
Earlier parts of this book have explored in detail all of the components of the PL/SQL language: cursors, exceptions, loops, variables, and so on. While you certainly need to know about these components when you write applications using PL/SQL, putting the pieces together to create well-structured, easily understood, and smoothly maintainable programs is even more important.
Few of our tasks are straightforward. Few solutions can be glimpsed in an instant and immediately put to paper or keyboard. The systems we build are usually large and complex, with many interacting and sometimes conflicting components. Furthermore, as users deserve, demand, and receive applications that are easier to use and vastly more powerful than their predecessors, the inner world of those applications becomes correspondingly more complicated.
One of the biggest challenges in our profession today is finding ways to reduce the complexity of our environment. When faced with a massive problem to solve, the mind is likely to recoil in horror. Where do I start? How can I possibly find a way through that jungle of requirements and features?
A human being is not a massively parallel computer. Even the brightest of our bunch have trouble keeping track of more than seven tasks (plus or minus two) at one time. We need to break down huge, intimidating projects into smaller, more manageable components, and then further decompose those components into individual programs with an understandable scope. We can then figure out how to build and test those programs, after which we can construct a complete application from these building blocks.
Whether you use “top-down design” (a.k.a. step-wise refinement, which is explored in detail in the “Local Modules” section of this chapter) or some other methodology, there is absolutely no doubt that you will find your way to a high-quality and easily maintainable application by modularizing your code into procedures, functions, and object types.
Modularization is the process by which you break up large blocks of code into smaller pieces (modules) that can be called by other modules. Modularization of code is analogous to normalization of data, with many of the same benefits and a few additional advantages. With modularization , your code becomes:
- More reusable
By breaking up a large program or entire application into individual components that “plug-and-play” together, you will usually find that many modules are used by more than one other program in your current application. Designed properly, these utility programs could even be of use in other applications!
- More manageable
Which would you rather debug: a 10,000-line program or five individual 2,000-line programs that call each other as needed? Our minds work better when we can focus on smaller tasks. You can also test and debug on a smaller scale (called unit testing ) before individual modules are combined for a more complicated system test.
- More readable
Modules have names, and names describe behavior. The more you move or hide your code behind a programmatic interface, the easier it is to read and understand what that program is doing. Modularization helps you focus on the big picture rather than on the individual executable statements.
- More reliable
The code you produce will have fewer errors. The errors you do find will be easier to fix because they will be isolated within a module. In addition, your code will be easier to maintain because there is less of it and it is more readable.
Once you become proficient with the different iterative, conditional, and cursor constructs of the PL/SQL language (the IF statement, loops, etc.), you are ready to write programs. You will not really be ready to build an application, however, until you understand how to create and combine PL/SQL modules.
PL/SQL offers the following structures that modularize your code in different ways:
- Procedure
A program that performs one or more actions and is called as an executable PL/SQL statement. You can pass information into and out of a procedure through its parameter list.
- Function
A program that returns a single value and is used just like a PL/ SQL expression. You can pass information into a function through its parameter list.
- Database trigger
A set of commands that are triggered to execute (e.g., log in, modify a row in a table, execute a DDL statement) when an event occurs in the database.
- Package
A named collection of procedures , functions, types, and variables. A package is not really a module (it’s more of a meta-module), but it is so closely related that I mention it here.
- Object type or instance of an object type.
Oracle’s version of (or attempt to emulate) an object-oriented class. Object types encapsulate state and behavior, combining data (like a relational table) with rules (procedures and functions that operate on that data).
Packages are discussed in Chapter 18; database triggers are explored in Chapter 19. You can read more about object types in Chapter 25. This chapter focuses on how to build procedures and functions, and how to design the parameter lists that are an integral part of well-designed modules.
I use the term module to mean either a function or a procedure. As is the case with many other programming languages, modules can call other named modules. You can pass information into and out of modules with parameters. Finally, the modular structure of PL/SQL also integrates tightly with exception handlers to provide all-encompassing error-checking techniques (see Chapter 6).
This chapter explores how to define procedures and functions, and then dives into the details of setting up parameter lists for these programs. We also examine some of the more “exotic” aspects of program construction, including local modules, overloading, forward referencing, deterministic functions, and table functions.
A procedure is a module that performs one or more actions. Because a procedure call is a standalone executable statement in PL/SQL, a PL/SQL block could consist of nothing more than a single call to a procedure. Procedures are key building blocks of modular code, allowing you to both consolidate and reuse your program logic.
The general format of a PL/SQL procedure is as follows:
PROCEDURE [schema.]name[(parameter[,parameter...] ) ] [AUTHID DEFINER | CURRENT_USER] IS [declarations] BEGINexecutable statements[ EXCEPTIONexception handlers] END [name];
where each element is used in the following ways:
- schema
Optional name of the schema that will own this procedure. The default is the current user. If different from the current user, that user will need privileges to create a procedure in another schema.
- name
The name of the procedure, which comes directly after the keyword PROCEDURE.
- parameters
An optional list of parameters that you define to both pass information to the procedure, and send information out of the procedure back to the calling program.
- AUTHID clause
Determines whether the procedure will execute under the authority of the definer (owner) of the procedure or under the authority of the current user. The former is known as the definer rights model, the latter as the invoker rights model.
- declarations
The declarations of local identifiers for that procedure. If you do not have any declarations, there will be no statements between the IS and BEGIN statements.
- executable statements
The statements that the procedure executes when it is called. You must have at least one executable statement after the BEGIN and before the END or EXCEPTION keywords.
- exception handlers
The optional exception handlers for the procedure. If you do not explicitly handle any exceptions, then you can leave out the EXCEPTION keyword and simply terminate the execution section with the END keyword.
Figure 17-1 shows the apply_discount procedure, which contains all four sections of the named PL/SQL block as well as a parameter list.
A procedure is called as an executable PL/SQL statement. In other words, a call to a procedure must end with a semicolon (;) and be executed before and after other SQL or PL/SQL statements (if they exist) in the execution section of a PL/SQL block.
The following executable statement runs the apply_discount procedure:
BEGIN apply_discount( new_company_id, 0.15 ); -- 15% discount END;

If the procedure does not have any parameters, then you call the procedure without any parentheses:
display_store_summary;
In Oracle8i Database and later, you can also include empty open and close parentheses as well, as in:
display_store_summary();
The portion of the procedure definition that comes before the IS keyword is called the procedure header. The header provides all the information a programmer needs to call that procedure, namely:
The procedure name
The AUTHID clause, if any
The parameter list, if any
A programmer does not need to know about the inside of the procedure (the body) to be able to call it properly from another program.
The header for the apply_discount procedure mentioned in the previous section is:
PROCEDURE apply_discount
(company_id_in IN company.company_id%TYPE,
discount_in IN NUMBER)It consists of the module type, the name, and a list of two parameters.
The body of the procedure is the code required to implement that procedure, and consists of the declaration, execution, and exception sections of the function. Everything after the IS keyword in the procedure makes up that procedure’s body. The exception and declaration sections are optional. If you have no exception handlers, leave off the EXCEPTION keyword and simply enter the END statement to terminate the procedure. If you have no declarations, the BEGIN statement simply follows immediately after the IS keyword.
You must supply at least one executable statement in a procedure. That is generally not a problem; instead, watch out for execution sections that become extremely long and hard to manage. You should work hard to keep the execution section compact and readable. See later sections in this chapter, especially “Improving readability,” for more specific guidance on this topic.
You can append the name of the procedure directly after the END keyword when you complete your procedure, as shown here:
PROCEDURE display_stores (region_in IN VARCHAR2) IS BEGIN ... END display_stores;
This name serves as a label that explicitly links the end of the program with its beginning. You should, as a matter of habit, use an END descriptor . It is especially important to do so when you have a procedure that spans more than a single page, or is one in a series of procedures and functions in a package body.
The RETURN statement is generally associated with a function because it is required to RETURN a value from a function (or else raise an exception). Interestingly, PL/SQL also allows you to use a RETURN statement in a procedure. The procedure version of the RETURN does not take an expression; it therefore cannot pass a value back to the calling program unit. The RETURN simply halts execution of the procedure and returns control to the calling code.
You do not see this usage of RETURN very often, and for good reason. Use of the RETURN in a procedure usually leads to very unstructured code because there would then be at least two paths out of the procedure, making execution flow hard to understand and maintain. Avoid using both RETURN and GOTO to bypass proper control structures and process flow in your program units.
A function is a module that returns a value. Unlike a procedure call, which is a standalone executable statement, a call to a function can exist only as part of an executable statement, such as an element in an expression or the value assigned as the default in a declaration of a variable.
Because a function returns a value, it is said to have a datatype. A function can be used in place of an expression in a PL/SQL statement having the same datatype as the function.
Functions are particularly important constructs for building modular code. For example, every single business rule or formula in your application should be placed inside a function. Every single-row query should also be defined within a function, so that it can be easily and reliably reused.
Tip
Some programmers prefer to rely less on functions , and more on procedures that return status information through the parameter list. If you are one of these programmers, make sure that your business rules, formulas, and single-row queries are tucked away into your procedures!
An application short on function definition and usage is likely to be difficult to maintain and enhance over time.
The structure of a function is the same as that of a procedure, except that the function also has a RETURN clause. The general format of a function is as follows:
FUNCTION [schema.]name[(parameter[,parameter...] ) ] RETURNreturn_datatype[AUTHID DEFINER | CURRENT_USER] [DETERMINISTIC] [PARALLEL ENABLE ...] [PIPELINED] IS [declaration statements] BEGINexecutable statements[EXCEPTIONexception handler statements] END [ name ];
where each element is used in the following ways:
- schema
Optional name of the schema that will own this function. The default is the current user. If different from the current user, that user will need privileges to create a function in another schema.
- name
The name of the procedure comes directly after the keyword FUNCTION.
- parameters
An optional list of parameters that you define to both pass information into the procedure and send information out of the procedure back to the calling program.
- return_datatype
The datatype of the value returned by the function. This is required in the function header and is explained in more detail in the next section.
- AUTHID clause
Determines whether the procedure will execute under the authority of the definer (owner) of the procedure or under the authority of the current user. The former is known as the definer rights model, the latter as the invoker rights model.
- DETERMINISTIC clause
An optimization hint that lets the system use a saved copy of the function’s return result, if available. The query optimizer can choose whether to use the saved copy or re-call the function.
- PARALLEL_ENABLE clause
An optimization hint that enables the function to be executed in parallel when called from within a SELECT statement.
- PIPELINED clause
Specifies that the results of this table function should be returned iteratively via the PIPE ROW command.
- declaration statements
The declarations of local identifiers for that function. If you do not have any declarations, there will be no statements between the IS and BEGIN statements.
- executable statements
The statements the function executes when it is called. You must have at least one executable statement after the BEGIN and before the END or EXCEPTION keywords.
- exception handler statements
The optional exception handlers for the function. If you do not explicitly handle any exceptions, then you can leave out the EXCEPTION keyword and simply terminate the execution section with the END keyword.
Figure 17-2 illustrates the PL/SQL function and its different sections. Notice that the tot_sales function does not have an exception section.

A PL/SQL function can return virtually any kind of data known to PL/SQL, from scalars (single, primitive values like dates and strings) to complex structures such as collections, object types, cursor variables, and LOBs. You may not, however, return an exception through a function, because in PL/SQL, exceptions do not have a type.
Here are some examples of RETURN clauses in functions:
Return a string from a standalone function:
CREATE OR REPLACE FUNCTION favorite_nickname ( name_in IN VARCHAR2) RETURN VARCHAR2 IS ... END;
Return a DATE from an object type member function:
CREATE TYPE pet_t IS OBJECT ( tag_no INTEGER, NAME VARCHAR2 (60), breed VARCHAR2(100), dob DATE, MEMBER FUNCTION age (new_tag_no IN INTEGER) RETURN DATE )Return a record with the same structure as the books table:
CREATE OR REPLACE PACKAGE book_info IS FUNCTION onerow (isbn_in IN books.isbn%TYPE) RETURN books%ROWTYPE; ...Return a cursor variable with the specified REF CURSOR type (based on a record type):
CREATE OR REPLACE PACKAGE book_info IS TYPE overdue_rt IS RECORD ( isbn books.isbn%TYPE, days_overdue PLS_INTEGER); TYPE overdue_rct IS REF CURSOR RETURN overdue_rt; FUNCTION overdue_info (username_in IN lib_users.username%TYPE) RETURN overdue_rct; ...
You can append the name of the function directly after the END keyword when you complete your function, as shown here:
FUNCTION tot_sales (company_in IN INTEGER) RETURN NUMBER IS BEGIN ... END tot_sales;
This name serves as a label that explicitly links the end of the program with its beginning. You should, as a matter of habit, use an END descriptor. It is especially important to do so when you have a function that spans more than a single page or that is one in a series of functions and procedures in a package body.
A function is called as part of an executable PL/SQL statement wherever an expression can be used. The following examples illustrate how the various functions defined in the section “The RETURN Datatype” can be invoked.
Assign the default value of a variable with a function call:
DECLARE v_nickname VARCHAR2(100) := favorite_nickname ('Steven'),Use a member function for the pet object type in a conditional expression:
DECLARE my_parrot pet_t := pet_t (1001, 'Mercury', 'African Grey', TO_DATE ('09/23/1996', 'MM/DD/YYYY')); BEGIN IF my_parrot.age < INTERVAL '50' YEAR -- 9i INTERVAL type THEN DBMS_OUTPUT.PUT_LINE ('Still a youngster!'), END IF;Retrieve a single row of book information directly into a record:
DECLARE my_first_book books%ROWTYPE; BEGIN my_first_book := book_info.onerow ('1-56592-335-9'), ...Obtain a cursor variable to overdue book information for a specific user:
DECLARE my_overdue_info overdue_rct; BEGIN my_overdue_info := book_info.overdue_info ('STEVEN_FEUERSTEIN'), ...Call a function of one’s own making from within a CREATE VIEW statement, utilizing a CURSOR expression to pass a result set as an argument to that function:
CREATE OR REPLACE VIEW young_managers AS SELECT managers.employee_id manager_employee_id FROM employees managers WHERE Most_Reports_Before_Manager ( CURSOR ( SELECT reports.hire_date FROM employees reports WHERE reports.manager_id = managers.employee_id ), managers.hire_date ) = 1;
If a function has no parameters, the function call is written without parentheses. The following code illustrates this with a call to a method named “age” of the pet_t object type:
IF my_parrot.age < INTERVAL '50' YEAR -- 9i INTERVAL type
In Oracle8i Database and later, you can also include empty open and close parentheses, as in:
IF my_parrot.age() < INTERVAL '50' YEAR
The portion of the function definition that comes before the IS keyword is called the function header. The header provides all the information a programmer needs to call that function, namely:
The function name
Modifiers to the definition and behavior of the function (e.g., is it deterministic? Does it run in parallel execution? Is it pipelined?)
The parameter list, if any
The RETURN datatype
A programmer should not need to look at the inside of the function (its body) in order to be able to call it properly from another program.
The header for the tot_sales function discussed earlier is:
FUNCTION tot_sales
(company_id_in IN company.company_id%TYPE,
status_in IN order.status_code%TYPE := NULL)
RETURN NUMBERIt consists of the module type, the name, a list of two parameters, and a RETURN datatype of NUMBER. This means that any PL/SQL statement or expression that references a numeric value can make a call to tot_sales to obtain that value. Here is one such statement:
DECLARE v_sales NUMBER; BEGIN v_sales := tot_sales (1505, 'ACTIVE'), ...
The body of the function is the code required to implement the function. It consists of the declaration, execution, and exception sections of the function. Everything after the IS keyword in the function makes up that function’s body.
Once again, the declaration and exception sections are optional. If you have no exception handlers, simply leave off the EXCEPTION keyword and enter the END statement to terminate the function. If you have no declarations, the BEGIN statement simply follows immediately after the IS keyword.
A function’s execution section should have a RETURN statement in it, although it is not necessary for the function to compile. If, however, your function finishes executing without processing a RETURN statement, Oracle will raise the following error (a sure sign of a very poorly designed function):
ORA-06503: PL/SQL: Function returned without value
A function must have at least one RETURN statement in its execution section of statements. It can have more than one RETURN, but only one is executed each time the function is called. The RETURN statement that is executed by the function determines the value that is returned by that function. When a RETURN statement is processed, the function terminates immediately and returns control to the calling PL/SQL block.
The RETURN clause in the header of the function is different from the RETURN statement in the execution section of the body. While the RETURN clause indicates the datatype of the return or result value of the function, the RETURN statement specifies the actual value that is returned. You have to specify the RETURN datatype in the header, but then also include at least one RETURN statement in the function. The datatype indicated in the RETURN clause in the header must be compatible with the datatype of the returned expression in the RETURN statement.
The RETURN statement can return any expression compatible with the datatype indicated in the RETURN clause. This expression can be composed of calls to other functions, complex calculations, and even data conversions. All of the following usages of RETURN are valid:
RETURN 'buy me lunch';
RETURN POWER (max_salary, 5);
RETURN (100 - pct_of_total_salary (employee_id));
RETURN TO_DATE ('01' || earliest_month || initial_year, 'DDMMYY'),You can also return complex data structures such as object type instances, collections, and records.
An expression in the RETURN statement is evaluated when the RETURN is executed. When control is passed back to the calling block, the result of the evaluated expression is passed along, too.
In the tot_sales function shown in Figure 17-2, I used two different RETURN statements to handle different situations in the function, which can be described as follows:
If I cannot obtain sales information from the cursor, I return NULL (which is different from zero). If I do get a value from the cursor, I return it to the calling program. In both of these cases, the RETURN statement passes back a value: in one case, the NULL value, and in the other, the return_value variable.
While it is certainly possible to have more than one RETURN statement in the execution section of a function, you are generally better off having just one: the last line in your execution section. The next section explains this.
Generally, the best way to make sure that your function always returns a value is to make the last executable statement your RETURN statement. Declare a variable named return_value (which clearly indicates that it will contain the return value for the function), write all the code to come up with that value, and then, at the very end of the function, RETURN the return_value, as shown here:
FUNCTION do_it_all (parameter_list) RETURN NUMBER IS return_value NUMBER; BEGIN ... lots of executable statements ... RETURN return_value; END;
Here is a rewrite of the logic in Figure 17-2 to fix the problem of multiple RETURN statements.
IF sales_cur%NOTFOUND THEN return_value:= NULL; END IF; CLOSE sales_cur; RETURN return_value;
Beware of exceptions, though. An exception that gets raised might “jump” over your last statement straight into the exception handler. If your exception handler does not then have a RETURN statement, you will get an ORA-06503: Function returned without value error, regardless of how you handled the actual exception.
Procedures and functions can both use parameters to pass information back and forth between the module and the calling PL/SQL block.
The parameters of a module are at least as important as the code that implements the module (the module’s body). Sure, you have to make certain that your module fulfills its promise. But the whole point of creating a module is that it can be called, ideally by more than one other module. If the parameter list is confusing or badly designed, it will be very difficult for other programmers to use the module, and the result is that few will bother. And it doesn’t matter how well you implemented a program if no one uses it.
Many developers do not give enough attention to a module’s set of parameters. Considerations regarding parameters include:
- Number of parameters
Too few parameters can limit the reusability of your program; with too many parameters, no one will want to reuse your program. Certainly, the number of parameters is largely determined by program requirements, but there are different ways to define parameters (such as bundling multiple parameters in a single record).
- Types of parameters
Should you use read-only, write-only, or read-write parameters?
- Names of parameters
How should you name your parameters so that their purpose in the module is properly and easily understood?
- Default values for parameters
How do you set defaults? When should a parameter be given defaults, and when should the programmer be forced to enter a value?
PL/SQL offers many different features to help you design parameters effectively. This section covers all elements of parameter definition.
Formal parameters are defined in the parameter list of the program. A parameter definition parallels closely the syntax for declaring variables in the declaration section of a PL/SQL block. There are two important distinctions: first, a parameter has a passing mode while a variable declaration does not; and second, a parameter declaration must be unconstrained.
A constrained declaration is one that constrains or limits the kind of value that can be assigned to a variable declared with that datatype. An unconstrained declaration is one that does not limit values in this way. The following declaration of the variable company_name constrains the variable to 60 characters:
DECLARE company_name VARCHAR2(60);
When you declare a parameter, however, you must leave out the constraining part of the declaration:
PROCEDURE display_company (company_name IN VARCHAR2) IS ...
We need to distinguish between two different kinds of parameters: actual and formal parameters . The formal parameters are the names that are declared in the parameter list of the header of a module. The actual parameters are the values or expressions placed in the parameter list of the actual call to the module.
Let’s examine the differences between formal and actual parameters using the example of tot_sales. Here, again, is the tot_sales header:
FUNCTION tot_sales
(company_id_in IN company.company_id%TYPE,
status_in IN order.status_code%TYPE := NULL)
RETURN std_types.dollar_amount;The formal parameters of tot_sales are:
- company_id_in
The primary key of the company
- status_in
The status of the orders to be included in the sales calculation
These formal parameters do not exist outside of the function. You can think of them as placeholders for real or actual parameter values that are passed into the function when it is used in a program.
When you use tot_sales in your code, the formal parameters disappear. In their place, you list the actual parameters or variables whose values will be passed to tot_sales. In the following example, the company_id variable contains the primary key pointing to a company record. In the first three calls to tot_sales, a different, hardcoded status is passed to the function. The last call to tot_sales does not specify a status; in this case, the function assigns the default value (provided in the function header) to the status_in parameter:
new_sales := tot_sales (company_id, 'N'), paid_sales := tot_sales (company_id, 'P'), shipped_sales := tot_sales (company_id, 'S'), all_sales := tot_sales (company_id);
When tot_sales is called, all the actual parameters are evaluated. The results of the evaluations are then assigned to the formal parameters inside the function to which they correspond (note that this is true only for IN and IN OUT parameters ; parameters of OUT mode are not copied in).
The formal parameter and the actual parameter that corresponds to it (when called) must be of the same or compatible datatypes. PL/SQL will perform datatype conversions for you in many situations. Generally, however, you are better off avoiding all implicit datatype conversions. Use a formal conversion function like TO_CHAR or TO_DATE (see Chapter 10), so that you know exactly what kind of data you are passing into your modules.
When you define the parameter, you also specify the way in which it can be used. There are three different modes of parameters:
Mode | Description | Parameter usage |
|---|---|---|
IN | Read-only | The value of the actual parameter can be referenced inside the module, but the parameter cannot be changed. |
OUT | Write-only | The module can assign a value to the parameter, but the parameter’s value cannot be referenced. |
IN OUT | Read/write | The module can both reference (read) and modify (write) the parameter. |
The mode determines how the program can use and manipulate the value assigned to the formal parameter. You specify the mode of the parameter immediately after the parameter name and before the parameter’s datatype and optional default value. The following procedure header uses all three parameter modes:
PROCEDURE predict_activity
(last_date_in IN DATE,
task_desc_inout IN OUT VARCHAR2,
next_date_out OUT DATE)The predict_activity procedure takes in two pieces of information: the date of the last activity and a description of the activity. It then returns or sends out two pieces of information: a possibly modified task description and the date of the next activity. Because the task_desc_inout parameter is IN OUT, the program can both read the value of the argument and change the value of that argument.
Let’s look at each of these parameter modes in detail.
An IN parameter allows you to pass values into the module but will not pass anything out of the module and back to the calling PL/SQL block. In other words, for the purposes of the program, IN parameters function like constants. Just like constants, the value of the formal IN parameter cannot be changed within the program. You cannot assign values to the IN parameter or in any other way modify its value.
IN is the default mode; if you do not specify a parameter mode, the parameter is automatically considered IN. I recommend, however, that you always specify a parameter mode so that your intended use of the parameter is documented explicitly in the code itself.
IN parameters can be given default values in the program header (see the later section "Default Values“).
The actual value for an IN parameter can be a variable, a named constant, a literal, or a complex expression. All of the following calls to display_title are valid:
DECLARE
happy_title CONSTANT VARCHAR2(30) := 'HAPPY BIRTHDAY';
changing_title VARCHAR2(30) := 'Happy Anniversary';
spc VARCHAR2(1) := CHR(32) -- ASCII code for a single space;
BEGIN
display_title ('Happy Birthday'), -- a literal
display_title (happy_title); -- a constant
changing_title := happy_title;
display_title (changing_title); -- a variable
display_title ('Happy' || spc || 'Birthday'), -- an expression
display_title (INITCAP (happy_title)); -- another expression
END;What if you want to transfer data out of your program? For that, you will need an OUT or an IN OUT parameter.
An OUT parameter is the opposite of the IN parameter, but perhaps you already had that figured out. Use the OUT parameter to pass a value back from the program to the calling PL/SQL block. An OUT parameter is like the return value for a function, but it appears in the parameter list, and you can have as many as you like.
Inside the program, an OUT parameter acts like a variable that has not been initialized. In fact, the OUT parameter has no value at all until the program terminates successfully (unless you have requested use of the NOCOPY hint, which will be described in a moment). During the execution of the program, any assignments to an OUT parameter are actually made to an internal copy of the OUT parameter. When the program terminates successfully and returns control to the calling block, the value in that local copy is then transferred to the actual OUT parameter. That value is then available in the calling PL/SQL block.
There are several consequences of these rules concerning OUT parameters:
You cannot assign an OUT parameter’s value to another variable or even use it in a reassignment to itself.
You also cannot provide a default value to an OUT parameter. You can only assign a value to an OUT parameter inside the body of the module.
Any assignments made to OUT parameters are rolled back when an exception is raised in the program. Because the value for an OUT parameter is not actually assigned until a program completes successfully, any intermediate assignments are therefore ignored. Unless an exception handler traps the exception and then assigns a value to the OUT parameter, no assignment is made to that parameter. The variable will retain the same value it had before the program was called.
An actual parameter corresponding to an OUT formal parameter must be a variable. It cannot be a constant, literal, or expression because these formats do not provide a receptacle in which PL/SQL can place the OUTgoing value.
With an IN OUT parameter, you can pass values into the program and return a value back to the calling program (either the original, unchanged value or a new value set within the program). The IN OUT parameter shares two restrictions with the OUT parameter:
An IN OUT parameter cannot have a default value.
An IN OUT actual parameter or argument must be a variable. It cannot be a constant, literal, or expression because these formats do not provide a receptacle in which PL/SQL can place the outgoing value.
Beyond these restrictions, none of the other restrictions apply.
You can use the IN OUT parameter in both sides of an assignment because it functions like an initialized, rather than uninitialized, variable. PL/SQL does not lose the value of an IN OUT parameter when it begins execution of the program. Instead, it uses that value as necessary within the program.
The combine_and_format_names procedure shown here combines the first and last names into a full name in the format specified (“LAST, FIRST” or “FIRST LAST”). I need the incoming names for the combine action, and I will uppercase the first and last names for future use in the program (thereby enforcing the application standard of all-uppercase for names of people and things). This program uses all three parameter modes: IN, IN OUT, and OUT.
PROCEDURE combine_and_format_names
(first_name_inout IN OUT VARCHAR2,
last_name_inout IN OUT VARCHAR2,
full_name_out OUT VARCHAR2,
name_format_in IN VARCHAR2 := 'LAST, FIRST')
IS
BEGIN
/* Upper-case the first and last names. */
first_name_inout := UPPER (first_name_inout);
last_name_inout := UPPER (last_name_inout);
/* Combine the names as directed by the name format string. */
IF name_format_in = 'LAST, FIRST'
THEN
full_name_out := last_name_inout || ', ' || first_name_inout;
ELSIF name_format_in = 'FIRST LAST'
THEN
full_name_out := first_name_inout || ' ' || last_name_inout;
END IF;
END;The first name and last name parameters must be IN OUT. The full_name_out is just an OUT parameter because I create the full name from its parts. If the actual parameter used to receive the full name has a value going into the procedure, I certainly don’t want to use it! Finally, the name_format_in parameter is a mere IN parameter because it is used to determine how to format the full name, but is not changed or changeable in any way.
Each parameter mode has its own characteristics and purpose. You should choose carefully which mode to apply to your parameters so that they are used properly within the module.
How does PL/SQL know which actual parameter goes with which formal parameter when a program is executed? PL/SQL offers two ways to make the association:
- Positional notation
Associate the actual parameter implicitly (by position) with the formal parameter.
- Named notation
Associate the actual parameter explicitly (by name) with the formal parameter.
In every example so far, I have employed positional notation to guide PL/SQL through the parameters. With positional notation, PL/SQL relies on the relative positions of the parameters to make the correspondence: it associates the Nth actual parameter in the call to a program with the Nth formal parameter in the program’s header.
With the following tot_sales example, PL/SQL associates the first actual parameter, :order.company_id, with the first formal parameter, company_id_in. It then associates the second actual parameter, N, with the second formal parameter, status_in:
new_sales := tot_sales (:order.company_id, 'N'),
FUNCTION tot_sales
(company_id_in IN company.company_id%TYPE,
status_in IN order.status_code%TYPE := NULL)
RETURN std_types.dollar_amount;Now you know the name for the way compilers pass values through parameters to modules. Positional notation, shown graphically in Figure 17-3, is certainly the most obvious method.

With named notation, you explicitly associate the formal parameter (the name of the parameter) with the actual parameter (the value of the parameter) right in the call to the program, using the combination symbol =>.
The general syntax for named notation is:
formal_parameter_name=>argument_value
Because you provide the name of the formal parameter explicitly, PL/SQL no longer needs to rely on the order of the parameters to make the association from actual to formal. So, if you use named notation, you do not need to list the parameters in your call to the program in the same order as the formal parameters in the header. You can call tot_sales for new orders in either of these two ways:
new_sales := tot_sales (company_id_in => order_pkg.company_id, status_in =>'N'), new_sales := tot_sales (status_in =>'N', company_id_in => order_pkg.company_id);
You can also mix named and positional notation in the same program call:
:order.new_sales := tot_sales (order_pkg.company_id, status_in =>'N'),
If you do mix notation, however, you must list all of your positional parameters before any named notation parameters, as shown in the preceding example. Positional notation has to have a starting point from which to keep track of positions, and the only starting point is the first parameter. If you place named notation parameters in front of positional notation, PL/SQL loses its place. Both of the following calls to tot_sales will fail. The first statement fails because the named notation comes first. The second fails because positional notation is used, but the parameters are in the wrong order. PL/SQL will try to convert ‘N’ to a NUMBER (for company_id):
:order.new_sales := tot_sales (company_id_in => order_pkg.company_id, 'N'),
:order.new_sales := tot_sales ('N', company_id_in => order_pkg.company_id);Now that you are aware of the different ways to notate the order and association of parameters, you might be wondering why you would ever use named notation. Here are two possibilities:
- Named notation is self-documenting
When you use named notation, the call to the program clearly describes the formal parameter to which the actual parameter is assigned. The names of formal parameters can and should be designed so that their purpose is self-explanatory. In a way, the descriptive aspect of named notation is another form of program documentation. If you are not familiar with all of the modules called by an application, the listing of the formal parameters helps reinforce your understanding of a particular program call. In some development environments, the standard for parameter notation is named notation for just this reason. This is especially true when the formal parameters are named following the convention of appending the passing mode as the last token. Then, the direction of data can be clearly seen simply by investigating the procedure or function call.
- Named notation gives you complete flexibility over parameter specification
You can list the parameters in any order you want. (This does not mean, however, that you should randomly order your arguments when you call a program!) You can also include only the parameters you want or need in the parameter list. Complex applications may at times require procedures with literally dozens of parameters. Any parameter with a default value can be left out of the call to the procedure. Using named notation, the developer can use the procedure by passing only the values needed for that usage.
Let’s see how these benefits can be applied. Consider the following program header:
/* File on web: namednot.sql */ PROCEDURE business_as_usual ( advertising_budget_in IN NUMBER , contributions_inout IN OUT NUMBER , merge_and_purge_on_in IN DATE DEFAULT SYSDATE , obscene_ceo_bonus_out OUT NUMBER , cut_corners_in IN VARCHAR2 DEFAULT 'WHENEVER POSSIBLE' );
An analysis of the parameter list yields these conclusions:
The minimum number of arguments that must be passed to business_as_usual is three. To determine this, add the number of IN parameters without default values to the number of OUT or IN OUT parameters.
I can call this program with named notation with either four or five arguments, because the last parameter has mode IN with a default value.
You will need at least two variables to hold the values returned by the OUT and IN OUT parameters.
Given this parameter list, there are a number of ways that you can call this program:
All positional notation, all actual parameters specified. Notice how difficult it is to recall the parameter (and significance) of each of these values.
DECLARE l_ceo_payoff NUMBER; l_lobbying_dollars NUMBER := 100000; BEGIN /* All positional notation */ business_as_usual (50000000 , l_lobbying_dollars , SYSDATE + 20 , l_ceo_payoff , 'PAY OFF OSHA' );All positional notation, minimum number of actual parameters specified. Still hard to understand.
business_as_usual (50000000 , l_lobbying_dollars , SYSDATE + 20 , l_ceo_payoff );All named notation, keeping the original order intact. Now my call to business_as_usual is self-documenting.
business_as_usual (advertising_budget_in => 50000000 , contributions_inout => l_lobbying_dollars , merge_and_purge_on_in => SYSDATE , obscene_ceo_bonus_out => l_ceo_payoff , cut_corners_in => 'DISBAND OSHA' );
Skip over all IN parameters with default values, another critical feature of named notation:
business_as_usual (advertising_budget_in => 50000000 , contributions_inout => l_lobbying_dollars , obscene_ceo_bonus_out => l_ceo_payoff );
Change the order in which actual parameters are specified with named notation, also provide just a partial list:
business_as_usual (obscene_ceo_bonus_out => l_ceo_payoff , merge_and_purge_on_in => SYSDATE , advertising_budget_in => 50000000 , contributions_inout => l_lobbying_dollars );
Blend positional and named notation. You can start with positional, but once you switch to named notation, you can’t go back to positional.
business_as_usual (50000000 , l_lobbying_dollars , merge_and_purge_on_in => SYSDATE , obscene_ceo_bonus_out => l_ceo_payoff );
As you can see, there is lots of flexibility when it comes to passing arguments to a parameter list in PL/SQL. As a general rule, named notation is the best way to write code that is readable and more easily maintained. You just have to take the time to look up and write the parameter names.
Starting with Oracle8i Database, PL/SQL offers an option for definitions of parameters: the NOCOPY clause. NOCOPY is a hint to the compiler about how you would like the PL/SQL engine to work with the data structure being passed in as an OUT or IN OUT parameter. To understand NOCOPY and its potential impact, it will help to review how PL/SQL handles parameters. There are two ways to pass parameter values: by reference and by value .
- By reference
When an actual parameter is passed by reference, it means that a pointer to the actual parameter is passed to the corresponding formal parameter. Both the actual and formal parameters then reference, or point to, the same location in memory that holds the value of the parameter.
- By value
When an actual parameter is passed by value, the value of the actual parameter is copied to the corresponding formal parameter. If the program then terminates without an exception, the formal parameter value is copied back to the actual parameter. If an error occurs, the changed values are not copied back to the actual parameter.
Parameter passing in PL/SQL without the use of NOCOPY follows these rules:
Parameter mode | Passed by value or reference? (default behavior) |
|---|---|
IN | By reference |
OUT | By value |
IN OUT | By value |
We can infer from these definitions and rules that when a large data structure (such as a collection, a record, or an instance of an object type) is passed as an OUT or IN OUT parameter, that structure will be passed by value, and your application could experience performance and memory degradation as a result of all this copying. The NOCOPY hint is a way for you to attempt to avoid this. The syntax of this feature is as follows:
parameter_name[ IN | IN OUT | OUT | IN OUT NOCOPY | OUT NOCOPY ]parameter_datatype
You can specify NOCOPY only in conjunction with the OUT or IN OUT mode. Here is a parameter list that uses the NOCOPY hint for both of its IN OUT arguments:
PROCEDURE analyze_results ( date_in IN DATE, values IN OUT NOCOPY numbers_varray, validity_flags IN OUT NOCOPY validity_rectype );
There are two things you should keep in mind about NOCOPY:
The corresponding actual parameter for an OUT parameter under the NOCOPY hint is set to NULL whenever the subprogram containing the OUT parameter is called.
NOCOPY is a hint, not a command. This means that the compiler might silently decide that it can’t fulfill your request for a NOCOPY parameter treatment. The next section lists the restrictions on NOCOPY that might cause this to happen.
A number of situations will cause the PL/SQL compiler to ignore the NOCOPY hint and instead use the default by-value method to pass the OUT or IN OUT parameter. These situations are the following:
- The actual parameter is an element of an associative array
You can request NOCOPY for an entire associative array (which could be an entire record structure), but not for an individual element in the table. A suggested workaround is to copy the structure to a standalone variable, either scalar or record, and then pass that as the NOCOPY parameter. That way, at least you aren’t copying the entire structure.
- Certain constraints are applied to actual parameters
Some constraints will result in the NOCOPY hint’s being ignored; these include a scale specification for a numeric variable and the NOT NULL constraint. You can, however, pass a string variable that has been constrained by size.
- The actual and formal parameters are record structures
One or both records were declared using %ROWTYPE or %TYPE, and the constraints on corresponding fields in these two records are different.
- In passing the actual parameter, the PL/SQL engine must perform an implicit datatype conversion
A suggested workaround is this: because you are always better off performing explicit conversions anyway, do that and then pass the converted value as the NOCOPY parameter.
- The subprogram requesting the NOCOPY hint is used in an external or remote procedure call
In these cases, PL/SQL will always pass the actual parameter by value.
Depending on your application, NOCOPY can improve the performance of programs with IN OUT or OUT parameters. As you might expect, these potential gains come with a tradeoff: if a program terminates with an unhandled exception, you cannot trust the values in a NOCOPY actual parameter.
What do I mean by “trust?” Let’s review how PL/SQL behaves concerning its parameters when an unhandled exception terminates a program. Suppose that I pass an IN OUT record to my calculate_totals procedure. The PL/SQL runtime engine first makes a copy of that record and then, during program execution, makes any changes to that copy. The actual parameter itself is not modified until calculate_totals ends successfully (without propagating back an exception). At that point, the local copy is copied back to the actual parameter, and the program that called calculate_totals can access that changed data. If calculate_totals terminates with an unhandled exception, however, the calling program can be certain that the actual parameter’s value has not been changed.
That certainty disappears with the NOCOPY hint. When a parameter is passed by reference (the effect of NOCOPY), any changes made to the formal parameter are also made immediately to the actual parameter. Suppose that my calculate_totals program reads through a 10,000-row collection and makes changes to each row. If an error is raised at row 5,000 and propagated out of calculate_totals unhandled, my actual parameter collection will be only half-changed.
The files named nocopy*.tst on the book’s web site demonstrate the challenges of working with NOCOPY. You should run them and make sure you understand the intricacies of this feature before using it in your application.
Beyond that and generally, you should be judicious in your use of the NOCOPY hint. Use it only when you know that you have a performance problem relating to your parameter passing, and be prepared for the potential consequences when exceptions are raised.
As you have seen from previous examples, you can provide default values for IN parameters. If an IN parameter has a default value, you do not need to include that parameter in the call to the program. Likewise, a parameter’s default value is used by the program only if the call to that program does not include that parameter in the list. You must, of course, include an actual parameter for any IN OUT parameters.
The parameter default value works the same way as a specification of a default value for a declared variable. There are two ways to specify a default value: either with the keyword DEFAULT or with the assignment operator (:=), as the following example illustrates:
PROCEDURE astrology_reading
(sign_in IN VARCHAR2 := 'LIBRA',
born_at_in IN DATE DEFAULT SYSDATE) ISBy using default values, you can call programs with different numbers of actual parameters. The program uses the default value of any unspecified parameters, and overrides the default values of any parameters in the list that have specified values. Here are all the different ways you can ask for your astrology reading using positional notation:
BEGIN
astrology_reading ('SCORPIO',
TO_DATE ('12-24-2001 17:56:10', 'MM-DD-YYYY HH24:MI:SS'),
astrology_reading ('SCORPIO'),
astrology_reading;
END;The first call specifies both parameters explicitly. In the second call, only the first actual parameter is included, so born_at_in is set to the current date and time. In the third call, no parameters are specified, so we cannot include the parentheses. Both of the default values are used in the body of the procedure.
What if you want to specify a birth time, but not a sign? To skip over leading parameters that have default values, you will need to use named notation. By including the name of the formal parameter, you can list only those parameters to which you need to pass values. In this (thankfully) last request for a star-based reading of my fate, I have successfully passed in a default of Libra as my sign and an overridden birth time of 5:56 p.m.
BEGIN
astrology_reading (
born_at_in =>
TO_DATE ('12-24-2001 17:56:10', 'MM-DD-YYYY HH24:MI:SS'),
END;A local module is a procedure or function that is defined in the declaration section of a PL/SQL block (anonymous or named). This module is considered local because it is defined only within the parent PL/SQL block. It cannot be called by any other PL/SQL blocks defined outside that enclosing block.
Figure 17-4 shows how blocks that are external to a procedure definition cannot “cross the line” into the procedure to directly invoke any local procedures or functions.
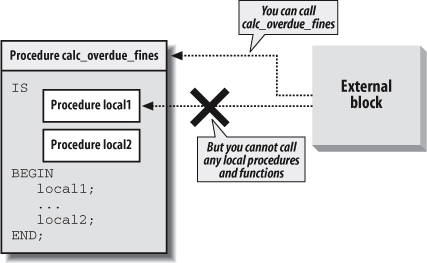
The syntax for defining the procedure or function is exactly the same as that used for creating standalone modules.
The following anonymous block, for example, declares a local procedure:
DECLARE
PROCEDURE show_date (date_in IN DATE) IS
BEGIN
DBMS_OUTPUT.PUT_LINE (TO_CHAR (date_in, 'Month DD, YYYY'),
END;
BEGIN
...
END;Local modules must be located after all of the other declaration statements in the declaration section. You must declare your variables, cursors, exceptions, types, records, tables, and so on before you type in the first PROCEDURE or FUNCTION keyword.
The following sections explore the benefits of local modules and offer a number of examples.
There are two central reasons to create local modules:
- To reduce the size of the module by stripping it of repetitive code
This is the most common motivation to create a local module; you can see its impact in the next example. The code reduction leads to higher code quality because you have fewer lines to test and fewer potential bugs. It takes less effort to maintain the code because there is less to maintain. And when you do have to make a change, you make it in one place in the local module, and the effects are felt immediately throughout the parent module.
- To improve the readability of your code
Even if you do not repeat sections of code within a module, you still may want to pull out a set of related statements and package them into a local module. This can make it easier to follow the logic of the main body of the parent module.
The following sections examine these benefits.
Let’s look at an example of reducing code volume . The calc_percentages procedure takes numeric values from the sales package (sales_pkg), calculates the percentage of each sales amount against the total sales provided as a parameter, and then formats the number for display in a report or form. The example you see here has only three calculations, but I extracted it from a production application that actually performed 23 of these computations!
PROCEDURE calc_percentages (tot_sales_in IN NUMBER)
IS
l_profile sales_descriptors%ROWTYPE;
BEGIN
l_profile.food_sales_stg :=
TO_CHAR ((sales_pkg.food_sales / tot_sales_in ) * 100,
'$999,999'),
l_profile.service_sales_stg :=
TO_CHAR ((sales_pkg.service_sales / tot_sales_in ) * 100,
'$999,999'),
l_profile.toy_sales_stg :=
TO_CHAR ((sales_pkg.toy_sales / tot_sales_in ) * 100,
'$999,999'),
END;This code took a long time (relatively speaking) to write, is larger than necessary, and is maintenance-intensive. What if I need to change the format to which I convert the numbers? What if the calculation of the percentage changes? I will have to change each of the individual calculations.
With local modules, I can concentrate all the common, repeated code into a single function, which is then called repeatedly in calc_percentages. The local module version of this procedure is shown here:
PROCEDURE calc_percentages (tot_sales_in IN NUMBER)
IS
l_profile sales_descriptors%ROWTYPE;
/* Define a function right inside the procedure! */
FUNCTION pct_stg (val_in IN NUMBER) RETURN VARCHAR2
IS
BEGIN
RETURN TO_CHAR ((val_in/tot_sales_in ) * 100, '$999,999'),
END;
BEGIN
l_profile.food_sales_stg := pct_stg (sales_pkg.food_sales);
l_profile.service_sales_stg := pct_stg (sales_pkg.service_sales);
l_profile.toy_sales_stg := pct_stg (sales_pkg.toy_sales);
END;All of the complexities of the calculation, from the division by tot_sales_in to the multiplication by 100 to the formatting with TO_CHAR, have been transferred to the function pct_stg. This function is defined in the declaration section of the procedure. By calling this function from within the body of calc_percentages, the executable statements of the procedure are much more readable and maintainable. Now, if the formula for the calculation changes in any way, I make the change just once in the function and it takes effect in all the assignments.
You can use local modules to dramatically improve the readability and maintainability of your code. In essence, local modules allow you to follow top-down design or stepwise refinement methodologies very closely. You can also use the same technique to decompose or refactor an existing program so that it is more readable.
The bottom-line result of using local modules in this way is that you can dramatically reduce the size of your execution sections (you are transferring many lines of logic from an inline location in the execution section to a local module callable in that section). By keeping your execution sections small, you will find that it is much easier to read and understand the logic.
Tip
I suggest that you adopt as a guideline in your coding standards that execution sections of PL/SQL blocks be no longer than 60 lines (the amount of text that can fit on a screen or page). This may sound crazy, but if you follow the techniques in this section, you will find it not only possible but highly advantageous.
Suppose that I have a series of WHILE loops (some of them nested) whose bodies contain a series of complex calculations and deep nestings of conditional logic. Even with extensive commenting, it can be difficult to follow the program flow over several pages, particularly when the END IF or END LOOP of a given construct is not even on the same page as the IF or LOOP statement that began it.
In contrast, if you pull out sequences of related statements, place them in one or more local modules, and then call those modules in the body of the program, the result is a program that can literally document itself. The assign_workload procedure offers a simplified version of this scenario that still makes clear the gains offered by local modules:
PROCEDURE assign_workload (department_in IN emp.deptno%TYPE)
IS
CURSOR emps_in_dept_cur (department_in IN emp.deptno%TYPE)
IS
SELECT * FROM emp WHERE deptno = department_in;
PROCEDURE assign_next_open_case
(emp_id_in IN NUMBER, case_out OUT NUMBER)
IS
BEGIN ... full implementation ... END;
FUNCTION next_appointment (case_id_in IN NUMBER)
RETURN DATE
IS
BEGIN ... full implementation ... END;
PROCEDURE schedule_case
(case_in IN NUMBER, date_in IN DATE)
IS
BEGIN ... full implementation ... END;
BEGIN /* main */
FOR emp_rec IN emps_in_dept_cur (department_in)
LOOP
IF analysis.caseload (emp_rec.emp_id) <
analysis.avg_cases (department_in);
THEN
assign_next_open_case (emp_rec.emp_id, case#);
schedule_case
(case#, next_appointment (case#));
END IF;
END LOOP
END assign_workload;The assign_workload procedure has three local modules :
assign_next_open_case next_appointment schedule_case
It also relies on two packaged programs that already exist and can be easily plugged into this program: analysis.caseload and analysis.avg_cases. For the purposes of understanding the logic behind assign_workload, it doesn’t really matter what code is executed in each of them. I can rely simply on the names of those modules to read through the main body of this program. Even without any comments, a reader can still gain a clear understanding of what each module is doing. Of course, if you want to rely on named objects to self-document your code, you’d better come up with very good names for the functions and procedures.
The modularized declaration section looks a lot like the body of a package, as you will see in Chapter 18. A package body also contains definitions of modules. The big difference between local modules and package modules is their scope. Local modules can be called only from within the block in which they are defined; package modules can—at a minimum—be called from anywhere in the package. If the package modules are also listed in the package specification, they can be called by any other program in your application.
You should therefore use local modules only to encapsulate code that does not need to be called outside of the current program. Otherwise, go ahead, and create a package!
These days it seems that whenever I write a program with more than 20 lines and any complexity whatsoever, I end up creating one or more local modules. Doing so helps me see my way through to a solution much more easily; I can conceptualize my code at a higher level of abstraction by assigning a name to a whole sequence of statements, and I can perform top-down design and stepwise refinement of my requirements. Finally, by modularizing my code even within a single program, I make it very easy to later extract a local module and make it a truly independent, reusable procedure or function.
You could also, of course, move that logic out of the local scope and make it a package body-level program of its own (assuming you are writing this code in a package). Taking this approach will reduce the amount of nesting of local procedures, which can be helpful. It also, however, can lead to package bodies with a very long list of programs, many of which are only used within another program. My general principle is to keep the definition of an element as close as possible to its usage, which naturally leads to the use of local modules.
I hope that as you read this, a program you have written comes to mind. Perhaps you can go back and consolidate some repetitive code, clean up the logic, and make the program actually understandable to another human being. Don’t fight the urge. Go ahead, and modularize your code.
When more than one program in the same scope share the same name, the programs are said to be overloaded. PL/SQL supports the overloading of procedures and functions in the declaration section of a block (named or anonymous), package specifications and bodies, and object type definitions. Overloading is a very powerful feature, and you should exploit it fully to improve the usability of your software.
Here is a very simple example of three overloaded modules defined in the declaration section of an anonymous block (therefore, all are local modules):
DECLARE
/* First version takes a DATE parameter. */
FUNCTION value_ok (date_in IN DATE) RETURN BOOLEAN IS
BEGIN
RETURN date_in <= SYSDATE;
END;
/* Second version takes a NUMBER parameter. */
FUNCTION value_ok (number_in IN NUMBER) RETURN BOOLEAN IS
BEGIN
RETURN number_in > 0;
END;
/* Third version is a procedure! */
PROCEDURE value_ok (number_in IN NUMBER) IS
BEGIN
IF number_in > 0 THEN
DBMS_OUTPUT.PUT_LINE (number_in || 'is OK!'),
ELSE
DBMS_OUTPUT.PUT_LINE (number_in || 'is not OK!'),
END IF;
END;
BEGINWhen the PL/SQL runtime engine encounters the following statement:
IF value_ok (SYSDATE) THEN ...
the actual parameter list is compared with the formal parameter lists of the various overloaded modules, searching for a match. If one is found, PL/SQL executes the code in the body of the program with the matching header.
Tip
Another name for overloading is static polymorphism . The term polymorphism refers to the ability of a language to define and selectively use more than one form of a program with the same name. When the decision on which form to use is made at compilation time, it is called static polymorphism. When the decision is made at runtime, it is called dynamic polymorphism ; this type of polymorphism is available through inherited object types.
Overloading can greatly simplify your life and the lives of other developers. This technique consolidates the call interfaces for many similar programs into a single module name, transferring the burden of knowledge from the developer to the software. You do not have to try to remember, for instance, the six different names for programs adding values (dates, strings, Booleans, numbers, etc.) to various PL/SQL tables. Instead, you simply tell the compiler that you want to add a value and pass it that value. PL/SQL and your overloaded programs figure out what you want to do and then do it for you.
When you build overloaded modules, you spend more time in design and implementation than you might with separate, standalone modules. This additional time up-front will be repaid handsomely down the line because you and others will find it much easier and more efficient to use your programs.
There are three different scenarios that benefit from overloading:
- Supporting many data combinations
When applying the same action to different kinds or combinations of data, overloading does not provide a single name for different activities, so much as it provides different ways of requesting the same activity. This is the most common motivation for overloading.
- Fitting the program to the user
To make your code as useful as possible, you may construct different versions of the same program that correspond to different patterns of use. This often involves overloading functions and procedures. A good indicator of the need for this form of overloading is when you find yourself writing unnecessary code. For example, when working with DBMS_SQL, you will call the DBMS_SQL.EXECUTE function, but for DDL statements, the value returned by this function is ignored. Oracle should have overloaded this function as a procedure, so that I could simply execute a DDL statement like this:
BEGIN DBMS_SQL.EXECUTE ('CREATE TABLE xyz ...'), as opposed to: DECLARE feedback PLS_INTEGER; BEGIN feedback := DBMS_SQL.EXECUTE ('CREATE TABLE xyz ...'),and then ignoring the feedback.
- Overloading by type, not value
This is the least common application of overloading. In this scenario, you use the type of data, not its value, to determine which of the overloaded programs should be executed. This really comes in handy only when you are writing very generic software. DBMS_SQL.DEFINE_COLUMN is a good example of this approach to overloading. I need to tell DBMS_SQL the type of each of my columns being selected from the dynamic query. To indicate a numeric column, I can make a call as follows:
DBMS_SQL.DEFINE_COLUMN (cur, 1, 1);
or I could do this:
DBMS_SQL.DEFINE_COLUMN (cur, 1, DBMS_UTILITY.GET_TIME);
It doesn’t matter which I do; I just need to say “this is a number,” but not any particular number. Overloading is an elegant way to handle this requirement.
Let’s look at an example of the most common type of overloading and then review restrictions and guidelines on overloading.
Use overloading to apply the same action to different kinds or combinations of data. As noted previously, this kind of overloading does not provide a single name for different activities so much as different ways of requesting the same activity. We illustrate this kind of overloading with the DBMS_OUTPUT.PUT_LINE procedure, which doesn’t even overload for the Boolean datatype.
Here is the relevant part of the DBMS_OUTPUT package specification:
CREATE OR REPLACE PACKAGE DBMS_OUTPUT AS PROCEDURE put_line (a VARCHAR2); PROCEDURE put_line (a NUMBER); END DBMS_OUTPUT;
And that’s it for overloadings of PUT_LINE! As mentioned above, this overloading is very inadequate. You cannot even ask DBMS_OUTPUT to display a Boolean variable’s value, for example. To see such a value, you must write an IF statement, as in:
IF l_student_is_registered
THEN
DBMS_OUTPUT.PUT_LINE ('TRUE'),
ELSE
DBMS_OUTPUT.PUT_LINE ('FALSE'),
END IF;Now, isn’t that silly? And a big waste of your time? Fortunately, it is very easy to fix this problem. Just build your own package, with lots of overloadings, on top of DBMS_OUTPUT.PUT_LINE. Here is a very abbreviated example of such a package. You can extend it easily, as I do with the do.pl procedure (why type all those characters just to say “show me,” right?). A portion of the package specification is shown here:
/* File on web: do.pkg */
CREATE OR REPLACE PACKAGE DO
IS
PROCEDURE pl (boolean_in IN BOOLEAN);
/* Display a string. */
PROCEDURE pl (char_in IN VARCHAR2);
/* Display a string and then a Boolean value. */
PROCEDURE pl (
char_in IN VARCHAR2,
boolean_in IN BOOLEAN
);
PROCEDURE pl (xml_in IN SYS.XMLType);
END DO;This package simply sits on top of DBMS_OUTPUT.PUT_LINE and enhances it. With do.pl, I can now display a Boolean value without writing my own IF statement, as in:
DECLARE
v_is_valid BOOLEAN :=
book_info.is_valid_isbn ('5-88888-66'),
BEGIN
do.pl (v_is_valid);Better yet, I can get really fancy and even apply do.pl to complex datatypes like XMLType:
/* File on web: xmltype.sql */
DECLARE
one_report XMLTYPE;
BEGIN
SELECT ea.report INTO one_report
FROM env_analysis ea
WHERE company = 'SMOKESTAX INC';
do.pl (one_report);
END;There are several restrictions on how you can overload programs. When the PL/SQL engine compiles and runs your program, it has to be able to distinguish between the different overloaded versions of a program; after all, it can’t run two different modules at the same time. So when you compile your code, PL/SQL will reject any improperly overloaded modules. It cannot distinguish between the modules by their names because by definition they are the same in all overloaded programs. Instead, PL/SQL uses the parameter lists of these sibling programs to determine which one to execute and/or the types of the programs (procedure versus function). As a result, the following restrictions apply to overloaded programs
- The datatype “family” of at least one of the parameters of overloaded programs must differ
INTEGER, REAL, DECIMAL, FLOAT, etc., are NUMBER subtypes. CHAR, VARCHAR2, and LONG are character subtypes. If the parameters differ only by datatype within the supertype or family of datatypes, PL/SQL does not have enough information to determine the appropriate program to execute.
- Overloaded programs with parameter lists that differ only by name must be called using named notation
If you don’t use the name of the argument, how can the compiler distinguish between calls to two overloaded programs? Please note, however, that it is always risky to use named notation as an enforcement paradigm. You should avoid situations where named notation yields different semantic meaning from positional notation.
- The parameter list of overloaded programs must differ by more than parameter mode
Even if a parameter in one version is IN and that same parameter in another version is IN OUT, PL/SQL cannot tell the difference at the point in which the program is called.
- All of the overloaded programs must be defined within the same PL/SQL scope or block (anonymous block, standalone procedure or function, or package)
You cannot define one version in one block (scope level) and define another version in a different block. You cannot overload two standalone programs; one simply replaces the other.
- Overloaded functions must differ by more than their return type (the datatype specified in the RETURN clause of the function)
At the time that the overloaded function is called, the compiler doesn’t know what type of data that function will return. The compiler therefore cannot determine which version of the function to use if all the parameters are the same.
Starting with Oracle Database 10g Release 1, you can now overload two subprograms if their formal parameters differ only in numeric datatype. Before getting into the details, let’s look at an example. Consider the following block:
DECLARE
PROCEDURE proc1 (n IN PLS_INTEGER) IS
BEGIN
DBMS_OUTPUT.PUT_LINE ('pls_integer version'),
END;
PROCEDURE proc1 (n IN NUMBER) IS
BEGIN
DBMS_OUTPUT.PUT_LINE ('number version'),
END;
BEGIN
proc1 (1.1);
proc1 (1);
END;When I try to run this code in Oracle9i Database, I get an error:
ORA-06550: line 14, column 4: PLS-00307: too many declarations of 'PROC1' match this call
When I run this same block in Oracle Database 10g, however, I see the following results:
number version pls_integer version
The PL/SQL compiler is now able to distinguish between the two calls. Notice that it called the “number version” when I passed a noninteger value. That’s because PL/SQL looks for numeric parameters that match the value, and it follows this order of precedence in establishing the match: it starts with PLS_INTEGER or BINARY_INTEGER, then NUMBER, then BINARY_FLOAT, and finally BINARY_DOUBLE. It will use the first overloaded program that matches the actual argument values passed.
While it is very nice that Oracle now offers this flexibility, be careful when relying on this very subtle overloading—make sure that it is all working as you would expect. Test your code with a variety of inputs and check the results. Remember that you can pass a string such as “156.4” to a numeric parameter; be sure to try out those inputs as well.
You can also qualify numeric literals and use conversion functions to make explicit which overloading (i.e., which numeric datatype) you want to call. If you want to pass 5.0 as a BINARY_FLOAT, for example, you could specify the value 5.0f or use the conversion function, TO_BINARY_FLOAT(5.0).
PL/SQL is rather fussy about its requirement that you declare elements before using them in your code. Otherwise, how can PL/SQL be sure that the way you are using the construct is appropriate? Because modules can call other modules, however, you may encounter situations where it is completely impossible to define all modules before any references to those modules are made. What if program A calls program B and program B calls program A? PL/SQL supports recursion , including mutual recursion, in which two or more programs directly or indirectly call each other.
If you find yourself committed to mutual recursion, you will be very glad to hear that PL/SQL supports the forward declaration of local modules, which means that modules are declared in advance of the actual definition of that program. This declaration makes that program available to be called by other programs even before the program definition.
Remember that both procedures and functions have a header and a body. A forward declaration consists simply of the program header followed by a semicolon (;). This construction is called the module header. This header, which must include the parameter list (and a RETURN clause if it’s a function), is all the information PL/SQL needs about a module in order to declare it and resolve any references to it.
The following example illustrates the technique of forward declaration. I define two mutually recursive functions within a procedure. Consequently, I have to declare just the header of my second function, total_cost, before the full declaration of net_profit:
PROCEDURE perform_calcs (year_in IN INTEGER)
IS
/* Header only for total_cost function. */
FUNCTION total_cost (...) RETURN NUMBER;
/* The net_profit function uses total_cost. */
FUNCTION net_profit (...) RETURN NUMBER IS
BEGIN
RETURN tot_sales (...) - total_cost (...);
END;
/* The total_cost function uses net_profit. */
FUNCTION total_cost (...) RETURN NUMBER IS
BEGIN
IF <condition based on parameters>
THEN
RETURN net_profit (...) * .10;
ELSE
RETURN <parameter value>;
END IF;
END;
BEGIN
...
END;Here are some rules to remember concerning forward declarations:
You cannot make forward declarations of a variable or cursor. This technique works only with modules (procedures and functions).
The definition for a forwardly declared program must be contained in the declaration section of the same PL/SQL block (anonymous block, procedure, function, or package body) in which you code the forward declaration.
In some situations, forward declarations are absolutely required; in most situations, they just help make your code more readable and presentable. As with every other advanced or unusual feature of the PL/SQL language, use forward declarations only when you really need the functionality. Otherwise, the declarations simply add to the clutter of your program, which is the last thing you want.
The following sections are most appropriate for experienced PL/SQL programmers. Here, I’ll touch on a number of advanced modularization topics, including calling functions in SQL, using table functions, and using deterministic functions.
Oracle allows you to call your own custom-built functions from within SQL. In essence, this flexibility allows you to customize the SQL language to adapt to application-specific requirements.
There are several requirements that a programmer-defined PL/SQL function must meet in order to be callable from within a SQL statement:
The function must be stored in the database. A function defined in a client-side PL/SQL environment cannot be called from within SQL; there would be no way for SQL to resolve the reference to the function.
All of the function’s parameters must use the IN mode. Neither IN OUT nor OUT parameters are allowed in SQL-embedded stored functions; you should never have IN OUT and OUT parameters in functions, period. Whether or not you are going to use that function inside a SQL statement, such parameters constitute side effects of the main purpose of the function, which is to return a single value.
The datatypes of the function’s parameters, as well as the datatype of the RETURN clause of the function, must be recognized within the Oracle server. While all of the Oracle server datatypes are valid within PL/SQL, PL/SQL has added new datatypes that are not (yet) supported in the database. These datatypes include BOOLEAN, BINARY_INTEGER, associative arrays, PL/SQL records, and programmer-defined subtypes.
Prior to Oracle8i Database, functions defined in packages must have an associated RESTRICT_REFERENCES pragma defined for them. If you want to call from SQL a function defined in a package, you will need to add a pragma to the package specification asserting explicitly that this function is valid for SQL execution. See the later section "The PRAGMA RESTRICT_REFERENCES (Oracle8 Database and earlier)" for more details on this step.
Tip
By default, user-defined functions that execute in SQL operate on a single row of data, not on an entire column of data that crosses rows, as the group functions SUM, MIN, and AVG do. It is possible to write aggregate functions to be called inside SQL, but this requires taking advantage of the ODCIAggregate interface , which is part of Oracle’s Extensibility Framework. See the Oracle documentation for more details on this functionality.
In order to guard against nasty side effects and unpredictable behavior, the Oracle RDBMS makes it impossible for your stored function in SQL to take any of the following actions:
The stored function may not modify database tables. It cannot execute an INSERT, DELETE, or UPDATE statement. Note that this restriction is relaxed if your function is defined as an autonomous transaction (described in Chapter 14); in this case, any changes made in your function occur independently of the outer transaction in which the query was executed.
A stored function that is called remotely or through a parallelized action may not read or write the values of package variables. The Oracle Server does not support side effects that cross user sessions.
A stored function can update the values of package variables only if that function is called in a select list, or a VALUES or SET clause. If the stored function is called in a WHERE or GROUP BY clause, it cannot write package variables.
Prior to Oracle8 Database, you can’t call RAISE_APPLICATION_ERROR from within the stored function.
The stored function may not call another module (stored procedure or function) that breaks any of the preceding rules. A function is only as pure as the most impure module that it calls.
The stored function may not reference a view that breaks any of the preceding rules. A view is a stored SELECT statement; that view’s SELECT may use stored functions.
The read consistency model of Oracle is simple and clear: once I start a query, that query will only see data as it existed (was committed in the database) at the time the query was started. So if my query starts at 9:00 a.m. and runs for an hour, then even if another user comes along and changes data, my query will not see those changes.
Yet unless you take special precautions with user-defined functions in your queries, it is quite possible that your query will violate (or, at least, appear to violate) the read consistency model of the Oracle RDBMS. To understand this issue, consider the following query and the function it calls:
SELECT name, total_sales (account_id)
FROM account
WHERE status = 'ACTIVE';
FUNCTION total_sales (id_in IN account.account_id%TYPE)
RETURN NUMBER
IS
CURSOR tot_cur
IS
SELECT SUM (sales) total
FROM orders
WHERE account_id = id_in
AND year = TO_NUMBER (TO_CHAR (SYSDATE, 'YYYY'));
tot_rec tot_cur%ROWTYPE;
BEGIN
OPEN tot_cur;
FETCH tot_cur INTO tot_rec;
RETURN tot_rec.total;
END;The account table has five million active rows in it (a very successful enterprise!). The orders table has 20 million rows. I start the query at 10:00 a.m.; it takes about an hour to complete. At 10:45 a.m., somebody with the proper authority comes along, deletes all rows from the orders table, and performs a commit. According to the read consistency model of Oracle, the session running the query should see all those deleted rows until the query completes. But the next time the total_sales function executes from within the query, it finds no order rows and returns NULL—and will do so until the query completes.
So if you are executing queries inside functions that are called inside SQL, you need to be acutely aware of read-consistency issues. If these functions are called in long-running queries or transactions, you will probably need to issue the following command to enforce read-consistency between SQL statements in the current transaction:
SET TRANSACTION READ ONLY
The DECODE function offers IF-like capabilities in the nonprocedural SQL environment provided by the Oracle Server. You can use the DECODE syntax to create matrix reports with a fixed number of columns or to perform complex IF-THEN-ELSE logic within a query. The downside to DECODE is that it can be difficult to write and very difficult to maintain. Consider the following example of using DECODE to determine whether a date is within the prescribed range and, if so, to add to the count of rows that fulfill this requirement:
SELECT FC.year_number,
SUM (DECODE (GREATEST (ship_date, FC.q1_sdate),
ship_date,
DECODE (LEAST (ship_date, FC.q1_edate),
ship_date, 1,
0),
0)) Q1_results,
SUM (DECODE (GREATEST (ship_date, FC.q2_sdate),
ship_date,
DECODE (LEAST (ship_date, FC.q2_edate),
ship_date, 1,
0),
0)) Q2_results,
SUM (DECODE (GREATEST (ship_date, FC.q3_sdate),
ship_date,
DECODE (LEAST (ship_date, FC.q3_edate),
ship_date, 1,
0),
0)) Q3_results,
SUM (DECODE (GREATEST (ship_date, FC.q4_sdate),
ship_date,
DECODE (LEAST (ship_date, FC.q4_edate),
ship_date, 1,
0),
0)) Q4_results
FROM orders O,
fiscal_calendar FC
GROUP BY year_number;The result set for this query might look like this:
YEAR NUMBER Q1 RESULTS Q2 RESULTS Q3 RESULTS Q4 RESULTS ------------ ---------- ---------- ---------- ---------- 1993 12000 14005 22000 40000 1994 10000 15000 21000 55004
While it is very handy to use DECODE to produce such a report, the SQL required to accomplish the task is more than a little frightening. Here is how you might try to interpret the Q1 RESULTS nested DECODE:
If the ship date is greater than or equal to the first quarter start date and less than or equal to the first quarter end date, then add one to the sum of the total number of orders shipped in that quarter. Otherwise, add zero.
Unfortunately, unless you are experienced in interpreting DECODE statements, you may find it difficult to glean this understanding from that convoluted SQL statement. The repetition in that single SELECT also cries out for modularization, which we can supply with the following stored function (incr_in_range means “increment if in the range”):
FUNCTION incr_in_range
(ship_date_in IN DATE, sdate_in IN DATE, edate_in IN DATE)
RETURN INTEGER
IS
BEGIN
IF ship_date_in BETWEEN sdate_in AND edate_in
THEN
RETURN 1;
ELSE
RETURN 0;
END IF;
END;Yep, that’s all there is to it! With the incr_in_range function, that long and winding SELECT statement simply becomes:
SELECT FC.year_number,
SUM (incr_in_range (ship_date, q1_sdate, q1_edate)) Q1_results,
SUM (incr_in_range (ship_date, q2_sdate, q2_edate)) Q2_results,
SUM (incr_in_range (ship_date, q3_sdate, q3_edate)) Q3_results,
SUM (incr_in_range (ship_date, q4_sdate, q4_edate)) Q4_results
FROM orders O,
fiscal_calendar FC
GROUP BY year_number;This stored function gets rid of the code redundancy and makes the SELECT statement much more readable. In addition, this function could be used in other SQL statements to perform the same logic.
Prior to Oracle8i Database, if you wanted to invoke within SQL a function that was defined inside a package specification, you would have had to provide a RESTRICT_REFERENCES pragma (a compiler directive or instruction) for that function. This pragma asserts the “purity level” of the function, in essence promising Oracle that the function has the specified side effects (or, more to the point, lack thereof).
Working with the RESTRICT_REFERENCES pragma can be very frustrating, so it was a great relief to many a PL/SQL developer when in Oracle8i Database this pragma was made unnecessary. However, this section talks briefly about some of the rules associated with this pragma for those still using Oracle8 Database and earlier.
You need a separate PRAGMA statement for each packaged function you wish to use in a SQL statement, and it must come after the function declaration in the package specification. To assert a purity level with the pragma, use the following syntax:
PRAGMA RESTRICT_REFERENCES
(function_name, WNDS [, WNPS] [, RNDS] [, RNPS])where function_name is the name of the function whose purity level you wish to assert, and the four codes have the following meanings:
- WNDS
Writes No Database State. Asserts that the function does not modify any database tables.
- WNPS
Writes No Package State. Asserts that the function does not modify any package variables.
- RNDS
Reads No Database State. Asserts that the function does not read any database tables.
- RNPS
Reads No Package State. Asserts that the function does not read any package variables.
Here is an example of two different purity-level assertions for functions in the company_financials package:
PACKAGE company_financials
IS
FUNCTION company_type (type_code_in IN VARCHAR2)
RETURN VARCHAR2;
FUNCTION company_name (
company_id_in IN company.company_id%TYPE)
RETURN VARCHAR2;
PRAGMA RESTRICT_REFERENCES (
company_type, WNDS, RNDS, WNPS, RNPS);
PRAGMA RESTRICT_REFERENCES (company_name, WNDS, WNPS, RNPS);
END company_financials;In this package, the company_name function reads from the database to obtain the name for the specified company. Notice that I placed both pragmas together at the bottom of the package specification; the pragma does not need to immediately follow the function specification. I also went to the trouble of specifying the WNPS and RNPS arguments for both functions. Oracle recommends that you assert the highest possible purity levels so that the compiler will never reject the function unnecessarily.
Tip
If a function you want to call in SQL calls a procedure or function in a package, you must also provide a RESTRICT_REFERENCES pragma for that program. You cannot call a procedure directly in SQL, but if it is going to be executed indirectly from within SQL, it still must follow the rules.
If your function violates its pragma, you will receive the error, PLS-00452: subprogram ‘program’ violates its associated pragma. Suppose, for example, that the body of the company_financials package looks like this:
CREATE OR REPLACE PACKAGE BODY company_financials
IS
FUNCTION company_type (type_code_in IN VARCHAR2)
RETURN VARCHAR2
IS
v_sal NUMBER;
BEGIN
SELECT sal INTO v_sal FROM emp WHERE empno = 1;
RETURN 'bigone';
END;
FUNCTION company_name (company_id_in IN company.company_id%TYPE)
RETURN VARCHAR2
IS
BEGIN
UPDATE emp SET sal = 0;
RETURN 'bigone';
END;
END company_financials;When I attempt to compile this package body I will get the following error:
3/4 PLS-00452: Subprogram 'COMPANY_TYPE' violates its associated pragma
because the company_type function reads from the database, and I have asserted the RNDS purity level. If I remove that silly SELECT statement, I will then receive this error:
11/4 PLS-00452: Subprogram 'COMPANY_NAME' violates its associated pragma
because the company_name function updates the database, and I have asserted the WNDS level. You will sometimes look at your function and say, “Hey, I absolutely do not violate my purity level. There is no UPDATE, DELETE, or UPDATE around.” Maybe not. But there is a good chance that you are calling a built-in package or in some other way breaking the rules. Again, if you are running Oracle8i Database and above, you no longer need to deal with RESTRICT_REFERENCES. The runtime engine will automatically check your code for any violations.
A table function is a function that can be called from within the FROM clause of a query, as if were a relational table. Table functions return collections (nested tables or VARRAYs), which can then be transformed with the TABLE operator into a structure that can be queried using the SQL language. Table functions come in very handy when you need to:
Perform very complex transformations of data, requiring the use of PL/SQL, but need to access that data from within an SQL statement.
Pass complex result sets back to the host (that is, non-PLSQL) environment. You can open a cursor variable for a query based on a table function, and let the host environment fetch through the cursor variable.
There are two kinds of table functions that merit special mention and attention in our examples:
- Streaming functions
Data streaming means that you can pass from one process or stage to another without having to rely on intermediate structures. Table functions, in conjunction with the CURSOR expression, enable you to stream data through multiple transformations, all within a single SQL statement.
- Pipelined functions
These functions return a result set in pipelined fashion, meaning that data is returned while the function is still executing. Add the PARALLEL_ENABLE to a pipelined function’s header, and you have a function that will execute in parallel within a parallel query.
Let’s explore how to define table functions and put them to use in your application.
To call a function from within a FROM clause, you must do the following:
Define the RETURN datatype of the function to be a collection (either a nested table or a VARRAY).
Make sure that all of the other parameters to the function are of mode IN and have SQL datatypes. (You cannot, for example, call a function with a Boolean or record type argument inside a query.)
Embed the call to the function inside the TABLE operator (if you are running Oracle8i Database, you will also need to use the CAST operator).
Here is an example that works for Oracle8i Database, Oracle9i Database, and Oracle Database 10g. First, I will create a nested table type based on an object type of pets:
/* File on web: pet_family.sql */ CREATE TYPE pet_t IS OBJECT ( NAME VARCHAR2 (60), breed VARCHAR2 (100), dob DATE); CREATE TYPE pet_nt IS TABLE OF pet_t;
Now I will create a function named pet_family. It accepts two pet objects as arguments: the mother and the father. Then, based on the breed, it returns a nested table with the entire family defined in the collection:
CREATE OR REPLACE FUNCTION pet_family (dad_in IN pet_t, mom_in IN pet_t)
RETURN pet_nt
IS
l_count PLS_INTEGER;
retval pet_nt := pet_nt ();
PROCEDURE extend_assign (pet_in IN pet_t) IS
BEGIN
retval.EXTEND;
retval (retval.LAST) := pet_in;
END;
BEGIN
extend_assign (dad_in);
extend_assign (mom_in);
IF mom_in.breed = 'RABBIT' THEN l_count := 12;
ELSIF mom_in.breed = 'DOG' THEN l_count := 4;
ELSIF mom_in.breed = 'KANGAROO' THEN l_count := 1;
END IF;
FOR indx IN 1 .. l_count
LOOP
extend_assign (pet_t ('BABY' || indx, mom_in.breed, SYSDATE));
END LOOP;
RETURN retval;
END;Tip
The pet_family function is silly and trivial; the point to understand here is that your PL/SQL function may contain extremely complex logic—whatever is required within your application and can be accomplished with PL/SQL—that exceeds the expressive capabilities of SQL.
Now I can call this function in the FROM clause of a query, as follows:
SQL>SELECT pets.NAME, pets.dob2FROM TABLE (pet_family (4pet_t ('Hoppy', 'RABBIT', SYSDATE),5pet_t ('Hippy', 'RABBIT', SYSDATE)6) AS pet_nt7) pets;NAME DOB ---------- --------- Hoppy 27-FEB-02 Hippy 27-FEB-02 BABY1 27-FEB-02 BABY2 27-FEB-02 ... BABY11 27-FEB-02 BABY12 27-FEB-02
If you are running Oracle8i Database, the above query will need to also include an explicit CAST operation as follows:
SELECT pets.NAME, pets.dob
FROM TABLE (CAST (pet_family (
pet_t ('Hoppy', 'RABBIT', SYSDATE)
, pet_t ('Hippy', 'RABBIT', SYSDATE)
) AS pet_nt
)) pets;Table functions help overcome a problem that developers have encountered in the past—namely, how do I pass data that I have produced through PL/SQL-based programming (i.e., the data is not intact inside one or more tables in the database) back to a non-PL/SQL host environment? Cursor variables allow me to easily pass back SQL-based result sets to, say, Java programs, because cursor variables are supported in JDBC. Yet if I first need to perform complex transformations in PL/SQL, how then do I offer that data to the calling program?
Now, we can combine the power and flexibility of table functions with the wide support for cursor variables in non-PL/SQL environments (explained in detail in Chapter 15) to solve this problem.
Suppose, for example, that I need to generate a pet family (bred through a call to the pet_family function, as shown in the previous section) and pass those rows of data to a frontend application written in Java. I can do this very easily as follows:
/* File on web: pet_family.sql */
CREATE OR REPLACE FUNCTION pet_family_cv
RETURN SYS_REFCURSOR
IS
retval SYS_REFCURSOR;
BEGIN
OPEN retval FOR
SELECT *
FROM TABLE (pet_family (pet_t ('Hoppy', 'RABBIT', SYSDATE)
, pet_t ('Hippy', 'RABBIT', SYSDATE)
)
);
RETURN retval;
END pet_family_cv;In this program, I am taking advantage of the predefined weak REF CURSOR type , SYS_REFCURSOR (introduced in Oracle9i Database), to declare a cursor variable. I “OPEN FOR” this cursor variable, associating with it the query that is built around the pet_family table function.
I can then pass this cursor variable back to the Java front end. Because JDBC recognizes cursor variables, the Java code can then easily fetch the rows of data and integrate them into the application.
A streaming function accepts as a parameter a result set (via a CURSOR expression) and returns a result set in the form of a collection. Because you can apply the TABLE operator to this collection and then query from it in a SELECT statement, these functions can perform one or more transformations of data within a single SQL statement.
Support for streaming functions was added in Oracle9i Database and can be used to hide algorithmic complexity behind a function interface and thus simplify the SQL in your application. We will walk through an example to explain the kinds of steps you will need to go through yourself to take advantage of table functions in this way.
Consider the following scenario. I have a table of stock ticker information that contains a single row for the open and close prices of stock:
CREATE TABLE StockTable ( ticker VARCHAR2(10), open_price NUMBER, close_price NUMBER);
I need to transform (or pivot) that information into another table:
CREATE TABLE TickerTable ( ticker VARCHAR2(10), PriceType VARCHAR2(1), price NUMBER);
In other words, a single row in StockTable becomes two rows in TickerTable. There are many ways to achieve this goal. A very traditional and straightforward approach in PL/SQL might look like this:
FOR rec IN (SELECT * FROM stocktable)
LOOP
INSERT INTO tickertable
(ticker, pricetype, price)
VALUES (rec.ticker, 'O', rec.open_price);
INSERT INTO tickertable
(ticker, pricetype, price)
VALUES (rec.ticker, 'C', rec.close_price);
END LOOP;There are also 100% SQL solutions, such as:
INSERT ALL
INTO tickertable
(ticker, pricedate, pricetype, price
)
VALUES (ticker, trade_date, 'O', open_price
)
INTO tickertable
(ticker, pricedate, pricetype, price
)
VALUES (ticker, trade_date, 'C', close_price
)
SELECT ticker, trade_date, open_price, close_price
FROM stocktable;Let’s assume, however, that the transformation that I must perform to move data from stocktable to tickertable is very complex and requires the use of PL/SQL. In this situation, a table function used to stream the data as it is transformed would offer a much more efficient solution.
First of all, if I am going to use a table function, I will need to return a nested table or VARRAY of data. I will use a nested table because VARRAYs require the specification of a maximum size, and I don’t want to have that restriction in my implementation. This nested table type must be defined as a schema-level element because the SQL engine must be able to resolve a reference to a collection of this type.
I would like to return a nested table based on the table definition itself. That is, I would like it to be defined as follows:
CREATE TYPE tickertype_nt IS TABLE of tickertype%ROWTYPE;
Unfortunately, this statement will fail because %ROWTYPE is not a SQL-recognized type. That attribute is available only inside a PL/SQL declaration section. So I must instead create an object type that mimics the structure of my relational table, and then define a nested table TYPE against that object type.
CREATE TYPE TickerType AS OBJECT ( ticker VARCHAR2(10), PriceType VARCHAR2(1), price NUMBER); CREATE OR REPLACE TYPE TickerTypeSet AS TABLE OF TickerType; /
For my table function to stream data from one stage of transformation to the next, it will have to accept as its argument a set of data, in essence, a query. The only way to do that is to pass in a cursor variable, so I will need a REF CURSOR type to use in the parameter list of my function.
I create a package to hold the REF CURSOR type based on my new nested table type:
CREATE OR REPLACE PACKAGE refcur_pkg IS TYPE refcur_t IS REF CURSOR RETURN StockTable%ROWTYPE; END refcur_pkg;
Finally, I can write my stock pivot function:
/* File on web: tabfunc_streaming.sql */ 1 CREATE OR REPLACE FUNCTION stockpivot (dataset refcur_pkg.refcur_t) 2 RETURN tickertypeset 3 IS 4 l_row_as_object tickertype := tickertype (NULL, NULL, NULL, NULL); 5 l_row_from_query dataset%ROWTYPE; 6 retval tickertypeset := tickertypeset (); 7 BEGIN 8 LOOP 9 FETCH dataset 10 INTO l_row_from_query; 11 12 EXIT WHEN dataset%NOTFOUND; 13 -- 14 l_row_as_object.ticker := l_row_from_query.ticker; 15 l_row_as_object.pricetype := 'O'; 16 l_row_as_object.price := l_row_from_query.open_price; 17 l_row_as_object.pricedate := l_row_from_query.trade_date; 18 retval.EXTEND; 19 retval (retval.LAST) := l_row_as_object; 20 -- 21 l_row_as_object.pricetype := 'C'; 22 l_row_as_object.price := l_row_from_query.close_price; 23 l_row_as_object.pricedate := l_row_from_query.trade_date; 24 retval.EXTEND; 25 retval (retval.LAST) := l_row_as_object; 26 END LOOP; 27 28 CLOSE dataset; 29 30 RETURN retval; 31 * END stockpivot;
As with the pet_family function, the specifics of this program are not important, and your own transformation logic will be qualitatively more complex. The basic steps performed here, however, will likely be repeated in your own code, so we will review them.
Line(s) | Description |
|---|---|
1-2 | The function header: pass in a result set as a cursor variable, and return a nested table based on the object type. |
4 | Declare a local object, which will be used to populate the nested table. |
5 | Declare a local record based on the table. This will be populated by the FETCH from the cursor variable. |
6 | The local nested table that will be returned by the function. |
8-12 | Start up a simple loop to fetch each row separately from the cursor variable, terminating the loop when no more data is in the cursor. |
14-19 | Use the “open” data in the record to populate the local object, and then place it in the nested table, after EXTENDing to define the new row. |
21-25 | Use the “open” data in the record to populate the local object, and then place it in the nested table, after EXTENDing to define the new row. |
28-30 | Close the cursor and return the nested table. Mission completed. Really. |
And now that I have this function in place to do all the fancy, but necessary footwork, I can use it inside my query to stream data from one table to another:
BEGIN
INSERT INTO tickertable
SELECT *
FROM TABLE (stockpivot (CURSOR (SELECT *
FROM stocktable)));
END;
/My inner SELECT retrieves all rows in the stocktable. The CURSOR expression around that query transforms the result set into a cursor variable, which is passed to stockpivot. That function returns a nested table, and the TABLE operator then translates it into a relational table format that can be queried.
It may not be magic, but it is a bit magical, wouldn’t you say? Well, if you think a streaming function is special, check out pipelined functions!
A pipelined function is a table function that returns a result set as a collection but does so asynchronous to the termination of the function. In other words, Oracle no longer waits for the function to run to completion, storing all the rows it computes in the PL/SQL collection, before it delivers the first rows. Instead, as each row is ready to be assigned into the collection, it is piped out of the function.
Let’s take a look at a rewrite of the stockpivot function and see more clearly what is needed to build pipelined functions:
/* File on web: tabfunc_pipelined.sql */ 1 CREATE OR REPLACE FUNCTION stockpivot (dataset refcur_pkg.refcur_t) 2 RETURN tickertypeset PIPELINED 3 IS 4 l_row_as_object tickertype := tickertype (NULL, NULL, NULL, NULL); 5 l_row_from_query dataset%ROWTYPE; 6 BEGIN 7 LOOP 8 FETCH dataset INTO l_row_from_query; 9 EXIT WHEN dataset%NOTFOUND; 10 11 -- first row 12 l_row_as_object.ticker := l_row_from_query.ticker; 13 l_row_as_object.pricetype := 'O'; 14 l_row_as_object.price := l_row_from_query.open_price; 15 l_row_as_object.pricedate := l_row_from_query.trade_date; 16 PIPE ROW (l_row_as_object); 17 18 -- second row 19 l_row_as_object.pricetype := 'C'; 20 l_row_as_object.price := l_row_from_query.close_price; 21 l_row_as_object.pricedate := l_row_from_query.trade_date; 22 PIPE ROW (l_row_as_object); 23 END LOOP; 24 25 CLOSE dataset; 26 RETURN; 27 * END;
The following table notes several changes to our original functionality:
Line(s) | Description |
|---|---|
2 | The only change from the original stockpivot function is the addition of the PIPELINED keyword. |
4-5 | I declare a local object and local record, as with the first stockpivot. What’s striking about these lines is what I don’t declare—namely, the nested table that will be returned by the function. A hint of what is to come ... |
7-9 | Start up a simple loop to fetch each row separately from the cursor variable, terminating the loop when no more data is in the cursor. |
12-15 and 19-21 | Populate the local object for the open and close tickertable rows to be placed in the nested table. |
16 and 22 | Use the PIPE ROW statement (valid only in pipelined functions) to “pipe” the objects immediately out from the function. |
26 | At the bottom of the executable section, the function doesn’t return anything! Instead, it calls the unqualified RETURN (formerly allowed only in procedures) to return control to the calling block. The function already returned all of its data with the PIPE ROW statements. |
You can call the pipelined function as you would the nonpipelined version. You won’t see any difference in behavior, unless you set up the pipelined function to be executed in parallel as part of a parallel query (covered in the next section) or include logic that takes advantage of the asynchronous return of data.
Consider, for example, a query that uses the ROWNUM pseudo-column to restrict the rows of interest:
BEGIN
INSERT INTO tickertable
SELECT *
FROM TABLE (stockpivot (CURSOR (SELECT *
FROM stocktable)))
WHERE ROWNUM < 10;
END;My tests show that on Oracle Database 10g, if I pivot 100,000 rows into 200,000, and then return only the first 9 rows, the pipelined version completes its work in 0.2 seconds, while the nonpipelined version took 4.6 seconds.
Clearly, piping rows back does work and does make a noticeable difference!
One enormous step forward for PL/SQL, introduced first in Oracle9i Database, is the ability to execute functions within a parallel query context. Prior to Oracle9i Database, a call to a PL/SQL function inside SQL caused serialization of that query—a major problem for data warehousing applications. With Oracle9i Database and Oracle Database 10g, you can now add information to the header of a pipelined function to instruct the runtime engine how the data set being passed into the function should be partitioned for parallel execution.
In general, if you would like your function to execute in parallel, it must have a single, strongly typed REF CURSOR input parameter.[*]
Here are some examples:
Specify that the function can run in parallel and that the data passed to that function can be partitioned arbitrarily:
CREATE OR REPLACE FUNCTION my_transform_fn ( p_input_rows in employee_info.recur_t ) RETURN employee_info.transformed_t PIPELINED PARALLEL_ENABLE ( PARTITION p_input_rows BY ANY )In this example, the keyword ANY expresses the programmer’s assertion that the results are independent of the order in which the function gets the input rows. When this keyword is used, the runtime system randomly partitions the data among the query slaves. This keyword is appropriate for use with functions that take in one row, manipulate its columns, and generate output rows based on the columns of this row only. If your program has other dependencies, the outcome will be unpredictable.
Specify that the function can run in parallel, that all the rows for a given department go to the same slave, and that all of these rows are delivered consecutively:
CREATE OR REPLACE FUNCTION my_transform_fn ( p_input_rows in employee_info.recur_t ) RETURN employee_info.transformed_t PIPELINED CLUSTER P_INPUT_ROWS BY (department) PARALLEL_ENABLE ( PARTITION P_INPUT_ROWS BY HASH (department) )Oracle uses the term clustered to signify this type of delivery, and cluster key for the column (in this case, “department”) on which the aggregation is done. But significantly, the algorithm does not care in what order of cluster key it receives each successive cluster, and Oracle doesn’t guarantee any particular order here. This allows for a quicker algorithm than if rows were required to be clustered and delivered in the order of the cluster key. It scales as order N rather than order N.log(N), where N is the number of rows.
In this example, we can choose between HASH (department) and RANGE (department), depending on what we know about the distribution of the values. HASH is quicker than RANGE and is the natural choice to be used with CLUSTER...BY.
Specify that the function can run in parallel and that the rows that are delivered to a particular slave process, as directed by PARTITION ... BY (for that specified partition), will be locally sorted by that slave. The effect will be to parallelize the sort:
CREATE OR REPLACE FUNCTION my_transform_fn ( p_input_rows in employee_info.recur_t ) RETURN employee_info.transformed_t PIPELINED ORDER P_INPUT_ROWS BY (C1) PARALLEL_ENABLE ( PARTITION P_INPUT_ROWS BY RANGE (C1) )
Because the sort is parallelized, there should be no ORDER...BY in the SELECT used to invoke the table function. (In fact, an ORDER...BY clause in the SELECT statement would subvert the attempt to parallelize the sort.) Thus it’s natural to use the RANGE option together with the ORDER...BY option. This will be slower than CLUSTER...BY, and so should be used only when the algorithm depends on it.
Tip
The CLUSTER...BY construct can’t be used together with the ORDER...BY in the declaration of a table function. This means that an algorithm that depends on clustering on one key, c1, and then on ordering within the set row for a given value of c1 by, say, c2, would have to be parallelized by using the ORDER ... BY in the declaration in the table function.
A function is called deterministic if it returns the same result value whenever it is called with the same values for its arguments. The following function (a simple encapsulation on top of SUBSTR) is such a function:
CREATE OR REPLACE FUNCTION betwnStr (
string_in IN VARCHAR2,start_in IN INTEGER, end_in IN INTEGER
)
RETURN VARCHAR2 IS
BEGIN
RETURN (
SUBSTR (string_in, start_in, end_in - start_in + 1));
END;As long as I pass in, for example, “abcdef” for the string, 3 for the start, and 5 for the end, betwnStr will always return “cde.” Now, if that is the case, why not have Oracle save the results associated with a set of arguments? Then when I next call the function with those arguments, it can return the result without executing the function!
You can achieve this effect by adding the DETERMINISTIC clause to the function’s header, as in the following:
CREATE OR REPLACE FUNCTION betwnStr (
string_in IN VARCHAR2,start_in IN INTEGER, end_in IN INTEGER
)
RETURN VARCHAR2 DETERMINISTIC IS
BEGIN
RETURN (
SUBSTR (
string_in, start_in, end_in - start_in + 1));
END;The decision to use a saved copy of the function’s return result (if such a copy is available) is made by the Oracle query optimizer. Saved copies can come from a materialized view, a function-based index, or a repetitive call to the same function in the same SQL statement.
Tip
You must declare a function DETERMINISTIC in order for it to be called in the expression of a function-based index, or from the query of a materialized view if that view is marked REFRESH FIRST or ENABLE QUERY REWRITE.
Oracle has no way of reliably checking to make sure that the function you declare to be deterministic actually is free of any side effects. It is up to you to use this feature responsibly. Your deterministic function should not rely on package variables, nor should it access the database in a way that might affect the result set.
As the PL/SQL language and Oracle tools mature, you will find that you are being asked to implement increasingly complex applications with this technology. To be quite frank, you don’t have much chance of success with such large-scale projects without an intimate familiarity with the modularization techniques available in PL/SQL.
While this book cannot possibly provide a full treatment of modularization in PL/SQL, it should give you some solid pointers and a foundation on which to build. There is still much more for you to learn: the full capabilities of packages, the awesome range of package extensions that Oracle now provides with the tools and database, the various options for code reusability, and more.
Behind all that technology, however, you must develop an instinct, a sixth sense, for modularization. Develop a deep and abiding allergy to code redundancy and to the hardcoding of values and formulas. Apply a fanatic’s devotion to the modular construction of true black boxes that easily plug-and-play in and across applications.
You will find yourself spending more time in the design phase and less time in debug mode. Your programs will be more readable and more maintainable. They will stand as elegant testimonies to your intellectual integrity. You will be the most popular kid in the class. But enough already! I am sure you are properly motivated.
Go forth and modularize!