
Latches
Latches come in two flavors—exclusive and shared read (the shared read latches became relatively common in 9i but, as I learned very recently, there were a few in Oracle 8.0), and to make things a little more confusing, it is possible to acquire a shared read latch in exclusive mode—so from now on I’ll refer to them as shareable latches.
There are also two ways of categorizing latch activity: the willing to wait gets (most of them) and the immediate gets. And again we have an area of overlap because some latch activity starts as immediate and then repeats as willing to wait, but we’ll ignore this topic for the moment.
Essentially a latch is the combination of a memory location in the SGA and an atomic CPU operation that can be used to check and change the value of that location. (There are also between 100 and 200 bytes of infrastructure and instrumentation, varying quite dramatically with version of Oracle, which go with the latch.)
![]() Note The significance of the word “atomic” is that on a multiuser system, most operations can be interrupted by the operating system scheduler, and on a multi-CPU system, different CPUs can be modifying memory at the same time. Ideally, the entire “check and change” operation needs to be a single CPU instruction so that it cannot be split into two pieces and descheduled in mid-change, but the key feature is that latching can work safely only if a single CPU can guarantee that the entire operation cannot be interrupted and, if you’re running with multiple CPUs, that the same memory location cannot be modified by two CPUs at the same time. The latter requirement leads to special CPU instructions that do things like locking the memory bus to ensure that only one CPU at a time can access the critical location.
Note The significance of the word “atomic” is that on a multiuser system, most operations can be interrupted by the operating system scheduler, and on a multi-CPU system, different CPUs can be modifying memory at the same time. Ideally, the entire “check and change” operation needs to be a single CPU instruction so that it cannot be split into two pieces and descheduled in mid-change, but the key feature is that latching can work safely only if a single CPU can guarantee that the entire operation cannot be interrupted and, if you’re running with multiple CPUs, that the same memory location cannot be modified by two CPUs at the same time. The latter requirement leads to special CPU instructions that do things like locking the memory bus to ensure that only one CPU at a time can access the critical location.
Logic Behind Latches
The fundamental logic of using latches is simple: “If I can set the latch memory location to some value N, then I can do something with the structure that the latch is protecting.” (And when it has finished the protected operation, of course, it has to reverse the change to the latch). The basic exclusive latch get can be represented by the following pseudocode:
Set register X to point at latch address A
If value at address A is zero set it to 0xff ***
If the value at address A is set to 0xff then you "own" the latch
If not then go back to the top and try again—for a couple of thousand attempts
We’ll postpone for a few pages the problem of what to do if you’ve still failed after a couple of thousand attempts. The line marked *** is the one that has to be atomic—our session has to be able to say, “if the latch bit was zero and is now 0xff, I must have set it.” If this operation, which is commonly implemented as a “test and set” CPU instruction, could be interrupted, then you could end up with the following sequence of events:
- Session A prepares the code loop.
- Session B prepares the code loop.
- Session A tests and finds zero and then gets interrupted.
- Session B tests, finds zero, sets the value to
0xff, and then gets interrupted. - Session A resumes, sets the value (redundantly) to
0xff, and assumes it has acquired the latch. - Session B resumes, finds the value set to
0xff, and assumes it has acquired the latch.
Similarly, if we couldn’t implement some form of memory locking in a system with multiple CPUs, we could change the last four steps to read as follows:
- Session A running on CPU 1 tests and finds zero.
- Session B running on CPU 2 tests and finds zero.
- Session A sets the value to
0xffand assumes it has acquired the latch. - Session B sets the value to
0xffand assumes it has acquired the latch.
In either case, we now have two processes that could take some mutually destructive action, while happily assuming that they have sole access to some critical resource.
![]() Note If you want to know more about the way in which multiple CPUs can interact, and the effects and costs of such activity, then the best book on the topic for the Oracle practitioner is still James Morle’s Scaling Oracle8i, which is now available as a free download at
Note If you want to know more about the way in which multiple CPUs can interact, and the effects and costs of such activity, then the best book on the topic for the Oracle practitioner is still James Morle’s Scaling Oracle8i, which is now available as a free download at www.scaleabilities.co.uk/index.php/Books/. (Ignore the 8i in the title—fundamental principles rarely change much.)
The drawback to the exclusive latch, of course, is that it is exclusive. Only one session can hold the latch at a time, which means only one session can access the protected resource at any one moment. This doesn’t scale very well in a highly concurrent system if many sessions simply want to read the protected memory structure and don’t want to change it. So in 9i, Oracle Corp. expanded its use of shareable latches into some of the busiest areas of code—perhaps aided by the appearance of the more subtle compare and swap operation appearing in common CPU architectures. There are variations in the CPU implementation, of course, but the basic pseudocode is typically something like this:
Set flag F to zero
Set register X to point to latch address L
Set register Y to hold the current value stored at L
Set register Z to hold a new value you want to see at L
If "value in Y" = "value in L" then set L to "value in Z" and set flag F to 1 ***
If flag F is set to 1 you have modified the latch value
Again, the line marked *** is the one that has to be uninterruptible. The advantage of this “word-sized” latch is that we can set up an algorithm that allows multiple readers to “count themselves on and off the latch” but also allows writers to block new readers (and other writers) by setting one bit of the word as an “exclusive write” bit. A reader’s request might work as follows:
Loop (spin) a few thousand times
If write bit is set then go back to top of loop
Attempt to set latch value to value+1 (to acquire right to read)
If flag is set exit loop
Again, we’ll postpone for a few more pages the question of what to do after a couple of thousand failures. As a reader process finishes with the object it is reading, it goes through a similar cycle to decrease the latch value by one—except that it doesn’t need to check the write bit.
On the other hand, a writer (who must have exclusive access) might go through a set of steps like the following:
Loop (spin) a few thousand times
If write bit is set then go back to top of loop
Attempt to set latch value to "write bit + current value" (to acquire write bit)
If flag set then exit loop
Wait for reader value to drop to zero
As you can see, the effect of the two different strategies is to allow a writer to grab the “exclusive” bit while readers are using the resource, and then wait while the readers “count themselves off” the resource. At the same time, new readers are not allowed to count themselves onto the resource if a writer is holding the write bit, and only one writer at a time can hold the write bit. So we maximize shareability for readers while minimizing the delay involved with writers.
![]() Note The details of how latches behave under concurrent activity have changed significantly over time, but the common understanding is still stuck around the version 8.0 timeline. If you want to learn more about the inner working of latches, the best online resource is probably the blog “Latch, Mutex and Beyond” published by Andrey Nikolaev at
Note The details of how latches behave under concurrent activity have changed significantly over time, but the common understanding is still stuck around the version 8.0 timeline. If you want to learn more about the inner working of latches, the best online resource is probably the blog “Latch, Mutex and Beyond” published by Andrey Nikolaev at http://andreynikolaev.wordpress.com/, who I would like to make a particular point of thanking for reviewing this chapter, and especially my comments about latches and mutexes. (Any mistakes you might find, though, are mine—and some of them are deliberate simplifications.)
In fact, Oracle’s read/write conflict resolution is a little more subtle than my original description. It is probably best explained with some examples of values, shown in Table 4-1, which I generated through various calls to oradebug (see Appendix for details).

As Table 4-1 suggests, if a writer has to compete with readers for a shareable latch, it goes through two steps to modify the latch, first using one bit to mark it as “blocked,” and then, when all the readers have finally counted themselves off the latch, using a different bit to mark it as write-only and stamping it with its process id. The process actually starts by assuming that there are no competing readers, though, and its first action is to attempt to go straight to the holding value.
Latch Activity Statistics
Before talking about what happens if you attempt to get a latch and fail, I’ll describe a few of the latch activity statistics. When you query v$latch (the basic latch statistics view, although you could be more particular and query v$latch_parent or v$latch_children), the most interesting statistics are those shown in Table 4-2.


Latch Misses
My initial description of latch activity included the directive “loop a few thousand times.” It’s now time to consider what happens if you fail to acquire the latch even after running around this loop.
Historically the session would set an alarm to wake itself up after a short interval and take itself off the operating system run queue. When it was put back on the run queue by the operating system scheduler and got to the top of the queue, it would go into a loop again to try and acquire the latch, and put itself back to sleep if it failed again. The sleep time was designed to use an exponential backoff algorithm—meaning the more times the session went to sleep, the longer the sleep interval became—and this could, occasionally, lead to very long delays as a process tried to get a latch. Here’s one of the extreme examples I once saw on an Oracle8i system when a session spent over 8 seconds trying to acquire one of the library cache latches:
WAIT #4: nam='latch free' ela= 1 p1=-1351741396 p2=62 p3=0
WAIT #4: nam='latch free' ela= 1 p1=-1351741396 p2=62 p3=1
WAIT #4: nam='latch free' ela= 1 p1=-1351741396 p2=62 p3=2
WAIT #4: nam='latch free' ela= 3 p1=-1351741396 p2=62 p3=3
WAIT #4: nam='latch free' ela= 3 p1=-1351741396 p2=62 p3=4
WAIT #4: nam='latch free' ela= 7 p1=-1351741396 p2=62 p3=5
WAIT #4: nam='latch free' ela= 9 p1=-1351741396 p2=62 p3=6
WAIT #4: nam='latch free' ela= 18 p1=-1351741396 p2=62 p3=7
WAIT #4: nam='latch free' ela= 15 p1=-1351741396 p2=62 p3=8
WAIT #4: nam='latch free' ela= 55 p1=-1351741396 p2=62 p3=9
WAIT #4: nam='latch free' ela= 33 p1=-1351741396 p2=62 p3=10
WAIT #4: nam='latch free' ela= 69 p1=-1351741396 p2=62 p3=11
WAIT #4: nam='latch free' ela= 100 p1=-1351741396 p2=62 p3=12
WAIT #4: nam='latch free' ela= 150 p1=-1351741396 p2=62 p3=13
WAIT #4: nam='latch free' ela= 151 p1=-1351741396 p2=62 p3=14
WAIT #4: nam='latch free' ela= 205 p1=-1351741396 p2=62 p3=15
In principle the elapsed time (ela= nnnn, reported here in hundredths of a second) should double every other wait until it hits the maximum of 2 seconds,1 but the extreme CPU overload on the machine made the queue times very unstable in this case.
![]() Note It is interesting to consider that the 1/100-second wait time was originally introduced in Oracle 6 (or earlier) at a time when “fast” CPUs were running at a few megahertz. Now that CPUs run at speeds of a few gigahertz, a wait time of 1/100 second is (relatively speaking) hundreds of times longer than it used to be.
Note It is interesting to consider that the 1/100-second wait time was originally introduced in Oracle 6 (or earlier) at a time when “fast” CPUs were running at a few megahertz. Now that CPUs run at speeds of a few gigahertz, a wait time of 1/100 second is (relatively speaking) hundreds of times longer than it used to be.
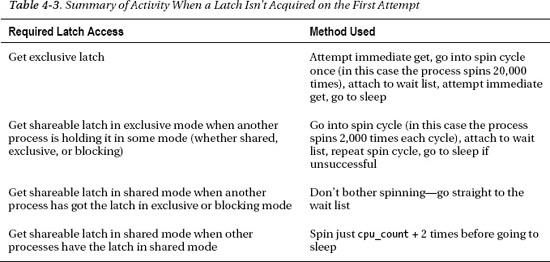
It’s important to note, though, that things no longer work like this: in outline, a process that doesn’t acquire its target latch almost immediately will attach itself to a latch wait list and go to sleep until woken. There are variations in the amount of effort a session will use before doing this, and Andrey Nikolaev, mentioned in an earlier note, has used DTrace on a Solaris system to track down the details, which are summarized in Table 4-3.
____________________
1 Steve Adams, Oracle8i Internal Services for Waits, Latches, Locks and Memory (Sebastopol, CA: O'Reilly Media, 1999).
The key point here is that when a process fails to acquire a latch, it attaches itself into a list, and then waits to be woken up. The wakeup mechanism is the thing that has changed most in the newer versions of Oracle—a process that is currently holding the desired latch will post the process at the top of the list when it releases the latch, and this can have some interesting side effects.
![]() Note The post/wait mechanism for latches was available in earlier versions of Oracle, but was not applied to many latches. The higher profile it enjoys in newer versions of Oracle depends on improvements in the available operating system features, and can (but shouldn’t) be controlled by the hidden parameter
Note The post/wait mechanism for latches was available in earlier versions of Oracle, but was not applied to many latches. The higher profile it enjoys in newer versions of Oracle depends on improvements in the available operating system features, and can (but shouldn’t) be controlled by the hidden parameter _enable_reliable_latch_waits.
If it’s not a very busy latch and no other processes are trying to acquire the latch, we can see that every process that is on the wait list is effectively in a queue, because when one process releases the latch it posts the next waiter.
Of course, if it’s not a very busy latch, it’s not very likely that a wait list will appear, but you have to ask what happens to a busy latch if a wait list appears and more processes are trying to acquire the latch. In this case it’s possible for a new process to acquire the latch even though other processes are still waiting to be posted—the queuing mechanism isn’t fair!
In the case of exclusive latches, the larger value for spin count may have been selected to minimize sleeping problems. You can assume that any code path a process follows while holding a latch should be as short as possible, so perhaps the 20,000 cycles around the loop is supposed to take longer than any code path protected by an exclusive latch. Nevertheless, we don’t appear to have any statistics available that tell us about the following type of scenario:
- Session 1 gets an exclusive latch.
- Session 2 tries to get the exclusive latch and goes to sleep.
- Session 1 releases the latch and posts session 2.
- Session 3 gets the latch before session 2 manages to get started.
- Session 2 wakes up, spins, and has to go to sleep again.
Perhaps there’s some cunning piece of code that we can’t see that stops this race condition from happening; perhaps it’s supposed to be such a rare event (or such a low-cost event) that it doesn’t really matter that it doesn’t get recorded directly.
We can infer the number of “recurrent sleeps” by noting that in principle a latch miss must eventually turn into a spin_get or a sleep, so misses = spin_gets + sleeps, or to put it another way, sleeps + spin_gets – misses = 0. But if the preceding scenario does happen, then we will record extra sleeps and the excess should be sleeps + spin_gets – misses.
There seem to be opportunities for a single latch get to take a long time, and I’d like to know what happens when that occurs; in the preceding scenario, does session 2 go back to the head of the queue or drop to the end of the queue? We can only hope that this mechanism is generally more efficient and fairer than the earlier mechanism where processes simply set alarms to wake themselves up so that they could fight over the latch acquisition.
![]() Note Throughout this chapter I have been talking about sessions getting latches; technically it is a process that gets, or misses, or waits for a latch—and a process that eventually holds a latch (as can be seen in the dynamic performance view
Note Throughout this chapter I have been talking about sessions getting latches; technically it is a process that gets, or misses, or waits for a latch—and a process that eventually holds a latch (as can be seen in the dynamic performance view v$latch_holder, which is underpinned by the structure x$ksuprlatch).
We can hope that the exclusive latch access is relatively low frequency and therefore less likely to cause major time loss, but there are threats built into the wait-list approach for sharable latches that really could matter.
If a sharable latch is held exclusively, then a request you make to get the latch shared drops your process to the end of the queue immediately, and a request you make to get the latch exclusively drops you to the end of the queue after a short spin. So a single call to get a shareable latch in exclusive mode can result in a long queue appearing. When the latch is released, one process from the queue can acquire the latch, and any concurrent processes not queued can now get the latch. If most of the processes are after shared latches, the queue should empty rapidly (every process releasing the latch allows one more process to dequeue). But as soon as another exclusive get occurs, the processes trying to get the latch in shared mode start extending the queue again, and you could easily end up with a long queue of shared waiters interspersed with a few scattered exclusive waiters. In cases like this, a relatively small number of exclusive waits could end up seeing some very long wait times.
There isn’t a lot you can do about long wait times for latches—it’s a side effect of how Oracle’s code handles the competition for critical memory. There are only three strategies for limiting the damage:
- As a designer/developer/coder, don’t do things that generate lots of latch activity; avoid, for example, splitting a job into a very large number of very small steps.
- As a DBA, look for (legal) opportunities to increase the number of latches covering a particular type of activity. A classic defensive measure here is to identify a hot spot in the data and find a way to spread that data across more blocks. It’s also a good idea to keep an eye open for the latest patches.
- As a designer/developer for Oracle Corp., create mechanisms that reduce our reliance on latch activity. (And this is what they’ve been doing with pins and mutexes.)
Figure 4-3 shows a (still very simplified) picture of the library cache; it simply expands Figure 4-1 to indicate the significance of one type of latch, the library cache latch.
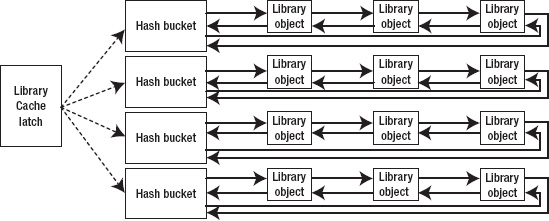
Figure 4-3. Second approximation to a small library cache, including the library cache latch
This picture, with minor variations, could be reused as a diagram of the library cache, the shared pool free lists, the data buffer cache, the dictionary (row) cache, locking, and many other patterns of memory management in Oracle.
We have created complex collections of memory structures and have set up known starting points for the structures so that we can either walk along linked lists or do arithmetic to find out where to jump to. We can find anything we need to find by doing arithmetic or following pointers—the latch mechanism ensures that it is safe to use those locations.
![]() Note Oracle made dramatic changes in 11g to the way it handles the library cache. The descriptions in this chapter are mainly about versions of Oracle up to 10g. Comments on the 11g implementation will appear in Chapter 7: Parsing and Optimising
Note Oracle made dramatic changes in 11g to the way it handles the library cache. The descriptions in this chapter are mainly about versions of Oracle up to 10g. Comments on the 11g implementation will appear in Chapter 7: Parsing and Optimising
Latch Scalability
I mentioned earlier in this chapter that I happened to have 131,072 hash buckets in my library cache. If I want to execute an SQL statement from the SQL*Plus command line, one of the steps taken by the server process managing my session will be to search for that statement in the library cache. This means doing some arithmetic to create a hash value from the text of the statement to produce the bucket number, and then walking along the linked list (hash chain). Critically, there is another piece of arithmetic that allows Oracle to work out which latch is protecting each hash bucket, so the code will acquire that latch, walk the linked list, do whatever it needs to do with the object if it finds it, and then drop the latch.
There are three important aspects, then, of latch contention:
- How many different latches are covering the library cache—one for each bucket, one for the whole library cache, or something in between? The more latches there are, the less likely you are to collide with someone who needs to walk a linked list covered by the latch you want; on the other hand, the more latches you have, the more work you may have to do in some form of maintenance, reporting, or garbage collection.
- How often will you need to go through the process of acquiring a given latch—once or twice when you first optimize a statement, every time you execute a statement, or something in between? The more times you have to get the latch and walk the list, the more likely you are to collide with someone who wants the same latch.
- How long do you have to hold the latch? The longer everyone holds latches, the more likely they are to have problems with other people holding latches that they want to acquire. It should be fairly obvious that you’re not going to hold a latch continuously while you execute a statement, but when is it safe to let go?
Until 10g the number of latches covering the library cache was remarkably small. On my little system I have three latches covering 131,072 buckets. The number is dependent on the number of CPUs (it’s roughly the same as the cpu_count parameter) up to a maximum of 67 latches. That’s a surprisingly small number, really, given the potential for collisions occurring on even a small number of frequently executed statements; and two processes don’t have to be executing the same SQL, or even accessing the same hash bucket, to be colliding on the same latch—they need only be accessing two hash buckets covered by the same latch.
Given the small number of latches involved, you won’t be surprised to learn that there are mechanisms in place to minimize the number of times we have to search the library cache for an object. We can attach a KGL lock to an object once we’ve found it so that we have a shortcut to it, and we can attach a KGL pin to it to show that we are actively using it. (Both these structures are the subject of changes due to the introduction of mutexes, which started to appear in 10g and have nearly taken over the library cache in 11g. I’ll say more about KGL locks, KGL pins, and mutexes in Chapter 7.)
As far as the amount of time you hold a latch is concerned, Oracle Corp. seems to make endless changes to the code as we go through different versions, point releases, and patches to minimize the time that any one latch is held. Sometimes this meant breaking tasks into smaller pieces and introducing new types of latch to protect (each of) the shorter operations. There are (or were) several different latch types associated with the library cache. To demonstrate how things keep changing, Table 4-4 provides a list of the latches that exist in a few different versions of Oracle.
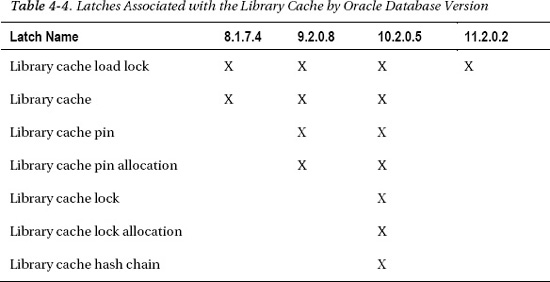
I’m not going to go into the details of what all these latches are for, and the structures they protect—especially since most of them have disappeared in 11g—but we will see similar mechanisms when we look at the buffer cache in Chapter 5.
MUTEXES, PART 1