
8
Steganalysis: Detection of Hidden Data in Multimedia Content
Rémi COGRANNE1, Marc CHAUMONT2 and Patrick BAS3
1 LIST3N, University of Technology of Troyes, France
2 LIRMM, Université de Montpellier, CNRS, University of Nîmes, France
3 CRIStAL, CNRS, University of Lille, France
In Chapter 5, we presented the concept of steganography, that is, methods of hiding information in digital images. In particular, we concentrated on the fact that steganography methods are constructed in a context where an enemy seeks to identify images used to spread hidden information (Stego images) from a list of images. In this chapter, we will see how to perform an analysis of a digital image to obtain information about the data that may have been hidden there.
8.1. Introduction, challenges and constraints
Before getting to the heart of the matter, we will briefly remind you that the purpose of steganography is to hide secret information in digital media so that the latter remain visually and statistically “as close as possible” to the original media. The example of the prisoner problem1 (Simmons 1984) helps to illustrate this situation. The aim of steganalysis can seem quite simple at first glance: it is a matter of “only” detecting media containing hidden information to prevent their transmission. In practice, the subject matter is much broader than that. In reality, as very often in the field of security, the goal of steganalysis largely depends on the scenario considered and, in particular, on the knowledge that Eve has “initially”2.
In this chapter, we will see that steganalysis has been widely studied as a tool for evaluating steganography methods. This approach sets down a very specific situation in which Eve is assumed to be omniscient, in that she can access (almost) all the information about the hidden data. In this scenario, we generally assume that Eve is only unaware of (1) what the hidden message is, although its statistical distribution is known; (2) what insertion key is used and (3) whether a message is actually inserted. This scenario is very practical for the steganographer, Alice, because, on the one hand, it allows her to focus on the problem of interest without taking into account the incidental “technical difficulties”. Furthermore, in this scenario, Alice considers the worst case in terms of steganalysis, so she can be sure that her assessment is pessimistic and that, in practice, a more realistic enemy will hardly be able to come up with such a precise steganalysis because they often do not know the size of the inserted message or the algorithm used. In section 8.6 we will see that the experimental conditions are also significantly different from the operational conditions under which steganalysis could be carried out.
8.1.1. The different aims of steganalysis
Many works have been proposed in order to implement different types of steganalysis; we will briefly describe them in the rest of this section:
- – on the one hand, different detection methods can be considered, depending on the Cover media3: images, sounds and videos being different media and compressed differently, they should be treated differently to find hidden information. More broadly, steganography in texts or in computer networks is so different by nature that it seems difficult to analyze them in a similar way;
- – other works, in a way which is more similar to what is done in cryptanalysis, focus on searching for the insertion key from images containing hidden information. These works often require the steganalyst, Eve, to have significant knowledge;
- – in quantitative steganalysis, the aim is to estimate the size of a possible hidden message. We can easily understand that estimating the size of the message can be compared to a binary detection problem. Quite a naive first view involves estimating the size of the hidden message and deciding that the medium is Stego when this estimate exceeds a given threshold;
- – finally, we can mention active steganalysis, in which Eve slightly modifies the transmitted medium in order to preserve its visual appearance while making extraction of the hidden message impossible.
Because of lack of space, it is difficult to tackle all the problems that make up steganalysis in only one chapter. In addition, even though these issues are interesting, we will stick to only the classical framework that concerns the detection of information hidden in digital images.
As we have explained previously, steganalysis was mainly developed to make the evaluation of steganography methods possible. Most works in this field refer to Kerckhoffs’ principle (Kerckhoffs 1883), reworked by Claude E. Shannon, like the fact that “the enemy knows the system used”. In accordance with this principle, steganalysis generally relies on the fact that Eve is only unaware of the inserted message and the insertion key used. We will return to this in greater detail in section 8.3 on the scenario of targeted steganalysis, but this assumes that Eve knows the type of media – generally an image, the insertion algorithm, the size of the message and its statistical properties.
8.1.2. Different methods to carry out steganalysis
The most effective methods for hidden information detection are undoubtedly those based on signatures. In this case, it is possible to detect steganography indirectly, by identifying a particular property that is found systematically when the insertion of a message has been carried out with a certain tool and only in this case. It is therefore a question of detecting a specific feature linked to the use of a precise tool, rather than the presence of hidden information itself. This approach can be compared to what is done for computer security (detection of network attacks or viruses, for example) and is discussed in section 8.2 through some examples.
A second family of more general steganalysis methods, based on modeling and statistical detection, is discussed in section 8.3. In practice, this sort of detection method is very complex to implement, since it requires a very precise statistical model of a Cover image and a Stego image in order to be able to statistically evaluate if a given image is more likely to come from one of these two models. In this section, we precisely define the framework of targeted steganalysis, which is necessary for building statistical models like this.
Section 8.4 deals with the use of statistical learning methods. The most effective steganalysis methods rely on this approach, and so naturally it is those which have been the most widely studied. Here, steganalysis can be subdivided into two distinct problems: the first relates to the extraction of relevant characteristics, and the second relates to learning to automatically classify, based on a vast set of examples, characteristics from Cover and Stego images.
Recently, we have witnessed a spectacular development of deep learning methods, or Deep Learning, which, on the other hand, is carried out in a single phase which combines characterization and classification. The use of these methods for steganalysis is discussed in section 8.5.
This chapter concludes, in section 8.6, with a short, non-exhaustive list of the topics that seem the most interesting and which remain largely open.
8.2. Incompatible signature detection
In the field of computer security, signature detection is generally defined as a detection method based on looking for specific patterns or characteristic traces indicating the use of a particular software or algorithm. Here, the software aspect is important, because a signature does not depend on the insertion method considered, but is quite specific to a given implementation. As we will see in this section, this signature can appear in the metadata of the media, or in the properties of the signal that form the media.
A simple example is illustrated by the F5 steganography algorithm, proposed by A. Westfeld in 2001 (Westfeld 2001). It is combined with a demonstrator in order to allow its use within the scientific community. Westfeld did not want to fully program the JPEG compression part and used an available encoder, but this encoder inserted the following comment systematically in the file header “JPEG Encoder Copyright 1998, James R. Weeks and BioElectroMech”. As this encoder is used very little, it was possible to detect the images containing hidden information with F5, not by directly detecting the hidden data, but by detecting this very specific comment. Here, it is a matter of detecting an “implementation error” and steganography software should generally not leave “signatures” that allow it to be identified. In this sense, a signature is always a flaw linked to a very specific implementation.
A second example of signature detection, this time using mathematical properties, was presented in Goljan and Fridrich (2015) and relates to color images. Remember that the sensor of a photographic camera is insensitive to color by nature. To show the color, a red, green or blue microfilter is placed in front of each photo-site of the sensor, which then records the color information corresponding to the color of the filter (Sharma and Bala 2017). You must then “reconstruct the two missing colors”, which is performed from neighboring pixels. It was found in Goljan and Fridrich (2015) that steganography can go against the fundamental rules of reconstruction of the value of the missing colors. For example, in the linear interpolation framework, if the green component of a pixel estimated from its neighbors becomes more important than all its neighboring pixels because of steganography, this value will become incompatible with its neighbor and the steganography will be shown.
Goljan and Fridrich (2015), therefore, proposed using seven features, which count the number of pixels whose value does not agree with the rules for reconstructing colors from neighboring pixels; these values are always assumed to be zero for a natural image and make it possible to detect steganography in color images by signature.
Another example of incompatible signature is that of Cover images encoded in the spatial domain, but which have been previously compressed in the JPEG format. This strategy may seem interesting at first, because an uncompressed image can theoretically accommodate a greater amount of hidden information than a compressed version. However, if an image encoded in the spatial domain was first compressed using the JPEG standard, the 8 × 8 block of pixels can be broken down as a sum of the components of the DCT representation, weighted by integer coefficients. More precisely, let us denote by X an 8 × 8 block of pixels which can be written as:
where qk,l is the elements of the quantization matrix, ck,l is the (unknown) coefficients of the components of the DCT base, noted Dk,l, and round(·) is the rounding function.
If some pixels of this block, X, are modified after JPEG compression, it becomes impossible to find integer coefficients, ck,l, that make it possible to show the X block. The steganalyst, Alice, can then conclude that this image seems to have been compressed in the JPEG format, but that some pixels conflict with what should have been obtained during the decompression. Once again, this mathematical incompatibility can be used to detect a Stego image.
More recently, a fairly similar signature, also based on what has been called “compatibility with JPEG compression”, is proposed in Butora and Fridrich (2020) and Cogranne (2020). In this case, it is a question of detecting steganography in the images compressed in JPEG format by using the fact that modifying the DCT coefficients can lead to the production of pixel values that are not possible for a natural image. This detection method uses a statistical steganalysis method and is described in more detail at the end of section 8.3.
Finally, note that while these signature detection methods are generally very reliable in the sense that errors are uncommon, each software or algorithm must nevertheless be carefully analyzed in order to find characteristic traces which reveal that it has been used. This type of analysis is very time consuming while also being difficult to generalize. The following steganalysis strategies are intended to be more common.
8.3. Detection using statistical methods
The detection methods presented in the rest of this chapter are often less reliable than signature detection methods, but have the advantage of being much more general, in the sense that they aim to detect changes related to hiding information in the very content of a medium.
We first introduce simple statistical methods. Consider an image X of size M × N, described as a matrix of pixels encoded on 8 bits, xm,n ∈ {0; . . . ; 255}, so the steganalysis involves choosing between the two following hypotheses:
- 1)
 0: pixels xm,n come from a Cover image;
0: pixels xm,n come from a Cover image; - 2) 0: pixels xm,n come from a Stego image.
The main difficulty is to define precisely what statistically characterizes a Cover image, and what differentiates it from a Stego image.
8.3.1. Statistical test of χ2
Historically, the first approach that addressed that this problem was proposed in Westfeld and Pfitzmann (1999). Unable to statistically describe what a natural image is, it has been proposed that we model the pixels after using steganography. To explain how this test works, we need to remember how the insertion of a message by least significant bits (LSB) works4. In order to insert the ith bit of the message mi ∈ {0; 1} into the pixel xm,n, steganography by substitution of the least significant bits modifies the pixel in the following way:
where zm,n is the pixel of the Stego image and LSB(xm,n) is the least significant bit of xm,n.
It is generally accepted in steganalysis that the message inserted, m = (m1, . . . , mI), is a sequence of all independent and identically distributed bits (i.i.d) according to a uniform law: ![]() [mi = 0] =
[mi = 0] = ![]() [mi = 1] = 1/2.
[mi = 1] = 1/2.
The result of the insertion of the bit mi in the pixel xm,n is that the Stego pixel can be modeled by the following probability distribution:
with ![]() = x + (−1)x the integer value x whose least significant bit has been inverted.
= x + (−1)x the integer value x whose least significant bit has been inverted.
Furthermore, assuming that all of the pixels are used to hide a (very) large secret message, the distribution of Stego pixels can be modeled as follows:
It then becomes possible to statistically test whether an image is a Stego image by measuring the difference between the theoretical distribution of equation [8.4] and that observed on an analyzed image. This is precisely the purpose of the χ2 test that measures the difference between a theoretical distribution and those from observations as follows:
where Nk represents the number of pixels whose value is k and ![]() represents the expected number of pixels with the value k.
represents the expected number of pixels with the value k.
In fact, equation [8.5] represents a measure of the difference between theoretical distribution and empirical distribution through the term: ![]() 2. Figure 8.1 illustrates the distribution models of equations [8.4] and [8.5] for a Stego image; in fact, we see a number of pixels k and
2. Figure 8.1 illustrates the distribution models of equations [8.4] and [8.5] for a Stego image; in fact, we see a number of pixels k and ![]() which are “equalized” on the Stego image.
which are “equalized” on the Stego image.
When the value of χ2 is beyond a given threshold, τ, the image is considered to be a Cover image, or statistically too different to the theoretical distribution to be considered a Stego image [8.4]. How should the threshold τ then be set? The authors in Westfeld and Pfitzmann (1999) propose choosing a threshold to make sure that, theoretically, a Stego image is considered as natural with a probability5 p0. For this, the authors use the distribution of χ2, which makes it possible to calculate this probability with the following relationship:
with ν = 128 − 1, the “number of degrees of freedom” defined by the number of “pairs of values”, which can be swapped between them.

Figure 8.1. Illustration of the impact of steganography by LSBR and its detection by the χ2 test
Figure 8.2 illustrates this way of setting the decision threshold depending on a “false-negative” probability, p0, set previously. It also allows us to compare the theoretical distribution of the statistic, χ2, from equation [8.5] with the theoretical distribution of χ2. The difference between the observations and the theoretical model is mainly due to the fact that the vast majority of the images do not have pixels with all the values between 0 and 255, and therefore have a number of degrees of freedom less than ν = 128 − 1.

Figure 8.2. Illustration of probability distributions (empirical and theoretical) for the result of the χ2 test and the resulting error probabilities
The strength of the χ2 test is that it offers a statistical test without having to solve the (very tricky) problem of modeling the statistical distribution of pixels of a Cover image. In fact, the test essentially proposes checking whether the pixels of an analyzed image correspond to the model of a Stego image; otherwise the image is considered to be a Cover image by default. Another use of this test is to try to set the detection threshold, τ, based on a missed detection probability, pχ2 (τ), defined in equation [8.6].
Unfortunately, this test is not very efficient, especially since it does not model the statistical distribution of a Cover image, but only the Stego image. In statistical detection, when only one of the two hypotheses can be characterized, we generally carry out a “goodness-of-fit” test, measuring the adequacy of the observations to this model, and this is generally less reliable than when you can exactly characterize the two competing hypotheses, as proposed by the likelihood-ratio test presented in section 8.3.2.
8.3.2. Likelihood-ratio test
In order to fully understand the approach presented in this section, it is necessary to formalize steganalysis and statistical detection.
A statistical test is a function δ, which, from a group of observations, X, returns a binary decision: δ : X → {0, 1}, so that the hypothesis, ![]() 0, is accepted if δ(X) = 0. Let us briefly recall that a test is never perfect and that there are two possible types of errors: false-positive and false-negative (or false alarm and no detection). In general, the hypothesis
0, is accepted if δ(X) = 0. Let us briefly recall that a test is never perfect and that there are two possible types of errors: false-positive and false-negative (or false alarm and no detection). In general, the hypothesis ![]() 0 is said to be “null”, and corresponds to a “normal” case, while the alternative hypothesis,
0 is said to be “null”, and corresponds to a “normal” case, while the alternative hypothesis, ![]() 1, corresponds to the difficult situation that we want to detect. The false-positive, therefore, corresponds to the case where the test decides to accept the hypothesis
1, corresponds to the difficult situation that we want to detect. The false-positive, therefore, corresponds to the case where the test decides to accept the hypothesis ![]() 1 when, in reality, the observations come from the hypothesis
1 when, in reality, the observations come from the hypothesis ![]() 0.
0.
In the case that we are interested in, the analyzed image is a Cover image which is classified as a Stego image. On the other hand, a false-negative corresponds to the case where the test accepts the hypothesis ![]() 0, when the observations really come from the alternative hypothesis
0, when the observations really come from the alternative hypothesis ![]() 1; for steganalysis, this is the case where the guardian, Eve, misses the detection of a Stego image.
1; for steganalysis, this is the case where the guardian, Eve, misses the detection of a Stego image.
In order to show how weak the χ2 test is, we need a statistical model of the Cover images. This is built by assuming that the pixels are statistically independent and all come from a Gausian distribution:
where µm,n represents the mathematical expectation of the pixel (i.e. its “average” or theoretical value), and ![]() represents the noise variance.
represents the noise variance.
This is a model commonly used in image processing, which assumes that an image can be decomposed into a theoretical “content” and noise, linked to the camera defects. To be more precise, the pixels are represented by integer values and, for the sake of simplicity, we assume that this has no impact on the probability distribution of the pixels:
First, we study the case where Alice uses steganography by LSB substitution6. Each pixel can be modified with the same probability of ![]() , which relates to the ratio of the number of bits of the inserted message (I), per pixel (MN), and the distribution of a Stego pixel then becomes:
, which relates to the ratio of the number of bits of the inserted message (I), per pixel (MN), and the distribution of a Stego pixel then becomes:
Table 8.1. The different possibilities of good and bad detection. For a color version of this table, see www.iste.co.uk/puech/multimedia1.zip
| Truth | Hypothesis 0: (Cover image) | Hypothesis 1: (Stego image) |
| Result | ||
| Accept Hypothesis 0 | Correct decision | False-negative (missed detection) (pFN: 1 − ς) |
| Accept Hypothesis 1 | False-positive (false alarm) (pFP: α= | Correct decision (ς= |
How can we use these statistical models to decide whether an examined image, X, comes from the hypothesis model instead ![]() 07, or from the hypothesis
07, or from the hypothesis ![]() 18?
18?
There are several solutions that have one central element in common, the likelihood ratio (LR), which is expressed as:
with p0 and p1, which are the statistical distribution models for Cover and Stego images, respectively, defined by equations [8.8] and [8.9], respectively.
The second part of the equality of equation [8.10] results directly from the statistical independence model between the pixels which, although not totally exact, is very widely used because it significantly simplifies things.
Clearly, the likelihood ratio (LR) is greater if the probability of observing the data to be analyzed is greater under ![]() 1 than under
1 than under ![]() 0; conversely, if the probability of observing these data is much greater under
0; conversely, if the probability of observing these data is much greater under ![]() 0 than under
0 than under ![]() 1, the LR will be low. Based on this observation, the likelihood ratio test simply involves thresholding this likelihood ratio: δ(X) =
1, the LR will be low. Based on this observation, the likelihood ratio test simply involves thresholding this likelihood ratio: δ(X) = ![]() 0 if Λ(X) < τ and δ(X) =
0 if Λ(X) < τ and δ(X) = ![]() 1 and Λ(X) ≥ τ.
1 and Λ(X) ≥ τ.
The use of the LR test is theoretically justified because the Neyman–Pearson lemma states that it helps achieve the greatest power9 ς for a false-positive probability, α, set at α = ![]() [Λ(X) > τ]. This last relationship also makes it possible to set the threshold in order to respect a previously established false-positive rate.
[Λ(X) > τ]. This last relationship also makes it possible to set the threshold in order to respect a previously established false-positive rate.
Using the Cover image model of equation [8.8] and the Stego image model of equation [8.9], the LR is written as:
For the sake of simplicity, the logarithm of LR is generally used. This is to replace the product in equation [8.11] by the sum. Moreover, by using the definition of p0(xm,n) equation [8.8], a (slightly tedious) calculation makes it possible to simplify the previous relationship as follows (Cogranne 2011):
In this approach, the most interesting thing is not so much having a simple relationship, making the calculation of the likelihood ratio possible (although some simplifications had to be made), but more being able to characterize the statistical distribution of the latter and therefore, in fine, controlling the probabilities of false alarms and non-detection.
In particular, it is possible to show the mathematical expectation and variance of the term log (Λ(X)) for a Cover image given by:
It is then possible to standardize the LR as follows:
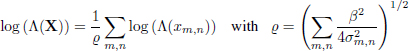
so that, in accordance with the central limit theorem (Lehmann and Romano 2005, theorem 11.2.5), it is possible to calculate the statistical distribution of the LR-log for a given image:
With the Gaussian distribution being fairly easy to use, we can easily calculate the decision threshold, τ, to ensure a fixed false-positive probability, α0: τ(α0) = Φ−1 (1 − α0) so that ![]() [log (Λ(X)) > τ (α0)|
[log (Λ(X)) > τ (α0)|![]() 0] = α0. Similarly, the power of the test ς can be calculated as the probability,
0] = α0. Similarly, the power of the test ς can be calculated as the probability, ![]() [log (Λ(X)) > τ |
[log (Λ(X)) > τ |![]() 0] = 1 − Φ (τ − ϱ).
0] = 1 − Φ (τ − ϱ).
Many observations are necessary to understand these different results. On the one hand, let us note that it is very “typical” for the mathematical expectation of the LR for a Stego image to be equal to its variance. It is for this reason that the normalization factor, ϱ, in equation [8.14] also corresponds to the expectation in equation [8.15].
We also note that all the previous calculations require knowledge of the mathematical expectation, µm,n, and the variance, ![]() , of each of the pixels, but, in practice, these variables are not known. It is therefore suggested that we replace them with estimates, which are quite hard to obtain “accurately”, and this is where the application of this approach becomes much more complicated and the guarantee of the error probabilities in particular becomes very difficult. Some results are presented in Figure 8.3, using the ALASKA image database (Cogranne et al. 2019). Figure 8.3(a) shows that the distribution of the LR-log obtained for Cover images is fairly consistent with the theory. For Stego images, it depends on the ϱ factor, which varies for each image, creating this “spread”. Figure 8.3(b) compares the false-positive probability depending on the decision threshold, τ, in theory and in practice, using two different image bases. We can also see that this property is valid for “fairly high” probabilities. However, note that, in the case where we want to obtain very low false-positive rates, the estimates are not precise enough to offer relevant guarantees. Finally, Figure 8.3(c) shows the performances obtained through a ROC (Receiver Operating Characteristic) curve, which presents a false-positive probability, α0(τ), depending on the detection power ς(τ). We can see that for an insertion rate β ≈ 0.09 (24 kilobits inserted into images of 512 × 512 pixels), the performance is very good on the two bases used for high error probabilities.
, of each of the pixels, but, in practice, these variables are not known. It is therefore suggested that we replace them with estimates, which are quite hard to obtain “accurately”, and this is where the application of this approach becomes much more complicated and the guarantee of the error probabilities in particular becomes very difficult. Some results are presented in Figure 8.3, using the ALASKA image database (Cogranne et al. 2019). Figure 8.3(a) shows that the distribution of the LR-log obtained for Cover images is fairly consistent with the theory. For Stego images, it depends on the ϱ factor, which varies for each image, creating this “spread”. Figure 8.3(b) compares the false-positive probability depending on the decision threshold, τ, in theory and in practice, using two different image bases. We can also see that this property is valid for “fairly high” probabilities. However, note that, in the case where we want to obtain very low false-positive rates, the estimates are not precise enough to offer relevant guarantees. Finally, Figure 8.3(c) shows the performances obtained through a ROC (Receiver Operating Characteristic) curve, which presents a false-positive probability, α0(τ), depending on the detection power ς(τ). We can see that for an insertion rate β ≈ 0.09 (24 kilobits inserted into images of 512 × 512 pixels), the performance is very good on the two bases used for high error probabilities.


Figure 8.3. Results of the application of the LRG test, equation [8.14]
8.3.3. LSB match detection
Essentially, the detectors presented in section 8.3.2 show that steganography by substitution of the LSB clearly introduces a bias by increasing even values and decreasing odd values. This explains why this insertion method is to be avoided, to benefit the correspondence (LSBM or LSB±1), which modifies the least significant bits, according to the insertion rule defined in section 5.3.1.
After having presented the application of a statistical test for steganalysis in detail, we can address the detection of LSB±1, which has been studied in the literature through “simple” tests much less. We will also consider the case of an adaptive steganography scheme, that is, the probability of using the pixel xm,n is potentially different for each pixel10 and will therefore be denoted βm,n. The reader will note that it is very easy to replace the “average insertion rate”, β with an insertion rate for each pixel, βm,n, without any additional modification, in equations [8.9] and [8.11]–[8.14].
We will not explain all the details of the calculations, which can be found in Cogranne (2011) and Sedighi et al. (2016a), but the LR-log calculation for the least significant bits correspondence leads, after a few simplifications, to:
Again, the most interesting thing here is calculating the error probabilities of this test and, using the central limit theorem like before, this requires knowing the first two moments, which are given by:

The comparison between the LR for LSB substitution detection, given in equation [8.12], and the LR for the detection of LSB±1, given in equation [8.16], shows that the detection of LSBR (substitution) is essentially based on a deviation from the expectation through the term (xm,nµm,n). Conversely, the detection of LSB±1 is essentially based on a difference between the theoretical variance and that observed through the term (xm,n − µm,n)2. However, if estimating the mathematical expectation of pixels is widely studied11, the precise estimate of the variance of pixels is much harder and has been studied much less. We also want to detect a deviation from a variance that is not known and needs to be estimated, regardless of the presence of hidden information. All of this explains why the statistical steganalysis methods tackling adaptive insertion methods are not as efficient as the LSB substitution steganalysis seen in section 8.3.2.
The application of statistical detection explains why the steganalysis of LSB±1 is more difficult; it should be noted that the performance study also shows that, for a given pixel, the “detectablility” essentially depends on the “insertion-on-noise relationship”, defined by ![]() in the relationships of equation [8.17].
in the relationships of equation [8.17].
An interesting application of the theory of hypothesis testing has been to use this result concerning the “statistical detectability” of each pixel to design an insertion algorithm (Sedighi et al. 2016a) which, instead of minimizing the heuristic distortion, minimizes the theoretical detectability. Although this requires estimating the mathematical expectation and the variance of each pixel (which remains an unresolved problem), it has shown its effectiveness. More details on this application of the theory of hypothesis testing in steganography are given in section 5.3.2.2.
To conclude this section on statistical steganalysis, let us mention that a method of statistical steganalysis on JPEG images has recently been proposed that amazes with how efficient it is. This method, presented by Butora and Fridrich (2020) and Cogranne (2020), exploits the fact that the pixels are quantized before using the discrete cosine transform (DCT). For a compressed image, it is possible to decompress it12 and to measure the variance of the quantization noise by:
where M and N are the number of lines and columns of image X, and round (·) is the rounding function to the closest integer value.
If information has been hidden in the DCT coefficients, the rounding error in the spatial domain makes it possible to obtain the statistic defined in equation [8.18], which will tend to increase. This test is really effective (it was slightly improved in Cogranne et al. (2020b) with a “near-perfect” detection of a few hundred bits). This can be explained by the fact that it is based on a very precise model and does not depend on the parameters to be estimated, but only on the quantization noise which is the same regardless of the image analyzed. However, this is a very specific case that can be equivalent to incompatible signature detection (see section 8.2).
8.4. Supervised learning detection
We will now describe steganalysis approaches that are radically different from what has been previously described. These methods are neither based on the presence of an incompatible signature, nor on the prior knowledge of a statistical model of the Cover and/or Stego image, but are based on supervised statistical learning methods, whose foundations can be broken down into two phases. First, it is a matter of extracting the “features” from objects in the database considered. These features must reveal the presence of hidden information (or what we want to detect in general) and must make it possible to reduce a complex and variable object, such as an image, of any size, to a real-valued vector of p. Based on these features, a learning method is used to determine a decision rule, which will provide a binary result, which will be the result of steganalysis. Thus learning is supervised, in that each image is associated, during this phase of learning, with a label that indicates if the image is a Cover or Stego. Determining a decision rule actually corresponds to the resolution of an optimization problem that seeks to associate a value that is as close as possible to the label to be predicted with each feature vector.

Figure 8.4. Illustration of the supervised learning principal, which aims to determine a detection rule from a labeled database (right image licensed under CC BY-SA 4.0, produced by Zirguezi)
In this section, we will now briefly describe how these two phases, (1) features extraction and (2) supervised learning, are usually implemented in steganography.
8.4.1. Extraction of characteristics in the spatial domain
8.4.1.1. SPAM characteristics
It would obviously take too long to describe the evolution of steganalysis up to modern techniques in detail, but note that, generally, a keystone of current methods originated in Pevný et al. (2010), which uses the differences between adjacent pixels that we will denote D→:
with →, which here represents the horizontal direction in which the differences are calculated, among the eight possible used ![]() .
.
On the basis of these differences, it is suggested that we estimate the frequency with which successive differences are found in an image. Representing an empirical frequency corresponds to a count that is generally, simply yet inaccurately, known as “histogram” in steganalysis. These counts are arranged in vector:
with ![]() [·], the indicator function,
[·], the indicator function, ![]() [e] = 1 if the event e is true – and
[e] = 1 if the event e is true – and ![]() [c] = 0 otherwise – and T, the maximum difference threshold considered.
[c] = 0 otherwise – and T, the maximum difference threshold considered.
Given that the values of adjacent differences together on neighboring positions are counted, these vectors are called “co-occurrence” in steganalysis. This concept can be generalized by using more than two disjoint values at the cost of increasing the number of possible co-occurrence values. In fact, by using co-occurrences of c adjacent differences between T and T, it gives (2T +1)c different values of possible co-occurrences. Finally, the last step proposed in Pevný et al. (2010) aims to limit the number of characteristics by gathering together the values calculated for opposite directions, for example ← and →, or even ↖ and ↘. The authors propose grouping together “diagonal” directions and horizontal and vertical directions:
This step, called “symmetrization”, aims to reduce the number of characteristics.
The original SPAM, Subtractive Pixel Adjacency Matrix (Pevný et al. 2010) characteristics, use triplets of three adjacent differences, c = 3, fk,l,m (kown as second order), and three distinct values for each T = 3. This means counting a distinct number of “co-occurrences” of (3 × 2 + 1)3 = 73 = 343. Adding the fact that diagonal co-occurrences are distinguished from horizontal and vertical co-occurrences during the symmetrization phase, this gives a total of 686 characteristics.
Clearly this is quite a high number of characteristics (also know as dimensions) compared to the problems generally studied in the field of statistical learning.
8.4.1.2. RM characteristics
However, it has been empirically observed that, for the particular case of steganalysis, which essentially involves a very weak signal detection within the Cover media, generalizing an approach like this makes it possible to improve the detection performance. The approach that we have briefly described was largely developed afterward in a methodology whose operating principle is illustrated in Figure 8.5. This figure illustrates the “Spatial Rich Model” operating as proposed in Fridrich and Kodovsk![]() (2012). This is essentially an improvement of the method proposed in Pevný et al. (2010). Furthermore, these models are fairly standard, and also illustrate the fact that the current methods of steganalysis are divided into four main stages, which are (1) calculation of residuals; (2) quantization and thresholding; (3) counting co-occurrences and finally (4) redundancy reduction by symmetrization.
(2012). This is essentially an improvement of the method proposed in Pevný et al. (2010). Furthermore, these models are fairly standard, and also illustrate the fact that the current methods of steganalysis are divided into four main stages, which are (1) calculation of residuals; (2) quantization and thresholding; (3) counting co-occurrences and finally (4) redundancy reduction by symmetrization.
Calculating residuals is generally done by using a linear filter. From an image, X, whose pixels are given by xm,n, we apply the same relationship between adjacent pixels on the whole image:
This weighted sum of neighboring pixels is a convolution operation, R(n) = X * K(n), whose kernel K(n) specifies the value of these weighting factors. We generally speak of a low-pass filter when ∑i,j ki,j = 1; it is typically a “smoothing”, aiming to decrease the “noise”. On the other hand, in steganalysis, the term “residuals” is used to characterize high-pass filtering, characterized by ∑i,j ki,j = 0, k0,0 = –1. In other words, it is about “estimating” the value of a pixel, xm,n, from its neighbors, ![]() , and then calculating the difference,
, and then calculating the difference, ![]() , which corresponds to the “estimation error”, due to the filter, K(n).
, which corresponds to the “estimation error”, due to the filter, K(n).
To be able to catch all the possible traces due to steganography, the number of filters is important; 78 residuals are used to construct the RM characteristics presented in Fridrich and Kodovsk![]() (2012).
(2012).

Figure 8.5. Illustration of the principle of extraction of RM characteristics (Spatial Rich Model)
The second step is quantization and thresholding. Generally, weighting factors used in the kernels K(n) are not integers, and the residuals R(n) must be grouped together into “close” values to be able to work out “histograms”. The general idea is dividing the residuals, R(n), by a quantization step, q, and then rounding the results. The quantization step, q, then determines the “granularity” of the histogram. A very large step gives a rough histogram: for example, a step of q = 10 leads to rounding to the nearest 10; on the other hand, a step of q = 1 leads to rounding to the nearest integer. Thresholding simply involves limiting the range of possible values (despite quantization) in order to limit the extent of resulting “co-occurrences”. It is simply suggested that we only count the values of the residuals below a certain threshold, T, and ignore the values beyond.
Finally, this second step can be represented by:
with ThresholdT, the thresholding operation with the threshold T, and Round, the rounding operation to the nearest integer.
In Spatial Rich Models (Fridrich and Kodovsk![]() 2012), three distinct quantization steps are used, (q = {1, 2, 3}), but the threshold is always set at T = 3, in order to be able to represent smaller or greater residue values, depending on the quantization step.
2012), three distinct quantization steps are used, (q = {1, 2, 3}), but the threshold is always set at T = 3, in order to be able to represent smaller or greater residue values, depending on the quantization step.
The third step aims to represent the “residuals” through histograms with several dimensions or co-occurrences. This mainly allows a better representation of the global statistical properties of the residuals, regardless of their positions in an image, but also to reduce the amount of data and, finally, to have an identical representation, whatever the size of the image analyzed. The co-occurrence calculation for a given type of residual, R(n), is done, as explained in equation [8.20], by counting the number of adjacent values, whose values are all equal to a certain pattern. It is therefore a generalization of equation [8.20] to a tuplet of c adjacent residuals. It is also worth noting that by using c adjacent residuals, we can also multiply the directions, which can be much more general than just the eight directions considered, in the case of pairs. The calculation of co-occurrences is generally limited to vertical and horizontal directions, since all possible paths would become too large with co-occurrences of dimension c = 4, like the ones used in Fridrich and Kodovsk![]() (2012).
(2012).
Finally, the last step involves merging, similar co-occurrences, typically vertical to the left or to the right, generally by calculating an average. The underlying principle is that there is no objective reason to assume that traces of steganography are represented differently in one direction than they are in another. Symmetrization is a harder step to generally define, since it greatly depends on the filters used to calculate the residuals, on the one, and the co-occurrences used, on the other. Generally, we agglomerate the different directions (vertical and horizontal co-occurrences), as well as the filters that can be deduced from one another by symmetry. This stage makes it possible to greatly reduce the number of characteristics used. In fact, consider the classic case of characteristics from rich spatial models (Fridrich and Kodovsk![]() 2012). We count 78 distinct filters with three quantification steps, a thresholding with the threshold T = 2, and co-occurrences calculated horizontally and vertically. Eventually, an image characterized by RMs has (after symmetrization) 34,761 features.
2012). We count 78 distinct filters with three quantification steps, a thresholding with the threshold T = 2, and co-occurrences calculated horizontally and vertically. Eventually, an image characterized by RMs has (after symmetrization) 34,761 features.
8.4.1.3. Extraction of characteristics in the JPEG domain
With regard to images compressed in the JPEG format, extraction of characteristics introduces a first problem: should the DCT coefficients be used directly, which can be modified, or is it better to “decompress” the image in order to analyze the pixels?
The two approaches have been studied and, today, detection in the decompressed images shows more interesting performances. This is specifically due to the fact that the modeling and analysis of contiguous pixels are much simpler than the analysis of the DCT coefficients, which are the result of different filters and have properties that do not allow an easy analysis.
A compromise between these two areas of analysis has been proposed by Holub and Fridrich (2015); we will briefly describe it since it performs well and has led to many more recent works, in particular (Song et al. 2015). This approach, called DCTR (for DCT residuals), analyzes an image by first decompressing it, then applying a DCT transformation to the pixels, similar to that used in JPEG compression. More precisely, we have briefly explained that JPEG compression applies a series of 64 (8 × 8) orthogonal filters to disjoint blocks of 64 (8 × 8) pixels. The principle of DCTR is based on the use of these 64 filters on non-disjoint blocks. More precisely, these filters are applied by convolution with the decompressed image, which amounts to calculating DCT coefficients in addition to those used in the JPEG compression on parts of adjacent 8 × 8 blocks. The result of this operation is 64 distinct images that are the same size as the original image, each one corresponding to the application of one of the DCT transformation filters. This stage is equivalent to calculating 64 residuals.
These images are then quantified, modified in absolute values (negative values are reported as positive values), and then thresholded. The quantization is all the greater as the quality factor is small (in a similar way to JPEG quantization matrices) and the threshold is set at 4. For each of these 64 “sub-images”, several histograms are calculated, depending on the position of the residuals. The idea is clearly to give a “reference” that is comparable to the DCT coefficients, which are used in JPEG compression (and therefore possibly modified by steganography) with those which are not used, but which correspond to images that are statistically very similar, as they are only shifted by a few pixels.
In the case of DCTR, no symmetrization is used; however, some positions of “DCT residuals” are gathered, and we end up with 25 histograms by DCT filters and 4 + 1 values in the thresholded histogram, that is, a total of 64 × 25 × 5 = 8,000 features.
8.4.2. Learning how to detect with features
Once the features have been extracted, a classification phase remains to be implemented. More precisely, it is necessary to extract these features for a large amount of Cover images in order to then hide information in these images using a steganography method to generate Stego images, and finally to extract characteristics from these Stego images. Learning a classification rule in such a framework is part of supervised statistical learning: we have seen two feature sets, the first for images without Cover information and the second for Stego images. There are many supervised statistical learning methods; in general, this corresponds mathematically to an optimization problem to find the parameters of a function, making it possible to maximize the detection performance. Since in steganalysis the main adapted classifiers are linear, we will focus on this type of method.
Consider two bases of L features calculated on I images, that we denote in matrix form C = (c(1), . . . , c(I)) for Cover images (of class – 1) and S = (s(1), . . . , s(I)) for Stego images (of class 1). A linear classifier is based on a projection of the features on a discrimination vector, ![]() . This operation is a weighted sum of features. The goal is therefore to find a vector of the weighting coefficients, w, which makes it possible to differentiate the Cover and Stego data after projection. A simple criterion for this involves seeking weighting coefficients, w, so that the vectors ci are close to the value −1, while the vectors si are close the value 1.
. This operation is a weighted sum of features. The goal is therefore to find a vector of the weighting coefficients, w, which makes it possible to differentiate the Cover and Stego data after projection. A simple criterion for this involves seeking weighting coefficients, w, so that the vectors ci are close to the value −1, while the vectors si are close the value 1.
If large vectors, y0 and y1, are created, with the first vector containing I times the value of −1 and the second vector containing I times the value of 1, it is then a question of finding the weighting factors, w, that minimize the difference between the values wT C and y0 (and vice versa between wT × S and y1), let ![]() +
+ ![]() .
.
This method actually comes to a minimization problem, in the sense of least squares. This approach is particularly interesting, since an analytical solution is given by:
where X is a matrix that groups together features X = (C, S) and, similarly, the vector y contains all label values y = (y0; y1).
Therefore, this method functions correctly, and it is generally useful to add a regularization factor, which makes it possible to find a compromise between a “simple” solution and a solution that is adapted to the data used for learning. It is this method which was proposed in Cogranne et al. (2015), and which allows performance that is very close to the state of the art in just a few seconds (for 10,000 images and 40,000 characteristics).
An interesting alternative approach that is based on another linear classifier is the Fisher approach, which is very similar to the previous one, but aims to maximize the separability criterion:
where µi is the mean of the features for the images of the class i, and Σi is the covariance matrix of the features of the class i.
This method also presents the advantage of having a directly calculable solution:
The main attraction of the method proposed in Kodovsk![]() et al. (2012) is the use of a variety of classifiers. For this, many classifiers are trained on “sub-sets” of images and/or on “sub-sets” of characteristics. The attraction is mainly based on the fact that this specific training and this procedure for multiplying classifiers makes it possible to eventually build a “robust”, nonlinear and efficient classifier. This method has been improved in Cogranne and Fridrich (2015), but, in both cases, the results are slightly better than those obtained with a simple linear classifier for a much greater computational complexity (of the order of 20–100 times more).
et al. (2012) is the use of a variety of classifiers. For this, many classifiers are trained on “sub-sets” of images and/or on “sub-sets” of characteristics. The attraction is mainly based on the fact that this specific training and this procedure for multiplying classifiers makes it possible to eventually build a “robust”, nonlinear and efficient classifier. This method has been improved in Cogranne and Fridrich (2015), but, in both cases, the results are slightly better than those obtained with a simple linear classifier for a much greater computational complexity (of the order of 20–100 times more).
8.5. Detection by deep neural networks
We now present the latest developments in learning-based steganalysis methods, namely, the use of deep neural networks. Neural networks have been studied since the 1950s. Initially, they were proposed to model brain behavior. In computer science, especially artificial intelligence, they have been used for 30 years for learning purposes. In the early 2000s (Hinton and Salakhutdinov 2006), deep neural networks were considered to have a learning time that was too long, and to be less efficient than classifiers like SVMs or random forests.
Thanks to recent advances in the field of neural networks (Bengio et al. 2013), computing power provided by graphics cards (GPU) and, finally, the profusion of data, deep learning approaches have been proposed as a natural extension of neural networks. Since 2012, these deep networks have profoundly marked the fields of signal processing and artificial intelligence, because their performance has made it possible to surpass the most efficient methods of the time, but also to solve problems that scientists could not solve until now (LeCun et al. 2015).
In steganalysis, over these last 10 years, detection of a hidden message in an image has mainly been carried out by the calculation of a rich model (RM)13 (Fridrich and Kodovsk![]() 2012) followed by a classification by an ensemble classifier (EC) (Kodovsk
2012) followed by a classification by an ensemble classifier (EC) (Kodovsk![]() et al. 2012). In 2015, the first study using a convolutional neural network (CNN) obtained the first results of steganalysis by “deep-learning”, coming close to the results of two-step approaches (EC + RM)14 (Qian et al. 2015). Since then, over the period 2015 to 2019, many publications have shown that it is possible to obtain better performances, for spatial images (uncompressed/steganalysis) and JPEG steganalysis, but also for informed steganalysis, quantitative steganalysis and color steganalysis.
et al. 2012). In 2015, the first study using a convolutional neural network (CNN) obtained the first results of steganalysis by “deep-learning”, coming close to the results of two-step approaches (EC + RM)14 (Qian et al. 2015). Since then, over the period 2015 to 2019, many publications have shown that it is possible to obtain better performances, for spatial images (uncompressed/steganalysis) and JPEG steganalysis, but also for informed steganalysis, quantitative steganalysis and color steganalysis.
In section 8.5.1, we present the structure of a deep neural network in a generic way. Reading this section can be supplemented by reading about artificial learning, and, in particular, about the definition of perceptron, stochastic gradient descent, backpropagation and the extension to the multi-classes case.
8.5.1. Foundation of a deep neural network
In the following sections, we recall major concepts of a CNN; we will recall the basic building blocks of a network based on the Yedroudj-Net network, which was published in 2018 (Yedroudj et al. 2018b) and which uses ideas that are present in Alex-Net (Krizhevsky et al. 2012), as well as those present in networks developed for steganalysis, including the very first network by Qian et al., the Xu-Net network (Xu et al. 2016) and the Ye-Net network (Ye et al. 2017).
8.5.1.1. Global view of a CNN
Before describing the structure of a neural network, as well as its foundations, it is useful to remember that a neural network belongs to the family of machine learning. In the case of supervised learning, which is what interests us, it is necessary to have an image database, with a label for each image, that is, its class.
Deep learning networks are large neural networks that can directly take raw data as input.
In image processing, the network is directly supplied by the pixels that make up the image. A deep learning network then learns to extract the intrinsic characteristics (generally called a feature map or latent space), and to draw the separation boundary of the different classes (separator planes).
The learning protocol is similar to classic machine learning methods. Each image is given at the input of the network. Each pixel value is transmitted to one or more neurons. The network is made up of a given number of blocks. One block is made up of neurons that take real values as input, perform calculations and then transmit the calculated real values to the next block. A neural network can then be represented by a directed graph where each node represents a computation unit. The learning is then carried out by providing the network with examples composed of an image and its label, and the network modifies the parameters of these computation units by learning, thanks to the backpropagation and stochastic gradient descent algorithms.
The CNNs used for steganalysis are mainly built in three parts called modules: the preprocessing module, the convolution module and the classification module. As an example, Figure 8.6 outlines the network proposed by Yedroudj et al. in 2018 (Yedroudj et al. 2018b). This network processes grayscale images of pixel size 256 × 256.
8.5.2. The preprocessing module
In Figure 8.6, we can see that, in the preprocessing module, the image is filtered by 30 high-pass filters. The use of one or many high-pass filters as preprocessing is present in the majority of networks used for steganalysis during the period between 2015 and 2019. As an example, the kernel “square S5a” (Fridrich and Kodovsk![]() 2012) is given by:
2012) is given by:
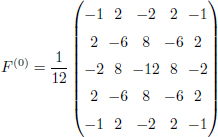
This initial filtering step allows the network to converge faster and is probably necessary for good performance when the training base is too small (Yedroudj et al. 2018a) (only 4,000 Cover/Stego pairs of pixel size 256 × 256). The filtered images are then transmitted to the first convolution block of the network. The Yedroudj-Net network has five convolution blocks (Yedroudj et al. 2018b), like the Qian et al. network (Qian et al. 2015) and the Xu et al. network (Xu et al. 2016).

Figure 8.6. The Yedroudj-Net (Yedroudj et al. 2018b) network
Note that the recent SRNet network (Boroumand et al. 2019) does not use fixed pre-filters, but learns the values of filters. This requires a much larger database (more than 15,000 Cover/Stego pairs of 256 × 256 pixels), and possibly using a preliminary training to start from a good initialization. There is also a debate in the community as to whether we should use fixed filter values, initialize the filter values with preselected values and then refine these values by training or have a random initialization and leave the network to learn the values of the filters. At the time of writing this chapter, we think that the best choice is related to the architecture of the network, the size of the training database used and the possibility of using pre-training/transfer learning.
8.5.2.1. The convolution module
To avoid any confusion on the terms, we will avoid using the term layer; the term operations will be preferred for an elementary function (convolution or activation, for example), and the term block for a set of these operations that can follow one another. A block is made up of computation units which take real values as input, perform calculations, then return real values, which are transmitted to the next block. In practical terms, a block takes a set of feature maps15 on input and return a set of feature maps at output. Inside a block, we find a certain number of operations, including the following four: convolution, activation, pooling and finally normalization.
Note that the concept of a neuron as defined in the literature before the appearance of convolutional networks is still present, but it has disappeared from the source codes of data structures. In convolution modules, we have to imagine a neuron as a computation unit which, for a position in the feature map taken by the convolution kernel during the convolution operation, performs the weighted sum between the kernel and the group of pixels considered. The concept of a neuron corresponds to the scalar product between the input data, the pixels and data specific to the neuron16 followed by the application of a function of ![]() in
in ![]() called the activation function. Then, by extension, we can consider that pooling and normalization are operations specific to neurons.
called the activation function. Then, by extension, we can consider that pooling and normalization are operations specific to neurons.
Not counting the preprocessing block, the Yedroudj-Net network (Yedroudj et al. 2018b) has a convolution module made up of five convolution blocks, like the Qian et al. network and the Xu et al. network (Xu et al. 2016). The Ye-Net network (Ye et al. 2017) has a convolution module made up of eight convolution blocks. The SRNet network (Boroumand et al. 2019) contains a convolution module made up of 11 convolution blocks.
In Figure 8.6, representing the Yedroudj-Net network, the first block of the convolution module generates 30 feature maps, each of pixel size 256 × 256. Note that this means 30 filters, and so 30 convolutions that are trained on the group of images given as input (30 filtered images) of pixel size 256 × 256. In each of the five blocks, there is a convolution operation, a normalization operation (“Batch” + “Scale”), an activation operation (ABS, trunc, ReLU) and a pooling operation (“average” or “max pooling”).
8.5.2.2. The classification module
The last block of the convolution module (see section 8.5.2.1) is connected to the classification module, which is generally a fully connected neural network made up of one to three blocks. This classification module is often a traditional neural network where each neuron is completely connected to the next layer of neurons and to the previous layer of neurons.
After this completely connected neural network, we often find a “softmax” function, which makes it possible to standardize the two outputs provided by the network, so that the produced values belong to [0, 1] and that their sum is equal to 1. The softmax function then returns a class membership score, that is, a score per output neuron. These scores are simply called probabilities. We will keep this name. In the typical scenario of binary steganalysis, the network therefore delivers two output values: one giving the probability of classification in the first class (e.g. the Cover class), and the other giving the probability of classification in the second class (e.g. the Stego class). The classification decision is then obtained by returning the class with the highest probability. The Yedroudj-Net network (see Figure 8.6) effectively provides two output values.
Note that before this classification module, we can find a particular pooling operation, such as a Global Average Pooling, a Spatial Pyramid Pooling (SPP) (He et al. 2014) or a Statistical Moment Extractor (Fuji-Tsang and Fridrich 2018). A pooling operation like this returns a vector of fixed size, that is, a feature map that is a fixed size, and this is whatever the dimension of the image at the input of the network. The block coming after this pooling operation is always connected to a vector of a fixed size, so it has a fixed number of input parameters. Therefore, it is possible to present images of all sizes to the network, without having to modify the topology of the network. This property is available in the Yedroudj-Net network (Yedroudj et al. 2018b), the Zhu-Net network (Zhang et al. 2020) or the (Fuji-Tsang and Fridrich 2018) network.
Note that Fuji-Tsang and Fridrich (2018) is the only article (up to 2019 and the ALASKA steganalysis competition (Cogranne et al. 2019; Yousfi et al. 2019)), which seriously considered the viability of a network invariant to the dimension of images. However, the problem remains unresolved. The solution proposed in Fuji-Tsang and Fridrich (2018) is a variation of the concept of “average pooling”. Up to 2019, the small number of studies is not enough to determine which network topology to choose, or how to build the training database, or to what extent the number of inserted bits influences learning.
We end here with the quick presentation of CNNs, seen through the major publications in steganography/steganalysis17.
8.5.2.3. Using the modification probability map (Selection Channel-Aware) (SCA)
The modification probability map, when known to Eve, can significantly improve performance in steganalysis. At the end of 2018, two approaches (Selection Channel-Aware [SCA]) combine this knowledge with deep neural networks: SCA-Ye-Net (which is the SCA version of Ye-Net) (Ye et al. 2017) and SCA-SRNet (which is the SCA version of SRNet) (Boroumand et al. 2019). The idea is to use a network used for uninformed steganalysis and to inject, not only an image to be steganalyzed, but also a modification probability map. Therefore, we assume that Eve knows, or can obtain, a good estimate (Sedighi and Fridrich 2015) from this map, that is, that Eve has access to information about the selection channel (SCA).
This modification probability map is given to the SCA-Ye-Net (Ye et al. 2017) preprocessing block, and equally to the first convolution block for SCA-SRNet (Boroumand et al. 2019), but the kernel values are replaced by their absolute value. After convolution, each feature map is added point-by-point to the corresponding filtered modification probability map. Note that the activation function of this first convolution (preprocessing block for SCA-Ye-Net or first block for SCA-SRNet) is (if this is not already the case) replaced by a “ReLU” activation. In SCA-Ye-Net, the truncation activation function is, in fact, replaced by a ReLU. This makes it possible to “virtually” spread the information relating to the image and the information relating to the probability map throughout the network.
Note that this procedure for transforming a classical network into an SCA network is inspired by the propagation of the modification probability map proposed by Denemark et al. (2016). The two articles cited in the previous paragraph are an improvement in comparison to the previous maxRM Rich Models (Denemark et al. 2014). In maxRM, instead of accumulating the number of occurrences in the co-occurrence matrix, we use an accumulation of the maximum of a local probability. In Denemark et al. (2016), the idea is to transform the modification probability map in the same way as filtering the image, then update the co-occurrence matrix using the modified version of the modification probability map rather than the initial modification probability map.
8.5.2.4. JPEG steganalysis
The best CNN for JPEG steganalysis at the end of 2018 was SRNet (Boroumand et al. 2019). At that time, it was the only network for JPEG steganalysis to obtain an SCA version. It is interesting to list and briefly discuss previous CNNs used for JPEG steganalysis. The first network, published in February 2017, was the Zeng et al. network. It was assessed with 1 million images (Zeng et al. 2017, 2018). Then, in June 2017, at IH&MMSec’2017, two networks were proposed: PNet (Chen et al. 2017) and Xu-Net-Jpeg (Xu 2017). Finally, SRNet (Boroumand et al. 2019) was put online in September 2018.
In the Zeng et al. network (Zeng et al. 2017, 2018), the preprocessing block takes as an input a “de-quantized” image (real values), convolves it with 25 DCT bases and then quantizes and truncates the 25 filtered images. This preprocessing block uses handcrafted filter kernels (DCT bases), the kernel values are fixed, and these filters are inspired by the rich DCTR models (Holub and Fridrich 2015). It is based on three different quantizations, and the preprocessing block produces 3 × 25 residual images. The CNN is then made up of three sub-networks that each produce a feature vector of dimension 512. The sub-networks are inspired by Xu-Net (Xu et al. 2016). The three characteristic vectors, returned by the three sub-networks, are then given to a fully connected structure, and the network ends with a softmax layer.
Like what was done for spatial steganalysis, this network uses a preprocessing block proposed by Holub and Fridrich (2015). Note that the most effective rich models are the Gabor Filter Rich Models (GFR) (Song et al. 2015). Also note that this network takes advantage of the concept of an ensemble of features, which comes from the three sub-networks. The Zeng et al. network is less effective than the Xu-Net-Jpeg network (Xu 2017), but gives an interesting first approach, guided by Rich Models.
The main idea of PNet (and also VNet which is less efficient, but takes up less memory) (Chen et al. 2017) is to mimic Phase-Aware Rich Models, such as DCTRs (Holub and Fridrich 2015) or GFRs (Song et al. 2015), and to obtain an input image, broken down into 64 feature maps, representing the 64 phases of a JPEG image. The preprocessing block takes a de-quantized image (real values) as an input, performs convolutions with four filters, the “SQUARE5 × 5” coming from the Spatial Rich Model (Fridrich and Kodovsk![]() 2012), a high-pass filter, “point”, (called “catalyst kernel”), which completes the “SQUARE5 × 5”, and two directional Gabor filters (angles 0 and π/2).
2012), a high-pass filter, “point”, (called “catalyst kernel”), which completes the “SQUARE5 × 5”, and two directional Gabor filters (angles 0 and π/2).
Straight after the second convolution block, a PhaseSplit Module divides the residual image into 64 feature maps (a map = a stage), in the same way as rich models. Some interesting procedures have been used, such as (1) linking convolutions with fixed values in the preprocessing block, with a second convolution whose weights are learned; (2) a smart update of the parameters of batch normalization; (3) the use of “Filter Group Option”, which potentially builds sub-networks; (4) bagging on five cross-validations; (5) using the last five evaluations to give the average error of a network; (6) shuffling the database at the start of each period in order to have better behavior of batch normalization and help generalization; and (7) potentially the use of an ensemble of networks of the same type with a pooling of the outputs by majority vote. With such expertise, PNet beat the classic two-step machine learning approaches in non-SCA and SCA (Classifier set + GFR) scenarios.
The Xu-Net-Jpeg (Xu 2017) is much more attractive as the approach is slightly better than PNet and does not require a strong domain inspiration, as you do for PNet. Xu-Net-Jpeg is heavily inspired by ResNet (He et al. 2016), a well-established network in the machine learning community. ResNet allows the use of deeper networks, thanks to the use of shortcuts. In Xu-Net, the preprocessing block takes a de-quantized image (real values) as an input, convolves the image with 16 DCT bases (in the same way as the Zeng et al. network (Zeng et al. 2017, 2018)) then applies an absolute value, a truncation and a set of BN convolutions, ReLU, until obtaining a feature vector of dimension 384, which is given to a fully connected block. Note that “max pooling” or “average pooling” is replaced by convolutions. This network is really simple and in 2017 it was the most effective method. In general, the networks proposed by the machine learning community are often very competitive, with little specific knowledge of the steganalysis field to integrate into the topology of a network to obtain a very efficient network18.
In 2018, the state-of-the-art CNN for JPEG steganalysis (which can also be used for spatial steganalysis) was SRNet (Boroumand et al. 2019). Note that for the SRNet version, which knows about the selection channel (SCA), the modification probability by DCT coefficient is first re-expressed in the spatial domain by applying an inverse DCT, and by using the absolute values for the DCT base. The selection map obtained then enters the network and is convolved with each kernel (this first convolution is equivalent to the preprocessing block). Note that convolutions in this first block of this selection map are such that the kernels of the filters are modified to their absolute values. After passing the convolution, the feature maps are added with the square root of the previously convolved values of the selection map. Note that this idea goes back over what was presented in the SCA Ye-Net version (SCA-TLU-CNN) (Ye et al. 2017), with integration of adjacent information, and the recent proposal for steganalysis with awareness of the selection channel (SCA) in JPEG with Rich Models (Denemark et al. 2016), or the construction of the selection map, and more specifically, the quantity ![]() 19.
19.
8.6. Current avenues of research
We finish this introductory chapter to steganalysis with a brief list of the open problems that seem to be the most interesting and the most important in this field.
8.6.1. The problem of Cover-Source mismatch
The first problem that we will describe is Cover-Source mismatch (CSM); this problem is actually a fairly general case in the field of statistical learning, where it is referred to as “generalization”. In practice, this is the mismatch between the learning base, on which the classifier is trained, and the test base on which we want to detect the presence of hidden information. The defining feature of steganalysis is double, compared to CSM. On the one hand, in steganalysis we want to detect very weak signals; on the other hand, we generally work with characteristics of (very) large dimensions. Together, these two features mean that the detection methods will be very sensitive to the learning bases and difficult to generalize.
A fairly exhaustive study concerning the evaluation of the factors leading to CSM was carried out in Giboulot et al. (2020), showing, for example, the major role of image processing. Unfortunately, there is no work to understand the root causes yet, and, as a result, it remains very difficult to overcome this problem.
8.6.2. The problem with steganalysis in real life
Similarly, steganalysis in real life been not been explored much (Ker and Pevný 2014). In fact, as we mentioned in the introduction, steganalysis was developed with the main aim of evaluating the different methods of steganography. To do this, the community generally works using the targeted steganalysis scenario and with specific image databases, in particular the BOSS (Bas et al. 2011) database consisting of images from seven reflex cameras (no smartphone or compact), all processed the same, starting from the RAW file. Work has shown that developing these RAW images in different ways can lead to very different results (Sedighi et al. 2016b). A first competition was launched for this purpose with a much more heterogeneous image base (Cogranne et al. 2019) and proposals show the difficulty of carrying out steganalysis on heterogeneous images. The winners, in particular, relied on a increase of learning, according to the JPEG compression parameters (Yousfi et al. 2019), but many questions about steganalysis in real-life remain open.
8.6.3. Reliable steganalysis
A problem that is fairly similar to the previous two concerns reliable steganalysis. In fact, as we mentioned in section 8.3.2, a test is inevitably full of errors (false-positives and false-negatives), and the result depends greatly on the application context. In steganalysis, it is important to minimize false-positives, given the large number of images that we may have to analyze. On the other hand, methods based on statistical learning generally aim to minimize the overall error rate, PE. However, assuming that it is possible to design a detection method where the probabilities of false-positive and false-negative are both about 1%, it is clearly unrealistic to use this method in practice. It is clear to argue that, with a Bayesian approach, an image considered as being steganographed by a detector like this would actually be more likely from a false-positive, given that on an image-sharing site such as Flickr, probably less than 1% of images actually contain hidden information.
Therefore, the crucial question arises of how to design a reliable steganalysis method that would guarantee a very low probability of false-positive; typically, a probability of false-positive less than 10−6 (i.e. less than 1 in 1 million). We have seen that the theory of hypothesis tests makes it possible to design methods of steganalysis like this, but relies on a statistical model of the images which is not necessarily exact, even more so when certain parameters have to be estimated. A very interesting study in Pevný and Ker (2015) studies the possibility of learning with the criterion of minimizing the probability of false-positive, if the power ς is fixed at 50%. However, this preliminary work deserves to be looked at in more depth, and steganalysis methods providing a precise “p-value”20 are sorely lacking.
8.6.4. Steganalysis of color images
As indicated in Chapter 4, the vast majority of images today are in color; for practical applications, it is therefore necessary to study this type of image. However, academic work differs from practical use since the vast majority of work in steganalysis relates to “grayscale” images (see Cogranne et al. 2019, 2020a, 2020b).
On the contrary, detection of hidden information in color images seems more interesting in practice. This subject remains largely undiscovered. In fact, a significant number of researchers think that a color image can be represented by three images in grayscale (one red, one green and one blue), which can be analyzed separately.
However, it seems intuitive to consider that the color channels are statistically correlated, in particular due to the “demosaicing” during the acquisition and processing of images. However, work which has been carried out in this field has not shown a great improvement by analyzing the components together (Goljan et al. 2014; Abdulrahman et al. 2016). For example, the first work in this field (Goljan et al. 2014) proposed adding histograms obtained from pixel values in different colors. This certainly allowed a slight improvement in detection, but below what was expected.
Finally, this field of study has not been studied very much for color images compressed with the JPEG standard. This is more harmful, because JPEG color images do not represent green, red and blue, but luminance/chrominance components whose statistical correlations are less significant. On the other hand, color channels are treated separately in the JPEG standard, so they should be analyzed in different ways. Unfortunately, detection of steganography in JPEG color channels has hardly ever been studied (see, for example, (Taburet et al. 2018) and the articles (Cogranne et al. 2019; Yousfi et al. 2019) relating to the ALASKA steganalysis challenge and about JPEG color images).
8.6.5. Taking into account the adaptivity of steganography
A very different problem, already mentioned in section 8.5.2.3 in the context of neural networks, is about the consideration of the “selection channel” for steganalysis. The channel selection shows the probabilities of using each pixel, βm,n. Clearly, it seems interesting (as shown by equations [8.14] and [8.16]) that a detector can use a, possibly misleading, estimate of these probabilities of use. But this is not very effective with current detection methods. For example, one of the first advances proposed in the field (Denemark et al. 2014) involves replacing the calculation of co-occurrence histograms (see section 8.4.1) by adding, for each of the blocks considered, the maximum probability of modification, βm,n, of this sample. In this study (Denemark et al. 2014), the authors indicate that they have tried several weighting functions and finally found that the maximum obtains the best results, in terms of performance. In addition, the authors indicate that this function is also robust to a misestimation of the selection channel, βm,n. This is particularly important, since this quantity is not directly attainable and therefore must be estimated. This requires knowing the insertion method and size of the message and, in practice, the performances obtained from the estimated probability or from the real probability are very similar. In all cases, SCA methods (SCA) remain very ad hoc, and they are empirically explained, mainly by results in terms of statistical detection performance.
8.6.6. Grouped steganalysis (batch steganalysis)
A problem that has also been studied very little concerns “grouped” steganography, also called “batch” steganography (Ker and Pevný 2012). This is a more general scenario where Alice can “spread out” her message in many different images, which are then sent to Bob. The steganalyst, Eve, must therefore observe a batch of images, q, and make a “grouped” decision about all of these images: they may all be Cover images, or some may contain a variable part of the message to hide. For steganography21, this case can be modeled as a problem of message allocation, which must be dispersed in several images in order to minimize the probability of detection. For the steganalyst, Eve, the job of analyzing a batch of images is much more tricky. Many questions remain open, in particular: How can you analyze a lot of images, unknown at first? Is it better to use a method designed to analyze several images together, or should you carry out q independent image analyzes? Finally, should not the order of the images be taken into account? Some works have been proposed, in particular (Cogranne et al. 2017; Pevný and Nikolaev 2015), which are based on a detector adapted to the analysis of each image individually. The first article studies how to regulate the “(continuous) scores” obtained for each image. The second work (Pevný and Nikolaev 2015) carries out a detection in two stages: a histogram of the same “scores” is first constructed, then a second classifier is trained to identify the batches of Cover images. More recently, a study relating to the lack of knowledge of the strategy of spreading the message has been proposed in Zakaria et al. (2019).
8.6.7. Universal steganalysis
The last issue that we want to tackle is universal steganalysis. Again, this is a more general framework than targeted binary decision, which, as we have shown, makes it possible to assess a specific method of steganography. In practice, it is interesting to design steganalysis methods that work when neither the size of the message nor the insertion algorithm are known. Steganalysis without knowing the size of the message refers to so-called “quantitative” approaches, that is, aiming to estimate the size of the inserted message (Pevný et al. 2009). The study of the performance of the general classifier (Cogranne and Fridrich 2015), in the context where the size of the message is unknown, specifically shows that the latter (Kodovsk![]() et al. 2012) cannot be used directly, since the detection threshold is fixed according to the steganographed images used during training. The approach proposed in Pevný et al. (2009) essentially involves using images containing different sized messages during training.
et al. 2012) cannot be used directly, since the detection threshold is fixed according to the steganographed images used during training. The approach proposed in Pevný et al. (2009) essentially involves using images containing different sized messages during training.
Similarly, multi-class steganalysis has not received much attention. Again, the extension of the general classifier has been considered with this in mind (Cogranne and Fridrich 2015) by using two simple and relatively efficient approaches; the first, known as “Cover media versus the rest”, involves creating an alternative hypothesis gathering all the possible insertion algorithms and, in the end, carrying out a statistical learning aimed at detecting any of the steganography methods. On the other hand, the second approach involves considering H + 1 hypotheses, relating to the H insertion algorithms considered, then the case of Cover images is added. To detect steganography and identify the insertion method, it is possible to create many classifiers that are specifically trained to distinguish between two hypotheses. Analyzing an image therefore requires using all the classifiers to then choose the hypothesis that gathers the most “votes” from the set of all the classifiers.
8.7. Conclusion
In this chapter, we have presented different steganalysis methods. Generally, we have presented “signature” detection methods, which essentially aim to detect traces linked to the use of specific software. Although very efficient, these methods are not very generalizable and not very interesting from a methodological point of view.
We have also studied statistical steganalysis methods, which require an exact model of statistical distribution of the Cover and Stego images. These methods are not very efficient in terms of detection, but allow us to understand how we can carry out steganalysis. This makes it possible to improve the stegananalysis in particular, or even to come up with a steganography method.
Finally, we have seen that, in practice, the most effective methods are based on statistical learning. This can be done by extraction of characteristics, and then classification. Recently, methods based on deep neural networks have made it possible to considerably improve the performance of steganalysis methods, at the expense of increased calculation complexity.
We have also seen that steganalysis is a constantly evolving field. In particular, we insisted on the fact that most academic work is difficult to use in practice. In particular, the main obstacles that remain to be studied have been described. In this field, the recent steganalysis “challenges” that we organized in 2019 (Cogranne et al. 2019) and in 2020 (Cogranne et al. 2020a) have made it possible to make significant progress and will certainly impact work in the coming years.
8.8. References
Abdulrahman, H., Chaumont, M., Montesinos, P., Magnier, B. (2016). Color image steganalysis based on steerable Gaussian filters bank. Workshop on Information Hiding and Multimedia Security, Vigo, 109–114.
Auguste, K. (1883). La cryptographie militaire. Journal des sciences militaires, 9(538), 5.
Bas, P., Filler, T., Pevný, T. (2011). “Break our steganographic system”: The ins and outs of organizing boss. In Information Hiding, Filler, T., Pevný, T., Craver, S., Ker, A. (eds). Springer, Prague.
Bengio, Y., Courville, A.C., Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1798–1828.
Boroumand, M., Chen, M., Fridrich, J. (2019). Deep residual network for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 14(5), 1181–1193.
Butora, J. and Fridrich, J. (2020). Reverse JPEG compatibility attack. IEEE Transactions on Information Forensics and Security, 15, 1444–1454.
Chaumont, M. (2020). Deep Learning in steganography and steganalysis. In Digital Media Steganography: Principles, Algorithms, Advances, Hassaballah, M. (ed.). Elsevier, Amsterdam.
Chen, M., Sedighi, V., Boroumand, M., Fridrich, J. (2017). JPEG-phase-aware convolutional neural network for steganalysis of JPEG images. Workshop on Information Hiding and Multimedia Security, Philadelphia, 75–84.
Cogranne, R. (2011). Détection statistique d’informations cachées dans une image naturelle à partir d’un modèle physique. PhD Thesis, University of Technology of Troyes.
Cogranne, R. (2020). Selection-channel-aware reverse JPEG compatibility for highly reliable steganalysis of JPEG images. ICASSP 2020, International Conference on Acoustics, Speech and Signal Processing, Barcelona, 2772–2776.
Cogranne, R. and Fridrich, J. (2015). Modeling and extending the ensemble classifier for steganalysis of digital images using hypothesis testing theory. IEEE Transactions on Information Forensics and Security, 10(12), 2627–2642.
Cogranne, R., Sedighi, V., Fridrich, J., Pevný, T. (2015). Is ensemble classifier needed for steganalysis in high-dimensional feature spaces? International Workshop on Information Forensics and Security, Rome, 1–6.
Cogranne, R., Sedighi, V., Fridrich, J. (2017). Practical strategies for content-adaptive batch steganography and pooled steganalysis. International Conference on Acoustics, Speech and Signal Processing, New Orleans, 2122–2126.
Cogranne, R., Giboulot, Q., Bas, P. (2019). The ALASKA steganalysis challenge: A first step towards steganalysis “into the wild”. Workshop on Information Hiding and Multimedia Security, New York, 125–137.
Cogranne, R., Giboulot, Q., Bas, P. (2020a). Challenging academic research on steganalysis with realistic images. In International Workshop on Information Forensics and Security, New York.
Cogranne, R., Giboulot, Q., Bas, P. (2020b). Steganography by minimizing statistical detectability: The cases of JPEG and color images. Information Hiding and MultiMedia Security, Denver.
Denemark, T., Sedighi, V., Holub, V., Cogranne, R., Fridrich, J. (2014). Selection-channel-aware rich model for steganalysis of digital images. International Workshop on Information Forensics and Security, Atlanta, 48–53.
Denemark, T., Boroumand, M., Fridrich, J. (2016). Steganalysis features for content-adaptive JPEG steganography. IEEE Transactions on Information Forensics and Security, 11(8), 1736–1746.
Fridrich, J. and Kodovsk![]() , J. (2012). Rich models for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 7(3), 868–882.
, J. (2012). Rich models for steganalysis of digital images. IEEE Transactions on Information Forensics and Security, 7(3), 868–882.
Fuji-Tsang, C. and Fridrich, J.J. (2018). Steganalyzing images of arbitrary size with CNNs. Electronic Imaging, 121(1)–121(8).
Giboulot, Q., Cogranne, R., Borghys, D., Bas, P. (2020). Effects and solutions of cover-source mismatch in image steganalysis. Signal Processing: Image Communication, 86, 115888.
Goljan, M. and Fridrich, J. (2015). CFA-aware features for steganalysis of color images. Media Watermarking, Security, and Forensics 2015 – Proceedings of SPIE, Alattar, A.M., Memon, N.D., Heitzenrater, C.D. (eds). SPIE Press, Bellingham.
Goljan, M., Fridrich, J., Cogranne, R. (2014). Rich model for steganalysis of color images. International Workshop on Information Forensics and Security, Atlanta, 185–190.
He, K., Zhang, X., Ren, S., Sun, J. (2014). Spatial pyramid pooling in deep convolutional networks for visual recognition. European Conference on Computer Vision, Zurich, 346–361.
He, K., Zhang, X., Ren, S., Sun, J. (2016). Deep residual learning for image recognition. Conference on Computer Vision and Pattern Recognition, Las Vegas, 770–778.
Hinton, G.E. and Salakhutdinov, R.R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504–507.
Holub, V. and Fridrich, J. (2015). Low-complexity features for JPEG steganalysis using undecimated DCT. IEEE Transactions on Information Forensics and Security, 10(2), 219–228.
Ker, A.D. and Pevný, T. (2012). Batch steganography in the real world. Multimedia and Security, New York, 1–10.
Ker, A.D. and Pevný, T. (2014). The steganographer is the outlier: Realistic large-scale steganalysis. IEEE Transactions on Information Forensics and Security, 9(9), 1424–1435.
Kodovsk![]() , J., Fridrich, J., Holub, V. (2012). Ensemble classifiers for steganalysis of digital media. IEEE Transactions on Information Forensics and Security, 7(2), 432–444.
, J., Fridrich, J., Holub, V. (2012). Ensemble classifiers for steganalysis of digital media. IEEE Transactions on Information Forensics and Security, 7(2), 432–444.
Krizhevsky, A., Sutskever, I., Hinton, G.E. (2012). ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems 25, Lake Tahoe, 1097–1105.
LeCun, Y., Bengio, Y., Hinton, G. (2015). Deep learning. Nature, 521(7553), 436–444.
Lehmann, E. and Romano, J. (2005). Testing Statistical Hypotheses, 2nd edition, Springer, Berlin/Heidelberg.
Pevný, T. and Ker, A.D. (2015). Towards dependable steganalysis. In Media Watermarking, Security and Forensics 2015 – Proceedings of SPIE, Alattar, A.M., Memon, A.D. and Heitzenrater, C.D. (eds). SPIE Press, Bellingham.
Pevný, T. and Nikolaev, I. (2015). Optimizing pooling function for pooled steganalysis. International Workshop on Information Forensics and Security, Rome, 1–6.
Pevný, T., Fridrich, J., Ker, A.D. (2009). From blind to quantitative steganalysis. IS&T Electronic Imaging Symposium, San Jose.
Pevný, T., Bas, P., Fridrich, J. (2010). Steganalysis by subtractive pixel adjacency matrix. IEEE Transactions on Information Forensics and Security, 5(2), 215–224.
Qian, Y., Dong, J., Wang, W., Tan, T. (2015). Deep learning for steganalysis via convolutional neural networks. IS&T Electronic Imaging Symposium, San Francisco.
Sedighi, V. and Fridrich, J. (2015). Effect of imprecise knowledge of the selection channel on steganalysis. Workshop on Information Hiding and Multimedia Security, Portland, 33–42.
Sedighi, V., Cogranne, R., Fridrich, J. (2016a). Content-adaptive steganography by minimizing statistical detectability. IEEE Transactions on Information Forensics and Security, 11(2), 221–234.
Sedighi, V., Fridrich, J.J., Cogranne, R. (2016b). Toss that BOSSbase, Alice! IS&T International Symposium on Electronic Imaging, San Francisco.
Sharma, G. and Bala, R. (2017). Digital Color Imaging Handbook. CRC Press, Boca Raton.
Simmons, G. (1984). The prisoners’ problem and the subliminal channel. In Proceedings of CRYPTO ’83, Chaum, D. (ed.). Plenum Press, New York.
Song, X., Liu, F., Yang, C., Luo, X., Zhang, Y. (2015). Steganalysis of adaptive JPEG steganography using 2D gabor filters. Workshop on Information Hiding and Multimedia Security, Portland, 15–23.
Taburet, T., Filstroff, L., Bas, P., Sawaya, W. (2018). An empirical study of steganography and steganalysis of color images in the JPEG domain. International Workshop on Digital Forensics and Watermarking, Jeju.
Tomàš, P. and Andrew D.K. (2015). Towards dependable steganalysis. In Media Watermarking, Security, and Forensics – Proceedings of SPIE, Alattar, A.M., Memon, N.D., Heitzenrater, C.D. (eds), SPIE Press, Bellingham.
Westfeld, A. (2001). F5 – A steganographic algorithm. Lecture Notes in Computer Science, 2137, 289–302.
Westfeld, A. and Pfitzmann, A. (1999). Attacks on steganographic systems. International Workshop on Information Hiding, Dresden, 61–76.
Xu, G. (2017). Deep convolutional neural network to detect J-UNIWARD. Workshop on Information Hiding and Multimedia Security, Philadelphia, 67–73.
Xu, G., Wu, H.Z., Shi, Y.Q. (2016). Structural design of convolutional neural networks for steganalysis. IEEE Signal Processing Letters, 23(5), 708–712.
Ye, J., Ni, J., Yi, Y. (2017). Deep learning hierarchical representations for image steganalysis. IEEE Transactions on Information Forensics and Security, 12(11), 2545–2557.
Yedroudj, M., Chaumont, M., Comby, F. (2018a). How to augment a small learning set for improving the performances of a CNN-based steganalyzer? International Symposium on Electronic Imaging, Burlingame, 7.
Yedroudj, M., Comby, F., Chaumont, M. (2018b). Yedroudj-Net: An efficient CNN for spatial steganalysis. International Conference on Acoustics, Speech and Signal Processing, Calgary, 2092–2096.
Yousfi, Y., Butora, J., Fridrich, J., Giboulot, Q. (2019). Breaking Alaska: Color separation for steganalysis in JPEG domain. Workshop on Information Hiding and Multimedia Security, Paris, 138–149.
Zakaria, A., Chaumont, M., Subsol, G. (2019). Pooled steganalysis in JPEG: How to deal with the spreading strategy? International Workshop on Information Forensics and Security, Delft, 1–6.
Zeng, J., Tan, S., Li, B., Huang, J. (2017). Pre-training via fitting deep neural network to rich-model features extraction procedure and its effect on deep learning for steganalysis. IS&T Symposium on Electronic Imaging, Burlingame, 6.
Zeng, J., Tan, S., Li, B., Huang, J. (2018). Large-scale JPEG image steganalysis using hybrid deep-learning framework. IEEE Transactions on Information Forensics and Security, 13(5), 1200–1214.
Zhang, R., Zhu, F., Liu, J., Liu, G. (2020). Depth-wise separable convolutions and multi-level pooling for an efficient spatial CNN-based steganalysis. IEEE Transactions on Information Forensics and Security, 15, 1138–1150.
- For a color version of all figures in this chapter, see www.iste.co.uk/puech/multimedia1.zip.
- 1 Also see section 5.1.
- 2 See section 5.1 for the definition of the roles of Alice, Bob and Eve.
- 3 See section 5.1 for the definition of the terms Cover and Stego.
- 4 See also section 5.3.1, in Chapter 5.
- 5 Probability known as “missed detection” or “false-negative”.
- 6 See also section 5.3.1.
- 7 Defined in equation [8.8].
- 8 Defined in equation [8.9].
- 9 See definition in Table 8.1.
- 10 And this via the use of an insertion cost, see sections 5.2.3 and 5.3.2.
- 11 It is a matter of “denoising”, which is of major interest for the improvement of images.
- 12 That is, to recalculate the value of the pixels from the quantized DCT coefficients.
- 13 See section 8.4.1.2.
- 14 EC + RM will generally refer to two-step approaches based on the calculation of a rich model (RM) then the use of an ensemble classifier (EC).
- 15 Which can be seen as a group of images.
- 16 That is, the convolution kernel.
- 17 For more details on the description of convolution, activation, pooling, normalization, effectiveness and complexity in terms of time and memory, or the link between Deep Learning and past approaches, or even integration approaches by Deep Learning, the reader can visit Chaumont (2020); available at: https://arxiv.org/abs/1904.01444.
- 18 The recent ALASKA#2 competition (Cogranne et al. 2020a) has also shown that networks from the Deep Learning community can be directly used in steganalysis producing excellent results.
- 19 uSA means upper bounded Sum of Absolute values.
- 20 That is, a probability that this detection corresponds to a false-positive for an given image.
- 21 See also Chapter 5.