
Chapter 4
Secure Software Implementation/Coding
4.1 Introduction
Although software assurance is more than just writing secure code, writing secure code is an important and critical component to ensuring the resiliency of software security controls. Reports in full disclosure and security mailing lists are evidence that software written today is rife with vulnerabilities that can be exploited. A majority of these weaknesses can be attributed to insecure software design and/or implementation, and it is vitally important that software first and foremost be reliable, and second less prone to attack and more resilient when it is. Successful hackers today are identified as individuals who have a thorough understanding of programming. It is therefore imperative that software developers who write code must also have a thorough understanding of how their code can be exploited, so that they can effectively protect their software and data. Today’s security landscape calls for software developers who additionally have a security mindset. This chapter will cover the basics of programming concepts, delve into topics that discuss common software coding vulnerabilities and defensive coding techniques and processes, cover code analysis and code protection techniques, and finally discuss building environment security considerations that are to be factored into the software.
4.2 Objectives
As a CSSLP, you are expected to
- Have a thorough understanding of the fundamentals of programming.
- Be familiar with the different types of software development methodologies.
- Be familiar with common software attacks and means by which software vulnerabilities can be exploited.
- Be familiar with defensive coding principles and code protection techniques.
- Know how to implement safeguards and countermeasures using defensive coding principles.
- Know the difference between static and dynamic analysis of code.
- Know how to conduct a code/peer review.
- Be familiar with how to build the software with security protection mechanisms in place.
This chapter will cover each of these objectives in detail. It is imperative that you fully understand the objectives and be familiar with how to apply them in the software that your organization builds.
4.3 Who Is to Be Blamed for Insecure Software?
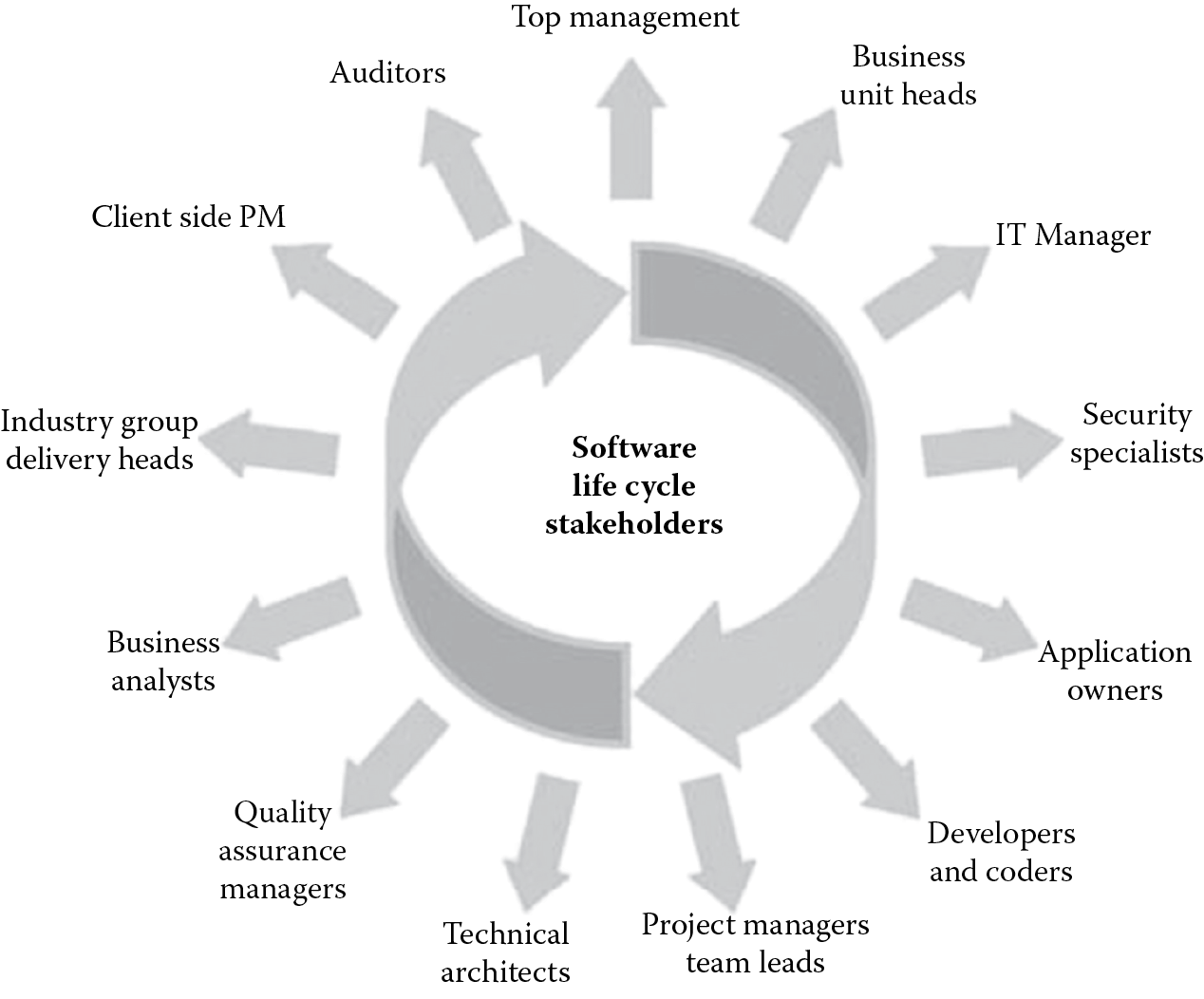
Although it may seem that the responsibility for insecure software lies primarily on the software developers who write the code, opinions vary, and the debate on who is ultimately responsible for a software breach is ongoing. Holding the coder solely responsible would be unreasonable since software is not developed in a silo. Software has many stakeholders, as depicted in Figure 4.1, and eventually all play a crucial role in the development of secure software. Ultimately, it is the organization (or company) that will be blamed for software security issues, and this state cannot be ignored.
4.4 Fundamental Concepts of Programming
Who is a programmer? What is their most important skill? A programmer is essentially someone who uses his/her technical know-how and skills to solve problems that the business has. The most important skills a programmer (used synonymously with a coder) has is problem solving. Programmers use their skills to construct business problem-solving programs (software) to automate manual processes, improving the efficiency of the business. They use programming languages to write programs. In the following section, we will learn about computer architecture, types of programming languages and code, and program utilities, such as assembler, compilers, and interpreters.
4.4.1 Computer Architecture
Most modern-day computers are primarily composed of the computer processor, system memory, and input/output (I/O) devices. Figure 4.2 depicts a simplified illustration of modern-day computer architecture.
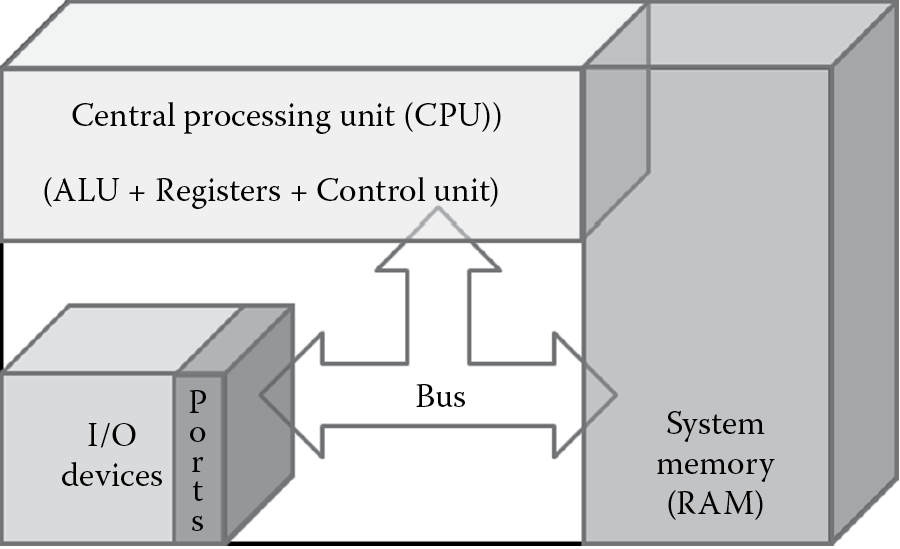
The computer processor is more commonly known as the central processing unit (CPU). The CPU is made up of the
- Arithmetic logic unit (ALU), which is a specialized circuit used to perform mathematical and logical operations on the data.
- Control unit, which acts as a mediator controlling processing instructions. The control unit itself does not execute any instructions, but instructs and directs other parts of the system, such as the registers, to do so.
- Registers, which are specialized internal memory holding spaces within the processor itself. These are temporary storage areas for instruction or data, and they provide the advantage of speed.
Because CPU registers have only limited memory space, memory is augmented by system memory and secondary storage devices, such as the hard disks, digital video disks (DVDs), compact disks (CDs), and USB keys/fobs. The system memory is also commonly known as random access memory (RAM). The RAM is the main component with which the CPU communicates. I/O devices are used by the computer system to interact with external interfaces. Some common examples of input devices include a keyboard, mouse, etc., and some common examples of output devices include the monitor, printers, etc. The communication between each of these components occurs via a gateway channel that is called the bus.
The CPU, at its most basic level of operation, processes data based on binary codes that are internally defined by the processor chip manufacturer. These instruction codes are made up of several operational codes called opcodes. These opcodes tell the CPU what functions it can perform. For a software program to run, it reads instruction codes and data stored in the computer system memory and performs the intended operation on the data. The first thing that needs to happen is for the instruction and data to be loaded on to the system memory from an input device or a secondary storage device. Once this happens, the CPU does the following four functions for each instruction:
- Fetching: The control unit gets the instruction from system memory.
- The instruction pointer is used by the processor to keep track of which instruction codes have been processed and which ones are to be processed subsequently. The data pointer keeps track of where the data are stored in the computer memory, i.e., it points to the memory address.
- Decoding: The control unit deciphers the instruction and directs the needed data to be moved from system memory onto the ALU.
- Execution: Control moves from the control unit to the ALU, and the ALU performs the mathematical or logical operation on the data.
- Storing: The ALU stores the result of the operation in memory or in a register. The control unit finally directs the memory to release the result to an output device or a secondary storage device.
The fetch–decode–execute–store cycle is also known as the machine cycle. A basic understanding of this process is necessary for a CSSLP because they need to be aware of what happens to the code written by a programmer at the machine level.
When the software program executes, the program allocates storage space in memory so that the program code and data can be loaded and processed as the programmer has intended it. The CPU registers are used to store the most immediate data; the compilers use the registers to cache frequently used function values and local variables that are defined in the source code of the program. However, since there are only a limited number of registers, most programs, especially the large ones, place their data values on the system memory (RAM) and use these values by referencing their unique addresses. Internal memory layout has the following segments: program text, data, stack, and heap, as depicted in Figure 4.3. Physically the stack and the heap are allocated areas on the RAM. The allocation of storage space in memory (also known as a memory object) is called instantiation. Program code uses the variables defined in the source code to access memory objects.
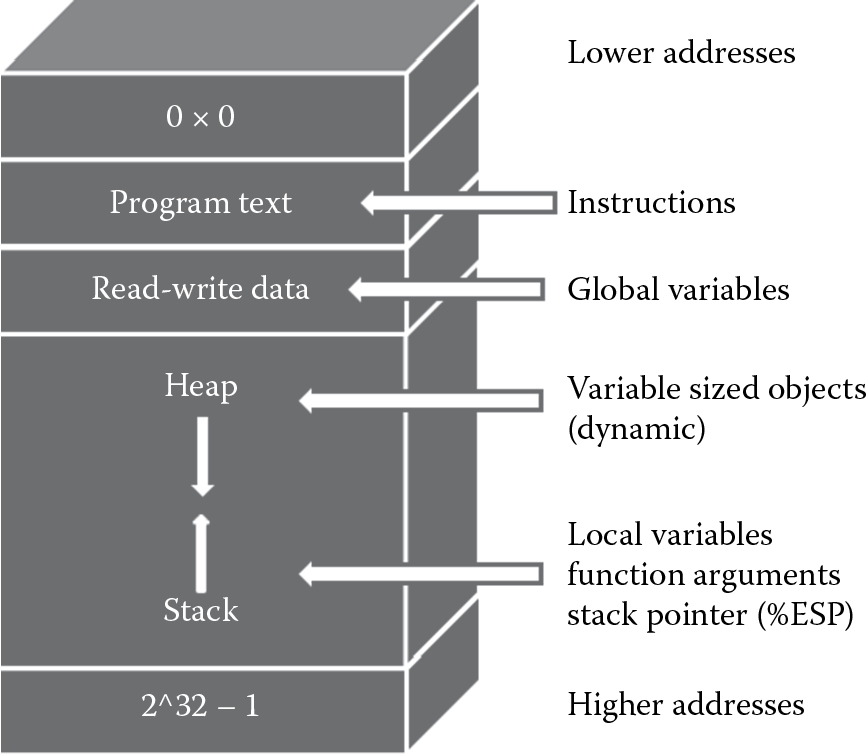
The series of execution instructions (program code) is contained in the program text segment. The next segment is the read–write data segment, which is the area in memory that contains both initialized and uninitialized global data. Function variables, local data, and some special register values, such as the execution stack pointer (ESP), are placed on the stack part of the RAM. The ESP points to the memory address location of the currently executing program function. Variable sized objects and objects that are too large to be placed on the stack are dynamically allocated on the heap part of the RAM. The heap provides the ability to run more than one process at a time, but for the most part with software, memory attacks on the stack are most prevalent.
The stack is an area of memory used to store function arguments and local variables, and it is allocated when a function in the source code is called to execute. When the function execution begins, space is allocated (pushed) on the stack, and when the function terminates, the allocated space is removed (popped off) the stack. This is known as the PUSH and POP operation. The stack is managed as a LIFO (last in, first out) data structure. This means that when a function is called, memory is first allocated in the higher addresses and used first. The PUSH direction is from higher memory addresses to lower memory addresses, and the POP direction is from lower memory addresses to higher memory addresses. This is important to understand because the ESP moves from higher memory to lower memory addresses, and, without proper management, serious security breaches can be evident.
Software hackers often have a thorough understanding of this machine cycle and how memory management happens, and without appropriate protection mechanisms in place, they can circumvent higher-level security controls by manipulating instruction and data pointers at the lowest level, as is the case with memory buffer overflow attacks and reverse engineering. These will be covered later in this chapter under the section about common software vulnerabilities and countermeasures.
4.4.2 Programming Languages
Knowledge of all the processor instruction codes can be extremely onerous on a programmer, if even humanly possible. Even an extremely simple program would require the programmer to write lines of code that manipulate data using opcodes, and in a fast-paced day and age where speed of delivery is critically important for the success of business, software programs, like any other product, cannot take an inordinate amount of time to create. To ease programmer’s effort and shorten the time to delivery of software development, simpler programming languages that abstract the raw processor instruction codes have been developed. There are many programming languages that exist today.
Software developers use a programming language to create programs, and they can choose a low-level programming language. A low-level programming language is closely related to the hardware (CPU) instruction codes. It offers little to no abstraction from the language that the machine understands, which is binary codes (0s and 1s). When there is no abstraction and the programmer writes code in 0s and 1s to manipulate data and processor instructions, which is a rarity, they are coding in machine language. However, the most common low-level programming language today is the assembly language, which offers little abstraction from the machine language using opcodes. Appendix C has a listing of the common opcodes used in assembly language for abstracting processor instruction codes in an Intel 80186 or higher microprocessor (CPU) chip. Machine language and assembly language are both examples of low-level programming languages. An assembler converts assembly code into machine code.
In contrast, high-level programming languages (HLL) isolate program execution instruction details and computer architecture semantics from the program’s functional specification itself. High-level programming languages abstract raw processor instruction codes into a notation that the programmer can easily understand. The specialized notation with which a programmer abstracts low-level instruction codes is called the syntax, and each programming language has its own syntax. This way, the programmer is focused on writing a code that addresses business requirements instead of being concerned with manipulating instruction and data pointers at the microprocessor level. This makes software development certainly simpler and the software program more easily understandable. It is, however, important to recognize that with the evolution of programming languages and integrated development environments (IDEs) and tools that facilitate the creation of software programs, even professionals lacking the internal knowledge of how their software program will execute at the machine level are now capable of developing software. This can be seriously damaging from a security standpoint because software creators may not necessarily understand or be aware of the protection mechanisms and controls that need to be developed and therefore inadvertently leave them out.
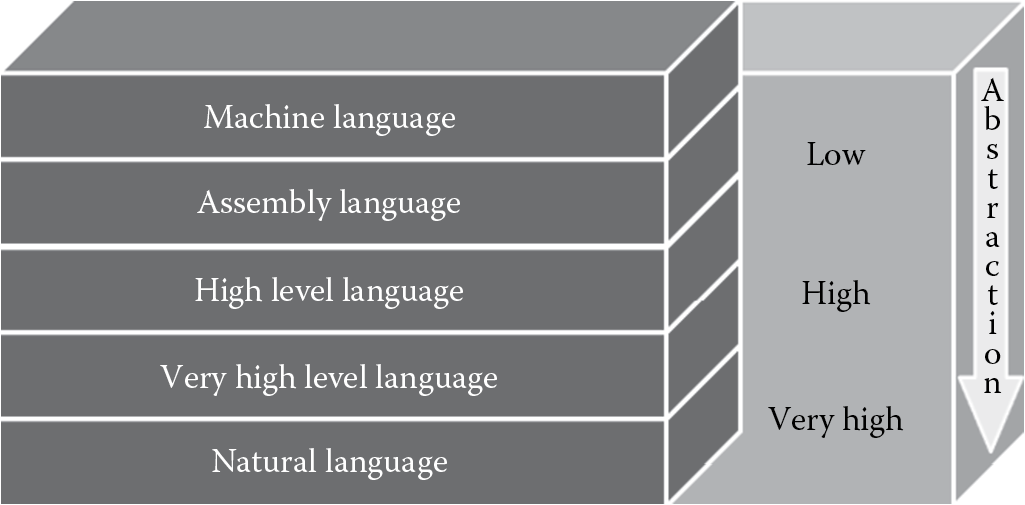
Today, the evolution of programming languages has given us goal-oriented programming languages that are also known as very high-level programming languages (VHLL). The level of abstraction in some of the VHLLs has been so increased that the syntax for programming in these VHLLs is like writing in English. Additionally, languages such as the natural language offer even greater abstraction and are based on solving problems using logic based on constraints given to the program instead of using the algorithms written in code by the software programmer. Natural languages are infrequently used in business settings and are also known as logic programming languages or constraint-based programming languages.
Figure 4.4 illustrates the evolution of programming languages from the low-level machine language to the VHLL natural language.
The syntax in which a programmer writes their program code is the source code. Source code needs to be converted into a set of instruction codes that the computer can understand and process. The code that the machine understands is the machine code, which is also known as native code. In some cases, instead of converting the source code into machine code, the source code is simply interpreted and run by a separate program. Depending on how the program is executed on the computer, HLL can be categorized into compiled languages and interpreted languages.
4.4.2.1 Compiled Languages
The predominant form of programming languages are compiled languages. Examples include COBOL, FORTRAN, BASIC, Pascal, C, C++, and Visual Basic. The source code that the programmer writes is converted into machine code. The conversion itself is a two-step process, as depicted in Figure 4.5, that includes two subprocesses: compilation and linking.
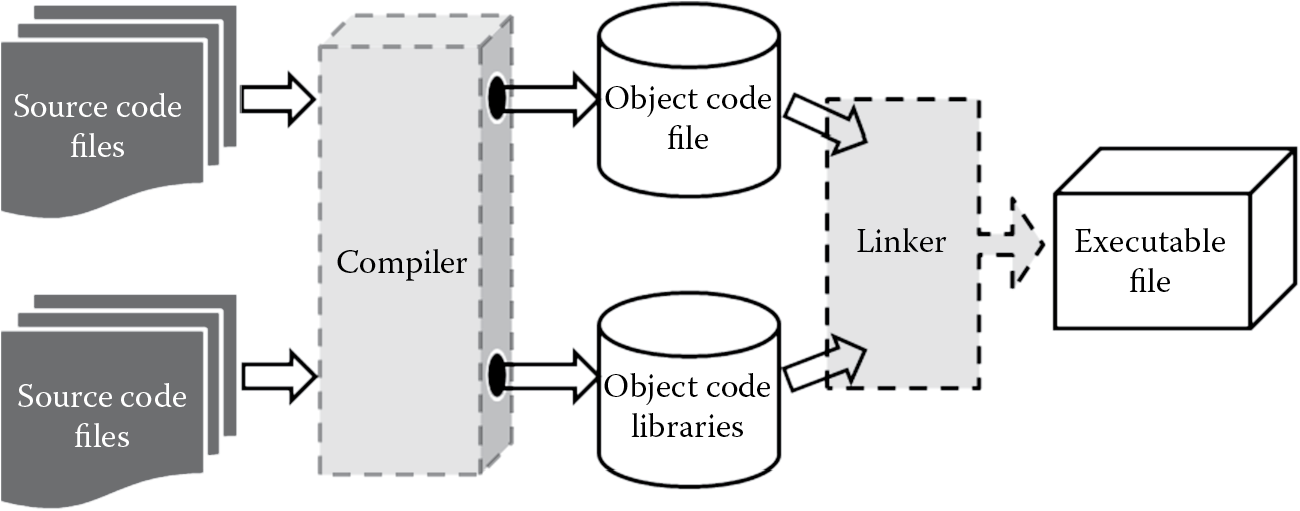
- Compilation: The process of converting textual source code written by the programmer into raw processor specific instruction codes. The output of the compilation process is called the object code, which is created by the compiler program. In short, compiled source code is the object code. The object code itself cannot be executed by the machine unless it has all the necessary code files and dependencies provided to the machine.
- Linking: The process of combining the necessary functions, variables, and dependencies files and libraries required for the machine to run the program. The output that results from the linking process is the executable program or machine code/file that machine can understand and process. In short, linked object code is the executable. Link editors that combine object codes are known as linkers. Upon the completion of the compilation process, the compiler invokes the linker to perform its function.
There are two types of linking: static linking and dynamic linking. When the linker copies all functions, variables, and libraries needed for the program to run into the executable itself, it is referred to as static linking. Static linking offers the benefit of faster processing speed and ease of portability and distribution because the required dependencies are present within the executable itself. However, based on the size and number of other dependencies files, the final executable can be bloated, and appropriate space considerations needs to be taken. Unlike static linking, in dynamic linking only the names and respective locations of the needed object code files are placed in the final executable, and actual linking does not happen until runtime, when both the executable and the library files are placed in memory. Although this requires less space, dynamically linked executables can face issues that relate to dependencies if they cannot be found at run time. Dynamic linking should be chosen only after careful consideration to security is given, especially if the linked object files are supplied from a remote location and are open source in nature. A hacker can maliciously corrupt a dependent library, and when they are linked at runtime, they can compromise all programs dependent on that library.
4.4.2.2 Interpreted Languages
While programs written in compiled languages can be directly run on the processor, interpreted languages require an intermediary host program to read and execute each statement of instruction line by line. The source code is not compiled or converted into processor-specific instruction codes. Common examples of interpreted languages include REXX, PostScript, Perl, Ruby, and Python. Programs written in interpreted languages are slower in execution speed, but they provide the benefit of quicker changes because there is no need for recompilation and relinking, as is the case with those written in compiled languages.
4.4.2.3 Hybrid Languages
To leverage the benefits provided by compiled languages and interpreted languages, there is also a combination (hybrid) of both compiled and interpreted languages. Here, the source code is compiled into an intermediate stage that resembles object code. The intermediate stage code is then interpreted as required. Java is a common example of a hybrid language. In Java, the intermediate stage code that results upon compilation of source code is known as the byte code. The byte code resembles processor instruction codes, but it cannot be executed as such. It requires an independent host program that runs on the computer to interpret the byte code, and the Java Virtual Machine (JVM) provides this for Java. In .Net programming languages, the source code is compiled into what is known as the common intermediate language (CIL), formerly known as Microsoft Intermediate Language (MSIL). At run time, the common language runtime’s (CLR) just in time compiler converts the CIL code into native code, which is then executed by the machine.
4.5 Software Development Methodologies
Software development is a structured and methodical process that requires the interplay of people expertise, processes, and technologies. The software development life cycle (SDLC) is often broken down into multiple phases that are either sequential or parallel. In this section, we will learn about the prevalent SDLC models that are used to develop software. These include:
- Waterfall model
- Iterative model
- Spiral model
- Agile development methodologies
4.5.1 Waterfall Model
The waterfall model is one of the most traditional software development models still in use today. It is a highly structured, linear, and sequentially phased process characterized by predefined phases, each of which must be completed before one can move on to the next phase. Just as water can flow in only one direction down a waterfall, once a phase in the waterfall model is completed, one cannot go back to that phase. Winston W. Royce’s original waterfall model from 1970 has the following order of phases:
- Requirements specification
- Design
- Construction (also known as implementation or coding)
- Integration
- Testing and debugging (also known as verification)
- Installation
- Maintenance
The waterfall model is useful for large-scale software projects because it brings structure by phases to the software development process. The National Institute of Standards and Technology (NIST) Special Publication 800-64 REV 1d, covering Security Considerations in the Information Systems Development Life Cycle, breaks the linear waterfall SDLC model into five generic phases: initiation, acquisition/development, implementation/assessment, operations/maintenance, and sunset (Figure 4.6). Today, there are several other modified versions of the original waterfall model that include different phases with slight or major variations, but the definitive characteristic of each is the unidirectional sequential phased approach to software development.
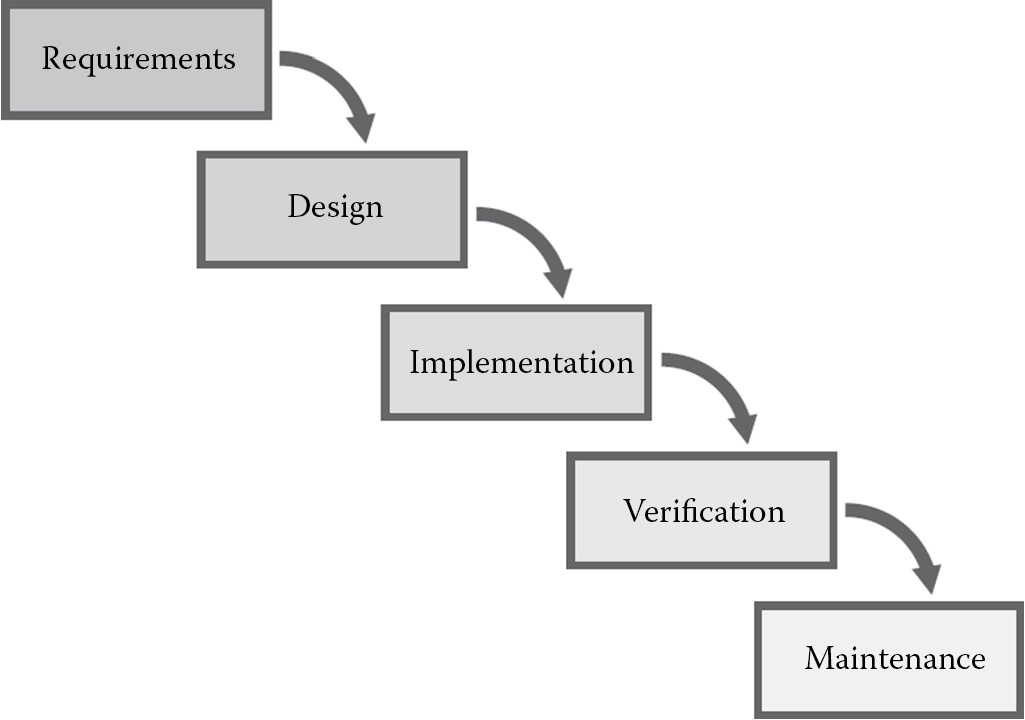
From a security standpoint, it is important to ensure that the security requirements are part of the requirements phase. Incorporating any missed security requirements at a later point in time will result in additional costs and delays to the project.
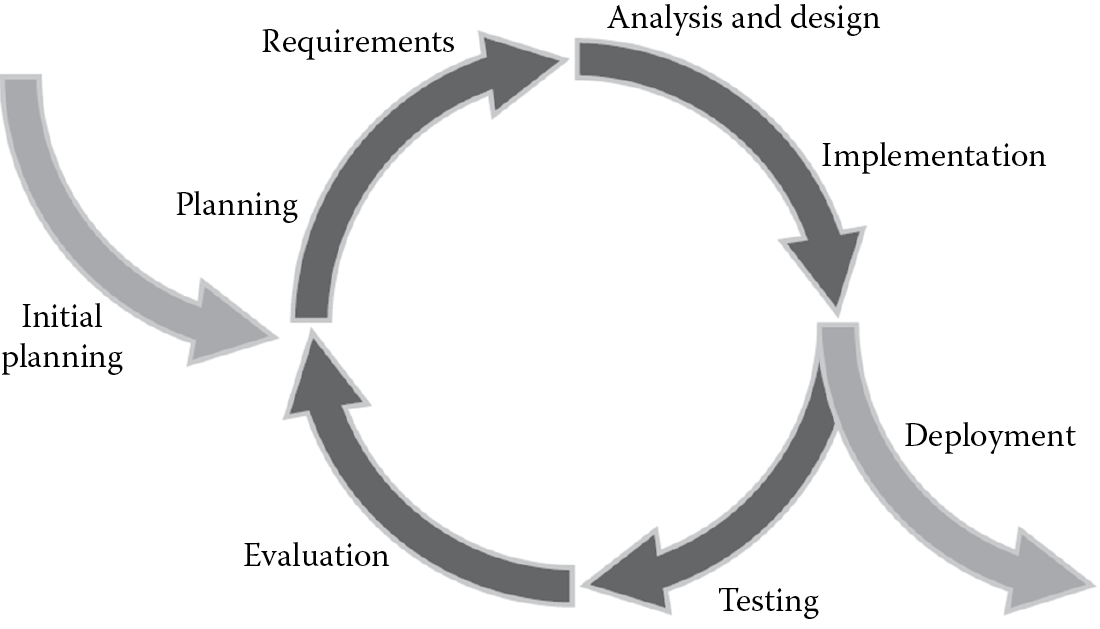
4.5.2 Iterative Model
In the iterative model of software development, the project is broken into smaller versions and developed incrementally, as illustrated in Figure 4.7. This allows the development effort to be aligned with the business requirements, uncovering any important issues early in the project and therefore avoiding disastrous faulty assumptions. It is also commonly referred to as the prototyping model in which each version is a prototype of the final release to manufacturing (RTM) version. Prototypes can be built to clarify requirements and then discarded, or they may evolve into the final RTM version. The primary advantage of this model is that it offers increased user input opportunity to the customer or business, which can prove useful to solidify the requirements as expected before investing a lot of time, effort, and resources. However, it must be recognized that if the planning cycles are too short, nonfunctional requirements, especially security requirements, can be missed. If it is too long, then the project can suffer from analysis paralysis and excessive implementation of the prototype.
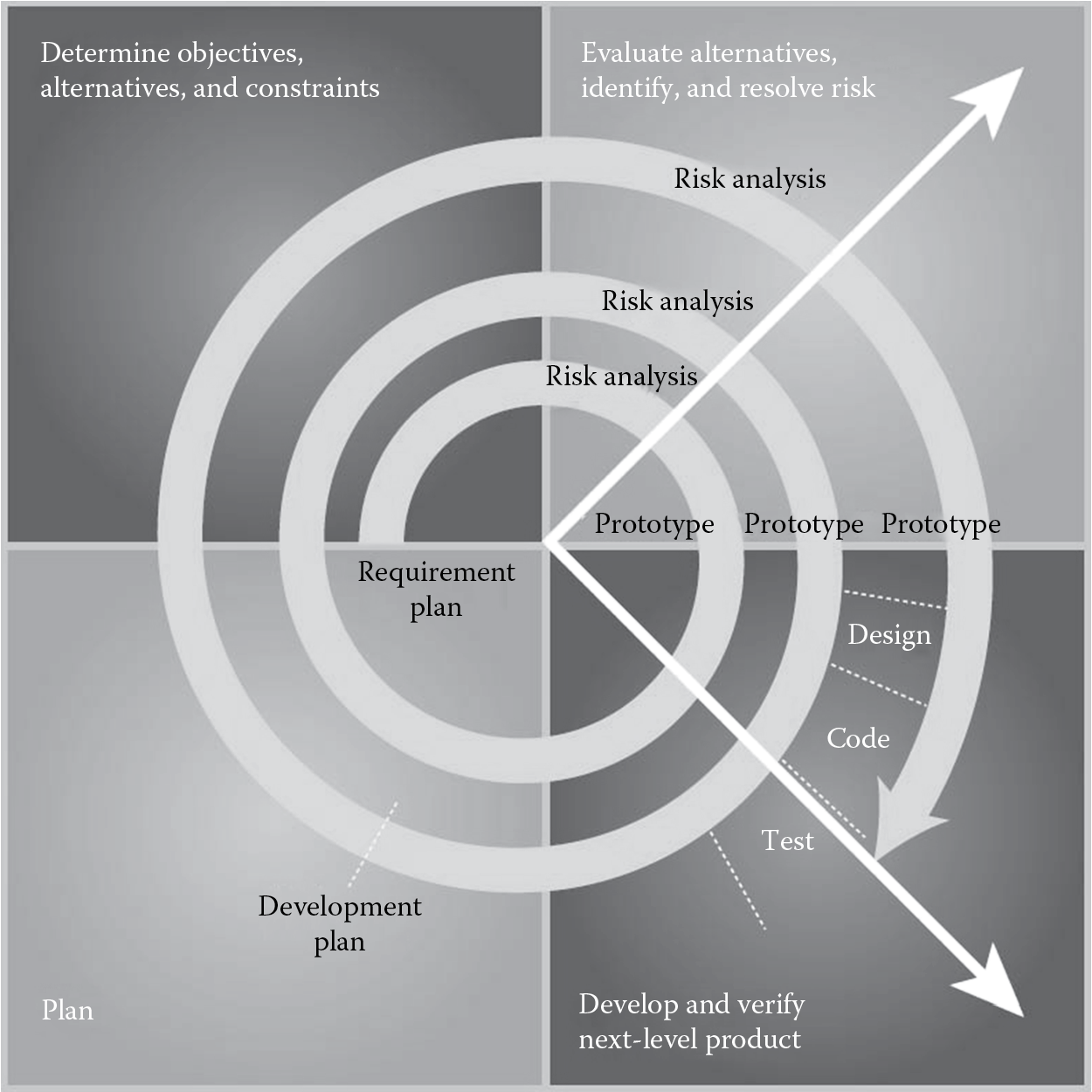
4.5.3 Spiral Model
The spiral model, as shown in Figure 4.8, is a software development model with elements of both the waterfall model and the prototyping model, generally used for larger projects. The key characteristic of this model is that each phase has a risk assessment review activity. The risk of not completing the software development project within the constraints of cost and time is estimated, and the results of the risk assessment activity are used to find out if the project needs to be continued or not. This way, should the success of completing the project be determined as questionable, then the project team has the opportunity to cut the losses before investing more into the project.
4.5.4 Agile Development Methodologies
Agile development methodologies are gaining a lot of acceptance today, and most organizations are embracing them for their software development projects. Agile development methodologies are built on the foundation of iterative development with the goal of minimizing software development project failure rates by developing the software in multiple repetitions (iterations) and small timeframes (called timeboxes). Each iteration includes the full SDLC. The primary benefit of agile development methodologies is that changes can be made quickly. This approach uses feedback driven by regular tests and releases of the evolving software as its primary control mechanism, instead of planning in the case of the spiral model.
The two main agile development methodologies include:
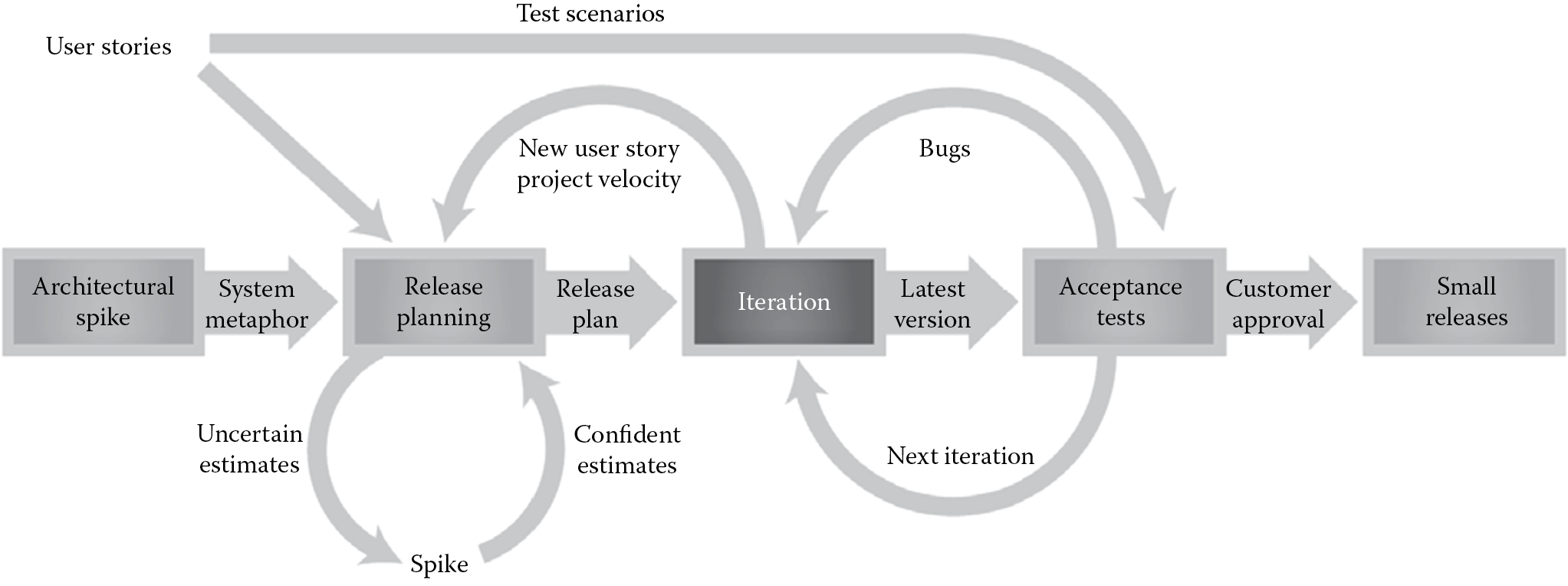
- Extreme Programming (XP) model: The XP model is also referred to as the “people-centric” model of programming and is useful for smaller projects. It is a structured process, as depicted in Figure 4.9, that storyboards and architects user requirements in iterations and validates the requirements using acceptance testing. Upon acceptance and customer approval, the software is released. Success factors for the XP model are: (1) starting with the simplest solutions and (2) communication between team members. Some of the other distinguishing characteristics of XP are adaptability to change, incremental implementation of updates, feedback from both the system and the business user or customer, and respect and courage for all who are part of the project.
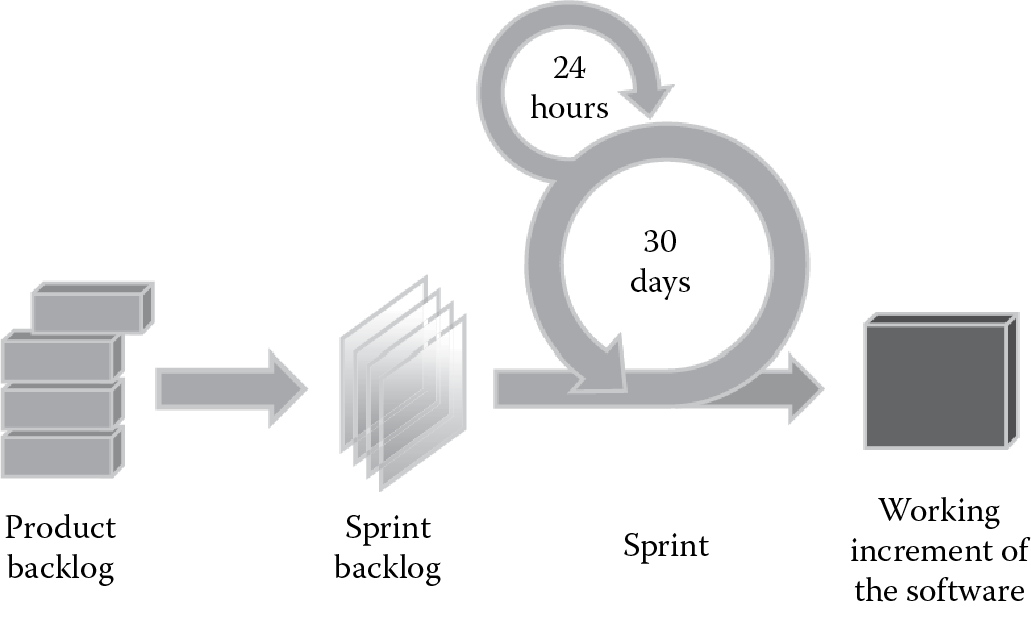
- Scrum: Another recent, very popular, and widely used agile development methodology is the Scrum programming approach. The Scrum approach calls for 30-day release cycles to allow the requirements to be changed on the fly, as necessary. In Scrum methodology, the software is kept in a constant state of readiness for release, as shown in Figure 4.10. The participants in Scrum have predefined roles of two types depending on their level of commitment: pig roles (those who are committed, whose bacon is on the line) and chicken roles (those who are part of the Scrum team participating in the project). Pig roles include the Scrum master who functions like a project manager in regular projects, the product owner who represents the stakeholders and is the voice of the customer, and the team of developers. The team size is usually between five and nine for effective communication. Chicken roles include the users who will use the software being developed, the stakeholders (the customer or vendor), and other managers. A prioritized list of high level requirements is first developed known as a product backlog. The time allowed for development of the product backlog, usually about 30 days, is called a sprint. The list of tasks to be completed during a sprint is called the sprint backlog. A daily progress for a sprint is recorded for review in the artifact known as the burn down chart.
4.5.5 Which Model Should We Choose?
In reality, the most conducive model for enterprise software development is usually a combination of two or more of these models. It is important, however, to realize that no model or combination of models can create inherently secure software. For software to be securely designed, developed, and deployed, a minimum set of security tasks needs to be effectively incorporated into the system development process, and the points of building security into the SDLC model should be identified.
4.6 Common Software Vulnerabilities and Controls
Although secure software is the result of a confluence between people, process, and technology, in this chapter, we will primarily focus on the technology and process aspects of writing secure code. We will learn about the most common vulnerabilities that result from insecure coding, how an attacker can exploit those vulnerabilities, and the anatomy of the attack itself. We will also discuss security controls that must be put in place (in the code) to resist and thwart actions of threat agents.
Nowadays, most of the reported incidents of security breaches seem to have one thing in common: they are attacks that exploited some weakness in the software layer. Analysis of the breaches invariably indicates one of the following to be the root cause of the breach: design flaws, coding (implementation) issues, and improper configuration and operations, with the prevalence of attacks exploiting software coding weaknesses. The Open Web Application Security Project (OWASP) Top 10 List and the Common Weakness Enumeration (CWE/SANS) Top 25 List of the most dangerous programming errors are testaments to the fact that software programming has a lot to do with its security. The 2010 OWASP Top 10 List, in addition to considering the most common application security issues from a weaknesses or vulnerabilities perspective (as did the 2004 and 2007 versions), views application security issues from an organizational risks (technical risk and business impact) perspective, as tabulated in Table 4.1. The 2009 CWE/SANS Top 25 List of the most dangerous programming errors is shown in Table 4.2.
The 2009 CWE/SANS Top 25 List of the most dangerous programming errors falls into the following three categories:
- Insecure interaction between components: includes weaknesses that relate to insecure ways in which data are sent and received between separate components, modules, programs, process, threads, or systems.
- Risky resource management: includes weaknesses that relate to ways in which software does not properly manage the creation, usage, transfer, or destruction of important system resources.
- Porous defenses: includes weaknesses that relate to defensive techniques that are often misused, abused, or just plain ignored.
The categorization of the 2009 CWE/SANS Top 25 List of most dangerous programming errors is shown in Table 4.3.
It is recommended that you visit the respective Web sites for the OWASP Top 10 List and the CWE/SANS Top 25 List, as a CSSLP is expected to be familiar with programming issues that can lead to security breaches and know how to address them. The most common software security vulnerabilities and risks are covered in the following section. Each vulnerability or risk is first described as to what it is and how it occurs and is followed by a discussion of security controls that can be implemented to mitigate it.
4.6.1 Injection Flaws
|
OWASP Top 10 Rank |
1 |
|
CWE Top 25 Rank |
2, 9 |
Considered one of the most prevalent software (or application) security weaknesses, injection flaws occur when the user-supplied data are not validated before being processed by an interpreter. The attacker supplies data that are accepted as they are and interpreted as a command or part of a command, thus allowing the attacker to execute commands using any injection vector. Almost any data accepting source are a potential injection vector if the data are not validated before they are processed. Common examples of injection vectors include QueryStrings, form input, and applets in Web applications. Injection flaws are easily discoverable using code review, and scanners, including fuzzing scans, can be used to detect them. There are several different types of injection attacks.
The most common injection flaws include SQL injection, OS command injection, LDAP injection, and XML injection.
- SQL Injection
This is probably the most well-known form of injection attack, as the databases that store business data are becoming the prime target for attackers. In SQL (Structured Query Language) injection, attackers exploit the way in which database queries are constructed. They supply input that, if not sanitized or validated, becomes part of the query that the database processes as a command. Let us consider an example of a vulnerable code implementation in which the query command text (sSQLQuery) is dynamically built using data supplied from text input fields (txtUserID and txtPassword) from the Web form.
string sSQLQuery = “ SELECT * FROM USERS WHERE user_id = ‘ ” + txtUserID.Text + ” ‘ AND user_password = ‘ ” + txtPassword.Text + ” ‘
If the attacker supplies ‘ OR 1=1 -- as the txtUserID value, then the SQL Query command text that is generated is as follows:
string sSQLQuery = “ SELECT * FROM USERS WHERE user_id = ‘ ” + ‘ OR 1=1 - - + ” ‘ AND user_password = ‘ ” + txtPassword.Text + ” ‘
This results in SQL syntax, as shown below, that the interpreter will evaluate and execute as a valid SQL command. Everything after the -- in T-SQL is ignored.
SELECT * FROM USERS WHERE user_id = ‘ ’ OR 1=1 - -
The attack flow in SQL injection comprises the following steps:
- Exploration by hypothesizing SQL queries to determine if the software is susceptible to SQL injection
- Experimenting to enumerate internal database schema by forcing database errors
- Exploiting the SQL injection vulnerability to bypass checks or modify, add, retrieve, or delete data from the database
Upon determining that the application is susceptible to SQL injection, an attacker will attempt to force the database to respond with messages that potentially disclose internal database structure and values by passing in SQL commands that cause the database to error. Suppressing database error messages considerably thwarts SQL injection attacks, but it has been proven that this control measure is not sufficient to prevent SQL injection completely. Attackers have found a way to go around the use of error messages for constructing their SQL commands, as is evident in the variant of SQL injection known as blind SQL injection. In blind SQL injection, instead of using information from error messages to facilitate SQL injection, the attacker constructs simple Boolean SQL expressions (true/false questions) to probe the target database iteratively. Depending on whether the query was successfully executed, the attacker can determine the syntax and structure of the injection. The attacker can also note the response time to a query with a logically true condition and one with a false condition and use that information to determine if a query executes successfully or not.
- OS Command Injection
This works in the same principle as the other injection attacks where the command string is generated dynamically using input supplied by the user. When the software allows the execution of operation system (OS) level commands using the supplied user input without sanitization or validation, it is said to be susceptible to OS Command injection. This could be seriously devastating to the business if the principle of least privilege is not designed into the environment that is being compromised. The two main types of OS Command injection are as follows:
- The software accepts arguments from the user to execute a single fixed program command. In such cases, the injection is contained only to the command that is allowed to execute, and the attacker can change the input but not the command itself. Here, the programming error is that the programmer assumes that the input supplied by users to be part of the arguments in the command to be executed will be trustworthy as intended and not malicious.
- The software accepts arguments from the user that specify what program command they would like the system to execute. This is a lot more serious than the previous case, because now the attacker can chain multiple commands and do some serious damage to the system by executing their own commands that the system supports. Here, the programming error is that the programmer assumes that the command itself will not be accessible to untrusted users.
An example of an OS Command injection that an attacker supplies as the value of a QueryString parameter to execute the bin/ls command to list all files in the “bin” directory is given below:
http://www.mycompany.com/sensitive/cgi-bin/userData.pl?doc=%20%3B%20/bin/ls%20-l %20 decodes to a space and %3B decodes to a ; and the command that is executed will be /bin/ls -l listing the contents of the program’s working directory.
- LDAP Injection
LDAP is used to store information about users, hosts, and other objects. LDAP injection works on the same principle as SQL injection and OS command injection. Unsanitized and unvalidated input is used to construct or modify syntax, contents, and commands that are executed as an LDAP query. Compromise can lead to the disclosure of sensitive and private information as well as manipulation of content within the LDAP tree (hierarchical) structure. Say you have the ldap query (_sldapQuery) built dynamically using the user-supplied input (userName) without any validation, as shown in the example below.
String _sldapQuery = ’’ (cn=’’ + $userName + ’’) ’ ’;
If the attacker supplies the wildcard ‘*”, information about all users listed in the directory will be disclosed. If the user supplies the value such as ‘’‘’sjohnson) (|password=*))‘’, the execution of the LDAP query will yield the password for the user sjohnson.
- XML Injection
XML injection occurs when the software does not properly filter or quote special characters or reserved words that are used in XML, allowing an attacker to modify the syntax, contents, or commands before execution. The two main types of XML injection are as follows:
- XPATH injection
- XQuery injection
In XPATH injection, the XPath expression used to retrieve data from the XML data store is not validated or sanitized before processing and built dynamically using user-supplied input. The structure of the query can thus be controlled by the user, and an attacker can take advantage of this weakness by injecting malformed XML expressions to perform malicious operations, such as modifying and controlling logic flow, retrieving unauthorized data, and circumventing authentication checks. XQuery injection works the same way as an XPath injection, except that the XQuery (not XPath) expression used to retrieve data from the XML data store is not validated or sanitized before processing and built dynamically using user-supplied input.
Consider the following XML document (accounts.xml) that stores the account information and pin numbers of customers and a snippet of Java code that uses XPath query to retrieve authentication information:
<customers>
<customer>
<user_name>andrew</user_name>
<accountnum>1234987655551379</accountnum>
<pin>2358</pin>
<homepage>/home/astrout</homepage>
</customer>
<customer>
<user_name>dave</user_name>
<accountnum>9865124576149436</accountnum>
<pin>7523</pin>
<homepage>/home/dclarke</homepage>
</customer>
</customers>
The Java code used to retrieve the home directory based on the provided credentials is:
XPath xpath = XPathFactory.newInstance().newXPath();
XPathExpression xPathExp = xpath.compile(“//customers/customer[user_name/text()=’” + login.getUserName() + “’ and pin/text() = ‘” + login.getPIN() + “’]/homepage/text()”);
Document doc = DocumentBuilderFactory.newInstance() .newDocumentBuilder().parse(new File(“accounts.xml”));
String homepage = xPathExp.evaluate(doc);
By passing in the value “andrew” into the getUserName() method and the value “’ or ‘’=’” into the getPIN() method call, the XPath expression becomes
//customers/customer[user_name/text()=’andrew’ or ‘’=’’ and pin/text() = ‘’ or ‘’=’’]/hompage/text()
This will allow the user logging in as andrew to bypass authentication without supplying a valid PIN.
Regardless of whether an injection flaw exploits a database, OS command, a directory protocol and structure, or a document, they are all characterized by one or more of the following traits:
- User-supplied input is interpreted as a command or part of a command that is executed. In other words, data are misunderstood by the interpreter as code.
- Input from the user is not sanitized or validated before processing.
- The query that is constructed is generated using user-supplied input dynamically.
The consequences of injection flaws are varied and serious. The most common ones include:
- Disclosed, altered, or destroyed data
- Compromise of the operating system
- Discovery of the internal structure (or schema) of the database or data store
- Enumeration of user accounts from a directory store
- Circumvention of nested firewalls
- Execution of extended procedures and privileged commands
- Bypass of authentication
4.6.1.1 Injection Flaws Controls
Commonly used mitigation and prevention strategies and controls for injection flaws are as follows:
- Consider all input to be untrusted and validate all user input. Sanitize and filter input using a whitelist of allowable characters and their noncanonical forms. Although using a blacklist of disallowed characters can be useful in detecting potential attacks or determining malformed inputs, sole reliance on blacklists can prove to be insufficient, as the attacker can try variations and alternate representations of the blacklist form. Validation must be performed on both the client and server side, or at least on the server side, so that attackers cannot simply bypass client-side validation checks and still perform injection attacks. User input must be validated for data type, range, length, format, values, and canonical representations. SQL keywords such as union, select, insert, update, delete, and drop must be filtered in addition to characters such as single-quote (‘) or SQL comments (--) based on the context. Input validation should be one of the first lines of defense in an in-depth strategy for preventing or mitigating injection attacks, as it significantly reduces the attack surface.
- Encode output using the appropriate character set, escape special characters, and quote input, besides disallowing meta-characters. In some cases, when the input needs to be collected from various sources and is required to support free-form text, then the input cannot be constrained for business reasons, this may be the only effective solution to preventing injection attacks. Additionally, it provides protection even when some input sources are not covered with input validation checks.
- Use structured mechanisms to separate data from code.
- Avoid dynamic query (SQL, LDAP, XPATH Expression or XQuery) construction.
- Use a safe application programming interface (API) that avoids the use of the interpreter entirely or that provides escape syntax for the interpreter to escape special characters. A well-known example is the ESAPI published by OWASP.
- Just using parameterized queries (stored procedures or prepared statements) does not guarantee that the software is no longer susceptible to injection attacks. When using parameterized queries, make sure that the design of the parameterized queries truly accepts the user-supplied input as parameters and not the query itself as a parameter that will be executed without any further validation.
- Display generic error messages that yield minimal to no additional information.
- Implement failsafe by redirecting all errors to a generic error page and logging it for later review.
- Remove any unused, unnecessary functions or procedures from the database server. Remove all extended procedures that will allow a user to run system commands.
- Implement least privilege by using views, restricting tables, queries, and procedures to only the authorized set of users and/or accounts. The database users should be authorized to have only the minimum rights necessary to use their account. Using datareader, datawriter accounts as opposed to a database owner (dbo) account when accessing the database from the software is a recommended option.
- Audit and log the executed queries along with their response times to detect injection attacks, especially blind injection attacks.
- To mitigate OS command injection, run the code in a sandbox environment that enforces strict boundaries between the processes being executed and the operating system. Some examples include the Linux AppArmor and the Unix chroot jail. Managed code is also known to provide some degree of sandboxing protection.
- Use runtime policy enforcement to create the list of allowable commands (whitelist) and reject any command that does not match the whitelist.
- When having to implement defenses against LDAP injection attacks, the best method to handle user input properly is to filter or quote LDAP syntax from user-controlled input. This is dependent on whether the user input is used to create the distinguish name (DN) or used as part of the search filter text. When the input is used to create the DN, the backslash () escape method can be used, and when the input is used as part of the search filter, the ASCII equivalent of the character being escaped needs to be used. Table 4.4 lists the characters that need to be escaped and their respective escape method. It is important to ensure that the escaping method takes into consideration the alternate representations of the canonical form of user input.
In the event that the code cannot be fixed, using an application layer firewall to detect injection attacks can be a compensating control.
LDAP Mitigation Character Escaping
|
User input used |
Character(s) |
Escape sequence substitute |
|
To create DN |
&, !, |, =, <, >, +,−,’’, ‘ , ; , and comma (,) |
|
|
As part of search filter |
( |
28 |
|
) |
29 |
|
|
5c |
||
|
/ |
2f |
|
|
* |
2a |
|
|
NUL |
�0 |
4.6.2 Cross-Site Scripting (XSS)
|
OWASP Top 10 Rank |
2 |
|
CWE Top 25 Rank |
1 |
Injection flaws and cross-site scripting (XSS) can arguably be considered as the two most frequently exploitable weaknesses prevalent in software today. Some experts refer to these two flaws as a “1-2 punch,” as shown by the OWASP and CWE ranking.
XSS is the most prevalent Web application security attack today. A Web application is said to be susceptible to XSS vulnerability when the user-supplied input is sent back to the browser client without being properly validated and its content escaped. An attacker will provide a script (hence the scripting part) instead of a legitimate value, and that script, if not escaped before being sent to the client, gets executed. Any input source can be the attack vector, and the threat agents include anyone who has access to supplying input. Code review and testing can be used to detect XSS vulnerabilities in software.
The three main types of XSS are:
- Nonpersistent or reflected XSS
As the name indicates, nonpersistent or reflected XSS are attacks in which the user-supplied input script that is injected (also referred to as payload) is not stored, but merely included in the response from the Web server, either in the results of a search or as an error message. There are two primary ways in which the attacker can inject their malicious script. One is that they provide the input script directly into your Web application. The other way is that they can send a link with the script embedded and hidden in it. When a user clicks the link, the injected script takes advantage of the vulnerable Web server, which reflects the script back to the user’s browser, where it is executed.
- Persistent or stored XSS
Persistent or stored XSS is characterized by the fact that the injected script is permanently stored on the target servers, in a database, a message forum, a visitor log, or an input field. Each time the victims visit the page that has the injected code stored in it or served to it from the Web server, the payload script executes in the user’s browser. The infamous Samy Worm and the Flash worm are well-known examples of a persistent or stored XSS attack.
- DOM-based XSS
DOM-based XSS is an XSS attack in which the payload is executed in the victim’s browser as a result of DOM environment modifications on the client side. The HTTP response (or the Web page) itself is not modified, but weaknesses in the client side allow the code contained in the Web page client to be modified so that the payload can be executed. This is strikingly different from the nonpersistent (or reflected) and the persistent (or stored) XSS versions because, in these cases, the attack payload is placed in the response page due to weaknesses on the server side.
The consequences of a successful XSS attack are varied and serious. Attackers can execute script in the victim’s browser and:
- Steal authentication information using the Web application.
- Hijack and compromise users’ sessions and accounts.
- Tamper or poison state management and authentication cookies.
- Cause denial of service (DoS) by defacing the Web sites and redirecting users.
- Insert hostile content.
- Change user settings.
- Phish and steal sensitive information using embedded links.
- Impersonate a genuine user.
- Hijack the user’s browser using malware.
4.6.2.1 XSS Controls
Controls against XSS attacks include the following defensive strategies and implementations:
- Handle the output to the client by either using escaping sequences or encoding. This can be considered as the best way to protect against XSS attacks in conjunction with input validation. Escaping all untrusted data based on the HTML context (body, attribute, JavaScript, CSS, or URL) is the preferred option. Additionally, setting the appropriate character encoding and encoding user-supplied input renders the payload that the attacker injects as script into text-based output that the browser will merely read and not execute.
- Validating user-supplied input with a whitelist also provides additional protection against XSS. All headers, cookies, URL querystring values, form fields, and hidden fields must be validated. This validation should decode any encoded input and then validate the length, characters, format, and any business rules on the data before accepting the input. Each of the requests made to the server should be validated as well. In .Net, when the validateRequest flag is configured at the application, Web, or page level, as depicted in Figure 4.11, any unencoded script tag sent to the server is flagged as a potentially dangerous request to the server and is not processed.
- Disallow the upload of .htm or .html extensions.
- Use the innerText properties of HTML controls instead of the innetHtml property when storing the input supplied, so that when this information is reflected back on the browser client, the data renders the output to be processed by the browser as literal and as nonexecutable content instead of executable scripts.
- Use secure libraries and encoding frameworks that provide protection against XSS issues. The Microsoft Anti-Cross-Site Scripting, OWASP ESAPI Encoding module, Apache Wicket, and SAP Output Encoding framework are well-known examples.
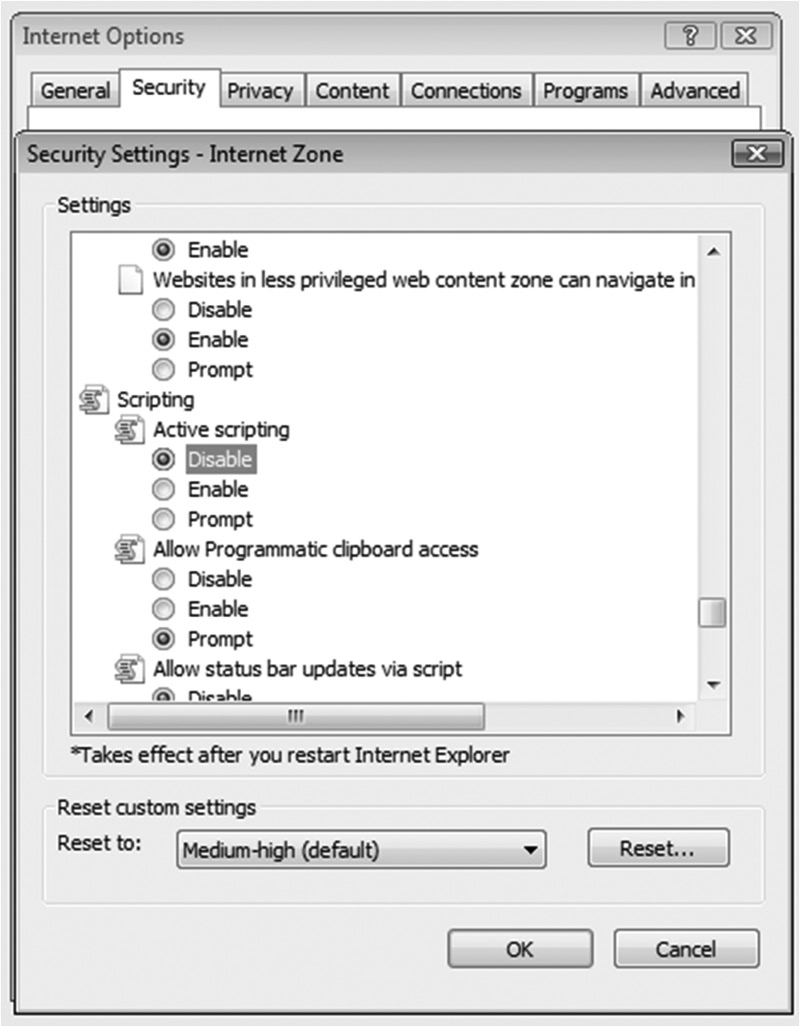
- The client can be secured by disabling the active scripting option in the browser so that scripts are not automatically executed on the browser. Figure 4.12 shows the configuration options for active scripting in the Internet Explorer browser. It is also advisable to install add-on plugins that will prevent the execution of scripts on the browser unless permissions are explicitly granted to run them. NoScript is a popular add-on for the Mozilla Firefox browser.
- Use the HTTPOnly flag on the session or any custom cookie so that the cookie cannot be accessed by any client-side code or script (if the browser supports it), which mitigates XSS attacks. However, if the browser does not support HTTPOnly cookies, then even if you have set the HTTPOnly flag in the Set-Cookie HTTP response header, this flag is ignored, and the cookie may still be susceptible to malicious script modifications and theft. Additionally, with the prevalence in Web 2.0 technologies, primarily Asynchronous JavaScript and XML (AJAX), the XMLHTTPRequest offers read access to HTTP headers, including the Set-Cookie HTTP response header.
- An application layer firewall can be useful against XSS attacks, but one must recognize that although this may not be preventive in nature, it is useful when the code cannot be fixed (as in the case of a third-party component).
4.6.3 Buffer Overflow
|
OWASP Top 10 Rank |
N/A |
|
CWE Top 25 Rank |
3, 12, 14, 17, 18 |

Historically, one of the most dangerous and serious attacks against software has been buffer overflow attacks. To understand what constitutes a buffer overflow, it is first important that you understand how program execution and memory management work. This was covered earlier in Section 4.4.1.
A buffer overflow is the condition that occurs when data being copied into the buffer (contiguous allocated storage space in memory) are more than what the buffer can handle. This means that the length of the data being copied is equal to (in languages that need a byte for the NULL terminator) or is greater than the byte count of the buffer. The two types of buffer overflows are:
- Stack overflow
A stack overflow occurs when the memory buffer has been overflowed in the stack space. When the software program runs, the executing instructions are placed on the program text segment of the RAM, global variables are placed on the read–write data section of the RAM, and the data (local variables, function arguments) and ESP register value that is necessary for the function to complete is pushed on to the stack (unless the datum is a variable sized object, in which case it is placed in the heap). As the program runs in memory, it calls each function sequentially and pushes that function’s data on the stack from higher address space to lower address space, creating a chain of functions to be executed in the order the programmer intended. Upon completion of a function, that function and its associated data are popped off the stack, and the program continues to execute the next function in the chain.
But how does the program know which function it should execute and which function it should go to once the current function has completed its operation? The ESP register (introduced earlier) tells the program which function it should execute. Another special register within the CPU is the execution instruction counter (EIP), which is used to maintain the sequence order of functions and indicates the address of the next instruction to be executed. This is the return address (RET) of the function. The return address is also placed on the stack when a function is called, and the protection of the return address from being improperly overwritten is critical from a security standpoint. If a malicious user manages to overwrite the return address to point to an address space in memory, where an exploit code (also known as payload) has been injected, then upon the completion of a function, the overwritten (tainted) return address will be loaded into the EIP register, and program execution will be overflowed, potentially executing the malicious payload.
The use of unsafe functions such as strcpy() and strcat() can result in stack overflows, since they do not intrinsically perform length checks before copying data into the memory buffer.
- Heap overflow
As opposed to a stack overflow, in which data flows from one buffer space into another, causing the return address instruction pointer to be overwritten, a heap overflow does not necessarily overflow, but corrupts the heap memory space (buffer), overwriting variables and function pointers on the heap. The corrupted heap memory may or may not be usable or exploitable. A heap overflow is not really an overflow, but rather a corruption of heap memory, and variable sized objects or objects too large to be pushed on the stack are dynamically allocated on the heap. Allocation of heap memory usually requires special function operators, such as malloc() (ANSI C), HeapAlloc() (Windows), and new() (C++), and deallocation of heap memory uses other special function operators, such as free(), HeapFree(), and delete(). Since no intrinsic controls on allocated memory boundaries exist, it is possible to overwrite adjacent memory chunks if there is no validation of size coded by the programmer. Exploitation of the heap space requires many more requirements to be met than is the case with stack overflow. Nonetheless, heap corruption can cause serious side effects, including DoS and exploit code execution, and protection mechanisms must not be ignored.
Any one of the following reasons can be attributed to causing buffer overflows:
- Copying of data into the buffer without checking the size of input.
- Accessing the buffer with incorrect length values.
- Improper validation of array (simplest expression of a buffer) index: When proper out-of-bounds array index checks are not conducted, reference indices in array buffers that do not exist will throw an out-of-bounds exception and can potentially cause overflows.
- Integer overflows or wraparounds: When checks are not performed to ensure that numeric inputs are within the expected range (maximum and minimum values), then overflow of integers can occur, resulting in faulty calculations, infinite loops, and arbitrary code execution.
- Incorrect calculation of buffer size before its allocation: Overflows can result if the software program does not accurately calculate the size of the data that will be input into the buffer space that it is going to allocate. Without this size check, the buffer size allocated may be insufficient to handle the data being copied into it.
4.6.3.1 Buffer Overflow Controls
Regardless of what causes a buffer overflow or whether a buffer overflow is on the stack or on the heap memory buffer, the one thing common in software susceptible to overflow attacks is that the program does not perform appropriate size checks of the input data. Input size validation is the number one implementation (programming) defense against buffer overflow attacks. Double-checking buffer size to ensure that the buffer is sufficiently large enough to handle the input data copied into it, checking buffer boundaries to make sure that the functions in a loop do not attempt to write past the allocated space, and performing integer type (size, precision, signed/unsigned) checks to make sure that they are within the expected range and values are other defensive implementations of controls in code.
Some programs are written to truncate the input string to a specified length before reading them into a buffer, but when this is done, careful attention must be given to ensure that the integrity of the data is not compromised.
In addition to implementation controls, there are other controls, such as requirements, architectural, build/compile, and operations controls, that can be put in place to defend against buffer overflow attacks:
- Choose a programming language that performs its own memory management and is type safe. Type safe languages are those that prevent undesirable type errors that result from operations (usually casting or conversion) on values that are not of the appropriate data type. Type safety (covered in more detail later in this chapter) is closely related to memory safety, as type unsafe languages will not prevent an arbitrary integer to be used as a pointer in memory. Ada, Perl, Java, and .Net programming languages are examples of languages that perform memory management and/or type safe. It is important, however, to recognize that the intrinsic overflow protection provided by some of these languages can be overwritten by the programmer. Also, although the language itself may be safe, the interfaces that they provide to native code can be vulnerable to various attacks. When invoking native functions from these languages, proper testing must be conducted to ensure that overflow attacks are not possible.
- Use a proven and tested library or framework that includes safer string manipulation functions, such as the Safe C String (SafeStr) library or the Safe Integer handling packages such as SafeInt (C++_ or IntegerLib (C or C++).
- Replace banned API functions that are susceptible to overflow issues with safer alternatives that perform size checks before performing their operations. It is recommended that you familiarize yourself with the banned API functions and their safer alternatives for the languages you use within your organization. When using functions that take in the number of bytes to copy as a parameter, such as the strncpy() or strncat(), one must be aware that if the destination buffer size is equal to the source buffer size, you may run into a condition where the string is not terminated because there is no place in the destination buffer to hold the NULL terminator.
- Design the software to use unsigned integers whenever possible, and when signed integers are used, make sure that checks are coded to validate both the maximum and minimum values of the range.
- Leverage compiler security if possible. Certain compilers and extensions provide overflow mitigation and protection by incorporating mechanisms to detect buffer overflows into the compiled (build) code. The Microsoft Visual Studio/GS flag, Fedora/Red Hat FORTIFY_SOURCE GCC flag, and StackGuard (covered later in this chapter in more detail) are some examples of this.
- Leverage operating system features such as Address Space Layout Randomization (ASLR), which forces the attacker to have to guess the memory address since its layout is randomized upon each execution of the program. Another OS feature to leverage is data execution protection (DEP) or execution space protection (ESP), which perform additional checks on memory to prevent malicious code from running on a system. However, this protection can fall short when the malicious code has the ability to modify itself to seem like innocuous code. ASLR and DEP/ESP are covered in more detail later in this chapter under the memory management topic.
- Use of memory checking tools and other tools that surround all dynamically allocated memory chunks with invalid pages so that memory cannot be overflowed into that space is a means of defense against heap corruption. MemCheck, Memwatch, Memtest86, Valgrind, and ElectricFence are examples of such tools.
4.6.4 Broken Authentication and Session Management
|
OWASP Top 10 Rank |
3 |
|
CWE Top 25 Rank |
6, 11, 19, 21, 22 |
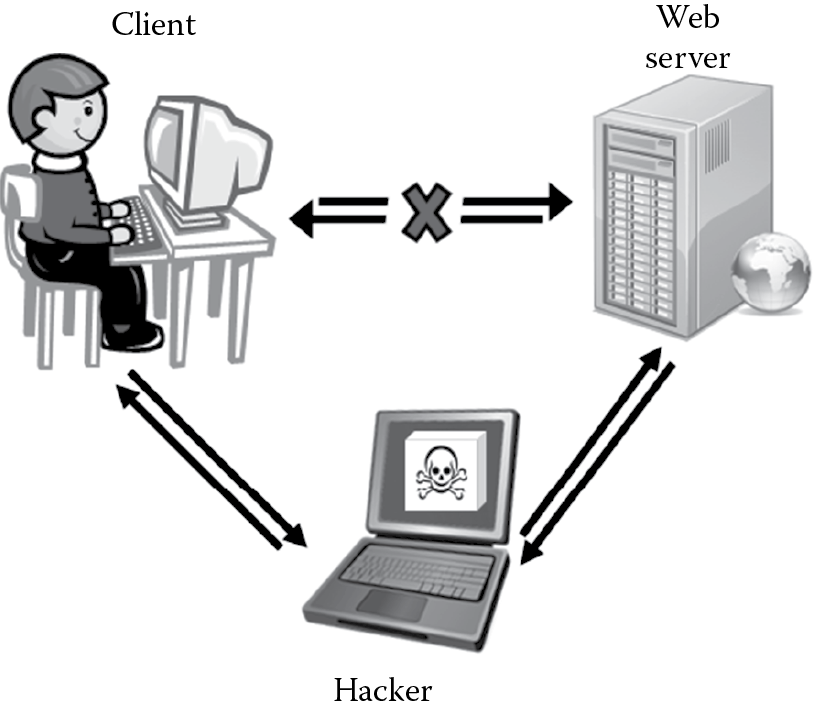
Weaknesses in authentication mechanisms and session management are not uncommon in software. Areas susceptible to these flaws are usually found in secondary functions that deal with logout, password management, time outs, remember me, secret questions, and account updates. Vulnerabilities in these areas can lead to the discovery and control of sessions. Once the attacker has control of a session (hijack) they can interject themselves in the middle, impersonating valid and legitimate users to both parties engaged in that session transaction. The man-in-the-middle (MITM) attack, as depicted in Figure 4.13, is a classic result of broken authentication and session management.
In addition to session hijacking, impersonation, and MITM attacks, these vulnerabilities can also allow an attacker to circumvent any authentication and authorization decisions that are in place. In cases when the account being hijacked is that of a privileged user, it can potentially lead to granting access to restricted resources and subsequently total system compromise.
Some of the common software programming failures that end up resulting in broken authentication and broken session management include, but are not limited to, the following:
- Allowing more than one set of authentication or session management controls that allow access to critical resources via multiple communication channels or paths
- Transmitting authentication credentials and session IDs over the network in cleartext
- Storing authentication credentials without hashing or encrypting them
- Hard coding credentials or cryptographic keys in cleartext inline in code or in configuration files
- Not using a random or pseudo-random mechanism to generate system-generated passwords or session IDs
- Implementing weak account management functions that deal with account creation, changing passwords, or password recovery
- Exposing session IDs in the URL by rewriting the URL
- Insufficient or improper session timeouts and account logout implementation
- Not implementing transport protection or data encryption
4.6.4.1 Broken Authentication and Session Management Controls
Mitigation and prevention of authentication and session management flaws require careful planning and design. Some of the most important design considerations include:
- Built-in and proven authentication and session management mechanisms: These support the principle of leveraging existing components as well. When developers implement their custom authentication and session management mechanisms, the likelihood of programming errors are increased.
- A single and centralized authentication mechanism that supports multifactor authentication and role-based access control: Segmenting the software to provide functionality based on the privilege level (anonymous, guest, normal, and administrator) is a preferred option. This not only eases administration and rights configuration, but it also reduces the attack surface considerably.
- A unique, nonguessable, and random session identifier to manage state and session along with performing session integrity checks: For the credentials, do not use claims that can be easily spoofed and replayed. Some examples of these include IP address, MAC address, DNS or reverse-DNS lookups, and referrer headers. Tamper-proof, hardware-based tokens can also provide a high degree of protection.
- When storing authentication credentials for outbound authentication, encrypt or hash the credentials before storing them in a configuration file or data store, which should also be protected from unauthorized users.
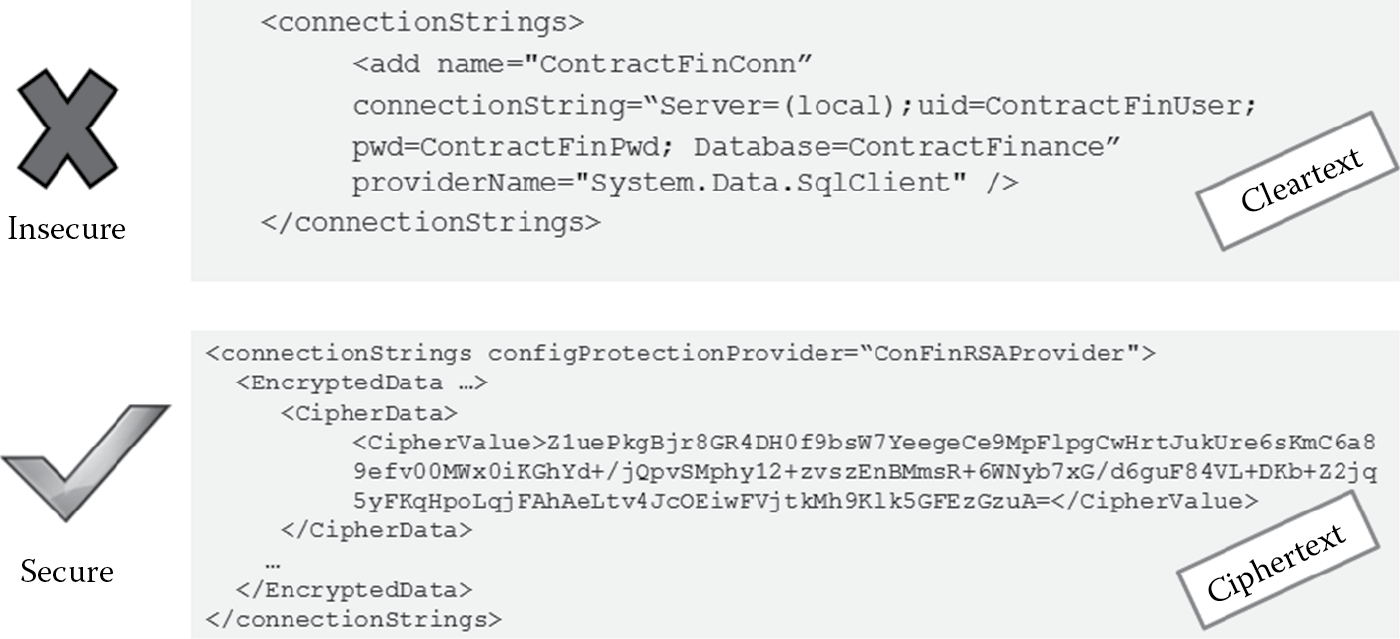
- Do not hard code database connection strings, passwords, or cryptographic keys in cleartext in the code or configuration files. Figure 4.14 illustrates an example of insecure and secure ways of storing database connecting strings in a configuration file.
- Identify and verify users at both the source as well as at the end of the communication channel to ensure that no malicious users have interjected themselves in between. Always authenticate users only from an encrypted source (Web page).
- Do not expose session ID in URLs or accept preset or timed-out session identifiers from the URL or HTTP request. Accepting session IDs from the URL can lead to what are known as session fixation and session replay attacks.
- Ensure that XSS protection mechanism are in place and working effectively, as XSS attacks can be used to steal authentication credentials and session IDs.
- Require the user to reauthenticate upon account update with such input as password changes, and, if feasible, generate a new session ID upon successful authentication or change in privilege level.
- Do not implement custom cookies in code to manage state. Use secure implementation of cookies by encrypting them to prevent tampering and cookie replay.
- Do not store, cache, or maintain state information on the client without appropriate integrity checking or encryption. If you are required to cache for user experience reasons, ensure that the cache is encrypted and valid only for an explicit period, after which it will expire. This is referred to as cache windowing.
- Ensure that all pages have a logout link. Do not assume that the closing of the browser window will abandon all sessions and client cookies. When the user closes the browser window, explicitly prompt the user to log off before closing the browser window. When you plan to implement user confirmation mechanisms, keep the design principle of psychological acceptability in mind: security mechanisms should not make the resource more difficult to access than if the security mechanisms were not present.
- Explicitly set a timeout, and design the software to log out of an inactive session automatically. The length of the timeout setting must be inversely proportional to the value of the data being protected. For example, if the software is marshalling and processing highly sensitive information, then the length of the timeout setting must be shorter.
- Implement the maximum number of authentication attempts allowed, and when that number has passed, deny by default and deactivate (lock) the account for a specific period or until the user follows an out-of-band process to reactivate (unlock) the account. Implementing throttle (clipping) levels prevents not only brute force attacks, but also DoS.
- Encrypt all client/server communications.
- Implement transport layer protection either at the transport layer (SSL/TLS) or at the network layer (IPSec), and encrypt data even if they are being sent over a protected network channel.
4.6.5 Insecure Direct Object References
|
OWASP Top 10 Rank |
4 |
|
CWE Top 25 Rank |
5 |
An insecure direct object reference flaw is one wherein an unauthorized user or process can invoke the internal functionality of the software by manipulating parameters and other object values that directly reference this functionality. Let us take a look at an example. A Web application is architected to pass the name of the logged-in user in cleartext as the value of the key “userName” and indicate whether the logged-in user is an administrator or not by passing the value to the key “isAdmin,” in the querystring of the URL, as shown in Figure 4.15.
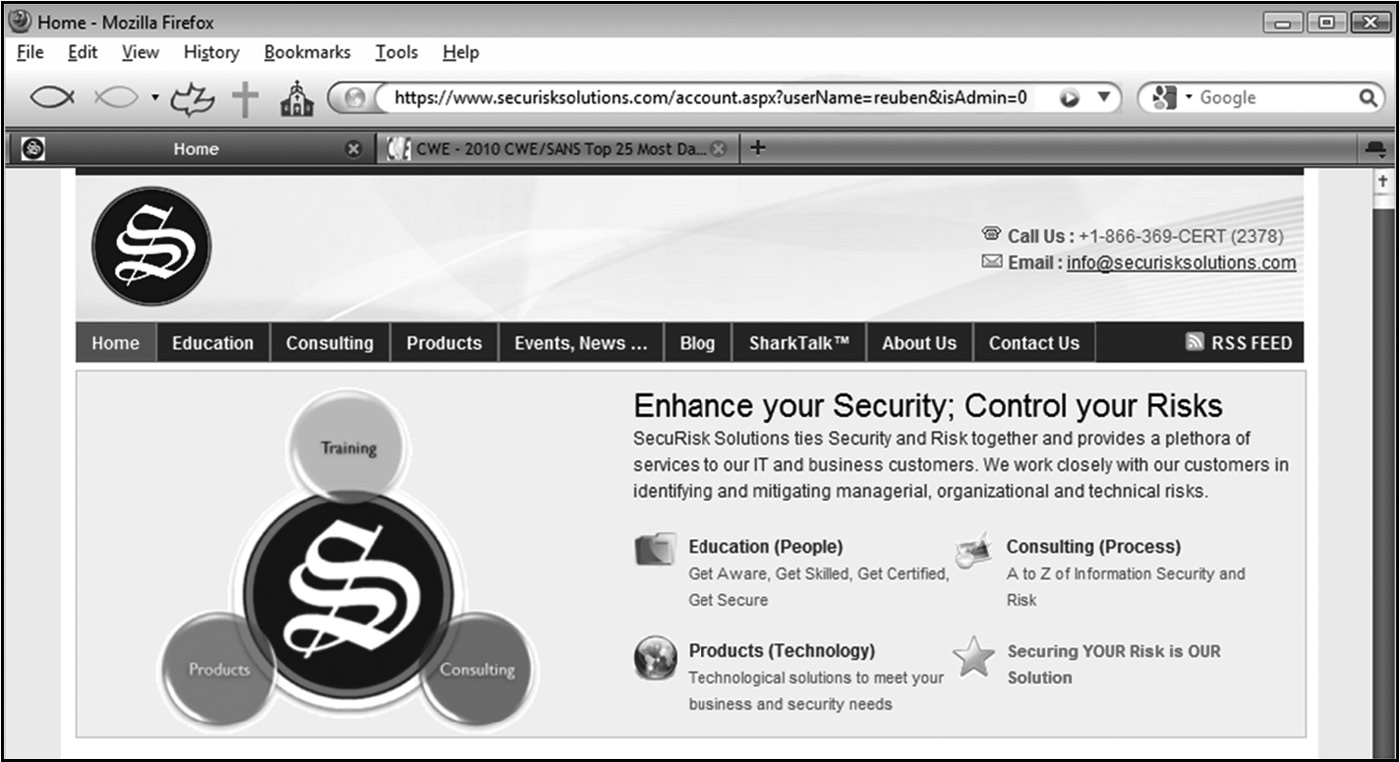
Upon load, this page reads the value of the userName key from the querystring and renders information about the user whose name was passed and displays it on the screen. It also exposes administrative menu options if the isAdmin value is 1. In our example, information about Reuben will be displayed on the screen. We also see that Reuben is not an administrator, as indicated by the value of the isAdmin key. Without proper authentication and authorization checks, an attacker can change the value of the userName key from “reuben” to “jessica” and view information about Jessica. Additionally, by manipulating the isAdmin key value from 0 to 1, a nonadministrator can get access to administrative functionality when the Web application is susceptible to an insecure direct object reference flaw.
Such flaws can be seriously detrimental to the business. Data disclosure, privilege escalation, authentication and authorization checks bypass, and restricted resource access are some of the most common impacts when this flaw is exploited. This can be exploited to conduct other types of attacks as well, including injection and scripting attacks.
4.6.5.1 Insecure Direct Object References Controls
The most effective control against insecure direct object reference attacks is to avoid exposing internal functionality of the software using a direct object reference that can be easily manipulated. The following are some defensive strategies that can be taken to accomplish this objective:
- Use indirect object reference by using an index of the value or a reference map so that direct parameter manipulation is rendered futile unless the attacker is also aware of how the parameter maps to the internal functionality.
- Do not expose internal objects directly via URLs or form parameters to the end user.
- Either mask or cryptographically protect (encrypt/hash) exposed parameters, especially querystring key value pairs.
- Validate the input (change in the object/parameter value) to ensure that the change is allowed as per the whitelist.
- Perform multiaccess control and authorization checks each and every time a parameter is changed, according to the principle of complete mediation. If a direct object reference must be used, first ensure that the user is authorized.
- Use RBAC to enforce roles at appropriate boundaries and reduce the attack surface by mapping roles with the data and functionality. This will protect against attackers who are trying to attack users with a different role (vertical authorization), but not against users who are at the same role (horizontal authorization).
- Ensure that both context- and content-based RBAC is in place.
Manual code reviews and parameter manipulation testing can be used to detect and address insecure direct object reference flaws. Automated tools often fall short of detecting insecure direct object reference because they are not aware of what object requires protection and what the safe or unsafe values are.
4.6.6 Cross-Site Request Forgery (CSRF)
|
OWASP Top 10 Rank |
5 |
|
CWE Top 25 Rank |
4 |
Although the cross-site request forgery (CSRF) attack is unique in the sense that it requires a user to be already authenticated to a site and possess the authentication token, its impact can be devastating and is rightfully classified within the top five application security attacks in both the OWASP Top 10 and the CWE/SANS Top 25. The most popular Web sites, such as ING Direct, NYTimes.com, and YouTube have been proven to be susceptible to this.
In CSRF, an attacker masquerades (forges) a malicious HTTP request as a legitimate one and tricks the victim into submitting that request. Because most browsers automatically include HTTP requests, that is, the credentials associated with the site (e.g., user session cookies, basic authentication information, source IP addresses, windows domain credentials), if the user is already authenticated, the attack will succeed. These forged requests can be submitted using email links, zero-byte image tags (images whose height and width are both 0 pixel each so that the image is invisible to the human eye), tags stored in an iFrames (stored CSRF), URLs susceptible to clickjacking (where the URL is hijacked, and clicking on an URL that seems innocuous and legitimate actually results in clicking on the malicious URL that is hidden beneath), and XSS redirects. Forms that invoke state changing function are the prime targets for CSRF. CSRF is also known by a number of other names, including XSRF, Session riding attack, sea surf attack, hostile linking, and automation attack.
The attack flow in a CSRF attack is as follows:
- User authenticates into a legitimate Web site and receives the authentication token associated with that site.
- User is tricked into clicking a link that has a forged malicious HTTP request to be performed against the site to which the user is already authenticated.
- Since the browser sends the malicious HTTP request, the authentication credentials, this request surfs or rides on top of the authenticated token and performs the action as if it were a legitimate action requested by the user (now the victim).
Although a preauthenticated token is necessary for this attack to succeed, the hostile actions and damage that can be caused from CSRF attacks can be extremely perilous, limited only to what the victim is already authorized to do. Authentication bypass, identity compromise, and phishing are just a few examples of impact from successful CSRF attacks. If the user is a privileged user, then total system compromise is a possibility. When CSRF is combined with XSS, the impact can be extensive. XSS worms that propagate and impact several Web sites within a short period usually have a CSRF attack fueling them. CSRF potency is further augmented by the fact that the forced hostile actions appear as legitimate actions (since they come with an authenticated token) and thereby may go totally undetected. The OWASP CSRF Tester tool can be used to generate test cases to demonstrate the dangers of CSRF flaws.
4.6.6.1 CSRF Controls
The best defense against CSRF is to implement the software so that it is not dependent on the authenticated credentials automatically submitted by the browser. Controls can be broadly classified into user controls and developer controls.
The following are some defensive strategies that can be employed by users to prevent and mitigate CSRF attacks:
- Do not save username/password in the browser.
- Do not check the “remember me” option in Web sites.
- Do not use the same browser to surf the Internet and access sensitive Web sites at the same time, if you are accessing both from the same machine.
- Read standard emails in plain text. Viewing emails in plain text format shows the user the actual link that the user is being tricked to click on by rendering the embedded malicious HTML links into the actual textual link. Figure 4.16 depicts how a phishing email is shown to a potential victim when the email client is configured to read email in HTML format and in plain text format.
- Explicitly log off after using a Web application.
- Use client-side browser extensions that mitigate CSRF attacks. An example of this is the CSRF Protector, which is a client-side add-on extension for the Mozilla Firefox browser.
The following are some defensive strategies that can be used by developers to prevent and mitigate CSRF attacks:

- The most effective developer defensive control against CSRF is to implement the software to use a unique session-specific token (called a nonce) that is generated in a random, nonpredictable, nonguessable, and/or sequential manner. Such tokens need to be unique by function, page, or overall session.
- CAPTCHAs (Completely Automated Public Turing Test to Tell Computers and Humans Apart) can be used to establish specific token identifiers per session. CAPTCHAs do not provide a foolproof defense, but they increase the work factor of an attacker and prevent automated execution of scripts that can exploit CSRF vulnerabilities.
- The uniqueness of session tokens is to be validated on the server side and not be solely dependent on client-based validation.
- Use POST methods instead of GET requests for sensitive data transactions and privileged and state change transactions, along with randomized session identifier generation and usage.
- Use a double-submitted cookie. When a user visits a site, the site first generates a cryptographically strong pseudorandom value and sets it as a cookie on the user’s machine. Any subsequent request from the site should include this pseudorandom value as a form value and also as a cookie value, and when the POST request is validated on the server side, it should consider the request valid if and only if the form value and the cookie value are the same. Since an attacker can modify form values but not cookie values as per the same-origin policy, an attacker will not be able to submit a form successfully unless she is able to guess the pseudorandom value.
- Check the URL referrer tag for the origin of request before processing the request. However, when this method is implemented, it is important to ensure that legitimate actions are not impacted. If the users or proxies have disabled sending the referrer information for privacy reasons, legitimate functionality can be denied. Also, it is possible to spoof referrer information using XSS, so this defense must be in conjunction with other developer controls as part of a defense in depth strategy.
- For sensitive transactions, reauthenticate each and every time (as per the principle of complete mediation).
- Use transaction signing to assure that the request is genuine.
- Build in automated logout functionality based on a period of inactivity, and log the user out when that timeframe elapses.
- Leverage industry tools that aid with CSRF defense. OWASP CSRF Guard and the OWASP ESAPI session management control provide anti-CSRF packages that can be used for generating, passing, and using a unique token per session. Code Igniter, a server-side plugin for the PHP MVC framework, is another well-known example of a tool that offers CSRF protection.
- Mitigate XSS vulnerabilities, as most CSRF defenses can be circumvented using attacker-controlled scripts.
4.6.7 Security Misconfiguration
|
OWASP Top 10 Rank |
6 |
|
CWE Top 25 Rank |
11, 20, 21 |
In addition to applying security updates and other updates to the operating system, it is critically important to harden the applications and software that run on top of these operating systems. Hardening software applications involves determining the necessary and correct configuration settings and architecting the software to be secure by default. We discuss software hardening in more detail in Chapter 7. In this chapter, we will primarily learn about the security misconfigurations that can render software susceptible to attack. These misconfigurations can occur at any level of the software stack and lead from data disclosure directly or, through an error message, to total system compromise.
Some of the common examples of security misconfigurations include:
- Hard coding credentials and cryptographic keys inline in code or in configuration files in cleartext.
- Not disabling the listing of directories and files in a Web server.
- Installation of software with default accounts and settings.
- Installation of the administrative console with default configuration settings.
- Installation or configuration of unneeded services, ports and protocols, unused pages, and unprotected files and directories.
- Missing software patches.
- Lack of perimeter and host defensive controls such as firewalls and filters.
4.6.7.1 Security Misconfiguration Controls
Effective controls against security misconfiguration issues include elements that design, develop, deploy, operate, maintain, and dispose of software in a reliable, resilient, and recoverable manner. The primary recommendations include:
- Installing software without the default configuration settings.
- Cryptographically protecting credentials and keys and not hard coding them inline in code.
- Removing any unneeded or unnecessary services and processes.
- Establishing and maintaining a configuration of the minimum level of acceptable security. This is referred to as the minimum security baseline (MSB).
- Establishing a process that hardens (locks down) the OS and the applications that run on top of it. Preferably, this should be an automated process using the established MSB to assure that there are no user errors.
- Handling errors explicitly using redirects and error messages so that a breach upon any misconfiguration does not result in the disclosure of more information than is necessary.
- Establishing a controlled patching process.
- Establishing a scanning process to detect and report automatically on software and systems that are not compliant to the established MSB.
4.6.8 Failure to Restrict URL Access
|
OWASP Top 10 Rank |
7 |
|
CWE Top 25 Rank |
5 |
One of the most easily exploitable weaknesses in Web applications is the failure to restrict URL access. In some cases, URL protection is provided and managed using configuration setting and code checks. In most cases, the only protection the software affords is not presenting the URL of the page to an unauthorized user. This kind of security by obscurity offers little to no protection against a determined and skilled attacker who can guess and/or forcefully browse to these URL locations and access unauthorized functionality. Furthermore, guessing of URLs is made easier if the URL naming pattern or scheme is predictable, defaulted, and/or left unchanged. Even if the URL is hidden and never displayed to an unauthorized user, without process authentication and access control checks, hidden URLs can be disclosed and their page functions invoked. Web pages that provide administrative functionality are the primary targets for this attack, but any page can be exploited if not protected properly. It is therefore imperative to verify the protection (authentication and authorization checks) of each and every URL, but this can be a daunting task when performed manually if the Web application has many pages.
4.6.8.1 Failure to Restrict URL Access Controls
RBAC of URLs that denies access by default, requiring explicit grants to users and roles, provides some degree of mitigation against the failure to restrict URL access attacks. In situations where the software is architected to accept a URL as a parameter before granting access (as in the case of checking the origin of referrer), the point at which the access control check is performed needs to be carefully implemented as well. Access control checks must be performed after the URL is decoded and canonicalized into the standard form. Obfuscation of URLs provides some defense against attackers who attempt forced browsing by guessing the URL. Additionally in cases where the Web page displays are based on a workflow, make sure that before the page is served to be displayed, proper checks for not just the authorization, but also state conditions are met. Whitelisting valid URLs and validating library files that are referenced from these URLs are other recommended prevention and mitigation controls. Do not cache Web pages containing sensitive information, and when these pages are requested, make sure to check that the authentication credentials and access rights of the user requesting access are checked and validated before serving the Web page. Authorization frameworks, such as the JAAS authorization framework and the OWASP ESAPI, can be leveraged.
4.6.9 Unvalidated Redirects and Forwards
|
OWASP Top 10 Rank |
8 |
|
CWE Top 25 Rank |
23 |
Redirection and forwarding users from one location (page) to another either explicitly on the client or internally on the server side (also known as transfer) is not uncommon in applications. Redirecting usually targets external links while forwarding targets’ internal pages. Scripts can also be used to redirect users from one document location to another, as depicted in Figure 4.17.

In situations where the target URL is supplied as an unvalidated parameter, an attacker can specify a malicious URL hosted in an external site and redirect users to that site. When an attacker redirects victims to an untrusted site, it is also referred to as open redirects. Once the victim lands on the malicious page, the attacker can phish for sensitive and personal information. They can also install malware automatically or by tricking users into clicking on masqueraded installation links. These unvalidated redirects and forwards can also be used by an attacker to bypass security controls and checks.
Detecting whether the application is susceptible to unvalidated redirects or forwards can be made possible by performing a code review and making sure that the target URL is a valid and legitimate one. A server responds to a client’s request by sending an HTTP response message that includes in its status line the protocol version, a success or error code, and a reason (textual phrase), followed by header fields that contain server information, metadata information (resource, payload), and an empty line to indicate the end of the header section and the payload body (if present). Looking at the HTTP response codes by manually invoking the server to respond or by spidering the Web site, one can determine redirects and forwards. The 3XX series HTTP response codes (300-307) deal with redirection. Appendix D briefly introduces and lists the HTTP/1.1 status codes and reason phrases.
4.6.9.1 Unvalidated Redirects and Forwards Controls
Some of the common controls against unvalidated redirects and forwards include:
- Avoiding redirects and forwards (transfers) if possible.
- Using a whitelist target URLS that a user can be redirected to.
- Not allowing the user to specify the target (destination) URL as a parameter. If you are required to for business reasons, validate the target URL parameter before processing it.
- Using an index value to map to the target URL and using that mapped value as the parameter. This way the actual URL or portions of the URL are not disclosed to the attacker.
- Architecting the software to inform the user using an intermediate page, especially if the user is being redirected to an external site that is not in your control. This intermediate page should clearly inform and warn the user that they are leaving your site. It is preferable to prompt the user modally before redirecting them to the external site.
- Mitigating script attack vulnerabilities that can be used to change document location.
4.6.10 Insecure Cryptographic Storage
|
OWASP Top 10 Rank |
9 |
|
CWE Top 25 Rank |
10, 24 |
The impact of cryptographic vulnerabilities can be extremely serious and disastrous to the business, ranging from disclosure of data that brings with it fines and oversight (regulatory and compliance) to identity theft of customers, reputational damage, and, in some cases, complete bankruptcy. When it comes to protecting information cryptographically, the predominant flaw in software is the lack of encryption of sensitive data. Even when it is, there are often other design and implementation weaknesses that plague the software. Insecure cryptographic vulnerabilities are primarily comprised of the following:
- The use of a weak or custom-developed unvalidated cryptographic algorithm for encryption and decryption needs.
- The use of older cryptographic APIs.
- Insecure and improper key management comprised of unsafe key generation, unprotected key exchange, improper key rotation, unprotected key archival and key escrow, improper key destruction, and inadequate and improper protection measures to ensure the secrecy of the cryptographic key when it is stored. A common example is storing the cryptographic key along with the data in a backup tape.
- Inadequate and improper storage of the data (data at rest) that need to be cryptographically secure. Storing the sensitive data in plaintext or as unsalted ciphertext (which can be bruteforced) are examples of this.
- Insufficient access control that gives users direct access to unencrypted data or to cryptographic functions that can decrypt ciphertext and/or to the database where sensitive and private information is stored.
- Violation of least privilege, giving users elevated privileges allowing them to perform unauthorized operations and lack of auditing of cryptographic operations.
Not encrypting data that are being transmitted (data in motion) is a major issue, but securing stored data (data at rest) against cryptographic vulnerabilities is an equally daunting challenge. In many cases, the efforts to protect data in motion are negated when the data at rest protection mechanisms are inadequate or insecure. Attackers typically go after weaknesses that are the easiest to break. When data that need to be cryptographically secure are stored as plaintext, the work factor for an attacker to gain access to and view sensitive information is virtually nonexistent, as they do not have the need to break the cryptography algorithm or determine the key needed to decrypt. When cryptographic keys are not stored securely, the work factor for the attacker is a little more, but it is still considerably reduced, as they now do not have to break the cryptography algorithm itself, but can find and use the keys to decrypt ciphertext to cleartext leading to disclosure that impacts the confidentiality tenet of security.
4.6.10.1 Insecure Cryptographic Storage Controls
Prevention and mitigation techniques to address insecure cryptographic storage issues can be broadly classified into the following:
- Data at rest protection controls
- Appropriate algorithm usage
- Secure key management
- Adequate access control and auditing
Data at rest protection controls include the following:
- Encrypting and storing the sensitive data as ciphertext, at the onset.
- Storing salted ciphertext versions of the data to mitigate bruteforce cryptanalysis attacks.
- Not allowing data that are deemed sensitive to cross trust boundaries from safe zones into unsafe zones (as determined by the threat model).
- Separating sensitive from nonsensitive data (if feasible) by using naming conventions and strong types. This makes it easier to detect code segments where data used are unencrypted when they need to be.
Appropriate algorithm usage means that:
- The algorithm used for encryption and decryption purposes is not custom developed.
- The algorithm used for encryption and decryption purposes is a standard (such as the AES) and not one historically proven weak (such as DES). AES is comprised of three block ciphers, each with a block size of 128 bits and key sizes of 128, 192, 256 bits (AES-128, AES-192, and AES-256), which are adopted from a larger collection originally published as Rijndael. A common implementation of AES in code is to use the RijndaelManaged class, but it must be understood that the use of the RijndaelManaged class does not necessarily make one compliant to the FIPS-197 specification for AES unless the block size and feedback size (when using the Cipher Feedback (CFB) mode) in both is 128 bits.
- Older cryptography APIs (CryptoAPI) are not used and are replaced with the Cryptography API Next Generation (CNG). CNG is intended to be used by developers to provide secure data creation and exchange over nonsecure environments, such as the Internet, and is extremely extensible because of its cryptography agnostic nature. It is recommended that the CSSLP be familiar with CNG features and its implementation.
- The design of the software takes into account the ability to swap cryptographic algorithms quickly as needed. Cryptographic algorithms that were considered to be strong in the past have been proven to be ineffective in today’s computing world, and without the ability to swap these algorithms in code quickly, downtime impacting the availability tenet of security can be expected.
Secure key management means that the
- Generation of the key uses a random or pseudo random number generator (RNG or PRNG) and is random or pseudo-random in nature.
- Exchange of keys is done securely using out-of-band mechanisms or approved key infrastructure that is secure as well.
- Storage of keys is protected, preferably in a system that is not the same as that of the data, whether it is the transactional system or the backup system.
- Rotation of the key, where the old key is replaced by a new key, follows the appropriate process of first decrypting data with the old key and then encrypting data with the new key. Not following this process sequentially has been proven to cause a DoS, especially in archived data, because data that were encrypted with an older key cannot be decrypted by the new key.
- Archival and escrowing of the key is protected with appropriate access control mechanisms and preferably not archived in the same system as the one that contains the encrypted data archives. When keys are escrowed, it is important to maintain the different versions of keys.
- Destruction of keys ensures that once the key is destroyed, it will never again be used. It is critically important to ensure that all data that were encrypted using the key that is to be destroyed are decrypted before the key is permanently destroyed.
Adequate access control and auditing means that for both internal and external users, access to the cryptography keys and data is
- Granted explicitly.
- Controlled and monitored using auditing and periodic reviews.
- Not inadvertently thwarted by weaknesses, such as insecure permissions configurations.
- Contextually appropriate and protected, regardless of whether the encryption is one-way or two-way. One-way encryption context implies that only the user or recipient needs to have access to the key, as in the case of PKI. Two-way encryption context implies that the encryption can be automatically performed on behalf of the user, but the key must be available so that plaintext can be automatically recoverable by that user.
4.6.11 Insufficient Transport Layer Protection
|
OWASP Top 10 Rank |
10 |
|
CWE Top 25 Rank |
10 |
It was mentioned earlier that cryptographic protection of data in motion is important, but this is only one of the means of protecting transmitted information. Monitoring network traffic using a passive sniffer is a common means by which attackers steal information.
Leveraging transport layer (SSL/TLS) and/or network layer (IPSec) security technologies augments security protection of network traffic. It is insufficient merely to use SSL/TLS just during the authentication process, as is observed to be the case with most software/applications. When a user is authenticated to a Web site over an encrypted channel, e.g., https://www.mybank.com, and then either inadvertently or intentionally goes to its clear text link, e.g., http://www.mybank.com, with little effort, the session cookie can now be observed by an attacker who is monitoring the network. This is referred to as the surf jacking attack. Lack of or insufficient transport layer protection often results in a confidentiality breach’s disclosing data. Phishing attacks are known to take advantage of this. It can result in session hijacking and replay attacks as well, once the authenticated victim’s session cookie is determined by the attacker.
Transport layer protection, such as SSL, can mitigate disclosure of sensitive information when the data are being traversed on the wire, but this type of protection does not completely prevent MITM attacks unless the protection is end-to-end. In the case of 3-tier Web architecture, transport layer protection needs to be from the client to the Web server and from the Web server to the database server. Failure to have end-to-end transport layer protection, as shown in Figure 4.18, can lead to MITM and disclosure attacks.
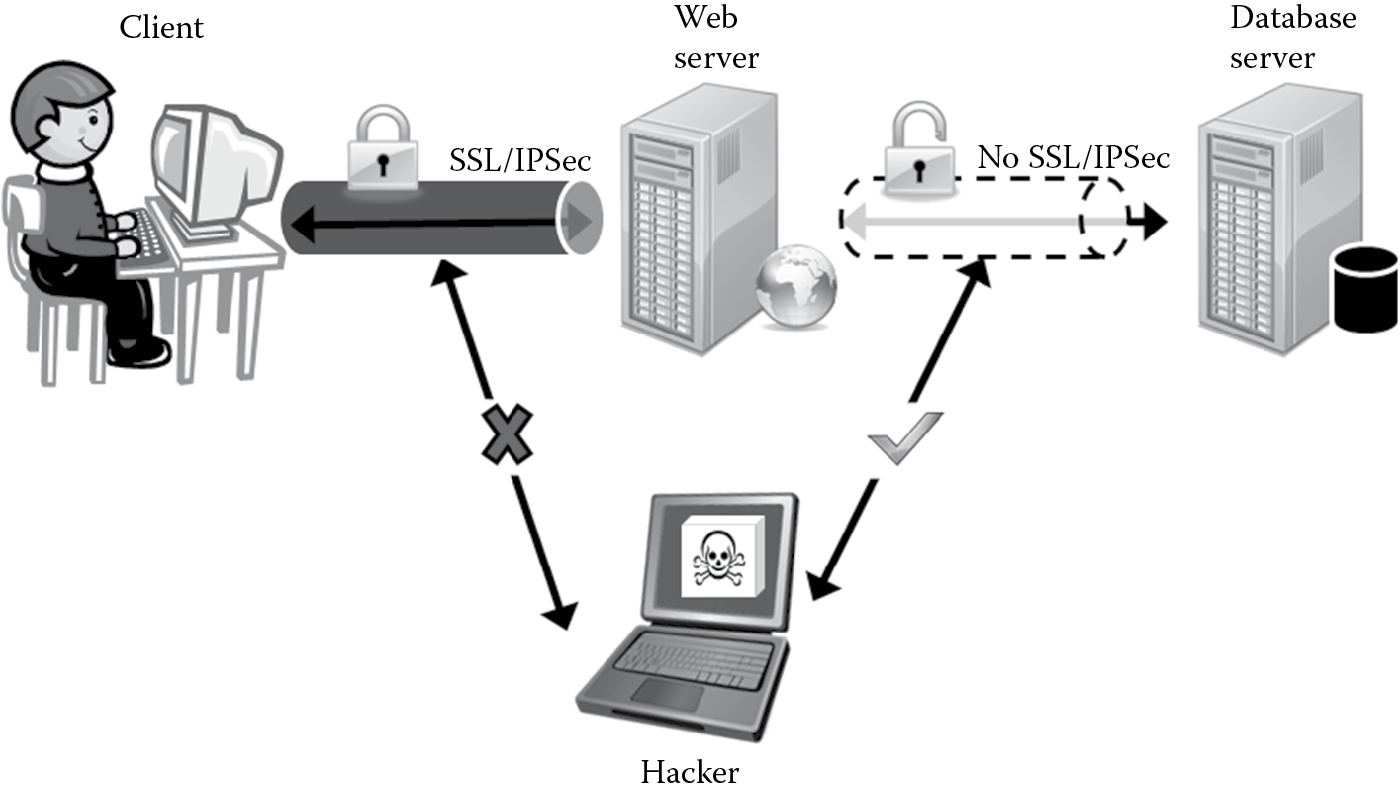
Additionally, when digital certificates are used to assure confidentiality, integrity, authenticity, and nonrepudiation, they should be protected, properly configured, and not set to expire so that they are not spoofed. When certificates are spoofed, MITM and phishing attacks are common. It is noteworthy to discuss in this context that improper configuration of certificates or using expired certificates cause the browser to warn the end user, but with the user’s familiarity with accepting browser warning prompts without really reading what they are accepting, this browser protection mechanism is rendered weak or futile. User education not to accept expired or lookalike certificates and browser warning prompts can come in handy to change this behavior and augment software security.
4.6.11.1 Insufficient Transport Layer Protection Controls
The following are some of the common preventative and mitigation recommendations against insufficient transport layer protection attacks:
- Provide end-to-end channel security protecting the channel using SSL/TLS or IPSec.
- Avoid using Mixed SSL when certain pages are protected using SSL while others are not because this can lead to the disclosure of session cookies from the unprotected pages. Redirect non-SSL pages to SSL ones.
- Ensure that the session cookie’s secure flag is set. This causes the browser cookie to be sent only over encrypted channels (HTTPS and not HTTP) mitigating surf jacking attacks.
- Provide cryptographic protection of data in motion and vetted and proven cryptographic algorithms or hashing functions compliant with FIPS 140-2 for cryptographic protection needs.
- Use unexpired and unrevoked digital certificates.
- Provide proper configuration of digital certificates. Educate users not to overlook warning prompts or accept lookalike certificates and phishing prompts.
It is important to note that, although it may seem that secure communications (using SSL/TLS or IPSec) is the most effective defense against insufficient transport layer protection attacks, a simple misconfiguration or partial implementation can render all other protection mechanisms ineffective. The best defense against these types of attacks is cryptographic protection of data (encryption or hashing) so that regardless of whether the data are being marshaled over secure communication channels or not, they are still protected.
4.6.12 Information Leakage and Improper Error Handling
|
OWASP Top 10 Rank (2007) |
6 |
|
CWE Top 25 Rank |
10, 11, 15, 16, 24 |
Without appropriate confidentiality controls in place, software can leak information about its configuration, state, and internal makeup that an attacker can use to steal information or launch further attacks. Because attackers usually have the benefit of time and can choose to attack at will, they usually spend a majority of their time in reconnaissance activities gleaning information about the software itself.
Phishing, a method of tricking users into submitting their personal information using electronic means such as deceptive emails and Web sites, is on the rise. The term “phishing” is believed to have its roots from the use of sophisticated electronic lures to fish out a victim’s personal (e.g., financial, login, passwords) information. This form of electronic social engineering is so rampant in today’s business computing that even large organizations have fallen prey to it. Although these sophisticated electronic lures usually target users en masse, they can also target a single individual, and when this is the case, it is commonly referred to as “spear phishing.” With the sophistication of such deceptive attacks to disclose information, attackers have come up with a variant of phishing, called pharming, which is a scamming practice in which malicious code is installed on a system or server that misdirects users to fraudulent Web sites without the user’s knowledge or consent. It is also referred to as “phishing without a lure.” Unlike phishing, wherein individual users who receive the phishing lure (usually in the form of an email) are targets, in pharming a large number of users can be victimized as the attack does not require individual user actions, but rather systems that can be compromised. Pharming often works by modification of the local system host files that redirect users to a fraudulent Web site even if the user types in the correct Web address. Another popular way in which Pharming works, which is even more dangerous, is known as domain name system (DNS) poisoning. In the DNS poisoning pharming attack, the DNS table in the server is altered to point to fraudulent Web sites even when requests to legitimate ones are made. With DNS poisoning, there is no need to alter individual user’s local system host files because the modification (exploit) is made on the server side, and all those who request resources from that server will now be potential victims without their knowledge or consent. Disclosure of personal information is often the result, and in some cases this escalates to identity theft. With Voice over IP (VoIP) telephony on the rise, phishing attacks have a new variant called vishing, which is made up of two words, “voice” and “phishing.” This is the criminal fradulent activity in which an attacker steals sensitive information using deceptive social engineering techniques on VoIP networks.
The prime target for a phisher/pharmer is not a weakness in technology, but human trust. Secondarily exploitable weaknesses, such as no proper ACLs to host systems and servers, lack of spyware protection that can modify settings, and weaknesses in software code, can also result in significant information disclosure. Phishers and pharmers attempt to exploit these weaknesses to masquerade and execute their phishing/pharming scams.
Sources of information leakage include but are not limited to the following:
- Browser history
- Cache
- Backup and unreferenced files
- Log files
- Configuration files
- Comments in code
- Error messages
Browser history can be stolen using cascading style sheet (CSS) hacks with or without using JavaScript or by techniques called browser caching. Information about sites that a user has visited can be stolen from a user. Although caches can be used to improve performance and user experience significantly, sensitive information, if cached, can be disclosed, breaching confidentiality. Attackers usually look for backup and unreferenced files, log files, and configuration files that inadvertently get deployed or installed on the system. These files can potentially have sensitive information that comes in very handy for an attacker as they attempt to exploit the software. Developers usually do not like to document their code, and when instrumenting (inline commenting) of code is done without proper education and training, these comments in code can reveal more sensitive information than is necessary. Some examples of sensitive information in comments include database connection strings, validation routines, production and test data, production and test accounts, and business logic. Figure 4.19 depicts an example of code that has sensitive information in its comments.
Error messages are one of the first sources an attacker will look at to determine the information about the software. Without proper handling of input and the response generated from that input in the form of an exception or error message, sensitive information can be leaked. Input validation and output error handling can be regarded as two of the most basic and effective protection mechanisms that can be used to mitigate a lot of software attacks. Figure 4.20 discloses how an unhandled exception reveals a lot of sensitive information, including the internal makeup of the software.

4.6.12.1 Information Leakage and Improper Error Handling Controls
To mitigate and prevent information leakage and improper error handling issues, it is important that proper security controls are designed and implemented, such as those listed below.
- Use private browsing mode in browsers and other plugins or extensions that do not cache the visited pages. Configure the browsers not to save history and clear all page visits upon closing the browser.
- Encrypt the cache and/or explicitly set cache timeouts (sometimes referred to as cache windows).
- Do not deploy backup files to production systems. For disaster recovery purposes, sometimes the backup file is deployed by renaming the file extension to a .bak or a .old extension. Attackers can guess and forcefully browse these files, and without proper access controls in place, information in these files can be potentially disclosed.
- Harden servers so that their log files are protected.
- Remove installation scripts and change logs from production systems and store them in a nonproduction environment if they are not required for the software to function.
- Comment your code to explain what the code does, preferably for each function, but do not reveal any sensitive or specific information. Code review must not ignore the reviewing of comments in code.
- Validate all input to prevent an attacker from forcing an error by using an input (e.g., type, value, range, length) that the software is not expecting.
- Use concise error messages with just the needed information. System-generated errors with stack information and code paths must be abstracted into generic user friendly error messages that are laconic, with just the needed information.
- Handle all exceptions preferably with a common approach.
- Use an index of the value or reference map. An example of using indices would be to use an Error Globally Unique Identifier (GUID) that maps to the internal error, but it is the GUID alone that is displayed to the user, informing the user to contact the support line for more assistance. This way, the internal error details are not directly revealed to the end user or to the attacker, who could be using them in their reconnaissance efforts as they plan to launch other attacks.
- Redirect errors and exceptions to a custom and default error handling location, and, depending on the context of where the user has logged in (remote or local), appropriate message details can be displayed.
- Leverage static code analysis tools to search for APIs that are known to leak information.
- Remember that user awareness and education are the best defense against phishing and pharming electronic social engineering scams. Additionally, SPAM control, disabling of links in emails and instant messaging (IM) clients, viewing emails in non-HTML format, transport layer protection (SSL/TLS), phishing filter plugins, and offensive strategies, such as dilution and takedown, are other safeguards and countermeasures against phishing and pharming attacks. Dilution, also known as “spoofback,” is sending bogus and faulty information to the phisher with the intent to dilute the real information that the attacker is soliciting. Takedown, on the other hand, involves actively bringing down the phishing/pharming Web site as a means to contain the exposure, but this must be down with proper legal guidance.
4.6.13 File Attacks
Attacks against software are also prevalent when data are exchanged in files. In this section, we will cover some of the most common attacks that involve files. These attacks include malicious file execution, path traversals, improper file includes, and download of code without integrity checks.
- Malicious File Execution
OWASP Top 10 Rank (2007)
3
CWE Top 25 Rank
7, 8, 13, 20
When software is designed and implemented to accept files as input, unvalidated and unrestricted file uploads could lead to serious compromises of the security state of the software. Any feature in software that uses external object references (e.g., URLs and file system references) and which allow the upload of images (e.g., .gif, .jpg, .png), documents (e.g., .docx, .xlsx, .pdf) and other files are potential sources of attack vectors. Insufficient and improper validation can lead to arbitrary remote and hostile code upload, invocation and execution, rootkit installations, and complete system compromise. All Web application frameworks are susceptible to malicious file execution if they accept filenames or files from users.
Malicious file execution attacks can occur in any of the following ways:
- Accepting user-supplied file names and files without validating them
- Not restricting files to nonexecutable types
- Uploading hostile data to the file system via image uploads
- Using compression or audio streams (e.g., zlib:// or ogg://) that allow the access of remote resources without the inspection of internal flags and settings
- Using input and data wrappers (e.g., php://input) that accept input from the request POST data instead of a file
- Using hostile document type definitions (DTDs) that force the XML parser to load a remote DTD and parse and process the results
- Path Traversals
In situations where the software is architected to accept path names and directory locations from the end user without proper security controls, attackers can exploit weaknesses that allow them to traverse from the intended file paths to unintended directories and files in the system. Software susceptible to attacks using canonicalization of file paths such as using “..” or similar sequences are known to fall prey frequently to path traversal attacks.
- Improper File Includes
Although file attacks are not limited to any one kind of programming language, programming languages such as PHP that allow remote file includes (RFI), where the file name can be built by concatenating user-supplied input using file or streams-based API, are particularly vulnerable. Breaking the software into smaller parts of a program (document) and then combining them into one big program (document) is a common way to build a program. When the location of the smaller parts of the program is user-defined and can be influenced by an end user, an attacker can point to locations with remote and dangerous files and exploit the software.
- Download of Code without Integrity Checks
When you download code (or files) without checking if the code is altered, it can lead to very serious security breaches and repercussions. An attacker can modify code before you download it. Even locations (sites) that hold files that you trust and download can be attacked and impersonated using DNS spoofing or cache poisoning, redirecting users to attacker locations. This is particularly important when software updates are published using files from trusted locations. Downloading code and files without integrity checks can lead to the download of files that have been maliciously altered by an attacker.
4.6.13.1 File Attacks Controls
Automated scanning can be used to determine sections in code that accept file names and file paths, but are not very efficient in identifying the legitimacy of parameters that are used in file includes. Static analysis tools can be useful in determining banned APIs, but they cannot ensure that appropriate validation is in place. Manual code review is recommended to search for file attack vulnerabilities.
Controls that prevent and mitigate file attacks are necessary to ensure that software security is assured when dealing with files and their associated properties.
The following are recommended controls against malicious file execution attacks:
- Use a whitelist of allowable file extensions. Ensure that the check for the valid list of file names takes into account the case sensitivity of the file name.
- Allow only one extension to a file name. For example, “myfile.exe.png” should not be allowed.
- Use an indirect object reference map and/or an index for file names. Cryptographically protecting the internal file name by salting and hashing the file name can prevent bruteforce discovery of file names.
- Explicitly taint check. Taint checking is a feature in some programming languages, such as Perl and Ruby, which protects against malicious file execution attacks. Assuming that all values supplied by the user can be potentially modified and untrusted, each variable that holds values supplied by an external user is checked to see if the variable has been tainted by an attacker to execute dangerous commands.
- Automatically generate a filename instead of using the user-supplied one.
- Upload the files to a hardened staging environment and inspect the binaries before processing them. Inspection should cover more than just file type, size, MIME content type, or filename attribute, so also inspect the file contents as attackers can hide code in some file segments that will be executed.
- Isolate applications using virtualization or other sandboxing mechanisms, such as chroot jail in Unix.
- Avoid using file functions and streams-based APIs to construct filenames.
- Configure the application to demand appropriate file permissions. Using the Java Security Manager and the ASP.Net partial trust implementations can be leveraged to provide file permissions security.
The following are recommended controls against path traversal attacks:
- Use a whitelist to validate acceptable file paths and locations.
- Limit character sets before accepting files for processing. Examples include allowing a single “.” character in the filename and disallowing directory separators such as “/” to mitigate path traversal attacks.
- Harden the servers by configuring them not to allow directory browsing or contents.
- Decode once and canonical file paths to internal representation so that dangerous inputs are not introduced after the checks are performed. Use built-in canonicalization functions that canonicalize pathname by removing “..” sequences and symbolic links. Examples include realpath() (C, Perl, PHP), getCanonicalPath (Java), GetFullPath() (ASP.Net), and abs_path() (Perl).
- Use a mapping of generic values to represent known internal actual file names and reject any values not configured explicitly.
- Run code using least privilege and isolated accounts with minimal rights in a sandbox (jail) that restricts access to other system resources. The Unix chroot jail, AppArmor, and SELinux are examples of OS-level sandboxing.
The following are recommended controls against improper file includes attacks:
- Store library, include, and utility files outside of the root or system directories. Using a constant in a calling program and checking for its existence in the library or include file is a common practice to identify files that are approved or are not.
- Restrict access to files within a specified directory.
- Run code using least privilege and isolated accounts with minimal rights, in a sandbox (jail) that restricts access to other system resources. The Unix chroot jail, AppArmor, and SELinux are examples of OS-level sandboxing.
- Limit the ability to include files from remote locations.
The following are recommended controls against download of code without integrity check attacks:
- Use integrity checking on code downloaded from remote locations. Examples include hashing, code signing, and Authenticode technologies. These can be used cryptographically to validate the authenticity of the code publisher and the integrity of the code itself. Hashing the code before it is downloaded and validating the hash value before processing the code can be used to determine whether the code has been altered.
- To detect DNS spoofing attacks, perform both forward and reverse DNS lookups. When this is used, be advised that this is only a partial solution as it will not prevent the tampering of code on the hosting site or when it is in transit.
- When source code is not developed by you or not available, the use of monitoring tools to examine the software’s interaction with the OS and the network can be used to detect code integrity issues. Some examples of common tools include process debuggers, system call tracing utilities, and system and process activity monitors (file monitors, registry monitors, system internals), sniffers, and protocol analyzers.
4.6.14 Race Condition
|
OWASP Top 10 Rank |
Not specified |
|
CWE Top 25 Rank |
25 |
In Chapter 2, we learned about what a race condition is, its properties (concurrency, shared object, change state), how it occurs, and defensive controls (avoid race windows, atomic operations, and mutual exclusions) that need to be identified as part of the requirements.
Attackers deliberately look for race conditions because they are often missed in general testing and exploit them, resulting in sometimes very serious consequences that range from DoS (deadlocks) to data integrity issues and in some cases total compromise and control. Easy to introduce but difficult to debug and troubleshoot, race conditions can occur anywhere in the code (e.g., local or global state variables, security logic) and in any level of code (source code, assembly code, or object code). They can occur within multiple threads, processes, and systems as well.
4.6.14.1 Race Condition Controls
Design and implementation controls against race conditions include
- Identifying and eliminating race windows
- Performing atomic operations on shared resources
- Using Mutex operations
- Selectively using synchronization primitives around critical code sections to avoid performance issues
- Using multithreading and thread-safe capabilities and functions and abstractions on shared variables.
- Minimizing the usage of shared resources and critical sections that can be repeatedly triggered
- Disabling interrupts or signals over critical code sections
- Avoiding infinite loop constructs
- Implementing the principle of economy of mechanisms, keeping the design and implementation simple, so that there are no circular dependencies between components or code sections
- Implementing error and exception handling to avoid disclosure of critical code sections and their operations
- Performing performance testing (load and stress testing) to ensure that software can reliably perform under heavy load and simultaneous resource requests conditions
4.6.15 Side Channel Attacks
|
OWASP Top 10 Rank |
Not specified |
|
CWE Top 25 Rank |
Not specified |
Although not listed as one of the top 10 or top 25 issues plaguing software, side channel attacks are an important class of attacks that can render the security protection effectiveness of a cryptosystem futile. They are of importance to us because attackers can use unconventional means to discover sensitive and secret information about our software, and even a full-fledged implementation of the controls determined from the threat model can fall short of providing total software assurance.
Although side channel attacks are predominantly observed in cryptographic systems, they are not limited to cryptography. In the context of cryptography, side channel attacks are those that use information that is neither plaintext nor ciphertext from a cryptographic device to discover secrets. Such information that is neither plaintext nor ciphertext is referred to as side channel information. A cryptographic device functions by converting plaintext to ciphertext (encryption) and from ciphertext to plaintext (decryption). Attackers of cryptosystems were required to know either the ciphertext (ciphertext-only attacks) or both the plaintext and the ciphertext (known plaintext attacks) or to be able to define what plaintext is to be encrypted and use the ciphertext output toward exploiting the cryptographic system (chosen plaintext attack). Nowadays, however, most cryptographic devices have or emit additional information that is neither plaintext nor ciphertext. Examples of some common side channel information include the time taken to complete an operation (timing information), power consumptions, radiations/emanations, and acoustic and fault information. These make it possible for an attacker to discover secrets, such as the key and memory contents, using all or some of the side channel information in conjunction with other known cryptanalysis techniques.
The most common classes of side channel attacks are the following:
Timing attacks
In timing attacks, the attacker measures how long each computational operation takes and uses that side channel information to discover other information about the internal makeup of the system. A subset of this timing attack is looking for delayed error messages, a technique used in blind SQL injection attacks.
Power analysis attacks
In power analysis attacks, the attacker measures the varying degrees of power consumption by the hardware during the computation of operations. For example, the RSA key can be decoded using the analysis of the power peaks, which represent times when the algorithms use or do not use multiplications.
TEMPEST attacks
These are also known as van Eck or radiation monitoring attacks. An attacker attempting TEMPEST attacks uses leaked electromagnetic radiation to discover plaintexts and other pertinent information that are based on the emanations.
Acoustic cryptanalysis attacks
Much like in the power analysis attacks, in acoustic cryptanalysis attacks, the attacker uses the sound produced during the computation of operations.
Differential fault analysis attacks
Differential fault analysis attacks aim at discovering secrets from the system by intentionally injecting faults into the computational operation and determining how the system responds to the faults. This is a form of fuzz testing (covered in Chapter 5) and can also be used to indicate the strength of the input validation controls in place.
Distant observation attacks
As the name suggests, distant observation attacks are shoulder surfing attacks, where the attacker observes and discovers information of a system indirectly from a distance. Observing through a telescope or using a reflected image off someone’s eye, eyeglasses, monitor, or other reflective devices are some well-known examples of distant observation attacks.
Cold boot attacks
In a cold boot attack, an attacker can extract secret information by freezing the data contents of memory chips and the booting up to recover the contents in memory. Data remanence in the RAM was believed to be destroyed when the system shut down, but the cold boot attack proved traditional knowledge to be incorrect. This is of importance because not only is this an attack against confidentiality, but it also demonstrates the importance of secure startup.
4.6.15.1 Side Channel Attacks Controls
The following are recommended defensive strategies against side channel attacks:
- Leverage and use vetted, proven, and standardized cryptographic algorithms, which are less prone to side channel information leakage.
- Use a system where the time to compute an operation is independent of the input data or key size.
- Avoid the use of branching and conditional operational logic (IF-THEN-ELSE) in critical code sections to compute operations as they will have an impact on the timing of each operation. Use simple and straightforward computational operations (AND, OR, XOR) to limit the amount of timing variances that can result and potentially be used for gleaning side channel timing and power consumption information.
- The most effective protection against timing attacks is to standardize the time that each computation will take. This means that each and every operation takes the same amount of time to complete its operation. However, this could have an impact on performance. A fixed time implementation is not very efficient from a performance standpoint, but makes it difficult for the attacker to conduct timing attacks. Adding a random delay is also known to increase the work factor of an attacker. Also, standardizing on the time needed to compute a multiplication or an exponentiation can leave the attacker guessing as to what operation was undertaken.
- Balancing power consumption independent of the type of operation along with reducing the signal size are useful controls to defend against power analysis attacks.
- Adding noise is a proven control against acoustic analysis.
- Physical shielding provides one of the best defenses against emanation or radiation security, such as TEMPEST attacks.
- Double encryption, which is characterized by running the encryption algorithm twice and outputting the results only if both the operations match, is a recommended control against differential fault analysis. This works on the premise that the likelihood of a fault’s occurring twice is statistically insignificant.
- Physical protection of the memory chips, preventing memory dumping software from execution, not storing sensitive information in memory, scrubbing and overwriting memory contents that are no longer needed periodically or at boot time (using a destructive Power-On Self-Test), and using the Trusted Platform Module (TPM) chip are effective controls against cold boot attacks. It is important to know that the TPM chip can prevent a key from being loaded into memory, but it cannot prevent the key from being discovered once it is already loaded into memory.
4.7 Defensive Coding Practices—Concepts and Techniques
We started this chapter with the premise that secure software is more than just writing secure code. In the previous section, we learned about various security controls that can be implemented in code. In addition to those controls, there are other defensive coding practices that include concepts and techniques that assure the reliability, resiliency, and recoverability of software. In this section, we will learn about the most common defensive coding practices and techniques.
4.7.1 Attack Surface Evaluation and Reduction
Attack surface evaluation was covered extensively in the secure software design section, and it is important to understand that the moment a single line of code is written, the attack surface has increased. At this juncture of our software development project, as code is written, it is important to recognize that the attack surface of the software code is not only evaluated, but also reduced. Some examples of attack surface reduction are:
- Reducing the amount of code and services that execute by default
- Reducing the volume of code that can be accessed by untrusted users by default
- Limiting the damage when the code is exploited
Determining the RASQ before and after the implementation of code can be used to measure the effectiveness of the attack surface reduction activities.
4.7.2 Input Validation
Although it is important to trust, it is even more important to verify. This is the underlying premise behind input validation. When it comes to software, we must, in fact, consider all input as evil and validate all user input.
Input validation is the verification process that ensures the data that are supplied for processing
- Are of the correct data type and format.
- Fall within the expected and allowed range of values.
- Are not interpreted as code as is the case with injection attacks (covered later in this chapter).
- Do not masquerade in alternate forms that bypass security controls.
4.7.2.1 How to Validate?
Regular expressions (RegEx) can be used for validating input. A listing of common RegEx patterns is provided in Chapter 5. This process of verification can be achieved using one of two means: filtration or sanitization.
4.7.2.1.1 Filtration (Whitelists and Blacklists)
Filtering user input can be accomplished using either a whitelist or a blacklist. A whitelist is a list of allowable good and nonmalicious characters, commands, and/or data patterns. For example, the application might allow only “@” and “.com” in the email field. Items in a whitelist are known and usually deemed to be nonmalicious in nature. On the other hand, a blacklist is a list of disallowed characters, commands, and/or data patterns that are considered to be malicious. Examples include the single quote (‘), SQL comment (- -), or a pattern such as (1=1).
4.7.2.1.2 Sanitization
Sanitization is the process of converting input that is considered to be dangerous into an innocuous form. For example, when the user supplies a character that is part of a blacklist, such as a single quote (‘), data sanitization would include replacing that single quote with a double quote (“). This is also referred to as quoting input. Converting the input into its innerText form that cannot be executed, instead of processing, storing, and reflecting its innerHTML form that can be executed on the client, is another means of sanitization. However, when data sanitization is performed, it is critically important to make sure that the integrity of the data is not compromised. For example, if O’Shea is the value supplied as the last name of a user, by quoting the input before storing it, the value will change to O’Shea, which is not accurate.
4.7.2.2 Where to Validate?
The point at which the input is validated is also critically important. Input can be validated on the client or on the server or on both. It is best recommended that the input is validated both on the client (frontend) as well as on the server (backend), if the software is a client/server architected solution. Minimally, server-side validation must be performed. It is also insufficient to validate input solely on the client side, as this can be easily bypassed and afford minimal to no protection.
4.7.2.3 What to Validate?
One can validate pretty much for anything, from generic whitelist and blacklist items to specific business-defined patterns. When validating input, the supplied input must at a bare minimum be validated for:
- Data type
- Range
- Length
- Format
- Values
- Alternate representations of a standard (canonical) form
4.7.3 Canonicalization
Canonicalization is the process of converting data that has more than one possible representation to conform to a standard canonical form. Since “canonicalization” is a difficult word for some people to pronounce, it has been abbreviated as C14N. (There are 14 characters between the first letter C and the last letter N.) Although canonicalization is predominantly evident in Internet-related software, canonicalization can be used to convert any data into its standard forms and approved formats. In XML, canonicalization is used to ensure that the XML document adheres to the specified format. The canonical form is the most standard or simplest form.
URL encoding to IP address translations are well-known applications of canonicalization. Canonicalization also has international implications as it pertains to character sets or code pages, such as ASCII and Unicode (covered under the international requirements section of Chapter 2). It is therefore imperative that the appropriate character set and output locale are set in the software to avoid any canonicalization issues. From a security standpoint, canonicalization has an impact on input filtration. When filters (RegEx) are used to validate that the canonical or standard form of the input is part of a blacklist, they can be potentially bypassed when an alternate representation of the canonical form is passed in, if the validate check occurs before the canonicalization process is complete. It is recommended to decode once and canonicalize inputs into the internal representation before performing validation to ensure that validation is not circumvented. An example of canonicalization is depicted in Figure 4.21.

4.7.4 Code Access Security
Unlike in the case of an unmanaged code environment, in a managed code environment, when a software program is run, it is automatically evaluated to determine the set of permissions that needs to be given to the code during runtime. Based on what permissions are granted, the program will execute as expected or throw a security exception. The security settings of the host computer system on which the program is run decides the permissions sets that the code is granted. Code access security (CAS) prevents code from untrustworthy sources or unknown origins from having run time permissions to perform privileged operations. CAS also protects code from trusted sources from inadvertently or intentionally compromising security. Important CAS concepts include the following:
4.7.4.1 Security Actions
The permissions to be granted are evaluated by the runtime when code is loaded into memory. The three categories of security actions that can be performed are request, demands, and overrides. Requests are used to inform the runtime about the permissions that the code needs in order for it to run. It cannot be used to influence the runtime to grant the code more permissions than it should be granted. Demands are used in code to assert permissions and help protect resources from callers. Overrides are used in code to override default security behavior.
4.7.4.2 Type Safety
In order to implement CAS, the code must be generated by a programming language that can produce verifiable type-safe code. Type-safe code cannot access memory at arbitrary locations out of the range of memory address space that belongs to the object’s publicly exposed fields. It cannot access memory locations it is not authorized to access. When the code is type safe, the runtime is given the ability to isolate assemblies from one another. Type-safe code accesses types only in explicitly defined (casted/converted) and allowed formats. Buffer overflow vulnerabilities are found to be prevalent in unmanaged non-type safe languages, such as C and C++. Type safety is an important consideration when choosing between a managed and unmanaged programming language. Parametric polymorphism or generics that allow a function or data type to be written generically so that it can handle values identically without depending on their type is a means to make a language more expressive while maintaining full type safety.
4.7.4.3 Syntax Security (Declarative and Imperative)
The two ways in which CAS can be implemented in the code syntax are by declarative or imperative security. We will cover later in this section the declarative vs. programmatic security concept as it pertains to container security. In the context of CAS, declarative security syntax means that the permissions are defined as security attributes in the metadata of the code, as shown in Figure 4.22. The scope of the security attributes that define the allowed security actions (requests, demands, and overrides) can be at the level of the entire assembly, a class, or the member level. Imperative security, on the other hand, is implemented using new instance of the permission object inline in code, as shown in Figure 4.23. The security action of demands and overrides are possible in imperative security, but imperative security cannot be used for requests. Imperative security is handy when the runtime permissions that are to be granted to the code are not known before it is run, in which case the permissions cannot be declaratively defined as security attributes of the code.

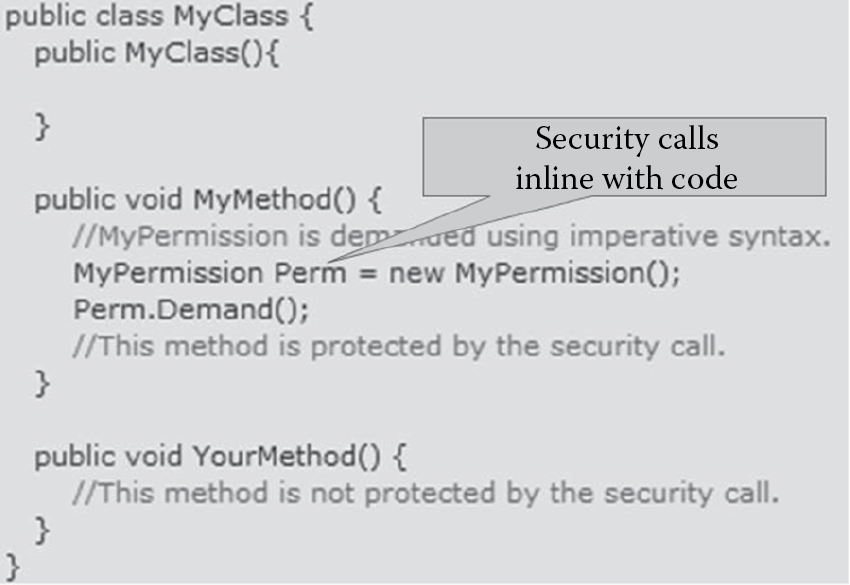
4.7.4.4 Secure Class Libraries
A secure class library is distinct in that it uses security demands to ascertain that the callers of the libraries have the permissions to access the functionality and resources it exposes. Code that does not have the necessary runtime permissions to access the secure class libraries will not be allowed to access the libraries resources. Additionally, even if code has the runtime permissions to call secure class libraries, if that code is in turn called by malicious code, then the malicious code (which is now the caller) will not be allowed to access the secure class libraries or its resources.
4.7.5 Container (Declarative) versus Component (Programmatic) Security
In addition to declarative syntax security to implement CAS, declarative security is also a container-managed approach to security. In this context, the main objective is to make the software portable, flexible, and less expensive to deploy, and the security rules are configured outside the software code as part of the deployment descriptor. Often this is server- (container-) based, and the server configuration settings for authentication and authorization are used to protect the resource from unauthorized access. It is usually an all-or-nothing kind of security. Since it is usually set up and maintained by the deployment personnel and not the developer, declarative security allows programmers to ignore the environment in which they write their software, and updates to the software do not require refactoring the security model.
Programmatic security, on the other hand, is a component-managed approach to security, and, much like the imperative CAS implementation, programmatic security works by defining the security rules in the component or code itself. This allows for a granular approach to implementing security, and it can be used to apply business rules when the all-or-nothing declarative container-based security cannot support the needed rules. Programmatic security is defined by the developer. If code reuse is a requirement, then programmatic component-based security that customizes code with business and security rules is not recommended. In such cases, declarative container-based security is preferred, which also leverages nonprogrammers and deployment personnel to enforce security policies.
4.7.6 Cryptographic Agility
One of the predominant flaws of cryptographic protection implementation in code is the use of unvalidated and custom-developed or weak cryptographic algorithms for encryption and decryption or noncollision free hashing functions for hashing purposes. The recommendation to address this concern was to use vetted, tested, and proven standardized algorithms. However, in the cryptanalysis cat-and-mouse game, cryptanalysts work equally hard to break secure algorithms that the cryptographers have been creating. It is no surprise that cryptographic algorithms that were once deemed secure are now proven to be broken, and some have even made into banned lists. Table 4.5 is a tabulation of some cryptographic algorithms and hashing functions that are banned by the security development life cycle (SDL) at Microsoft and their recommended alternatives.
SDL Banned and Acceptable/Recommended Cryptographic Algorithms
|
Type of Algorithm |
Banned Algorithm |
Acceptable or Recommended Algorithm |
|
Symmetric |
DES, DESX, RC2, SKIPJACK, SEAL, CYLINK_MEK, RC4 (<128 bit) |
3DES (2 or 3), RC4 (≥128 bit), AES |
|
Asymmetric |
RSA (<2048 bit), Diffie–Hellman (<2048 bit) |
RSA (≥2048 bit), Diffie–Hellman (≥2048 bit), ECC (≥256 bit) |
|
Hash (including HMAC usage) |
SHA-0 (SHA), SHA-1, MD2, MD4, MD5 |
SHA-2 (includes: SHA-256, SHA-384, SHA-512) |
Code containing cryptographic algorithms that was once considered secure but is now determined to be insecure and found in a banned list needs to be reviewed and updated. This is not an easy task unless the code has been designed and implemented to be cryptographically agile or agnostic of the cryptographic algorithm. Cryptographic agility is the ability of the code to be able to switch from insecure algorithms to approved ones with ease, because the way in which the code is constructed is agnostic of the algorithm to provide cryptographic operations (encryption, decryption, and/or hashing). This means that a specific algorithm or the way it can be used is not hard-coded inline in code, and so replacing algorithms does not require code changes, rebuild, regression testing, updates (patches and service packs), and redeployment. Code that is cryptographically agile is characterized by maintaining the specification of the algorithm or hashing function outside the application code itself. Configuration files at the application or machine level are usually used to implement this. Additionally, even when the algorithm is specified in a configuration file, the implementation of the algorithm should be abstract within the code. Coding just the abstract type of the algorithm (e.g., SymmetricAlgorithm or AsymmetricAlgorithm) instead of a specific algorithm (e.g., RijndaelManaged or RSACryptoServiceProvider) provides greater agility. In addition to the benefit of quick and easy replacement of algorithms, cryptographic agility can be used to improve performance when newer and more efficient CNG implementations are leveraged.
CNG is the replacement to the CryptoAPI and is very extensible and cryptographically agnostic in nature. It was developed to give developers the ability to enable users to create and exchange documents and data in a secure manner over nonsecure environments, such as the Internet. The main features of CNG include:
- A new cryptographic configuration system that supports better cryptographic agility
- Abstraction for key storage and separation of the storage from the algorithm operations
- Process isolation for operations with long-term keys
- Replaceable random number generators
- Better export signing support
- Thread-safety throughout the stack
- Kernel-mode cryptographic API
Cryptographically agile code, however, poses some challenges. Cryptographic agility is observed to work better with nonpersisted transient data than persisted data. Persisted (stored) data that are encrypted with an algorithm that is being replaced may not be recoverable once the algorithm is replaced. This can also lead to a DoS to legitimate users when authentication relies on comparative matching of computed hashes and the account credentials are stored after being computed using a hashing function that has been replaced. It is recommended that, in such situations, the original hashing function be stored as metadata along with the actual hash value. Additionally, it is important to plan for the storage size of the outputs as the algorithm used to replace the insecure one can yield an output with a different size. For example, the MD5 hash is always 128 bits in length, bit the SHA-2 functions can yield a 256-bit (SHA-256), 384-bit (SHA-384), or 512-bit (SHA-512) length output, and if storage is not planned for allocated in advance, the upgrade may not even be a possibility.
4.7.7 Memory Management
We have covered the importance of memory management under the section on computer architecture and buffer overflow attacks. The following are other important memory management concepts that a CSSLP must be familiar with to assist appropriately in the implementation of security controls.
4.7.7.1 Locality of Reference
The locality of reference, also known as the principle of locality, is the principle that subsequent data locations referenced when a program is run are often predictable and in proximity to previous locations based on time or space. This is primarily to promote the reuse of recently used data and instructions. The main types of locality of reference are temporal, spatial, branch, and equidistant locality.
Temporal (or time-based) locality means that the same memory locations that have been recently accessed are more likely to be referenced again in the near future. Spatial (or space-based) locality means that memory locations near to recently accessed memory locations are more likely to be referenced in the near future. Branch locality means that, on the basis of the prediction of the memory manager, the processor uses branch predictors (such as conditional branching) to determine the location of the memory locations that will be accessed in the near future. Equidistant locality is halfway between spatial and branch locality and uses simple functions (usually linear) that look for equidistant locations of memory to predict which location will be accessed in the near future.
An understanding of the principle of locality is important since appropriate protection of memory can be implemented to avoid memory buffer overflow attacks.
4.7.7.2 Dangling Pointers
Dangling pointers are those pointers that do not point to a valid object of the appropriate type in memory. These occur when the object that the pointer was originally referencing was deleted or deallocated without the pointer value’s being modified. Dangling pointers reference the memory location of the deallocated memory, and when that deallocated memory location is loaded with some other data, unpredictable results, including system instabilities, segmentation and general protection faults, can occur. Additionally, if an attacker can take advantage of the dangling pointer, serious overflow attacks can result. Dangling pointers differ from wild pointers in the sense that the wild pointers are used before being initialized, but they have been known to result in similar erratic, unpredictable, and dangerous results as do dangling pointers.
4.7.7.3 Address Space Layout Randomization (ASLR)
In order for most memory exploits and malware to be successful, the attacker must be able to identify and determine accurately the memory address where a specific process or function will be loaded. Due to the principle of locality (primarily temporal), processes and functions were observed to load in the same memory locations upon each run. This made it easy for the attackers to discover the memory location and exploit the process or function by telling their payload exploit code the memory address of the process or function they wished to exploit. ASLR is a memory management technique that can be used to protect against memory location discovery. It works by randomizing and moving the function entry points (addresses) in memory each time the program is run. An executable or dynamic link library (dll) can be loaded into any of the 256 memory locations, which means that, with ASLR turned on, the attacker has a 1 in 256 chance of discovering the exact memory address of the process or function they wish to exploit. ASLR protection is available in both Windows and Linux operating systems and is often used in conjunction with other memory protection techniques, such as data execution prevention (DEP) or executable space protection (ESP).
4.7.7.4 Data Execution Prevention (DEP)/Executable Space Protection (ESP)
DEP, as the name implies, protects computers’ systems by keeping software programs from accessing and manipulating memory in an unsafe manner. It is also known as no-execute (NX) protection because it marks the data segments (usually injected as part of a buffer overflow) that a vulnerable software will otherwise process as executable instructions as no-execute. If the software program attempts to execute the code from memory in an unapproved manner, DEP will terminate the process and close the program. Executable space protection (ESP) is the Unix or Linux equivalent of the Windows DEP. DEP can be implemented as a hardware-based technology or as a software-based technology.
Leveraging compiler switches and techniques can be useful to provide memory protection and pointer integrity checking. This limits the chances of buffer overflow attacks and increases the overall security of the software. The common compiler security switch (/GS flag) and technique (StackGuard) are discussed below.
4.7.7.5 /GS Flag
When the /GS flag is used in compilers that support it, the executable that is compiled is given the ability to detect and mitigate buffer overflows of the return address pointer stored on the stack memory. When the code compiled with the /GS flag turned on is run, before the execution of the functions that the compiler deems susceptible to buffer overflow attacks, space is allocated on the stack before the return address. On function entry, the allocated space is loaded with a security cookie that is the computed post load of the function. Upon exiting the function, a helper function is invoked that verifies that the security cookie value is not altered, which happens when the stack memory space is overwritten, indicating an overflow. If the security cookie value upon function exit is determined to be different from what it was when the function was entered, then the process will simply terminate to avoid any further consequences.
4.7.7.6 StackGuard
StackGuard is a compiler technique that provides code pointer integrity checking and protection of the return address in a function against being altered. It is implemented as a small patch of the GNU gcc compiler and works by detecting and defeating stack memory overflow attacks. StackGuard works by placing a known value (referred to as a canary or canary word) before the return address on the stack so that, should a buffer overflow occur, the first datum that will be corrupted is the canary. When the function exits, the code run to move the return address to its next instruction location (also known as the tear down code) checks to make sure that the canary word is not modified before jumping to the next return address. However, attackers have been known to forge a canary by embedding the canary word in their overflow exploit. StackGuard uses two methods to prevent forgery. These include using either a terminator canary or a random canary. A terminator canary is made up of common termination symbols for C standard string library functions, such as 0 (null), CR, LF (carriage return, line feed), and -1 (End of File or EOF), and when the attacker specifies these common symbols in their overflow string as part of their exploit code (shellcode or payload), the functions will terminate immediately. A random canary is a 32-bit random number that is set on function entry (on program start) and maintained only for the time frame of that function call or program execution. Each time the program starts, a new random canary word is set, and this makes the predictability and forging of the canary word by an attacker nearly impossible.
4.7.8 Exception Management
We covered error handling and exception management at length in previous sections. Additionally, an important exception management feature that can be leveraged during the compilation and linking process is to use the safe security exception handler (/SAFESEH) flag in systems that support it.
When the /SAFESEH flag is set, the linker will produce the executable’s safe exception handlers table and write that information into the program executable (PE). This table in the PE is used to verify safe (or valid) exceptions by the OS. When an exception is thrown, the OS will check the exception handler against the safe exception handler list that is written in the PE, and if they do not match, the OS will terminate the process.
4.7.9 Anti-Tampering
The code (source or object) needs to be protected from unauthorized modifications to assure the reliable operations and integrity of the software. Source code anti-tampering assurance can be achieved using obfuscation. Obfuscation of the source code is the process of making the code obscure and confusing using a special program called the obfuscator so that, even if the source code is leaked to or stolen by an attacker, the source code is not easily readable and decipherable. This process usually involves complicating the code with generic variable names, convoluted loops, and conditional constructs and renaming text and symbols within the code to meaningless character sequences. Obfuscated code is also known as shrouded code. Obfuscation is not limited to source code; it can be used for object code as well. When object code is obfuscated, it acts as a deterrent to reverse engineering.
Reverse engineering or reversing is the process of gleaning information about the design and implementation details of the software from object code. It is analogous to going backward (reverse) in the SDLC. It can be used for legitimate purposes, such as understanding the blueprint of the software, especially in cases where the documentation is not available, but has legal ramifications if the software does not belong to the reverser. From a security standpoint, reverse engineering can be used for security research and to determine vulnerabilities in published software. However, skillful attackers are also known to reverse engineer and crack software, circumventing security protections, such as license restrictions, implemented in code. They can also tamper and repackage software with malicious intent. This is why anti-tampering protection of object code is necessary.
Besides using obfuscation as a deterrent control against reverse engineering, object code or executables can be also be protected from being reverse engineered using other anti-tampering protection mechanisms, such as removing symbolic information from the PE and embedding anti-debugger code. The removal of symbolic information involves the process of eliminating any symbolic information, such as class names, class member names, and names of global instantiated objects, and other textual information from the program executable by stripping them out before compilation or using obfuscation to rename symbols into meaningless sequences of characters. Embedding anti-debugger code means a user or kernel level debugger detector is included as part of the code, and it detects the presence of a debugger and terminates the process when one is found. The IsDebuggerPresent API and SystemKernelDebuggerInformation API are examples of common APIs that can be leveraged to implement anti-debugger code.
Additionally, code signing (covered in Chapter 3) assures the authenticity of published code (especially mobile code) besides providing integrity and anti-tampering protection.
4.7.10 Secure Startup
It is important to recognize that software can be secure by default in design and implementation, but being without adequate levels of protection for the integrity of the software when it begins to execute can thwart the assurance of the software. It is therefore imperative to ensure that the software startup process itself is secure. Usually during the bootstrapping process of the startup phase, environment variables and configuration parameters are initialized. These variables and parameters need to be protected from disclosure, alteration, or destruction threats. Bootstrapping security is covered in more detail in Chapter 7. Secure startup prevents and mitigates side channel attacks, such as the cold boot attack.
4.7.11 Embedded Systems
A generic definition of an embedded system is a computer system that is a component of a larger machine or system. They are usually present as part of the whole system and are assigned to perform specific operations. The specificity of their operations often gives the embedded system increased reliability over a general multipurpose system. Embedded systems can respond to and are governed by events in real time. They are usually standalone devices, but they need not be. The program instructions that are written for embedded systems are known as firmware and are usually stored in read-only chips or flash memory chips. If the firmware is stored in a read-only chip, then the embedded system microcontroller or digital signal processor (DSP) is not programmable by the end user. Another important aspect of many prominent embedded systems today is the open operating system that runs on the devices. The Microsoft Windows CE (to an extent) and the Apple iPhone applications are prime examples of open operating systems that allow third parties to develop software applications that can run on these devices.
Some common examples of embedded systems devices include home appliances, cars, traffic lights, mp3 players, watches, cellular telephones, and personal digital assistants (PDAs).
With the changes in technologies and the increase in the use of embedded systems for daily living, attackers are targeting embedded systems to compromise the security of the device or the host system of which the embedded system is a part. The threat agents of embedded systems are usually more sophisticated and skilled than the general software attacker, and this means that the defenders need to be equally qualified to address embedded system security threats.
Most attacks on embedded systems are primarily disclosure attacks, so it is essential that the embedded device that stores or displays sensitive and private information has product design and security controls in place to assure confidentiality. Nowadays, with embedded devices such as PDAs that handle personal and corporate data, it is critical to ensure that such devices support and implement a transport or network layer encryption and/or DRM scheme to protect sensitive and copyrighted information that is transmitted to, stored on, and displayed on these devices. A software technique that is used on devices today to ensure that private and sensitive information is not disclosed is to implement auto-erase functionality in the software. This way, when the necessary credentials to access the device data are not provided and the configured number of attempts has been superseded, the software will execute an auto-destruct function that erases all data on the device.
Memory management in embedded systems is critical because the memory in embedded systems usually holds both the data and the product’s firmware as well. Leveraging a tamper-resistant sensor to detect and assure that memory remanence disclosure and alteration is mitigated is important.
In addition to disclosure threats, embedded systems also face a plethora of other attacks. The small size and portability often make them the target to side channel attacks (e.g., radiation and power analysis) and fault injection attacks. This mandates the need to protect the internal circuitry of the devices with physical deterrent controls, such as seals (epoxies), conformal coatings, and tapes that need to be broken before the device can be opened. The software running on these systems can then be used to signal physical breaches or tampering activities. Another technique that product designers use to deter reconnaissance and reverse engineering of the device itself is that they hide critical signals in the internal board layers.
When third-party applications and software are allowed to run on these embedded system devices, it is necessary to ensure that a safe execution environment is provided to the owner of the device. The third-party applications should be isolated from other applications running on the device and must be limited from accessing the owner’s private and sensitive data stored on the device.
All of the security controls that are applicable in pervasive computing are also applicable to embedded systems. This means that before users are allowed to use the secure embedded system device, they must first verify their identity and be authenticated. Multifactor authentication is recommended to increase security. Additionally, the TPM chip on the device can be used for node-to-node authentication and provide for the tamper-resistant storage of keys and secrets.
The recognized ISO 15408 (common criteria) standard and the multiple independent levels of security (MILS) standard can be leveraged for embedded systems security. The MILS architecture makes it possible to create a verified, always invoked, and tamperproof application code with security features that thwart the attempts of an attacker. It is expected that future embedded systems development projects will focus their attention on increasing the security of the firmware and of the devices themselves.
4.7.12 Interface Coding
Software today is mostly developed using and leveraging APIs. APIs make the internal functionality of a software function accessible to external callers (other entities and code functions). They abstract the internal function details, and as long as the caller meets the interface requirements, they can invoke and benefit from the processing of the function. Interfaces are useful to implement the design principle of leveraging existing components. Threat modeling should identify APIs as potential entry points. Banned and deprecated APIs that are susceptible to security breaches should be avoided and replaced with secure counterparts.
When interfaces are used to access administrative features, Web services, or other third-party components, it is essential to ascertain that proper authentication is in place. It is also important to audit the access and user/system actions that are performed upon the invocation of privileged functions exposed by the interfaces. When confidentiality of sensitive information (e.g., usernames, passwords, connection string, keys) is required, CNG can be used. When an application’s internal APIs are opened up to third-party developers, necessary protection mechanisms need to be in place.
4.8 Secure Software Processes
Software assurance is a confluence of secure processes and technologies implemented by trained and skilled people who understand how to design, develop, and deploy secure software. In addition to writing secure code, there are certain processes that must be conducted during the implementation phase that can assure the security of the software. These include:
- Versioning
- Code analysis
- Code/Peer review
4.8.1 Versioning
Configuration management has a direct impact on the state of software assurance and is applicable as part of development as well as deployment. Configuration management as it applies to deployment is covered in more detail in Chapter 7. In this chapter, we will cover the importance of configuration management as it pertains to code development and implementation, more particularly source code versioning or version control.
Versioning or version control of software not only ensures that the development team is working with the correct version of code, but also gives the ability to rollback to a previous version should there be a need. Additionally, software versioning provides the ability to track ownership and changes of code. If each version of the software is tracked and maintained, determining and analyzing the attack surface for each version can give insight into the RASQ and the overall trend of software security. Version control can reduce the incidences of a condition known as regenerative bugs, where previously fixed bugs reappear (are regenerated). This is known to occur when bug fixes are inadvertently overwritten when the correct version of code is not used.
From a security standpoint, it is important to ensure that the versioning uses file locks or reserved checkouts. This means that when the code is checked out by someone for changes, no one else can make changes to the code until it has been checked back in. Most current software development IDEs incorporate versioning. Well-known examples of version control software include Visual SourceSafe (VSS), Concurrent Versions System (CVS), StarTeam, and Team Foundation Server (TFS).
4.8.2 Code Analysis
Code analysis is the process of inspecting the code for exploitable weaknesses. It is primarily accomplished by two means: static and dynamic.
Static code analysis involves the inspection of the code without executing the code (or software program). This analysis can be performed manually by a code review (covered next in this section) or in an automated manner using tools. Any code, regardless of whether it is source code, bytecode, or object code, can be analyzed. Tools that are used to perform static source code analysis are commonly referred to as source code analyzers, and tools that are used to analyze intermediate bytecode are known as bytecode scanners. Tools used to analyze object code statically are referred to as binary analyzers or binary code scanners.
The benefits of performing static code analysis are that errors and vulnerabilities can be detected early and addressed before deployment of the software. Additionally, static code analysis does not need a simulated production environment and can be performed in the development or testing environment.
Dynamic code analysis is the inspection of the code when it is being executed (run as a program). Just because the code compiles without any errors that can be analyzed in static code analysis, it does not mean that it will run without any errors. Dynamic code analysis can be performed to ascertain that the code is reliably functioning as expected and is not prone to errors or exploitation. In order to perform dynamic analysis accurately, a simulated environment that mirrors the production environment where the code will be deployed is necessary. Tools used for dynamic code analysis are known as dynamic code analyzers, and they can be used to determine how the program will run as it interacts with other processes and the operating system itself.
4.8.3 Code/Peer Review
One way to inspect the code statically is to perform a code review. A code review is also referred to as a peer review when peers from the development team are part of the code review process. A code review can be performed manually or by using tools. It is a systematic evaluation of the source code with the goal of finding out syntax issues and weaknesses in the code that can impact the performance and security of the software. Semantic issues, such as business logic and design flaws, are usually not detected in a code review, but a code review can be used to validate the threat model generated in the design phase of the software development project. Tools can be used to automate and identify vulnerabilities quickly, but they must not be done in lieu of manual human review.
When a code review is conducted for security reasons, the code must at a bare minimum be inspected for the following:
- Insecure code
- Inefficient code: Code that has exploitable weaknesses in it
Common insecure code implementations include:
- Injection Flaws: Check for code that makes injection attacks possible. Examples include the lack of input validation or the dynamic construction of queries that accept user supplied data without proper validation or sanitization. Code review must check to ensure that proper input validation is in place.
- Nonrepudiation Mechanisms: Code review should ensure that auditing is properly implemented and that the authenticity of the code and the user or system actions are not disputable. If delayed signing is not the case, checks to make sure that the code is correctly signed should be undertaken as part of the review.
- Spoofing Attacks: Check for code that makes spoofing attacks possible. This check should ensure that session identifiers are not predictable, passwords are not hard-coded, credentials are not cached, and code that allows changes to the impersonation context is not implemented.
- Errors and Exception Handling: Code review must check to make sure that errors when reported do not reveal more information than is necessary and that the software fails securely when errors occur. Code should be implemented to handle exceptions. The check for the presence of try-catch-finally blocks must also check to make sure that objects created in code are destroyed in the finally blocks.
- Cryptographic Strength: Code that uses nonstandard or custom cryptographic algorithms are considered weak and must be avoided. Algorithms must not be hard-coded as they will impair the cryptographic agility of the software. The use of random number generators (RNG) and pseudo-random number generators (PRNG) must be validated. Keys must also not be hard-coded, and code review should ensure that cryptographic protections are strong enough to avoid any cryptanalytic attacks.
- Unsafe and Unused Functions and Routines in Code: The code must be reviewed to ascertain that deprecated and banned APIs are not used. Also, any unused functions in code should be removed. Explicit checks for Easter eggs and bells-and-whistles in code must be performed. A good way to determine if the code is required is to use the requirements traceability matrix.
- Reversible Code: Code that can be used to determine the internal architecture and design and implementation details of software functionality. Code must be reviewed to check for debugger detectors, and any symbolic and textual information that can aid a reverse engineer should be removed.
- Privileged Code: Code that violates the principle of least privilege. As part of the code review, checks must be performed to ensure that any code that requires administrative rights to execute is explicitly controlled and monitored.
Additionally, the code should also be reviewed for:
- Maintenance Hooks: Intentionally introduced, seemingly innocuous code that is implemented primarily to provide for maintenance needs. They are implanted to ease troubleshooting and better support. Maintenance hooks can be used to impersonate a user who is experiencing issues with the software to recreate the issue as a way to troubleshoot the issue. They can also function as a back door and allow developers access to privileged systems (usually in a production environment), even if they are not granted authorization rights to those systems. They are to be considered critical or privilege code because they usually provide administrative access with unrestricted rights. However, these maintenance hooks should not be deployed into the production environment because an attacker could easily take advantage of the maintenance hook and gain back door entry into the system, often circumventing all security protection mechanisms.
- Logic Bombs: Serious code security issues as they can be placed in the code and go undetected if a code review is not performed. Based on the logic (such as a condition or time), a logic bomb can be triggered to go off to perform some malicious and unintended operation when that logic is met. Logic bombs are implanted by an insider who has access to the source code. Disgruntled employees who feel wronged by their employers have been known to implant logic bombs in their code as a means of revenge. A logic bomb not only causes destruction of data, it can also disrupt or bring the business to a complete halt. They have been used for extortion scams as well where the publisher of the code threatens the subscriber that they will trigger the logic bomb in code unless the subscriber agrees to the terms of the publisher. When the software code is not directly developed and controlled by you, as in the case of an outsourcer or third party, code review to determine logic bombs becomes extremely critical. It is also important to note that to deactivate a trial piece of software after a certain period of time has elapsed (the condition), as it was communicated in advance, is not regarded as a logic bomb because it is nonmalicious and functions as intended.
The review of the code must also identify code that is inefficient as it can have a direct impact on the security of the software. Making an improper system call and infinite loop constructs are some examples of inefficient code that can lead to system compromise, memory leaks, resource exhaustion, and DoS, impacting the core confidentiality, integrity, and availability tenets of software security. Specifically, code should be reviewed to eliminate the following inefficiencies:
- Timing and Synchronization Implementations: Race conditions in code that can result in covert channels and resource deadlocks can be identified using a code review. It is important to make sure that the code is constructed to be executed in a mutually exclusive (Mutex) manner so that timing and synchronization issues can be avoided. This is particularly important if the code is written to alter the state of a shared object simultaneously.
- Cyclomatic Complexity: A measure of the number of linearly independent paths in a program. This software metric used to find out the extent of decision logic within each module of the code. Highly cohesive and loosely coupled code will have little to no circular dependencies and will thus be less complex. The results of determining the cyclomatic complexity can be used as indicators of the software design as it pertains to the design principle of economy of mechanisms and least common mechanisms.
It is also important to recognize that the code review process is a structured and planned activity and must be conducted in a constructive manner. First and foremost, it is the code and not the coder that is being reviewed, and so mutual respect of all team members who are part of the code review is critically important. It is recommended that explicit roles and responsibilities are assigned to the participants of the code review. Moderators who facilitate the code review must be identified. A CSSLP is expected to function in this manner. It is also important to identify who the reviewers of the code will be and appoint a scribe who will be responsible to record the minutes of the code review meeting so that action items that arise from it are addressed. Informing the reviewer about the code that is going to be reviewed in the code review meeting in advance and securely giving them access to the code is advised, so that the reviewers come prepared to the meeting. As a means to demonstrate separation of duties, the programmer who wrote the code should not also be the moderator or the scribe. They are to participate in the code review with a mindset to accept action items that need to be addressed. The findings of the code review are to be communicated as constructive feedback rather than criticisms of the programmer’s coding style or ability. Leveraging the coding standards and internal policies and external regulatory and compliance requirements to prioritize and handle code review findings is recommended.
4.9 Build Environment and Tools Security
Earlier in this chapter, we covered the different types of programming languages and code. Source code that is written by the programmer needs to be converted into a form that the machine can understand. This conversion process is generically referred to as the build process. The integrity of the build environment where the source code is converted into object code is important. The integrity of the build environment can be assured by:
- Physically securing access to the systems that build code
- Using access control lists (ACLs) that prevent access to unauthorized users
- Using version control software to assure that the code built is of the right version
It is also important to ensure that legacy source code can be built without errors. This mandates the need to maintain the legacy source code, the associated dependency files that need to be linked, and the build environment itself. Since most legacy code has not been designed and developed with security in mind, it is critical to ascertain that the secure state of the computing ecosystem is not reduced when legacy source code is rebuilt and redeployed.
During the build process, the security of the software can be augmented using features in the build tools. The main kinds of build tools are packagers, compilers, and packers.
Packagers are used to build software so that the software can be seamlessly installed without any errors. They make sure that all dependencies and resources necessary for the software to run are part of the software build. The Red Hat Package Manager (RPM) and the Microsoft Installer (MSI) are examples of packagers. When software is packaged, it is important to ensure that no new vulnerabilities are introduced.
Packers are used to compress executables primarily for the purpose of distribution and to reduce secondary storage requirements. Packed executables reduce the time and bandwidth required by users who download code and updates. Packed software executables need to be unpacked with the appropriate unpacker, and when proprietary and unpublished packers are used for packing the software executable, they provide some degree of protection against reverse engineering. Packed executables pose more challenges to a reverse engineer and are deterrent in nature, but they do not prevent reversing efforts. Packing software can also be used to obfuscate the contents of the executable. It is also important to recognize that attackers, especially malware writers, use packers to pack their malware programs because the packers transform the executables appearance to evade signature-based malware detection tools, but they do not affect its execution semantics in any way.
4.10 Summary
Although programmers primarily function as problem solvers for the business, the software that they write can potentially become the problem for the business, if it is written without a thorough understanding of how their programs run or without necessary security protection mechanisms. A fundamental understanding of programming utilities, such as the assembler, compiler, interpreters, and computer architecture, is essential so that code is first reliable and second resilient and recoverable when attacked. There are several different types of software development methodologies, and each has its benefits and disadvantages. Choosing a software development methodology must factor in the security advantages or lack thereof.
It is important to be familiar with common coding vulnerabilities that plague software and have a thorough understanding of how an attacker will try to exploit the software, so that the code has security protection controls implemented in it. Some of the basic characteristics of secure code are illustrated in Figure 4.24.

Secure software development processes include versioning, code analysis, and code review. Source code version control is necessary to track owners and changes to the code and to provide the ability to rollback to previous versions as needed. Code can be analyzed either statically or dynamically, and it is advisable that both static and dynamic analysis is conducted before code is deployed or released after it is tested. Statically reviewing the code involves checking the code for insecure and inefficient code issues, either manually as a code (or peer) review or using automatically by using tools.
Attack surface reduction, CAS, container (declarative) vs. component (programmatic) security, cryptographic agility, memory management, exception management, anti-tampering mechanisms, and interface coding security are other important security concepts that cannot be ignored while writing secure code. Maintaining the integrity of the build environment and process and knowing how to leverage the features of packagers, compilers (switches), and packers to augment the security protection in code is important.
4.11 Review Questions
- Software developers write software programs primarily to
A. create new products
B. capture market share
C. solve business problems
D. mitigate hacker threats
- The process of combining necessary functions, variables, and dependency files and libraries required for the machine to run the program is referred to as
A. compilation
B. interpretation
C. linking
D. instantiation
- Which of the following is an important consideration to manage memory and mitigate overflow attacks when choosing a programming language?
A. locality of reference
B. type safety
C. cyclomatic complexity
D. Parametric polymorphism
- Using multifactor authentication is effective in mitigating which of the following application security risks?
A. injection flaws
B. Cross-Site Scripting (XSS)
C. buffer overflow
D. Man-in-the-Middle (MITM)
- Implementing Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) protection is a means of defending against
A. SQL injection
B. Cross-Site Scripting (XSS)
C. Cross-Site Request Forgery (CSRF)
D. insecure cryptographic storage
- The findings of a code review indicate that cryptographic operations in code use the Rijndael cipher, which is the original publication of which of the following algorithms?
A. Skipjack
B. Data Encryption Standard (DES)
C. Triple Data Encryption Standard (3DES)
D. Advanced Encryption Standard (AES)
- Which of the following transport layer technologies can best mitigate session hijacking and replay attacks in a local area network (LAN)?
A. Data Loss Prevention (DLP)
B. Internet Protocol Security (IPSec)
C. Secure Sockets Layer (SSL)
D. Digital Rights Management (DRM)
- Verbose error messages and unhandled exceptions can result in which of the following software security threats?
A. spoofing
B. tampering
C. repudiation
D. information disclosure
- Code signing can provide all of the following except
A. anti-tampering protection
B. authenticity of code origin
C. runtime permissions for code
D. authentication of users
- When an attacker uses delayed error messages between successful and unsuccessful query probes, he is using which of the following side channel techniques to detect injection vulnerabilities?
A. distant observation
B. cold boot
C. power analysis
D. timing
- When the runtime permissions of the code are defined as security attributes in the metadata of the code, it is referred to as
A. imperative syntax security
B. declarative syntax security
C. code signing
D. code obfuscation
- When an all-or-nothing approach to code access security is not possible and business rules and permissions need to be set and managed more granularly inline in code functions and modules, a programmer can leverage which of the following?
A. cryptographic agility
B. parametric polymorphism
C. declarative security
D. imperative security
- An understanding of which of the following programming concepts is necessary to protect against memory manipulation buffer overflow attacks? Choose the best answer.
A. error handling
B. exception management
C. locality of reference
D. generics
- Exploit code attempt to take control of dangling pointers that
A. are references to memory locations of destroyed objects
B. are the nonfunctional code left behind in the source
C. are the payload code that the attacker uploads into memory to execute
D. are references in memory locations that are used prior to being initialized
- Which of the following is a feature of most recent operating systems (OS) that makes it difficult for an attacker to guess the memory address of the program as it makes the memory address different each time the program is executed?
A. Data Execution Prevention (DEP)
B. Executable Space Protection (ESP)
C. Address Space Layout Randomization (ASLR)
D. Safe Security Exception Handler (/SAFESEH)
- When the source code is made obscure using special programs in order to make the readability of the code difficult when disclosed, the code is also known as
A. object code
B. obfuscated code
C. encrypted code
D. hashed code
- The ability to track ownership, changes in code, and rollback abilities is possible because of which of the following configuration management processes?
A. version control
B. patching
C. audit logging
D. change control
- The main benefit of statically analyzing code is that
A. runtime behavior of code can be analyzed
B. business logic flaws are more easily detectable
C. the analysis is performed in a production or production-like environment
D. errors and vulnerabilities can be detected earlier in the life cycle
- Cryptographic protection includes all of the following except
A. encryption of data when it is processed
B. hashing of data when it is stored
C. hiding of data within other media objects when it is transmitted
D. masking of data when they are displayed
- Assembly and machine language are examples of
A. natural language
B. Very High-Level Language (VHLL)
C. High-Level Language (HLL)
D. Low-Level Language
References
Aho, A., R. Sethi, and J. Ullman. 2007. Compilers: Principles, Techniques, & Tools. Boston, MA: Pearson/Addison Wesley.
Anley, C., and J. Koziol. 2007. The Shellcoder’s Handbook: Discovering and Exploiting Security Holes. Indianapolis, IN: Wiley Pub.
Blum, R. 2005. Professional Assembly Language. Indianapolis, IN: Wrox.
Cannings, R., H. Dwivedi, and Z. Lackey. 2008. Hacking Exposed Web 2.0: Web 2.0 Security Secrets and Solutions. New York, NY: McGraw-Hill.
Cowan, C., P. Wagle, C. Pu, S. Beattle, and J. Walpole. 2003. Buffer overflows: Attacks and defenses for the vulnerability of the decade. Foundations of Intrusion Tolerant Systems: 227−237.
CWE. 2010. CWE/SANS top 25 most dangerous programming errors. http://cwe.mitre.org/top25 (accessed Apr. 5, 2010).
Eilam, E., and E. J. Chikofsky. 2005. Reversing Secrets of Reverse Engineering. Indianapolis, IN: Wiley.
Farley, J., and W. Crawford. 2006. Java Enterprise in a Nutshell. Sebastopol, CA: O’Reilly.
Fielding, R. et al. 1999. Hypertext Transfer Protocol—HTTP/1.1. Internet Engineering Task Force (IETF) RFC 2616. June 1999. http://www.ietf.org/rfc/rfc2616.txt (accessed May 1, 2010).
Foster, J. C. 2005. Buffer Overflow Attacks: Detect, Exploit, Prevent. Rockland, MA: Syngress.
Gauci, S. Surf jacking—HTTPS will not save you. EnableSecurity. 10 Aug. 2008. http://enablesecurity.com/2008/08/11/surf-jack-https-will-not-save-you (accessed Apr. 30 2010).
Hagai Bar-El. Side channel attacks. http://www.hbarel.com/Misc/side_channel_attacks.html (accessed May 1, 2010).
Halderman, J., S. Schoen, N. Heninger, W. Clarkson, W. Paul, J. Calandrino, A. Feldmen, J. Applebaum, and E. Felten. 2008. Lest we remember: Cold boot attacks on encryption keys. Proc. 17th USENIX Security Symposium.
Herzog, P. 2008. Hacking Exposed Linux Security Secrets and Solutions. Berkeley, CA: McGraw-Hill Osborne Media.
Howard, M., and D. LeBlanc. 2003. Writing Secure Code. Redmond, WA: Microsoft.
Howard, M., and S. Lipner. 2006. The Security Development Lifecycle: SDL, a Process for Developing Demonstrably More Secure Software. Redmond, WA: Microsoft.
Jegerlehner, R. Intel Assembler CodeTable 80x86—Overview of Instructions (Cheat Sheet). http://www.jegerlehner.ch/intel (accessed May 1, 2010).
Litchfield, D. 2005. The Database Hacker’s Handbook: Defending Database Servers. Indianapolis, IN: Wiley.
McClure, S., J. Scambray, and G. Kurtz. 2003. Hacking Exposed: Network Security Secrets & Solutions. Fourth ed. Berkeley, CA: McGraw-Hill Osborne Media.
Microsoft Developer Network. 2010. Security in the .NET framework. http://msdn.micro soft.com/en-us/library/fkytk30f%28VS.80%29.aspx (accessed May 1, 2010).
MITRE Corporation. 2011. Common attack pattern enumeration and classification. http://capec.mitre.org (accessed May 1, 2010).
Morrison, J. 2009. Preventing race conditions in code that accesses global data. It Goes To Eleven. http://blogs.msdn.com/b/itgoestoeleven/archive/2009/11/11/preventing-race-conditions-in-code-that-accesses-global-data.aspx (accessed May 1, 2010).
Ogorkiewicz, M., and P. Frej. 2004. Analysis of buffer overflow attacks. http://www.windowsecurity.com/articles/Analysis_of_Buffer_Overflow_Attacks.html (accessed Apr. 30, 2010).
OWASP. 2010. Developer guide. http://www.owasp.org/index.php/Developer_Guide (accessed May 1, 2010).
OWASP. 2010. OWASP top 10 web application security risks. http://www.owasp.org/index.php/Top_Ten (accessed Apr. 19, 2010).
Paul, M. 2008a. Phishing: Electronic social engineering. Certification Magazine, Sept. 2008.
Paul, M. 2008b. TMI syndrome in Web applications. Certification Magazine, Apr. 2008.
Scambray, J., and S. McClure. 2008. Hacking Exposed Windows: Windows Security Secrets & Solutions. New York, NY: McGraw-Hill.
Scambray, J., M. Shema, and C. Sima. 2006. Hacking Exposed: Web Applications. New York, NY: McGraw-Hill.
Schneier, B. 1996. Applied Cryptography: Protocols, Algorithms, and Source Code in C. New York, NY: Wiley.
Schneier, B. 1998. Security pitfalls in cryptography. Schneier on Security. http://www.schneier.com/essay-028.html (accessed Apr. 30 2010).
Schneier, B., N. Ferguson, and T. Kohno. 2010. Cryptography Engineering. New York, NY: Wiley.
Shiel, S., and I. Bayley. 2005. A translation-facilitated comparison between the common language runtime and the Java Virtual Machine. Electronic Notes in Theoretical Computer Science (ENTCS) 141.1: 35–52.
Sullivan, B. 2009. Cryptographic agility. MSDN: Microsoft Development, MSDN Subscriptions, Resources, and More. http://msdn.microsoft.com/en-us/magazine/ee321570.aspx (accessed Aug. 2009).
Toll, D. C., S. Weber, P. A. Karger, E. R. Palmer, S. K. McIntosh. 2008. Tooling in support of common criteria evaluation of a high assurance operating system. Build Security In. https://buildsecurityin.us-cert.gov/bsi/961-BSI.html (accessed).
Web Application Security Consortium. Web Hacking Incident Database. http://projects.webappsec.org/w/page/13246995/Web-Hacking-Incident-Databasev (accessed May 1, 2010).
Webb, W. 2004. Hack this: Secure embedded systems. EDN: Information, News, & Business Strategy for Electronics Design Engineers. July 22, 2004. http://www.edn.com/article/479692-Hack_this_secure_embedded_systems.php (accessed May 1, 2010).
Zeller, W., and E. W. Felten. 2008. Cross-site request forgeries: Exploitation and prevention. Center for Information Technology Policy. Princeton, 15 Oct. 2008. http://from.bz/public/documents/publications/csrf.pdf (accessed Apr. 30, 2010).