
In Figure 2.2 through Figure 2.4, we’ve referred to the connection networks used in cluster, MPP, and NUMA architectures as high-speed interconnects . Performance of this interconnect is an important consideration in parallel architectures. Interconnect performance is measured in two dimensions: bandwidth and latency. Bandwidth is the rate at which data can be moved between nodes and is measured in megabytes (MB) per second. Latency is defined as the time spent in setting up access to a remote node so that communications can occur. Interconnects should have low latency in order to maximize the number of messages that can be set up and placed on the interconnect in a given period of time. As the number of nodes in a configuration increases, more data and messages are passed around between nodes. It’s important that the interconnect have a high enough bandwidth and a low enough latency to support this message traffic.
Cluster interconnects often are implemented using standard LAN-based technology such as Ethernet or Fiber Distributed Data Interchange (FDDI). When a cluster is configured with a large number of nodes, the limitations of the network can degrade performance. The bandwidth and latency of the cluster interconnect is the key to improving the scalability of a cluster.
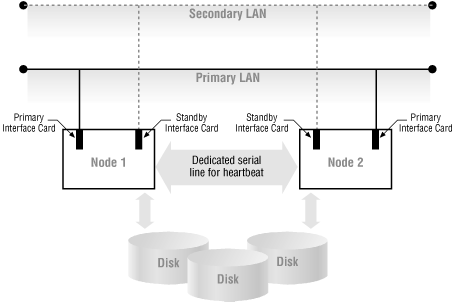
Figure 2.5 shows a sample network configuration in a two-node cluster. Nodes in the cluster are connected to the network with both primary and standby interface cards. When the primary interface fails, the operating system switches the IP address assigned to the primary interface to the standby interface, and the system continues to operate. In addition to redundant network interface cards, a secondary LAN also is provided. In the event that the primary LAN fails, the secondary LAN will take over, and the cluster will continue to operate.
The interconnect in IBM RS/6000 (an MPP architecture) is referred to as a high-performance switch (HPS). The switch architecture is such that as the number of nodes is increased in an MPP system, switching components are added to maintain node-to-node bandwidth. Because of this feature, HPS scales well and can support a large number of nodes. RS/6000 SP systems have latency on the order of a microsecond, and peak node-to-node bandwidth of 100 MB per second.
IBM uses a low-latency connection network called IQ-link for their NUMA-Q systems. IQ-link is based on a recently developed technology called a scalable coherent interconnect (SCI) and provides a bandwidth of 1 GB per second. When data is not available in local memory, SCI transmits the data request to the remote node. The remote node then sends the requested data back to the node that requested it. This interconnect creates a large, single, coherent view of all the memory from the individual SMP groups that make up the NUMA system.