
The Dictionary Cache
The dictionary cache—also called the row cache because, effectively, it is used to cache individual rows of data from the data dictionary rather than data blocks—is the place where Oracle stores details of object definitions. We can view a summary of the content of this cache with a query against view v$rowcache. The results below come from an instance running 10g.
If you run the sample query against v$rowcache in 11g, you will see a couple of anomalies. One of the caches (cache# 11: dc_object_ids) has disappeared from v$rowcache, although it is still visible in v$rowcache_parent as cache# 11 but renamed to dc_objects; and cache# 7 has lost its parent entry, which seems to have migrated into cache# 10. Whether these are accidents or deliberate I don’t know, but there are clear indications that at least some of the code to expose the dictionary cache structures has gone wrong in 11g (x$kqrpd, as a particular case, is a total mess—not that you’re supposed to look at it anyway).
If you run the query against Oracle 9i you may find each item appearing multiple times—in the 9.2.0.8 instance I’m looking at currently there are eight rows for each combination of parameter, type, and subordinate#. This is affected by the (9.2.0.8 only) parameter _more_rowcache_latches, which defaults to true.
select
cache#, parameter, type, subordinate#, count, usage, fixed, gets, getmisses
from
v$rowcache
order by
cache#, type, subordinate#
;
CACHE# PARAMETER TYPE SUB COUNT USAGE FIXED GETS GETMISSES
------ ---------------------- ------------ ---- ------ ------ ------ ------- ---------
0 dc_tablespaces PARENT 8 8 0 62439 28
...
7 dc_users PARENT 10 10 0 157958 52
7 dc_users SUBORDINATE 0 0 0 0 0 0
7 dc_users SUBORDINATE 1 5 5 0 2600 31
7 dc_users SUBORDINATE 2 0 0 0 0 0
8 dc_objects PARENT 917 917 55 37716 3200
8 dc_object_grants SUBORDINATE 0 30 30 0 2079 196
9 dc_qmc_cache_entries PARENT 0 0 0 0 0
10 dc_usernames PARENT 11 11 0 4075 42
11 dc_object_ids PARENT 1225 1225 55 171218 2886
12 dc_constraints PARENT 1 1 0 362 131
...
This reports a list of lists. For example, we have a cache named dc_objects, which currently holds 917 items, all of which are currently valid; we have searched the list to find an item 37,716 times (gets) and failed to find that item 3,200 times (getmisses—that would require us to run the relevant recursive SQL statement to copy something from the data dictionary to the dictionary cache). The dc_objects cache also holds 55 fixed objects.
![]() Note As we have seen Oracle may have to run some recursive SQL to find the information that tells it how to run your SQL. But how does it get started—surely it can’t run any SQL until after it has run some SQL. The answer, as so often, is that Oracle cheats. There is some “bootstrap” code that knows the physical location of the first few objects in the database, and contains enough information to allow the optimizer to query them for further information. It is these bootstrap objects that appear as the fixed objects in
Note As we have seen Oracle may have to run some recursive SQL to find the information that tells it how to run your SQL. But how does it get started—surely it can’t run any SQL until after it has run some SQL. The answer, as so often, is that Oracle cheats. There is some “bootstrap” code that knows the physical location of the first few objects in the database, and contains enough information to allow the optimizer to query them for further information. It is these bootstrap objects that appear as the fixed objects in v$rowcache.
If you want to know what the bootstrap objects are, read $ORACLE_HOME/rdbms/admin/sql.bsq up to the line holding “//”. You can also see the SQL to recreate the bootstrap objects in the table sys.bootstrap$. At database creation time Oracle writes this information into the database and records the physical location of the start of sys.bootstrap$ in the header block of the first file in the system and uses this back door into the database to read the table and learn about the base data dictionary at startup time. You can see this address if you dump the file header at level 3 (oradebug dump file_hdrs 3), and search for the entry root dba.
You’ll notice that the rows reported fall into two groups—Parent and Subordinate. This relates to the way that Oracle will collate information in the cache—take cache# 8 as an example: it has a parent of dc_objects and a subordinate of dc_object_grants; this suggests that Oracle may be taking the (intuitively sensible) step of storing information about grants on TableX (say) together with the information about TableX itself.
As its name implies, this particular cache# holds the list of all objects currently known to the instance; roughly speaking it is a copy of all the rows from dba_objects (or, more specifically, the table obj$) that have been read by Oracle in its attempt to interpret SQL or PL/SQL statements. In fact, the list is somewhat longer than that because it will also record non-existent objects—a comment I can best explain by running the following SQL from my personal schema:
select count(*) from all_objects;
After I’ve run the query, there will be at least three items in the dc_objects cache named all_objects. One of them will be the definition of a view owned by sys, another will be a synonym owned by public, and the third will be a non-existent owned by my schema. This last item is an entry in the dictionary cache that doesn’t exist in the data dictionary but allows Oracle to note that when I run a statement referencing (unqualified) all_objects it’s not a statement about an object in my schema. In the absence of this entry in the dictionary cache Oracle would have to keep checking the data dictionary by running a query against obj$ whenever I ran a query against (unqualified) all_objects. The presence of such objects of type non-existent in the cache is just a small argument in favor of making sure that your code uses fully qualified object names—but there are arguments against, and there are more important things you should do before you worry too much about this detail.
You can see a similar strategy in the data dictionary itself in the view dba_dependencies (and its subordinates) when you create objects that are dependent on public synonyms; for example, the following:
SQL> create or replace view my_objects as select * from user_objects;
View created
SQL> select
2 referenced_owner, referenced_name, referenced_type
3 from
4 user_dependencies
5 where
6 name = 'MY_OBJECTS'
7 ;
REFERENCED_OWNER REFERENCED_NAME REFERENCED_TYPE
------------------ ----------------- -----------------
PUBLIC USER_OBJECTS SYNONYM
TEST_USER USER_OBJECTS NON-EXISTENT
The correct interpretation of the view my_objects depends on the fact that my schema doesn’t currently hold a real object called user_objects, so Oracle creates a real entry in the data dictionary to express this fact. If I now create a real object called user_objects, Oracle would delete the dependency on the non-existent one, hence recognizing that it has to invalidate the definition of the view my_objects.
So if Oracle is keeping a list of objects (and various other lists) in memory this raises two questions—how does Oracle maintain the list, and how does it search the list efficiently. The answers for the dictionary cache are the same as the answers we’ve already seen in Chapter 4 for the buffer cache, the library cache and enqueues. We have a collection of hash chain latches, hash chains and linked lists.
We can infer the presence of the hash buckets by switching our attention from the summary view (v$rowcache) to the two detail views of the row cache—v$rowcache_parent and v$rowcache_subordinate, both of which have a hash column showing values between zero and 65,535. To see the hash chain latches we need only query v$latch_children (in this case on an instance running 11.2.0.2), as follows:
SQL> select
2 name, count(*)
3 from
4 V$latch_children
5 where
6 name like '%row%cache%'
7 group by
8 name
9 ;
NAME COUNT(*)
------------------------------ ----------
row cache objects 51
Having seen that we have multiple latches related to the dictionary cache we can go one step further. There are 51 latches, but a count(*) from v$rowcache (again on 11.2.0.2) reports 61 rows. If we check x$qrst (the X$ structure underlying v$rowcache), we find that it contains an interesting column, as follows:
SQL> desc x$kqrst
Name Null? Type
----------------------------------------- -------- ----------------------------
...
KQRSTCLN NUMBER
...
This turns out to the Child Latch Number (CLN) for that part of the row cache, so we can write a simple query to associate each part of the row cache with its latch, and then do things like compare dictionary cache gets with latch gets, for example:
select
dc.kqrstcid cache#,
dc.kqrsttxt parameter,
decode(dc.kqrsttyp,1,'PARENT','SUBORDINATE') type,
decode(dc.kqrsttyp,2,kqrstsno,null) subordinate#,
dc.kqrstgrq gets,
dc.kqrstgmi misses,
dc.kqrstmrq modifications,
dc.kqrstmfl flushes,
dc.kqrstcln child_no,
la.gets,
la.misses,
la.immediate_gets
from
x$kqrst dc,
v$latch_children la
where
dc.inst_id = userenv('instance')
and la.child# = dc.kqrstcln
and la.name = 'row cache objects'
order by
1,2,3,4
;
To my surprise (and I can’t explain this to my satisfaction, yet) there was a common pattern indicating three latch gets for each dictionary cache get. I was expecting two, rather than three, and still have to spend some time thinking about why the third one appears.
The Structure
Having established that the dictionary cache is very similar in structure to the library cache and buffer cache, it’s worth drawing a picture of one row from v$rowcache and the associated items from v$rowcache_parent and v$rowcache_subordinate, as shown in Figure 7-1.
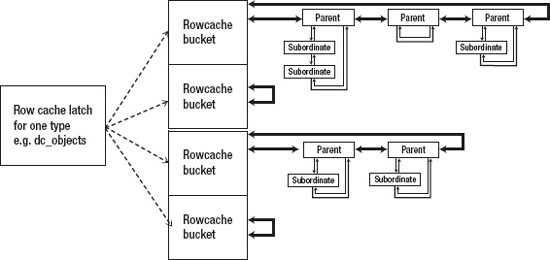
Figure 7-1. A subset of the dictionary cache
There are several assumptions built into this picture.
- I’ve assumed that each latch covers one parent type and all its subordinate types, and linked them together. On the other hand the structures
x$kqrpdandx$kqrsdmay be the rowcache hash buckets for the parent and subordinate types respectively and the existence of these structures suggest that parents and subordinates have been kept apart even though each set of parent and subordinate caches is covered by a single latch. - I’ve assumed (though it’s not obvious from the figure) that every latch covers 65,536 buckets so that any bucket is likely to hold only a small number of items. It’s possible there’s another layer between the hash value and the hash bucket that reduces the number of buckets per latch. We know, for example, that there are things called row cache enqueues (and/or locks)—so there may be an intermediate level before the individual hash buckets at which the latches operate.
- I’ve assumed that there are doubly linked lists between parent items in a bucket, and between a parent item and the subordinate items for that parent. Although
x$kqrpdandx$kqrsdlook as if they might represent the hash buckets, they expose nothing but counts and sizes—however their record lengths (as derived from theaddrcolumn of each object) are too long for the exposed information and, by usingoradebug peek(see appendix) to dump the full record length, we can see lots of things that look like pointers in the hidden areas of the record.
Although I’ve suggested that each dictionary cache hash bucket is likely to hold only a very small number of items, it’s worth pausing briefly to consider histograms. When we collect column statistics we have the option for collecting a histogram of up to 254 buckets (each of which could hold a 32 byte endpoint_actual_value among other things). Histogram data (dc_histogram_data) is subordinate to histogram definitions (dc_histogram_defs) though, so we might worry that a single dictionary cache hash bucket holding the data about a histogram might need to hold 254 items—in fact I think Oracle constructs a single (possibly large) item from the histogram data before transferring it to the dictionary cache—nevertheless histograms in the dictionary cache could use quite a lot of memory.
If you want to see the impact the dictionary cache has on memory you can run the following query against v$sgastat:
SQL> select * from V$sgastat where name like '%KQR%' order by name;
POOL NAME BYTES
------------ -------------------------- ----------
shared pool KQR ENQ 82080
shared pool KQR L SO 65540
shared pool KQR M PO 1874488
shared pool KQR M SO 455312
shared pool KQR S PO 147288
shared pool KQR S SO 19456
shared pool KQR X PO 8016
I think we can probably decode the name as follows:
- KQR relates to the rowcache
- ENQ is presumably for row cache enqueues
- X / L / M / S for extra large / large / medium / small
- PO / SO for parent object / subordinate object
If you’ve ever seen your session crash with the error message >>> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<< you’ll appreciate that KQR ENQ is probably about rowcache enqueues; but apart from a couple of wait events (e.g. row cache lock) there is very little visibility to row cache enqueues. In fact, the sample output above came from an instance of 10.2.0.3 but when I ran the same query against an instance of 11.2.0.2 there was no entry for KQR ENQ—this may mean that Oracle has changed the code handling the dictionary cache, it may simply mean that the memory used for row cache enqueues has acquired a new label.
If we want more information about the memory allocation we could query x$kqrpd and x$kqrsd—the former will produce results like the following (curtailed) list:
SQL> select * from x$kqrpd where kqrpdnmk != 0;
ADDR INDX INST_ID KQRPDCID KQRPDOSZ KQRPDNMK KQRPDTSZ
-------- ---------- ---------- ---------- ---------- ---------- ----------
1FE45394 0 1 0 260 7 3584
1FE45474 2 1 2 208 406 103936
1FE454E4 3 1 3 216 68 17408
1FE456A4 7 1 7 284 9 4608
1FE45714 8 1 8 432 510 261120
1FE457F4 10 1 10 176 4 1024
...
Checking this against v$rowcache, we can see that x$kqrpd.kqrpdnmk corresponds to the v$rowcache.count; a quick check confirms that kqrpdtsz is kqrpdnmk times “kqrpdosz rounded up to one of 256 (S), 512 (M) or 1,024(L)” (with the exception of the largest (X) values for kqrpdosz that may simply be increased by 8 (or 16 in 64-bit Oracle)). Summing kqrpdtsz according to these rounding rules results in numbers that are close (but not perfect) matches for the stats from v$sgastat—and we’ll explain the difference when we address memory allocation from the shared pool later on in the chapter. Notice, however, that this rounding means Oracle is prepared to waste memory in order to reduce the risk of memory fragmentation in the shared pool as dictionary cache entries are allocated and de-allocated. Strangely, if you do a heapdump (level 2 will be sufficient—but don’t do it on a production system) of the SGA heap (shared pool) you will find the memory allocations in the heap are usually 28 bytes larger than the values listed earlier, viz: 284, 540, and 1,052.
Dictionary Cache Activity
Having seen the structure of the dictionary cache and its similarity to some aspects of the buffer cache, library cache and enqueue structures you won’t be surprised to hear that the way in which Oracle uses the dictionary cache is fairly similar.
To find an item in the dictionary cache we have to protect the hash chains from being modified while we search them (and vice versa, to modify a chain we have to stop other sessions from reading it). Since the dictionary cache is broken into discrete sections based on the type of object, Oracle can easily work out the correct latch for that object type; but from this point onwards I have to start waving my hands about the strategies involved.
I can see that a dictionary cache get involves three latch gets—but I can’t work out a strategy that makes this necessary and sufficient. It’s possible, for example, that there is one more structure between the latch and the final hash bucket (after all, 65,536 buckets per latch does seem like a lot), forcing us to do two latch gets to pin and unpin that structure in shared mode and one more latch get while we read the hash bucket itself.
Whatever the specific order of events on reading (or modifying) the dictionary cache, the bottom line on the activity is that it’s based on the same pattern of hash buckets and hash chains as so much of Oracle is—and chains have to be protected from read/write collisions.
We can see the effect this has with a simple example (see core_dc_activity_01.sql in the code library at www.apress.com) that involves running a large number of very similar statements through a simple PL/SQL loop and watching the dictionary cache activity, along with the related latch activity. The core of the test looks like the following:
execute snap_rowcache.start_snap
execute snap_latch_child.start_snap('row cache objects')
declare
m_n number;
m_v varchar2(10);
begin
for i in 1..1000 loop
execute immediate
'select n1 from t1 where id = ' || i
into m_n;
end loop;
end;
/
execute snap_latch_child.end_snap('row cache objects')
execute snap_rowcache.end_snap
The two snap_xxx procedures take snapshots of v$latch_children and v$rowcache and report the change caused by the PL/SQL. The PL/SQL constructs 1,000 slightly different queries by concatenating a value to the end of a template, and the resulting query accesses one row in the table by primary key index. The following results come from 10.2.0.3 (the script in the code library includes the results from 11.2.0.2, which show some interesting differences):
----------------
Dictionary Cache
----------------
Parameter Usage Fixed Gets Misses
--------- ----- ----- ---- ------
dc_segments 0 0 2,000 0
dc_tablespaces 0 0 2 0
dc_users 0 0 1,014 0
dc_objects 0 0 1,000 0
dc_global_oids 0 0 12 0
dc_object_ids 0 0 3,012 0
dc_histogram_defs 0 0 2,000 0
-----------------------------
row cache objects latch waits
-----------------------------
Address Gets Misses
------- ---- ------
1FE4846C 6,000 0
1FEC84D4 3 0
1FEC910C 3,021 0
1FF495DC 3,000 0
1FFC9644 18 0
1FFCAF14 9,018 0
1F8B4E48 6,000 0
Latches reported: 7
As you can see, allowing for tiny variations, the pattern of activity reflects the link between each part of the dictionary cache and the associated latch and each get on the dictionary cache results in three gets on the corresponding latch.
We have accessed dc_segments twice per query because we accessed the table and its index. We have accessed dc_users once per query—possibly for reasons of authentication. We have accessed dc_objects and dc_object_ids a total of 4,000 times—with a 1,000 / 3,000 split rather than the 2,000 / 2,000 you might expect for the table and its index; there is an anomaly with this that disappears in 11g when the dc_object_ids cache merges into the dc_objects cache. Finally we have accessed dc_histogram_defs 2,000 times—once for each query for each column referenced in the query; if we had selected two columns and used two columns in the predicate there would have been 4,000 gets from the dictionary cache. (If you needed an argument why you should select only the columns you need in a query, rather than using select *, the extra cost of accessing dc_histogram_defs should be enough to convince you.)
You can appreciate that a busy system generating a lot of lightweight SQL statements will cause a lot of latch activity on the row cache objects latches—particular the ones related to the column definitions—and could easily run into latch contention issues. This is (in part) why you will see so much fuss made about using bind variables for OLTP systems rather than constructing SQL by building values into literal strings.
Modify the test (see core_dc_activity_02.sql) to use a slightly different approach and the results change dramatically, as shown by the following—which lists the fragment of code that had to change and the resulting dictionary cache stats:
execute immediate
'select n1 from t1 where id = :n'
into m_n using i;
---------------------------------
Dictionary Cache
---------------------------------
Parameter Usage Fixed Gets Misses
--------- ----- ----- ---- ------
dc_segments 0 0 2 0
dc_tablespaces 0 0 2 0
dc_users 0 0 15 0
dc_objects 0 0 1 0
dc_global_oids 0 0 12 0
dc_object_ids 0 0 15 0
dc_histogram_defs 0 0 2 0
The number of gets (and the associated latch activity) has virtually disappeared; so much so that the “random noise” effects from background database activity could actually appear as a noticeable distraction on the complete result set. We have changed the text of the SQL statement so that it remains constant; but we have included a placeholder (:n)—which we typically refer to as a bind variable—in the text and added a using clause to the code so that each call to execute the text can pass in a different value with the text.
CURSOR_SHARING
To understand why bind variables have such an impact on the dictionary cache activity we need to know more about the difference between parsing and parse calls, and how the library cache works.