
7
Software Deployment, Operations, Maintenance, and Disposal
7.1 Introduction
Once software has been formally accepted by the customer or client and is ready to be installed or released, the installation must be performed with security in mind. Just because software was designed and developed with security considerations, it does not necessarily mean that it will also be deployed with security controls in place. All of the software assurance efforts to design and build the software can be rendered useless if the deployment process does not take security into account. In fact, it has been observed that allowing the software to run with elevated privileges or turning off the monitoring and auditing functionality can adversely impact the overall security of the software.
Once software is deployed, it needs to be monitored to guarantee that the software will continue to function in a reliable, resilient, and recoverable manner as expected. Ongoing operations and maintenance include addressing incidents impacting the software and patching the software for malware threats.
Finally, there is a need to identify the software and conditions under which software needs to be disposed of or replaced, because insecure and improper disposal procedures can have serious security ramifications.
In this chapter, we will cover the security aspects that one needs to bear in mind when dealing with the last stage of the system/software development life cycle (SDLC), i.e., the deployment, operations, maintenance, and disposal of software.
7.2 Objectives
As a CSSLP, you are expected to
- Understand the importance of secure installation and deployment.
- Be familiar with secure startup or bootstrapping concepts.
- Know how to harden the software and hardware to assure trusted computing.
- Be familiar with configuration management concepts and how they can impact the security of the software.
- Understand the importance of continuous monitoring.
- Know how to manage security incidents.
- Understand the need to determine the root cause of problems that arise in software as part of problem management.
- Know what it means to patch software and how patching can impact the state of software security.
- Be aware of sunset criteria that must be used to determine and identify software to comply with end-of-life (EOL) policies.
This chapter will cover each of these objectives in detail. We will learn about security considerations that must be taken during installation and deployment, followed by a discussion of security processes, such as continuous monitoring, incident and problem management, and patching, to maintain operationally hack-resilient software. Finally we will learn about what it means to securely replace or remove old, unsupported, insecure software. It is imperative that you fully understand the objectives and be familiar with how to apply them to the software that your organization deploys or releases.
7.3 Installation and Deployment
When proper installation and deployment processes are not followed, there is a high likelihood that the software and the environment in which the software will operate can lack or have a reduced level of security. It is of prime importance to keep security in mind before and after software is installed. Without the necessary pre- and postinstallation software security considerations, expecting software to be operationally hack-resilient is a far-fetched objective.
Software needs to be configured so that security principles, such as least privilege, defense in depth, and separation of duties, are not violated or ignored during the installation or deployment phase. According to the Information Technology Infrastructure Library (ITIL), the goal of configuration management is to enable the control of the infrastructure by monitoring and maintaining information on all the resources that are necessary to deliver services.
Some of the necessary pre- and postinstallation configuration management security considerations include:
- Hardening (both software and hardware/minimum security baselines [MSBs])
- Enforcement of security principles
- Environment configuration
- Bootstrapping and secure startup
7.3.1 Hardening
Even before the software is installed into the production environment, the host hardware and operating system need to be hardened. Hardening includes the processes of locking down a system to the most restrictive level appropriate so that it is secure. These minimum (or most restrictive) security levels are usually published as a baseline with which all systems in the computing environment must comply. This baseline is commonly referred to as an MSB. An MSB is established to comply with the organizational security policies and help support the organization’s risk management efforts. Hardening is effective in its defense against vulnerabilities that result from insecure, incorrect, or default system configurations.
Not only is it important to harden the host operating system by using an MSB, it is also critically important to harden the applications and software that run on top of these operating systems. Hardening of software involves implementing the necessary and correct configuration settings and architecting the software to be secure by default. In this section, we will primarily learn about the security misconfigurations that can render software susceptible to attack. These misconfigurations can occur at any level of the software stack and lead anywhere from data disclosure to total system compromise.
Some of the common examples of security errors and/or misconfigurations include:
- Hard coding credentials and cryptographic keys in inline code or in configuration files in clear text.
- Not disabling the listing of directories and files in a Web server.
- Installation of software with default accounts and settings.
- Installation of the administrative console with default configuration settings.
- Installation or configuration of unneeded services, ports and protocols, unused pages, or unprotected files and directories.
- Missing software patches.
- Lack of perimeter and host defensive controls, such as firewalls and filters.
- Enabling tracing and debugging, as these can lead to attacks on confidentiality assurance. Trace information can contain security-sensitive data about the internal state of the server and workflow. When debugging is enabled, errors that occur on the server side can result in presenting all stack trace data to the client browser.
Although the hardening of host OS is usually accomplished by configuring the OS to an MSB and updating patches (patching is covered later in this chapter), hardening software is more code-centric and, in some cases, more complex, requiring additional effort. Examples of software hardening include:
- Removal of maintenance hooks before deployment.
- Removal of debugging code and flags in code.
- Modifying the instrumentation of code not to contain any sensitive information. In other words, removing unneeded comments (dangling code) or sensitive information from comments in code.
Hardening is a very important process in the installation phase of software development and must receive proper attention.
7.3.2 Enforcement of Security Principles
Preinstallation checklists are useful to ensure that the needed parameters required for the software to run are appropriately configured, but since it is not always possible to identify issues proactively, checklists provide no guarantee that the software will function without violating the security principles with which it was designed and built.
A common error is granting inappropriate administrative rights to the software during the installation process. This is a violation of least privilege. Enabling disabled services, ports, and protocols so that the software can be installed to run is an example of defense in depth violations. When operations personnel allow developers access to production systems to install software, this violates the principle of separation of duties. If one is lax about the security principles with which the software was designed and built during the installation phase, then one must not be surprised when that software gets hacked.
7.3.3 Environment Configuration
When software that worked without issues in the development or test environment no longer functions as expected in the production environment, it is indicative of a configuration management issue with the environments. Often this problem is dealt with in an insecure manner. The software is granted administrative privileges to run in a production environment upon installation, and this could have serious security ramifications. It is therefore imperative to ensure that the development and test environment match the configuration makeup of the production environment, and simulation testing identically emulates the settings (including the restrictive settings) of the environment in which the software will be deployed postacceptance. Additional configuration considerations include:
- Test and default accounts need to be turned off.
- Unnecessary and unused services need to be removed in all environments.
- Access rights need to be denied by default and granted explicitly even in development and test environments, just as they would be in the deployed production environment.
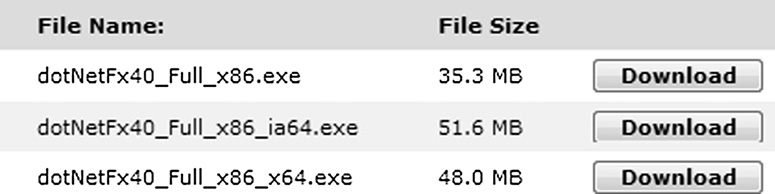
Configuration issues are also evident in disparate platforms or when platforms are changed. Software developed to run in one platform has been observed to face hiccups when the platform changes. The x86 to x64 processor architecture change has forced software development organizations to rethink the way they have been doing software development so that they can leverage the additional features in the newer platform. It has also mandated the need in these organizations to publish and support software in different versions so that it will function as expected in all supported platforms. Figure 7.1 shows an example of how the .Net Framework 4.0 software has to be published and supported for the x86, IA64, and x64 platforms.
Another environment consideration issue that is evident in software today is that bugs that were previously fixed reappear. In Chapter 4, we established that regenerative bugs can occur due to improper versioning or version management. It is also possible that regenerative bugs can result from improper configuration management. Say, for example, that during the user acceptance testing phase of the software development project, it was determined that there were some bugs that needed to be fixed. Proper configuration management would mandate that the fix happens in the development environment, which is then promoted to the test environment, where the fix is verified, and then promoted to the user acceptance testing environment, where the business can retest the functionality and ensure that the bug is fixed. But sometimes, the fix is made in the user acceptance testing environment and then deployed to the production environment upon acceptance. This is a configuration management issue as the correct process to address the fix is not followed or enforced. The fix is never back-ported to the development and test environments, and subsequent revisions of the software will yield in the reappearance of bugs that were previously fixed.
It is also important to ensure that the program database (pdb) file is not deployed into the production environment. The program database file holds debugging and project state information. It is used to link the debug configuration of the program incrementally, but an attacker can use it to discover the internal workings of the software using the debug information contained in the program database file.
To manage software configuration management properly, one of the first things is to document and maintain the configuration information in a formal and structured manner. Most organizations have what is called a configuration management database (CMDB) that records and consists of all the assets in the organization. The ISO/IEC 15408 (Common Criteria) requirements mandate that the implementation, documentation, tests, project-related documentation, and tools, including build tools, are maintained in a configuration management system (CMS). Changes to the security levels must be documented, and the MSB must be updated with the latest changes. Without proper software configuration management, managing software installations and releases/deployment is a very arduous undertaking and, more importantly, potentially insecure.
7.3.4 Bootstrapping and Secure Startup
Upon the installation of software, it is also important to make certain that the software startup processes do not in any way adversely impact the confidentiality, integrity, or availability of the software. When a host system is started, the sequences of events and processes that self-start the system to a preset state is referred to as booting or bootstrapping. Booting processes in general are also sometimes referred to as the initial program load (IPL). This includes the power-on self-test (POST), loading of the operating system, and turning on any of the needed services and settings for computing operations. The POST is the first step in an IPL and is an event that needs to be protected from tampering so that the trusted computing base (TCB) is maintained. The system’s basic input/output system (BIOS) has the potential to overwrite portions of memory when the system undergoes the booting process. To ensure that there is no information disclosure from the memory, the BIOS can perform what is known as a destructive memory check during POST, but this is a setting that can be configured in the system and can be overridden or disabled. It is also important to recognize that protecting access to the BIOS using the password option provided by most chip manufacturers is only an access management control, and it provides no integrity check as the secure startup process does.
Secure startup refers to all the processes and mechanisms that assure the environment’s TCB integrity when the system or software running on the system starts. It is usually implemented using the hardware’s trusted platform module (TPM) chip, which provides heightened tamperproof data protection during startup. The TPM chip can be used for storing cryptographic keys and providing identification information on mobile devices for authentication and access management. Physically, the TPM chip is located on the motherboard and is commonly used to create a unique system fingerprint within the boot process. The unique fingerprint remains unchanged unless the system has been tampered with. Therefore, the TPM fingerprint validation can be used to determine the integrity of the system’s bootstrapping process. Once the fingerprint is verified, the TPM can also be used for disk cryptographic functions, specifically disk decryption of secure startup volumes, before handing over control to the operating system. This protection alleviates some of the concerns around data protection in the event of physical theft.
Interruptions in the host bootstrapping processes can lead to the unavailability of the systems and other security consequences. Side channel attacks, such as the cold boot attack (covered in Chapter 4), have demonstrated that the system shutdown and bootstrapping processes can be circumvented, and sensitive information can be disclosed. The same is true when it comes to software bootstrapping. Software is often architected to request a set of self-start parameters that need to be available and/or loaded into memory when the program starts. The parameter can be supplied as input from the system, a user, the code when coded inline, or from global configuration files. Application_Start events are used in Web applications to provide software bootstrapping. Malicious software (malware) threat agents, such as spyware and rootkits, are known to interrupt the bootstrapping process and interject themselves as the program loads.
7.4 Operations and Maintenance
Once the software is installed, it is operated to provide services to the business or end users. Released software needs to be monitored and maintained. Software operations and maintenance need to take into account the assurance aspects of reliable, resilient, and recoverable processing. Since total security (100% security), signified by no risk, is utopian and unachievable, all software that is deployed has a level of residual risk that is usually below the acceptable threshold as defined by the business stakeholders, unless the risk has been formally accepted. Despite best efforts, software deployed can still have unknown security and privacy issues. Even in software where software assurance is known at release time, due to changes such as those in the threat landscape and computing technologies, the ability of the software to withstand new threats (resiliency) and attacks may not be sufficient. Furthermore, many designs and technologies that have been previously deemed secure are no longer considered to be secure, as is evident with banned cryptographic algorithms and banned APIs. The resiliency of software must always be above the acceptable risk level/threshold, as depicted in Figure 7.2. The point at which the software’s ability to withstand attacks falls below the acceptable threshold is the point when risk avoidance procedures, such as a version release, must be undertaken.
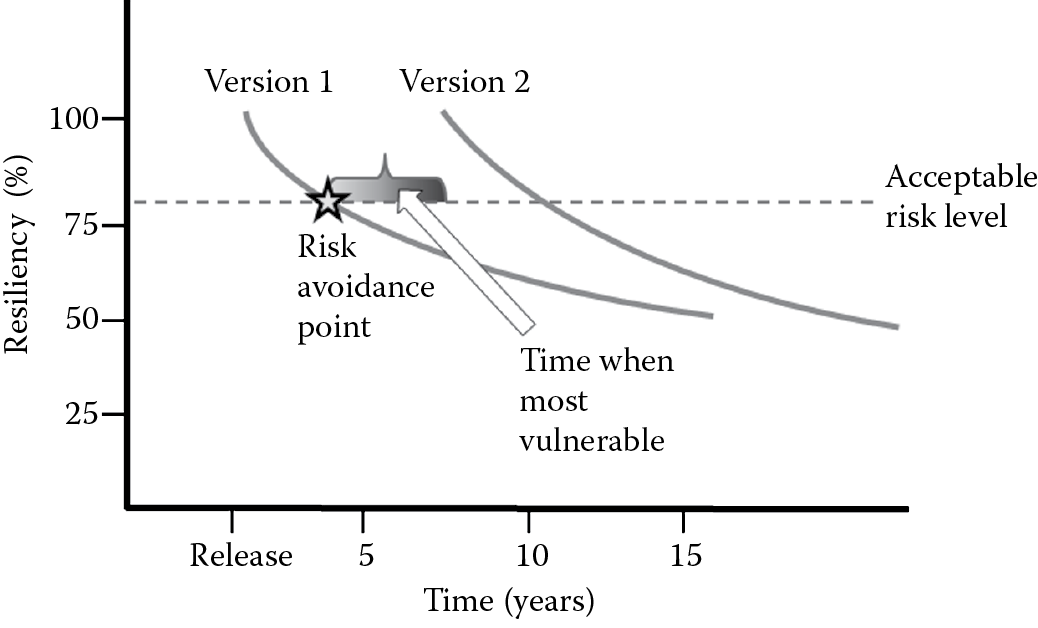
Continuing to operate without mitigating the risk in the current version and delaying the implementation of the next version defines the time when the software is most vulnerable to attack. This is where operations security comes into effect. Operations security is about staying secure or keeping the resiliency levels of the software above the acceptable risk levels. It is the assurance that the software will continue to function as expected, in a reliable fashion for the business, without compromising its state of security and includes monitoring, managing, and applying the needed controls to protect resources (assets).
These resources can be broadly grouped into hardware, software, media, and people. Examples of hardware resources include:
- Networking devices, such as switches, routers, and firewalls
- Communication devices, such as phones, fax, PDA, and VoIP devices
- Computing devices, such as servers, workstations, desktops, and laptops
Software resources are of the following type:
- In-house developed software
- External third party software
- Operating system software
- Data
All data need to be protected, whether they are transactional or stored in backups, archives, log files, and the like. Examples include an organization’s proprietary information, customer information, and supplier or vendor information.
Examples of media resources are USB, tapes, hard drives, and optical CD/DVDs. People resources are comprised of employees and nonemployees (e.g., contractors, consultants). The types of operational security controls are broadly classified as follows:
- Detective controls are those that can be used to build historical evidence of user and system/process actions. They are directly related to the reliability aspect of software assurance. If the software is not reliable, i.e., not functioning as expected, those anomalous operations must be tracked and reviewed. These controls are usually passive in nature. Auditing (logging) and intrusion detection systems (IDS) are some examples of detective software operations controls.
- Preventive controls are those that make the success of the attacker difficult, as their goal is to prevent the attack actively or proactively. They are directly related to the resiliency aspect of software assurance. They are useful to mitigate the impact of an attack while containing and limiting the consequences of a successful attack. Input validation, output encoding, bounds checking, patching, and intrusion prevention systems (IPS), are some examples of preventive software operations controls.
- Deterrent controls are those that do not necessarily prevent an attack nor are merely passive in nature. Their aim is to dissuade an attacker from continuing their attack. For example, auditing can be a deterrent control when the users of the software are aware of being audited. In such situations, auditing can be used to deter an attacker while also serving as a detective control to determine what happened where, when, and by whom.
- Corrective controls aim to provide the recoverability of software assurance. This means that when software fails, either due to accidental user error or due to being intentionally attacked, the software should have the necessary controls to bounce back into the normal operations state by use of corrective controls. Load balancing, clustering, and failover of data and systems are some examples of corrective software operations controls.
- Compensating controls are those controls that must be implemented when the prescribed software controls, as mandated by a security policy or requirement, cannot be met due to legitimate technical or documented business constraints. Compensating controls must sufficiently mitigate the risk associated with the security requirement. The Payment Card Industry Data Security Standard (PCI DSS) standard is a set of requirements for enhancing payment account data security. It prescribes that compensating controls must satisfy all of the following criteria:
- Meet the intent and rigor of the original requirement.
- Provide a similar level of defense as the original requirement.
- Be part of a defense in depth implementation so that other requirements are not adversely impacted.
- Be commensurate with additional risk imposed by not adhering to the requirement.
When compensating controls are considered, the requirements that will be addressed by the controls need to be identified, and the controls need to be defined, documented, validated, maintained, and assessed periodically for their effectiveness. Figure 7.3 shows an example of how the PCI DSS expects the documentation of compensating controls.

In addition to understanding the types of controls, a CSSLP must also be familiar with some of the ongoing control activities that are useful to ensure that the software stays secure. These include:
- Monitoring
- Incident management
- Problem management
- Patching and vulnerability management
In the following section, we will learn about each of these operations security activities in more detail. As a CSSLP, you are expected not only to be familiar with the concepts covered in this section, but also be able to function in an advisory role to the operations personnel who may or may not have a background in software development or ancillary disciplines that are related to software development.
7.4.1 Monitoring
The premise behind monitoring is that what is not monitored cannot be measured and what is not measured cannot be managed. One of the defender’s dilemmas is that the defender has the role of playing vigilante all the time whereas the attacker has the advantage of attacking at will, anytime. This is where continuous monitoring can be helpful. As part of security management activities pertinent to operations, continuous monitoring is critically important.
7.4.1.1 Why Monitor?
Monitoring can be used to:
- Validate compliance with regulations and other governance requirements.
- Demonstrate due diligence and due care on the part of the organization toward its stakeholders.
- Provide evidence for audit defense.
- Assist in forensics investigations by collecting and providing the requested evidence if tracked and audited.
- Determine that the security settings in the environment are not below the levels prescribed in the MSBs.
- Assure that the confidentiality, integrity, and availability aspects of software assurance are not impacted adversely.
- Detect insider and external threats that are orchestrated against the organization.
- Validate that the appropriate controls are in place and working effectively.
- Identify new threats, such as rogue devices and access points that are being introduced into the organization’s computing environment.
- Validate the overall state of security.
7.4.1.2 What to Monitor?
Monitoring can be performed on any system, software, or their processes. It is important first to determine the monitoring requirements before implementing a monitoring solution. Monitoring requirements need to be solicited from the business early on in the SDLC. Besides using the business stakeholders to glean monitoring requirements, governance requirements, such as internal and external regulatory policies, can be used. Along with the requirements, associated metrics that measure actual performance and operations should be identified and documented. When the monitoring requirements are known, the software development team has the added benefit of assisting with operations security, because they can architect and design their software either to provide information useful for monitoring themselves or leverage APIs of third party monitoring devices, such as IDS and IPS.
Any operations that can have a negative impact on the brand and reputation of the organization, such as when it does not function as expected, must be monitored. This could include any operations that can cause a disruption to the business (business continuity operations) and/or operations that are administrative, critical, and privileged in nature. Additionally, systems and software that operate in environments that are of low trust, such as in a demilitarized zone (DMZ), must be monitored.
Even physical access must be monitored, although it may seem like there is little or no significant overlap with software assurance. This is because software assurance deals with data security issues, and if physical devices that handle, transport, or store these data are left unmonitored, they can be susceptible to disclosure, alteration, and destruction attacks, resulting in serious security breaches. The PCI DSS, as one of its requirements, mandates that any physical access to cardholder data or systems that house cardholder data must be appropriately restricted and the restrictions periodically verified. Physical access monitoring using surveillance devices such as video cameras is recommended. The surveillance data that are collected must also be reviewed and correlated with the entry and exit of personnel into these restricted areas. This data must be stored for a minimum of 3 months, unless regulatory requirements warrant a higher archival period. The PCI DSS also requires that access is monitored and tracked regularly.
7.4.1.3 Ways to Monitor
The primary ways in which monitoring is accomplished within organizations today is by
- Scanning
- Logging
- Intrusion detection
Scanning to determine the makeup of the computing ecosystem and to detect newer threats in the environment is important. It is advisable that you familiarize yourself with the concepts pertinent to scanning that were covered in Chapter 5. Logging and tracking user activities are critical in preventing, detecting, and mitigating data compromise impacts. The National Computer Security Center (NCSC), in their publication, A Guide to Understanding Audits in Trusted Systems, prescribes the following reasons as the five core security objectives of audit mechanisms, such as logging and tracking user activities. It states that the audit mechanism should:
- Make it possible to review access patterns and histories and the presence and effectiveness of various protection mechanisms (security controls) supported by the system.
- Make it possible to discover insider and external threat agents and their activities that attempt to circumvent the security control in the system or software.
- Make it possible to discover the violations of the least privilege principle. When an elevation of privilege occurs (e.g., change from programmer to administrator role), the audit mechanisms in place should be able to detect and report on that change.
- Be able to act as a deterrent against potential threat agents. This requires that the attacker is made aware of the audit mechanisms in place.
- Be able to contain and mitigate the damage upon violation of the security policy, thereby providing additional user assurance.
IDS are used to monitor potential attacks and threats to which the organizational systems and software are subjected. As part of monitoring real threats that come into the network, it is not uncommon to see the deployment of bastion hosts in an IDS implementation. The name “bastion host” is said to be borrowed from medieval times when fortresses were built with bastions, or projections out of the wall, that allowed soldiers to congregate and shoot at the enemy. In computing, a bastion host is a fortified computer system completely exposed to external attack and illegal entry. It is deployed on the public side of the DMZ as depicted in Figure 7.4. It is not protected by a firewall or screened router. The deployment of bastion hosts must be carefully designed, as insecure design of these can lead to easy penetration by external threat agents into the internal network. The bastion hosts need to be hardened, and any unnecessary services, protocols, ports, programs, and services need to be disabled before deployment. Firewalls and routers themselves can be considered as bastion hosts, but other types of bastion hosts include DNS, Web servers, and mail servers.
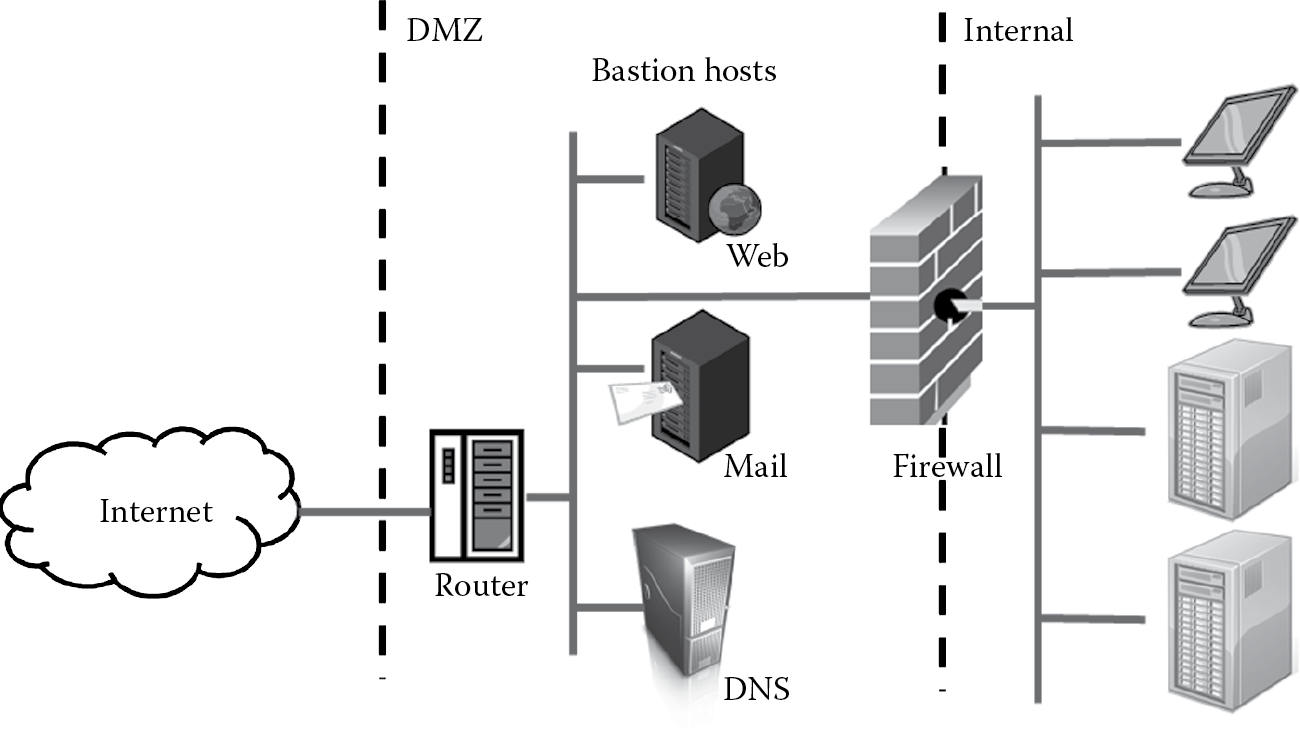
Bastion hosts can be used in both a deterrent as well as in a detecting manner. They provide some degree of protection against script kiddies and curious, nonserious attackers. It is important that the bastion hosts are configured to record (log) all security-related events, and that the logs themselves are protected from tampering. When bastion hosts have logging enabled, they can be used to find out the threats that are coming into the network. In such situations, they assist in detective functions. A bastion host can also function as a honeypot. A honeypot is a monitored computer system that acts as a decoy and has no production value in it. When bastion hosts function as honeypots, they are useful for several reasons, including:
- Distracting attackers away from valuable resources within the network. In this case, the bastion host is also a deflective control, because it deflects the threat agent away from valuable resources.
- Acting as warning systems.
- Conducting research on newer threats and attacker techniques.
A honeypot functions as an enticer because it lures an attacker who is looking forward to breaking into your network or software. Enticement is not necessarily illegal, and the evidence collected from these honeypots may or may not be admissible in a court of law. Entrapment, on the other hand, which is characterized by encouraging someone to commit a crime when they originally had no intentions of committing it, is illegal, and the evidence is not admissible in a court of law. This means that while bastion hosts must undoubtedly be monitored, it must be performed without active solicitation of someone to come and test the security of your network and using the evidence collected against them, should they break in.
7.4.1.4 Metrics in Monitoring
Two other important operations security concepts related to monitoring are metrics and audits. Metrics are measurement information. These must be identified beforehand and clearly defined. Monitoring can then be used to determine if the software is operating optimally and securely at the levels as defined in the metrics definition. The service level agreement (SLA) often contains these metrics, but metrics are not just limited to SLAs. An example of an availability metric would be the uptime and downtime metric. The acceptable number of errors and security weaknesses in the released version of the software is another metric that indicates the quality of the software. Metrics are not only useful in measuring the actual state of security, but can also be useful in making information decisions that can potentially improve the overall state of security.
Not so long ago, when regulations and compliance initiatives did not mandate secure software development, making the case to have organizations adopt secure software processes as part of their software development efforts was always a challenge. The motivators that were used to champion security initiatives in software development were fear, uncertainty, and doubt (FUD), but these were not very effective. Telling management that something disastrous (fear) could happen that could cause the organization great damage (doubt) anytime (uncertainty) was not often well received, and security teams earned the reputation of being naysayers and traffic cops, impeding business. Organizations that were willing to accept high levels of risk often ignored security in the SDLC, and those that were more paranoid sometimes ended up with overly excessive implementations of security in their SDLC. Metrics takes the FUD out of decision making and provides insight into the real state of security. Metrics also give the decision makers a quantitative and objective view of what their state of security is. Key performance indicators (KPIs) are metrics used by organizations to measure their progress toward their goals, and security metrics must be part of the organization’s KPI.
The quality of decisions made is directly proportional to the quality of metrics used in decision making. Good metrics help facilitate comprehensive secure decisions and bad metrics do not. So what makes a metric a good metric or a bad metric? Characteristics of good metrics include:
- Consistency: Consistency implies that, no matter how many times the metric is measured, each time the results from the same data sets must be the same or at least equivalent. There should be no significant deviation between each measurement.
- Quantitative: Good metrics are precise and expressed in terms of a cardinal number or as a percentage. A cardinal number is one that expresses the count of the items being measured, as opposed to an ordinal number, which expresses a thing’s position. “The number of injection flaws in the payroll application is 6” is an example of a metric expressed in terms of a cardinal number. “65% of the 30 application security vulnerabilities that were measured can be protected by input validation” is an example of a metric expressed as a percentage. Expressing the value as a cardinal number or percentage is more specific to the subset than expressing it in terms of a term such as “high,” “medium,” or “low.”
- Objectivity: Objectivity implies that, regardless of who is collecting the metric data, the results will be indicative of the real state of affairs. It should be that the numbers (metric information) tell the story, and not the other way around. Metrics that are not objective and depend on the subjective judgment of the person conducting the measurement are really not metrics at all, but a rating.
- Contextually Specific: Good metrics are usually expressed in more than one unit of measurement, and the different units provide the context of what is being measured. For example, it is better to measure “the number of injection flaws in the payroll application” or “the number of injection flaws per thousand lines of code (KLOC),” instead of simply measuring “the number of injection flaws in an application.” Contextually specific metrics makes it not only possible to make informed and applicable decisions, but it also allows for determining trending information. Determining the number of security defects in different versions of a particular application gives insight into whether the security of the application is increasing or decreasing and also provides the ability to compute the relative attack surface quotient (RASQ) between the versions.
- Inexpensive: Good metrics are usually collected using automated means that are generally less expensive than using manual means to collect the same information.
In contrast, the characteristics of bad metrics are the opposite of those of good metrics, as tabulated comparatively in Table 7.1.
Characteristics of Metrics
|
Attribute |
Good Metrics |
Bad Metrics |
|
Collection |
Consistent |
Inconsistent |
|
Expressed |
Quantitatively (cardinal or percentage) |
Qualitatively (ratings) |
|
Results |
Objective |
Subjective |
|
Relevance |
Contextually specific |
Contextually irrelevant |
|
Cost |
Inexpensive (automated) |
Expensive (manual) |
Although it is important to use good metrics, it is also important to recognize that not all bad metrics are useless. This is particularly true when qualitative and subjective measurements are used in conjunction with empirical measurements because comparative analysis may provide insight into conditions that may not be evident from just the cardinal numbers.
7.4.1.5 Audits for Monitoring
Audits are monitoring mechanisms by which an organization can ascertain the assurance aspects (reliability, resiliency, and recoverability) of the network, systems, and software that they have built or bought. It is an independent review and examination of system records and activities. An audit is conducted by an auditor, whose responsibilities include the selection of events to be audited on the system, setting up of the audit flags that enable the recording of those events, and analyzing the trail of audit events. Audits must be conducted periodically and can give insight into the presence and effectiveness of security and privacy controls. They are used to determine the organization’s compliance with the regulatory and governance (policy) requirements and report on violations of the security policies. In and of itself, the audit does not prevent any noncompliance, but it is detective in nature. Audits can be used to discover insider attacks and fraudulent activities. They are effective in determining the implementation and effectiveness of security principles, such as separation of duties and least privilege. Audits have now become mandatory for most organizations. They are controlled by regulatory requirements, and a finding of noncompliance can have serious repercussions for the organization.
Some of the goals of periodic audits of software include:
- Determining that the security policy of the software is met.
- Assuring data confidentiality, integrity, and availability protections.
- Making sure that authentication cannot be bypassed.
- Ensuring that rights and privileges are working as expected.
- Checking for the proper function of auditing (logging).
- Determining whether the patches are up to date.
- Finding out if the unnecessary services, ports, protocols, and services are disabled or removed.
- Reconciling data records maintained by different people or teams.
- Checking the accuracy and completeness of transactions that are authorized.
- Determining that physical access to systems with sensitive data is restricted only to authorized personnel.
7.4.2 Incident Management
Whereas continuous monitoring activities are about tracking and monitoring attempts that could potentially breach the security of systems and software, incident management activities are about the proper protocols to follow and the steps to take when a security breach (or incident) occurs.
The first revision of the NIST Special Publication on Computer Security Incident Handling Guide (SP 800-61) prescribes guidance on how to manage computer security incidents effectively. Starting with the detection of the incident, which can be accomplished by monitoring, using incident detection and prevention systems (IDPS), and other mechanisms, the first step in incident response is to determine if the reported or suspected incident is truly an incident. If it is a valid incident, then the type of the incident must be determined. Upon the determination of valid incidents and their type, steps to minimize the loss and destruction and to correct, mitigate, remove, and remediate exploited weakness must be undertaken so that computing services can be restored as expected by the business. Clear procedures to assess the current and potential business impact and risk must be established along with the implementation of effective and efficient mechanisms to collect, analyze, and report incident data. Communication protocols and relationships to report on incidents both to internal teams and to external groups must also be established and followed. In the following section, we will learn about each of these activities in incident management in more detail. As a CSSLP, you are not only expected to know what constitutes an incident but also how to respond to one and advise your organization to do the same.
7.4.2.1 Events, Alerts, and Incidents
In order to determine if a security incident has truly occurred or not, it is first important to define what constitutes an incident. Failure to do so can lead to potential misclassification of events and alerts as real incidents, and this could be costly. It is therefore imperative to understand the differences and relationships between
- Events
- Alerts
- Incidents
Any action that is directed at an object that attempts to change the state of the object is an event. In other words, an event is any observable occurrence in a network, system, or software. When events are found, further analysis is conducted to see if these events match patterns or conditions that are being evaluated using signature-based pattern-matching or anomalous behavioral analysis.
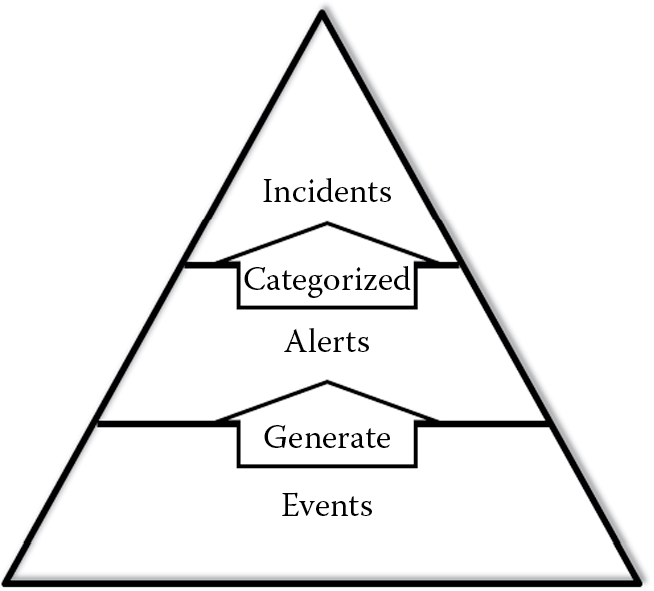
When events match preset conditions or patterns, they generate alerts or red flags. Events that have negative or detrimental consequences are adverse events. Some examples of adverse events include flooded networks, rootkit installations, unauthorized data access, malicious code executions, and business disruptions. Alerts are flagged events that need to be scrutinized further to determine if the event occurrence is an incident. Alerts can be categorized into incidents, and adverse events and can be categorized into security incidents if they violate or threaten to violate the security policy of the network, system, or software applications. Events, alerts, and incidents have a pyramidal relationship; this means that there are more events than there are alerts and more alerts than there are incidents. It is on incidents, not events or alerts, that management decisions are made. It can be said that the events represent raw information and the system view of things happening. Alerts give a technical or operational view and incidents provide the management view. Events generate alerts that can be categorized into incidents. This relationship is depicted in Figure 7.5.
7.4.2.2 Types of Incidents
There are several types of inidents, and the main security incidents include the following:
- Denial of Service (DoS): Purportedly the most common type of security incident, DoS is an attack that prevents or impairs an authorized user from using the network, system, or software application by exhausting resources.
- Malicious code: This type of incident has to do with code-based malicious entities, such as viruses, worms, and Trojan horses, which can successfully infect a host.
- Unauthorized access: Access control-related incidents refer to those wherein a person gains logical or physical access to the network, system, or software application, data, or any other IT resource without being granted the explicit rights to do so.
- Inappropriate usage: Inappropriate usage incidents are those in which a person violates the acceptable use of system resources or company policies. In such situations, the security team (CSSLP) is expected to work closely with personnel from other teams, such as human resources (HR), legal, or, in some cases, even law enforcement.
- Multiple component: Multiple component incidents are those that encompass two or more incidents. For example, a SQL injection exploit at the application layer allowed the attacker to gain access and replace system files with malicious code files by exploiting weaknesses in the Web application that allowed invoking extended stored procedures in the insecurely deployed backend database. Another example of this is when a malware infection allows the attacker to have unauthorized access to the host systems.
The creation of what is known as a diagnosis matrix is also recommended. A diagnosis matrix is helpful to lesser-experienced staff and newly appointed operations personnel because it lists incident categories and the symptoms associated with each category. It can be used to provide advice on the type of incident and how to validate it.
7.4.2.3 Incident Response Process
There are several phases to the incident response process, ranging from initial preparation to postincident analysis. Each phase is important and must be thoroughly defined and followed within the organization as a means to assure operations security. The major phases of the incident response process are preparation, detection and analysis, containment, eradication and recovery, and postincident analysis, as depicted in Figure 7.6.
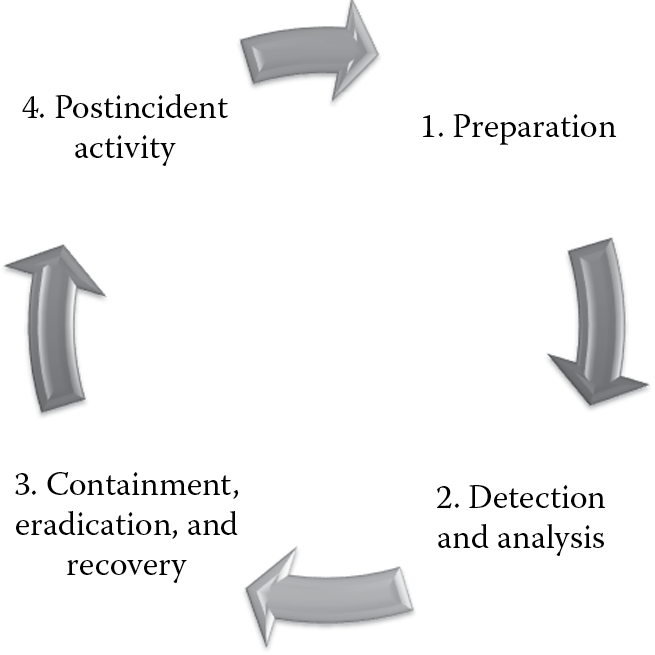
7.4.2.3.1 Preparation
During the preparation phase, the organization aims to limit the number of incidents by implementing controls that were deemed necessary from the initial risk assessments. Today regulations and standards such as FISMA and PCI DSS mandate that organizations must create, provision, and operate a formal incident response plan (IRP).
The following are recommendations of activities to perform during this phase:
- Establish incident response policies and procedures.
- Create and train an incident response team (IRT) that will be responsible for responding to and handling the incident.
- Perform periodic risk assessments, and reduce the identified risks to an acceptable level so that they are effective in reducing the number of incidents.
- Create an SLA that documents the appropriate actions and maximum response times.
- Identify additional personnel, both internal and external to the organization, who may have to be called upon to address the incident.
- Acquire tools and resources that the IRT personnel can use. The effectiveness of incident response is tied closely to the tools and resources they have readily available when responding to an incident. Some common examples include contact lists, network diagrams, backup configurations, computer forensic software, port lists, security patches, encryption software, and monitoring tools.
- Conduct awareness and training on the security policies and procedures and how they are related to actions that are prescribed in the IRP.
7.4.2.3.2 Detection and Analysis
Without the ability to detect security breaches, the organization will not be aware of incidents before or when they occur. If the incident is disruptive and goes undetected, appropriate actions that have to be taken will not be, and this could be very detrimental to the reputation of the organization.
One of the first activities performed in incident management is to look at the logs or audit trails that have been captured in the IDPS. The logs hold raw data. The log analysis process is made up of the following steps: collection, normalization, correlation and visualization. Automation of log analysis may be needed to select events of interest that can be further analyzed. Logging, reporting, and alerting are all parts of the information gathering activity and the first steps in incident analysis.
The different types of logs that should be collected for analysis include:
- Collection
- Network and host intrusion detection systems (NIDS and HIDS) logs
- Network access control lists (ACL) logs
- Host logs, such as OS system messages, logon success and failure information, and system errors, that are written locally on the host or as configured by administrators.
- Application (software) logs that provide information about the activity and interactions between users/processes and the applications.
- Database logs. These are difficult to collect and often require auditing configurations in the database so that database performance is not adversely impacted. They serve as an important source for security-related information and need to be protected with great care because databases can potentially house intellectual property and critical business data.
It is critical to ensure that the logs themselves cannot be tampered with when the data are being collected or transmitted. Cryptographic computation of the hash value of the logs before and after being processed provides anti-tampering and integrity assurance.
- Normalization
The quality of the incident handling process is dependent on the quality of the incident data that are collected. Organizations must be able to identify data that are actionable and pertinent to the incident instead of working with all available data that are logged. This is where normalization can be helpful. Normalization is also commonly referred to as parsing the logs to glean information from them. Regular expressions are handy in parsing the log data. The collected logs must be normalized so that redundant data are eliminated, especially if the logs are being aggregated from various sources. It is also very important to ascertain that the timestamps of the logs are appropriately synchronized so the log analysis provides the true sequence of actions that were conducted.
- Correlation
Log analysis is performed to correlate the events to threats or threat agents. Some examples of log correlation are discussed here. The presence of “wait for delay” statements in your log must be correlated against SQL statements that were run in the database to determine if an attacker were attempting blind SQL injection attacks. If the logs indicate several “failed login” entries, then this must be correlated with authentication attempts that were either brute-forced (threat) or tried by a hacker (threat agent). The primary reason for the correlation of logs with threat or threat agent is to deduce patterns. Secondarily, it can be used to determine the incident type.
It is important to note that the frequency of the log analysis is directly related to the value of the asset whose logs are being analyzed. For example, the logs of the payroll application may have to be reviewed and analyzed daily, but the logs from the training application may not be.
- Visualization
There is no point in analyzing the logs to detect malicious behavior or correlate occurrences to threats if that correlated information is not useful in addressing the incident. Visualization helps in depicting the incident information in a user-friendly and easy-to-understand format. The use of graphical constructs is common to communicate patterns and trends to technical, operations, management personnel, and decision makers.
The following are recommendations of activities to perform during this phase:
- Continuously monitor using monitoring software and IDPS that can generate alerts from events they record. Some examples of monitoring software include anti-virus, anti-spyware, and file integrity checkers.
- Provide mechanisms for both external parties and internal personnel to report incidents. Establishing a phone number and/or email address that assure anonymity is useful to accomplish this objective.
- Ensure that the appropriate level of logging is enabled. Activities on all systems must be logged to defined levels in the MSB, and crucial systems/software should have additional logging in place. For example, the verbosity of logs for all systems must be set to log at an “informational” level, whereas that for the sales or payroll application must log at a “full details” level.
- Since incident information can be recorded in several places to obtain a panoramic view of the attacks against your organization, it is a best practice to use centralized logging and create a log retention policy. When aggregating logs from multiple sources, it is important to synchronize the clocks of the source devices to prevent timing issues. The log retention policy is helpful because it can help detect repeat occurrences.
- Profile the network, systems, and software so that any deviations from the normal profile are alerted as behavioral anomalies that should warrant attention. Understanding the normal behavior also provides the team members the ability to recognize abnormal operations more easily.
- Maintain a diagnosis matrix, and use a knowledge base of information that is useful to incident handlers. They act as a quick reference source during critical times of containing, eradicating, and recovering activities.
- Document and timestamp all steps taken from the time of the incident’s being detected to its final resolution. This could serve as evidence in a court of law if there is a need for legal prosecution of the threat agent. Documented procedures help in handling the incident correctly and systematically and, subsequently, more efficiently. Since the documentation can be used as evidence, it is also critical to make sure that the incident data themselves are safeguarded from disclosure, alteration, or destruction.
- Establish a mechanism to prioritize the incidents before they are handled. Incidents should not be on a first-come first-served basis. Incidents must be prioritized based on the impact the incident has on the business. It is advisable to establish written guidelines on how quickly the IRT must respond to an incident, but it is also important to establish an escalation process to handle situations when the team does not respond within the times prescribed in the SLA.
7.4.2.3.3 Containment, Eradication, and Recovery
Upon detection and validation of a security incident, the incident must first be contained to limit any further damage or additional risks. Examples of containment include shutting down the system, disconnecting the affected systems from the network, disabling ports and protocols, turning off services, and taking the application offline. Deciding how the incident is going to be contained is critical. Inappropriate ways of containing the security incident can not only prevent tracking the attacker, but can also contaminate the evidence being collected, which will render it inadmissible in a court of law should the attacker be taken to court for their malicious activities.
Containment strategies must be based on the type of incident since each type of incident may require a different strategy to limit its impact. It is a best practice for organizations to identify a containment strategy for each listed incident in the diagnosis matrix. Containment strategies can range from immediate shutdown to delayed containment. Delayed containment is useful in collecting more evidence by monitoring the attacker’s activity, but this can be dangerous, as the attacker may have the opportunity to elevate privilege and compromise additional assets. Even when a highly experienced IRT capable of monitoring all attackers’ activity and terminating attacker access instantaneously is available, the high risks posed by delayed containment may not make it an advisable strategy. Willingly allowing a known compromise to continue can have legal ramifications, and when delayed containment is chosen as the strategy to execute, it must first be communicated to and determined as feasible by the legal department.
Criteria to determine the right containment strategy include the following:
- Potential impact and theft of resources.
- The need to preserve evidence. The ways in which the collected evidence is and will be preserved must be clearly documented. Discussions on how to handle the evidence must be held with the organization’s internal legal team and external law enforcement agencies, and their advice must be followed. What evidence to collect must also be discussed. Any data that are physically not persisted (volatile), when collected as evidence, need to be collected and preserved carefully. Subjects who have access to and custody of these data must be granted explicitly and monitored to prevent any unauthorized tampering or destruction. Maintaining the chain of custody is crucial in making the evidence admissible in a court of law. Some well-known examples of volatile data include:
- List of network connections
- Login sessions
- Open files
- Network interface configurations
- Memory contents and processes
In some cases, a snapshot of the original disk may need to be made since forensic analysis could potentially alter the original. It such situations, it is advisable that a forensic backup be performed instead of a full system backup, and that the disk image is made in sanitized write-once or write-protectable media for forensics and evidentiary purposes.
- The availability requirements of the software and its services.
- Time and resources needed to execute the strategy.
- The completeness (partial containment or full containment) and effectiveness of the strategy.
- The duration (temporary or permanent) and criticality (emergency or workaround) of the solution.
- The possibility of the attack to cause additional damage when the primary attack is contained. For example, disconnecting the infected system could trigger the malware to execute data destruction commands on the system to self-destruct, causing system compromise.
Incident data and information are privileged information and not “water cooler” conversation material. The information must be restricted to the authorized personnel only, and the principle of need-to-know must be strictly enforced.
Upon the containment of the incident, the steps necessary to remove and eliminate components of the incident must be undertaken. An eradication step can be performed as a standalone step in and of itself, or it may be performed during recovery. It is important to ensure that any fixes or steps to eradicate the incident are taken only after appropriate authorization is granted. When dealing with licensed or third party components or code, it is important to ensure that appropriate contractual requirements as to which party has the rights and obligations to make and redistribute security modifications is present and documented in the associated SLAs.
Recovery mechanisms aim to restore the resource (network, system, or software application) back to its normal working state. These are usually OS- or application-specific. Some examples include restoring systems from legitimate backups, rebuilding services, restoration of compromised accounts and files with correct ones, patch installations, password changes, and enhanced perimeter controls. A recovery process must also include putting a heightened degree of monitoring and logging in place to detect repeat offenders.
7.4.2.3.4 Postincident Analysis
One of the most important steps in the incident response process that can easily be ignored is the postmortem analysis of the incident. Lessons learned activities must produce a set of objective and subjective data regarding each incident. These action items must be completed within a certain number of days of the incident and can be used to achieve closure. For an incident that had minimal to low impact on the organization, the lessons learned meetings can be conducted periodically. This is important because a lesson learned activity can:
- Provide the data necessary to identify and address the problem at its root.
- Help identify security weaknesses in the network, system, or software.
- Help identify deficiencies in policies and procedures.
- Be used for evidentiary purposes.
- Be used as reference material in handling future incidents.
- Serve as training material for newer and lesser experienced IRT members.
- Help improve the security measures and the incident handling process itself so that future incidents are controlled.
Maintaining an incident database with detailed information about the incident that occurred and how it was handled is a very useful source of information for an incident handler.
Additionally, if the organization is required to communicate the findings of the incident externally either to those affected by the incident, law enforcement agencies, vendors, or to the media, then it is imperative that the postincident analysis is conducted before that communication. Figure 7.7, taken from The Computer Security Incident Handling Guide special publication (SP 800-61), illustrates some of the outside parties that may have to be contacted and communicated with when security incidents occur within the organization.
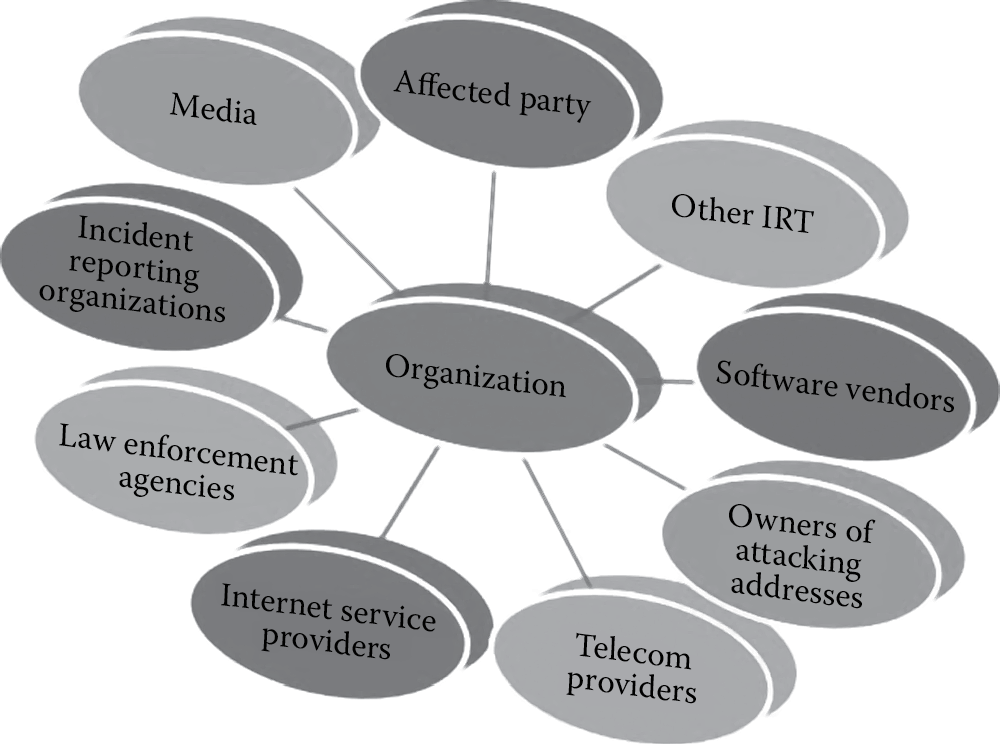
In order to limit the disclosure of incident-related sensitive information to outside parties, which could potentially cause more damage than the incident itself, appropriate communication protocols need to be followed. This means that communication guidelines are established in advance, and a list of internal and external point of contacts (POCs) (along with backup for each) is identified and maintained. No communication to outside parties must be made without the IRT’s discussing the issue with the need-to-know management personnel, legal department, and the organization’s public affairs office POC. Only the authorized POC should then be authorized to communicate the incident to the associated parties. Additionally, only the pertinent information about the incident that is deemed applicable to the party receiving the information must be disclosed.
Not all incidents require a full-fledged postincident analysis, but at a bare minimum the following, which is referred to as the 5Ws, need to be determined and reported on:
- What happened?
- When did it happen?
- Where did it happen?
- Who was involved?
- Why did it happen?
It is the “Why” that we are particularly interested in, since it can provide us with insight into the vulnerabilities in our networks, systems, and software applications. Determining the reasons as to why the incident occurred in the first place is the first step in problem management (covered in the next section).
7.4.3 Problem Management
Incident management aims at restoring service and business operations as quickly as possible, whereas problem management is focused on improving the service and business operations. When the cause of an incident is unknown, it is said to be a problem. A known error is an identified root cause of a problem. The goal of problem management is to determine and eliminate the root cause and, in doing so, improve the service that IT provides to the business so the same issue may not be repeated again.
For example, it is observed that the software does not respond and hangs repeatedly after it has run for a certain period. This causes the software to be extremely slow or unavailable to the business. As part of addressing this issue, the incident management perspective would be to reboot the system repeatedly each time the software hangs so that the service can be restored to the business users within the shortest time possible. The problem management perspective would not be so simple. This problem of resource exhaustion and eventual DoS will need to be evaluated to determine what could be causing the problem. The root cause of the incident could be one of several things. The configuration settings of the system on which the software is run may be restricting the software to function, the code may be having extensive native API and memory operations calls, or the host system may have been infected by malicious software that is causing the resource exhaustion. Suppose it were determined that the calls to memory operations in the code were the reason why this incident was happening. Problem management would continue beyond simple identification of the root cause until the root cause was eliminated. Insecure memory calls would now be the known error, and it would need to be addressed. In this case, the code would need to be fixed with the appropriate coding constructs or throttling configuration, and the system might have to be upgraded with additional memory to handle the load.
The objective in problem management after fixing the identified root cause is to make sure that the same problem does not occur again. Avoidance of repeated incidents is one of the two main critical success factors (CSFs) of problem management. The other is to minimize the adverse impacts of incidents and problems on the business.
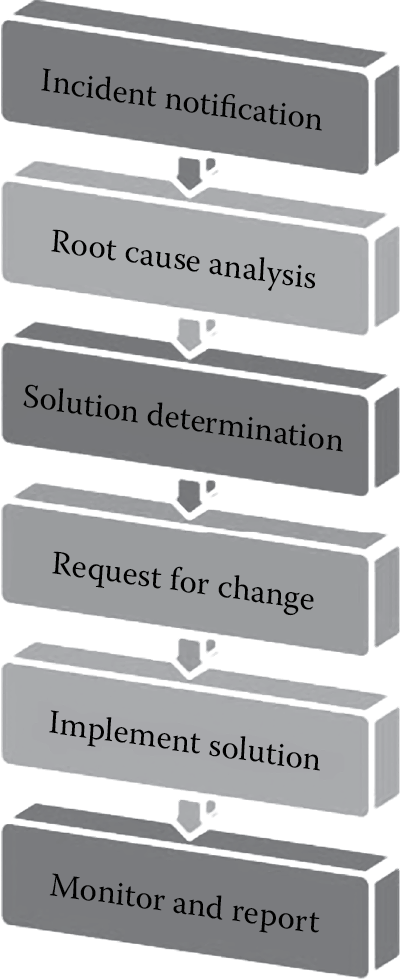
7.4.3.1 Problem Management Process
Problem management begins with notification and ends with reporting, as illustrated in Figure 7.8. Upon notification of the incident, root cause analysis (RCA) steps are taken to determine the reason for the problem.
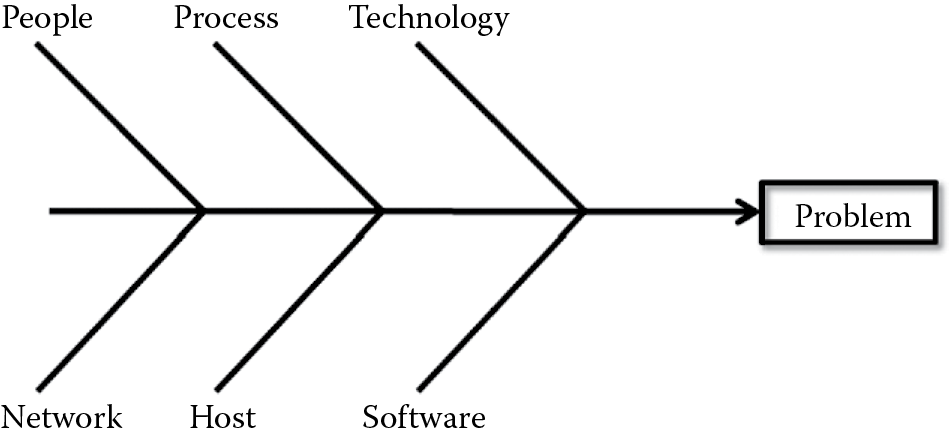
RCA is performed to determine why the problem occurred in the first place. It is not just asking the question, “Why did the problem happen?” once, but repeatedly and systematically until there are no more reasons (or causes) that can be answered. A litmus test to classify an answer as the root cause is that, when the condition identified as the root cause is fixed, the problem no longer exists. Brainstorming using fishbone diagrams instead of ad hoc brainstorming and rapid problem resolution (RPR) problem diagnosis are common techniques that are used to identify root cause. Fishbone diagrams are also known as cause and effect diagrams. Fishbone diagrams help the team graphically to identify and organize possible causes of a problem (effect), and, using this technique, the team can identify the root cause of the problem. When brainstorming using fishbone diagrams, the RCA process can benefit if categories are used. These categories, when predefined, help the team to focus on the RCA activity appropriately. Some examples of categories that can be used are people (e.g., awareness, training, or education), process (e.g., nonexistent, ill-defined), technology, network, host, software (e.g., coding, third party component, API), and environment (e.g., production, development, test). Figure 7.9 shows an example of a fishbone diagram used for RCA. In the RPR problem diagnosis, a step-by-step approach to identifying the root cause is taken in three phases: discovery, investigation, and fixing. RPR is fully aligned with ITIL v3.
RCA can give us insight into such issues as systemic weaknesses, software coding errors, insecure implementation of security controls, improper configurations, and improper auditing and logging. When RCA is performed, it is important to identify and differentiate the symptoms of the incident from the underlying reason as to why the problem occurred in the first place. Incident management treats symptoms, whereas problem management addresses the core of the problem. In layman’s terms, incident management is akin to spot control of lawn weeds, whereas problem management would be analogous to pulling out the weeds by the root. For security incidents, without activity logs, determining the root cause of an incident could be very difficult.
After the root cause is identified, workarounds (if needed), recovery, and resolution of the problem are then determined. A request for change is then initiated. It must also be recognized that problem management often results in changes to internal processes, procedures, or infrastructure. When change is determined to be a necessity upon undertaking problem management activities, the change management processes and protocols should be followed as published by the organization. At no time must the need to resolve the problem supersede or force the organization to circumvent the change management process. The appropriate request for change (RFC) must be made after the root cause is identified even if the solution to the problem is not a permanent fix, but just a workaround. Following the implementation of the change, it is important to monitor the problem resolution to ensure that it was effective and that the problem does not happen again and finally to report on the process improvement activities.
7.4.4 Patching and Vulnerability Management
Business applications and systems software are prone to exploitation, and as newer threats are discovered and orchestrated against software, there is a need to fix the vulnerabilities that make the attacks possible. In such situations, the software is not completely removed. Instead additional pieces of code that address the vulnerability or problems (also known as bugs) are developed and deployed. These additional pieces of code (used to update or fix existing software so that the software is not susceptible to the bugs), are known as patches, and patching is the process of applying these updates or fixes. Patches can be used to address security problems in software or simply provide additional functionality. Patching is a subset of hardening.
Patches are often made available from vendors in one of two ways. The most common mechanisms are:
- Hotfix or Quick Fix Engineering (QFE): A hotfix is a functional or security patch that is provided by the software vendor or developer. It usually includes no new functionality or features and makes no changes to the hardware or software. It is usually related to the operating system itself or to some related platform component (e.g., IIS, SQL Server) or product (e.g., MS Word, MS Outlook). Today the term QFE is being used in place of hotfix. The benefit of using a hotfix (or QFE) is that it allows the organization to apply the fix one at a time or selectively.
- Service Pack: Usually a roll up of multiple hotfixes (or QFEs), a service pack is an update to the software that fixes known problems and in some cases provides additional enhancements and functionality as well. Periodic software updates are often published as service packs, and newer product versions should incorporate all previously published service packs to ensure that there are no regression issues, particularly those related to security. The benefit of using a service pack is that multiple hotfixes (or QFEs) can be applied more efficiently because it eliminates the need to apply each fix one at a time.
Although the process of patching is viewed to be reactive, patch and vulnerability management is the security practice developed to prevent attacks and exploits against software and IT systems proactively. Applying a patch after a security incident has occurred is costly and time-consuming. With a well-defined patch and vulnerability management process in place, the likelihood of exploitation and the efforts to respond and remediate incidents will be reduced, thereby adding greater value and savings to the organization.
Although the benefits of patch and vulnerability management programs are many, there are some challenges that come with patching. The main challenge with patching is that the applied patch might cause a disruption of existing business processes and operations. If the application of the patch is not planned and properly tested, it could lead to business disruptions. In order to test the patch before it is deployed, an environment that simulates the production environment must be available. Lack of a simulated environment combined with lack of time, budget, and resources are patching challenges that must be addressed. Since making a change (such as installing a patch) has the potential of breaking something that is working, both upstream and downstream dependencies of the software being patched must be considered. Architecture, DFD, and threat model documentation that gives insight into the entry and exit points and dependencies can be leveraged to identify systems and software that could be affected by the installation of the patch. Additionally, the test for backward compatibility of software functionality must also be conducted postinstallation of patches. Furthermore, patches that are not tested for their security impact can potentially revert configuration settings from a secure to an insecure state. For example, ports that were disabled get enabled or unnecessary services that were removed are reinstalled along with the patch installation. This is why patches must be validated against the MSBs. The success of the patching process must be tested and postmortem analysis should be conducted. The MSB must be updated with successful security patches.
It is important to recognize that not all vulnerabilities have a patch associated with them. A more likely case is that a single patch addresses many software security vulnerabilities. This is important because, as part of the patch and vulnerability management process, the team responsible for patching must know what vulnerabilities are addressed by which patches. As part of the patch management process, not only must vulnerabilities alone be monitored, but remediations and threats as well. Vulnerabilities could be design flaws, coding bugs, or misconfigurations in software that weaken the security of the system. The three primary ways to remediate are the installation of the software patch, adjusting configuration settings, and removal of the affected software. Software threats usually take the form of malware (e.g., worms, viruses, rootkits, Trojan horses) and exploit scripts, but they can be human in nature. There is no software patch for human threats, but the best proactive defense in such situations is user awareness, training, and education.
Timely application of the patch is also an important consideration in the patch and vulnerability management process. If the time frame between the release of the patch and its installation is large, then it gives an attacker the advantage of time. Thus, they can reverse engineer how the patch will work, identify vulnerabilities that will or will not be addressed by the patch or those that will be introduced as a result of applying the patch, and write exploit code accordingly. Ironically, it has been observed that the systems and software are most vulnerable shortly after a patch is released.
It is best advised to follow a documented and structured patching process. Some of the necessary steps that need to be taken as part of the patching process include:
- Notifying the users of the software or systems about the patch.
- Testing the patch in a simulated environment so that there are no backward compatibility or dependency (upstream or downstream) issues.
- Documenting the change along with the rollback plan. The estimated time to complete the installation of the patch, criteria to determine the success of the patch, and the rollback plan must be included as part of the documentation. This documentation needs to be provided along with a change request to be closely reviewed by the change advisory board (CAB) team members and their approvals obtained before the patch can be installed. This can also double as an audit defense as it demonstrates a structured and calculated approach to addressing changes within the organization.
- Identifying maintenance windows or the time when the patch is to be installed. The best time to install the patch is when there is minimal disruption to the normal operations of the business. However, with most software operating in a global economy setting, identifying the best time for patch application is a challenge today.
- Installing the patch.
- Testing the patch postinstallation in the production environment is also necessary. Sometimes a reboot or restart of the system where the patch was installed is necessary to read or load newer configuration settings and fixes to be applied. Validation of backward compatibility and dependencies also needs to be conducted.
- Validating that the patch did not regress the state of security and that it leaves the systems and software in compliance with the MSB.
- Monitoring the patched systems so that there are no unexpected side effects upon the installation of the patch.
- Conducting postmortem analysis in case the patch has to be rolled back and using the lessons learned to prevent future issues. If the patch is successful, the MSB needs to be updated accordingly.
The second revision of the special publication 800-40 published by NIST prescribes the following recommendations:
- Establish a patch and vulnerability group (PVG).
- Continuously monitor for vulnerabilities, remediations, and threats.
- Prioritize patch applications and use phased deployments as appropriate.
- Test patches before deployment.
- Deploy enterprise-wide automated patching solutions.
- Use automatically updating applications as appropriate.
- Create an inventory of all information technology assets.
- Use standardized configurations for IT resources as much as possible.
- Verify that vulnerabilities have been remediated.
- Consistently measure the effectiveness of the organization’s patch and vulnerability management program, and apply corrective actions as necessary.
- Train applicable staff on vulnerability monitoring and remediation techniques.
- Periodically test the effectiveness of the organization’s patch and vulnerability management program.
Patch and vulnerability management is an important maintenance activity, and careful attention must be given to the patching process to assure that software is not susceptible to exploitation and that security risks are addressed proactively for the business.
7.5 Disposal
As was covered earlier, the ability of the software to withstand attacks decreases over a period of time, due to either the discovery of newer threats and exploits or changes in technological advancements that provide a greater degree of security protection. It is therefore important not to forget about security once the software is deployed and running in an operations or maintenance mode. As long as the software is operational, there is always going to be an amount of residual risk to deal with, and all software is vulnerable until it is disposed of (or sunsetted) in a secure manner. In this section, we will learn about the criteria and processes that must be considered and undertaken to dispose of software securely.
7.5.1 End-of-Life Policies
The first requirement in secure disposal of software and its related data and documents is to establish an EOL policy. The Risk Management Guide for Information Technology Systems, published by the NIST as Special Publication 800-30 (SP 800-30), prescribes that risk management activities need to be performed for system components that will be disposed of or replaced to ensure that the hardware and software are properly disposed. Additionally, it is important to make sure that residual data are appropriately handled and that system migration is conducted in not just a systematic manner, but also in a secure manner. In order to manage risk during the disposal phase, it is essential that we have an EOL policy developed and followed. For commercial off-the-shelf (COTS) software, the EOL policy begins with the formal notification of end-of-sale (EOS) date; the goal is to provide customers with needed information to plan their migration confidently to replacement technologies. The EOL policy must provide the conditions in which systems and software must be securely disposed and provide guidance on how to accomplish this objective.
An EOL Policy must, in general, contain:
- Sunsetting criteria
- A notice of all the hardware and software that are being discontinued or replaced
- The duration of support for technical issues from the date of sale and how long that would be valid after the notice of disposal has been published
- Recommendations and alternatives for migration and transition along with the versions or products of software that will be supported in the future
- The duration of time when maintenance releases, workarounds, patches, and upgrades will be released and supported
- Contract renewal terms in cases of licensed or third party software
7.5.2 Sunsetting Criteria
Sunsetting criteria provide guidance as to when a particular product (software or the hardware on which the software runs) must be disposed of or replaced. There are several sunsetting criteria for software. We will focus primarily on sunsetting criteria for software alone as listed below in this section.
- Newer threats and attacks against software are discovered, and the risks they bring cannot be mitigated to the acceptable levels defined by the organization due to technical, operational, or management constraints.
- Contractual agreements to continue to use the software have come to an end, and the cost of maintaining and using the software is prohibitive for the business.
- The software has reached its end-of-warranty period.
- The software has reached its end of product support, especially COTS.
- The software has reached its end of vendor support.
- The software is no longer compatible with the architecture of the hardware. Platform/architecture changes, such as the move from x86 processor architecture to the x64 processor architecture, are examples of this.
- Software that can provide the same functionality in a more secure fashion is available as new products, upgrades, or versions release.
7.5.3 Sunsetting Processes
As a general rule, software or software-related technologies that are deemed insecure, but which have no means to mitigate the risk to the acceptable levels of the organization must be sunsetted as soon as possible. However, this may not be as easy a task as it may seem. In compliance with the organization’s EOL policy, appropriate EOL processes must be established. EOL processes are the series of technical and business milestones and activities that when complete make the hardware or software obsolete and no longer produced, sold, improved, repaired, maintained, or supported. It also ensures that any related artifacts, such as data in media, code, and documents, are securely disposed.
Just as the deployment of software is governed by a plan, and necessary approvals from the change control or CAB are required, so also is disposal. The steps to follow as software is sunsetted are:
- Have a replacement if needed before disposing of software. The replacement software must already be built or bought, tested, and deployed in the operational environment before the previous software is retired, so that data and system migration and verification can be operationally viable.
- Obtain the necessary approvals from the authorized officials.
- Update the asset inventory database and CMDB with information related to the software being retired as well as the one replacing it (if that is the case).
- Shut down services and adjust or remove any monitoring that was in place for the software being sunsetted. When software that is monitored and configured to create trouble tickets automatically upon failure or unavailability of services is sunsetted, the failure to adjust or remove monitoring and ticket generation can lead to a lot of unnecessary trouble tickets generated and wasted time.
- Ensure that termination access control (TAC) processes are performed to de-provision digital identities and user accounts. If the software is being replaced with another, then it is important to set access control explicitly for the new software and not just copy and migrate the access control information and rights from the old to the new.
- Archive the software and associated data offline. This may be mandated as part of a regulatory or internal policy requirement. Archiving the software and data also allows for a reload of data if the migration process fails and the data are corrupted during the migration process.
- Do not just uninstall, but securely delete the software and data. Uninstalling software may not be sufficient to provide total removal of the software and software assurance. Sometimes the uninstall scripts do not remove all the directories and files or registry entries that were created when the software was installed. In some cases, the uninstall process and scripts generate an uninstall log file that is left behind on the system. This log file can have sensitive information, such as version information, location of configuration and code files, and default settings, which an attacker can find useful to profile your software and its operations. If you build software that use packagers for generating the installation packages, e.g., .msi, .rpm, or scripts, it is important to ensure that the uninstall scripts that come with the packagers do not leave any residue when executed. This is why the software must be securely deleted and not just uninstalled. Secure delete includes additional manual steps that are taken after the uninstall process to ensure that there is no software-related information about the software being retired left behind on the system. This can include manual cleanup and deletion of the registry entries, directories, and files. It also includes the secure disposal of residual or remnant data from storage media (covered in the next section).
7.5.4 Information Disposal and Media Sanitization
The importance of information disclosure protection cannot be overstressed when software that processes and stores that information in some media is being discontinued. Just as software disposal steps are taken to ensure that software assurance is maintained, an important part in that process is also to ensure that the media that stored the information are also sanitized or destroyed appropriately. Sanitization is the process of removing information from media such that data recovery and disclosure are not possible. It also includes the removal of classified labels, marking, and activity logs related to the information. It is not the media themselves, but the information recorded in them that needs protection. It is therefore important first to think in terms of information confidentiality assurance and then consider the type of media when selecting the best method to sanitize or destroy information and associated media.
Information is primarily stored in one of the following two types of media:
- Hardcopy or physical representation of information. Examples include paper printouts (e.g., internal memoranda, software architecture and design documents, and printed software code), printer and facsimile ribbons, drums, and platens. Usually this type of media is uncontrolled, so without appropriate media protection methods, information can be susceptible to unauthorized individuals and dumpster divers.
- Softcopy or electronic representation of information where the information is stored in the form of bits and bytes. Examples of this type of media include hard drives, RAM, read-only memory (ROM), disks, memory devices, mobile computing devices, and networking equipment.
Depending on the type of media and future plans for the media, different sanitization techniques can be used. The three most common means of media sanitization include:
- Clearing
- Purging
- Destroying
Disposal is the act of discarding media without giving any considerations to sanitization. This is often done by recycling hardcopy media when no confidential information is present. Disposal is technically not a type of sanitization, but it is still a valid approach to handling media containing nonconfidential information.
Clearing is the process of sanitizing media by using software or hardware products that overwrite logical (e.g., file allocation tables) and addressable storage space on the media with nonsensitive random data. Clearing, however, does not guarantee that the data in the media have been successfully and securely erased. When data remain as residual information, the condition is referred to as data remanence. Clearing by overwriting cannot, however, be used for media that are either damaged or of the write-once read-many (WORM) type.
Purging is the process of sanitizing media by rendering the data into an unrecoverable state. Common methods to purge data in magnetic media are degaussing and executing the secure erase command in ATA drives. Degaussing is the process of reducing the magnetic flux of the media to virtual zero by applying a reverse magnetizing field. This will render the drive permanently unusable since the track location information stored in the drives between data sectors will be affected when subjected to a powerful reversed magnetic field.
Destroying or destruction is the process of ensuring that the media can no longer be reused as originally intended and the recovery of data from the media is virtually impossible or prohibitively costly. There are many ways in which media can be destroyed. Media containing classified information labeled as highly sensitive are best protected if they are completely destroyed. Upon the destruction of media with highly sensitive information, it is important to validate and verify that media are not susceptible to a laboratory attack. A laboratory attack is one where specially trained and skilled threat agents use nonstandard resources and systems to perform data recovery on media outside of their normal operating settings. The different techniques that can be used for physically destroying media for sanitization purposes are as follows:
- Disintegration is the act of separating the media into component parts.
- Pulverization is the act of grinding the media into a powder or dust.
- Melting is the act of changing the state of the media from a solid into liquid by using an extreme application of heat.
- Incineration or burning is the act of completely burning the media into ashes.
- Shredding is the act of cutting or tearing the media into small particles. The shred size is an important consideration when choosing a shredder or a shredding service (if outsourced). The shred size should be small enough to provide a reasonable assurance that information cannot be reconstructed from the shredded output.
Knowing the type of sanitization method that should be used is important. If data are backed up on optical storage media such as compact disks (e.g., CD-ROM, CD-R), optical disks (DVD), and WORM types, then physical destruction using either pulverization, shredding, or burning is recommended. Figure 7.10 is an adaptation from the Guidelines for Media Sanitization special publication by NIST (SP 800-88), and it illustrates the data sanitization and decision flow. It is important to recognize that the last steps in the sanitization process are to validate that information reconstruction or recovery is not possible and to document the steps taken and the results from it.
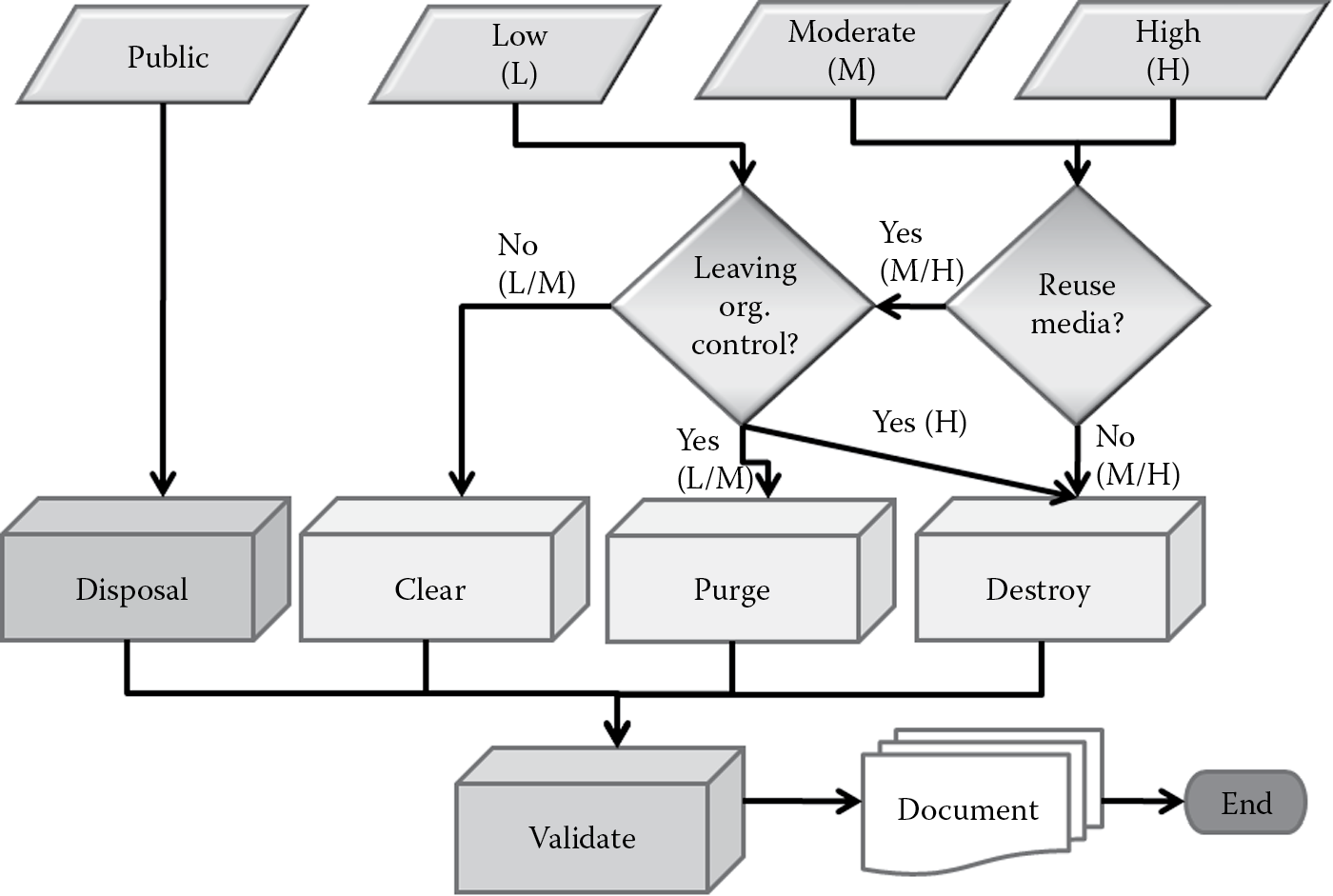
7.6 Summary
In this chapter, we learned about the importance of security during the final stages of the SDLC. Security considerations during installation and deployment, operations, maintenance, and disposal are all important.
After software is accepted for deployment or release, the installation and deployment activity should not ignore the security aspects of software. Before deploying software, it is imperative that the host operating systems and the computing network in which the software will operate are locked down or hardened. After the hardening process, the installation of the software must not violate the principle of least privilege. When software starts, the booting process must also be resilient to common or side channel attacks. The startup variables and configuration parameters must be guarded to protect against attacks that impact the confidentiality or integrity of software. Without a proper and well defined configuration management process in place, the likelihood of regenerative bugs in software is high.
During the operations phase of SDLC, continuous monitoring of software is important to ensure the goal of operations security, which is to make certain that software remains secure. Knowing how to monitor software is just as important as why it should be monitored. Scanning, logging, and IDS are common ways to monitor, and monitoring can not only validate the state of security, but also provide insight on the state of compliance with security policies. Metrics can be used as a tool to provide management and operations team members with information about the real state of security affairs within the organization. Periodic audits are useful to validate compliance. Incident management is useful in restoring services and software functionality. The incident response process requires careful planning and is composed of the following phases: preparation, detection and analysis, containment, eradication and recovery, and postincident analysis. The analysis of software audit logs can provide valuable support and information to detect both insider and external threats attempted against the software. The goal of problem management is to improve the service. RCA is a very important means to answer why the problem occurred in the first place so that the core issue can be resolved once and for all. Patch and vulnerability management are necessary ongoing activities during the maintenance phase of the SDLC. Patching can adversely impact the state of software security if the patch is not tested in an environment that simulates the production environment. Patches can be delivered as a single hotfix or as components of a service pack. Patches must be tested for backward compatibility issues, upstream and downstream dependencies, impact, and regression of security features.
Software that is no longer required is not secure until it or its data and related components have been completely removed from the computing environment. Security cannot be ignored during the disposal stage of the software life cycle. EOL policies must be established and sunsetting criteria understood as part of the software disposal process. Along with the disposal or replacement of software, it is also important to address securely the information that was processed and stored by the software. Secure disposal of information is dependent on the type of media that contain it and the need for the media to be reused or not. Additionally, determining how the information and media containing it must be disposed of is dependent on whether the information will leave the organization’s control. The primary protection methods against data remanence are clearing (overwriting), purging (degaussing), and destroying.
Software must be monitored, operated, maintained, and disposed of with security in mind so that the reliability, resiliency, and recoverability of software can be guaranteed, and the stakeholders can be assured of their trust in your organization.
7.7 Review Questions
- When software that worked without any issues in the test environments fails to work in the production environment, it is indicative of
A. Inadequate integration testing
B. Incompatible environment configurations
C. Incomplete threat modeling
D. Ignored code review
- Which of the following is not characteristic of good security metrics?
A. Quantitatively expressed
B. Objectively expressed
C. Contextually relevant
D. Collected manually
- Removal of maintenance hooks, debugging code and flags, and unneeded documentation before deployment are all examples of software
A. Hardening
B. Patching
C. Reversing
D. Obfuscation
- Which of the following has the goal of ensuring that the resiliency levels of software are always above the acceptable risk threshold as defined by the business post deployment?
A. Threat modeling
B. Code review
C. Continuous monitoring
D. Regression testing
- Audit logging application events, such as failed login attempts, sales price updates, and user roles configuration, are examples of which of the following type of security control?
A. Preventive
B. Corrective
C. Compensating
D. Detective
- When a compensating control is to be used, the Payment Card Industry Data Security Standard (PCI DSS) prescribes that the compensating control must meet all of the following guidelines except
A. Meet the intent and rigor of the original requirement
B. Provide a higher level of defense than the original requirement
C. Be implemented as part of a defense in depth measure
D. Be commensurate with additional risk imposed by not adhering to the requirement
- Software that is deployed in a high trust environment such as the environment within the organizational firewall when not continuously monitored is most susceptible to which of the following types of security attacks? Choose the best answer.
A. Distributed denial of service (DDoS)
B. Malware
C. Logic bombs
D. DNS poisoning
- Bastion host systems can be used continuously to monitor the security of the computing environment when it is used in conjunction with intrusion detection systems (IDS) and which other security control?
A. Authentication
B. Authorization
C. Archiving
D. Auditing
- The first step in the incident response process of a reported breach is to
A. Notify management of the security breach
B. Research the validity of the alert or event further
C. Inform potentially affected customers of a potential breach
D. Conduct an independent third party evaluation to investigate the reported breach
- Which of the following is the best recommendation to champion security objectives within the software development organization?
A. Informing the developers that they could lose their jobs if their software is breached
B. Informing management that the organizational software could be hacked
C. Informing the project team about the recent breach of the competitor’s software
D. Informing the development team that there should be no injection flaws in the payroll application
- Which of the following independent processes provides insight into the presence and effectiveness of security and privacy controls and is used to determine the organization’s compliance with the regulatory and governance (policy) requirements?
A. Penetration testing
B. Audits
C. Threat modeling
D. Code review
- The process of using regular expressions to parse audit logs into information that indicate security incidents is referred to as
A. Correlation
B. Normalization
C. Collection
D. Visualization
- The final stage of the incident management process is
A. Detection
B. Containment
C. Eradication
D. Recovery
- Problem management aims to improve the value of information technology to the business because it improves service by
A. Restoring service to the expectation of the business user
B. Determining the alerts and events that need to be continuously monitored
C. Depicting incident information in easy-to-understand, user-friendly format
D. Identifying and eliminating the root cause of the problem
- The process of releasing software to fix a recently reported vulnerability without introducing any new features or changing hardware configuration is referred to as
A. Versioning
B. Hardening
C. Patching
D. Porting
- Fishbone diagramming is a mechanism that is primarily used for which of the following processes?
A. Threat modeling
B. Requirements analysis
C. Network deployment
D. Root cause analysis
- As a means to assure the availability of the existing software functionality after the application of a patch, the patch needs to be tested for
A. The proper functioning of new features
B. Cryptographic agility
C. Backward compatibility
D. The enabling of previously disabled services
- Which of the following policies needs to be established to dispose of software and associated data and documents securely?
A. End-of-life
B. Vulnerability management
C. Privacy
D. Data classification
- Discontinuance of a software with known vulnerabilities with a newer version is an example of risk called
A. Mitigation
B. Transference
C. Acceptance
D. Avoidance
- Printer ribbons, facsimile transmissions, and printed information when not securely disposed of are susceptible to disclosure attacks by which of the following threat agents? Choose the best answer.
A. Malware
B. Dumpster divers
C. Social engineers
D. Script kiddies
- System resources can be protected from malicious file execution attacks by uploading the user-supplied file and running it in which of the following environments?
A. Honeypot
B. Sandbox
C. Simulated
D. Production
- As a means to demonstrate the improvement in the security of code that is developed, one must compute the relative attack surface quotient (RASQ)
A. At the end of development phase of the project
B. Before and after the code is implemented
C. Before and after the software requirements are complete
D. At the end of the deployment phase of the project
- When the code is not allowed to access memory at arbitrary locations that are out of range of the memory address space that belong to the object’s publically exposed fields, it is referred to as which of the following types of code?
A. Object code
B. Type safe code
C. Obfuscated code
D. Source code
- Modifications to data directly in the database by developers must be prevented by
A. Periodically patching database servers
B. Implementing source code version control
C. Logging all database access requests
D. Proper change control management
- Which of the following documents is the best source to contain damage, and which needs to be referred to and consulted upon the discovery of a security breach?
A. Disaster Recovery Plan
B. Project Management Plan
C. Incident Response Plan
D. Quality Assurance and Testing Plan
References
Cannon, J. C. 2009. Privacy: What Developers and IT Professionals Should Know. Reading: MA: Addison-Wesley Professional.
Colville, R. 2008. Recommendations for security patch management. Gartner Research. http://www.gartner.com/DisplayDocument?doc_cd=161535&ref=g_rss (accessed 6 March 2011).
Egan, M., and T. Mather. 2004. The Executive Guide to Information Security: Threats, Challenges, and Solutions. Reading: MA: Addison-Wesley Professional.
Fernandes, A. 2007. Operations security. March 23rd, 2007. Global Information Assurance Certification. http://www.giac.org/resources/whitepaper/operations/272.php (accessed 6 March 2011).
Fry, C., and M. Nystrom. 2009. Security Monitoring: Proven Methods for Incident Detection on Enterprise Network. Cambridge, MA: O’Reilly Media.
Grimes, R. 2006. Professional Windows Desktop and Server Hardening (Programmer to Programmer). West Sussex, UK: Wrox Press.
Howard, M., and D. LeBlanc. 2002. Writing Secure Code: Practical Strategies and Proven Techniques for Building Secure Applications in a Networked World. 2nd ed. Cambridge, MA: Microsoft Press.
Howard, M. and D. LeBlanc. 2007. Writing Secure Code for Windows Vista (Pro - Step By Step Developer). Cambridge, MA: Microsoft Press.
Howard, M., and S. Lipner. 2006. The Security Development Lifecycle SDL: A Process for Developing Demonstrably More Secure Software. Cambridge, MA: Microsoft Press.
Information Technology Infrastructure Library. 2010. ITIL Open Guide. http://www.itlibrary.org/index.php?page=ITIL (accessed March 23, 2010).
Jaquith, A. 2007. Security Metrics: Replacing Fear, Uncertainty, and Doubt. Reading: MA: Addison-Wesley Professional.
Kissel, R., M. Scholl, S. Skolochenko, and X. Li. 2006. Guidelines for Media Sanitization. NIST SP 800-88. http://csrc.nist.gov/publications/nistpubs/800-88/NISTSP800-88_rev1.pdf (accessed 6 March 2011).
Litchfield, D., C. Anley, J. Heasman, B. Grindlay. 2005. The Database Hacker’s Handbook: Defending Database Servers. New York, NY: John Wiley & Sons, Inc.
Mell, P., T. Bergeron, and D. Henning. 2005. Creating a Patch and Vulnerability Management Program. NIST SP 800-40. http://csrc.nist.gov/publications/nistpubs/800-40-Ver2/SP800-40v2.pdf (accessed 6 March 2011).
NASA Process Control Focus Group. Root Cause Analysis. http://process.nasa.gov/documents/RootCauseAnalysis.pdf (accessed 6 March 2011).
Nicolett, M., and R. J. Colville. 2006. Patch management best practices. Gartner Research. http://www.pixel.com.au/documentation//products/lumension/patchlink/Gartner%20-%20Patch%20Management%20Best%20Pratices.pdf (accessed 6 March 2011).
Scarfone, K., T. Grance, and K. Masone. 2008. Computer Security Incident Handling Guide. NIST SP 800-61. http://csrc.nist.gov/publications/nistpubs/800-61-rev1/SP800-61rev1.pdf (accessed 6 March 2011).
Scarfone, K., W. Jansen, and M. Tracy. 2008. Guide to General Server Security. NIST SP 800-123. http://csrc.nist.gov/publications/nistpubs/800-123/SP800-123.pdf (accessed 6 March 2011).
Swiderski, F., and W. Snyder. 2004. Threat Modeling. Cambridge, MA: Microsoft Press.
Venkatakrishnan, V. N., R. Sekar, T. Kamat, S. Tsipa, and Z. Liang. 2002. An Approach for Secure Software Installation. http://www.comp.nus.edu.sg/~liangzk/papers/lisa02.pdf (accessed 6 March 2011).
Williams, B. 2009. The art of the compensating control. ISSA Journal April 2009. https://www.brandenwilliams.com/brwpubs/publishedversions/Williams-The%20Art%20of%20the%20Compensating%20Control.pdf (accessed 6 March 2011).