microservices data management: event-sourcing, CQRS, and Sagas. While discussing these important topics, we will also try to demonstrate them on practical examples using our sample project.
Design Considerations For Data Management in Microservices
Before we dive into the design considerations of data behind microservices, let’s take a moment to remember the general design considerations for microservices themselves. In Chapter 7 we mentioned that Sam Newman suggests microservices should generally be:
-
Loosely coupled from each other. Which also means independently deployable.
-
They should be highly cohesive vis-a-vis capabilities inside the microservices
-
Generally people also add that microservice boundaries should be aligned with business capabilities, rather than being driven by technical constraints. This is certainly true during the early design stages when microservices are still quite coarsely-grained. You may however remember that over time microservices become increasingly granular, so eventually there may be multiple microservices aligned with a single business capability.
When services are loosely coupled, a change to one service should not result in a change to another one. Any kind of ripple effects are highly damaging to achieving the goals of microservice architecture. You may remember that the main benefit of microservice architecture is increased speed, in harmony with safety and quality, at scale. And this benefit is achieved by eliminating, or at least decreasing, coordination needs between microservices. Considering different teams may be responsible for different microservices, such elimination, or decrease, of the “coordination needs” allows teams to move independently, at high speed, without compromising quality and safety of the overall, complex solution. One critical, specific aspect of this loose coupling is what we call independent deployability - being able to make a change to one microservice, and deploy it, without the need to change or deploy any other parts of the system, any other microservices. This is really important. A loosely coupled service, a loosely coupled microservice knows as little as possible about the services with which it collaborates.
A change a developer is implementing, is usually version-controlled in a branchable source control system, such as Git. Many readers probably have used Github.com previously, for this. The branchability is important to allow parallel tracks of development while several developers may be working on the same codebase. In a simple setup, the main branch known as “trunk” represents the latest releasable code. Multiple additional branches will typically exist for ongoing improvements. All new work usually happens on these other branches that are not “trunk”. These branches are usually known as “feature branches” or “bug fix branches” depending on whether we are coding-up something new or fixing existing code.
When a developer is finished with the code implementation, they will create what is known as a “pull request”. A pull request is a snapshot state of the code that compares changes made within that feature or bug-fix branch to the state of the code on the trunk. The opening of a pull request triggers a code review for other developers on the team. Discussions during the review and any requested updates may take anywhere from several hours, for trivial changes, to several days. Eventually the team agrees that the implementation is of adequate quality and satisfies what was intended. More often than not, progressing from this stage, also requires that code passes minimal set of automated tests called unit tests, verifying that the code works as intended in a number of circumstances.
What happens next? At this point, the new code is merged from branch into the trunk. The merge triggers a sequence of activities to take code to live, production system: building a deployable unit, such as a docker image, deploying it to an integration environment in which your microservice will be tested against other parts of the software (e.g. other microservices), progressing to quality-assurance environment where end-to-end tests may be performed with the code, possibly: including by humans. In parallel, the code will also be deployed to “performance testing” environment where it will be stress-tested under high amounts of generated traffic and synthetically produced, large amounts of data. This makes sure that your code doesn’t just work when one user or five users access it, but it can work for millions of users, as well (if that is the traffic you expect). Considering the complexity of the activities and the need for reliable repeatability, these steps are usually not done manually, but they are automated as a “deployment pipeline” managed by continuous integration and continuous deployment (CI/CD) software such as open-source tooling called Jenkins, or commercial Circle CI, or another open source tool called Spinnaker by Netflix, etc. On [Link to Come] you can see a simplified graphical representation of deployment pipelines, for multiple microservices, going through several environments, on their way to production.

Figure 8-1. Example Multi-Environment Release Pipeline for Microservices
The entire process of releasing code through a CI/CD pipeline becomes significantly more complex if a deployment of your microservice triggers ripple effects of having to also redeploy other parts of the application. For instance, if the deployment of “microservice one” necessitates changes in “microservice two” and three, etc. the whole process becomes much slower and more fragile. It can compromise both speed and safety of the entire system. Alternatively, if we can ensure that we can always deploy each microservice independently, without having to worry about the ripple effects, we can keep our deployments nimble and safe.
There can be a number of reasons why you may not be able to make deployment of your microservices independent, but in the context of data management, the most common offender is co-ownership of a data space by multiple microservices. Such co-ownership can compromise their loose coupling and our ability to independently deploy code.
We will start exploring techniques for avoiding data sharing across microservices by discussing the notion of microservice-embedded data, in the next sections.
Microservices Embed Their data
Lets look at an example scenario when two microservices share ownership of a Customer table in a database, as depicted on [Link to Come]. And by that we mean that both microservices read and modify data from the shared table. Now imagine that first microservice needs to change field type of one of the columns in the table. If the developers of the first microservice just go ahead and do it – let’s say from integer to float or something like that, the change could break, the second microservice, that also accesses the same table and relies on that field to have values of certain type. So in order to not introduce bugs, when we change the data model because of the needs of the first microservice, we will also need to accordingly change the code of the second microservice or potentially more microservices. And we will have to redeploy all of the changed microservices in one concerted effort. Ripple effects due to a changing data layer are very common when multiple components co-own data, and they can cause significant coupling of various services, which would be a problem for independent deployability.
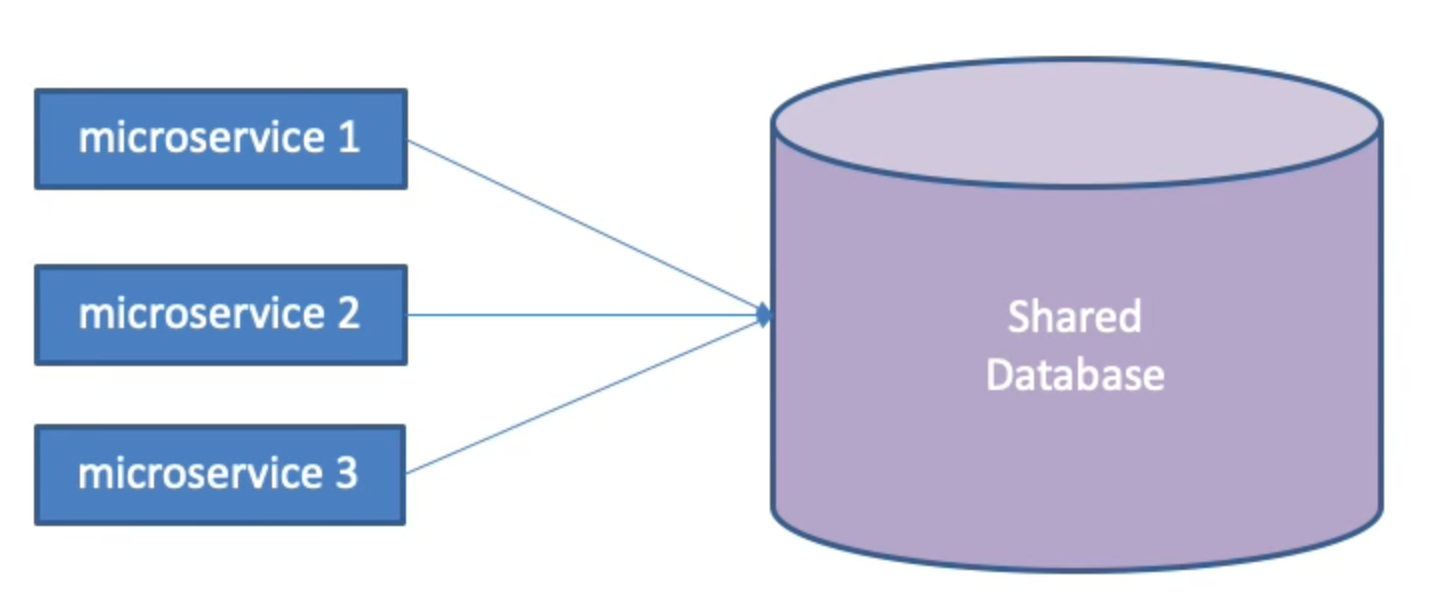
Figure 8-2. Microservices Sharing a Data Space Is a Major Anti-Pattern
In monolith architectures, sharing of data is a common practice. In typical legacy systems, even so-called service-oriented architecture (SOA) ones, code components co-own data across multiple services as a regular practice. It is actually very much expected—shared data is a primary pattern of integrating various modularized parts of a larger system. Sometimes when we speak of a “monolith”, people imagine that the monoliths have no modularization; that it is indeed just one big thing that is not divided into any kind of components. That is not true. Developers have long known that dividing a large code-base into smaller ones is highly beneficial for code organization and manageability. But the key shortcoming, before microservices, was that the modules that the monoliths were divided into were not independently deployable. That made them not loosely coupled, in the context of coordination costs! Which is why the monoliths can be a complicated mess to manage and evolve even when they are broken-up into modularized, SOA services. Due to data coupling, SOA designs never achieved ability to both go fast as well as go safely at high scale.
Sharing data spaces is a primary killer of independent development and independent deployability, in monoliths. By contrast, in microservice architecture, independent deployability is emphasized as a core value and consequently, data sharing is prohibited - microservices are never allowed co-own responsibility for a data space in a database. For any data set in the database, it should be very clear which microservice owns that data set, or as we commonly state the principle: microservices must own (embed) their data. On [Link to Come] we can see a graphical representation of this principle.

Figure 8-3. Microservices Embed And Exclusively Own Their Data
While embedding own data is a universal rule for microservices, there are some important nuances to this principle that are critical to understand clearly. In the next section we will discuss them in great detail.
Important Nuances of Embedding Data with Microservices.
When building complex applications, we can often end up with different kinds of databases. Data sets in those databases (e.g. “tables” for relational databases) should never have multiple microservices as co-owners. When you build big systems you could eventually have hundreds of microservices. Does it then mean that we have to deploy hundreds of distinct clusters of Cassandra, Postgres, Redis or MySQL? Teams implementing microservices need clarity on how far they should take the notion of “microservices must embed their data”. Databases are complex software systems themselves, they’re not deployed on just one server, rather most databases are deployed on multiple servers, for redundancy, reliability, and scalability – possibly dozens of servers across different geographic regions. When we introduce the concept of data embedding, teams will wonder if they need to create massive database clusters for each microservice they create. Because, guess what: doing that for each microservice would be very, very expensive, and it would also be very hard to manage. The microservices themselves are nimble, but database clusters are huge and expensive.
If massive number of database clusters, one or more per microservice, is what is required by a microservice architecture, then it may well be the most expensive architectural style in our industry’s history. Or close to it. Fortunately, that is absolutely not the case. Data independence does not mean that each microservice has to deploy its own cluster of scalable, redundant, complex database installations.
Tip
Microservices can and should share physical installations of database clusters. As long as services never share the same logical table space and never modify the same data, sharing physical installations is ok, in practice.
Independence of data management is more about not crossing the streams, than anything else. It’s about ability to take your microservices and deploying with another database installation if you need to. But you don’t have to deploy each service with a different DB cluster, out of the gate. Cost is an important consideration and so is simplicity. As long as multiple microservices are not accessing (most importantly: modifying) the same data space, the data independence requirement is intact.
Data Embedding Example For Our Sample Project
Let’s look at an example in the context of our online reservation system. In the beginning we will look at the case in which the system is built with a conventional monolithic, N-tier architecture. Now, such application would still be divided into different, smaller modules. These modules could even be deployed as networked services. And they could definitely be small enough to be called “micro”. That does not necessarily mean they are microservices, however. The can only be considered to be microservices if these components were modularized with the elimination of coordination as the goal, and more specifically: if they are loosely coupled and independently deployable. If services are split arbitrarily and they are not loosely coupled, we can not call such system an example of a microservice architecture.
In our scenario, depicted in [Link to Come], we have three services all requiring data from the “flights” table: flight search service, reservations management service, and flight tracker service.

Figure 8-4. Example of a Monolithic Data Management, Characterized by Data Sharing.
Clearly, based on our earlier analysis in this chapter, this data design is problematic for a microservice architecture, because three services are sharing data space and thus are compromising independent deployability.
How can we fix this situation? This particular case is actually quite easy to resolve, and we can employ a simple technique of hiding shared data behind a delegate service, visualized in [Link to Come].

Figure 8-5. A Simple Graphical Representation Of the Data Hiding Via a Delegate
Essentially, what we do here is that we declare the Flight Inventory service to be the authoritative service for all things related to flight information. Further, any service which requires information about flights or needs to update information about flights is required to invoke an appropriate endpoint in the flight inventory service. If we implement sufficiently flexible flight lookup API call, in the flight inventory service, the former “flights search” service just becomes part of the functionality of the new flight inventory service. More importantly, this allows us to stop accessing the Flights table directly from the Reservations and Flight Tracking services. Any information they need about a flight they can obtain through the flight inventory service, going forward.
For example, when reservations system needs to know if there are enough seats left on a flight, it will send a corresponding query to the inventory service instead of querying the flights table directly in the database. Or when a flight tracking service needs to know or update the location of the plane in a flight, it will again do so via the flight inventory service, not: accessing and modifying the flights table directly. This way the flight inventory service can be the delegate that hides data behind itself, encapsulates the data and wraps around the data. This will stop multiple services sharing the same data table.
Please note that in this pattern, when several services need access to the same data, we don’t have to necessarily convert one of them into a delegate. In the previous solution we converted flight search service into inventory service and made it encapsulate the Flights table. We could have instead introduced a new service. For exaomple, we could introduce a new service called Flight Inventory and have the Flight Search microservice refer to it , just like reservations and tracking services do.
The approach of introducing a delegate is very elegant and will work in many different cases. Unfortunately not all data sharing needs can be addressed this way. It would be extremely naive to think that the pattern we just discussed works for all scenarios. There are use cases where the required functionality legitimately needs to access or modify data across the boundaries of microservices. Examples of such needs are found in analytics, data audit, and machine learning contexts, among others. Traditional approaches to distributed transactions also require locking on shared data.
Fortunately, there are reasonable solutions for those other use-cases as well, solutions that are also capable of avoiding data-sharing. To understand the solutions in this space, let’s first explore various data access patterns we commonly encounter.
Using Data Duplication To Solve For Independence
When we need read-only access to distributed data, with no modification requirements, as in the contexts of enterprise analytics, machine learning, audit etc., a common solution is to copy data sets from all concerned microservices into a shared space. The shared space is usually called a Data Lake. Please note that we are copying data, not moving it! Data lakes are read-only, query-able data sinks. Microservices still remain the authoritative sources of the corresponding data-sets and act as the primary “owners” of the data. They just stream relevant data into the data lake where it gets accumulated and becomes ready for querying. For the sake of data integrity and clarity of data lineage, it’s important that we never ever operationally update such data in an aggregate index like a data lake. Data Lakes may never be treated as the databases of record. They are reference data stores. We can see a generic graphical representation of this setup on [Link to Come]

Figure 8-6. Streaming Data From Microservices Into Data Lakes
Once data is streamed from a system of record (SOR) data-stores, such as microservices into data sinks, the aggregate data is indexed in a way that is optimized for query-ability. Streaming of data from SORs into Data Lakes usually happens using a reliable messaging infrastructure. IBM MQ and RabbitMQ have been used for many years in this context, Kafka seems to be the current most popular solution, while Apache Pulsar is probably the most prominent and interesting new entrant of the space.
Data lakes and shared data indexes can solve for many read-only use-cases. But what should we do when distributed data is not read-only? In the next section we explore a solution for the cases when we need to modify data across the data-sets owned by multiple microservices, in a coordinated fashion. We will discuss how to implement distributed transactions in a microservices eco-system.
Distributed Transactions and Surviving Failures
Let’s consider an example from our online reservations sample project. Specifically, let’s explore what happens when somebody books a seat on a flight and in order to fulfill it we need to execute a distributed transaction, a coordinated update across multiple microservices that are in charge of things like: charging a card payment, securing a seat, and sending an itinerary to the customer’s email. Such transactions span across multiple microservices: payments processing, reservations, and notifications one, to be specific. Most importantly we would typically want all three steps to happen or none of them to happen. For instance, let’s say we suddenly find out that the requested seat is no longer available. Perhaps we started the process of charging the payment method, the seat was available, but by the time we got through it, somebody had already reserved that seat. Obviously we can’t reserve that seat twice, so we have to think about what to do in that situation. In a busy-enough system, such race conditions and failures are inevitable, so when they do occur, we need to roll back the entire process. We clearly need to refund the money, at the very least. Let’s understand how we would coordinate such distributed transaction.
In conventional monolithic applications, a process like the one we described would be safely managed using database transactions. More specifically: database transactions that are said to exhibit ACID characteristics of safety, even in the event of failures. ACID stands for Atomicity, Consistency, Isolation, and Durability. They are defined as follows:
- Atomicity
-
the steps in a transaction are “all or nothing”, either all of them get executed, or none of them do.
- Consistency
-
any transaction should bring the system from one valid state, into another valid state.
- Isolation
-
parallel execution of various transactions should result in the same state as if the transactions were executed sequentially.
- Durability
-
once a transaction is committed (fully executed), data won’t be lost despite any possible failures.
When we talk about microservices allowing to build systems safely, at scale, we get asked if that means that microservices allow to design complex systems in a way that avoids failures ever happening. The answer to this question is an unequivocal “no”, because it’s an impossible task. Failures will always be present, what we need to do is – account for failures happening, and be able to recover from them. ACID transactions are a great example of such thinking, they assume that failures of all kinds happen all the time, but we design our system in a way to make it resilient to them.
Unfortunately, ACID transactions are not a viable solution for distributed systems where functionality is spread across multiple microservices, deployed across a network independently. ACID transactions typically rely on usage of exclusive locks. Given that microservices embed their data and do not allow code to manipulate data in another microservice, such locks would be either impossible or very expensive for a microservices system to implement. Instead, we need to use patterns that work better in distributed architectures. In the next section we introduce a popular solution of this type called Saga Transactions.
Distributed Transactions with Sagas.
Sagas were first described by Clemens Vasters as a solution for distributed systems, in a blog post, published in 2012.
In Sagas, every step of a transaction not only performs the required action for that step, but also defines a compensating action that should execute if we need to “roll back” the transaction due to a later failure. A pointer (e.g. discovery information on a queue) to this compensating action is registered on a “routing slip” and passed along to the next step. If one of the later steps fails, it kicks-off execution of all compensating actions on the routing slip, thus “undoing” the modifications and bringing the system to a reasonably compensated state.
Sagas Are Not Directly Equivalent To ACID Transactions
Saga does not promise that when a distributed transaction is rolled back, the system will necessarily get back to the initial state. Rather, it should get to a reasonable state that reflects acceptable level of undoing of the partially completed transaction.
To understand wha we mean by “reasonably compensate state”, let’s look at our initial example of a seat reservation, as depicted on [Link to Come]:

Figure 8-7. A Transaction Distributed Across Multiple Microservices
If a reservation booking attempt fails, for whatever reason, it will be cancelled, but we will also invoke the compensating action of the previous steps: notification and payment. The compensating action of a payment refunds money to the customer. A refund, depending on the type of payment, may not get processed immediately so the system may not return to its initial state immediately, but eventually customer will get all their money. In case of a notification, however, we won’t be able to literally recall an email or a text message that was sent, so the compensating transaction may involve sending a new message notifying the customer that the previous message should be disregarded and booking was actually unsuccessful. It is a reasonable solution, but doesn’t bring the system to the initial state: a customer will see two messages, instead of not seeing any. This is how compensating transactions, in Sagas, are different from traditional, ACID transactions in conventional database systems. Please also note that the sequence of events in a saga does matter and should be constructed carefully. It usually pays off to move steps that are harder to compensate for, towards the end of the transaction. For instance, if business rules allow it, moving notification at the very end may save us from having to send a lot of correction messages, because by the time transaction gets to it we will know the previous steps have succeeded.
Delegate services, Data Lakes, and Sagas are powerful patterns. They can solve many data isolation challenges in microservice architecture, but not all of them. In the next section we will discuss a powerful duo of design patterns: Event Sosurcing and CQRS. Those two can pretty much address everything else, remaining, providing a complete tool-set for data management in a microservices environment.
Event Sourcing and CQRS
Up to this point we have discussed some ways to avoid data sharing when using traditional, relational data modeling. We showed how you can solve some of the data sharing challenges, but eventually, for advanced scenarios, we will run into cases where relational modeling itself falls short of allowing desired levels of data isolation and loose coupling. At its core, relational data modeling rooted into such foundational principles as data normalization, data reuse and cross-referencing common data elements, i.e. it is fundamentally biased towards favoring data sharing.
Event Sourcing
Sometimes, rather than trying to go around the predisposition for relational modeling, we should switch to a completely different way of modeling data. A data modeling approach that allows avoidance of data-sharing, and thus has become popular in microservices, is known as: Event Sourcing.
Event Sourcing was coined as a term and popularized by Greg Young. In his own words, event sourcing is an approach to data modeling that is all about storing events, not the state of the system. And anytime you need a current state of a system, it’s calculated as a function of all the relevant events that have transpired before:
Event sourcing is all about storing facts and any time you have “state” (structural models)—they are first-level derivative off of your facts. And they are transient. 1
Greg Young, Code on the Beach 2014
In this context, by “facts” Young means the representative values of event occurrences. An example could be “price of an economy seat on LAX-IAD flight increased by $200.” The big idea here is that in conventional data systems such as relational databases, or even the more contemporary noSQL and document databases, we usually store a state of something, like we may store the current price of an economy seat on a flight. In Event Sourcing, we operate with completely different approach. In Event Sourcing we do not store current state, rather we store “facts"--the incremental changes of the data. The current state of the system is a derivative, it is a value that is calculated off of the sequence of changes (events).
Let’s look at an example. A relational data-model describing customer management system for a air travel reservations system may look like the diagram in [Link to Come]

Figure 8-8. Example of a Relational Data Model
We can see that the data model could consist of a table storing customer’s contact information, which has one-to-many relationships with customer accounts and payment methods. In turn, each customer account (e.g. business vs. personal account) record can point to multiple completed trips, open reservations, and preferences related to the account. While the details may vary, this is the kind of data model most software engineers would design using conventional databases.
Using event-sourcing, we can design the same data-model as a sequence of events shown in [Link to Come]. Here you can see a representation of events that lead to the same state of the system as described in the state-oriented model above: first customer contact information was collected, then a personal account was opened, which was followed by entering a personal payment method. After several reservations, and completed trips, this customer apparently decided to also open a business account, added payment information and started booking trips with this new account. Along the way several preferences were also added and updated, bringing the system to the same state as in the diagram above, except here we can see the exact sequence of “facts” that lead to the current state, as opposed to just looking at the result in the state-oriented representation.
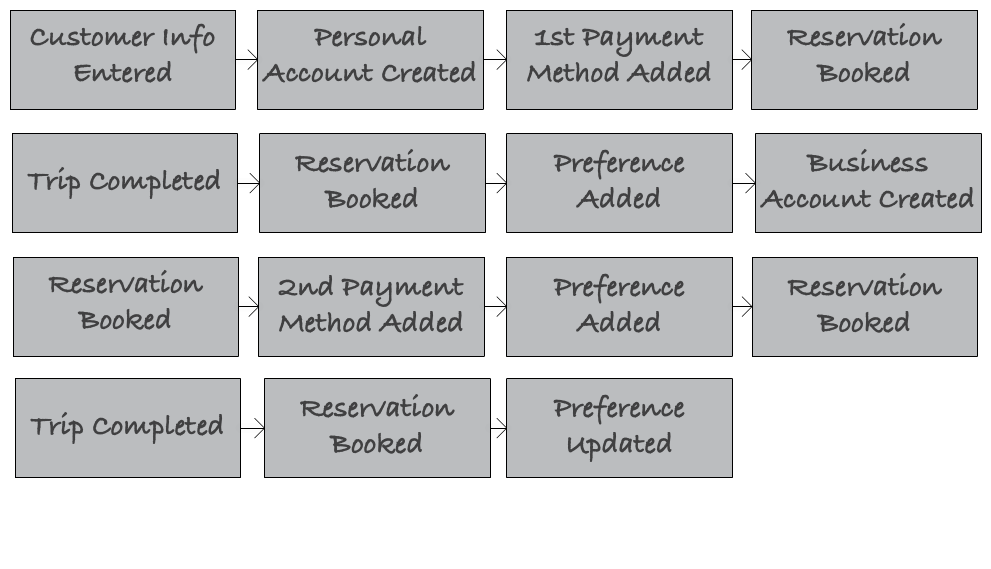
Figure 8-9. Example of an Event-Sourced Data Model
So the sequence of events on the diagram gives you the same exact state that we had in the relational data model. It is equivalent to what we had there, except this looks very, very different. For instance, you may notice it looks much more uniform. There’re significantly less number of “snowflake” decisions to be made about the various entity types and their relationships with each other. Event Sourcing in some ways is much simpler in that you just have a variety of business events that happen and then you can calculate current state various derivatives based on these events.
Not only event sourcing is more straightforward and more predictable there are also no referential relationships between various entities. So if we wanted to do a brute force data segregation here, all we would need to do is say each type of event is owned by a different microservice and voila, we would have no data sharing whatsoever. So we could have a microservice that is a customer demographics microservice and “customer info entered” would be an event that very naturally belongs to that system of record.
Despite simplicity, unless you have prior experience with event-sourcing, it may feel odd. Most people who haven’t worked on systems dealing with high-frequency trading platforms (which is where Event Sourcing was originally often used), or haven’t had ton of advanced experience with microservices, probably do not have any experience with Event Sourcing. That said, we can easily find examples of event-sourcing systems in real life. If you have ever seen an accounting journal, it is a classic event store. Accountants record individual transactions and the balance is a result of summing-up all transactions. Accountants are not allowed to record “state” i.e. just write-down the resulting balance after each transaction, without capturing the transactions themselves. Similarly, if you have played chess and have recorded a chess game, you would not write-down the position of each piece on the board, after each move. Instead you are recording moves individually, and after each move the state of the board is a result of the sum of all moves that have happened.
For instance, the record of the first seven moves of the historical game 6 between many-times world chess champion Gary Kasparov and the IBM supercomputer Deep Blue, in 1997, represented in algebraic notation, looks like the following:
-
e4 c6
-
d4 d5
-
Nc3 dxe4
-
Nxe4 Nd7
-
Ng5 Ngf6
-
Bd3 e6
-
N1f3 h6
and the corresponding state, after the initial seven moves is depicted on [Link to Come]

Figure 8-10. Deep Blue vs. Kasparov. Source: Wikipedia
We can completely recreate state of a chess game, such as that between Kasparov and Deep Blue, if we have the event log of all moves. This is an analog equivalent of event sourcing, from real life.
Now that we hopefully have a good intuitine about event sourcing and how it works, let’s dig a little bit deeper into what data modeling and data management looks like in Event Sourcing. It’s an approach of capturing sequence of events and the state is just something you calculate off of these events - a state is a function of events. Okay, sounds a bit mathematical, but what does an event even look like? Well, events are very simple. If we look at a “shape” of an event data structure, all it needs to have are three parts. First, it needs some kind of unique identifier, you could for instance use UUIDs, since they are globally unique, and global uniqueness obviously helps in distributed systems. They also need to have event type, so we don’t mistake different event types. And then there’s just data, whatever data is relevant for that event type:
{"eventId":"afb2d89d-2789-451f-857d-80442c8cd9a1","eventType":"priceIncreased","data":{"amount":120.99,"currency":"USD"}}
So things are fairly simple when designing events. There’s much less of the kind of “artisanal” data crafting that we engage in with the relational approach. Data capturing is straightforward in Event Sourcing.
What happens when we actually need to calculate point-in-time (e.g. current) state of something? We run, what in Event Sourcing, is called “projections”. Projections give us state based on events and they’re also fairly simple. To run a projection, we need a projection function. A projection function takes current state and a new event to calculate new state. For instance, priceUp projection functions, for a airline ticket price, may look like the following
functionpriceUp(state,event){state.increasePrice(event.amount)}
and it would be equivalent to an “UPDATE prices SET price=…” SQL query in a relational model. If we also had a corresponding price decrease projection function and we wanted to calculate price (state) at some point, we could run a projection by calling the projection functions for all relevant events, like the following:
functionpriceUp(state,event){state.increasePrice(event.amount)}functionpriceDown(state,event){state.decreasePrice(event.amount)}letprice=priceUp(priceUp(priceDown(s,e),e),e);
If you have ever worked with functional programming, you may notice that the current state is the left fold of the events that occurred until current time. Please note that, using event sourcing you can calculate not just current state, but state as of any point in time. This capability opens-up endless possibilities for sophisticated analytics, where you can ask questions like:name: value “ok, I know what the state of the entity is now, but what was the state at a date in the past that I am interested in?”. This flexibility can become one of the powerful benefits of using event sourcing, if you frequently need to answer such questions.
One thing to note here is that projections can be computationally expensive. If a value is a current state and it’s a result of a sequence of thousands of state changes, like a bank account balance, anytime you need the value of a current balance – would you want to calculate it from scratch? You could argue that such approach is slow and it can waste time and computational resources. It also cannot be as instantaneous as just retrieving the current state. You would be correct in that, however we can optimize for speed and it doesn’t necessarily require change in the approach. Instead of recalculating everything from the beginning—for example, the opening of a bank account—we can keep saving intermediary values, along the way, and later we can quickly calculate the state from the last snapshot. That would significantly speed-up calculations.
Depending on the event store implementation, it is common to snapshot intermediary values at various time points. For instance, in a banking system, you may snapshot account balances on the last day of every month, so that if you need the balance on January 15, 2020 you will already have it from December 31, 2019 and will just need to calculate the projection for two weeks, rather than the entire life of the bank account. The specifics of how you implement rolling snapshots and projections may depend on the context of your application.
Later in this chapter we will see that with a related pattern called Command-Query Responsibility Segregation (CQRS), we can do much more than just cache states in rolling snapshots.
Having acquired understanding and appreciation of Event Sourcing, let learn more about how to implement one. What would the event store itself look like? And how would we go about implementing one? We will answer these questions in the next section.
Event Store
Event Stores are fairly simple systems. You can use almost any data storage system to implement one. Simple files on the file system, S3 buckets, or any database storage that can reliably store a sequence of data entries can all do the job. The interface of an event store needs to support three basic functions:
-
Be able to store new events and assign the correct sequence so we can retrieve events in the order they were saved.
-
Notify event subscribers, that are building projections, about new events they care about and enable the Competing Consumers Pattern
-
Support ability to get N number of events after event X for a specific event type, for reconciliation flows - i.e. recalculation in case projection is lost, compromised, or doubted.
So, at its essence, the basic interface of an event store is comprised of just two functions:
save(x)getNAfterX()
and some kind of a robust notification system, that allows consumers to subscribe to events. By robust we mean conformance to the Competing Consumers Pattern. This pattern is important because whatever system is building a projection off of your events, they likely will want to have multiple instances of a client “listening” to the events, both for redundancy and scalability’s sake. Our notifier must reasonably accommodate only-once delivery to a single instance of a listener, to avoid accidental event duplication leading to data corruption. There are two approaches you can employ here:
-
Use a message queue implementation that already provides such guarantees to its consumers, e.g.: Apache Kafka.
-
Allow consumers to register HTTP endpoints as callbacks. Invoke the callback endpoint for each new event and let a load-balancer on the consumer side handle the distribution of work.
Neither of these two approaches is inherently better. One is a push-based approach, the other is a pull-based approach and depending on what you are doing, you may prefer one over another.
Check Out Sample Implementation
As part of working on this book, we have published an opinionated reference implementation of a skeleton event store on Github: https://github.com/implementing-microservices/gevent-store which you can check out, take for a test drive, or contribute to.
To implement robust projections, Event Sourcing systems often use a complementary pattern known as Command-Query Responsibility Segregation, or CQRS. In the next section we will explore the ideas behind it and try to understand its essence.
Command Query Responsibility Segregation (CQRS)
Projections for advanced event-sourced systems are typically built using
command-query responsibility Segregation (CQRS) pattern. The idea of CQRS is
that the way we query systems and the way we store data do not have to be the
same. When we were talking about the event store and how simple it can be, one
thing we skipped over was that the simple interface of save(x) and
getNAfterX() functions is not going to allow us to run elaborate queries over
that data. For instance, it won’t allow us to run queries like: give me all
reservations where a passenger has updated their seat in the last 24 hours.
Those kind of queries are not implemented against the event store, to keep event
store simple and focused. Event Sourcing should only solve the problem of
authoritatively and reliably storing an egent log. For advanced queries, every
time an event occurs, we let another system, subscribed to the event store,
know about it and that system can then start building the indices that are
optimized for querying the data any way they need. The idea behind CQRS is that
you should not try to solve the data storage, data ownership and data
query-ability with the same system. These concerns should be solved for
independently.
The big win with using event sourcing and CQRS is that they allow us to design very granular, loosely coupled components. With event sourcing, we can create microservices so tiny that they just manage one type of an event or run a single report. Targeted use of event sourcing and CQRS can take us to the next level of autonomous granularity in microservice architecture. As such, they play a crucial role in the architectural style.
ES And CQRS Should Not Be Abused As A Cure-All Soltuion
Be careful not to overuse Event Sourcing and CQRS. You should only use Event Sourcing and CQRS when necessary, since they can complicate your implementation. They should not be used as one and only data modelling approach for your entire system. There are still many use cases in which the conventional, relational model is much simpler and should be utilized.
Now that we have acquired a solid, foundational understanding of Event Sourcing and CQRS, let’s also address where else these patterns can and should be used, beyond just helping with loose data coupling for microservices data-embedding needs.
ES/CQRS Beyond Microservices
Event Sourcing and CQRS can certainly be invaluable in avoiding data sharing and achieving loose coupling of microservices. Their benefit is not limited to lose coupling or even microservice architecture, however. ES/CQRS are powerful data modeling tools that can bring benefits for a variety of systems.
Consider ES/CQRS in relation to CAP Theorem. This theorem, was famously formulated as a conjecture by Eric Brewer, in his 2000 keynote 2 at the Symposium on Principles of Distributed Computing. The theorem, in its original form, stated that any distributed shared-data system can only have two out of three desirable properties:
-
Consistency - having a single view of the latest state of the data
-
Availability - ability to always read or update data
-
Partition-Tolerance - getting accurate data even in the face of network partitions
Over time, it was clarified that not all combinations of CAP are valid 3 4. For a distributed system we have to account for partition-tolerance because network partitions cannot be avoided and the choice becomes a sacrifice between Consistency or Availability. But what do we do if we really need both? It sounds childish to insist on wanting everything if a mathematically proven theorem (which CAP became eventually) tells you that you cannot have it all.
But there is a catch! CAP theorem tells us that a single system, with data sharing cannot violate a CAP theorem. However, what if, using CQRS, we employ multiple systems and minimize data sharing? In such case, we can prioritize consistency in the event store, and prioritize availability in the query indices. Certainly, that means whatever system we use for query indices may get consistency wrong, but they are not authoritative sources, so we can always re-index from the event store, if need be. In a way, this allows us to, indeed have the best of both worlds.
The second major benefit of ES/CQRS approach is related to audit-ability. When we use a relational data model, we do in-place updates. For instance, if we decide that customer’s address or phone number are wrong we will update them in the corresponding table. But what happens if the customer later disputes their record? With a relational model, we may have lost the history and find ourselves helpless. With event sourcing, we have a perfect history of every change safely preserved and we can see what the value of customer data was at any time in the past, as well as how and when it got updated.
Some of the readers may point out that even when they use relational modeling, it doesn’t necessarily mean that they lose the history of data. They may be logging every change in some file, or systems like Splunk, or ELK. So, how is logging different from Event Sourcing? Are we just talking about good old logging here, branding it with some new buzz name? The answer is: absolutely, no. It all comes down to: which system is the source of truth in our architecture. Who do I “trust”, if my log disagrees with my current state? In Event Sourcing, the “state” is calculated from the events so the answer is self-evident. In case of Splunk logs that is not the case, so your source of truth is most likely your relational model, even if you occasionally double-check it from the logs to hunt down some bugs. When your reliable log of events is your source of truth, you are using event-sourcing as your data modeling approach. Otherwise - you are not, no matter how many logs you may be generating.
Summary
In this chapter we discussed a fundamental concept of Microservice Architecture: data isolation and the principle of embedding data into corresponding microservices. We have also explored how this principle, while necessary for loose coupling and independent deployability, can lead us to significant data management challenges if we approach them with conventional data modeling solutions, the ones designed for monolithic N-Tier Application. Further we looked into a complete tool-set of solutions to the described challenges in the form of powerful, true-and-tried patterns that address those challenges head-on. Last but not least, we introduced a whole new approach to data modelling, disntinctly different from conventional, relational modeling—an Event Sourcing and CQRS-based one, and explained its benefits, appropriate usage contexts and where we can use it, even beyond microservices needs.
Armed with this powerful, foundational knowledge, we can now dive deep into implementation of the sample project. We will first start by setting up a productive developer workspace, and then we will try to implement some sample microservices, leveraging all of the knowledge we have accumulated so far in this book.
1 https://www.youtube.com/watch?v=JHGkaShoyNs Greg Young, Code on the Beach
2 https://people.eecs.berkeley.edu/~brewer/cs262b-2004/PODC-keynote.pdf Eric Brewer’s Conjecture
3 https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/ Eric Brewer - CAP Twelve Years Later
4 https://codahale.com//you-cant-sacrifice-partition-tolerance/ Coda Hale - You Can’t Sacrifice Partition Tolerance