
6 MySQL Optimization
Optimization is a complex task because ultimately it requires understanding of the entire system to be optimized. Although it may be possible to perform some local optimizations with little knowledge of your system or application, the more optimal you want your system to become, the more you will have to know about it.
This chapter tries to explain and give some examples of different ways to optimize MySQL. Remember, however, that there are always additional ways to make the system even faster, although they may require increasing effort to achieve.
The most important factor in making a system fast is its basic design. You also need to know what kinds of things your system will be doing, and what your bottlenecks are.
The most common system bottlenecks are:
![]() Disk seeks. It takes time for the disk to find a piece of data. With modern disks, the mean time for this is usually lower than 10ms, so we can in theory do about 100 seeks a second. This time improves slowly with new disks and is very hard to optimize for a single table. The way to optimize seek time is to distribute the data onto more than one disk.
Disk seeks. It takes time for the disk to find a piece of data. With modern disks, the mean time for this is usually lower than 10ms, so we can in theory do about 100 seeks a second. This time improves slowly with new disks and is very hard to optimize for a single table. The way to optimize seek time is to distribute the data onto more than one disk.
![]() Disk reading and writing. When the disk is at the correct position, we need to read the data. With modern disks, one disk delivers at least 10-20MB/s throughput. This is easier to optimize than seeks because you can read in parallel from multiple disks.
Disk reading and writing. When the disk is at the correct position, we need to read the data. With modern disks, one disk delivers at least 10-20MB/s throughput. This is easier to optimize than seeks because you can read in parallel from multiple disks.
![]() CPU cycles. When we have the data in main memory (or if it was already there), we need to process it to get our result. Having small tables compared to the amount of memory is the most common limiting factor. But with small tables, speed is usually not the problem.
CPU cycles. When we have the data in main memory (or if it was already there), we need to process it to get our result. Having small tables compared to the amount of memory is the most common limiting factor. But with small tables, speed is usually not the problem.
![]() Memory bandwidth. When the CPU needs more data than can fit in the CPU cache, main memory bandwidth becomes a bottleneck. This is an uncommon bottleneck for most systems, but one to be aware of.
Memory bandwidth. When the CPU needs more data than can fit in the CPU cache, main memory bandwidth becomes a bottleneck. This is an uncommon bottleneck for most systems, but one to be aware of.
When using the MyISAM storage engine, MySQL uses extremely fast table locking that allows multiple readers or a single writer. The biggest problem with this storage engine occurs when you have a steady stream of mixed updates and slow selects on a single table. If this is a problem for certain tables, you can use another table type for them. See Chapter 8, “MySQL Storage Engines and Table Types.”
MySQL can work with both transactional and non-transactional tables. To be able to work smoothly with non-transactional tables (which can’t roll back if something goes wrong), MySQL has the following rules:
![]() All columns have default values.
All columns have default values.
![]() If you insert a “wrong” value in a column, such as a too-large numerical value into a numerical column, MySQL sets the column to the “best possible value” instead of giving an error. For numerical values, this is 0, the smallest possible value, or the largest possible value. For strings, this is either the empty string or the longest possible string that can be stored in the column.
If you insert a “wrong” value in a column, such as a too-large numerical value into a numerical column, MySQL sets the column to the “best possible value” instead of giving an error. For numerical values, this is 0, the smallest possible value, or the largest possible value. For strings, this is either the empty string or the longest possible string that can be stored in the column.
![]() All calculated expressions return a value that can be used instead of signaling an error condition. For example, 1/0 returns
All calculated expressions return a value that can be used instead of signaling an error condition. For example, 1/0 returns NULL.
The implication of these rules is that you should not use MySQL to check column content. Instead, you should check values within your application before storing them in the database.
Because all SQL servers implement different parts of standard SQL, it takes work to write portable SQL applications. It is very easy to achieve portability for very simple selects and inserts, but becomes more difficult the more capabilities you require. If you want an application that is fast with many database systems, it becomes even harder!
To make a complex application portable, you need to determine which SQL servers it must work with, then determine what features those servers support.
All database systems have some weak points. That is, they have different design compromises that lead to different behavior.
You can use the MySQL crash-me program to find functions, types, and limits that you can use with a selection of database servers. crash-me does not check for every possible feature, but it is still reasonably comprehensive, performing about 450 tests.
An example of the type of information crash-me can provide is that you shouldn’t have column names longer than 18 characters if you want to be able to use Informix or DB2.
The crash-me program and the MySQL benchmarks are all very database independent. By taking a look at how they are written, you can get a feeling for what you have to do to make your own applications database independent. The programs can be found in the sql-bench directory of MySQL source distributions. They are written in Perl and use the DBI database interface. Use of DBI in itself solves part of the portability problem because it provides database-independent access methods.
For crash-me results, visit http://dev.mysql.com/tech-resources/crash-me.php. See http://dev.mysql.com/tech-resources/benchmarks/ for the results from the benchmarks.
If you strive for database independence, you need to get a good feeling for each SQL server’s bottlenecks. For example, MySQL is very fast in retrieving and updating records for MyISAM tables, but will have a problem in mixing slow readers and writers on the same table. Oracle, on the other hand, has a big problem when you try to access rows that you have recently updated (until they are flushed to disk). Transactional databases in general are not very good at generating summary tables from log tables, because in this case row locking is almost useless.
To make your application really database independent, you need to define an easily extendable interface through which you manipulate your data. Because C++ is available on most systems, it makes sense to use a C++ class-based interface to the databases.
If you use some feature that is specific to a given database system (such as the REPLACE statement, which is specific to MySQL), you should implement the same feature for other SQL servers by coding an alternative method. Although the alternative may be slower, it will allow the other servers to perform the same tasks.
With MySQL, you can use the /*! */ syntax to add MySQL-specific keywords to a query. The code inside /**/ will be treated as a comment (and ignored) by most other SQL servers.
If high performance is more important than exactness, as in some Web applications, it is possible to create an application layer that caches all results to give you even higher performance. By letting old results “expire” after a while, you can keep the cache reasonably fresh. This provides a method to handle high load spikes, in which case you can dynamically increase the cache and set the expiration timeout higher until things get back to normal.
In this case, the table creation information should contain information of the initial size of the cache and how often the table should normally be refreshed.
An alternative to implementing an application cache is to use the MySQL query cache. By enabling the query cache, the server handles the details of determining whether a query result can be reused. This simplifies your application. See Section 4.10, “The MySQL Query Cache.”
This section describes an early application for MySQL.
During MySQL initial development, the features of MySQL were made to fit our largest customer, which handled data warehousing for a couple of the largest retailers in Sweden.
From all stores, we got weekly summaries of all bonus card transactions, and were expected to provide useful information for the store owners to help them find how their advertising campaigns were affecting their own customers.
The volume of data was quite huge (about seven million summary transactions per month), and we had data for 4-10 years that we needed to present to the users. We got weekly requests from our customers, who wanted to get “instant” access to new reports from this data.
We solved this problem by storing all information per month in compressed “transaction” tables. We had a set of simple macros that generated summary tables grouped by different criteria (product group, customer id, store, and so on) from the tables in which the transactions were stored. The reports were Web pages that were dynamically generated by a small Perl script. This script parsed a Web page, executed the SQL statements in it, and inserted the results. We would have used PHP or mod_perl instead, but they were not available at the time.
For graphical data, we wrote a simple tool in C that could process SQL query results and produce GIF images based on those results. This tool also was dynamically executed from the Perl script that parsed the Web pages.
In most cases, a new report could be created simply by copying an existing script and modifying the SQL query in it. In some cases, we needed to add more columns to an existing summary table or generate a new one, but this also was quite simple because we kept all transaction-storage tables on disk. (This amounted to about 50GB of transaction tables and 200GB of other customer data.)
We also let our customers access the summary tables directly with ODBC so that the advanced users could experiment with the data themselves.
This system worked well and we had no problems handling the data with quite modest Sun Ultra SPARCstation hardware (2x200MHz). Eventually the system was migrated to Linux.
This section should contain a technical description of the MySQL benchmark suite (and crash-me), but that description has not yet been written. Currently, you can get a good idea of the benchmarks by looking at the code and results in the sql-bench directory in any MySQL source distribution.
This benchmark suite is meant to tell any user what operations a given SQL implementation performs well or poorly.
Note that this benchmark is single-threaded, so it measures the minimum time for the operations performed. We plan to add multi-threaded tests to the benchmark suite in the future.
To use the benchmark suite, the following requirements must be satisfied:
![]() The benchmark suite is provided with MySQL source distributions. You can either download a released distribution from http://dev.mysql.com/downloads/, or use the current development source tree (see Section 2.3.3, “Installing from the Development Source Tree”).
The benchmark suite is provided with MySQL source distributions. You can either download a released distribution from http://dev.mysql.com/downloads/, or use the current development source tree (see Section 2.3.3, “Installing from the Development Source Tree”).
![]() The benchmark scripts are written in Perl and use the Perl DBI module to access database servers, so DBI must be installed. You will also need the server-specific DBD drivers for each of the servers you want to test. For example, to test MySQL, PostgreSQL, and DB2, you must have the
The benchmark scripts are written in Perl and use the Perl DBI module to access database servers, so DBI must be installed. You will also need the server-specific DBD drivers for each of the servers you want to test. For example, to test MySQL, PostgreSQL, and DB2, you must have the DBD::mysql, DBD::Pg, and DBD::DB2 modules installed. See Section 2.7, “Perl Installation Notes.”
After you obtain a MySQL source distribution, you will find the benchmark suite in its sql-bench directory. To run the benchmark tests, build MySQL, then change location into the sql-bench directory and execute the run-all-tests script:
shell> cd sql-bench
shell> perl run-all-tests --server=server_name
server_name is one of the supported servers. To get a list of all options and supported servers, invoke this command:
shell> perl run-all-tests --help
The crash-me script also is located in the sql-bench directory. crash-me tries to determine what features a database supports and what its capabilities and limitations are by actually running queries. For example, it determines:
![]() What column types are supported
What column types are supported
![]() How many indexes are supported
How many indexes are supported
![]() What functions are supported
What functions are supported
![]() How big a query can be
How big a query can be
![]() How big a
How big a VARCHAR column can be
You can find the results from crash-me for many different database servers at http://dev.mysql.com/tech-resources/crash-me.php. For more information about benchmark results, visit http://dev.mysql.com/tech-resources/benchmarks/.
You should definitely benchmark your application and database to find out where the bottlenecks are. By fixing a bottleneck (or by replacing it with a “dummy module”), you can then easily identify the next bottleneck. Even if the overall performance for your application currently is acceptable, you should at least make a plan for each bottleneck, and decide how to solve it if someday you really need the extra performance.
For an example of portable benchmark programs, look at the MySQL benchmark suite. See Section 6.1.4, “The MySQL Benchmark Suite.” You can take any program from this suite and modify it for your needs. By doing this, you can try different solutions to your problem and test which really is fastest for you.
Another free benchmark suite is the Open Source Database Benchmark, available at http://osdb.sourceforge.net/.
It is very common for a problem to occur only when the system is very heavily loaded. We have had many customers who contact us when they have a (tested) system in production and have encountered load problems. In most cases, performance problems turn out to be due to issues of basic database design (for example, table scans are not good at high load) or problems with the operating system or libraries. Most of the time, these problems would be a lot easier to fix if the systems were not already in production.
To avoid problems like this, you should put some effort into benchmarking your whole application under the worst possible load! You can use Super Smack for this. It is available at http://jeremy.zawodny.com/mysql/super-smack/. As the name suggests, it can bring a system to its knees if you ask it, so make sure to use it only on your development systems.
First, one factor affects all statements: The more complex your permission setup is, the more overhead you will have.
Using simpler permissions when you issue GRANT statements enables MySQL to reduce permission-checking overhead when clients execute statements. For example, if you don’t grant any table-level or column-level privileges, the server need not ever check the contents of the tables_priv and columns_priv tables. Similarly, if you place no resource limits on any accounts, the server does not have to perform resource counting. If you have a very high query volume, it may be worth the time to use a simplified grant structure to reduce permission-checking overhead.
If your problem is with some specific MySQL expression or function, you can use the BENCHMARK() function from the mysql client program to perform a timing test. Its syntax is BENCHMARK(loop_count,expression). For example:
mysql> SELECT BENCHMARK(1000000,1+1);
+---------------------------------+
| BENCHMARK(1000000,1+1) |
+---------------------------------+
| 0 |
+---------------------------------+
1 row in set (0.32 sec)
This result was obtained on a Pentium II 400MHz system. It shows that MySQL can execute 1,000,000 simple addition expressions in 0.32 seconds on that system.
All MySQL functions should be very optimized, but there may be some exceptions. BENCHMARK() is a great tool to find out if this is a problem with your query.
EXPLAIN tbl_name
Or:
EXPLAIN SELECT select_options
The EXPLAIN statement can be used either as a synonym for DESCRIBE or as a way to obtain information about how MySQL will execute a SELECT statement:
![]() The
The EXPLAIN tbl_name syntax is synonymous with DESCRIBE tbl_name or SHOW COLUMNS FROM tbl_name.
![]() When you precede a
When you precede a SELECT statement with the keyword EXPLAIN, MySQL explains how it would process the SELECT, providing information about how tables are joined and in which order.
This section provides information about the second use of EXPLAIN.
With the help of EXPLAIN, you can see when you must add indexes to tables to get a faster SELECT that uses indexes to find records.
You should frequently run ANALYZE TABLE to update table statistics such as cardinality of keys, which can affect the choices the optimizer makes.
You can also see whether the optimizer joins the tables in an optimal order. To force the optimizer to use a join order corresponding to the order in which the tables are named in the SELECT statement, begin the statement with SELECT STRAIGHT_JOIN rather than just SELECT.
EXPLAIN returns a row of information for each table used in the SELECT statement. The tables are listed in the output in the order that MySQL would read them while processing the query. MySQL resolves all joins using a single-sweep multi-join method. This means that MySQL reads a row from the first table, then finds a matching row in the second table, then in the third table, and so on. When all tables are processed, it outputs the selected columns and backtracks through the table list until a table is found for which there are more matching rows. The next row is read from this table and the process continues with the next table.
In MySQL version 4.1, the EXPLAIN output format was changed to work better with constructs such as UNION statements, subqueries, and derived tables. Most notable is the addition of two new columns: id and select_type. You will not see these columns when using servers older than MySQL 4.1.
Each output row from EXPLAIN provides information about one table, and each row consists of the following columns:
![]()
id
The SELECT identifier. This is the sequential number of the SELECT within the query.
![]()
select_type
The type of SELECT, which can be any of the following:
![]()
SIMPLE
Simple SELECT (not using UNION or subqueries)
![]()
PRIMARY
Outermost SELECT
![]()
UNION
Second or later SELECT statement in a UNION
![]()
DEPENDENT UNION
Second or later SELECT statement in a UNION, dependent on outer subquery
![]()
SUBQUERY
First SELECT in subquery
![]()
DEPENDENT SUBQUERY
First SELECT in subquery, dependent on outer subquery
![]()
DERIVED
Derived table SELECT (subquery in FROM clause)
![]()
table
The table to which the row of output refers.
![]()
type
The join type. The different join types are listed here, ordered from the best type to the worst:
![]()
system
The table has only one row (= system table). This is a special case of the const join type.
![]()
const
The table has at most one matching row, which will be read at the start of the query. Because there is only one row, values from the column in this row can be regarded as constants by the rest of the optimizer. const tables are very fast because they are read only once!
const is used when you compare all parts of a PRIMARY KEY or UNIQUE index with constant values. In the following queries, tbl_name can be used as a const table:
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name
WHERE primary_key_part1=1 AND primary_key_part2=2;
![]()
eq_ref
One row will be read from this table for each combination of rows from the previous tables. Other than the const types, this is the best possible join type. It is used when all parts of an index are used by the join and the index is a PRIMARY KEY or UNIQUE index.
eq_ref can be used for indexed columns that are compared using the = operator. The comparison value can be a constant or an expression that uses columns from tables that are read before this table.
In the following examples, MySQL can use an eq_ref join to process ref_table:
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
![]()
ref
All rows with matching index values will be read from this table for each combination of rows from the previous tables. ref is used if the join uses only a leftmost prefix of the key or if the key is not a PRIMARY KEY or UNIQUE index (in other words, if the join cannot select a single row based on the key value). If the key that is used matches only a few rows, this is a good join type.
ref can be used for indexed columns that are compared using the = operator.
In the following examples, MySQL can use a ref join to process ref_table:
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
This join type is like ref, but with the addition that MySQL will do an extra search for rows that contain NULL values. This join type optimization is new for MySQL 4.1.1 and is mostly used when resolving subqueries.
In the following examples, MySQL can use a ref_or_null join to process ref_table:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
See Section 6.2.6, “How MySQL Optimizes IS NULL.”
![]()
index_merge
This join type indicates that the Index Merge optimization is used. In this case, the key column contains a list of indexes used, and key_len contains a list of the longest key parts for the indexes used. For more information, see Section 6.2.5, “How MySQL Optimizes OR Clauses.”
![]()
unique_subquery
This type replaces ref for some IN subqueries of the following form:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery is just an index lookup function that replaces the subquery completely for better efficiency.
![]()
index_subquery
This join type is similar to unique_subquery. It replaces IN subqueries, but it works for non-unique indexes in subqueries of the following form:
value IN (SELECT key_column FROM single_table WHERE some_expr)
![]()
range
Only rows that are in a given range will be retrieved, using an index to select the rows. The key column indicates which index is used. The key_len contains the longest key part that was used. The ref column will be NULL for this type.
range can be used for when a key column is compared to a constant using any of the =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, or IN operators:
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1= 10 AND key_part2 IN (10,20,30);
This join type is the same as ALL, except that only the index tree is scanned. This usually is faster than ALL, because the index file usually is smaller than the data file.
MySQL can use this join type when the query uses only columns that are part of a single index.
![]()
ALL
A full table scan will be done for each combination of rows from the previous tables. This is normally not good if the table is the first table not marked const, and usually very bad in all other cases. Normally, you can avoid ALL by adding indexes that allow row retrieval from the table based on constant values or column values from earlier tables.
![]()
possible_keys
The possible_keys column indicates which indexes MySQL could use to find the rows in this table. Note that this column is totally independent of the order of the tables as displayed in the output from EXPLAIN. That means that some of the keys in possible_keys might not be usable in practice with the generated table order.
If this column is NULL, there are no relevant indexes. In this case, you may be able to improve the performance of your query by examining the WHERE clause to see whether it refers to some column or columns that would be suitable for indexing. If so, create an appropriate index and check the query with EXPLAIN again.
To see what indexes a table has, use SHOW INDEX FROM tbl_name.
![]()
key
The key column indicates the key (index) that MySQL actually decided to use. The key is NULL if no index was chosen. To force MySQL to use or ignore an index listed in the possible_keys column, use FORCE INDEX, USE INDEX, or IGNORE INDEX in your query.
For MyISAM and BDB tables, running ANALYZE TABLE will help the optimizer choose better indexes. For MyISAM tables, myisamchk --analyze will do the same. See Section 4.6.2, “Table Maintenance and Crash Recovery.”
![]()
key_len
The key_len column indicates the length of the key that MySQL decided to use. The length is NULL if the key column says NULL. Note that the value of key_len allows you to determine how many parts of a multiple-part key MySQL will actually use.
![]()
ref
The ref column shows which columns or constants are used with the key to select rows from the table.
![]()
rows
The rows column indicates the number of rows MySQL believes it must examine to execute the query.
This column contains additional information about how MySQL will resolve the query. Here is an explanation of the different text strings that can appear in this column:
![]()
Distinct
MySQL will stop searching for more rows for the current row combination after it has found the first matching row.
![]()
Not exists
MySQL was able to do a LEFT JOIN optimization on the query and will not examine more rows in this table for the previous row combination after it finds one row that matches the LEFT JOIN criteria.
Here is an example of the type of query that can be optimized this way:
SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id
WHERE t2.id IS NULL;
Assume that t2.id is defined as NOT NULL. In this case, MySQL will scan t1 and look up the rows in t2 using the values of t1.id. If MySQL finds a matching row in t2, it knows that t2.id can never be NULL, and will not scan through the rest of the rows in t2 that have the same id value. In other words, for each row in t1, MySQL needs to do only a single lookup in t2, regardless of how many rows actually match in t2.
![]()
range checked for each record (index map: #)
MySQL found no good index to use. Instead, for each row combination in the preceding tables, it will do a check to determine which index to use (if any), and use it to retrieve the rows from the table. This is not very fast, but is faster than performing a join with no index at all.
![]()
Using filesort
MySQL will need to do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the WHERE clause. The keys then are sorted and the rows are retrieved in sorted order.
![]()
Using index
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
![]()
Using temporary
To resolve the query, MySQL will need to create a temporary table to hold the result. This typically happens if the query contains GROUP BY and ORDER BY clauses that list columns differently.
A WHERE clause will be used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if the Extra value is not Using where and the table join type is ALL or index.
If you want to make your queries as fast as possible, you should look out for Extra values of Using filesort and Using temporary.
You can get a good indication of how good a join is by taking the product of the values in the rows column of the EXPLAIN output. This should tell you roughly how many rows MySQL must examine to execute the query. If you restrict queries with the max_join_size system variable, this product also is used to determine which multiple-table SELECT statements to execute. See Section 6.5.2, “Tuning Server Parameters.”
The following example shows how a multiple-table join can be optimized progressively based on the information provided by EXPLAIN.
Suppose that you have the SELECT statement shown here and you plan to examine it using EXPLAIN:
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
For this example, make the following assumptions:
![]() The columns being compared have been declared as follows:
The columns being compared have been declared as follows:
|
Table |
Column |
Column Type |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]() The tables have the following indexes:
The tables have the following indexes:
|
Table |
Index |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
![]() The
The tt.ActualPC values are not evenly distributed.
Initially, before any optimizations have been performed, the EXPLAIN statement produces the following information:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
do ALL PRIMARY NULL NULL NULL 2135
et_1 ALL PRIMARY NULL NULL NULL 74
tt ALL AssignedPC, NULL NULL NULL 3872
ClientID,
ActualPC
range checked for each record (key map: 35)
Because type is ALL for each table, this output indicates that MySQL is generating a Cartesian product of all the tables; that is, every combination of rows. This will take quite a long time, because the product of the number of rows in each table must be examined. For the case at hand, this product is 74 * 2135 * 74 * 3872 = 45,268,558,720 rows. If the tables were bigger, you can only imagine how long it would take.
One problem here is that MySQL can use indexes on columns more efficiently if they are declared the same. (For ISAM tables, indexes may not be used at all unless the columns are declared the same.) In this context, VARCHAR and CHAR are the same unless they are declared as different lengths. Because tt.ActualPC is declared as CHAR(10) and et.EMPLOYID is declared as CHAR(15), there is a length mismatch.
To fix this disparity between column lengths, use ALTER TABLE to lengthen ActualPC from 10 characters to 15 characters:
mysql> ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
Now tt.ActualPC and et.EMPLOYID are both VARCHAR(15). Executing the EXPLAIN statement again produces this result:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC, NULL NULL NULL 3872 Using
ClientID, where
ActualPC
do ALL PRIMARY NULL NULL NULL 2135
range checked for each record (key map: 1)
et_1 ALL PRIMARY NULL NULL NULL 74
range checked for each record (key map: 1)
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
This is not perfect, but is much better: The product of the rows values is now less by a factor of 74. This version is executed in a couple of seconds.
A second alteration can be made to eliminate the column length mismatches for the tt.AssignedPC = et_1.EMPLOYID and tt.ClientID = do.CUSTNMBR comparisons:
mysql> ALTER TABLE tt MODIFY AssignedPC VARCHAR(15),
-> MODIFY ClientID VARCHAR(15);
Now EXPLAIN produces the output shown here:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using
ClientID, where
ActualPC
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
This is almost as good as it can get.
The remaining problem is that, by default, MySQL assumes that values in the tt.ActualPC column are evenly distributed, and that is not the case for the tt table. Fortunately, it is easy to tell MySQL to analyze the key distribution:
mysql> ANALYZE TABLE tt;
Now the join is perfect, and EXPLAIN produces this result:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC NULL NULL NULL 3872 Using
ClientID, where
ActualPC
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
Note that the rows column in the output from EXPLAIN is an educated guess from the MySQL join optimizer. You should check whether the numbers are even close to the truth. If not, you may get better performance by using STRAIGHT_JOIN in your SELECT statement and trying to list the tables in a different order in the FROM clause.
In most cases, you can estimate the performance by counting disk seeks. For small tables, you can usually find a row in one disk seek (because the index is probably cached). For bigger tables, you can estimate that, using B-tree indexes, you will need this many seeks to find a row: log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1.
In MySQL, an index block is usually 1024 bytes and the data pointer is usually 4 bytes. For a 500,000-row table with an index length of 3 bytes (medium integer), the formula indicates log(500,000)/log(1024/3*2/(3+4)) + 1 = 4 seeks.
This index would require storage of about 500,000 * 7 * 3/2 = 5.2MB (assuming a typical index buffer fill ratio of 2/3), so you will probably have much of the index in memory and you will probably need only one or two calls to read data to find the row.
For writes, however, you will need four seek requests (as above) to find where to place the new index and normally two seeks to update the index and write the row.
Note that the preceding discussion doesn’t mean that your application performance will slowly degenerate by log N! As long as everything is cached by the OS or SQL server, things will become only marginally slower as the table gets bigger. After the data gets too big to be cached, things will start to go much slower until your application is only bound by disk-seeks (which increase by log N). To avoid this, increase the key cache size as the data grows. For MyISAM tables, the key cache size is controlled by the key_buffer_size system variable. See Section 6.5.2, “Tuning Server Parameters.”
In general, when you want to make a slow SELECT ... WHERE query faster, the first thing to check is whether you can add an index. All references between different tables should usually be done with indexes. You can use the EXPLAIN statement to determine which indexes are used for a SELECT. See Section 6.4.5, “How MySQL Uses Indexes,” and Section 6.2.1, “EXPLAIN Syntax (Get Information About a SELECT)"/>.”
Some general tips for speeding up queries on MyISAM tables:
![]() To help MySQL optimize queries better, use
To help MySQL optimize queries better, use ANALYZE TABLE or run myisamchk --analyze on a table after it has been loaded with data. This updates a value for each index part that indicates the average number of rows that have the same value. (For unique indexes, this is always 1.) MySQL will use this to decide which index to choose when you join two tables based on a non-constant expression. You can check the result from the table analysis by using SHOW INDEX FROM tbl_name and examining the Cardinality value. myisamchk --description --verbose shows index distribution information.
![]() To sort an index and data according to an index, use
To sort an index and data according to an index, use myisamchk --sort-index --sort-records=1 (if you want to sort on index 1). This is a good way to make queries faster if you have a unique index from which you want to read all records in order according to the index. Note that the first time you sort a large table this way, it may take a long time.
This section discusses optimizations that can be made for processing WHERE clauses. The examples use SELECT statements, but the same optimizations apply for WHERE clauses in DELETE and UPDATE statements.
Note that work on the MySQL optimizer is ongoing, so this section is incomplete. MySQL does many optimizations, not all of which are documented here.
Some of the optimizations performed by MySQL are listed here:
![]() Removal of unnecessary parentheses:
Removal of unnecessary parentheses:
((a AND b) AND c OR (((a AND b) AND (c AND d))))
-> (a AND b AND c) OR (a AND b AND c AND d)
![]() Constant folding:
Constant folding:
(a<b AND b=c) AND a=5
-> b>5 AND b=c AND a=5
![]() Constant condition removal (needed because of constant folding):
Constant condition removal (needed because of constant folding):
(B>=5 AND B=5) OR (B=6 AND 5=5) OR (B=7 AND 5=6)
-> B=5 OR B=6
![]() Constant expressions used by indexes are evaluated only once.
Constant expressions used by indexes are evaluated only once.
![]()
COUNT(*) on a single table without a WHERE is retrieved directly from the table information for MyISAM and HEAP tables. This is also done for any NOT NULL expression when used with only one table.
![]() Early detection of invalid constant expressions. MySQL quickly detects that some
Early detection of invalid constant expressions. MySQL quickly detects that some SELECT statements are impossible and returns no rows.
![]()
HAVING is merged with WHERE if you don’t use GROUP BY or group functions (COUNT(), MIN(), and so on).
![]() For each table in a join, a simpler
For each table in a join, a simpler WHERE is constructed to get a fast WHERE evaluation for the table and also to skip records as soon as possible.
![]() All constant tables are read first before any other tables in the query. A constant table is any of the following:
All constant tables are read first before any other tables in the query. A constant table is any of the following:
![]() An empty table or a table with one row.
An empty table or a table with one row.
![]() A table that is used with a
A table that is used with a WHERE clause on a PRIMARY KEY or a UNIQUE index, where all index parts are compared to constant expressions and are defined as NOT NULL.
All of the following tables are used as constant tables:
SELECT * FROM t WHERE primary_key=1;
SELECT * FROM t1,t2
WHERE t1.primary_key=1 AND t2.primary_key=t1.id;
![]() The best join combination for joining the tables is found by trying all possibilities. If all columns in
The best join combination for joining the tables is found by trying all possibilities. If all columns in ORDER BY and GROUP BY clauses come from the same table, that table is preferred first when joining.
![]() If there is an
If there is an ORDER BY clause and a different GROUP BY clause, or if the ORDER BY or GROUP BY contains columns from tables other than the first table in the join queue, a temporary table is created.
![]() If you use
If you use SQL_SMALL_RESULT, MySQL uses an in-memory temporary table.
![]() Each table index is queried, and the best index is used unless the optimizer believes that it will be more efficient to use a table scan. At one time, a scan was used based on whether the best index spanned more than 30% of the table. Now the optimizer is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size, so a fixed percentage no longer determines the choice between using an index or a scan.
Each table index is queried, and the best index is used unless the optimizer believes that it will be more efficient to use a table scan. At one time, a scan was used based on whether the best index spanned more than 30% of the table. Now the optimizer is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size, so a fixed percentage no longer determines the choice between using an index or a scan.
![]() In some cases, MySQL can read rows from the index without even consulting the data file. If all columns used from the index are numeric, only the index tree is used to resolve the query.
In some cases, MySQL can read rows from the index without even consulting the data file. If all columns used from the index are numeric, only the index tree is used to resolve the query.
![]() Before each record is output, those that do not match the
Before each record is output, those that do not match the HAVING clause are skipped.
Some examples of queries that are very fast:
SELECT COUNT(*) FROM tbl_name;
SELECT MIN(key_part1),MAX(key_part1) FROM tbl_name;
SELECT MAX(key_part2) FROM tbl_name
WHERE key_part1=constant;
SELECT ... FROM tbl_name
ORDER BY key_part1,key_part2,... LIMIT 10;
SELECT ... FROM tbl_name
ORDER BY key_part1 DESC, key_part2 DESC, ... LIMIT 10;
The following queries are resolved using only the index tree, assuming that the indexed columns are numeric:
SELECT key_part1,key_part2 FROM tbl_name WHERE key_part1=val;
SELECT COUNT(*) FROM tbl_name
WHERE key_part1=val1 AND key_part2=val2;
SELECT key_part2 FROM tbl_name GROUP BY key_part1;
The following queries use indexing to retrieve the rows in sorted order without a separate sorting pass:
SELECT ... FROM tbl_name
ORDER BY key_part1,key_part2,... ;
SELECT ... FROM tbl_name
ORDER BY key_part1 DESC, key_part2 DESC, ... ;
The Index Merge method is used to retrieve rows with several ref, ref_or_null, or range scans and merge the results into one. This method is employed when the table condition is a disjunction of conditions for which ref, ref_or_null, or range could be used with different keys.
This “join” type optimization is new in MySQL 5.0.0, and represents a significant change in behavior with regard to indexes, because the old rule was that the server is only ever able to use at most one index for each referenced table.
In EXPLAIN output, this method appears as index_merge in the type column. In this case, the key column contains a list of indexes used, and key_len contains a list of the longest key parts for those indexes.
Examples:
SELECT * FROM tbl_name WHERE key_part1 = 10 OR key_part2 = 20;
SELECT * FROM tbl_name
WHERE (key_part1 = 10 OR key_part2 = 20) AND non_key_part=30;
SELECT * FROM t1,t2
WHERE (t1.key1 IN (1,2) OR t1.key2 LIKE 'value%')
AND t2.key1=t1.some_col;
SELECT * FROM t1,t2
WHERE t1.key1=1
AND (t2.key1=t1.some_col OR t2.key2=t1.some_col2);
MySQL can do the same optimization on col_name IS NULL that it can do with col_name = constant_value. For example, MySQL can use indexes and ranges to search for NULL with IS NULL.
SELECT * FROM tbl_name WHERE key_col IS NULL;
SELECT * FROM tbl_name WHERE key_col <=> NULL;
SELECT * FROM tbl_name
WHERE key_col=const1 OR key_col=const2 OR key_col IS NULL;
If a WHERE clause includes a col_name IS NULL condition for a column that is declared as NOT NULL, that expression will be optimized away. This optimization does not occur in cases when the column might produce NULL anyway; for example, if it comes from a table on the right side of a LEFT JOIN.
MySQL 4.1.1 and up can additionally optimize the combination col_name = expr AND col_name IS NULL, a form that is common in resolved subqueries. EXPLAIN will show ref_or_null when this optimization is used.
This optimization can handle one IS NULL for any key part.
Some examples of queries that are optimized, assuming that there is an index on columns a and b or table t2:
SELECT * FROM t1 WHERE t1.a=expr OR t1.a IS NULL;
SELECT * FROM t1,t2 WHERE t1.a=t2.a OR t2.a IS NULL;
SELECT * FROM t1,t2
WHERE (t1.a=t2.a OR t2.a IS NULL) AND t2.b=t1.b;
SELECT * FROM t1,t2
WHERE t1.a=t2.a AND (t2.b=t1.b OR t2.b IS NULL);
SELECT * FROM t1,t2
WHERE (t1.a=t2.a AND t2.a IS NULL AND ...)
OR (t1.a=t2.a AND t2.a IS NULL AND ...);
ref_or_null works by first doing a read on the reference key, and then a separate search for rows with a NULL key value.
Note that the optimization can handle only one IS NULL level. In the following query, MySQL will use key lookups only on the expression (t1.a=t2.a AND t2.a IS NULL) and not be able to use the key part on b:
SELECT * FROM t1,t2
WHERE (t1.a=t2.a AND t2.a IS NULL)
OR (t1.b=t2.b AND t2.b IS NULL) ;
DISTINCT combined with ORDER BY will need a temporary table in many cases.
Note that because DISTINCT may use GROUP BY, you should be aware of how MySQL works with columns in ORDER BY or HAVING clauses that are not part of the selected columns.
MySQL extends the use of GROUP BY so that you can use columns or calculations in the SELECT list that don’t appear in the GROUP BY clause. This stands for any possible value for this group. You can use this to get better performance by avoiding sorting and grouping on unnecessary items. For example, you don’t need to group on customer.name in the following query:
mysql> SELECT order.custid, customer.name, MAX(payments)
-> FROM order,customer
-> WHERE order.custid = customer.custid
-> GROUP BY order.custid;
In standard SQL, you would have to add customer.name to the GROUP BY clause. In MySQL, the name is redundant if you don’t run in ANSI mode.
Do not use this feature if the columns you omit from the GROUP BY part are not unique in the group! You will get unpredictable results.
In some cases, you can use MIN() and MAX() to obtain a specific column value even if it isn’t unique. The following gives the value of column from the row containing the smallest value in the sort column:
SUBSTR(MIN(CONCAT(RPAD(sort,6,' '),column)),7)
When combining LIMIT row_count with DISTINCT, MySQL stops as soon as it finds row_count unique rows.
If you don’t use columns from all tables named in a query, MySQL stops scanning the not-used tables as soon as it finds the first match. In the following case, assuming that t1 is used before t2 (which you can check with EXPLAIN), MySQL stops reading from t2 (for any particular row in t1) when the first row in t2 is found:
SELECT DISTINCT t1.a FROM t1,t2 where t1.a=t2.a;
A LEFT JOIN B join_condition is implemented in MySQL as follows:
![]() Table
Table B is set to depend on table A and all tables on which A depends.
![]() Table
Table A is set to depend on all tables (except B) that are used in the LEFT JOIN condition.
![]() The
The LEFT JOIN condition is used to decide how to retrieve rows from table B. (In other words, any condition in the WHERE clause is not used.)
![]() All standard join optimizations are done, with the exception that a table is always read after all tables on which it depends. If there is a circular dependence, MySQL issues an error.
All standard join optimizations are done, with the exception that a table is always read after all tables on which it depends. If there is a circular dependence, MySQL issues an error.
![]() All standard
All standard WHERE optimizations are done.
![]() If there is a row in
If there is a row in A that matches the WHERE clause, but there is no row in B that matches the ON condition, an extra B row is generated with all columns set to NULL.
![]() If you use
If you use LEFT JOIN to find rows that don’t exist in some table and you have the following test: col_name IS NULL in the WHERE part, where col_name is a column that is declared as NOT NULL, MySQL stops searching for more rows (for a particular key combination) after it has found one row that matches the LEFT JOIN condition.
RIGHT JOIN is implemented analogously to LEFT JOIN, with the roles of the tables reversed.
The join optimizer calculates the order in which tables should be joined. The table read order forced by LEFT JOIN and STRAIGHT_JOIN helps the join optimizer do its work much more quickly, because there are fewer table permutations to check. Note that this means that if you do a query of the following type, MySQL will do a full scan on b because the LEFT JOIN forces it to be read before d:
SELECT *
FROM a,b LEFT JOIN c ON (c.key=a.key) LEFT JOIN d ON (d.key=a.key)
WHERE b.key=d.key;
The fix in this case is to rewrite the query as follows:
SELECT *
FROM b,a LEFT JOIN c ON (c.key=a.key) LEFT JOIN d ON (d.key=a.key)
WHERE b.key=d.key;
Starting from 4.0.14, MySQL does the following LEFT JOIN optimization: If the WHERE condition is always false for the generated NULL row, the LEFT JOIN is changed to a normal join.
For example, the WHERE clause would be false in the following query if t2.column1 would be NULL:
SELECT * FROM t1 LEFT JOIN t2 ON (column1) WHERE t2.column2=5;
Therefore, it’s safe to convert the query to a normal join:
SELECT * FROM t1,t2 WHERE t2.column2=5 AND t1.column1=t2.column1;
This can be made faster because MySQL can now use table t2 before table t1 if this would result in a better query plan. To force a specific table order, use STRAIGHT_JOIN.
In some cases, MySQL can use an index to satisfy an ORDER BY or GROUP BY clause without doing any extra sorting.
The index can also be used even if the ORDER BY doesn’t match the index exactly, as long as all the unused index parts and all the extra ORDER BY columns are constants in the WHERE clause. The following queries will use the index to resolve the ORDER BY or GROUP BY part:
SELECT * FROM t1 ORDER BY key_part1,key_part2,... ;
SELECT * FROM t1 WHERE key_part1=constant ORDER BY key_part2;
SELECT * FROM t1 WHERE key_part1=constant GROUP BY key_part2;
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 DESC;
SELECT * FROM t1
WHERE key_part1=1 ORDER BY key_part1 DESC, key_part2 DESC;
In some cases, MySQL cannot use indexes to resolve the ORDER BY, although it still will use indexes to find the rows that match the WHERE clause. These cases include the following:
![]() You use
You use ORDER BY on different keys:
SELECT * FROM t1 ORDER BY key1, key2;
![]() You use
You use ORDER BY on non-consecutive key parts:
SELECT * FROM t1 WHERE key_part2=constant ORDER BY key_part2;
![]() You mix
You mix ASC and DESC:
SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
![]() The key used to fetch the rows is not the same as the one used in the
The key used to fetch the rows is not the same as the one used in the ORDER BY:
SELECT * FROM t1 WHERE key2=constant ORDER BY key1;
![]() You are joining many tables, and the columns in the
You are joining many tables, and the columns in the ORDER BY are not all from the first non-constant table that is used to retrieve rows. (This is the first table in the EXPLAIN output that doesn’t have a const join type.)
![]() You have different
You have different ORDER BY and GROUP BY expressions.
![]() The type of table index used doesn’t store rows in order. For example, this is true for a
The type of table index used doesn’t store rows in order. For example, this is true for a HASH index in a HEAP table.
In those cases where MySQL must sort the result, it uses the following algorithm:
1. Read all rows according to key or by table scanning. Rows that don’t match the WHERE clause are skipped.
2. Store the sort key value in a buffer. The size of the buffer is the value of the sort_buffer_size system variable.
3. When the buffer gets full, run a qsort (quicksort) on it and store the result in a temporary file. Save a pointer to the sorted block. (If all rows fit into the sort buffer, no temporary file is created.)
4. Repeat the preceding steps until all rows have been read.
5. Do a multi-merge of up to MERGEBUFF (7) regions to one block in another temporary file. Repeat until all blocks from the first file are in the second file.
6. Repeat the following until there are fewer than MERGEBUFF2 (15) blocks left.
7. On the last multi-merge, only the pointer to the row (the last part of the sort key) is written to a result file.
8. Read the rows in sorted order by using the row pointers in the result file. To optimize this, we read in a big block of row pointers, sort them, and use them to read the rows in sorted order into a row buffer. The size of the buffer is the value of the read_rnd_buffer_size system variable. The code for this step is in the sql/records.cc source file.
With EXPLAIN SELECT ... ORDER BY, you can check whether MySQL can use indexes to resolve the query. It cannot if you see Using filesort in the Extra column. See Section 6.2.1, “EXPLAIN Syntax (Get Information About a SELECT).”
If you want to increase ORDER BY speed, first see whether you can get MySQL to use indexes rather than an extra sorting phase. If this is not possible, you can try the following strategies:
![]() Increase the size of the
Increase the size of the sort_buffer_size variable.
![]() Increase the size of the
Increase the size of the read_rnd_buffer_size variable.
![]() Change
Change tmpdir to point to a dedicated filesystem with lots of empty space. If you use MySQL 4.1 or later, this option accepts several paths that are used in round-robin fashion. Paths should be separated by colon characters (’:’) on Unix and semicolon characters (’;’) on Windows, NetWare, and OS/2. You can use this feature to spread the load across several directories. Note: The paths should be for directories in filesystems that are located on different physical disks, not different partitions of the same disk.
By default, MySQL sorts all GROUP BY col1, col2, ... queries as if you specified ORDER BY col1, col2, ... in the query as well. If you include an ORDER BY clause explicitly that contains the same column list, MySQL optimizes it away without any speed penalty, although the sorting still occurs. If a query includes GROUP BY but you want to avoid the overhead of sorting the result, you can suppress sorting by specifying ORDER BY NULL. For example:
INSERT INTO foo
SELECT a, COUNT(*) FROM bar GROUP BY a ORDER BY NULL;
In some cases, MySQL will handle a query differently when you are using LIMIT row_count and not using HAVING:
![]() If you are selecting only a few rows with
If you are selecting only a few rows with LIMIT, MySQL uses indexes in some cases when normally it would prefer to do a full table scan.
![]() If you use
If you use LIMIT row_count with ORDER BY, MySQL ends the sorting as soon as it has found the first row_count lines rather than sorting the whole table.
![]() When combining
When combining LIMIT row_count with DISTINCT, MySQL stops as soon as it finds row_count unique rows.
![]() In some cases, a
In some cases, a GROUP BY can be resolved by reading the key in order (or doing a sort on the key) and then calculating summaries until the key value changes. In this case, LIMIT row_count will not calculate any unnecessary GROUP BY values.
![]() As soon as MySQL has sent the required number of rows to the client, it aborts the query unless you are using
As soon as MySQL has sent the required number of rows to the client, it aborts the query unless you are using SQL_CALC_FOUND_ROWS.
![]()
LIMIT 0 always quickly returns an empty set. This is useful to check the query or to get the column types of the result columns.
![]() When the server uses temporary tables to resolve the query, the
When the server uses temporary tables to resolve the query, the LIMIT row_count is used to calculate how much space is required.
The output from EXPLAIN will show ALL in the type column when MySQL uses a table scan to resolve a query. This usually happens under the following conditions:
![]() The table is so small that it’s faster to do a table scan than a key lookup. This is a common case for tables with fewer than 10 rows and a short row length.
The table is so small that it’s faster to do a table scan than a key lookup. This is a common case for tables with fewer than 10 rows and a short row length.
![]() There are no usable restrictions in the
There are no usable restrictions in the ON or WHERE clause for indexed columns.
![]() You are comparing indexed columns with constant values and MySQL has calculated (based on the index tree) that the constants cover too large a part of the table and that a table scan would be faster. See Section 6.2.4, “How MySQL Optimizes
You are comparing indexed columns with constant values and MySQL has calculated (based on the index tree) that the constants cover too large a part of the table and that a table scan would be faster. See Section 6.2.4, “How MySQL Optimizes WHERE Clauses.”
![]() You are using a key with low cardinality (many rows match the key value) through another column. In this case, MySQL assumes that by using the key it will probably do a lot of key lookups and that a table scan would be faster.
You are using a key with low cardinality (many rows match the key value) through another column. In this case, MySQL assumes that by using the key it will probably do a lot of key lookups and that a table scan would be faster.
For small tables, a table scan often is appropriate. For large tables, try the following techniques to avoid having the optimizer incorrectly choose a table scan:
![]() Use
Use ANALYZE TABLE tbl_name to update the key distributions for the scanned table.
![]() Use
Use FORCE INDEX for the scanned table to tell MySQL that table scans are very expensive compared to using the given index.
SELECT * FROM t1, t2 FORCE INDEX (index_for_column)
WHERE t1.col_name=t2.col_name;
![]() Start
Start mysqld with the --max-seeks-for-key=1000 option or use SET max_seeks_for_key=1000 to tell the optimizer to assume that no key scan will cause more than 1,000 key seeks. See Section 4.2.3, “Server System Variables.”
The time to insert a record is determined by the following factors, where the numbers indicate approximate proportions:
![]() Connecting: (3)
Connecting: (3)
![]() Sending query to server: (2)
Sending query to server: (2)
![]() Parsing query: (2)
Parsing query: (2)
![]() Inserting record: (1 x size of record)
Inserting record: (1 x size of record)
![]() Inserting indexes: (1 x number of indexes)
Inserting indexes: (1 x number of indexes)
![]() Closing: (1)
Closing: (1)
This does not take into consideration the initial overhead to open tables, which is done once for each concurrently running query.
The size of the table slows down the insertion of indexes by log N, assuming B-tree indexes.
You can use the following methods to speed up inserts:
![]() If you are inserting many rows from the same client at the same time, use
If you are inserting many rows from the same client at the same time, use INSERT statements with multiple VALUES lists to insert several rows at a time. This is much faster (many times faster in some cases) than using separate single-row INSERT statements. If you are adding data to a non-empty table, you may tune the bulk_insert_buffer_size variable to make it even faster. See Section 4.2.3, “Server System Variables.”
![]() If you are inserting a lot of rows from different clients, you can get higher speed by using the
If you are inserting a lot of rows from different clients, you can get higher speed by using the INSERT DELAYED statement.
![]() With
With MyISAM tables you can insert rows at the same time that SELECT statements are running if there are no deleted rows in the tables.
![]() When loading a table from a text file, use
When loading a table from a text file, use LOAD DATA INFILE. This is usually 20 times faster than using a lot of INSERT statements.
![]() With some extra work, it is possible to make
With some extra work, it is possible to make LOAD DATA INFILE run even faster when the table has many indexes. Use the following procedure:
1. Optionally create the table with CREATE TABLE.
2. Execute a FLUSH TABLES statement or a mysqladmin flush-tables command.
3. Use myisamchk --keys-used=0 -rq /path/to/db/tbl_name. This will remove all use of all indexes for the table.
4. Insert data into the table with LOAD DATA INFILE. This will not update any indexes and will therefore be very fast.
5. If you are going to only read the table in the future, use myisampack to make it smaller. See Section 8.1.3.3, “Compressed Table Characteristics.”
6. Re-create the indexes with myisamchk -r -q /path/to/db/tbl_name. This will create the index tree in memory before writing it to disk, which is much faster because it avoids lots of disk seeks. The resulting index tree is also perfectly balanced.
7. Execute a FLUSH TABLES statement or a mysqladmin flush-tables command.
Note that LOAD DATA INFILE also performs the preceding optimization if you insert into an empty MyISAM table; the main difference is that you can let myisamchk allocate much more temporary memory for the index creation than you might want the server to allocate for index re-creation when it executes the LOAD DATA INFILE statement.
As of MySQL 4.0, you can also use ALTER TABLE tbl_name DISABLE KEYS instead of myisamchk --keys-used=0 -rq /path/to/db/tbl_name and ALTER TABLE tbl_name ENABLE KEYS instead of myisamchk -r -q /path/to/db/tbl_name. This way you can also skip the FLUSH TABLES steps.
![]() You can speed up
You can speed up INSERT operations that are done with multiple statements by locking your tables:
LOCK TABLES a WRITE;
INSERT INTO a VALUES (1,23),(2,34),(4,33);
INSERT INTO a VALUES (8,26),(6,29);
UNLOCK TABLES;
A performance benefit occurs because the index buffer is flushed to disk only once after all INSERT statements have completed. Normally there would be as many index buffer flushes as there are different INSERT statements. Explicit locking statements are not needed if you can insert all rows with a single statement.
For transactional tables, you should use BEGIN/COMMIT instead of LOCK TABLES to get a speedup.
Locking also lowers the total time of multiple-connection tests, although the maximum wait time for individual connections might go up because they wait for locks. For example:
Connection 1 does 1000 inserts
Connections 2, 3, and 4 do 1 insert
Connection 5 does 1000 inserts
If you don’t use locking, connections 2, 3, and 4 will finish before 1 and 5. If you use locking, connections 2, 3, and 4 probably will not finish before 1 or 5, but the total time should be about 40% faster.
INSERT, UPDATE, and DELETE operations are very fast in MySQL, but you will obtain better overall performance by adding locks around everything that does more than about five inserts or updates in a row. If you do very many inserts in a row, you could do a LOCK TABLES followed by an UNLOCK TABLES once in a while (about each 1,000 rows) to allow other threads access to the table. This would still result in a nice performance gain.
INSERT is still much slower for loading data than LOAD DATA INFILE, even when using the strategies just outlined.
![]() To get some more speed for
To get some more speed for MyISAM tables, for both LOAD DATA INFILE and INSERT, enlarge the key cache by increasing the key_buffer_size system variable. See Section 6.5.2, “Tuning Server Parameters.”
Update queries are optimized as a SELECT query with the additional overhead of a write. The speed of the write depends on the amount of data being updated and the number of indexes that are updated. Indexes that are not changed will not be updated.
Also, another way to get fast updates is to delay updates and then do many updates in a row later. Doing many updates in a row is much quicker than doing one at a time if you lock the table.
Note that for a MyISAM table that uses dynamic record format, updating a record to a longer total length may split the record. If you do this often, it is very important to use OPTIMIZE TABLE occasionally.
The time to delete individual records is exactly proportional to the number of indexes. To delete records more quickly, you can increase the size of the key cache. See Section 6.5.2, “Tuning Server Parameters.”
If you want to delete all rows in the table, use TRUNCATE TABLE tbl_name rather than DELETE FROM tbl_name.
This section lists a number of miscellaneous tips for improving query processing speed:
![]() Use persistent connections to the database to avoid connection overhead. If you can’t use persistent connections and you are initiating many new connections to the database, you may want to change the value of the
Use persistent connections to the database to avoid connection overhead. If you can’t use persistent connections and you are initiating many new connections to the database, you may want to change the value of the thread_cache_size variable. See Section 6.5.2, “Tuning Server Parameters.”
![]() Always check whether all your queries really use the indexes you have created in the tables. In MySQL, you can do this with the
Always check whether all your queries really use the indexes you have created in the tables. In MySQL, you can do this with the EXPLAIN statement. See Section 6.2.1, “EXPLAIN Syntax (Get Information About a SELECT).”
![]() Try to avoid complex
Try to avoid complex SELECT queries on MyISAM tables that are updated frequently, to avoid problems with table locking that occur due to contention between readers and writers.
![]() With
With MyISAM tables that have no deleted rows, you can insert rows at the end at the same time that another query is reading from the table. If this is important for you, you should consider using the table in ways that avoid deleting rows. Another possibility is to run OPTIMIZE TABLE after you have deleted a lot of rows.
![]() Use
Use ALTER TABLE ... ORDER BY expr1, expr2, ... if you mostly retrieve rows in expr1, expr2, ... order. By using this option after extensive changes to the table, you may be able to get higher performance.
![]() In some cases, it may make sense to introduce a column that is “hashed” based on information from other columns. If this column is short and reasonably unique, it may be much faster than a big index on many columns. In MySQL, it’s very easy to use this extra column:
In some cases, it may make sense to introduce a column that is “hashed” based on information from other columns. If this column is short and reasonably unique, it may be much faster than a big index on many columns. In MySQL, it’s very easy to use this extra column:
SELECT * FROM tbl_name
WHERE hash_col=MD5(CONCAT(col1,col2))
AND col1='constant' AND col2='constant';
![]() For
For MyISAM tables that change a lot, you should try to avoid all variable-length columns (VARCHAR, BLOB, and TEXT). The table will use dynamic record format if it includes even a single variable-length column. See Chapter 8, “MySQL Storage Engines and Table Types.”
![]() It’s normally not useful to split a table into different tables just because the rows get “big.” To access a row, the biggest performance hit is the disk seek to find the first byte of the row. After finding the data, most modern disks can read the whole row fast enough for most applications. The only cases where it really matters to split up a table is if it’s a
It’s normally not useful to split a table into different tables just because the rows get “big.” To access a row, the biggest performance hit is the disk seek to find the first byte of the row. After finding the data, most modern disks can read the whole row fast enough for most applications. The only cases where it really matters to split up a table is if it’s a MyISAM table with dynamic record format (see above) that you can change to a fixed record size, or if you very often need to scan the table but do not need most of the columns. See Chapter 8, “MySQL Storage Engines and Table Types.”
![]() If you very often need to calculate results such as counts based on information from a lot of rows, it’s probably much better to introduce a new table and update the counter in real time. An update of the following form is very fast:
If you very often need to calculate results such as counts based on information from a lot of rows, it’s probably much better to introduce a new table and update the counter in real time. An update of the following form is very fast:
UPDATE tbl_name SET count_col=count_col+1 WHERE key_col=constant;
This is really important when you use MySQL storage engines such as MyISAM and ISAM that have only table-level locking (multiple readers / single writers). This will also give better performance with most databases, because the row locking manager in this case will have less to do.
![]() If you need to collect statistics from large log tables, use summary tables instead of scanning the entire log table. Maintaining the summaries should be much faster than trying to calculate statistics “live.” It’s much faster to regenerate new summary tables from the logs when things change (depending on business decisions) than to have to change the running application!
If you need to collect statistics from large log tables, use summary tables instead of scanning the entire log table. Maintaining the summaries should be much faster than trying to calculate statistics “live.” It’s much faster to regenerate new summary tables from the logs when things change (depending on business decisions) than to have to change the running application!
![]() If possible, you should classify reports as “live” or “statistical,” where data needed for statistical reports is created only from summary tables that are generated periodically from the live data.
If possible, you should classify reports as “live” or “statistical,” where data needed for statistical reports is created only from summary tables that are generated periodically from the live data.
![]() Take advantage of the fact that columns have default values. Insert values explicitly only when the value to be inserted differs from the default. This reduces the parsing that MySQL needs to do and improves the insert speed.
Take advantage of the fact that columns have default values. Insert values explicitly only when the value to be inserted differs from the default. This reduces the parsing that MySQL needs to do and improves the insert speed.
![]() In some cases, it’s convenient to pack and store data into a
In some cases, it’s convenient to pack and store data into a BLOB column. In this case, you must add some extra code in your application to pack and unpack information in the BLOB values, but this may save a lot of accesses at some stage. This is practical when you have data that doesn’t conform to a rows-and-columns table structure.
![]() Normally, you should try to keep all data non-redundant (what is called “third normal form” in database theory). However, do not be afraid to duplicate information or create summary tables if necessary to gain more speed.
Normally, you should try to keep all data non-redundant (what is called “third normal form” in database theory). However, do not be afraid to duplicate information or create summary tables if necessary to gain more speed.
![]() Stored procedures or UDFs (user-defined functions) may be a good way to get more performance for some tasks. However, if you use a database system that does not support these capabilities, you should always have another way to perform the same tasks, even if the alternative method is slower.
Stored procedures or UDFs (user-defined functions) may be a good way to get more performance for some tasks. However, if you use a database system that does not support these capabilities, you should always have another way to perform the same tasks, even if the alternative method is slower.
![]() You can always gain something by caching queries or answers in your application and then performing many inserts or updates together. If your database supports table locks (like MySQL and Oracle), this should help to ensure that the index cache is only flushed once after all updates.
You can always gain something by caching queries or answers in your application and then performing many inserts or updates together. If your database supports table locks (like MySQL and Oracle), this should help to ensure that the index cache is only flushed once after all updates.
![]() Use
Use INSERT DELAYED when you do not need to know when your data is written. This speeds things up because many records can be written with a single disk write.
![]() Use
Use INSERT LOW_PRIORITY when you want to give SELECT statements higher priority than your inserts.
![]() Use
Use SELECT HIGH_PRIORITY to get retrievals that jump the queue. That is, the SELECT is done even if there is another client waiting to do a write.
![]() Use multiple-row
Use multiple-row INSERT statements to store many rows with one SQL statement (many SQL servers support this).
![]() Use
Use LOAD DATA INFILE to load large amounts of data. This is faster than using INSERT statements.
![]() Use
Use AUTO_INCREMENT columns to generate unique values.
![]() Use
Use OPTIMIZE TABLE once in a while to avoid fragmentation with MyISAM tables when using a dynamic table format. See Section 8.1.3, “MyISAM Table Storage Formats.”
![]() Use
Use HEAP tables when possible to get more speed. See Chapter 8, “MySQL Storage Engines and Table Types.”
![]() When using a normal Web server setup, images should be stored as files. That is, store only a file reference in the database. The main reason for this is that a normal Web server is much better at caching files than database contents, so it’s much easier to get a fast system if you are using files.
When using a normal Web server setup, images should be stored as files. That is, store only a file reference in the database. The main reason for this is that a normal Web server is much better at caching files than database contents, so it’s much easier to get a fast system if you are using files.
![]() Use in-memory tables for non-critical data that is accessed often, such as information about the last displayed banner for users who don’t have cookies enabled in their Web browser.
Use in-memory tables for non-critical data that is accessed often, such as information about the last displayed banner for users who don’t have cookies enabled in their Web browser.
![]() Columns with identical information in different tables should be declared to have identical data types. Before MySQL 3.23, you get slow joins otherwise.
Columns with identical information in different tables should be declared to have identical data types. Before MySQL 3.23, you get slow joins otherwise.
![]() Try to keep column names simple. For example, in a table named
Try to keep column names simple. For example, in a table named customer, use a column name of name instead of customer_name. To make your names portable to other SQL servers, you should keep them shorter than 18 characters.
![]() If you need really high speed, you should take a look at the low-level interfaces for data storage that the different SQL servers support! For example, by accessing the MySQL
If you need really high speed, you should take a look at the low-level interfaces for data storage that the different SQL servers support! For example, by accessing the MySQL MyISAM storage engine directly, you could get a speed increase of two to five times compared to using the SQL interface. To be able to do this, the data must be on the same server as the application, and usually it should only be accessed by one process (because external file locking is really slow). One could eliminate these problems by introducing low-level MyISAM commands in the MySQL server (this could be one easy way to get more performance if needed). By carefully designing the database interface, it should be quite easy to support this type of optimization.
![]() If you are using numerical data, it’s faster in many cases to access information from a database (using a live connection) than to access a text file. Information in the database is likely to be stored in a more compact format than in the text file, so accessing it will involve fewer disk accesses. You will also save code in your application because you don’t have to parse your text files to find line and column boundaries.
If you are using numerical data, it’s faster in many cases to access information from a database (using a live connection) than to access a text file. Information in the database is likely to be stored in a more compact format than in the text file, so accessing it will involve fewer disk accesses. You will also save code in your application because you don’t have to parse your text files to find line and column boundaries.
![]() Replication can provide a performance benefit for some operations. You can distribute client retrievals among replication servers to split up the load. To avoid slowing down the master while making backups, you can make backups using a slave server. See Chapter 5, “Replication in MySQL.”
Replication can provide a performance benefit for some operations. You can distribute client retrievals among replication servers to split up the load. To avoid slowing down the master while making backups, you can make backups using a slave server. See Chapter 5, “Replication in MySQL.”
![]() Declaring a
Declaring a MyISAM table with the DELAY_KEY_WRITE=1 table option makes index updates faster because they are not flushed to disk until the table is closed. The downside is that if something kills the server while such tables are open, you should ensure that they are okay by running the server with the --myisam-recover option, or by running myisamchk before restarting the server. (However, even in this case, you should not lose anything by using DELAY_KEY_WRITE, because the key information can always be generated from the data rows.)
Currently, MySQL supports table-level locking for ISAM, MyISAM, and MEMORY (HEAP) tables, page-level locking for BDB tables, and row-level locking for InnoDB tables.
In many cases, you can make an educated guess about which locking type is best for an application, but generally it’s very hard to say that a given lock type is better than another. Everything depends on the application and different parts of an application may require different lock types.
To decide whether you want to use a storage engine with row-level locking, you will want to look at what your application does and what mix of select and update statements it uses. For example, most Web applications do lots of selects, very few deletes, updates based mainly on key values, and inserts into some specific tables. The base MySQL MyISAM setup is very well tuned for this.
Table locking in MySQL is deadlock-free for storage engines that use table-level locking. Deadlock avoidance is managed by always requesting all needed locks at once at the beginning of a query and always locking the tables in the same order.
The table-locking method MySQL uses for WRITE locks works as follows:
![]() If there are no locks on the table, put a write lock on it.
If there are no locks on the table, put a write lock on it.
![]() Otherwise, put the lock request in the write lock queue.
Otherwise, put the lock request in the write lock queue.
The table-locking method MySQL uses for READ locks works as follows:
![]() If there are no write locks on the table, put a read lock on it.
If there are no write locks on the table, put a read lock on it.
![]() Otherwise, put the lock request in the read lock queue.
Otherwise, put the lock request in the read lock queue.
When a lock is released, the lock is made available to the threads in the write lock queue, then to the threads in the read lock queue.
This means that if you have many updates for a table, SELECT statements will wait until there are no more updates.
Starting in MySQL 3.23.33, you can analyze the table lock contention on your system by checking the Table_locks_waited and Table_locks_immediate status variables:
mysql> SHOW STATUS LIKE 'Table%';
+-----------------------+---------+
| Variable_name | Value |
+-----------------------+---------+
| Table_locks_immediate| 1151552|
| Table_locks_waited | 15324 |
+-----------------------+---------+
As of MySQL 3.23.7 (3.23.25 for Windows), you can freely mix concurrent INSERT and SELECT statements for a MyISAM table without locks if the INSERT statements are non-conflicting. That is, you can insert rows into a MyISAM table at the same time other clients are reading from it. No conflict occurs if the data file contains no free blocks in the middle, because in that case, records always are inserted at the end of the data file. (Holes can result from rows having been deleted from or updated in the middle of the table.) If there are holes, concurrent inserts are re-enabled automatically when all holes have been filled with new data.
If you want to do many INSERT and SELECT operations on a table when concurrent inserts are not possible, you can insert rows in a temporary table and update the real table with the records from the temporary table once in a while. This can be done with the following code:
mysql> LOCK TABLES real_table WRITE, insert_table WRITE;
mysql> INSERT INTO real_table SELECT * FROM insert_table;
mysql> TRUNCATE TABLE insert_table;
mysql> UNLOCK TABLES;
InnoDB uses row locks and BDB uses page locks. For the InnoDB and BDB storage engines, deadlock is possible. This is because InnoDB automatically acquires row locks and BDB acquires page locks during the processing of SQL statements, not at the start of the transaction.
Advantages of row-level locking:
![]() Fewer lock conflicts when accessing different rows in many threads.
Fewer lock conflicts when accessing different rows in many threads.
![]() Fewer changes for rollbacks.
Fewer changes for rollbacks.
![]() Makes it possible to lock a single row a long time.
Makes it possible to lock a single row a long time.
Disadvantages of row-level locking:
![]() Takes more memory than page-level or table-level locks.
Takes more memory than page-level or table-level locks.
![]() Is slower than page-level or table-level locks when used on a large part of the table because you must acquire many more locks.
Is slower than page-level or table-level locks when used on a large part of the table because you must acquire many more locks.
![]() Is definitely much worse than other locks if you often do
Is definitely much worse than other locks if you often do GROUP BY operations on a large part of the data or if you often must scan the entire table.
![]() With higher-level locks, you can also more easily support locks of different types to tune the application, because the lock overhead is less than for row-level locks.
With higher-level locks, you can also more easily support locks of different types to tune the application, because the lock overhead is less than for row-level locks.
Table locks are superior to page-level or row-level locks in the following cases:
![]() Most statements for the table are reads.
Most statements for the table are reads.
![]() Read and updates on strict keys, where you update or delete a row that can be fetched with a single key read:
Read and updates on strict keys, where you update or delete a row that can be fetched with a single key read:
UPDATE tbl_name SET column=value WHERE unique_key_col=key_value;
DELETE FROM tbl_name WHERE unique_key_col=key_value;
![]()
SELECT combined with concurrent INSERT statements, and very few UPDATE and DELETE statements.
![]() Many scans or
Many scans or GROUP BY operations on the entire table without any writers.
Options other than row-level or page-level locking:
Versioning (such as we use in MySQL for concurrent inserts) where you can have one writer at the same time as many readers. This means that the database/table supports different views for the data depending on when you started to access it. Other names for this are time travel, copy on write, or copy on demand.
Copy on demand is in many cases much better than page-level or row-level locking. However, the worst case does use much more memory than when using normal locks.
Instead of using row-level locks, you can use application-level locks, such as GET_LOCK() and RELEASE_LOCK() in MySQL. These are advisory locks, so they work only in well-behaved applications.
To achieve a very high lock speed, MySQL uses table locking (instead of page, row, or column locking) for all storage engines except InnoDB and BDB.
For InnoDB and BDB tables, MySQL only uses table locking if you explicitly lock the table with LOCK TABLES. For these table types, we recommend you to not use LOCK TABLES at all, because InnoDB uses automatic row-level locking and BDB uses page-level locking to ensure transaction isolation.
For large tables, table locking is much better than row locking for most applications, but there are some pitfalls.
Table locking enables many threads to read from a table at the same time, but if a thread wants to write to a table, it must first get exclusive access. During the update, all other threads that want to access this particular table must wait until the update is done.
Table updates normally are considered to be more important than table retrievals, so they are given higher priority. This should ensure that updates to a table are not “starved” even if there is heavy SELECT activity for the table.
Table locking causes problems in cases such as when a thread is waiting because the disk is full and free space needs to become available before the thread can proceed. In this case, all threads that want to access the problem table will also be put in a waiting state until more disk space is made available.
Table locking is also disadvantageous under the following scenario:
![]() A client issues a
A client issues a SELECT that takes a long time to run.
![]() Another client then issues an
Another client then issues an UPDATE on the same table. This client will wait until the SELECT is finished.
![]() Another client issues another
Another client issues another SELECT statement on the same table. Because UPDATE has higher priority than SELECT, this SELECT will wait for the UPDATE to finish. It will also wait for the first SELECT to finish!
The following list describes some ways to avoid or reduce contention caused by table locking:
![]() Try to get the
Try to get the SELECT statements to run faster. You might have to create some summary tables to do this.
![]() Start
Start mysqld with --low-priority-updates. This gives all statements that update (modify) a table lower priority than SELECT statements. In this case, the second SELECT statement in the preceding scenario would execute before the INSERT statement, and would not need to wait for the first SELECT to finish.
![]() You can specify that all updates issued in a specific connection should be done with low priority by using the
You can specify that all updates issued in a specific connection should be done with low priority by using the SET LOW_PRIORITY_UPDATES=1 statement.
![]() You can give a specific
You can give a specific INSERT, UPDATE, or DELETE statement lower priority with the LOW_PRIORITY attribute.
![]() You can give a specific
You can give a specific SELECT statement higher priority with the HIGH_PRIORITY attribute.
![]() Starting from MySQL 3.23.7, you can start
Starting from MySQL 3.23.7, you can start mysqld with a low value for the max_write_lock_count system variable to force MySQL to temporarily elevate the priority of all SELECT statements that are waiting for a table after a specific number of inserts to the table occur. This allows READ locks after a certain number of WRITE locks.
![]() If you have problems with
If you have problems with INSERT combined with SELECT, switch to using MyISAM tables, which support concurrent SELECT and INSERT statements.
![]() If you mix inserts and deletes on the same table,
If you mix inserts and deletes on the same table, INSERT DELAYED may be of great help.
![]() If you have problems with mixed
If you have problems with mixed SELECT and DELETE statements, the LIMIT option to DELETE may help.
![]() Using
Using SQL_BUFFER_RESULT with SELECT statements can help to make the duration of table locks shorter.
![]() You could change the locking code in
You could change the locking code in mysys/thr_lock.c to use a single queue. In this case, write locks and read locks would have the same priority, which might help some applications.
Here are some tips about table locking in MySQL:
![]() Concurrent users are not a problem if you don’t mix updates with selects that need to examine many rows in the same table.
Concurrent users are not a problem if you don’t mix updates with selects that need to examine many rows in the same table.
![]() You can use
You can use LOCK TABLES to speed up things (many updates within a single lock is much faster than updates without locks). Splitting table contents into separate tables may also help.
![]() If you encounter speed problems with table locks in MySQL, you may be able to improve performance by converting some of your tables to
If you encounter speed problems with table locks in MySQL, you may be able to improve performance by converting some of your tables to InnoDB or BDB tables. See Chapter 9, “The InnoDB Storage Engine.” See Section 8.4, “The BDB (BerkeleyDB) Storage Engine.”
MySQL keeps row data and index data in separate files. Many (almost all) other databases mix row and index data in the same table. We believe that the MySQL choice is better for a very wide range of modern systems.
Another way to store the row data is to keep the information for each column in a separate area (examples are SDBM and Focus). This will cause a performance hit for every query that accesses more than one column. Because this degenerates so quickly when more than one column is accessed, we believe that this model is not good for general-purpose databases.
The more common case is that the index and data are stored together (as in Oracle/Sybase, et al). In this case, you will find the row information at the leaf page of the index. The good thing with this layout is that it, in many cases, depending on how well the index is cached, saves a disk read. The bad things with this layout are:
![]() Table scanning is much slower because you have to read through the indexes to get at the data.
Table scanning is much slower because you have to read through the indexes to get at the data.
![]() You can’t use only the index table to retrieve data for a query.
You can’t use only the index table to retrieve data for a query.
![]() You lose a lot of space, because you must duplicate indexes from the nodes (because you can’t store the row in the nodes).
You lose a lot of space, because you must duplicate indexes from the nodes (because you can’t store the row in the nodes).
![]() Deletes will degenerate the table over time (because indexes in nodes are usually not updated on delete).
Deletes will degenerate the table over time (because indexes in nodes are usually not updated on delete).
![]() It’s harder to cache only the index data.
It’s harder to cache only the index data.
One of the most basic optimizations is to design your tables to take as little space on the disk as possible. This can give huge improvements because disk reads are faster, and smaller tables normally require less main memory while their contents are being actively processed during query execution. Indexing also is a lesser resource burden if done on smaller columns.
MySQL supports a lot of different table types and row formats. For each table, you can decide which storage/index method to use. Choosing the right table format for your application may give you a big performance gain. See Chapter 8, “MySQL Storage Engines and Table Types.”
You can get better performance on a table and minimize storage space using the techniques listed here:
![]() Use the most efficient (smallest) data types possible. MySQL has many specialized types that save disk space and memory.
Use the most efficient (smallest) data types possible. MySQL has many specialized types that save disk space and memory.
![]() Use the smaller integer types if possible to get smaller tables. For example,
Use the smaller integer types if possible to get smaller tables. For example, MEDIUMINT is often better than INT.
![]() Declare columns to be
Declare columns to be NOT NULL if possible. It makes everything faster and you save one bit per column. If you really need NULL in your application, you should definitely use it. Just avoid having it on all columns by default.
![]() For
For MyISAM tables, if you don’t have any variable-length columns (VARCHAR, TEXT, or BLOB columns), a fixed-size record format is used. This is faster but unfortunately may waste some space. See Section 8.1.3, “MyISAM Table Storage Formats.”
![]() The primary index of a table should be as short as possible. This makes identification of each row easy and efficient.
The primary index of a table should be as short as possible. This makes identification of each row easy and efficient.
![]() Create only the indexes that you really need. Indexes are good for retrieval but bad when you need to store things fast. If you mostly access a table by searching on a combination of columns, make an index on them. The first index part should be the most used column. If you are always using many columns, you should use the column with more duplicates first to get better compression of the index.
Create only the indexes that you really need. Indexes are good for retrieval but bad when you need to store things fast. If you mostly access a table by searching on a combination of columns, make an index on them. The first index part should be the most used column. If you are always using many columns, you should use the column with more duplicates first to get better compression of the index.
![]() If it’s very likely that a column has a unique prefix on the first number of characters, it’s better to index only this prefix. MySQL supports an index on the leftmost part of a character column. Shorter indexes are faster not only because they take less disk space, but also because they will give you more hits in the index cache and thus fewer disk seeks. See Section 6.5.2, “Tuning Server Parameters.”
If it’s very likely that a column has a unique prefix on the first number of characters, it’s better to index only this prefix. MySQL supports an index on the leftmost part of a character column. Shorter indexes are faster not only because they take less disk space, but also because they will give you more hits in the index cache and thus fewer disk seeks. See Section 6.5.2, “Tuning Server Parameters.”
![]() In some circumstances, it can be beneficial to split into two a table that is scanned very often. This is especially true if it is a dynamic format table and it is possible to use a smaller static format table that can be used to find the relevant rows when scanning the table.
In some circumstances, it can be beneficial to split into two a table that is scanned very often. This is especially true if it is a dynamic format table and it is possible to use a smaller static format table that can be used to find the relevant rows when scanning the table.
All MySQL column types can be indexed. Use of indexes on the relevant columns is the best way to improve the performance of SELECT operations.
The maximum number of indexes per table and the maximum index length is defined per storage engine. See Chapter 8, “MySQL Storage Engines and Table Types.” All storage engines support at least 16 indexes per table and a total index length of at least 256 bytes. Most storage engines have higher limits.
With col_name(length) syntax in an index specification, you can create an index that uses only the first length bytes of a CHAR or VARCHAR column. Indexing only a prefix of column values like this can make the index file much smaller.
The MyISAM and (as of MySQL 4.0.14) InnoDB storage engines also support indexing on BLOB and TEXT columns. When indexing a BLOB or TEXT column, you must specify a prefix length for the index. For example:
Prefixes can be up to 255 bytes long (or 1000 bytes for MyISAM and InnoDB tables as of MySQL 4.1.2). Note that prefix limits are measured in bytes, whereas the prefix length in CREATE TABLE statements is interpreted as number of characters. Take this into account when specifying a prefix length for a column that uses a multi-byte character set.
As of MySQL 3.23.23, you can also create FULLTEXT indexes. They are used for full-text searches. Only the MyISAM table type supports FULLTEXT indexes and only for CHAR, VARCHAR, and TEXT columns. Indexing always happens over the entire column and partial (prefix) indexing is not supported.
As of MySQL 4.1.0, you can create indexes on spatial column types. Currently, spatial types are supported only by the MyISAM storage engine. Spatial indexes use R-trees.
The MEMORY (HEAP) storage engine supports hash indexes. As of MySQL 4.1.0, the engine also supports B-tree indexes.
MySQL can create indexes on multiple columns. An index may consist of up to 15 columns. For certain column types, you can index a prefix of the column (see Section 6.4.3, “Column Indexes”).
A multiple-column index can be considered a sorted array containing values that are created by concatenating the values of the indexed columns.
MySQL uses multiple-column indexes in such a way that queries are fast when you specify a known quantity for the first column of the index in a WHERE clause, even if you don’t specify values for the other columns.
Suppose that a table has the following specification:
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name));
The name index is an index over last_name and first_name. The index can be used for queries that specify values in a known range for last_name, or for both last_name and first_name. Therefore, the name index will be used in the following queries:
SELECT * FROM test WHERE last_name='Widenius';
SELECT * FROM test
WHERE last_name='Widenius' AND first_name='Michael';
SELECT * FROM test
WHERE last_name='Widenius'
AND (first_name='Michael' OR first_name='Monty'),
SELECT * FROM test
WHERE last_name='Widenius'
AND first_name >='M' AND first_name < 'N';
However, the name index will not be used in the following queries:
SELECT * FROM test WHERE first_name='Michael';
SELECT * FROM test
WHERE last_name='Widenius' OR first_name='Michael';
The manner in which MySQL uses indexes to improve query performance is discussed further in the next section.
Indexes are used to find rows with specific column values fast. Without an index, MySQL has to start with the first record and then read through the whole table to find the relevant rows. The bigger the table, the more this costs. If the table has an index for the columns in question, MySQL can quickly determine the position to seek to in the middle of the data file without having to look at all the data. If a table has 1,000 rows, this is at least 100 times faster than reading sequentially. Note that if you need to access almost all 1,000 rows, it is faster to read sequentially, because that minimizes disk seeks.
Most MySQL indexes (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT) are stored in B-trees. Exceptions are that indexes on spatial column types use R-trees, and MEMORY (HEAP) tables support hash indexes.
Strings are automatically prefix- and end-space compressed.
In general, indexes are used as described in the following discussion. Characteristics specific to hash indexes (as used in MEMORY tables) are described at the end of this section.
![]() To quickly find the rows that match a
To quickly find the rows that match a WHERE clause.
![]() To eliminate rows from consideration. If there is a choice between multiple indexes, MySQL normally uses the index that finds the smallest number of rows.
To eliminate rows from consideration. If there is a choice between multiple indexes, MySQL normally uses the index that finds the smallest number of rows.
![]() To retrieve rows from other tables when performing joins.
To retrieve rows from other tables when performing joins.
![]() To find the
To find the MIN() or MAX() value for a specific indexed column key_col. This is optimized by a preprocessor that checks whether you are using WHERE key_part_# = constant on all key parts that occur before key_col in the index. In this case, MySQL will do a single key lookup for each MIN() or MAX() expression and replace it with a constant. If all expressions are replaced with constants, the query will return at once. For example:
SELECT MIN(key_part2),MAX(key_part2)
FROM tbl_name WHERE key_part1=10;
![]() To sort or group a table if the sorting or grouping is done on a leftmost prefix of a usable key (for example,
To sort or group a table if the sorting or grouping is done on a leftmost prefix of a usable key (for example, ORDER BY key_part1, key_part2). If all key parts are followed by DESC, the key is read in reverse order. See Section 6.2.9, “How MySQL Optimizes ORDER BY.”
![]() In some cases, a query can be optimized to retrieve values without consulting the data rows. If a query uses only columns from a table that are numeric and that form a leftmost prefix for some key, the selected values may be retrieved from the index tree for greater speed:
In some cases, a query can be optimized to retrieve values without consulting the data rows. If a query uses only columns from a table that are numeric and that form a leftmost prefix for some key, the selected values may be retrieved from the index tree for greater speed:
SELECT key_part3 FROM tbl_name WHERE key_part1=1
Suppose that you issue the following SELECT statement:
mysql> SELECT * FROM tbl_name WHERE col1= val1 AND col2 =val2;
If a multiple-column index exists on col1 and col2, the appropriate rows can be fetched directly. If separate single-column indexes exist on col1 and col2, the optimizer tries to find the most restrictive index by deciding which index will find fewer rows and using that index to fetch the rows.
If the table has a multiple-column index, any leftmost prefix of the index can be used by the optimizer to find rows. For example, if you have a three-column index on (col1, col2, col3), you have indexed search capabilities on (col1), (col1, col2), and (col1, col2, col3).
MySQL can’t use a partial index if the columns don’t form a leftmost prefix of the index. Suppose that you have the SELECT statements shown here:
SELECT * FROM tbl_name WHERE col1=val1;
SELECT * FROM tbl_name WHERE col2=val2;
SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;
If an index exists on (col1, col2, col3), only the first of the preceding queries uses the index. The second and third queries do involve indexed columns, but (col2) and (col2, col3) are not leftmost prefixes of (col1, col2, col3).
An index is used for columns that you compare with the =, >, >=, <, <=, or BETWEEN operators.
MySQL also uses indexes for LIKE comparisons if the argument to LIKE is a constant string that doesn’t start with a wildcard character. For example, the following SELECT statements use indexes:
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';
In the first statement, only rows with 'Patrick' <= key_col < 'Patricl' are considered. In the second statement, only rows with 'Pat' <= key_col < 'Pau' are considered.
The following SELECT statements will not use indexes:
SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE other_col;
In the first statement, the LIKE value begins with a wildcard character. In the second statement, the LIKE value is not a constant.
MySQL 4.0 and up performs an additional LIKE optimization. If you use ... LIKE '%string%' and string is longer than three characters, MySQL will use the Turbo Boyer-Moore algorithm to initialize the pattern for the string and then use this pattern to perform the search quicker.
Searching using col_name IS NULL will use indexes if col_name is indexed.
Any index that doesn’t span all AND levels in the WHERE clause is not used to optimize the query. In other words, to be able to use an index, a prefix of the index must be used in every AND group.
The following WHERE clauses use indexes:
... WHERE index_part1=1 AND index_part2=2 AND other_column=3
/* index = 1 OR index = 2 */
... WHERE index=1 OR A=10 AND index=2
/* optimized like "index_part1='hello'" */
... WHERE index_part1='hello' AND index_part3=5
/* Can use index on index1 but not on index2 or index3 */
... WHERE index1=1 AND index2=2 OR index1=3 AND index3=3;
These WHERE clauses do not use indexes:
/* index_part1 is not used */
... WHERE index_part2=1 AND index_part3=2
/* Index is not used in both AND parts */
... WHERE index=1 OR A=10
/* No index spans all rows */
... WHERE index_part1=1 OR index_part2=10
Sometimes MySQL will not use an index, even if one is available. One way this occurs is when the optimizer estimates that using the index would require MySQL to access a large percentage of the rows in the table. (In this case, a table scan is probably much faster, because it will require many fewer seeks.) However, if such a query uses LIMIT to only retrieve part of the rows, MySQL will use an index anyway, because it can much more quickly find the few rows to return in the result.
Hash indexes have somewhat different characteristics than those just discussed:
![]() They are used only for
They are used only for = or <=> comparisons (but are very fast).
![]() The optimizer cannot use a hash index to speed up
The optimizer cannot use a hash index to speed up ORDER BY operations. (This type of index cannot be used to search for the next entry in order.)
![]() MySQL cannot determine approximately how many rows there are between two values (this is used by the range optimizer to decide which index to use). This may affect some queries if you change a
MySQL cannot determine approximately how many rows there are between two values (this is used by the range optimizer to decide which index to use). This may affect some queries if you change a MyISAM table to a hash-indexed MEMORY table.
![]() Only whole keys can be used to search for a row. (With a B-tree index, any prefix of the key can be used to find rows.)
Only whole keys can be used to search for a row. (With a B-tree index, any prefix of the key can be used to find rows.)
To minimize disk I/O, the MyISAM storage engine employs a strategy that is used by many database management systems. It exploits a cache mechanism to keep the most frequently accessed table blocks in memory:
![]() For index blocks, a special structure called the key cache (key buffer) is maintained. The structure contains a number of block buffers where the most-used index blocks are placed.
For index blocks, a special structure called the key cache (key buffer) is maintained. The structure contains a number of block buffers where the most-used index blocks are placed.
![]() For data blocks, MySQL uses no special cache. Instead it relies on the native operating system filesystem cache.
For data blocks, MySQL uses no special cache. Instead it relies on the native operating system filesystem cache.
This section first describes the basic operation of the MyISAM key cache. Then it discusses changes made in MySQL 4.1 that improve key cache performance and that enable you to better control cache operation:
![]() Access to the key cache no longer is serialized among threads. Multiple threads can access the cache concurrently.
Access to the key cache no longer is serialized among threads. Multiple threads can access the cache concurrently.
![]() You can set up multiple key caches and assign table indexes to specific caches.
You can set up multiple key caches and assign table indexes to specific caches.
The key cache mechanism also is used for ISAM tables. However, the significance of this fact is on the wane. ISAM table use has been decreasing since MySQL 3.23 when MyISAM was introduced. MySQL 4.1 carries this trend further; the ISAM storage engine is disabled by default.
You can control the size of the key cache by means of the key_buffer_size system variable. If this variable is set equal to zero, no key cache is used. The key cache also is not used if the key_buffer_size value is too small to allocate the minimal number of block buffers (8).
When the key cache is not operational, index files are accessed using only the native filesystem buffering provided by the operating system. (In other words, table index blocks are accessed using the same strategy as that employed for table data blocks.)
An index block is a contiguous unit of access to the MyISAM index files. Usually the size of an index block is equal to the size of nodes of the index B-tree. (Indexes are represented on disk using a B-tree data structure. Nodes at the bottom of the tree are leaf nodes. Nodes above the leaf nodes are non-leaf nodes.)
All block buffers in a key cache structure are the same size. This size can be equal to, greater than, or less than the size of a table index block. Usually one of these two values is a multiple of the other.
When data from any table index block must be accessed, the server first checks whether it is available in some block buffer of the key cache. If it is, the server accesses data in the key cache rather than on disk. That is, it reads from the cache or writes into it rather than reading from or writing to disk. Otherwise, the server chooses a cache block buffer containing a different table index block (or blocks) and replaces the data there by a copy of required table index block. As soon as the new index block is in the cache, the index data can be accessed.
If it happens that a block selected for replacement has been modified, the block is considered “dirty.” In this case, before being replaced, its contents are flushed to the table index from which it came.
Usually the server follows an LRU (Least Recently Used) strategy: When choosing a block for replacement, it selects the least recently used index block. To be able to make such a choice easy, the key cache module maintains a special queue (LRU chain) of all used blocks. When a block is accessed, it is placed at the end of the queue. When blocks need to be replaced, blocks at the beginning of the queue are the least recently used and become the first candidates for eviction.
Prior to MySQL 4.1, access to the key cache is serialized: No two threads can access key cache buffers simultaneously. The server processes a request for an index block only after it has finished processing the previous request. As a result, a request for an index block not present in any key cache buffer blocks access by other threads while a buffer is being updated to contain the requested index block.
Starting from version 4.1.0, the server supports shared access to the key cache:
![]() A buffer that is not being updated can be accessed by multiple threads.
A buffer that is not being updated can be accessed by multiple threads.
![]() A buffer that is being updated causes threads that need to use it to wait until the update is complete.
A buffer that is being updated causes threads that need to use it to wait until the update is complete.
![]() Multiple threads can initiate requests that result in cache block replacements, as long as they do not interfere with each other (that is, as long as they need different index blocks, and thus cause different cache blocks to be replaced).
Multiple threads can initiate requests that result in cache block replacements, as long as they do not interfere with each other (that is, as long as they need different index blocks, and thus cause different cache blocks to be replaced).
Shared access to the key cache allows the server to improve throughput significantly.
Shared access to the key cache improves performance but does not eliminate contention among threads entirely. They still compete for control structures that manage access to the key cache buffers. To reduce key cache access contention further, MySQL 4.1.1 offers the feature of multiple key caches. This allows you to assign different table indexes to different key caches.
When there can be multiple key caches, the server must know which cache to use when processing queries for a given MyISAM table. By default, all MyISAM table indexes are cached in the default key cache. To assign table indexes to a specific key cache, use the CACHE INDEX statement.
For example, the following statement assigns indexes from the tables t1, t2, and t3 to the key cache named hot_cache:
mysql> CACHE INDEX t1, t2, t3 IN hot_cache;
+---------+--------------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------------+----------+----------+
| test.t1 | assign_to_keycache | status | OK |
| test.t2 | assign_to_keycache | status | OK |
| test.t3 | assign_to_keycache | status | OK |
+---------+--------------------+----------+----------+
Note: If the server has been built with the ISAM storage engine enabled, ISAM tables use the key cache mechanism. However, ISAM indexes use only the default key cache and cannot be reassigned to a different cache.
The key cache referred to in a CACHE INDEX statement can be created by setting its size with a SET GLOBAL parameter setting statement or by using server startup options. For example:
mysql> SET GLOBAL keycache1.key_buffer_size=128*1024;
To destroy a key cache, set its size to zero:
mysql> SET GLOBAL keycache1.key_buffer_size=0;
Key cache variables are structured system variables that have a name and components. For keycache1.key_buffer_size, keycache1 is the cache variable name and key_buffer_size is the cache component.
By default, table indexes are assigned to the main (default) key cache created at the server startup. When a key cache is destroyed, all indexes assigned to it are reassigned to the default key cache.
For a busy server, we recommend a strategy that uses three key caches:
![]() A hot key cache that takes up 20% of the space allocated for all key caches. This is used for tables that are heavily used for searches but that are not updated.
A hot key cache that takes up 20% of the space allocated for all key caches. This is used for tables that are heavily used for searches but that are not updated.
![]() A cold key cache that takes up 20% of the space allocated for all key caches. This is used for medium-sized intensively modified tables, such as temporary tables.
A cold key cache that takes up 20% of the space allocated for all key caches. This is used for medium-sized intensively modified tables, such as temporary tables.
![]() A warm key cache that takes up 60% of the key cache space. This is the default key cache, to be used by default for all other tables.
A warm key cache that takes up 60% of the key cache space. This is the default key cache, to be used by default for all other tables.
One reason the use of three key caches is beneficial is that access to one key cache structure does not block access to the others. Queries that access tables assigned to one cache do not compete with queries that access tables assigned to another cache. Performance gains occur for other reasons as well:
![]() The hot cache is used only for retrieval queries, so its contents are never modified. Consequently, whenever an index block needs to be pulled in from disk, the contents of the cache block chosen for replacement need not be flushed first.
The hot cache is used only for retrieval queries, so its contents are never modified. Consequently, whenever an index block needs to be pulled in from disk, the contents of the cache block chosen for replacement need not be flushed first.
![]() For an index assigned to the hot cache, if there are no queries requiring an index scan, there is a high probability that the index blocks corresponding to non-leaf nodes of the index B-tree will remain in the cache.
For an index assigned to the hot cache, if there are no queries requiring an index scan, there is a high probability that the index blocks corresponding to non-leaf nodes of the index B-tree will remain in the cache.
![]() An update operation most frequently executed for temporary tables is performed much faster when the updated node already is in the cache and need not be read in from disk first. If the size of the indexes of the temporary tables are comparable with the size of cold key cache, the probability is very high that the updated node already will be in the cache.
An update operation most frequently executed for temporary tables is performed much faster when the updated node already is in the cache and need not be read in from disk first. If the size of the indexes of the temporary tables are comparable with the size of cold key cache, the probability is very high that the updated node already will be in the cache.
By default, the key cache management system of MySQL 4.1 uses the LRU strategy for choosing key cache blocks to be evicted, but it also supports a more sophisticated method called the “midpoint insertion strategy.”
When using the midpoint insertion strategy, the LRU chain is divided into two parts: a hot sub-chain and a warm sub-chain. The division point between two parts is not fixed, but the key cache management system takes care that the warm part is not “too short,” always containing at least key_cache_division_limit percent of the key cache blocks. key_cache_division_limit is a component of structured key cache variables, so its value is a parameter that can be set per cache.
When an index block is read from a table into the key cache, it is placed at the end of the warm sub-chain. After a certain number of hits (accesses of the block), it is promoted to the hot sub-chain. At present, the number of hits required to promote a block (3) is the same for all index blocks. In the future, we will allow the hit count to depend on the B-tree level of the node corresponding to an index block: Fewer hits will be required for promotion of an index block if it contains a non-leaf node from the upper levels of the index B-tree than if it contains a leaf node.
A block promoted into the hot sub-chain is placed at the end of the chain. The block then circulates within this sub-chain. If the block stays at the beginning of the sub-chain for a long enough time, it is demoted to the warm chain. This time is determined by the value of the key_cache_age_threshold component of the key cache.
The threshold value prescribes that, for a key cache containing N blocks, the block at the beginning of the hot sub-chain not accessed within the last N*key_cache_age_threshold/100 hits is to be moved to the beginning of the warm sub-chain. It then becomes the first candidate for eviction, because blocks for replacement always are taken from the beginning of the warm sub-chain.
The midpoint insertion strategy allows you to keep more-valued blocks always in the cache. If you prefer to use the plain LRU strategy, leave the key_cache_division_limit value set to its default of 100.
The midpoint insertion strategy helps to improve performance when execution of a query that requires an index scan effectively pushes out of the cache all the index blocks corresponding to valuable high-level B-tree nodes. To avoid this, you must use a midpoint insertion strategy with the key_cache_division_limit set to much less than 100. Then valuable frequently hit nodes will be preserved in the hot sub-chain during an index scan operation as well.
If there are enough blocks in a key cache to hold blocks of an entire index, or at least the blocks corresponding to its non-leaf nodes, then it makes sense to preload the key cache with index blocks before starting to use it. Preloading allows you to put the table index blocks into a key cache buffer in the most efficient way: by reading the index blocks from disk sequentially.
Without preloading, the blocks still will be placed into the key cache as needed by queries. Although the blocks will stay in the cache, because there are enough buffers for all of them, they will be fetched from disk in a random order, not sequentially.
To preload an index into a cache, use the LOAD INDEX INTO CACHE statement. For example, the following statement preloads nodes (index blocks) of indexes of the tables t1 and t2:
mysql> LOAD INDEX INTO CACHE t1, t2 IGNORE LEAVES;
+---------+--------------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+---------+--------------+----------+----------+
| test.t1 | preload_keys | status | OK |
| test.t2 | preload_keys | status | OK |
+---------+--------------+----------+----------+
The IGNORE LEAVES modifier causes only blocks for the non-leaf nodes of the index to be preloaded. Thus, the statement shown preloads all index blocks from t1, but only blocks for the non-leaf nodes from t2.
If an index has been assigned to a key cache using a CACHE INDEX statement, preloading places index blocks into that cache. Otherwise, the index is loaded into the default key cache.
MySQL 4.1 introduces a new key_cache_block_size variable on a per-key cache basis. This variable specifies the size of the block buffers for a key cache. It is intended to allow tuning of the performance of I/O operations for index files.
The best performance for I/O operations is achieved when the size of read buffers is equal to the size of the native operating system I/O buffers. But setting the size of key nodes equal to the size of the I/O buffer does not always ensure the best overall performance. When reading the big leaf nodes, the server pulls in a lot of unnecessary data, effectively preventing reading other leaf nodes.
Currently, you cannot control the size of the index blocks in a table. This size is set by the server when the .MYI index file is created, depending on the size of the keys in the indexes present in the table definition. In most cases, it is set equal to the I/O buffer size. In the future, this will be changed and then key_cache_block_size variable will be fully employed.
A key cache can be restructured at any time by updating its parameter values. For example:
mysql> SET GLOBAL cold_cache.key_buffer_size=4*1024*1024;
If you assign to either the key_buffer_size or key_cache_block_size key cache component a value that differs from the component’s current value, the server destroys the cache’s old structure and creates a new one based on the new values. If the cache contains any dirty blocks, the server saves them to disk before destroying and re-creating the cache. Restructuring does not occur if you set other key cache parameters.
When restructuring a key cache, the server first flushes the contents of any dirty buffers to disk. After that, the cache contents become unavailable. However, restructuring does not block queries that need to use indexes assigned to the cache. Instead, the server directly accesses the table indexes using native filesystem caching. Filesystem caching is not as efficient as using a key cache, so although queries will execute, a slowdown can be anticipated. Once the cache has been restructured, it becomes available again for caching indexes assigned to it, and the use of filesystem caching for the indexes ceases.
When you execute a mysqladmin status command, you’ll see something like this:
Uptime: 426 Running threads: 1 Questions: 11082
Reloads: 1 Open tables: 12
The Open tables value of 12 can be somewhat puzzling if you have only six tables.
MySQL is multi-threaded, so there may be many clients issuing queries for a given table simultaneously. To minimize the problem with multiple client threads having different states on the same file, the table is opened independently by each concurrent thread. This takes some memory but normally increases performance. With MyISAM tables, one extra file descriptor is required for the data file for each client that has the table open. (By contrast, the index file descriptor is shared between all threads.) The ISAM storage engine shares this behavior.
You can read more about this topic in the next section. See Section 6.4.8, “How MySQL Opens and Closes Tables.”
The table_cache, max_connections, and max_tmp_tables system variables affect the maximum number of files the server keeps open. If you increase one or more of these values, you may run up against a limit imposed by your operating system on the per-process number of open file descriptors. Many operating systems allow you to increase the open-files limit, although the method varies widely from system to system. Consult your operating system documentation to determine whether it is possible to increase the limit and how to do so.
table_cache is related to max_connections. For example, for 200 concurrent running connections, you should have a table cache size of at least 200 * N, where N is the maximum number of tables in a join. You also need to reserve some extra file descriptors for temporary tables and files.
Make sure that your operating system can handle the number of open file descriptors implied by the table_cache setting. If table_cache is set too high, MySQL may run out of file descriptors and refuse connections, fail to perform queries, and be very unreliable. You also have to take into account that the MyISAM storage engine needs two file descriptors for each unique open table. You can increase the number of file descriptors available for MySQL with the --open-files-limit startup option to mysqld_safe. See Section A.2.17, “File Not Found.”
The cache of open tables will be kept at a level of table_cache entries. The default value is 64; this can be changed with the --table_cache option to mysqld. Note that MySQL may temporarily open even more tables to be able to execute queries.
An unused table is closed and removed from the table cache under the following circumstances:
![]() When the cache is full and a thread tries to open a table that is not in the cache.
When the cache is full and a thread tries to open a table that is not in the cache.
![]() When the cache contains more than
When the cache contains more than table_cache entries and a thread is no longer using a table.
![]() When a table flushing operation occurs. This happens when someone issues a
When a table flushing operation occurs. This happens when someone issues a FLUSH TABLES statement or executes a mysqladmin flush-tables or mysqladmin refresh command.
When the table cache fills up, the server uses the following procedure to locate a cache entry to use:
![]() Tables that are not currently in use are released, in least recently used order.
Tables that are not currently in use are released, in least recently used order.
![]() If a new table needs to be opened, but the cache is full and no tables can be released, the cache is temporarily extended as necessary.
If a new table needs to be opened, but the cache is full and no tables can be released, the cache is temporarily extended as necessary.
When the cache is in a temporarily extended state and a table goes from a used to unused state, the table is closed and released from the cache.
A table is opened for each concurrent access. This means the table needs to be opened twice if two threads access the same table or if a thread accesses the table twice in the same query (for example, by joining the table to itself). Each concurrent open requires an entry in the table cache. The first open of any table takes two file descriptors: one for the data file and one for the index file. Each additional use of the table takes only one file descriptor, for the data file. The index file descriptor is shared among all threads.
If you are opening a table with the HANDLER tbl_name OPEN statement, a dedicated table object is allocated for the thread. This table object is not shared by other threads and is not closed until the thread calls HANDLER tbl_name CLOSE or the thread terminates. When this happens, the table is put back in the table cache (if the cache isn’t full).
You can determine whether your table cache is too small by checking the mysqld status variable Opened_tables:
mysql> SHOW STATUS LIKE 'Opened_tables';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Opened_tables | 2741 |
+---------------+-------+
If the value is quite big, even when you haven’t issued a lot of FLUSH TABLES statements, you should increase your table cache size. See Section 4.2.3, “Server System Variables,” and Section 4.2.4, “Server Status Variables.”
If you have many MyISAM or ISAM tables in a database directory, open, close, and create operations will be slow. If you execute SELECT statements on many different tables, there will be a little overhead when the table cache is full, because for every table that has to be opened, another must be closed. You can reduce this overhead by making the table cache larger.
We start with system-level factors, because some of these decisions must be made very early to achieve large performance gains. In other cases, a quick look at this section may suffice. However, it is always nice to have a sense of how much can be gained by changing things at this level.
The default operating system to use is very important! To get the best use of multiple-CPU machines, you should use Solaris (because its threads implementation works really well) or Linux (because the 2.2 kernel has really good SMP support). Note that older Linux kernels have a 2GB filesize limit by default. If you have such a kernel and a desperate need for files larger than 2GB, you should get the Large File Support (LFS) patch for the ext2 filesystem. Other filesystems such as ReiserFS and XFS do not have this 2GB limitation.
Before using MySQL in production, we advise you to test it on your intended platform.
Other tips:
![]() If you have enough RAM, you could remove all swap devices. Some operating systems will use a swap device in some contexts even if you have free memory.
If you have enough RAM, you could remove all swap devices. Some operating systems will use a swap device in some contexts even if you have free memory.
![]() Use the
Use the --skip-external-locking MySQL option to avoid external locking. This option is on by default as of MySQL 4.0. Before that, it is on by default when compiling with MIT-pthreads, because flock() isn’t fully supported by MIT-pthreads on all platforms. It’s also on by default for Linux because Linux file locking is not yet safe.
Note that the --skip-external-locking option will not affect MySQL’s functionality as long as you run only one server. Just remember to take down the server (or lock and flush the relevant tables) before you run myisamchk. On some systems this option is mandatory, because the external locking does not work in any case.
The only case when you can’t use --skip-external-locking is if you run multiple MySQL servers (not clients) on the same data, or if you run myisamchk to check (not repair) a table without telling the server to flush and lock the tables first.
You can still use LOCK TABLES/UNLOCK TABLES even if you are using --skip-external-locking.
You can determine the default buffer sizes used by the mysqld server with this command (prior to MySQL 4.1, omit --verbose):
shell> mysqld --verbose --help
This command produces a list of all mysqld options and configurable system variables. The output includes the default variable values and looks something like this:
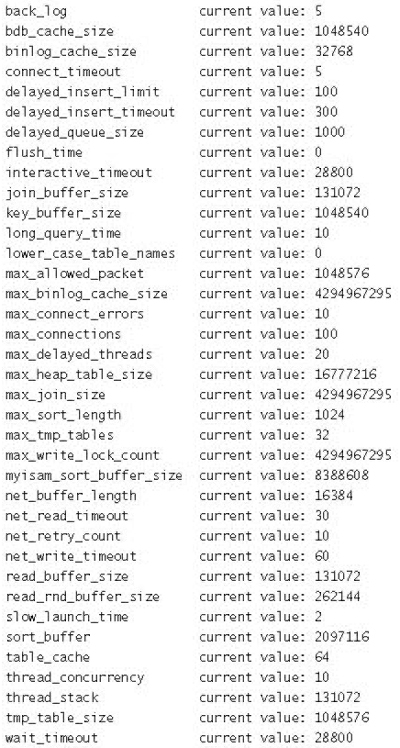
If there is a mysqld server currently running, you can see what values it actually is using for the system variables by connecting to it and issuing this statement:
mysql> SHOW VARIABLES;
You can also see some statistical and status indicators for a running server by issuing this statement:
mysql> SHOW STATUS;
System variable and status information also can be obtained using mysqladmin:
shell> mysqladmin variables
shell> mysqladmin extended-status
You can find a full description for all system and status variables in Section 4.2.3, “Server System Variables,” and Section 4.2.4, “Server Status Variables.”
MySQL uses algorithms that are very scalable, so you can usually run with very little memory. However, normally you will get better performance by giving MySQL more memory.
When tuning a MySQL server, the two most important variables to configure are key_buffer_size and table_cache. You should first feel confident that you have these set appropriately before trying to change any other variables.
The following examples indicate some typical variable values for different runtime configurations. The examples use the mysqld_safe script and use --var_name=value syntax to set the variable var_name to the value value. This syntax is available as of MySQL 4.0. For older versions of MySQL, take the following differences into account:
![]() Use
Use safe_mysqld rather than mysqld_safe.
![]() Set variables using
Set variables using --set-variable=var_name=value or -O var_name=value syntax.
![]() For variable names that end in
For variable names that end in _size, you may need to specify them without _size. For example, the old name for sort_buffer_size is sort_buffer. The old name for read_buffer_size is record_buffer. To see which variables your version of the server recognizes, use mysqld --help.
If you have at least 256MB of memory and many tables and want maximum performance with a moderate number of clients, you should use something like this:
shell> mysqld_safe --key_buffer_size=64M --table_cache=256
--sort_buffer_size=4M --read_buffer_size=1M &
If you have only 128MB of memory and only a few tables, but you still do a lot of sorting, you can use something like this:
shell> mysqld_safe --key_buffer_size=16M --sort_buffer_size=1M
If there are very many simultaneous connections, swapping problems may occur unless mysqld has been configured to use very little memory for each connection. mysqld performs better if you have enough memory for all connections.
With little memory and lots of connections, use something like this:
shell> mysqld_safe --key_buffer_size=512K --sort_buffer_size=100K
--read_buffer_size=100K &
Or even this:
shell> mysqld_safe --key_buffer_size=512K --sort_buffer_size=16K
--table_cache=32 --read_buffer_size=8K
--net_buffer_length=1K &
If you are doing GROUP BY or ORDER BY operations on tables that are much larger than your available memory, you should increase the value of read_rnd_buffer_size to speed up the reading of rows after sorting operations.
When you have installed MySQL, the support-files directory will contain some different my.cnf sample files: my-huge.cnf, my-large.cnf, my-medium.cnf, and my-small.cnf. You can use these as a basis for optimizing your system.
Note that if you specify an option on the command line for mysqld or mysqld_safe, it remains in effect only for that invocation of the server. To use the option every time the server runs, put it in an option file.
To see the effects of a parameter change, do something like this (prior to MySQL 4.1, omit --verbose):
shell> mysqld --key_buffer_size=32M --verbose --help
The variable values are listed near the end of the output. Make sure that the --verbose and --help options are last. Otherwise, the effect of any options listed after them on the command line will not be reflected in the output.
For information on tuning the InnoDB storage engine, see Section 9.12, “InnoDB Performance Tuning Tips.”
Most of the following tests were performed on Linux with the MySQL benchmarks, but they should give some indication for other operating systems and workloads.
You get the fastest executables when you link with -static.
On Linux, you will get the fastest code when compiling with pgcc and -O3. You need about 200MB memory to compile sql_yacc.cc with these options, because gcc/pgcc needs a lot of memory to make all functions inline. You should also set CXX=gcc when configuring MySQL to avoid inclusion of the libstdc++ library, which is not needed. Note that with some versions of pgcc, the resulting code will run only on true Pentium processors, even if you use the compiler option indicating that you want the resulting code to work on all x586-type processors (such as AMD).
By just using a better compiler and better compiler options, you can get a 10-30% speed increase in your application. This is particularly important if you compile the MySQL server yourself.
We have tested both the Cygnus CodeFusion and Fujitsu compilers, but when we tested them, neither was sufficiently bug-free to allow MySQL to be compiled with optimizations enabled.
The standard MySQL binary distributions are compiled with support for all character sets. When you compile MySQL yourself, you should include support only for the character sets that you are going to use. This is controlled by the --with-charset option to configure.
Here is a list of some measurements that we have made:
![]() If you use
If you use pgcc and compile everything with -O6, the mysqld server is 1% faster than with gcc 2.95.2.
![]() If you link dynamically (without
If you link dynamically (without -static), the result is 13% slower on Linux. Note that you still can use a dynamically linked MySQL library for your client applications. It is the server that is most critical for performance.
![]() If you strip your
If you strip your mysqld binary with strip mysqld, the resulting binary can be up to 4% faster.
![]() For a connection from a client to a server running on the same host, if you connect using TCP/IP rather than a Unix socket file, performance is 7.5% slower. (On Unix, if you connect to the hostname
For a connection from a client to a server running on the same host, if you connect using TCP/IP rather than a Unix socket file, performance is 7.5% slower. (On Unix, if you connect to the hostname localhost, MySQL uses a socket file by default.)
![]() For TCP/IP connections from a client to a server, connecting to a remote server on another host will be 8-11% slower than connecting to the local server on the same host, even for connections over 100Mb/s Ethernet.
For TCP/IP connections from a client to a server, connecting to a remote server on another host will be 8-11% slower than connecting to the local server on the same host, even for connections over 100Mb/s Ethernet.
![]() When running our benchmark tests using secure connections (all data encrypted with internal SSL support) performance was 55% slower than for unencrypted connections.
When running our benchmark tests using secure connections (all data encrypted with internal SSL support) performance was 55% slower than for unencrypted connections.
![]() If you compile with
If you compile with --with-debug=full, most queries will be 20% slower. Some queries may take substantially longer; for example, the MySQL benchmarks ran 35% slower. If you use --with-debug (without =full), the slowdown will be only 15%. For a version of mysqld that has been compiled with --with-debug=full, you can disable memory checking at runtime by starting it with the --skip-safemalloc option. The end result in this case should be close to that obtained when configuring with --with-debug.
![]() On a Sun UltraSPARC-IIe, a server compiled with Forte 5.0 is 4% faster than one compiled with
On a Sun UltraSPARC-IIe, a server compiled with Forte 5.0 is 4% faster than one compiled with gcc 3.2.
![]() On a Sun UltraSPARC-IIe, a server compiled with Forte 5.0 is 4% faster in 32-bit mode than in 64-bit mode.
On a Sun UltraSPARC-IIe, a server compiled with Forte 5.0 is 4% faster in 32-bit mode than in 64-bit mode.
![]() Compiling with
Compiling with gcc 2.95.2 for UltraSPARC with the -mcpu=v8 -Wa,-xarch=v8plusa options gives 4% more performance.
![]() On Solaris 2.5.1, MIT-pthreads is 8-12% slower than Solaris native threads on a single processor. With more load or CPUs, the difference should be larger.
On Solaris 2.5.1, MIT-pthreads is 8-12% slower than Solaris native threads on a single processor. With more load or CPUs, the difference should be larger.
![]() Compiling on Linux-x86 using
Compiling on Linux-x86 using gcc without frame pointers (-fomit-frame-pointer or -fomit-frame-pointer -ffixed-ebp) makes mysqld 1-4% faster.
Binary MySQL distributions for Linux that are provided by MySQL AB used to be compiled with pgcc. We had to go back to regular gcc due to a bug in pgcc that would generate code that does not run on AMD. We will continue using gcc until that bug is resolved. In the meantime, if you have a non-AMD machine, you can get a faster binary by compiling with pgcc. The standard MySQL Linux binary is linked statically to make it faster and more portable.
The following list indicates some of the ways that the mysqld server uses memory. Where applicable, the name of the system variable relevant to the memory use is given:
![]() The key buffer (variable
The key buffer (variable key_buffer_size) is shared by all threads; other buffers used by the server are allocated as needed. See Section 6.5.2, “Tuning Server Parameters.”
![]() Each connection uses some thread-specific space:
Each connection uses some thread-specific space:
![]() A stack (default 64KB, variable
A stack (default 64KB, variable thread_stack)
![]() A connection buffer (variable
A connection buffer (variable net_buffer_length)
![]() A result buffer (variable
A result buffer (variable net_buffer_length)
The connection buffer and result buffer are dynamically enlarged up to max_allowed_packet when needed. While a query is running, a copy of the current query string is also allocated.
![]() All threads share the same base memory.
All threads share the same base memory.
![]() Only compressed
Only compressed ISAM and MyISAM tables are memory mapped. This is because the 32-bit memory space of 4GB is not large enough for most big tables. When systems with a 64-bit address space become more common, we may add general support for memory mapping.
![]() Each request that performs a sequential scan of a table allocates a read buffer (variable
Each request that performs a sequential scan of a table allocates a read buffer (variable read_buffer_size).
![]() When reading rows in “random” order (for example, after a sort), a random-read buffer may be allocated to avoid disk seeks. (variable
When reading rows in “random” order (for example, after a sort), a random-read buffer may be allocated to avoid disk seeks. (variable read_rnd_buffer_size).
![]() All joins are done in one pass, and most joins can be done without even using a temporary table. Most temporary tables are memory-based (
All joins are done in one pass, and most joins can be done without even using a temporary table. Most temporary tables are memory-based (HEAP) tables. Temporary tables with a large record length (calculated as the sum of all column lengths) or that contain BLOB columns are stored on disk.
One problem before MySQL 3.23.2 is that if an internal in-memory heap table exceeds the size of tmp_table_size, the error The table tbl_name is full occurs. From 3.23.2 on, this is handled automatically by changing the in-memory heap table to a disk-based MyISAM table as necessary. To work around this problem for older servers, you can increase the temporary table size by setting the tmp_table_size option to mysqld, or by setting the SQL option SQL_BIG_TABLES in the client program.
In MySQL 3.20, the maximum size of the temporary table is record_buffer*16; if you are using this version, you have to increase the value of record_buffer. You can also start mysqld with the --big-tables option to always store temporary tables on disk. However, this will affect the speed of many complicated queries.
![]() Most requests that perform a sort allocate a sort buffer and zero to two temporary files depending on the result set size. See Section A.4.4, “Where MySQL Stores Temporary Files.”
Most requests that perform a sort allocate a sort buffer and zero to two temporary files depending on the result set size. See Section A.4.4, “Where MySQL Stores Temporary Files.”
![]() Almost all parsing and calculating is done in a local memory store. No memory overhead is needed for small items, so the normal slow memory allocation and freeing is avoided. Memory is allocated only for unexpectedly large strings; this is done with
Almost all parsing and calculating is done in a local memory store. No memory overhead is needed for small items, so the normal slow memory allocation and freeing is avoided. Memory is allocated only for unexpectedly large strings; this is done with malloc() and free().
![]() For each
For each MyISAM and ISAM table that is opened, the index file is opened once and the data file is opened once for each concurrently running thread. For each concurrent thread, a table structure, column structures for each column, and a buffer of size 3 * N are allocated (where N is the maximum row length, not counting BLOB columns). A BLOB column requires five to eight bytes plus the length of the BLOB data. The MyISAM and ISAM storage engines maintain one extra row buffer for internal use.
![]() For each table having
For each table having BLOB columns, a buffer is enlarged dynamically to read in larger BLOB values. If you scan a table, a buffer as large as the largest BLOB value is allocated.
![]() Handler structures for all in-use tables are saved in a cache and managed as a FIFO. By default, the cache has 64 entries. If a table has been used by two running threads at the same time, the cache contains two entries for the table. See Section 6.4.8, “How MySQL Opens and Closes Tables.”
Handler structures for all in-use tables are saved in a cache and managed as a FIFO. By default, the cache has 64 entries. If a table has been used by two running threads at the same time, the cache contains two entries for the table. See Section 6.4.8, “How MySQL Opens and Closes Tables.”
![]() A
A FLUSH TABLES statement or mysqladmin flush-tables command closes all tables that are not in use and marks all in-use tables to be closed when the currently executing thread finishes. This effectively frees most in-use memory.
ps and other system status programs may report that mysqld uses a lot of memory. This may be caused by thread stacks on different memory addresses. For example, the Solaris version of ps counts the unused memory between stacks as used memory. You can verify this by checking available swap with swap -s. We have tested mysqld with several memory-leakage detectors (both commercial and open source), so there should be no memory leaks.
When a new client connects to mysqld, mysqld spawns a new thread to handle the request. This thread first checks whether the hostname is in the hostname cache. If not, the thread attempts to resolve the hostname:
![]() If the operating system supports the thread-safe
If the operating system supports the thread-safe gethostbyaddr_r() and gethostbyname_r() calls, the thread uses them to perform hostname resolution.
![]() If the operating system doesn’t support the thread-safe calls, the thread locks a mutex and calls
If the operating system doesn’t support the thread-safe calls, the thread locks a mutex and calls gethostbyaddr() and gethostbyname() instead. In this case, no other thread can resolve hostnames that are not in the hostname cache until the first thread unlocks the mutex.
You can disable DNS hostname lookups by starting mysqld with the --skip-name-resolve option. However, in this case, you can use only IP numbers in the MySQL grant tables.
If you have a very slow DNS and many hosts, you can get more performance by either disabling DNS lookups with --skip-name-resolve or by increasing the HOST_CACHE_SIZE define (default value: 128) and recompiling mysqld.
You can disable the hostname cache by starting the server with the --skip-host-cache option. To clear the hostname cache, issue a FLUSH HOSTS statement or execute the mysqladmin flush-hosts command.
If you want to disallow TCP/IP connections entirely, start mysqld with the --skip-networking option.
![]() Disk seeks are a big performance bottleneck. This problem becomes more apparent when the amount of data starts to grow so large that effective caching becomes impossible. For large databases where you access data more or less randomly, you can be sure that you will need at least one disk seek to read and a couple of disk seeks to write things. To minimize this problem, use disks with low seek times.
Disk seeks are a big performance bottleneck. This problem becomes more apparent when the amount of data starts to grow so large that effective caching becomes impossible. For large databases where you access data more or less randomly, you can be sure that you will need at least one disk seek to read and a couple of disk seeks to write things. To minimize this problem, use disks with low seek times.
![]() Increase the number of available disk spindles (and thereby reduce the seek overhead) by either symlinking files to different disks or striping the disks:
Increase the number of available disk spindles (and thereby reduce the seek overhead) by either symlinking files to different disks or striping the disks:
![]() Using symbolic links
Using symbolic links
This means that, for MyISAM tables, you symlink the index file and/or data file from their usual location in the data directory to another disk (that may also be striped). This makes both the seek and read times better, assuming that the disk is not used for other purposes as well. See Section 6.6.1, “Using Symbolic Links.”
![]() Striping
Striping
Striping means that you have many disks and put the first block on the first disk, the second block on the second disk, and the Nth block on the (N mod number_of_disks) disk, and so on. This means if your normal data size is less than the stripe size (or perfectly aligned), you will get much better performance. Striping is very dependent on the operating system and the stripe size, so benchmark your application with different stripe sizes. See Section 6.1.5, “Using Your Own Benchmarks.”
The speed difference for striping is very dependent on the parameters. Depending on how you set the striping parameters and number of disks, you may get differences measured in orders of magnitude. You have to choose to optimize for random or sequential access.
![]() For reliability you may want to use RAID 0+1 (striping plus mirroring), but in this case, you will need 2*
For reliability you may want to use RAID 0+1 (striping plus mirroring), but in this case, you will need 2*N drives to hold N drives of data. This is probably the best option if you have the money for it! However, you may also have to invest in some volume-management software to handle it efficiently.
![]() A good option is to vary the RAID level according to how critical a type of data is. For example, store semi-important data that can be regenerated on a RAID 0 disk, but store really important data such as host information and logs on a RAID 0+1 or RAID
A good option is to vary the RAID level according to how critical a type of data is. For example, store semi-important data that can be regenerated on a RAID 0 disk, but store really important data such as host information and logs on a RAID 0+1 or RAID N disk. RAID N can be a problem if you have many writes, due to the time required to update the parity bits.
![]() On Linux, you can get much more performance by using
On Linux, you can get much more performance by using hdparm to configure your disk’s interface. (Up to 100% under load is not uncommon.) The following hdparm options should be quite good for MySQL, and probably for many other applications:
hdparm -m 16 -d 1
Note that performance and reliability when using this command depends on your hardware, so we strongly suggest that you test your system thoroughly after using hdparm. Please consult the hdparm man page for more information. If hdparm is not used wisely, filesystem corruption may result, so back up everything before experimenting!
![]() You can also set the parameters for the filesystem that the database uses:
You can also set the parameters for the filesystem that the database uses:
If you don’t need to know when files were last accessed (which is not really useful on a database server), you can mount your filesystems with the -o noatime option. That skips updates to the last access time in inodes on the filesystem, which avoids some disk seeks.
On many operating systems, you can set a filesystem to be updated asynchronously by mounting it with the -o async option. If your computer is reasonably stable, this should give you more performance without sacrificing too much reliability. (This flag is on by default on Linux.)
You can move tables and databases from the database directory to other locations and replace them with symbolic links to the new locations. You might want to do this, for example, to move a database to a file system with more free space or increase the speed of your system by spreading your tables to a different disk.
The recommended way to do this is to just symlink databases to a different disk. Symlink tables only as a last resort.
On Unix, the way to symlink a database is to first create a directory on some disk where you have free space and then create a symlink to it from the MySQL data directory.
shell> mkdir /dr1/databases/test
shell> ln -s /dr1/databases/test /path/to/datadir
MySQL doesn’t support linking one directory to multiple databases. Replacing a database directory with a symbolic link will work fine as long as you don’t make a symbolic link between databases. Suppose that you have a database db1 under the MySQL data directory, and then make a symlink db2 that points to db1:
shell> cd /path/to/datadir
shell> ln -s db1 db2
Now, for any table tbl_a in db1, there also appears to be a table tbl_a in db2. If one client updates db1.tbl_a and another client updates db2.tbl_a, there will be problems.
If you really need to do this, you can change one of the source files. The file to modify depends on your version of MySQL. For MySQL 4.0 and up, look for the following statement in the mysys/my_symlink.c file:
if (!(MyFlags & MY_RESOLVE_LINK) ||
(!lstat(filename,&stat_buff) && S_ISLNK(stat_buff.st_mode)))
Before MySQL 4.0, look for this statement in the mysys/mf_format.c file:
if (flag & 32 || (!lstat(to,&stat_buff) && S_ISLNK(stat_buff.st_mode)))
Change the statement to this:
if (1)
On Windows, you can use internal symbolic links to directories by compiling MySQL with -DUSE_SYMDIR. This allows you to put different databases on different disks. See Section 6.6.1.3, “Using Symbolic Links for Databases on Windows.”
Before MySQL 4.0, you should not symlink tables unless you are very careful with them. The problem is that if you run ALTER TABLE, REPAIR TABLE, or OPTIMIZE TABLE on a symlinked table, the symlinks will be removed and replaced by the original files. This happens because these statements work by creating a temporary file in the database directory and replacing the original file with the temporary file when the statement operation is complete.
You should not symlink tables on systems that don’t have a fully working realpath() call. (At least Linux and Solaris support realpath()). You can check whether your system supports symbolic links by issuing a SHOW VARIABLES LIKE 'have_symlink' statement.
In MySQL 4.0, symlinks are fully supported only for MyISAM tables. For other table types, you will probably get strange problems if you try to use symbolic links on files in the operating system with any of the preceding statements.
The handling of symbolic links for MyISAM tables in MySQL 4.0 works the following way:
![]() In the data directory, you will always have the table definition file, the data file, and the index file. The data file and index file can be moved elsewhere and replaced in the data directory by symlinks. The definition file cannot.
In the data directory, you will always have the table definition file, the data file, and the index file. The data file and index file can be moved elsewhere and replaced in the data directory by symlinks. The definition file cannot.
![]() You can symlink the data file and the index file independently to different directories.
You can symlink the data file and the index file independently to different directories.
![]() The symlinking can be done manually from the command line with
The symlinking can be done manually from the command line with ln -s if mysqld is not running. With SQL, you can instruct the server to perform the symlinking by using the DATA DIRECTORY and INDEX DIRECTORY options to CREATE TABLE.
![]()
myisamchk will not replace a symlink with the data file or index file. It works directly on the file a symlink points to. Any temporary files are created in the directory where the data file or index file is located.
![]() When you drop a table that is using symlinks, both the symlink and the file the symlink points to are dropped. This is a good reason why you should not run
When you drop a table that is using symlinks, both the symlink and the file the symlink points to are dropped. This is a good reason why you should not run mysqld as root or allow users to have write access to the MySQL database directories.
![]() If you rename a table with
If you rename a table with ALTER TABLE ... RENAME and you don’t move the table to another database, the symlinks in the database directory are renamed to the new names and the data file and index file are renamed accordingly.
![]() If you use
If you use ALTER TABLE ... RENAME to move a table to another database, the table is moved to the other database directory. The old symlinks and the files to which they pointed are deleted. In other words, the new table will not be symlinked.
![]() If you are not using symlinks, you should use the
If you are not using symlinks, you should use the --skip-symbolic-links option to mysqld to ensure that no one can use mysqld to drop or rename a file outside of the data directory.
SHOW CREATE TABLE doesn’t report if a table has symbolic links prior to MySQL 4.0.15. This is also true for mysqldump, which uses SHOW CREATE TABLE to generate CREATE TABLE statements.
Table symlink operations that are not yet supported:
![]()
ALTER TABLE ignores the DATA DIRECTORY and INDEX DIRECTORY table options.
![]()
BACKUP TABLE and RESTORE TABLE don’t respect symbolic links.
![]() The
The .frm file must never be a symbolic link (as indicated previously, only the data and index files can be symbolic links). Attempting to do this (for example, to make synonyms) will produce incorrect results. Suppose that you have a database db1 under the MySQL data directory, a table tbl1 in this database, and in the db1 directory you make a symlink tbl2 that points to tbl1:
shell> cd /path/to/datadir/db1
shell> ln -s tbl1.frm tbl2.frm
shell> ln -s tbl1.MYD tbl2.MYD
shell> ln -s tbl1.MYI tbl2.MYI
Now there will be problems if one thread reads db1.tbl1 and another thread updates db1.tbl2:
![]() The query cache will be fooled (it will believe
The query cache will be fooled (it will believe tbl1 has not been updated so will return out-of-date results).
![]()
ALTER statements on tbl2 will also fail.
Beginning with MySQL 3.23.16, the mysqld-max and mysql-max-nt servers for Windows are compiled with the -DUSE_SYMDIR option. This allows you to put a database directory on a different disk by setting up a symbolic link to it. This is similar to the way that symbolic links work on Unix, although the procedure for setting up the link is different.
As of MySQL 4.0, symbolic links are enabled by default. If you don’t need them, you can disable them with the skip-symbolic-links option:
[mysqld]
skip-symbolic-links
Before MySQL 4.0, symbolic links are disabled by default. To enable them, you should put the following entry in your my.cnf or my.ini file:
[mysqld]
symbolic-links
On Windows, you make a symbolic link to a MySQL database by creating a file in the data directory that contains the path to the destination directory. The file should be named db_name.sym, where db_name is the database name.
Suppose that the MySQL data directory is C:mysqldata and you want to have database foo located at D:datafoo. Set up a symlink like this:
1. Make sure that the D:datafoo directory exists by creating it if necessary. If you already have a database directory named foo in the data directory, you should move it to D:data. Otherwise, the symbolic link will be ineffective. To avoid problems, the server should not be running when you move the database directory.
2. Create a file C:mysqldatafoo.sym that contains the pathname D:datafoo.
After that, all tables created in the database foo will be created in D:datafoo. Note that the symbolic link will not be used if a directory with the database name exists in the MySQL data directory.