
Chapter 5
Secure Software Testing
5.1 Introduction
Just because software architects design software with a security mindset and developers implement security by writing secure code, it does not necessarily mean that the software is secure. It is imperative to validate and verify the functionality and security of software, and this can be accomplished by quality assurance (QA) testing, which should include testing for security functionality and security testing. Security testing is an integral process in the secure software development life cycle (SDLC). The results of security testing have a direct bearing on the quality of the software. Software that has undergone and passed validation of its security through testing is said to be of relatively higher quality than software that has not.
In this chapter, what to test, who is to test, and how to test for software security issues will be covered. The different types of functional and security testing that must be performed will be highlighted, and criteria that can be used to determine the type of security tests to be performed will be discussed. Security testing is necessary and must be performed in addition to functional testing. Testing standards such as the ISO 9126 and methodologies such as the Open Source Security Testing Methodology Manual (OSSTMM) and Systems Security Engineering Capability Maturity Model® (SSE-CMM) that were covered in chapter 1 can be leveraged when security testing is performed.
5.2 Objectives
As a CSSLP, you are expected to
- Understand the importance of security testing and how it impacts the quality of software.
- Have a thorough understanding of the different types of functional and security testing and the benefits and weaknesses of each.
- Be familiar with how common software security vulnerabilities (bugs and flaws) can be tested.
- Understand how to track defects and address test findings.
This chapter will cover each of these objectives in detail. It is imperative that you fully understand the objectives and be familiar with how to apply them in the software that your organization builds or procures. The CSSLP is not expected to know all the tools that are used for software testing, but must be familiar with what tests need to be performed and how they can be performed. In the last section of this chapter, we will cover some common tools for security testing, but this is primarily for informational purposes only. Appendix E describes several common tools that can be used for security testing, more particularly application security tests.
5.3 Quality Assurance
In many organizations, the software testing teams are rightfully referred to as QA teams. QA of software can be achieved by testing its reliability (functionality), recoverability, resiliency (security), interoperability, and privacy. Figure 5.1 illustrates the categorization of the different types of software QA testing.
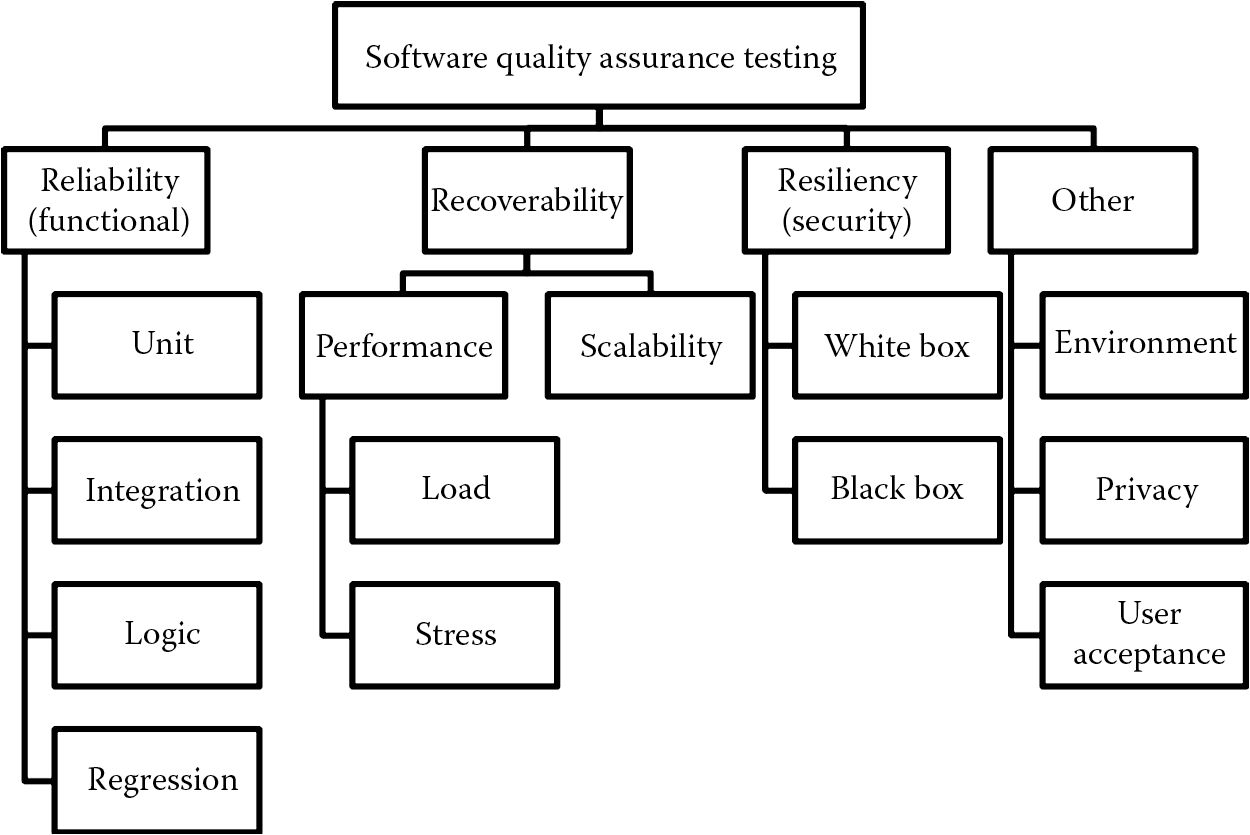
Reliability implies that the software is functioning as is expected by the business or customer. Since software is generally complex, the likelihood that all functionality and code paths will be tested is less and this can lead to the software’s being attacked. Resiliency is the measure of how strong the software is against attacks attempting to compromise it. Nonintentional and accidental user errors can cause downtime. Software attacks can also cause unavailability of the software. Software that is not highly resilient to attack will be susceptible to compromise, such as injection threats, denial of service (DoS), data theft, and memory corruption, and when this occurs, the ability of the software to be able to recover its operations should also be tested. Recoverability is the software’s ability to restore itself to an operational state after downtime, which can be caused accidentally or intentionally. Interoperability testing validates the ability of the software to function in disparate environments. Privacy testing is conducted to check that personally identifying information (PII), personal health information (PHI), personal financial information (PFI), and any information that is exclusive to the owner of the information is assured confidentiality without intrusion.
The results of these various types of testing can provide insight into the quality of software. However, as established in Chapter 1, software that is of high quality may not necessarily mean that it is secure. Software that performs efficiently to specifications may not have adequate levels of security controls in place. This is why security testing (covered later) is necessary, and since security is another attribute of quality, as is privacy and reliability, software that is secure can be considered as being of relatively higher quality. Testing can validate this.
5.4 Types of Software QA Testing
The following section will cover the different types of testing for software QA. It is important that you are familiar with the definition of these tests and what they are used for.
5.4.1 Reliability Testing (Functional Testing)
Software testing is performed primarily to attest to the functionality of the software as expected by the business or customer. Functional testing is also referred to as reliability testing. We test to check if the software is reliable (is functioning as it is supposed to) according to the requirements specified by the business owner.
5.4.1.1 Unit Testing
Although unit tests are not conducted by software testers but by the developers, it is the first process to ensure that the software is functioning properly, according to specifications. It is performed during the implementation phase (coding) of the SDLC by breaking the functionality of the software into smaller parts and testing each part in isolation for build and compilation errors as well as functional logic. If the software is architected with modular programming in mind, conducting unit tests are easier because each of the features is already isolated as discrete units (high cohesiveness) and has few dependencies (loose coupling) with other units.
In addition to functionality validation, unit testing can be used to find quality of code (QoC) issues as well. By stepping through the units of code methodically, one can uncover inefficiencies, cyclomatic complexities, and vulnerabilities in code. Some common examples of code that are inefficient include dangling code, code in which objects are instantiated but not destroyed, and infinite loop constructs that cause resource exhaustion and eventually DoS. Within each module, code that is complex in logic with circular dependencies on other code modules (not being linearly independent) is not only a violation of the least common mechanisms design principle, but is also considered to be cyclomatically complex (covered in Chapter 4). Unit testing is useful to find out the cyclomatic complexities in code. Unit testing can also help uncover common coding vulnerabilities, such as hard coding values, and sensitive information, such as passwords and cryptographic keys inline in code.
Unit testing can start as soon as the developer completes coding a feature. However, software development is not done in a silo, and there are usually many developers working together on a single project. This is especially true with current-day, agile programming methodologies such as extreme programming (XP) or Scrum. Additionally, a single feature that the business wants may be split into multiple modules and assigned to different developers. In such a situation, unit testing can be a challenge. For example, the feature to calculate the total price could be split into different modules: one to get the shipping rate (getShippingRate()), one to calculate the Tax (calcTax()), another to get the conversion rate for international orders (getCurrencyConversionRate()), and one to compute any discounts (calcDiscount) offered. Each of these modules can also be assigned to different developers, and some modules may be dependent on others. In our example, the getShippingRate() is dependent on the completion of the getCurrencyConversionRate(), and before its operation can complete, it will need to invoke the getCurrencyConversionRate() method and expect the output from the getCurrencyConversionRate() method as input into its own operation. In such situations, unit testing one module that is related to or dependent on other modules can be a challenge, particularly when the method that is being invoked has not yet been coded. The developer who is assigned to code the getShippingRate() method has to wait on the developer who is assigned the getCurrencyConversionRate() for the unit test of getShippingRate() to be completed. This is where drivers and stubs can come in handy. Implementing drivers and stubs is a very common approach to unit testing. Drivers simulate the calling unit whereas stubs simulate the called unit. In our case, the getShippingRate() method will be the driver because it calls the getCurrencyConversionRate() method, which will be the stub. Drivers and stubs are akin to mock objects that alleviate unit testing dependencies. Drivers and stubs also mitigate a very common coding problem, which is the hard coding of values inline code. By calling the stub, the developer of the driver does not have the need to hard code values within the implementation code of the driver method. This helps with the integrity (reliability) of the code. Additionally, drivers and stubs programming eases the development with third party components when the external dependencies are not completely understood or known ahead of time.
Unit testing also facilitates collective code ownership in agile development methodologies. With the accelerated development efforts and multiple software teams collectively responsible for the code that is released, unit testing can help identify any potential issues raised by a programmer on the shared code base before it is released.
Unit testing provides many benefits, including the ability to:
- Validate functional logic.
- Find out inefficiencies, complexities, and vulnerabilities in code, as the code is tested after being isolated into units, as opposed to being integrated and tested as a whole. It is easier to find that needle in a haystack when the code is isolated into manageable units and tested.
- Automate testing processes by integrating easily with automated build scripts and tools.
- Extend test coverage.
- Enable collective code ownership in agile development.
5.4.1.2 Integration Testing
Just because unit testing results indicate that the code tested is functional (reliable), resilient (secure), and recoverable, it does not necessarily mean that the system itself will be secure. The security of the sum of all parts should also be tested. When individual units of code are aggregated and tested, it is referred to as integration testing. Integration testing is the logical next step after unit testing to validate the software’s functionality, performance, and security. It helps to identify problems that occur when units of code are combined. If individual code units have successfully passed unit testing, but fail when they are integrated, then it is a clear-cut indication of software problems upon integration. This is why integration testing is necessary.
5.4.1.3 Logic Testing
Logic testing validates the accuracy of the software processing logic. Most developers are very intelligent, and good ones tend to automate recurring tasks by leveraging and reusing existing code. In this effort, they tend to copy code from other libraries or code sets that they have written. When this is done, it is critically important to validate the implementation details of the copied code for functionality and logic. For example, if code that performs the addition of two numbers is copied to multiply two numbers, the copied code needs to be validated to be make sure that the sign within the code that multiples two numbers is changed from “+” to “×,” as shown in Figure 5.2. Line-by-line manual validation of logic or step-by-step debugging (which is a means to unit test) ensures that the code is not only reliably functioning, but also provides the benefit of extended test coverage to uncover any potential issues with the code.

Logic testing also includes the testing of predicates. A predicate is something that is affirmed or denied of the subject in a proposition in logic. Software that has a high measure of cyclomatic complexity must undergo logic testing before being shipped or released, especially if the processing logic of the software is dependent on user input.
Boolean predicates return a true or false depending on whether the software logic is met. Logic testing is usually performed by negating or mutating (varying) the intended functionality. Variations in logic can be created by applying operators (e.g., AND, OR, NOT EQUAL TO, EQUAL TO) to Boolean predicates. The source of Boolean predicates can be one or more of the following:
- Functional requirements specifications, such as UML diagrams and RTM
- Assurance (security) requirements
- Looping constructs (for, foreach, do while, while)
- Preconditions (if-then)
Testing for blind SQL Injection is an example of logic testing in addition to being a test for error and exception handling.
5.4.1.4 Regression Testing
Software is not static. Business requirements change, and newer functionality is added to the code as newer versions are developed. Whenever code or data are modified, there is a likelihood for those changes to break something that was previously functional. Regression testing is performed to validate that the software did not break previous functionality or security and regress to a nonfunctional or insecure state. It is also known as verification testing.
Regression testing is primarily focused on implementation issues over design flaws. A regression test must be written and conducted for each fixed bug or database modification. It is performed to ensure that:
- It is not merely the symptoms of bugs that are fixed, but that the root cause of the bugs.
- The fixing of bugs does not inadvertently introduce any new bugs or errors.
- The fixing of bugs does not make old bugs that were once fixed recur.
- Modifications are still compliant with specified requirements.
- Unmodified code and data have not been impacted.
Not only functionality needs to be tested, but also the security of the software. Sometimes implementation of security itself can deny existing functionality to valid users. An example of this is that a menu option previously available to all users is no longer available upon the implementation of role-based access control of menu options. Without proper regression testing, legitimate users will be denied functionality. It is also important to recognize that data changes and database modifications can have side effects, reverting functionality or reducing the security of the software, and so these need to be tested for regression as well.
Adequate time needs to be allocated for regression testing. It is recommended that a library of tests be developed that includes a predefined set of tests to be conducted before the release of any new version. The challenge with this approach is determining what tests should be part of the predefined set. At a bare minimum, tests that involve boundary conditions and timing should be included. Determining the relative attack surface quotient (RASQ) for newer versions of software with the RASQ values of the software before it was modified can be used as a measure to determine the need for regression testing and the tests that need to be run.
Usually, software QA teams perform regression testing, but since the changes that need to be made are often code-related, changes that need to be made are costly and project timelines can be affected. It is therefore advisable that regression testing be performed by developers after integration testing for code-related changes and also in the testing phase before release.
5.4.2 Recoverability Testing
In addition to testing for reliability, software testing must be performed to assure the recoverability of software. Such tests check if the software will be available when required and that it has the appropriate replication, load balancing, and disaster recovery (DR) mechanisms functioning properly. Recoverability testing validates that the software meets the customer’s maximum tolerable downtime (MTD) and recovery time objective (RTO) levels.
Performance testing (load testing, stress testing) and scalability testing are examples of common recoverability testing, which are covered in the following section.
5.4.2.1 Performance Testing
Testing should be conducted to ensure that the software is performing to the service level agreement (SLA) and expectations of the business. The implementation of secure features can have a significant impact on performance, and this must be taken into account. Having smaller cache windows, complete mediation, and data replication are examples of security design and implementation features that can adversely impact performance. However, performance testing is not performed with the intent of finding vulnerabilities (bugs or flaws), but with the goal of determining any bottlenecks in the software. It is used to find and establish a baseline for future regression tests (covered later in this chapter). The results of a performance test can be used to tune the software to organizational or established industry benchmarks. Bottlenecks can be reduced by tuning the software. Tuning is performed to optimize resource allocation. You can tune the software code and configuration, the operating system, or the hardware. Examples of configuration tuning include setting the connection pooling limits in a database server, setting the maximum number of users allowed in a Web server, and setting time limits for sliding cache windows.
The two common means to test for performance are load testing and stress testing the software.
- Load Testing: In the context of software QA, load testing is the process of subjecting the software to volumes of operating tasks or users until it cannot handle any more, with the goal of identifying the maximum operating capacity for the software. Load testing is also referred to as longevity, endurance, or volume testing. It is important to understand that load testing is an iterative process. The software is not subjected to maximum load the very first time a load test is performed. The software is subjected to incremental load (tasks or users). Generally, the normal load is known, and in some cases the peak (maximum) load is known as well. When the peak load is known, load testing can be used to validate it or determine areas of improvement. When the peak load is not already known, load testing can be used to find it by identifying the threshold limit at which the software no longer meets the business SLA.
- Stress Testing: If load testing is to determine the zenith point at which the software can operate with maximum capacity, stress testing is taking that test one step further. It is mainly aimed to determine the breaking point of the software, i.e., the point at which the software can no longer function. In stress testing, the software is subjected to extreme conditions such as maximum concurrency, limited computing resources, or heavy loads.
It is performed to determine the ability of the software to handle loads beyond its maximum capabilities and is primarily performed with two objectives. The first is to find out if the software can recover gracefully upon failure after the software breaks. The second is to assure that the software operates according to the design principle of failing securely. For example, if the maximum number of allowed authentication attempts has been passed, then the user must be notified of invalid login attempts with a specific nonverbose error message, while at the same time, that user’s account needs to be locked out, as opposed to granting the user access automatically, even if it is only low-privileged guest access. Stress testing can also be used to find timing and synchronization issues, race conditions, resource exhaustion triggers, and events and deadlocks.
5.4.2.2 Scalability Testing
Scalability testing augments performance testing. It is a logical next step from performance testing the software. Its main objectives are to identify the loads (obtained from load testing) and to mitigate any bottlenecks that will hinder the ability of the software to scale to handle more load or changes in business processes or technology. For example, if order_id, which is the unique identifier in the ORDER table, is set to be of an integer type (Int16), with the growth in the business, there is a high likelihood that the orders that are placed after the order_id has reached the maximum range (65535) supported by the Int16 datatype will fail. It may be wiser to set the datatype for order_id to be a long integer (Int32) so that the software can scale with ease and without failure. Performance test baseline results are usually used in testing for the effectiveness of scalability. Degraded performance upon scaling implies the presence of some bottleneck that needs to be addressed (tuned or eliminated).
5.4.3 Resiliency Testing (Security Testing)
While functional testing is done to make sure that the software does not fail during operations or under pressure, security testing is performed with the intent of trying to make the software fail. Security testing is a test for the resiliency of software. It is testing that is performed to see if the software can be broken. It differs from stress testing (covered earlier) in the sense that stress testing is primarily performed to determine the software’s recoverability, whereas security testing is conducted to attest to the presence and effectiveness of the security controls that are designed and implemented in the software. It is to be performed with a hostile user (attacker or blackhat) mindset. Good security testers are focused on one thing and one thing only, which is to break the software by circumventing any protection mechanisms in the software. Typically, attackers think out of the box as a norm and are usually very creative, finding new ways to attack the software, while learning from and improving their knowledge and expertise from each experience. Security testing begins with creating a test strategy of high-risk items first, followed by low-risk items. The threat model from the design phase that was updated during the implementation phase can be used to determine critical sections of code and software features.
5.4.3.1 Motives, Opportunities, and Means
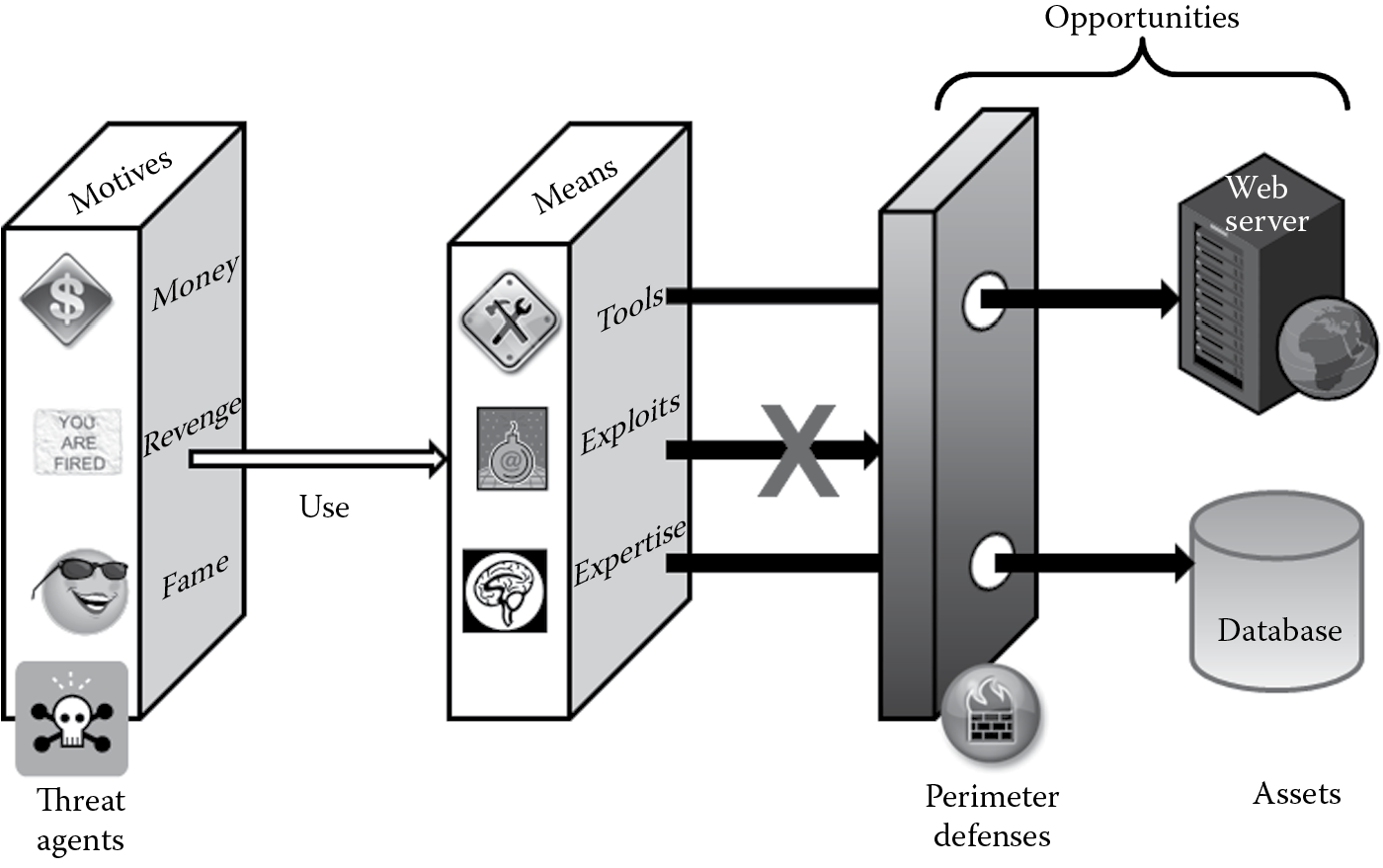
In the physical security world, for an attack to be successful there needs to be a confluence of three aspects: motive, opportunity, and means. The same is true in the information security space, as depicted in Figure 5.3. For cyber crime to be proven in a court of law, the same three aspects of crime must be determined. The motive of the attacker is usually tied to something that the attacker seeks to gain. This could range from just being recognized (fame) among peers, revenge from a disgruntled employee, or money. The opportunity for an attacker is directly related to the connectivity of the software and the vulnerabilities that exist in it. The expertise of and tools available to the hacker are the means by which they can exploit the software. Security testing can address two of the three aspects of crime. It can do little about the motive of an attacker, but the opportunities and means by which an attacker can exploit the software can be determined by security testing.
5.4.3.2 Testing of Security Functionality versus Security Testing
It is also important to distinguish between the testing of security functionality and security testing. Security testing is testing with an attacker perspective to validate the ability of the software to withstand attack (resiliency), while testing security functionality (e.g., authentication mechanisms, auditing capabilities, error handling) in software is meant to assure that the functionality of protection mechanisms is working properly. Testing security functionality is not necessarily the same as security testing.
Although security testing is aimed at validating software resiliency, it can also be performed to attest to the reliability and recoverability of software. Since integrity of data and systems is a measure of its reliability, security testing that validates data and system integrity issues attest to software reliability. Security testing can validate controls, such as fail secure mechanisms, and that proper error and exception handling are in place and are working properly to resume its functional operations as per the customer’s MTD and RTO, which are measures of the software’s recoverability. Security testing is also indicative of due diligence and due care measures that the organization takes to develop and release secure software for its customers.
5.4.3.3 The Need for Security Testing
Security testing should be part of the overall SDLC process, and engaging the testers to be part of the process early on is recommended. They should be allowed to assist in threat modeling exercises and be participants in the review of the threat model. This gives the software developer team an opportunity to discover and address prospective threats and gives the software testing team an advantage to start developing test scripts early on in the process. Architectural and design issues, weaknesses in logic, insecure coding, effectiveness of safeguards and countermeasures, and operational security issues can all be uncovered by security testing.
5.5 Security Testing Methodologies
Security testing can be accomplished using several different methodologies.
5.5.1 White Box Testing
Also known by other names such as glass box or clear box testing, white box testing is a security testing methodology based on the knowledge of how the software is designed and implemented. It is broadly known as full knowledge assessment because the tester has complete knowledge of the software. It can be used to test both the use case (intended behavior) as well as the misuse case (unintended behavior) of the software and can be conducted at any time after the development of code, although it is best advised to do so while conducting unit tests. In order to perform white box security testing, it is imperative first to understand the scope, context, and intended functionality of the software so that the inverse of that can be tested with an attacker’s perspective.
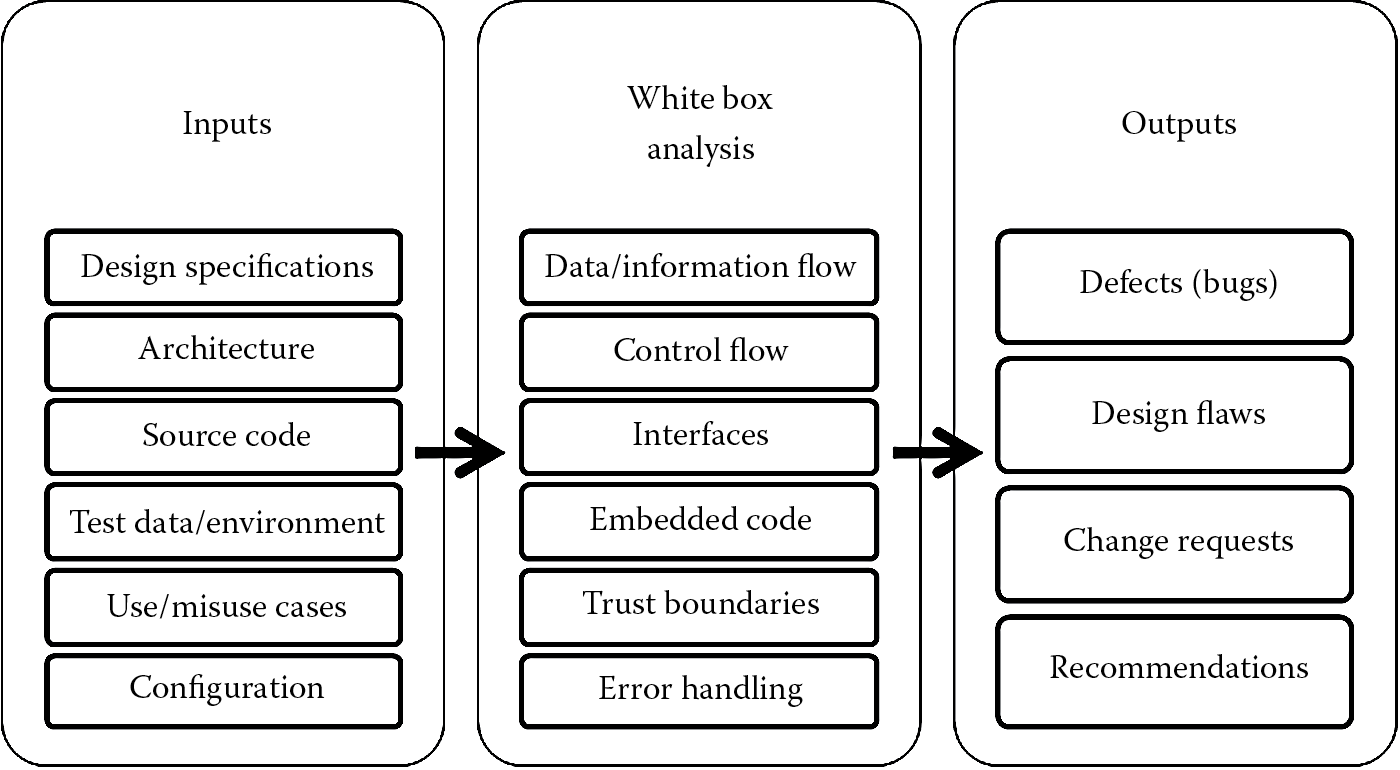
Inputs to the white box testing method include architectural and design documents, source code, configuration information and files, use and misuse cases, test data, test environments, and security specifications. White box testing of code requires access to the source code. This makes it possible to detect embedded code issues, such as Trojans, logic bombs, impersonation code, spyware, and backdoors, implanted by insiders. These inputs are structurally analyzed to ensure that the implementation of code follows design specifications, and whether security protection mechanisms or vulnerabilities exist. White box testing is also known as structural analysis. Data/information flow, control flow, interfaces, trust boundaries (entry and exit points), configuration, and error handling are methodically and structurally analyzed for security. Source code analyzers can be used to automate some of the source code testing. The output of a white box test is the white box test report, which includes defects (or incidents), flaws and deviations from design specifications, change requests, and recommendations to address security issues. The white box security testing process is depicted in Figure 5.4.
5.5.2 Black Box Testing
If white box testing is full knowledge assessment, black box testing is its opposite. It is broadly known as zero knowledge assessment, because the tester has very limited to no knowledge of the internal workings of the software being tested. Architectural or design documents, configuration information or files, use and misuse cases, and the source code of the software is not available to or known by the testing team conducting black box testing. The software is essentially viewed as a “black box” that is tested for its resiliency by determining how it responds (outputs) to the tester’s input, as illustrated in Figure 5.5. White box testing is structural analysis of the software’s security, whereas black box testing is behavioral analysis of the software’s security.
Black box testing can be performed before deployment (predeployment) or periodically once it is deployed (postdeployment). Depending on when black box testing is conducted, its objectives are different. Predeployment black box testing is used to identify and address security vulnerabilities proactively, so that the risk of the software’s getting hacked is minimized. Postdeployment black box testing helps to find out vulnerabilities that exist in the deployed production (or actual runtime environment) and can also be used to attest to the presence and effectiveness of the software security controls and protection mechanisms. Because identifying and fixing security issues early in the life cycle is less expensive, it is advisable to conduct black box testing predeployment. But doing so will not give insight into actual runtime environment issues, so when predeployment black box tests are conducted, an environment that mirrors or simulates the deployed production environment should be used.
5.5.3 Fuzzing
Also known as fuzz testing or fault injection testing, fuzzing is a brute-force type of testing in which faults (random and pseudo-random input data) are injected into the software and its behavior observed. It is a test whose results are indicative of the extent and effectiveness of input validation. Fuzzing can be used not only to test applications and their programming interfaces (application programming interfaces [APIs]), but also protocols and file formats. It is used to find coding defects and security bugs that can result in buffer overflows that cause remote code execution, unhandled exceptions, and hanging threads that cause DoS, state machine logic faults, and buffer boundary checking defects. The data that are used for fuzzing are commonly referred to as fuzz data or fuzzing oracles. Fuzz data can be either synthesized or mutated. Synthesized fuzz data are data that generated from scratch without being based on previous input, whereas mutated data are valid data that are corrupted so that their format (data structure) is not what the application expects.
Although fuzzing is a very common methodology of black box testing, not all fuzz tests are necessarily black box tests. Fuzzing can be performed as a white box test as well. Black box fuzzing is the sending of malformed data with any verification of the actual code paths that were covered and ones that were not. White box fuzzing is sending malformed data with verification of all code paths. When there is zero knowledge of the software and debugging the software to determine weaknesses is not an option, black box fuzzing is used, and when information about the makeup of the software (e.g., target code paths, configuration) is known, white box fuzzing is performed.
The two types of fuzzing prevalent today are dumb fuzzing and smart fuzzing. When truly random data without any consideration for the data structure is used, it is known as dumb fuzzing. This can be dangerous and lead to DoS, destruction, and complete disruption of the software’s operations. Smart fuzzing is preferred because the data structure, such as encoding and relations (checksums, bit flags, and offsets), are known, and the input data are variations of these data structures.
Black box dumb fuzzing covers the least amount of code and finds the least number of bugs, whereas white box smart fuzzing has maximum code coverage and can detect all of the bugs or weaknesses in code.
5.5.4 Scanning
I once asked one of my students, “Why do we need to scan our networks and software for vulnerabilities?” and his response, although amusing, was profound. He said, “If we don’t, someone else will.” When there is very limited or no prior knowledge about the software makeup, its internal workings, or the computing ecosystem in which it operates, black box testing can start by scanning the network as well as the software for vulnerabilities. Network scans are performed with the goal of mapping out the computing ecosystem. Wireless access points and wireless infrastructure scans must also be performed. These scans help determine the devices, operating system software (applications), services (daemons), ports, protocols, application and infrastructural interfaces, and Web server versions that make up the environment in which the software will run. They can also be used to find out vulnerabilities that exist in the network or in the software that an attacker can exploit.
The process of determining an operating system version is known as OS fingerprinting. OS fingerprinting is possible because each operating system has a unique way it responds to packets that hit the TCP/IP stack. An example of OS fingerprinting using the Nmap (Network Mapper) scanner is illustrated in Figure 5.6.
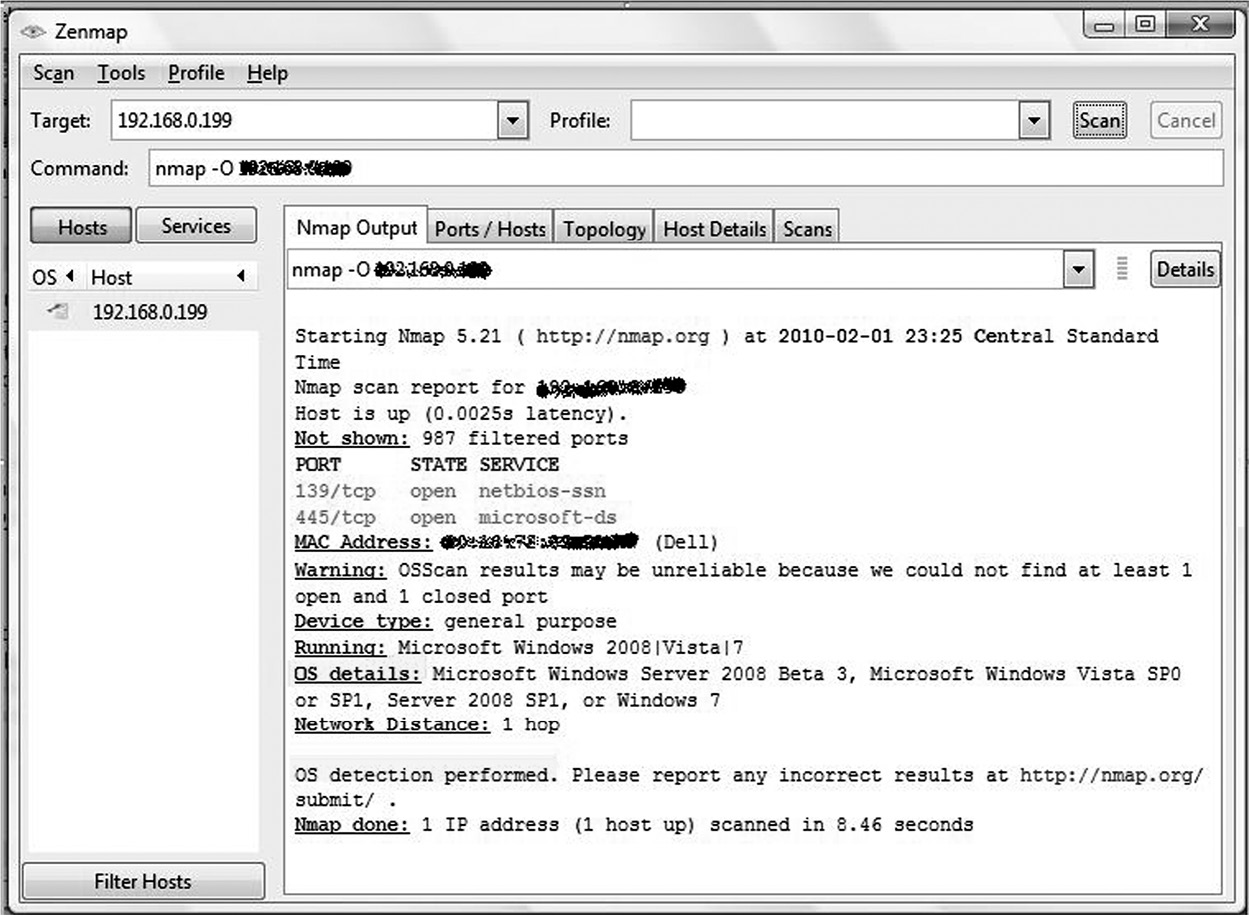
There are two main means by which an OS can be fingerprinted: active and passive. Active OS fingerprinting involves the sending of crafted, abnormal packets to the remote host and analyzing the responses from the remote host. If the remote host network is monitored and protected using intrusion detection systems, active fingerprinting can be detected. The popular Nmap tool uses active fingerprinting to detect OS versions. Unlike active fingerprinting, passive OS fingerprinting does not contact the remote host. It captures traffic originating from a host on the network and analyzes the packets. In passive fingerprinting, the remote host is not aware that it is being fingerprinted. Tools such as Siphon, which was developed by the HoneyNet project, and P0f use passive fingerprinting to detect OS versions. Active fingerprinting is fast and useful when there are a large number of hosts to scan, but it can be detected by IDS and IPS. Passive fingerprinting is relatively slower and best used for single host systems, especially if there is historical data. Passive fingerprinting can also go undetected since there is no active probe of the remote host being fingerprinted.
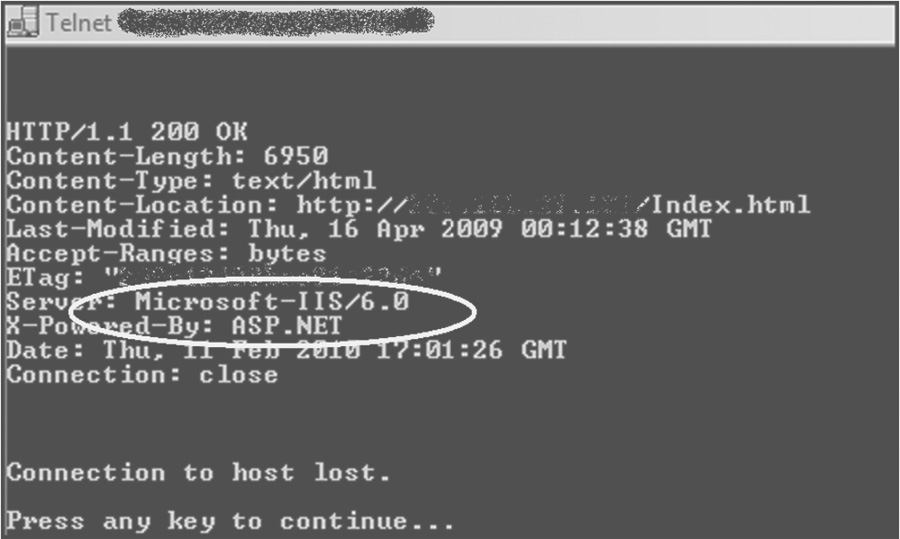
A scanning technique that can be used to enumerate and determine server versions is known as banner grabbing. Banner grabbing can be used for legitimate purposes, such as inventorying the systems and services on the network, but an attacker can use banner grabbing to identify network hosts that have vulnerable services running on them. The File Transfer Protocol (FTP) port 21, Simple Mail Transfer Protocol (SMTP) port 25, and Hypertext Transfer Protocol (HTTP) port 80 are examples of common ports used in banner grabbing. By looking at the server field in a HTTP response header, upon request, one can determine the Web server and its version. This is a very common Web server fingerprinting exercise when black box testing Web applications. Tools such as Netcat or Telnet are used in banner grabbing. Figure 5.7 depicts banner grabbing a Web server version using Telnet.
In addition to scanning the network (wired and wireless), software can be scanned. Software scanning can be either static or dynamic. Static scanning includes scanning the source code for vulnerabilities; dynamic scanning means that the software is scanned at runtime. Static scanning using source code analyzers is usually performed during the code review process in the development phase, whereas dynamic scanning is performed using crawlers and spidering tools during the testing phase of the SDLC.
Compliance with the Payment Card Industry Data Security Standard (PCI DSS) requires that organizations must periodically test their security systems and processes by scanning for network, host, and application vulnerabilities in the card holder data environment. The scan report should not only describe the type of vulnerability, but also provide risk ratings and recommendations on how to fix the vulnerabilities. Figure 5.8 is an illustration of a sample vulnerability scan report for PCI compliance.

Scanning can therefore be used to
- Map the computing ecosystems, infrastructural, and application interfaces.
- Identify server versions, open ports, and running services.
- Inventory and validate asset management databases.
- Identify patch levels.
- Prove due diligence due care for compliance reasons.
5.5.5 Penetration Testing (Pen-Testing)
Vulnerability scanning is passive in nature, meaning we use it to detect the presence of weaknesses and loopholes that can be exploited by an attacker. On the other hand, penetration testing is active in nature, because it goes one step further than vulnerability scanning. The main objective of penetration testing is to see if the network and software assets can be compromised by exploiting the vulnerabilities that were determined by the scans. The subtle difference between vulnerability scans and penetration testing (commonly referred to as pen-testing) is that a vulnerability scan identifies issues that can be attacked, whereas penetration testing measures the resiliency of the network or software by evaluating real attacks against those vulnerabilities. In penetration testing, attempts to emulate the actions of a potential threat agent (e.g., hacker or malware) are performed. In most cases, pen-testing is done after the software has been deployed, but this need not be the case. It is advisable to perform black box assessments using penetration testing techniques before deployment for the presence of security controls and after deployment to ensure that they are working effectively to withstand attacks.
When penetration testing is performed after deployment, it is important to recognize that rules of engagement need to be followed, and the penetration test itself is methodically conducted. The rules of engagement should explicitly define the scope of the penetration test for the testing team, regardless of whether they are an internal team or an external security service provider. Definition of scope includes restricting IP addresses and the software interfaces that can be tested. Most importantly, the environment, data, infrastructural, and application interfaces that are not within the scope must be identified before the test and communicated to the pen-testing team and, during the test monitoring, must be in place to assure that the pen-testing team does not go beyond the scope of the test. The technical guide to information security testing and assessment, published as Special Publication (SP) 800-115 by the National Institute of Standards and Technology (NIST), provides guidance on conducting penetration testing. The OSTMM (covered in Chapter 1) is known for its prescriptive guidance on the activities that need to be performed before, during, and after a penetration test, including the measurement of results. When conducted postdeployment, penetration testing can be used as a mechanism to certify the software (or system) as part of the validation and verification (V&V) activity inside of certification and accreditation (C&A). V&V and C&A are covered in Chapter 7.
Generically, the pen-testing process includes the following steps:
- Reconnaissance (Enumeration and Discovery): Enumeration techniques (covered under scanning), such as fingerprinting, banner grabbing, port and services scans, and vulnerability scanning, can be used to probe and discover the network layout and the internal workings of the software within that network. WHOIS, ARIN, and DNS lookups along with Web-based reconnaissance are common techniques for enumerating and discovering network infrastructure configurations.
- Resiliency Attestation (Attack and Exploitation): Upon completion of reconnaissance activities, once potential vulnerabilities are discovered, the next step is to try to exploit those weaknesses. Attacks can include brute forcing of authentication credentials, escalation of privileges to administrator (root) level privileges, deletion of sensitive logs and audit records, disclosure of sensitive information, and alteration/destruction of data to causing DoS by crashing the software or system. Defensive coding tests for software threats and vulnerabilities are covered later in this chapter.
- Removal of Evidence (Cleanup Activities) and Restoration: Penetration testers often establish back doors, turn on services, create accounts, elevate themselves to administrator privileges, load scripts, and install agents and tools in target systems. After attack and exploitation, it is important that any changes made in the target system or software for conducting the penetration test are removed and the original state of the system is restored. Not cleaning up and leaving behind accounts, services, and tools and not restoring the system leave it with an increased attack surface, and any subsequent attempts to exploit the software are made easy for the real attacker. It is therefore essential not to exit from the penetration testing exercise until all cleanup and restoration activities have been completed.
- Reporting and Recommendations: The last phase of penetration testing is to report on the findings of the penetration test. This report should include not only technical vulnerabilities covering the network and software, but also noncompliance with organization policy and weaknesses in organizational processes and people know-how. Merely identifying, categorizing, and reporting vulnerabilities are important, but value is added when the findings of the penetration test result in a plan of action and milestones (POA&M) and mitigation strategies. The POA&M is also referred to as a management action plan (MAP). Some examples of POA include updating policies and processes, redesigning the software architecture, patching and hardening, defensive coding, user awareness, and deployment of security technologies and tools. When choosing a mitigation strategy, it is recommended to compare the POA&M against the operational requirements of the business, balance the functionality expected with the security that needs to be in place, and use the computed residual risk to implement them.
The penetration test report has many uses as listed below. It can be used
- To provide insight into the state of security.
- As a reference for corrective action.
- To define security controls that will mitigate identified vulnerabilities.
- To demonstrate due diligence due care processes for compliance.
- To enhance SDLC activities such as security risk assessments, C&A, and process improvements.
5.5.6 White Box Testing versus Black Box Testing
As we have seen, security testing can be accomplished using either a white box approach or a black box approach. Each methodology has its merits and challenges. White box testing can be performed early in the SDLC processes, thereby making it possible to build security into the software. It can help developers to write hack-resilient code, as vulnerabilities that are detected can be identified precisely, in some cases to the exact line of code. However, white box testing may not cover code dependencies (e.g., services or libraries) or third party components. It provides little insight into the exploitability of the vulnerability itself and so may not present an accurate risk picture. Just because the vulnerability is present, it does not mean that it will be exploited, as compensating controls may be in place that white box testing may not uncover. On the other hand, black box testing can attest to the exploitability of weaknesses in both simulated and actual production systems. The other benefit of black box testing is that there is no need for source code, and the test can be conducted both before (pre-) and after (post-) deployment. The limitations of black box testing are that the exact cause of vulnerability may not be easily detectable, and the test coverage itself can be limited to the scope of the assessment.
The following section covers different criteria that can be used to determine the type of approach to take when validating software security. These include:
- Root cause identification: When vulnerability is detected, the first and appropriate course of action that must be taken is to determine and address the root cause of the vulnerability. Root cause analysis (RCA) of software security is easier when the source code is available for review. Black box testing can provide information about the symptoms of vulnerabilities, but with white box testing, the exact line of code that causes the vulnerability can be determined and handled so that fixed bugs do not resurface in subsequent version releases.
- Extent of code coverage: Because white box testing requires access to source code and each line of code can be analyzed for security issues, it provides greater code coverage than does black box testing. When complete code coverage is necessary, white box testing is recommended. Software that processes highly sensitive information and which is mission critical in nature must undergo complete code analysis for vulnerabilities.
- Number of false positives and false negatives: When a vulnerability is reported and in reality it is not a true vulnerability, it is referred to as a false positive result of security testing. On the other hand, when a vulnerability that exists goes undetected in the results of security testing, it is said to be a false negative. The number of false positives and false negatives are relatively higher in black box testing than in white box testing because black box testing looks at the behavior of the software as opposed to its structure and normal or abnormal behavior may not be known.
- Logical flaws detection: It is important to recognize that logical flaws are not really implementation bugs and syntactic in nature, but are design issues and semantic in nature. So white box testing using just source code analysis cannot help uncover these flaws. However, since, in white box testing, other contextual artifacts, such as the architectural and design documents and configuration information, are present, it is easier to find logical flaws using white box testing rather than black box testing.
- Deployment issues determination: Since source code should not be available in the production environment, white box testing is done in the development or test environments, unlike black box testing, which can be done in a production or production-like environment. The attestation of deployment environment resilience and discovery of actual configuration issues in the environment where the software will be deployed is possible with black box testing. Both data and environment issues need to be covered as part of the attestation activity.
Table 5.1 tabulates the comparison between the white box and black box security testing methodologies.
Comparison between White Box and Black Box Security Testing
|
White Box |
Black Box |
|
|
Also known as |
Full knowledge assessment |
Zero knowledge assessment |
|
Assesses the software’s |
Structure |
Behavior |
|
Root cause identification |
Can identify the exact line of code or design issue causing the vulnerability |
Can analyze only the symptoms of the problem and not necessarily the cause |
|
Extent of code coverage possible |
Greater; the source code is available for analysis |
Limited; not all code paths may be analyzed |
|
Number of false positives and false negatives |
Low; contextual information is available |
High; since normal behavior is unknown, expected behavior can also be falsely identified as anomalous |
|
Logical flaws detection |
High; design and architectural documents are available for review |
Low; limited to no design and architectural documentation is available for review |
|
Deployment issues identification |
Limited; assessment is performed in predeployment environments |
Greater; assessment can be performed in pre- as well as postdeployment production or production-like simulated environment |
So then, what kind of testing is “best” to assure the reliability, resiliency and recoverability of software? The answer is, “It depends.” For determining syntactic issues early on in the SDLC, white box testing is appropriate. If the source code is not available and testing needs to be performed with a truly hostile user perspective, then black box testing is the choice. In reality, however, usually a hybrid of the two approaches, also referred to as gray box or translucent box, is performed to validate security protection mechanisms in place. For a comprehensive security assurance assessment, the hybrid gray box approach is recommended, in which white box testing is conducted predeployment in development and test environments, and black box testing is performed pre- and postdeployment as well in production-like and actual production environments.
5.6 Software Security Testing
We have covered so far the various types of software testing for QA and the different methodologies for security testing. In the following section, security testing as it is pertinent to software security issues will be covered. We will learn about the different types of tests and how they can be performed to attest to the security of code that is developed in the development phase of the SDLC.
Before we start testing for software security issues in code, one of the first questions to ask is whether the software being tested is new or a version release. If it is a version release, we must check to ensure that the state of security has not regressed to a more insecure state than it had in its previous version. This can be accomplished by conducting regression tests (covered earlier) for security issues. We should specifically test for the introduction of any newer side effects that impact security and the use of banned or unsafe APIs in previous versions.
For software revisions, regression testing must be conducted, and for all versions, new or revisions, the following security tests must be performed, if applicable, to validate the strength of the security controls. Using a categorized list of threats as a template of security testing is effective in ensuring comprehensive coverage of the varied threats to software. The National Security Agency (NSA) identity and access management (IAM) threat list and STRIDE threat lists are examples of categorized threat lists that can be used in security testing. Ideally, the same threat list that was used when threat modeling the software will be used for conducting security tests. This way, security testing can be used to validate the threat model.
5.6.1 Testing for Input Validation
Most software security vulnerabilities can be mitigated by input validation. Such hostile actions as buffer overflows, injection flaws, and scripting attacks can be effectively reduced if the software performs validation of input before accepting it for processing.
In a client/server environment, input validation tests for both the client and the server should be performed. Client-side input validation tests are more a test for performance and user experience than for security. If you only have the time or resource to perform input validation tests on either the client or the server, choose to ensure that validation of input happens on the server side.
Attributes of the input, such as its range, format, data type, and values, must all be tested. When these attributes are known, input validation tests can be conducted using pattern matching expression and/or fuzzing techniques (covered earlier). Regular expression (RegEx) can be used for pattern matching input validation. Some common examples of RegEx patterns are tabulated in Table 5.2. Tests must be conducted to ensure that the whitelist (acceptable list) of input is allowed whereas the blacklist (dangerous or unacceptable) of input is denied. Not only must the test include the validation of the whitelists and blacklists, but it must also include the anti-tampering protection of these lists. Since canonicalization can be used to bypass input filters, both the normal and canonical representations of input should be tested. When the input format is known, smart fuzzing can be used, otherwise dumb fuzzing using random and pseudo-random inputs values can be used to attest the effective of input validation.
Commonly Used Regular Expressions (RegEx)
|
Regular Expression |
Validates |
Description |
Example |
|
^[a-zA-Z’’-’s]{1,20}$ |
Name |
Allows up to 20 uppercase and lowercase characters and some special characters that are common to some names |
John Doe O’ Hanley Johnson-Paul |
|
^([0-9a-zA-Z]([-.w]*[0-9a-zA-Z])*@([0-9a-zA-Z][-w]*[0-9a-zA-Z].)+[a-zA-Z]{2,9 })$ |
|
Validates an email address |
|
|
^(ht|f)tp(s?)://[0-9a-zA-Z]([-.w]*[0-9a-zA-Z])*(:(0-9)*)*(/?)([a-zA-Z0-9-.?,’/\+&%$#_]*)?$ |
URL |
Validates a uniform resource locator (URL) |
|
|
(?!^[0-9]*$)(?!^[a-zA-Z]*$)^([a-zA-Z0-9]{8,15})$ |
Password |
Validates a strong password; it must be between eight and 15 characters, contain at least one numeric value and one alphabetic character, and must not contain special characters |
|
|
^(-)?d+(.dd)?$ |
Currency |
Validates currency format; if there is a decimal point, it requires two numeric characters after the decimal point |
289.00 |
5.6.2 Injection Flaws Testing
Since injection attacks take the user-supplied input and treat it as a command or part of a command, input validation is an effective defensive safeguard against injection flaws. In order to perform input validation tests, it is first important to determine the sources of input and the events in which the software will connect to the backend store or command environment. These sources can include authentication forms, search input fields, hidden fields in Web pages, querystrings in the URL address bar, and more. Once these sources are determined, input validation tests can be used to ensure that the software will not be susceptible to injection attacks.
There are other tests that need to be performed as well. These include tests to ensure that
- Parameterized queries that are not themselves susceptible to injection are used.
- Dynamic query construction is disallowed.
- Error messages and exceptions are explicitly handled so that even Boolean queries (used in blind SQL injection attacks) are appropriately addressed.
- Nonessential procedures and statements are removed from the database.
- Database-generated errors do not disclose internal database structure.
- Parsers that prohibit external entities are used. External entities is a feature of XML that allows developers to define their own XML entities, and this can lead to XML injection attacks.
- Whitelisting that allows only alphanumeric characters is used when querying LDAP stores.
- Developers use escape routines for shell command instead of custom writing their own.
5.6.3 Testing for Nonrepudiation
The issue of nonrepudiation is enforceable by proper session management and auditing. Test cases should validate that audit trails can accurately determine the actor and their actions. It must also ensure that misuse cases generate auditable trails appropriately. If the code is written to perform auditing automatically, then tests to assure that an attacker cannot exploit this section of the code should be performed. Security testing should not fail to validate that user activity is unique, protected, and traceable. Tests cases should also include verifying the protection and management of the audit trail and the integrity of audit logs. NIST Special Publication 800-92 provides guidance on the protection of audit trails and the management of security logs. The confidentiality of the audited information and its retention for the required period of time should be checked as well.
5.6.4 Testing for Spoofing
Both network and software spoofing test cases need to be executed. Network spoofing attacks include address resolution protocol (ARP) poisoning, IP address spoofing, and media access control (MAC) address spoofing. On the software side, user and certificate spoofing tests, phishing tests, and verification of code that allows impersonation of other identities, as depicted in Figure 5.9, need to be performed. Testing the spoofability of the user and/or certificate along with verifying the presence of transport layer security can ensure secure communication and protection against man-in-the-middle (MITM) attacks. Cookie expiration testing must also be conducted, along with verifying that authentication cookies are encrypted.

The best way to check for defense against phishing attacks is to test users for awareness of social engineering techniques and attacks.
5.6.5 Failure Testing
Software is prone to failure due to accidental user error or intentional attack. Not only should software be tested for QA so that it does not fail in its functionality, but failure testing for security must be performed. Requirement gaps, omitted design, and coding errors can all result in defects that cause the software to fail. Testing to determine if the failure is a result of multiple defects or if a single defect yields multiple failures must be performed.
Software security failure testing includes the verification of the following security principles:
- Fail Secure (Fail Safe): Tests to verify if the confidentiality, integrity, and availability of the software or the data it handles when the software fails must be conducted. Special attention should be given to verifying any authentication processes. Test cases must be conducted to validate the proper functioning of account lockout mechanisms and denying access by default when the configured number of allowed authentication attempts has been exceeded.
- Error and Exception Handling: Errors and exception handling tests include testing the messaging and encapsulation of error details. Tests conducted should attempt to make the software fail, and when the software fails, error messages must be checked to make sure that they do not reveal any unnecessary details. Assurance tests to verify that exceptions are handled and the details are encapsulated using user-defined messages and redirects must be performed. If configuration settings allow displaying the error and exception details to a local user, but redirect a remote user to a default error handling page, then error handling tests must be conducted simulating the user to be local on the machine as well as coming from a remote location.
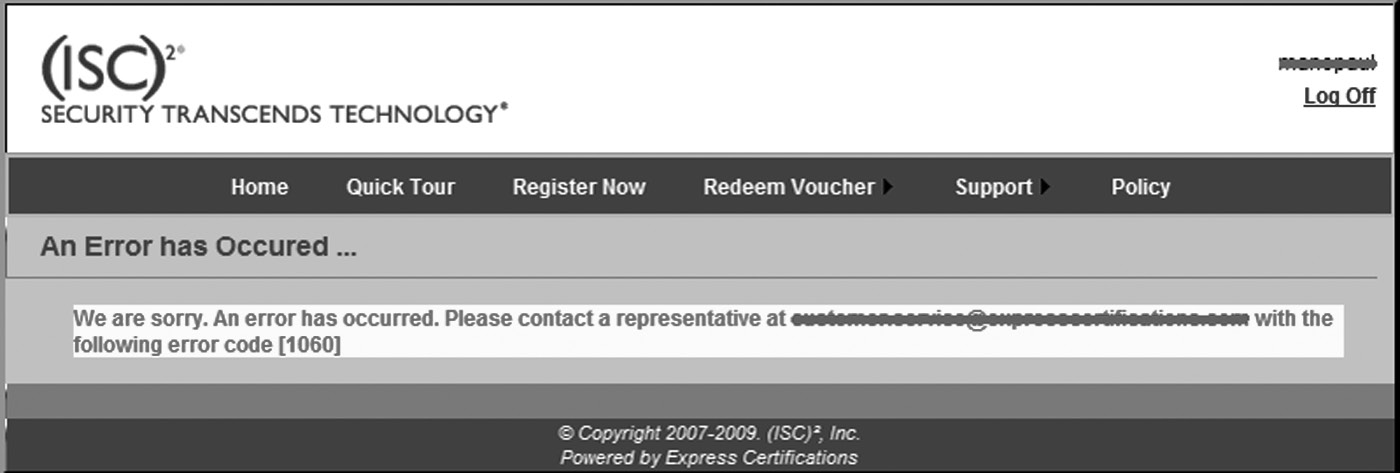
If the errors and exceptions are logged and only a reference identifier for that issue is displayed to the end user, as depicted in Figure 5.10, then tests to assure that the reference identifier mapping to the actual error or exception is protected need to be performed as well.
5.6.6 Cryptographic Validation Testing
Cryptographic validation includes the following attestation:
- Standards Conformance: Confirmation that cryptographic modules conform to prescribed standards, such as the Federal Information Processing Standards (FIPS) 140-2, and that cryptographic algorithms used are standard algorithms, such as AES, RSA, and DSA, is necessary. FIPS 140-2 testing is conducted against a defined cryptographic module and provides a suite of conformance tests to four security levels, from the lowest to the highest security. Knowledge of the details of each security level is beyond the scope of this book, but it is advisable that the CSSLP be familiar with the FIPS 140-2 requirements, specifications, and testing as published by NIST.
- Environment Validation: The computing environment in which cryptographic operations occur must be tested as well. The ISO/IEC 15408 common criteria (CC) evaluation can be used for this attestation. CC evaluation assurance levels do not directly map to the FIPS 140-2 security levels, and a FIPS 140-2 certificate is usually not acceptable in place of a CC certificate for environment validation.
- Data Validation: FIPS 140-2 testing considers data in unvalidated cryptographic systems and environments as data that are not protected at all, i.e., as unprotected cleartext. The protection of sensitive, private, and personal data using cryptographic protection should be validated for confidentiality assurance.
- Cryptographic Implementation: Seed values needed for cryptographic algorithms should be checked to be random and not easily guessable. The uniqueness, randomness, and strength of identifiers, such as session ID, can be determined using phase space analysis, and resource and time permitting, these tests need to be conducted. White box tests to make sure that cryptographic keys are not hard code inline code in clear text should be conducted. Additionally, key generation, exchange, storage, retrieval, archival, and disposal processes must be validated as well. The ability to decrypt cipher text data when keys are cycled must be checked as well.
5.6.7 Testing for Buffer Overflow Defenses
Since the consequences of buffer overflow vulnerabilities are extremely serious, testing to ensure defense against buffer overflow weaknesses must be conducted. Buffer overflow defense tests can be both black box and white box in nature. Black box testing for overflow defense can be performed using fuzzing techniques. White box testing includes verifying
- That the input is sanitized and its size validated.
- Bounds checking of memory allocation is performed.
- Conversion of data types from one are explicitly performed.
- Banned and unsafe APIs are not used.
- Code is compiled with compiler switches that protect the stack and/or randomize address space layout.
5.6.8 Testing for Privilege Escalations Defenses
Testing for elevated privileges or privilege escalation is to be conducted to verify that the user or process cannot gain access to more resources or functionality than they are allowed. Privilege escalation can be either vertical or horizontal or both. Vertical escalation is the condition wherein the subject (user or process) with lower rights gets access to resources that are to be restricted to subjects with higher rights. An example of vertical escalation is a nonadministrator gaining access to administrator or super user functionality. Horizontal escalation is the condition wherein a subject gets access to resources that are to be restricted to other subjects at their same privilege level. An example of horizontal escalation is an online banking user’s being able to view the bank accounts of other online banking users.
Insecure direct object reference design flaws and coding bugs with complete mediation can lead to privilege escalation, so parameter manipulation checks need to be conducted to verify that privileges cannot be escalated. In Web applications, both POST (form) and GET (querystring) parameters need to be checked.
5.6.9 Anti-Reversing Protection Testing
Testing for anti-reversing protection is particularly important for shrink wrap, commercial off-the-shelf (COTS) software, but even in business applications, tests to assure anti-reversing should be conducted. The following are some of the recommended tests.
- Testing to validate the presence of obfuscated code is important. Equally important is the testing of the processes to obfuscate and de-obfuscate code. The verification of the ability to de-obfuscate obfuscated code, especially if there is a change in the obfuscation software, is critically important.
- Binary analysis testing can be used to check if symbolic (e.g., class names, class member names, names of instantiated global objects) and textual information that will be useful to a reverse engineering is removed from the program executable.
- White box testing can be used to verify the presence of code that detects and prevents debuggers by terminating the executing program flow. User-level and kernel-level debugger APIs, such as the IsDebuggerPresent API and SystemKernelDebuggerInformation API, can be leveraged to protect against reversing debuggers, and testing should verify their presence and function. Tests should attempt to attach debuggers to executing programs to see how the program responds. Figure 5.11 depicts how the Skype program is not compatible with debuggers such as SoftICE.
5.7 Other Testing
5.7.1 Environment Testing
Another important aspect of software security assurance testing includes the testing of the security of the environment itself in which the software will operate. Environment testing needs to verify the integrity not just of the configuration of the environment, but also that of the data. Trust boundaries demarcate one environment from another, and end-to-end scenarios need to be tested. With the adoption of Web 2.0 technologies, the line between the client and server is thinning, and in cases where content is aggregated from various sources (environments), as in the case of mashups, testing must be thorough to assure that the end user is not subject to risk. Interoperability testing, simulation testing, and DR testing are important verification exercises that must be performed to attest to the security aspects of software.

5.7.1.1 Interoperability Testing
When software operates in disparate environments, it is imperative to verify the resiliency of the interfaces that exist between the environments. This is particularly important if credentials are shared for authentication purposes between these environments, as is the case with single sign-on. The following is a list of interoperability testing that can be performed to verify that
- Security standards (such as WS-Security for Web services implementation) are used.
- Complete mediation is effectively working to ensure that authentication cannot be bypassed.
- Tokens used for transfer of credentials cannot be stolen, spoofed, or replayed.
- Authorization checks postauthentication are working properly.
It is also necessary to check the software’s upstream and downstream dependency interfaces. For example, it is important to verify that there is secure access to the key by which a downstream application can decrypt data that were encrypted by an application upstream in the chain of dependent applications. Furthermore, tests to verify that the connections between dependent applications are secure need to be conducted.
5.7.1.2 Simulation Testing
The effectiveness of least privilege implementation and configuration mismatches can be uncovered using simulation testing. A common issue faced by software teams is that the software functions as desired in the development and test environments, but fails in the production environment. A familiar and dangerous response to this situation is that the software is configured to run with administrative or elevated privileges. The most probable root cause for such varied behavior is that the configuration settings in these environments differ. When production systems cannot be mirrored, assurance can still be achieved by simulation testing. By simulating the configuration settings between these environments, configuration mismatch issues can be determined. Additionally, the need to run the software in elevated privileges in the production environment can be determined and appropriate least privilege implementation measures can be taken.
It is crucially important to test data issues as well, but this can be a challenge. It may be necessary to test cascading relationships, but data to support that relationship may not be available in the test environment. Usually, production data are migrated to the testing environments, and this is a serious threat to confidentiality. It can also have compliance and legal ramifications. Production data must never be ported and processed in test environments. For example, payroll data of employees or credit card data of real customers should never be available in the test environments. It is advisable to use dummy data by creating them from scratch in the test or simulated environment. In cases where production data need to be migrated to maintain referential integrity between sets of data, then only nonconfidential information must be migrated, or the data must be obfuscated or masked. Testing must verify that data in test environments do not violate security and simulation testing for data issues must be controlled.
5.7.1.3 Disaster Recovery (DR) Testing
An important aspect of environment testing is the ability of the software to restore its operation after a disaster happens. DR testing verifies the recoverability of the software. It also uncovers data accuracy, integrity, and system availability issues. DR testing can be used to gauge the effectiveness of error handling and auditing in software as well. Important questions to answer using DR testing include: Does the software fail securely, and how does it report errors upon downtime? Is there proper logging of the failure in place? Failover testing is part of disaster testing, and the accuracy of the tests is dependent on how closely a real disaster can be simulated. Since this can be a costly proposition, proper planning, resource, and budget allocation is necessary, and testing by simulating disasters must be undertaken for availability assurance.
5.7.2 Privacy Testing
Software should be tested to assure privacy. For software that handles personal data, privacy testing must be part of the test plan. This should include the verification of organizational policy controls that impact privacy. It should also encompass the monitoring of network traffic and the communication between end points to assure that personal information is not disclosed. Tests for the appropriateness of notices and disclaimers when personal information is collected must also be conducted. This is critically important when collecting information from minors or children and privacy testing of protection data, such as the age of the child and parental controls, cannot be ignored in such situations. Both opt-in and opt-out mechanisms need to be verified. The privacy escalation response mechanisms upon a privacy breach must also be tested for accuracy of documentation and correctness of processes.
5.7.3 User Acceptance Testing
During the software acceptance phase before software release, the end user needs to be assured that the software meets their specified requirements. This can be accomplished using user acceptance testing (UAT), which is also known as end user testing or smoke testing. As the penultimate step before software is released, UAT is a gating mechanism used to determine whether the software is ready for release and can help with security because it gives the opportunity to prevent insecure software from being released into production or to the end user. Additionally, it brings the benefit of extending software testing to the end users, as they are the ones who perform the UAT before accepting it. The results of the UAT are used to provide the end user with confidence of the software’s reliability. It can also be used to identify design flaws and implementation bugs that are related to the usability of the software.
Prerequisites of UAT include the following:
- The software must have exited the development (implementation) phase.
- Other QA and security tests, such as unit testing, integration testing, regression testing, and software security testing, must be completed.
- Functional and security bugs need to be addressed.
- Real world usage scenarios of the software are identified, and test cases to cover these scenarios are completed.
UAT is generally performed as a black box test that focuses primarily on the functionality and usability of the application. It is most useful if the UAT test is performed in an environment that most closely simulates the real world or production environment. Sometimes UAT is performed in a real production environment postdeployment to get a more accurate picture of the software’s usability. However, when this is the case, the test should be conducted within an approved change window with the possibility of rolling back.
The final step in the successful completion of an UAT is a go/no-go decision, best implemented with a formal sign off. The decision is to be captured in writing and is the responsibility of the signature authority representing the end users.
5.8 Defect Reporting and Tracking
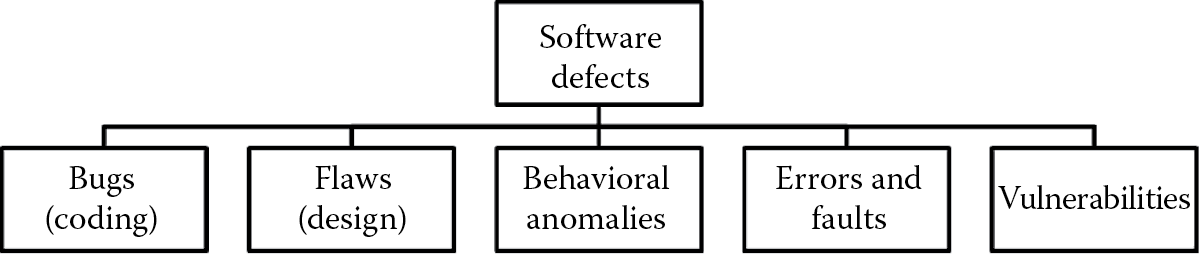
Coding bugs, design flaws, behavioral anomalies (logic flaws), errors, faults, and vulnerabilities all constitute software defects, as depicted in Figure 5.12, and once any defect is suspected and/or identified, it needs to be appropriately reported, tracked, and addressed before release. In this section, we will focus on how to report and track software defects. In the following section, we will learn about how these defects can be addressed based upon the potential impact they have and what corrective actions can be taken.
Software defects need first to be reported and then tracked. Reporting defects must be comprehensive and detailed enough to provide the software development teams the information that is necessary to determine the root cause of the issue so that they can address it.
5.8.1 Reporting Defects
The goal of reporting defects is to ensure that they get addressed. Information that must be included in a defect report is discussed in the following subsections.
- Defect Identifier (ID)
A unique number or identifier must be given to each defect report so that each defect can be tracked appropriately. Do not clump multiple issues into one defect. Each issue should warrant its own defect report. Most defect tracking tools have an automated means to assign a defect ID when a new defect is reported.
- Title
Provide a concise yet descriptive title for the defect. For example, “Image upload fails.”
- Description
Provide a summary of the defect to elaborate on the defect title you specified. For example, “When attempting to insert an image into a blog, the software does not allow the upload of the image and fails with an error message.”
- Detailed Steps
If the defect is not reproducible, then the defect will not get fixed, so detailed steps are necessary as to how the defect can be reproduced by the software development team. For example, it is not sufficient to say that the “Upload feature does not work.” Instead, it is important to list the steps taken by the tester, such as:
- Provided username and password and clicked on “Log in.”
- Upon successful authentication, clicked on “New blog.”
- Entered blog title as “A picture is worth a thousand words” in “Title” field.
- Entered description as “Please comment on the picture you see” in the “Description” field.
- Clicked on the “Upload image” icon.
- Clicked on the “Browse” button in the “Image Upload” popup screen.
- Browsed to the directory and selected the image to upload and clicked “Open” in the “Browse Directory” popup window.
- The “Browse Directory” windows closed and the “Image Upload” popup screen got focus.
- Clicked on the button “Upload” in the “Image Upload” popup screen.
- An error message was shown stating that the upload directory could not be created, and the upload failed.
- Expected Results
It is important to describe what the expected result of the operation is so that the development teams can understand the discrepancy from intended functionality. The best way to do this is to tie the defect ID with the requirement identifier in the requirements traceability matrix (RTM). This way any deviations from intended functionality as specified in the requirements can be reviewed and verified against.
- Screenshot
If possible and available, a screenshot of the error message should be attached. This proves very helpful to the software development team because:
- It provides the development team members a means to visualize the defect symptoms that the tester reports.
- It assures the development team members that they have successfully reproduced the same defect that the tester reported.
An example of a screenshot is depicted in Figure 5.13.
Note that, if the screenshot image contains sensitive information, it is advisable to not capture the screenshot. If, however, a screenshot is necessary, then appropriate security controls, such as masking of the sensitive information in the defect screenshot or role-based access control, should be implemented to protect against disclosure threats.
- Type
If possible, it is recommended to categorize the defect based on whether it is a functional issue or an assurance (security) one. You can also subcategorize the defect. Figure 5.14 is an example of categories and subcategories of software defects.
This way, pulling reports on the types of defects in the software is made easy. Furthermore, it makes it easy to find out the security defects that are to be addressed before release.
- Environment
Capturing the environment in which the defect was evident is important. Some important considerations to report on include:
- Was it in the test environment, or was it in the production environment?
- Was the issue evident only in one environment?
- Was the issue determined in the intranet, extranet, or Internet environment?
- What is the operating system and the service pack on which the issue was experienced? Are systems with other service packs experiencing the same issue?
- Was this a Web application issue, and if so, what was the Web address?
- Build Number
The version of the product in which the defect was determined is an important aspect in defect reporting. This makes it possible to compare versions to see if the defect is universal or specific to a particular version. From a security perspective, the build number can be used to determine the RASQ between versions, based on the number of security defects that are prevalent in each version release.
- Tester Name
The individual who detected the defect must be specified so that the development team members know whom they need to contact for clarification or further information.
- Reported On
The date and time (if possible) as to when the defect was reported needs to be specified. This is important in order to track the defect throughout its life cycle (covered later in this chapter) and determine the time it takes to resolve a defect, as a means to identify process improvement opportunities.
- Severity
This is to indicate the tester’s determination of the impact of the defect. This may or may not necessarily be the actual impact of the defect, but it provides the remediation team with additional information that is necessary to prioritize their efforts. This is often qualitative in nature, and some examples of severity types are:
- Critical: The impact of the defect will not allow the software to be functional as expected. All users will be affected.
- Major: Some of the expected business functionality has been affected, and operations cannot continue since there is no work-around available.
- Minor: Some of the expected business functionality has been affected, but operations can continue because a work-around is in place.
- Trivial: Business functionality is not affected, but can be enhanced with some changes that would be nice to have. UI enhancements usually fall into this category.
- Priority
The priority indicator is directly related to the extent of impact (severity) of the defect and is assigned based on the amount of time within which the defect needs to be addressed. It is a measure of urgency and supports the availability tenet of software assurance. Some common examples of priority include mission critical (0 to 4 hours), high (>4 to 24 hours), medium (>24 to 48 hours), and low (>48 hours).
- Status
Every defect that is reported automatically starts with the “new” status, and as it goes through its life cycle the status is changed from “new” to “confirmed”, “assigned”, “work-in-progress”, “resolved/fixed”, “fix verified”, “closed”, “reopened”, “deferred”, and so on.
- Assigned To
When a software defect is assigned to a development team member so that it can be fixed, the name of the individual who is working the issue must be specified.
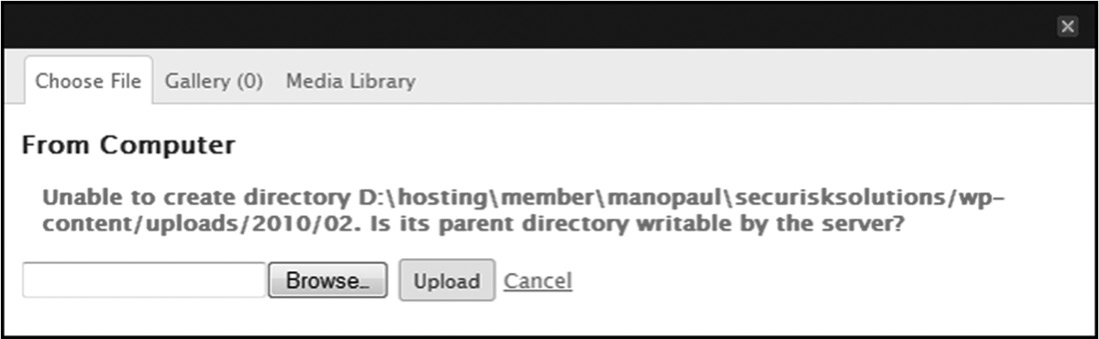
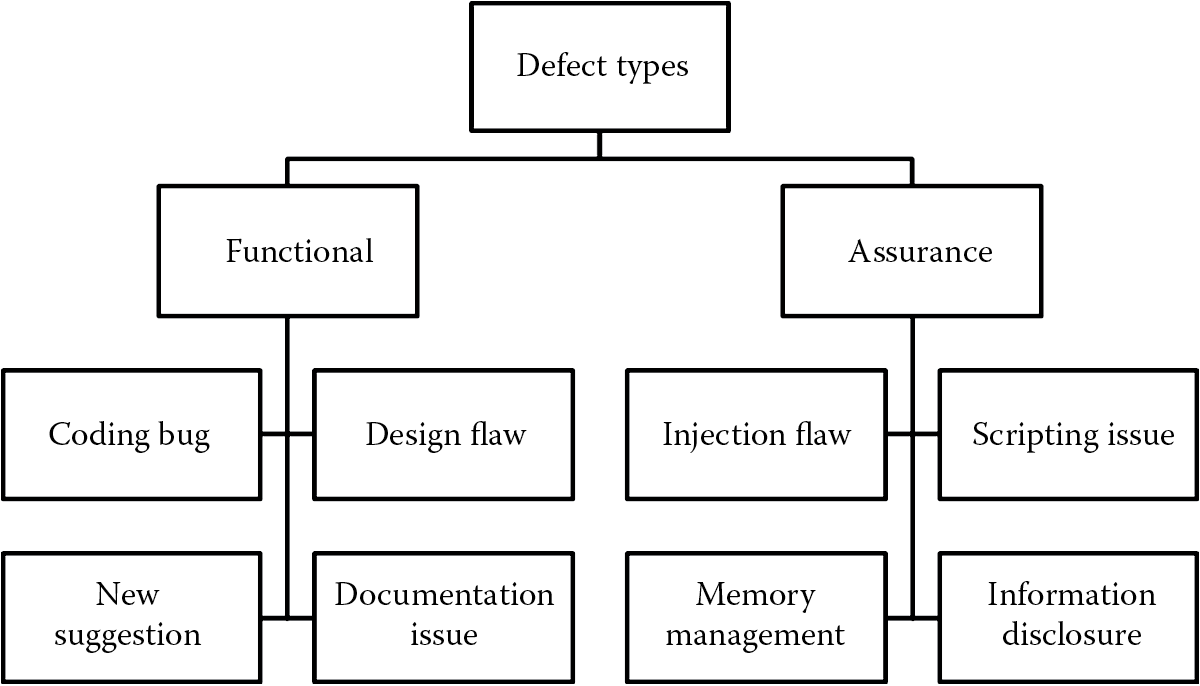
5.8.2 Tracking Defects
Upon the identification and verification of a defect, the defect needs to be tracked so that it can be addressed accordingly. It is advisable to track all defects related to the software in a centralized repository or defect tracking system. Centralization of defects makes it possible to have a comprehensive view of the software functionality and security risk. It also makes it possible to ensure that no two individuals are working on the same defect. A defect tracking system should have the ability to support the following requirements:
- Defect Documentation: All required fields from a defect report must be recorded. In situations where additional information needs to be recorded, the defect tracking system must allow for the definition of custom fields.
- Integration with Authentication Infrastructure: A defect tracking system that has the ability to fill the authenticated user information automatically by integrating with the authentication infrastructure is preferred to prevent user entry errors. It also makes it possible to track user activity as they work on a defect.
- Customizable Workflow: A software defect continues to be a defect until it has been fixed or addressed. Each defect goes through a life cycle, an example of which is depicted in Figure 5.15. As the software defect moves from one status to another, workflow information pertinent to that defect must be tracked and, if needed, customized.
- Notification: When a software defect state moves from one status to another, it is necessary to notify the appropriate personnel of the change so that processes in the SDLC are not delayed. Most defect tracking systems provide a notification interface that is configurable with whom and what to notify upon status change.
- Auditing Capability: For accountability reasons, all user actions within the software defect tracking system must be audited, and the software defect tracking system must allow for storing and reporting on the auditable information in a secure manner.
5.9 Impact Assessment and Corrective Action
Testing findings that are reported as defects need to be addressed. We can use the priority (urgency) and severity (impact) levels from the defect report to address software defects. High-impact, high-risk defects are to be addressed first. When agile or extreme programming methodologies are used, identified software defects need to be added to the backlog. Risk management principles (covered in Chapter 1) can be used to determine how the defect is going to be handled. Corrective actions have a direct bearing on the risk. These can include one or more of the following:
- Fixing the defect (mitigating the risk)
- Deferring the functionality (not the fix) to a latter version (transferring the risk)
- Replacing the software (avoiding the risk)
Knowledge of security defects in the software and ignoring the risk can have serious and detrimental effects when the software is breached. All security defects must be addressed and preferably mitigated.
Additionally, it is important to fix the defects in the development environment, attest the solution in the testing environment, verify functionality in the UAT environment, and only then release (promote) the fix to production environments, as illustrated in Figure 5.16.
5.10 Tools for Security Testing
It is not important for a CSSLP to have a thorough understanding of how each security tool can be used, but they must be familiar with what each tool can be used for and how it can impact the overall state of software security. Some of the common security tools include:
- Reconnaissance (information gathering) tools
- Vulnerability scanners
- Fingerprinting tools
- Sniffers/protocol analyzers
- Password crackers
- Web security tools (e.g., scanners, proxies, vulnerability management)
- Wireless security tools
- Reverse engineering tools (assembler and disassemblers, debuggers, and decompilers)
- Source code analyzers
- Vulnerability exploitation tools
- Security-oriented operating systems
- Privacy testing tools
It is recommended that you be familiar with some of the common tools that are described in Appendix E.
5.11 Summary
Security testing validates the resiliency, recoverability, and reliability of software, whereas functionality testing is primarily focused on the reliability and secondarily on the recoverability aspects of software. It is imperative to complement functionality testing with security testing of software. Security testing can be used to determine the means and opportunities by which software can be attacked. Both white box and black box security testing are used to determine the threats to software. Knowledge of how to test for common software vulnerabilities, such as failures in input validation, output encoding, improper error handling, least privilege implementation, and use of unsafe programming libraries and interfaces, is important. Various tools are used to conduct security testing. Both functional and security defects need to be reported, tracked through their life cycle, and addressed using risk management principles. Fixing defects must never be performed directly in the production environment, and proper change management principles must be used to promote fixes from development and test environments into the UAT and production environment.
5.12 Review Questions
- The ability of the software to restore itself to expected functionality when the security protection that is built in is breached is also known as
A. Redundancy
B. Recoverability
C. Resiliency
D. Reliability
- In which of the following software development methodologies does unit testing enable collective code ownership and is critical to assure software assurance?
A. Waterfall
B. Agile
C. Spiral
D. Prototyping
- The use of if-then rules is characteristic of which of the following types of software testing?
A. Logic
B. Scalability
C. Integration
D. Unit
- The implementation of secure features, such as complete mediation and data replication, needs to undergo which of the following types of test to ensure that the software meets the service level agreements (SLA)?
A. Stress
B. Unit
C. Integration
D. Regression
- Tests that are conducted to determine the breaking point of the software after which the software will no longer be functional is characteristic of which of the following types of software testing?
A. Regression
B. Stress
C. Integration
D. Simulation
- Which of the following tools or techniques can be used to facilitate the white box testing of software for insider threats?
A. Source code analyzers
B. Fuzzers
C. Banner-grabbing software
D. Scanners
- When very limited or no knowledge of the software is made known to the software tester before she can test for its resiliency, it is characteristic of which of the following types of security tests?
A. White box
B. Black box
C. Clear box
D. Glass box
- Penetration testing must be conducted with properly defined
A. Rules of engagement
B. Role-based access control mechanisms
C. Threat models
D. Use cases
- Testing for the randomness of session identifiers and the presence of auditing capabilities provides the software team insight into which of the following security controls?
A. Availability
B. Authentication
C. Nonrepudiation
D. Authorization
- Disassemblers, debuggers, and decompilers can be used by security testers primarily to determine which of the following types of coding vulnerabilities?
A. Injection flaws
B. Lack of reverse engineering protection
C. Cross-site scripting
D. Broken session management
- When reporting a software security defect in the software, which of the following also needs to be reported so that variance from intended behavior of the software can be determined?
A. Defect identifier
B. Title
C. Expected results
D. Tester name
- An attacker analyzes the response from the Web server that indicates that its version is the Microsoft Internet Information Server 6.0 (Microsoft-IIS/6.0), but none of the IIS exploits that the attacker attempts to execute on the Web server are successful. Which of the following is the most probable security control that is implemented?
A. Hashing
B. Cloaking
C. Masking
D. Watermarking
- Smart fuzzing is characterized by injecting
A. Truly random data without any consideration for the data structure
B. Variations of data structures that are known
C. Data that get interpreted as commands by a backend interpreter
D. Scripts that are reflected and executed on the client browser
- Which of the following is most important to ensure when the software is forced to fail as part of security testing? Choose the best answer.
A. Normal operational functionality is not restored automatically
B. Access to all functionality is denied
C. Confidentiality, integrity, and availability are not adversely impacted
D. End users are adequately trained and self-help is made available for the end user to fix the error on their own
- Timing and synchronization issues such as race conditions and resource deadlocks can be most likely identified by which of the following tests? Choose the best answer.
A. Integration
B. Stress
C. Unit
D. Regression
- The primary objective of resiliency testing of software is to determine
A. The point at which the software will break
B. If the software can restore itself to normal business operations
C. The presence and effectiveness of risk mitigation controls
D. How a blackhat would circumvent access control mechanisms
- The ability of the software to withstand attempts of attackers who intend to breach the security protection that is built in is also known as
A. Redundancy
B. Recoverability
C. Resiliency
D. Reliability
- Drivers and stub-based programming are useful to conduct which of the following tests?
A. Integration
B. Regression
C. Unit
D. Penetration
- Assurance that the software meets the expectations of the business as defined in the SLAs can be demonstrated by which of the following types of tests?
A. Unit
B. Integration
C. Performance
D. Regression
- Vulnerability scans are used to
A. Measure the resiliency of the software by attempting to exploit weaknesses
B. Detect the presence of loopholes and weaknesses in the software
C. Detect the effectiveness of security controls that are implemented in the software
D. Measure the skills and technical know-how of the security tester
References
Brown, J. 2009. Fuzzing for fun and profit. Krakow Labs Literature, 02 Nov.
Cannings, R., H. Dwivedi, and Z. Lackey. 2008. Hacking Exposed Web 2.0: Web 2.0 Security Secrets and Solutions. New York, NY: McGraw-Hill.
Cox, K., and C. Gerg. 2004. Anatomy of an attack: The five Ps. Managing Security with Snort and IDS Tools. Sebastopol, CA: O’Reilly.
Eilam, E., and E. J. Chikofsky. 2005. Reversing Secrets of Reverse Engineering. Indianapolis, IN: Wiley.
Gallagher, T., B. Jeffries, and L. Landauer. 2006. Hunting Security Bugs. Redmond, WA: Microsoft.
Herzog, P. 2010. Open Source Security Testing Methodology Manual. ISECOM. Apr. 23, 2010. http://www.isecom.org/osstmm (accessed March 6, 2011).
Howard, M., and D. LeBlanc. 2003. Writing Secure Code. Redmond, WA: Microsoft.
Kaminski, G. n.d. Software logic mutation testing. Lecture.
Kelley, D. 2009. Black box and white box testing: Which is best? SearchSecurity.com. Nov. 18, 2009. http://searchsecurity.techtarget.com/tip/0,289483,sid14_00,00.html (accessed March 6, 2011).
Microsoft. 2008. Patterns & Practices: Performance Testing Guidance for Web Applications. CodePlex. Aug. 28, 2008. http://perftestingguide.codeplex.com (accessed March 6, 2011).
Microsoft Developer Network. 2010. Unit testing. http://msdn.microsoft.com/en-us/library/aa292197(VS.71).aspx (accessed Apr. 30, 2010).
Neystadt, J. 2008. Automated penetration testing with white-box fuzzing. MSDN: Microsoft Development, MSDN Subscriptions, Resources, and More. Microsoft, Feb. 2008. http://msdn.microsoft.com/en-us/library/cc162782.aspx (accessed March 6, 2011).
OWASP. 208. OWASP Testing Guide V3. Sept. 15, 2008. Web. http://www.owasp.org/index.php/OWASP_Testing_Project (accessed March 6, 2011).
PCI Security Standards Council. Security scanning procedures. Sept. 2006. Web. https://www.pcisecuritystandards.org/pdfs/pci_scanning_procedures_v1-1.pdf (accessed March 6, 2011).
Petersen, B. 2010. Intrusion detection FAQ: What is P0f and what does it do? SANS.org. Apr. 30, 2010. http://www.sans.org/security-resources/idfaq/p0f.php (accessed March 6, 2011).
Piliptchouk, D. 2005. WS-security in the enterprise. ONJava.com. Sept. 2, 2005. http://onjava.com/pub/a/onjava/2005/02/09/wssecurity.html (accessed March 6, 2011).
Rogers, L. 2000. Library | Cybersleuthing: Means, motive, and opportunity. InfoSec Outlook June. http://www.sei.cmu.edu/library/abstracts/news-at-sei/securitysum00.cfm.
Scarfone, K., M. Souppaya, A. Cody, and A. Orebaugh. 2008. Technical Guide to Information Security Testing and Assessment. National Institute of Standards and Technology. Sept. 2008. http://csrc.nist.gov/publications/nistpubs/800-115/SP800-115.pdf (accessed Apr. 30, 2010).
Sundmark, T., and D. Theertagiri. 2008. Phase space analysis of session cookies. Thesis, Linköpings Universitetet, Sweden. http://www.ida.liu.se/~TDDD17/oldprojects/2008/projects/9.pdf (accessed March 6, 2011).
U.S. Department of Homeland Security. Security testing. Apr. 30, 2010. https://buildsecuri tyin.us-cert.gov/bsi/articles/best-practices/testing.html (accessed March 6, 2011).
Yarochki, F. V., O. Arkin, M. Kydyraliev, S. Dai, Y. Huang, and S. Kuo. Xprobe2++: Low volume remote network information gathering tool. Department of Electrical Engineering, National Taiwan University. http://xprobe.sourceforge.net/xprobe-ng.pdf (accessed Apr. 30, 2010).
Zalewski, M. 2005. Silence on the Wire: A Field Guide to Passive Reconnaissance and Indirect Attacks. San Francisco, CA: No Starch.