
Chapter 2
Secure Software Requirements
2.1 Introduction
As a preface, it is important to establish the fact that “Without software requirements, software will fail and without secure software requirements, organizations will.” Without properly understood, well-documented, and tracked software requirements, one cannot expect the software to function without failure or to meet expectations. It is vital to define and explicitly articulate the requirements of software that is to be built or acquired. Software development projects that lack software requirements suffer from a plethora of issues. These issues include and are not limited to poor product quality, extensive timelines, scope creep, increased cost to re-architect missed requirements or fix errors, and even customer or end user dissatisfaction. Software development projects that lack security requirements additionally suffer from the threats to confidentiality, integrity, and availability, which include unauthorized disclosure, alteration, and destruction. It is really not a question of “if” but “when,” because it is only a matter of time before software built without security considerations will get hacked, provided the software is of some value to the attacker.
It would be extremely difficult to find a building architect who would engage in building a skyscraper without a blueprint or a chef who will indulge in baking world-famous pastries and cakes without a recipe that lists the ingredients. However, we often observe that when software is built, security requirements are not explicitly stated. The reasons for such a modus operandi are many. Security is first and foremost viewed as a nonfunctional requirement and in an organization that has to deal with functional requirements owing to the constraints posed by budget, scope, and schedule (iron triangle constraints), security requirements are considered to be an additional expense (impacting budget), increased nonvalue added functionality (impacting scope), and were time-consuming to implement (impacting schedule). Such an attitude is what leaves secure software requirements on the sidelines. Second, incorporating security in software is often misconstrued as an impediment to business agility and not necessarily as an enabler for the business to produce quality and secure software. Secure software is characterized by the following quality attributes:
- Reliability: The software functions as it is expected to.
- Resiliency: The software does not violate any security policy and is able to withstand the actions of threat agents that are posed intentionally (attacks and exploits) or accidentally (user errors).
- Recoverability: The software is able to restore operations to what the business expects by containing and limiting the damage caused by threats that materialize.
Third, depending on the security knowledge of business analysts who translate business requirements to functional specifications, security may or may not make it into the software that is developed. In certain situations, security in software is not even considered, leave alone being ignored! And in such situations, when an abuse of the software is reported, security is retrofitted and bolted on, instead of having been built in from the very beginning.
The importance of incorporating security requirements in the software requirements gathering and design phases is absolutely critical for the reliability, resiliency, and recoverability of software. When was the last time you noticed security requirements in the software requirement specifications documents? Explicit software security requirement such as “The user password will need to be protected against disclosure by masking it while it is input and hashed when it is stored” or “The change in pricing information of a product needs to be tracked and audited, recording the timestamp and the individual who performed that operation” are usually not found within the software requirements specifications document. What are usually observed are merely high-level nontestable implementation mechanisms and listing of security features such as passwords need to be protected, Secure Sockets Layer (SSL) needs to be in place or a Web application firewall needs to be installed in front of our public facing Web sites. It is extremely important to explicitly articulate security requirements for the software in the software requirements specifications documents.
2.2 Objectives
Leveraging the wisdom from the famous Chinese adage that “a journey of a thousand miles begins with the first step,” we can draw the parallel that the first step in the journey to design, develop, and deploy secure software is the determination of security requirements in software.
As a CSSLP, you are expected to:
- Be familiar with various internal and external sources from which software security requirements can be determined.
- Know how to glean software security requirements from various stakeholders and sources.
- Be thorough in the understanding on the different types of security requirements for software.
- Understand and be familiar with data classification as a mechanism to elicit software security requirements from functional business requirements.
- Know how to develop misuse cases from use case scenarios as a means to determine security requirements.
- Know how to generate a subject–object matrix (SOM) and understand how it can be used for generating security requirements.
- Be familiar with timing and sequencing aspects of software as it pertains to software security.
- Be familiar with how the requirements traceability matrix (RTM) can be used for software security considerations.
This chapter will cover each of these objectives in detail. It is imperative that you fully understand the objectives and be familiar with how to apply them in the software that your organization builds or buys.
2.3 Sources for Security Requirements
There are several sources from which security requirements can be gleaned. They can be broadly classified into internal and external sources. Internal sources can be further divided into organizational sources that the organization needs to comply with. These include policies, standards, guidelines, and patterns and practices. The end user business functionality of the software itself is another internal source from which security requirements can be gleaned. Just as a business analyst translates business requirements into functionality specifications for the software development team, a CSSLP must be able to assist the software teams to translate functional specifications into security requirements. In the following section, we will cover the various types of security requirements and discuss requirements elicitation from software functionality in more detail. External sources for security requirements can be broadly classified into regulations, compliance initiatives, and geographical requirements. Equal weight should be given to security requirements regardless of whether the source of that requirement is internal or external.
Business owners, end users, and customers play an important role when determining software security requirements, and they must be actively involved in the requirements elicitation process. Business owners are responsible for the determination of the acceptable risk threshold, which is the level of residual risk that is acceptable. Business owners also own the risk, and they are ultimately accountable, should there be a security breach in their software. They should assist the CSSLP and software development teams in prioritizing the risk and be active in “what is important?” trade-off decisions. Business owners need to be educated on the importance and concepts of software security. Such education will ensure that they do not assign a low priority to security requirements or deem them as unimportant. Furthermore, supporting groups such as the operations group and the information security group are also vital stakeholders and are responsible for ensuring that the software being built for deployment or release is reliable, resilient, and recoverable.
2.4 Types of Security Requirements
Before we delve into mechanisms and methodologies by which we can determine security requirements, we must first be familiar with the different types of security requirements. These security requirements need to be explicitly defined and must address the security objectives or goals of the company. Properly and adequately defining and documenting security requirements makes the measurement of security objectives or goals once the software is ready for release or accepted for deployment possible and easy. A comprehensive list of security requirements for software is as tied as hand to glove to the software security profile, which is depicted in Figure 2.1.
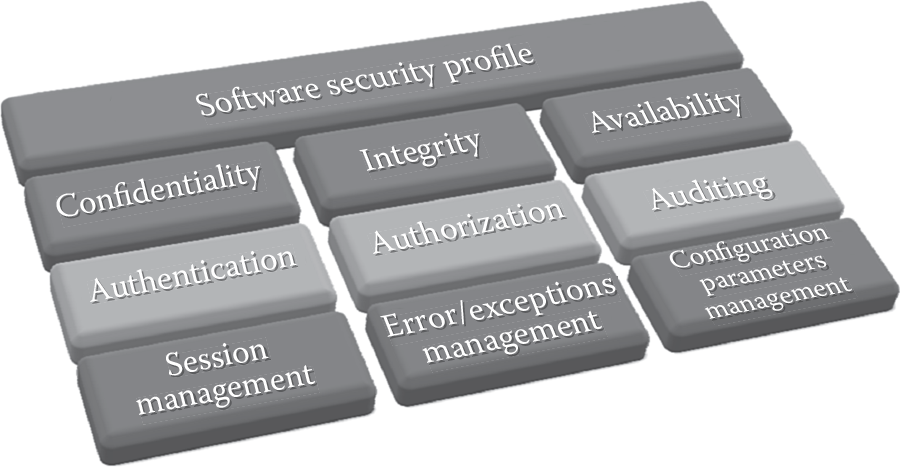
For each characteristic of the software security profile, security requirements need to be determined. In addition, other requirements that are pertinent to software must be determined as well. The different types of software security requirements that need to be defined as illustrated in Figure 2.2 include the following:
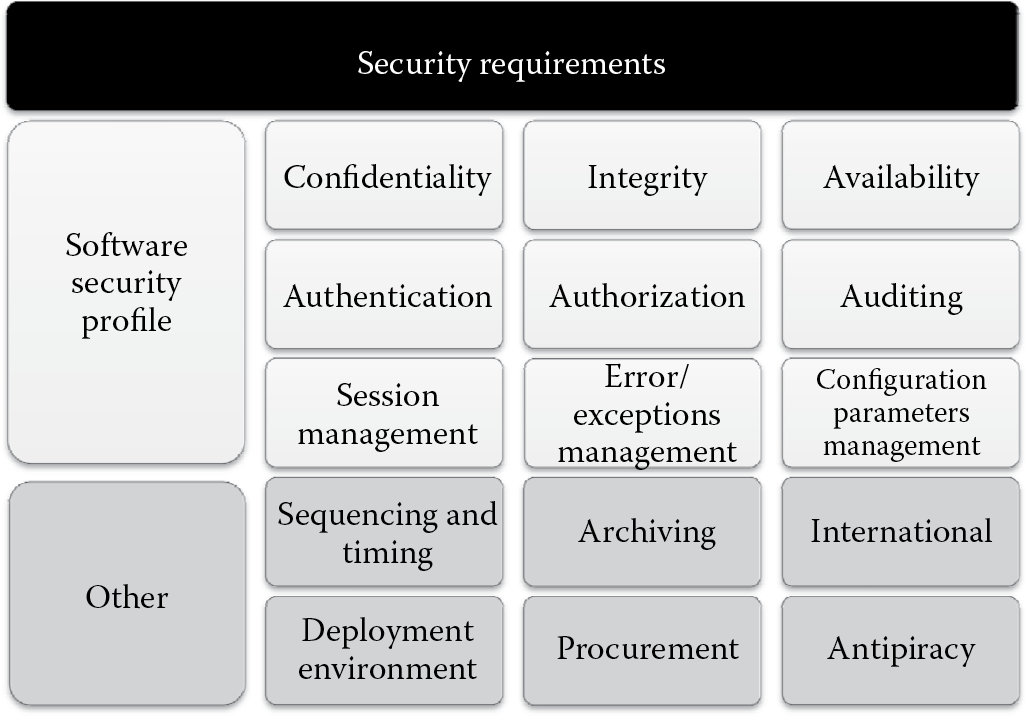
- Confidentiality requirements
- Integrity requirements
- Availability requirements
- Authentication requirements
- Authorization requirements
- Auditing requirements
- Session management requirements
- Errors and exceptions management requirements
- Configuration parameters management requirements
- Sequencing and timing requirements
- Archiving requirements
- International requirements
- Deployment environment requirements
- Procurement requirements
- Antipiracy requirements
In the requirements gathering phase of the software development life cycle (SDLC), we are only required to identify which requirements are applicable to the business context and the software functionality serving that context. Details on how these requirements will be implemented are to be decided when the software is designed and developed. In this chapter, a similar approach with respect to the extent of coverage of the different types of security requirements for software is taken. In Chapter 3, we will cover in-depth the translation of the identified requirements from the requirements gathering phase into software functionality and architecture, and in Chapter 4, we will learn about how the security requirements are built into the code to ensure software assurance.
2.4.1 Confidentiality Requirements
Confidentiality requirements are those that address protection against the disclosure of data or information that are either personal or sensitive in nature to unauthorized individuals. The classification of data (covered later in this chapter) into sensitivity levels is often used to determine confidentiality requirements. Data can be broadly classified into public and nonpublic data or information. Public data are also referred to as directory information. Any nonpublic data warrant protection against unauthorized disclosure, and software security requirements that afford such protection need to be defined in advance. The two common forms of confidentiality protection mechanisms as depicted in Figure 2.3 include secret writing and masking.
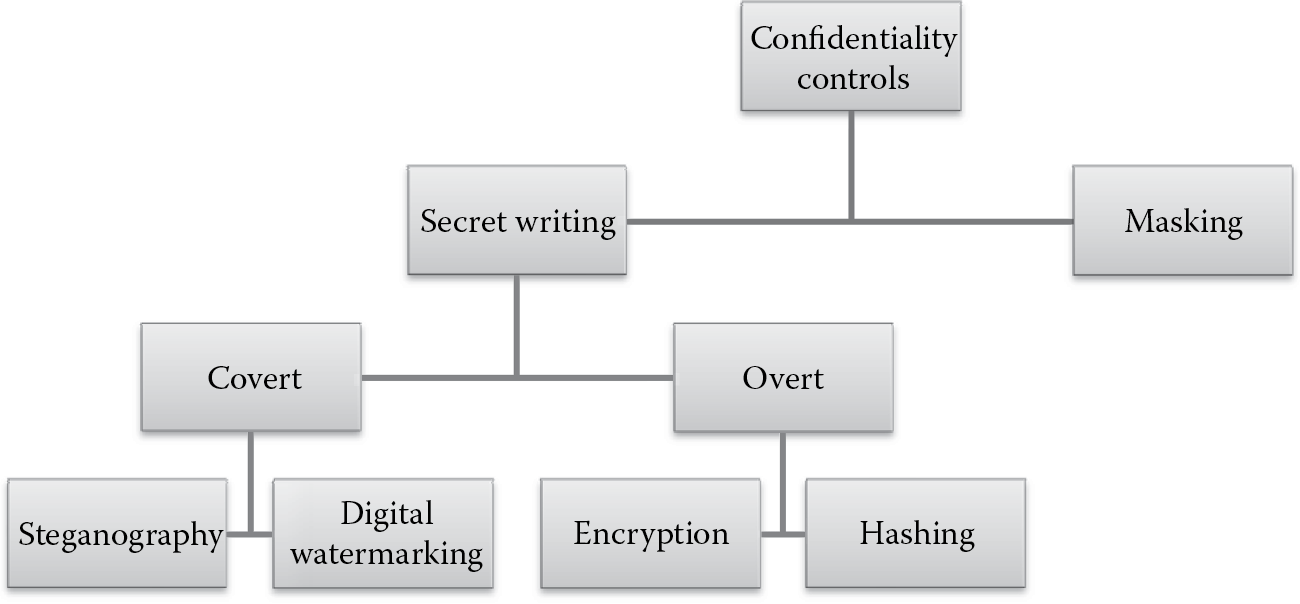
Secret writing is a protection mechanism in which the goal is to prevent the disclosure of the information deemed secret. This includes overt cryptographic mechanisms such as encryption and hashing or covert mechanisms such as steganography and digital watermarking (Bauer, 2000). The distinction between the overt and covert forms of secret writing lies in their objective to accomplish disclosure protection. The goal of overt secret writing is to make the information humanly indecipherable or unintelligible even if disclosed, whereas the goal of covert secret writing is to hide information within itself or in some other media or form.
Overt secret writing, also commonly referred to as cryptography, includes encryption and hashing. Encryption uses a bidirectional algorithm in which humanly readable information (referred to as clear text) is converted into humanly unintelligible information (referred to as cipher text). The inverse of encryption is decryption, the process by which cipher text is converted into plain text. Hashing, on the other hand, is a one-way function where the original data or information that needs protection is computed into a fixed length output that is indecipherable. The computed value is referred to as a hash value, digest, or hash sum. The main distinction between encryption and hashing is that, unlike in encryption, the hashed value or hashed sum cannot be converted back to the original data and hence the one-way computation. So hashing is primarily used for integrity (nonalteration) protection, although it can be used as a confidentiality control, especially in situations when the information is stored and the viewers of that information should not be allowed to resynthesize the original value by passing it through the same hashing function. A good example of this is when there is a need to store passwords in databases. Only the creator of the password should be aware of what it is. When the password is stored in the backend database, its hashed value should be the one that is stored. This way hashing provides disclosure protection against insider threat agents who may very well be the database administration within the company. When the password is used by the software for authentication verification, the user can supply their password, which is hashed using the same hashing function and then the hash values of the supplied password and the hash value of the one that is stored can be compared and authentication decisions can be accordingly undertaken.
The most common forms of covert secret writing are steganography and digital watermarking (Johnson, Duric, and Jajodia, 2000). Steganography is more commonly referred to as invisible ink writing and is the art of camouflaging or hidden writing, where the information is hidden and the existence of the message itself is concealed. Steganography is primarily useful for covert communications and is useful and prevalent in military espionage communications. Digital watermarking is the process of embedding information into a digital signal. These signals can be audio, video, or pictures. Digital watermarking can be accomplished in two ways: visible and invisible. In visible watermarking, there is no special mechanism to conceal the information, and it is visible to plain sight. This is of little consequence to us from a security standpoint. However, in invisible watermarking, the information is concealed within other media and the watermark is used to uniquely identify the originator of the signal, thereby making it possible for authentication purposes as well, besides confidentiality protection. Invisible watermarking is, however, mostly used for copyright protection, deterring and preventing unauthorized copying of digital media. Digital watermarking can be accomplished using steganographic techniques as well.
Masking is a weaker form of confidentiality protection mechanism in which the original information is either asterisked or X’ed out. You may have noticed this in input fields that take passwords. This is primarily used to protect against shoulder surfing attacks, which are characterized by someone looking over another’s shoulder and observing sensitive information. The masking of credit card numbers or social security numbers (SSN), except for the last four digits, when printed on receipts or displayed on a screen is an example of masking providing confidentiality protection.
Confidentiality requirements need to be defined throughout the information life cycle from the origin of the data in question to its retirement. It is necessary to explicitly state confidentiality requirements for nonpublic data:
- In transit: When the data are transmitted over unprotected networks
- In processing: When the data are held in computer memory or media for processing
- In storage: When the data are at rest, within transactional systems as well as nontransactional systems including archives
Confidentiality requirements may also be time bound, i.e., some information may require protection only for a certain period. An example of this is news about a merger or acquisition. The date when the merger will occur is deemed sensitive and if stored or processed within internal information technology (IT) systems, it requires protection until this sensitive information is made public. Upon public press release of the merger having been completed, information deemed sensitive may no longer require protection as it becomes directory or public information. The general rule of thumb is that confidentiality requirements need to be identified based on the classification data given, and when that classification changes (say from sensitive to public), then appropriate control requirements need to be redefined.
Some good examples of confidentiality security requirements that should be part of the software requirements specifications documentation are given in the following:
- “Personal health information must be protected against disclosure using approved encryption mechanisms.”
- “Password and other sensitive input fields need to be masked.”
- “Passwords must not be stored in the clear in backend systems and when stored must be hashed with at least an equivalent to the SHA-256 hash function.”
- “Transport layer security (TLS) such as Secure Socket Layer must be in place to protect against insider man-in-the-middle (MITM) threats for all credit card information that is transmitted.”
- “The use of nonsecure transport protocols such as File Transfer Protocol (FTP) to transmit account credentials in the clear to third parties outside your organization should not be allowed.”
- “Log files must not store any sensitive information as defined by the business in humanly readable or easily decipherable form.”
As we determine requirements for ensuring confidentiality in the software we build or acquire, we must take into account the timeliness and extent of the protection required.
2.4.2 Integrity Requirements
Integrity requirements for software are those security requirements that address two primary areas of software security, namely, reliability assurance and protection or prevention against unauthorized modifications. Integrity refers not only to the system or software modification protection (system integrity) but also the data that the system or software handles (data integrity). When integrity protection assures reliability, it essentially refers to ensuring that the system or software is functioning as it is designed and expected to. In addition to reliability assurance, integrity requirements are also meant to provide security controls that will ensure that the accuracy of the system and data is maintained. This means that data integrity requires that information and programs be changed only in a specified and authorized manner by authorized personnel. Although integrity assurance primarily addresses the reliability and accuracy aspects of the system or data, it must be recognized that integrity protection also takes into consideration the completeness and consistency of the system or data that the system handles.
Within the context of software security, we have to deal with both system and data integrity. Injection attacks such as SQL injection that makes the software act or respond in a manner not originally designed to is a classic example of system integrity violation. Integrity controls for data in transit or data at rest need to provide assurance against deliberate or inadvertent unauthorized manipulations. The requirement to provide assurance of integrity needs to be defined explicitly in the software requirements specifications. Security controls that provide such assurance include input validation, parity bit checking and cyclic redundancy checking (CRC), and hashing.
Input validation provides a high degree of protection against injection flaws and provides both system and data integrity. Allowing only valid forms of input to be accepted by the software for processing mitigates several security threats against software (covered in the secure software implementation chapter). In Chapters 3 and 4, we will cover input validation in depth and the protections it provides. Parity bit checking is useful in the detection of errors or changes made to data when they are transmitted. Mathematically, parity refers to the evenness or oddness of an integer. A parity bit (0 or 1) is an extra bit that is appended to a group of bits (byte, word, or character) so that the group of bits will either have an even or odd number of 1’s. The parity bit is 0 (even) if the number of 1’s in the input bit stream is even and 1 (odd) if the number of 1’s in the input bit stream is odd. Data integrity checking is performed at the receiving end of the transmission by computing and comparing the original bit stream parity with the parity information of the received data. A common usage of parity bit checking is to do a cyclic redundancy check (CRC) for data integrity as well, especially for messages longer than 1 byte (8 bits) long. Upon data transmission, each block of data is given a computed CRC value, commonly referred to as a checksum. If there is an alteration between the origin of data and its destination, the checksum sent at the origin will not match with the one that is computed at the destination. Corrupted media (CDs and DVDs) and incomplete downloads of software yield CRC errors. The checksum is the end product of a nonsecure hash function. Hashing provides the strongest forms of data integrity. Although hashing is mainly used for integrity assurance, it can also provide confidentiality assurance as we covered earlier in this chapter.
Some good examples of integrity security requirements that should be part of the software requirements specifications documentation are given in the following:
- “All input forms and query string inputs need to be validated against a set of allowable inputs before the software accepts it for processing.”
- “Software that is published should provide the recipient with a computed checksum and the hash function used to compute the checksum, so that the recipient can validate its accuracy and completeness.”
- “All nonhuman actors such as system and batch processes need to be identified, monitored, and prevented from altering data as it passes on systems that they run on, unless explicitly authorized to.”
As we determine requirements for ensuring integrity in the software we build or acquire, we must take into account the reliability, accuracy, completeness, and consistency aspects of systems and data.
2.4.3 Availability Requirements
Although the concept of availability may seem to be more closely related to business continuity or disaster recovery disciplines than it is to security, it must be recognized that improper software design and development can lead to destruction of the system/data or even cause denial of service (DoS). It is therefore imperative that availability requirements are explicitly determined to ensure that there is no disruption to business operations. Availability requirements are those software requirements that ensure the protection against destruction of the software system and/or data, thereby assisting in the prevention against DoS to authorized users. When determining availability requirements, the maximum tolerable downtime (MTD) and recovery time objective (RTO) must both be determined. MTD is the measure of the maximum amount of time that the software can be in a state of not providing expected service. In other words, it is the measure of the minimum level of availability that is required of the software for business operations to continue without unplanned disruptions as per expectations. However, because all software fails or will fail eventually, in addition to determining the MTD, the RTO must also be determined. RTO is the amount of time by which the system or software needs to be restored back to the expected state of business operations for authorized business users when it goes down. Both MTD and RTO should be explicitly stated in the service level agreements (SLAs). There are several ways to determine availability requirements for software. These methods include determining the adverse effects of software downtime through business impact analysis (BIA) or stress and performance testing.
BIA must be conducted to determine the adverse impact that the unavailability of software will have on business operations. This may be measured quantitatively such as loss of revenue for each minute the software is down, cost to fix and restore the software back to normal operations, or fines that are levied on the business upon software security breach. It may also be qualitatively determined, including loss of credibility, confidence, or loss of brand reputation. In either case, it is imperative to include the business owners and end users to accurately determine MTD and RTO as a result of the BIA exercise. BIA can be conducted for both new and existing versions of software. In situations when there is an existing version of the software, then stress and performance test results from the previous version of the software can be used to ensure high-availability requirements are included for the upcoming versions as well. Table 2.1 tabulates the downtime that will be allowed for a percentage of availability that is usually measured in units of nines. Such availability requirements and planned downtime amounts must be determined and explicitly stated in the SLA and incorporated into the software requirements documents.
High-Availability Requirements as Measures of Nines
|
Measurement |
Availability (%) |
Downtime per year |
Downtime per month (30 days) |
Downtime per week |
|
Three nines |
99.9 |
8.76 hours |
43.2 min |
10.1 min |
|
Four nines |
99.99 |
52.6 min |
4.32 min |
1.01 min |
|
Five nines |
99.999 |
5.26 min |
25.9 s |
6.05 s |
|
Six nines |
99.9999 |
31.5 s |
2.59 s |
0.605 s |
In determining availability requirements, understanding the impact of failure due to a breach of security is vitally important. Insecure coding constructions such as dangling pointers, improper memory deallocations, and infinite loop constructs can all impact availability, and when requirements are solicited, these repercussions of insecure development must be identified and factored in. End-to-end configuration requirements ensure that there is no single point of failure and should be part of the software requirements documentation. A single point of failure is characterized by having no redundancy capabilities, and this can undesirably affect end users when a failure occurs. In addition to end-to-end configuration requirements, load balancing requirements need to be identified and captured as well. By replicating data, databases, and software across multiple computer systems, a degree of redundancy is made possible. This redundancy also helps to provide a means for reducing the workload on any one particular system. Replication usually follows a master–slave or primary–secondary backup scheme in which there is one master or primary node and updates are propagated to the slaves or secondary node either actively or passively. Active/active replication implies that updates are made to both the master and slave systems at the same time. In the case of active/passive replication, the updates are made to the master node first and then the replicas are pushed the changes subsequently. When replication of data is concerned, special considerations need to be given to address the integrity of data as well, especially in active/passive replication schemes.
Some good examples of availability requirements that have a bearing on software security are given in the following and should be part of the software requirements specifications documentation.
- “The software shall ensure high availability of five nines (99.999%) as defined in the SLA.”
- “The number of users at any one given point of time who should be able to use the software can be up to 300 users.”
- “Software and data should be replicated across data centers to provide load balancing and redundancy.”
- “Mission critical functionality in the software should be restored to normal operations within 1 hour of disruption; mission essential functionality in the software should be restored to normal operations within 4 hours of disruption; and mission support functionality in software should be restored to normal operations within 24 hours of disruption.”
2.4.4 Authentication Requirements
The process of validating an entity’s claim is authentication. The entity may be a person, a process, or a hardware device. The common means by which authentication occurs is that the entity provides identity claims and/or credentials that are validated and verified against a trusted source holding those credentials. Authentication requirements are those that verify and assure the legitimacy and validity of the identity that is presenting entity claims for verification.
In the secure software concepts domain, we learned that authentication credentials could be provided by different factors or a combination of factors that include knowledge, ownership, or characteristics. When two factors are used to validate an entity’s claim and/or credentials, it is referred to as two-factor authentication, and when more than two factors are used for authentication purposes, it is referred to as multifactor authentication. It is important to determine, first, if there exists a need for two- or multifactor authentication. It is also advisable to leverage existing and proven authentication mechanisms, and requirements that call for custom authentication processes should be closely reviewed and scrutinized from a security standpoint so that no new risks are introduced in implementing custom and newly developed authentication validation routines.
There are several means by which authentication can be implemented in software. Each has its own pros and cons as it pertains to security. In this section, we cover some of the most common forms of authentication. However, depending on the business context and needs, authentication requirements need to be explicitly stated in the software requirements document so that when the software is being designed and built, security implications of those authentication requirements can be determined and addressed accordingly. The most common forms of authentication are:
- Anonymous
- Basic
- Digest
- Integrated
- Client certificates
- Forms
- Token
- Smart cards
- Biometrics
2.4.4.1 Anonymous Authentication
Anonymous authentication is the means of access to public areas of your system without prompting for credentials such as username and password. As the name suggests, anyone—even anonymous users—are allowed access and there is no real authentication check for validating the entity. Although this may be required from a privacy standpoint, the security repercussions are serious because with anonymous authentication there is no way to link a user or system to the actions they undertake. This is referred to as unlinkability, and if there is no business need for anonymous authentication to be implemented, it is best advised to avoid it.
2.4.4.2 Basic Authentication
One of the Hypertext Transport Protocol (HTTP) 1.0 specifications is basic authentication that is characterized by the client browser prompting the user to supply their credentials. These credentials are transmitted in Base-64 encoded form. Although this provides a little more security than anonymous authentication, basic authentication must be avoided as well, because the encoded credentials can be easily decoded.
2.4.4.3 Digest Authentication
Digest authentication is a challenge/response mechanism, which unlike basic authentication, does not send the credentials over the network in clear text or encoded form but instead sends a message digest (hash value) of the original credential. Authentication is performed by comparing the hash values of what was previously established and what is currently supplied as an entity claim. Using a unique hardware property, that cannot be easily spoofed, as an input (salt) to calculate the digest provides heightened security when implementing digest authentication.
2.4.4.4 Integrated Authentication
Commonly known as NTLM authentication or NT challenge/response authentication, like Digest authentication, the credentials are sent as a digest. This can be implemented as a stand-alone authentication mechanism or in conjunction with Kerberos v5 authentication when delegation and impersonation is necessary in a trusted subsystem infrastructure. Wherever possible, especially in intranet settings, it is best to use integrated authentication since the credentials are not transmitted in clear text and it is efficient in handling authentication needs.
2.4.4.5 Client Certificate-Based Authentication
Client certificate-based authentication works by validating the identity of the certificate holder. These certificates are issued to organizations or users by a certification authority (CA) that vouches for the validity of the holder. These certificates are usually in the form of digital certificates, and the current standard for digital certificates is ITU X.509 v3. If you trust the CA and you validate that the certificate presented for authentication has been signed by the trusted CA, then you can accept the certificate and process access requests. These are particularly useful in an Internet/e-commerce setting, when you cannot implement integrated authentication across your user base. Figure 2.4 illustrates an example of a digital SSL server certificate that provides information about the CA, its validity, and fingerprint information.

2.4.4.6 Forms Authentication
Predominantly observed in Web applications, forms authentication requires the user to supply a username and password for authentication purposes, and these credentials are validated against a directory store that can be the active directory, a database, or configuration file. Because the credentials collected are supplied in clear text form, it is advisable to first cryptographically protect the data being transmitted in addition to implementation TLS such as SSL or network layer security such as IPSec. Figure 2.5 illustrates an example of a username and password login box used in Forms authentication.

2.4.4.7 Token-Based Authentication
The concept behind token-based authentication is pretty straightforward. It is usually used in conjunction with forms authentication where a username and password is supplied for verification. Upon verification, a token is issued to the user who supplied the credentials. The token is then used to grant access to resources that are requested. This way, the username and password need not be passed on each call. This is particularly useful in single sign-on (SSO) situations. While Kerberos tokens are restricted to the domain they are issued, Security Assertion Markup Language (SAML) tokens, which are XML representations of claims an entity makes about another entity, are considered the de facto tokens in cross-domain federated SSO architectures. We will cover SSO in more detail in Chapter 3.
2.4.4.8 Smart Cards–Based Authentication
Smart cards provide ownership-based (something you have) authentication. They contain a programmable embedded microchip that is used to store authentication credentials of the owner. The security advantage that smart cards provide is that they can thwart the threat of hackers stealing authentication credentials from a computer, because the authentication processing occurs on the smart card itself. However, a major disadvantage of smart cards is that the amount of information that can be stored is limited to the size of the microchip’s storage area and cryptographic protection of stored credentials on the smart card is limited as well.
One-time (dynamic) passwords (OTP) provide the maximum strength of authentication security and OTP tokens (also known as key fobs) require two factors: knowledge (something you know) and ownership (something you have). These tokens dynamically provide a new password at periodic intervals. Like token-based authentication, the user enters the credential information they know and is issued a personal identification number (PIN) that is displayed on the token device such as an Radio Frequency Identification (RFID) device they own. Because the PIN is not static and dynamically changed every few seconds, it makes it virtually impossible for a malicious attacker to steal authentication credentials.
2.4.4.9 Biometric Authentication
This form of authentication uses biological characteristics (something you are) for providing the identity’s credentials. Biological features such as retinal blood vessel patterns, facial features, and fingerprints are used for identity verification purposes. Because biological traits can potentially change over time owing to aging or pathological conditions, one of the major drawbacks of biometric-based authentication implementation is that the original enrollment may no longer be valid, and this can yield to DoS to legitimate users. This means that authentication workarounds need to be identified, defined, and implemented in conjunction to biometrics, and these need to be captured in the software requirements. The FIPS 201 Personal Identity Verification standard provides guidance that the enrollment data in systems implementing biometric-based authentication needs to be changed periodically.
Additionally, biometric authentication requires physical access that limits its usage in remote access settings.
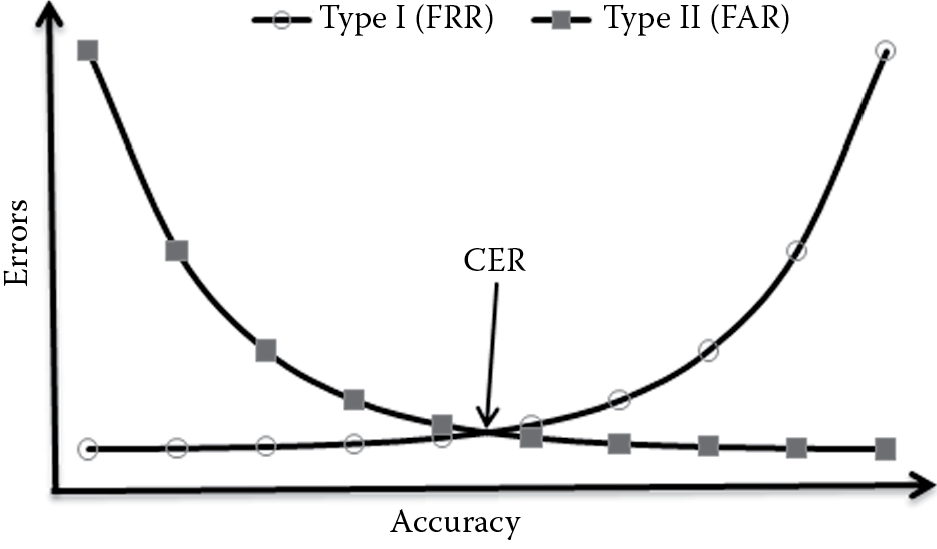
Errors observed in biometric-based authentication systems are of two types: type I error and type II error. Type I error is otherwise known as false rejection error where a valid and legitimate enrollee is denied (rejected) access. It is usually computed as a rate and is referred to as false rejection rate (FRR). Type II error is otherwise known as false acceptance error where an imposter is granted (accepted) access. This is also computed as a rate and is referred to as false acceptance rate (FAR). The point at which the FRR equals the FAR is referred to as the crossover error rate (CER) as depicted in Figure 2.6. CER is primarily used in evaluating different biometric devices and technologies. Devices that assure more accurate identity verification are characterized by having a low CER.
Some good examples of authentication requirements that should be part of the software requirements documentation are given in the following:
- “The software will be deployed only in the Intranet environment, and the authenticated user should not have the need to provide username and password once they have logged on to the network.”
- “The software will need to support single sign on with third party vendors and suppliers that are defined in the stakeholder list.”
- “Both Intranet and Internet users should be able to access the software.”
- “The authentication policy warrants the need for two- or multifactor authentication for all financially processing software.”
Identifying the proper authentication requirements during the early part of the SDLC helps to mitigate many serious security risks at a later stage. These need to be captured in the software specifications so that they are not overlooked when designing and developing the software.
2.4.5 Authorization Requirements
Layered upon authentication, authorization requirements confirm that an authenticated entity has the needed rights and privileges to access and perform actions on a requested resource. These requirements answer the question of what one is allowed or not allowed to do. To determine authorization requirements, it is important to first identify the subjects and objects. Subjects are the entities that are requesting access, and objects are the items that subject will act upon. A subject can be a human user or a system process. Actions on the objects also need to be explicitly captured. Actions as they pertain to data or information that the user of the software can undertake are commonly referred to as CRUD (create, read, update, or delete data) operations. Later in this chapter, we shall cover subject–object modeling in more detail as one of the mechanisms to capture authorization requirements.
Access control models are primarily of three types:
- Discretionary access control (DAC)
- Nondiscretionary access control (NDAC)
- Mandatory access control (MAC)
- Role based Access Control (RBAC)
- Resource Based Access Control
2.4.5.1 Discretionary Access Control (DAC)
DAC restricts access to objects based on the identity of the subject (Solomon and Chapple, 2005) and is distinctly characterized by the owner of the resource deciding who has access and their level of privileges or rights.
DAC is implemented by using either identities or roles. Identity-based access control means that the access to the object is granted based on the subject’s identity. Because each identity will have to be assigned the appropriate access rights, the administration of identity-based access control implementations is an operational challenge. An often more preferred alternative in cases of a large user base is to use roles. Role-based access control (RBAC) uses the subject’s role to determine whether access should be allowed or not. Users or groups of users are defined by roles and the owner (or a delegate) decides which role is granted access rights to objects and the levels of rights. RBAC is prominently implemented in software and is explained in more detail later in this section.
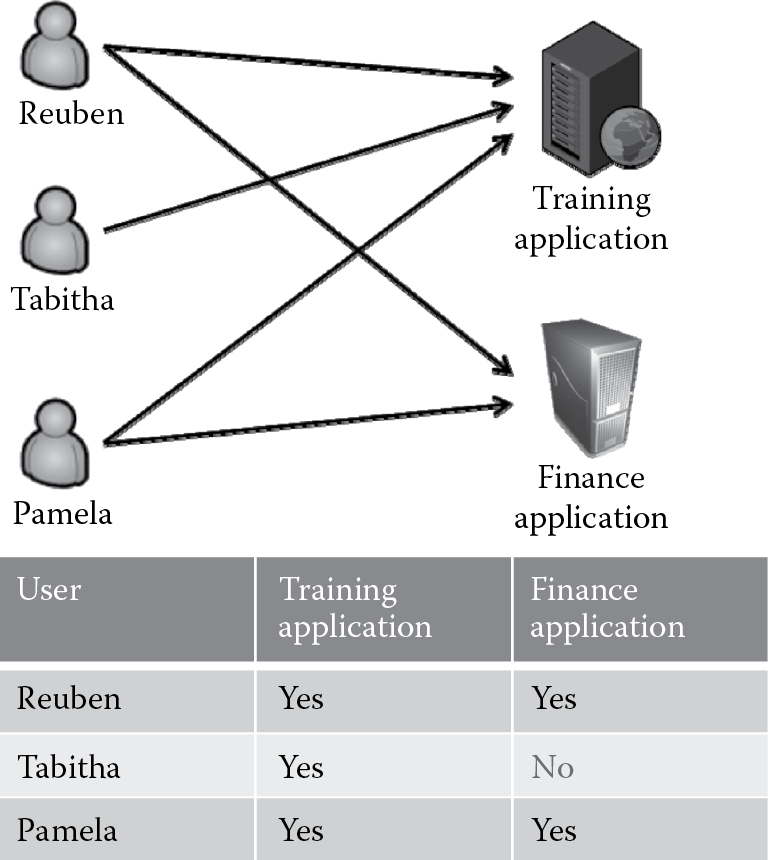
Another means by which DAC is often observed to be implemented is by using access control lists (ACLs). The relationship between the individuals (subjects) and the resources (objects) is direct, and the mapping of individuals to resources by the owner is what constitutes the ACLs as illustrated in Figure 2.7.
2.4.5.2 Nondiscretionary Access Control (NDAC)
NDAC is characterized by the system enforcing the security policies. It does not rely on the subject’s compliance with security policies. The nondiscretionary aspect is that it is unavoidably imposed on all subjects. It is useful to make sure that the system security policies and mechanisms configured by the systems or security administrators are enforced and tamper-proof. NDACs can be installed on many operating systems. Because NDAC does not depend on a subject’s compliance with the security policy as in the case of DAC but is universally applied, it offers a higher degree of protection. Without NDAC, even if a user attempts to comply with well-defined file protection mechanisms, a Trojan horse program could change the protection controls to allow uncontrolled access.
2.4.5.3 Mandatory Access Control (MAC)
In MAC, access to objects is restricted to subjects based on the sensitivity of the information contained in the objects. The sensitivity is represented by a label. Only subjects that have the appropriate privilege and formal authorization (i.e., clearance) are granted access to the objects. MAC requires sensitivity labels for all the objects, and clearance levels for all subjects and access is determined based on matching a subject’s clearance level with the object’s sensitivity level. Examples of government labels include top secret, secret, confidential, etc., and examples of private sector labels include high confidential, confidential-restricted, for your eyes only, etc.
MAC provides multilevel security because there are multiple levels of sensitivity requirements that can be addressed using this form of access control.
MAC systems are more structured in approach and more rigid in their implementation because they do not leave the access control decision to the owner alone as in the case of DAC, but both the system and the owner are used to determine whether access should be allowed or not. A common implementation of MAC is rule-based access control. In rule-based access control, the access decision is based on a list of rules that are created or authorized by system owners who specify the privileges (i.e., read, write, execute) that the subjects (users) have on the objects (resources). These rules are used to provide the need-to-know level of the subject. Rule-based MAC implementation requires the subject to possess the need-to-know property that is provided by the owner; however, in addition to the owner deciding who possesses need to know, in MAC, the system determines access decisions based on clearance and sensitivity.
2.4.5.4 Role-Based Access Control (RBAC)
Because the mapping of each subject to a resource (as in the case of DAC) or the assignment of subjects to clearance levels and objects to sensitivity levels (as in the case of MAC) can be an arduous task, for purposes of ease of user management, a more agile and efficient access control model is RBAC. Roles are defined by job functions that can be used for authorization decisions. Roles define the trust levels of entities to perform desired operations. These roles may be user roles or service roles. In RBAC, individuals (subjects) have access to a resource (object) based on their assigned role. Permissions to operate on objects such as create, read, update, or delete are also defined and determined based on responsibilities and authority (permissions) within the job function.
Access that is granted to subjects is based on roles. What this mainly provides is that the resource is not directly mapped to the individual but only to the role. Because individuals can change over time, whereas roles generally do not, individuals can be easily assigned to or revoked from roles, thereby allowing ease of user management. Roles are then allowed operations against the resource as depicted in Figure 2.8.
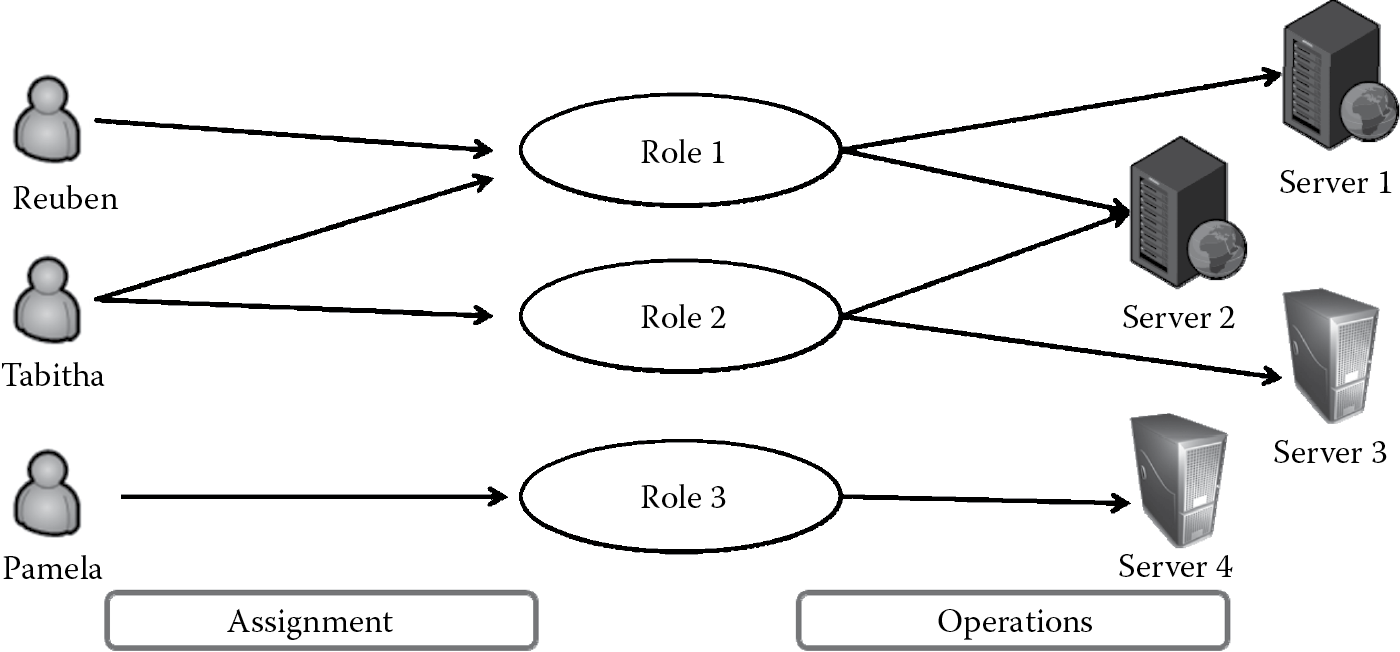
RBAC can be used to implement all three types of access control models, i.e., DAC, NDAC, and MAC. The discretionary aspect is that the owners need to determine which subjects need to be granted what role. The nondiscretionary aspect is that the security policy is universally enforced on the role regardless of the subject. It is also a form of MAC where the role is loosely analogous to the process of clearance levels (granting memberships) and the objects requested are labeled (associated operational sensitivities), but RBAC is not based on multilevel security requirements.
2.4.5.4.1 RBAC in Relation to Least Privilege and Separation of Duties
Roles support the principle of least privilege, because roles are given just the needed privileges to undertake an operation against a resource. When RBAC is used for authorization decisions, it is imperative to ensure that the principle of separation of duties (SoD) is maintained. This means that no individual can be assigned to two roles that are mutually exclusive in their permissions to perform operations. For example, a user should not be in a datareader role as well as a more privileged database owner role at the same time. When users are prevented from being assigned to conflicting roles, then it is referred to as static SoD. Another example that demonstrates SoD in RBAC is that a user who is in the auditor role cannot also be in the teller role at the same time. When users are prevented from operating on resources with conflicting roles, then it is referred to as dynamic SoD.
RBAC implementations require explicit “role engineering” to determine roles, authorizations, role hierarchies, and constraints. The real benefit of RBAC over other access control methods includes the following:
- Simplified subjects and objects access rights administration
- Ability to represent the organizational structure
- Force enterprise compliance with control policies more easily and effectively
2.4.5.4.2 Role Hierarchies
Roles can be hierarchically organized and when such a parent–child tree structure is in place, it is commonly referred to as a role hierarchy. Role hierarchies define the inherent relationships between roles. For example, an admin user may have read, write, and execute privileges, whereas a general user may have just read and write privileges and a guest user may only have read privilege. In such a situation, the guest user role is a subset of the general user role, which, in turn, is a subset of the admin user role as illustrated in Figure 2.9.
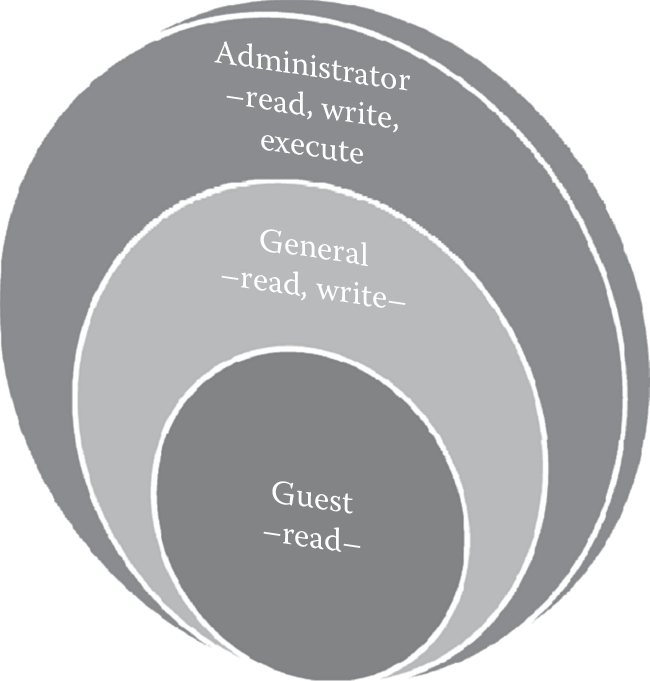
In generating role hierarchies, we start with the most common permissions for all users (e.g., read) and then iterate permissions to be more restrictive (read, write, execute), assigning them to roles (guest, general, admin) that are then assigned to users. It is also important to recognize that when determining role hierarchy it is also important to identify contextual and content-based constraints and grant access rights based on “only if” or “if and only if” relationships. Just basing the access decisions on an if relationship does not provide real separation of duties. For example, a doctor should be allowed to view the records of a patient, only if or if and only if that patient whose records are requested for is assigned to the doctor, not just if the requestor is a doctor.
2.4.5.4.3 Roles and Groups
Although it may seem like there is a high degree of similarity between roles and groups, there is a distinction that make RBAC more preferable for security than groups. A group is a collection of users and not a collection of permissions. In a group, permissions can be assigned to both users and groups to which users are part of. The ability to associate a user directly with permissions in group-based access control can be the Achilles’ heel for circumventing access control checks, besides making it more difficult to manage users and permissions. RBAC mandates that all access is done only through roles and permissions are never directly assigned to the users but to the roles; this addresses the challenges that one can have with group-based access control mechanisms.
2.4.5.5 Resource-Based Access Control
When the list of all users of your software are not known in advance, as in the case of a distributed Internet application, then DAC and MAC implementation using subject (user) mapping to objects (resources) may not always be possible. In such situations, access can also be granted based on the resources. Resource-based access control models are useful in architectures that are distributed and multitiered including service-oriented architectures. Resource-based access control models can be broadly divided into
- Impersonation and Delegation Model
- Trusted Subsystem Model
2.4.5.5.1 Impersonation and Delegation Model
Allowing a secondary entity to act on one’s behalf is the principle of delegation. All of the privileges necessary for completing an operation are granted to the secondary entity. The secondary entity is considered to impersonate the identity of the primary entity when the complete sets of permissions of the primary entity are assigned to it. The identity of the primary entity is propagated to downstream systems. Kerberos uses the delegation and impersonation model where the user upon successful authentication is granted a Kerberos ticket, and the ticket is delegated the privileges and rights (sets of permission) to invoke services downstream. The ticket is the secondary entity that acts as if it is the primary entity by impersonating the user identity.
2.4.5.5.2 Trusted Subsystem Model
In a trusted subsystem model, access request decisions are granted based on the identity of a resource that is trusted instead of user identities. Trusted subsystem models are predominantly observed in Web applications. For example, a user logs into their bank account using a Web browser to transfer funds from one account to another. The Web application identity calls the database to first authenticate the user-supplied credentials. It is not the user identity that is checked but the Web application identity that is trusted and that can invoke the call to the database. Although this simplifies access management, it needs to be designed with security in mind, and such architectures need to be layered with additional defense in depth measures such as transport or network layer security controls.
Regardless of whether it is user- or resource-based access control models that need to be implemented, authorization requirements need to be explicitly identified and captured in the software specifications documentation. Some good examples of authorization requirements that should be part of the software requirements documentation are given in the following:
- “Access to highly sensitive secret files will be restricted to users with secret or top secret clearance levels only.”
- “User should not be required to send their credentials each and every time once they have authenticated themselves successfully.”
- “All unauthenticated users will inherit read-only permissions that are part of guest user role while authenticated users will default to having read and write permissions as part of the general user role. Only members of the administrator role will have all rights as a general user in addition to having permissions to execute operations.”
2.4.6 Auditing/Logging Requirements
Auditing requirements are those that assist in building a historical record of user actions. Audit trails can help detect when an unauthorized user makes a change or an authorized user makes an unauthorized change, both of which are cases of integrity violations. Auditing requirements not only help with forensic investigations as a detective control but can also be used for troubleshooting errors and exceptions, if the actions of the software are tracked appropriately.
Auditing requirements at the bare minimum must include the following elements:
- Identity of the subject (user or process) performing an action (who)
- Action (what)
- Object on which the action was performed (where)
- Timestamp of the action (when)
What is to be logged (audit trail) and what is not is a decision that is to be made in discussions with the business managers. As a best practice for security, all critical business transactions and administrative functions need to be identified and audited. Some examples of critical business transactions include the changing of the price of a product, discounts by sales agents, or changing customer banking information. The business owner should be asked for audit trail information to be incorporated into the software requirements specification. Some examples of administrative functionality include authentication attempts such as log-on and log-off actions, adding a user to an administrator role, and changing software configuration.
Some good examples of auditing requirements that should be part of the software requirements documentation are given below.
- “All failed logon attempts will be logged along with the timestamp and the Internet Protocol address where the request originated.”
- “A before and an after snapshot of the pricing data that changed when a user updates the pricing of a product must be tracked with the following auditable fields—identity, action, object and timestamp.”
- “Audit logs should always append and never be overwritten.”
- “The audit logs must be securely retained for a period of 3 years.”
2.4.7 Session Management Requirements
Sessions are useful for maintaining state but also have an impact on the secure design principles of complete mediation and psychological acceptability. Upon successful authentication, a session identifier (ID) is issued to the user and that session ID is used to track user behavior and maintain the authenticated state for that user until that session is abandoned or the state changes from authenticated to not authenticated. Without session management, the user/process would be required to reauthenticate upon each access request (complete mediation), and this can be burdensome and psychologically unacceptable to the user. Because valid sessions can be potentially hijacked where an attacker takes control over an established session, it is necessary to plan for secure session management.
In stateless protocols, such as the HTTP, session state needs to be explicitly maintained and carefully protected from brute force or predictable session ID attacks. In Chapter 4, we will be covering attacks on session management in more detail.
Session management requirements are those that ensure that once a session is established, it remains in a state that will not compromise the security of the software. In other words, the established session is not susceptible to any threats to the security policy as it applies to confidentiality, integrity, and availability. Session management requirements assure that sessions are not vulnerable to brute force attacks, predictability, or MITM hijacking attempts.
Some good examples of session management secure software requirements that should be part of the requirements documentation are given in the following:
- “Each user activity will need to be uniquely tracked.”
- “The user should not be required to provide user credential once authenticated within the Internet banking application.”
- “Sessions must be explicitly abandoned when the user logs off or closes the browser window.”
- “Session identifiers used to identify user sessions must not be passed in clear text or be easily guessable.”
2.4.8 Errors and Exception Management Requirements
Errors and exceptions are potential sources of information disclosure. Verbose error messages and unhandled exception reports can result in divulging internal application architecture, design, and configuration information. Using laconic error messages and structured exception handling are examples of good security design features that can thwart security threats posed by improper error or exception management. Software requirements that explicitly address errors and exceptions need to be defined in the software requirements documentation to avoid disclosure threats.
Some good examples of error and exception management secure software requirements that should be part of the requirements documentation are given in the following:
- “All exceptions are to be explicitly handled using try, catch, and finally blocks.”
- “Error messages that are displayed to the end user will reveal only the needed information without disclosing any internal system error details.”
- “Security exception details are to be audited and monitored periodically.”
2.4.9 Configuration Parameters Management Requirements
Software configuration parameters and code that make up the software need protection against hackers. These parameters and code usually need to be initialized before the software can run. Identifying and capturing configuration settings is vital to ensure that an appropriate level of protection is considered when the software is designed, developed, and, more importantly, deployed.
Some good examples of configuration parameters management secure software requirements that should be part of the requirements documentation are given in the following:
- “The Web application configuration file must encrypt sensitive database connections settings and other sensitive application settings.”
- “Passwords must not be hard coded in line code.”
- “Initialization and disposal of global variables need to be carefully and explicitly monitored.”
- “Application and/or session OnStart and OnEnd events must include protection of configuration information as a safeguard against disclosure threats.”
2.4.10 Sequencing and Timing Requirements
Sequencing and timing design flaws in software can lead to what is commonly known as race conditions or time of check/time of use (TOC/TOU) attacks. Race conditions are, in fact, one of the most common flaws observed in software design. It is also referred to sometimes as race hazard. Some of the common sources of race conditions include, but are not limited to, the following:
- Undesirable sequence of events, where one event that is to follow in the program execution order attempts to supersede its preceding event in its operations.
- Multiple unsynchronized threads executing simultaneously for a process that needs to be completed atomically.
- Infinite loops that prevent a program from returning control to the normal flow of logic.
2.4.10.1 Race Condition Properties
In order for race conditions to occur, the following three properties need to be fulfilled:
- Concurrency property
- Shared object property
- Change state property
Concurrency property means that there must be at least two threads or control flows executing concurrently. Shared object property means that the threads executing concurrently are both accessing the same object, i.e., the object is shared between the two concurrent flows. Change state property means that at least one of the control flows must alter the state of the shared object.
Only when all of these conditions are fulfilled does a race condition occur.
2.4.10.2 Race Conditions Protection
It is not only important to understand how race conditions occur but also to know about the protection mechanisms that are available to avoid them. Some of the prevalent protection measures against race conditions or TOC/TOU attacks are:
- Avoid race windows
- Atomic operations
- Mutual exclusion (Mutex)
A race window is defined as the window of opportunity when two concurrent threads race against one another trying to alter the same object. The first step in avoiding race conditions is to identify race windows. Improperly coded segments of code that access objects without proper control flow can result in race windows. Upon identification of race windows, it is important to fix them in code or logic design to mitigate race conditions. In addition to addressing race windows, atomic operations can also help prevent race condition attacks.
Atomic operations means that the entire process is completed using a single flow of control and that concurrent threads or control flow against the same object is disallowed. Single threaded operations are a means to ensure that operations are performed sequentially and not concurrently. However, such design comes with a cost on performance, and it must be carefully considered by weighing the benefits of security over performance.
Race conditions can also be eliminated by making two conflicting processes or race windows, mutually exclusive of each other. Race windows are referred to as critical sections because it is critical that two race windows do not overlap one another. Mutual exclusions or Mutex can be accomplished by resource locking, wherein the object being accessed is locked and does not allow any alteration until the first process or threat releases it. Resource locking provides integrity assurance. Assume, for example, in the case of an online auction, Jack bids on a particular item and Jill, who is also interested in that same item, places a bid as well. Both Jack and Jill’s bids should be mutually exclusive of one another, and until Jack’s bid is processed entirely and committed to the backend database, Jill bid’s operation should not be allowed. The backend record that holds the item information must be locked from any operations until Jack’s transaction commits successfully or is rolled back in the case of an error.
If software requirements do not explicitly specify protection mechanisms for race conditions, there is a high degree of likelihood that sequencing and timing attack flaws will result when designing it. Race windows and Mutex requirements must be identified as part of security requirements.
2.4.11 Archiving Requirements
If the business requires that archives be maintained either as a means for business continuity or as a need to comply with a regulatory requirement or organizational policy, the archiving requirement must be explicitly identified and captured. It is also important to recognize that organizational retention policies, especially if the information will be considered sensitive or private, do not contradict but complement regulatory requirements. In situations when there is a conflict between the organizational policy and a regulatory requirement, it is best advice to follow and comply with the regulatory requirement. Data or information may be stored and archived until it has outlived its usefulness or there is no regulatory or organizational policy requirement to comply with.
During the requirements gathering phase, the location, duration, and format of archiving information must be determined. Some important questions that need to be answered as part of this exercise are:
- Where will the data or information be stored?
- Will it be in a transactional system that is remote and online or will it be in offline storage media?
- How much space do we need in the archival system?
- How do we ensure that the media is not rewritable? For example, it is better to store archives in read-only media instead of read–write media.
- How fast will we need to be able to retrieve from archives when needed? This will not only help in answering the online or offline storage location question but also help with determining the type of media to use. For example, for a situation when fast retrieval of archived data is necessary, archives in tape media is not advisable because retrieval is sequential and time consuming in tape media.
- How long will we need to store the archives for?
- Is there a regulatory requirement to store the data for a set period of time?
- Is our archival retention policy contradictory to any compliance or regulatory requirements?
- In what format will the data or information be stored? Clear text or cipher text?
- If the data or information are stored in cipher text, how is this accomplished and are there management processes in place that will ensure proper retrieval?
- How will these archives themselves be protected?
It is absolutely essential to ensure that archiving requirements are part of the required documentation and that they are not overlooked when designing and developing the software.
2.4.12 International Requirements
In a world that is no longer merely tied to geographical topographies, software has become a necessary means for global economies to be strong or weak. When developing software, international requirements need to be factored in. International requirements can be of two types: legal and technological.
Legal requirements are those requirements that we need to pay attention to so that we are not in violation of any regulations. For example, a time accounting system must allow the employees in France to submit their timesheets with a 30-hour workweek (which is a legal requirement according to the French employment laws) and not be restrictive by disallowing the French employee to submit if his total time per week is less than 40 hours, as is usually the case in the United States. This requirement by country must be identified and included in the software specifications document for the time accounting system.
International requirements are also technological in nature, especially if the software needs to support multilingual, multicultural, and multiregional needs. Character encoding and display direction are two important international software requirements that need to be determined. Character encoding standards not only define the identity of each character and its numeric value (also known as code point) but also how the value is represented in bits. The first standard character encoding system was ASCII, which was a 7-bit coding system that supported up to 128 characters. ASCII supported the English languages, but fell short of coding all alphabets of European languages. This limitation led to the development of the Latin-1 international coding standard, ISO/IEC 646, that was an 8-bit coding system that could code up to 256 characters and was inclusive of European alphabets. But even the ISO/IEC 646 encoding standard fell short of accommodating logographic and morphosyllabic writing systems such as Chinese and Japanese. To support these languages, the 16-bit Unicode standard was developed that could support 65,536 characters, which was swiftly amended to include 32 bits supporting more than 4 billion characters. The Unicode standard is the universal character encoding standard that is fully compatible and synchronized with the versions of the ISO/IEC 10646 standard. The Unicode standard supports three encoding forms that make it possible for the same data to be transmitted as a byte (UTF-8), a word (UTF-16), or double word (UTF-32) format. UTF-8 is popular for the Hypertext Markup Language (HTML) where all Unicode characters are transformed into a variable length encoding of bytes. Its main benefit is that the Unicode characters that correspond to the familiar ASCII set have the same byte values as ASCII, which makes conversion of legacy software to support UTF-8, not require extensive software rewrites. UTF-16 is popular in environments where there is a need to balance efficient character access with economical use of storage. UTF-32 is popular in environments where memory space is not an issue but fixed width single code unit access to characters is essential. In UTF-32, each character is encoded in a single 32-bit code unit. All three encoding forms at most require 4 bytes (32 bits) of data for each character. It is important to understand that the appropriate and correct character encoding is identified and set in the software to prevent Unicode security issues such as spoofing, overflows, and canonicalization. Canonicalization is the process of converting data that has more than one possible representation into a standard canonical form. We will cover canonicalization and related security considerations in more detail in Chapter 4.
In addition to character encoding, it is also important to determine display direction requirements. A majority of the western languages that have their roots in Latin or Greek, such as English and French, are written and read left to right. Other languages such as Chinese are written and read top to bottom and then there are some languages, such as Hebrew and Arabic, that are bidirectional, i.e., text is written and read right to left, whereas numbers are written and read left to right. Software that needs to support languages in which the script is not written and read from left to right must take into account the directionality of their written and reading form. This must be explicitly identified and included in the software user interface (UI) or display requirements.
2.4.13 Deployment Environment Requirements
While eliciting software requirements, it is important to also identify and capture pertinent requirements about the environment in which the software will be deployed. Some important questions to have answered include:
- Will the software be deployed in an Internet, Extranet, or Intranet environment?
- Will the software be hosted in a demilitarized zone (DMZ)?
- What ports and protocols are available for use?
- What privileges will be allowed in the production environment?
- Will the software be transmitting sensitive or confidential information?
- Will the software be load balanced and how is clustering architected?
- Will the software be deployed in a Web farm environment?
- Will the software need to support SSO authentication?
- Can we leverage existing operating system event logging for auditing purposes?
Usually, production environments are far more restrictive and configured differently than development/test environments. Some of these restrictions include ports and protocols restrictions, network segmentation, disabled services, and components. Infrastructure, platform, and host security restrictions that can affect software operations must be elicited. Implementation of clustering and load balancing mechanisms can also have a potential impact on how the software is to be designed and these architectural considerations must be identified. Special attention needs to be given to implementing cryptographic protection in Web farm environments to avoid data corruption issues, and these need to be explicitly identified. Additionally, compliance initiatives may require certain environmental protection controls such as secure communications to exist. As an example, the Payment Card Industry Data Security Standard (PCI DSS) mandates that sensitive card holder data needs to be protected when it is transmitted in public open networks. Identifying and capturing constraints, restrictions, and requirements of the environment in which the software is expected to operate, in advance during the requirements gathering phase, will alleviate deployment challenges later besides assuring that the software will be deployed and function as designed.
2.4.14 Procurement Requirements
The identification of software security requirements is no less important when a decision is made to procure the software instead of building it in-house. Sometimes the requirement definition process itself leads to a buy decision. As part of the procurement methodology and process, in addition to the functional software requirements, secure software requirements must also be communicated and appropriately evaluated. Additionally, it is important to include software security requirements in legal protection mechanisms such as contracts and SLAs. The need for software escrow is an important requirement when procuring software. Chapter 6 will cover these concepts in more detail.
2.4.15 Antipiracy Requirements
Particularly important for shrink-wrap commercial off-the-shelf (COTS) software as opposed to business applications developed in-house, antipiracy protection requirements should be identified. Code obfuscation, code signing, antitampering, licensing, and IP protection mechanisms should be included as part of the requirements documentation especially if you are in the business of building and selling commercial software. Each of these considerations will be covered in more detail in Chapter 4, but for now, in the requirements gathering phase, antipiracy requirements should not be overlooked.
2.5 Protection Needs Elicitation
In addition to knowing the sources for security requirements and the various types of secure software requirements that need to be determined, it is also important to know the process of eliciting security requirements. The determination of security requirements is also known as protection needs elicitation (PNE). PNE is one of the most crucial processes in information systems security engineering. For PNE activities to be effective and accurate, strong communication and collaboration with stakeholders is required, especially if the stakeholders are nontechnical business folks and end users. With varying degrees of importance placed on security requirements, combined with individual perceptions and perspectives on the software development project, PNE activities have been observed to be a challenge.
PNE begins with the discovery of assets that need to be protected from unauthorized access and users. The Information Assurance Technical Framework (IATF) issued by the U.S. National Security Agency (NSA) is a set of security guidelines that covers Information Systems Security Engineering (ISSE). It defines a methodology for incorporation assurance/security requirements for both the hardware and software components of the system. The first step in the IATF process is PNE, which is suggested to be conducted in the following order:
- Engage the customer
- Information management modeling
- Identify least privilege applications
- Conduct threat modeling and analysis
- Prioritize based on customer needs
- Develop information protection policy
- Seek customer acceptance
PNE activities may be conducted in several ways as Figure 2.10 illustrates.

Some of the most common mechanisms to elicit security requirements include:
- Brainstorming
- Surveys (questionnaires and interviews)
- Policy decomposition
- Data classification
- Subject–object matrix
- Use and misuse case modeling
2.5.1 Brainstorming
Brainstorming is the quickest and most unstructured method to glean security requirements. In this process, none of the expressed ideas on security requirements are challenged, but instead they are recorded. Although this may allow for a quick-and-dirty way to determine protection needs, especially in rapid application development situations, it is not advised for PNE because it has several shortcomings. First, there is a high degree of likelihood that the brainstormed ideas do not directly relate to the business, technical, and security context of the software. This can either lead to ignoring certain critical security considerations or going overboard on a nontrivial security aspect of the software. Additionally, brainstorming solutions are usually not comprehensive and consistent because it is very subjective. Brainstorming may be acceptable to determine preliminary security requirements, but it is imperative to have a more structured and systematic methodology for consistency and comprehensiveness of security requirements.
2.5.2 Surveys (Questionnaires and Interviews)
Surveys are effective means to collect functional and assurance requirements. The effectiveness of the survey is dependent on how applicable the questions in the surveys are to the audience that is being surveyed. This means that the questionnaires are not a one size fits all type of survey. This also means that both explicitly specified questions as well as open-ended questions should be part of the questionnaire. The benefit of including open-ended questions is that the responses to such questions can yield security-related information that may be missed if the questions are very specific. Questionnaires developed should take into account business risks, process (or project) risks, and technology (or product) risks. It is advisable to have the questions developed so that they cover elements of the software security profile and secure design principles. This way, the answers to these questions can be directly used to generate the security requirements. Some examples of questions that be asked are:
- What kind of data will be processed, transmitted, or stored by the software?
- Is the data highly sensitive or confidential in nature?
- Will the software handle personally identifiable information or privacy-related information?
- Who are all the users who will be allowed to make alterations and will they need to be audited and monitored?
- What is the MTD for the software?
- How quickly should the software be able to recover and restore to normal operations when disrupted?
- Is there a need for SSO authentication?
- What are the roles of users that need to be established and what privileges and rights (such as create, read, update, or delete) will each role have?
- What are the set of error messages and conditions that you would need the software to handle when an error occurs?
These questions can be either delivered in advance using electronic means or asked as part of an interview with the stakeholders. As a CSSLP, it is expected that one will be able to facilitate this interview process. It is also a recommended practice to include and specify a scribe who records the responses provided by the interviewee. Like questionnaires, the interview should also be conducted in an independent and objective manner with different types of personnel. Additional PNE activities may be necessary, especially if the responses from the interview have led to new questions that warrant answers. Collaboration and communications between the responders and the interviewers are both extremely important when conducting a survey-based security requirements exercise.
2.5.3 Policy Decomposition
One of the sources for security requirements is internal organizational policies that the organization needs to comply with. Because these policies contain in them high-level mandates, they need to be broken down (or, in other words, decomposed) into detailed security requirements. However, this process of breaking high-level mandates into concrete security requirements is not limited only to organizational policies. External regulations, privacy, and compliance mandates can also be broken down to glean detailed security requirements. To avoid any confusion, for the remainder of this chapter, we will refer all these high-level sources of security requirements as policy documents, regardless of whether they are internal or external in their origin.
Although superficially it may seem as though the policy decomposition process may be pretty simple and straightforward, because policies are high level and open to interpretation, careful attention is paid to the scope of the policy. This is to ensure that the decomposition process is objective and compliant with the security policy, and not merely someone’s opinion. The policy decomposition process is a sequential and structured process as illustrated in Figure 2.11.
It starts by breaking the high-level requirements in the policy documents into high-level objectives, which are, in turn, decomposed to generate security requirements, the precursors for software security requirement. As an illustration, consider the following PCI DSS requirement 6.3 example, which mandates the following:
Develop software applications in accordance with PCI DSS and based on industry best practices, and incorporate information security throughout the SDLC.
This requirement is pretty high level and can be subject to various interpretations. What is the meaning of incorporating information security through the SDLC? Additionally, what may be considered as an industry best practice for someone may not even be applicable to another. This is why the high-level policy document requirement must be broken down into high-level objectives such as:
- CFG: Configuration management
- SEG: Segregated environments
- SOD: Separation of duties
- DAT: Data protection
- PRC: Production readiness checking
- CRV: Code review
These high-level objectives can be used to glean security requirements as shown:
- CFG1: Test all security patches and system and software configuration changes before deployment.
- SEG1: Separate development/test and production environment.
- SOD1: Separation of duties between development/test and production environments.
- DAT1: Production data (live sensitive cardholder data) are not used for testing or development.
- PRC1: Removal of test data and accounts before production systems become active.
- PRC2: Removal of custom application accounts, user IDs, and passwords before applications become active or are released to customers.
- CRV1: Review of custom code before release to production or customers in order to identify any potential coding vulnerability.
From each security requirement, one or more software security requirements can be determined. For example, the CFG1 high-level objective can be broken down into several security requirements as shown below.
- CFG1.1: Validate all input on both server and client end.
- CFG1.2: Handle all errors using try, catch, and finally blocks.
- CFG1.3: Cryptographically protect data using 128-bit encryption of SHA-256 hashing when storing it.
- CFG1.4: Implement secure communications using Transport (TLS) or Network (IPSec) secure communications.
- CFG1.5: Implement proper RBAC control mechanisms.
Decomposition of policy documents is a crucial step in the process of gathering requirements, and an appropriate level of attention must be given to this process.
2.5.4 Data Classification
Within the context of software assurance, data or information can be considered to be the most valuable asset that a company has, second only to its people. Like any asset that warrants protection, data as a digital asset need to be protected as well. But not all data need the same level of protection, and some data that make up public data or directory information require minimal to no protection against disclosure. Data classification is the conscious effort to assign a level of sensitivity to data assets, based on potential impact upon disclosure, alteration, or destruction. The results of the classification exercise can then be used to categorize the data elements into appropriate buckets as depicted in Figure 2.12. NIST Special Publication 800-18 provides a framework for classifying information assets based on impact to the three core security objectives, i.e., confidentiality, integrity, and availability. This is highly qualitative in nature, and the buckets used to classify are tied to impact as high, medium, and low. This categorization is then used to determine security requirements and the appropriate levels of security protection by category.
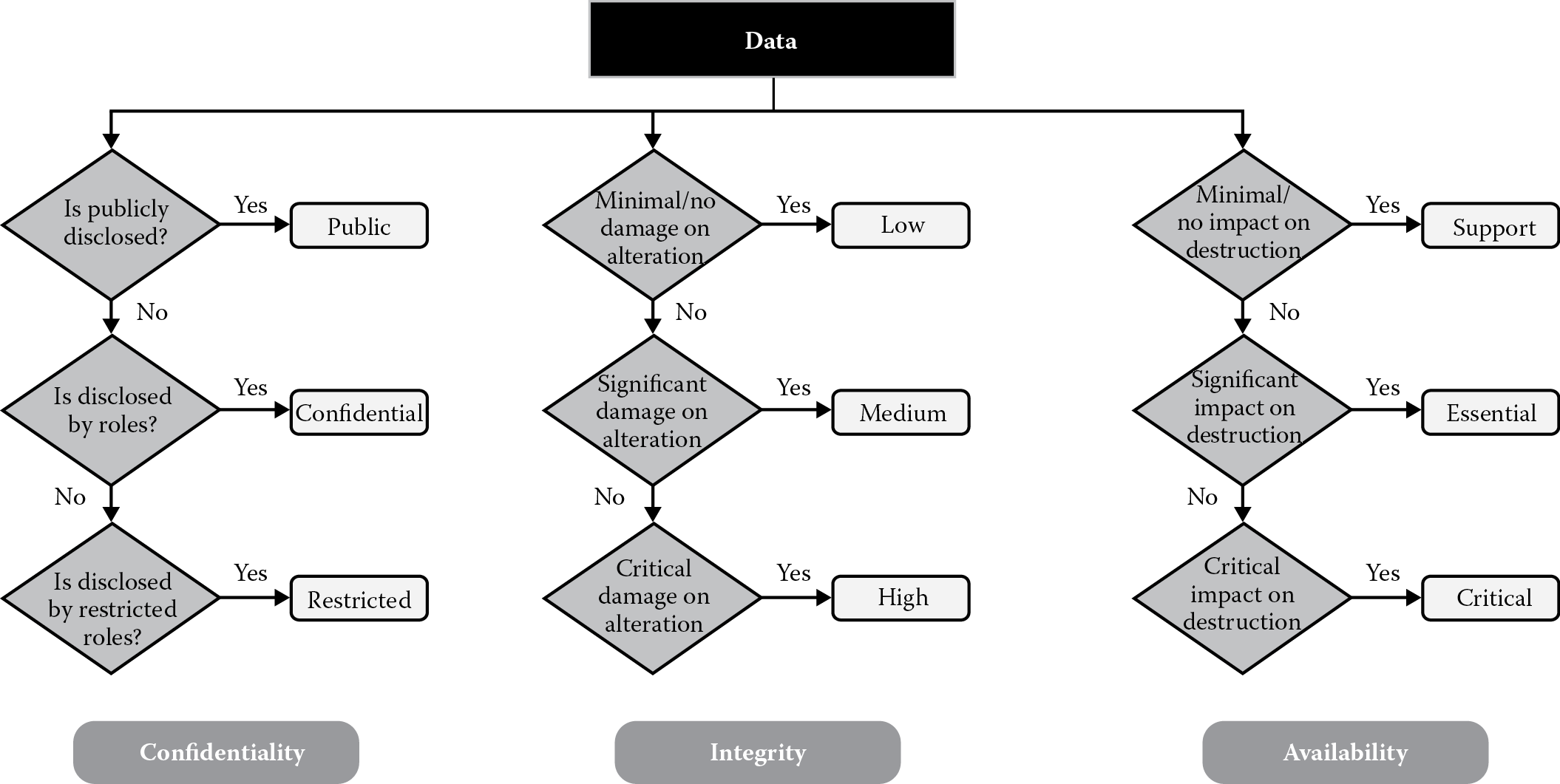
The main objective of data classification is to lower the cost of data protection and maximize the return on investment when data are protected. This can be accomplished by implementing only the needed levels of security controls on data assets based on their categorization. In other words, security controls must commensurate with the classification level. For example, there is no point to encrypt data or information that is to be publicly disclosed or implementing full-fledged load balancing and redundancy control for data that have a very limited adverse effect on organizational operations, assets, or individuals. In addition to lowering the cost of data protections and maximizing return on investment (ROI) data classification can also assist in increasing the quality of risk-based decisions. Because the data quality and characteristics are known upon classification, decisions that are made to protect them can also be made appropriately.
Decisions to classify data (e.g., who has access and what level of access) are decisions that are made by the business owner. It is also imperative to understand that it is the business that owns the data and not IT. The business owner or data owner has the responsibility for the following:
- Ensure that information assets are appropriately classified.
- Validate that security controls are implemented as needed by reviewing the classification periodically.
- Define authorized list of users and access criteria based on information classification. This supports the separation of duties principle of secure design.
- Ensure appropriate backup and recovery mechanisms are in place
- Delegate as needed the classification responsibility, access approval authority, backup, and recovery duties to a data custodian.
The data custodian is delegated by the data owner and is the individual who is responsible for the following:
- Perform the information classification exercise.
- Perform backups and recovery as specified by the data owner.
- Ensure records retention is in place according to regulatory requirements or organizational retention policy.
It is also important to recognize that data need to be protected throughout the information life cycle, i.e., from the time they are created to the time they are disposed or deleted. Information life cycle management (ILM) includes the creation, use, archival, and removal of data. When data are created and used (processed, transmitted, or stored), appropriate protection mechanisms need to exist. Security requirements when archiving data, covered earlier in this chapter, must be considered when data are archived. However, when data have outlived their usefulness and there is no regulatory or compliance requirement to retain them, the data must be deleted. The rules for data retention are determined by the corporate data retention period, which must complement local legal and legislative procedures.
Proper implementation of data classification can be effective in determining security requirements because a one-size-fits-all security protection mechanism is not effective in today’s complex heterogeneous computing ecosystems. Data classification can ensure that confidentiality, integrity, and availability security requirements are adequately identified and captured in the software specifications documentation.
2.5.5 Use and Misuse Case Modeling
2.5.5.1 Use Cases
Like data classification, use case modeling is another mechanism by which software functional and security requirements can be determined. A use case models the intended behavior of the software or system. In other words, the use case describes behavior that the system owner intended. This behavior describes the sequence of actions and events that are to be taken to address a business need. Use case modeling and diagramming is very useful for specifying requirements. It can be effective in reducing ambiguous and incompletely articulated business requirements by explicitly specifying exactly when and under what conditions certain behavior occurs. Use case modeling is meant to model only the most significant system behavior and not all of it and so should not be considered a substitute for requirements specification documentation.
Use case modeling includes identifying actors, intended system behavior (use cases), and sequences and relationships between the actors and the use cases. Actors may be an individual, a role, or nonhuman in nature. As an example, the individual John, an administrator, or a backend batch process can all be actors in a use case. Actors are represented by stick people and use case scenarios by ellipses when the use case is diagrammatically represented. Arrows that represent the interactions or relationships connect the use cases and the actors. These relationships may be an includes or extends type of relationship. Figure 2.13 depicts a use case for an online auction. There are two types of actors, namely, an authenticated user and an anonymous user depicted in this use case. The user must first sign in and be authenticated before an item can be added to their watch list or a bid for an item can be placed in the system. This sequence of actions is not represented within the use case itself, but this is where a sequence diagram comes handy. Sequence diagrams usually go hand in hand with use case diagrams. Preconditions such as a user must be authenticated before placing a bid and postconditions such as when the user logs off the system, should be required to re-log-in before performing authenticated user actions, can be used to clarify the scope of the use case and document any assumptions the use case author has made about the system.
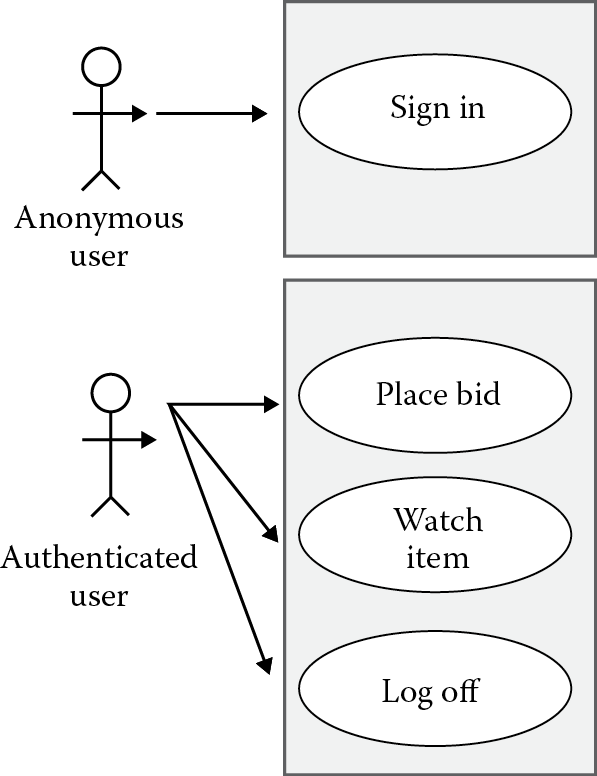
2.5.5.2 Misuse Cases
From use cases, misuse cases can be developed. Misuse cases, also known as abuse cases, help identify security requirements by modeling negative scenarios (McGraw, 2006). A negative scenario is an unintended behavior of the system, one that the system owner does not want to occur within the context of the use case. Misuse cases provide insight into the threats that can occur against the system or software. It provides the hostile users point of view and is an inverse of the use case. Misuse case modeling is similar to the use case modeling, except that in misuse case modeling, mis-actors and unintended scenarios or behaviors are modeled. Misuse cases may be intentional or accidental. One of the most distinctive traits of misuse cases is that they can be used to elicit security requirements unlike other requirements determination methods that focus on end user functional requirements.
Misuse cases can be created through brainstorming negative scenarios like an attacker. A misuse case can also be generated by thwarting the sequence of actions that is part of the use case scenario. In our online auction example, if an anonymous user is able to place a bid on an item before first signing it, a misuse of intended behavior has occurred. Misuse cases must not only take into account adversaries that are external to the company but also the insider. A database administrator who has direct access to unprotected sensitive data in the databases is a potential insider mis-actor and a misuse case to represent this scenario must be specified. Auditing can assist in determining insider threats, and this must be a security control that is taken into account when generating misuse cases for mis-actors that are internal to the company. Additionally, a Subject–Object Matrix can also be very useful in determining misuse cases.
2.5.6 Subject–Object Matrix
When there are multiple subjects (roles) that require access to functionality within the software, it is critical to understand what each subject is allowed to do. Objects (components) are those items that a subject can act upon. They are the building blocks of software. Higher-level objects must be broken down into more granular objects for better accuracy of subject–object relationship representations. For example, the “database” object can be broken down into finer objects such as “data table,” “data view,” and “stored procedures,” and each of these objects can now be mapped to subjects or roles. It is also important to capture third party components as objects in the software requirements specification documents.
A Subject–Object Matrix is used to identify allowable actions between subjects and objects based on use cases. Once use cases are enumerated with subjects (roles) and the objects (components) are defined, a Subject–Object Matrix can be developed. A Subject–Object Matrix is a two-dimensional representation of roles and components. The subjects or roles are listed across the columns and the objects or components are listed down the rows. A Subject–Object Matrix is a very effective tool to generate misuse cases. Once a Subject–Object Matrix is generated, by inversing the allowable actions captured in the Subject–Object Matrix, one can determine threats, which, in turn, can be used to determine security requirements. In a Subject–Object Matrix, when the subjects are roles, it is also referred to as a role matrix.
2.5.7 Templates and Tools
Some of the common templates that can be used for use and misuse case modeling are templates by Kulak and Guiney and by Cockburn. The Security Quality Requirements Engineering (SQUARE) methodology consists of nine steps that generate a final deliverable of categorized and prioritized security requirements (Allen et al. 2008). The SQUARE process model tool has been developed by the U.S. Computer Emergency Readiness Team (US-CERT). Objectiver is software that uses a goal-oriented methodology to build requirements specifications. The Microsoft Threat Analysis and Modeling (TAM) tools enable nonsecurity subject matter experts to enter business information and intended software design features that are used to generate use cases, misuse cases, SOM, and threat models.
2.6 Requirements Traceability Matrix (RTM)
The output from the data classification exercise, use and misuse case modeling, SOM, and other requirement elicitation processes can be tabulated into the RTM. A generic RTM is a table of information that lists the business requirements in the leftmost column, the functional requirements that address the business requirements are in the next column. Next to the functional requirements are the testing requirements. From a software assurance perspective, a generic RTM can be modified to include security requirements as well.
RTMs provide the following benefits to software development:
- Ensures that no scope creep occurs, i.e., the software development team has not inadvertently or intentional added additional features that were not requested by the user.
- Assures that the design satisfies the specified security requirements.
- Ensures that implementation does not deviate from secure design.
- Provides a firm basis for defining test cases.
By incorporating security requirements in the RTM, the chances of security functionality being missed out in design are reduced considerably. Specifying security requirements next to functional requirements also provides the business with insight into how security functionality maps to the end user business requirements. Additionally, requirements documentation also allows for appropriate resource allocation as needed.
2.7 Summary
In this chapter, we have covered the need for and the importance of eliciting security requirements early in the SDLC. Sources for security requirement include both internal organizational policy documents as well as external regulatory and compliance requirements. It is also extremely important to engage the appropriate stakeholders from the business, end user, IT, legal, privacy, networking, and software development teams. There are several types of security requirements that address the various tenets of software security, and the applicability of each of these types of requirements within the business context of the software being designed and developed must be determined. Protection needs can be elicited using several methods including brainstorming, surveys, policy decomposition, data classification, and use and misuse case modeling. The policy decomposition process is made up of breaking down high-level requirements into granular finer level software security requirements. Data classification can help with assuring that appropriate levels of security controls are assigned to data based on their sensitivity levels. Use and misuse case modeling, sequence diagrams, and subject–object models can be used to glean software security requirements. Software security requirements help ensure that the software that will be designed, developed, and deployed include secure features that make it reliable, resilient, and recoverable.
2.8 Review Questions
- Which of the following must be addressed by software security requirements? Choose the best answer.
A. Technology used in building the application
B. Goals and objectives of the organization
C. Software quality requirements
D. External auditor requirements
- Which of the following types of information is exempt from confidentiality requirements?
A. Directory information
B. Personally identifiable information (PII)
C. User’s card holder data
D. Software architecture and network diagram
- Requirements that are identified to protect against the destruction of information or the software itself are commonly referred to as
A. Confidentiality requirements
B. Integrity requirements
C. Availability requirements
D. Authentication requirements
- The amount of time by which business operations need to be restored to service levels as expected by the business when there is a security breach or disaster is known as
A. Maximum tolerable downtime (MTD)
B. Mean time before failure (MTBF)
C. Minimum security baseline (MSB)
D. Recovery time objective (RTO)
- The use of an individual’s physical characteristics such as retinal blood patterns and fingerprints for validating and verifying the user’s identity is referred to as
A. Biometric authentication
B. Forms authentication
C. Digest authentication
D. Integrated authentication
- Which of the following policies is most likely to include the following requirement? “All software processing financial transactions need to use more than one factor to verify the identity of the entity requesting access.”
A. Authorization
B. Authentication
C. Auditing
D. Availability
- A means of restricting access to objects based on the identity of subjects and/or groups to which they belong is the definition of
A. Nondiscretionary access control (NDAC)
B. Discretionary access control (DAC)
C. Mandatory access control (MAC)
D. Rule-based access control
- Requirements that when implemented can help to build a history of events that occurred in the software are known as
A. Authentication requirements
B. Archiving requirements
C. Auditing requirements
D. Authorization requirements
- Which of the following is the primary reason for an application to be susceptible to a man-in-the-middle (MITM) attack?
A. Improper session management
B. Lack of auditing
C. Improper archiving
D. Lack of encryption
- The process of eliciting concrete software security requirements from high-level regulatory and organizational directives and mandates in the requirements phase of the SDLC is also known as
A. Threat modeling
B. Policy decomposition
C. Subject–object modeling
D. Misuse case generation
- The first step in the protection needs elicitation (PNE) process is to
A. Engage the customer
B. Model information management
C. Identify least privilege applications
D. Conduct threat modeling and analysis
- A requirements traceability matrix (RTM) that includes security requirements can be used for all of the following except
A. Ensuring scope creep does not occur
B. Validating and communicating user requirements
C. Determining resource allocations
D. Identifying privileged code sections
- Parity bit checking mechanisms can be used for all of the following except
A. Error detection
B. Message corruption
C. Integrity assurance
D. Input validation
- Which of the following is an activity that can be performed to clarify requirements with the business users using diagrams that model the expected behavior of the software?
A. Threat modeling
B. Use case modeling
C. Misuse case modeling
D. Data modeling
- Which of the following is least likely to be identified by misuse case modeling?
A. Race conditions
B. Mis-actors
C. Attacker’s perspective
D. Negative requirements
- Data classification is a core activity that is conducted as part of which of the following?
A. Key Management Life Cycle
B. Information Life Cycle Management
C. Configuration management
D. Problem management
- Web farm data corruption issues and card holder data encryption requirements need to be captured as part of which of the following requirements?
A. Integrity
B. Environment
C. International
D. Procurement
- When software is purchased from a third party instead of being built in-house, it is imperative to have contractual protection in place and have the software requirements explicitly specified in which of the following?
A. Service level agreements (SLAs)
B. Nondisclosure agreements (NDA)
C. Noncompete agreements
D. Project plan
- When software is able to withstand attacks from a threat agent and not violate the security policy it is said to be exhibiting which of the following attributes of software assurance?
A. Reliability
B. Resiliency
C. Recoverability
D. Redundancy
- Infinite loops and improper memory calls are often known to cause threats to which of the following?
A. Availability
B. Authentication
C. Authorization
D. Auditing
- Which of the following is used to communicate and enforce availability requirements of the business or client?
A. Nondisclosure agreement (NDA)
B. Corporate contract
C. Service level agreements
D. Threat model
- Software security requirements that are identified to protect against disclosure of data to unauthorized users is otherwise known as
A. Integrity requirements
B. Authorization requirements
C. Confidentiality requirements
D. Nonrepudiation requirements
- The requirements that assure reliability and prevent alterations are to be identified in which section of the software requirements specifications (SRS) documentation?
A. Confidentiality
B. Integrity
C. Availability
D. Auditing
- Which of the following is a covert mechanism that assures confidentiality?
A. Encryption
B. Steganography
C. Hashing
D. Masking
- As a means to assure confidentiality of copyright information, the security analyst identifies the requirement to embed information insider another digital audio, video, or image signal. This is commonly referred to as
A. Encryption
B. Hashing
C. Licensing
D. Watermarking
- Checksum validation can be used to satisfy which of the following requirements?
A. Confidentiality
B. Integrity
C. Availability
D. Authentication
- A requirements traceability matrix (RTM) that includes security requirements can be used for all of the following except
A. Ensure scope creep does not occur
B. Validate and communicate user requirements
C. Determine resource allocations
D. Identifying privileged code sections
References
Allen, J. H., S. Barnum, R. J. Ellison, G. McGraw, and N. R. Mead. 2008. Software Security Engineering: A Guide for Project Managers. Boston, MA: Addison-Wesley.
Bauer, F. L. 2000. Decrypted Secrets: Methods and Maxims of Cryptology. New York, NY: Springer.
Ferraiolo, D., and P. Mell. 2006. Operating system security: Adding to the arsenal of security techniques. NIST, Computer Security Division, Information Technology Laboratory. http://csrc.nist.gov/publications/nistbul/itl99-12.txt (accessed Mar 3, 2011).
Guidance Share. 2007. .Net 2.0 security guidelines—Exception management. http://www .guidanceshare.com/wiki/.NET_2.0_Security_Guidelines_-_Exception_Management.
Johnson, N. F., Z. Duric, and S. Jajodia. 2000. Information Hiding: Steganography and Watermarking. New York, NY: Springer.
Lindell, A. 2007. Anonymous authentication. Security token and smart card authentication Whitepaper. Blackhat. http://searchsecurity.techtarget.com/tip/0,289483,sid14_gci1338503,00.html (accessed Mar 3, 2011).
McGraw, G. 2006. Software Security: Building Security. Boston, MA: Addison-Wesley.
NIST. 2007. Role-based access control—Frequently asked questions. Computer Security Division, Computer Security Resource Center. http://csrc.nist.gov/groups/SNS/rbac/faq.html.
Seacord, R. C. 2006. CERT: File I/O secure programming. Carnegie Mellon University. https://www.securecoding.cert.org/confluence/download/attachments/3524/07+Race+Conditions.pdf (accessed Mar 3, 2011).
Solomon, M., and M. Chapple. 2005. Information Security Illuminated. Sudbury, MA: Jones & Bartlett Learning.
Tsai, C.-H. 2004. On unicode and the Chinese writing system. http://technology.chtsai.org/unicode/ (accessed Mar 3, 2011).