
For decades the Enterprise Data Warehouse has been the central repository for corporate data. It is an integral part of every organization’s business intelligence infrastructure.
Data warehouses come in various shapes and forms. For years, Microsoft and Oracle sold relational database management software for data warehouses on SMP (Symmetric Multiprocessing) systems. Others, such as Teradata, sell large integrated MPP (Massively Parallel Processing) systems. A cloud provider such as Microsoft offers a fully managed cloud data warehouse such as Azure SQL Data Warehouse. The Apache Hive project was developed to provide a data warehouse infrastructure built on top of Hadoop. i Whatever form or shape it takes, the data warehouse’s purpose remains the same – to provide a platform where structured data can be efficiently stored, processed, and analyzed.
In this chapter, I’ll discuss how big data (and more specifically Cloudera Enterprise) is disrupting data warehousing. I assume the readers are familiar with data warehousing so I won’t cover the basics and theory of data warehousing. For a definitive guide to data warehousing, consult Ralph Kimball’s The Data Warehouse Toolkit. ii
Note
I will be using terms “big data” and “Hadoop” interchangeably in this chapter (and throughout the book). Technically big data refers to a whole ecosystem of technologies and frameworks of which Hadoop is a part of. I will also use the terms “data lake,” “data hub,” and “big data platform” interchangeably throughout the book.
Enterprise Data Warehousing in the Era of Big Data
The era of big data has disrupted data warehousing as we know it. The pioneers of big data invented new methods in data processing and analysis that make traditional data warehousing seem outdated. The ability of big data platforms to process and analyze both structured and unstructured data as well as new techniques like ELT (extract, load, and transform), schema on read, data wrangling, and self-service data analysis exposed the limits of data warehousing, making traditional data modeling and ETL development life cycles look slow and rigid.
Big data platforms are generally more scalable than traditional data warehousing platforms from a cost and technical perspective. Generally, the largest data warehouses can only handle up to hundreds of terabytes of data, requiring significant hardware investment to scale beyond that. Big data platforms can easily process and analyze petabytes of data using low-cost commodity servers. Perhaps the most practical concern for most organizations is the financial burden of implementing and maintaining a commercial data warehouse. Companies spend millions of dollars in licensing, infrastructure, and development costs in order to have a fully functional enterprise data warehouse. Open source MPP Apache projects such as Impala, Drill, and Presto offer comparable performance and scalability at a fraction of the cost.
Structured Data Still Reigns Supreme
It’s not all doom and gloom for data warehousing, far from it. Despite all the hype around big data, a survey conducted by Dell showed that more than two-thirds of companies reported that structured data represents 75% of data being processed, with one-third of the companies reported not analyzing unstructured data at all. The survey also shows that structured data is growing at a faster rate than unstructured data. iii
EDW Modernization
Impala and Kudu vs. a Traditional Data Warehouse
Feature | Impala and Kudu | Data Warehouse Platform |
|---|---|---|
Multi-row and multi-table transactions | No | Yes |
Auto-increment column | No | Yes |
Foreign key constraint | No | Yes |
Secondary indexes | No | Yes |
Materialized views | No | Yes |
Triggers | No | Yes |
Stored procedures | No | Yes |
Database caching | No | Yes |
OLAP support | No | Yes |
Procedural extension to SQL | No | Yes |
Advanced backup and recovery | No | Yes |
Decimal and Complex Data Types | No | Yes |
Hadoop vendors usually market their platform as a “data hub” or “data lake” that can be used to augment or modernize data warehouses, instead of replacing it. In fact, most companies these days have both a data warehouse and a data lake. There are various ways a data lake can be used to modernize an enterprise data warehouse: ETL Offloading, Active Archive and Analytics Offloading, and Data Consolidation. These use cases are relatively easy to implement. The return on investment is also easy to measure and justify to management.
ETL Offloading
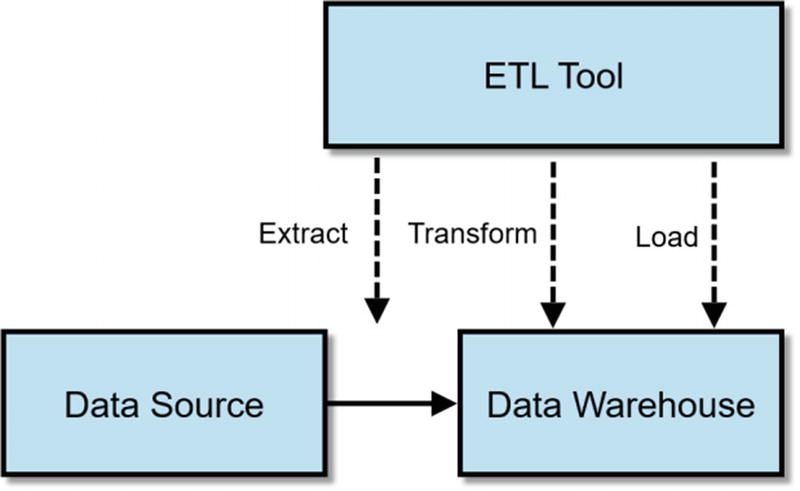
Traditional ETL
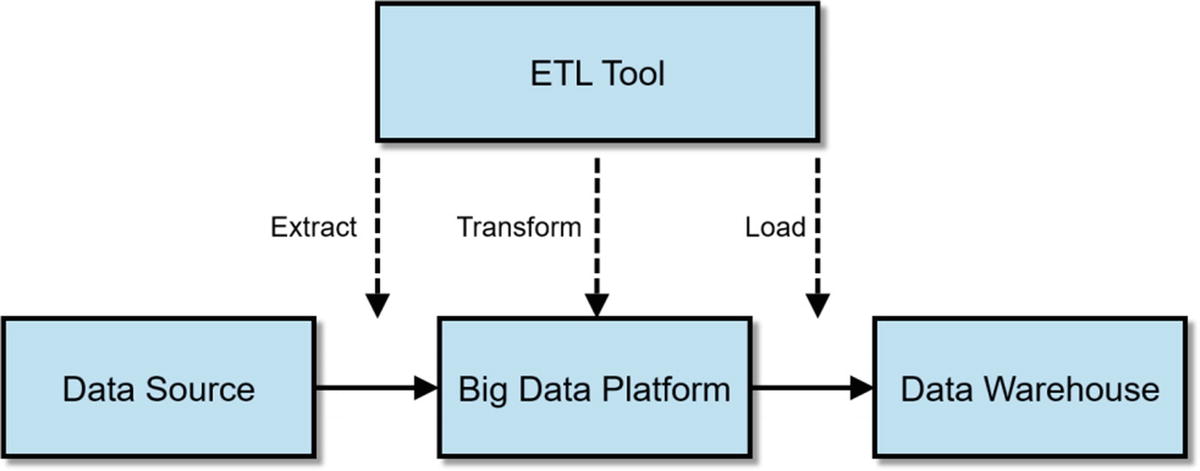
ETL Offloading with Big Data
Analytics Offloading and Active Archiving
You can also use your data lake to offload some of your expensive reports and ad hoc queries. By offloading some of your analytics, you free up your data warehouse for more important tasks. Analytics offloading also allows your data warehouse to handle more data and concurrent users while keeping a small data warehouse footprint – saving your organization millions in data warehouse upgrades.
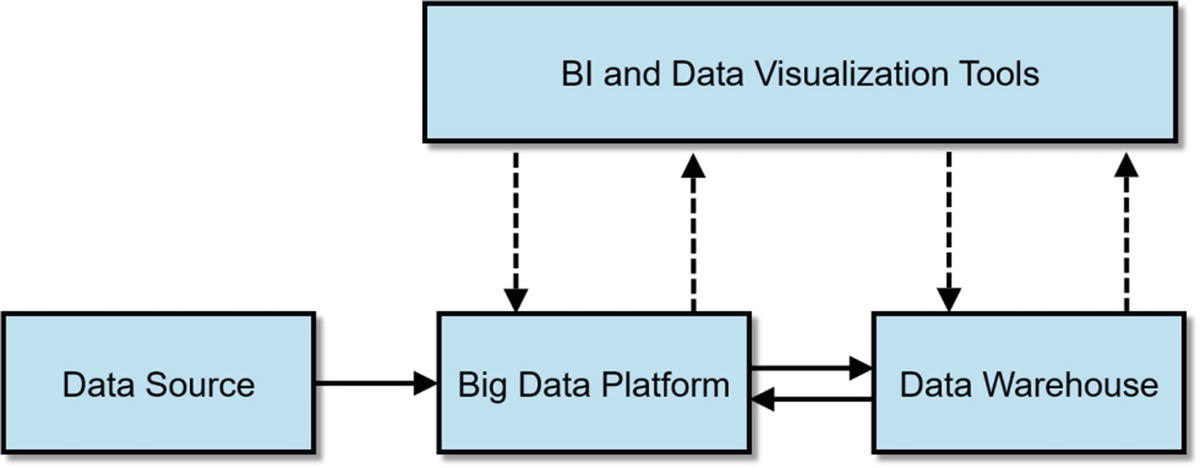
Some of the analytics are offloaded to the big data platform
Data Consolidation
One of Hadoop’s best features is its ability to store massive amounts of data. By combining storage from commodity hardware and providing distributed storage engines such as HDFS, HBase, and Kudu, Hadoop made storage and processing of large data sets not just possible but also practical. Unlike the data warehouse, which can only store structured data, data lakes can store and process structured and unstructured data sets, making it a true repository of corporate data.
Consolidating your data in a centralized data lake delivers several benefits. First, it enhances data analysis by making it easier to join and correlate data. Second, because your data is in one central location, it makes it easier for users to run SQL joins across various data sets providing, for example, a 360-degree view of your customer. Third, feature engineering – choosing and processing attributes and creating feature sets for your predictive models is also easier. Fourth, data governance and master data management becomes straightforward once data is consolidated in one central location, providing you with one golden copy of the data instead of having multiple copies of the same piece of data spread across multiple data silos.
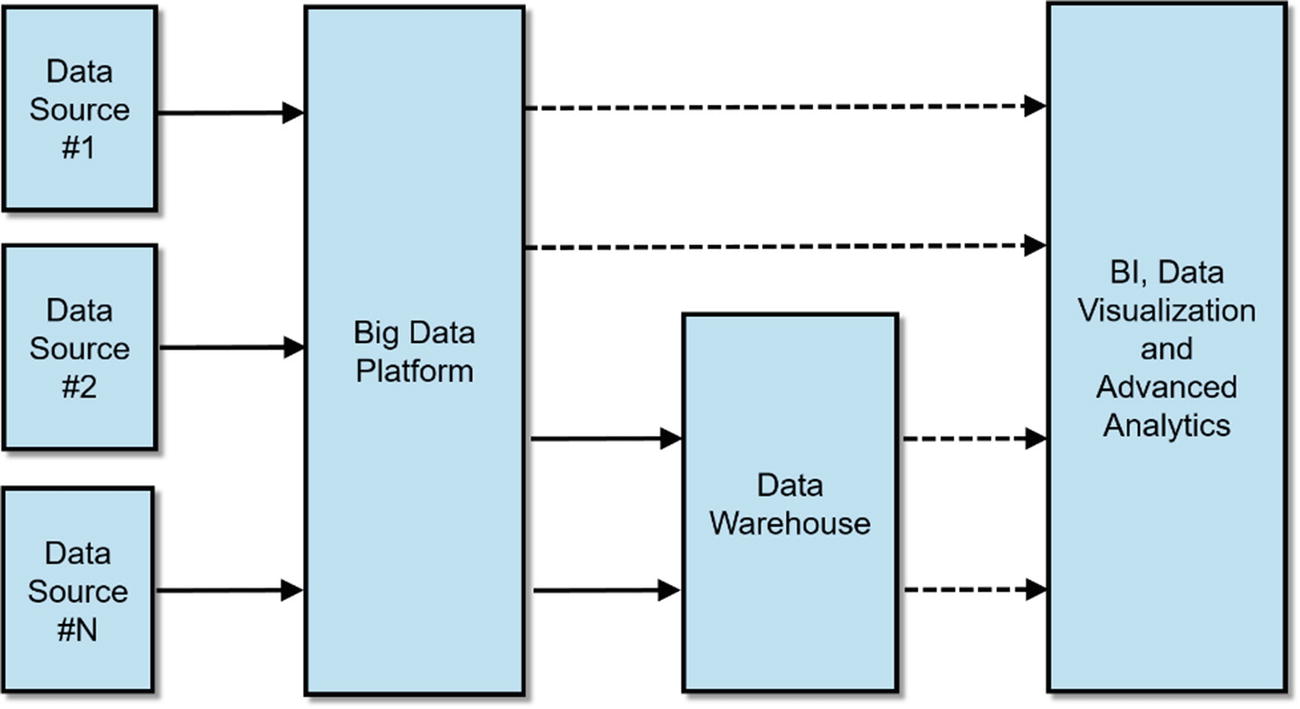
Consolidating data in a data lake or data hub
Replatforming the Enterprise Data Warehouse
This is probably the reason why you’re reading this book or chapter. It is technically possible to replace or replatform data warehouses with Cloudera Enterprise. Plenty of companies have successfully done it, and in the rest of the chapter we’ll discuss how to do it.
Note
A word of caution. Unless you have a really compelling reason, I suggest you think twice before you replatform your data warehouse with Cloudera Enterprise. There are a multitude of things to consider. You need to carefully evaluate your company’s data management and analytic needs. You also need to assess Cloudera Enterprise’s capabilities and weaknesses. Will your BI and OLAP tools work with Impala? Will you need to migrate thousands of ETL jobs? How hard is it to port PL/SQL or T-SQL to Impala SQL? These are just some of the questions you need to ask yourself before you go through the ordeal of migrating your data warehouse to Cloudera Enterprise.
Big Data Warehousing 101
We’ll use the AdventureWorksDW free sample database from Microsoft iv for our examples. You can download the database from Microsoft’s website if you want to follow our examples.
Dimensional Modeling
Dimensional modeling is a way of logically modeling database tables for ease of use and fast SQL query performance. Dimensional models serve as the logical basis for most business intelligence and OLAP systems in the market today. In fact, most data warehouse platforms are designed and optimized with dimensional modeling in mind. Dimensional modeling has several concepts:
Facts
A dimensional model has fact tables, which contains measures, or numerical values that represent a business metric such as sales or cost. A data warehouse will usually have several fact tables for different business processes. Before Kudu, Fact tables were usually stored in Parquet format for performance reasons.
Dimension Tables
Dimension tables contains attributes that describe or give context to the measures stored in the fact tables. Typical attributes are dates, locations, ages, religions, nationality, and gender to mention a few.
Star Schema
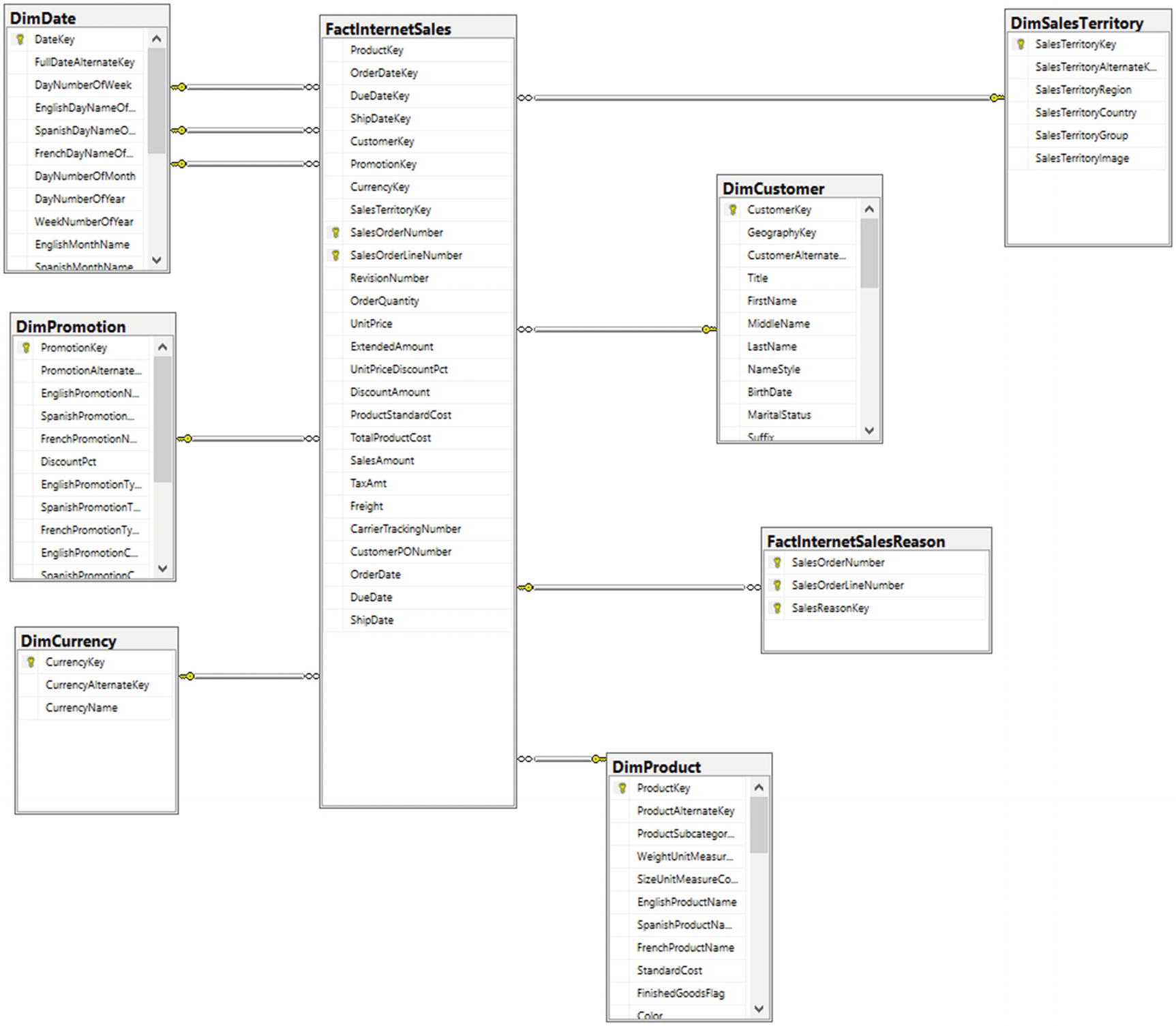
Star Schema
Snowflake Schema
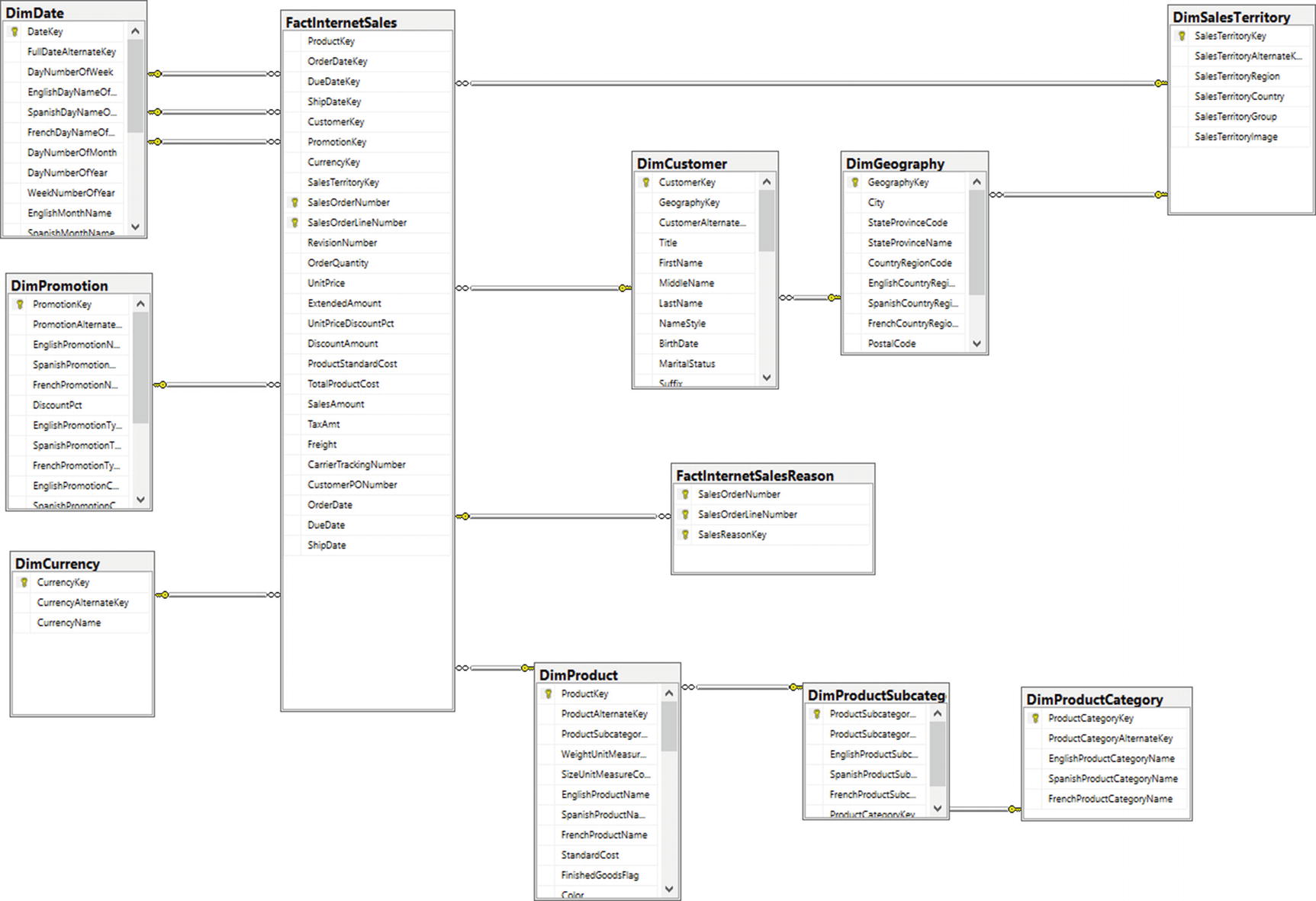
Snowflake Schema
Slowly Changing Dimensions
One of the biggest stumbling blocks for effectively using Hive or Impala for data warehousing was its inability to perform one simple thing – update a table. Columnar file formats such as Parquet stored in HDFS cannot be updated. This might come as a shock to people who have an RDBMS background. Users need to overwrite the whole table or partition in order to change values stored in the Parquet table. This limitation becomes a major headache when dealing with slowly changing dimensions. Before Kudu, the best way to handle slowly changing dimensions was to store dimension tables in HBase and then creating an external Hive table on top of the table to make it accessible from Impala. Impala doesn’t support the SQL update statement but because HBase supports versioning, updates can be imitated by executing insert statements using the same rowkey. vi
Big Data Warehousing with Impala and Kudu
For years, Hive was used to implement rudimentary data warehouses in Hadoop. It was painfully slow and unwieldy, but it was way easier to use than MapReduce and it got the job done so users tolerated it.
Years later Impala and other open source MPP engines appeared. Used together with columnar file formats such as Parquet, it paved the way for Hadoop in the Enterprise, enabling BI and OLAP tools to connect to Hadoop clusters and get fast performance. ETL and dimensional modeling with Impala and Parquet were still cumbersome, but the benefits outweighed the costs, so users endured using it.
Impala and Kudu just made it a whole lot easier to store, process, and analyze relational data on Cloudera Enterprise. While it still doesn’t have all of the advanced features of a commercial data warehouse platform, its capabilities are now close enough to a relational database.
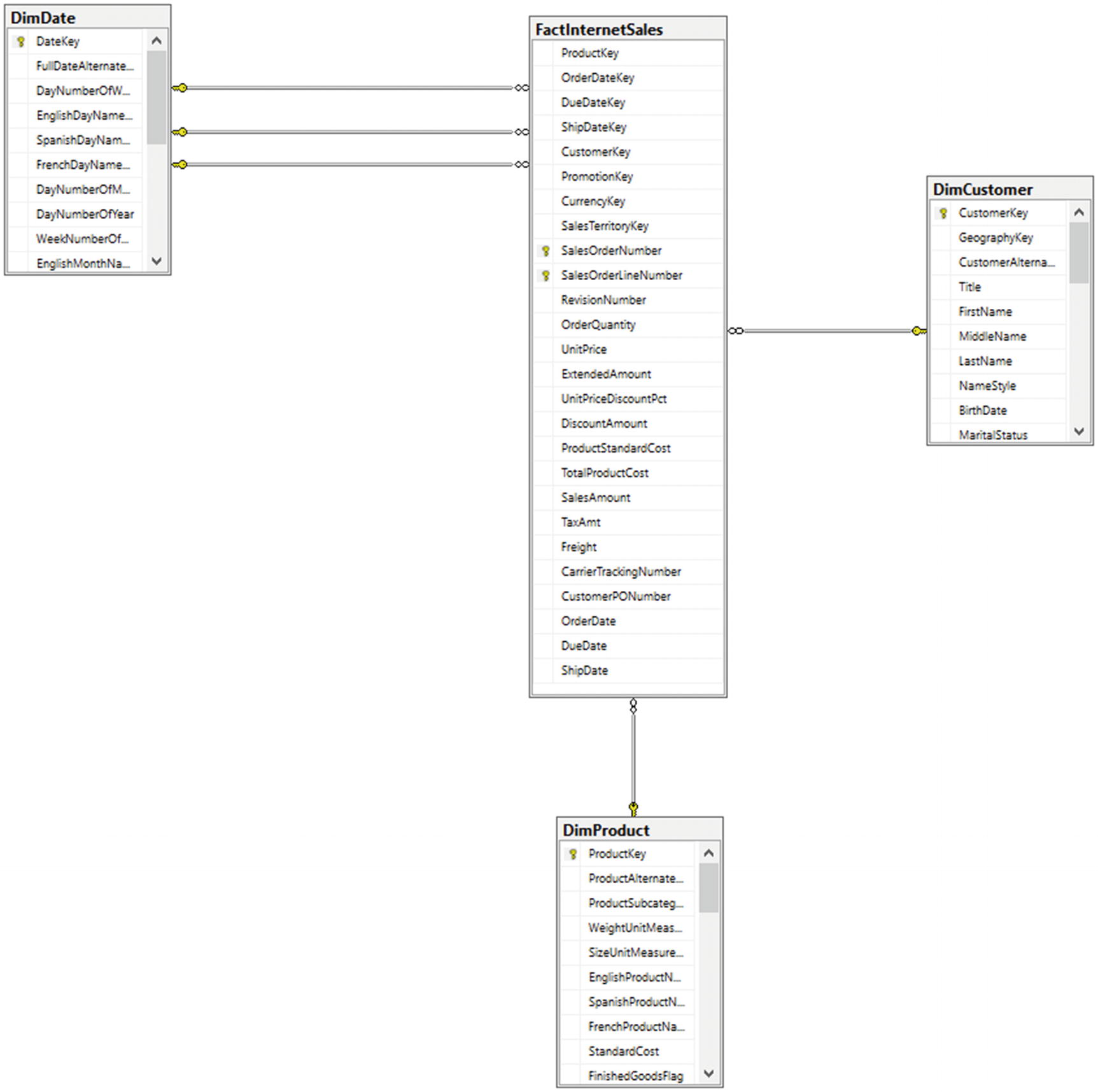
Example schema
Fact Internet Sales
DimCustomer
DimProduct
DimDate
I need to copy the tables from SQL Server to Impala. To do that, I manually generate a CSV file for each table. You can use any of the ETL tools we covered in Chapter 7. In this case, I used SQL Server’s data export and import tool to generate the CSV files. Don’t forget to exclude the column headers. I then move the files to HDFS and create an external table on top of each file. Listing 8-1 shows the steps.
Copy the tables from SQL Server to Impala
Now that the data is accessible from Impala, We can create the Kudu tables and populate it with the data from the external tables. The steps are shown in Listing 8-2.
Note
As discussed in Chapter 2, Kudu does not support multi-row and multi-table ACID-compliant transactions. An ETL job will continue to run successfully even if some rows are rejected due to primary key or constraint violations. Additional data validation must be performed after an ETL process to ensure data is in a consistent state. Also, consider denormalizing your tables to reduce the possibility of data inconsistencies in Kudu. vii
Build Kudu tables and populate it with data
There are a few important things to discuss here. Notice that I used the Impala built-in function uuid() to generate a unique ID for the fact and dimension tables. Impala and Kudu do not include an auto-increment feature, which is actually considered an anti-pattern on distributed environments. With Kudu, Spanner, and similar distributed systems, range partitioning on a column whose values are monotonically increasing will direct all inserts to be written to a single tablet at a time, causing the tablet to grow much larger than other tablets and limiting the scalability of inserts. This is also known as hot spotting. Hot spotting also happens in HBase when inserting rows with monotonically increasing row keys.
While using UUIDs as a primary key on a database running on a single SMP server is a disaster, in distributed MPP environments, hash partitioning using a unique key that is not derived from the business or data contained in the table will spread the workload across the nodes in your cluster. Hash partitioning protects from data and workload skew and increases scalability of data ingestion by enabling inserts to go to multiple tablets in parallel. viii
Some database systems such as Microsoft SQL Server have a native UUID data type that provide a more efficient storage for UUIDs. Kudu doesn’t have a UUID data type, therefore you have to use the STRING data type to store the UUID. The 36-character UUID does take up some space; however benchmarks indicate that having a 36-character primary key in Kudu doesn’t affect performance for most queries, although your experience may vary. If you are concerned about using UUIDs, then another option is to hash the UUID to generate a non-sequential BIGINT value to serve as your primary key. You can use Impala’s built-in hashing function fnv_hash() (which is not cryptographically secure, which means collision may occur when generating unique ID’s) or a more cryptographically secure hashing algorithm. Just make sure you test the performance of your insert statements. Calling built-in functions every insert statement may potentially cause performance bottlenecks. Of course, there are other ways to generate a non-sequential unique key.
As you can see, the fact table is hash and range partitioned. By combining the two partitioning strategies, we gain the benefit of both, while reducing the limitations of each. ix By using range partitioning on the date column, your query can take advantage of partition pruning when scanning by date ranges. In addition, new partitions can be added as new data is added to the table (which will result in 16 additional tablets). By using hash partitioning on the ID column (which is a non-sequential UUID), inserts are spread evenly across multiple tablets up to the number of hash partitions (which in our case is 16), increasing throughput and performance of data ingestion. Comparing this strategy with the current AdventureWorksDW schema, you will find a couple of differences. First off, FactInternetSales’ primary key is on SalesOrderNumber and SalesOrderLineNumber. This is adequate for an SQL Server database running on one server. However, this breaks several of the rules we’ve just discussed about partitioning and choosing primary key values on distributed systems. SalesOrderNumber is monotonically increasing, and the majority of SalesOrderLineNumber’s value is 1. If we use these two columns as our primary key, all inserts will be directed to one partition, causing data and workload skew and slowing down data ingestion.
Dimensions tables are usually small and mostly read-only. Slowly changing dimensions doesn’t usually require the kind of performance consideration as fact tables so we’ll just hash partition the dimension tables using a unique UUID as the primary key. Larger dimension tables may require a different partitioning strategy.
While Kudu requires all tables to have primary keys, it doesn’t have foreign key constraints. Therefore, data inconsistencies are possible in a Kudu data warehouse. However, it is common practice for data warehouses to have foreign key constraints disabled due to performance and manageability reasons. Listing 8-3 shows the structure of the Kudu tables we just created.
Structure of Kudu tables
Note
As mentioned earlier in this chapter, Kudu does not support the decimal data type. The float and double data types only store a very close approximation of the value instead of the exact value as defined in the IEEE 754 specification. x Because of this, behavior float and double are not appropriate for storing financial data. At the time of writing, support for decimal data type is still under development (Apache Kudu 1.5 / CDH 5.13). Refer to KUDU-721 for more details. A workaround is to store financial data as string then use Impala to cast the value to decimal every time you need to read the data. Since Parquet supports decimals, another workaround would be to use Parquet for your fact tables and Kudu for dimension tables.
We can now run Impala queries against our data warehouse in Kudu.
For example, here’s a query to get a top 20 list of everyone who earns more than $100,000 and are also home owners.
To get a list of everyone who bought a “Sport-100 Helmet” and also owns more than two cars.
Summary
Congratulations! You’ve just used Impala and Kudu for data warehousing! You can connect your favorite business intelligence, data visualization, and OLAP tools to Impala via JDBC/ODBC to create dashboards, reports, and OLAP cubes against the tables we just created. I refer you to Chapter 9 for more information on data visualization tools. You can use Spark to process and ingest massive amounts of data into Kudu. That is discussed in detail in Chapter 6. You can also use commercial third-party ETL applications such as StreamSets and Talend to load data into Kudu. That’s covered in Chapter 7. It looks like you have everything you need to build a data warehouse!
This chapter discussed several ways to take advantage of Impala and Kudu. You can modernize your data warehouse or replace it altogether. Just make sure that you have carefully evaluated its strengths and weaknesses, and whether it is the correct solution for your organization.
References
- i.
Hortonworks; “Data Warehousing with Apache Hive,” Hortonworks, 2018, https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.6.2/bk_data-access/content/ch_using-hive.html
- ii.
The Kimball Group; “The Data Warehouse Toolkit, 3rd Edition,” The Kimball Group, 2018, http://www.kimballgroup.com/data-warehouse-business-intelligence-resources/books/data-warehouse-dw-toolkit/
- iii.
Dell; “Dell Survey: Structured Data Remains Focal Point Despite Rapidly Changing Information Management Landscape,” Dell, 2018, http://www.dell.com/learn/us/en/uscorp1/press-releases/2015-04-15-dell-survey
- iv.
Microsoft; “AdventureWorks Databases and Scripts for SQL Server 2016 CTP3,” Microsoft, 2018, https://www.microsoft.com/en-us/download/details.aspx?id=49502
- v.
Oracle; “Star and Snowflake Schemas,” Oracle, 2018, http://www.oracle.com/webfolder/technetwork/tutorials/obe/db/10g/r2/owb/owb10gr2_gs/owb/lesson3/starandsnowflake.htm
- vi.
Cloudera; “Using Impala to Query HBase Tables,” Cloudera, 2018, https://www.cloudera.com/documentation/enterprise/latest/topics/impala_hbase.html
- vii.
Cloudera; “Using Impala to Query Kudu Tables,” Cloudera, 2018, https://www.cloudera.com/documentation/enterprise/5-12-x/topics/impala_kudu.html
- viii.
Apache Kudu; “Kudu: Frequently Asked Questions,” Apache Kudu, 2018, https://kudu.apache.org/faq.html
- ix.
Apache Kudu; “Hash and Range Partitioning Example,” Apache Kudu, 2018, https://kudu.apache.org/docs/schema_design.html#hash-range-partitioning-example
- x.
Microsoft; “Using decimal, float, and real Data,” Microsoft, 2018, https://technet.microsoft.com/en-us/library/ms187912(v=sql.105).aspx