
I am far from thinking that nomenclature is a remedy for every defect in art or science: still I cannot but feel that confusion of terms generally springs from, and always leads to, confusion of ideas. | ||
| --John Louis Petit, Architectural Studies in France, 1854[1] | ||
A problem well stated is a problem half solved. | ||
| --Charles Kettering | ||
Now that we have concluded that networking is best modeled as a single repeating layer and reviewed some of the results we have arrived at over the past 30 years, we can construct the elements of a general model of networking, a Platonic ideal, that we can use both to analyze our previous work and to use as a guide going forward. Over the past decade or so, we have seen a growing attitude that the only criteria for measuring a solution was whether it could be made to work. The trouble is that with software anything can be made to work. This may be acceptable in some engineering domains, but this doesn’t really tell us much about the nature of the problem. It isn’t science. In science, the solution to any problem must always be evaluated in terms of “the theory.” It is either consistent with the theory or it is not. And if not, we must determine what is wrong with the solution or what is wrong with the theory.[2] The task of science is constructing and testing theories. The task of building things from those theories is engineering. The question then is how do we evaluate theories. In most sciences, theories attempt to describe and predict observations of important aspects of Nature and come as close as possible to achieving Newton’s Regulae Philosophandi. In computing systems, there is not much Nature we can draw on, so we must rely more heavily on Newton.
Over the past six chapters, we have uncovered several elements of the model we came to in last chapter. Now we need to assemble the elements of the model and describe its operation in one place. As we saw in the preceding chapter, a layer is a distributed IPC application, embodied as a collection of processes cooperating to manage a particular range of bandwidth and QoS. Not all layers will require the full complement of functionality and, in some cases, will require only minimal functionality. The components outlined here should not be taken as an implementation strategy, but a logical model. Although the model will be described in terms of a single layer, the reader should be aware that this is probably not the preferred implementation strategy (at least not how I would do it), and as always there will be advantages to different implementation strategies for specific environments. For now, you should concentrate on shifting your mindset from the traditional networking model of custom static layers to thinking in terms of distributed applications that provide IPC recursively. This isn’t as easy as it sounds.
We need to introduce terminology for various common elements. This will facilitate describing the behavior of a single layer and the operation of multiple layers. We start by introducing this terminology, then progressing to a description of the components, and then how layers are assembled. We will consolidate our gains from the first six chapters taking the opportunity to throw away a few more ladders. Many of these functions have been described elsewhere, and forms of them exist in conventional systems, although not necessarily arranged in this manner. This can be a rather mind-numbing exercise. On the one hand, we want to be reasonably precise and abstract to capture the invariances in their full generality. On the other hand, it needs to be readable and understandable. This is a hard balance to achieve.
One small contribution to readability is to drop the (N)- notation except when it is required to relate to a layer above or below. We will leave the (N)-notation in the definitions to indicate which elements are part of the repeating structure. Some might find the introduction of definitions at the beginning of each section disconcerting. Please bear with me. This avoids having to say everything twice: once to describe it and once to define it. Think of this as defining a family of implementations.
Processing system. The hardware and software capable of supporting tasks that can coordinate with a “test and set” instruction (i.e., the tasks can all atomically reference the same memory).
Computing system. The collection of all processing systems (some specialized) under the same management domain (with no restrictions of their connectivity, but recognizing that for a significant portion of this population the elements of the management domain are directly connected (i.e., one physical hop).
(N)-layer. The collection of application processes cooperating as a distributed application to provide interprocess communication (IPC) (see Figure 7-1).
(N)-distributed-IPC-facility (DIF). A distributed application consisting of at least one IPC application in each participating processing system. The (N)-DIF provides IPC services to applications via a set of (N)-API primitives that are used to exchange information with the application’s peer. The corresponding application processes may be in other processing systems. This definition makes IPC in a single processing system a degenerate close.
Application process, AP. The instantiation of a program executing in a processing system intended to accomplish some purpose. An application contains one or more application protocol machines.[3]
Distributed application. A collection of cooperating APs that exchange information using IPC and maintain shared state.
(N)-IPC-process. An AP that is a member of (N)-DIF and implements locally the functionality to support IPC using multiple subtasks.
(N)-protocol. The syntax of PDUs, and associated set of procedures, which specifies the behavior between two (N)-PMs for the purpose of maintaining coordinated shared state.
(N)-protocol-machine, (N)-PM. A finite state machine that implements an (N)-protocol, which exchanges PDUs with a peer to maintain shared state with a corresponding (N)-PM, usually in another processing system.
(N)-API-primitive. A library or system call used by an application or an application-protocol to invoke system functions, in particular IPC functions, such as requesting the allocation of IPC resources.
(N)-service-data-unit, (N)-SDU. A contiguous unit of data passed by an APM in an IPC API primitive whose integrity is to be maintained when delivered to a corresponding application protocol machine.
(N)-protocol-data-unit, (N)-PDU. The unit of data exchange by (N)-PMs consisting of (N)-PCI and (N)-user-data.
(N)-protocol-control-information, (N)-PCI. That portion of an (N)-PDU that is interpreted by the (N)-PM to maintain shared state of the protocol.
(N)-user-data. That portion of an (N)-PDU that is not interpreted and is not interpretable by the (N)-PM and is delivered transparently to its client, as an (N)-SDU. (N)-user-data may consist of part of, precisely one, or more than one (N)-SDU. If more than one (N)-SDU, then SDUs in the (N)-user-data are delimited by the (N)-PCI.
Application protocol. A protocol that is a component of an AP, characterized by modifying state external to the protocol.
Application PM, APM. The instantiation of an application protocol within an application. Even though the communicating applications may be different, communicating application PMs must support the same application protocol.
(N)-data-transfer-protocol. An (N)-protocol used by an (N)-DIF to transparently deliver (N)-user-data with specific characteristics; except for the transparent sending or receiving of (N)-SDUs, all operations of the protocol are internal to the state of the protocol.
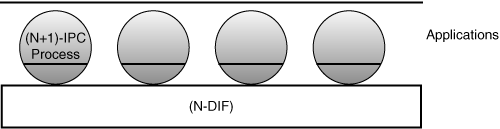
Fundamentally, we are concerned with applications communicating via an IPC facility. The case we will be most interested in is when the applications execute on separate processing systems. The case of applications communicating in the same system is a degenerate case of this description. The external behavior of the system is precisely the same, and the functions required are for the most part the same,[4] only the internal mechanisms to accomplish the functions differ.
Although not the primary a subject of this book, it is necessary to say something about the abstract environment that this architecture lives in. Networking is distributed IPC. A distributed IPC facility consists of a collection of two or more (N)-IPC processes.
In this model, we distinguish a processing system and a computing system. This distinction recognizes the inherent distributed-ness that systems are moving toward (and to a large extent are already there).[5] A processing system is represented by all computing resources within the scope of a “test and set” instruction.[6] All peripherals are viewed as specialized processing systems (e.g., disks, screens, keyboard, printers). All communication is accomplished by IPC.[7]
In this model, an operating system consists of three fundamental components: processor scheduling, memory management, and IPC. “Device drivers” are applications, kernel applications, but applications nonetheless.[8] Drivers exist only to manage the various hardware media interfaces (e.g., modem, bus, FireWire, USB, wireless). Interface drivers map the hardware to a logical communication model for the applications running on the hardware. Communication media should be distinguished only by their QoS and bandwidth characteristics, not by assumptions about the applications for which they will be used. The role of device drivers is assumed by applications, in most cases what have been called kernel processes or threads, that use IPC to communicate with a peer.
A computing system is defined to correspond to our traditional view of “my computer” (i.e., the collection of processing systems taken together for a particular purpose). In many cases, these are one physical hop away, but there is no requirement that this be the case. Basically, a computing system is the collection of processing systems under a common management regime.
A layer is a distributed IPC facility, DIF. A distributed IPC facility is a distributed application consisting of at least one IPC process in each processing system participating in the DIF. (Although rare, more than one IPC process in the same processing system may be a member of the same DIF. It is more likely that multiple IPC processes on the same processing system will be members of different DIFs. This would occur with VPNs or DIFs [lower layers] handling specific media.)
Traditionally, the scope of an (N)-layer has been defined as the set of protocol machines that communicate without relaying at the (N+1)-layer. This is still the case. But a more correct characterization would be that the scope of an (N)-layer is the set of cooperating IPC processes that comprise an (N)-DIF. Generally, the scope of layers increases with greater N. However, there exist configurations where an (N+1)-DIF may have less scope, such as VPNs or other distributed applications, mail, transaction processing, and so on. Throughout we will speak of DIFs rather than layers.
An (N+1)-DIF with less scope should involve a proper subset of the (N)-DIF processing systems. If an (N+1)-DIF with less scope involves processing systems of more than one (N)-DIF, there is a potential for security compromises potentially allowing corrupting data (viruses and so on) from a less-secure DIF to be introduced to a more-secure DIF.
There can be more than one DIF of the same rank. More frequently, the sets of processing systems participating in different DIFs are mutually exclusive. When this is the case, systems in different (N)-DIF cannot communicate without relaying at the (N+1)-DIF. Communication between peer DIFs within the same processing system must use either an AP with only local knowledge (e.g., a protocol converter or NAT) or with knowledge of a wider scope (for instance, relaying by an (N+1)-DIF).
Applications in the same processing systems may use different DIFs. Note that the (N)- notation does not apply to APs. APs operate over any (N)-DIF that they have access to and has sufficient scope to communicate with any destination AP required. Hence, an application may communicate with more than one DIF at the same time. However, this does create the potential for security compromises. Where security is a concern, the only APs capable of communicating with two or more DIFs should be an (N+1)-IPC process (i.e., a member of an (N+1)-DIF). The operating system would have to enforce this constraint.
For two processes to communicate, they must have some shared “understanding.” There must be a set of objects they have in common and an agreement on a “language” for talking about these objects and for performing operations on them. This common understanding is the protocol specification, and the language is the set of formats of the messages they exchange and the rules governing their generation and action taken when they are received.
A protocol, as indicated by the earlier definition, creates a shared domain of discourse (a fancy term for the set of things they know how to talk about) about a set of objects. A protocol establishes the rules and formats for exchanging PDUs to create and maintain this shared state and is implemented by a finite state machine. (This is a constraint. All protocols are no more computationally complex than an FSM.) A PDU consists of PCI and optionally user-data. PCI is information on the state of those shared objects, and the user-data consists of uninterpretable data. In other words, PCI is what the protocol understands, and user-data is what it doesn’t.
There are two kinds of protocols: application protocols and data transfer protocols. Application protocols perform operations on shared state external to the protocal. For example, FTP performs operations on a computing system’s file system, a management protocol performs operations on a Management Information Base (MIB), and so on. Data transfer protocols, on the other hand, perform operations on shared state internal to the protocol. The only “external affect” of a data transfer protocol is delivering SDUs transparently. As discussed in Chapter 6, “Divining Layers,” the relaying and multiplexing protocols described in Chapter 3, “Patterns in Protocols,” degenerate into a common PCI fragment. Strictly speaking of course, this is a protocol. Any written procedure is a protocol.
This description of protocols is taking a necessarily purist stance so that we can clearly see the forms. I fully recognize that real protocols may not (and today do not) follow these definitions. However, there are good arguments that following these definitions would greatly streamline protocol processing and open the door to simpler much more effective implementations
Protocols progress through two phases: a synchronization phase in which the shared state necessary to support this communication is created, and the data transfer phase in which the communication takes place. For application protocols, the synchronization phase is primarily concerned with establishing that correspondents are who they say they are. A discussion of these methods can be found in Aura and Nikander (1997). The synchronization phase of data transfer protocols is concerned only with creating the initial shared state necessary to support the mechanisms of the protocol. This was discussed in some detail in Chapter 2, “Protocol Elements,” and Chapter 3, “Patterns in Protocols.” We have tended to consider establishment as a single concept. But we see here that there are two very different forms: IPC synchronization and application initialization.
The data transfer phase of an application protocol is concerned with performing operations on external structures and ensuring the proper sequencing of those operations. The data transfer phase of a data transfer protocol is concerned with ensuring that the properties requested for the communication (e.g., bit-error rate, loss rate, jitter, and so on) are provided. This shared state allows the application to act on information at a distance. However, it should always be kept in mind that the representation of state maintained by any PM about its peer is only an approximation. There is always a time delay in the exchange of state information such that events may occur such that the information no longer represents the state of the peer.
Conjecture: Any state associated with the correspondent in an application protocol is part of the application and not associated with the application protocol. Any shared state that must be maintained during a communication is associated with IPC. For example, checkpointing is an IPC function corresponding to acknowledgments in traditional data transfer protocols. Similarly, “recovering a connection” reduces to recovering the state of the application, not the connection. An application may record information about a correspondent and about actions taken for the correspondent, but this is independent of what the correspondent does. This is not shared state in the sense we have used it. This would imply that all application protocols are stateless, whereas data transfer protocols may or may not be stateless.
It appears that all application protocols can be modeled as a small set of remote operations (e.g., read, write, create, delete, start, and stop) on objects. Differences in the “protocols” primarily involve the structures to control the sequencing and parallelism of these operations, or common sequences of operations. This is more the domain of programming languages than communicating remote operations.[9] The other “difference” is whether operations are requested (client/server) or notified (publish/subscribe). But Telnet showed us that this kind of request/response or publish/subscribe of an information base can be seen as symmetrical and does not warrant a distinct protocol. Therefore, we can conclude that architecturally there is only one application protocol and it is stateless.
An AP is the instantiation of a program in a processing system to accomplish some purpose (see Figure 7-2). The component of the AP that implements an application protocol is called an APM. This construction of the APM is done for two reasons: First, it must be a component or else there is an infinite regress. Second, the APM is a module that may appear in more than one AP. This is the structure discussed in Chapter 4, “Stalking the Upper-Layer Architecture,” and applied in Chapter 6, “Divining Layers.”

An AP may contain any number of different APMs and may also have multiple instances of the same APM. An AP must have at least one APM. Otherwise, it would have no input or output and hence serve no purpose. APs (and consequently their PMs) are constructed by combining application protocol modules (AP-Mods), some of which may implement common functions (see Figure 7-3). A coordinating FSM governs the interaction of these modules. (It is not a PM because it does not generate PDUs.) Some modules may have fairly complex state machines themselves. (Although this construct is not strictly required, it is intended to indicate that commonality and reuse of components is possible.) The concept of an application protocol (and protocol machine) is inherently recursive.

But we just indicated that there is only one application protocol. If that’s the case, aren’t all APMs just instances of this one protocol? The reader has caught my “oversimplification.” Strictly speaking, yes. But in practice, one will want to combine these elemental operations on external objects operations on the IPC channel, such as synchronization, two-phase commit, and so on. Also, it will be useful to further distinguish APMs by the collection of external objects they manipulate for purposes of access control and so on. So, there really are “different protocols”; they just look very similar.[10]
Conjecture: All protocols involve two and only two correspondents. Shared state involving multiple correspondents (i.e., more than two) is a property of the AP, not an APM. In other words, all “multiparty” protocols are distributed applications.[11]
To communicate, the APM must exchange information with its peer. To do this, it generates PDUs and invokes the services of a DIF via an API to pass the PDU to its peer. We will consider the nature of this interaction in more detail later.
The relation between an AP and its APMs varies widely. For some APs, the APM has very little functionality; in others it is essentially synonymous with the AP itself. The APM APIs are internal to the AP and may be ad hoc or published (i.e., the subject of standardization). They may be general or quite specific to the AP and may run the gamut of rich APIs that correspond almost 1:1 with the objects of the application protocol;[12] to APIs that resemble the IPC API; or to an API that simply populates an Information Base that is then accessed by the AP or other APMs and so on.
The components for application protocols would be defined as common modules that could be reused in different protocols. Given the complexities of providing security, one can expect that common modules would be made available for authentication and similar security functions and so on.
Application process name space. The set of strings that may be assigned to the APs and used to reference them by other applications in the same naming domain.
Application process name, AP name. A string assigned to an AP from an AP name space and assigned to no other AP while bound to the one it is assigned.
Application process instance. The instantiation of an AP on an operating system.
These definitions provide for multiple instances of the same application and allows them to be separately accessed.
Application process instance-id. This is an identifier bound to AP instance that when combined with the AP name is unambiguous AP name space.
Application PM name space. The set of strings that may be assigned to application PMs and used to reference them by other applications in the same naming domain.
Application PM-id. This is an identifier that is unambiguous within the scope of the AP. An application PM-id when concatenated with an AP name is also unambiguous AP name space.
These definitions allow an AP to have multiple application protocols.
Application PM instance. The instantiation of an application PM within an AP.
Application PM instance-id. This is an identifier that is unambiguous in the AP name space when qualified by the AP name, AP instance-id, and the application PM-id.
These definitions allow naming multiple instances of application protocols within an instance of an AP.
IPC process name. An AP name that is assigned to an IPC process. This is the external name of an IPC process.
There is nothing special about IPC processes or their names. A different term is used purely to make it clear when we are talking about the elements of IPC.
Distributed application name, DAN. A name generally taken from the same name space as APs to identify a distributed application. An important type of distributed application is a DIF (i.e., the set of cooperating IPC processes). A DAN acts as an anycast or multicast name for the set of APs comprising this distributed application depending on the operation.
(N)-port-id. An identifier unambiguous within the scope of the processing system used to distinguish a particular (N)-IPC allocation.
The scope of an AP name space is arbitrary and subject to the discretion of network design. At a minimum, the scope of an AP name space must be at least as great as the scope of an (N)-DIF. However, there is no logical constraint on its maximum size, given that there can be multiple DIFs of the same rank in the same system.
The scope of AP names can be as great as the union of the scope of all DIFs with processing systems in common. This requires essentially following a chain of commonality as follows:
Pick a DIF, A. Consider the processing systems of all IPC processes comprising A. The AP name space must cover all the applications reachable by this DIF. In addition, if any of these processing systems have distinct DIFs other than A, the scope of the application name space must also include all applications reachable by these DIFs (i.e., by their IPC processes and so on). (This is true because applications in processing systems with more than one DIF may relay between them.) The set thus formed represents the scope of the AP name space.
Scope defined in this way allows any two APs with names within the scope of the name space to communicate, although an AP acting as either a protocol converter or an (N+1)-DIF may be required. (A relay would be required when two APs wanted to communicate that did not have a DIF in common. If the relay uses local knowledge to relay PDUs to a destination, it is called a protocol converter. If the relay is the member of a DIF, it is an IPC process.)
The structure of these name spaces will depend on their scope. In domains of small scope, they may be simple and flat. For domains with large scope, they may be hierarchical (or some other organization). These name spaces may exhibit structure that can be exploited in their use. As noted earlier, how the name structure is reflected to humans is a matter of user-interface design. Here we are only concerned with the kinds of names required, their properties, and the relations among them.
The name space for the APM is a component of the AP and generally would be coordinated with it. A name space is required for the APs and APMs for all the APs that need to communicate. This name space should be location independent or more precisely have the capability of being location independent. For most applications, it does not matter where they are, but there are a few for which it does matter. For example, the name of a printer application that indicates where the printer is, as in PrintStation3rdFloorSWCorner, could be useful. There is no need to artificially disguise this fact; but on the other hand, there is no reason to impose it on all applications.
The DIF is composed of a number of IPC processes. For external purposes, each IPC process is assigned an AP name.[13] The DIF is a distributed application that is identified externally by a distributed application name. The distributed application name is used to distinguish it from other distributed applications in the same name space, whether a DIF or not. Note that a distributed application name is a multicast-application-name, see Chapter 9, “Multihoming, Multicast, and Mobility.”
In most cases, requests for IPC will not require communication with specific instances of APs, but only with the AP and perhaps the APM[14] resulting in the instantiation of a new instance of the AP or APM. There are situations, such as recovery or certain long-lived processes, where the initial request will require communication with a particular instance on an AP/APM. Similarly, there are situations where it is known at the outset that there will be no communications initiated to an instance (e.g., dedicated IPC).
The use of APs, APMs, and their instances is not rigid or unique. For example, a teleconferencing service might be implemented such that the application name designates the service and each teleconference is a distinct application protocol instance. It might just as well be implemented such that each teleconference is an AP instance. Either is possible, and there are good arguments for both. The model should not force the designer to one or the other, nor should the designer not have the choice.
When an APM requests service from the IPC facility, it is given an (N)-port-id. The port-id is used by the APM instance and the DIF to refer to all interactions regarding this flow. In general, the scope of the port-id should be the processing system. We explore why this is the case in more detail latter.
As mentioned earlier, these represent the complete set of names required for applications. Some combinations will see much less use than others. It is highly doubtful that all of them would be presented to the human user, although they would probably be available to the developer. The kind of naming syntax and the conventions necessary for human use will and should be quite different. This is just the bare bones of the structure required.
(N)-error-and-flow-control-protocol (EFCP). The data transfer protocol required to maintain an instance of IPC within a DIF between corresponding port-ids. The functions of this protocol ensure reliability, order, and flow control as required.
This is equivalent to UDP, TP2, TP4, HDLC, delta-t, and TCP.
(N)-relaying/multiplexing-task (RMT). The task within IPC process that performs multiplexing/relaying of (N)-PDUs and prepends the Relaying PCI to all PDUs primarily for purposes of addressing.
(N)-connection-identifier.[15]. An identifier internal to the DIF and unambiguous within the scope of two communicating EFCPMs of that DIF that identifies this connection. The connection-id is commonly formed by the concatenation of the port-ids associated with this flow by the source and destination EFCPMs.
(N)-address. A location-dependent identifier internal to the DIF and unambiguous within DIF. This identifier is used in the coordination and maintenance of the DIF’s state.
(N)-EFCPM. A task within the IPC process that is an instance of the EFCP that creates a single instance of shared state representing a full-duplex channel, connection, association, flow, and so on.
(N)-delimiting. The first operation performed by the DIF, usually by the API primitives, to delimit an SDU so that the DIF can ensure being able to deliver the SDU to its recipient.
(N)-Relaying-PCI. The designation of the Relaying PCI used by the RMT of a IPC process. This is the PCI of the data transfer phase of the distributed IPC application.
This corresponds to IP, CLNP, or MAC protocols.
(N)-SDU-protection. The (optional) last operation performed by RMT to ensure the SDU is not corrupted while in transit.
Resource Information Exchange Protocol (RIEP). An application protocol internal to a DIF used to exchange resource information among the IPC processes of a DIF. Logically, RIEP is updating the distributed Resource Information Base (RIB).
IPC access protocol (IAP). An application of RIEP that finds the address of an application process and determines whether the requesting application has access to it, and communicates the policies to be used.
What we need to do now is to describe in the abstract the elements that make up an IPC process. We will not be concerned with specific protocols or algorithms, but with the class of functionality represented by each element. It is in the next level of abstraction down where specific sets of protocols and algorithms would be specified.
The IPC process is an AP, a component of a distributed IPC facility, consisting of two major components: the IPC task and the IPC management task. The IPC task consists of a RMT and one EFCPM for each connection/flow that originates in this IPC process. There is one IPC management task in an IPC process. (All instances within an IPC process have the same concrete syntax and policy range.)
The IPC task itself naturally divides into four functions:
Delimiting and PDU protection, which consists of fairly straightforward functions amenable to pipelining
Relaying and multiplexing, which is concerned with managing the utilization of the layer below
Data transfer, which distinguishes flows and sequencing if necessary
Data transfer control functions responsible for feedback mechanisms and their synchronization, which control data transfer queues and retransmission, requiring high performance but having a longer cycle time than data transfer and more complex policies
This is not the first recognition of this pattern, although I have yet to see a textbook that points it out to students. Complicating the matter is that protocols with a single PDU syntax make it difficult to take advantage of it. As noted in Chapter 3, this structure allows a single protocol to address the entire range of protocols from connectionless to fully reliable connections.
The IPC management task uses RIEP. RIEP is used to exchange information among the IPC processes necessary for the management of the DIF. Events, including timeouts, can cause RIEP to issue updates (in a publish/subscribe mode), or an IPC process or network management system may request information from an IPC process (client/server mode). The IPC management task corresponds to what some investigators have referred to as the control plane. However, this term is strongly associated with the beads-on-a-string model. As discussed in Chapter 6, IAP performs the function of search rules and access control for distributed IPC. One major use of RIEP can be seen as a generalization of routing update protocols.
Notice that this yields a fundamental structure for the IPC process consisting of three relatively independent loci of processing with decreasing “duty cycles” loosely coupled by some form of Information Base.
The IPC APM consists of six distinct subtasks:
IPC API
SDU delimiting
The EFCP, which provides the error and flow control on a per-connection basis. This protocol decomposes into two parts:
EFCP data transfer PM, which handles tightly coupled mechanisms and carries user data
EFCP control PM, which provides the support for loosely coupled mechanisms
The relaying and multiplexing task, which appends the Common Data Transfer PCI, also known as the relaying and multiplexing protocol
PDU protection, consisting of CRC and encryption functions
The IPC service primitives[16] are used by an AP to request IPC facilities. The primitives are as follows:
Reason <- Allocate_Request (Destination, Source, QoS Parameters, Port-id). An asymmetrical request/response issued by an application to the IPC facility to create an instance of a connection with an application,[17] or by an IPC process to an AP to notify it of a request for communication.
Reason <- Allocate_Response (Destination, QoS Parameters, Port-id). An asymmetrical request/response issued by an application to the IPC facility to respond to a request to create an instance of a connection with an application, or by an IPC process to notify the requesting AP of the result of its request.
Reason <- Send (Port-id, buffer). Issued by either AP to send an SDU to the destination application on this port.
Reason <- Receive (Port-id, buffer). Issued by either AP to receive an SDU from the destination application on this port.
Reason <- De-allocate (Port-id). Issued by either AP or DIF to request or notify of the de-allocation of the resources held for this allocation and destroys all shared state associated with it and notifies the communicating applications.
The IPC API communicates requests from the APM to the DIF. Contrary to current designs that see the API as a direct input to the EFCPM, the Allocate_Request goes to the IPC management task (described later), which determines what action is to be taken. The APM communicates the characteristics of the IPC it wants, but it is the IPC management task that determines what policies will be utilized to provide those characteristics. It is important that how these characteristics are communicated by the application is decoupled from the selection of policies. This gives the DIF important flexibility in using different policies but also allows new policies to be incorporated. But first it must find the destination application and determine whether the requestor has access to it.
Previously, we said that all communication goes through three phases: enrollment, allocation, and data transfer. Earlier in this chapter, we noted that the EFCP has a synchronization phase. This is not a contradiction. Allocation is the function that occurs at the API (layer) boundary of the DIF. Applications request the allocation of communication resources. The DIF then determines how to provide those resources, which will require assigning port-ids, allocating resources, and instantiating an instance of the EFCP, which depending on the mechanisms required to support the request may require synchronization.
Chapter 6 showed how the IAP decouples the EFCP from requests by the APM. This decoupling is important and has been missing in our previous thinking. Allocation is an asymmetric operation. Synchronization is (generally) a symmetric operation. The decoupling of allocation and EFCP instantiation is key. It allows the IPC process greater flexibility in managing the allocation and binding of EFCP connections to the APMs.
This protocol provides the IPC connection/flow associated with each allocation request. It provides for the transfer of data between APs. The discussion in Chapter 3 made it clear that the protocol cleaves naturally into tightly bound mechanisms and loosely bound mechanisms. Chapter 6 showed how the distinction between the IPC function and a common header for relaying and multiplexing arises.
The binding of an APM connection to an IPC connection is made after a successful response by the IAP, not by the EFCP as is common today. The decoupling of allocation requests and EFCP synchronization would also allow a pool of EFCP connections to be maintained between frequently used destinations and simply bound to an APM request once it was determined the requested AP existed and access was permitted. Of course, an IPC with weak access control requirements could further optimize this procedure.
The IPC function requires a protocol to maintain synchronization and provide error and flow control. The EFCP is divided into two cooperating protocols. These are described as two separate protocols and are implemented by two distinct protocol machines, sharing a state vector. The EFCP supports both stream and idempotent operations. Different PDU types facilitate flexibility simplifying execution when mechanisms are not used.[18]
In the late 1970s and early 1980s, one of the differences in transport protocol proposals was whether two establishment requests to the same ports created two, one, or no (an error) connections. The Americans said one, preferring the elegance of the symmetric establishment. The European proposals preferred either two or none, being inclined to explicit control and special cases. Here we can work out the answer. The protocol should be symmetrical, but the service is necessarily asymmetric because one side or the other initiates the allocation. Of course, if the protocol is timer based, the point is moot.
An application protocol will deliver an amount of data to a DIF, called a SDU or service data unit. An SDU is a contiguous piece of data that has meaning to the application’s correspondent. Unless otherwise directed, the DIF will deliver the same SDU to the other side. To do this, the layer may find it necessary to either fragment the SDU or concatenate it with other SDUs. Hence, the first operation on an SDU will be to delimit it.
This is the Data Transfer PDU used for the IPC tightly coupled mechanisms. It is a very simple header requiring minimal processing. The PDU contains only source and destination port-ids as a connection- or flow-id, a length field, a PDU-id (message-id), and an optional checksum. For some IPC connections/flows, this is the only PDU required (i.e., traditionally referred to as unit data). There is a distinct instantiation (flow) of this protocol for each Allocation request. Interactions between flows are performed by the RMT and IPC management task. The only change to this protocol to support more robust connections is that the PDU-id is interpreted as a sequence number. Actually, it is always a sequence number; it is just that sometimes it isn’t used for ordering.
The IPC control protocol provides the loosely coupled mechanisms as required. There is a distinct instantiation (flow) of this protocol for each Allocation request that requires initial state synchronization. Coordination of the data transfer PM and the control PM is done through a shared state vector. Interactions between flows are performed by the RMT and IPC management task. The IPC control protocol has three modes of operation that are present, depending on the mechanisms and policies, depending on the QoS the application has requested and the QoS provided by the underlying (N−1)-DIF:
No synchronization. Null, corresponding to the functionality of UDP. The binding of an instance of the IPC data transfer is made by the IPC Management Task upon receipt of a successful IAP request. In this mode, there is no instantiation of the control protocol in this case.
Weak synchronization. The synchronization mechanism establishes shared state between the endpoints. This weak synchronization may use a two-way handshake. The PDU-id field of the PCI is interpreted as a sequence number. Only tightly bound mechanisms are available (i.e., PDUs may be ordered) but no feedback mechanisms.
Strong synchronization. Synchronization may require a three-way handshake. Loosely bound mechanisms are available, such as retransmission control (i.e., acknowledgment and flow control mechanisms). The IPC control protocol operates independently (in parallel) of the data transfer protocol but shares the same state vector.
Although this description might seem a radical departure from the traditional EFCP designs, it is actually quite close to protocols such as UDP, OSI Transport Unit-Data, delta-t, CYCLADES TS, and TP2/4. However, using a timer-based approach found in delta-t (Watson, 1981) would avoid the need for distinct two-way and three-way handshakes. The necessary levels of synchronization could be achieved by just modifying the policies associated with the timers. This would clearly be the simplest solution.
As discussed in Chapter 6, the primary purpose of this task is to moderate the multiplexing and relaying of all PDUs passing through this IPC process. The RMT is responsible for the real-time delivery of PDUs to the lower layer. RMTs come in three forms depending on where they occur in the architecture[19]:
A multiplexing application primarily found in hosts and the lower layers of routers
A relaying application primarily found in the “top” layer of interior routers
An aggregation relaying application primarily found in the “top” layer of border routers
All PDUs for all EFCP connections have Relaying PCI prepended to the PDUs. This Relaying PCI is associated with the relaying and multiplexing function. When a DIF has more than two IPC processes (i.e., most of the time), this task must also add addressing information to the PCI. The PCI contains the source and destination addresses. This corresponds to IP or CLNP in traditional models. Note that with a recursive architecture, the requirements for other capabilities, such flow-ids, and various options are avoided. Flow-ids are provided by the EFCP of the layer and different policies can be the policies associated with different flow-ids. In other words, the only PDUs that would invoke a “slow path” would be IPC Control Protocol PDUs, which weren’t going any further any way.
A Host RMT is primarily responsible for managing the use of local resources and multiplexing traffic onto local interfaces (see Figure 7-4). Typically, it does not have much to work with (unless it is a system with a large number of APs [for example, a server]).

The Interior Router RMT (see Figure 7-5) handles transit flows. It must have high performance and minimal processing overhead. This process most closely resembles traditional packet forwarding. It receives PDUs from an input queue, inspects the destination RMT-id, refers to a forwarding table, and sends PDUs as quickly as possible to an output queue. (Lower layers of an interior router will have RMTs similar to a host.) Aggregation is degenerate in interior routers. PDUs have already been concatenated and assigned to flows.

The Border Router RMT (see Figure 7-6) does relaying but also manages high-traffic intermediate flows. Traffic with similar QoS requirements and common intermediate paths are aggregated onto these flows, and the (N+1)-PDUs may be aggregated to increase efficiency and lower switching overhead.

Actual systems may well be various combinations of these.
The last function performed on PDUs before they are delivered to the layer below is taking necessary precautions to safeguard their integrity. Any data-corruption protection over the data and PCI, including lifetime guards (hop count) and/or encryption, are performed here. Not only is the last function performed on outgoing PDUs, but it also must be the first function performed on incoming PDUs, and as such is a component of the DIF, not the protocol.
Note that delimiting and PDU protection are components of the DIF, not the protocols used by the DIF. This is contrary to the common view. It is not possible to have more than one delimiting or PDU protection function operating in a DIF because the DIF would have no way to determine which one to apply (because it cannot inspect the PDU until it has performed the function).
As shown in Chapter 6, a protocol is required to carry the source and destination application names to the remote IPC process along with the necessary access control and authentication information, but first it must find the IPC process of this DIF that resides on the processing system that has access to the requested application. Note that the destination application is not necessarily resident on this processing system. It may be acting as a relay.
This protocol accomplishes three functions:
Finding the address of the destination IPC process with access to the requested AP
Determining whether the requested AP is actually at that destination and the requesting AP has permission to access the requested AP
Carrying information to the destination IPC process on the policies to be used for the requested communication and returning the destination’s response to the source
The IAP response will return a PDU indicating success or failure. If successful, destination address and connection-id information will also be returned along with suggested policy choices. This gives the IPC processes sufficient information to then bind the port-ids to an EFCPM instance (i.e., a connection)[20] so that data transfer may proceed (as described below).
This protocol may use the (N−1)-DIF. As shown in Chapter 6, the requirement for this protocol corresponds to the search rules and access control functions of an operating system. There are a variety of ways in which it may work, none of which require changes to the protocol. It is easy to see how this could start out as a local cache of recent activity, which broadcasts queries when there are cache misses, and evolve into any number of dedicated caches, a hierarchical directory, and so on, with search rules on where to go next. A failure at a cache could be noted with updates to these caches when the request is satisfied. As with an operating system, the search rules should be configurable.
If the necessary address information is not in a local cache, it must be found in distributed caches. Then, any cache where the information is found is “on the way” to the destination. The likelihood is fairly strong that it will be found closer to the destination than to the source. Regardless, it would be inefficient to pass a request most of the way (or even part way) from the source to the destination, just to go back to the source, and then immediately back to the destination to determine access control and to complete the request. It is simpler, more efficient, and more useful to continue to the destination and complete the operation.
The cache where the information was found may be incorrect. We will only know for sure that the application is accessible at the address in the cache when we get to the IPC process indicated by the address and determine whether the requested AP can be accessed. At that point, it may be useful to send the response directly back to the source IPC process and a separate update back along the cache trail to update the caches. If the application is no longer at the address found, but has been and left a forwarding address (or more likely, the new information is propagating out from this host and had not reached the database where the out-of-date information was found), the request merely continues looking for the destination.
As we see, the DNS or X.500 approach inherently assumes that any information found is correct, and if not, puts the onus of finding the correct information on the application, which has no means to redirect its search, except blindly trying again. This approach believes that such assumptions cannot be made. Instead, this approach withholds a response until the location of the application has actually been confirmed and the requestor has access. By taking this approach, we also provide for important aspects of mobility as a natural consequence. Furthermore, it is the IAP that can cause the databases to be updated and thus fix the out-of-date information problem.
Similarly, APs can be made available to the DIF in a variety of ways. Application processes might be registered with the DIF, or all APs made available. A more interesting possibility is because IAP carries access control information, systems using the DIF could create access control domains associated with distributed services, making only those applications that are members of the domain visible.
A DIF is a distributed application and as such it must exchange information on its state to effectively allocate resources. Traditionally, this has been referred to as the routing update protocol and was associated only with routing. Given our more general context, we generalize the concept and decouple it from routing. We will view it as a general tool for sharing information among the members of the DIF. Routing-related information is only one kind of information exchanged within the DIF, whether related to connectivity, queue length, processing load, resource allocation, and so on. RIEP can be used in both a request/response mode and a notify/confirm mode using the same managed objects. This allows IPC processes to notify the other members of the DIF when there is a significant change or to request information. It also allows the RIEP to act as the management protocol. In general, the (N)-RIEP of an (N)-DIF uses the IPC facility of the (N−1)-DIF, but there is no prohibition on using the (N)-IPC task, too.
The RIEP is responsible for disseminating from other subsystems in this DIF the information necessary to coordinate the distributed IPC. This includes information on the mappings of AP names to the IPC process names (and addresses) of nearest neighbors, the connectivity provided by the DIF, and resource usage and allocation information. There is no requirement that the same update strategy be used for all information in the DIF. It will be advantageous to use different strategies for different kinds of information. The RIEP collects information from other RIEPs in the DIF. Several events can cause a RIEP to query or update peers: events (e.g., failures) in the network, new subsystems, periodically, or as a matter of policy imposed by its users. Some of these events may involve some or all members.
This protocol could be confused with a Network Management Protocol (NMP) and should be. The difference being that the NMP uses the request/response mode. The NMP is used by a network management system to monitor and manage the systems comprising the network. The object models used by the two are the same. The NMS will generally retrieve aggregated data from the systems under its management, but it will also access the same kind of detailed information when diagnosing and repairing a problem.
At the higher layers, this information may be characterized by a large number of destinations and a small number of relays. However, this does not change the basics. In these cases, a RIB is a cache of the mappings required by this IPC process. If a mapping is requested that is not in the cache, this RIEP-PM communicates with its peers to obtain the necessary information. At lower layers, the RIB tends to have complete information on all members of the DIFs; at higher layers, this is less often the case.
The Resource Information Base is the logical store of local information on the state of the DIF. Each IPC process maintains a RIB. The RIB is a replicated Information Base. The assumption is made that if all data transfer activity ceased, the collection of RIBs in the DIF would reach a consistent state. However, tasks using this information can never assume that is the case. This is very similar to what is traditionally called the MIB or Management Information Base. A different term was used here to indicate that this may include information for other than network management (recognizing, however, that any information that is kept may prove useful for management).
The information distributed and collected by REIP is then used by various IPC management functions. We briefly survey these to give some flavor of what they are
Enrollment. Enrollment was defined as those procedures required to create sufficient shared state that allocation could occur. Traditionally, enrollment has been ignored, swept under the rug, or done by ad hoc or even manual procedures. DHCP has been our only slight foray into enrollment. In multicast, there has been a tendency to confuse enrollment and allocation operations (Chapter 9).
In this model, enrollment falls out as an integral part of the model. Enrollment occurs when an IPC process establishes an application connection (using an (N−1)-DIF) with another IPC process, which is already a member of an existing DIF, to join the DIF. Once this occurs, the IPC process may authenticate the newcomer, using RIEP initialize various managed objects and their attributes, including assigning an address. These parameters characterize the operation of this DIF and might include parameters such as max PDU size, various timeout ranges, ranges of policies, and so on, as well as a full update of routing and resource allocation information. Similarly, the new IPC process will have new information to share with the DIF. The robustness of the authentication is a policy of the DIF. It may range from null or a simple password to a more robust cryptographic-based authentication procedure.
Routing. This task performs the analysis of the RIB to provide connectivity input to the creation of a forwarding table. To support flows with different QoS will in current terminology require using different metrics to optimize the routing. However, this must be done while balancing the conflicting requirements for resources. Current approaches can be used, but new approaches to routing will be required to take full advantage of this environment. The choice of routing algorithms in a particular DIF is a matter of policy.
Directory. As shown in Chapter 5, “Naming and Addressing,” each DIF must maintain the mapping (N)- to (N−1)-names and addresses of nearest neighbors for both its upper and lower boundary; that is, name to address at the upper boundary (usually referred to as a directory function) and address to point of attachment at the lower boundary (to select the path to the next hop). The primary user of this information is IAP and routing. Because scope tends to increase with higher layers, we should expect the number of elements for which this mapping must be maintained to increase dramatically with higher DIFs. Hence the caching strategies and search rules will vary radically across DIFs. Updates to these caches are made using RIEP and are triggered by local events. IAP requests forwarding requests to other caches.
Resource allocation. If a DIF is to support different qualities of service, different flows will have to be allocated, and traffic for them treated differently. To meet the QoS requirements, different resources will have to be allocated to different flows, and information about the allocations distributed to the members of the DIF. There are three classes of such flows:
Flows requested by an AP, usually in a host
Flows created by IPC management for distinct classes of QoS to aggregate traffic and enhance efficiency, generally in border routers and among them
Flows that transit a system (i.e., traditional routing)
When an IAP request returns successfully, IPC management must determine whether and how to allocate the flow/connection to a new or existing flow (a matter of policy). This process uses input from routing, current allocations, and current conditions within the DIF. This may include creating flows of similar or aggregated QoS, creating high-density flows between intermediate points in the network, and so on, depending on the context in which the DIF operates. It should be remembered that flows in this context does not necessarily imply that traffic is following a single fixed route through the DIF, and it is unlikely there would be much, if any, error control, and flow control would probably be done by pacing. One would expect that the management of such flows would be more useful nearer the backbone. Flows between intermediate points in DIFs nearer the backbone will tend to have very long lifetimes of hours, days, or even months.
Some IPC processes may only be transit subsystems and thus have relatively simple resource-allocation functionality, whereas those on the borders of subnets may be more complex. The degree to which this is automatic or under direct control of a central network management system is a matter of policy. There is considerable opportunity for policy differentiation. DiffServ and IntServ could be considered opposite extremes of this task. With this model, it is straightforward to support much more diverse approaches to resource-allocation strategies.
Security management. A DIF requires three security functions:
Authentication to ensure that an IPC process wanting to join the DIF is who it says it is and is an allowable member of the DIF. This is similar to the application authentication requirements that any AP should have when establishing communication with another AP.
Protection against the tampering or eavesdropping by an (N−1)-DIF.
Access control to determine whether APs requesting an IPC flow with a remote application has the necessary permissions to establish communication. The particular security procedures used for these security functions are a matter of policy.
A DIF need place very little trust in (N−1)-DIFs: only that an (N−1)-DIF will attempt to deliver PDUs to something.
The most that a DIF can guarantee is that the IPC process with the destination address believes that it has created an IPC channel with the requested application. There can be no guarantee that it is. Therefore, it is the responsibility of every AP, including the IPC processes of a DIF, to ensure that the application it is exchanging PDUs with is the intended application (authentication) and to protect its PDUs from eavesdropping and tampering (confidentiality and integrity). The only information that an application has about the communication is the local port-id for this IPC and the application name of the destination.
An authentication mechanism is used to ensure that an IPC process is a valid member of the DIF. This part of enrollment is able to use existing techniques. If a DIF distrusts (N−1)-DIFs, authentication is used to ensure that PDUs are being delivered to the appropriate IPC process, and PDU protection is used to protect against tampering and eavesdropping.
IAP provides access control generally implemented as capabilities, which are used to determine whether the requesting application has access to the requested application.
While the IPC processes that comprise the DIF are exchanging information on their operation and the conditions they observe, it is generally necessary to also have an outside window into the operation of DIFs comprising the network. Normally, this will require monitoring of the multiple DIFs that constitute a network (i.e., a management domain). The purpose of network management is monitor and repair, not control. Each processing system in the network (which may include hosts) contains a management agent responsible for collecting information from IPC processes in all DIFs in the system and communicating it to a network management system (NMS).
The NMS exerts a strong influence on enrollment. The enrollment tasks acts for the NMS. The NMS may determine when a layer is to be created and initiate the action, but it is the enrollment tasks that carry it out. This includes creating the ability for the enrollment agents to sense the correct conditions and to make the decision automatically. The NMS management strategy may run the gamut from hands-on to quite light.
This is one of the few places in this architecture where it is necessary to recognize the systems that are hosting the IPC process. We assume that there is a management agent (MA) that is an AP (see Figure 7-7). An MA has access to all DIFs in a system. It communicates with an NMS, just as any other application, using a DIF. Although Figure 7-7 shows the MA as above all other DIFs, this should not be taken too literally. The MA only has to use an (N)-DIF with sufficient scope to be able to communicate with the NMS. An MA can communicate over a lower DIF and still collect information from higher DIFs.[21]

It is easy to imagine situations where it would be convenient to allow multiple MAs responsible for different DIFs in the same processing system. For example, one might create DIFs as VPNs and allow them to be managed by their “owners”; or one could imagine different DIFs belonging to different providers at the border between two providers and so on. Although there are good reasons to do this, and one can fully expect it to be done, the network designer must be careful. There is only one processing system to meet the requirements of these MAs. One MA (and management system) must be empowered to resolve conflicts or to bound the capabilities of other MAs.
In general, a processing system in a network can be managed by one and only one manager at any particular time. Other managers may be given permission to read (i.e., observe) the system but not write to it (i.e., change configuration). Management systems will have mechanisms for defining management domains and changing their composition.
It is time to step back and take a look at what we can now say about the nature of layers. In Chapter 6, we noted that there has been considerable dissatisfaction with layers as an organizing principle, but on the other hand, the inherent nature of distributed shared state of different scopes implied that there was something like a layer inherent in the problem. A repeating structure of common elements makes it much easier to characterize the nature of a “layer.” You might have already gotten an inkling of the model we are moving to with the description in this chapter. To some degree, we have been too stringent in our characterization of layers and have also not fully taken into account the environment in which it exists. We were looking for easy answers and not listening to what the problem was telling us.
A distributed IPC facility or DIF is a layer. The ranking (stacking) of DIFs is purely a relation among DIFs and hence apply only to DIFs. Applications belong to no layer, unless they are IPC processes and a member of a DIF. This is why in the definitions in this chapter, the (N)- notation does not appear in front of any application related concepts. Applications execute on a processing system. Layering based on concepts of kernel or user applications is a property of the operating system and not of the communications. If any rank is applied to an application it is only that implied by its use of a DIF of a given rank. Potentially any application can use any DIF of any rank as long as the DIF has sufficient scope to access the necessary remote applications and appropriate access controls. An application may have IPC connections with other applications using DIFs of different ranks at the same time as long as the access control policies permit it. The same is true of applications, which are IPC processes. In this case, there are constraints that must be recognized to ensure that shared state for data transfer is maintained and PCI is properly removed.
Working out the repeating structure of a DIF has also cleaned up the interactions at the layer boundary. In other architectures, layers caused problems where conflicts were constantly appearing about what goes in what layer. This is now rendered moot by the realization that all layers/DIFs do one thing and only one thing: IPC. The primary purpose of layers is organizing the scope of shared state, on the one hand, and organizing information (PCI) for processing in layer order on the other. This is very much the case for the primary purpose of IPC: the data transfer aspect.
This shifts the data transfer model from moving PDUs between layers to process, moving along the PDU processing PCI as required. The feared data copy is only an artifact of the hardware, not of the architecture. And context switches across DIFs are only necessary if desired; they’re not implied by the architecture. This, along with the natural partitioning of information flow into three largely independent functions of differing duty cycles, opens the door for much more effective processing models for routers and hosts.
As we have seen, management is “extra-dimensional.” As shown in the preceding section, not only is network management the sphere that can see inside all the data transfer inhabitants of Flatland but, IPC management has this property, too. IPC management must maintain mappings of (N+1)- to (N)- (nominally application names to node addresses) and (N)- to (N−1)- (nominally node addresses to point of attachment addresses). Data transfer is Flatland, and management is the sphere visiting it. IPC management must have the ability to share information among adjacent layers.
Notice I said adjacent layers, not all layers. A consequence of the recursion that we touched on earlier in this chapter is that most processing systems have a rank of DIFs no more than three deep. Hosts might have more, but not many more, and these would be specialized DIFs for other IPC-related distributed applications (e.g., mail or transaction processing). For the hosts and routers, this creates something of a hook-and-eye structure across layers. Only the NMS potentially has the ability to see information about DIF operation across all DIFs in a network. If the access control is appropriate between adjacent layers, so that addresses are available, effective mappings between (N)-addresses and (N−1)-addresses can make routing much more effective.
This gives us a structure that is layered as the loci of shared state requires, but is at one and the same time more structured and more flexible than our previous attempts and also translates into a simple implementation.
In this section, we briefly consider the operation of a DIF. In particular, we look at three fundamental operations: how an IPC process joins a DIF, how a new DIF is created, and how an application requests IPC services. The operation of a DIF is driven by the action of the APs (i.e., its users and by its internal coordination). The IPC processes must coordinate their actions with the other members of the DIF.
Traditionally, the enrollment phase has been ignored as a collection of ad hoc procedures that must be done at startup that are very implementation specific. In this model, the enrollment phase is an integral part of the model and essential to its operation. There are two aspects of enrollment: new systems joining an existing DIF, and creating a new DIF.
Let’s consider how a processing system joins a DIF. One variation of this process is a new system attaching to a network. Suppose that DIF A consists of a number of IPC processes on a set of systems, ai. Suppose that the DIF B wants to join the DIF A. The DIF B represents a single IPC process. The IPC process, b, in B has the AP name of an IPC process, a, in A (or it might have the name of the DIF A), not its address. B has no way to know the addresses of any elements of A. A and B are connected by the (N−1)-DIF, which ultimately will be the physical media (see Figure 7-8).
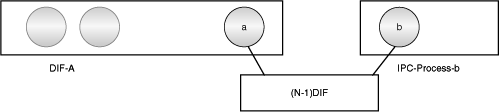
Using the (N−1)-DIF, b requests that the (N−1)-DIF establish an IPC channel with a in the same manner it would with any other application using the AP name of a. The (N−1)-DIF determines whether a exists and whether b has access to a.
After the application connection has been established (see Figure 7-9), a authenticates b and determines whether it can be a member of A. If the result is positive, a assigns an (N)-address to b.[22] b uses the (N)-address to identify itself to other members of the DIF A. This (N)-address is used in the Data Transfer PCI of the enrollment application protocol, also called the Relaying PCI. Other initialization parameters associated with DIF A are exchanged with b (see Figure 7-10).
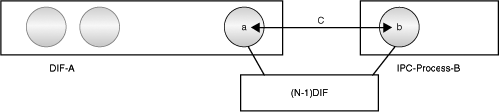
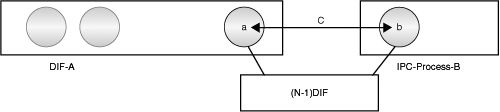
The IPC process, b, is now a member of the DIF A (see Figure 7-11). Soon after this, b also establishes similar communication with all members of A that are nearest neighbors. (Because the (N−1)-DIF may have less scope than A, there may be members of A that b cannot communicate with directly.) These flows are used to exchange RIEP information to maintain the shared state of the (N)-DIF. The b is now ready to participate in the (N)-DIF and can now accept requests from its applications for IPC.

Some readers will jump to the conclusion from what I have just described that this is a connection-oriented architecture. Nothing could be further from the case. Enrollment is simply creating the necessary shared state among the IPC management tasks, so that there is sufficient shared state for IPC. Whether IPC within the DIF is connectionless or connection-like is an entirely separate matter. That will depend on how the routing and forwarding are done. In a sense what we have done is to establish the logical “wires” over which this DIF will operate. Of course, these “wires” are a little “cloudier” than normal wires. To the DIF, they range in quality and type: Some are point to point and fairly reliable (real wires); some are multipoint and unreliable (wireless); some are multipoint with a few stations on them and fairly reliable (LANs); some are multipoint with large numbers of stations on them and somewhat reliable (subnets with multiple routes); and so on.
Although this is described in terms of a single DIF, the protocols could be designed to allow several DIFs (layers) to be joined at the same time within the constraints of the security policies for the DIFs.
Creating a new DIF is a simple matter. An NMS or similar application with the appropriate permissions causes an IPC process to be created and initialized, including pointing it at one or more (N−1)-DIFs. As part of its initialization, the IPC process is given the means to recognize allowable members of the DIF (e.g., a list of application process names, a digital signature, and so on). Or it might be directed to initiate enrollment with them or to simply wait for them to find this initial IPC process. When this has been achieved, the creation of the DIF proceeds as described earlier.
When enrollment initialization is complete, the DIF is available to provide IPC to APs residing on its processing system or to act as a relay. APs will request the allocation of IPC resources via library calls.
Let’s assume (see Figure 7-12) that the AP, A, wants to establish an IPC connection with the AP B. A resides on a processing system using a DIF that is represented by the IPC process, a.

A generates an Allocate request that will cause the IPC management of a to evaluate the request according to its allocation policies. The IAP request will contain the application process name of A; a’s address, a-addr; the local port-id, ai-port; B’s application process name; access control and capability information for A; and the proposed policies for the connection. If the request is acceptable and the (N)-address of the IPC process B is not in the local RIB, a’s local IPC management task will use IAP to find B. a uses its search rules to forward the IAP request to another IPC process in the DIF (see Figure 7-13). For this information, the search rules may organize the elements of the DIF into a logical hierarchy.

The IAP request may be forwarded within this hierarchy until the location of B is found. When the address of the destination IPC process is found, the information may be forwarded back through the intermediate IPC processes to update their caches. The IAP request is forwarded to the destination IPC process, b (see Figure 7-14). When the presence of B can be confirmed, b determines whether it can honor the request and A has access to B. (The degree of access control is policy. It could be quite elaborate or like the current Internet, none.)

If it does, B may be instantiated if it was not active and notified of the request from A using the IPC API primitives. b will allocate a local port-id, bi-port, and make a suggestion for policies on the IPC connection to be created and send an IAP response back to a. Now is a much better time to forward the result of the IAP request back through the intermediate IPC processes because we know the information is correct (see Figure 7-15).
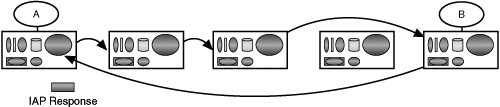
When the IAP response arrives at a and with a positive result, the Allocate_Request is returned[23] to A with the destination, source, a port-id to be used with all subsequent interactions on this allocation, and a positive reason code.[24] At the same time, a allocates an EFCPM instance (i.e., a connection); binds the port-id assigned to A to it, with the appropriate policies; and initiates any synchronization exchanges, if they are required (see Figure 7-16). A may now start sending Application PDUs to its peer by invoking the transfer API primitive. The transfer primitive is used to pass APM PDUs to the IPC facility as an SDU. The SDU is delimited and transformed into user-data for a PDU.

The SDU is delivered to the EFCPM specified by the port-id and is processed. The resulting PDU(s) are delivered to the RMT for transmission. The RMT may have created a number of (N−1)-flows of various QoS characteristics to various destinations. Based on the allocations determined by the IPC manager, the PDU is queued on an outgoing (N−1)-flow to be sent by the (N)-RMT, which may also combine it with other PDUs into a single (N−1)-SDU.
When A has finished its communication and terminated its communication with B, A, B, or both invoke the close API primitive to inform the DIF that it may release the resources (see Figure 7-17). a and b will de-allocate their respective local port-ids. Whether the EFCP instance is de-allocated is a matter of policy. Of course, if a timer-based protocol is used this consideration is moot.

We have found that six kinds of identifiers are needed (three externally visible, one internal to the processing system, and two internal to the DIF). The three external identifiers are as follows:
The distributed application names that designate a set of APs cooperating to perform a particular task
AP names to identify APs
The APM names that identify application PMs, which are unambiguous within the AP
The one identifier internal to the processing system is the port-id.
The two identifiers internal to DIF are as follows:
The (N)-addresses assigned to the IPC processes
The connection-id used in the EFCP to distinguish connections
The DIF requires identifiers to distinguish multiple IPC flows. APs need them for the same purpose. When the connection is established, the APM and the DIF use the port-id when referring to the communication. The port-ids are unambiguous within the processing system. When the IPC protocol creates shared state with its correspondent, the connection is distinguished by a connection-id. The connection-id is generally formed by concatenating the port-ids of the source and destination, thus unambiguously identifying it within the scope of the communicating IPC processes.
Figure 7-18. By exchanging information on connectivity and resource usage and allocation, the IPC processes that constitute the layer create a distributed application, essentially a distributed operating system. The (N)-addresses need only be known among the IPC processes (i.e., internal to the distributed operating system). Application names are externally visible in the layer; (N)-addresses are not.
The port-ids play a crucial role in linking the (N)-addresses to the (N−1)-addresses in adjacent layers while at the same time insulating (N)-addresses from both AP names and (N+1)-addresses, if they exist. The only identifier an AP has associated with a flow is the port-id and the destination application name. It has no knowledge of the destination port-id or the (N)-addresses.
All IPC requests are assigned a local port-id to distinguish multiple instances of IPC within a processing system. Port-ids are defined to be unambiguous within a processing system. This choice is not made arbitrarily. This choice implies that PDUs need only carry addresses and connection-ids (created from port-ids). If the scope of port-ids is defined to be unambiguous only within the DIF and the system was allowed to be a member of more than one DIF at the same rank, the PDUs must include the DIF name, too. By defining the port-id as we have, the DIF name is only needed when an IPC process is joining a DIF.
Application process names are used by a new system to establish initial communications when it joins a DIF. Traditionally, it has been assumed that a processing system participated in one and only one DIF per rank, except at the bottom, where there was one per interface. In some cases, there are good reasons for this to be the case. But this does not have to be the case. However, this does have some implications for naming that must be understood. It is possible (and actually useful) to have more than one DIF in the same systems or set of systems. This implies that when there is more than one DIF in a system and a new system wants to join a layer, it must know which DIF it is joining (i.e., it must have its distributed application name or DAN). The DAN is used to establish communication with the DIF using the (N−1)-DIF.
The names used for routing PDUs are not just the names of the IPC process but are identifiers internal to the DIF formed by the collection of IPC processes. In other words, they are not visible outside the DIF. Addresses are used by the IPC processes of the DIF for their internal coordination. This may not have been apparent looking at traditional network layer routing but is more obvious if one considers relaying applications, such as mail. E-mail addresses are used for routing mail and strictly speaking are internal to the mail application. E-mail addresses and IP-addresses are two examples of the same concept.
The routing function of IPC requires two kinds of information:
Information on the graph of RMTs (node addresses in Saltzer’s terms) formed by being directly connected by the (N−1)-DIFs
The mapping of (N)-addresses to (N−1)-IPC process names[25] (Saltzer’s point of attachments) for all nearest neighbors (i.e., capable of direct connection) at the (N−1)-DIF
A traditional routing application uses the connectivity information to calculate routes from a source to a destination. This is, in turn, used to construct a forwarding table to the “next hop” or next RMT to which PDUs are sent for relaying or delivery. The mapping of the neighboring (N)- to (N−1)-addresses is used to choose the specific path to the next hop.
(N)-DIFs, in general, have greater scope than (N−1)-DIFs. However, this is not the case with configurations such as virtual private networks or specialized applications, where a closed subnet is created on top of DIFs. The RIEP protocol collects information to create a local database of the mapping of (N)-addresses to (N−1)-addresses and the logical connectivity of the IPC processes constituting this DIF (i.e., routes). As the scope of layers increases, the number of “nearest neighbors” will tend to increase combinatorially. This will require more complex distribution and caching strategies (e.g., imposing a hierarchical structure on the RIBs). These applications exchange information on the contents of their caches and to respond to queries that cannot be answered with the information in their local cache.
The primary function of (N)-addresses in a DIF is to establish and maintain the mappings among (N)-addresses, the (N+1)-addressing above, and the (N−1)-addresses below, and as a consequence facilitate routing. Enrollment is used to assign addresses and to manage changes of addresses. These mappings of the current connectivity are maintained by the tasks associated with resource allocation and routing protocols. These protocols maintain databases of routes to different parts of the network topology and “forwarding tables” indicating the (N−1)-addresses PDUs are to be sent on. These databases are also interrogated to get information necessary to initiate communication. This is generally referred to as a directory function.
Saltzer and everyone else agree that an address is a location-dependent name. From the beginning of networking, the analogy to operating systems was utilized to recognize that names specified the what; addresses, the where; and routes, the how to get there. For most networks to date, addresses were not location dependent. They were flat identifiers. None of the routing protocols in use today utilize the location-dependent property. The names used by these algorithms are used purely as labels, not as indications of where. For small networks, this is adequate. But in large networks or networks where less-complex operations are desired, true addresses can be used to great advantage.[26] The key aspect of this problem, which has always been recognized, was how to make addresses location dependent and route independent. In other words, how to achieve the properties that addressing serves on a Midwest grid on a much less-regular network graph. In the next chapter, we consider how to develop the concept of addresses, which are location dependent without being route dependent.
The scope of the address space is the DIF within which it is used. This is the set of (N)-IPC processes that can communicate either directly or by relaying and without relaying at a higher layer. Although this is still true, it is less important. An (N)-address is an internal location-dependent identifier assigned to each (N)-IPC process.
The scope of the (N)-address is the DIF to which it belongs. Route dependence is at least relative to the layer in which the relaying occurs. A (N)-address is route independent, but the (N−1)-address (or point of attachment) is necessarily route dependent relative to relaying in layer (N). From the point of view of an IPC process, choosing an (N−1)-address is the act of choosing a path. Thus, all (N−1)-addresses available at the lower boundary of an IPC process are route dependent with respect to that IPC process. Each one represents the first hop on all routes going in that direction. The same (N−1)-addresses may be (and should be) route independent relative to relaying in (N−1)-DIF and so on to the physical layer where addresses must be, by their nature, route dependent. Route dependence is an inherent property of addresses only at the physical layer.
Postponing the introduction of explicit route-dependent addresses into a network architecture (i.e., not adopting a naming convention that is inherently route dependent) will greatly improve the flexibility of the configurations that the network can have. However, it is always possible to create an address space that is inherently route dependent. For example, traditionally, the most common means to make an address route dependent is to include an (N−1)-address as part of the (N)-address (e.g., a MAC address or EUI-64 address) as part of the network address. It is these architectures that are unnecessarily plagued with problems.
As a consequence of layer independence, a good architecture makes this transition at each layer. A viable addressing scheme must make a transition from physical (route dependent) to logical (route independent) at least once. In a very real sense for the recursive structure we have developed here, the (N)-layer provides the “logical” addressing for the “physical” addressing of the (N−1)-layer. In this approach, we have simply made this relation relative. In other words, Saltzer’s concepts of node address and point of attachment address are relative. An (N)-address is a node address; and an (N−1)-address is a point of attachment address. In a complete architecture, addresses at the layer below are points of attachments for the layer above.
However, one can make address spaces in adjacent layers too independent and make routing inefficient. A judicious choice of a relation can be very advantageous. In particular, a topological relation between adjacent spaces can be quite useful. This is discussed in the next chapter.

This is a good point to contrast this with Internet. In the current Internet architecture, the closest thing to an application process name is the URL. The syntax of the URL allows specifying an application protocol and the host on which it resides. The host part has essentially become the application name. It is not at all clear how one would build an application with multiple application protocols and whether it would work in all cases. Would ftp://ftp.myappl.com and http://www.myappl.com actually create connections to the same AP? Doubtful. If I want my corporate websites on a hosting service and my internal company websites, I must have multiple domain names or other such subterfuge. Rather than simply having a branch for my corporate application names that I can assign and locate the applications wherever I please. If there were a special protocol for my project, say mynewprot, it would have to be registered with IANA. There is no support for connecting to specific multiple instances of either APs or application protocols associated with specific APs. This makes constructing anything but the most rudimentary distributed applications difficult if not prohibitive.
There is only a partial equivalent of the IPC access protocol. DNS allows the application to determine the address of the destination application. This puts more burden on the application and also represents a security problem. There is no access control and the application has knowledge of the address.
The Internet is based on a “one size fits all” model or maybe two sizes: UDP, and TCP. However, this now seems to be breaking down with the addition of RTP, SCTP, DCCP, and others. This contributes considerable complexity to the architecture. The inability to couple these EFCPs with resource allocation associated with IP further adds to the problems.
In the current Internet architecture, there are only point-of-attachment addresses. Hence, routes are calculated as a sequence of (N−1)-addresses. Consequently, it is difficult to accommodate multiple paths[27] between adjacent nodes. It is done, but it is a kludge. Each path is a separate segment of a route. Consequently, the existence of multiple paths increases the number of routes combinatorially. In a very real sense, today multihoming is not even supported in the routers let alone the hosts. In these architectures, multihoming and mobility cannot be supported without expensive and cumbersome mechanisms. As we saw in Chapter 5, although the CLNP approach had both node addresses and points of attachment, it didn’t solve all the problems. Scope is either very local or the whole world. Nothing in between. Changes in points of attachment can be handled effectively, changes in node address take too long to update because the scope of the network layer is too great. In this model, with topological addresses and repeating layers, both capabilities work easily and scale. (We look at this more closely in Chapter 9.)
The problem here is not that there are not workarounds to solve all of these problems. There are. Lots of them. Therein lies the problem. They all increase the “parts” count and hence the complexity, which reduces the reliability and increases the effort required to field new capabilities and manage the ones already there. Just finding something that works isn’t good enough. It has to simplify as well.
All applications using a DIF are “one hop” away. The traditional concept of a directory or DNS is an inherent part of the information associated with the mapping of (N)- to (N−1)-address information collected for routing, in essence a degenerate case of the layer structure. But some applications, such as mail, do relay. Mail relaying[28] is simply this same structure (i.e., another layer) that uses a particular set of addresses. E-mail addresses are another form of address. Strictly speaking, a mail protocol should only be concerned with the composition and sending of the “letter.” The delivery of the letter is merely the routing of an often, large PDU.
A DIF always interfaces to an (N−1)-DIF or the physical media. In general, each DIF interfaces to m (N−1)-DIFs, because the scope of IPC tends to increase with higher rank.
To the DIF, a request may contain either an AP name or (N+1)-address. The DIF maintains a mapping between its addresses and these AP names and (N+1)-addresses. In other words, it is responsible for knowing what applications are available to whom on its system.[29] The mapping of AP names to (N)-addresses is arbitrary (by definition). However, the mapping of (N+1)-addresses to (N)-addresses may be a topological mapping.
However, a DIF must be able to confirm that an AP is an (N+1)-IPC process and can be guaranteed to obey certain rules (i.e., that addresses are valid and have not been tampered with). (Because the (N)-DIF carries the (N+1)-IPC facility PDUs transparently, the possibilities for compromise are limited to the parameters passed as part of the API and relate mostly to addressing.)
At enrollment, a DIF may be authenticated with the (N−1)-DIF. This is how the (N−1)-DIF knows that the AP requesting services is itself part of an IPC facility. If this is done, the (N−1)-DIF knows it can trust the (N)-address information it is given from the DIF. The (N)- and (N−1)-DIFs exchange information on their capabilities and policies. Each determines the degree it can trust the other. The (N−1)-DIF is in a better position to protect itself because it can always refuse requests by the DIF. The two biggest threats are that regardless, the (N)- and (N−1)-DIFs share the same processing systems and the possibility of a rogue IPC process successfully negotiating the enrolment authentication policy. If no authentication agreement can be reached, all communication is done with application names. It still works, but is less efficient.
We have already seen that a single IPC process is necessary to manage multiple users of a single physical interface. We have also seen that having a single IPC process to manage multiple users of multiple interfaces is also advisable. But this raises the question of whether this is always the case.
Multiple IPC processes can occur at any rank. Let’s consider briefly the conditions where this makes sense. Layers are created for essentially two purposes: for organizational reasons and for managing specific ranges of bandwidth and QoS.
Starting at the bottom, it would seem at first blush this is the one place where there would be one IPC process per physical interface. However, this is not the case. Consider, for example, a TDM physical medium, which creates some number of independent channels. Theoretically, each one could have a separate IPC process to manage its use. The number of IPC processes that are possible in this case is between one and the number of channels.
There are two forms that a lowest DIF may take:
A point-to-point media, which will have an EFCP, but no RMT
A multiaccess media, which will require both an RMT and EFCP policies determined by the error
Our early, constrained view of layers prohibited (at least discouraged) routing in the data link or media layer. Bridges began the slippery slope, which was promoted by the use of spanning trees by LANs and so on. With this model, we step back and do what should have been done sooner, recognize routing is a natural capability in all layers. In this case, LAN spanning trees become a minimal form of routing. Similarly, many of us (me included) looked at LLC in LANs as acquiescence to the beads-on-a-string proponents and not appropriate for LANs at all. LANs are sufficiently reliable that an EFCP with robust policies is not required. But with the popularity of wireless media, we see cases where a more robust EFCP might be required. (In other words, not all layers need all the capabilities but be careful about claiming that they are never needed.)
Error control in the data link layer should be sufficient to make error control at the transport layer cost-effective. In other words, if the purpose transport layer error control is to handle losses due to routing, data link error control should ensure that losses are at a lower rate than the rate of loss due to routing. Recognize that propagating errors to the wider scope of a higher layer will incur greater cost to recover, while keeping in mind the impact on delay incurred by retransmissions. We will want to generalize this relation with this model.
Above this level, the same principle applies. Depending on the desired configurations, one or more DIFs may exist. Above the first layer, creating DIFs will essentially create distinct and separate networks.
In some common configurations, there would be one (N−1)-DIF per interface and one (N)-DIF for the system. Above this, (N+1)-DIFs might be created as closed networks (e.g., VPNs, transaction processing, peer-to-peer application, and so on). In these upper layers, we are likely to have multiple DIFs within a system that are not dedicated to a specific media. Note that (N−1) here is with respect to the architecture but may not be the (1)-layer within a particular subnet (i.e., immediately above the physical medium). In Chapter 8, “Making Addresses Topological,” we explore the relation between public, private, organizational, and provider networks.
We will not attempt a thorough security analysis at this point, but a few remarks are worthwhile. We assume that all the current security mechanisms can and would be applied to the protocols and procedures developed to fit an architecture based on this model.
As a first step, let’s assume that only applications are threats, not other IPC processes; then we will relax this assumption to consider that case. First, we note that the only IPC-related information that an application has access to is the destination application name and its local port-id. The application has no access to addresses or destination port-ids. The access control mechanisms of the IAP have limitations. The most that can be guaranteed is that the DIF is providing access to an application that to the best ability of the DIF is the application being requested. It is then the responsibility of the requesting application to determine that this is the application it requested.
Because IPC processes are applications, this also applies to IPC processes. As we saw with the sequence for joining a DIF, the DIF determines whether the requesting IPC process can join according to the authentication policies of the DIF. This is part of the initial enrollment phase. This leads to the conclusion that the degree of trust that an (N)-DIF can put in an (N−1)-DIF can be characterized as follows:
A (N)-DIF can only assume that the (N−1)-DIF will try to deliver PDUs to something and may copy or modify them in the process. If the (N)-DIF does not trust the (N−1)-DIF, it should invoke the appropriate PDU protection and authentication mechanisms. If the applications using the (N)-DIF trusts the (N−1)-DIF less than the (N)-DIF does, that is their responsibility.
Let’s consider a compromised IPC process joining a DIF. We will assume that compromise is such that the new member can pass the authentication and become a member of the DIF. What damage can it do? The answer is some. However, unless the policies of the DIF are incredibly loose, it will always be possible to find the offender and terminate its membership. If a timer-based EFCP is used, SYN attacks are not possible. The offender could try to flood IAP requests, but these will be fairly diffuse and mostly negative responses. There are no well-known sockets to attack. Depending on how access control and application naming is handled, many application names may not actually be recorded in any RIB. In general, the potential threats are at best fewer than with current architectures and at worse no more than current architectures.
As we can see, the nature of the recursion of DIFs is such that any system will only have access to management information in the (N+1)-, (N)-, and (N−1)-DIFs that it implements. Further, the (N−1)-DIF will have less scope, and thus information available to the system will have much less utility. The only (N+1)- information available will be about the application names available to the (N)-DIF. This too has limited ability. The greatest threat that a compromised system can have is to distribute bad resource allocation and routing information with its peers.
One aspect that this model has no affect on is virus attacks perpetrated on communicating applications. Compromises based on weaknesses in the application software or the local operating system cannot be addressed by this model. Although stronger authentication by IPC can help, it cannot prevent such compromises.
This chapter has defined the elements of an abstract model for a IPC model of networking. By taking our cues from key elements of our past experience, and carefully listening to the problem, we have been able to assemble a simple model that is much less complex than previous architectures and far more capable. But at the same time, it has greater capability and solves problems with little or no additional mechanism that cannot be solved in previous architectures. The recursive structure implies that the architecture will scale indefinitely. There will still be bounds, but they won’t be because the architecture has “run out of gas.” In the process, we have found that the internal structure naturally cleaves into three functional areas of increasing complexity and longer “duty cycle” times. This points the way to significant simplifications in implementations.
It is curious that from the earliest days of the ARPANET we saw operating systems as our guide, but now we find that we just didn’t follow it closely enough. Looking back from this vantage point, our current architecture looks more like DOS than UNIX—more like a collection of partial solutions strapped together with Moore’s law, baling wire and binder twine—but mainly Moore’s law.
Some will say that this is a general theory of networking. It isn’t. It may be a model on which we can construct such a theory, but this is not the general theory. Some will be disappointed that I have not addressed important issues such as performance, congestion control, quality of service, routing, and so on. This was quite deliberate. This book has been purposely restricted to only the architectural problems. The first task must be to get the fundamental structure right. Now that the structure is in place, we can consider these other issues.
This model now forms a foundation for tackling these problems. It provides the needed orthogonality and regularity at different scales that help to shed light on the solution of these problems. Of course, these issues had to be a consideration while working this model out. But truthfully, the structure of the problem was a greater factor in determining the direction than these issues. In a very real sense, the problem provided the answer, once it was well stated.
Now we have one more problem to look at—not so much how to solve, but how to think about it: how to think about location dependence in a network that is not route dependent.
Then we look at the implications that this structure has for multihoming, mobility, and multicast.
[1] Noel Chiappa found this one, too!
[2] Of course, there is no ex post facto. Solutions developed before the theory can’t be blamed for not following a theory not yet recognized. But these solutions often shed light on what we were struggling with and contribute to the theory.
[3] All of the terms associated with this concept are heavily loaded. We have chosen to use application process in the sense of processes used in most operating system textbooks. The (N)- notation is not applied to applications since they are in the system and not part of the IPC.
[4] There are some error conditions that must be accommodated in the distributed case that do not occur in the single system case.
[5] However, most operating systems and processor architectures are still firmly entrenched in the traditional model.
[6] I have used this definition for nearly 30 years, and it seems to get at the crux of the matter without having to reference specific configurations of processors and memory. If two processes can’t coordinate with a test and set, they are in different systems. (An atomic swap is equivalent. Some authors seem to define a swap as a test and set.)
[7] Obviously, IPC is a form of I/O; however, the term I/O has been associated with the hardware arrangement where devices were essentially “bolted” to the side of the computer by highly specialized electronics. This is quickly becoming a thing of the past in modern computers. Bringing all communication under the umbrella of IPC has advantages and simplifies the system.
[8] Again, the term driver originates with this very asymmetrical view of peripherals where all the managing of the peripheral was done by the processing system. This configuration is changing.
[9] If we include these “control structures” and sequences of operations in the protocol, we are basically sending small programs, which is simply a write one level down. One must draw the line somewhere, and doing so at this elemental level seems to create the fewest problems. Also it seems reasonable that IPC gives way to “programming.”
[10] OSI called this the application entity not the application protocol, for several good reasons: consistency with the use of entity in the other layers and to emphasize that the AE was part of the communications environment, whereas the AP was not wholly contained in it; because they realized that it wasn’t just the protocol, and it created abbreviation problems (two APs). I used APM here to give the reader a familiar concept.
[11] This might appear to be a pedantic nit. However, this appears to follow from our previous conjecture and is the case for traditional routing protocols, multicast, P2P, and transaction-processing protocols. As we apply this model both here and beyond this book, this distinction will prove useful.
[12] These may be rich APIs but they are poor black boxes.
[13] We stress that these names have external visibility, because we will also want to discuss important classes of identifiers that are internal to (N)-DIFs.
[14] An application that uses only a single protocol would not necessarily have to specify the application PM.
[15] I have debated about the name of this term. Early drafts used flow. Connection is a heavily laden word, and many will want to associate much more with it than is intended. But just as I dislike having a half-dozen terms for PDU, I don’t want to do it here. The reader is reminded that here the term identifies the entire range of possibilities from minimal shared state of a flow (e.g., UDP-like) to considerably more shared state (e.g., TCP-like).
[16] As noted in Chapter 1, service primitives are a language- and system-independent abstraction of an API. It is assumed that a real API would look different and include parameters of local necessity. Other service disciplines are possible. This one is provided just so there is one we can talk to.
[17] Note that whereas the interface must be asymmetrical to ensure the requested AP can respond to a specific request, the underlying protocol can and should be symmetrical.
[18] It differs from TCP by having different PDU types for loosely coupled mechanisms. However, traffic analysis of TCP indicates that it is used as if it had different PDU types, so in fact it isn’t that different.
[19] As you will see, the three forms differ little in functionality.
[20] In some cases, this will be redundant.
[21] I realize that this sounds contradictory. Management always has a role, a bit like the sphere visiting Flatland (Abbott, 1884). An MA is an application in a processing system and, hence, can access anything it is given permission to access by the operating system.
[22] Or based on where the IPC process, b, is in the topology of the DIF A and the address space (see Chapter 8). For (N)-addresses in the model, we will retain the (N)- notation to minimize confusion with other uses of the term address.
[23] Whether the Allocate request is returned immediately or only after the requested APM accepts is a matter that can be left for later. With this approach, the requested APM may refuse the request, in which case a De-allocate will have to be delivered to the requesting APM to notify it.
[24] This might seem like a radical departure from the current behavior of the Internet, which never refuses any new traffic. It isn’t. If one desires all new allocations to be accepted, that is a matter of policy. This approach allows both without additional overhead or the inflexible constraints of circuits.
[25] Or (N−1)-addresses, depending on the level of trust between the (N)-DIF and (N−1)-DIF.
[26] Recently, location dependence has been used to aggregate addresses for purposes of route calculation, but this preprocessing simply moderates the scaling issues associated with the fact that the route calculation itself uses addresses as labels.
[27] The reason being that the routing now interferes with load balancing.
[28] As is peer to peer, OLTP, or another distributed application that involves relaying.
[29] As part of access control policy, a processing system may not make all (N)-application names available to a particular (N)-DIF.